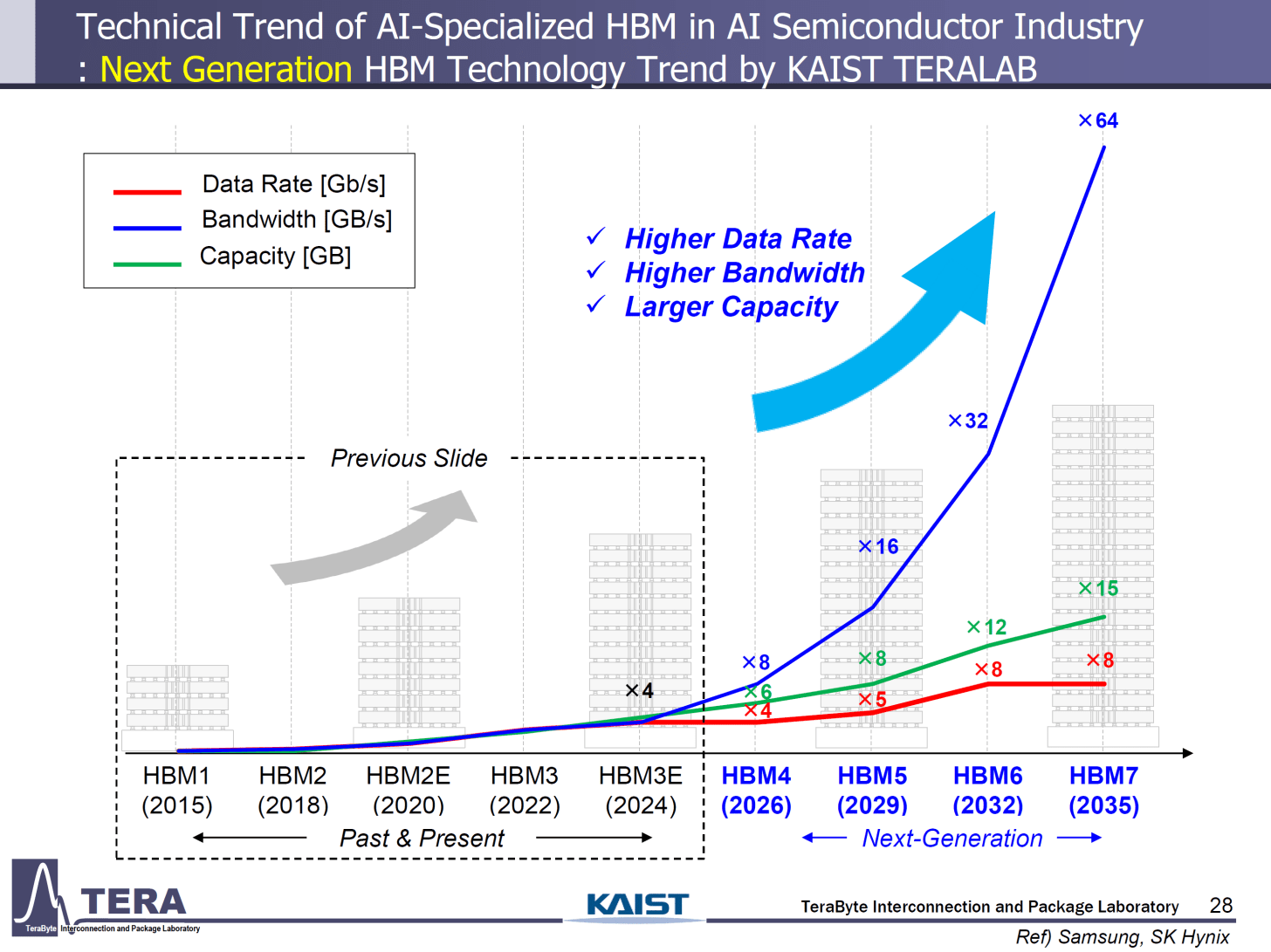
Render Unto Caesar, Not Unto Claude
Habemus the Pope’s AI takes! To dive in, ChinaTalk’s chips analyst and resident Catholic explains what is going on below. In the second half of the newsletter, you can find the transcript of the podcast (that you should really just listen to your favorite podcast app), featuring of the Institute for Christian Machine Intelligence and John-Clark Levin of Kurzweil Technologies.
On May 25, 2026, Pope Leo XIV released the first encyclical of his pontificate, Magnifica humanitas, which discusses “safeguarding the human person in the time of artificial intelligence.”
The much-awaited encyclical was the first deliverable that addresses AI, a topic that the Church has been attempting to address since the pontificate of Pope Francis.1 The current Pope picked his name in part after his predecessor Pope Leo XIII, whose encyclical Rerum novarum addressed the effects of the Industrial Revolution. By taking his name, Pope Leo XIV indicated that he would treat the impending AI revolution with equal seriousness.
After Magnifica humanitas was released, my X feed was flooded with half-baked takes on the encyclical, with posts by everyone from Dean Ball to Butlerian jihadists. The outpouring of takes from non-Catholics indicate that, for some reason, people care about the Pope’s stance on AI. Why do they care, and why should you care?

Although the pervasiveness of the encyclical in secular society is a welcome sign from the Church’s perspective, misunderstandings inevitably arise when people are approaching the encyclical with eyes uninitiated in Catholic theology. This is how we get some people saying the encyclical was weak tea while others are declaring it a fatwa against AI.
Well fear not! This is not my first rodeo with Church documents and certainly not my first encyclical. Let me be your guide as we wade through the waters of Catholic jargon and explain what the encyclical does and does not say, and why the text is neither weak tea nor jihad.
Why People (and Why You Should) Care
Some of the SF bubble tuned in to the Magisterium’s teachings because of the attendance of Chris Olah, co-founder of Anthropic, at the encyclical’s presentation.2 He sat alongside the Pope and delivered remarks at the ceremony, giving the ceremony some Silicon Valley street cred.
