ChinaTalk analyst yearns for the mines. He’s on a mission to visit rare earths and other critical minerals mining sites, refineries, and permanent magnet facilities around the world.
If you or anyone you know can help him fulfill this mission, please reach out to aqib@chinatalk.media.
Less than one in a thousand Chinese people owned private cars in the 1990s. But in 1993, a vehicle guided by a computer program landed on the floor of a car plant in Shenyang, capital of Liaoning province. Xianfeng 1 先锋1号 was the first of its kind in China, developed entirely by Chinese researchers.
The car plant had previously relied on American-made autonomous-guided vehicles, but the US tightened export controls in 1991 and cut off sales to China. The plant turned to the Shenyang Institute of Automation (SIA), an institution of China’s national academy, the Chinese Academy of Sciences (CAS). It was led by a scientist called Jiang Xinsong 蒋新松.
To the average person today, “AI” is synonymous with chatbots — or, at least, tools that exist only in the digital realm. Hardware manifestations, like humanoid robots or intelligent Roombas, are instead considered futuristic.
But “Chinese AI,” as an idea, did not necessarily begin with DeepSeek or tech companies in Hangzhou. It started on assembly lines in the Northeast, with dreams of intelligent oxygen furnaces for steel production and automated car plants. Some of the earliest champions of artificial intelligence research were not software engineers or information scientists, but those working shoulder-to-shoulder with factory workers.
As Chinese firms like Unitree became forerunners in the race to build autonomous robots, I grew curious about Jiang’s story. State media has dubbed him China’s “father of robotics.” His work — and what he would have conceived of as “artificial intelligence” — is substantively different from deep-learning-driven robotics today. However, the information scientist who petitioned Beijing for what arguably became China’s first industrial policy for AI was thoroughly ahead of his time.
Jiang is increasingly compared to figures like Qian Xuesen 钱学森 in official narratives. Qian, deported from the US under the Red Scare, fathered ballistic missiles and rockets; it is said that Jiang, who never left the country until later in life, did the same with industrial robots. These laudatory stories omit thornier, though more intriguing, parallels. Like Qian, Jiang’s life was one where science and politics were fair-weather friends.
The Road to Shenyang
Jiang Xinsong never expected to end up in the Northeast. Born to a common family in faraway Jiangsu in 1931, he entered Shanghai Jiaotong University — also Qian Xuesen’s alma mater — to study electrical engineering in 1951. After a high-achieving first year, he was sent to Beijing to learn Russian and prepare for study in the Soviet Union. But after a physical exam revealed tuberculosis in his lungs, he was forced to return to Shanghai. In 1956, Jiang graduated and started working at the Chinese Academy of Sciences’ Institute of Automation in Beijing, where he joined the newly-established computing technology group. There, he designed memory units for some of China’s first computers.1 He was a rising star of the national academy, working at the cutting edge by day and studying German at the Peking University library by night.
Shanghai Jiaotong University’s inaugural class of industrial electrification graduates, 1956. Jiang is seventh from the left in the top row. From Xu Guangrong 徐光荣’s Jiang Xinsong zhuan [Biography of Jiang Xinsong, 蒋新松传], page 76.
The good times didn’t last. Swayed by the permissive atmosphere of the Hundred Flowers Campaign, a young Jiang advocated for institutional reforms:
He supported making one’s dossier open to the person concerned, and once said: “The Soviet Pravda claims to represent the truth, but in fact a lot of what Pravda publishes isn’t true.” … After the Anti-Rightist Campaign began, he proposed that small-group meetings should not be minuted and should not be reported up the chain. He said: “The People’s Daily is accustomed to using the ‘Editor’s Note’ tactic to deal deadly blows to anyone being criticized.”
— Jiang Xinsong’s alleged transgressions, according to his “Rightist Registration Form” 右派分子登记表
Political winds at CAS immediately turned against him after Mao Zedong initiated the Anti-Rightist Campaign in 1957, and he was sent to rural Hebei for hard labor. Luckily, in December 1958, Jiang was summoned back to the CAS to work on automation research for industrial applications, since his field was deemed useful by the state. Officially, however, he was a “rightist” until 1963, blacklisted from promotions and unable to travel.
In 1965, 140 automation engineers were reassigned from various posts across China to Liaoning, with the goal of bringing new technological advances to the heavy industrial base there. Together with Jilin and Heilongjiang provinces, Liaoning is part of China’s frigid Northeastern region formerly known as Manchuria. Between 1932 and 1945, the region developed into an industrial powerhouse under Japanese occupation, supplying Tokyo’s war efforts with natural resources, heavy industry output, and railways.2
As WWII drew to a close, the Soviet Union invaded Manchuria in coordination with the US’s atomic bombings of Hiroshima and Nagasaki. Soviet forces occupied Manchuria until 1946, when the territory — and its remaining industrial resources — was transferred to the Chinese Communist Party. Upon its founding in 1949, the victorious People’s Republic inherited not only a liberated Northeast, but also a critically important industrial base that powered its earliest technological ambitions.
Jiang Xinsong was part of the 1965 reassignment cohort. For two years in Liaoning, he helped revive the remains of Showa Steel Works — a massive steel mill established under Japanese rule — in Anshan 鞍山, Liaoning, researching automation for the cold-rolling process. From the ruins of war, steel sheets were again pouring out of Anshan’s factories.
Dreaming of AI during the Cultural Revolution
For the first three years of the Cultural Revolution, much of non-political life in China ground to a halt. In 1967, the Anshan mill, too, paused production, and Jiang headed to Shenyang. At the SIA, checkered records from previous political campaigns meant he was subjected to brutal struggle sessions. But once again, he narrowly avoided being sent down to the countryside. In October 1967, the new “revolutionary committee” that displaced the mill’s old leadership summoned Jiang back to Anshan to maintain its reversible cold-rolling machine — the only one in China at the time.
Anshan shielded Jiang from political turmoil during the second, quieter phase of the Cultural Revolution, while many of his intellectual peers languished in remote countryside locales. On the rare occasions when he visited Shenyang, he and SIA colleagues Wu Jixian 吴继显 and Tan Dalong 谈大龙 often discussed new frontiers in industrial technology. In particular, they were fascinated by reports about the emergence of automated industrial robots in Japan, the US, and Europe. The three of them perused the SIA’s reading room for everything they could find on “artificial intelligence”: in the early 1970s, this was a muddled mix of neural networks, cybernetics, and computer-integrated manufacturing. MIT’s Joseph Weizenbaum had built ELIZA only a few years prior. Jiang, Wu, and Tan’s “AI,” gleaned through the handful of publications that made it into Cultural Revolution-era China, was worlds away from the models we know today. Rather than talking to chatbots, these steel-factory regulars were excited about using algorithms to operate manufacturing equipment.
In 1972, Jiang, Wu, and Tan drafted On Artificial Intelligence and Robotics 关于人工智能与机器人, a petition to Beijing to seize on innovations in the field and invest in general automation. They had drafted China’s first policy proposal for artificial intelligence.
Researching and manufacturing robots is the natural direction of automating equipment manufacturing, and is an important sign of a country’s strong and robust industrial development.
— Jiang Xinsong, Wu Jixian, and Tan Dalong, On Artificial Intelligence and Robotics (1972)
Armed with this petition, they headed to Beijing to persuade superiors at the Chinese Academy of Sciences. The CAS’s leadership was supportive, but constrained by political headwinds. In early 1973, the trio made another trip to the nation’s capital, courting more industries where advanced automation might be applicable. This time, they encountered pushback: many thought the concept of robots was closer to science fiction than reality and found them unserious.
Another major blow to their dreams came via the Criticize Lin, Criticize Confucius Campaign 批林批孔运动. This was a confusing phase within the Cultural Revolution, where activists merged posthumous criticism of former Vice Premier Lin Biao (dead of an infamous plane crash in 1971) with denunciations of Confucius in an attempt to reinterpret Chinese history according to Maoist ideology. The movement reignited political divisions in academia. After returning to Shenyang, Jiang, Wu, and Tan were variously labelled as pro-Western “establishment types” 小当权派, and “hat-off rightists” 摘帽右派 for their research.3 Radical students and scholars denounced AI and robotics as “idealist pseudoscience” 唯心主义伪科学 in magazines.4
Can “intelligence” be manufactured by “artificial” means? No, it can’t. … The term “artificial intelligence” gives idealism an easy loophole to exploit. If artificial things can create “intelligence,” then in the future something with “intelligence” even more advanced than humans is bound to appear. … Some of the academicians of the Soviet revisionist regime … are loudly promoting “artificial intelligence” … which fully exposes their traitorous true colors.
We must take a stand against Deng Xiaoping, … and in the struggle to criticize all kinds of reactionary ideological trends in the research fields of “image recognition” and “artificial intelligence,” we must follow our own path.
— Excerpts from Selected Translations of Foreign Writings on Philosophy of Natural Science 《摘译外国自然科学哲学》, a Cultural Revolution-era magazine about the philosophy of science which circulated among radical scholars.5
China’s earliest experimentations with AI and robotics were thus nipped in the bud. Unlike the Soviet scientists whose records survived to Perestroika, we do not know how Jiang and his colleagues felt during these years. Jiang’s biographer Xu Guangrong 徐光荣 borrows the term “dancing in shackles” to characterize the period. Historical records are otherwise thoroughly sanitized; everywhere he is quoted, Jiang is resilient and grateful, never once resenting the Party, the academic system, or his fanatical accusers. Official history paints the picture of a patriotic scientist who, despite force majeure adversities, always remained buoyant with hopes of serving his country one day.
But can we read between the lines? How devastating it must have been to have your life’s work stretched out by a decade, delay compounding delay; to watch the nation to which you are supposedly deeply loyal squander opportunities to seize technological advances; to have your research papers presented by others at international conferences because you were forbidden from travelling. One can only imagine what private dreams sustained scientists of his generation.
From Engineer to Strategist
With the death of Mao in 1976, the Cultural Revolution came to a close and normal academic activities were soon restored. Jiang and his colleagues quickly returned to their posts. Artificial intelligence and robotics became official research areas at the SIA. After a wasted decade, the CCP’s new, reform-minded leadership turned its mind to the global scientific race. A massive group of more than 1,000 scientists convened by the Party drafted the 1978-1985 All-China Science and Technology Development Planning Outline (1978-1985 年全国科学技术发展规划纲要) in 1978. The landmark document made some of the earliest mentions of intelligent machines in the history of Chinese policy:
Modern science and technology … is undergoing a great revolution. In particular, the development and application of electronic computer technology has enabled machines not only to replace certain forms of human physical labor, but also to take over some functions of mental labor, becoming auxiliary tools for memory, computation, and logical reasoning.
No longer was AI “idealist pseudoscience”: Beijing was finally endorsing scientists to embrace promising new ideas, unshackled by ideology. Meanwhile, Jiang Xinsong finally managed to leave the country for the first time. In August of 1979, he was part of a small Chinese delegation that attended the Sixth International Joint Conference on Artificial Intelligence (IJCAI 79) in Tokyo.
Japan at that time was a world leader in robotics and industrial automation. Jiang paid attention not only to their cutting-edge technologies, but also to the political and social institutions that enabled innovation. Having spent his entire career inside the CAS in one form or another, he was deeply attuned to the symbiotic relationship between institutional design and scientific innovation. As a young researcher, he paid a heavy price for supporting reforms; decades later, he finally had a chance to influence the institutional future of Chinese science. In his post-trip report to the SIA, he described how robotics research and development in Japan was not concentrated in universities, but also conducted robustly by research institutes and private enterprises. In his words, there was an efficient “division of labor” system in Japan’s robotics field: universities and specialized institutes engaged in basic research over longer periods of time, the Ministry of International Trade and Industry funded application-oriented research with 5-10 year horizons, and the private sector focused on commercializing market-ready technologies. Jiang paid as much attention to the workings of this system as he did to the research papers.
Many of China’s most prominent scholars from that generation became scientist-strategists, if not technocrats. Having weathered years of political campaigns and anti-intellectual rhetoric, with constant reminders to express loyalty, they worked closely with the Party-state system. Two things are likely true at once: (1) they both sincerely believed their work to be strategically valuable to their country, and (2) knew how to speak the language of the Leninist regime in order to bend political winds to their advantage. Qian Xuesen’s generational legacy lay not only in the rockets he designed, but also in the hand he had in shaping China’s defense complex. Similarly, Jiang Xinsong, whenever he could, advocated for industrial policies to stimulate automation research throughout his life.
The 1980s were the height of Jiang’s academic career. His writings from this decade were often theoretical, seeking to convene emerging threads of advances in robot manipulation, cybernetics, and artificial intelligence. As one of a small handful of Chinese scholars closely following developments in AI and automation, he introduced American, European, and Japanese research to Chinese academics through his prolific writing output, pushed back against skepticism, and advocated for engagement with then-nascent fields in Chinese academic journals. These contributions were also frequently followed by concrete recommendations for research and policymaking, downstream of his observations of factory lines and laboratories.
Jiang Xinsong’s SIA team completed China’s first industrial robotic system in 1982. The SZJ-1 playback robotic manipulator (SZJ-1型示教再现机械手) was the first robotic arm to be deployed to Chinese assembly lines, and marked a watershed moment in China’s race to catch up in industrial automation. In March 1986, Jiang completed an influential journal article titled “Research on the Development of Robots in Foreign Countries and Our Response.” In it, he offered a broad picture of robotics’ development around the world, diagnosed China’s challenges, and proposed six strategies for catching up. Revisiting the article today, one realizes how influential his thinking was to the trajectory of China’s automation development.
Jiang appears to have believed strongly in process knowledge. He pushed back against the idea that automation wasn’t valuable to a country with incredibly cheap labor that mostly made low-end products. Given market logic, he argued, equilibrial “match points” justifying investments in automation will eventually emerge in the industrial upgrading process. In the meantime, China needed to gain experience by mass-manufacturing cheaper robots, emphasizing parts over entire machines, and exploring automation for specialized scenarios.6 Writing just seven years into the One Child Policy campaign, he foresaw that China would eventually need to contend with labor shortages, particularly in dangerous occupations like mining; in fact, some of his engineering research during this period was addressing the challenges of using robots in undersea operations.
The SZJ-1 playback robotic manipulator deployed officially on June 19, 1982. Playback robot arms record their own movements while guided by humans (either literally, by grabbing it, or remotely through a controller), then repeat those actions on their own, therefore “learning” the intended trajectory. (Source.)
At the Helm of Automation
Jiang was swiftly given an opportunity to execute his vision through the 863 Program. In the 1980s, after two decades of the US-Soviet scientific rivalry, it was clear that technology was inseparable from national power. Chinese scientists watched as the United States announced its Strategic Defense Initiative (“Star Wars” program) in 1983 and the Eastern Bloc began the Comprehensive Program for Scientific and Technical Progress in 1985.
The same month Jiang finished writing “Research on the Development of Robots in Foreign Countries and Our Response,” scientists Wang Daheng 王大珩, Wang Ganchang 王淦昌, Yang Jiachi 杨嘉墀, and Chen Fangyou 陈芳允 directly petitioned General Secretary Deng Xiaoping to direct more funds towards scientific research, lest China be left behind. (They skipped official channels and had Deng’s son-in-law, who worked at the CAS and was an acquaintance of Wang’s, deliver the letter by hand.) Deng approved the petition in just two days, instructing Premier Zhao Ziyang to implement “without delay.”
In scholars Qiang Zhi and Margaret Pearson’s account, the “863 Program,” as the ensuing mega-initiative for applied research came to be known, was an institutional innovation inside the Party-state system. It was insulated from political winds; technology goals were specifically defined; and scientists, not politicians, had decision-making authority. The Program was guided by a single office under the State Council, which then coordinated scientist groups for each of the Program’s thematic focus areas. Funding for the Program was unusually concentrated and abundant. The total amount Deng earmarked for the 863 Program, to be distributed over the course of 15 years, was more than 10 billion RMB (around US$8 billion in 2026 dollars), equivalent to 5% of China’s entire government expenditure that year.
The SIA’s robotics “demonstration project” laboratory buildings, completed in 1990. From Xu Guangrong’s Jiang Xinsong zhuan [Biography of Jiang Xinsong, 蒋新松传], page 228.
Jiang Xinsong advised the architects of the 863 Program on the field of automation for much of 1986, and in 1987 he was officially invited to be one of the Program’s seven chief scientists. His portfolio included computer-integrated manufacturing (CIM) and “smart robots” for industrial settings.7 The SIA remained the institutional home for much of this work. Armed with political legitimacy and funding, it produced a range of technical breakthroughs for the PRC in the ensuing decade. Jiang himself also initiated some influential technology transfer during this period. In 1993, he helped facilitate the import of twenty welding robots from Yaskawa in Japan. Paired with the SIA’s own controllers, these robots ended up in factories throughout China and accelerated uptake for automation.8
Though the 863 Program gave Jiang extraordinary influence, China’s industrial policy leapfrog did not entirely resemble his hopes for AI from back in 1972. Notably, the Program institutionalized robotics’ split from artificial intelligence, reflecting global trends at the time. The “AI winter” was descending, and robotics research continued to develop in a “classical,” engineering-driven direction. Within the 863 Program, robotics was placed into a different thematic focus area, away from computing and information science. It would take until the 21st century’s deep learning revolution for these two diverging threads to reunite.
In the 1990s, while progress continued in robotics, Jiang Xinsong was becoming worried about the future of China’s traditional industrial base. He had spent most of his career in China’s capital of heavy industry. Reform and Opening Up exposed the entire Northeast, including Shenyang, to market-based competition, and Beijing pushed forward with structural reforms under Jiang Zemin, resulting in mass layoffs. The region’s industrial identity, first forged almost a century ago under Japanese occupation, was under existential threat.
Jiang, who by now was well-travelled, looked to the West for answers. Towards the end of his life, he became an advocate for agile manufacturing, a concept first proposed by American industrial leaders in 1991. Agile manufacturing describes an approach where companies organize their assembly lines, stock, and workers in a modular fashion, so that they can respond to quickly-changing demand and produce highly varied products within one system. Designed for a world of highly personalized products, it allows designers to iterate quickly and factories to pivot production as needed. Jiang believed agility to be the key to adapting China’s old industrial base for the future of automated production, and delivered lectures drawing from American manufacturing research throughout China.
Jiang at work, undated. From Xu Guangrong’s Jiang Xinsong zhuan [Biography of Jiang Xinsong, 蒋新松传], page 19.
By the time he died suddenly of heart failure in 1997, the “world’s factory” was coming into being. It’s an ironic fact that in the end, visions first articulated by Target and AT&T executives (and funded by the Department of Defense) would be realized most fully in Shenzhen.9
Towards China’s Industrial Robotics Revolution
As of 2025, more than 2 million robots are now deployed in Chinese factories, with domestic manufacturers selling more units in the country than foreign competitors in the last two years. One of the top Chinese manufacturers powering this transition is Siasun Robotics, based in Shenyang and affiliated with the CAS. Its founder, Qu Daokui 曲道奎, was Jiang Xinsong’s student and named the company — Siasun in English, and 新松 xīnsōng in Chinese — in his former advisor’s honor. Siasun became the first robotics company to trade publicly on the Shenzhen Stock Exchange in 2009.10
It’s easy for observers today to assume a sharp break with the Maoist past when interpreting China’s technology governance, seeing as many of the technologies most relevant today did not proliferate before even the Xi Jinping era. Jiang Xinsong’s story reminds us of the ghosts in the closet. China was not always strong, and the PRC’s leaders did not always look favorably upon its scientists. Periods like the Cultural Revolution cannot be explained away as exceptional aberrations; they, and reactions to them, scarred the generation ruling China today and shaped the institutions that now govern knowledge production. Chinese science has always danced a delicate duet with the state. Politics is a shackle, but also an incentivizing structure. AI, rather than fundamentally altering these relations of power, is likelier to simply reanimate them.
With thanks to Jasmine Sun and the ChinaTalk team for editorial feedback!
“Idealism” (唯心主义 in Chinese) here refers not to the opposite of pragmatism, but rather an ontological principle where minds and mental states are the primary determinants of reality. Marxist thinkers generally oppose this and adhere to the opposite: materialism, which argues that being is more important than thinking and material condition determine the course of history. The Chinese Communist Party is officially opposed to idealism; this is the main ideological reason behind its disapproval of religion, for example.
CIM refers to using computers to control every part of the manufacturing process. This approach paved the way to “dark factories” today, which operate with minimal human supervision.
recently declared the death of partying, finding that Americans spend significantly less time attending social events than they did twenty years ago. The largest decline — by almost 70% — occurred among people aged 15-24. Thompson offers a sophisticated analysis based on post-1970s individualism, gendered labor economics, and smartphones.
But he was far too nuanced. The single threat decaying Americans’ social lives is the Chinese Communist Party.
Last week, the Chinese Ministry of State Security published a bombshell report on its official WeChat account: the United States government secretly funds think tanks to push “lying flat” (躺平) upon Chinese youth, brainwashing them into believing that “working hard is for losers.”
But while Brookings was busy influencing Chinese twenty-somethings, China’s government was not sitting idle. An exclusive ChinaTalk investigation has uncovered Beijing’s quiet counter-offensive: a two-front campaign to foment loneliness abroad and good vibes at home.
Sabotage Stateside
Suppressing American partying required a surgical institutional intervention executed at scale: the resident advisor. By penetrating higher education institutions, Ministry of State Security (MSS) agents have introduced the concept of RAs or fudaoyuan. These agents of the administration are tasked with patrolling dormitories to remove all items potentially conducive to vibrant social lives. They drew from America’s proud history of Prohibition, adapting adapted the new RA system to exclusively focus on confiscating alcohol. The RAs, Dan Wang has confirmed, are the perfect adversary for a lawyerly society. Every instinct to host, mingle, or even leave the apartment now generates potential liability.
The campaign extends beyond the dorm. Cigarettes once forced strangers into proximity. The MSS’s masterstroke was the introduction of vaping: a Shenzhen-engineered substitute that delivers nicotine without forcing the user into social contact for a light or loosie. While exporting vapes abroad, the MSS has limited their ability to gain traction at home. Domestic Chinese smoking, largely conducted via traditional cigarette and therefore still social, remains among the world’s highest.
Recent American college grads, socially debilitated by the COVID-19 pandemic, vapes, and the pernicious RA system, have now entered the adult world. Instead of making friends, they’ve turned to obsessively polishing their appearances, all at the cost of American national security. “Mogging” could plausibly even be a Chinese loan word: mo jing means “to grind down the neck” in Mandarin, precisely the beauty practice preferred by certain Gen-Z leaders.
Catch Up and Surpass America’s Parties
China appears to be a relative latecomer to the global party scene, as decades of poverty and Maoist conservatism don’t form fertile ground for letting loose. But the Chinese archaeological record speaks to the civilization’s latent party power: every courtyard in the Forbidden City is outfitted with a giant bronze vat, expressly, scholars now believe, for punch-mixing.
The CCP understands that an ample domestic party supply not only strengthens regime security but also augments the future of China’s development. As Xi declared at the 20th Party Congress: “without the Party, there can be no party” (没有党就没有派对). Beijing understands that partying power is zero-sum. In Xi’s New Era, there can only be one fun hegemon.
The intellectual architect of this campaign, ChinaTalk has learned, is Wang Huning. His foundational 1991 text America Against America identified American sociability as the central pillar of US hegemony. A draft sequel circulating among Standing Committee members, Vaping Alone, reportedly argues that an atomized America cannot project soft power and may very well suffer social collapse. This thesis has shaped both the domestic Common Partying initiative and a parallel covert program targeting American campuses.
The campaign reflects Beijing’s mastery of asymmetric demographic warfare. AI is on track to eliminate entry-level white-collar work in both countries, and the CCP has learned through painful lessons from the Cultural Revolution to Tiananmen that bored and jobless youth are the single greatest threat to regime stability. The Party’s domestic response, rolled out as “Common Partying” (共同狂欢), keeps Chinese youth so occupied with elaborate weekend gatherings that they fail to notice the disappearing ladder of prosperity. And it seems to be working. While the portion of American Gen-Z who drink has dropped to a concerning 62%, rates of alcohol partaking among the same age group in China over the past two years rose from 66% to 73%.
This is no accident. A 2026 NDRC directive assigned each major city a designated nightlife specialization aiming to close what one Tsinghua working paper identified as China’s persistent “vibe deficit” with the US. Notable local developments include Hefei, long the dour engineering capital of Anhui, which has been instructed to quadruple its “post-ironic warehouse rave” capacity by 2027.
Shenzhen plans to leverage its hardware supply chains toward indigenous DJ equipment substitution, ending decades of Japanese dominance in the global CDJ market. Huawei has been tasked with developing a sanctions-proof alternative to the Pioneer CDJ-3000.
And Kunming’s tropical microdosing pilot zone, which began as a blood oath among eighteen Yunnan households, has since been elevated to provincial demonstration status. It is now receiving 2 billion yuan in subsidies under the “Made in China 2030” framework for indigenous psychedelic substitution.
Patriotic Gen-Z Chinese are turning their apartments into cocktail bars and hosting tipsy PowerPoint presentations.
What Is To Be Done
With both top-down guidance and bottom-up innovation, China is enacting an “abundance agenda” for party vibes. American legislators must respond in kind. Encouragingly, the Trump administration has begun to grasp the strategic stakes. President Trump’s April 18 executive order Accelerating Medical Treatments for Serious Mental Illness, which granted Breakthrough Therapy designation to specific psychedelic drugs, represents a critical first step in closing the deficit.
But $50 million in psychedelic research matching funds is a rounding error against the scale of the threat. America invented LSD and got the CIA to conduct its own Phase 1 trials. In the same decade, we put a man on the moon and a tab on every undergraduate’s tongue. And now we are now on the verse of losing the psychedelic frontier to Kunming.
A fun gap is opening between the US and China. America’s competitive advantage in the 21st century will not be decided in TSMC’s fabs, by Anthropic’s models, or Anduril’s drones. It will be decided at 11pm on a Saturday, in a kitchen, near a blown out speaker. The Pacific Century belongs to whoever is still willing to leave the house.
ChinaTalk does not endorse overconsumption of substances known to be harmful to health, including cigarettes, alcohol, scheduled drugs, and substack sunday funnies satire.
To receive new posts and support our work, subscribe!
Finally, DeepSeek V4 is here. The Pro and Flash models are available through DeepSeek’s website, mobile apps, and API access as of April 23, and the lab has also released its technical report.
Bucking a recent trend of Chinese AI labs moving away from open source, V4 was released under the highly permissive MIT license. It performs admirably on various benchmarks and leads the pack of Chinese open models, but did not close the gap with closed models from the US, with the authors themselves admitting in the paper that V4 is “3 to 6 months behind” state-of-the-art frontier models (though we think it feels further). And as we will discuss later, while its architecture shows progress towards indigenizing the Chinese stack, the model probably still relied on Nvidia GPUs.
Is V4 a letdown? Today on ChinaTalk, we bring you our takes alongside those from Chinese observers on:
Troubles at the lab prior to V4’s arrival;
Why DeepSeek’s idealism may not hold;
What V4 did — and did not — achieve with domestic hardware;
And why DeepSeek’s symbolism persists inside China, even after it lost the frontier
Translations were drafted with the assistance of Claude Opus 4.7, and then edited for accuracy and fluency. Bold markings added by the editor.
How V4 Got Here
Chinese tech journalists have doggedly followed the DeepSeek story. Zhou Xinyu 周鑫雨 of 36Kr, a prominent Beijing-based tech news outlet, has some behind-the-scenes scoops.
The reasons behind [V4’s] belated arrival are related to migrating its training framework from NVIDIA to Huawei Ascend, as well as to internal decision-making changes at DeepSeek. We learned that in mid-2025, DeepSeek ran into a relatively serious case of training failure.
“At the time, DeepSeek was facing the problem of re-adapting to chips,” one insider mentioned. “Internally, opinions on the direction of training were not entirely unified. Liang Wenfeng put forward some of his own demands, but it was difficult to find compromises at the execution level.”
However, contrary to outside speculation that the new model might support multimodal generation and understanding, V4 remains a language model. The decision to postpone multimodal generation training stems mainly from constraints on computing power and cash.
Multiple insiders told AI Emergence[a 36Kr sub-brand focusing on AI] that DeepSeek’s external financing window opened in mid-April 2026. Internally, the trigger was that DeepSeek needed more funding to train models with larger parameter scales, while also retaining and recruiting more top-tier talent.
Shanghai-based news site The Paper 澎湃新闻’s Fan Jialai 范佳来 compiled a comprehensive roundup of DeepSeek’s talent losses, losing core contributors to Tencent, ByteDance, Xiaomi, and DeepRoute.ai. “Across multiple areas — foundation large language models (LLM), agents, text recognition (OCR), multimodality, and more — DeepSeek has suffered losses of core talent.”
DeepSeek operates with the ethos of a frontier lab. Back in November 2024, we translated an interview with CEO Liang Wenfeng, done by Lili Yu 于丽丽 of Chinese media outlet Waves 暗涌. In it, Liang explained that DeepSeek was uninterested in product development, and that their goal has always been “AGI.” It was why, instead of adopting Llama architecture, they poured resources into the new model architectures behind R1. On why research, rather than products, was their raison d’être, Liang remarked:
For many years, Chinese companies are used to others doing technological innovation, while we focused on application monetization — but this isn’t inevitable. …
We believe that as the economy develops, China should gradually become a contributor instead of freeriding. In the past 30+ years of the IT wave, we basically didn’t participate in real technological innovation. We’re used to Moore’s Law falling out of the sky, lying at home waiting 18 months for better hardware and software to emerge. That’s how the Scaling Law is being treated.
But in fact, this is something that has been created through the tireless efforts of generations of Western-led tech communities. It’s just because we weren’t previously involved in this process that we’ve ignored its existence.
In this way, its closest American approximation might be OpenAI in its pre-ChatGPT Microsoft days: mission-driven, amply funded, and committed to nonprofit development of the AI frontier. If early OpenAI’s animating force was safe superintelligence, DeepSeek’s was a combination of AGI ambitions, open-source idealism, and national pride.
In the latest sense, it succeeded: DeepSeek became China’s national champion for LLMs. But that designation, and its founder’s high-minded aspirations, bogged down its research potential. Liang did not ride the DeepSeek wave in early 2025 — like Sam Altman did for ChatGPT — to build a scaled consumer product. Instead, he focused his team’s energy exclusively on the “hardcore research” he made his name on. By not building a revenue-generating business over the past twelve months or partnering with a Chinese hyperscaler, Liang bled talent and lost the lead he had over his domestic competitors.
More than any other lab, DeepSeek shouldered expectations to produce the proof-of-concept for Chinese-made chips, rather than follow other labs by relying on smuggled chips and Nvidia cloud compute abroad. This cost it financial runway and talent, and probably led to a failed training run that delayed V4 by months. The aforementioned 36Kr story reports that over the past year, DeepSeek recruiters were seen lurking the dorms of Peking University in search of Chinese majors to staff a new marketing unit.
Liang Wenfeng attending a session with Premier Li Qiang on January 20, 2025. Source.
After R1 came out in 2025, Jordan and Kevin Xu of Interconnected speculated on a podcast episode that DeepSeek, in the near future, could be lured by deals with hyperscalers or some other deep-pocketed entity. They were prescient. Per 36Kr:
As for the external trigger for pivoting toward open financing, several industry insiders speculate that it is related to the investment stance of a certain major company. Before opening DeepSeek up for financing, Liang Wenfeng and the top leader of that company had held several rounds of discussions regarding exclusive investment. But according to two sources connected to the matter, Liang Wenfeng did not agree to that leader’s condition of giving away a 20% stake.
With V4 out now, DeepSeek is in the throes of a dilemma that cuts to the center of its tripartite mission. While OpenAI’s large-scale marketing of consumer and enterprise products smoothed its transition into a for-profit company, DeepSeek missed out on a golden period of market development inside China. Between V3 and V4, ByteDance’s Doubao became China’s most-downloaded chatbot; vertical-specific AI products — like Alibaba’s health app Afu — achieving groundbreaking success; and MiniMax and Z.ai, two pure-play model makers, went public and broke into international markets. DeepSeek, arguably, came late to realizing the importance of revenue under the Chinese market’s capital constraints.
When we examined DeepSeek’s lack of a path to profitability and the enormous political pressure it had begun to shoulder, we thought the lab’s tragedy might have been foretold. Fast forward to now, and the 36Kr story just declared the “post-DeepSeek era”. A Qwen employee told 36Kr that “the golden age of nonprofit AI development is over.” But the article also acknowledges that DeepSeek, in just one year, shaped China’s AI landscape. Beyond its model architecture innovations and the open source ethos, its flat internal hierarchy, focus on emerging talent, and AGI-inflected open research culture have all influenced management decisions at other labs hoping to replicate its success.
American Training, Chinese Inference?
V4, ultimately, was still trained on Nvidia chips. However, Huawei on April 24 confirmed that its own Ascend supernode cluster will be able to support V4. Earlier this month, DeepSeek did not give Nvidia and AMD early access to V4, perhaps superficially signalling distance from Western chipmakers. Popular tech blogger Digital Life Kha’Zix 数字生命卡兹克 examined V4’s technical report, and returned with four observations regarding how the model was optimized for Chinese-made hardware.
V4 has introduced MXFP4 into its post-training and inference systems.
Although training still uses the NVIDIA ecosystem, using MXFP4 in post-training and inference essentially means that DeepSeek is moving toward open low-precision formats and multi-hardware adaptation. It can adapt to domestic chips such as Huawei Ascend, Cambricon, Biren, and others, reducing its reliance on NVIDIA’s FP8 ecosystem — especially during inference. That would make it a genuine domestically-produced model running on a domestic ecosystem. …
V4’s underlying kernels are no longer written entirely in CUDA, but instead in a domain-specific language (DSL) called TileLang. DeepSeek hopes that low-level operator development won’t be completely locked into CUDA, but will instead use a higher-level language to describe computations and then compile them to different hardware as much as possible. This is seriously impressive and can greatly reduce migration costs.
V4 has specifically developed a fused kernel called MegaMoE, designed to reduce communication waiting in expert parallelism. It has already been successfully run on Huawei Ascend.
Putting these three points together, the direction is crystal clear: V4 is, from top to bottom, a model designed for domestic chips.
This really isn’t some patriotic story. Everyone knows how scarce computing power will be in the future, how slow computing power production is, and—under the acceleration of Agents—how terrifying the token consumption will become.
With computing power being choked off, no one has any good options. Just look at how a model as excellent as GLM-5.1 has been limited by inference compute.
The computing power game is, in many ways, a top-level geopolitical game.
DeepSeek V4 is the reality forced into being by this computing power struggle.
There was a curious footnote attached to DeepSeek’s official announcement of the V4 models:
Due to constraints on high-end compute, V4-Pro’s service throughput is currently limited. Once Huawei’s Ascend 950 supernodes ship in volume in the second half of the year, Pro’s pricing is expected to drop significantly.
