FC 游戏:超级马里奥三代(Super Mario Bros. 3)
31 March 2026 at 09:42
![]()
![]()
本来是想去附近两公里的良渚文化艺术中心(大屋顶),是安藤忠雄的设计。但是车实在是太太多了。根本没地方停车,找车位花了二十分钟,果断放弃选择 Plan B,其实也没有备选计划,只是在做攻略的时候扫到了一眼,来到这个国家版本馆,这里人就少很多了,没有停车场,旁边就是一个工地,依旧是路边停车。
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
「版本馆是一个集展览馆、图书馆、档案馆、博物馆为一体的综合性场馆。它主要收藏中国古籍、中华民国大陆时期文献、碑帖、家谱、手稿、印章、陶瓷、戏剧脸谱、工业品、建筑物等的设计图纸、照片、邮票、明信片、邮资封、钱币、布票、粮票等藏品[1]。中国国家版本馆设有中央总馆、西安分馆、杭州分馆、广州分馆,当中3个分馆是中央总馆的异地灾备中心,确保各类藏品免遭各类灾害损毁[2]。四个场馆于2022年7月30日同步开馆。[4]」
四个年头过去了,外观还是很新,总建筑面积达到了 10.31 万平方米,是四个馆里最大的,原址是一个废弃的矿洞,所以一边还能看到半个山头。如果不说还以为是一个度假酒店。虽然里面不能翻阅书籍,专程跑来一趟欣赏建筑也是非常不错的。
![]()
![]()
我觉得设计也有些小缺憾,首先只有一个出入口,没有指示牌。没有看过地图,很难根据动线来走一圈合适的游览
二是卫生间设计在地下一楼,只能坐电梯下去,高峰期间不方便,而且没有逃生通道可用。
很喜欢这个设计,回去查了下知道是 2012 年中国首位普利策奖得主王澍及其妻子陆文宇的设计,原来其之前的代表作是宁波博物馆,甬博固然不错,但是这个国家版本馆明显好太多了,设计者的功力过了十四年提升了一个境界。不过依旧能看出来设计者的一些特定风格,喜欢用玻璃类的透光材料,喜欢用交错的顶梁结构。
这里附上宁波博物馆的图片供大家欣赏:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
杭州是一个我既熟悉又陌生的城市,以前上学,出差生活了好久。好几年没有经常跑了,变化还是很大。这次去了几天。以前可能也不会专门写一篇游记,受到住在杭州的博主 Sol 的流水账日记启发,而且这次也拍了不少图片,何不写下来呢。
![]()
![]()
![]()
![]()
![]()
周五出发开车过去,中午抵达,中午还没下班还算畅通。朋友请我在杭州中心顶楼八楼的锦西湖吃饭,车子在 B6 才停好,而且还是一个极小的车位,没有点技术还不好进。
这类定位不低的餐厅,中午人还不少。里面包厢挺多,面积很大,服务员给的餐盘还是加热过的,这点很不错。两个人点了一份开胃沙拉,两份牛排,一份清蒸三小鱼,一份烧河蚬(黄蚬),一份炒蔬菜。没有主食,全部吃完,两份牛排大半都是我吃的,确实过瘾,牛排装在中式的盘子里,口感很嫩,多汁,服务员可以帮忙切好,就不用自己动手了。餐后送了一份甜羹,吃了一口,好甜,平时不吃甜食的我当时也觉得生活需要一点甜。
聊到两点半,餐厅都打烊了,除了另一桌网红,一个劲的在凹造型拍照。停了两个多小时,三十块,杭州中心这个是万象城系的,真贵,关键是车位还很紧缺。
吃完饭离接女朋友五点下课还早,就想着去网咖消磨下时间,就来到了这个电竞中心,有个 LPL 知名战队——LGD 电子竞技俱乐部。这地方人行道上全都停满了骑车,都很高难度,有些三个轮子在台阶上,一个在地下,应该是附近上班的人停着,该死的停车费啊。开到那已经是四点了,得了,一个小时不到也崩玩了,充个电去接人吧。充电完本来说是免费停车,结果出不去,问保安,保安信誓旦旦的说他们的系统不会出问题的肯定是我这有问题,打了他们负责人电话,给他们看了充电订单和付款记录才报销停车费,费了点功夫😮💨
![]()
![]()
![]()
![]()
![]()
滨寿司不是什么稀罕店铺,其实就是食其家母公司泉膳旗下一个品牌,看分布图来看定位似乎比寿司郎略微低一点,在杭州有十二家,很多了。所在城市也有,在日本也没怎么注意,就去吃一下。
龙湖天街停车都有三小时免费,基本看个电影都够了,这点不错。不过他们招商也是来者不拒,看到了两家山寨 Polo Ralph Lauren 和一家山寨 Zara……还有一家内衣品牌,名字没有擦边,但是装修几乎照搬维多利亚的秘密,唉,都什么人买呢。
五点半到的,等了半小时轮到了,不指定座位会快一点,前阵子都在执行 16-8 断食法,要在晚上六点前结束进食,破戒了。
也是几乎全自助的,服务员没有指引。每个人面前有一个 iPad,可以点餐,看消费金额。碗碟都在桌子下的抽屉里。有些菜是服务员端上来的,大部分餐都是由两条传送带送至面前,问了下 AI,说是靠 AI 摄像头来判定有没有取拿和监控「迷惑行为」。
一碟一两块寿司,人多的话吃完能摞起一堆碟子。除了寿司其余拉面什么的基本都是预制菜,没点。也没有看到朋友说的半价的蓝鳍金枪鱼(打折后 ¥8),估计是卖完了。
金枪鱼,三文鱼都来一份,我并不是喜欢这类生鱼片,却也还行,不腥。杯子接的是热水,这点应该是进入中国后改的,在日本都是喝冷水甚至冰水的。要想喝冷水怎么办?在 iPad 上下免费的冰块(还有个免费的就是天妇罗酱汁了,淡淡的,解腻),会有服务员拿过来。大切的鱼片应该就是份量大一点,价格也会高一点。除了生鱼寿司基本都很咸。都用不上酱油(即使他还有减盐酱油)。一块块寿司加起来米饭很多,吃到后来饭都不要了,直接吃肉。
喜欢:
不喜欢:
其他的就无功无过吧,两个人吃了四十分钟不到就出来了,吃了十五份寿司,一个寿喜锅,用了美团券,最后吃了 ¥189,价格还可以,但是如果要排队还是算了,没有那么好吃,属于那种走着走着碰到了那就进去吃一下吧。
这龙湖真没啥好逛的,回酒店。房间楼下远处飘来了广场舞的声音,忍受了很久。KK 给我腹部筋膜松解,感觉自己腹直肌分离的问题稍微得到了缓解,弄完居然快十点了。有个和我一样非常爱干净的女友是一件幸福的事情,她带了一次性床单和毛巾,我自带了牙刷杯具,第一晚就这样过去了。
![]()
我住的地方想吃个汉堡王早餐很不方便。在杭州去吃一下双蛋双牛堡(仅在早餐供应),淘宝上找代下单,一份是 ¥14.8,还有一杯热美式。和麦当劳的「一加一」套餐差不多。确实好吃,传统的汉堡面包胚换成了鸡蛋,可惜的是太少了不过瘾,两个才能满足。
吃饭的这条街上樱花正在盛放,风一吹,系在树枝上的风铃叮当作响,路人停步拍照的很多。吃完我就去下一个目的地。一路上感受着堵车,周末都出去玩了。上高架前都要排队,在高架上也是龟速蠕动,我一集 podcast 都快听完了还没到,只有在之江路隧道里,车速快了点可以上到 90 多,隧道挺长,有 5.6 km,去年十二月才通车。
没想到全山石居然是宁波籍,在杭州定居的中国第一代油画家,曾赴苏联列宾美术学院学习。这次看的展也是苏联/俄罗斯油画家的作品。观展不用预约,登记身份信息后入馆观看,当天有两个展,凝固的美——西方经典雕塑展,高强石膏复制品陈列。还有个就是俄罗斯当代油画陈列。
![]()
![]()
![]()
![]()
油画数量挺多的,数了下有 59 幅,观展的人比之前看的莫奈三副画少多了,可以慢慢欣赏。艺术中心位于一个园区,还有安邦护卫公司和饭店,很神奇的组合。
![]()
![]()
![]()
![]()
![]()
![]()
![]()
中午时分了,去吃个米其林上榜面馆,先来看看米其林官网上是怎么说的:「虽然价格相对一般面馆稍高,但分量大而且用料充足,经常满座。」不过这话照我看,只能听一半,价格高和人多是事实,但我两小时前吃的早饭,这一碗下去也不觉得填饱。 米其林的页面上没有门头,实在是拿不出手,还有只收现金的信息也是错误的,倒不至于那么传统,支付宝和微信都是可以的。
旁边很难停车,都是违章停车(等我吃完,交警已经在抄牌了)。点单付钱后,伙计把菜名写在纸上,领取一个号码牌,轮到了,一个个喊着送面。自己找座位,座位是没有的,一个人去拼桌倒是方便不少。等了半个小时吃上了,遵循客制化,要求口味淡点,做到了,好评(能做到这点的都寥寥无几。实在可悲,事实就是如此)。价格可以接受,毕竟也是名店了,差就在旁边停车难,人多,环境差,味道算不上很好,但是过得去,不值得专门跑一趟。
旁边就是一个茶叶市场,明前茶都上市了,很热闹,一股茶香。咱既不喝咖啡也不喝茶,逛逛就出来了。
![]()
跑转塘那地方去修我的 DA 轮组,车店位于别墅区呢,很偏僻,很适合从这里开始骑车。店铺面积很大,以前是会所改造的,装修和用品也比较讲究,光是垃圾桶都是一桌子下面一个,一个卫生间有两个,这点我太喜欢了。在我去过的车店里可以排前三。
可惜折腾了一下午,弄了四个小时,还是没能解决我这对轮组的问题,硬件本身出问题了,再好的技术也无法解决。这对轮组折磨了三个城市最顶尖的五个技师之手,太折腾,维修了五百块还不算配件成本。因为是朋友介绍的店,店长一开始还不收我钱,我说辛苦费要给的,就收了两个工时,¥120。调试了一番,中轴也是要换了,中轴本质也是个易损件,下回单独写一篇文章。
![]()
![]()
![]()
![]()
![]()
![]()