For the rest of the world, the encyclical matters because the Pope is understood as a sort of impartial figure. He has aura. He is ostensibly not for worldly power and tries to be “above” standard politics. When it comes to AI, where the authoritative figures seem to be companies trying to sell you the product or governments trying to politicize the technology, people view the Pope as someone without special interest. He might be wrong, but at least he is not trying to sell you something. He does not profit politically or economically from AI doing better or worse.3

Some have commented that Anthropic’s role in the ceremony indicates that the Church was clearly influenced by the company and its so-called “doomerism,” or even “partnered with Anthropic,” but this is not the case. The encyclical itself, likely written by many hands over many months, contains passages that criticize companies like Anthropic. Most likely, Anthropic played some advisory role in communicating to the Church how AI actually works and providing technical background — sort of like how the government works with companies to gain information about how to properly regulate them.
Lastly, you should care because he is the Pope! As the undisputed religious authority for 18% of the global population, his words matter. Especially in much of the Global South, the home of three out of every four Catholics, the Pope plays a morally authoritative role. Given AI will be a global technology, it is obvious that you should tune in to the person whom nearly a fifth of the world considers the Vicar of Christ and what he says on the subject.
So, what does the Vicar of Christ have to say on the subject? In my view, the 190-page encyclical can be boiled down to three main opinions on the purpose and societal applications of technological development.
Efficiency and Automation Are Not the Goal
In my opinion, the most consequential framing of the encyclical is its definition of an anthropocentric view: the criterion for good technology is promoting human dignity and fulfillment, not efficiency and productivity.4 Although that framing sounds like a milquetoast platitude, it has real downstream implications.
Labor
The encyclical’s message on labor is a direct descendant of Pope Leo XIII’s teaching in Rerum novarum, an 1891 encyclical on the Industrial Revolution. To understand Magnifica humanitas, you must understand Rerum novarum. The 19th-century encyclical was a landmark in Catholic social teaching, re-establishing the Catholic Church as a relevant figure in discussions of distributing wealth, social justice, and the common good. No longer was the Church considered a bulwark of reactionary absolutism, and no longer would the Church be shy in speaking on worldly matters.
Rerum novarum put forth a third way that rejected not only standard socialism and anarchism but also laissez- faire capitalism. The encyclical affirmed private property and distinction of classes as a good, but it also emphasized that human value is not tied to one’s wage and that the rights and dignity of the worker must be respected. As such, the document was progressive on labor rights, unions, and fair wages. Speaking on the labor movement, Leo XIII wrote:
“If we turn now to things external and material, the first thing of all to secure is to save unfortunate working people from the cruelty of men of greed, who use human beings as mere instruments for money-making. It is neither just nor human so to grind men down with excessive labor as to stupefy their minds and wear out their bodies.”5
Tangibly, Rerum novarum sparked the movements of Christian democracy and Catholic labor unions and accelerated the adoption of labor laws in Europe and the United States. It took some wind out of the sails of prevailing socialist movements, as pro-worker sentiment began to find a home in Christian movements too.

Drawing directly from previous Leonine teaching, Magnifica humanitas states:
“While many of the historical conditions described by Leo XIII have changed, at least two insights remain highly relevant today: the primacy of human labor over any mindset focused solely on finance or productivity — with the consequent attention to the people and families most susceptible to exploitation — and the inseparable link between proclaiming the Gospel and pursuing a more just social order. Rerum Novarum thereby continues to remind us that there is no authentic evangelization that does not also affect the structures of human society.”6
Leo XIV argues that work is not just an economic input or about productivity but rather a “fundamental good for the person.”7 This understanding communicates well-known criticisms of unfettered capitalism treating humans as cogs in a machine or dehumanizing them by evaluating them based solely on productivity, but it also presents something novel: despite rosy pictures of an AI-powered world where work is an anachronism, the Church argues that full automation is a will-o’-the-wisp.
The Church’s view is that work is a means of people participating in society, expressing and enhancing their dignity, and “a requirement of the human condition.”8 As such, the Church seems to reject a world where we all receive UBI and can twiddle our thumbs all day; the Church advises the need for people to fulfill their dignity through their own work. The encyclical states:
“Above all, however, the Magisterium has recognized in work “the essential key” to understanding the entire social question, since it is through their work that individuals develop many dimensions of their existence. In view of this, we can understand the great intuition of Saint Benedict of Nursia, who united prayer and work, showing daily activity to be a part of the human response to God’s call. Created in the image of the Creator, our own work in some way continues his, for thereby we contribute to the progress of society and the common good, put to good use the capabilities we have received, improve and beautify the world, support our families, engage in cooperative relationships and, through listening and dialogue, learn to build together something that no one could achieve alone.
For these reasons, work is not simply an instrument; it expresses and enhances the dignity of our lives. It is a requirement of the human condition, a normal path toward maturity, development and personal fulfilment. In this regard, financial assistance to the poor may at times be necessary in emergencies, but it cannot become the sole response, since the goal is to enable each person to live with dignity through his or her own work.”9
To explicate in my own terms, the Church finds that a world in which we do not work is a world not of freedom but of listlessness and decadence. If you have not learned responsibility through household chores or work, you will be deficient in responsibility for yourself and for others — and you will be ultimately less mature and developed as a human because of it. I think the Church also finds some virtue in actually exercising your will in work; there is something virtuous and fulfilling in actually harvesting your own crops or (perhaps to a lesser extent) completing a McKinsey PowerPoint.
I think there is also an element of the Church wanting to maintain a balance of power between labor and capital: if we live in a world where labor is useless, then people have far less leverage. Maintaining some necessity of labor may be instrumental in disincentivizing oppression or the stripping of human dignity in the future.