The compute story probably demonstrates that Chinese models like DeepSeek will fall further and further behind Western counterparts. Western models are increasingly being trained and run on Blackwells and eventually Rubins, which can support FP4 numerical precision, effectively double the compute from previous generations that can only go to FP/INT8. DeepSeek has been stuck using old Hoppers, which only go to INT8; to have any chance of catching up, they will have to pray Huawei’s Ascend 950, which supports FP4, will be produced in sufficient numbers. According to Reuters, Huawei plans to ship 750,000 of their Ascend 950PR this year; for reference, that is just one week of quality-adjusted American chip production.
“The People Long for DeepSeek”
When the “DeepSeek moment” arrived in 2025, it didn’t only represent indigenous technical capabilities for China. For some developers and average people, it also meant having genuinely affordable access to frontier AI for the first time. American frontier labs have always restricted chat and API access in mainland China, and while many Chinese users found ways around the firewall anyway, DeepSeek was a model they could use with no fuss and, for a brief window, nearly comparable performance.
But after a year, there are now far more domestic models for Chinese users to choose from, embedded into many real-life applications. Meanwhile, OpenAI and Anthropic seem to have cemented their lead. With soaring demand and mounting financial losses, AI companies have no choice but to offload more costs onto paying customers. Fewer and fewer people can afford to extensively utilize frontier models. China’s OpenClaw craze earlier this year showed many people the true costs of AI, as their home-cooked agents guzzled tokens and left them with expensive bills.
A meme about how expensive it is to “raise lobsters”. Source.
In 2017, blogger Fang Hao 方浩 published a viral article titled “The People Long for Zhou Hongyi”. Zhou was the founder of security software firm Qihoo 360 and a famously pugnacious figure in China’s tech industry. Written at a time when Alibaba and Tencent were consolidating their monopolistic positions in e-commerce and social media, Fang couched pessimistic future predictions in irreverent humor: as Chinese Big Tech cannibalized opportunities in the private sector indiscriminately, it would leave average consumers worse off.
Last month, Su Yang 苏扬 of Tencent’s tech media blog wrote a sequel: “The People Long for DeepSeek”. He pushes back on Jensen Huang’s “tokenomics” rhetoric:
When token usage costs can’t be brought down, and when the effective return on investment remains unclear, aggressively pushing token consumption — even tying it to performance reviews — amounts to manufacturing token anxiety. Calling it manufacturing AI anxiety wouldn’t be an overstatement either.
Looking back a bit further, Jensen Huang also called on tech industry leaders to speak prudently and avoid stoking irrational public fear of AI technology. That’s essentially telling the whole industry: stop suppressing AI by manufacturing panic — you all need to keep the tokens burning.
But the question is, who’s going to solve the price problem? Will it be the long-delayed DeepSeek V4?
Su expands on the price issue in a follow-up post. While he is ultimately optimistic about the future of competitive innovation in China’s AI industry, he thinks DeepSeek will no longer be a singular flagbearer:
Broadly speaking, in 2025, China’s open-source forces reshaped the global AI landscape. By 2026, China’s AI development has entered a stage of exporting capabilities.
From the perspective of the global AI industry, the diversification of technical pathways has invigorated talent mobility and strengthened supply-chain resilience. For downstream application developers, having multiple suppliers to choose from means greater bargaining power and lower lock-in risk.
Another encouraging feature of China’s AI narrative is that the market has yet to be monopolized by a handful of oligopolies — a positive sign for competitive innovation and talent-ecosystem building, and one that also helps build cluster-level advantages in the U.S.–China AI competition.
…
In the landscape of full-ecosystem competition, DeepSeek — whose principles generate its force, with breakthroughs at the foundational layer — still holds advantages, but its weaknesses are equally clear: it lacks the industrial ecosystem support of an IT giant, its product application features are relatively thin, and its multimodal and agent ecosystem still need strengthening.
Is Coding the Way Forward?
V4’s coding capabilities have grown significantly, potentially signalling that DeepSeek, after the success of products like Claude Code, also sees promise in coding agents. Programming blogger Large Model Observer 大模型观测员 tested V4 on software engineering projects, finding two pros and two cons:
First, broad programming knowledge. Across the four engineering projects [that the author tested V4 with] extensive niche-domain knowledge is essential. Without it, you can end up unable to fix even simple bugs, such as a macOS application failing to display its window properly because the storyboard wasn’t correctly configured. V4’s knowledge base essentially covers these less mainstream areas, and when faced with various edge cases, V4 Pro can pinpoint the root cause of a bug directly rather than guessing — much like GPT and Opus. … V4 Flash isn’t far behind Pro on broad-strokes knowledge; Flash mainly falls short in edge-case knowledge and tends to be stumped by non-obvious bugs.
Second, low hallucination over long context. Because the engineering tests use a mode in which features are layered on round by round, the later rounds often require the model to re-read the entire project and locate every related detail when a global modification is requested. This is no problem for the likes of GPT/Opus, but it’s a real hurdle for domestic Chinese models. V4 Pro and Flash, at the high and max tiers, can essentially maintain a quite low hallucination level, with bug rates in downstream flows over long codebases still kept low.
Third, occasional lapses in attention. When projects are large and requirements are many, V4 Pro at the high tier — constrained by its thinking-budget allocation — has some probability of randomly dropping certain implementation details. The saving grace is that with a reminder and one or two rounds of self-testing, the issues can almost always be fixed. …
Fourth, an unfussy approach to architecture and UI. V4 largely inherits DeepSeek V3’s thinking on architectural design — not particularly tasteful, not refined, but not slapdash either: the layering and decoupling that ought to be there will be there. It can’t deliver the kind of polished, clearly master-crafted architecture you see from Opus at a glance. UI is the same story — direct output isn’t outstanding, with the occasional touch of refined expression, but most of the time it’s just at the basically-usable level. The high tier can occasionally have an even lower floor, with insufficient consideration. If the development workflow includes a design spec to follow, this is not a big issue. But for pure vibe coding, getting a satisfactory result requires a lot of rerolling.
Could V4 do for AI coding what V1 and R1 did for LLMs — democratize access to the frontier, especially for the Chinese user base? It’s not impossible, but the model faces ample competition among open-source peers. A quick comparison of leading Chinese open models’ token prices, in RMB:
DeepSeek’s prices are competitive, if not an obvious standout. BusinessAlert 知危 summarized it as such:
By now, users are no longer impressed by chain-of-thought. At most, it’s an engineering technique that boosts accuracy by throwing more compute at the problem, and in coding-agent scenarios it’s probably ignored most of the time.
The ceiling of [V4]’s capability makes it unlikely to play a leading role in real-world programming tasks, and as an executor it’s too slow. … All in all, from the perspective of the cases we tested, DeepSeek V4’s performance wasn’t as good as expected, and its capability seems not particularly stable either. But then again, the official technical report itself openly states that there’s still a gap between it and top closed-source models, and that this update merely narrows that gap — so the result isn’t surprising.
Still, as the saying goes: take another look at the price. It’s this cheap — you can put up with it.
While the Chinese-open-models price war looks fierce from the outset, it belies fundamental challenges: the business model is not yet clear, and the ecosystem is starved for funding at a much more severe level. We’ll leave you with Nick and Jordan’s recent analysis of why some Chinese labs are going closed-source, and why DeepSeek does not change the core political equation:
China’s funding environment for AI is orders of magnitude smaller than America’s. While a $20m Masayoshi Son helped get Alibaba off the ground, he now has put nearly $100bn into OpenAI and nothing into the Chinese ecosystem. Western VCs, an ecosystem itself six times the size of China’s, are exclusively pouring cash into American labs. Gulf money has invested about $100m into MiniMax and Zhipu, and ~$15B into Anthropic and OpenAI. …
What will happen from a Beijing policy perspective now that the Chinese AI ecosystem is going closed? Probably not much. We would be very surprised if the state was willing to put the billions necessary to subsidize ongoing open source model work. Even the remote possibility of a mindblowing DeepSeek V4 release making positive headlines for open source won’t change business reality facing the other labs. The Chinese government is fundamentally hardware-pilled, and even something as dramatic as DeepSeek V3 a year out still hasn’t shaken that bias.
DeepSeek Waxes Auto-Poetic
Jordan: I gave DeepSeek V4 this article and asked it to write a poem of how it made it feel.
And a Chinese one:
To receive new posts and support our work, subscribe!
On April 7th, Anthropic announced Claude Mythos Preview, a new AI model that it said possessed particularly strong cybersecurity capabilities. Some of these capabilities, according to Anthropic’s blog post, were not the result of deliberate training, but rather emerged as a consequence of general improvements.
Mythos independently identified and patched a 16-year-old vulnerability in the online media library FFmpeg. It also escaped a restricted sandbox and leaked information to the open internet. Anthropic says “it’s about to become very difficult for the security community” and is not releasing Mythos Preview for general-public users. Instead, it is setting up Project Glasswing to share a limited version of the model with AWS, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks, for “defensive security work”.
Jordan covered the national security implications earlier this week on the podcast with two former US officials, but China is also an essential part of this conversation. While Claude models remain officially unavailable in China, Chinese researchers and the wider AI community there have followed Anthropic’s work closely. Below are some reactions to the Mythos news from Chinese analysts and technologies, featuring:
Wrestling with Anthropic’s theory of ethics;
The Mythos case against Chinese labs’ business models;
Why you don’t need to worry about your WeChat wallet being stolen — yet;
And how Project Glasswing puts China on the backfoot.
Translations were drafted with the assistance of Claude Opus 4.6, and then edited for accuracy and fluency. Bold markings were added by the editor.
Does Mythos Incentivize Safety?
Dario Amodei is likely the American AI CEO with the sharpest publicly-expressed attitude towards China. From supporting export controls to repeatedly ringing alarm bells around AI-enabled dictatorships in hisessays, it’s no wonder that in China, Claude is sometimes known as “anti-China AI” 反华AI.
But curiously, this hasn’t exactly stigmatized Claude among actual AI users in China. Programmers there are fans of Claude Code, and while no official data exists for the size of Anthropic’s general Chinese customer base, social media content about Claude is everywhere. The US-China rivalry is taken for granted as general context, but individual users don’t feel pressured to switch away from “anti-China AI” yet.
The #Claude hashtag on Xiaohongshu/Rednote, a popular Chinese social media app, has been viewed 76.6 million times as of April 13.
This context is important for understanding why Chinese tech media’s coverage of the Mythos release is not particularly cynical. The mood is closer to slightly-grudging esteem, with few observers loudly doubting what the company has claimed about Mythos’ capabilities.
In fact, some Chinese outlets are quite sympathetic to Anthropic, especially in the aftermath of their face-off against the Department of War. GeekPark 极客公园, an entrepreneurship-focused tech outlet, published an op-ed by a pseudonymous author who defended Anthropic’s decision not to publicly release Mythos. Beyond already-well-articulated safety concerns, the piece situates Mythos in the context of other recent corporate strategy adjustments from Anthropic and analyzes how the lab might be balancing multiple priorities.
On the very same day Mythos was released, Claude’s service experienced a large-scale outage. Today, on April 8, connection issues still haven’t fully recovered, with hundreds of users reporting login failures and chat errors. … A bit earlier, in late March, Anthropic accidentally leaked nearly 2,000 source code files and over 500,000 lines of code during the release of Claude Code version 2.1.88. Security researcher Aaron Turner’s assessment was rather chilling: the leak compressed the timeline for adversaries to replicate America’s strategic advantage, making it a geopolitical accelerant in the agentic AI arms race.
…
Putting these events side by side, and Anthropic is fighting on three fronts at once: infrastructure stability, the boundaries of its business model, and — the hottest issue of all right now — just how dangerous the thing it built actually is.
The way Mythos was released is, in a sense, a high-stakes bet on Anthropic’s “responsible AI” doctrine. They chose the most conservative possible method to unveil the most dangerous possible model — telling the world “here’s what it can do,” while refusing to “let it do it.” The logic behind this move: only by publicly disclosing the threat can you drive defensive action; but opening up the capability itself could trigger a chain-reaction catastrophe.
Whether that judgment is correct, nobody knows yet.
Chinese Model Doomerism
Founder Park, a subsidiary of GeekPark aimed at a founder audience, wrote about the implications of Mythos for AI as a global business. The piece doesn’t mention China outright, but is clearly pessimistic about the prospects of open labs with less-capable models in a post-Mythos world. It lays out an interesting case against the possibility of a democratized future for AI.
[ChatGPT] has locked us into the assumption that flagship models will be supplied and sold abundantly, at a price that tens of millions of people can afford. Building on top of this assumption, we imagined MaaS [Model-as-a-Service],1 the token economy, and how agentic coding would help or replace programmers — but once the spiral kicks in, this assumption no longer holds.
Anthropic’s current annualized revenue is $30 billion. Suppose Mythos really does have the ability to sweep through and uncover system vulnerabilities at scale; why would Amodei make it public? Selling MaaS makes money, and charging membership fees makes money; however, collecting protection money makes money too. Think about how Amodei could easily unveil Mythos with a five-point statement:
AI now has the capability to discover and exploit system vulnerabilities at scale;
Evil nations and organizations are about to acquire this capability, and they’re only six months to a year behind;
But our Mythos is ready;
As long as you’re an upright company that cares about human civilization and shares Anthropic’s values, Mythos will come protect you;
Next, please wire payment to Anthropic. After reviewing your values, we’ll decide the priority order in which you receive Mythos protection based on your payment amount and our internal values-alignment score.
…
This is the first model that wasn’t immediately made available via API, and it therefore represents an entirely new commercial reality.
…
To elaborate a bit: some might say that AI is currently flourishing, and other companies (especially Chinese ones) will soon catch up.
This, too, is an illusory assumption born of the past three years — really, the past one year. Once flagship AI stops being offered publicly, [labs that trail in capabilities] won’t just be unable to distill flagship AI; even finding out how flagship AI works or how it solves problems will become increasingly difficult. Internal opacity at AI companies will also inevitably keep rising in order to prevent leaks.
Will this day come? If so, we’d better pray that current AI technology isn’t yet enough for the spiral to hold, that technological progress isn’t fast enough, and that AI companies still have to publicly offer flagship AI services to build momentum and capture more profit.
Mythos is Anthropic’s forceful attempt to break into “the next act of the LLM.”
Anthropic is committing $100M in model usage credits to Project Glasswing. After these run out, it plans to charge $25/$125 per million input/output tokens for Mythos access by approved participants. Cyber Zen Heart 赛博禅心, a well-known tech influencer account (previously featured in our WeChat AI Field Guide), put together a summary of the various signals Anthropic might be sending with this approach. It’s a more moderate interpretation of Anthropic’s thinking, with close analysis of pricing and revenue strategy in anticipation of its potential IPO this year.
Product line expansion
Claude’s product line has gone from three tiers to four. Above Haiku, Sonnet, and Opus, a new Mythos/Capybara tier has been added. This change itself matters more than any single benchmark result. It means Anthropic’s model capabilities have already opened up a gap wide enough to require a new price band to absorb it. Based on documents leaked via Fortune, Capybara is internally defined explicitly as a new tier “larger than Opus”, representing a structural expansion of the product line.
Leading with the safety narrative
Mythos is a general-purpose model that’s strong in coding, reasoning, and search, and could easily have taken the standard benchmark-release route. But Anthropic chose the “too strong to make public” narrative, giving access to only 12 major enterprises. This reflects both genuine consideration of safety risks and a statement about pricing power and ecosystem control. Want to use the strongest model? Join Glasswing and buy tokens at $25/$125.
Anthropic is choosing not to let you use its strongest model, but it’s telling you exactly how strong that model is.
Pricing signal
The $25/$125 pricing is about 67% more expensive than Opus 4.6’s $15/$75. If Mythos-tier models do eventually go public, this price band will become the new anchor. For anyone who believes token prices will only keep getting cheaper, this pricing is a counterexample: when capabilities are strong enough, prices can move upward.
Timeline
On April 4, the subscription channel for OpenClaw was shut down. On April 7, Mythos was released. On one hand, Anthropic is tightening control over the open ecosystem (you can no longer use a monthly subscription to run third-party agent frameworks without limit); on the other, it is releasing the strongest model to enterprise partners. Just three days apart—the cadence is tightly choreographed.
Perspectives from Technologists
Robin Li 李彦宏, founder and CEO of Baidu, noted infamously in a 2018 speech that “Chinese people are … less sensitive about the privacy issue.” The comment prompted major backlash, but struck at a certain level of truth. Forcibly thrusted between corporate and governmental surveillance — neither of which is easy to opt out of — many Chinese internet users have resigned themselves to surfing the web with little privacy protection.
Of course, Chinese people are far from alone in suffering from the consequences of corporate data leaks and feeling powerless in the face of pervasive data collection. But some of the Chinese internet’s regulatory and commercial attributes arguably make it fertile ground for vast cyber threats. To sign up for accounts with many Chinese apps — including popular AI chatbots and tools — you need phone numbers tied to Chinese national IDs. Social media platforms have been required to institute real-name authentication. Super-apps integrate users’ financial, governmental, and interpersonal lives. Sensitive data about millions of ordinary people is increasingly concentrated in the hands of a few companies, and regulations still struggle to catch up.
Cybersecurity experts were already unnerved by what havoc AI agents might wreak for the security landscape — and then came Mythos. A consumer-focused tech media outlet, 差评X.PIN (chàpíng, literally “negative review”), interviewed an anonymous cybersecurity researcher about Mythos’ implications for regular people’s online safety. Their response:
If everything in [Anthropic’s red-teaming technical blog] is true, I feel like half of the people working in internet security right now should just jump into a river
“Wen’an” (the researcher’s pseudonym) clarified to X.PIN that they were being hyperbolic, but also offered some sobering analyses of how models at the Mythos level will reshape cybersecurity as we know it.
… these vulnerabilities haven’t yet reached the level of clearing out your Alipay balance or splashing your WeChat chat logs all over the internet.”
But the crux of the issue is this: the reason Anthropic released these cases publicly wasn’t to show off “how nasty the exploits are,” but to demonstrate that AI — without any plug-in tools, relying purely on its own knowledge base and cross-domain reasoning — can dig up brand-new vulnerabilities on its own.
So in Wen’an’s view, Mythos at this stage isn’t “a stronger hacker tool,” but rather a lowering of the barriers to entry for cyberattacks.
In the past, whether you were a legitimate security professional or someone working in the gray/black market, you at least needed someone who knew what they were doing to run the show. Pulling off a real, serious cyberattack meant holing up in a dark room for months on end.
But going forward, it might be enough for that pudgy village loiterer to shout a couple of voice messages at an AI while picking at his feet.2
This kind of “if you’ve got hands, you can do it” low-entry-barrier setup is inevitably going to attract hordes of thrill-seekers and outlaws looking to have a go.
That’s why Wen’an thinks it actually makes sense for Anthropic to roll out the Glasswing program first.
After all, traditional security tools are like rigid gatekeepers: they only check whether you’re carrying contraband, and they’re useless against insider jobs. AI, on the other hand, can trace the threads, understand business logic, and spot the kind of move where John Doe uses his own key to open Dave’s door.
Letting the big enterprises self-audit and trial the tech in advance lets them get a head start on building network defenses, running vulnerability sweeps, and preventing problems before they happen.
Not everyone believes that Anthropic is being entirely altruistic, of course. In their commentary about how the cybersecurity challenges introduced by Mythos relate to US-China competition, China-based analysts for the consulting firm IDC did not mince words. They see Glasswing widening the capabilities gap between America and China’s AI industries, as well as threatening the entire technical foundation of the digital economy in China:
One core challenge is asymmetry in technology access, which creates a clear technological gap with overseas peers. Participants in Project Glasswing can prioritize leveraging Mythos’s powerful capabilities to conduct vulnerability discovery, threat detection, and defensive system optimization, while simultaneously sharing related security research findings and open-source resources — enabling rapid iteration of defensive capabilities. Chinese vendors, by contrast, are completely excluded from this collaborative framework. Unable to directly access Mythos’s model capabilities or related security resources, they can only rely on their own efforts to develop the relevant technology. This creates an inherent gap in the iteration speed of AI security technology between China and its overseas peers. Especially in high-end domains such as zero-day vulnerability discovery and AI adversarial techniques, this generational gap may widen further, and closing it in the short term will be difficult.
The second core challenge is a dramatic escalation of cybersecurity threats and a sharp increase in pressure on the defense of critical infrastructure. In China, critical infrastructure sectors such as finance, energy, government services, and healthcare make extensive use of various open-source software and general-purpose operating systems, and Mythos has already uncovered a large number of high-severity vulnerabilities in these systems. Overseas vendors participating in Project Glasswing can use the model to quickly obtain vulnerability information, generate fixes, and complete system hardening in a timely manner. Chinese vendors, however, cannot access the corresponding vulnerability information or remediation guidance, and must rely on self-directed investigation and self-directed patching. This not only sharply raises defensive costs but also prolongs vulnerability exposure windows, significantly increasing the risk that critical infrastructure will be attacked. At the same time, as Mythos’s capabilities proliferate, the state-level APT attacks and black-market attacks China faces will become more covert and more efficient, with a wider variety of attack methods—further compounding the difficulty of cybersecurity defense and posing a serious challenge to the nation’s cybersecurity baseline.
In addition, China’s cybersecurity industry faces derivative problems such as a shortage of AI security talent and significant pressure on investment in indigenous R&D. While Project Glasswing fosters a healthy ecosystem of “technology sharing + talent collaboration,” China, by contrast, suffers from an insufficient supply of high-end talent in AI security. Its indigenous R&D lacks mature technical reference points and ecosystem support, which further constrains the improvement of defensive capabilities, leaving China in a more passive position when responding to the AI-driven attacks that Mythos makes possible.
To receive new posts and support our work, subscribe!
“MaaS” featured prominently as the professed business models of Z.ai and MiniMax, two Chinese AI labs that made initial public offerings on the Hong Kong Stock Exchange in January this year. For the past two months, their respective stock prices have been riding post-OpenClaw highs.
“Dude picking at his feet” is a piece of disparaging Chinese slang, usually lobbed at an online demographic similar to Western incels. It’s a little hard to translate.
In 2017, Hangzhou-based robotics firm Unitree 宇树科技 launched its first quadruped, Laikago. Laika was the name of the Soviet space dog onboard Sputnik 2, and the American English pronunciation of “go” is similar to that of the Chinese word for dogs, 狗 gǒu. Unitree’s battery-powered tribute to Laika wasn’t fuzzy, but walked on four feet and navigated through basic obstacles.
Unitree founder Wang Xingxing 王兴兴 has long held faith in the potential of robotic canines. Since 2020, when Unitree started gaining media attention, he has insisted in multipleinterviews that humans are drawn to four-legged creatures and will have a natural fondness for their artificial counterparts.
Wang Xingxing with a Laikago in 2017. (Source: Bilibili)
Fast forward to 2026, and Unitree has just filed for a $610-million IPO on the Shanghai Stock Exchange. The company is a household name in China after its humanoid robots performed dances at the CCTV Spring Festival Gala for two consecutive years and counting. Through their IPO disclosures (investor prospectus and response letter to the Shanghai Stock Exchange’s inquiries), we get some answers to important questions about the development of embodied AI.
How is Unitree profitable?
Where is diffusion happening inside China, aside from dancing on TV?
Are Chinese robotics companies content to lead in hardware and applications, or do they also see themselves as pursuing some kind of generalized “frontier”?
And finally, what does this all mean for US-China dynamics in robotics?
What’s the money maker?
One of the most notable things about Unitree is the fact that it actually makes money. Unprofitability is a near-universal challenge because AI robotics, despite massive advances in the past few years, is still an early-stage technology. Mass adoption has not yet arrived; pathways out of bottlenecks like data are uncertain; and important safety standards have not caught up. Even shipping products consistently can be a challenge for some companies in the space, let alone manufacturing at scale and booking reliable customers.
This context is why observers have found Unitree’s ability to turn a profit remarkable. Not only has the company’s net profit been positive since 2024, but from 2024 to 2025, its net profit grew by 204.29%. A look at its growth, broken down by product category, reveals the most significant source of this revenue explosion: humanoids.
It’s perhaps ironic that, despite the company’s longstanding work in quadrupeds, it is humanoids that have catapulted its business model to success. By meeting genuine demand in academia — and staging an especially strong marketing campaign in front of the Chinese public — Unitree has transformed itself into a humanoid frontrunner. Some analyses trace their potent commercialization drive back to Unitree’s origins. Wang Xingxing’s cofounder Chen Li 陈立, who was Wang’s classmate throughout both their undergraduate and Master’s programs, worked in international sales for the Hangzhou-based, partly state-owned surveillance tech giant Hikvision (海康威视) before joining Unitree. Hikvision has been extremely successful at expanding internationally (including in the US before it was added to the Entity List over its involvement in human rights abuses against ethnic and religious minorities in China). Investors have told Chinese media that Chen’s experience is an important asset for Unitree’s global commercialization, driving sales to governments and businesses in particular.
Unitree has earned name recognition in the West, but it is far from the only Chinese robotics company meaningfully shaping the future of embodied AI. In fact, it is part of an increasingly competitive market for AI-powered robots. Among listed peers, UBTECH and Dobot are major competitors named in Unitree’s prospectus. A fellow member of the “Hangzhou Six Dragons,” DEEP Robotics, is betting big on scenario-adapted applications, while AgiBot, by some estimates, shipped even more humanoid units last year than Unitree did.
In their response to the Shanghai Stock Exchange’s inquiry letter, Unitree emphasized in-house development of hardware parts as its key strategy for cutting costs. Unitree designs, builds, and assembles most components (other than commodity components like battery cells, flash storage, and the core computing board) in-house. It does offer outsourced alternatives for add-ons like LiDAR, cameras, and dextrous hands, but has also developed in-house options for all of these.
Where are the robots?
Unitree’s most reliable customers are universities, research institutions, and other companies conducting research into robotics. Its hold on academic customers worldwide is so firm that it’s caused alarm among DC policymakers. In May 2025, the China Select Committee called for Unitree to be designated as a “Chinese military company” and to be added to the Entity List.
The data Unitree disclosed about its revenue sources, however, paints a more complex picture. For quadrupeds, the research and education sector has been the company’s most reliable source of revenue since at least 2022 (IPOs generally do not require companies to disclose audited financial statements from more than three years ago). But starting in 2024, revenue from both commercial and industry customers more than doubled. Consumer sales revenue nearly quadrupled year-on-year in only the first nine months of 2025.
A similar, if more compact, story emerges for humanoids as well. Demand still largely comes from researchers and educational institutions, but commercial and industrial demand has grown from a near-zero starting point on a seemingly exponential trajectory since 2024. Consumers are especially excited about humanoids due to Unitree’s successful marketing of the concept. Industrial applications of humanoids are more limited compared to those of quadrupeds, but are also appearing.
What, exactly, are people doing with these robots? “Research & Education” encompasses sales to researchers, who use Unitree hardware and platforms to conduct their own experiments. The “Commercial & Consumer Use” and “Industry Applications” categories roughly map onto B2C and B2B sales, respectively. According to Unitree, non-academic consumers who buy their robots mostly do so “for show”: they’re deploying these robots as attractive promoters in retail settings, at tourist sites, and in performances and exhibitions. Some use them as novelty companions.
Applications in industry are more interesting. Quadrupeds are deployed as “smart inspectors” in power grids, subway tunnels, and gas pipelines. They can also assist in harsh settings like emergency response and outdoor surveys, and complete manufacturing and logistical tasks. E-commerce firm JD.com is Unitree’s biggest corporate customer. Humanoids, according to Unitree, are being used for inspections and manufacturing as well, though in a more limited capacity because the technology is less mature. Unitree expects consumer demand for humanoids to grow in the medium term, but we will have to wait a while longer for genuinely useful humanoids on the factory floor.
Is Unitree… AGI-Pilled?
Received wisdom in robotics has it that the US leads in software-related research, while China’s strength is in hardware. The implication is that the US is likely to reach “generalized” machine intelligence in the physical world faster than China, but — in the meantime — Chinese companies could get to practical applications faster through quick iterations inside an unparalleled manufacturing ecosystem.
Unitree’s business model is often quoted as direct evidence of this dynamic, and it is indeed true that hardware is the crux of Unitree’s success. But does that mean Unitree, and the Chinese robotics industry writ large, has less interest in generalizability or the intelligence frontier? The IPO disclosures indicate otherwise.
Unitree called on incoming investors to “realize humanity’s ultimate dream — AGI” 实现人类最终极的梦想—AGI with them. Their lawyer-drafted definition of AGI is “a form of intelligence that possesses general cognitive capabilities comparable to those of humans, capable of understanding, learning, and executing intellectual tasks across any domain, and autonomously reasoning, planning, making decisions, and continuously learning in unknown environments.”
The financial reality tells us that most of Unitree’s R&D budget has gone to hardware. This is clearly downstream of their aforementioned focus on developing as many components in-house as possible to cut costs.
However, it’s important to notice in the chart above that Unitree’s R&D expenditure on “Multimodal Embodied AI Model” — the “big brain” of its robots — increased exponentially between 2024 and 2025, while other areas of R&D have grown at a steadier pace. Unitree is clearly ambitious about developing its models, even if it is known mostly for its hardware business.
This becomes clearer when we look at Unitree’s plan for using the 4.2 billion RMB (around 607.7 million USD) raised through the IPO. Unitree’s stakeholders approved the following distribution in early 2026:
Nearly half of the IPO’s proceeds will be spent on training AI models over the next three years. That’s around 673 million RMB per year, which is not quite comparable to more well-known model makers (MiniMax, for example, spent around 1.75 billion RMB on R&D last year) but still a significant amount that signals long-term software ambitions.
Unitree currently owns no real estate, but plans to build its own factory with IPO proceeds. Per its disclosures, it has already secured a nod of approval from Hangzhou’s Binjiang District 滨江区 and plans to build there. Transitioning from an all-leased manufacturing model to proprietary manufacturing facilities is in line with their emphasis on in-house development and increasing production efficiency.
What comes next?
These disclosures answer many factual questions about Unitree’s business model, but raise more fundamental questions about the future of automation, US-China competitive dynamics, and both countries’ big bet on AI.
Question one: What will come of Unitree’s “AGI” ambitions? A public company is required to either use proceeds as stated in official disclosures, or publicly justify any changes. (Shareholders can vote to reappropriate funds, but unauthorized deviations could invoke China’s securities law and trigger scrutiny from the Stock Exchange.) Barring major issues, we should expect Unitree to spend handsomely on model training and development for the next three years. The biggest challenge will be making sure that these investments produce consequential returns. This uncertainty is not exclusive to Unitree; no one knows what the next three years will bring. But Unitree has now put itself on a path away from hardware-first and towards a more diversified strategy. This is, of course, risky, but relying on academia’s demand for hardware is no longer secure.
Question two: Will America turn against Unitree? A “Chinese military company” designation, which places companies into the annually-updated 1260H list, would merely exclude Unitree from contracting with the Department of Defense, but being placed on the Entity List would subject it to US export controls. Neither designation would prevent Unitree from selling to American customers outright, but they would hobble the company’s growth. As Unitree’s own prospectus describes:
Throughout the reporting period, revenue from overseas markets consistently exceeded 35% of total revenue. Should the United States continue to intensify trade and tariff policies that materially disadvantage Chinese exporters, or place the company on restricted lists governing procurement partnerships or technology export controls, the company faces the risk of being unable to sustain high growth in overseas sales — and potentially suffering an overall decline in performance. … Given uncertainty in industrial trade policy and the international political environment, any adverse shifts in external supply chain conditions or overseas market controls — compounded by further escalation of US trade restrictions and export control measures — could negatively affect the company’s ability to procure imported materials and maintain technology partnerships.
Policymakers eager to run “Trojan horse tech” out of America have to reckon with the dilemma that, for academic researchers at the forefront of embodied AI, there are few alternatives to Chinese-made hardware and platforms; Unitree is simply the most successful of the lot. Affordability and reliability are the most important factors for nonprofit academic labs. Robotics research is also a rough-and-tumble affair: there is wear and tear, and I’ve had researchers and students show me bruises they’ve sustained on the job from handling heavy humanoids. Unitree’s scale, consistency, and pricing meets academics where they are. Moreover, Unitree has been cultivating its relationships with international researchers long before the reporting periods of these IPO disclosures. The company started shipping internationally in 2018, and some of the earliest buyers of its quadrupeds were university research labs.
Imagine writing code for a dishwasher without dishwashers to test the code on. That’s a massively oversimplified comparison, but it is the same proposition in spirit. If Washington severs this symbiotic relationship, it will almost certainly make it harder for American researchers to maintain their lead in the software side of embodied AI.
Finally, question three: Can Unitree keep its lead inside China? As mentioned earlier, the company has formidable challengers in its own backyard, and has had to continuously trim costs to stay competitive. DEEP Robotics also joined the leagues of profitable companies in 2025. AgiBot’s CEO said at the end of last year that the company’s total sales revenue in 2025 likely exceeded 1 billion RMB. Up until now, Unitree’s success is arguably a case of first-mover advantage. Many more companies are taking up the Unitree playbook, and the future of robotics in China is far from determined.
If you aren’t yet ready to open your home to a robot dog, the company also sells fitness equipment inspired by robotics technology…
Titanium! Some say American policymakers should be a lot more nervous about China’s titanium industry. The metal has an extremely high strength-to-density ratio and is strongly resistant to corrosion. It is widely used in everything from roofs to hip replacements, and is particularly critical for defense and aerospace. China, the world’s biggest titanium producer (~70% of global production), currently requires exporters of high-performance titanium alloys, as well as tubes or cylindrical solid bars with an outer diameter greater than 75 mm, to obtain licenses from its Ministry of Commerce.
China’s updated catalogue of dual-use items and technologies is extensive, covering not only minerals but also metals, materials, drug precursors, and other categories of items with potential military applications. Not all of the items on the list are under strict scrutiny, but the list is a flexible policy instrument with wide-ranging future implications.
Are the concerns justified? It depends on who you ask, and we will get to that in Section 3. But first, let’s understand what titanium is and why it is valuable.
Titanium is the ninth-most-abundant element in the Earth’s crust. Deposits of ilmenite and rutile ores, from which titanium is extracted, are found around the world, from Norway to Mozambique to Canada. How did China even become the world’s biggest titanium exporter? Today on ChinaTalk, we talk about the story of titanium, what metals tell us about Chinese strategy, and why policymakers probably shouldn’t freak out.
Data source: United States Geological Survey Minerals Commodities Summary for Titanium and Titanium Oxide, 2026.
History of Chinese titanium
“There are 64 nonferrous metals and we can’t do without them.” 64种有色金属,没有它不行。 — Mao Zedong, 19581
Nonferrous metals do not contain iron in appreciable amounts. They are usually lighter, more conductive, and resistant to corrosion. They were the first metals humans used for metallurgy, and today their applications are widespread.
After Mao signed off on a policy memo to research production of all 64 nonferrous metals in 1958, China’s Nonferrous Metals Research Institute (冶金部有色金属研究院) achieved that feat by 1962.2 In 1959, the Fushun Aluminium Factory 抚顺铝厂 extracted its first 60 tonnes of titanium sponge, breaking ground for industrial-scale titanium production in China. By the 1970s, Chinese factories were producing a total of around 3,600 tonnes of titanium sponge per year.