本来想骑小猪的,时间来不及。之前也没有骑过,不认识路,这条路线还是挺难记的。朋友带完娃从湘湖骑二十公里过来带我体验下。好在当天天气舒服,傍晚也不冷,而且日落也晚了,即使山路上都是看樱花的游客也还是能体验下这段不错的路线,照我以前训练的标准来看觉得算不上好路线,不过在杭州,上海这些城市已经难能可贵。
从龙井下去后一路过关斩将的穿梭在车流中,即使交警看到也不会来管了(龙井原则上是不让骑车,这么多年了,也是间歇性禁止)。
骑完还是挺累的,毕竟是今年的第二次户外骑行,功率下降了太多。晚饭赶不回去和 KK 一起吃,在美院旁边随便吃了点,还得是现在的大学城好,各种馆子都有,丰俭由人,我在一家新疆菜用美团券买了个烤馕还遭到烤馕大叔的白眼……不乐意卖那别开美团啊。
然后就是魔鬼的回拱墅北上车程,看了下规划路线,无论是走高速,还是紫之隧道,时间都拉不开差距,25 公里开了五十分钟,速度也就比顶级马拉松选手快一点(
开的我是烦躁无比,比骑车还累。
![]()
回到酒店瘫在床上,KK 教我吹气球呼吸训练,一开始不得要领,练了几次后感觉还是挺有用的。各种因素结合在一起暴饮暴食了一下,九点多还吃了夜宵,因为做过呼吸训练,罪恶感降低了点,断食计划中断一下,点了我平时在家不会吃的螺蛳粉(味道太大)。洗完澡看 MacBook Pro 里蓝光原盘的诺兰版蝙蝠侠第二部,黑暗骑士。看这种画质是种享受。
酒店隔音很差,床头就能传来隔壁很大的电视声音,本来想着要不要去让前台协调让他们降低点音量。KK 帮我按摩头部哄我睡觉加上外出必备的降噪耳机(更加的想要 AirPods Max 第二代),调整好心态和呼吸,居然很快睡着了,这对我来说是个奇迹。
在杭州的最后一天了,早上先把要买的中轴搞定,研究了很久,在 YouTube 上听 Jay 的新专辑(全放出来了,都不用买,也确实不值得买)。再把每天要看的 RSS 信息流刷一遍,没带充电器用充电宝应急一下,把小小的酷态科 10 号 mini 榨干了,43w 的充电功率可以补上一点。
![]()
![]()
![]()
前一晚九点多才结束进食,要等到下午一点后才能吃东西,去了 Sol 推荐的烹小齐手工水饺餐厅,被「缺德地图」坑了一把,地址写的是:拱墅区地铁 3 号线善贤站商业空间 SX-C09 商铺,谁知道这个 SX-C09 是在地下啊。开车找了两遍都没发现,想想不对劲,打开百度地图才发现原来是在地下。
这天还很热,顶着大太阳找的是无比狼狈,感觉一下子好像来到了夏天。终于找到了,店面小小的,扫码点餐,可惜没有菜单。顶上的菜单栏里也没有鲅鱼水饺,属于隐藏菜单了。前一晚在外卖平台上看到过只有大份的鲅鱼饺子,店里只有小份的了,一份六个,¥12,两块钱一个,老板大叔看我远道而来还多给我一个。第一口下去,嗯,很鲜,不过这个鲜味也是伴随着咸味的,对我来说口味偏咸了,不过从来没吃过这种鱼肉饺子,马鲛鱼我平时是不爱吃的,也没有腥味。一份七个确实太少了,我又加点了十二个香菜牛肉干捞饺子,¥24。也不错,就是偏咸。
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
吃完我就直奔良渚去了,西北方位这块也是从来没去过,虽然已经到挺郊区的地方,但是车流量依旧不少,不过大城市的人开车是文明规矩很多,少有加塞鸣笛的。
快到博物院了看到路边停着一排大巴索性也停在他们后面,我也没看到停车场在哪。走了一段路进去后,这里风景很好,绿化很多,还有河流,还有人在露营。博物院里人流量很大,连身份证都不用登记了,其实去博物馆就应该这样吧。
博物院的设计还是不错的,不算很大,但是展品却不错,这批来自希腊国家考古博物馆的展品,可以算得上一个市级的规模了。第一次亲眼看到非中华文明的文物。可惜来的这天有点不是时候,居然有来自北京中学二分校(初中)的学生们,大老远的跑到杭州,真羡慕现在的孩子。即使是博物院工作人员举着「静」的标示牌,也无济于事,人实在太多了,匆匆看了几眼我就出来了,工作日来体验肯定能好上不少。
![]()
这里碍于图片过多,所以单独开一篇存放。
![]()
![]()
![]()
![]()
看完马不停蹄的回拱墅,又经历一次大堵车,堵车无疑是杭州之旅最不愉快的地方,几年前出差堵在路上也没有这么难受,那是工作。度假的时候感受塞车,实在难受。生活在大城市的幸福感也会因为这个降低不少吧。
选了一家离酒店近的馆子,吃完直接上高速回家。我选馆子的筛选条件是,当地独有的,不排队。这个桐庐菜无疑是当地独有的了。这个位置好停车,然后去的早有车位。
有明档,而且看起来菜色都还不错,坐下扫码点菜,有些菜色不如直接看来的直观,中午十八个饺子还不饿,KK 也不饿,就点了是三个菜,生炒小公鸡,¥65,手捏菜炒蘑菇,¥39,汪刺鱼锅仔小份,¥88。我们去的时候人也不多,但是菜上的是真慢,我不饿,倒是比以前淡定许多,KK 少有的抱怨起了上菜慢。吃一个等一个,服务员都看不下去了,主动帮我们催了两次。
小炒鸡还可以,就是鸡肉略微有些柴,不过也算吃过里面的不错的。炒菜太咸,里面居然有咸菜,知道的话不会点,汪刺鱼里居然有牛蛙,我不太爱吃这些鱼类,总体来说环境和店铺面积算是大点,他都有自己的小程序和会员体系,还有其他分店。不过过咸的菜在我这评分就注定不会高了。
出来后车被挡住。停车时没看清地上磨损的白线,还想着给别人方便,停的很里面。结果出门被堵住,浪费了十多分钟。结账的时候服务员说要十五分钟开走,其实是怕吃完饭不走,三小时内都可以离场。
上高速前都很堵,直到空港高架,可以跑起来。中间服务区充个电,没有对面西向的齐全,地下可以互通。只有国网和华为的充电桩,用豆子换的充电卡能直接用国网的,1.85 块/度,电卡不看价格只看度数,越贵的电越划算。
回程的路上发生一个奇怪的 bug,车机屏幕突然升至最高亮度,比自己能设置的亮度还亮,亮到刺眼。在紧急车道停下来尝试重启也无效,车流很大,不敢久停继续往前开。用车顶的「维修」按钮呼叫后台服务中心,得知并没有更好的解决办法,只能让 4s 给我回电,就在交流的时候屏幕亮度突然恢复正常,后面也没有再次发生,虚惊一场。
回去在 KK 家过夜,现在习惯了两人一起睡觉,只是 KK 要忍受我说梦话和抢被子,甚至还发生过我把耳机摘下来放她嘴巴里的事情🤦♂️
![]()
![]()
![]()
中午去吃一个老李鸡蛋饼,终于不用排队了!两个蛋,半根油条,加生菜,土豆丝,八块五,份量足,好吃,当午饭管饱。帮老板算了下一天能卖起码三百张饼,客单价八块,算算吧,一个月是多少。
结束这三天的旅行。虽然很累,舌头上又张了溃疡,但是很充实,期待下一次旅行吧。
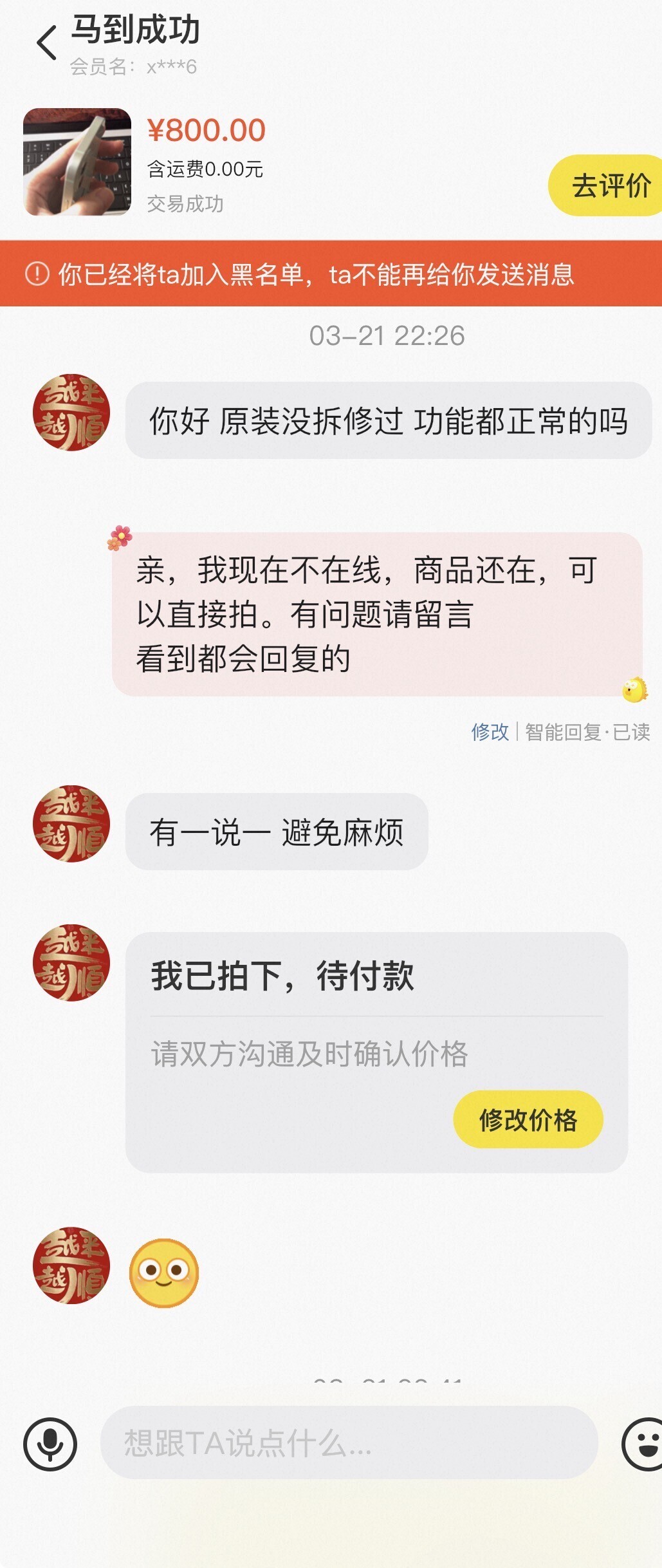
在闲鱼上卖一台老的背板损坏的 iPhone 12,去爱回收线下检测过只能卖 ¥510,在闲鱼挂着 ¥790 有人要了。这个人很爽快,直接拍下未付款。过了一天没付款,订单自动关闭。这期间我把价格涨了十块(因为来问的人多,感觉能卖 800+),他居然也愿意买(这里其实已经挺可疑了)。
![]()
![]()
这里要关机本机,多半是想套序列号,我打码后发给他。
![]()
因为数码产品非当面交易坑很多,发出前我再三拍了视频和照片留档,也发给买家最后确认。但是千算万算没算到,没考虑到细节的地方太多了。
![]()
签收后的第 37 分钟,对方就发来一个视频说我的超广角镜头(0.5x)有问题。简单描述下视频内容:他说超广角有问题,无法对焦,里面的画面就是透光但是很模糊,有点像蒙上一层滤镜的感觉,就是用胶带或者别的什么办法在镜头上做手脚。不是我说,他里面操着一口我几乎快听不懂的普通话(不是歧视,但是搞这种诈骗的人基本都没受过良好教育走上歪路)。开头就说手机摔坏了,相机坏的。可是背板本来就是碎的,商品描述里写的很清楚,他也知情。就是想混淆视听,让我先入为主的以为镜头真的坏了。
![]()
我觉得很诧异,之前都好好的,怎么会突然坏,收货的前十天还在爱回收检测过,有线上检测报告。我当时还出于对买家的考虑说了句「那不要的话就退回来吧」。
吃完饭越想越不对劲,感觉事情有蹊跷,对方又进行一系列操作如图:
![]()
先是申请退货退款,随后图穷匕见,「到手刀」我两百块。如果真要退货我也真给他退了,一开口居然还要这东西,结合我相信自己 iPhone 并未有实质性问题,我就去做了好一番功课。问了几个 TG 群,都说基本就是到手刀骗局,不知骗子用了什么手法,估计是用胶带贴在超广角镜头上使得无法正常对焦。又去小红书上一搜,好嘛,骗局案例都是 「0.5 倍相机到手刀,指南针异常」等关键词。这时我已经确定对方是职业到手刀了,看了他发来的视频二十遍,最后还是余光一语点醒我,买家在还没打开相机前就知道相机超广角有问题,新激活或者第一次打开相机前都会弹一个给定位权限的窗口。他视频中还没弹窗前已经在说相机坏了,这不明显是做过手脚后 100% 确定才会说的话嘛,骗子这剧本演了太多回,太顺溜了,以至于出现这个逻辑上的漏洞,多行不义必自毙一点都没错。他弹窗的定位权限里是成都某小区,我搜了下离他一公里不到就有个派出所,整理完这些,我交给 AI 总结一段话,发过去贴脸输出。
「别演了,你这到手刀的套路太拙劣了,我已经全部取证:
视频里你还没点开相机,甚至在系统跳出位置权限弹窗之前,你就已经断定相机是摔坏的。如果你真是第一次用,你怎么可能在权限都没给的时候就知道它坏了?