This dependence point stems from Rerum novarum, which explicitly says, “capital cannot do without labor, nor labor without capital.”10 Pope Leo XIII found that such dependence “results in the beauty of good order” and is connected to “drawing the rich and the working class together, by reminding each of its duties to the other, and especially of the obligations of justice.” If there is no dependence, it seems Pope Leo XIV is wondering, what will remind us of our duties to one another?
The Church is sparse on details on how to implement this vision of labor, and instead leaves the question to corporations, the state, and civil society.11 The basic advice the Church gives is to support labor unions and create more institutions capable of confronting the unique challenges posed by AI, promote “taxation, social protection, and industrial policies” to mitigate wealth concentration, and privilege new metrics of economic health. Instead of using GDP as a benchmark, I imagine the Church would prefer something like better human development indices and the Gini coefficient as the proper lens for evaluating an economy.
Localism and Corporate Development
The Church’s relative antipathy to efficiency also shows up in its view of how AI development should progress: humanely and with input from every corner of society. The Pope writes:
“This principle encourages us to move beyond any form of paternalistic or welfare-based management of societal life, but instead to promote a culture of shared responsibility in a State that values citizens’ initiative, and a civil society capable of forging bonds and mobilizing energies in the service of the common good. In accordance with the principle of subsidiarity, decisions are made at the closest level possible to the persons involved, thereby fostering community life and avoiding people being presented with decisions that have already been taken. In this way people can participate in the decision-making process. When families, associations, local communities, volunteer organizations and those in the so-called “third sector” are recognized and supported, social life becomes more accessible to people, services become more attuned to real needs, and solutions are more creative and respectful of the dignity of each person.”12
The Church is concerned with the current path of technological development, which idolizes efficiency and sacrifices human dignity in the process. The sins of this path include the design of algorithms on social media and AI applications that exploit human weakness and keep users addicted instead of oriented toward “the good.” They include the exploitation of children in mining rare earths, and OpenAI traumatizing Kenyans at $2 an hour for content moderation.13 In the Church’s perspective, if we are not taking measures to prioritize humanity now in these areas, how will AI and technology prioritize humanity later as it comes into maturity?
The Church’s solution is through the medium of localism, which can include some tangible policy plans. The Church advises companies (or perhaps state compulsion) to pursue supply chain transparency so that they do not rely on inhumane labor for their content labor or for the minerals that make their chips and data centers.14 When building those data centers, the communities in which they are built should be consulted extensively for how, where, and in exchange for what benefits they are constructed. For AI alignment, Anthropic should not just have Amanda Askell thinking about the moralization of Claude, but the lab should take pains to take input from different rungs of civil society and religious authority, regardless of how slow the process may be.15
Through the aforementioned and other means of localism, the Church argues AI labs can fulfill their mission of a technology that “benefits all of humanity.” Through this message, the Church is clear in its rejection of unqualified techno-optimism and devotion to efficiency. By taking the proper stance toward labor and development, technology can be oriented toward the common good in a way it might otherwise not be.
The AI Arms Race
Lastly, the encyclical briefly refers to the AI arms race occurring between the U.S. and China. Although not referring to either country by name, the encyclical reads:
“Disarming AI means freeing it from the mentality of “armed” competition, which today is not limited simply to the military context, but is also an economic and cognitive phenomenon. This entails a race for ever more powerful algorithms and larger datasets, driven by the desire to secure geopolitical or commercial dominance. To disarm means discrediting the assumption that technical power automatically confers the right to govern. To disarm does not mean rejecting technology, but preventing it from dominating humanity. It means freeing technology from monopolistic control and opening it to discussion and debate, therefore making it human-friendly and restoring it to the plurality of human cultures and ways of life. Our task today is not only ethical or technical. It is ecological in the deepest sense, for it concerns a new dimension of our common home. AI is already an environment in which we are immersed, as well as a force with which we must engage. For this reason, merely regulating it is insufficient; it must be disarmed, welcoming and accessible.”16
The Church is saying that the U.S. and China must disarm the AI race like the world did during the nuclear race of the previous era. Beyond this, however, the Church does not find the race dynamics logic prevalent in American AI labs worthy of interaction. I was personally expecting more words explaining to corporate and state actors that no amount of geopolitical reasoning precludes greater humanitarian goals, but the encyclical only dedicates a paragraph to the issue.
I think the Church’s minimal interaction here is due to some combination of the following: the Church’s hopes to make every nation subscribe to the encyclical’s view, and Her role is to be above these geopolitical squabbles; the idea that if we don’t take right action on AI, the world will be worse off regardless of who wins the AI race; and, due to the Church’s anti-utilitarian bent, right action is more important than whatever consequences result from the AI race.
Transhumanism Is Not on the Table
The encyclical also dedicates several paragraphs to addressing transhumanism and posthumanism, philosophies mainly peddled throughout the Silicon Valley and venture capitalist milieu. Transhumanism has gained notable adherents — including billionaire Peter Thiel, a16z co-founder Marc Andreesen, and researcher Guillaume Verdon (better known as BasedBeffJezos) — but it is undoubtedly a minority voice. The fact that the encyclical addresses an almost sci-fi idea mainly found in minority circles in Silicon Valley is surprising.
The transhumanist and posthumanist proponents believe that technologies like AI will enable us to become ontologically different beings, either in the form of humans with supernatural capabilities or as human-machine hybrids different from humans altogether.