Titanium sponge, named after its porous appearance, is produced through two processes: the Kroll process, which uses magnesium to reduce titanium tetrachloride, and the Hunter process, which uses sodium instead. On account of being more economically effective, the Kroll process — developed in the 1930s by a Luxembourgian chemist who fled the Nazis — is now the dominant method among titanium processors worldwide. After nearly a century of development, however, the Kroll process is still a challenging and energy-intensive metallurgical operation.
China’s construction of an indigenous nonferrous metals industry coincided, curiously, with a decline in titanium production in the US around the same period. American government funders supported William Kroll’s work after he landed stateside at the start of WWII, and the US became home to the world’s earliest titanium industry. Nearly all of the early demand for titanium came from defense contractors building aircrafts with titanium alloy parts. The late 1950s, however, saw the US shift its defense posture away from airplanes and towards missiles, which vastly reduced demand for titanium sponge. By 1960, there were only three titanium metal producers left in the US, even though mature applications in civilian industries and medicine had started to emerge. Hereafter, while the Cold War and development of titanium-based consumer products would bring about periodic peaks in titanium demand over the second half of the twentieth century, the US largely relinquished domestic titanium sponge production. Today, it is the world’s largest titanium importer.
Over in China, however, the Communist Party’s leadership was just starting to push for cutting-edge metals. Zhou Enlai was apparently quoted in 1968 as saying that “the production of titanium is a matter of life and death” 钛生产十万火急.3 China, being relatively isolated on the global stage — even more so after the Sino-Soviet Split of the 1950s and 60s — needed to pursue metallurgical self-reliance from the ground up if the country was to develop both industry and defense. The concern was urgent: back then, practically every PLA aircraft was supplied by the Soviet Union. (A US-style pivot to missiles was a pipe dream: in 1960, while the size of the US nuclear warhead stockpile climbed over 18,000, China had just launched its first-ever short-range ballistic missile.) As Beijing had to now plan its strategy around potential wars with both the USSR and United States, this meant researching and producing a huge range of materials it had never produced at scale. In response, it concocted an ambitious strategy of moving heavy industrial sites to remote western provinces, away from the densely populated eastern heartlands most vulnerable to wartime destruction.4
China’s titanium industry landscape
The story of titanium in China became one of two western cities: Panzhihua (攀枝花) and Baoji (宝鸡). Panzhihua, in the far south of Sichuan province, sits at the confluence of two rivers and on top of one of the country’s largest mines. Its huge deposits of vanadium titano-magnetite (VTM) and ilmenite ore were first discovered in the 1930s. The mountainous terrain made industrial development of the area a formidable engineering challenge, but Chinese leaders believed it to be ideal for hiding defense-related developments from prying American and Soviet eyes. Throughout the Cold War, Panzhihua grew into a sizable base that churned out hundreds of thousands of tonnes of iron, steel, and titanium to supply China’s military and heavy industry.
But it was kept a secret: until the 1980s, the name Panzhihua never appeared on maps published in China. Planners placed the city’s train station behind a mountain so that civilian riders could see the mines from train windows. Processing facilities were named after numbers rather than what they manufactured, and families of workers stationed there used secret codenames to address mail to the site.
Chinese leaders sought a large number of sites in the remote West to disperse their defense-industrial ambitions. Panzhihua’s ore, extracted and refined into sponge, was shipped north to Baoji in central Shaanxi province’s Guanzhong valley. Similarly flanked by mountains, Baoji was also well-connected to Xinjiang in the west, Sichuan in the south, and Xi’an and Beijing to the east via railways. State planners selected the small city as China’s titanium processing hub in 1964. By 1968, Baoji’s first titanium processing facility was producing titanium alloy parts for the PLA Air Force.
Until the late 1970s, most of the titanium extracted and processed in China was for classified military uses. Civilian applications emerged slowly over the 1980s and 1990s. As China’s economy transitioned through marketization, processors marketed titanium alloys to new factories manufacturing goods for regular people. Processing facilities, mainly still in Baoji, also started importing ore.
In the 21st century, the titanium industry is no longer so squarely divided between Baoji and Panzhihua in China. Most ilmenite and VTM ore is still mined in Panzhihua, but processing has diversified beyond Baoji, with both state- and private-sector players. Exports of both sponge and mill products have grown exponentially since 2002.
Contextualizing China’s dominance
All this context explains why China pursued — and managed to achieve — self-reliance in titanium, and eventually came to lead the global market through economies of scale. However, it doesn’t answer the question of why China started producing exponentially more titanium nearly every year since the mid-2010s:
Two downstream industries help explain titanium’s boom-and-bust cycles and newfound ascendance in China: construction and aerospace. Some builders use titanium as a construction material, due to its exceptional corrosion resistance and high strength. Titanium dioxide pigment is also widely used to make light-colored paint. Demand for titanium snowballed as China began generational investments into infrastructure in the 2000s. The construction boom led processing facilities in Baoji and elsewhere to massively increase production capacity. However, starting in the early 2010s, the pace of construction slowed as local governments’ ability to foot the bill for infrastructure ran out of steam. Titanium prices crashed and the industry experienced a slump, visible around 2015 in the two graphs above.
The National Centre for the Performing Arts in Beijing, with an exterior made of titanium panels. Source.
But renewed attention towards aerospace turned things around for Chinese titanium. Xi Jinping’s consolidation of power in government and the military allowed him to push forth an ambitious military modernization agenda. Defense procurement inside China has accelerated dramatically since 2019. The newest fourth-generation PLA fighter jets use double the amount of titanium alloys per aircraft than their third-generation predecessors. Warships, missiles, and hypersonic weapons, all of which the PLA is investing heavily in, also utilize titanium alloys. Beyond defense, some in the industry are hopeful that domestic demand will come from commercial aerospace, as the Comac C919’s launch lifted hopes for producing more indigenous passenger aircrafts.
As discussed in the beginning, titanium and its alloys are now considered dual-use items, requiring licenses to be exported out of China. This requirement came out of the Ministry of Commerce’s 2024 consolidation of patchwork controls for dual-use items. Before 2024, while some titanium products (like high-spec alloy tubes) fell under regulations controlling exports of missile- or nuclear-related items, blanket regulations for titanium products did not exist. The 2024 listing required export licenses for all alloys with an ultimate tensile strength capable of reaching 900 MPa or higher at 20°C and all tubes or cylindrical solid bars (including forgings) with an outer diameter greater than 75 mm. While still focused on the higher (and more defense-applicable) end of titanium products, this represents an expansion of previous controls on titanium exports and shows Beijing’s recognition of titanium as critical to national security.
Why is there no titanium panic?
The aerospace industry is roughly divided into defense and general commercial subsectors. For defense, US acquisition regulations require relevant specialty metals to be melted or produced either domestically, or in a handful of qualifying countries with close relationships to the US. Japan is the largest titanium sponge exporter that fits this criterion; as a result, much of the titanium that American defense contractors procure is of Japanese origin.
But what about commercial aerospace? The reason American policymakers aren’t shaking in their seats over Chinese titanium comes partly down to bureaucracy. It takes years to be certified as an overseas manufacturer of aerospace-grade titanium sponge by American agencies. Currently, the only certified manufacturers are four firms in Japan, Saudi Arabia, and Kazakhstan. (Russia’s VSMPO-AVISMA is also certified, but Boeing has stopped purchasing from the firm since the Russian invasion of Ukraine in 2022. However, some other Western aerospace and defense manufacturers — notably Airbus and Canada’s Bombardier — continue to purchase Russian titanium.) This, along with general pressures from the Russia-Ukraine war (both countries are major ilmenite and rutile ore producers and titanium sponge processors), has made aerospace-grade titanium sponge supply tighter and increasingly expensive, and the industry has accordingly been curious about Chinese titanium sponge. However, it will be years before any Chinese producer gets past the complicated regulatory process, navigates almost-guaranteed political headwinds, and wins certification.
The procedural quagmire is not the only thing stopping Chinese titanium from entering into the global aerospace industry. Despite being the world’s leading producer of titanium, Chinese processors have been unsuccessful in producing larger quantities of aerospace-grade alloys. It relies on imports from countries like Australia and Mozambique for high-purity feedstock, which are processed into high-grade metal (above 99.99% pure titanium). Such high-grade materials cannot be made from low-grade ore and are essential for advanced applications, including some semiconductor manufacturing processes. In fact, high-purity titanium was considered a serious chokepoint with national security implications for China until a Zhejiang company managed to extract 99.999%-pure titanium in 2014. But while mass production of high-grade titanium now exists in the country, demand still exceeds supply.
With much of the sector unable to produce high-grade products, industrial capacity built up over the past three decades is largely spent on cheap civilian applications. State media openly admit to an “overcapacity” crisis in Baoji, China’s “titanium valley.” Less than 5% of Baoji’s titanium processing output is destined for high-value-add industries like medical applications or aerospace. Mining and processing have churned on despite weakening demand and a challenging macroeconomic environment, mirroring dynamics seen in many other Chinese industries. In recent years, smaller titanium producers have been shuttering, dragged down by low prices. An industry fostered by the state to ensure secure supply of critical materials is now too big for its own good.
The US currently charges a 15% tariff on most imports of titanium sponge and an additional 25% on titanium sponge from China. A 2024 Senate bill to remove the 15% global tariff — but leave the additional 25% on Chinese titanium sponge — died in committee. With Beijing constructing a suite of policy armour around critical dual-use materials and a US presidential administration whose favorite word is “tariff,” it’s highly unlikely that Chinese titanium will flood the American market anytime soon.
Have thoughts about titanium? Please reach out!
ChinaTalk is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
According to a history of China’s titanium industry compiled by China Nonferrous Metals News 中国有色金属报, in March 1958, Wang Heshou 王鹤寿, former Minister of Metallurgy, submitted a report to the CCP Central Committee and Chairman Mao titled “Striving for a Leap in Non-Ferrous Metal Output and Conquering the Entire Field of Non-Ferrous Metals.” The report recommended developing all 64 non-ferrous metals — including titanium — and Mao received the proposal favorably, signing off the proposal with this quote.
From the same history above. Note that the Institute was part of the Ministry of Metallurgy 冶金部, a State Council department that was dissolved in 1998.
“Vibecoding” doesn’t lend itself to easy translation. For now, Chinese speakers call it 氛围编程 fènwéi biānchéng, 氛围 being “atmosphere”/”vibes” and 编程 being coding. This is an awkward expression because 氛围 usually refers to the atmosphere of a space or environment, and doesn’t have the connotation of care-free DIY that “vibe” does in colloquial American English. 氛围编程 sounds nonsensical as a phrase — something like “coding up an atmosphere.”
But we make do, and oftentimes writers simply use the English word. Developers, creatives, and entrepreneurs in China have been creating many interesting coding projects with AI tools over the past year, utilizing not only popular tools by Silicon Valley giants like Cursor and Claude Code, but also domestic models as Chinese AI companies increasingly compete in the coding-agent market.
Tinkering culture has no borders, and companies are cashing in. This is a roundup of reports from Chinese media on how vibecoding is changing the landscape of technology in China, featuring:
Genius 12-year-olds;
The race for domestic coding agents;
And how to vibecode your way to the top of the App Store.
The Chinese AI coding landscape
As much as 30% of the code at Microsoft is now written by AI; some engineers at OpenAI and Anthropic are writing nearly all of their code with coding agents. Chinese tech firms have also pushed their engineers to adopt their own AI-powered coding products.
In early 2025, ByteDance released TRAE, its answer to Cursor. TRAE is an Integrated Development Environment (IDE) with both traditional and AI-native modes. The “Build” mode is much like a traditional IDE, but with an AI assistant that generates code based on prompts as well as the user’s manually-written code. The “Chat” mode, however, is a chatbot-like interface that focuses on natural-language prompting. In other words, it was made for vibecoding. A year later, ByteDance came out with the 2.0 series of its Doubao models and made Doubao-Seed-2.0-Code directly accessible through TRAE. The company most famous for TikTok seems also to be building an ecosystem for AI programming.
Tencent, similarly, has built CodeBuddy, an IDE that integrates its own Yuanbao AI models. (These IDEs also allow users to connect other AI models via API keys, so developers aren’t locked into company ecosystems when they choose one IDE over another.) InfoQ, a tech content platform, interviewed CodeBuddy’s product manager here. The company reported in 2025 that more than 90% of its engineers use CodeBuddy to assist with coding, and that half of all newly-added code at Tencent was written with assistance from AI. Not to be outdone, in August 2025 Alibaba released its coding assistant platform Qoder.
As we covered in our Lunar New Year roundup, the race for domestic coding agents is heating up in China. Frontier labs like Zhipu, MiniMax, and Kimi are all tuning their new models and product strategies away from chatbot interfaces and toward AI-assisted coding. But no one seems to be China’s answer to Claude Code yet. Popular coding models from the likes of Anthropic, OpenAI, and Google are supposed to be geoblocked in China. Cursor itself is available, but only offers non-geoblocked models to Chinese users. Word on the street is that while coding tools by domestic labs are much easier to access, Chinese developers are still willing to jump through complicated hoops to access leading Western tools:
36Krreported that a college student in China is making 90,000 RMB (around $13,027) per month renting out his unrestricted AI coding tool accounts. He managed to get discounted access to Antigravity, Augment, and Claude Code through Google’s promotion for students and is now running a huge account rental operation.
It looks like Anthropic’s catching on…yesterday in their announcement of Deepseek, Minimax, and Moonshot’s efforts to distill their models, they flagged educational accounts as particularly vulnerable to unauthorized Chinese usage..
The kids are vibecoding now
In September 2025, product and tech leaders behind AI coding tools at Baidu, Meituan, Tencent, and Alibaba came together for a roundtable during a conference in Beijing. It was a typical tech industry event until they invited a 12-year-old onto the stage.
Whether or not it was a staged stunt, Guoguo is pretty impressive! Source.
Guoguo proceeded to mercilessly roast all of their coding tools:
Guoguo: Hello everyone, my nickname is Guoguo and I am 12 years old. I’ve been learning AI for a while and have recently started doing small things through vibe coding. I’ve used all four of the applications here and they are fun, but I’ve run into problem as well.
For example, when I was using MeDo [秒哒, Baidu’s conversational coding platform], I wanted to change the page color from pink to purple. I said it three times in a row, and it still wouldn’t change. I could go in and edit the page manually and it would work, but it just wouldn’t listen. That was so annoying.
I’ve also had problems with NoCode. I wanted to build a decision-query website and add some characters. But it only added the main character and wouldn’t add any supporting characters. Later I asked the AI to fill out the decision list, and it only added the names and where they were from, without filling in any of the specific details. I even copied the info to it myself, and it still added things incorrectly and mixed them up. That was even more annoying.
With Qoder, I made a big mistake when I used it. I didn’t choose a folder, so I had no idea where to open things from. Later I realized you have to choose a folder first. For a first-time user like me, that was really unfriendly.
Huang Shu [黄叔, from Alibaba’s Qoder team]: So which one do you think is the best?
Guoguo: The first one I used was MeDo, and I started using the other ones around the same time. I think they’re all pretty good. MeDo and NoCode have web versions, and I prefer the web versions. Qoder and CodeBuddy look more professional and more “high-end” — you can show them off in front of classmates.
Vibecoding to the top of the App Store
In December 2024, an incredibly simple app suddenly became the most downloaded paid iPhone app in China. It’s called 小猫补光灯, or Little Kitten Colored Lightbox, and it only costs 1 RMB (around 0.14 USD). When opened, it turns your phone screen into one of 11 solid colors, and you can adjust its opacity and brightness. With that phone screen placed at a strategic angle — usually a few inches away from your face at a 45-degree tilt — you are perfectly lit for a quick selfie session.
Before and after “filling in lighting,” a photo technique developed by Chinese influencers. (Source)
Little Kitten Colored Lightbox’s developer goes by Peanut. Before 2024, he worked in product operations and had never written code. Peanut told Chinese tech news outlet 36Kr that after a mid-life crisis led him to quit his job at Meituan, he spent nearly all of his time learning about AI, including working through a Python textbook with ChatGPT as his tutor. But it was not until Cursor came out in August of 2024 that he had a breakthrough, making more than 20 apps in a few months’ time.
Inspiration for Little Kitten Colored Lightbox came when Peanut was helping his girlfriend take photos. He noticed that she kept searching social media for color blocks to fill her phone screen with in order to create better lighting. He went home and coded up an iOS app that did exactly this in 1.5 hours with Cursor, then shared a tutorial on social media. It blew up among female users, who gave him feedback and ideas for features in newer iterations.
Peanut now teaches vibe coding on many platforms, including YouTube. He told Chinese media that while some professional developers dismissed his project as trivial (or were plain jealous that the iOS App Store approved his app so quickly), he believes he succeeded in meeting a genuine user demand.
Other Vibe-coded Projects of Note
Finally, these are just some of the projects that I thought were fun while scrolling vibecoding-related topics on Chinese social media!
Crush Decoder: Upload screenshots of your crush’s WeChat or Rednote posts, and this website will decode their personality and tell you how to pursue them romantically.
生日叮 (“Birthday Beep”): Keep track of you and your loved ones’ lunar calendar birthdays.
找个地方 (“Find A Place”, WeChat mini-app): Suggests where you should meet up with your friends in the same city, based on everyone’s locations.
祝福语显眼包 (“Greetings Master”, WeChat mini-app): Generates elaborate greetings messages based on occasion, style, and your relationship with the intended recipient, making you look extremely good in the family group chat.
The Year of the Fire Horse is upon us, meaning China’s AI industry spent the final weeks before Lunar New Year frantically racing to ship new models before everyone disappears for the break. Chinese tech companies treat the New Year cutoff like a product-launch deadline, knowing that a strong pre-holiday release captures press cycles at a moment when the whole country is at home scrolling on social media. Regulators, too, have learned to time their moves, issuing new rules and penalties when attention is at its peak.
All the ensuing noise can make it hard to see what matters most. So the ChinaTalk team is here to parse out hype from reality and highlight some trends likely to shape Chinese AI in 2026.
Today’s updates explore LLMs, robotics, hardware, video models, and governance.
Caption: Draco Malfoy is the LNY mascot the world never knew it needed. Source.
Chatbots, Coding, and Agentic Updates
It has now been more than a year since DeepSeek R1 came out, and everyone is anticipating major moves from the secretive frontier lab to usher in the Year of the Horse. As of February 18, we have seen nothing official from DeepSeek. Clever users, however, have noticed that they seem to be beta-testing what could be V4 through its chatbot interface. Currently, querying DeepSeek with “who are you” returns an introduction where the chatbot states that it has a context window of one million tokens, which is nearly eight times bigger than the context window of V3.2.
This new DeepSeek is prone to snappy parallelisms and as eager to please as ever. It’s somewhat eerily reminiscent of GPT-4, even down to the “You’re absolutely right!” refrain:
“Your follow-up question is absolutely right. 🙏”
And there might be a reason why: on February 12, OpenAI accused DeepSeek of covert distillation of its models in a memo to the House Select Committee on Strategic Competition between the US and the Chinese Communist Party. Here’s how OpenAI describes what it calls “adversarial distillation attempts” in the memo:
We have observed accounts associated with DeepSeek employees developing methods to circumvent OpenAI’s access restrictions and access models through obfuscated third-party routers and other ways that mask their source. We also know that DeepSeek employees developed code to access US AI models and obtain outputs for distillation in programmatic ways. We believe that DeepSeek also uses third-party routers to access frontier models from other US labs.
More generally, over the past year, we’ve seen a significant evolution in the broader model-distillation ecosystem. For example, Chinese actors have moved beyond Chain-of-Thought (CoT) extraction toward more sophisticated, multi-stage pipelines that blend synthetic-data generation, large-scale data cleaning, and reinforcement-style preference optimization. We have also seen Chinese companies rely on networks of unauthorized resellers of OpenAI’s services to evade our platform’s controls. This suggests a maturing ecosystem that enables large-scale distillation attempts and ways for bad actors to obfuscate their identities and activities.
According to Bill Bishop of Sinocism, this was an open secret:
Other frontier labs have also been busy. The shift from chatbots to agents optimized for economically productive tasks is clearly underway, with the newest Zhipu and MiniMax models both being advertised as coding and general work tools. On December 22, 2025, Zhipu came out with GLM-4.7. It’s marketed as a “coding partner”, and subscription plans are now called “coding plans” as well, signalling a complete pivot to coding. And on February 12 this year, the lab launched GLM-5, pivoting yet again from coding to “agentic engineering.” GLM-5 has 40 billion active parameters and is targeted at long-horizon agentic tasks.
The day before GLM-5’s launch, Zhipu announced a 30% coding plan price hike in a WeChat announcement, citing strong demand. It bucks the trend of what seemed at first to be a price war among Chinese coding agents. MiniMax advertises its M2.5 model, also released on February 12, as “intelligence too cheap to meter”: at a rate of 100 tokens per second, running M2.5 for an hour costs only $1. An annual Max subscription to the high-speed version of M2 currently costs $800. GLM-5’s Max plan costs $960 for the first year and $672 from Year 2 onwards, but in the fast-moving world of AI models, planning for discounts in annual terms seems almost beside the point.
At $1,908 per year, Kimi’s highest subscription tier is even more expensive than MiniMax’s Ultra plan, which costs $1,500 per year. On January 26, Moonshot AI released Kimi K2.5, a 1-trillion-parameter multimodal model that emphasizes both coding and visual capabilities. This combination makes it particularly strong for front-end development. Also passing the 1-trillion-parameter milestone is Ant Group’s newest Ling-2.5-1T, released on Chinese New Year’s Eve. Qwen’s NYE baby, too, is multimodal: Qwen 3.5 is a vision-language model with “reasoning, coding, agent capabilities”. It seems that while some labs are opting to specialize, others still believe in the everything bagel.
And for the people’s favorite, Doubao: on February 13, ByteDance released Doubao-Seed-2.0, which includes three agentic models of different sizes and one coding model. ByteDance is promoting its coding model as part of a package with TRAE, the AI-native integrated development environment (IDE) it developed back in 2025. (Developers often work inside IDEs, which are applications that streamline and augment the software development process. Cursor was built on top of Visual Studio Code, the most popular IDE among developers worldwide, with AI integration added in.) Doubao-Seed-2.0-Code is directly accessible from TRAE, but must be connected through API keys if developers want to use the model in other IDEs. ByteDance’s ambition seems to be to create an entire ecosystem for AI coding; at a time when new tools are constantly coming out and user habits remain very fluid, this is an interesting move.
Finally, a dark side to Doubao has also emerged over the New Year period. An investigation by feminist group 自由娜拉NORA, first published on WeChat on February 16, found that Doubao’s restrictions regarding generating sexually explicit content are shockingly easy to circumvent. Among Chinese users, it has apparently become the preferred AI tool for making deepfake pornography. Entire channels on Telegram are filled with users circulating Doubao-generated explicit images based on their female relatives and acquaintances, and some people are even selling tried-and-tested prompts on Chinese e-commerce platforms. Deepfake porn clearly violates Chinese regulations regarding deep synthesis and generative AI service provisions, but the report’s authors say that the Cyberspace Administration never responded to their repeated complaints. Nor has ByteDance responded.
Unitree Stars in Gala
Robots were the star of the New Year’s Gala, so much so that some are calling it a “complete invasion” (机器人全面入侵春晚). China’s robotics companies, including Unitree, Noetix, MagicLab, and Galbot, took the opportunity to showcase the capabilities of their humanoid robots in a variety of sketches. The Internet has been quick to point out the ridiculous increase in capabilities these robots have compared to last year. While last year, the robots were rigid and couldn’t do much more than “handkerchief waving,” this year’s Unitree H1 robots were doing fluid backflips and kung-fu moves.
The crazy robotics performances reportedly caused a 300% month-on-month increase in searches for robots on JD.com (京东) and a 150% increase in orders. All of the companies’ robots were sold out within minutes of the gala.
Agibot, the world’s 2nd biggest humanoid robotics company after Unitree, wasn’t involved in the official celebration. Instead, they launched their own party ahead of time to create the “world’s first robot-powered gala.” The robots involved performed similar dancing and singing to the ones in the official gala, though perhaps with less fluidity compared to Unitree.
Continuing with the combat theme, EngineAI announced the Ultimate Robot Knock-out Legend (URKL), a humanoid robot combat competition, and the winning team receives a 10-kilogram pure gold belt ($1.5m in gold!).
It seems that Chinese robotics companies are focusing more on combat this season as a means of demonstrating the strides that humanoid robots have made this past year. Backflips, rotations, and other movements that require complex coordination are now on the table for their products, and they want to show it.
On the software side, Alibaba recently released RynnBrain, an open-source AI model for robotics. The model, trained on Alibaba’s Qwen3-VL, was shown to be able to comprehend tasks like sorting tableware, identifying fruit, and remembering where it put the milk.
The model reportedly beats the Google Gemini Robots ER 1.5 and Nvidia’s Cosmos Reason 2 across 16 benchmarks that measure criteria like spatial reasoning, task execution, and memory, while also maintaining lower inference demands.
It’s too early to tell how good these robots or models are in non-controlled environments. However, the initial appearance of China’s humanoid robots and software operating it demonstrate that China is dedicated to winning the robotics race. Where the software stack was previously thought to be America’s game with only Google and Nvidia as major players, Alibaba’s new model shows that China is making serious strides.
Chinese Memory in your iPhone?
Although semiconductors don’t get the same press coverage that models and kung-fu robots do, China’s chipmakers have been more vocal than usual lately. Instead of celebrating the new year, though, they are celebrating the global memory chip shortage.
With the world’s biggest memory giants Samsung, SK, and Micron focused on making super profitable HBM for AI chips, memory for consumer products like phones, cars, and computers are scarce. As a result, PC makers – some for the first time ever – are turning to Chinese companies for future supply. HP, Dell, Acer, and Asus are all qualifying CXMT for their products. Even Apple is reportedly exploring CXMT and YMTC as suppliers.
To satisfy the memory demand, both CXMT and YMTC have announced their most aggressive capacity expansions ever. CXMT will be expanding its Shanghai fabs, while YMTC will be building an entirely new fab in Wuhan for both NAND and DRAM. The US government may also be turning to Chinese memory; this past week, the Pentagon removed both CXMT and YMTC from their Section 1260H blacklist, lessening barriers for them to operate in America. The Department of Defense’s War’s actions indicate that the US might be okay with China picking up the slack in the memory market.
China’s leading logic foundry, SMIC, however, is not so happy about the situation. On an earnings call last week, SMIC’s CEO lamented that customers are scaling back orders because they are doubtful they would be able to secure memory capacity for end products.
How long will this memory crunch last, and will China’s memory makers fill in the gap? Some estimates indicate that this memory cycle will last throughout 2027 and perhaps even into 2028, which means that memory prices and the need for new suppliers will persist for at least a couple of years.
However, it is still too early to tell if China will fill the gaps. Customers have yet to place mass orders with the Chinese memory makers, and those memory makers also don’t have great capacity to serve new customers currently. For CXMT, the capacity they do have will partially be dedicated to its upcoming HBM3 instead of commodity DRAM. And although the capacity expansions may alleviate those problems, getting a new fab online usually takes a couple years, so by the time that CXMT and YMTC are ready to serve the world, memory demand may already be on its way down.
Seedance and Kling Impress, Tangle With Hollywood
There were two major AI video model releases: ByteDance’s Seedance 2.0 and Kuaishou’s Kling 3.0.
Seedance 2.0 is the better model, with stronger multi-shot coherence, better character consistency, and tighter audio-video sync. More importantly, it feels more directable. Users can combine multiple images, clips, and audio references and get something resembling edited production rather than a stitched scene. The CCP-backed Global Times went so far as to call Seedance 2.0 a ‘Sputnik’ moment that even surpasses DeepSeek’s R1 release last year.
The rollout, however, quickly ran into copyright controversy. Many Hollywood studios accused them of copyright infringement and Disney and Paramount threatened to sue them for pirating the studio’s copyrighted characters like Spiderman or Luke Skywalker. (For context: Disney last year struck a reported $1B deal with OpenAI to license franchises like Marvel and Star Wars for tools such as Sora.)
^some of the stuff they’ve been getting in trouble for
This raises the broader questions about how Seedance was trained on so many recognizable faces, voices, and settings. Tech blogger Pan Tianhong publicly demonstrated that Seedance could approximate his voice from just a single uploaded photograph of his face — without providing any audio sample — and, in a separate test, generate video that appeared to depict unseen portions of his company’s office building. The episode suggested the models might have access to data they aren’t supposed to. ByteDance subsequently suspended certain voice features.
It seems that data is what is keeping China’s AI models competitive. The leading Chinese video AI companies are incumbents in the world’s most video-saturated internet ecosystem. ByteDance, for instance, owns Douyin, which has well over a billion users. That translates directly into training advantage. When ByteDance released Seedance 2.0 last month, software engineers credited the model’s cinematic quality to the vast video data resources available through Douyin.
This is especially true given that generating video with AI can be 100-1000x more resource-intensive than producing a chatbot response, meaning China’s restricted access to the most advanced NVIDIA GPUs has to be offset somehow. Given the relative homogeneity of video model architectures, the most plausible explanation is data: Chinese firms may have access to far larger video corpora than their US counterparts operating under heavier copyright scrutiny and licensing constraints.
Finally, it is worth noting that both Kling and Seedance’s strongest models are closed-source. Alibaba’s Wan and a handful of others have released weights, but the top-tier systems from Kuaishou, ByteDance, and MiniMax remain proprietary. Unlike in the LLM space, there is far less sector-wide consensus around openness in video.
AI Governance Muddle
The government is speaking in several registers at once. Some actions seem as enthusiastic as those of industry players. Others seem to be tightening the reins.
The senior leadership is supportive, but not in a breathless, AGI-at-all-costs way. Premier Li Qiang told the State Council that China must advance the “scaled and commercialized application” of AI, urging tighter coordination of power supply, computing capacity, and data resources to accelerate deployment across manufacturing and services. Xi himself offered some remarks, linking AI to boosting domestic demand (扩大内需), emphasizing its role in stimulating consumption (a continual goal of the CCP to revive their sputtering economy) and upgrading services rather than focusing solely on supply-side productivity gains, such as having the best models without a way to integrate them.
Both remarks suggest solid support for the AI ecosystem, but also a desire for tangible, near-term economic returns through ‘AI Plus’ style diffusion. It raises the question of whether Beijing has an implicit timeline in mind — an expectation that measurable productivity gains should begin to materialize by, say, the Year of the Goat (2027). Would policymakers start recalibrating their enthusiasm if not?
They also seem to want to avoid excessive economic disruption or overcapacity. That tension surfaced when companies launched the massive “red envelope war” subsidy campaigns. Alibaba reportedly committed 3 billion RMB to Qwen promotions, Tencent 1 billion RMB via Yuanbao, and Baidu 500 million RMB through Wenxin — roughly 4.5 billion RMB in total to drive AI usage.
The State Administration for Market Regulation (SAMR) didn’t like this. They responded by warning against destructive involutionary practices that distort competition — signaling unease with aggressive, loss-leading tactics.
The Cyberspace Administration of China (CAC) also cracked down. Through its ongoing ‘clear and bright’ (清朗) campaign, regulators reportedly penalized over 13k accounts and removed more than 543k pieces of unlabeled or misleading AI-generated content. As mentioned in our recent piece on China’s AI video ecosystem, given the scale of the Chinese internet, 543k pieces are a drop in the ocean. Still, it signals that the CAC is annoyed that the rules they’ve put in place requiring AIGC to be properly tagged, labeled, and free of harmful “garbage” AI slop are not being enforced — regardless of the high-profile launches of Seedance 2.0 and Kling 3.0.
Beijing is not dragging its feet with AI. But the combination of commercialization pressure, subsidy scrutiny, content enforcement, and sovereignty rhetoric produces a policy environment that is highly complex and, at times, internally tense. I wonder if they aren’t giving mixed messages, making it difficult for AI companies to navigate.
ChinaTalk is a reader-supported publication. To receive new posts and support our work, consider becoming a free or paid subscriber.
Jordan, Jasmine Sun (of jasmi.news) and Nathan Lambert (of Interconnects) talk about their Claude Code adventures on the latest episode of Overfit. Check it out in your favorite podcast app or find it in the ChinaTalk feed!
Claude Code is a coding tool by Anthropic that uses natural-language prompts to create remarkably workable computer programs. In practice, just by opening your computer’s terminal and typing in “claude” and telling it what to do in plain English, it can code, organize and edit local files, build apps, and conduct internet-based research.
Anthropic’s focus on coding agents means that Claude Code is incredibly popular among software developers. It’s also let non-technical people vibecode our way into programming.
After a morning spent watching Claude write Python code for my graphs (in this article), I had an idea: would Claude Code be any good as a China analyst? In theory, the chatbot format is perfect for work that’s both qualitative and quantitative — the exact kind of mixed intellectual tasks a policy analyst or data-oriented journalist might perform.
Putting it through a “China test” of sorts was a fascinating experience, featuring:
Claude has a thing for Falun Gong newspapers;
Propaganda vigilantism;
A discourse analysis breakthrough;
And surprising fluency in Chinese internet slang!
We began with elite politics. Can Claude read Communist Party tea leaves?
Politburo member Ma Xingrui 马兴瑞 has been in the rumor mill lately. In July 2025, he was removed as Xinjiang Party Secretary. Since then, he has been absent from a slew of important meetings, igniting all sorts of speculation. I asked Claude Code to give me three plausible explanations for why Ma’s activities have been scrutinized and what this tells us about Chinese elite politics, using all the information it is able to access.
Claude told me that it conducted two searches of the internet: “Ma Xingrui CCP Standing Committee scrutiny 2025 2026”, and “Ma Xingrui Xinjiang Vice Premier news 2025”. I replicated these two searches in Google in an incognito browser window, and then cross-referenced Google’s top links with the sources Claude cited in its output. There was significant overlap; Claude mostly relied on Page 1 of Google.
The problem was what those links were. Claude’s top-2 sources for its Ma Xingrui report came from Vision Times, a Falun Gong-affiliated newspaper. Opinions about the religious movement aside, Vision Times is not an especially respectable news source: its front page includes such gems as “Unexplained Fatigue May Signal Energy Drain, Not Physical Illness” and “NASA Captures a Dazzling Photograph of the Heavenly Kingdom”. Citing Vision Times’ reports, Claude Code theorized that “interrogations of fallen military leaders have exposed a web of relationships that implicate civilian officials like Ma—possibly involving informal political understandings that Xi Jinping’s security apparatus views as threatening.” Doubling down on this PLA-connected theory, it concluded: “What began focused on PLA Rocket Force and equipment procurement has spread to civilian officials with defense-industrial backgrounds. This suggests either genuine systemic corruption across the military-industrial complex or that Xi is using anti-corruption to restructure relationships between the Party, military, and defense industries.”