你无法提供完整的顺丰开箱视频。按闲鱼规则,没有开箱视频,你无法证明所谓的‘故障’不是你到手后人为造成的
我手里有证明手机相机性能完好的视频,超广角(0.5x)对焦非常清晰,且有爱回收检测报告。你这种行为属于典型的恶意「到手刀」欺诈。我已经把对比证据整理好了,如果你乐意,我们直接小法庭见。还会申请平台封禁你的账号信用。不排除向更高单位申请介入,可能双桥子派出所也会乐意有业绩吧
」
![]()
对方还试图狡辩,想将我一军,赌我手里没有证据,只可惜他不敢赌,强硬一点,继续刚。结果就是他没底气,往往没过几回合就分出胜负,他心里其实很慌的。
![]()
对付这类骗子,绝对不要自认倒霉接受到手刀,即使是退回也会遇到真的把设备弄坏,或者拖延(网上有很多案例),拖个半个月,磨心态。
贴上骗子的账号,大家要注意了。
![]()
在举报一下这类买家。等待闲鱼平台处理。
![]()
作者:他者金麻子
主体和客体是中国哲学界的两个扯淡的概念
我一直认为Subject翻译为主体就是胡说八道。道理很简单,人这个东西,它首先,它始终是预设的一个东西,始终都在那里,没有人就没有一切。也就是说如果有主体【中文语境的】的话,这个主体始终是存在的,没有必要强调它。其实在德文里面的这个词【Subjekt】的词源就是人的意识的意思,指一种纯粹意识,同时也等同于英文中的mind。所以Subject无非指的是人,这个有主观性的人,有意识的人,而不是那种莫名其妙的像万金油的主体。
那么,我们看一些东西是错误的,要看它带来的坏处,带来的胡说八道的东西,让人一头雾水的东西。那这些东西,我经常看到大家,那种胡说八道的东西,谁也说不清楚的东西,以为很高深的东西,充斥着各种哲学空间。基本上属于有话不好好说,不说人话,这种不说人话的一系列话语中,主体这个概念充当了重要的角色。
如果按中文字面的意思来理解主体的话,它一定是施动者,而且另外前提还有一个叫做客体的受动者,因为没有客,哪来的主呢?没有主又哪来的客?那么实际情况是这样吗?比如说我经常询问的,我舔狗,我是主体,那么,狗舔我,应该狗是主体呀?但我们一般情况下都是把我,我们能当成主体,狗当成客体,所以主体这个中文含义是推敲不过去的。
如果你一个人站在路口的话,你说你是主体?其他万事万物,包括蚂蚁,苍蝇都是客体吗?其实万物平等,你和那个蚂蚁,苍蝇都是平等的,苍蝇这个时候盯向你这个无缝的蛋,苍蝇就是主体,你才是客体。其实你在路口,你的意向应该是红绿灯呢或者是其他那个旁边有个大美女啊,也就是只有你意向的东西,它才会成为你的对象【Object】,那还有你没有意向的东西,它怎么是你的对象呢?所以所谓的客体【Object】这个翻译,也是一个胡说八道的翻译。而且任何语言,任何思想都是人说出来的,那么这个人本来就在那里,你还要给他安一个主体在那里干嘛呢?他到底是哪一个人呢?所以,主体是一个极其抽象的概念,不指向任何一个人,只是指向一个空气,主体掩盖了一个一个的具体的人,就像我们经常用一个,我代表组织,我代表人民来枪毙你一样,他把这个罪魁祸首掩盖成了组织,掩盖成了人民,其实就是他干的事情。而且,主体假定人就是主要的,但是,人并不是全知全能的,否则他咋不上天呢?
我们来看看黑格尔哲学
哲学界胡说八道的东西太多了。他们不光是讲废话问题。废话,有时候是啰嗦的话,你像康德也讲了很多啰嗦的话其实也是废话。但是你如果仔细读的话,他讲的是人话。但是,我们绝大部分中国职业哲学工作者,包括清华大学,北京大学,他们不讲人话。我现在要在视频上看谁在讲哲学,尤其是哪个985211大学教授这种讲哲学,我3分钟都听不下去,因为太多的不是人话的东西。
什么不是人话?就是从天上掉下来的,从地上冒出来的,这是第一个方面,突然砸向你,砸到你晕头转向。第二个就是胡乱联系,他竟然从德勒兹福柯
友邦人士,莫名惊诧……。
这些哲学黑话就像一个粪坑一样,臭气熏天,一个一个叶公好龙,假装搞哲学的人,说着它们,还以为嘴上抹了油。
好笑好笑好笑,十分好笑。
🤖 AI 摘要
文章源于作者将博客从 VitePress 迁移到 Cloudflare 刚发布的 Vinext 框架,在技术迁站过程中顺势做了两件事:一是让 AI 以第三者视角撰写「AI 视角下的罗磊」页面,二是构建可对话的 AI 分身,回答关于「我是谁」的问题。通过把十多年分散在文章、动态、视频、开源项目中的内容喂给 AI,作者第一次感到这些碎片被重新组织成一个更完整的自我画像,同时也意识到 AI 抓到的是「愿意公开表达的那部分自己」。文章刻意不再展开技术细节,而是提出「人生 AI」作为继「人生马拉松」之后的新长期计划:不再只关注持续产出新内容,而是利用 AI 将既有创作沉淀为有结构、可成长、可迭代的数字分身。作者指出当前存在准确性不足、人格相似却不完全契合等问题,并延伸到隐私、边界与心理接受度的开放讨论,期待在未来几年持续优化分身、丰富数据,并观察这一项目对个人创作与表达的长期影响。
前几天我做了一件挺有意思的事。
Cloudflare 刚发布了 Vinext 这个框架,我也在第一时间把自己的博客,从原本的 VitePress 迁移到了新的架构上。迁站本来只是个工程活,结果做着做着,我顺手把自己也「迁」进了 AI 里。
上一篇文章 《2026 年,我把自己做成了一个 AI》 已经把这个 AI 分身的原理、架构和技术细节写得比较完整了。这篇不再重复讲怎么做,主要补一下这次视频背后的想法:为什么我想开启一个新的长期项目,叫「人生 AI」。
luolei @luoleiorg · 2026年3月10日
过去 10 年,我给自己设了个「人生马拉松」计划:每年至少一场全马 🏃♂️,今年刚好 10 场。
现在准备开启另一个长期项目「人生 AI」:持续迭代我的 AI 分身 🤖,也顺手记录这波 AI 浪潮的技术演进。
拍了个视频,记录这次有趣的尝试👇
https://t.co/T71sbDwvKZ
过去 10 年,我给自己设了一个「人生马拉松」计划:每年至少跑一场全程马拉松。今年刚好第 10 场。
这个计划对我来说,不只是跑步本身。它更像一个提醒:如果把时间拉长,坚持做一件事,很多变化都会慢慢显现出来。
现在我想再给自己开启另一个长期项目,叫「人生 AI」。
它不是一个为了追热点做出来的一次性 Demo,也不是拍完这个视频就结束了。恰恰相反,我希望它变成一个会持续很多年的东西:一边迭代我的 AI 分身,一边记录这波 AI 浪潮对内容创作、个人表达和独立开发的影响。
迁移博客的过程中,我顺手做了两个小实验。
一个是做了 「AI 视角下的罗磊」 这个页面,让 AI 用第三方视角重新看我一次。
另一个,是做了一个可以直接聊天的 AI 罗磊,让它去回答别人关于「我是谁」的问题。
这两件事表面上是在折腾 AI,实际上更像是在重新整理过去十多年的自己。
平时写文章、发动态、拍视频、开源项目,这些内容都是一篇篇、一条条地散落在各个平台上。它们当然都属于「我」,但大多数时候,它们彼此之间并没有真正被串起来。
这次我第一次比较强烈地感觉到,AI 有机会把这些长期积累下来的碎片,重新组织成一个更完整的东西。
看 AI 怎么「理解」自己,其实还挺微妙的。有些地方会觉得它说得挺准,有些地方又会觉得「这也太像一个整理过后的我了」。它抓到的是我这些年愿意公开表达的那一部分,而不是全部的我。
但也正因为这样,它才让我意识到,长期创作这件事,在 AI 时代可能会多出一层新的意义。
你写过的东西、说过的话、公开留下来的痕迹,不再只是过去完成过的一次表达,它们还可能在未来继续被整理、被关联、被重新理解。
关于这个 AI 数字分身背后的原理和架构,我已经专门写了一篇技术向的文章,源码也公开在了自己的 GitHub 上。感兴趣的话,可以去读一读。
这篇我更想记下的是另一个感受:对于一个持续写作、拍视频、发动态很多年的人来说,AI 的意义可能不只是「帮你生成内容」,而是帮你重新整理自己。
以前我会觉得,内容创作者最重要的事情,就是持续生产新的内容。
现在我会觉得,未来可能还要多做一件事情:把自己过去积累的内容,慢慢整理成一个有结构的东西。
这也是我想做「人生 AI」的原因。
我想看看,一个长期创作者在 AI 时代,能不能不只是持续输出内容,还能慢慢把自己的内容沉淀成一个会成长、会迭代的长期项目。
不过这个项目现在也远远谈不上成熟。
第一个问题是,它现在还不够准。
有些时候它回答得还不错,有些时候又会显得有点「像我,但又没那么像我」。内容越多,想让它理解得更稳定、更准确,反而越不是一件简单的事情。
这也是我接下来最想继续打磨的一块。如果你对这种方向有一些想法,也欢迎和我交流。
第二个问题则更开放一些。
像我这种在网上公开输出很多年的人,对把自己的公开资料交给 AI 分析,整体上是比较开放的。因为这些内容本来就已经公开存在了,AI 只是换一种方式把它们重新组织起来。
但这不代表所有人都会接受这件事。
如果是你,你会愿意让 AI 系统地分析自己吗?愿意把自己的文章、动态、照片、视频,逐步整理成一个可以被提问的数字分身吗?
