
我们还年轻,可不想看到这个世界处在毫无自由、隐私的边缘。
按:本文原作者为 Chris Wellons,最初于 2024 年 11 月 10 日发表在其个人网站 null program 上,并声明归属公有领域。我们据此制作译文,以便中文读者阅读。
本文在 Hacker News 发表后的相关讨论也非常值得一读,有兴趣的朋友可前往查阅。
过去一个月以来,我一直在研究日新月异的大语言模型(Large Language Models,下称 LLM),尝试一窥其中奥妙。如今,一台树莓派就能运行比初版 ChatGPT(2022 年 11 月版本)还聪明的 LLM,换成一台普通的台式电脑或者笔记本电脑的话,运行更聪明的 AI 也不在话下。除了方便以外,本地化运行的 LLM 隐私有保障、数据不联网、不需要注册、也没有诸多限制。大模型正以前所未有的速度发展,现有的知识可能用不了几个月就过时了。我写这篇文章是为了记录我在上手 LLM 时积累的的实用经验和心得,希望这些必备知识能够帮你少走弯路。不过归根结底我也只是一个 LLM 菜鸟,文章中未必有什么独到之处,而且有些地方我可能也没弄明白。一想到一年之后这篇文章大概率就会成为历史的注脚,激动之余我自然也会有些惶恐。
就让我这个刚入门的菜鸟带你们入个门吧:LLM 是一种基于神经网络的技术;2022 年,人们在训练 LLM 进行「聊天」式对话方面取得了突破性进展,使得用户能够与这些人工智能自然地互动。这些模型不仅可以轻松通过图灵测试,与真人对话几乎无异,还展现出令人惊叹的创造力。如果这是你第一次接触这种大模型,感受到的不安可能一连几天都挥之不去。回想一下上次你买电脑的时候,你大概没想过人可以和机器有来有回地对话吧。
这让我回想起上世纪 90 年代桌面电脑快速革新的时候,新买的电脑刚刚送到家里就感觉已经过时了。而到如今,LLM 的发展速度更是快得出奇,几乎每周都有新变化,所以对于那些一年前发布的信息我基本上看都不看。想要掌握最新的资讯的话,可以关注 Reddit 的 LocalLLaMa 板块,但是这里的帖子个个吹得天花乱坠,所以记得别轻信其中的一面之词。
正是因为曾经经历过服务关闭、变更、或者因为其他原因导致我的服务器实例被停用的情况,我才对厂商绑定格外警惕。换新的服务提供商对我来说并非无法接受,但得让我能继续用下去才行。正因如此,过去几年内我对 LLM 并未抱有太大兴趣,因为那些所谓「封闭」的模型只能作为第三方提供的一项服务而存在,几乎涉及了所有上述的锁定问题,其中就包括模型的静默劣化(silent degradation)。直到某天,我了解到可以将接近顶尖的模型运行在自己的设备上,从而彻底摆脱这些束缚,这才让我改变了对 LLM 的看法。
这篇文章讲的是 LLM 的运行,并不涉及针对模型的微调和训练。而且这篇文章也只涉及文本,并不涉及图像、声音,或者其他任何「多模态」能力,因为就我来说还用不太到这些。
具体而言,想要在你自己的设备上运行 LLM,你需要的是分别是软件和模型。
llama.cpp 令人惊叹,也是我的唯一选择。原因在于,在基本的 CPU 推理这方面,也就是使用 CPU 而不是 GPU 来产生 token 时,llama.cpp 仅需一个 C++ 工具链,不像其他大多数方案那般都需要繁琐的 Python 配置,这点让它在众多可选项中脱颖而出。在 Windows 系统上,只需要一个 5MB 大小的 llama-server.exe 文件,不需要其他运行时依赖(runtime dependency)。更重要的是,由于 EXE 和 GGUF(模型)这两个关键文件都采用内存映射方式加载,所以很有可能即便过了几十年,你也可以在未来某个版本的 Windows 上以同样的方式运行同样的 LLM,且同样不需要额外配置。
我就直说了,我喜欢它是因为官方提供的 Windows 版本编译程序用的是 w64devkit。这些人真的是有点品味的!话虽如此,如果能用 GPU 做推理的话,就别用 CPU 做推理。虽然在台式或笔记本电脑上对 10B1 左右参数的模型的效果还不错,但是速度还是会更慢。我的主要用例并不是使用 w64devkit 构建的,因为我用的是 CUDA 来推理,而这需要用到 MSVC2 工具链。为了好玩,我曾把 llama.cpp 移植到了 Windows XP 上,并且成功在一台 2008 年的笔记本电脑上运行了一个 360M 参数的模型。能够在那台老旧的笔记本上运行这项技术的感觉真的太神奇了,毕竟在那会儿,这项技术的价值恐怕得值个几十亿美元吧。
GPU 推理的瓶颈在于显示内存(VRAM,下称显存)。因为这些模型真的相当大,而为了能够使用更大的模型,处理更长的上下文窗口(context window),对内存的要求也就更高。模型越大就越智能,上下文窗口也就越长,一次性可以处理的信息也就更多。VRAM 不足 8GB 的时候,使用 GPU 推理就不划算了。如果遇到「GPU Poor」的情况,就请用 CPU 来推理,这样的好处一是更简单,二是更容易上手。
llama.cpp 中提供了很多工具,但是本文只重点讲其中的 llama-server。它本质上就是一个 HTTP 服务器(默认端口为 8080),并提供了一个聊天 UI,以及供程序(包括其他用户界面)使用的 API。一个典型的调用命令如下:
上下文大小(context size)是将输入和输出计算在内,一个 LLM 一次可以处理的最大 token 数量。上下文 token 的数量通常在 8K 到 128K 之间,具体取决于模型的 tokenizer3。普通英语文本使用 wc -w 来统计的话,每个词大约 1.6 个 token。如果模型支持较大的上下文,内存可能会先一步告急。此时应该把上下文大小调低一些,比如 --ctx-size $((1<<13))(即 8K 个 token)。
我还没完全理解 flash attention 是做什么的,也不知道为什么 --flash-attn 或者 -fa 不是默认开启的(也许是因为精度较低?),但你无论如何都应该加上它,因为启用它可以减少内存需求,即便会降低精度也值了。
如果服务器成功地启动了,可以尝试访问(http://localhost:8080/)来先试一试。虽然你还是得先有个模型才可以。
Hugging Face(下称 HF)被誉为「LLM 界的 GitHub」,这是因为它提供了卓越的模型托管服务:无论是数 GB 的「小」模型,还是动辄数百 GB 的「大」模型,HF 都免费托管,获得此殊荣可谓实至名归。此外,大多数模型无需注册即可下载(个别例外),也就是说,你随时都可以下载我接下来提到的模型,自己试试。如此慷慨的服务让我十分震撼,以至于连我这种平日精打细算的人也在几天后开通了 Pro 账号。
如果你现在去 HF 逛一逛的话,你可能想问:「这里什么都有,那我到底要选哪个呢?」我一个月也和你有同样的疑问。对于 llama.cpp 来说,搜索 GGUF 即可。虽说 GGUF 并不是模型在创建或存储时的原生格式4,但你只需要找名字里面带有「GGUF」的仓库(repository)的话就好。这些仓库通常都是由更新频繁、助人为乐的第三方「量化器」(quantizer)提供的。
(官方文档里也没有明确解释「GGUF」究竟是什么意思,习惯了就好了。这就是走在技术最前沿的感觉:无论是什么,要么需要费很大劲才能找到,要么干脆就没有。你可能会想把 LLM 运行起来之后问问它,但我很快就会告诉你这样也行不通。至少据我所知,「GGUF」目前没有官方定义(更新:「U」代表「统一」(Unified)),但其他三个字母的含义仍未确定5。)
虽然以 Meta 最强模型命名的 llama.cpp 确实表现不俗,但并非我的最爱。最新版本是 Llama 3.2,但现在6能用在 llama.cpp 上的模型只有只有约 10 亿参数的 1B 和约 30 亿参数的 3B 版本。这两个模型有点太小了,实用性较为有限,而且只要你不是在树莓派上运行,即便用的是 CPU 推理,也可以有更好的选择,比如说 Llama 3.1 8B(如果你有至少 24GB 显存的话你没准还能试试 Llama 3.1 70B)。
搜 Llama 3.1 8B 时你会发现两个版本,其中一个标注了「instruct」,而另一个没有。instruct 表示该模型经过训练,能够依据指令完成任务,也就是用来聊天的,一般来说你要的就是这个。而没有标注的版本是「基础」(base)模型,只能续写文本(从技术上讲,instruct 模型同样也只是文本补全而已,但这个我们稍后会详细讨论)。如果基础模型也能标上「base」就好了,但是因为某些路径依赖问题,通常都不会这样去标注。
在 instruct 模型的「文件」一列中你是找不到 GGUF 文件的,如果你想要下载这些模型,你需要注册一个账号然后同意社区许可。这时我们回到搜索栏,在后面加上 GGUF,找相对应的 GGUF 模型就可以了:例如 bartowski/Meta-Llama-3.1-8B-Instruct-GGUF。bartowski 更新频繁,而且名声在外,这不但是 llama.cpp 专用的格式,而且无需注册即可下载。
你现在可以在「文件」页面里看到许多 GGUF 格式的文件了,这些是同一模型的不同量化版本。原始模型使用的是 bfloat16 张量,但如果只是为了把模型跑起来,我们可以舍弃大部分精度,同时将损失控制在最小。模型确实会变笨一点,懂得少一点;但是这样做可以大幅减少其所需资源。推荐的最多的是用 Q4_K_M 这种 4 位量化的版本,从我个人体验来看,这确实是个不错的选择。一般来说,一个大模型的 4 位量化比一个小模型的 8 位量化效果更好。一旦你把基本概念搞清楚了,就可以尝试不同的量化方式,看看哪种最适合你!