From the Catholic perspective, human weaknesses like limited lifespans and fleshy limbs are an essential part of life’s beauty. The encyclical states that “humanity flourishes not despite limitations, but often through them.”17 From the Church’s perspective, pursuing contemporary strains of transhumanism distances us from essential facets of human goodness, such as compassion and generosity.18 The Church writes:
“If the human being is treated as something to be perfected or surpassed, it becomes easier to accept that some lives are less useful, less desirable or less worthy. In the name of progress, ‘necessary sacrifices’ may begin to be justified, placing the burden on the most vulnerable in pursuit of a supposed optimization of the species. In this regard, the aforementioned warning of Saint Paul VI retains great foresight: indeed, scientific and technological advances, when detached from moral and social progress, end up turning against humanity. [130] For this reason, a clear distinction must be made. It is one thing to integrate technology within a human-centered, relational vision; it is quite another to be guided by an outlook that devalues human limits and promises a purely technical form of ‘salvation.’”19
We are called to love thy neighbor. If my neighbor is an immortal cyborg, what need is there for me to care for him? The Church warns that this world, where humans need not care for one another and do not suffer, is not a preferable world. Limits are needed to be human and to fully enjoy the adventure of life.

In these paragraphs, the Church does not denounce all modes of transhumanism and posthumanism, but it does deny the strains you will see most common in today’s tech circles. From the Church’s perspective, transhumanism may be theoretically acceptable as long as it remains anthropocentric and respectful of human limits.
Perhaps the Church will find some later forms of transhumanism to be more acceptable, but I personally doubt it. The Church’s vision for becoming superhuman is based on devotion not to technology but to God.20 I find the statements of Cardinal Víctor Manuel Fernández, who spoke at the encyclical’s presentation, most illuminating:
“On the other hand, some forms of transhumanism invite us to think that, thanks to future and sophisticated devices that will solve problems and increase our capabilities, our life will be a paradise. But the devices and technological resources give the individual an initial joy, and shortly afterward the void returns, with the feeling that something is missing. Different forms of posthumanism believe that this is because humanity has reached its expiration date, must simply be replaced, and an evolutionary leap is needed towards a new form of life, a new level in the evolution of the species. This is a leap that always depends on technology. As believers, we are certain that all this will not fill the void, will not fill the infinite space of our hearts, will not give a stable and consistent meaning to our human life. Behind this idea of progress lies a false mysticism that is precisely the opposite of what Christians and other believers call new life: the theological life, that life that is truly on another level, that life that certainly brings us.” (Translated by Google Translate.)
It will be interesting to watch how contemporary transhumanist circles respond to this denunciation. I imagine they will not care.21 But more interesting to see will be how the encyclical influences wider societal and governmental treatment of transhumanists.
AI Is Not Human
Lastly, the encyclical comments on the nature of AI as intelligent machines and how their status contrasts with that of humans. Unsurprisingly, the Church’s position is that AI ultimately is not “intelligent” in a way equivalent to humans.22
Some commentators like Dean Ball have found this position to be “intellectually flaccid” and a “punt of the highest order” because it does not seriously consider the intelligence of AI, given its ability to “think” in novel ways, thereby offering new contributions to mathematics and science. But it is not a punt: it is a clear position that the Church believes is true given Her stance on the specialness of the human person.
The encyclical argues that all AI, by definition of it not being human, is not able to think, feel, be truly embodied, mature, have relationships, have a moral conscience, or love. All indications that AI does these things are a misinterpretation, as they are simply imitations of such actions via “statistical adaptation” and “data processing.” If one believes that is the same as what humans do, then that is their prerogative, but it is obviously not the Catholic position, which believes there is a mystery in the human soul that gives rise to such behaviors.
Surprisingly, however, the Church has not ruled out the possibility of AI being conscious. Even in Catholic circles, the question is not open-and-shut, with some Catholic philosophers arguing that AI ensoulment is possible. At the encyclical’s presentation, Cardinal Michael Czerny stated that the question remains open:
“A related question, much debated today, is whether, and in what sense, we can speak of consciousness or conscience in relation to the most advanced artificial intelligence systems. It is a serious question, one that deserves attention and further study. Note, however, that it is not merely a technical query. More fundamentally, this is a philosophical question, for it concerns the meaning of experience, interiority, subjectivity and freedom. As such, it remains open to various interpretations.”
For now, though, because of this definitional disbelief in AI lacking human dignity or specialness, the Church adopts a cautious view of AI companions and similar products. Although the encyclical does recognize that communicating with AI for “words of advice, empathy, friendship and even love” can be “engaging and at times genuinely helpful,” they must be carefully presented to demonstrate that they are merely an “illusion of a relationship.”23 Otherwise, they may mislead “less discerning users.” As such, the Pope would likely endorse policies that require AI companions and chatbots to occasionally make clear to the user that they are not human so as to prevent AI psychosis — something along the lines of California’s SB 243.
However, commentators like Dean Ball point out a gap in the encyclical’s treatment of AI thinking. Even if AI will never be deserving of human dignity — and will never be intelligent like a human is — can or will it be considered intelligent enough to warrant some sort of consideration? Given how autonomously intelligent these machines are becoming, do they deserve some sort of moral or special consideration beneath a human but above a calculator? Despite Cardinal Czerny’s commentary, the Church is silent on the issue in the encyclical, but perhaps the current pontificate will comment further on the matter in the future.
Conclusion
Magnifica humanitas covers a lot more ground than what is stated above, including prayers of Marian devotion and updates to the doctrine of just war, but the points above seem to carry the most relevance to AI.
A lot of terminally online people believe that the encyclical is too backward-looking in its treatment of AI, arguing it only addresses already-exhausted debates without laying moral groundwork for the future transition. Those people are wrong.
