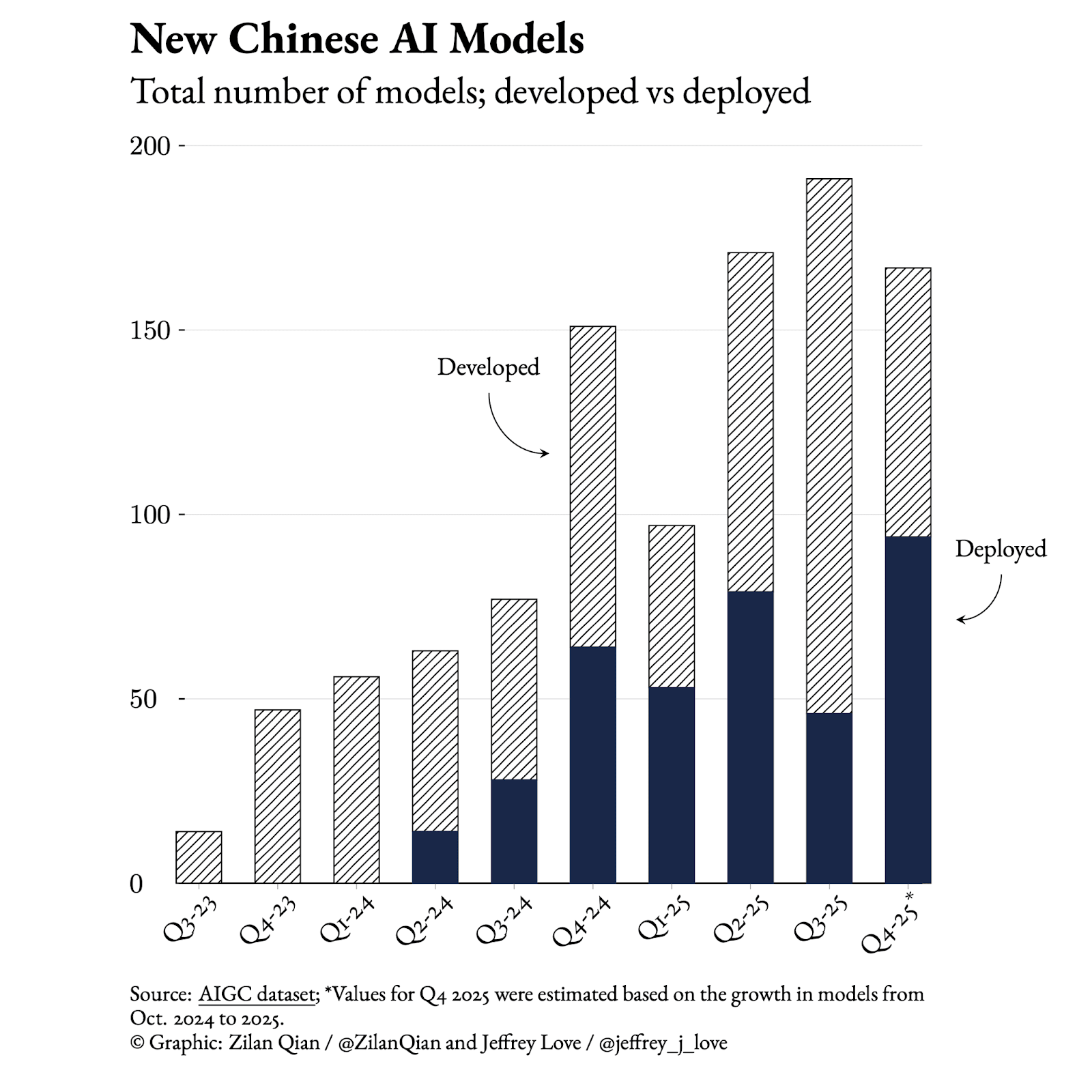
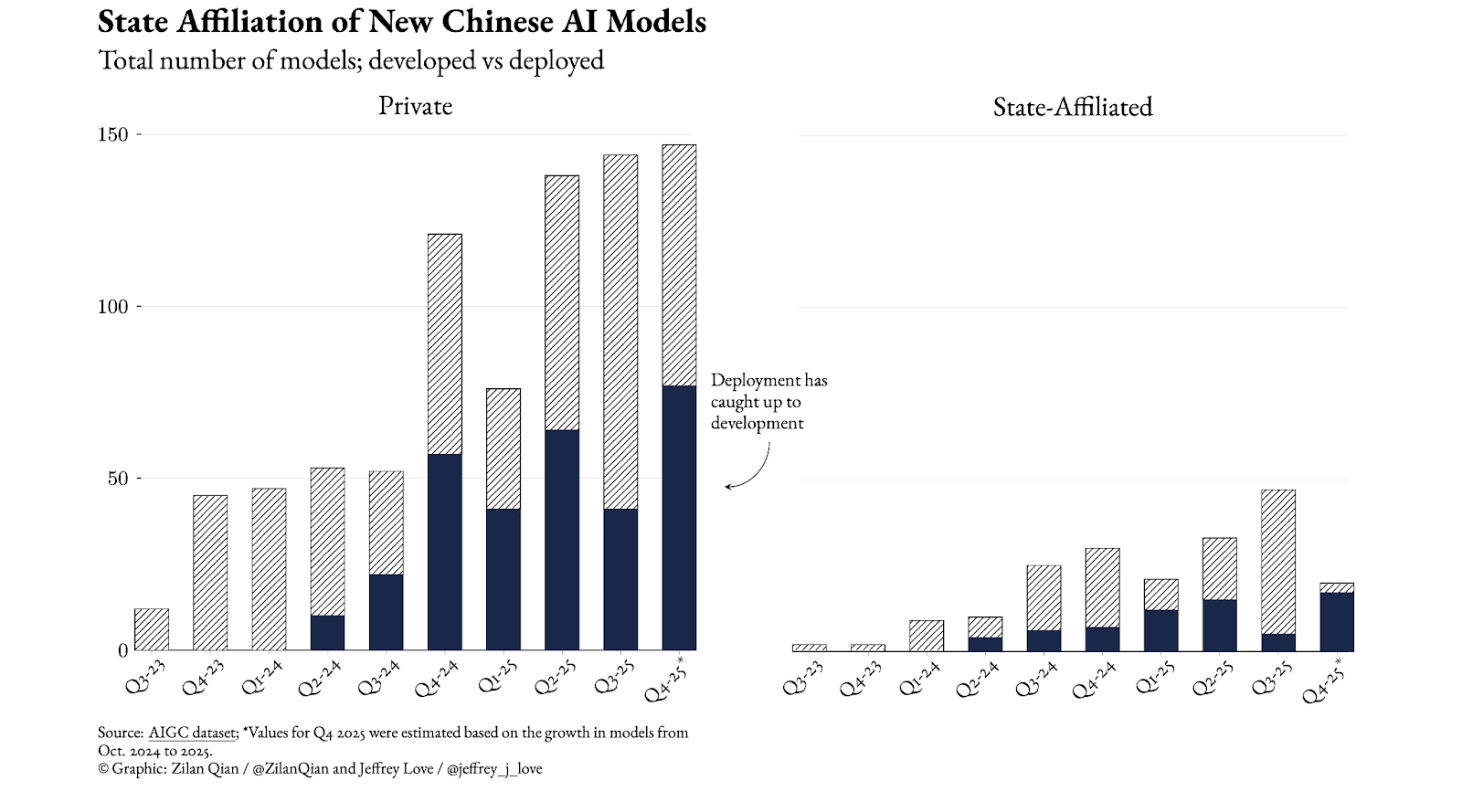
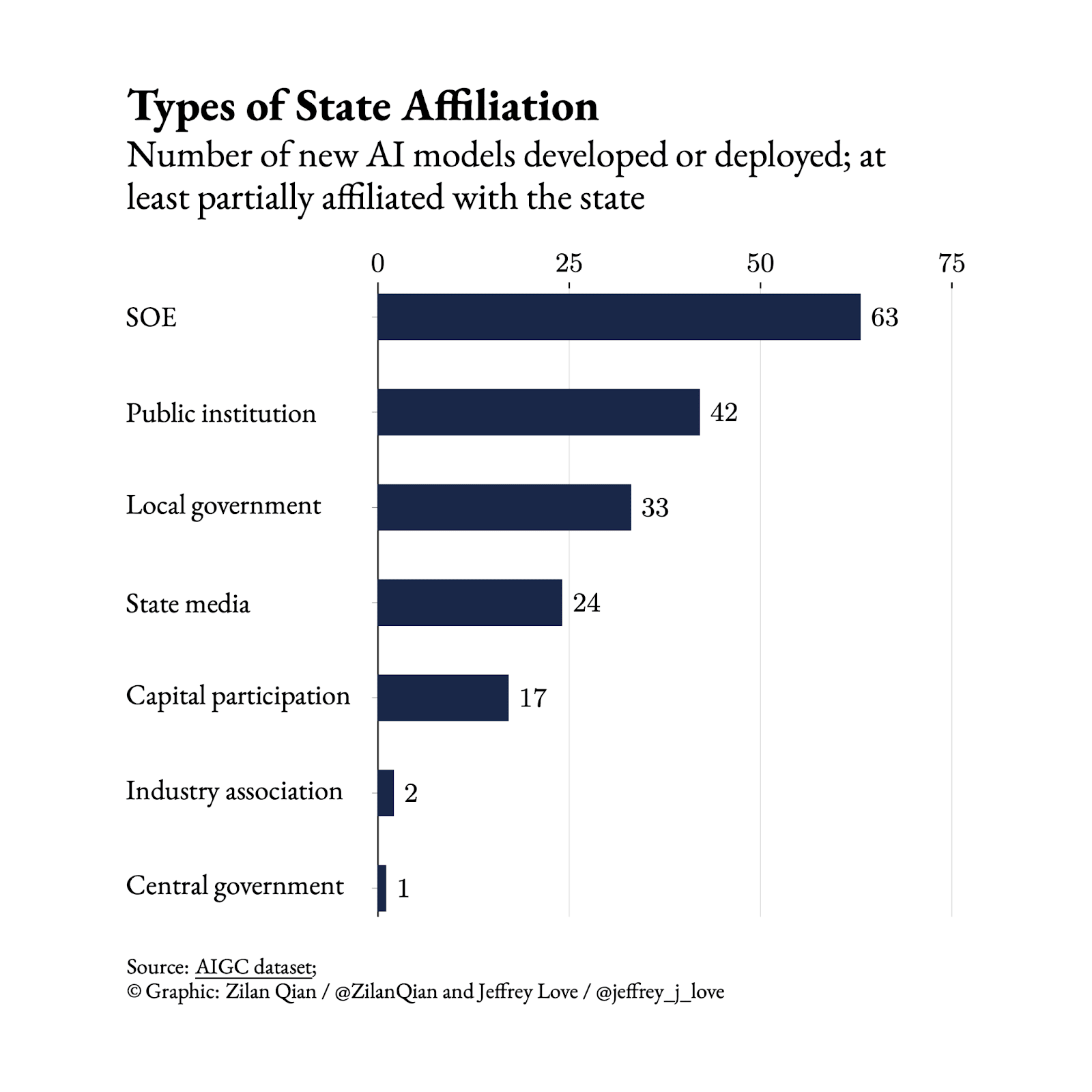
China’s AI optimism isn’t what it seems
Zilan Qian is a research associate at the Oxford China Policy Lab and holds a Master’s degree in Social Science of the Internet from the University of Oxford.
This article was originally published in Asterisk Magazine.
Americans — left, right, and everywhere in between — seem to be afraid of AI. They fear data centers speeding up climate change, disinformation and deepfakes, AI companionship, and, above all, job loss from automation. Meanwhile, the Chinese public seems to be perfectly fine with the technology, or even “optimistic” about it.
The polling data is striking: Stanford University’s 2026 AI Index Report shows that more than 85% of Chinese respondents see AI as more beneficial than harmful, compared to less than 45% of respondents in the United States. A 2025 report published by the University of Queensland and KPMG Australia revealed that 73% of Chinese respondents are willing to trust AI system outputs and share relevant information with AI at work, and 88% intentionally use the technology, compared to 52% and 48% of Americans, respectively.
Why does Chinese society, which suffers from acute job loss and a youth unemployment rate close to 17%, embrace a technology it knows is likely to take away more jobs?
The question was answered three decades ago. The answer is not a narrative about AI, but about an earlier transformation also perceived as inevitable. It is a story about how Chinese society has learned, through repeated upheaval, what it believes to be the only permissible response to disruption. Accurately interpreting that response — which is often misleadingly called “enthusiasm” — is essential to understanding that worried Americans watching China’s AI frenzy might not be looking at a rival but into a mirror.