不同的模型在训练时有不同的权衡,所以没有哪个模型是最优的,在 GPU 性能不足时更是如此。我的电脑装了一块 8GB 显存的 RTX 3050 Ti,所以这方面的限制也影响了我对模型的选择。对于大约 10B 参数的模型,运行起来相对轻松;而若是想测试有着 30B 参数的模型的能力的话则稍显力不从心;运行 70B 参数的模型时我就会用第三方托管的方式了。以下我列出的「t/s」数据都是在这个系统上运行 4 位量化模型得到的。
表中省略了模型名字中的 instruct 字样,除非另有说明,否则这些列出的都是 instruct 模型。部分模型,至少在 LLM 能开源的范围内,是真正的开源项目,我已在后面标明了它们的许可证。其余的模型则对使用和分发都有限制。
这是 Mistral AI 和英伟达合作的模型(代号 Nemo),是我用过的最为均衡的 10B 模型,同时也是我的首选。其推理速度从 30 t/s 起步,令人十分舒适。它的强项在于写作和校对,并且在代码审查方面几乎能与 70B 的模型相媲美。虽然该模型训练的上下文长度为 128K,但是根据我的实际使用经验,其有效的上下文长度更接近 16K。
模型名称中「2407」表示它的发布日期是 2024 年 7 月,我个人很支持将日期写入版本号的这种命名方式,这样一来,你就知道这个模型的知识更新日期和技术水平,找起来也方便。如果不是这样做,版本管理就是一团糟。AI 公司搞不懂版本管理,就像开源项目不会起名字一样。
这是由阿里云推出的 Qwen 模型,其在不同规模的表现都超出了我的预期。14B 模型的推理速度从 11 t/s 起步,能力与 Mistral Nemo 相当。如果我的硬件跑得动 72B 模型的话,我可能就会选这个了,但目前我都是通过 Hugging Face 的推理 API 来试用这个模型。Qwen 同样提供了一个 32B 的版本,但是因为我的硬件跑不动,所以我也没花太多时间研究它。
谷歌推出的模型很受欢迎,大概是因为它有趣的特性吧。对我来说,2B 模型很适合快速翻译。和谷歌翻译相比,尽管 LLM 更耗费资源,并且如果遇到了它觉得冒犯的文本就罢工,像是科幻电影一样——但是在 LLM 面前,谷歌翻译就像是老古董了,更不必提 LLM 还可以离线运行。在我的翻译脚本中,我给它一段带有 HTML 标记的文本,并且要求 Gemma 保留标记,它执行得简直完美!9B 模型效果更好但会慢一些,我会选择用它来翻译自己的消息。
微软的特色是使用合成数据训练。而结果是,该模型在测试中表现不错,但在实际应用中效果不如预期。对我来说,它的强项是文档评估。因为它是一个 4B 模型,我曾加载过最多 40K token 的文档,并成功地获取到了准确的摘要和数据列表。
Hugging Face 可不仅仅是托管模型这么简单,就同等体量的模型而言,他们自家的 360M 模型同样异常出色。我那台赛扬处理器、1GB 内存、32 位系统的 2008 年的笔记本电脑也能用,在一些旧款树莓派上也可以跑起来。这个模型有创意、速度快、能沟通、会写诗,适合在资源有限的环境中使用,算是一个有趣的玩具。
这是另外一个 Mistral AI 模型,但其表现稍逊一筹。48B 听起来相当大,但这是一个 Mixture of Experts(MoE)模型,进行推理时只会用到 13B 的参数。这使得它非常适合在至少有 32G 内存的配置上进行 CPU 推理。该模型更像一个数据库,保留了更多的训练输入数据,但它在应用中可能不如预期,其中缘由我们很快就会说明。
又是两个我没法在自己的电脑上运行的模型,所以我会通过远程托管的方式来使用这两个。后者名字里的 Nemotron 代表这个模型经过英伟达的微调。如果我能跑得动 70B 模型的话,可能 Nemotron 就是我的首选了。我还是要花更多时间把它和 Qwen2.5-72B 做对比评估。
这些模型大多数都有特殊编辑过(abliterated)的「去审查」版本,消除操作可以减少模型的拒绝行为,但是也会以模型的性能下降作为代价。拒绝行为是很讨厌的,比如说 Gemma 就不愿意翻译它不喜欢的文字。可能是因为我比较无聊吧,我遇到的拒绝的次数不多,所以我还没必要做出这样的取舍。另外,似乎上下文的长度增长之后,拒绝行为就会变少,感觉有点「既然开始了,那就做到底」的意思。
接下来的一组是专为编程而训练过的「写码用」模型。具体来讲,他们进行了中间填充(fill-in-the-middle,FIM)训练,使得模型可以在现有程序内部插入代码——我稍后会解释这是什么意思。但是依我看来,这些模型不论是在代码审查还是其他指令导向的任务上都没有更出色,实际情况正好相反:FIM 训练是在基础模型上进行的,指令训练是在此基础上进行的,因此指令训练反而与 FIM 不兼容!换句话说,基础模型的 FIM 输出要明显更好,尽管你无法与这些模型进行对话。
我会在后文进行更详细的评估,但在此我想先提一点:即便是目前最顶尖的 LLM 生成的代码,其质量也相当一般。以下排名是基于与其他模型的对比,并不是它们在整体能力上的排名。
这是 DeepSeek 自己命名并推出的模型。推理时它只使用 2B 参数,所以它既和 Gemma 2 的 2B 版本一样快,又像 Mistral Nemo 一样智能,堪称一个完美的平衡。尤其是在代码生成方面,它的表现超越了 30B 的模型,如果我想要鼓捣 FIM 的话,这就是我的首选了。
Qwen Coder 的排名紧随其后。论输出结果的话和 DeepSeek 不分伯仲,但是因为并不是 MoE 模型,所以速度会稍慢些。如果你的内存是瓶颈,那么它就是比 DeepSeek 更好的选择。在写这篇文章的时候,阿里云发布了新的 Qwen2.5-Coder-7B,但是令人迷惑的是,其版本号并没有更新。社区里已经在用 Qwen2.5.1 来称呼这个版本了。刚才我还在说 AI 公司搞不懂版本管理来着……(更新:在发布一天后,14B 和 32B 的 Coder 模型也发布了,我两个都试了,但是都不如 DeepSeek-Coder-V2-Lite,所以我的排名没有变。)
IBM 推出的系列模型名为 Granite。总体来说,Granite 无法令人满意,唯独在 FIM 中表现异常优秀。以我的体验来说,它和 Qwen2.5 7B 并列第二。
我同样也测试了 CodeLlama、CodeGemma、Codestral、StarCoder 这四个模型。这些模型在 FIM 任务上的表现非常差,几乎毫无价值,我想不到任何使用这些模型的理由。指令训练所导致的负面效果在 CodeLlama 上最为明显。
我在前文提过,llama.cpp 是自带 UI 的,其他 LLM 中的 UI 我也用过,我感觉都大差不差。但是我本来就不喜欢 UI,尤其是在生产力环境下,所以我为我自己量身定制了 Illume。这是一个命令行程序,它能将标准输出转换成 API 查询,并在查询过后将响应转换回标准输出。把它集成到任何一个支持拓展的文本编辑器中应该都不成问题,但是我只需要它支持 Vim 就够了。因为 Vimscript 太烂了,估计在我接触过的最烂的编程语言里能排上第二,所以我的目标是尽量少写代码。
创建 Illume 的初衷是为了解决我自己的痛点,为了让我更好地探索 LLM 的世界。我总是会把东西搞崩,然后再去添加新功能来补救,所以稳定性方面我没法保证(大概你还是不要尝试使用它比较好)。
以 ! 开头的行是 Illume 解释后的指令,这样写是因为正常文本中很少有这种写法。在一个缓冲区(buffer)中,!user 和 !assistant 交替进行对话。
这些仍然在文本缓冲区之内,所以在继续对话之前,我可以编辑 assistant 的回复,也可以修改我的原始请求。如果我想要它来创作小说的话,我可以要求它补全(completion)一段文本(而这并不需要指令训练就可以完成):
我可以打断它的回复,进行修改或添加一段自己写的内容,然后让它继续生成;这方面我还得多练练。LLM 也会识别出你添加的注释语法,这样你就可以用注释来引导 LLM 写你想要的内容。
虽然 Illume 主要是为 llama.cpp 设计的,但我也会使用不同 LLM 软件实现的 API 进行查询,且由于各个 API 之间存在不兼容性(例如一个 API 所需的参数被另一个 API 禁止),所以 Illume 的指令需要足够灵活和强大,因此指令可以设置任意的 HTTP 和 JSON 参数。Illume 并不会试图将 API 抽象化,而是会直接呈现出其较低层级的设置,所以要对远程 API 有所了解才能有效地使用它。比如说,与 llama.cpp 进行通信的「配置文件」(Profile)是长这样的:
其中 cache_prompt 是一个 llama.cpp 所特有的 JSON 参数( !: )。大多数情况下启用提示缓存(prompt cache)会更好,但可能是因为某些原因,它默认是没有启用的。其他 API 会拒绝带有此参数的请求,所以我需要将其删除或禁用。Hugging Face 的「配置文件」是这个样子的:
为了兼容 HF,Illume 允许将 JSON 参数插入到 URL 中。因为 HF API 会过于频繁地进行缓存,所以我提供了一个 HTTP 参数( !> )来将其关闭。
llama.cpp 独有一个用于 FIM 的 /infill 端点(endpoint)。该端点需要一个拥有更多元数据并进行过特定训练的模型,但是这种情况比较少见。因此,尽管 Illume 支持使用 /infill ,我还是添加了 FIM 配置,这样在读过该模型的文档,把 Illume 为该模型的行为配置好之后,我可以在任何为 FIM 训练的模型上通过正常补全 API 实现 FIM 补全,甚至是在非 llama.cpp 的 API 上也是如此。
该是讨论 FIM 的时候了。为了彻底弄懂什么是 FIM,我就必须追溯到知识的源头,也就是最原始的讨论 FIM 的论文:Efficient Training of Language Models to Fill in the Middle。这篇论文帮助我理解了这些模型是如何针对 FIM 训练的,至少足够让我也将这种训练方法应用到实际中。即便如此,在模型的文档中关于 FIM 的说明通常也很少,因为它们更希望你去直接运行他们的代码。
从根本上讲,LLM 只能预测下一个 token。所以 FIM 的方法是在大型训练语料库(corpus)中选取一些会在输入中出现的特殊 token,用它们来区隔前缀(prefix)、后缀(suffix),和中段(middle)部分(三者合称 PSM,有时也称「后缀-前缀-中段」,即 SPM)。在之后的推理中,我们可以用这些 token 来提供前缀和后缀,并让模型「推测」出中段内容。听起来很离谱,但这真的很有效!
比如在填补 dist = sqrt(x*x + y*y) 中括号里的内容时:
为了让 LLM 填补括号中的内容,我们在 <MID> 停下,并且让 LLM 从这里开始预测。注意到 <SUF> 起到的效果就好比一个光标。顺带一提,指令训练的方法差不多也是这样,但是在指令训练中,使用特殊标记分隔的是「指令(instructions)」和「对话(conversation)」,而并非前缀和后缀。
有些 LLM 开发者严格按照论文所写,直接使用 <PRE> 等作为 FIM 标记,并不在乎这些标记和模型的其他标记看起来完全是两个样子。更用心的训练者则会使用类似 <|fim_prefix|> 的标记。Illume 支持 FIM 模板,我也为常见的模型编写了相应的模板,例如针对 Qwen (PSM) 的模板如下:
Mistral AI 的习惯则是使用方括号、SPM 格式,并且省略「中段」token:
有了这些模板,我就可以在不被 llama.cpp 的 /infill API 支持的模型中进行 FIM 训练了。
我在使用 FIM 时遇到的第一大问题是无法生成正确的内容,而第二大问题就是 LLM 不知道什么时候该停下。比如在我要求模型填充以下函数时(如给 r 赋值):
(补充一点:静态类型(static types)提示(包括这里的)可以帮助 LLM 更好地生成代码,起到防护栏的作用。)得到这样的结果并不奇怪:
原本的 return r 变成了 norm4 函数的返回值。得到这样的结果固然没问题,但显然这不是我想要的内容。所以当结果开始跑偏的时候,最好做好狂按停止按钮的准备。我推荐的三个 coder 模型较少出现这种情况,而更保险的做法是将其与一个能够理解代码语义的非 LLM 系统结合,这样在 LLM 开始生成超出范围的代码时可以自动停止。这种做法可以让更多 coder 模型变得更实用,但这就不是我折腾的范围了。
对于 FIM 的摸索和实践让我意识到 FIM 仍处在其早期阶段,也几乎没有人用 FIM 来生成代码。或许大家还是在用普通的补全方法?