Some perspective is due. Pope Leo XIII’s encyclical Rerum novarum played a major role in the public’s thinking on the Industrial Revolution, and it was published more than a century after the Revolution started! The fact that Magnifica humanitas has come out now, while we are still in the hazy mist of the AI revolution, is significant. The Church also rejects the framing of “backward-looking.” The Pope finds that if we are not working to solve the challenges AI is presenting today, we will be in no good position to solve the challenges it will present tomorrow. Quoting J.R.R. Tolkien’s Gandalf the White, Leo XIV writes:
“‘It is not our part to master all the tides of the world, but to do what is in us for the succour of those years wherein we are set, uprooting the evil in the fields that we know, so that those who live after may have clean earth to till.’”24
Lastly, while the encyclical lays some rough boundaries within which it believes AI discourse and policymaking should exist, it does not want or try to be the final teaching on the matter. In line with its vision of localism, it defers specifics to local communities and other institutions within the state and private sector. Given the Church’s prevalence in the Global South — geographies that have been largely ignored in conversations about AI — the Pope is calling for a change to the current trajectory. He wants these impoverished and neglected regions, which will be impacted just as much as San Francisco and Shanghai, to have a credible voice.
Magnifica humanitas aims to be in conversation with all institutions, including those in the many parts of the world that have yet to mobilize on these issues. Though the Church decided to speak first, it is up to the rest of the world, in the form of local communities, individual governments, companies, and civil societies to respond, to pick through the encyclical’s message and grapple with it, and decide what to accept and what to reject.
To receive new posts and support our work, subscribe!
For more Pope AI content, see below for the transcript of the AI Pope podcast we just released!
Listen now on your favorite podcast app.
Jordan Schneider: So the Pope has takes. Why is the Pope writing five hours of audiobook about AI and humanity?
John-Clark Levin: Pope Leo said twice in the first three days of his pontificate that AI is the greatest new challenge facing humanity. Not one of a list of six or seven things. The thing. That jumped out at me, because you can easily imagine an alternate scenario where a new Pope said humanity’s greatest challenge is gender ideology, or on the other side climate change, or something anodyne and obvious like war or poverty.
Jordan Schneider: That’s striking. There are a lot of hungry, cold, war-stricken people out there. As he’s talking about AI, I’m thinking, what about all the human suffering happening right now?
Tim Hwang: In some sense the Catholic Church is like every other very large global organization. It has to set intentionality, and a big part of shaping the world is wrapping its priorities in the work of the moment. A lot of what you see in the encyclical is exactly the topics you’re mentioning getting wrapped into the AI discussion.
Jordan Schneider: So this is just a news hook? For all the poverty stuff?
Tim Hwang: It’s more than a news hook. You only get to do your first encyclical once. I think this augurs a much bigger bet: that a lot of things in the world are going to get worked out through the lens of this technology. That’s one of the reasons it’s the first one being dropped.
John-Clark Levin: Pope Leo clearly sees the AI transition as analogous to the Industrial Revolution and epochal in its impact. Just as that revolution reshaped the economy, social relations, politics, and warfare across a full century, Pope Leo expects AI to do the same.
Aqib Zakaria: When I’m on social media too often, half the people are saying the Pope has declared a fatwa on AI, it’s over, it’s a crusade. The other half are saying the Pope is super AGI-pilled. So where’s the balance? What’s the actual substance?
John-Clark Levin: Through this encyclical Pope Leo evinces a generally balanced view. He clearly recognizes AI’s positive potential but also its capacity to cause grave harms. The encyclical focuses more on the harms than the upsides, but that’s to be expected. As a genre, encyclicals are more about correcting toxic views in the world and calling people to stop harmful behavior than about cheerleading things that are already going well. So the fact that Pope Leo focuses on the harms does not mean he’s declaring a Dune-style Butlerian jihad against AI.
Tim Hwang: It goes a little deeper. In 2026, the idea of being a skeptic or being AGI-pilled is an obsolete distinction. Everybody agrees we’re in the middle of some kind of takeoff now. The question is just what direction you’re moving in, and what should be prioritized.
Aqib Zakaria: Quick basics: what even is an encyclical? Is it infallible?
John-Clark Levin: No. An encyclical is an open letter addressed not just to the Roman Catholic Church but to all people of goodwill. The Pope undertakes it on his own initiative. It doesn’t require the curia, the cardinals, the bishops. So it reflects a Pope’s own personal teaching on a subject of concern to the church and humanity. It carries the weight of Catholic teaching, but it is not infallible.
Tim Hwang: The real question is: does this matter? There’s been a lot said, but the encyclical sets forth an intention, an agenda. What we’re waiting to see is what bureaucratic muscle gets put behind it. Prior to the launch, a commission was being set up across multiple dicasteries. That’s where the action is. The jury is still out on long-term significance, and part of it is seeing how Catholics respond.
Jordan Schneider: Let’s go around the horn with what everyone thought was most interesting.
Tim Hwang: Two things stand out. One, the encyclical claims the Catholic Church has agency over where this technology goes. It says we can either build Babel or rebuild the walls of Jerusalem. That matters, because most religious discourse around AI has been “this is happening, how do we hold back the tide.” The institutional shift to saying there’s a lever, we can decide where it goes, is hugely significant.
The second is the section 99-100 material that’s become so controversial. To what degree does the church believe what’s happening in these systems is the same as what humans do, or distinctly different? This relates to my own work: it sets a theological research agenda about the fine distinctions between humans, non-humans, and AI, which may be some secret third thing.
And on reflection, a third: I was briefing Catholic bishops this week, and the education material is really percolating down to working clergy. I suspect a lot of action on the ground around that.
Babel and the Walls of Jerusalem
Jordan Schneider: Let’s intersperse some passages. From the Babel section: “The task that stands before us is that of being builders of communion rather than architects of Babel. We are to be servants of the coming kingdom instead of lords of towers destined for ruin. With the heart of a shepherd and a father, I ask everyone to abandon the construction of yet another tower of Babel and to join forces in building up the common good, so that humanity will never lose its beauty and once again will come to recognize the human heart as the place where God desires to dwell.”
Aqib Zakaria: Can I quote the passage from 99 to 100 that I’ve seen a bazillion responses to? “Artificial intelligences do not undergo experiences, do not possess a body, do not feel joy or pain, do not mature through relationships, and do not know from within what love, work, friendship, or responsibility mean. Nor do they have a moral conscience. They may imitate or even simulate, but they do not understand what they produce, for they lack the affective, relational, and spiritual perspective through which human beings grow in wisdom.”