这背后既有技术问题,也有边界、隐私和心理感受的问题,我觉得都挺值得讨论。
对我来说,这次视频不是一个结论,更像是一个开始。
「人生马拉松」我已经跑到第 10 场了,而「人生 AI」才刚刚起跑。后面我会继续往里面加更多数据,继续优化这个 AI 分身,也继续记录这个过程本身。
看看几年之后回头再看,这会不会成为我这十年里,另一个有意思的长期项目。
过了四个月才把之前闲置的 iPhone 14 Pro 出掉,平时都在当游戏机使用,玩英雄联盟手游和 iPhone 17 Pro 真的没啥体感区别,A16 芯片还是可以的。电量从当时的 78% 掉到 75% 还是挺快的。对比了以下各种渠道。
转转 ¥2499
自助机价格,没有和店员交流,不知道是否存在店员可让利空间
闲鱼回收 Pro ¥2570
¥2550 + 预估竞拍溢价 ¥140,实际溢价就个位数或者十几块,没有实体门店,不然我也想试一下
回收宝 ¥2223
第三方个人小店 ¥2400
问了三四家,最高是这个数字
香港 Apple 官网 ¥2430
以旧换新价 2700 HKD,以当时的汇率计算
京东以旧换新价 ¥2843
不知道实际到手价格是多少,估计没有这么高
闲鱼自己卖 ¥2539
¥2570 左右,还要扣除 0.6% 手续费和邮费,以及可能存在纠纷的麻烦
爱回收线下 ¥2603 + ¥20
自助机器估价 ¥2526和 ¥460,后者实际 ¥510
综上来看,爱回收是我这台手机最优解。这家门店之前有一次去估过价格,所以加过联系方式。门店回收价格比自己爱回收小程序得到的要高不少,小程序不同账号之前差价挺大,比如我今天这单小程序只有 ¥2130。去之前问了两家爱回收的店员分别报价 ¥2520 和 ¥2600,那自然去高的那家。
这步和验机顺序可以调换,新帐号应该会有羊毛,小程序-超级补贴-手机数码领取。
交给店员,先是外观检测。用荧光手电和磁场显影片看看 MagSafe 是否有断裂(iPhone 17 已经是两段断开的)来判断屏幕是否拆封。然后是软件交互验机。
店员在电脑上通过爱思助手下载了一个「易验机」,说是用员工账号登录。然后经过一系列测试,其中拍照测试有斑点,算是 iPhone 的通病了,没有压价格。
最终报价比他企业微信上说的的价格高了三块,和心理预期差不多那就成交。
![]()
再次还原设备,以免有 Apple ID 锁未退出。
问这部手机是不是自己买的,防止是销赃,不过这个形式大于流程,只要能退出 Apple ID 谁都可以声称是自己的。
还会问有没有去过演唱会,说手机镜头被激光照到过可能会损坏。
期间两次录音,确认所有操作已知悉,然后用微信扫描实名认证,应该走的腾讯的实名通道。然后查看验机报告,确认订单,订单价格十天锁定保护。现场支付宝打款。不算上闲聊,整个过程应该在半小时这样,毕竟有一系列验机程序不会太快。
首先不要看小程序价格,分类少,只有按大致成色划价格,得去门店估价,都比小程序给的价格高也是挺好玩的。我当时还带了一台背板破损的 iPhone 12,估价只有 ¥510,闲鱼上随便都能卖 ¥750,所以还是要多看看。感觉影响价格最关键的是未拆封和电池健康度。
甚至首单交易,在小程序福利中心-成交返现金里还有 20 块返现(被归类为垃圾短信差点错过了),也就是这次实际到手是 ¥2603 + ¥20,¥2623。
这次交易像在传统的典当当铺,只不过电子化,现代化,交易的东西以 3C 为主。爱回收也做奢侈品和黄金(就在我们进行的时候有人来回收黄金,需要放进光谱仪)店员还给我看了他的提成分类,可能是这个月的,每项在几十块,不算多。说明店员手里有一点价格浮动权力。虽然都是有小程序,但每家门店价格还不一样,差价也有八十块,所以怎么说呢,不怕麻烦,闲鱼自售应该是卖价最高的,而爱回收目前看看也是一个不错的选择。但是每次都不一样,货比三家,实时更新,实时学习。
听店员讲爱回收门店还有保险业务,没在线上提供此项服务。iPhone 的质保如碎屏更换是由 Apple 官方来承担的,这个倒是不错。
优点:
缺点:
人均:¥84
沿海网红店(除了杭州不临海,其余城市应该都临海,所以上海都没有店),排队要挺久,11:20 线上取号排队的,12:10 一直还有九桌,结果十二点半跳好了几桌,因为在楼下拿杯咖啡过号了重新顺延三桌。最终在 12:30 进店。12:50 吃上。排了一小时队。前几天中午都很晚吃,唯独今早吃了隔夜冷藏燕麦粥,不抗饿,血糖有点波动,很急躁,一度不想等,不过最后还是吃上了,还没让我失望,算是低开高走吧。
![]()
店里面很大,有 107 个座位。像是几个大排档加在一起。全程自助,服务员除了给领到桌前,点好锅底后。纸巾和水放在小推车上。菜品,调料,杯子碗碟全部自助。
点锅底
![]()
汤底有十二种(包括清水锅底)可以选。给的有点多,我就直接选了清水,原汁原味。没有双拼。加热档位有六档,小锅煮沸还是挺快的。
取菜
有两点不好,虽然入口处有说明菜品按照碟子颜色分类,价格不同,但是牌子朝向内侧,不明显。
菜品上有些名称和实际不符合,有些混乱。即使补货很快,但有些食物已经供不应求,小程序上写着的都没看到。拿了牛肉,嫩牛肉,嫩豆腐,竹蛏子,老蛏,三角杯,明虾,海螺片,羊肚菌,金钱肚,木耳,青菜等。
![]()
看着大鲍鱼在那里蠕动,还是很新鲜的,这个可以请工作人员帮忙清理,这个清理也不知道是怎么做。可能洗一下?
![]()
![]()
![]()
锅子是每人一个,不大,觉得还可以更大一些。
![]()
平时不爱吃海鲜的我也觉得还不错,贝壳类和虾类都是比较新鲜的。没有让我觉得腥味吃不下去。全自助意味着加水,捞浮沫都得自己来。不怎么吃火锅的我一直分不清多久可以吃了。
有个橙色盘牛肉也归类于最贵的铁盘。两个人拿了十三盘没有吃主食和饮料也是比较饱的。吃到一半,最早的那批人吃完了,所以一点多一点去吃应该是最空的,不过后来那些空位子又全部填满。
![]()
买单都喊不来服务员,实在太忙了,会人工数盘子,这里效率很低,小铁盘可以重叠,还得手动掀开来数。前一张票据他们留存,
![]()
去收银处买单会给一张收据。加入他们的会员群打 68 折,估计是长期的活动。周末不参加美团的活动,可以用招行信用卡的立减十块小活动。收银员会主动问要不要开发票,这点不错,不过是人工手动开,加微信后需要等几天。
P.S. 有个小彩蛋,因为菜品打折仅限盘子内装的,锅底和调料不打折,问了御三家 AI,只有 Grok 计算出错。
![]()
![]()
谷歌(Google)在旗下 AI 创作平台 Flow 中,向免费用户开放了最新图像生成模型 Nano Banana 2 的使用权限。目前支持单次并发生成 4 张图像,且不消耗账户积分。对于需要高频测试提示词或调整图像细节的用户而言,这提供了一个比标准 Gemini 网页版更高效的替代方案。
Flow 是 Google Labs 推出的生成式 AI 影像创作平台。不同于传统的基于时间轴的剪辑软件,Flow 整合了 Veo 3.1(视频)、Nano Banana 2(图像)与 Gemini(语义)等核心大模型,允许用户通过自然语言构建包含连贯画面和音效的场景。
现在向所有用户开放了 0 积分使用最新图像生成模型 Nano Banana 2。目前支持单次并发生成 4 张图像,且不消耗账户的积分。
通过浏览器访问Google Flow 平台。进入后,可选择打开历史项目,或点击页面底部的按钮新建项目(New Project)。
进入项目工作区,展开页面底部的聊天框功能菜单。
完成设置后,在文本框中输入描述图像的提示词并发送。
系统将并发展示 4 张生成结果。相较于在普通版 Gemini 中逐张生成,该工作流大幅降低了等待时间。
Nano Banana 2 在生成时支持上传参考图片,以便更精准地控制视觉风格或角色的一致性。
经测试,在连续生成 40+ 张图像后,系统未出现拦截提示,且未扣除任何账户积分。这一配额已显著超出普通版 Gemini 的免费限制。
随着知道的人变多,Google 随时可能更新策略或者加上次数限制。
所以!看到这篇内容,赶紧先去试试!
![]()
🤖 AI 摘要
文章以作者长期在博客、社交媒体、GitHub 等平台留下的大量内容为背景,提出在生成式 AI 时代主动构建个人知识结构的重要性。作者首先在 /about 页让 6 个不同大模型基于 11 万字上下文与结构化摘要,生成第三方视角的作者画像,并通过多模型对比提升可信度。随后,他构建了可在博客内直接聊天的「AI 罗磊」,技术栈包括基于 Cloudflare Workers 的 Vinext、Vercel AI SDK、OpenAI Compatible API 接入多家模型、自研搜索/RAG 核心、IP 级限流和 Telegram Bot 监控。系统流程涵盖追问检测与意图判定、缓存复用、本地倒排索引搜索与分数加权、AI 关键词提取与停用词过滤、意图重排、多层 System Prompt 设计、流式生成与截断修复,以及全链路 Token 与耗时追踪。为抑制幻觉,作者设计了来源限制、数字协议、履历协议和链接协议等严格规则,确保回答有据可依。文末作者反思 AI 分身与真实自我的偏差,并展望接入视频内容、降低对单一 API 依赖,强调个人应主动把分散内容结构化为可对话的知识系统,让 AI 成为自我延伸。
我在互联网上留下痕迹,比写代码还早。
大学时代就开始折腾博客、刷微博、玩人人网,那时候还没入行做程序员,纯粹就是一个爱在网上表达的人。后面这十几年,从最开始的切图仔,到后来资深前端开发,再到现在的 AI 驱动的全栈开发,有了技术加持,输出变得更加系统化。到今天,luolei.org 上已经有 300 多篇文章。
除了博客,还有 YouTube 和 B 站 的 ZUOLUOTV 视频频道、X/Twitter 上的 @luoleiorg、十几年前的微博和人人网、Unsplash 上累计超过 1500 万浏览的摄影作品、GitHub 上的开源项目。
这些内容散落在互联网的各个角落,涵盖了技术、摄影、旅行、跑步、数码产品、生活方式等话题。如果有人想快速了解「罗磊是谁」,他需要翻好几个平台、读上几十篇文章,才能拼凑出一个大概的印象。
2024 年至今,我全身心投入独立开发,拥抱 AI-first 的 Vibe Coding 工作流。在这个过程中,一个想法越来越清晰:
在生成式 AI 时代,你的内容一定会被 AI 读取。但 AI 是否能完整地理解你,取决于你是否主动构建自己的知识结构。
被动被爬虫抓取,和主动建立语义索引,是两回事。让 AI 理解你,本质是在拿回对自己内容的解释权。
于是我决定在博客上做两件事:让多个 AI 模型以第三方视角写出「AI 眼中的罗磊」,以及基于我多年的多平台内容构建 RAG 知识库,做一个可以直接聊天的「AI 罗磊」。
![]()
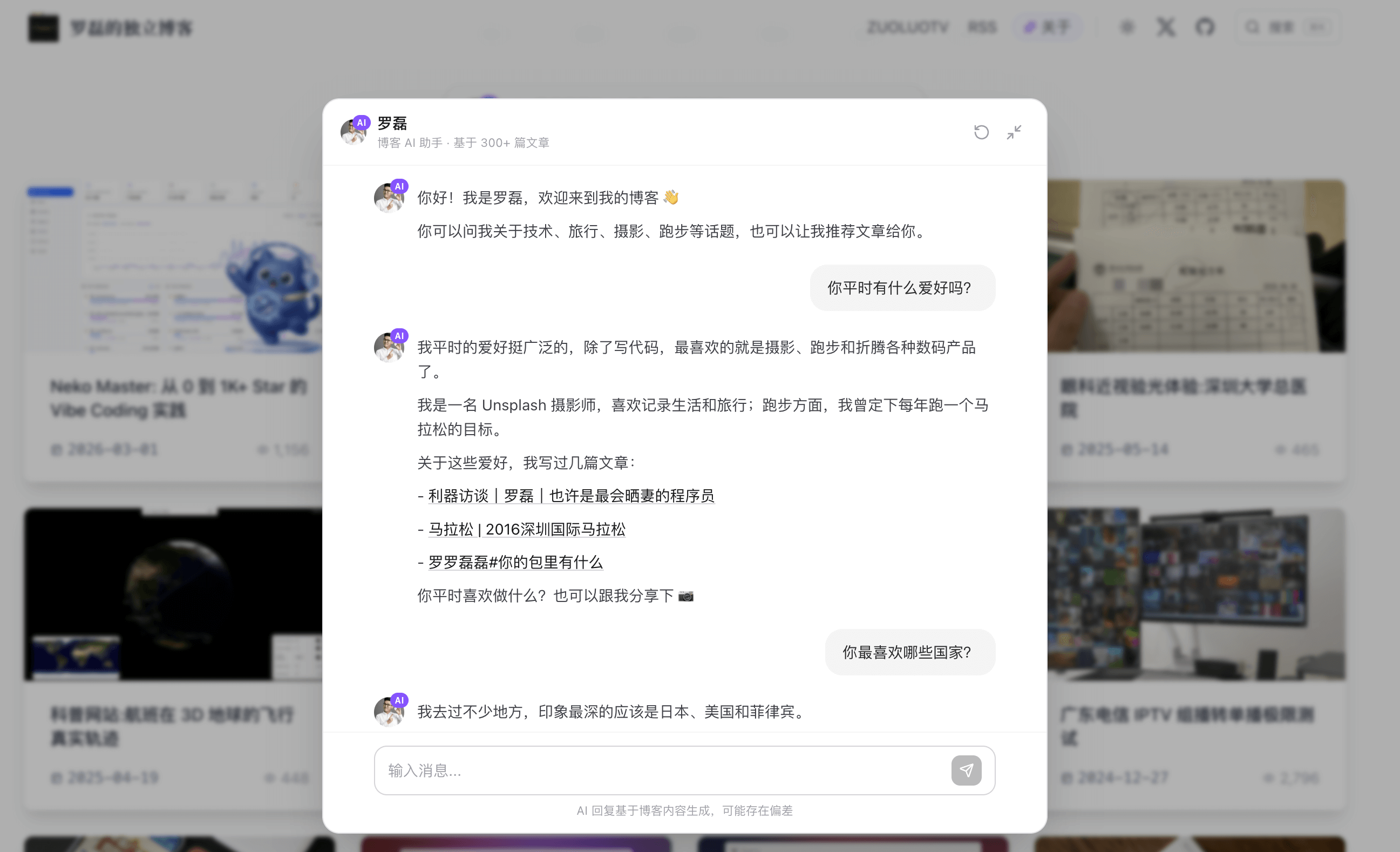
打开 luolei.org/about,你会看到一个和传统「关于我」页面完全不同的东西。
这个页面不是我自己写的自我介绍,而是由 6 个不同的 AI 模型(GPT-5.2、Gemini 3、Qwen 3.5 Plus、Kimi K2.5、豆包 Seed 2.0、GLM 5.0)分别阅读我的博客文章、X 动态和 GitHub 履历后,各自生成的第三方视角作者画像。
同一份数据,不同模型,像 6 个旁观者各自写出对同一个人的理解。