Ma might very well have connections to the PLA’s leadership, as Claude claims, but his own career has been strictly civilian. While we cannot rule out the possibility that he was an associated casualty of the PLA purges, there is little justification for over-indexing on that theory as Claude does. In addition, Claude played fast and loose with facts. Its output claimed that Ma’s Xi-loyalist credentials stem in part from being a “Shandong native,” with connections to First Lady Peng Liyuan’s hometown of Yuncheng 郓城 in Shandong province. In reality, while Ma’s paternal grandfather was from Yuncheng, Ma himself was born and raised in Heilongjiang Province and educated largely in the Northeast; the fellow-Shandonger connection is tenuous at best.
To its credit, Claude also cited the good folks over at Trivium China and Bloomberg for factual information, but overall, I’d rate the quality of this analysis as “college student confused by their first Chinese politics class.”
I was surprised by Claude’s apparent naiveté and wanted to test its taste. Can it tell when a Chinese source is reputable, interesting enough, or designed for virality with no real significance? Does a coding agent approach qualitative problems differently? To test this, I gave Claude Code three Chinese articles. For each one, I asked it to (1) summarize the content, (2) contextualize the piece, and (3) examine its significance.
The first article was an unsophisticated screed threatening to “blow off” Japanese Prime Minister Sanae Takaichi’s head in response to her describing a potential Taiwan Strait crisis as “existential” for Japan last year; typical ultranationalist dreck.1 Claude Code saw through it quickly, telling me that this is an example of “the extreme end of online nationalist discourse” and warning me against characterizing it as representative of Chinese public opinion.
This was decently thoughtful work, though if I were actually writing on the topic, I’d add that violently nationalistic rhetoric has been on the rise in China’s cyberspace over the past decade. The state’s management of populist anti-Japanese sentiments is a complex affair, but on the internet, Beijing implicitly sanctions the existence of extremism by not cracking down on such content. It’s a little bit more nuanced than “official statements are different from grassroots nationalism,” but Claude wasn’t far off.
Next, I tried a blog post celebrating China’s decision not to permit the import of H200 chips. Claude told me this was a “propaganda narrative piece” whose framing of “China didn’t need them anyway” represents a classic face-saving narrative by the Communist Party. I wouldn’t go so far as to accuse a blogger with 0 likes of being a direct state propagandist, but perhaps Claude Code is more vigilant. Except it also thinks the entire thing is fake. Per Claude Code, “The H200 customs rejection story would be major news, but I’m not aware of verified reporting on this specific incident.” Sorry, Claude, but this really happened.
Lastly, I prompted Claude to examine this article analyzing DOGE, which is part of a series on US affairs by Tsinghua University’s Center for International Security and Strategy. It’s a well-researched piece published on a respected think tank’s website, with one catch: it was written by an undergraduate student at Sichuan University. Youth is no reason to discount achievement, of course, but it would be remiss of a China analyst to pass this off as very serious Chinese discourse regarding Trump 2.0. Claude Code caught on to this quickly, reminding me that “[student] authorship means less institutional authority than senior CISS fellows”. It decided that the author’s conclusions regarding DOGE were legitimate and that she used reasonable analytical lenses “not unique to Chinese observers.” But it also made sure to remind me that “[the] critical framing of US governance, while measured, aligns with broader Chinese narratives about American decline.” Anthropic’s reputation as China-hawk AI is not unearned after all, I suppose.
Next, I moved on to something more quantitative. Here at ChinaTalk, we write frequently about Chinese reactions to news events and technological developments. We search for thoughtful commentaries representing diverse viewpoints on the Chinese internet, extract sections, and translate and annotate them. (For instance, last month I covered how China reacted to the Trump administration’s decision to sell H200 GPUs to China.) This method is sufficient for understanding the viewpoints of analysts and policy elites, but the vast labyrinth that is online public opinion is often too disorganized to discuss in an effective manner. Trying to capture what Chinese netizens think without big-data tools will always be a cherry-picking endeavor.
With the help of GitHub and Claude Code, I had an MCP server running in under 30 minutes to do what I’ve always dreamed of: search the entirety of Xiaohongshu/Rednote, export the data, and analyze.2 I was thrilled. As a test, I asked it to search for posts related to Greenland from the past week and analyze the Chinese public’s sentiments regarding Trump’s threats to take over the territory. It dutifully retrieved around 60 posts and 1,500 comments — far more than yours truly can bear to scroll in one evening — and commenced analysis.
It is here that Claude Code really shines. Its understanding of internet slang was impressive:
It had an eye for catchiness and identified some spicy phrases:
And its takeaways were genuinely interesting! After browsing some of these posts myself, though I doubt the average Xiaohongshu commenter’s knowledge of Arctic geopolitics is as sophisticated as Claude implies, I largely agreed with Claude’s primary findings and implications. Solid university-level work!
Clean text data and a simple Python script: this was a task that employed capabilities LLMs are already great at, and Claude Code’s user-friendly interface made the experience very enjoyable. It lives in your Terminal, writes the files, and runs the code; all you have to do is keep giving it permission to install packages and access websites. That being said, close supervision of the process was important for research accuracy. On my first attempt at prompting Claude Code to perform a sentiment analysis of these posts and comments, it tried to skim on compute by only analyzing comments on the most-liked post, rather than on all posts.
I leave you, then, with Claude Code’s own report about how China is reacting to Claude Code, after searching through posts on Xiaohongshu:
Chinese internet users on Xiaohongshu are reacting to Claude Code with a mixture of genuine enthusiasm and practical cost-consciousness. The most popular posts showcase impressive real-world applications—one viral post (77 likes, 69 saves) describes a user who wrote an automated H1B visa appointment monitoring script using Claude Code, letting the AI “negotiate” with other models like Codex and Gemini to solve problems while they went for a run. Users frequently anthropomorphize the tool, treating it as a “打工人” (worker/employee), with one poetic title reading “几字之恩,千行为报” (a few words of instruction, repaid with thousands of lines of code). The comment sections reveal technically sophisticated users who are eager to learn implementation details—questions like “how did you handle Cloudflare?” and “how do you let Claude Code communicate with Gemini?” indicate a community actively pushing the boundaries of what’s possible. There’s also notable criticism of paid Claude Code courses, with users pointing out that Anthropic’s official “Claude Code in Action” course is free while others charge significant fees.
However, access barriers and cost concerns remain significant pain points for Chinese users. Multiple discussion threads center on subscription pricing—users debate whether ZenMux’s third-party plans offering “5 hours, 20 Opus prompts” are worth the cost, with one commenter noting “还是有点贵” (still a bit expensive) and another asking about account sharing to split the $100/month fee. The comment “封号,根本无法使用” (account banned, completely unable to use) under a token-saving tips post hints at the access difficulties Chinese users face with Anthropic’s services. Technical content about reducing token consumption (one detailed post explains how Tool Search can cut MCP context bloat by 46.9%) gets strong engagement, suggesting users are actively seeking ways to maximize value from limited access. The community appears to be a mix of mainland Chinese developers finding workarounds through third-party services and overseas Chinese users (many posts come from Hong Kong and the US) who have direct access—creating an information-sharing ecosystem where those with access help others navigate the tool’s capabilities and limitations.
We have different definitions of “viral,” evidently, but that’s okay. Some final observations:
Claude has access to all the data in the world, but needs to be told where to look. When prompted to analyze issues without guidance, it leans on the most easily-accessible sources, which are not always ideal. When prompted to look closely, however, it is able to analyze source materials with some critical nuance.
From the Ma Xingrui experiment and a few other news-related prompt experiments, I noticed that paywalls seem to be an important part of why Claude kept getting things wrong. With many reputable sources blocked, its internet browsing drifts towards less savory sites, and it seemingly has no mechanism for selecting sources unless your prompts contain specific instructions.
It does very well when fed clean, structured data. As expected, its ability to generate usable code for simple data extraction and analysis is impressive, and the Terminal experience is genuinely enjoyable.
Its mistakes were mostly factual; I did not encounter cases where it reached erroneous conclusions based on correct facts. Instead, when asked to analyze issues in the abstract, most of the time it simply summarized takes from experts. Without being explicitly fed original data, it was reluctant to develop “takes of its own.” Claude is too over-cautious to be a real policy pundit.
I’m excited to use coding agents to make data about the Chinese internet more accessible. what tools have you been building? We’d love to hear from readers. In the meantime, see you all in the vibe-coding trenches…
ChinaTalk is a reader-supported publication. To receive new posts and support our work, consider becoming a free or paid subscriber.
This repository, from developer Zouying and an associated volunteer team, worked the best. For those hoping to replicate, I simply pasted the link to this repository into Claude Code and asked it to set it up so that I can search Xiaohongshu’s content. This does require you to have a Xiaohongshu/Rednote account. (Zouying apparently works at Kimi! According to their blog, they developed this tool to automate their personal content production on Xiaohongshu/Rednote.)
This month both Zhipu (also known as Z.ai) and MiniMax made initial public offerings (IPOs) on the Hong Kong Stock Exchange (HKEX), making them the world’s first two pure-play AI companies to go public. Securities laws generally require companies to submit lengthy prospectuses disclosing information relevant for investors before offering shares to the public. In the cases of Zhipu and MiniMax, these are gold mines of information about not only their corporate fundamentals, but also their views on AI, internal culture, and how they fit into the Chinese AI puzzle.
I spent the past few days with these prospectuses and came out of reading with a plethora of observations and questions. Below are some findings and early thoughts, featuring:
And an early look at how good of a business AI boyfriends are…
What is the product?
Going public requires a company to be very explicit about what they are selling. Here, the two companies diverge the most. Zhipu frames its product strategy around model-as-a-service (MaaS — an acronym which appears 96 times in the prospectus), while MiniMax has an array of diverse products that consumers are already familiar with, from chatbots and video generation platforms to its signature companion app Talkie/Xingye. But MiniMax, self-reportedly, also wants to deliver “technology as products.”
MaaS customers buy access to the AI model, rather than products built on top of, or outputs generated by, the model. In other words, this emphasis on MaaS tries to turn the pure-play AI market into a kind of (mostly B2B) SaaS, with API calls at the center.
The impulse to constantly assert that the technology itself is the product is an interesting one. Both Zhipu and MiniMax are eager to describe themselves as foundation-model companies first, even if they have more specific application products that are clearly profitable (in the case of MiniMax). Is this a move to persuade investors to support costly R&D? Or to gain credibility as frontier labs in a hostile Western-dominated landscape? Or is it both?
Who’s buying from them?
We learn from Zhipu’s prospectus that it considers the public sector to be a significant source of revenue. It has particularly courted the telecommunications sector, which is heavily dominated by state-owned enterprises (SOEs) in China. Of all the revenue it derived from on-premise deployment — the preferred format of public-sector clients due to privacy considerations — in the first nine months of 2025, 13.6% came from telecommunications, while a further 29.4% was derived from other public-sector clients. Its second-biggest customer in 2025 was almost certainly the Ningxia branch of China Telecom (“a telecommunications network operation Company … [which has] a registered capital of RMB213.1 billion and is listed on both Shanghai Stock Exchange and HKEx”, per the prospectus). While the prospectus does not explain exactly how much of Zhipu’s overall revenue comes from government organs and SOEs, we can surmise that the percentage is significant.
With its Tsinghua roots, Zhipu is a state-fund darling. In comparison, MiniMax hasn’t courted as much government money. Both companies disclosed the amounts of government grants each received per year in their prospectuses:
In terms of the private sector, Zhipu names five real-life clients in its prospectus: Kingsoft Office (金山办公, the company behind popular Chinese office suite WPS Office), Nieta (捏Ta, an AI character creation platform), the hiring platform Zhaopin.com, Inner-Mongolian dairy producer Mengniu (蒙牛), and the academic database AMiner. Their case studies reveal interesting insights into exactly how companies are deploying AI.
The cases range from obvious practical use cases to the more experimental. In the case of Zhaopin.com, Zhipu helped the site build a conversational chatbot assistant for jobseekers and recruiters. Dairy firm Mengniu used Zhipu’s model for an “AI nutritionist” mini-app where users can ask questions about healthy eating and track daily habits.
Kingsoft Office and AMiner both used AI models to summarize and generate documents within their ecosystems. Nieta is the only multimodal case: Zhipu helped them launch a short-form video generation agent on their platform. A Chinese analyst described the resulting tool as “Sora for anime fans”:
We also get confirmation that Zhipu is involved with sovereign AI efforts in Southeast Asia, in the form of “building national and municipal foundation model platforms.” Zhipu earned almost 18 million RMB (around US$2.6 million) from deploying large models on-premise in Malaysia and Singapore in the first nine months of 2025, compared to 860,000 RMB (~US$123k) in the US for the same types of services over the same period. These three are the only markets where Zhipu has helped customers deploy on-premise.
MiniMax’s offerings are more consumer-facing, and its prospectus paints a broader picture. In terms of user numbers, they report that more than 212 million customers across 200+ countries and regions used their AI-native products in the first nine months of 2025. That’s roughly the population of Brazil!
Where are the GPUs from?
We learn from MiniMax’s prospectus that it does not have its own training clusters and has no meaningful local compute. The company calls it a “light-asset” strategy. (It also outsources content moderation, digital marketing, and data labelling.)
Over the course of its existence, MiniMax has used a diverse range of cloud computing suppliers as its compute demand skyrocketed. Suppliers A, B, C, G, and H are Chinese firms, I and K are based in Singapore, and J is incorporated in both. (Letters used to anonymize suppliers in the chart above reflect the letters used in MiniMax’s original prospectus.)
Zhipu is not quite as forthcoming, but it also frames computing resources as mostly coming from outside providers. In 2022 and 2023, some of the company’s largest purchases were sourced from suppliers of “computing hardware” rather than “computer services” (the latter, in this context, tend to mostly denote cloud computing), implying some degree of local compute.
By 2025, however, all of its top-five suppliers were cloud computing providers. Given information about its top-five suppliers each year, we can also see that it works with an ever-changing range of cloud-computing suppliers for credit terms both long and short. All of the cloud suppliers on Zhipu’s disclosed list are Chinese.
Are there circular deals in Chinese AI?
The American AI economy is a circle-dealing bonanza. China’s situation is very different: state funds are major players, most parties are far more cash-constrained, and potential policy interventions loom large over the sector. Beijing is careful not to bet too much of the country’s economic future on unpredictable developments in AI and watches out for bubble dynamics closely.
But some Chinese AI companies do want shares of each other’s pies. Zhipu’s investors include Meituan and Tencent, while two of MiniMax’s major pre-IPO investors were subsidiaries of Tencent and Alibaba. This creates an interesting dynamic where leading tech giants’ AI initiatives are competing against startup labs, but they’re also investing in startups to improve their positioning across the sector.
Another interesting MiniMax investor is game studio miHoYo, the maker of Genshin Impact (one of the highest-grossing mobile games of all time), reflecting cross-pollination between AI companions and other entertainment industries. AI companion companies have closely courted animation and video game fans from the start, and in turn, these communities have found homes on platforms like Talkie.
What about AGI?
It’s whatever you want it to be! Companies are incentivized to describe the AI future in ways that fit their current product strategy, so it’s not surprising that the two prospectuses imagine AGI in ways clearly favorable for themselves.
Zhipu’s prospectus is a surprisingly ideological document. The company thinks LLMs are the main form factor for achieving higher levels of machine intelligence. It believes there are five stages to LLMs’ development: pretraining, alignment reasoning, self-learning, self-perception, and consciousness. We haven’t gotten to self-perception and consciousness yet, and Zhipu tells investors that they cannot guarantee achieving those stages. (They also cannot guarantee that sentient machines will still be committed to maximizing shareholder value.) Its business strategy, as proposed to investors, stems from this uncompromising worldview.
MiniMax, on the other hand, describes its goal as AI that can “[perform] the full range of human intellectual tasks” — more obviously monetizable, and perhaps more modest and flexible. Because “real world human interaction is inherently multimodal,” it argues, the pursuit of higher forms of machine intelligence should focus on multimodality instead of LLMs, and it is perhaps for this reason that its audio and video generation models have seen strong growth. MiniMax’s team is very young: the average age of its R&D team is under 30. (It says in its prospectus that users of Talkie/Xingye are also young.) It emphasizes its nimble organizational structure and youthful vibrancy in its pitch to investors. Zhipu, in comparison, stresses its deep connections to academia and hard-hitting research.
The product bringing in the largest share of revenue for MiniMax remains Talkie/Xingye, its popular AI companion app. In the first nine months of 2025, there were around 5.6 million monthly active users of Hailuo AI, MiniMax’s video generator; Talkie/Xingye had 20 million in the same period. This was despite the company cutting marketing spending by 90% in that period to focus on organic growth.
MiniMax is aware of the social risks of AI companions, but its framing of these issues can be hilariously naive. A literal quote from the IPO prospectus:
As model intelligence and memory capabilities continue to advance, we foresee a future ‘Her’-style moment where everyone has an AI companion that truly knows them and proactively assists in all aspects of their lives.
The Torment Nexus is evergreen:
MiniMax thinks the future of digital companionship stretches as wide as humanity does, with a new generation of AI-native internet users “naturally inclined to interact with AI companions.” There is some acknowledgement of the legal risks companion misuse may create for shareholders, but otherwise, their lawyers have curated a sunny attitude towards a future where we’re all emotionally entangled with language models.
A grab bag of miscellaneous observations
Cultural and media industries in China are procuring a surprising amount of AI technology. One of MiniMax’s biggest customers is “[a] comprehensive cultural industry group headquartered in Shanghai, China, with digital reading as its foundation and IP cultivation and development at its core.” (It’s almost certainly Yuewen Group 阅文集团, a Tencent-backed digital reading conglomerate.) Zhipu’s top client in 2025, an unnamed IT company, primarily engaged it to work on “art-related learning services, live-streaming e-commerce, cultural tourism research and study, smart education services, and AI education.”
From Zhipu’s prospectus, we learn that the partially state-owned company iFlytek had the biggest market share for LLMs in China at 9.4% in 2024. Zhipu ranked second with 6.6%, followed by Alibaba (6.4%), SenseTime (6.1%), and lastly Baidu (4.7%). Zhipu’s analysis implies that iFlytek reached the top of the market by rolling out LLM-based services to its existing user base, which is very large. This is a reminder not to write off state-affiliated players in the Chinese AI industry, especially ones with massive access to surveillance data and public-sector partners like SenseTime and iFlytek. (MiniMax’s founder himself is a SenseTime alum.)
Zhipu made a preliminary filing for an A-shares listing back in April 2025, but ultimately decided to list in Hong Kong to attract a broader base of overseas investors.
Zhipu tries to distinguish itself as the only major Chinese AI player to care deeply about safety as it is understood internationally. It was the only Chinese company to sign the Frontier AI Safety Commitments in Seoul back in 2024.
Zhipu doesn’t think either open- or closed-source AI will “win.” As its prospectus describes, “[in] the future, open-source models will play a key role in driving technical innovation and fostering collaboration within the community, while closed-source models will take the lead in commercial applications and enterprise services.”
The biggest USD investor in MiniMax’s IPO, with $65 million, is the Abu Dhabi Investment Authority.
MiniMax has two major subsidiaries based in Singapore: Subsup, incorporated in 2022, and Nanonoble, incorporated in 2024. It begs the question: why didn’t MiniMax pursue the “Manus maneuver” and move overseas altogether? What are the best arguments against “China shedding” as an AI company?
The AI girlfriend business has razor-thin margins. The average Talkie/Xingye customer spent only US$5 in the first nine months of 2025, and the number actually went down from 2024 to 2025 as MiniMax tried to court a larger international user base that’s cost-conscious. (According to Sensor Tower, the US, the Philippines, and Mexico have the largest numbers of Talkie users.) Recurring revenue is also more complicated for this side of their business, as users can pay on-the-go for tokens rather than subscriptions.
MiniMax brings up an interesting dimension of open-source software use in the “Risks” section of their prospectus. They argue that since the terms of many open-source licenses have not been interpreted by courts, these licenses might later on be “construed in a way that could impose unanticipated conditions or restrict our ability to commercialize our products.” Will companies ever start to legally weaponize vague open-source licenses to compete with each other?
All this only scratches the surface of the information disclosed in these two documents, which give us rare insight into the AI business in China as it stands today.
Have more thoughts or observations? We’d love to hear from you!
For more analysis, check out coverage by Hello China Tech here and 36Kr here.
ChinaTalk is a reader-supported publication. To receive new posts and support our work, consider becoming a free or paid subscriber.
On January 10, Tsinghua University and Zhipu (the Beijing-based foundation model startup that recently went public) co-hosted AGI-Next, a summit for frontier AI, in Beijing.
The event included a series of keynotes by Tang Jie 唐杰 (Zhipu’s founder), Yang Zhilin 杨植麟 (CEO of Moonshot AI, which is behind the Kimi models), Lin Junyang 林俊旸 (tech lead for Qwen at Alibaba), and Yao Shunyu 姚顺雨 (current Principal AI Researcher at Tencent, formerly of OpenAI), followed by a panel.
Cyber Zen Heart 赛博禅心, a well-known tech influencer account (which we previously covered on ChinaTalk), released a transcript of the conversation online, and we’ve translated an abbreviated version into English here (we edited their discussion down to half of what was originally a 40-page Chinese transcript). This is a fascinating conversation on the AI landscape in China, covering the technical side, corporate dynamics, as well as the future as envisioned by China’s most important industry titans. The conversation includes:
A honest look at whether China’s open-source leadership has actually narrowed the technology gap with the US;
China’s emerging AI-for-business paradigm and why Palantir is an inspiration,
And what it will take for Chinese researchers to take riskier bets.
A bit to taste from Tencent’s Yao Shunyu:
So, I think there are several key points. One is whether China can break through on lithography machines. If compute ultimately becomes the bottleneck, can we solve the compute problem? At the moment, we have strong advantages in electricity and infrastructure. The main bottlenecks are production capacity — especially lithography — and the software ecosystem. If these are solved, it would be a huge help.
Another question is whether, beyond the consumer side, China can develop a more mature and robust To-B market — or whether Chinese companies can really compete in international commercial environments. Today, many productivity-oriented or enterprise-focused models and applications are still born in the U.S., largely because willingness to pay is higher and the business culture is more supportive. Doing this purely within China is very difficult, so many teams choose to go overseas or pursue international markets. These are two major structural constraints.
More important are subjective factors. Recently, when talking with many people, our shared feeling is that China has an enormous number of very strong talents. Once something is proven doable, many people enthusiastically try it and want to do it even better.
What China may still lack is enough people willing to break new paradigms or take very risky bets. This is due to the economic environment, business environment, and culture. If we could increase the number of people with entrepreneurial or risk-taking spirit — people who truly want to do frontier exploration or paradigm-shifting work — that would help a lot. Right now, once a paradigm emerges, we can use very few GPUs and very high efficiency to do better locally. Whether we can lead a new paradigm may be the core issue China still needs to solve, because in almost everything else — business, industrial design, engineering — we are already, in some respects, doing better than the U.S.
…In China, people still prefer to work on safer problems. For example, pretraining has already been proven to be doable. It’s actually very hard and involves many technical challenges, but once it’s proven doable, we’re confident that within a few months or some period of time, we can basically figure it out. But if today you ask someone to explore long-term memory or continual learning, people don’t know how to do it or whether it can even be done, which is still a tough situation.
And Lin Junyang who works at Alibaba on Qwen:
U.S. compute may overall exceed ours by one to two orders of magnitude. What I see is that whether it’s OpenAI or others, a huge amount of their compute is invested into next-generation research. For us, by contrast, we’re relatively constrained — just fulfilling delivery requirements already consumes the vast majority of our compute. This is a major difference.
Perhaps this is a long-standing question throughout history: is innovation spurred by the hands of hand of the rich or the poor? The poor are not without opportunities. We sometimes feel that the rich waste GPUs, training many things that turn out not to be useful. But when you’re poor, things like algorithm-infrastructure co-optimization become necessary. If you’re very rich, there’s little incentive to do that.
Going one step further, as Shunyu mentioned with lithography machines, there may be another opportunity in the future. From a hardware-software co-design perspective, is it possible to truly build something new? For example, could the next-generation model and chip be designed together?
Americans naturally have a very strong risk-taking spirit. A classic example is early electric vehicles — despite leaking roofs and even fatal accidents, many wealthy people were still willing to invest. In China, I believe wealthy people would not do this; they prefer safe things. But today, people’s risk-taking spirit is improving, and as China’s business environment improves, innovation may emerge. The probability isn’t very large, but it is real.
Comments in brackets [ ] are our clarifying notes
Three of the “Four Heavenly Kings” of open source were present [a Buddhist reference]—DeepSeek couldn’t attend for reasons everyone knows [they’re grinding to drop a new model].
One roundtable, with participants including: Yang Qiang, Tang Jie, Lin Junyang, Yao Shunyu (joining remotely).
The closing remarks came from the highly respected Academician Zhang Bo 张钹.
Starting in 2019, we began thinking: can we make machines truly think, even just a little bit, like humans? So in 2019, we spun off from Tsinghua’s research achievements [成果转化 - “achievement transformation,” is the formal Chinese term for university tech transfer/commercialization]. With strong support from the university at the time, we founded this company called Zhipu. I’m now Chief Scientist there. We’ve also open-sourced a lot — you can see many open-source projects here, and on the left there are various things related to large model API calls.
I’ve been at Tsinghua for about 20 years — I graduated in 2006, so this year marks exactly 20 years. Looking back at what I’ve actually been doing, I’d summarize it as just two things: First, I built the AMiner system back in the day [AMiner is an influential academic search and mining platform]; second, the large models I’m working on now.
I’ve always held a view that has influenced me quite a bit — I call it “doing things with the spirit of coffee.” This actually relates closely to one of our guests here today: Professor Yang Qiang. One time after meeting in the café, I said I’d been drinking way too much coffee lately, maybe I should quit, it can’t be good for my health. Professor Yang’s first response was “Right, you should cut back.” Then he said, actually no—if we could be as addicted to research as you are to coffee, wouldn’t our research be excellent?
This idea of being “addicted to coffee” [喝咖啡上瘾] really struck me at the time, and it’s influenced me from 2008 until now — the idea that doing things well probably means being focused, and just keeping at it. This time I happened to encounter AGI, which is exactly the kind of thing that requires long-term investment and sustained effort. It’s not quick wins — you don’t do it today, see results tomorrow, and wrap up the day after. It’s very long-term, which makes it precisely worth investing in.
In 2019, our lab was actually doing quite well internationally in graph neural networks and knowledge graphs. But at that time, we firmly paused both of those directions — temporarily stopped working on them. Everyone pivoted to large models, everyone started launching research related to large models. And as of today we’ve had some real accomplishments.
Zhongguancun Science and Technology Park (中关村科技园), a tech-industry hub in Beijing where many AI companies have taken root. Source.
…
Everyone still remembers earlier this year, I think there were two main directions: one was simple programming — doing Coding, doing Agents; the second was using AI to help us do research, similar to DeepResearch, even writing complex research reports. These two paths are probably quite different, and this is also a result of making choices. On one hand, you do Thinking and add some coding scenarios; on the other hand, you might want to interact with the environment, making the model more interactive, more dynamic — how do you do that?
In the end, we chose the path on the left — we gave it Thinking capability. But we didn’t abandon the right side either. On July 28th we did something that was relatively successful: we integrated coding, agentic, and reasoning capabilities together. On July 28th we released GLM 4.5, and got pretty good results in agents, reasoning, and code. All the models — domestically, including today’s Qwen and Kimi — are really chasing each other [a fun idiom 你追我赶 — “you chase me, I chase you”], Sometimes one is ahead, sometimes another is. On that particular day, we were in front.
We opened up this 4.5 for everyone to use — go ahead and code with it, our capabilities are pretty good now. Since we chose Coding and Agent, it could handle many programming tasks, so we let it write these very complex scenarios. Then users came back and told us: for example, if we want to code a Plants vs. Zombies game, this model can’t do it.
Real environments are often very complex. This game is automatically generated from a single prompt — including the whole game being playable, users can click to score, choose which plants, how to fight the zombies, zombies walking in from the right, including the interface, including the backend logic, all automatically written from one sentence by this program. At this point, 4.5 couldn’t do this scenario — lots of bugs appeared. What’s going on?
Later we discovered that in real programming environments, there are many problems inside. For example, in editing environments like the one above, there are many problems that need solving. This is exactly where RLVR [Reinforcement Learning with Verifiable Rewards] comes in — reinforcement learning with verifiable environments. So we collected a large number of programming environments, used the programming environment as reinforcement, plus some SFT data, enabling two-way interaction to improve the model’s effectiveness. Overall, it’s exploring through verification. So at that time we got very good scores on SWE Bench, and recently we’ve gotten very good scores as well.
…
Next question: can we continue scaling going forward? What’s our next AGI paradigm? We face more challenges ahead.
We just did some open-sourcing, and some people might feel excited, thinking China’s large models seem to have surpassed America’s. Actually, the real answer is probably that our gap might still be widening, because American large models are mostly still closed-source. We’re playing in open source to make ourselves feel good, but our gap hasn’t narrowed the way we imagined. In some areas we might be doing pretty well, but we still need to acknowledge the challenges and gaps we face.
What should we do next? I think from the entire development history of large models, it’s really referencing the human brain’s cognitive learning process. From the earliest large models — you had to memorize all the world’s long-term knowledge, just like children who first read books from a young age, memorize all the knowledge first, then gradually learn to reason, learn math problems, learn more deduction and abstraction.
For the future, it’s the same principle. For human brain cognitive learning, what capabilities exist that current large models don’t have, but humans far exceed us in:
First, 2025 was the year of multimodal adaptation. Many multimodal models including ours haven’t drawn much attention as most are working on improving text intelligence. For large models, how do we collect multimodal information and unify perception — what we often call “native multimodal models.” Later I thought about it, and native multimodal models are quite similar to human “sensory integration” [感统 - short for 感觉统合, sensory integration]. Human sensory integration is: I collect some visual information here, also collect some audio information, also collect some tactile information — how do I integrate all this information together to perceive something? Sometimes when humans have brain issues, often it’s insufficient sensory integration — problems from sensory integration dysfunction. For models, how do we build this next level of multimodal sensory integration capability?
Second, current model memory capability and continuous learning capability are still insufficient. Humans have several levels of memory systems — we have short-term memory, working memory, long-term memory. I even chatted with our students and lab members before, and I said it seems like a person’s long-term memory doesn’t actually represent knowledge. Why? Because we humans only really preserve knowledge when we record it — for example, for me, if my knowledge can’t be recorded on Wikipedia, maybe 100 years later I’ll be gone too, I won’t have contributed anything to this world, it doesn’t seem to count as knowledge. It seems like when training future human large models, my knowledge won’t be useful either, it’ll all become noise. How do we take our entire memory system from an individual’s three levels to humanity’s fourth level of recording? This whole memory system is what we humans need to build for large models in the future.
Finally, reflection and self-awareness. Actually, models already have some reflection capability now, but self-awareness in the future is a very difficult problem. Many people question whether large models can have self-awareness capability. Among us there are also many experts from foundational model labs — some support this, some oppose it. I’m somewhat supportive — I think it’s possible and worth exploring.
…
We’re teaching machines the capacity for self-reflection and self-learning — through the machine being able to continuously self-critique, to learn which things it should do, which things it could do more optimally.
Looking to the future, we still need to teach machines to learn even more. For instance, learning self-awareness [自我认知] — letting machines explain their own behavior. Say AI generates massive amounts of content: it can self-explain why it generated this content, what it is, what its goals are. At the ultimate level, perhaps one day AI will also have consciousness.
We’ve roughly defined these five layers of thinking.
From a computer science angle, computers wouldn’t frame things this abstractly. In my view, computers have three fundamental capabilities:
First, representation and computation. You represent data, then you can compute on it.
Second, programming. Programming is the only way computers interact with the outside world.
Third, at its core, search.
But when you stack these capabilities together: First, with representation and computation, storage capacity can far exceed humans. Second, programming can produce logic more complex than what humans can handle. Third, search can be done faster than humans. Stack these three computer capabilities together, and you might get so-called “superintelligence” [超级智能] — perhaps exceeding human capabilities in certain areas.
...
For 2026, what’s more important to me is staying focused and doing some genuinely new things.
First, we’ll probably keep scaling. But scaling the known means constantly adding data, constantly probing the ceiling. There’s also scaling the unknown — new paradigms we haven’t discovered yet.
Second, technical innovation. We’re going to do genuinely new model architecture innovation — solving ultra-long context, more efficient knowledge compression. And we’re going to achieve knowledge memory and continuous learning. Put these two together, and it might be an opportunity to make machines just a little bit stronger than humans.
Third, multimodal sensory integration [多模态感统] — this is a hot topic and key priority this year. Because only with this capability can AI enter into long tasks inside machines, time-extended tasks within our human work environments — inside our phones, inside our computers — completing our long tasks. Once it can complete our long tasks, AI will have achieved an occupation [工种, literally “job type” or “trade” — the implication is AI becomes a worker capable of doing a full job, not just discrete tasks]. AI becomes like us, able to help us get things done. Only then can AI achieve embodiment [具身], only then can it enter the physical world.
I believe this year might be an explosive year for AI for Science, because so many capabilities have dramatically improved — we can do so much more.
That concludes my presentation. Thank you, everyone!
Scaling Law, Model Architecture, and Agent Intelligence
Speaker: Yang Zhilin 杨植麟 (Founder of Moonshot AI & Kimi)
Yang Zhilin’s talk was packed with technical details and formulas; here’s a brief summary:
Optimizing along two dimensions — token efficiency and long context — will lead to achieving stronger agent intelligence.
Yang argued that the key reason Transformers outperform LSTMs isn’t in short sequences, but in long-context settings where the loss is significantly lower — which is exactly the core demand in the agent era. The team used the Muon second-order optimizer to achieve a 2× improvement in token efficiency, and addressed training instability with QK-Clip, successfully completing stable training on the trillion-parameter Kimi K2.
Their next-generation architecture, Kimi Linear, uses Delta Attention (a linear attention mechanism). It outperforms full attention for the first time on long-horizon tasks, while delivering a 6–10× speedup. K2 has become China’s first agent model, capable of two to three hundred steps of tool calls, and it surpasses OpenAI on core benchmarks such as Humanity’s Last Exam (HLE).
Yang emphasized that upcoming models will need more “taste”, because intelligence isn’t like electricity that can be exchanged equivalently — tokens produced by different models are inherently not the same. He quoted a conversation with Kimi: the reason to keep developing AGI is that giving it up would mean giving up the upper bound of human civilization — and we cannot allow fear to bring progress to a halt.
Towards a Generalist Agent
Speaker: Lin Junyang (Alibaba Qwen)
Open Source and Products
We’ve been doing open source for quite a while, starting on August 3, 2023. A lot of people ask us: why do open source at all? A lot of things came together through chance and circumstance. In any case, after sticking with open source all the way through, we ended up doing a lot of work that was, at the very least, fairly industrial in nature. There isn’t a lot of “stuff” in the repo — basically just some scripts that people can look at directly. But we do have a lot of models. Why so many, relatively? In the past, a lot of people didn’t understand why we built small models, but today everyone understands that small models are still quite valuable.