LLM 好玩归好玩,但是它们能为提高生产力提供什么帮助呢?过去的一个月以来我一直在思考这个问题,但始终没有找到一个令我满意的答案。我们不如先划清一些界限,明确一下有哪些事情是 LLM 无能为力的。
首先,如果结果的准确性无法被轻易验证,那么使用 LLM 就毫无意义。LLM 会产生幻觉(hallucination),这也让它们变得并非绝对可靠。很多时候,如果你能够验证 LLM 的输出是否正确的话,你其实也就没必要用它了。这也就解释了为什么 Mixtral 如此庞大的「数据库」反而没什么用。同时这也说明,把 LLM 输出的结果投放到搜索结果里有多么的危险且不负责任,说难听点就是不道德。
然而即便是那些对 LLM 了如指掌的爱好者们也还是会踩这个坑,并且去传播这些虚构的内容。这使得针对 LLM 的讨论更为不可信,看 LLM 给我提供的信息的时候我得多留几个心眼。举例说:还记得我说过 GGUF 没有一个官方定义吗?你去搜一下就能搜得到一个明显是幻觉的结果,结果它还进了 IBM 的官方文档。我在这儿就不再提了,免得问题变得更严重。
其次,LLM 都是金鱼脑,「过目就忘」。也就是说,较短的上下文长度限制了它们的发挥。虽然有些模型使用了更大的上下文长度来训练,但是其有效上下文长度通常小的多。实际上,一个 LLM 一次只能在它的「大脑」中记住相当于一本书里几章的内容,如果是代码的话则是 2000 到 3000 行(因为代码的 token 密集度更高),一次性能够处理的也就这么多了,这和人类相比简直微不足道。当然也可以通过微调或者使用检索增强生成这类的工具来尝试改善,但是只能说……收效甚微。
第三,LLM 写代码的能力很差。往好了说,它们的写码能力也只不过是一个读过大量文档的本科生的水平。这话听起来还行,但实际上,很多毕业生在进入职场时几乎对软件工程一无所知,第一天上班才是他们的真正学习的开始。从这个角度看,现在的 LLM 甚至还没开始「学习」这一步呢。
但是说实话,LLM 写代码能有如今的水准已经很不错了!即便是把带有我强烈个人风格的代码丢给它,LLM 也能顺利理解并使用其中的自定义接口(但是需要说明的是:我自己的的代码和写作也是大部分 LLM 的训练数据中的一部分)。因此,只要是不超出有效上下文长度的限制,上下文长度越大越好。问题在于训练 LLM 写代码似乎并不比我自己写更省时间。
其实,单纯去写新的代码都算简单的了。困难的地方在于维护代码,以及在考虑到维护代码的同时再去写新的代码。即便 LLM 确实能写出可以运行的代码,也考虑不到维护问题,或者说,它根本没办法去思考这些问题。生成代码的可靠性与代码长度通常成反比平方关系,一次生成十几行代码就已经很不靠谱了。无论我怎么试,LLM 输出的能让我觉得还凑合的代码根本就超不过三行。