The millennium that broke two ways
Lived this way for thirty years
Until the great mansion collapsed
The deep, dark clouds
Are drowning the view in my heart.
如此生活三十年 ruci shenghuo sanshi nian
直到大厦崩塌 zhidao dasha bengta
云层深处的黑暗啊 yunceng shenchu de hei’an a
淹没心底的景观 yanmo xindi de jingguan
– “Killing the One from Shijiazhuang,” Omnipotent Youth Society, 2010
In December 1978, reeling from the economic wreckage of the Great Leap Forward and the Cultural Revolution, China’s Communist Party formally shifted its central task from class struggle to economic construction, launching Deng Xiaoping’s “Reform and Opening Up” and beginning a gradual dismantling of three decades of central planning. In 1992, the country formally declared a turn toward a socialist market economy — an acknowledgment that market forces, not central planners, would now drive growth.
The country’s enterprises, built for a planned economy, were suddenly exposed to market competition — and consequently began hemorrhaging money, especially in industries like steel and textiles. By 1997, the state had decided to consolidate the strategic enterprises and let the rest restructure, merge, or collapse. The slogan it coined was 减员增效 (jianyuan zengxiao) — “reduce headcount, increase efficiency.”
The consequences of this transformation depended on where you lived. Over 24 million workers in China lost their jobs in the state sector by the end of 1999. The layoffs were concentrated in the northeast — Liaoning, Heilongjiang, Jilin — once the industrial heartland of socialist China and now called China’s rust belt. In 1957, the city of Shenyang’s Tiexi district produced the nation’s entire output of lathes, rock drills, gliders, rubber boats, and tower cranes, earning it the nickname “the Eastern Ruhr.”
By the late 1990s, 80% of the companies responsible for this output had gone out of production, and half of the district’s 300,000 industrial workers had been laid off. Between 1998 and 2000, nearly every year saw 7 to 9 million workers laid off nationally. Liaoning, for example, was laying off nearly 1,700 workers every single day. The moment was so unique that even the act of being laid off had a special name: 下岗 (xiagang), which literally means “stepping down from the post.”
Yet while the transition led northern China into economic crisis, the Pearl River Delta — geographically proximate to Hong Kong and Macau, home to China’s first Special Economic Zones, and the ancestral homeland of much of the Chinese diaspora in Southeast Asia and beyond — embraced rapid modernization and internationalization. The historical “land of fish and rice” became the “world factory.” Hong Kong investors established over 65,000 factories, employing about six million workers in the Delta. From 1991 to 2001, the Pearl River Delta’s regional GDP grew almost eightfold, and its population increased from 20 to 43 million.
For these citizens, the new economy meant good lives, which now included new technology. In 1998, Microsoft unveiled the mainland China version of Windows 98, and signed musician Pu Shu to endorse it. “New Boy,” a track on his 1999 album, name-checks Windows 98 and Pentium computers in its chorus and became a genuine millennium anthem for a generation.
Put on new clothes, get a new haircut
Relax with Windows 98
The road ahead will have no more suffering
How cool our future will be.
穿新衣吧, 剪新发型呀 chuan xinyi ba, jian xin faxing a
轻松一下, Windows 98 qingsong yixia, Windows 98
以后的路不再会有痛苦 yihou de lu, bu zai hui you tongku
我们的未来该有多酷 women de weilai gai you duo ku
– “New Boy,” Pu Shu, 1999
China’s tech giants — Alibaba, Tencent, and Baidu — were all founded between 1998 and 2000. By the end of 2000, the number of internet users in China had jumped from 3000 in early 1995 to 22.5 million. In 2001, China joined the WTO. Urbanization accelerated, and the growth of the middle class fueled demand for luxury goods, tourism, and better nutrition. The number of private cars in China went up from 1 million in 1992 to almost 10 million by 2002. Many people envisioned a hopeful future in which they could acquire new clothes, new luxuries, and new technology in the new millennium.
But the “many” did not include the 100 million people residing in the Northeast — roughly 8.5% of China’s total population as of 2000. By the 1990s, urban shrinkage, which is measured by sustained population loss, had already taken hold across 52 cities in the Northeast. And of the 68 cities across China whose populations diminished continuously into the 2010s, half were in this region. The regional birth rate has been trending lower than the national average for more than three decades, and net outmigration has become an increasing problem since 2000. In 1990, the Northeast represented 8.66% of the country’s population; by 2016, that proportion had dropped to 7.9%. The one-time cradle of China’s industrial development has become a place that many would rather not raise kids or live in, given the choice.