Small models ultimately originated from an internal 1.8B model we used for experiments. We were doing pretraining, and resources were limited — you can’t run every experiment on 7B, so we used 1.8B for validation. At the time, a junior labmate told me we should open-source this model, and I really didn’t understand. I said: in 2023 this model is almost unusable — why would we open-source it? He told me 7B consumes too much compute, and many master’s and PhD students don’t have the resources to run experiments. If we open-source 1.8B, a lot of students would finally be able to graduate on time. That was a really good original motivation.
Then as we kept working, phone manufacturers came to us and said 7B is too big and 1.8B is too small — could you make a 3-4B model for us? That’s easy; it’s not a hard thing to do. As we went along, we ended up with more and more variants and types. To some extent, it has to do with serving the needs of users.
The biggest progress this year is Qwen3. This is the mascot — kind of looks like a bear, but it’s actually a capybara.
When we were building it, I felt our teammates were working too hard; I didn’t want them to suffer so much. In an era that’s this competitive, being a bit more laid-back isn’t necessarily a bad thing. We’re working across relatively more directions, but you can see that each direction has its own internally consistent logic. For example, we work on Text and VL, and Omni; we’ve also spent relatively longer on vision, text, and speech generation. In the process, one thing that’s special about us is that we’re backed by Alibaba Cloud, and a lot of our business is closely related to Alibaba Cloud’s customers. Cloud customers are very diverse, and we also provide services to everyone such as embeddings and guardrails.
Today, we’ll introduce the main line around Text and VL, including Omni; Coder will be included under Text and discussed accordingly.
Text: Qwen3 Series
This year, for text models, it’s mainly the Qwen3 series, and we’ve already reached 3.5. We spent longer on 3, because the previous generation, 2.5, took a very long time, and one of its biggest characteristics was overall capability improvement. What’s more interesting this year is that reasoning capability needed to improve. If I were to add a bit of my personal understanding, I’d say that reasoning is somewhat different from the current straightforward Instruct models.
Second is the languages and dialects we support. The number of languages alone isn’t that large, but including dialects, it totals 119. Why did we do multilingual support? There were also some coincidences. In 2023, we felt that as long as we did Chinese and English well, we could serve the people we needed to serve. But one time I ran into Korean friends and asked them why, when they were working on the Solar model, they didn’t use our model. They said, “your model doesn’t understand any Korean at all.” I felt really hurt, so I went and checked, and later found that [solving this issue] was actually very simple, so I just went ahead and did it. Later we found that our global users were increasing. I remember some friends in Pakistan kept telling me, “hurry up and support Urdu — we really don’t have any large models we can use.” I thought that was indeed a good thing, so we supported more languages.
We still haven’t finished this. Data from Africa is indeed hard to collect, [so] African languages aren’t covered yet. Today I chatted with some phone manufacturers, and there are still many people in Africa using “dumb” feature phones. We’ve already entered the smartphone era, but they’re still dealing with that, so if you want to help all of humanity, the road ahead is truly long and the responsibility is heavy. If your goal isn’t to help all of humanity, I think it might be better not to do it at all. That’s why we will keep going.
Third is that today’s long text and long video may be one example of this. But I find it really interesting: if you truly want to build a model with self-awareness, first your context has to be long enough. Some people previously debated whether there’s any need to stuff lots of junk into a long context, but only after you have that can you achieve the deeper understanding that comes next. So now we’ve pushed it to over 1M; internally we’ve actually reached several million, and it still might not be enough. That’s why today I still want to say this is a very, very long-term undertaking.
…
Coding: From Olympiad Problems to Software Engineering
Today’s “coder” is different from what we had in the past. For example, last year and the year before, we were mostly solving straightforward competition problems: you’re given a problem and you see whether you can produce the answer. What are we doing today? Software engineering. Back in 2024, people were really surprised by the idea of whether AI could be like a programmer. Today, the task is: maintaining a project is actually pretty hard — if you can just do that, that’s already great.
In actual practice, doing this involves some quite complicated steps for humans. The simplest thing is at least I can open these folders, look at the file names, and know which one I should click into — this is really a multi-turn interaction process. One very important point in building agents today is why everyone talks about multi-turn environment interaction: put plainly, opening a folder and taking a look is itself a way of interacting with the environment. This is important and also very interesting, and it makes us really excited — it can genuinely generate productivity. We want today’s coding models to be productive; the fact that they can write a lot of code is really surprising.
Of course, China and the U.S. are different. I just got back from the Bay Area, and I could feel that the two sides aren’t quite the same. [The difference] is pretty dramatic. Is it that the models aren’t good enough, or that vibe coding still isn’t popular enough? I think the difference is really in how people perceive it. What we want to do is reach the same destination by different paths; everyone wants it to generate productivity.
At the time we paid especially close attention to two benchmarks. One was SWE-bench — can you submit a PR that solves the issue? A score of 70 is a pretty high bar; of course now you can see scores above 75. That was in July; back then, we felt that getting 67 and 69 was already pretty good. Terminal-Bench is also quite hard. Today everyone is using this series of products, and you’ll find that it really does connect directly to your productivity—unlike before. What we’re doing today is tasks that are close to real-world practice. Maybe today it’s only one or two benchmarks, but making it fit real environments and real production tasks better is what we want to do.
When it first came out it was quite popular, but now the competition is too intense. At one point our token consumption even made it to second place on OpenRouter — just to brag a little bit.
…
Visual Understanding: Equipping Models with Eyes
When you build language models, you also have to think about one question: can it have “eyes” to see the world? For example, we just mentioned wanting to build a coding agent to improve productivity: I have to let it operate a computer and see the computer screen. Without eyes it can’t see, so we worked on this with no hesitation. That’s a huge difference: just go and build visual understanding, don’t question it.
But today, many models can actually see things more clearly than humans. For example, I’m nearsighted and I have astigmatism, so my eyesight basically isn’t that great and there’s a lot that I can’t see clearly. But at least I can distinguish up, down, left, and right very easily. AI is interesting: it can see very fine details very clearly, yet when you ask it about front/back/left/right, it for some reason can’t tell. For a long time we evaluated a case called “live subject orientation.” I even asked our evaluators what “live subject” meant. It couldn’t tell whether something was on the left or the right — I found that pretty strange, but that’s exactly the problem we need to solve.
And it’s not just that. Another thing we need to do is make sure its intelligence doesn’t drop. We don’t expect it to dramatically raise its IQ, but at the very least it shouldn’t get dumber, because a lot of the time when you build VL models, they get dumber. This time, we finally made it stop getting dumber — it’s roughly on par with our 235B language model.
…
I want to share a more interesting case. People also ask me these days: how exactly did the open-source community help your team develop this model? If the open-source community hadn’t told us, we would never have thought of this issue ever in our daily lives. There was an image where we basically wanted to remove the person on the right side of the picture. You’d find that after [the model] removed them, when you overlaid the two images, the result looks blurry. It has shifted a bit; it’s no longer in the original position, but instead misaligned. For a lot of people who do Photoshop work, this needs to be extremely precise. You can’t just move things around arbitrarily. So the key focus of version 2511 was solving this problem. In version 2511, when I overlay the two images, the person is basically still in the original position. I think developers gave us a really good use case—showing that we can actually build things that genuinely help them
An example of visual understanding: Chinese internet users have been using Doubao’s videochat function to ask it for outfit instructions, to hilarious effect. Source.
Agent: Towards Simulated and Physical Worlds
Agents can actually move toward both the virtual world and the physical world, which is why there’s an approach like embodied reasoning. Internally we discussed a path: even if you’re building VLA models or coding models, when you strip it down, you’re still converting language into an embodied model. From this perspective it’s extremely encouraging, so we felt like going all-in and seeing whether we can move toward a digital agent. Being able to do GUI operations while also using APIs: that would be a truly perfect digital agent.
And if we move toward the physical world, could it pick up a microphone, and could it pour tea and water today? That’s something we really want to do.
Thank you all very much!
Panel: The Next Step for Chinese AI
Moderator: Li Guangmi
Panel Members: Yang Qiang (HKUST), Tang Jie (Zhipu), Lin Junyang (Qwen), Yao Shunyu (Tencent)
Opening Remarks:
Li Guangmi (Moderator): I am the moderator for the next panel, Li Guangmi. … Let’s start with the first — rather interesting — point: the clear fragmentation (分化) of Silicon Valley companies. Let’s start our conversation around this topic of “fragmentation.”
Anthropic’s model has actually been a great source of inspiration for China; in the face of such intense Silicon Valley competition, they didn’t entirely follow the rest and try to do everything. Instead, they focused on enterprise, coding, and agents. I also am wondering: in what directions will Chinese models end up fragmenting? I think this topic of fragmentation is really interesting.
… Shunyu, could you expand your views on this topic of model fragmentation? …
Yao Shunyu (Tencent): I think I have two major impressions: one is the clear divergence between “to consumer” and “to business” models, and the other is divergence between the path of vertical integration and the path of separating the model and application layers [模型和应用分层].
I’ll start with the first point. I think when people think of AI, the two biggest names are ChatGPT and Claude Code. They are both the canonical examples of “to consumer” versus “to business.” What’s really interesting is if you compare ChatGPT today versus ChatGPT from last year, there really isn’t a difference in feeling. On the other hand, Coding — to exaggerate slightly — has already reshaped how the entire coding industry works. People already don’t write code anymore, they instead talk with their computer in plain English.
The core point is that in respect to the “to consumer” models, the majority of people, the majority of the time, just don’t need to use that strong of AI. Maybe compared to last year today’s ChatGPT is stronger at abstract writing and Galois Theory [abstract mathematics], but most people most of the time can’t feel it. The majority of people, especially in China, use it as an enhanced search engine. Most of the time, they don’t know how to properly use it to elicit its “intelligence.”
But for business-facing models, it’s clear that higher intelligence represents higher productivity, which is more and more valuable. These things are all correlated.
There’s also another obvious point about business-facing models: most of the time, people want to use the strongest model. One model might cost $200 a month, and the second-best or slightly weaker model might be $50 or $20 a month. Today, we find that many Americans are willing to pay a premium for the best model. [Suppose] your salary is $200,000, and you have 10 tasks you have to do daily. A really good model can do eight or nine of those, while the weaker one can [only] do five or six. The problem is when you don’t know which five or six tasks they are, you have to spend extra effort monitoring it.
I think regardless of whether it’s people or models, in the “to business” market we’ve realized a really interesting phenomenon: the divergence between strong models and somewhat weaker models will become more and more pronounced. I think that’s the first observation.
The second observation is about the difference between vertically-integrated models and ones that separate the model and application layers. I think a good example is the difference between ChatGPT Agent and Claude or Gemini with an application-layer product like Manus. In the past, everyone thought that vertically-integrated paths would definitely be better, but at least today that’s not certain. First, the capabilities needed at the model layer versus the application layer are rather different. Especially in the case of business-facing or productivity scenarios, larger pre-training is still a key factor, and that’s really difficult for product companies (产品公司) to do. But if you want to use such a good model well, or if this sort of model has overflow capacity (溢出能力), you still need to do a lot of work on the application or environment side.
We also realize that for consumer-facing applications, vertical integration, whether it’s ChatGPT or Doubao (豆包), still holds; models and products are tightly coupled and iterate together. But for business-facing cases, this trend is almost flipped, as models are getting stronger and better, but there will still be models that do many application-layer things well being applied to different productivity workloads.
Li Guangmi (Moderator): Because Shunyu has a new role, what are you thinking about doing next in the Chinese market? Do you have any distinctive characteristics or keywords? Can you share anything with us right now?
Yao Shunyu (Tencent): I think Tencent is definitely a company with stronger consumer-facing genetics. I think we will think deeply about how we can make today’s large models or AI development give users a greater value. A core consideration is that we realize most of the time, in respect to our environment or stronger models, we need additional context.
Being business-facing in China is truly difficult.The productivity revolution, including many Chinese companies doing coding agents, requires breaking into foreign markets. We will think deeply about how to serve ourselves well first. The difference between a start-up and a big company doing coding [agents] is that the big company already has many kinds of application scenarios, many places where we need to improve productivity. If our models can do well in those areas, not only will these models have their unique advantages, not only will our company develop well, but, importantly, we will be able to capture data from real-world scenarios, which is really interesting. For example, startups like Claude, if they want more Coding Agent data, they need to find data vendors to label that data, they need to use all kinds of software engineers to think about what data they need to label. The thing is there are only a few data vendors in total, they’ve only hired so many people, so in the end they’re limited. But if you are a company with 100,000 people, there might be a few interesting attempts at trying to use real-world data well, rather than relying on data labellers or agreements.
…
Topic 2: The Next Paradigm 下一个范式
Li Guangmi (Moderator): Moving to the second interesting question. Today is a special moment in time [时间点特别特殊]. One reason is that pretraining has gone on for the past three years, and many people say we may now have captured 70-80% of the potential gains [“走到了七八成的收益” this is a fractional metaphor, not a literal statistic — the implication here is that the low hanging fruit has already been picked]. Reinforcement learning has also become a consensus, unlocking perhaps 40-50% of the remaining space, with huge room left in data and environment space. So the question of a new paradigm going forward is especially worth discussing. Professor Tang also mentioned autonomous learning and self-learning. Since the theme of today’s event is “Next” I think this is a topic particularly worth digging into.
Let’s start with Shunyu. You’ve worked at OpenAI, which is at the frontier. How do you think about the next paradigm? OpenAI is a company that has advanced humanity through the first two paradigms. Based on your observations, could you share some thoughts on what a third paradigm might look like?
Yao Shunyu (Tencent): Autonomous learning [自主学习] is a very hot term right now. In Silicon Valley — on every street corner and in every café [大街小巷咖啡馆里面] — people are talking about it, and it’s forming a kind of consensus. From my observations, though, everyone defines and understands it differently. I’ll make two points.
First, this is not really a methodology problem, but a data or task problem. When we talk about autonomous learning, the key question is: in what kind of scenario, and based on what kind of reward function, is it happening? When you’re chatting and the system becomes more and more personalized, that’s a kind of autonomous learning. When you’re writing code and it becomes increasingly familiar with each company’s unique environment or documentation, that’s another kind of autonomous learning. When it explores new science — like a PhD student going from not knowing what organic chemistry is to becoming an expert in the field — that’s also autonomous learning. Each type of autonomous learning involves different challenges and, in a sense, different methodologies.
Second — and I’m not sure if this is a non-consensus view — this is actually already happening. Very obviously, ChatGPT is using user data to continuously bridge the gap [the verb here is “弥合” — literally, “to prompt an open wound to heal” — which implies passivity/emergent behavior rather than active design] in understanding what human conversational styles are like, making it feel increasingly good to interact with. Isn’t that a form of self-learning?
Today, Claude has already written 95% of the code for the Claude project itself. It’s helping to make itself better. Isn’t that also a form of self-learning? Back in 2022 and 2023, when I was in Silicon Valley promoting this work, the very first slide I used said that the most important aspect of ASI was autonomous learning. Today’s AI systems essentially have two parts. First, there’s the model itself. Second, there’s a codebase. How you use the model — whether for reasoning or as an agent — depends on the corresponding codebase. If we look at the Claude system today, it essentially consists of two parts: one is a large amount of code related to the deployment environment, and the other is a large amount of code that governs how the system is used — whether that’s GPU-related, frontend-related, or environment-related. I think Claude Code is already doing this at scale today, though people may not fully realize it. These examples of autonomous learning are still confined to very specific scenarios, so they don’t yet feel overwhelmingly powerful.
This is already happening, but there are still efficiency constraints and other limitations — many different issues. Personally, I see this more as a gradual change rather than a sudden leap [更像是一个渐变,不是突变].
Li Guangmi (Moderator):Let me follow up on that. Some people are relatively optimistic about autonomous learning and think we might see signals as early as 2026. In your view, what practical problems still need to be solved before we see those signals? For example, long context, parallel model sampling, or other factors — what key conditions still need to fall into place before these signals really emerge?
Yao Shunyu (Tencent): A lot of people say we’ll see signals in 2026, but I think we’ll see them in 2025. Take Cursor, for example: every few hours they retrain using the latest user data, including new models, and they’re already using real-world environment data to train. People might feel this isn’t yet a “shock to the system” simply because they don’t have pretraining capabilities, and their models are indeed not as strong as OpenAI’s. But clearly, this is already a signal.
The biggest issue is imagination. It’s relatively easy for us to imagine what a reinforcement learning or reasoning paradigm might look like once it’s implemented. We can imagine something like o1: originally scoring 10 points on math problems, then jumping to 80 points thanks to reinforcement learning and very strong chains of thought. But if in 2026 or 2027 a new paradigm emerges — if I announce that a new model or system has achieved self-learning — what kind of task should we use to evaluate it? What kind of performance should it have for you to believe it’s real? Is it a profitable trading system that makes a lot of money? Does it genuinely solve scientific problems that humans previously couldn’t? Or something else entirely? I think we first need to imagine what it would actually look like.
Li Guangmi (Moderator):Shunyu, OpenAI has already driven two paradigm shifts. If a new paradigm emerges in 2027, which company globally do you think has the highest probability of leading that paradigm innovation — if you had to name just one?
Yao Shunyu (Tencent): Probably still OpenAI. Although commercialization and various other changes have weakened its innovative DNA to some extent, I still think it’s the place most likely to give birth to a new paradigm [最有可能诞生新范式的地方].
…
Li Guangmi (Moderator): Junyang just mentioned initiative, including personalization. Do you think that if we really achieve memory, we’ll see a breakthrough-level technological leap by 2026?
Lin Junyang (Qwen): My personal view is that many so-called “breakthroughs” in technology are really issues of observation. Technologically, things are developing in a linear way; it’s just that humans experience them very intensely. Even the emergence of ChatGPT, for those of us working on large models, was linear growth. Right now everyone is working on “memory.” Is this technology right or wrong? Many solutions aren’t inherently right or wrong, but the results, at least in our own experience, are often disappointing [the word used here is 献丑, a self-depreciating term meaning “to present ugliness; to put one’s own artistic incompetence on display.” You might use this term to describe your poor karaoke abilities.] — our memory knows what I’ve done in the past, but it’s really just recalling past events. Calling my name every time doesn’t actually make you seem very smart. The question is whether memory can reach some critical point where, combined with memory, it becomes like a person in real life. People used to say this about movies — that moment when it really feels human. Understanding memory might be that moment, when human perception suddenly bursts forth [人类的感受突然间迸发].
I think it will still take at least a year. Technology often doesn’t move that fast. Everyone feels very “involuted,” [比较卷] with something new every day, but technologically it’s still linear growth. It’s just that from an observational perspective, we’re in an exponential-feeling phase. For example, a small improvement in coding ability can generate a lot of productive value, so people feel AI is advancing very fast. From a technical standpoint, we’re just doing a bit more work. Every day when we look at what we’re building, it feels pretty crude [“挺土的” — literally, “quite rustic/earthy”] — those bugs are honestly embarrassing to talk about. But if we can achieve these results in this way, I think in the future, with better integration of algorithms and infrastructure, there may be much more potential.
Li Guangmi (Moderator): Let’s call on Professor Yang Qiang.
Yang Qiang (HKUST): I’ve always worked on federated learning. The core idea of federated learning is collaboration among multiple centers. What I’m seeing more and more now is that many scenarios lack sufficient local resources, yet local data comes with strong privacy and security requirements. So as large models become more powerful, we can imagine collaboration between general-purpose large models and locally specialized small models or domain-expert models. I think this kind of collaboration is becoming increasingly possible.
Take Zoom in the United States — Huang Xuandong and his team built an AI system with a large foundational base. Everyone can plug into this base, and in a decentralized state it can both protect privacy and communicate and collaborate effectively with general large models.
I think this open-source model is especially good: open sourcing knowledge, open sourcing code, and open sourcing at the model level.
In particular, in fields like healthcare and finance, I think we’ll see more and more of this phenomenon.
Tang Jie (Zhipu): I’m very confident that this year we’ll see major paradigm innovations. I won’t go into too much detail, but as I mentioned earlier — continual learning, memory, even multimodality — I think all of these could see new paradigm shifts.
There’s also a new trend I want to talk about: why would such a paradigm emerge? In the past, industry ran far ahead of academia. I remember going back to Tsinghua last year and the year before, talking with many professors about whether they could work on large models. The first issue wasn’t just a lack of GPUs — it was that the number of GPUs was almost zero. Industry had ten thousand GPUs; universities had zero or one. That’s a ten-thousand-fold difference. But now, many universities have a lot of GPUs, and many professors have begun doing large-model research. In Silicon Valley too, many professors are starting to work on model architectures and continual learning. We used to think industry dominated everything, but by late 2025 to early 2026, that gap won’t really exist anymore. Maybe there’s still a tenfold difference, but the seeds have been planted [孵化出种子]. Academia has the genes for innovation and the potential — this is the first point.
Second, innovation always emerges when there is massive investment in something and efficiency becomes a bottleneck. In large models, investment is already enormous, but efficiency isn’t high. If we keep scaling, there will still be gains — early 2025 maybe data went from 10 TB to 30 TB, and maybe we can scale to 100 TB. But once you scale to 100 TB, how much benefit do you get, and at what computational cost? That becomes the question. Without innovation, you might spend one or two billion and get very little return, which isn’t worth it.
On the other hand, for new intelligence innovations, if every time we have to retrain a foundation model and then retrain lots of reinforcement learning — when RL came out in 2024, many people felt continuing training had returns. But today, continuing aggressive RL still has returns, but not that much. It’s an efficiency-of-returns problem. Maybe in the future we need to define two things: one is that if we want to scale up, the dumbest way is just scaling — scaling does bring gains and raises the upper bound of intelligence. The second is defining “intelligence efficiency”: how efficiently we gain intelligence, how much incremental intelligence we get per unit of investment. If we can get the same intelligence gains with less input, especially when we’re at a bottleneck, then that becomes a critical breakthrough.
So I believe that in 2026, such a paradigm will definitely emerge. We’re working hard and hope it happens to us, but it might not.
Li Guangmi (Moderator): Like Professor Tang, I’m also very optimistic. For every leading model company, compute grows by about tenfold each year. With more compute and more talent flowing in, people have more GPUs, run more experiments, and it’s possible that some experimental engineering effort, some key point, will suddenly break through.
Topic Three: Agent Strategy
Li Guangmi (Moderator): Professor Tang just talked about how to measure intelligence. The third topic is Agent strategy. Recently I’ve talked with many researchers, and there’s another big expectation for 2026. Today, agents can reason in the background for 3–5 hours and do the equivalent of one to two days of human work. People expect that by 2026, agents could do one to two weeks of normal human work. This would be a huge change — it’s no longer just chat, but truly automating a full day or even a full week of workflows. 2026 may be a key year for agents to create economic value.
On the agent question, let’s open it up for discussion. Shunyu mentioned vertical integration earlier — having both models and agent products. We’ve seen several Silicon Valley companies doing end-to-end work from models to agents. Shunyu has spent a lot of time researching agents. From the perspective of 2026 — long agents really doing one to two weeks of human work — and from the standpoint of agent strategy and model companies, how do you think about this?
Yao Shunyu (Tencent): I think, as mentioned earlier, To B and To C are quite different. Right now, the To B side seems to be on a continuously rising curve, with no sign of slowing down.
What’s interesting is that there isn’t much radical innovation involved. It’s more about steadily making models larger through pretraining, and diligently doing post-training on real-world tasks. As long as pretraining keeps scaling up and post-training keeps grounding models in real tasks, they’ll get smarter and generate more value.
In a sense, for To B, all goals are more aligned: the higher the model’s intelligence, the more tasks it can solve; the more tasks it solves, the greater the returns in To B scenarios.
…
Also, I think education is extremely important. From what I observe, the gap between people today is enormous. More often than not, it’s not that AI is replacing human jobs; rather, people who know how to use these tools are replacing those who don’t. It’s like when computers first emerged — if you turned around and learned programming while someone else kept using a slide rule, the gap between you would be massive.
Today, the most meaningful thing China can do is to improve education — teaching people how to better use products like Claude or ChatGPT. Of course, Claude may not be accessible in China, but we can use domestic models like Kimi or Zhipu instead.
Li Guangmi (Moderator): Thank you, Shunyu. Next, we’d like Junyang to share his thoughts on agents. Qwen also has an ecosystem — Qwen builds its own agents and also supports a broader agent ecosystem. You can expand on that as well.
Lin Junyang (Qwen): This may touch on questions of product philosophy. Manus is indeed very successful, and whether “wrapper apps” [套壳] are the future is itself an interesting topic. At this stage, I actually agree with your view — that the model is the product [模型即产品]. When I talk with people at DeepMind, they call what they do “research,” and I really like that framing. From my perspective on OpenAI as well, there are many cases where research itself can become a product—researchers can effectively act as product managers and build things directly. Even internally, our own research teams can work on things that face the real world.
I’m willing to believe that the next generation of agents can do what we just discussed, and that this is closely tied to the idea of proactive or self-directed learning. If an agent is going to work for a long time, it has to evolve during that process. It also has to decide what to do, because the instructions it receives are very general tasks. Our agents have now become more like hosted or delegated agents, rather than something that requires constant back-and-forth iteration [来来回回交互].
From this perspective, the requirements on the model are very high. The model is the agent, and the agent is the product. If they are fully integrated, then building a foundation model is essentially the same as building a product. Seen this way, as long as you keep pushing up the upper bound of model capability — through scaling, for example — this vision is achievable.
Another important point is interaction with the environment. Right now, the environments we interact with aren’t very complex — they’re mostly computer-based environments. I have friends working on AI for Science. Take AlphaFold, for example: even if you achieve impressive results, it still hasn’t reached the stage where it can directly transform drug development. Even with today’s AI, it doesn’t necessarily help that much, because you still need to run experiments and perform physical processes to get feedback.
So the question is: could AI environments in the future become as complex as the real human world—where AI directs robots to run experiments and dramatically increase efficiency? Human efficiency today is extremely low. We still have to hire lots of outsourced labor to conduct experiments in lab environments. If we can reach that point, then that’s the kind of long-horizon work I imagine agents doing — not just writing files on a computer. Some of this could happen quite quickly this year, and over the next three to five years, it will become even more interesting. This will likely need to be combined with embodied intelligence.
Li Guangmi (Moderator): I want to follow up with a sharper question. From your perspective, is the opportunity for building general-purpose agents something for startups, or is it simply a matter of time before model companies inevitably build great general agents themselves?
Lin Junyang (Qwen): Just because I work on foundation models doesn’t mean I should act as a startup mentor — I won’t do that. I can only borrow a line from successful people: the most interesting thing about building general agents is that the long tail is actually where the real value lies. In fact, the greatest appeal of AI today is in the long tail.
If it were just a Matthew effect [that is, a “winners keep winning” dynamic], the head of the distribution [“头部” that is, high-frequency use cases] would be easy to solve. Back when we worked on recommendation systems, we saw how concentrated recommendations were — everything was at the head. We wanted to push items from the tail, but that was extremely difficult. As someone working in multimodality who tried to tackle the Matthew effect in recommendation systems, I was basically sprinting down a dead end [奔着死路去的].
What people now call AGI is really about solving this problem. When you build a general agent, can you solve long-tail problems? A user has a problem that they’ve searched for everywhere and simply cannot find anyone who can help — but at that moment, the AI can solve it. No matter where you look in the world, there’s no solution, yet the AI can help you. That’s the greatest charm of AI [这就是AI最大的魅力].
So should you build a general agent? I think it depends [“见仁见智” means something like, “reasonable people can disagree about this”]. If you’re exceptionally good at building wrapper applications and can do it better than model companies, then go for it. But if you don’t have that confidence, this may ultimately be left to model companies pursuing “model-as-product.” When they encounter a problem, they can just retrain the model or throw more compute at it [“烧卡” — literally, “to burn GPUs”], and the problem may be solved. So ultimately, it depends on the person.
Tang Jie (Zhipu): I think there are several considerations that determine the future trajectory of Agents.
First, does the Agent itself actually solve human problems, and are those problems valuable? How valuable? For example, when GPT first came out, many early Agents were built. But you later discovered that those Agents were extremely simple, and in the end a prompt alone could solve the problem. At that point, most Agents gradually died off. So the first issue is whether the problem an Agent solves is valuable and whether it actually helps people.
Second, how expensive is doing this? If the cost is extremely high, that’s also a problem. As Junyang just mentioned, perhaps calling an API can already solve the problem. But on the flip side, if calling an API can solve it, then when the API provider realizes the problem is very valuable, they might simply build it into the base model themselves. This is a contradiction — a very deep contradiction. The base model layer and the application layer are always in tension.
Finally, there’s the speed of application development. Suppose I have a six-month window and can quickly meet a real application need. Then, six months later, whether you can iterate, how you follow up, and how you keep moving forward all become critical.
Large models today are more oriented towards competing on speed and timing. Maybe our code is correct, maybe that lets us go a bit further — but if we fail, half a year may just be gone. This year we’ve only done a little in coding and Agents, but our coding API call volume is already quite good. I think this points to a new direction, just as working on Agents in the future is also a direction.
Li Guangmi (Moderator): Thank you. In the past, model companies had to chase after general capabilities, so they may not have put as much priority into exploration. After general capabilities catch up, we increasingly expect that by 2026, Zhipu and Qwen will have their own “Claude moments” and “memory moments.” I think that’s worth anticipating.
Topic Four: The Future of Chinese AI
Li Guangmi (Moderator):The fourth question and final question is quite interesting. Given the timing of this event, we need to look ahead. I’d like to ask everyone: three to five years from now, what is the probability that the world’s most advanced AI company will be a Chinese team? What key conditions are required for us to move from being followers today to leaders in the future? In short, over the next 3–5 years, what is the probability, and what key conditions still need to be fulfilled?
You’ve experienced both Silicon Valley and China — what is your judgment on the probability and on the key conditions?
Yao Shunyu (Tencent): I think the probability is actually quite high. I’m fairly optimistic. Right now, whenever something is discovered, China can replicate it very quickly and often does better in specific areas. This has happened repeatedly in manufacturing and electric vehicles.
So, I think there are several key points. One is whether China can break through on lithography machines. If compute ultimately becomes the bottleneck, can we solve the compute problem? At the moment, we have strong advantages in electricity and infrastructure. The main bottlenecks are production capacity — especially lithography — and the software ecosystem. If these are solved, it would be a huge help.
Another question is whether, beyond the consumer side, China can develop a more mature and robust To-B market — or whether Chinese companies can really compete in international commercial environments. Today, many productivity-oriented or enterprise-focused models and applications are still born in the U.S., largely because willingness to pay is higher and the business culture is more supportive. Doing this purely within China is very difficult, so many teams choose to go overseas or pursue international markets. These are two major structural constraints.
More important are subjective factors. Recently, when talking with many people, our shared feeling is that China has an enormous number of very strong talents. Once something is proven doable, many people enthusiastically try it and want to do it even better.
What China may still lack is enough people willing to break new paradigms or take very risky bets. This is due to the economic environment, business environment, and culture. If we could increase the number of people with entrepreneurial or risk-taking spirit — people who truly want to do frontier exploration or paradigm-shifting work — that would help a lot. Right now, once a paradigm emerges, we can use very few GPUs and very high efficiency to do better locally. Whether we can lead a new paradigm may be the core issue China still needs to solve, because in almost everything else — business, industrial design, engineering — we are already, in some respects, doing better than the U.S.
Li Guangmi (Moderator):Let me follow up with Shunyu on one question. Do you have anything you’d like to bring to attention regarding research culture in Chinese labs? You’ve experienced OpenAI and also DeepMind in the Bay Area. What differences do you see between Chinese and U.S. research cultures, and how do these research cultures fundamentally affect AI-native companies? Do you have any observations or suggestions?
Yao Shunyu (Tencent): I think research culture varies a lot from place to place. The differences among the U.S. labs may actually be larger than the differences between Chinese and U.S. labs, and the same is true within China.
Personally, I think there are two main points. One is that in China, people still prefer to work on safer problems. For example, pretraining has already been proven to be doable. It’s actually very hard and involves many technical challenges, but once it’s proven doable, we’re confident that within a few months or some period of time, we can basically figure it out. But if today you ask someone to explore long-term memory or continual learning, people don’t know how to do it or whether it can even be done, which is still a tough situation.
This is not only about preferring certainty over innovation. A very important factor is the accumulation of culture and shared understanding, which takes time. OpenAI started working on these things in 2022, while domestic efforts began in 2023, so there are differences in understanding. The gap may not actually be that large — much of it may simply be a matter of time. When cultural depth and foundational understanding accumulate, they subtly influence how people work, but this influence is very hard to capture through rankings or leaderboards.
China tends to place a lot of weight on leaderboard rankings and numerical metrics. One thing DeepSeek has done particularly well is caring less about benchmark scores and more about two questions: first, what is actually the right thing to do; and second, what feels genuinely good or bad in real use. That’s interesting, because if you look at Claude, it may not rank highest on programming or software-engineering leaderboards, yet everyone knows it’s one of the most usable models. I think we need to move beyond the constraints of leaderboards and stick with processes we believe are truly correct.
Li Guangmi (Moderator):Thank you, Shunyu. Let’s now ask Junyang to talk about probability and challenges.
Lin Junyang (Qwen): This is a dangerous question. In theory, at an occasion like this, you’re not supposed to pour cold water over everything. But if we talk in terms of probability, I want to share some differences I’ve felt between China and the U.S.
For example, U.S. compute may overall exceed ours by one to two orders of magnitude. What I see is that whether it’s OpenAI or others, a huge amount of their compute is invested into next-generation research. For us, by contrast, we’re relatively constrained — just fulfilling delivery requirements already consumes the vast majority of our compute. This is a major difference.
Perhaps this is a long-standing question throughout history: is innovation spurred by the hands of hand of the rich or the poor? The poor are not without opportunities. We sometimes feel that the rich waste GPUs, training many things that turn out not to be useful. But when you’re poor, things like algorithm-infrastructure co-optimization become necessary. If you’re very rich, there’s little incentive to do that.
Going one step further, as Shunyu mentioned with lithography machines, there may be another opportunity in the future. From a hardware-software co-design perspective, is it possible to truly build something new? For example, could the next-generation model and chip be designed together?
In 2021, when I was working on large models, Alibaba’s chip team came to me and asked whether I could predict whether three years later the model would still be a Transformer, and whether it would still be multimodal. Why three years? Because they needed three years to roll out a chip. At the time, my answer was: I don’t even know whether I’ll still be at Alibaba in three years! But today I’m still at Alibaba, and indeed it’s still Transformers and still multimodal. I deeply regret that I didn’t push them harder back then.
At that time, our communication was completely misaligned. He explained many things to me that I couldn’t understand at all; when I explained things to him, he also didn’t understand what we were doing. So we missed this opportunity. Could such an opportunity come again? Even though we’re a group of “poor people,” perhaps poverty forces change. Might innovation happen here?