代码质量在很大程度上受到编程语言的影响。LLM 在 Python 上表现好过 C 语言;C 语言的表现又好过汇编语言。我觉得这多半取决于语言难度和输入质量:给大模型做训练的 C 语言素材多半都很烂,毕竟烂资源网上一抓一大把;而大模型对汇编语言的唯一了解就是糟糕的新手教程。当要求大模型使用 SDL2 时,它也不出所料地犯了常见的错误,毕竟它就是这样训练出来的嘛。
那训练大模型去写标准化代码(boilerplate)7呢?大概 LLM 在这方面会犯更少的错误,可能还有一定的价值,但处理标准化代码最快的方式其实就是——避免编写它。去简化问题,不去依赖标准化代码就是了。
不必只轻信我一家之言,看看大模型在赚钱方面怎么样就明白了:如果 AI 公司真的能够实现他们所宣传的生产力提升,他们就不会出售 AI 技术,反而会独自利用其技术去吞并整个软件行业。你也可以看看位于 AI 科技最前沿的公司的软件产品,和其他公司的产品一样,是同样的老旧、同样的臃肿、同样的垃圾。(而浏览这些糟糕的网站也是研究 LLM 的环节之一,一想到这里我就感觉很不爽。)
在生成代码时,「幻觉」造成的影响会小一些。因为你在提出需求时就知道自己想要什么,因此可以检查生成结果,同时还有编辑器来帮你检查你漏掉的问题(比如调用了虚构的方法)。然而,有限的上下文和不佳的代码生成仍然是障碍,我至今尚未能有效地解决这些问题。
那么,我可以用 LLM 做什么呢?我们列个表吧,毕竟 LLM 最喜欢列表了:
尽管有用的应用场景不多,但是这已经是近些年来我对新技术最兴奋的一次啦!



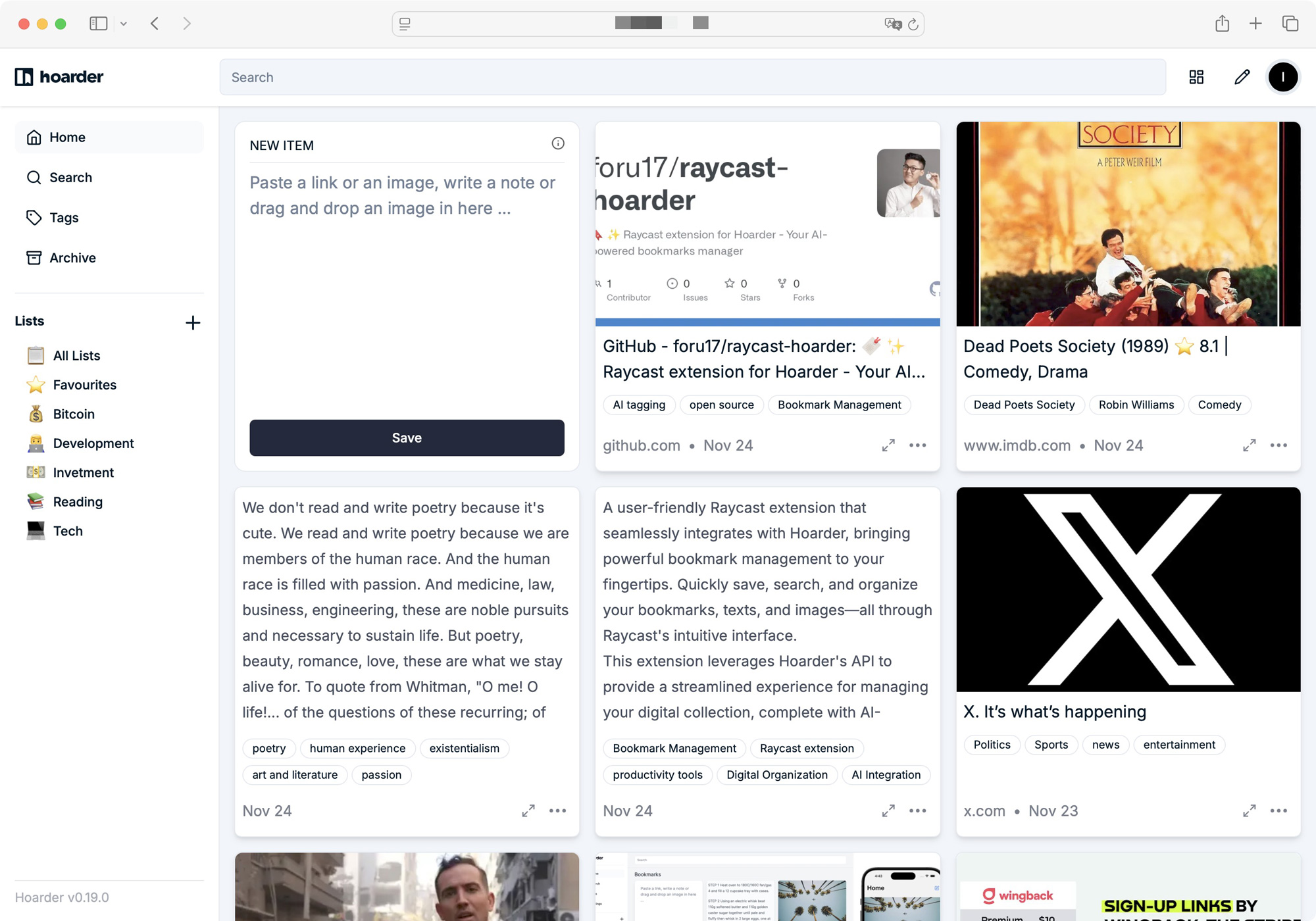
 列表直接查看书签,支持网址、图片、文本三种格式的预览。
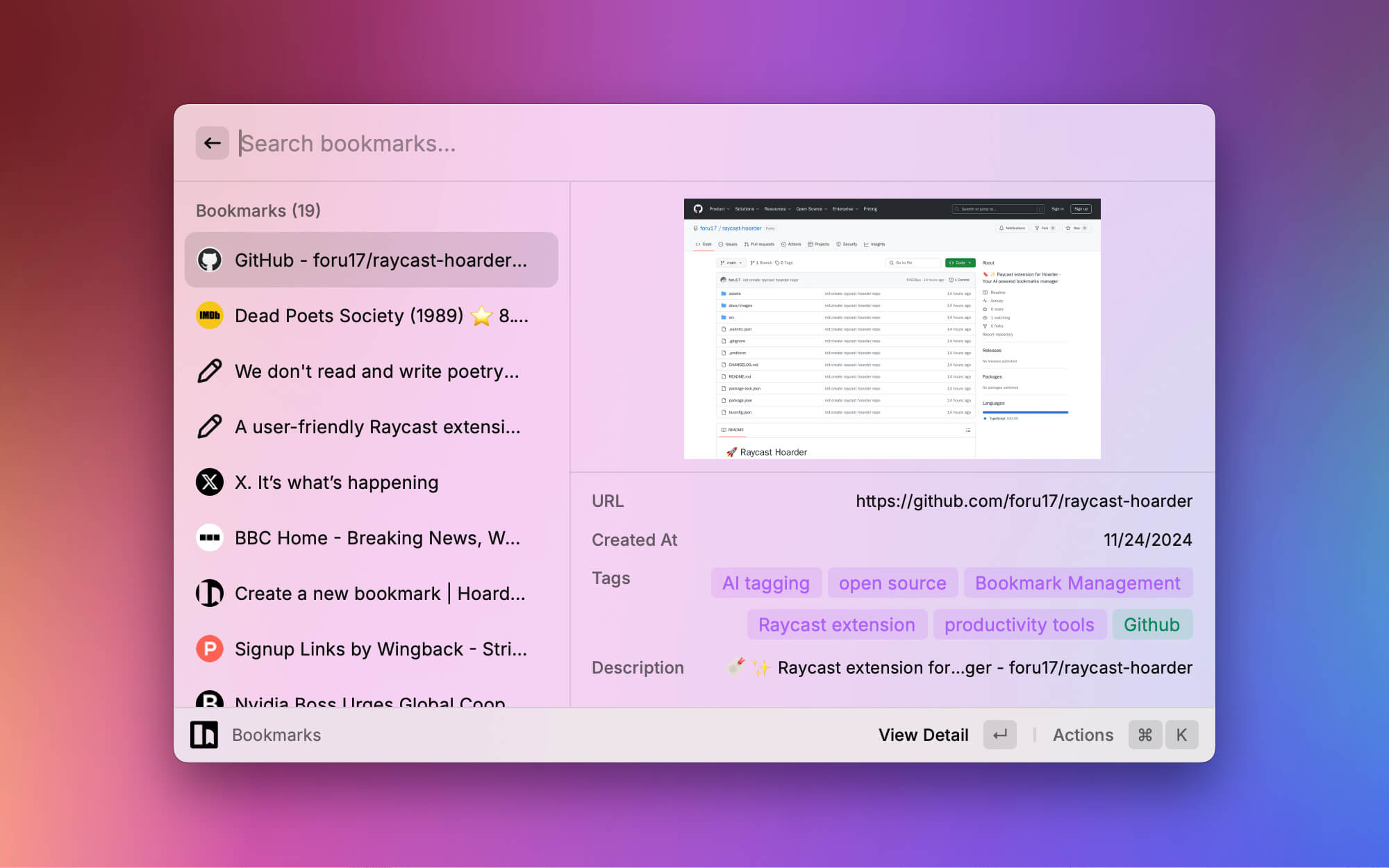
列表直接查看书签,支持网址、图片、文本三种格式的预览。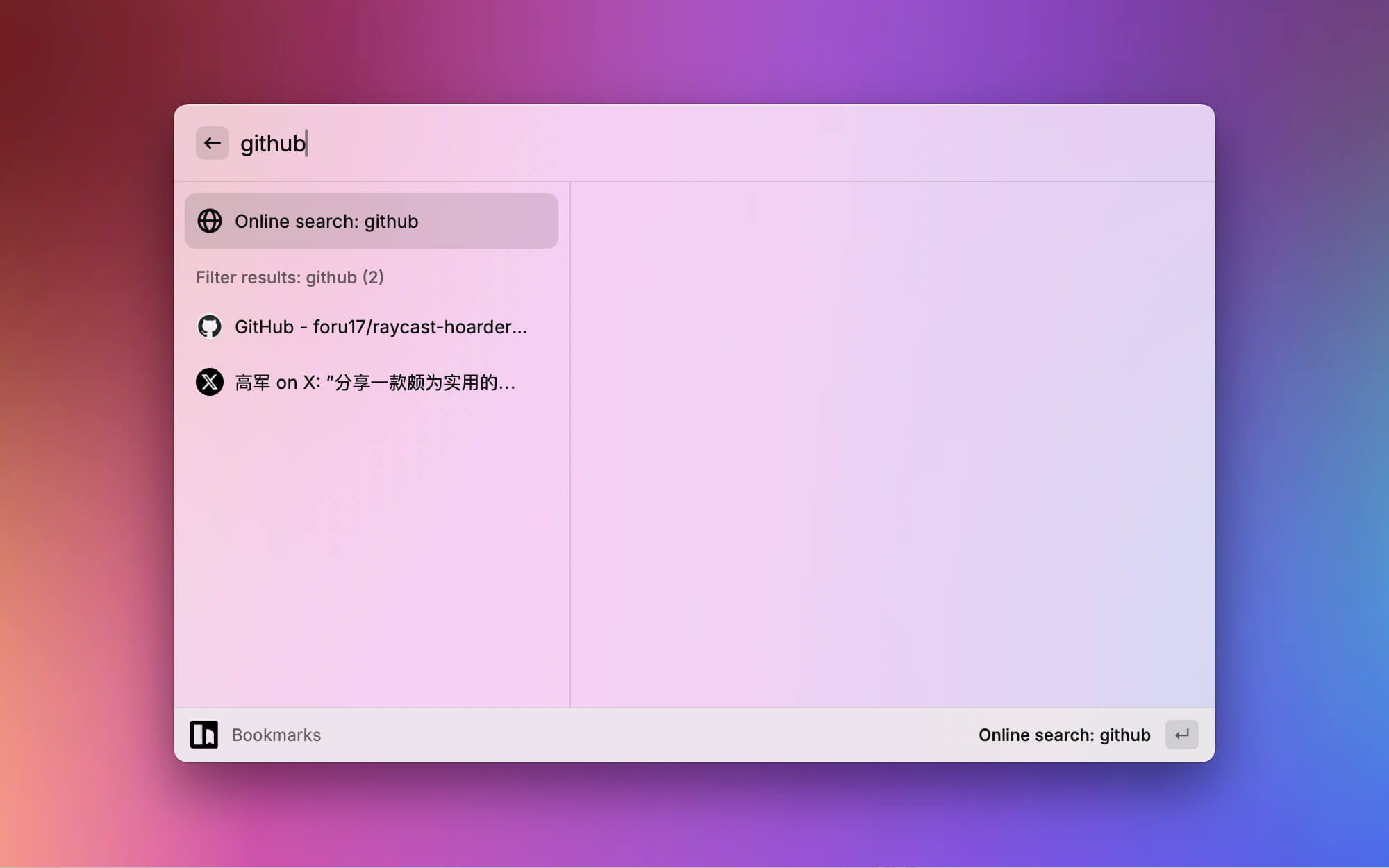 增强了搜索功能,支持本地权重搜索和在线搜索。
增强了搜索功能,支持本地权重搜索和在线搜索。 书签详情页支持查看、编辑、删除、打开链接等操作。
书签详情页支持查看、编辑、删除、打开链接等操作。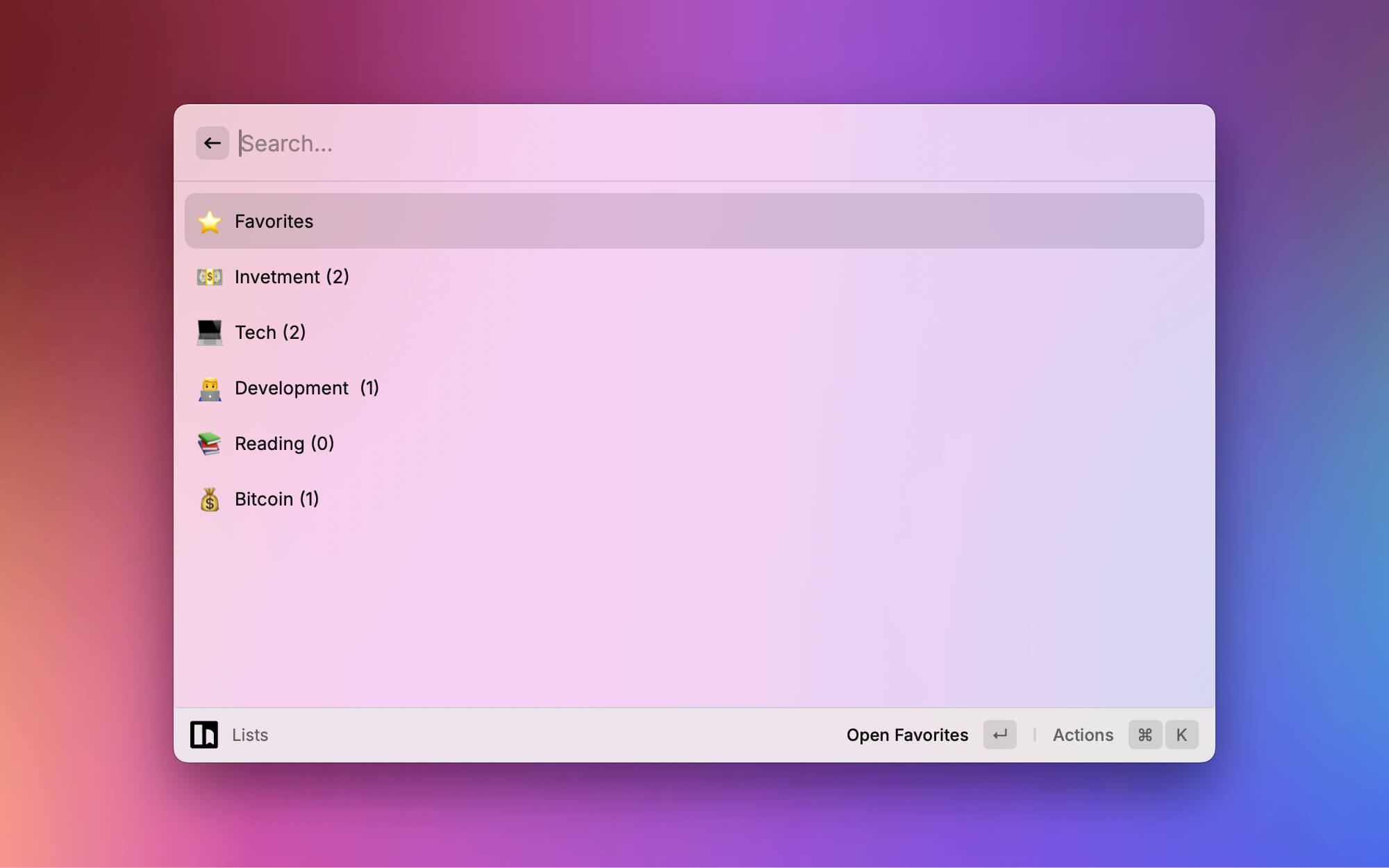
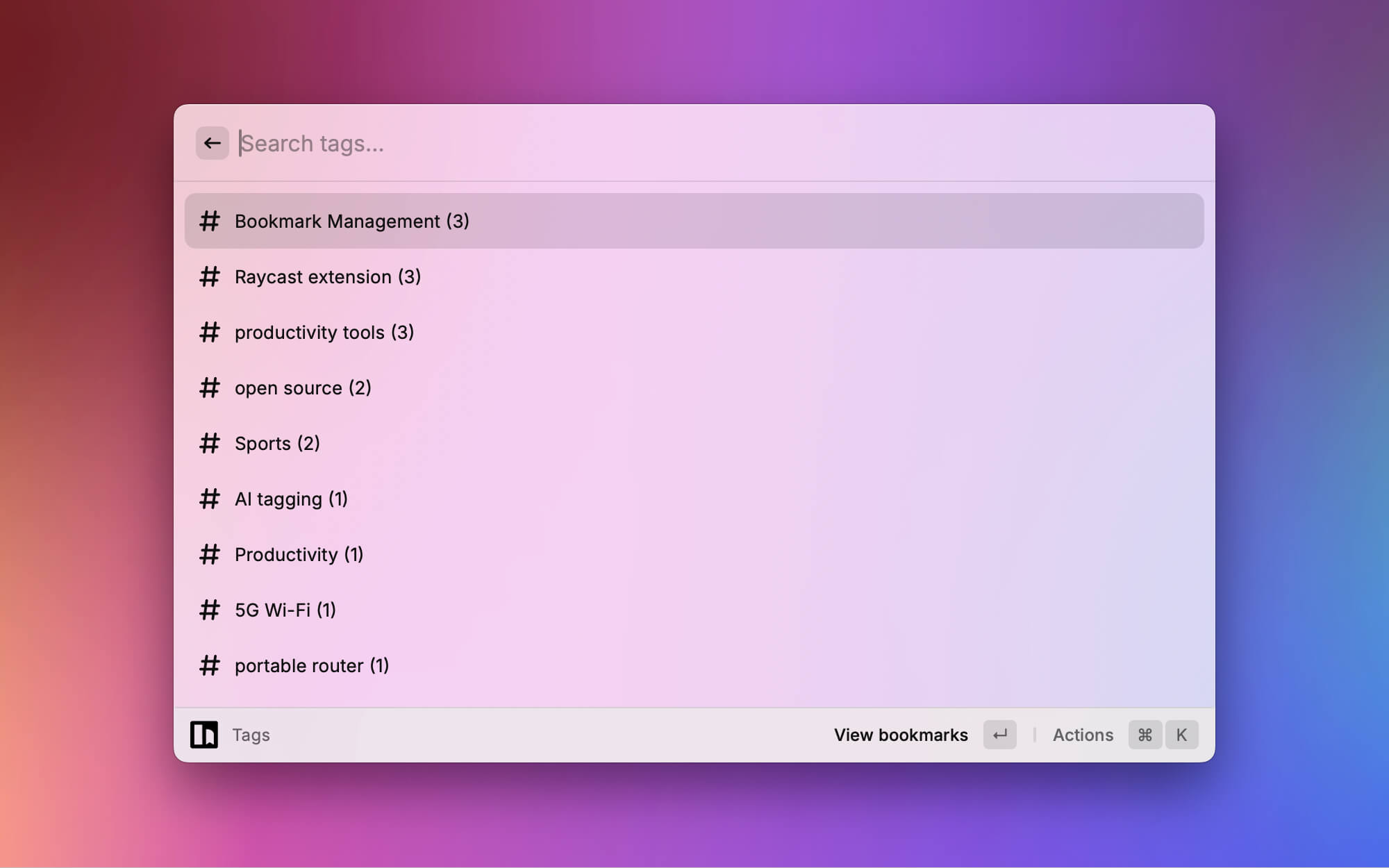 支持列表和标签列表。