In the span of a decade, Chinese society simultaneously experienced rapid economic growth and extreme economic precarity. Individuals were offered transformative opportunities and faced catastrophic crises, all due to the same factors put in place by a select elite who generated the incredible promise and acute challenges modern China still faces. To many Americans watching AI reshape their economy, this narrative may sound familiar, though calls to regulate, pause, or stop the technology reflect a belief that the transformation can still be steered or stopped. That option did not exist for Chinese workers in the 1990s.

Painful, “rewarding” reform
For China’s policymakers, slowing development was never an option. A 1931 quote from Joseph Stalin — “落后就要挨打 (luohou jiu yao aida) or “those who fall behind get beaten” — that adapted by Mao Zedong in 1956 permeated society, serving as a cornerstone of high-level policy narratives. In China’s mnemonic practices, this phrase, linked to the idea that only development can sustain a nation’s independence, is the most significant lesson from the past, necessary to remember from China’s 20th-century history of war and colonization. “The reform is painful but rewarding,” wrote the state in 2012 in reference to the previous century.
At the turn of the century, then, the policy question was therefore not whether to reform; instead, it was how to make the transformation less painful. The government attempted to address the pain. In 1998, the state established re-employment Service Centers, which provided laid-off workers with living allowances, basic social security, and job training. The state taxation administration introduced tax incentives for businesses that hired displaced workers. Xiagang workers were entitled to tax exemptions, fee waivers, and preferential access to microloans when starting small businesses or seeking new employment. The Minimum Living Security System was established in 1999 to guarantee basic income for urban residents and expanded to rural areas in the 2000s. Higher education grew in 1999 and university attendance increased 600% in less than 10 years. This expansion was partially aimed at delaying China’s youth from entering the job market, thus leaving spaces for the re-employment of laid-off workers.
For some workers, these policies provided a bridge. But the scale of the problem overwhelmed the response. Funds were too small or simply did not arrive. When funds did arrive, they rarely reached the people they were meant for. In one case, one former deputy director of the city-level Development and Reform Commission — an institution responsible for implementing national economic policies — embezzled the subsidies of 556 xiagang workers.
Even as market reform and industrial upgrades brought new job opportunities, there were simply not enough: In 2004-2005, 24 million people entered the workforce, but only 9 million new roles were created. Even within these new jobs, there was a mismatch between supply and demand. The workers who had been laid off were predominantly in their forties and fifties with industrial skills, while the foreign companies entering China wanted fresh university graduates or young rural migrants who were willing to work for less. And though the expansion of higher education benefited many, it eventually produced young workers who were overqualified for many jobs, resulting in high youth unemployment that persists in China today. And much of the suffering was silently buried under cold numbers and grand policies.
In 2002, economist and writer Wu Xiaobo conducted fieldwork in Shenyang’s Tiexi district. Writing for the Financial Times China, he recorded stories from two families who had experienced layoffs. One husband biked his wife to the red light district for sex work in exchange for money for survival. In the other, the father jumped off of a building after his wife complained that they could not afford to buy their son sneakers for a school sports meet. Other accounts described families folding poison into dumplings, robbers and their victims begging each other to end the other’s suffering, and workers lying across railway tracks waiting for trains to hit them.
It may be hard to understand why people would resort to such extreme situations in the face of mere unemployment. But for many workers in the northeast, employment was everything. Before xiagang, most workers’ lives were organized around the danwei — the work unit that was not simply an employer but a total social world. The danwei provided housing, medical care, pensions, childcare, and entertainment. Colleagues were neighbors. People were born in the danwei clinic, went to danwei-sponsored schools, worked in danwei upon graduation, found partners through danwei-organized dates, and moved into danwei-sponsored dorms or housing. From birth to death, a worker’s life was closely linked to their danwei. In his 2004 book, sociologist Li Hanlin argues that danwei was not only a workplace but also a chosen lifestyle that provided a sense of reliance and an anchor of hope. It was a society without strangers, because people formed close bonds through everyday work and life. Danwei gave people social identity and legitimacy.