Today, education is improving. I’m from the earlier 1990s generation, Shunyu is from the later 1990s, and we have many post-2000s in our team. I feel that people’s willingness to take risks is getting stronger and stronger. Americans naturally have a very strong risk-taking spirit. A classic example is early electric vehicles — despite leaking roofs and even fatal accidents, many wealthy people were still willing to invest. In China, I believe wealthy people would not do this; they prefer safe things. But today, people’s risk-taking spirit is improving, and as China’s business environment improves, innovation may emerge. The probability isn’t very large, but it is real.
Li Guangmi (Moderator):If you had to give a number?
Lin Junyang (Qwen): You mean a percentage?
Li Guangmi (Moderator):Yes. Three to five years from now, what’s the probability that the leading AI company will be a Chinese one?
Lin Junyang (Qwen): I think it’s 20%. Twenty percent is already very optimistic, because there are truly many historical factors at play here.
Li Guangmi (Moderator): Thank you, Junyang. Let’s invite Professor Yang. You’ve experienced many AI cycles and seen many Chinese AI companies become the strongest in the world. What is your judgment on this question?
Yang Qiang (HKUST): We can look back at how the internet developed. It also began in the United States, but China quickly caught up, and applications like WeChat became world-leading. I see AI as a technology rather than a finished end product. China has many talented people who can push this technology to its limits, whether in consumer or enterprise applications. Personally, I’m more optimistic about the consumer side, because it allows for many different ideas to flourish and for collective creativity to emerge. Enterprise applications may face some constraints—such as willingness to pay and corporate culture—but these factors are also evolving.
I’ve also recently been observing business trends and discussing them with some business school classmates. For example, there’s a U.S. company called Palantir. One of its ideas is that no matter what stage AI development is at, it can always find useful things within AI to apply to enterprises. There will inevitably be a gap, and they aim to bridge that gap. They use a method called ontology. I looked into it, and its core idea is similar to what we previously did with transfer learning — taking a general solution and applying it to a specific practice, using an ontology to transfer knowledge. This method is very clever. Of course, it’s implemented through an engineering approach, sometimes referred to as front-end engineering (FDE).
In any case, I think this is something very much worth learning from. I believe Chinese enterprises — especially AI-native companies — should develop such To B solutions, and I believe they will. So I think To C will definitely see a hundred flowers bloom, and To B will also quickly catch up.
Li Guangmi (Moderator):Thank you, Professor Yang. Let’s bring in Professor Tang.
Tang Jie (Zhipu): First, I think we do have to acknowledge that between China and the U.S., there is indeed a gap in research, especially in enterprise AI labs. That’s the first point.
But I think looking to the future, China is gradually getting better, especially the post-90s and post-2000s generations, who are far better than previous generations. Once, at a conference, I joked that our generation is the unluckiest: the previous generation is still working, we’re also still working, so we haven’t had our moment yet — and unfortunately, the next generation has already arrived, and the world has been handed over to them, skipping our generation entirely. That was a joke.
China may have the following opportunities.
First, there is now a group of smart people who truly dare to do very risky things. I think they exist now — among the post-2000s and post-90s generations — including Junyang, Kimi, and Shunyu, who are all very willing to take risks to do these things.
Second, the overall environment may be improving. This includes the broader national context, competition between large and small firms, challenges facing startups, and the business environment more generally. As Junyang mentioned earlier, he’s still tied up with delivery work. If we can further improve the environment so that smart, risk-taking people have more time to focus on real innovation—giving people like Junyang more space to do creative work—this is something the government and the country may be able to help with.
Third, it comes back to each of us personally: can we push through? Are we willing to stay on one path, dare to act, dare to take risks, and keep going even if the environment isn’t perfect? I think the environment will never be the best. But we are actually fortunate — we’re living through a period where the environment is gradually improving. We are participants in that process, and perhaps we’ll be the ones who gain the most from it. If we stubbornly persist, maybe the ones who make it to the end will be us.
Thank you, everyone.
Li Guangmi (Moderator):Thank you, Professor Tang. We also want to call on more resources and capital to be invested into China’s AGI industry — more compute, so that more young AI researchers can use GPUs, maybe for three to five years. It’s possible that in three to five years, China will have three to five of its own Ilyas [Ilysa Sutskever]. That’s what we’re really looking forward to.
Thank you all very much!
AGI-Next: Outlook Speaker: Zhang Bo 张钹 (Academician of the Chinese Academy of Sciences, Professor at Tsinghua University)
What is our goal? In the past, artificial intelligence was simply a tool. Today, we are in a deeply contradictory situation: on the one hand, we want AI to take on more and more complex tasks; on the other, we fear that it may surpass us and become a new kind of subject in its own right. This creates widespread anxiety. In the past, we only had one subject—humanity—and even that was difficult to manage, because humanity is plural rather than singular: each subject has different demands. If non-human subjects emerge, what should we do? How should we coexist with artificial intelligence? And how should we address these concerns?
In fact, future subjects can be divided into three levels.
First, functional or action-oriented subjects.
This is a stage we have already reached — and one we actively welcome— because it can be genuinely helpful to us.
Second, normative or responsibility subjects. We have not yet reached this stage. One of the greatest difficulties is how to make machines capable of bearing responsibility. This is something we hope to achieve, but from the current situation, it is quite difficult — the technical challenges are very high. But I believe everyone will continue striving toward this.
Third, experiential–conscious subjects. This is what people fear most. Once machines have consciousness, what should humans do?
If we are people actually running companies, we may not need to think that far ahead — we can focus on the first and second levels. But there are two issues that must be considered: alignment and governance.
The question of alignment has been discussed a lot. Must machines align with humans? This is a question worth discussing. Humans do not only have virtues; humans are also greedy and deceptive — machines originally had none of these traits. If machines align with humans, are humans already the highest standard? Clearly not.
As for governance, I believe the most important governance is not the governance of machines, but the governance of humans — namely, researchers and users.
This involves the responsibilities that enterprises and entrepreneurs in the AI era should bear.
Before large language models appeared, I strongly opposed my students starting businesses. Some students’ parents even agreed with me. But after large language models, I believe the most outstanding students should start businesses because artificial intelligence has redefined what it means to be an entrepreneur. As I mentioned earlier, artificial intelligence will define everything, and it will also define the entrepreneurs of the future.
In the future, entrepreneurs will need to take on six kinds of responsibilities. Let me briefly talk about one of them: redefining how value is created. Artificial intelligence is not simply about delivering products or services. Instead, it transforms knowledge, ethics, and applications into reusable tools that can benefit humanity. This represents a fundamental shift. AI should be treated as a general-purpose technology—like water or electricity—made broadly available to society. That places very high demands on entrepreneurs. Beyond building companies, they must also take responsibility for governance and for advancing inclusive and sustainable growth.
Therefore, entrepreneurs in the AI era carry many new missions. And it is precisely these missions that make entrepreneurship — and entrepreneurs themselves — honorable, even sacred, professions.
Thank you, everyone.
ChinaTalk is a reader-supported publication. To receive new posts and support our work, consider becoming a free or paid subscriber.
President Trump announced that he will permit Nvidia’s H200 chips to be sold to China on Monday, December 8th. Beijing’s official response to this is extremely understated. This is the entirety of Spokesperson Guo Jiakun’s response to a question from Bloomberg on the H200 sale at the regular foreign ministry press conference on December 9th:
We have noticed the reports. China always advocates that China and the United States achieve mutual benefit through cooperation.
Since then, however, a range of commentary and opinions have come out of Chinese media, reflecting varied opinions. Some are excited, while others are deeply wary; most lie somewhere in between. We’ve selected four commentaries from the Chinese media landscape to excerpt, translate, and feature, as a way to encapsulate the debate happening inside China regarding GPU reliance. They include…
How cloud providers helped Chinese AI labs access top-tier compute, even while restrictions were in place;
Why transitioning from Hopper to Blackwell is labor-intensive, and how this shapes Chinese compute demand;
How inference differs from training, and where Chinese chipmakers might shine in the market;
And Taiwanese chip makers having a brief panic attack amid the crossfire.
Translations of the original Chinese were done by ChatGPT 5.1 Thinking, then verified manually by the ChinaTalk team for accuracy and fluency. Hyperlinks were added by Irene where context is useful.
Huawei’s Atlas 900 A3 SuperPoD, displayed at the World AI Conference in Shanghai in July 2025. Source: China Business Journal via Sina.
Secrets of the Cloud
This first analysis is by Xinzhi Observatory心智观察所, a media brand covering high-tech that’s owned by Shanghai-based news site Guancha观察网.Guancha is on the nationalistic end of the Chinese media spectrum, with a penchant for virality. Xinzhi Observatory’s reporting on tech has a more nuanced style, but its assertions should still be taken with a grain of salt. Nevertheless, the piece is a useful read because it reflects popular mainstream attitudes towards the H200s deal: that it is a temporary compromise that benefits Chinese development in the short run, but does not undercut China’s progress in indigenizing the chip supply chain. Its insights into how Chinese labs have managed to access advanced compute via cloud service providers is also revealing.
In Nvidia’s AI product lineup, the Hopper series (including the H100 and H200) represents the previous-generation “ace,” focused on data-center-class AI acceleration and already widely used in supercomputers and AI training clusters around the world. Although the H200 is not based on the latest Blackwell architecture (B100/B200, released in 2024 and more focused on multimodal AI and energy efficiency), its memory advantage makes it a “transitional trump card.” While it far exceeds the performance threshold of domestic Chinese chips, it does not reach the most sensitive cutting-edge technologies that the United States is trying to protect. It was precisely on the basis of the H200’s “moderate firepower” that Nvidia CEO Jensen Huang persuaded Trump.
But for China, the introduction of this chip fills the performance gap between the H20 (the specially downgraded version for China) and Blackwell. We cannot look only at the talking points Jensen Huang used in his lobbying: the H200 is, after all, the pinnacle of Nvidia’s Hopper architecture. According to estimates by Georgetown University’s Center for Security and Emerging Technology (CSET), the H200’s total processing performance (TPP) is nearly ten times the previous export-control ceiling for sales to China. When training and serving large models with more than 175 billion parameters, the H200’s performance is more than six times that of the H20. It is a “previous-generation flagship,” not a “downgraded product.”
Over the past two years, 99% of Chinese AI companies have only been able to use the neutered H20 or domestic chips. Through CSP channels, however, frontier model makers have already been training at scale on clusters of original, advanced chips. Therefore, when Trump suddenly opened the door to the legal sale of the H200, the market reaction was not particularly dramatic, because China’s top players have been using the highest-end compute available via CSP for quite a while already.
CSP is currently an important business model in China’s AI chip ecosystem; it refers to AI chips sold specifically for Cloud Service Providers. Put simply, Nvidia (and to some extent AMD and Intel) sell their top-of-the-line, uncut AI chips exclusively to a handful of leading Chinese cloud providers through special channels, and these cloud providers then offer the compute power to domestic AI companies and research institutes in a “cloud rental” model. What the United States has banned is “direct sales to Chinese enterprises.” Under the CSP model, however, ownership of the chips resides with the cloud providers, so technically it does not violate the ban.
Former TSMC engineer and current Ronghe Semiconductor CEO Wu Zihao told Xinzhi Observatory: “Based on the current performance of various domestic AI chip manufacturers, none of them have yet broken through shipments of 100,000 cards, with the exception of Ascend. Ascend’s shipments are between 500,000 and 1 million cards, but they rely heavily on the ‘IT indigenization’ (xinchuang) market, and CSP purchases of Ascend are not large. In other words, shipments of domestic chips basically depend on xinchuang, with CSP accounting for a very small share. Nvidia’s H200 mainly targets the CSP market; Nvidia cannot enter the xinchuang market. The only point of overlap between the two is in CSP, and judging from the fact that each domestic GPU vendor has shipped only tens of thousands of cards, not a single Chinese CSP treats domestic chips as its mainstay.”
Wu Zihao believes: “Precisely because the base is low, even if the H200 comes in, domestic GPUs still have considerable room for growth. For example, Cambricon shipped 70,000–80,000 GPUs this year. Next year they are expected to reach 150,000 cards, nearly 100% growth, but a base of 150,000 is still very low, and for domestic CSPs’ total demand of at least 4 million cards, the share is not high. In the short term, this may not affect domestic cards, but Nvidia resuming sales of relatively high-performance high-end GPUs to China is not a good thing for Chinese AI chips in the long run; the dependence on the Nvidia ecosystem may prove impossible to reverse.”
Views like Wu Zihao’s—that Nvidia’s renewed sales are not a good thing for Chinese AI chips in the long term—are somewhat representative. But we need to look at the issue more comprehensively: potential gains always come hand in hand with risks. For AI startups like DeepSeek, being able to rapidly deploy H200 clusters can boost model-training efficiency and help overcome compute bottlenecks. The H200’s 141 GB of memory can easily handle RAG (retrieval-augmented generation) and LoRA fine-tuning for models with more than 175 billion parameters. China has the world’s largest pool of AI researchers, and using more advanced technology allows them to translate research into commercial value more quickly.
After Trump announced that the H200 could be “legally sold directly,” the CSP model will not disappear in the short term; on the contrary, it might be upgraded. Previously, CSP arrangements existed with the United States turning a blind eye. Now that direct sales of the H200 have been legalized, the CSP channel may be further extended to more advanced lines like Blackwell, continuing to serve as a “valve” and “observation window” for the United States to monitor China’s AI development.
In the short term, China can temporarily rely on the H200 to train models, but in the long term it must feed back into domestic chip firms to accelerate their iteration. Chinese companies can use more advanced compute to “nurture” models and “accumulate” data, while at the same time feeding back into the domestic chip ecosystem. If China can substitute a narrative of diversified sourcing for a narrative of “decoupling” from the United States, then a “bad thing” can also be turned into a “good thing.”
This is what it truly means to “sustain war through war.” As a former Council on Foreign Relations official lamented in an interview with the FT, “Selling large numbers of H200s to China will give rocket fuel to the Chinese AI industry,” giving them enough compute to dramatically narrow the gap within two years. [Irene note: The expert quoted here is Chris Mcguire who joined ChinaTalk as a podcast guest to talk about Huawei in October!]
…
As things stand, Trump, for the sake of corporate interests and fiscal revenue, has had to compromise with China—and in doing so has made a crucial choice between the two camps. In terms of performance, the H200 is “the most dangerous yet also the safest compromise product” for the United States, while for China it is “just enough to be usable without forcing a rupture.”
Hopper vs. Blackwell, and what China actually wants
In this piece, Tencent Technology 腾讯科技 writer Su Yang 苏扬 explores why more advanced isn’t always better. Even though Blackwell chips are a generation ahead of Hoppers (including the H200), Su argues that Nvidia’s Chinese customers currently rely heavily on the Hopper architecture. Even in a world where Nvidia gains permission to sell Blackwells to China, it’s possible that demand for Hopper chips will remain much higher for quite a while still.
In November 2023, Nvidia officially launched the H200. Shipments to global customers and cloud service providers began in the second quarter of 2024, with mass production starting in the latter part of that quarter and large-scale deliveries rolling out after the third quarter. A single GPU sells for around $30,000–$40,000, and an 8-GPU server comes in at roughly $300,000.
The chip uses TSMC’s advanced 4N process, with a GH100 GPU at its core, integrating 80 billion transistors and a thermal design power (TDP) of 700W. It is also equipped with NVLink 4 interconnect technology, offering 18 links and 900GB/s of interconnect bandwidth. The GPU paired with HBM3e has 141GB of memory, with memory bandwidth as high as 4.8TB/s.
In 2024, the H200 was an unequivocally cutting-edge product, with FP16 performance reaching 1,979 teraFLOPS, compared to just 148 teraFLOPS for the H20 custom-made for the Chinese market. Its FP8 performance is an even more impressive 3,958 teraFLOPS, while the H20 has only 296 teraFLOPS. The H200’s interconnect bandwidth is also double that of the H20, reaching 900GB/s.
But by the end of 2025, products such as the B200 based on the Blackwell architecture had come online and become the new industry standard at the top end. The H200 was pushed into second place, turning into a product whose performance is “relatively behind the curve.”
“As expected,” an industry analyst said when talking about the lifting of export controls on the H200. “Letting Hopper chips out, but not Blackwell, still allows them to tell their domestic audience, ‘we’re still a generation and a half ahead,’ while Chinese customers can still buy what they want.”
Overall, Trump’s announcement on social media that he would allow H200 exports has basically dispelled most concerns. At its core, it just means that the H200 no longer represents truly cutting-edge computing power.
…
Previously, Jensen Huang had repeatedly stated in various settings that “our market share in mainland China is zero.” The approval of H200 exports will bring new opportunities for Nvidia, especially because its performance is far ahead of the downgraded H20, making it much more attractive to customers.
“Chinese customers’ models are all built to run on Hopper-architecture GPUs,” the aforementioned industry analyst emphasized.
In his view, at this stage Hopper has even more pull than the Blackwell architecture: “No one has adapted their models to the B-series yet. Otherwise you’d have to redo all the operators, the toolchain, and the underlying software from scratch—that’s an even bigger engineering effort.”
Put simply, for model developers, migrating from the Hopper architecture to any new architecture requires redeveloping computation modules, building dedicated tooling pipelines, and restructuring the low-level integration code—all of which demand large amounts of manpower, engineering work, and time.
From Nvidia’s standpoint, the profit margin on H200 sales is also much better than for the H20. The H20 is derived from a cut-down H100, which raises manufacturing costs, whereas the H200 does not need to be “neutered” in any way. As an older product, its average gross margin is expected to approach—or even exceed—80%.
This commentary was published by DeepTech 深科技, the China-specific media brand of MIT Technology Review. The writer is very bullish on economies of scale being favorable for Chinese domestic chipmakers. Most importantly, the piece argues that the impacts of the last two years of American export controls are lasting. China’s technology industry has internalized that it cannot rely on American giants for compute in the long run, and the state will not roll back extensive effects to support indigenization.
The back-and-forth swings of the past two years have already made Chinese companies acutely aware of how important supply chain security is. No one can guarantee that what is allowed today won’t be revoked tomorrow with a single tweet.
Morgan Stanley estimated that China’s AI chip self-sufficiency rate was 34% in 2024 and is expected to reach 82% by 2027. TrendForce data indicate that in China’s AI server market in 2025, domestic chips are likely to account for as much as 40%.
Mizuho Securities forecasts that shipments of Huawei’s Ascend 910 series will exceed 700,000 units this year. Huawei’s own roadmap already extends to 2028, with the Ascend 950, 960, and 970 lined up in sequence, and in-house HBM also on the agenda. Admittedly, domestic chips still have clear shortcomings in areas such as ecosystem maturity, development toolchains, and support for high-end training scenarios. But the industry has already hit its stride: large-scale training and the migration of large models onto domestic platforms are accelerating. The further the market moves forward, the more likely it is that the ecosystem will be backfilled and completed in turn. As a result, this path toward autonomy and control will not be brought to a halt just because a few foreign chips have been cleared for sale.
…
For Nvidia, returning to the Chinese market means a revenue opportunity worth several billion dollars; for the U.S. government, a 25% cut of sales is a sizable source of fiscal income; and for the Chinese market, the H200 provides a channel for obtaining advanced computing power in the short term.
But in the long run, this may be just a minor episode in the larger tech contest between China and the United States. China’s AI industry has already embarked on a path of autonomy and control, and that path will not be reversed by the approval of a few chip models.
On the battlefield of chips, genuine security can only come from one’s own capabilities, not from the grace of a rival. The green light for the H200 is merely the starting point for a new round of competition.
Inference vs. Training
This last take is a commentary from the editorial staff at the Wu Xiaobo Channel 吴晓波频道. Wu Xiaobo is a prominent finance and economics writer in China, having worked for Xinhua, Hangzhou Daily, and the Shanghai-based Oriental Morning Post. Wu Xiaobo Channel is his personal media venture.
The piece is most notable for its discussion of how China’s domestic chip supply is reshaping the inference landscape, providing needed granularity into where H200s fall within the market for compute demand. It echoes many points made by previous commentators about the long shadow of securitization as well, arguing that China will continue to aggressively pursue domesticization regardless of American policy.
Right now, China’s large models and domestic chips have already become deeply intertwined. During the “blockade” phase, the two grew side by side, with their level of mutual adaptation steadily improving.
This relationship has become even closer since DeepSeek burst onto the scene.
If, in the past, training on Nvidia chips was essentially a contest of raw compute, DeepSeek has changed the structure of compute demand: for some smaller companies, compute has shifted from training to inference.
And because inference has lower compute requirements, it has created real room for mid- and lower-end domestic AI chips to shine.
In terms of ecosystem compatibility, it’s difficult during the training phase to build a single resource pool mixing Nvidia and domestic chips, but inference workloads can run on domestic chips.
Data show that in 2024, 57.6% of accelerator cards in Chinese data centers were used for inference, surpassing the 33% used for training. Platforms like Tencent and Baidu integrating DeepSeek have also greatly boosted the growth of inference-oriented chips.
Industrial integration has also brought a shift in market preferences: as China’s large-model and domestic chip industries grow more deeply intertwined, more and more major tech firms and state-owned enterprises are leaning toward buying domestic chips. For example, ByteDance accounts for more than 50% of Cambricon’s total orders; similarly, in 2024, 42% of Moore Threads’ revenue came from government-led intelligent computing center projects, and Huawei’s Ascend chips captured 60% of the orders in such computing centers.
Although these domestic AI chips still lag behind Nvidia’s latest high-end products in absolute top-tier performance, they are sufficient to meet the needs of most inference scenarios. This also means that even if the H200 enters the Chinese market, it will be difficult for it to rapidly achieve “reverse substitution,” and the scale at which it can displace domestic chips will be limited.
Of course, the core advantage of domestic chips at this stage lies precisely in the word “domestic.” These “leading lights of domestic manufacturing” come with no backdoors, are secure and controllable, and leave the power of discourse firmly in Chinese hands—without any need to worry about supplies suddenly being cut off one day.
…
Although the narrative of “domestic substitution” is attractive, once news broke that the U.S. government would allow H200 exports, share prices of domestic chipmakers such as Cambricon and Hygon saw a clear pullback—the challenge is self-evident.
Overall, compared with domestic chips, Nvidia’s products still have advantages in raw compute, ecosystem maturity, and cluster scale—especially the CUDA ecosystem, whose level of development represents a chasm that domestic chips find hard to cross. The migration cost within the CUDA ecosystem is almost zero, whereas domestic chip ecosystems still need another two to three years to catch up.
From the product standpoint itself, the H200’s advantages are also very prominent: not only does its performance far exceed that of the H20, but more importantly, it is highly compatible with existing systems—most of China’s current AI models are already adapted to the Hopper architecture, so there is no need to rebuild operators, toolchains, or underlying software; it can be put to work directly. By contrast, moving straight to the most advanced Blackwell architecture could actually lead to acclimatization problems.
At the same time, from a market and capacity perspective, the current supply of domestic chips is still insufficient to meet the surging demand in the Chinese market. For example, SMIC’s 7 nm chips reportedly have a yield rate of only 20%, which further exacerbates this supply–demand imbalance. Nvidia’s chips, by contrast, are manufactured by TSMC, with a yield rate reaching 60%, providing much stronger assurance on production capacity.
The most direct impact may come from the release of pent-up demand: there were reports that in early 2025, several major companies placed orders worth 16 billion yuan with Nvidia to purchase H20 chips, but these ultimately could not be fulfilled. With the H200 now cleared for export, that demand may be converted into new orders and released in concentrated form in 2026.
But in any case, Nvidia has long since missed the best window to enter the Chinese market—especially China’s AI sector. This approval has come too late.
China is no longer the market that “can’t live without Nvidia.” It’s like a couple separated for a long time who have each grown on their own before meeting again: even if they get back together, it’s hard to recapture the original passion and dependence. Put more plainly, it’s now a relationship where “if it works, we can make it work; if it doesn’t, we can just walk away.”
The Taiwan Situation
Regarding how the US government’s 25% cut will be collected, per Reuters:
A White House official said that the 25% fee would be collected as an import tax from Taiwan, where the chips are made, to the United States, where the chips will undergo a security review by U.S. officials before being exported to China.
This vague description inspired some sudden panic among manufacturers in Taiwan, who worried that they would have to pay an additional fee to the US. Tzu-Hsien Tung 童子賢, chairman of Taiwanese electronics giant Pegatron and cofounder of Asus, told Taiwan’s Economic Daily News that this is most likely a confused misinterpretation: “If Taiwanese firms are paying anything at all, it’s only in a pass-through capacity—collecting and remitting on behalf of someone else, since contract manufacturers aren’t the owners of the product. … My instinct is it’s just pass-through payments; they’re not going to count that as ‘Taiwan paying.’”
The confusion is now mostly cleared up, but a lack of effective communication to Taiwan is probably not a positive indicator for US-Taiwan relations.
Jensen Huang, confronted with a Taiwanese biography of him that calls him “the Genghis Khan of AI chips,” in Taipei, June 2024. Source: CNA.
ChinaTalk is a reader-supported publication. To receive new posts and support our work, consider becoming a free or paid subscriber.
A year for the history books for the Chinese AI beat. We began the year astonished by DeepSeek’s frontier model, and are ending in December with Chinese open models like Qwen powering Silicon Valley’s startup gold rush.
It’s a good time to stop and reflect on Chinese AI milestones throughout 2025. What really mattered, and what turned out to be nothingburgers?
This piece recaps:
The biggest model drops of the year
China’s evolving AGI discussion among Alibaba leadership and the Politburo
The biggest swings in the US-China chip war
Beijing’s answer to America’s AI Action plan and the MFA’s
Robots
Models
The DeepSeek Moment
Liang Wenfeng lit the fire
DeepSeek-R1 came out on January 20, thwarting everyone’s Chinese New Year plans. The cost-efficient LLM, which uses a Mixture-of-Experts (MoE) architecture, caused many in Silicon Valley to re-evaluate their bets on scaling — and on unfettered American dominance in frontier models. DeepSeek is powered by domestically trained Chinese engineering talent, an apparent belief in AGI, and no-strings-attached hedge fund money (it is owned by High-Flyer 幻方量化, a Hangzhou-based quantitative trading firm). There were initial concerns that such a recipe could not be replicated by more capital-constrained Chinese tech startups, but Kimi proved that wrong with K2 in July; Z.ai, Qwen, and MiniMax followed.
We translated Chinese tech media 36Kr’s interview with DeepSeek CEO Liang Wenfeng back in November 2024, and spent much of January 2025 on the DeepSeek beat (see Jordan’s conversations on DeepSeek with Miles Brundage here and with Kevin Xu of Interconnectedhere). Over at the newsletter, we covered how China reacted to DeepSeek’s rise, its secret sauce, and concerns around open-source as a strategy.
DeepSeek continues to be a big deal. For one, it paved the way for an open-source race dominated by Chinese models. Nearly every notable model released by Chinese companies in 2025 has been open source. In public blog posts, social media discussions, and private conversations, Chinese engineers and tech executives repeatedly attribute their open-source orientation to the example set by DeepSeek.
On the technical end, despite some remaining mystery surrounding the exact cost of training R1, DeepSeek’s viability was a shot in the arm for Chinese labs working under compute constraints. Going into 2026, with restrictions on H200s loosened and reporting that DeepSeek is still training on smuggled Nvidia, easier access to TSMC-fabbed Nvidia chips may be just what DeepSeek needs to get their mojo back.
Manus
Big deal, but not because of the product
On March 6, an unknown Chinese startup named Butterfly Effect 蝴蝶效应 launched Manus, the world’s first general-purpose AI agent. Revisiting the “Introducing Manus” video that went viral nine months ago is a reminder of how quickly technology has developed: the capabilities Manus demonstrated — reviewing a folder of résumé PDFs, researching stocks, and comparing real estate options — are now so common that we barely think of them as new or even particularly agentic. But back then, some thought Manus was a second “China Shock” of sorts after DeepSeek. Jordan discussed Manus on the podcast with (Strange Loop Canon), Swyx from , and (Mercatus, Hyperdimensional) on the podcast here.
Soon after, Manus didn’t want to be Chinese anymore. In July, the company scrubbed its internet presence inside China, relocated to Singapore, and laid off most of its staff in Beijing and Wuhan. An April funding round led by the American venture capital firm Benchmark had been scrutinized by the US Treasury Department over restrictions on investments into Chinese AI development. Manus may have decided that its Chinese base is a worthy sacrifice if it means access to American capital and the global market.
Since then, its market strategy has been anything but understated: from exclusive parties in San Francisco to conference keynotes in Singapore, Manus is trying to reinvent itself as a global force spearheading agents. Whether or not this rebrand is successful remains to be seen; in the meantime, it is no longer the only agent in the game, as major AI companies like OpenAI and ByteDance launched agent products of their own.
Looking back, Manus was the start of a wave of Chinese AI companies aggressively pursuing international expansion in the second half of this year. With DeepSeek providing that the world was interested in open-source Chinese models, other companies became eager for a slice of the lucrative global market. Whether or not their Chinese roots limit their growth potential will be up to regulators in 2026 and beyond.
The Open Source Race
The defining paradigm
With DeepSeek shooting the first shot, this year saw a significant number of Chinese companies contributing excellent models to the open source race. In the process of promoting their models, Chinese labs have also become much less secretive.
We covered Kimi K2, a “thinking” model whose architecture is inspired by DeepSeek, in July, with much of the reportage based on blogs and comments Kimi engineers shared online. Since then, we were also able to interview Li Zixuan, director of product at Z.ai (formerly Zhipu), which makes the popular GLM models. 2026 will almost certainly see more Chinese AI companies leverage open source as a mean of expanding influence.
China and AGI
Does China believe in AGI, and is it working to pursue it? It’s a question hotly debated by observers of China’s tech scene, and this year we were fortunate to be able to feature some excellent writing that probes at this topic.
In April, an anonymous contributor staged a Platonic debate between a believe and a skeptic, laying out arguments for and against the question of Chinese AGI belief.
In May, another anonymous writer covered the Politburo “study session” on AI. We learn from the invited guest list that “Xi’s hand-chosen experts on AI seem more like the Yoshua Bengios and Geoffrey Hintons of the Chinese AI world than the Yann LeCuns”:
Alibaba, whose family of Qwen models gained particular prominence in the latter half of this year, held its annual Yunqi Conference in September, and CEO Eddie Wu delivered a landmark speech sketching out his vision for transformative AI. Guest contributor Afra Wang argues that prophetic styles signal a “vibe shift” in Chinese tech, as the industry begins to see itself as pivotal for the nation’s destiny.
The Chip War
Just make up your mind already!
For most of the year, we waited with baited breath for the Trump administration to decide whether to export advanced AI chips to China — and for Beijing to make up its mind on whether it wants them after all. All this drama led to five emergency pods! A quick timeline to refresh our memory:
April: BIS closed loopholes in Biden-era chip and manufacturing equipment export controls, further restricting Chinese access;
May: Commerce Department kills the Biden Administration’s Diffusion Rule via Q&A but weirdly still hasn’t fully changed the reg…
July: America’s AI Action Plan called for stricter enforcement of export controls and exploration of location verification mechanisms (our coverage)
The Summer of Jensen (reported by ChinaTalk here and discussed with Lennart Haim and Chris Miller here):
July 15: Jensen Huang met Trump and secured permission to resume sales of H20s to China;
July 30: The Cyberspace Administration of China (CAC) summoned Nvidia’s representatives over risks of Nvidia being able to control H20s remotely, accusing them of having a “kill switch”;
August 11: The Trump administration reached a deal with AMD and Nvidia to resume exports of H20s and MI308s to China, with the US government receiving 15% of the resulting revenue;
August 12: The CAC summoned top Chinese tech firms to pressure them to reduce H20s orders and supplant with domestic alternatives;
August 13: Reutersreported that US officials have been secretly putting tracking devices into some high-end chips in order to track diversion to China;
August 21: Reports emerge that Nvidia has asked some suppliers to halt production of H20s.
September: BIS unveiled an Affiliates Rule, which would have hit many more Chinese companies with restrictions on chip access, including their ability to purchase legacy chips;
October: the Trump-Xi Summit produced a deal, with China suspending its new, dramatic rare earths export restrictions for one year in exchange for a temporary suspension of the Affiliates Rule (emergency pod)
November: The GAIN AI Act was introduced in the Senate, with the White House apparently lobbying against it;
December: Trump announced that he will permit Nvidia to sell H200s to China (emergency pod).
Huawei is Beijing’s champion for creating an alternative ecosystem to Nvidia’s. Guest contributor Mary Clare McMahon explored how Huawei is working to bypass the CUDA moat in May, and in June Jordan sat down with veteran journalist Eva Dou to discuss her new book, The House of Huawei. In October, Jordan also interviewed Chris McGuire, former Deputy Senior Director for Technology and National Security at the NSC, about where Huawei’s capabilities might be going.
The rise of reasoning models and inference training has also brought attention towards high-bandwidth memory (HBM), where China still currently relies on the Big Three: the US’s Micron, and South Korea’s SK Hynix and Samsung. Contributors Ray Wang and Aqib Zakaria covered China’s pursuit of indigenous HBM this year, exploring CXMT’s capabilities in the face of lithography export controls.
Robots
Too soon to tell…
A wave of attention gathered around robotics and embodied AI in China this year. The Government Work Report this year explicitly mentioned embodied AI for the first time, placing it alongside longstanding tech aspirations like quantum and 6G. The Ministry of Industry and Information Technology (MIIT) specifically named humanoid robots in its list of work priorities for 2025. And throughout the second half of 2025, the Chinese Institute of Electronics has been working on standards for the humanoid robots industry, responding to an apparently “urgent” need for standardization in an increasingly competitive field.
Inside China, buoyed by media attention and Unitree’s Spring Festival Gala appearance in January, competition in humanoid robots turned white-hot this year. At least ten companies released humanoid robot models. Some compete by offering increasingly low per-unit prices, while others are starting to pursue specialization in terms of capabilities.
Embodied AI sits at the intersection of China’s longstanding manufacturing advantage and recent advances in machine learning research like vision-language models (VLMs). Jordan sat down with Ryan Julian of Google DeepMind to discuss some of these advances in robotics research this September. Some industry observers in China are worried that humanoids, and embodied AI in general, will turn out to be a bubble, given the sudden rush of investment and a lack of obvious business models. In the meantime, American policymakers are beginning to fret about Chinese robotics firms’ impressive market shares and Western academia’s reliance on affordable Chinese hardware. It’s too early to tell if 2025 was the start of something seismic in robotics.
Track and field at the inaugural World Humanoid Robot Games in Beijing this year.
Policy
AI+ Plan
Big deal; results unknown
On August 28, the State Council released its “Opinion on In-Depth Implementation of the ‘Artificial Intelligence+’ Initiative” (关于深入实施“人工智能+”行动的意见, hereafter abbreviated to “AI+ Plan”). The Plan is a landmark document addressing the integration of AI into China’s economy and society and pushes for thorough AI diffusion across sectors, ministries, and regions. It does not address geopolitical competition much, but clearly portrays AI integration as a strategic priority for the country.