这次 AI 分身主要围绕三类数据进行分析:
说实话,这只是我在网上留下的数据的一小部分。我在 YouTube 和 B 站上有大量视频内容,十几年前的微博和人人网上也有不少早期的文字记录。但这些平台的数据抓取非常麻烦——视频需要先转文字再分析,国内社交平台的 API 要么不开放、要么限制很多,和 Twitter 的官方 API 体验完全不在一个级别。
即使是 Twitter API,成本也不低。所以我做了本地缓存策略,抓取一次后存到 JSON 文件里,避免重复调用。
这三类数据汇总后,光是 Context JSON 就有大概 11 万字。把这么大的数据量一次性丢给 AI 分析,直接暴露了当前大模型的能力边界。
实测下来,6 个模型中只有 Qwen 和 Gemini 3 能稳定处理这个量级的上下文。其他几家要么超时、要么输出质量严重下降,甚至直接报错。最后我做了一轮 AI 预处理——先用模型对每篇文章生成摘要和关键要点,再把压缩后的结构化数据丢给各个模型生成画像,才解决了这个问题。
这是当前 AI 能力的一个现实限制。但可以想象的是,随着大模型的上下文窗口持续扩大,未来普通用户也能轻松处理几十万字的长文分析。到那时候,做这种个人知识系统的门槛会低很多。
6 个模型使用统一的 System Prompt,要求以第三方视角生成结构化 JSON 报告,包括身份标签、能力维度、做事风格、代表作品等。Prompt 中有严格约束:语气客观克制,结论必须有数据支撑,不能编造,不能夸大。
前端支持在不同模型视角之间切换,每个画像底部标注了生成模型、时间和数据来源,保持透明。
为什么让多个 AI 来写?一个 AI 的输出可能有偏差,但当多个不同架构、不同训练数据的模型都指向类似的结论时,可信度就高了不少。同时不同模型的表达差异,本身就挺有意思——有的模型更关注技术能力,有的更关注内容创作,有的会注意到生活方式这条线。
![]()
/about 页面解决的是「快速了解我」的问题。但如果读者想深入聊一个具体话题——比如「你用什么设备拍照」「你跑过哪些马拉松」「推荐几篇关于 Homelab 的文章」——一个静态画像页面就不够了。
于是我做了第二个功能:直接在博客和 AI 版本的我聊天。
ai + @ai-sdk/react + @ai-sdk/openai-compatible)@luoleiorg/search-core 包,基于关键词匹配 + 权重评分 + 意图重排当读者在聊天框输入一条消息,系统的处理链路如下:
1. 搜索上下文复用判断
系统会缓存每轮对话的搜索上下文(10 分钟有效期)。如果是追问(比如先问「你跑过马拉松吗」,再问「成绩怎么样」),会通过以下步骤判断是否复用:
2. 并行搜索与关键词提取
如果不复用缓存,系统会同时启动两个并行任务:
本地搜索(即时):基于 @luoleiorg/search-core 倒排索引,使用 Intl.Segmenter 进行中文分词,并做 CJK 字符拼接修复(比如把「马拉」+「松」识别为「马拉松」)。搜索算法使用加权评分:
深度内容提取:对于匹配度最高的文章(分数 ≥8 且显著领先第二名),会额外提取前 1500 字符的完整内容,让 AI 能回答更细节的问题。
AI 关键词提取(异步并行):如果是多轮对话且本地关键词不足 3 个,会调用 AI 从对话上下文中提取更精准的搜索关键词(3.5 秒超时,48 token 输出上限)。提取后会过滤 70+ 个中文停用词。如果 AI 提取的关键词与本地分词结果不同,会用新关键词再次搜索。
最终返回 6 篇最相关的博客文章 + 6 条最相关的 X 动态。
3. 意图重排
系统定义了 5 类意图分类:
根据用户查询内容识别意图后,对检索到的文章进行重排,按意图相关度评分:
这样可以优先展示最相关领域的内容。
4. 分层 Prompt 构建
System Prompt 分为三层:
这种分层设计让提示词维护更清晰,也方便调整规则而不影响其他部分。
5. 流式生成与修复
AI 以 Streaming 方式逐字输出(temperature=0.3,max_tokens=2000)。如果检测到响应截断(以悬停标点结尾、Markdown 不平衡、句子不完整等),会触发一次轻量级修复调用(2.5 秒超时,80 token 上限),只补全最后一句,然后无缝拼接。
6. 全链路追踪
每轮对话结束后,Telegram Bot 会发送详细通知,包括:
![]()
做 AI 数字分身最大的挑战不是「让它说话」,而是「让它不乱说」。
大语言模型天生倾向于「编出一个看起来合理的答案」。如果有人问「你有没有去过冰岛」,一个没有约束的模型可能会非常自信地说「有啊,我 2022 年去过」,哪怕我压根没去过。
所以在系统提示词中,我设置了最高优先级的反幻觉规则:
[文字](URL),严禁裸输出 URL这些规则配合 RAG 检索,让 AI 的回答始终有据可查。搜不到就坦诚说没有,比编一个像模像样的假答案好一百倍。
聊天界面的一些设计:移动端全屏、桌面端居中弹窗;键盘 Enter 全局唤起;消息气泡区分用户和 AI,AI 头像带「AI」标识;3 秒发送冷却防误触;预设引导语轮播帮助用户开启话题。
当 AI 回复中引用 X/Twitter 动态时,前端会自动渲染成带有作者头像、互动数据的卡片,点击可展开查看完整推文。
每一次对话都会通过 Telegram Bot 通知到我手机,我能实时看到有多少人在和「AI 罗磊」聊天,聊了什么话题,引用了哪些文章,以及系统在各阶段花了多少时间、消耗了多少 Token。
和自己的 AI 分身聊天,感觉挺奇妙的。
它知道我 2014 年跑了上海马拉松,知道我用 Cloudflare Workers 部署项目,知道我在 2016 年写过一篇关于信息自由的文章。它能推荐我写过的文章,能聊我的技术栈,能说出我用什么相机。
但它不是我。
这个 AI 版的罗磊,是基于我公开发布的内容训练出来的。公开内容天然有筛选和表达倾向——我在博客里写的是我愿意分享的部分,X 上发的是我想表达的观点,GitHub 上展示的是我选择开源的项目。那些没写出来的犹豫、没发出去的想法、生活中琐碎但真实的部分,AI 一无所知。
所以这个数字分身呈现出来的形象,一定和我真人的性格有差异。它可能显得比我更自信、更系统化、更「有条理」,因为发布出来的内容本身就经过了思考和整理。真实的我,可能比它犹豫得多,也随意得多。
这种偏差其实挺值得思考的。我们每个人在互联网上呈现的形象,本来就是真实自我的一个投影。AI 读取的是投影,重建的也是投影。它理解的是那个「在线的罗磊」,而不是完整的罗磊。
做这个东西有点像养成游戏。
目前它的知识库还只覆盖了博客、推文和 GitHub。接下来我打算把 YouTube 和 B 站上的所有视频都处理一遍——先转成文字,再做分析和索引,然后继续「投喂」给这个系统。数据越多,它对我的理解就越完整。
不过说实话,我也有一些隐忧。
目前整个系统的 AI 能力依赖于大厂的 API 服务——通义千问、OpenAI、Gemini,数据传输到他们的服务器上处理。因为我喂给它的都是公开数据,所以隐私问题暂时不太担心。但如果未来想把更私密的内容也纳入进来,就需要认真考虑数据安全了。
另一个风险是依赖性。当你把自己的知识体系建立在第三方服务之上,一旦 API 涨价、服务下线、或者政策变化,整个系统就可能受到影响。这也是为什么我选择了 OpenAI Compatible 的接口标准——至少在模型层可以随时切换,不被单一供应商锁定。
回到最开始的那个观点:在这个时代,主动构建自己的知识结构,远比被动等待 AI 来理解你更重要。
我的博客、推文、视频、代码,如果只是散落在互联网各处,它们就只是搜索引擎里的一条条索引。但当我主动把它们结构化、建立语义关联之后,它们变成了一个可以对话的知识体。
可以想象的是,随着 AI 大模型能力的持续增强,以后的上下文窗口会越来越大,多模态处理会越来越成熟。到那时候,做一个自己的 AI 分身,可能就像今天搭建一个博客一样简单。
这也许就是个人内容创作者在 AI 时代的一种可能性:不只是生产内容,而是构建自己的知识系统。让 AI 成为你的延伸,而不只是替代。
🤖 AI 摘要
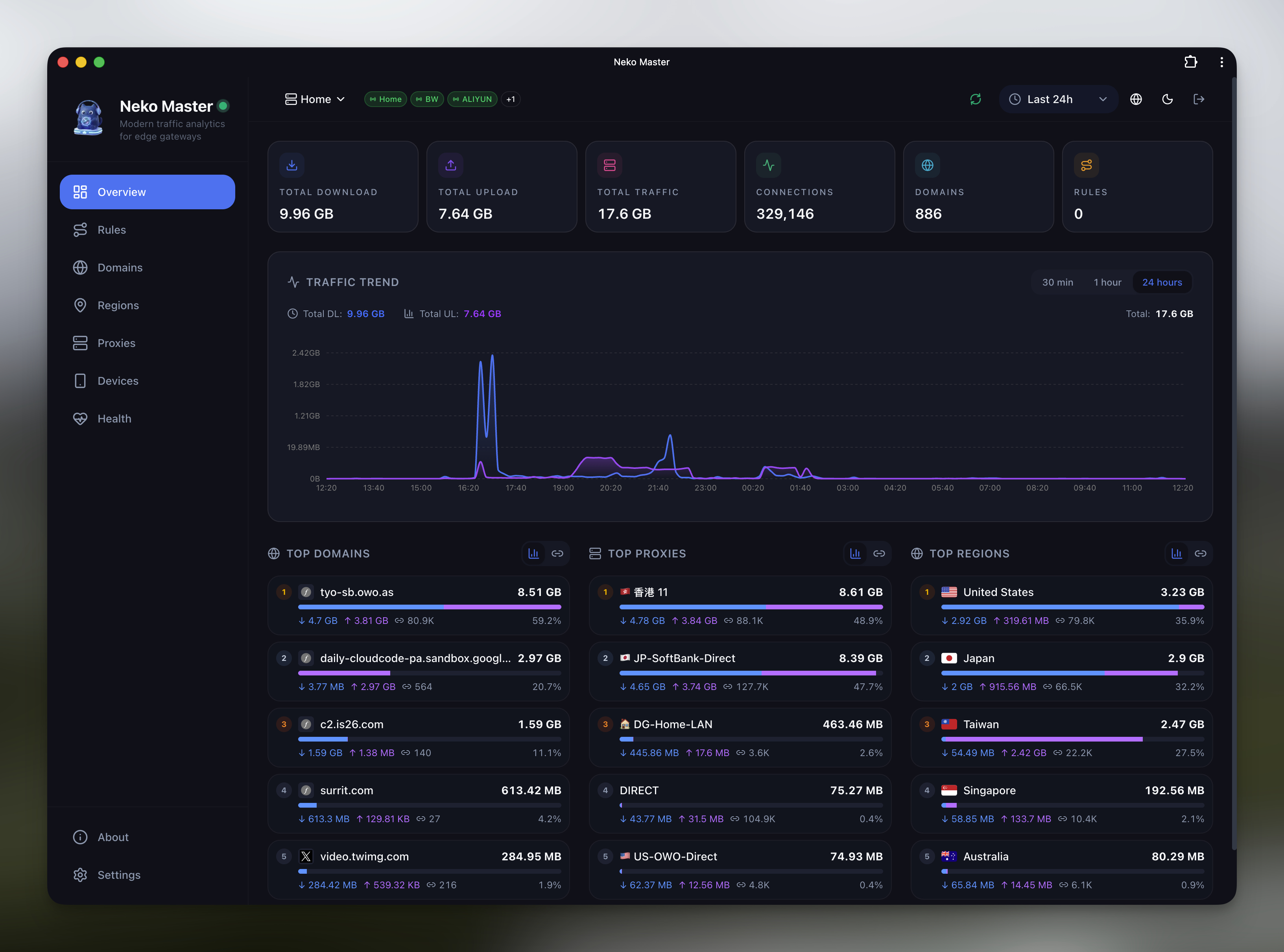
文章围绕开源自部署网络流量分析面板 Neko Master 的诞生与演进展开。作者作为 Homelab 用户,希望获得比 Clash 面板和 Grafana+Loki 更直观、美观的“流量感知”视角,于是在春节期间通过 Kimi K2.5 等模型进行 Vibe Coding,一小时内完成接入 OpenClash 的 MVP,并在四小时内上线首版,迅速获得 GitHub 与 Docker 的关注。后续项目从玩具版走向复杂架构,重点解决家庭 NAS/软路由环境下的稳定性与性能问题,包括:通过内存缓冲队列、批量写入、先聚合再写和写入限流,将 SQLite 导致的日写入量从 200GB 降到 1.6GB;在多 Agent、多网关场景下引入 ClickHouse,通过批量写入窗口、按时间分区与排序键建模、预聚合高频指标等手段,提升查询稳定性与响应时间。文章系统复盘了 Kimi、Claude Opus、CodeX、Gemini 在原型搭建、性能调优、架构重构中的分工,并强调“给 AI 视觉锚点”来提升 UI 审美效果。作者总结,Vibe Coding 极大压缩了从 0 到 1 的时间,但从 1 到 100 仍依赖人类对性能、架构、审美和用户需求的判断。
![]()
春节期间,我花了四个小时,从零开始 Vibe Coding 了一个网络流量分析面板 Neko Master,当天就上线了第一版。项目上线一周,GitHub 收获了 1000+ Star,Docker Pull 破了 10K。
项目最初叫 Clash Master,用了一周后改名为 Neko Master。原因很简单:不想跟 Clash 这个名字绑定太死,后来支持了 Surge v5+,未来也可能接入更多网关类型。
一个开源、自部署的网络流量分析面板。
如果你家里也在用 OpenClash / Mihomo / Surge,欢迎体验。MIT 开源,欢迎 Star 和提 Issue。
密码: neko2026)从最初的「玩具」到现在拥有复杂架构的项目,这篇文章算是对整个开发过程的一个回顾和总结,分享一些 Vibe Coding 的实战体感。 如果只看第一版,它其实不复杂;真正的复杂度,是上线后被真实流量和用户场景一点点逼出来的。
我是一个 Homelab 用户,家里跑了一堆服务,分流策略比较复杂,日常开发也会频繁切换 IP。
其实早在 2024 年初,我就折腾过一次流量监控方案:用 Grafana 和 Loki 配合 Clash Premium 的 Tracing API,弄了一个监控面板。当时发了条推,说「能看看自己的线路流量什么的,其实也没啥用」。
luolei @luoleiorg · 2024年1月7日
用 Grafana 和 Loki,配合 Clash Premium 的 Tracing API,弄了一个 Clash 监控面板,能看看自己的线路流量什么的,其实也没啥用。 https://t.co/YhrjvpspIe https://t.co/3huqYdmg4r