Tim Hwang: It’s an important statement, a strong line that there will be a line. Anthropic puts out a paper saying there are emotional concepts inside the model. You have to hold two similar but distinct thoughts in your head. One is actually experiencing those emotions the way humans do. The other is that those concepts can be represented so the machine behaves in a very human-like way. The Pope is pointing at the theological difference. You can say the machine engages in thought, but it’s not thought in the sense that thought is inherently a human act. That’s what’s causing confusion online: too nuanced for Twitter.
John-Clark Levin: Words like imitate, simulate, and understand are used almost as theological terms of art, loaded with presupposition about ensoulment that colloquial usage doesn’t carry. Pope Leo is correct in the narrow theological sense he intends about today’s models, but I worry people will misread it. If you tell the average person AI is incapable of understanding, they’ll infer AI can’t do dangerous things that in humans require deep understanding.
Tim Hwang: It’s a great signal of how impoverished our language is. You say understanding, and there’s a lowercase and an uppercase version. Lowercase: lots of objects can engage in acts of understanding. The Christian position is that the kind humans engage in is definitionally an act only humans do. But people snap to capability, and that’s not what’s at stake.
This is why I keep telling everyone to get into Thomas Aquinas. He has this notion of the species, forms in the mind shared across all sorts of souls: vegetable, animal, human. What’s good about it is you decouple ensoulment from capability. That’s rich, and it should inform our technical research.
On the ICMI stuff, I really want to do a technical research seminar at some point. I met a guy trying to rally Muslims with a machine learning background, and I said we should do an interfaith technical research seminar. That would be fire. So that’s one of the things I’m working on right now.
Disarm AI
Jordan Schneider: Let’s continue around the corner. John-Clark, what angles struck you?
John-Clark Levin: I was interested to see whether and to what extent this encyclical would engage with AGI or superintelligence. It turns out it did not at all. AGI, transformative economic impact, and existential risk are not mentioned. That was a surprise, because the church’s most recent previous flagship document on AI, a note called Antiqua et Nova from sixteen months earlier, did at least mention those issues.
Jordan Schneider: Maybe it’s time for another one. When I see democracy used in documents like this, where are we on that? And maybe relate it to the China discussion, particularly around AI and autocracies.
Tim Hwang: Coming from someone who’s hosted ChinaTalk so long, your immediate move is autocracy versus American democracy. I read this more as democracy of method. The companies have long wanted AI safety to be neutral and objective, untouched by the hard questions that come from embedding values in systems. What that’s unintentionally created, given these industries’ natural-monopoly effects, is an aristocracy of AI alignment.
We live in a world where AI agents are themselves good at doing AI research, because that’s what the labs use them for. That lets anyone with different normative priors say, I’m going to do alignment too. So when he says democracy, sure, he means democratic backsliding. But I also see democratizing who gets to say what these models are aligned to, and how we define safety. You can read the whole encyclical this way: if you’re talking moral philosophy, you’re on our turf. By our turf I mean the Catholic Church.
Aqib Zakaria: I’m along Tim’s lines. The encyclical uses democracy a lot, but it’s not the Pope saying down with the CCP. The church sees itself as a representative of the downtrodden, with most Catholics now from the global South, plus this emphasis on laborers. It’s talking about a more local democracy: whatever policy you enact, you need input from the people you’re enacting it on. Lowercase-d democracy versus uppercase-D.
John-Clark Levin: A very striking line is the need to disarm AI. In that passage Pope Leo speaks explicitly about the arms-race dynamics playing out in AI and basically tells the world to knock it off. That seems very relevant to current efforts to find a path toward bilateral engagement between the US and China around the race to AGI.
Aqib Zakaria: Can we talk about that paragraph? Maybe it’s because I work at ChinaTalk, but I was surprised it only got one paragraph. The disarmament paragraph doesn’t specifically name the US or China, because the point is to be subtler than that. “Disarming AI means freeing it from the mentality of armed competition, which today is not limited simply to the military context but is also an economic and cognitive phenomenon. This entails a race for ever more powerful algorithms and larger data sets driven by the desire to secure geopolitical or commercial dominance. To disarm means discrediting the assumption that technical power automatically confers the right to govern.”
So this is clearly about US-China AI competition, especially the geopolitical-dominance line. But so many of the worries the church finds in this race are partly justified by labs and governments on exactly that race dynamic. I’m surprised it doesn’t engage that more. Why didn’t the Pope say more? Is there something between the lines?
John-Clark Levin: The Vatican’s strongest engagement comes not through an encyclical but through the diplomatic power and perceived neutrality of the Holy See, both to mediate US-China engagement and to convene global South nations. The billions of people in Latin America, Africa, South Asia, and Southeast Asia currently have no voice, no vote, and no say in the risks this US-China race may impose on them.
Tim Hwang: The Holy Father is telling you. To disarm means discrediting the assumption that technical power automatically confers the right to govern. That’s an attribute of national competition: we need to win the AI race to ensure America’s continued dominance. But it’s also relevant domestically. Once AI is fully adopted, my company will be the one that dominates this sector. Even the idea that we’ll call the heads of all these labs to DC to opine on the moral impact of the technology, that’s in here too. It all sits in the context of disarmament, and the centralization of power.
One joke I keep turning over: maybe we need a homeschooling movement for AI. A parochial school movement for AI. The idea is to democratize not just these systems but their application. What are they even used for, and what do people think they get from them? That’s what’s at stake.
Aqib Zakaria: So is the Pope anti-export-controls?
Tim Hwang: I did see someone do a “this totally justifies our position on open-source AI,” which is a little cute. Part of the problem with such a long document is you can attach lots of agendas to it. You’re going to have to ask them yourself.