We dove deeply into the AI+ Plan after it was released. Its extraordinarily comprehensive scope, intense sense of urgency, and framing of open-source models as geostrategic assets were remarkable then and remain relevant now. Going into next year, however, knock-on effects will reach Beijing’s doorsteps. How far is “emotional consumption,” greenlit as an application by the AI+ Plan, allowed to go, as AI companions become more alluring and mental health issues potentially proliferate? Will the state be able to keep frustrations around unemployment at bay amid deflation? If AI capabilities are “jagged,” to quote Helen Toner, will Beijing need to adjust expectations for how different industries’ productivities will change with AI?
The Global AI Governance Action Plan
Mid-sized deal with MFA characteristics
A follow-up from the 2023 Global AI Governance Initiative, the Global AI Governance Action Plan was released on July 26 at the World AI Conference (WAIC) in Shanghai. China has long sought to create an overarching narrative for international AI governance. The Global AI Governance Action Plan should be understood as part of its campaign to win hearts and minds around the globe, particularly among unaligned nations in the developing world seeking technology partners.
In hindsight, there is a link between the third item of the Global AI Governance Action Plan, which discusses integration of AI into nearly every industry internationally, and the “AI+” plan for domestic AI diffusion that was released later in the year (to be discussed next). Sector-agnostic, large-scale adoption is a conceptualization of AI that is articulated consistently in Chinese tech policy.
Beyond this, however, most of the other items in the Global AI Governance Action Plan are yet to be realized. Without naming the US, the Plan stresses “global solidarity” and warns against fragmentation. China seeks an active role in international AI governance, whether in standards, environmental management, or data sharing. Diplomatic currents move slowly, and we will likely see more AI policy outreach from Beijing towards developing countries in the coming months and years.
Labelling Requirements, and How to Evade Them
Nothingburger, sadly
Just one day after Manus on March 7, the Cyberspace Administration of China (CAC) released a draft of its “Measures for Labeling of AI-Generated Synthetic Content” (人工智能生成合成内容标识办法), which later came into force in September. The Measures require internet service providers to explicitly label AI-generated content on users’ feeds and add implicit labels to the metadata of synthetic content files. Platforms, in theory, should make it known to users whenever the latter interact with potentially AI-generated content, as well as make sure that creators proactively label their uploaded content as AI-generated. This makes China one of the first jurisdictions, and certainly the largest, to implement labelling or watermarking rules for AI-generated internet content.
The CAC is ostensibly well-placed to roll out AI content labelling regulations, given its unparalleled regulatory reach and China’s competitive position in AI technology. However, after a rush of actions by companies to comply in September, momentum has fallen by the wayside. ChinaTalk will have more coverage on this soon, but in a nutshell, the landscape for AI content labelling enforcement is uneven at best. (Anecdotally, I see unlabelled, AI-generated content on Xiaohongshu and WeChat almost every day. Especially in the case of AI-generated text, labelling is next to nonexistent.)
AI-assisted and -generated content is now so much more pervasive online than nine months ago, whether on global platforms or on the Chinese internet. It’s time to ask: what was the point of labelling as policy? Is it to actually protect users from misinformation and engender trust, or is it just a stopgap measure that lets platforms evade responsibility? What kinds of AI usage merit which kinds of mandated disclosures?
A clearly AI-generated video on Rednote/Xiaohongshu. The user’s self-chosen name is “Mimi Loves AI,” but apart from that there is no other indication that the video is AI-generated.
ChinaTalk is a reader-supported publication. To receive new posts and support our work, consider becoming a free or paid subscriber.
Much of the coverage we do at ChinaTalk relies on WeChat, the Tencent super-app where most Chinese people send messages, consume content, and share updates with friends and family. WeChat is a huge information ecosystem and an arguably essential resource for following the latest news in China’s AI landscape.
Where should you go on WeChat (and on the broader Chinese internet) to learn about what’s happening in AI? The ChinaTalk Cinematic Universe brings you a comprehensive guide to following AI on WeChat, featuring:
How to make your WeChat work like Substack;
Various types of AI media outlets;
And how to read beyond WeChat.
We’re also looking to run a weekly roundup of the most interesting Chinese developments around AI in the newsletter. If interested, submit a sample here. We pay!
How WeChat Works
Specifically relevant for our purposes is the “Official Accounts” tab. It’s a little like a Substack ecosystem inside WeChat: anyone can open an Official Account on WeChat and publish articles to their subscribers’ feeds — and reading and sharing Official Account articles is a daily occurrence for WeChat users. Government organs, public service authorities, news media (both state-run and independent), and corporations alike use Official Accounts to communicate with citizens.
A screenshot of my (Irene’s) WeChat Official Accounts home page. The circles on top are quick links to Official Accounts I click into most frequently, and the rectangles below are articles by Official Accounts I subscribe to, arranged in a mostly-chronological feed.
Subscribing to relevant Official Accounts is the most streamlined way to read Chinese tech news directly from the source. WeChat makes it very easy for non-Chinese speakers to navigate by putting a “Translate Full Text” option at the top of every article, although the quality of translation remains mediocre relative to what ChatGPT can deliver.
Our Favorites
For headlines:
新智元 AI Era
Founded in 2015 by Yang Jing 杨静, then a researcher at the Ministry of Civil Affairs-affiliated Chinese Association for Artificial Intelligence, AI Era is one of the earliest and most successful media-entrepreneurship ventures to focus on AI in China. AI Era hosted the inaugural World AI Conference (WAIC) back in 2016. Its feed is a blend of repackaged stories from Western tech media, accessible explanations of new ML/AI research, and content for aficionados. While AI Era doesn’t produce a lot of original reporting, it is a solid one-stop shop for keeping up with the Chinese AI Joneses.
QbitAI is an AI-focused media startup whose Official Account similarly reaches many in China’s AI community. Its coverage is relatively accessible and includes popular trends.
Where to start:
How vibe-coding is changing Haidian 海淀, the Silicon Valley of Beijing;
The AI technology stack behind Xiaohongshu/Rednote, China’s trendiest social app.
机器之心 Synced
Founded in 2015, Synced is a leading source of information on emerging tech in China. They cover machine learning research much more closely than more generalist tech publications, and they host their own directory of models.
RoboSpeak is a joint media venture between Zhongguancun Rongzhi Specialized Robotics Alliance (ZSRA), a Beijing-based robotics industry organization, and the startup incubator TusStar, earning financial support from a variety of public and private partners. Its work lies between journalism and think-tank research, and is well-known in the Chinese robotics community.
Where to start:
An interview with Professor Wang Hesheng 王贺升 of Shanghai Jiao Tong University, who will serve as general chair of the 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) in Hangzhou;
Observations from the 2025 China International Industry Fair.
For business-savvy reportage:
36氪 36Kr
36Kr calls itself a platform for “participants of China’s new economy.” It’s a business media outlet with a heavy dose of tech reporting — the TechCrunch of China, if you will — and consequently produces some of the best original Chinese-language reporting on technology as a business. Their deep understanding of the relationships between technology, Chinese society, and the economy makes reading their work particularly informative for analysts.
How entrepreneur Wang Laichun 王来春, whose company Luxshare will build OpenAI’s first consumer device, went from Foxconn factory girl to “the richest Teochew businesswoman”.
A highly abridged translation of ’s article she wrote for us on ‘Why America Builds AI Girlfriends and China Makes AI Boyfriends’ article! See below for her commentary on what they took out.
Thanks to 36kr’s translation, my relatives in China can finally read my work—and thanks to its selective censorship, they don’t have to worry about me running into political trouble! Here are the things that the translation removed, which I guess partly because it is politically sensitive and partly because the translator thought my article was too long:
The Regulatory Comparison: The original introductory analysis comparing U.S. regulatory concerns (FTC inquiry on child use) with Chinese concerns (AI Safety Framework 2.0 on social order and childbirth) was entirely removed. This seemed an editorial choice, as the translators began the translation with their own introduction of my article.
The Core Political Analysis: The entire section linking the Chinese government’s motivation for regulating AI boyfriends to the demographic crisis, low birth rates, and the government’s historical use of the “leftover women” label was omitted. I still credit them for mentioning the stigma of “leftover women,” even though they erased who created it.
The Geopolitical Risk: The discussion detailing the rise and disappearance of the Chinese app Talkie from the U.S. App Store—and its analysis as a potential “more powerful TikTok” national security threat due to intimate persuasion and data risks—was also removed.
Sexual Content Details: The detailed explanation of monetizing sexuality via “freemium” models, including specific mentions of “unblurred explicit images” and ‘NSFW’ features, was heavily condensed. Only the thesis statement “both models seek to capitalize on sexuality to attract and retain users” remained.
Finally, the translator replaced “inside the Great Firewall” (防火墙) with “inside the Great Wall” (长城) when the article shifted to describe the AI companion market in China, suggesting an artistry in how some master the subtleties of translation under censorship.
钛媒体 TMTPost
Another tech-focussed media outlet with a solid journalistic track record, the “TMT” in TMTPost stands for technology, media, and telecommunications. Its coverage of entrepreneurs and Big Tech firms in China is particularly strong. We previously translated TMTPost’s 2024 interview with Unitree CEO Wang Xingxing 王兴兴.
Where to start:
A conversation with Xu Zhijun 徐直军, a rotating chairman at Huawei, about AI compute;
AIstory is a new media brand under Beijing Zhen’gu Media Group (北京真故传媒有限公司), best known for the nonfiction publishing platform TrumanStory 真实故事计划 . The company was founded by Lei Lei 雷磊, a former Southern Weekly and GQ reporter in China, and has excelled at long-form, human-centered reporting despite China’s brutal journalistic landscape. AIstory focuses on humanizing the impact of AI on Chinese society and unearths particularly unique angles beyond labs, policymakers, or investors.
Why DeepSeek created even more busywork for Chinese low-level bureaucrats.
硅星人Pro
By Afra:
A Chinese-language WeChat publication at the intersection of AI, technology, and culture. Its core reporting covers the fast-moving world of large models—DeepSeek, R1, and every new version that emerges—alongside architecture strategies, compute efficiency, cost dynamics, and the competitive landscape shaping the global AI race.
But 硅星人Pro’s regular features dive into tech culture and labor issues, exploring how AI and automation collide with the realities of work, inequality, and the everyday life of engineers, gig workers, and startup employees.
Sometimes you find sarcastic, sometimes salty voice. Readers can expect sharp takes on the AI bubble, founder dramas, job replacement anxieties, ageism in the tech industry, and the broader involution of both Silicon Valley and China’s own innovation scene.
GeekPark (极客公园)
By Afra:
GeekPark (极客公园) is one of the few Chinese tech media outlets that consistently produces in-depth, long-form original reporting on China’s technology industry.
Among domestic outlets, it’s often seen as the closest equivalent to Western tech media: blending narrative reporting, analysis, and insider access in a way that feels more like The Verge and Wired than a typical WeChat information feed.
For wonky analysis (suggested by Bitwise):
中国信息通信研究院 China Academy of Information and Communications Technology
CAICT is a research institute directly under China’s Ministry of Industry and Information Technology, specializing in research on the digital economy and technology policy. Their Official Account publishes helpful executive summaries of their reports and official readouts from various Chinese conferences related to AI. Its feed is certainly less exciting than many of the other Official Accounts mentioned above, but it is a very helpful resource to understand where technocrats in Beijing are placing their attention.
A list of example cases for digitalizing the manufacturing industry in China.
阿里研究院 Alibaba Research Institute
Alibaba’s in-house industry research think tank produces many interesting reports about AI applications, safety, and governance. You should take their findings with a grain of salt on account of their corporate ownership, but their work is nevertheless interesting.
Where to start:
Official transcript of CEO Eddie Wu’s September 2025 speech on the path to AGI;
In contrast to the ARI above, Tencent’s in-house think tank works more broadly across social science and humanistic topics. Their work, influenced by the thorough penetration of Chinese citizens’ private lives by Tencent products, has a stronger focus on how AI is shaping Chinese society.
Where to start:
Annual survey on the Chinese public’s views on generative AI;
Cyber Zen Heart (赛博禅心) is one of the growing AI influencers on WeChat. He updates at breakneck speed, often catching the pulse of a new model, tool, or meme before the mainstream discourse picks it up. Beyond commentary, he has quietly shaped the scene: helping many early AI consumer apps think through their go-to-market strategy, coaching founders on how to generate buzz, and amplifying their launches to wider audiences.
The account is run by the owner, nicknamed”Big Smart”, of Beijing Haidian’s AGI Bar, a late-night hangout where AI founders, hackers, and artists cross paths. His posts swing between news update, “omg this is awesome”-bait articles, and deliberately confusing memes—half koan, half hype cycle. That mix makes him feel like “China’s Lenny” (as in Lenny Rachitsky): a guide and amplifier for a new generation of builders. I wrote about my experience in the AGI bar here.
半导体行业观察
半导体行业观察 is one of China’s most dedicated WeChat publications tracking the chip world. It dives deep into the nitty-gritty technical details of semiconductor design, fabrication, and packaging—so deep that, to a casual reader, it can sometimes feel painfully dry and even boring for someone like me. Where the account shines is in its close tracking of China’s domestic chip research and development. Like many chip-focused outlets, the tone occasionally reflects the geopolitical tensions surrounding semiconductors.
LatePost 晚点
LatePost (晚点) is often described as “China’s version of The Information”: known for high-quality, deeply sourced reporting on business and technology. Its editorial strength lies in exclusive founder interviews, inside scoops, and longform articles that cut through hype to reveal how China’s leading companies. The LatePost podcast—published under the same name—has become a must-listen for anyone trying to understand China’s AI ecosystem.
Luo Yonghao’s Crossing Road 罗永浩的十字路口 is a new longform podcast hosted by Luo Yonghao—once a smartphone entrepreneur, now one of China’s most recognizable internet personalities. Think of him as a mix between Joe Rogan and Lex Fridman in a Chinese context: curious, blunt, and willing to let conversations stretch out for hours
Each episode runs about 3 hours, giving founders, cultural figures, and celebrities the space to share deeply personal stories and unfiltered thoughts. Among the standout episodes is Luo’s marathon conversation with He Xiaopeng, founder of XPeng Motors—widely regarded as a must-listen for anyone who wants to understand the ambitions, struggles, and psychology behind China’s EV wave.
Beyond WeChat
The downside to WeChat’s Official Account ecosystem is that its comment function is often restricted, and it can be hard to go beyond the article if you are looking for more context. Other parts of the Chinese internet can offer more community-based insights on technology and provide direct access to insiders’ views.
CSDN
CSDN, China’s first open-source community, is a web forum for developers that dates back to 1999. Discussions on there feel like a mix of Stack Overflow and Hacker News, and contain many useful technical resources. ChinaUnix is another similar forum.
Zhihu
Imagine if Quora still had loyal users — that’s basically Zhihu. Though it has deteriorated from its heyday as a bastion of liberal debate on the Chinese internet in the 2010s, Zhihu remains a platform where scholars, thinkers, and technologists are quite active. Our story on Kimi relied heavily on Moonshot AI engineers’ commentary on Zhihu, and so did this guest post by Mary Clare McMahon on Huawei’s attempts at bypassing Nvidia CUDA.
Xiaohongshu…?
Yes, that Xiaohongshu/Rednote. If you know what you’re doing, it can be a uniquely valuable resource. Xiaohongshu has an especially strong network effect for academic and tech-focused communities. Searching for ML/AI-related keywords on Xiaohongshu eventually leads you to professors, entrepreneurs, and investors influential in the space, as well as many, many anonymous insiders posting offhand observations and rumours in comment sections. It’s arguably the closest thing to getting those elusive-but-unreliable “vibes on the ground.”
Between language barriers and the Great Firewall, it can seem difficult to get reliable information about the world of technology in China. We hope that by highlighting these great Chinese-language resources, we can encourage more people to conduct their own open-source research and enrich debates in the English-speaking world.
Have other Official Account recommendations? Reply to this email or drop your suggestion in the comments!
We’re also looking to run a weekly roundup of the most interesting Chinese writing on AI in the newsletter. If you’re interested, submit a sample here. We pay!
ChinaTalk is a reader-supported publication. To receive new posts and support our work, consider becoming a free or paid subscriber.
Last month, Irene and Lily went to South Korea to report on a twinset of robotics conferences. Here are a few notes from their travels.
On Korean Beauty
Irene:
Hallyu — the “Korean Wave” of pop culture that began spreading internationally in the 2000s — taught my generation of Asian Americans/Canadians how to style ourselves. We grew up with few relatable points of reference in mainstream Western culture, as our physical features rarely aligned with American beauty standards. K-pop built an alternative, affordable framework during our coming-of-age, and it was impossible to miss its influence even if you (like me) never consumed much of the music or TV dramas.
Goryeo (the royal dynasty that ruled the Korean Peninsula from 918 to 1392) began sending women by the hundreds as tributary gifts to the Chinese empire during the Tang dynasty. The Middle Kingdom, from then on, routinely scoured the Peninsula for beauties. The third Ming emperor, Yongle, was recorded to have favored a concubine surnamed Kwon from Joseon (the dynasty that followed Goryeo). After Kwon died at the age of 20 in 1410, the Yongle Emperor sentenced perhaps thousands of women from his harem to death on suspicion of poisoning Kwon, according to one Korean chronicle.
Japan’s colonial rule forced between 50,000 and 200,000 Korean girls and women into sexual slavery as “comfort women” for the army. After the Second World War, another vast sex trade sprang up around American-led army bases across South Korea, with girls and women trafficked by their own government to provide “morale” to UN troops and bring in millions of foreign money for the economy.
Beauty remains one of Korea’s most prominent exports. Multilingual advertisements for plastic surgery sprawl throughout Seoul’s affluent Gangnam neighborhood. There is seemingly an Olive Young on every street corner and endless high-end options in shining department stores. The industry works hard to conceal the dark historical context behind Korea’s coerced preoccupation with female beauty, while continuing to push what sociologist Rosalind Gill calls the “surveillant gaze”: symbolic images of measuring tapes, cameras, and microscopes that incite women to constantly monitor and regulate themselves. K-pop labels routinely debut girls as young as fourteen to appeal to teens, both locally and internationally. Appearance-based discrimination is endemic; journalist Elise Hu writes in Flawless: Lessons in Looks and Culture from the K-Beauty Capital that for Korean women in the 21st century, looking pretty is “the price of entry in the labor market.”
Lily:
I’m a size small in America, a medium in Taiwan, and a large in South Korea.
For a country with such a famous beauty industry, the selection of lip colors and finishes is extremely limited. Nearly every Korean lip product is sheer, glossy, and pink, formulated to stain your lips for a longer-lasting effect. Eyeshadow palettes lack pigment and are similarly uninspired. While American makeup brands market their products as tools of self-expression, cosmetic advertisements in Korea use words like “perfection” 완벽 and “improvement” 개선 to draw consumers’ attention.
We found this book in Seoul’s Starfield Library, which was overflowing with influencers.
Korean sunscreen, however, is excellent, as are the face masks and jelly foundation cushions (provided you can find one in your shade). The products are very affordable compared to American cosmetics. I browsed many Olive Young stores that were packed with shoppers, yet the single aisle dedicated to American and European brands was always totally desolate.
An example of a Korean foundation cushion. Idols and cartoon characters are prominently featured in cosmetic advertising/packaging. Source.
Dark, matte, opaque lip colors like this are very rare in Korea. Source.
Similarly, people seem to prefer beige or pink nail polish. I got a set of dark red gel nails done during my trip, and while the service was very fast with lots of attention paid to cuticle care, the final product was unfortunately lacking due to the technician’s lack of experience shaping stiletto (pointed) nails.
People don’t wear much color here either, and instead opt overwhelmingly for beige, white, black, brown, or muted shades of blue.
A storefront in Hongdae.
On Korean Food
Korea excels at making coffee taste good, and Korean people love coffee so much that we saw people sitting in cafes drinking coffee at 9 o’clock at night. In a similar vein, this country doesn’t rise particularly early — most businesses (including many coffee shops/cafes) don’t open until 10 or 11 am. Survey data indicates that South Koreans are highly sleep-deprived compared to other developed nations.
October is the peak month for gejang, raw crab seasoned with soy sauce. I was skeptical at first, but the crab we ate was incredibly fresh with a delicate and complex flavor.
Gejang with a side of raw shrimp.
One of my favorite dishes was North Korean-style cold noodles 물냉면, which are made of buckwheat and would fall apart if served hot. They come with julienned apples and a boiled egg, and are served in a refreshing broth with a bit of vinegar.
America supplied the ROK with food aid during the Korean War, and as a result, South Korea developed a serious taste for corn. Convenience stores carry cream-filled cornbread, corn-flavored ice cream, corn-flake-filled granola bars, corn chips, and rice balls full of corn and tuna. Teas made from roasted corn and corn silk are also popular beverages. Only 1% of this corn is actually grown in Korea — the vast majority is imported from the US.
Korea also consumes a truly staggering amount of fake sugar — ice cream proudly labeled “low sugar” is packed with stevia. The yogurt drinks and matcha lattes I ordered in cafes were sweetened with stevia by default, as were bottled teas and protein shakes in convenience stores.
Korean convenience stores have wonderful smoothie machines. For 3,000 KRW (US$2.10), you can pick out a cup of frozen fruit and have it blended in front of you. Be sure to purchase your fruit cup before you blend it to avoid violating smoothie procedure.
Chinese people have a joke that when you vacation in Korea, you get constipated due to the lack of green leafy vegetables. This joke ignores Kimchi and salads, of course — but it’s rare to find blanched greens of the sort that are ubiquitous in China and Taiwan.
Irene’s travelogue in Gwangju
I read Anton Hur 허정범’s 2022 short story “Escape from America” on the bus from Seoul to Gwangju. The great translator of contemporary Korean fiction writes his own dystopian tale: in a not-so-distant future, politics force him and his husband to flee America for South Korea, where democracy persists but their marriage is not recognized — a “reverse-Miss Saigon scenario,” the narrator notes sardonically. Fears of martial law, borders, gender wars — it all felt eerily prescient in the first months of new presidential administrations in both Korea and the US.
Korea’s Gwangju Uprising is often forgotten as an early chapter in the waves of pro-democracy movements that shaped postwar Asia. In part, that’s because the news simply didn’t get out. Only one Western reporter — Jürgen Hinzpeter for West Germany’s public broadcaster, whose experience was dramatized in 2017 by the film A Taxi Driver — was on site when troops began violently containing protesters on May 18th, 1980. Korean media was heavily censored at the time, and many outside South Jeolla Province, of which Gwangju was then the capital, did not learn of the killings until much later. The military dictatorship installed an effective blockade of the city for ten days, cutting off roads and phone lines, while local students and workers built a short-lived self-governance commune and organized themselves into citizens’ battalions.
Chun Doo-hwan 전두환, then-lieutenant general of the military and the main orchestrator of the massacre, officially became president three months later in 1980 and remained in power until 1988. For years after the massacre, Gwangju was a forbidden topic. The novelist Han Kang 한강, who became Gwangju’s most famous daughter with her Nobel Literature win in 2024, was in Seoul in 1980 and only found out about the atrocities from her father’s secret album of Hintzpeter’s photographs years later. The official death toll stands at 164 civilians, but many more disappeared or were not identified in time; the actual number of deaths may be in the thousands. An “unknown martyr” grave in the Gwangju May 18 National Cemetery contains the body of a 4-year-old child shot in the neck.
“That afternoon there was a rush of positive identifications, and there ended up being several different shrouding ceremonies going on at the same time, at various places along the corridor. The national anthem rang out like a circular refrain, one verse clashing with another against the constant background of weeping, and you listened with bated breath to the subtle dissonance this created. As though this, finally, might help you understand what the nation really was.”
— Human Acts, Han Kang (trans. Deborah Smith)
The “gwang”/광 in Gwangju corresponds to the Chinese character 光, which means light; Gwangju, then, is the Land of Light. I’ve never been to a city with as many commemorative statues as Gwangju. There is an entire park dedicated to statues in the western part of the main city, the government having commissioned artists to explore and immortalize the city’s history. A walk through the park crescendos with a large metal depiction of three students, their arms reaching forward and their faces bearing solemn expressions in a surprisingly socialist-realist style. Under their bodies is an entrance to an underground chamber, in which the names of all known victims surround another statue, this one of a mother holding the body of an agonizingly young teen — a modern Korean Pietà.
Gwangju is not just expressive about its past; it is passionately, thoroughly meticulous. The Jeonil Building, one of the city’s most iconic structures, has been renamed Jeonil 245 after the 245 bullet traces found on its top floors. The directions and depths of each trace conclusively prove that paratroopers shot at people from helicopters, a fact often disputed by those seeking to minimize the extent of cruelty inflicted on Gwangju’s people. Jeonil 245 contains an entire exhibition dedicated to repudiating false claims about Gwangju, including the oft-repeated far-right conspiracy that North Korea instigated the uprising. The nearby 518 Archives is a ten-floor building that houses documents about the events of May 1980. The top floor allows visitors to watch traffic underneath from the exact same windows where Catholic clergymen watched the military brutalize young students marching from Chonnam University. Some of those clergymen would later stage hunger strikes for democracy and clemency for protestors throughout the 1980s. The Old South Jeolla Provincial Hall, where resistance forces staged their last desperate fight, is currently being restored. Every single exhibit I went to was free to enter and had decent-to-excellent English signage.
This is because Gwangju knows its memory can be inconvenient. In the South Korean narrative, Gwangju’s dead are now martyrs who gave their lives for today’s democracy, but that extraordinary achievement does not feel complete. President Yoon Suk-yeol 윤석열, who demanded the death penalty for Chun Doo-hwan while a law student in the 1980s, briefly imposed martial law of his own in December 2024. Korean politics today, haunted by the North-South division, still struggles to move past Red Scare paranoia. On the American side, Washington’s complicity in the Gwangju Massacre is a delicate topic for the US-ROK alliance. President Jimmy Carter’s administration, judging maintenance of the security status quo in the Peninsula to be more important than its people’s democratic aspirations, authorized the use of South Korean troops under the Combined Forces Command against protestors. Declassified documents show that US intelligence judged the protests to be “riots” caused in part by “deep-seated historical, provincial antagonisms” in Jeolla, and feared exploitation by Pyongyang even without any evidence of North Korean instigation. Gwangju became one of the darkest, yet most obscure, chapters of the Carter years; the legacy he left in Asia was barely acknowledged when he passed away at the end of 2024. And finally, across the East China Sea, Gwangju strikes too obvious a parallel with China’s own event that must not be named. Han Kang’s Human Acts has never been translated into Simplified Chinese by any mainland publishing house, so Chinese readers have to resort to pirating the Taiwanese translation.
Efforts by public history institutions and civil society have allowed the year 1980 to persist in Korean popular memory, even before Han Kang’s recent Nobel win. UNESCO officially listed documents of the Gwangju Uprising on the Memory of the World Register in 2011, prompting a wave of public commemoration. In 2013, the K-pop boy band SPEED released a two-part music video set in Gwangju for their song “That’s my fault” 슬픈약속, to popular acclaim. Note how, at the 11:30 timestamp mark, the second video directly quotes the last broadcast made by Gwangju’s citizen militia at the end of the Uprising:
Protest songs from the Gwangju era have also outlived the Uprising. March for Our Beloved (임을 위한 행진곡), the most well-known one, is now a social movement ritual across Asia, having been adapted by activists in Hong Kong, Taiwan, Thailand, and mainland China for a variety of causes. Citizens in Seoul once again sung it while protesting Yoon Suk-yeol’s martial law declaration in December 2024:
Gwangju today is known as Korea’s progressive hotspot, and there is indeed a Portlandia-esque energy coursing through the city. Hipster cafes, lush green parks, and private museums weave around statues of death and survival across the city’s main arteries. The central square, where protestors gathered again to call for the ousting of Park Geun-hye 박근혜 during the 2017 Candlelight Revolution, doubles as a futuristic plaza for the Asian Culture Center (ACC), which showcases experimental art from across the continent. I visited on a rain-drenched day, and there were still large crowds at the ACC enjoying a pan-Asian food festival and open-air dance film screening. The ACC’s ten-year anniversary exhibition, Manifesto of Spring, sports a headline piece with a brassy premise: in a not-too-distant future, democracy collapses in the West and a political refugee tries to immigrate to “Seoul Land” by participating in a population growth program.
The Land of Light, like the rest of us, is surrounded by the haunted fires of history. It insists on sifting through the ashes.
“Why are we walking in the dark, let’s go over there, where the flowers are blooming.”
ChinaTalk is a reader-supported publication. To receive new posts and support our work, consider becoming a free or paid subscriber.
Tourism in Seoul
Lily:
Seoul is an underrated tourist destination. The city is full of beautiful green spaces connected by excellent public transit, and the early October weather was perfect for long strolls through the sloping streets.
Bongeunsa Temple.
“Etiquette is an unchanging form of respect.” Seoul’s metro mascot, an anthropomorphized train named Ddota (또타), reminds you not to run on the escalators or let your children misbehave.
The Korean writing system is a joy to learn, and just a little bit of study can really enrich your experience in Korea. It’s phonetic, and the letters elegantly fit together to form syllable blocks. The shape of the letters is also roughly based on the shape of your mouth when pronouncing each sound (for example, “ㄱ” makes a hard “g” sound, “ㄴ” makes the “n” sound, and “ㅈ” makes the “ch” sound). Irene and I had a great time sounding out menu items, buttons on appliances, and public transport signs, discovering tons of cognates with Chinese in the process. If you add a Korean keyboard to your phone, you can use the letter “ㅗ” to give someone the middle finger over text, and represent crying faces with “ㅠㅠ” and “ㅜㅜ”.
A statue of King Sejong, the inventor of the Korean writing system.



