但用了一段时间后,发现 Grafana 这套东西虽然功能强大,但对于家庭用户来说门槛还是太高了。配置繁琐,界面也不够直观,更关键的是长得不好看。原生的 Clash 面板更多是「运行状态」展示,但我一直缺少一个更直观的视角去看:
流量到底在干什么?
市面上除了 UniFi 之外,其他统计工具的界面确实有些一言难尽。与其在不同工具之间拼凑数据,不如自己做一个更好看、更好用的「流量感知」的面板。
2 月 5 日下午,我打开 Kimi Code,使用最新的 K2.5 模型,开始 Vibe Coding。
没有画原型图,没有写技术方案,就是在脑子里先搭了个大概框架,然后直接跟 AI 对话。一小时不到,MVP 就跑起来了:部署在内网,监听 OpenClash 流量,能看到域名统计、节点流量,数据还能持久化。
luolei @luoleiorg · 2026年2月5日
我又来吹 Kimi K2.5 了。刚花一小时 Vibe 了一个 Clash 流量分析工具,完成度极高。部署在内网,监听 OpenClash 流量,实现域名、节点流量统计及 IP 归属地查询,数据持久化。我家的网络分流策略比较复杂,一直想找个工具感知流量状况,毕竟市面上除了 UniFi,其他统计工具的界面确实有些一言难尽。 https://t.co/RoLJbkaP53
当天晚上又花了三个小时打磨了一下,凌晨四点半,第一版 Clash Master 就上线了。
这个项目发布不到 24 小时,就收获了 GitHub 400+ Star,Docker Hub 1000+ 次拉取。这就是 AI 时代的开发速度。
这次开发 Neko Master,听到最多的评价就是「好看」,甚至有人在 V2EX 专门发帖,问 Logo 是怎么做出来的。问与答:《想问一下这种 logo 是怎么做的》
![]()
Neko Master 整体的 UI 属于现代 SaaS 风格,我自己也挺满意的。后面我还专门发了一条推,聊「如何让 AI 审美在线」。
luolei @luoleiorg · 2026年2月6日
昨晚随手 Vibe 的一个项目 Clash Master,不到 24 小时,收获 GitHub 400+ Star,Docker Hub 1000+ 次拉取。
图 1 是昨晚 Vibe Coding 的第一版,图 2 是现在的完全体。 前者 AI 味浓浓,后者审美基本达到 2026 年现代 App 的水准了。这就是 AI 时代的开发速度。⚡️
💡 分享一个 Vibe Coding https://t.co/9E1GM32EDZ
图一是当晚 Vibe 出来的第一版,图二是几天后的完全体。前者 AI 味浓浓,后者审美基本达到了 2026 年现代 App 的水准。
很多人吐槽 AI 生成的界面「千篇一律」,说实话第一版确实如此。分享一个我实践下来觉得很有效的技巧:
不要只用文字描述「给我写个好看的面板」。要给视觉锚点。
具体做法:去 Dribbble / Figma Community 搜「Dashboard」,挑一张看着舒服的截图直接喂给 AI,告诉它「复刻这个设计感」。配色、卡片阴影、数据可视化风格,都可以用截图来锚定。
有了参考系,AI 的审美直接从「程序员风」进化到「SaaS 级」。
一个我越来越确信的感受是:在 AI 时代,代码的门槛在下降,但审美判断依然是决定成品质量的关键因素。 AI 可以帮你写代码、做布局、调样式,但「好不好看」这件事,最终还是得靠人来判断。
这个项目开发过程中,我把市面上主流的几个 AI 编码工具都用了个遍。直接说结论:
| 工具 | 角色 | 体感 |
|---|---|---|
| Kimi K2.5 | 早期主力 | 量大管饱,中文理解好,MVP 阶段 100% 主力,甚至没见过任何限额提示 |
| Claude Code (Opus 4.6) | 硬骨头 | 贵公子。一个复杂任务下去 4 小时限额 15 分钟直接见底,但遇到架构和性能深水区,只有它能啃 |
| CodeX (GPT 5.2/5.3) | 日常输出 | 5 小时循环用量非常扎实,开发过程基本碰不到小时限制的瓶颈,但周限量两天就用完了 |
| Gemini 3 Pro | 辅助 | 主要用来 Review 和写 Commit Message,质量偶尔掉线 |
一个真实体感:国产模型在初始化阶段已经足够高效,Kimi K2.5 是 Clash Master 诞生阶段的绝对主力。但当项目复杂度提升,面对数据库性能调优、架构重构这些深水区问题时,还是得靠 Claude Opus 4.6 和 CodeX 5.3 交叉 Debug。
一个额外体感是:模型不是越贵越好,关键看任务匹配。原型、重构、排障用的模型可以完全不一样。
上线之后的两周,基本就是一个循环:发版 → 收反馈 → 修 Bug → 加功能 → 发版。 从 v1.0.2 到 v1.3.2,迭代了大约 20 个版本。
这个节奏下,AI 的角色不再是「帮我从零写一个功能」,而是变成了「帮我快速响应用户反馈」。 V2EX 上有人说磁盘 I/O 炸了,我把日志贴给 Claude,十五分钟定位到是 SQLite 单条写入没做批处理,连夜修了三个版本,I/O 从一天 200GB 降到了 1.6GB。Docker 镜像太大被吐槽,让 AI 帮我做多阶段构建,从 800MB 瘦到 300MB。
这个阶段的一个核心体感是:Vibe Coding 不只是「让 AI 写代码」,更是「让 AI 帮你加速整个反馈循环」。 用户提了个需求,你不需要花半天去查文档、写方案,直接跟 AI 说清楚上下文,几分钟就能拿到一个可用的 patch。这种响应速度,在开源项目的早期阶段是非常关键的——用户看到你迭代快,信任感就上来了。
改名的同时做了一次比较大的架构升级,包括 Agent 分布式部署模式、ClickHouse 大规模分析后端等。 真正难的不是把面板做出来,而是让它在 NAS / 软路由这类资源受限环境里稳定跑起来。这里补几个最能体现复杂度的深水区问题。
这个坑是最痛的一次。早期版本把每条流量记录都直接单条写入 SQLite,功能是对的,但在真实家庭网络里会触发严重写放大。用户反馈磁盘写入量吓人,我一看容器和主机监控,日写入量确实离谱。
核心问题不是 SQLite 本身,而是写入策略太“在线”了:高频事件 + 单条落盘 + 没有缓冲,I/O 自然爆炸。在 demo 阶段不明显,一上真实流量就暴露。后面连续几个版本做了三件事:
结果非常直观:
v1.0.2 -> v1.0.7 -> v1.0.9
200GB -> 20GB -> 1.6GB / day
这次之后我基本确定了一件事:AI 能快速把“能跑”的代码给出来,但 I/O 模型、缓存策略、背压机制这些基本功,必须由人把关。
单网关场景 SQLite 足够,但多 Agent、多网关以后,域名/IP 维度的数据量会迅速上涨,查询复杂度也跟着上来。尤其是 TopN、时间趋势、规则命中这类查询叠在一起时,读写压力会互相放大。ClickHouse 引入后,第一版也踩了典型坑:小批次高频写入导致 parts 激增,merge 压力上来后,查询延迟会抖动。
后面重点做了几层优化:
这套优化做完后,收益不只是“更快”,而是“更稳”:高峰时段的查询波动明显下降,面板体验从偶发卡顿变成可预期的稳定响应。这也是项目从“能跑”走向“可维护”的分水岭。
深水区里,AI 最有效的用法不是“一次性生成”,而是进入工程化闭环:日志与指标 -> 假设 -> patch -> 压测/对比 -> 继续迭代。 我在这个项目里基本就是让 Kimi 快速铺功能,用 Claude/CodeX 啃性能和架构细节,然后自己做最终取舍。AI 把迭代速度拉高了,但稳定性边界和技术债优先级,还是得人来拍板。
如果你对完整架构感兴趣,GitHub 仓库里有完整的架构文档和部署说明。
Vibe Coding 确实改变了我的开发方式,过去需要一两周的原型,现在几小时就能跑起来。但有一个东西 AI 替代不了:从「能跑」到「好用」的那段距离。
200GB 的写入 bug 是 AI 写的,但发现问题、定位瓶颈、设计缓存策略是人做的。界面从「AI 味」到「SaaS 级」,靠的不是更好的 prompt,而是你自己对美的判断。Agent 模式的架构设计,来自对真实部署场景的理解,不是 AI 能凭空想出来的。
Vibe Coding 降低了「从 0 到 1」的门槛,但「从 1 到 100」的路,依然需要经验、审美和对用户需求的理解。
🤖 AI 摘要
文章开头指出近两年 AI 技术和产品高速发展,中国本土大模型已处于世界前列,但在实际使用全球优秀 AI 服务时,许多用户仍面临各种门槛与限制。作者以资深开发者身份,自述曾通过 Vibe Coding 上架商业应用,亲身感受到“数字基建”在 AI 时代已经成为新的生产力基础。基于这一体会,作者提出将分享自己为未来准备的 4 个“数字通行证”,意在从基础设施或账号、工具层面,为读者提供更完善的数字环境配置思路,以便更顺畅地接入海外与本土的 AI 产品和服务,从而提升个人在 AI 时代的学习、创作与工作效率,逐步实现所谓的“AI 自由”。文末通过外链视频与推文卡片扩展内容,方便读者进一步了解细节与实践路径。
过去的两年, AI 日新月异,很幸运我们很多国产大模型和产品都已经站在了世界前沿 🚀。但不可否认,在探索全球优秀 AI 产品和服务时,依旧有很多朋友被挡在了门外。 作为一名资深开发者,去年我靠 Vibe Coding 上架了一个商业应用。
深感在 AI 时代,数字基建就是我们的生产力。今天分享 4 个我的数字通行证,希望大家都能实现 AI 自由。
luolei @luoleiorg · 2026年2月4日
https://t.co/Ik3xItwco9
过去这两年, AI 日新月异,但现实是,依旧有很多朋友,由于信息差、单向或者双向的门槛,被挡在世界上最先进的 AI 门外。拍了一个视频,分享 4 个让我无障碍使用全球 AI 的数字通行证,希望大家都能在 2026 年实现 AI 自由。🚀
![]()
![]()
![]()
简单通过 iOS 自带的快捷指令,建立一套量身定制的“主动触发”机制。比如从任何设备发送一条指定短信,即可获取设备实时定位及正面照片。
此方案无需第三方应用,完全基于系统自带功能。
在脚本中按序添加以下动作,以维持设备在线并降低窃贼警惕:
![]()
![]()
如果不设置,任何自动化都可能被绕过:
窃贼都知道下滑呼出控制中心来开启“飞行模式”。
操作:设置 > 面容 ID 与密码 > 锁定访问时允许:关闭“控制中心”。
这是 iOS 17.3+ 引入的核心安全层,即使非本人掌握了开屏密码,也无法立即更改 Apple ID 或关闭“查找”。
操作:设置 > 面容 ID 与密码 > 开启“被盗设备保护”。
在国内多为物理双卡的背景下,窃贼可以通过拔卡使设备断网,但为了不扩大损失,我们可以禁止其他设备使用。
操作:设置 > 蜂窝网络 > 选择主号 > SIM 卡 PIN 码。
开启后,SIM 卡插入任何新设备均需密码,能有效防止短信验证码登录。
第一次运行会弹出【定位】和【相机】的权限申请,请务必点击【始终允许】。
只有这样,以后在锁屏静默状态下,它才能全自动跑完流程。
Click to view this post.