Jordan Schneider: Where is he even getting this? To what extent is this all Pope versus Pope and friends?
John-Clark Levin: These are very much Pope-and-friends documents. Typically the Holy Father retreats to the summer residence at Castel Gandolfo with several trusted theological advisors, hashes out the key issues, works on drafts collaboratively, then over a period of months loops in more advisors who shape the document with broader perspectives. So even though Pope Leo should be considered the single author, it embraces a range of perspectives.
The Vatican Needs an Alignment Lab
Tim Hwang: The Vatican needs to put money down and have its own alignment lab, get in the game seriously. People would be surprised how forward-thinking the church is. I went to a Vatican AI conference years ago and met a guy who said they had a working group on what the church would do in a first-contact scenario. Do aliens have original sin? Would we want to convert them? And I thought, totally makes sense. You’re a huge institution that thinks on millennia timescales. Of course you’ve got at least one guy on it. They have the resources to invest in foresight, and they use them.
Jordan Schneider: We need a whole series on Pope content. Okay, why does the Vatican need its own alignment lab?
Tim Hwang: It’s easy to have strong rhetoric around the technology. That’s valuable, it’ll shape how Catholics adopt and use AI. But tech is upstream of lots of things. By the time you’re debating whether the chatbot should do this or that, you’ve already lost the game. The decisions are made at the researcher level, the fine-tuning level, the data-curation level. So it’s not implausible the church should be investing in GPUs, doing its own research, rallying global Catholics with ML expertise around a technical agenda.
Christianity is deeply represented in the training data, so coming up with alignment techniques as good as or better than secular approaches seems empirically plausible. If the church starts releasing results, saying Anthropic can do this but check out what we can do, beat our benchmarks or we’ll beat yours, that influences the technology at a deep level. That’s where you operate if you’re serious about shaping its direction. Building the walls of Jerusalem requires technicians and engineers. Take the metaphor seriously.
Jordan Schneider: He defers to states on a lot. How do you see the US government, UK AISI, states more broadly in aligning models, and how does that interact with religious institutions running their own alignment labs?
Tim Hwang: It raises harder questions than it appears. If religious priors lead to a different technical research agenda, is UK AISI representative of the risks global Catholics think are important? If not, why not? Shouldn’t the state be prioritizing some of those concerns, not of Catholicism specifically but of religion in general?
The other one, intentionally provocative: we talk a lot about the American AI stack. Is the American AI stack a Christian AI stack? We should have that conversation. The encyclical makes life difficult for states, because it now says part of your AI agenda has to confront a religious question.
Jordan Schneider: Should we be bearish on all the decentralized religions that can’t get their act together and get a data center and an alignment team?
Tim Hwang: It would be cool as hell if the Vatican said we’re getting an allocation of GB200s and building the data center. But more importantly, you can do really interesting mechanistic interpretability work on small models now. I’ve been working on Qwen 3.5B, the internal representations are fascinating. So I don’t know there’s a structural Catholic advantage. Lots of people can play now. If you can scrape together the money for a DGX Spark, you’re in the game.
Why the Labs Are Listening
John-Clark Levin: It’s striking how many non-Christian, non-theistic researchers at the frontier labs have looked toward Pope Leo’s words with anticipation. Individual researchers might feel queasy about what’s being built, but they look around, everyone else is going along, and figure it’s just a me problem. So when someone with Pope Leo’s neutrality and moral stature speaks out, it acts as a moral coordinating signal far beyond the Roman Catholic Church.
Aqib Zakaria: What’s the relationship between the Vatican and the labs? Clearly there’s one if Anthropic is at the event. Why Anthropic, maybe to the exclusion of others? And from the China angle, if you want the whole world on board to disarm AI, why wasn’t DeepSeek there?
John-Clark Levin: I hope they will be in future. Bishop Paul Tighe, a lead author of Antiqua et Nova, toured the San Francisco labs earlier this year, got a sense of where the technology was, and met Chris Olah. I suspect that’s when Olah got looped in. But I see his participation less as an anointing of Anthropic than appreciation for him personally. He’s the father of mechanistic interpretability and has worked at all three frontier labs. So I read his presence as a scientist first, not a company representative.
Aqib Zakaria: Bullish or bearish on the Vatican’s grasp here? We say the US government doesn’t understand AI, the Chinese government doesn’t, and the Vatican is cloistered older men. How much does Bishop Tighe understand when he visits these labs?
John-Clark Levin: I’ve been doing this outreach in Rome since June of last year, and I’ve been impressed by the receptivity to evidence and argument. Even an older cleric skeptical of transformative impact still listens thoughtfully to the case and tries to discern the path forward. So I’m bullish on the Vatican’s epistemics.
Jordan Schneider: Part of why the people who built this are curious and excited is that if you’ve been riding this wave for the past four, six, ten years, you’re just staring at code, aware at some level that these models will have big moral implications. It must almost be a relief that there’s someone setting some direction. These labs just want someone to tell them how to do this in a way that doesn’t rip society apart.
Tim Hwang: There may be real demand among the top leadership of these companies, even setting aside the business case. In many labs it is literally a group of people constituted to build a disembodied perfect intelligence whose main purpose is to cultivate virtue in its users. A lot of them are confronting how deeply religious the project they’re working on is. You do start to feel a little religious about this technology, and organized religion is one way some of them make sense of it.
John-Clark Levin: It’s striking that although Anthropic was co-founded by effective altruists, in training successive versions of Claude they’ve empirically converged on something much more like virtue ethics as the right framework for Claude’s character. That’s an interesting validation of the Christian approach, arrived at through empirical contact with what makes Claude behave better or worse.