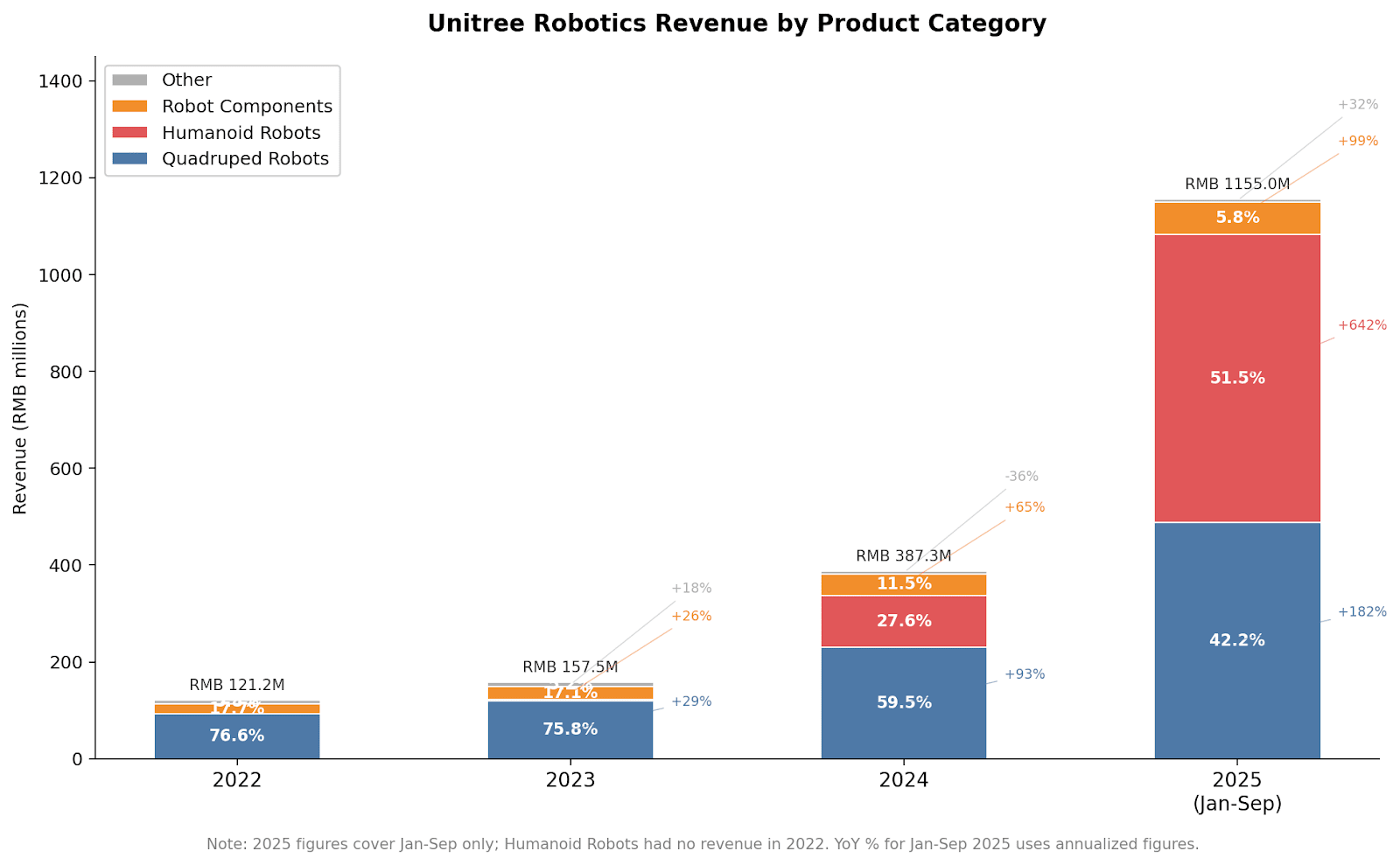
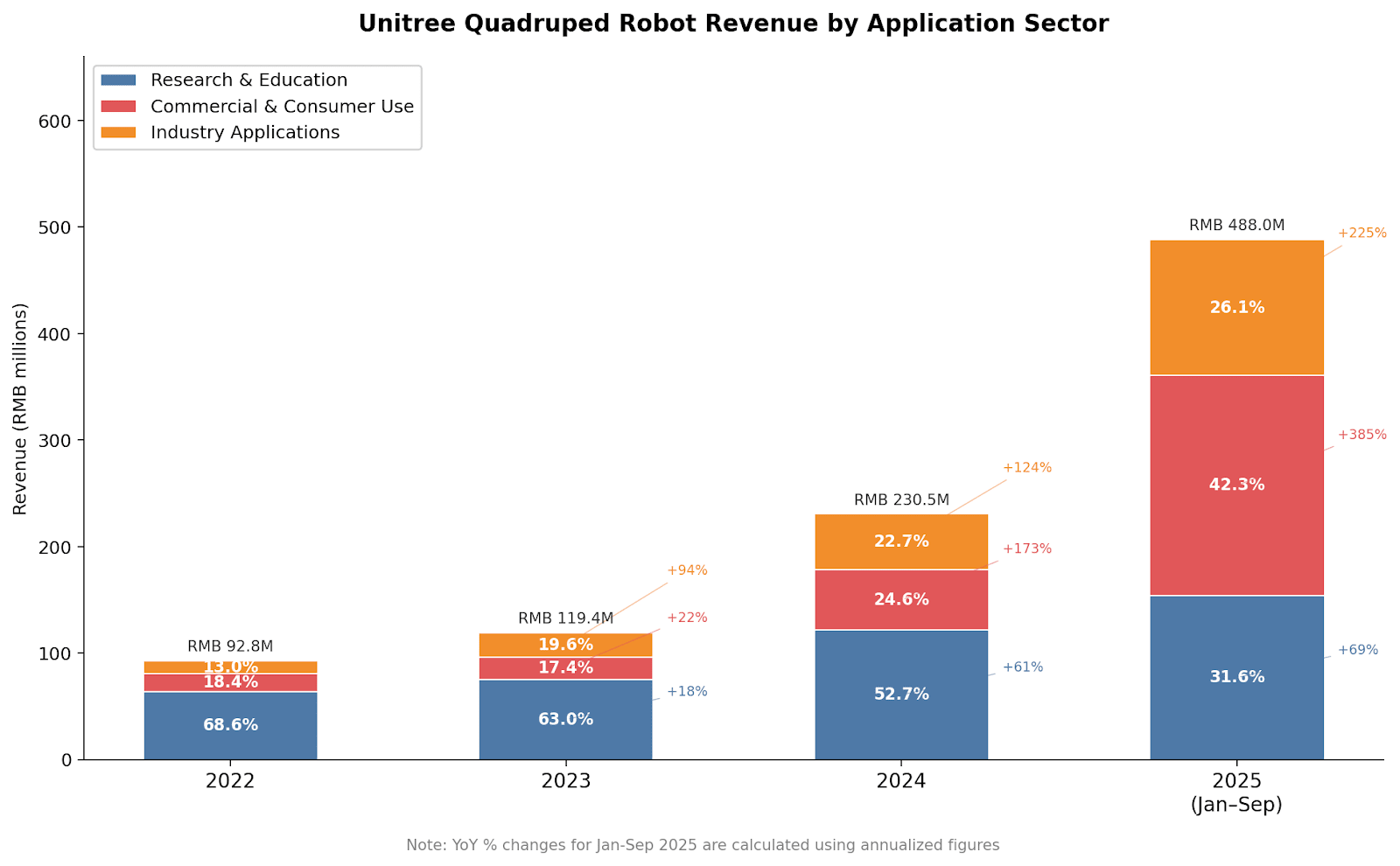
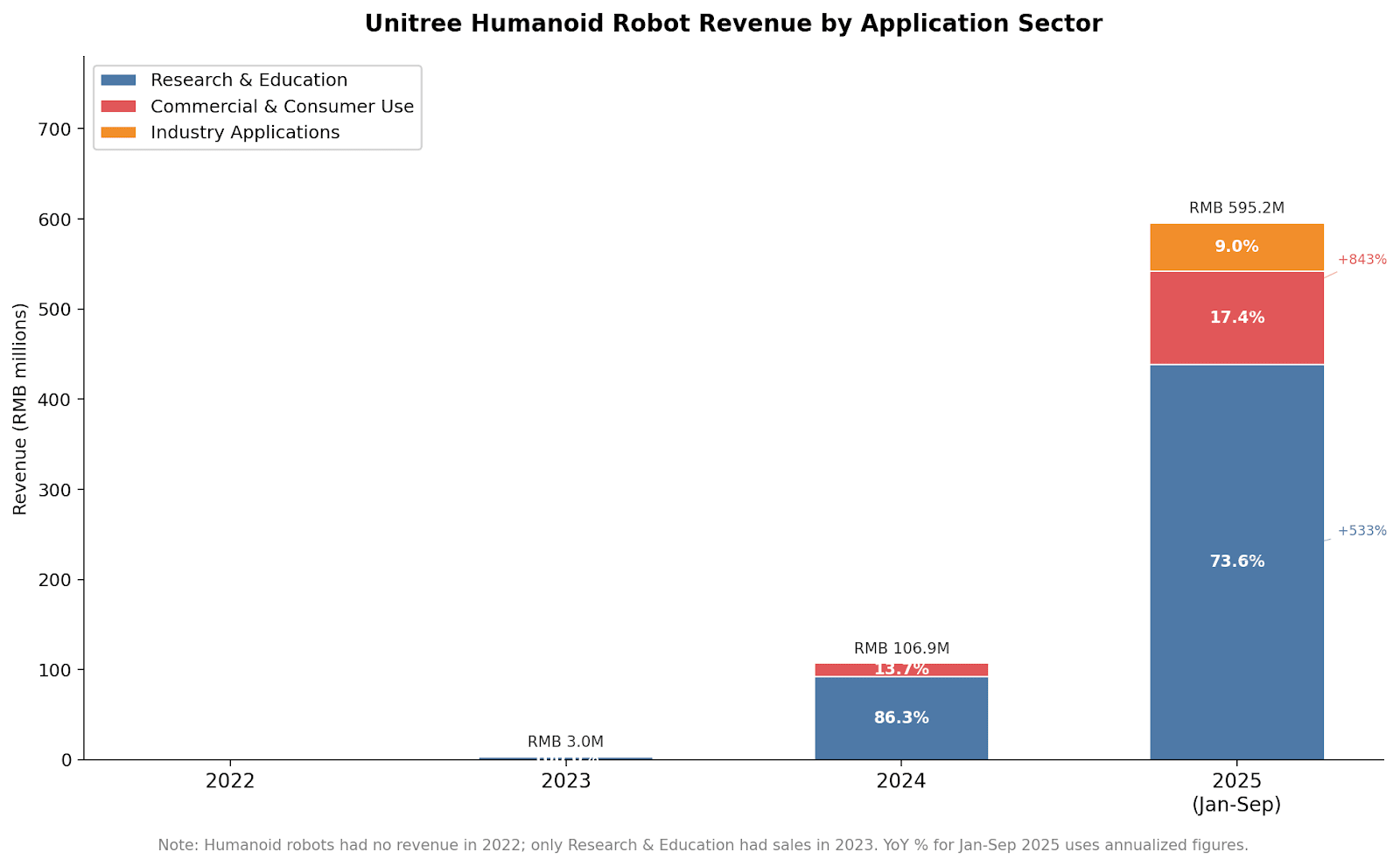

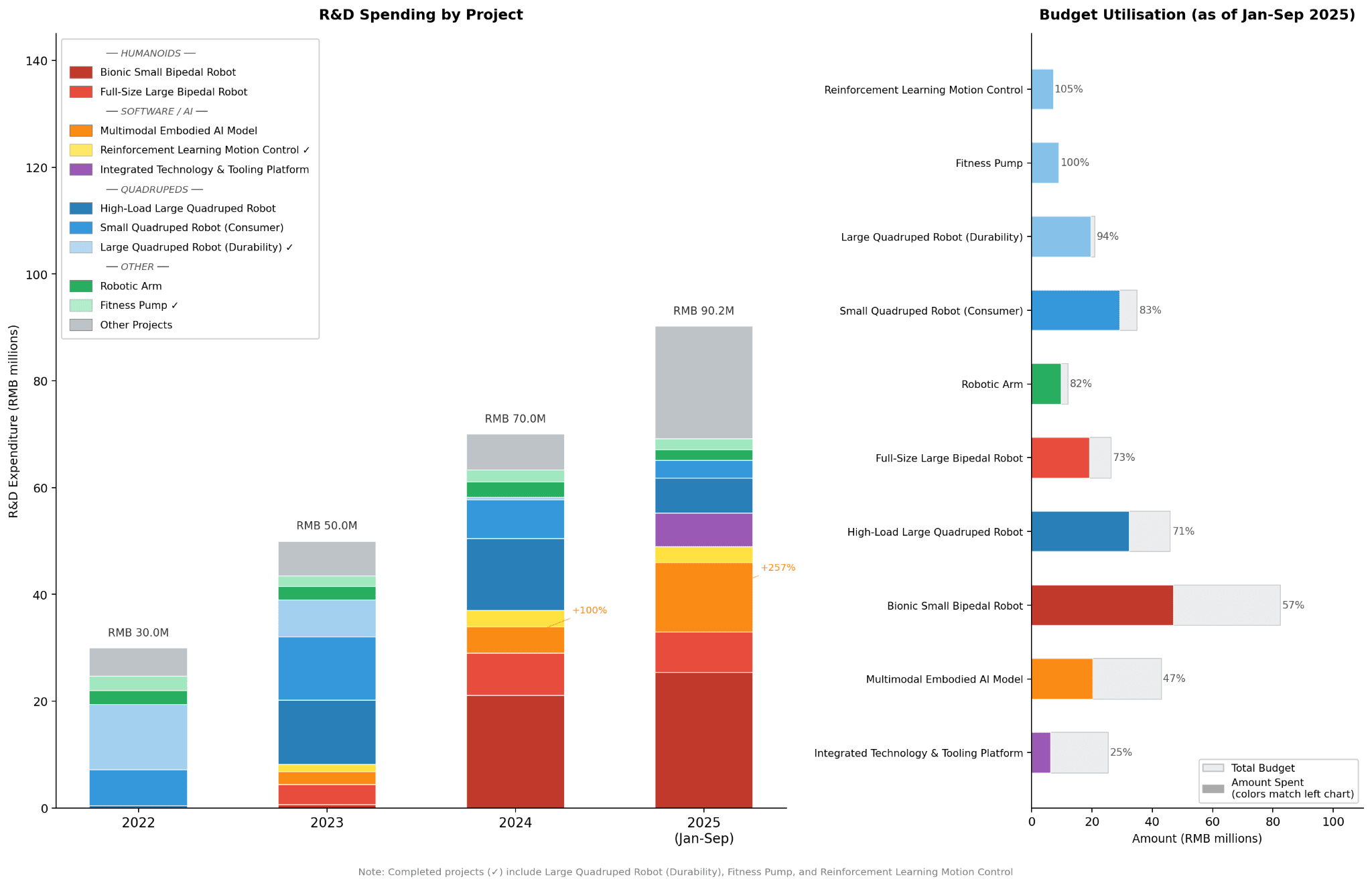
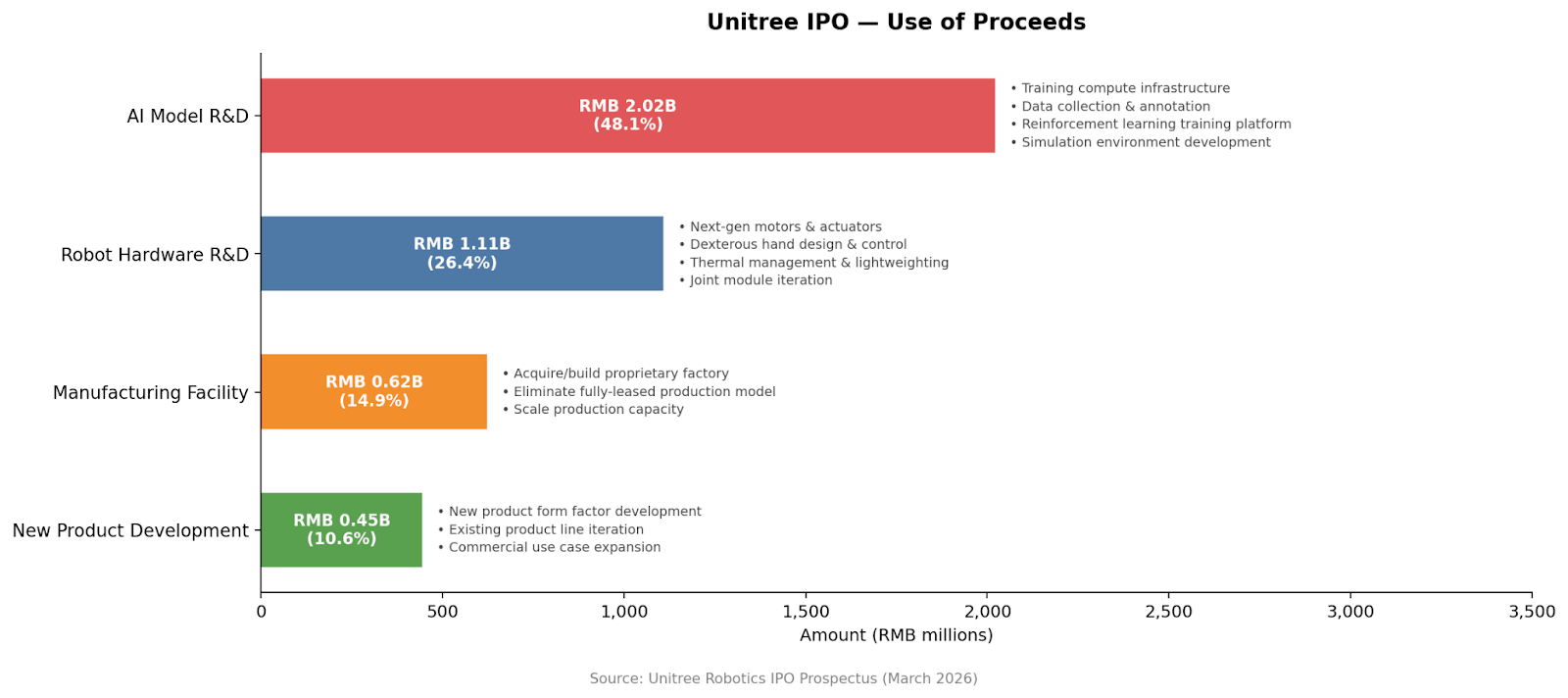


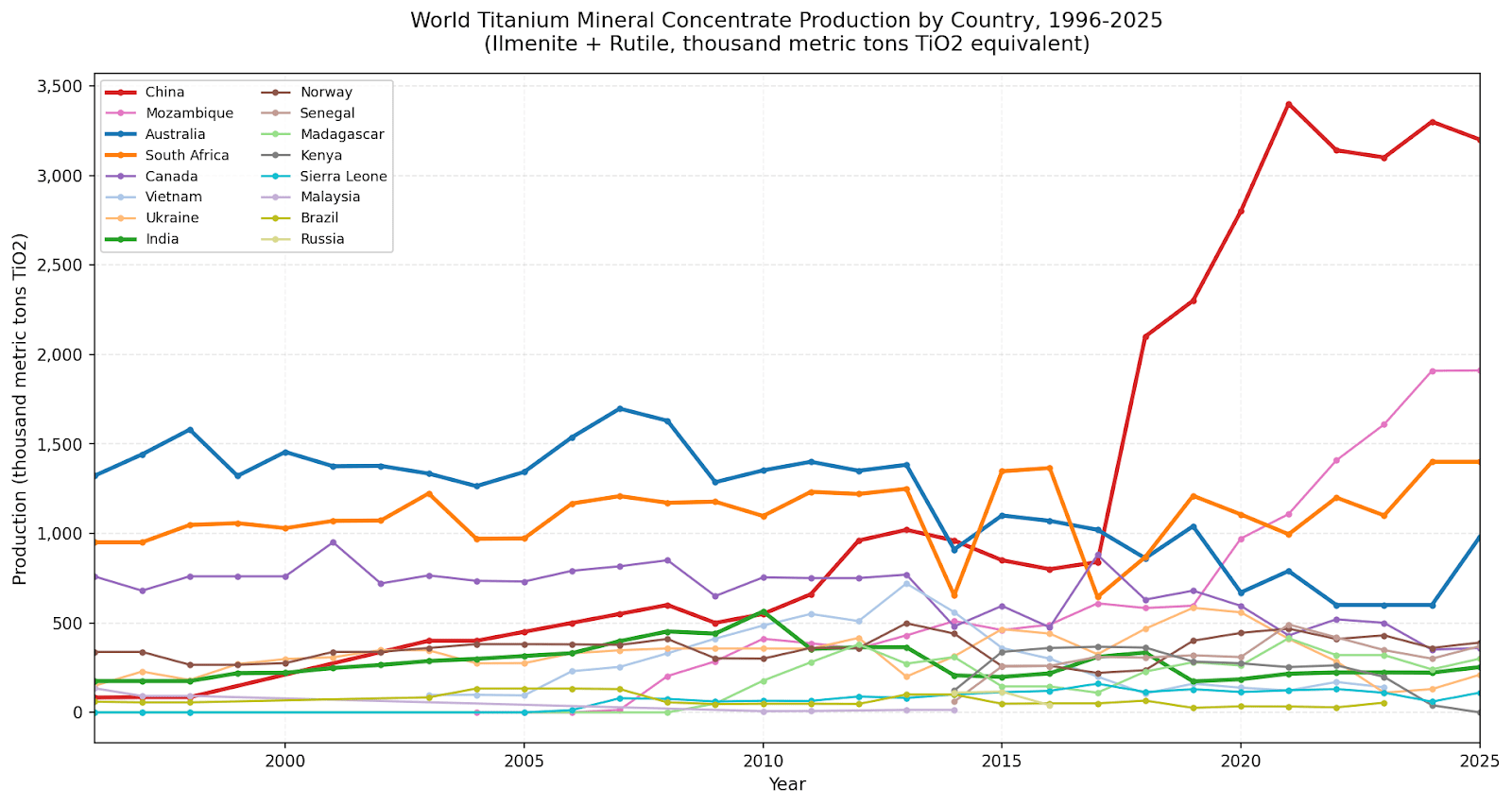
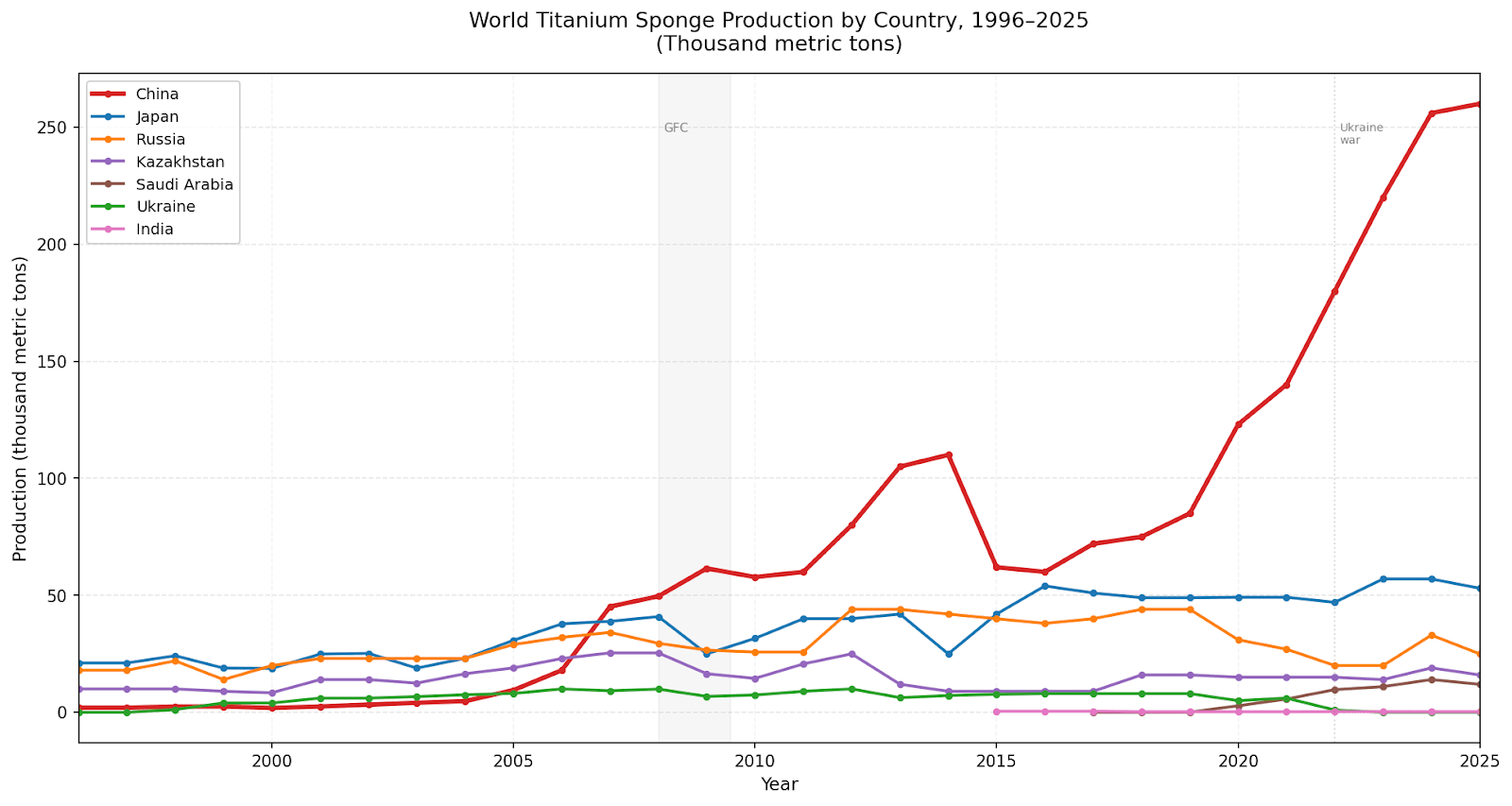













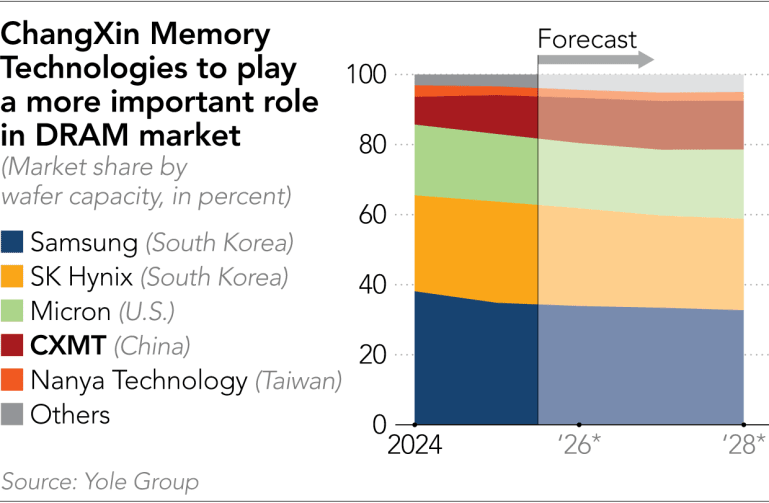
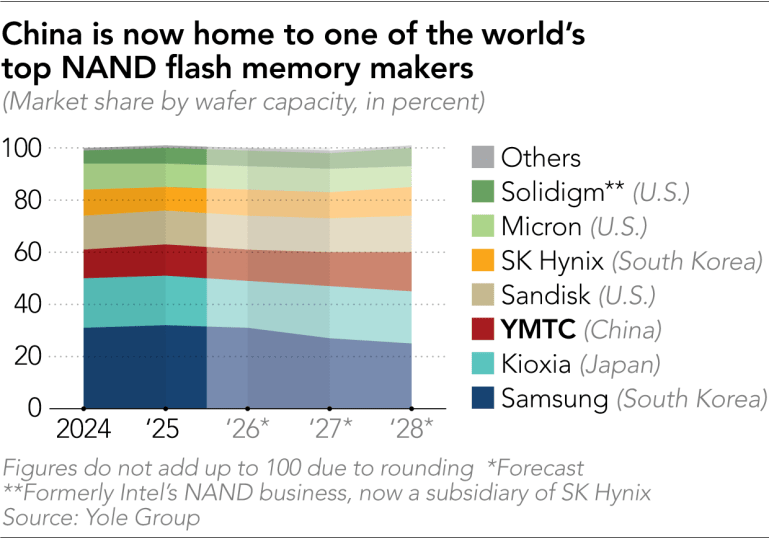










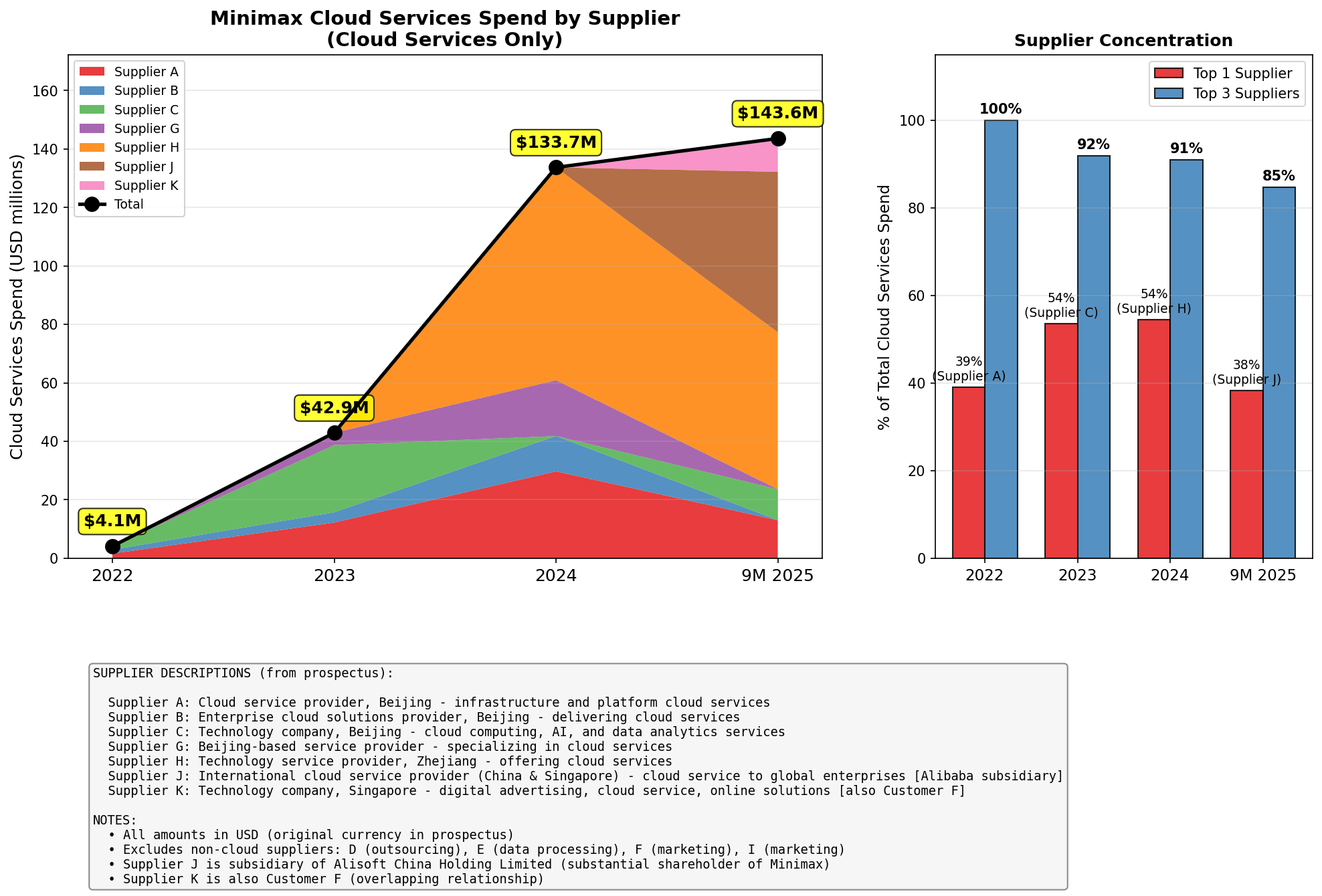
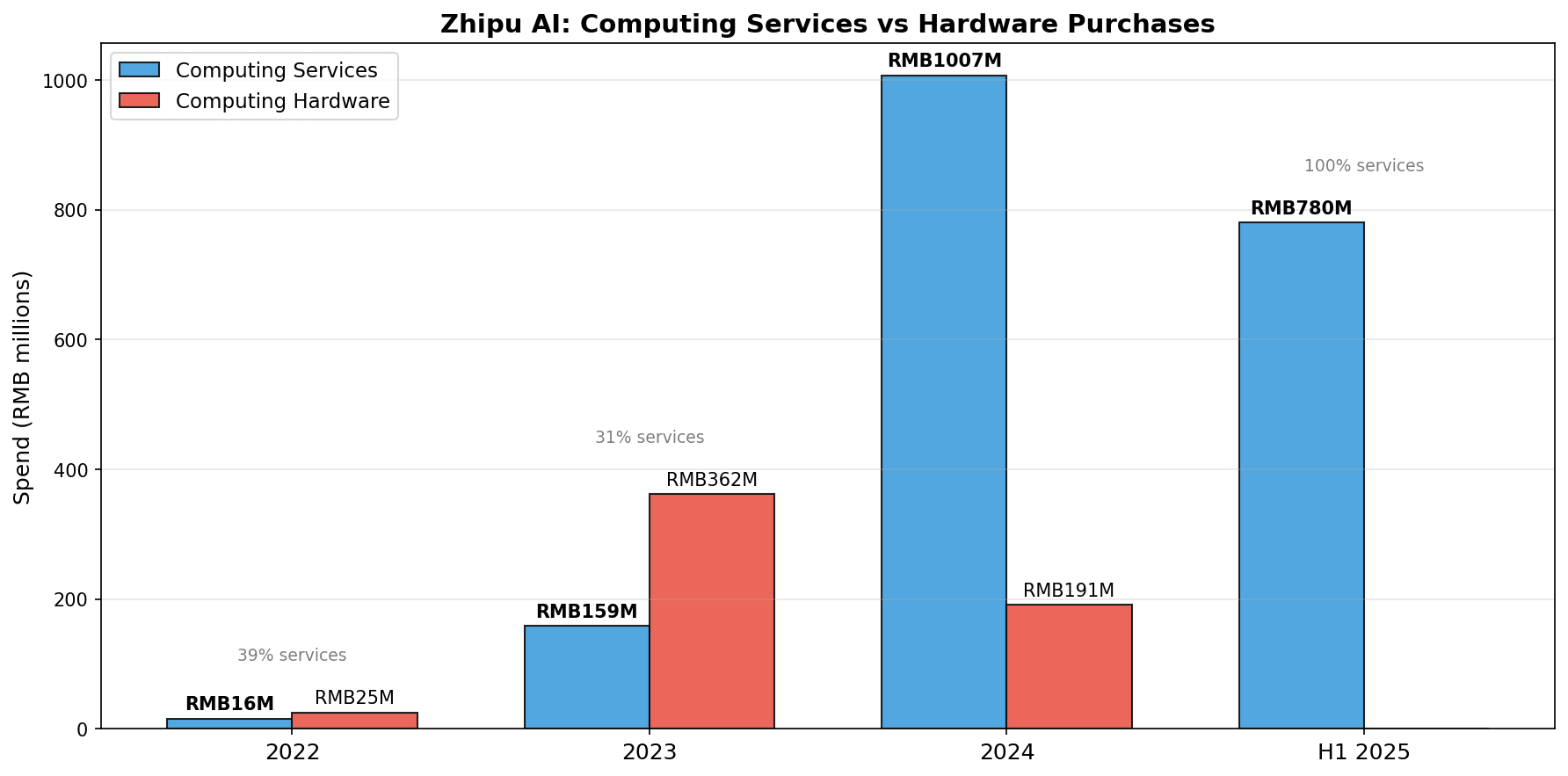
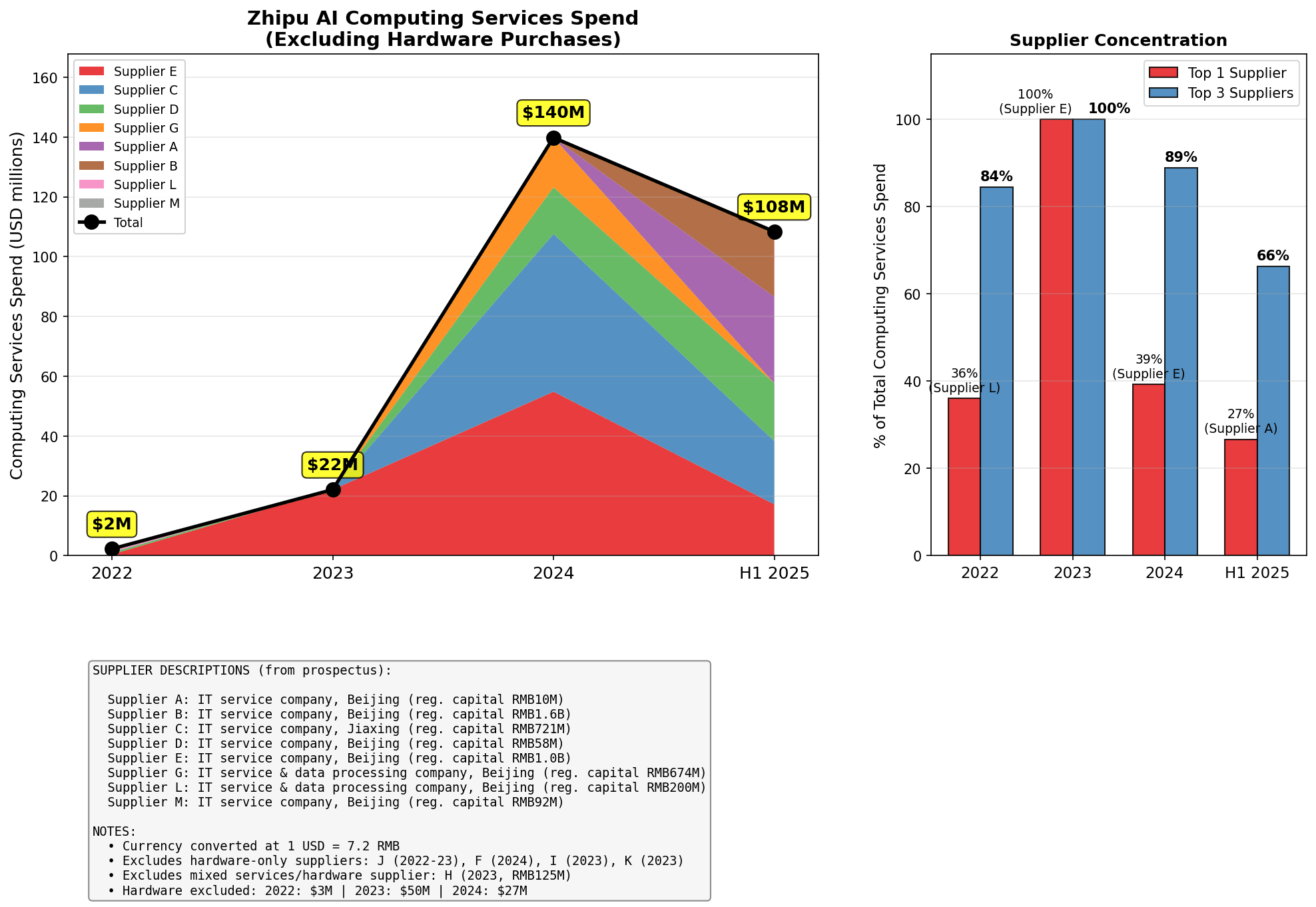


































{kind=link}
{kind=link}
_025.png){kind=link}