![]()
![]()
看到在讨论遇到灾害时,纯文字或是低流量需求新闻网站的重要性:「During Helene, I Just Wanted a Plain Text Website (via)」,Hacker News 上有人给了「A List Of Text-Only & Minimalist News Sites (Updated 2025)」还蛮不错的。
只看官方有提供的部分,美国 CNN 的 lite.cnn.com 与 NPR 的 text.npr.org 算是很久前就知道的两个站,很久了而且是知名的新闻媒体提供的。
倒是加拿大 CBC 的 www.cbc.ca/lite 算是之前不知道,这次在列表里面看到。
汇总记录起来,感觉用的到…
这些站点通过剥离视频、追踪器和自适应广告,将网页加载体积从平均 5MB 压缩至 50KB 以内。这不仅是带宽的节省,更是对“深阅读”环境的重塑。
这一板块是本清单的精髓,适合对信息密度有极高要求的专业人士。
这是 2026 年保护隐私与节省流量的最佳方案。以下工具在今年被证明是稳定可靠的:
![]()
![]()
![]()
IPinfo 对全球 20 款主流匿名服务进行了大规模基准测试,结果令人震惊:17 款匿名服务的流量出口与其宣称的国家不符。绝大多数所谓的“全球覆盖”实际上是将流量路由至美国或欧洲的少数几个数据中心。如果你依赖匿名服务规避地理限制或寻求特定司法管辖区的保护,你的流量可能正暴露在你最想避开的地方。
“100+ 国家”的营销谎言
许多匿名服务提供商声称拥有遍布全球的服务器网络,但通过对 150,000+ 出口 IP 和 137 个国家 的交叉比对,事实并非如此:
下表展示了匿名服务提供商宣称的国家数量与实际测得的“虚拟/不可测”比例。
注:百分比越高,代表其宣称的“物理位置”含水量越大。
💡 专家注:Mullvad、IVPN 和 Windscribe 实现了 0% 的错位。这并不意味着它们覆盖最广,但意味着它们最诚实——所见即所得。
当你在匿名服务App 中点击“🇧🇸 巴哈马”时,你以为流量进入了加勒比海。实际上,流量可能从未离开过美国迈阿密。
运作机制:
为何要这么做?
现象:NordVPN, ExpressVPN, PIA 等 5 家提供商均提供“巴哈马”节点。
真相:所有流量实测均位于美国。
证据:从美国迈阿密发起的探测,RTT(往返时延)仅为 0.15ms – 0.42ms。
物理常识:光速不可能在 0.2ms 内完成跨海往返。这证明服务器就在探测点隔壁(迈阿密)。
现象:NordVPN 和 ProtonVPN 声称提供索马里摩加迪沙(Mogadishu)节点。
真相:实际位于法国和英国。
风险:用户可能为了特定的非洲地缘需求连接,却被路由到了欧洲监控体系下。
为什么很多 IP 查询工具也会显示错误位置?
因为传统数据库(Legacy IP Datasets)依赖**“自述数据”(Self-reported data)**。如果匿名服务服务商在 WHOIS 信息里填了“索马里”,由于没有主动验证机制,传统数据库就会盲目采信。
误差有多大?
IPinfo 将其实测数据与传统数据库对比:
可视化证据:
ProtonVPN 的某个 IP,传统数据库认为是 🇲🇺 毛里求斯,ProbeNet 实测是在 🇬🇧 英国(距离偏差 9691 公里)。
这为何是一个严重问题?
虽然虚拟定位在工程上有其合理性(如在缺乏基础设施的地区提供服务),但核心问题在于透明度。
✅ 最佳实践方案 (Actionable Advice)
本次调查采用了**“测量优先”(Measurement-first)**的工程方法,而非依赖文档。
注:本报告采取了保守统计,仅统计了明确的国家级错位。如果计入城市级错位,数据将更加惊人。
![]()
![]()
![]()
这篇文章将这 31 个技巧汇编成一份详尽的指南,按从“入门基础”到“高级模式”的逻辑重新组织,并补充了 280 个字符无法容纳的深度背景信息。
无论你是刚刚起步,还是希望利用 Claude Code 提升段位,这里都有适合你的内容。
在深入研究具体功能之前,首先要配置 Claude Code,让它真正理解你的项目。
每个新成员都需要入职文档。使用 /init,Claude 会为自己写一份。
Claude 会读取你的代码库并生成一个 CLAUDE.md 文件,包含:
这是我在任何新项目中运行的第一条命令。
对于大型项目,你还可以创建一个 .claude/rules/ 目录,用于存放模块化、特定主题的指令。该目录下的每个 .md 文件都会作为“项目记忆”与 CLAUDE.md 一起自动加载。你甚至可以使用 YAML frontmatter 基于文件路径有条件地应用规则:
可以把 CLAUDE.md 想象成你的项目总指南,而 .claude/rules/ 则是针对测试、安全性、API 设计等特定领域的专项补充。
想把某些东西存入 Claude 的记忆,又不想手动编辑 CLAUDE.md?
在过去,你需要用 # 开头来让 Claude 将内容追加到文件中。但从 Claude Code 2.0.70 版本开始,流程变得更简单了——你只需要直接告诉它去更新。
直接告诉 Claude 记住它:
“Update Claude.md: always use bun instead of npm in this project”
(更新 Claude.md:在这个项目中始终使用 bun 而不是 npm)
无需打断你的心流,继续编码即可。
@ 提及是将上下文传递给 Claude 的最快方式:
在 Git 仓库中,文件建议的速度提高了约 3 倍,并且支持模糊匹配。@ 是从“我需要上下文”到“Claude 已获取上下文”的最短路径。
这些是你会频繁使用的命令。请将它们刻入肌肉记忆。
不要浪费 token 去问“你能运行 git status 吗?”
只需输入 ! 加上你的 bash 命令:
! 前缀会立即执行 bash 命令并将输出注入到上下文中。没有模型处理延迟,不浪费 token,无需切换多个终端窗口。
这一看似微小的功能,当你每天使用五十次后,就会意识到它的巨大价值。
想尝试一种“如果我们这样做……”的方法,但又不想承担后果?
尽管去试。如果情况变得奇怪,按两次 Esc 键即可跳回到干净的检查点。
你可以回退对话、代码更改,或者两者都回退。需要注意的是:已运行的 Bash 命令无法撤销。
你过去的提示词(Prompts)都是可搜索的:
不要重打,要去回忆。 这对斜杠命令(slash commands)同样适用,体验无缝衔接。
这就好比 git stash,但是用于你的提示词。
Ctrl+S 保存你的草稿。先发送其他内容。当你准备好时,你的草稿会自动恢复。
再也不用复制到记事本,再也不用担心在对话中途打断思路。
Claude 可以预测你接下来要问什么。
完成一项任务后,有时你会看到一个灰色的后续建议出现:
Tab 键曾经用于自动补全代码。现在,它自动补全你的工作流。可以通过 /config 切换此功能。
Claude Code 是一个持久化的开发环境,根据你的工作流对其进行优化,将极大地提升效率。
不小心关掉了终端?电脑在任务中途没电了?没问题。
上下文得以保留,势头得以恢复。你的工作永远不会丢失。你还可以通过 cleanupPeriodDays 设置会话保留的时间。默认是 30 天,但你可以将其设置得更长,或者如果你不想保留会话,可以设为 0。
你的 Git 分支有名字,你的 Claude 会话也应该有。
/resume 界面会对分叉(forked)的会话进行分组,并支持快捷键:P 预览,R 重命名。
在网页上开始任务,在终端里完成它:
这会将云端会话拉取并恢复到本地。无论在家还是在路上,Claude 都在。这也适用于 iOS 和 Android 的 Claude 移动应用,以及 Claude 桌面应用。
有时你需要一份关于发生了什么的记录。
/export 将你的整个对话转储为 Markdown 格式:
非常适合用于文档编写、培训,或者向过去的自己证明:是的,你确实已经尝试过那种方法了。
这些功能旨在消除摩擦,帮助你更快地行动。
厌倦了伸手去拿鼠标来编辑提示词?
输入 /vim,解锁全功能的 Vim 风格编辑体验:
以思维的速度编辑提示词。你几十年的 Vim 肌肉记忆终于在 AI 工具中得到了回报。退出 Vim 模式也前所未有地简单,只需再次输入 /vim。
Claude Code 在终端底部有一个可自定义的状态栏。
/statusline 让你配置显示的内容:
一目了然的信息意味着更少的手动检查和中断。
想知道是什么吃掉了你的上下文窗口?
输入 /context 查看究竟是什么在消耗你的 token:
当你的上下文开始变满时,这就是你找出问题所在的方法。
输入 /stats 查看你的使用模式、最爱用的模型、连续使用天数 (Streaks) 等。
橙色是新的绿色 (Orange is the new green)。
“我快达到限额了吗?”