People in the Northeast therefore lost not only income, but their way of life, their sense of belonging to the small communities they had built around their work, and their dignity as socialist workers. In a society that for decades had told them workers were the masters of the nation, the sudden sense that they were surplus, inefficient, and unwanted imposed a burden that no severance payment could address. Many felt deceived when forced to sign labor contracts that stripped away their protections: “I believed in the government and the party. I relied on the enterprise for a living, and the enterprise also needed me for further development,” said one laid-off mining worker in rural Beijing. “I didn’t have the slightest idea that the enterprise would take advantage of me.” Others felt invisible when they were excluded from decisions that would determine the rest of their lives by an institution they had always called their larger family.
The fear and the frenzy
The paradox of the era was that as much of China’s population was losing jobs, an emerging group of poor people, predominantly in the southeastern coastal areas, was growing rich overnight. And because others were enjoying upward mobility, the ones left behind internalized Social Darwinist views that claimed that only lazy and useless workers had been laid off and that people who failed to find new jobs simply were not skilled or determined enough to do so.
In rural Liaoning, a northeastern province greatly impacted by xiagang, many people sought to migrate overseas for better opportunities. Local villagers explained to anthropologist Xiang Biao that they looked down on neighbors who could not find work overseas to earn big money. They wondered to themselves, “why have others gone overseas successfully but you can’t?” and assumed that those who stayed had failed because of individual shortcomings rather than structural forces. This view, which originated in northeast China, makes the fault of the layoff a problem with individual capabilities: When rapid stratification turned neighbours’ fates in opposite directions almost overnight, individual effort became the easiest explanation for diverging outcomes — a logic the state then reinforced by replacing collectivist language with individualistic discourses of self-improvement and personal advancement.
Most narratives of the period, even sympathetic ones, treat economic restructuring as a natural force, with individual adaptation as the only response. In 2002, a documentary about the Tiexi district depicted the marginal lives and struggles of xiagang workers in this once-vibrant industrial area. Lyu Xinyu, one of China’s most prominent scholars in the study of rural-urban inequities, interprets the documentary as a sad depiction of an inevitable historical event:
Today’s (2003) Tiexi District is nothing more than a replay of the decline of the traditional industrial Rust Belt in the American Midwest and the traditional industrial Ruhr area in Germany in the 1970s and 80s. It is the unfolding of a common historical rationality in different times and spaces, and we have no possibility of escaping the compulsion of this law. Industry, in a dialectical and historical sense, is an object of the natural laws of society.
If economic restructuring was an unstoppable force of nature, then the only possible response was to move with it before it moved without you. Xiang Biao diagnosed this as a “last bus” mentality: a collective fear that missing the opportunity to seize a piece of post-socialist accumulation meant missing everything. You either catch this bus towards success or be left out forever. It was a frenzy born not of greed or enthusiasm, but of the desperate realization that the old world was gone and the new one had no reserved seats. What began as a northeastern industrial experience has, amid decades of social change and competition, became a prevalent psychological structure spanning different socioeconomic classes and regions.
The state’s official rhetoric consistently reinforced this reading. In the 1990s, China needed marketization and reform of state-owned enterprises. These were, they said, inevitable moves to save the country from its economic crisis. China, under this logic, also needs urbanization, industrial upgrades, or AI integration, because history is irreversible and technological progress is inevitable. Describing major societal changes, the official language is always that one needs to “seize the new opportunities (抓住新机遇; zhuazhu xin jiyu)” and “ride the trend of the time (站在时代的风口上; zhan zai shidai de fengkou shang).” The rhetoric still prevails two decades later, as a top state newspaper wrote in 2019, “when the era discards you, it will not even say goodbye.”
The signal for individuals was clear: You had better catch the “last bus” to seize the fleeting opportunity. If you fail, no one, even the state, will back you up. This mentality undergirded China’s development at the turn of the century and prevails today. Whether it involves market, education, industrial, or technological reforms, people in China are frenetic about new things because they are always seeking the trend to follow. In Xiang’s words, “every bus is the last bus.”