支持列表和标签列表。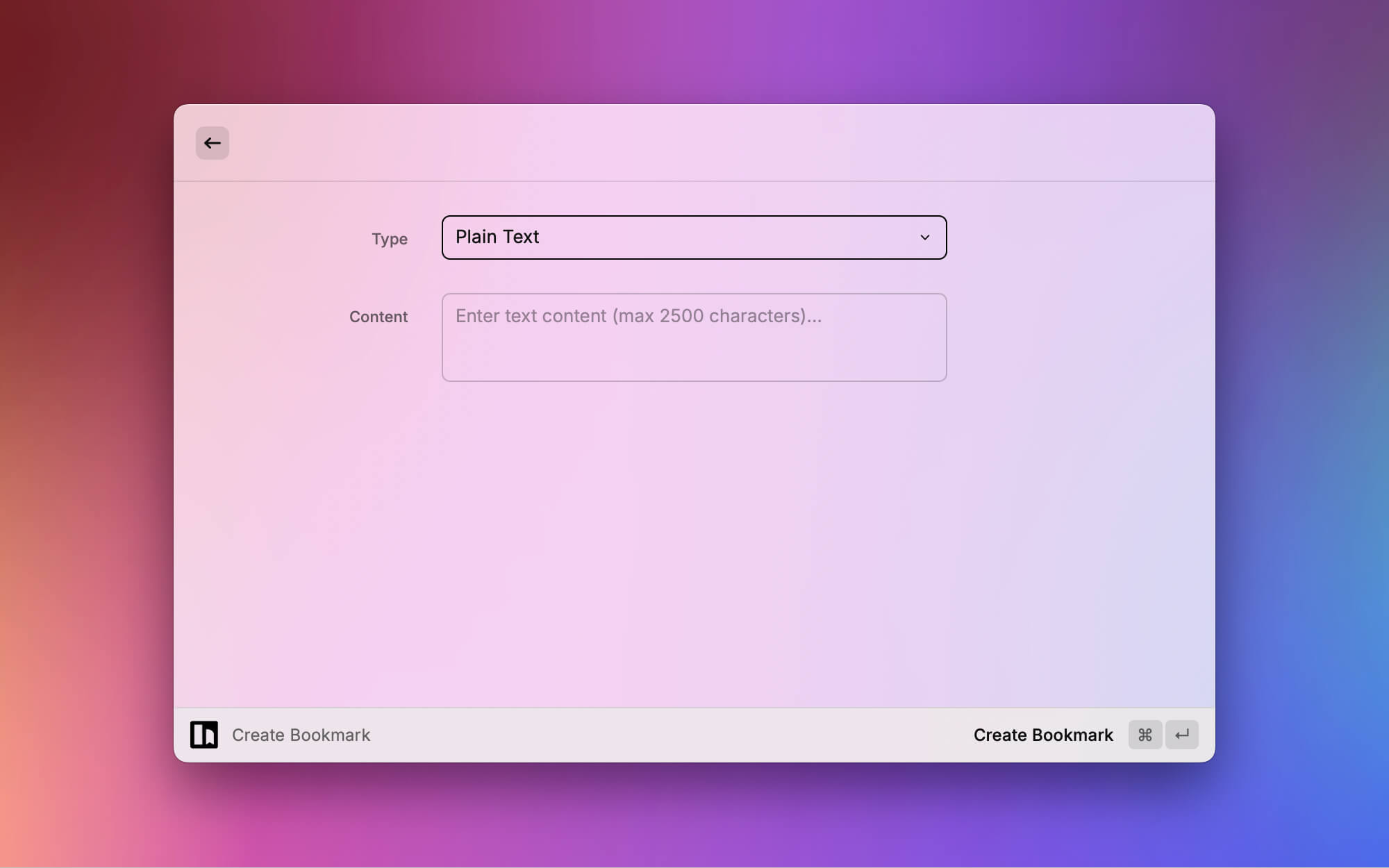 由于 Hoarder API有点问题,暂时支持快捷增加文本和链接的书签。
由于 Hoarder API有点问题,暂时支持快捷增加文本和链接的书签。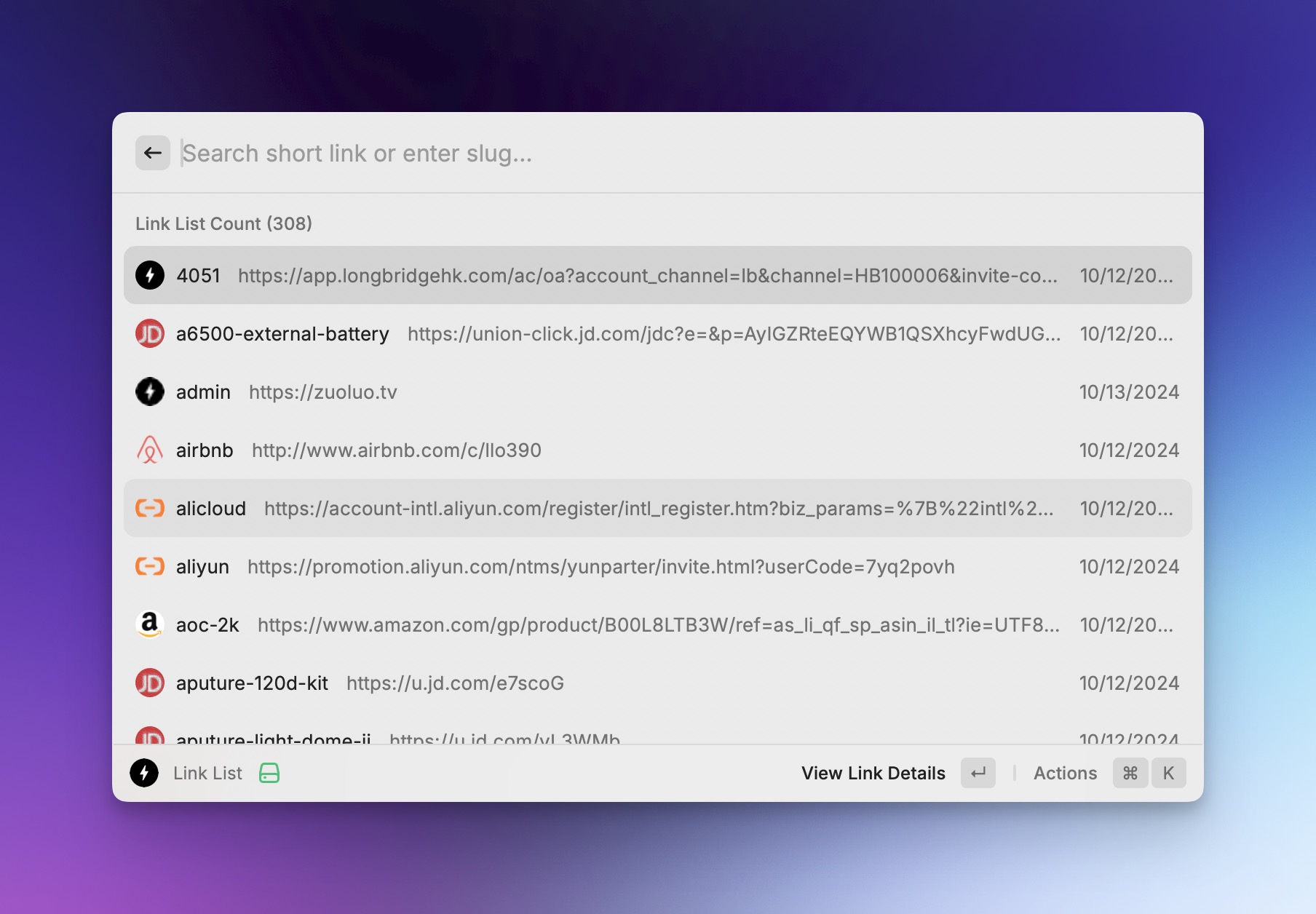 一键查看所有短链接列表,支持
一键查看所有短链接列表,支持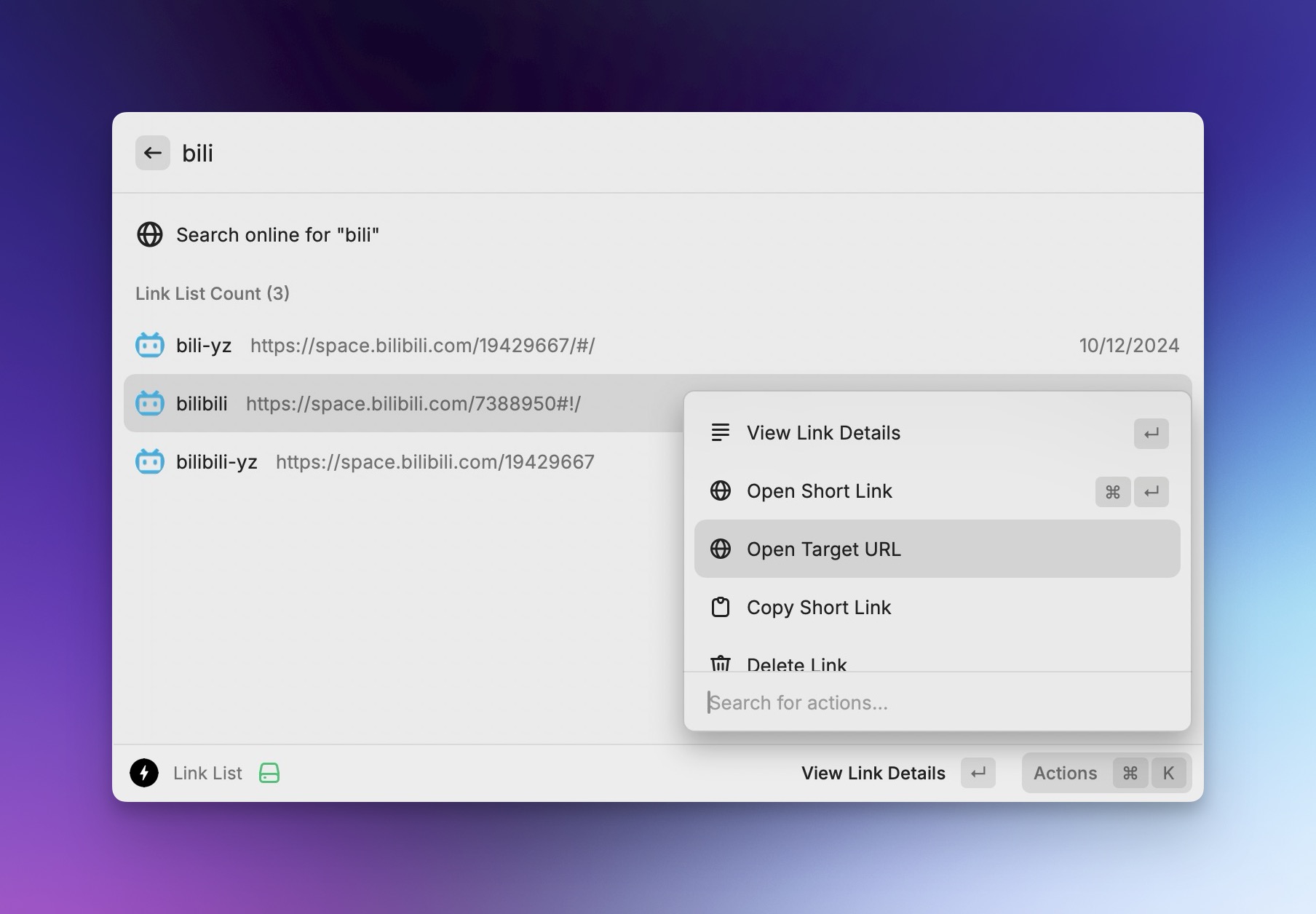 控制台快捷管理短链接,支持
控制台快捷管理短链接,支持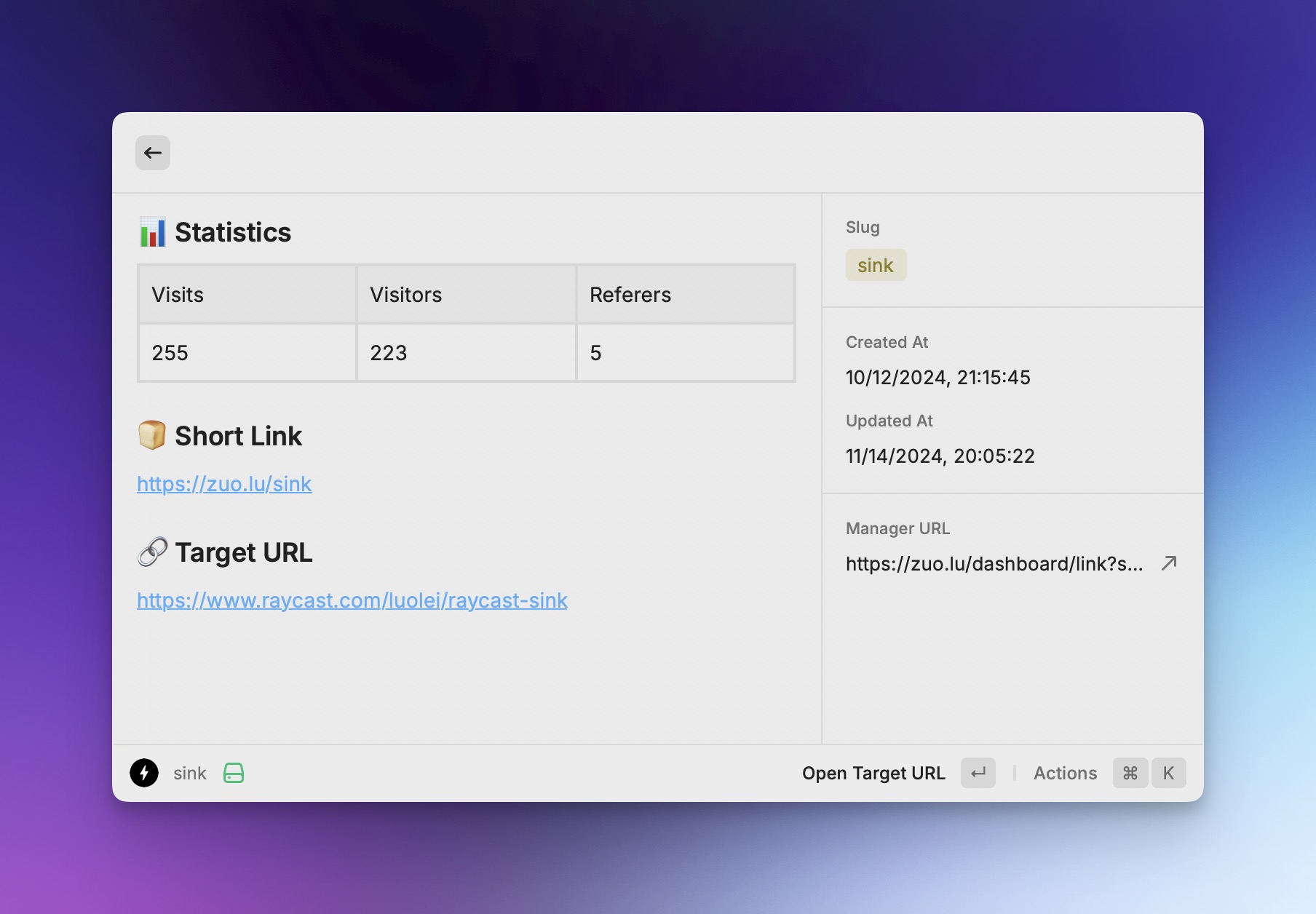 支持查看短链的详情、统计信息。
支持查看短链的详情、统计信息。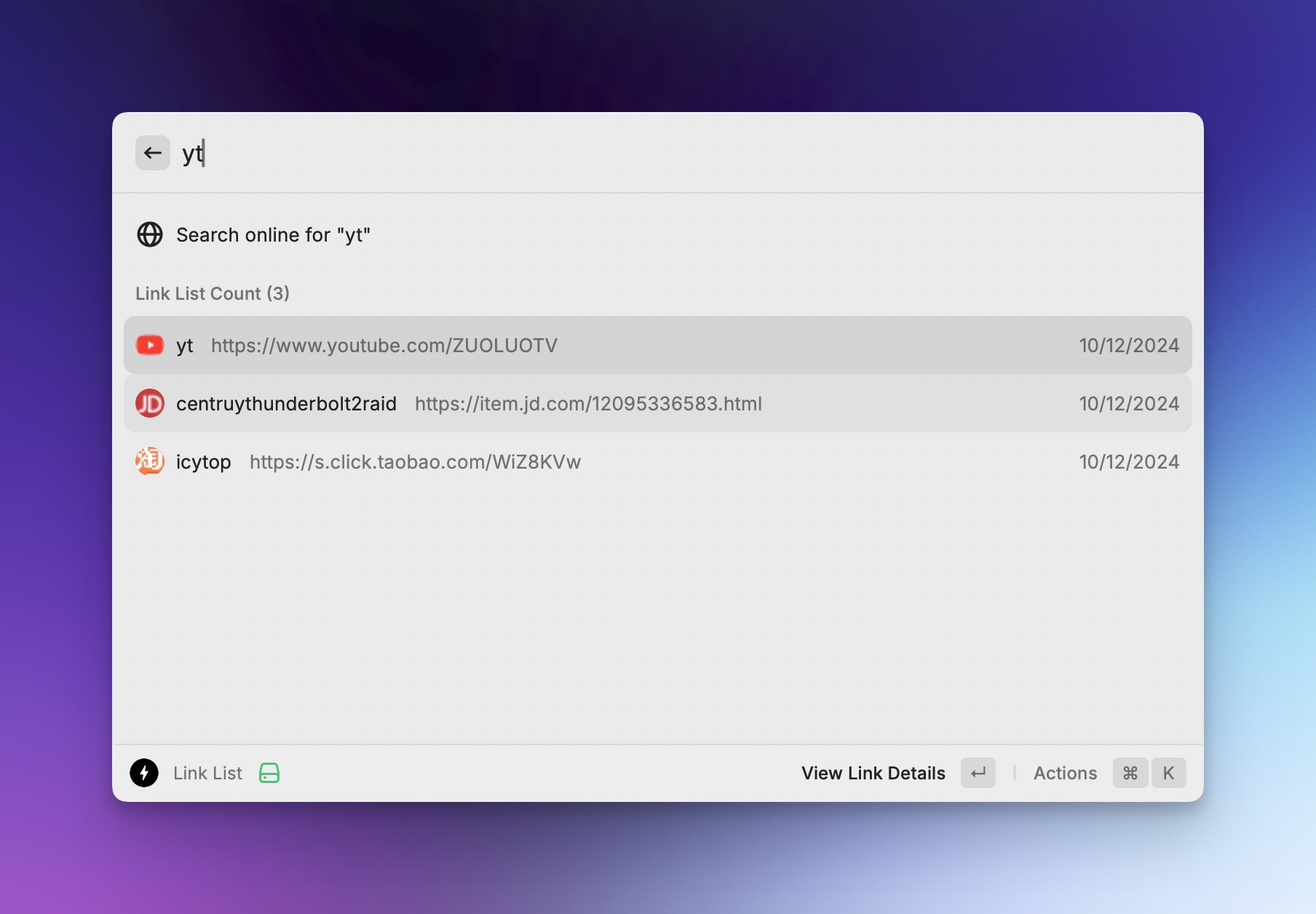 本地和在线搜索短链接,按照字段权重排序。
本地和在线搜索短链接,按照字段权重排序。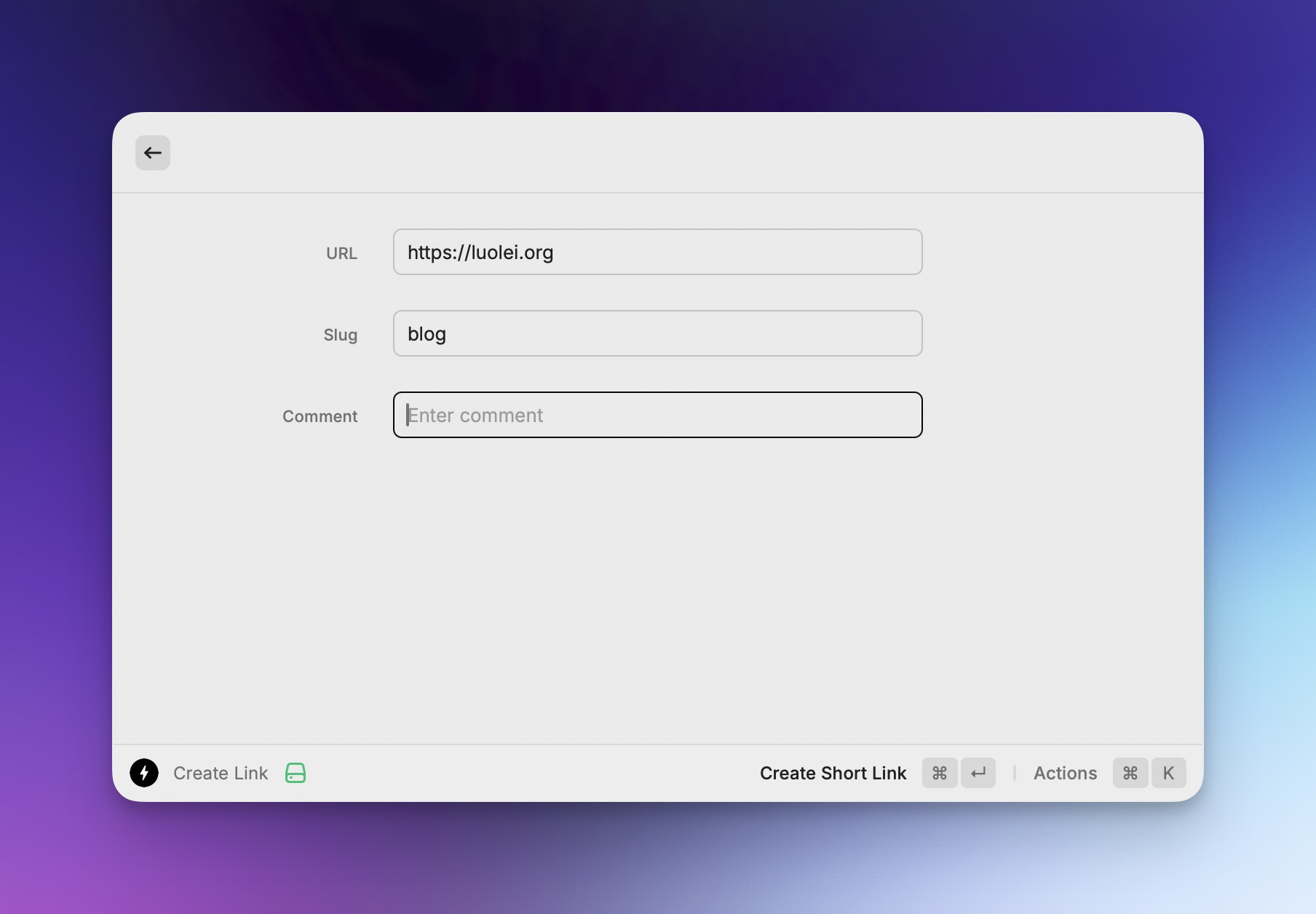 快捷创建短链接。
快捷创建短链接。


 盒内物件,除了简单的说明书,还附送了个卡针和短 Type-C 数据线。
盒内物件,除了简单的说明书,还附送了个卡针和短 Type-C 数据线。 设备的颜值不错,左上角的 5G 红标有设计感。
设备的颜值不错,左上角的 5G 红标有设计感。 右上角有两个指示灯灯,分别表示基站网络和 Wi-Fi 状态
右上角有两个指示灯灯,分别表示基站网络和 Wi-Fi 状态 与身份证大小对比,的确很小巧。
与身份证大小对比,的确很小巧。
 SIM 卡槽和卡托,还能放一个 TF 卡,对于我来说读卡器是个鸡肋功能,相机用的都是 SD 卡,没有什么其他设备用到 TF 卡。
SIM 卡槽和卡托,还能放一个 TF 卡,对于我来说读卡器是个鸡肋功能,相机用的都是 SD 卡,没有什么其他设备用到 TF 卡。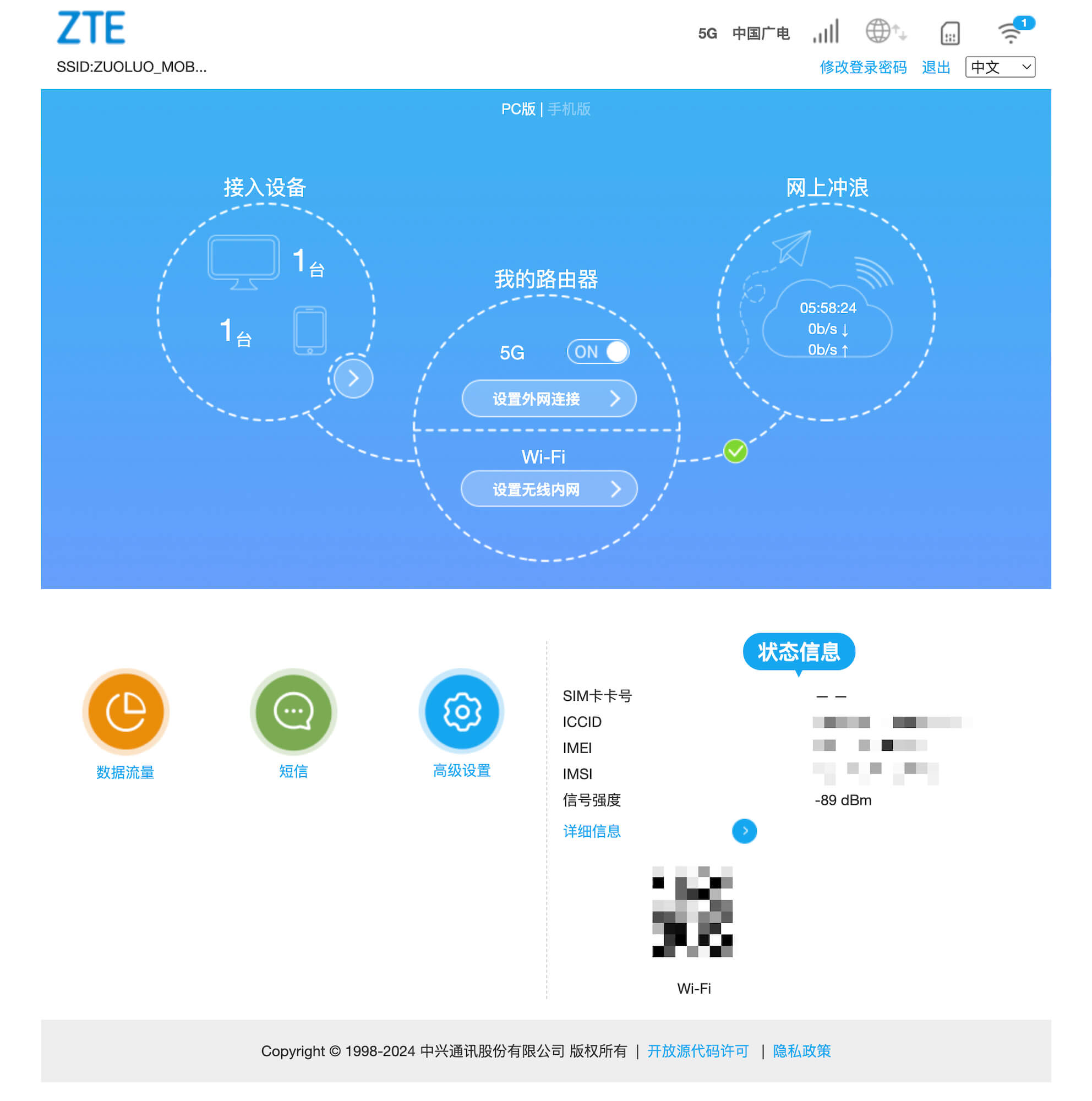 连接上 Wi-Fi 或者网络之后,就可以通过浏览器访问管理后台。后台可以查看当前的网络状态,也能查看短信。
连接上 Wi-Fi 或者网络之后,就可以通过浏览器访问管理后台。后台可以查看当前的网络状态,也能查看短信。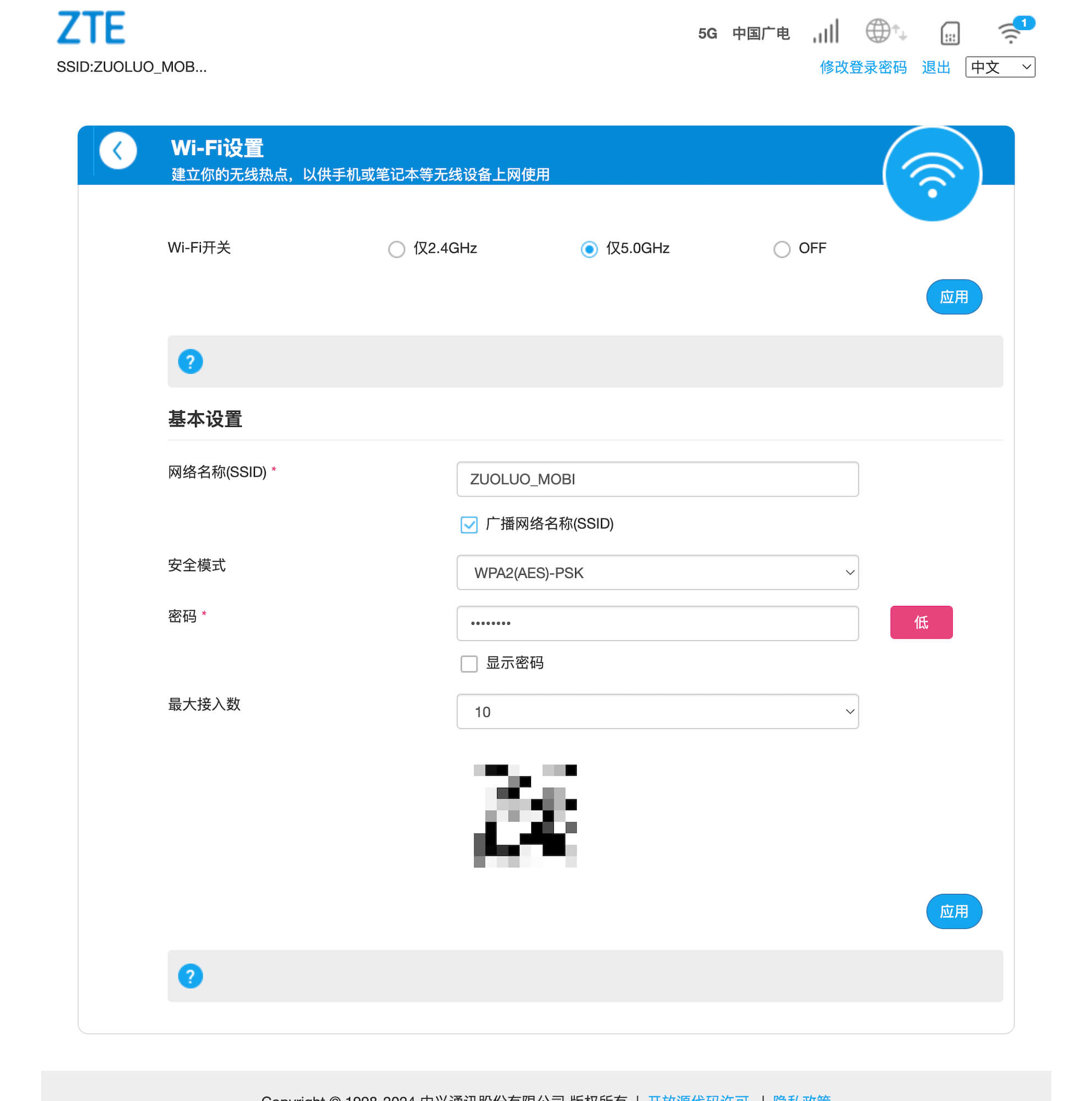 5G/4G 网络配置,Wi-Fi 配置,跟常见的家用路由器没有太多差别。
5G/4G 网络配置,Wi-Fi 配置,跟常见的家用路由器没有太多差别。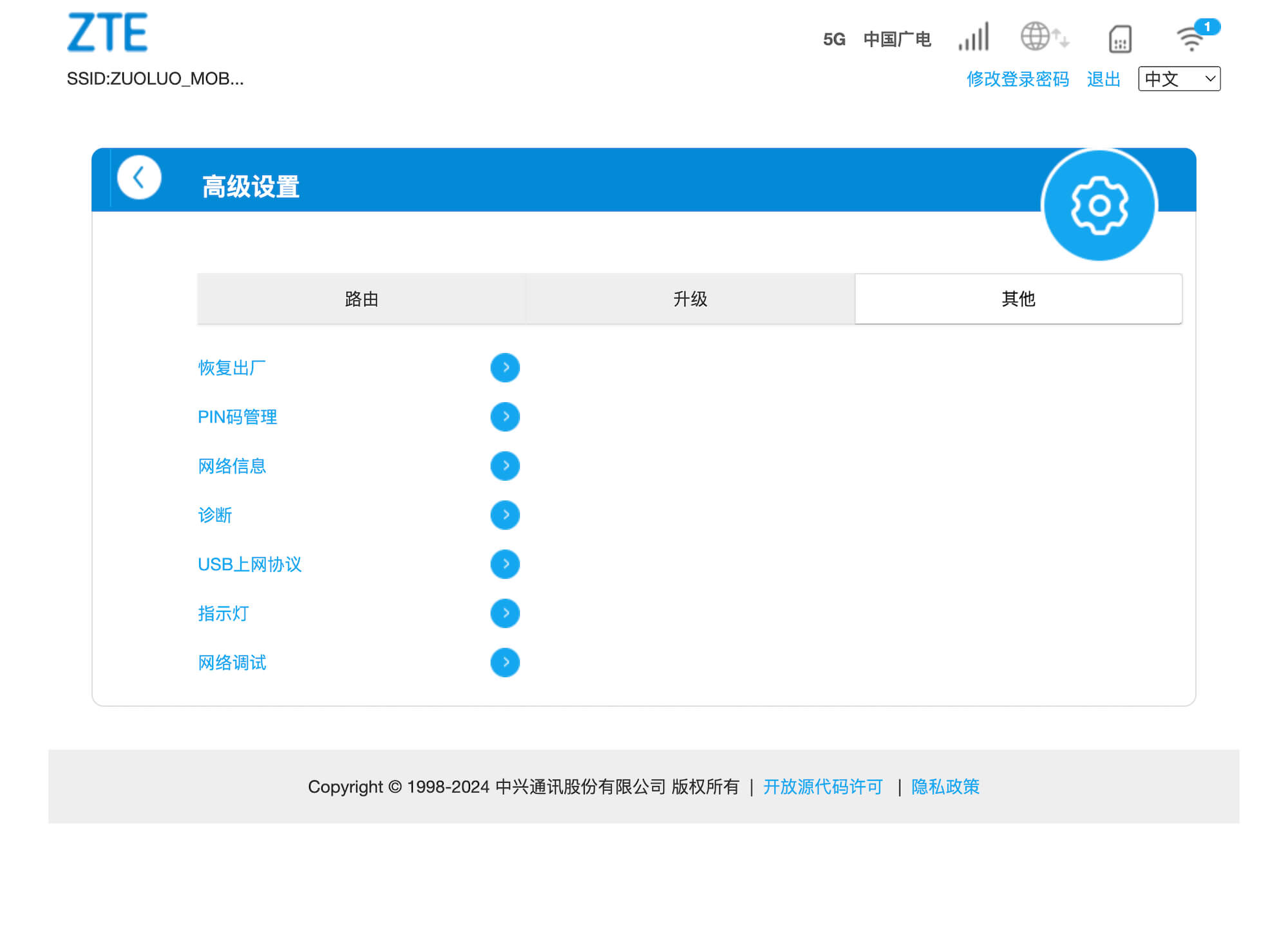 高级配置里可以配置更多的信息,报错指定频段、USB 协议等等。