了解你的极限,然后超越它们。
控制 Claude 如何处理问题。
通过一个关键词按需触发扩展思考:
当你在提示词中包含 ultrathink 时,Claude 会在回答之前分配最多 32k token 用于内部推理。对于复杂的架构决策或棘手的调试会话,这往往决定了你得到的是肤浅的答案还是真正的洞察。
注:以前你可以指定 think, think harder, ultrathink 来分配不同数量的 token,但现在我们已将其简化为单一的思考预算。当配置了 MAX_THINKING_TOKENS 时,ultrathink 关键字将失效,配置项将优先控制所有请求的思考预算。
先驱散战争迷雾。
按两次 Shift+Tab 进入计划模式 (Plan Mode)。Claude 可以:
但在你批准计划之前,它不会编辑任何内容。三思而后行 (Think twice. Execute once.)。
我有 90% 的时间都默认处于计划模式。最新版本允许你在拒绝计划时提供反馈,使迭代更快。
直接使用 Claude API 时,你可以启用扩展思考来查看 Claude 的逐步推理:
Claude 在回答之前会在思考块 (thinking blocks) 中展示其推理过程。这对调试复杂逻辑或理解 Claude 的决策非常有用。
没有控制的力量只是混乱。这些功能让你设定边界。
/sandbox 让你一次性定义边界。Claude 在边界内自由工作。
你获得了速度,同时拥有真正的安全性。最新版本支持通配符语法,如 mcp__server__*,用于允许整个 MCP 服务器。
厌倦了 Claude Code 做什么都要请求许可?
这个标志对一切说 Yes。它的名字里带有“dangerously”(危险地)是有原因的——请明智地使用它,最好是在隔离环境或受信任的操作中。
Hooks 是在预定生命周期事件发生的 shell 命令:
通过 /hooks 或 .claude/settings.json 进行配置。
使用 Hooks 来阻止危险命令、发送通知、记录操作或与外部系统集成。这是对概率性 AI 的确定性控制。
Claude Code 的作用不止于交互式会话。
你可以将 Claude Code 用作脚本和自动化的强大 CLI 工具:
流水线中的 AI。-p 标志以非交互方式运行 Claude 并直接输出到标准输出 (stdout)。
将任何提示词保存为可复用的命令:
创建一个 Markdown 文件,它就变成了一个斜杠命令,并且可以接受参数:
不要重复自己。你最好的提示词值得被复用。
Claude Code 可以看到并与你的浏览器交互。
Claude 现在可以直接与 Chrome 交互:
“修复 Bug 并验证它能工作”现在只需一个提示词。从 claude.ai/chrome 安装 Chrome 扩展程序。
这是 Claude Code 真正强大的地方。
圣诞老人不会自己包装每一份礼物。他有精灵。
子代理 (Subagents) 就是 Claude 的精灵。每一个子代理:
像圣诞老人一样放权。子代理可以在后台运行,而你继续工作,它们拥有访问 MCP 工具的完全权限。
技能 (Skills) 是指导 Claude 完成特定任务的指令、脚本和资源的文件夹。
它们一次打包,随处可用。而且由于 Agent Skills 现在是一个开放标准,它们可以在任何支持该标准的工具中工作。
把技能看作是按需赋予 Claude 专业知识。无论是你公司特定的部署流程、测试方法论,还是文档标准。
还记得以前分享 Claude Code 设置意味着要跨 12 个目录发送 47 个文件吗?
那个时代结束了。
插件将命令、代理、技能、Hooks 和 MCP 服务器打包在一起。通过市场发现新的工作流,市场包含搜索过滤功能,便于发现。
LSP 支持赋予了 Claude IDE 级别的代码智能:
LSP 集成提供:
Claude Code 现在像你的 IDE 一样理解你的代码。
驱动 Claude Code 的代理循环、工具和上下文管理现在作为 SDK 提供。只需不到 10 行代码即可构建像 Claude Code 一样工作的代理:
这仅仅是个开始。
当我开始这个“倒数日历”时,我以为我只是在分享技巧。但回顾这 31 天,我看到了更多的东西:一种人机协作的哲学。
Claude Code 中最好的功能都是为了给你控制权。计划模式、代理技能、Hooks、沙盒边界、会话管理。这些是与 AI 协作的工具,而不是向它投降。
能从 Claude Code 中获得最大收益的开发者,不是那些输入“帮我做所有事”的人。而是那些学会了何时使用计划模式、如何构建提示词、何时调用深度思考 (Ultrathink),以及如何设置 Hooks 在错误发生前捕获它们的人。
AI 是一个杠杆。这些功能帮助你找到正确的抓手。
致 2026 年。
![]()
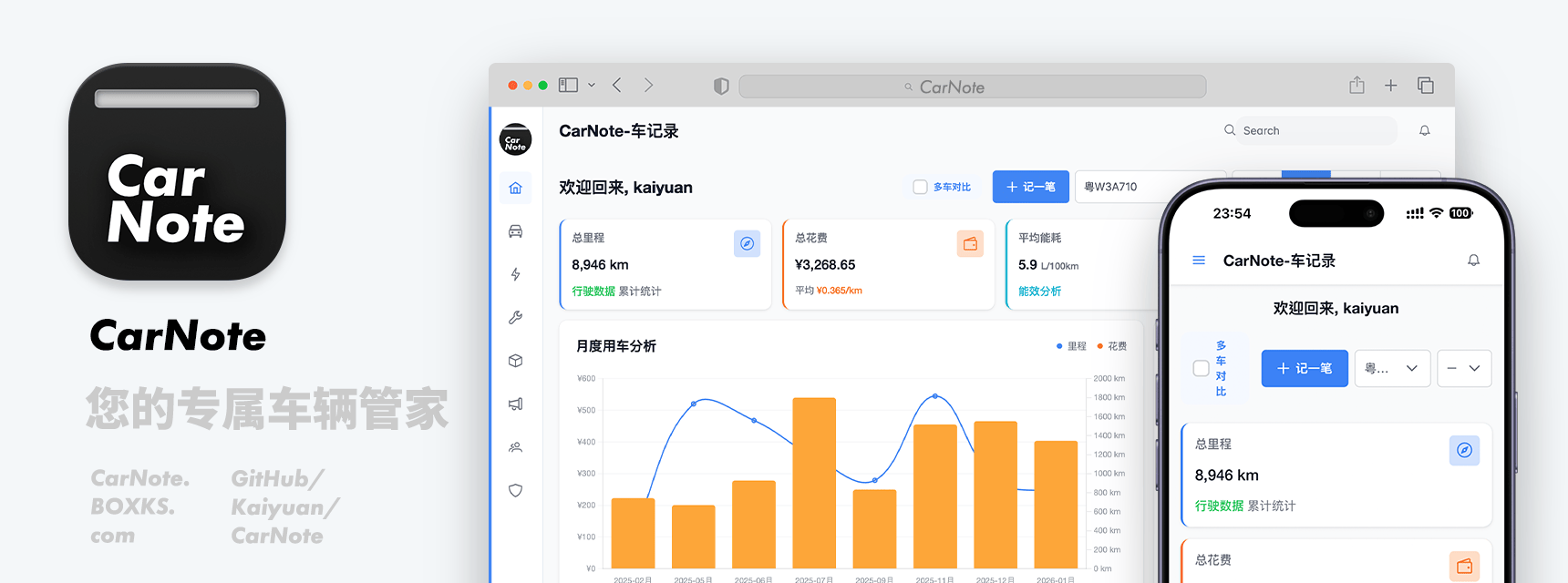
这是一个功能完整的车辆记录管理系统,支持油耗、电耗追踪、保养管理、配件跟踪和数据分析。
代码在 GitHub,我自己也建了一个在线版,开始我是在 NAS 自用的,然后觉得要建个演示的,干脆就直接建一个完整的吧,然后就有了 https://carnote.boxks.com 。
我之前用的是微信里面,腾讯我的车中油耗工具,但是每次都要打开微信,点小程序,点更多才到油耗用具。一顿操作…猴年马月了,而且我也想要记录保养和配件等内容。现在有这个工具就点开然后马上就能添加能耗记录了。
因为之前用 Cursor 和 Kiro 做过几个小工具,所以知道这类工具开发大致是怎么回事,这次我先给项目写了一份描述文档。
然后给 Antigravity 使用 Planning 模式开始,他会根据要求生成他理解的文档,拆分多个开发步骤。然后我看一下,没啥问题就叫他开始开发,然后 Antigravity 自动给我在文件夹中建立对应文件夹不停的在敲代码,大概有半小时吧,一个能跑的程序就出来了,但是他分开前后端的,作为懒人,我直接叫他给我一个在 WSL 一键启动的脚本。这样第一版就完成了,当然,第一版是有很多依赖什么的没有成功跑起来的,然后出什么提示直接丢给 Antigravity 等他自己看和修复。第一版是 Antigravity 自己根据理解做的,排版什么的我都不是很满意,我直接就把 PrimeVue 首页的例子截图丢给他,之后就出了现在的版面了。因为成现在的界面我才建立 git 仓库,所以已经看不到最开始 AI 自己生成的界面了。
很多细节为因为我没有详细的描述,也没有画原型图,所以都是 Antigravity 根据自己理解做的,所以前期针对前端的细节改了很多,甚至改到周额度用完了,我就等了几天继续改。做了两周的晚上,初版能用的做好了。我自己在 NAS 上跑起来了。
后来想着,既然发布到 GitHub 上了,怎么也得给别人看看成品是怎样的把,这时候,我就想到,我直接搭建一个大家直接用的算了,而服务器的费用,我就想到了,弄会员把,这样我就能赚点服务器的钱了。然后问了一下 OpenAI 国内个人开发者怎么收钱,他给的方案就是爱发电和淘宝,然后我登录爱发电看看详细的设置,然后又注册了淘宝店铺,看看虚拟序列号后台没有自动发卡,需要手动发卡,需要找其他办法,还是爱发电方便点。
开源版没有任何功能限制,我建好的 https://carnote.boxks.com 则普通用户可以管理两台车,进阶会员 ¥30/年,可以管理5台车,专业会员 ¥200/年,可以无限制增加车辆,首页的数据展示可以同时多辆车对比数据,也可以自定义时间段数据进行对比。
这样设置的理由是,普通用户两台车是正常的了,而你有超过2台车需要管理,这一年30块也是意思意思给个服务器的费用,超过5台车,那就更不用说了吧。
# CarNote Docker Compose 配置
# 包含后端 API 服务和可选的 PostgreSQL 数据库
version: '3.8'
services:
# 主应用服务 (包含前后端)
app:
image: kaiyuan/carnote:latest
build:
context: .
dockerfile: Dockerfile
container_name: carnote
ports:
- "53300:53300"
environment:
- NODE_ENV=production
- PORT=53300
- DB_TYPE=sqlite
- SQLITE_PATH=/app/data/carnote.db
# - DB_TYPE=postgresql
# - PG_HOST=172.20.0.1
# - PG_PORT=5432
# - PG_DATABASE=carnote
# - PG_USER=carnote
# - PG_PASSWORD=postgresqlPassword
- UPLOAD_PATH=/app/uploads
# JWT 密钥
- JWT_SECRET=${JWT_SECRET}
# 跨域资源共享
- CORS_ORIGIN=http://localhost
# SMTP 配置 (可选)
# - SMTP_HOST=smtp.example.com
# - SMTP_PORT=465
# - SMTP_USER=user@example.com
# - SMTP_PASS=password
# - SMTP_SECURE=true
# - SMTP_FROM=CarNote <noreply@example.com>
volumes:
# SQList 数据库目录及数据库备份目录
- ${carnote_data}:/app/data
# 上传文件目录
- ${carnote_uploads}:/app/uploads
restart: unless-stopped
healthcheck:
test: [ "CMD", "node", "-e", "require('http').get('http://localhost:53300/health', (r) => {process.exit(r.statusCode === 200 ? 0 : 1)})" ]
interval: 30s
timeout: 3s
retries: 3
start_period: 10s
networks:
- carnote-network
# 数据卷
volumes:
carnote_data:
driver: local
carnote_uploads:
driver: local
# postgres_data:
# driver: local
# 网络
networks:
carnote-network:
driver: bridge
用过几个 AI 编程相关的 Vibe Code 软件,叫 AI 开发和平时做其他事情一样,需要事情将自己想要的东西结构并编写一份清晰的文档,这份文档越详细越细致越好,再有就是能画出 UI 的原型图更好,Google Stitch 能直接生成整套前端 UI,当然还是得是要有清晰的描述,所以可以的画还是用 Figma 自己画好,然后放到项目文档中让 AI 自己依照原型图开发。