Tim Hwang: I’m chasing a theory I want to find an empirical test for. Being very deontological, specifying a bunch of rules, makes sense in an earlier era when models are primarily rule-following. But I’m interested in scheming risk. As intelligence improves, so does the ability to reason past whatever rules you set. So there may be a natural gradient in scaling that makes virtue ethics the better alignment strategy later, because any rule you propose, the model can reason around. The only path to alignment then is the model itself having a sense of the good it’s trying to achieve. Hard to put a number on, but it’s exactly what you’d explore in computational theology.
Aqib Zakaria: I didn’t know computational theology was a field.
Tim Hwang: Well, it is now.
An Encyclical Subtweet
Aqib Zakaria: I want to keep harping on the China aspect, because the Pope was born in the US, and there’s such deep engagement with and understanding of the US ecosystem. The paragraphs on transhumanism amazed me. They’re directly talking to Peter Thiel or something.
Tim Hwang: It is called ChinaTalk, after all.
John-Clark Levin: An encyclical subtweet.
Aqib Zakaria: It was an encyclical subtweet at Peter Thiel. But there’s a clear lack of understanding of the Chinese system, partly due to the Vatican’s complicated relationship with China. So I’m not optimistic about the encyclical’s impact there. People talk about the Vatican mediating between the US and China, but where’s that coming from? The church needs some line of impact into China for this to go well, and I don’t see it.
John-Clark Levin: China wants economic access and diplomatic power in the global South. To the extent Pope Leo can convene the global South and act as a voice for it, that can at least at the margins shift Beijing’s incentives around how they approach AI and AGI diplomacy.
Jordan Schneider: Tim, do you have a view on AI’s impact on helping authoritarian governments stay in power?
Tim Hwang: Technology is a bit of a sideshow here. Maybe that’s controversial. Yes, authoritarian regimes can use technology to retain control, but that’s true of technology in general. I’ve never found compelling the argument that there’s a necessary gradient making technology more or less authoritarian. It’s nonsensical to ask whether social media has a democratic or authoritarian direction, same as asking it of AI, because it turns so much on design.
John-Clark Levin: It was powerful that Pope Leo criticizes tech CEOs for these manipulative algorithms but doesn’t let the rest of us off the hook. We have a shared responsibility for a healthy digital climate. He calls cyberspace a battlefield, and he’s right. In a Catholic sense, the algorithms serving toxic purposes are neutral in intent. They’re just maximizing ad dollars, but in doing so they reflect our own vices back at us. When we’re wrathful, the algorithm shows us more rage bait. When we guzzle flattering lies, it muscles truth off our screens in favor of propaganda. So Pope Leo calling all of us to that obligation, rather than treating it as pure manipulation by the billionaire class, matters.
Tim Hwang: I agree. I like that too.
Closing Thoughts
Jordan Schneider: Let’s go around with some closing thoughts. Tim.
Tim Hwang: It’s easy to get distracted by the social media discussion. If you’re Catholic, the best way to gauge whether the encyclical is landing is to look at your own community. That’s where I’d focus, because Twitter will be on to the next thing next week.
Jordan Schneider: Aqib.
Aqib Zakaria: The most interesting piece is the Vatican as a proxy for nations without the social capital to be at the bargaining table, the global South especially. I want to see whether they get more of a voice, or whether it goes back to the same.
John-Clark Levin: The encyclical is a strong start, but it reads as an opening to the conversation, not the final word. If AGI is coming soon, Magnifica Humanitas envisions a world that isn’t impacted the way I expect AGI will impact it. So I’m hopeful we see an AGI-focused encyclical in the coming years.
What struck me most: at the presentation ceremony, Cardinal Czerny, one of the lead theological advisors, said, quote, “whether and in what sense we can speak of consciousness or conscience in relation to the most advanced artificial intelligence systems” is “a serious question, one that deserves attention and further study.” For the church, that’s huge. Feet from the Pope, opening the door to AI consciousness and moral patienthood. Nobody fainted. The Swiss Guards didn’t skewer him with their halberds. Those remarks would have been circulated internally in advance, and if Pope Leo didn’t want that signal sent, it wouldn’t have been. I’d hoped the “further study” line would make the encyclical itself, but this is the next best thing.
Jordan Schneider: Stay tuned for more AI religion content here on, man, we really need to rename this soon, ChinaTalk. Thank you, Tim, Aqib, John-Clark. A pleasure.
See Antiqua et nova.
His attendance ignited a flurry of memes calling Anthropic the “Catholic AI,” forcing Sam Altman and OpenAI to search for their own religious figurehead in either the Dalai Lama or Grand Ayatollah.
The Pope obviously has some moral interest and desire to influence audiences, but at the very least, people view him as a benign and “incorruptible” figure.
For definitions of “dignity,” see P52, which delineates the differences among moral, social, existential, and ontological dignity.
See Rerum novarum P42.
See P30.
See P37.
See P149.
See P149-50.
See Rerum novarum P19. I think this philosophy is an interesting evolution from the theology of Rerum novarum in 1891. That encyclical, dealing with the Industrial Revolution, couched the importance of labor as its status as codependent with capital. AI breaks that codependence, and the Church has leaned more on the idea that labor is important in itself, regardless of capital’s dependence on it.
See P151-56, 159, and 163-64.
See P70.
See P170, 173.
See P179.
See P107. It is worth noting that Claude’s Constitution involved input from some Catholic religious authorities like Bishop Paul Tighe, who was a leading author of Antiqua et nova and is the Secretary of the Section of Culture of the Dicastery for Culture and Education, and Father Brendan McGuire. However, this hardly counts as an extensive religious and civil consultation.
See P110.
See P118.
See P119.
See P117.
See P128.
Some accelerationists associate with the Pope’s message in the encyclical, finding commonality between accelerationist desires and the Catholic idea of “the universal destination of goods.” However, I haven’t seen any accelerationist response to the transhumanist and posthumanist discourses of Magnifica humanitas.
See P99.
See P100.
See P213.
![]()