高级配置里可以配置更多的信息,报错指定频段、USB 协议等等。


 马拉松在周日举行,我周五提前到,从长沙南站坐地铁一站到国际会展中心。
马拉松在周日举行,我周五提前到,从长沙南站坐地铁一站到国际会展中心。 由于是周五,很多参赛者还没来(大多会在周六报道),人不太多,我领取物资的过程十分顺利,但是周六那天,听说由于人太多,很多人排队两三个小时,被很多跑友吐槽组织得不行。
由于是周五,很多参赛者还没来(大多会在周六报道),人不太多,我领取物资的过程十分顺利,但是周六那天,听说由于人太多,很多人排队两三个小时,被很多跑友吐槽组织得不行。
 领取物资的地方。
领取物资的地方。 这次领取到的参赛包。
这次领取到的参赛包。 我的号码牌,这次我长沙马拉松报名错过了报名时间,是通过赞助商渠道弄到的名额,分配我到了 F 区,属于比较后的区。
我的号码牌,这次我长沙马拉松报名错过了报名时间,是通过赞助商渠道弄到的名额,分配我到了 F 区,属于比较后的区。 今年是长沙马拉松第 10 年,参赛包里的物资展开(也有一些我在博览会打卡领取的物资),感觉一般般,广告和廉价的食物比较多。
今年是长沙马拉松第 10 年,参赛包里的物资展开(也有一些我在博览会打卡领取的物资),感觉一般般,广告和廉价的食物比较多。
 周六闲着没事,直奔国金中心,一出地铁,人潮涌动,真热闹。
周六闲着没事,直奔国金中心,一出地铁,人潮涌动,真热闹。

 长沙最高楼国金中心,楼下有 Apple Store,楼上也是一个网红打卡地。
长沙最高楼国金中心,楼下有 Apple Store,楼上也是一个网红打卡地。

 街头执勤的交警在给一个大妈指路。
街头执勤的交警在给一个大妈指路。 我去年减肥之后,已经戒糖很久了。但是都来长沙了,一杯茶颜悦色还是必须的,完成打卡任务。
我去年减肥之后,已经戒糖很久了。但是都来长沙了,一杯茶颜悦色还是必须的,完成打卡任务。 在五一广场逛了逛,走到了江边,又来到了文和友,也算是长沙的一个餐饮网红,前几年也开到了广州和深圳,最近看新闻听说要倒闭了。
在五一广场逛了逛,走到了江边,又来到了文和友,也算是长沙的一个餐饮网红,前几年也开到了广州和深圳,最近看新闻听说要倒闭了。 逛得差不多了,穿过坡子街,走回五一广场地铁站,坐车回家休息。
逛得差不多了,穿过坡子街,走回五一广场地铁站,坐车回家休息。
 早上 5 点半就起床了,吃了两个面包,换好衣服,坐地铁前往起跑点,今天马拉松参赛者乘坐长沙地铁免费,地铁为了方便跑友,还提前到 5:30 发车。