In the late 1990s and early 2000s, learning English was the last bus. Globalization was the irreversible trend; only by learning English could Chinese people interact with the greater world. The state mandated English education as a core Gaokao subject and pushed it into primary schools in 2001, giving rise to cultural phenomena like “Crazy English“ (疯狂英语; fengkuang yingyu), wherein tens of thousands of people gathered in public stadiums to scream English phrases at the top of their lungs in a desperate collective bid for fluency. In the late 2010s, the mobile internet boom was the last bus. As tech giants like Alibaba and Tencent offered unmatched salaries in other industries, millions rushed to learn coding and enroll in computer science degrees in universities that were aggressively expanding computer science programs, only to find themselves facing a constantly decreasing employment rate.
In 2023, understanding AI was the last bus, and over 250 thousand people paid for rudimentary AI crash courses, terrified of being rendered obsolete overnight. In 2026, OpenClaw was the last bus, with thousands of people — retirees, white-collar workers, housewives — lining up outside tech company offices for engineers to install the agent directly onto their phones.
Underlying pessimism
Tomorrow morning, I guess the sun will be good
I want to clean myself up
Sell off everything old and broken
Oh, this will be so good
Come on, Pentium computer
Let them think on my behalf
明天一早, 我猜阳光会好
我要把自己打扫
把破旧的全部卖掉
哦这样多好
快来吧奔腾电脑
就让它们代替我来思考
– “New Boy,” Pu Shu, 1999
Today, the history of marketization is largely depicted in a rosy way. Chinese TV dramas — ranging from official historical fiction to romantic melodrama — celebrate people who rode the tide of the trend and raised themselves. The trauma of xiagang has found cultural expression only at the margin.: The so-called “Dongbei Renaissance” is a loose wave of literature, film, and dark comedy that has emerged from northeastern writers and directors since the 2010s and treats the rust belt’s collapse with a bleakness official culture cannot condone. Beyond that, the majority of the records of xiagang have been censored or simply left out.
But even if you burn the records, you cannot erase the wound. And no matter how much whitewash one applies to that period, the core mentality — seize the last bus or die — has become deeply ingrained. This persistent anxiety continues to intensify and spread whenever new, potentially transformative shifts occur in Chinese society. While not everyone successfully boards every “last bus,” the alternative of not trying to board at all is a social stigma. As Xiang Biao observed, there seems to be no way to live outside of competing and striving, even when it is unclear what exactly one is striving toward; quitting the race means facing utter failure. Even when the young generation claims to embrace “lying flat,” the pressure from the state, society, and even they themselves means that they actually do not give up at all.
This history offers a new perspective on the “AI enthusiasm” we are now seeing in China. Many are correct to point out that the enthusiasm arises from the top-down state discourse portraying technology as a redemption against the history of the “century of humiliation,” as well as people’s ground-up experience of benefits from rapid technology development in the past few decades. Technology is good because it makes the nation stronger. The lesson of how the late Qing government closed its door, missed the industrial revolution, and was defeated and humiliated by the Europeans and Japanese is a core section of the history education mandatory for every Chinese student. On the other hand,industrialization and digitization have made many people’s lives better, compressing what took the West decades into a single generation. China grew from no high-speed rail in 2003 to a 50,000km network in 2025, compared with 8,500km in the whole of the EU as of 2023, linking 97% of cities with populations of more than half a million; the society leapfrogged credit card infrastructure, going straight from cash to mobile payments in a transition that reached people who had never held a bank card.
However, these two elements also instill a profound sense of precarity. The desire to access the transformative benefits of technology is inseparable from the fear of being left behind. Citizens adopt cashless payments not only because of the convenience it offers, but also because of the penalty for not doing so: finding oneself unable to pay at most stores, locked out of basic services, and adrift in a banking system built for a phone screen. The same will be true for AI — or, at least, most Chinese people seem to believe so.
China’s culture of techno-optimism, analysts argue, may allow AI to be diffused and deployed at scale. Some analysts contrast China’s Star Trek techno-optimism, which some believe will allow AI to be more quickly deployed at scale, with the West’s Black Mirror mindset, wherein public anxiety about various AI risks stifles deployment. It is too easy, however, to draw a binary between the American and Chinese responses to AI, or to think that the Chinese public would be purely enthusiastic about a technology that will automate more jobs. It is true that Chinese respondents in some surveys likely have some genuine enthusiasm — particularly many who lived through and benefited from the market transformation of the 1990s, for whom technology has been a story of concrete improvement. However, enthusiasm and fear are not mutually exclusive. A person can genuinely believe some AI products are beneficial and feel they have no real choice but to adopt it; can welcome a technology because it seems useful while worried that not mastering the usefulness renders themselves obsolete. Most survey questions were too binary in design to shed light on which sentiment is driving the response, or a respondent’s ratio of enthusiasm to anxiety.