早上 5 点半就起床了,吃了两个面包,换好衣服,坐地铁前往起跑点,今天马拉松参赛者乘坐长沙地铁免费,地铁为了方便跑友,还提前到 5:30 发车。
 到达五一广场换乘去贺龙体育中心,密密麻麻基本都是跑马的人。
到达五一广场换乘去贺龙体育中心,密密麻麻基本都是跑马的人。
 马拉松 7点30 起跑,我到达才 6点45,还有半个多小时。此时人已经很多了。
马拉松 7点30 起跑,我到达才 6点45,还有半个多小时。此时人已经很多了。 由于我在 F 区,发枪时间是 8:00,在这里等的时候让跑友给我拍了张照片,腰上鼓鼓的里面装满了补给用的能量胶。
由于我在 F 区,发枪时间是 8:00,在这里等的时候让跑友给我拍了张照片,腰上鼓鼓的里面装满了补给用的能量胶。 前面 A 区已经发枪了,我们 EF 两区也慢慢开始往前挪动。
前面 A 区已经发枪了,我们 EF 两区也慢慢开始往前挪动。 7点 55,慢慢到了起跑线,大家在等等起跑。
7点 55,慢慢到了起跑线,大家在等等起跑。 发枪咯,从我的位置到通过计时毯,只用了 1 分钟,这也是分区发枪(间隔15、30分钟)的好处。
发枪咯,从我的位置到通过计时毯,只用了 1 分钟,这也是分区发枪(间隔15、30分钟)的好处。

 到达 5Km,第一个补给点。橘子洲里的道路比较窄。
到达 5Km,第一个补给点。橘子洲里的道路比较窄。
 到达毛泽东头像,来都来了,自拍打个卡,不少跑友还专门停下来留影。
到达毛泽东头像,来都来了,自拍打个卡,不少跑友还专门停下来留影。 跑了没多久,我追上了第三枪 445 的兔子。他们比我们先 15 分钟发枪,我跑马前半程的速度还是比较稳,基本都能保持 10公里/h 的速度。
跑了没多久,我追上了第三枪 445 的兔子。他们比我们先 15 分钟发枪,我跑马前半程的速度还是比较稳,基本都能保持 10公里/h 的速度。 跑了两个多小时,终于到达半程,对于半马的人来说他们今天的比赛已经结束了,而我们全马的比赛才刚刚开始。
跑了两个多小时,终于到达半程,对于半马的人来说他们今天的比赛已经结束了,而我们全马的比赛才刚刚开始。 去年跑完珠海马拉松之后,2024 整个一年,我都没有跑过超过 10km,一般就在健身房跑 5km,过了 25 公里之后,我就能感觉到自己的体能下降了,后面开始慢慢走走跑跑结合。
去年跑完珠海马拉松之后,2024 整个一年,我都没有跑过超过 10km,一般就在健身房跑 5km,过了 25 公里之后,我就能感觉到自己的体能下降了,后面开始慢慢走走跑跑结合。 到达 30 公里,除了跑不动,身体倒没有其他什么不适,用时 3 小时 17分钟,这 10 公里比前面慢了 15 分钟,虽然我平时跑步少,但是一直坚持健身,今年的身体素质还是明显强了很多。
到达 30 公里,除了跑不动,身体倒没有其他什么不适,用时 3 小时 17分钟,这 10 公里比前面慢了 15 分钟,虽然我平时跑步少,但是一直坚持健身,今年的身体素质还是明显强了很多。 终于到达40公里,30 公里到 40 公里这一段,我一直在看自己的配速,计算如果我这次要跑进 5 小时,需要保持多少的速度。一开始 30 到 35 公里还比较紧张,越到后面,发现自己好像能稳定,倒轻松不少。
终于到达40公里,30 公里到 40 公里这一段,我一直在看自己的配速,计算如果我这次要跑进 5 小时,需要保持多少的速度。一开始 30 到 35 公里还比较紧张,越到后面,发现自己好像能稳定,倒轻松不少。 最后 400 米,终点就在前面,长沙马拉松最后两公里是一个长上坡,很折磨人。
最后 400 米,终点就在前面,长沙马拉松最后两公里是一个长上坡,很折磨人。 终点就在前面,最后这几百米,加快了速度又跑了起来。
终点就在前面,最后这几百米,加快了速度又跑了起来。 成功达到终点,十分开心,完成了今年的「人生马拉松」。
成功达到终点,十分开心,完成了今年的「人生马拉松」。 看了下自己的手表计时 4 小时 56 分,也达成了我的目标(进入 5 小时以内)。
看了下自己的手表计时 4 小时 56 分,也达成了我的目标(进入 5 小时以内)。
 领完奖牌和纪念品,开心再记录几张。
领完奖牌和纪念品,开心再记录几张。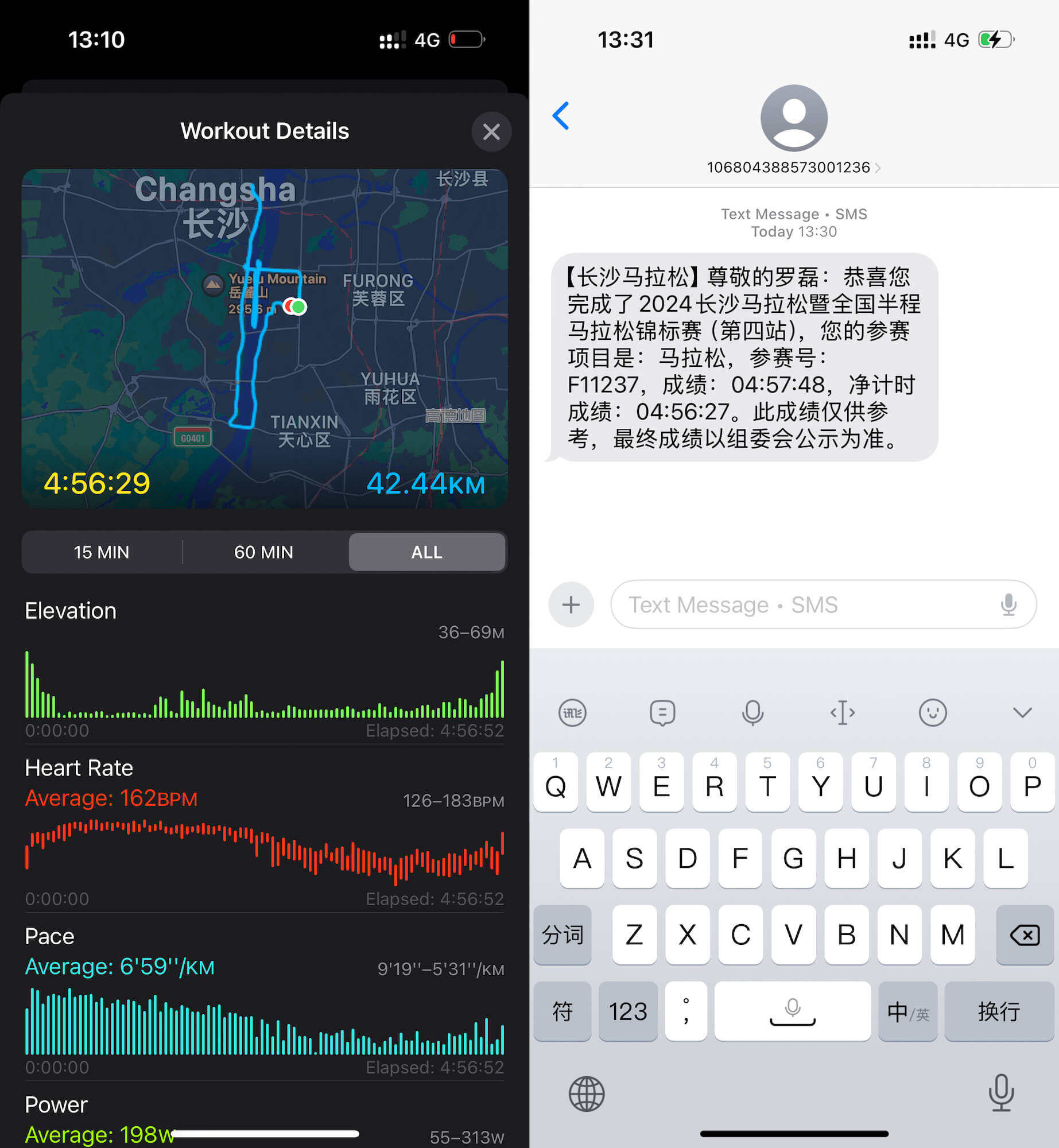 过了一会,比赛确认的成绩发送到了我的手机。跟我手表记录的时间差不多。
过了一会,比赛确认的成绩发送到了我的手机。跟我手表记录的时间差不多。
 湖南博物院是一个很多人推荐的地方,预约参观,人很多。
湖南博物院是一个很多人推荐的地方,预约参观,人很多。 博物馆展示湖南地区历年来的不少文物。
博物馆展示湖南地区历年来的不少文物。 一个萌萌的鼎。
一个萌萌的鼎。
 看到 Yale 的文凭,这个也是现在「雅礼中学」的前身。
看到 Yale 的文凭,这个也是现在「雅礼中学」的前身。



 逛完博物馆,时间尚早,又去五一广场附近逛了逛,这个黄金楼也是一个网红点。
逛完博物馆,时间尚早,又去五一广场附近逛了逛,这个黄金楼也是一个网红点。 吃了黑色经典臭豆腐,味道不错。
吃了黑色经典臭豆腐,味道不错。 看到一个辣条博物馆,给老婆拍了张照,感觉下次可以带老婆再来玩一玩。
看到一个辣条博物馆,给老婆拍了张照,感觉下次可以带老婆再来玩一玩。 还看到一个俄罗斯国家馆。
还看到一个俄罗斯国家馆。