Today, some evidence-based “optimism” claims draw from the Chinese public’s extremely high responses like “AI products and services have more benefits than drawbacks”, how much one “trust AI,” or “willing to accept AI,” all of which cannot differentiate a net excitement of AI from the belief that AI is important, inevitable, and cannot be missed. Are AI products viewed positively because people really benefit from them, or are they simply thought to be so important, just like how learning English is “beneficial” in the sense that people believe the language means modernization and the future, even though in real life it may have little practical use? Asking “How much do you trust the technology?” is inherently ambiguous: does answering yes mean you trust AI as a technology, trust AI’s output, or trust that AI will bring opportunities that you cannot afford to miss? Furthermore, behind the 95% reponse of willingness to accept AI lies the 49% belief that AI will replace jobs. So while AI is viewed as a threat to job security, a possible coping mechanism is to rapidly accept and embrace it, because history has taught the Chinese that the only coping mechanism is to change oneself.
The mixture of enthusiasm and fear pulls on a tension that has emerged throughout China’s recent history — whether people believe a change will benefit society as whole or merely themselves as individuals. There is a difference between believing a technology is useful, beneficial, or necessary for society as a whole — that AI will become the fate of the nation, which one needs to work hard to adapt to — and trusting that the technology will automatically benefit individuals’ lives. Under the grand narrative today, Xiagang is acceptable, necessary, and has more benefits than drawbacks — for the nation-state more than for those workers laid off. “The 1998 SOE reforms were like major surgery. Without it, the patient would not have survived,” said economist Huihua Nie, implying that although xiagang was a painful process for some, Chinese society must endure this individual suffering for the collective good
When polled only three decades later, perhaps every respondent genuinely believes that AI is good for both society and for themselves. Or perhaps they see AI as another surgery necessary to survival, knowing full well that flesh will be cut away and discarded, but convinced that the pain borne by individuals — however devastating to them — is small against the benefits at large. The polls, as they are written, cannot distinguish between these narratives. .
Meanwhile, the reality suggests that there is no homogenous or unwavering optimism in AI among the Chinese public. For example, even when the state issued multiple warnings about OpenClaw security risks, people nevertheless rushed to install the agent on their personal phones and laptops. Behind the seemingly massive adoption of AI agent tools is not a population mobilized behind a coherent national AI strategy, but many individuals running blindly, supervised by a government that benefits from the momentum but cannot meaningfully control the direction. Resource waste, security vulnerabilities, scams, and market oversupply are the predictable outputs of a system running on fear as much as ambition. China’s AI enthusiasm is not as strategic an “advantage” as some may think, as the bottom-up fear can easily lead to a frenzy that is outside the top-down AI agenda.
This is, perhaps, a situation that one could simply dismiss as “AI hype” or “AI bubble” if it happened in the US, where some hawk AI classes, many try out every new AI product as they emerge, and some attend AI hackathons every week. But because it is happening in China, and because the American analysts themselves now treat domestic AI backlash as a strategic vulnerability, they’d rather believe the Chinese public is different, or the Chinese government has better leverage in a so-called “U.S.-China AI race” as they can engineer an optimistic public.
But can it?
In January 2026, Pu Shu’s “New Boy” was remade to “New Bot” by the state media, aiming to highlight how AI and robotics, just like Windows 98, can bring hope and the promise of a new and improved life. However, despite its eye-catching music video, the song did not become a hit. People continue to listen to the 1999 original, leaving comments lamenting that there will never again be an era of such optimism. What they are mourning, perhaps, is not AI’s failure to match Windows 98’s appeal. “I have never been able to accept that this is a purely cheerful song. The melancholy of being pushed into a new era is the real theme — pessimism hidden inside a melody that looks happy,” wrote one listener.
“向前走,你的路,猜猜未来会给你什么礼物 (xiang qian zou, ni de lu, caicai weilai hui gei ni shenme liwu) ,” sings Pu Shu in the outro of the song. “Walk forward, your road is ahead — guess what gift the future holds for you.” The gift, it turns out, is mandatory. You did not order it, you cannot return it, and the era will not wait while you decide if you want it.
subscribe to Zilan’s substack!
![]()