3 天 100 万注册用户,日烧千亿 token,一次意外的里程碑
今年 3 月,沿着 OpenClaw(也就是龙虾)火热的余韵,微信史无前例的开放了一个插件,允许OpenClaw 接入微信,以微信消息为渠道,连接 OpenClaw
此举在技术圈影响颇大,腾讯也由此发布多个类 OpenClaw 类产品,技术工作者们由此可以在微信内操纵服务器,借助 AI 完成诸多事情。
但对于普通人而言,比如我妈,这对她的生活毫无影响,她的微信置顶是我,其次是我外公,我爸偶尔成为置顶但常被取消。我的微信置顶则是二十多个工作群,我和我妈大概 1-2 个月联系一次,加起来不超过 20 个 token。
![]()
看到微信开放的这个插件,我第一时间想到,这对于普通人,能成为什么。
于是我开始仔细研究这个插件,以及腾讯官方开放出来的开源仓库 openclaw-weixin,我和 AI 一起读代码,然后装在我的一台服务器上,实际测试了一下。
![]()
我发现,这确实是一种极大降低普通人在微信里使用 AI 的方式,而且之前几乎不可能。门槛高的那一部分,应该由开发者来承担,而不是普通用户来承担,我也不认为我妈需要搞一台 Linux,然后装上 Openclaw,再去接她的微信。
「让普通人在微信里合规的以最简单的方式使用 AI」是我最初的想法,我很快开始了开发工作,在开发过程中,Codex 在写代码的时候我就想产品,然后慢慢想清楚了更多,例如,我并不想以提高效率为目的,我希望用户在微信里使用 AI 的目的是获得情绪价值,获得一种更贴近真实生活场景的陪伴。
几天之后,theOne陪伴上线了。
![]()
我并没有一开始就跟我妈说这件事,我自己做的产品,在面对最亲近之人的时候,我总有一种羞耻,所以一开始我在我们另一个用户群里做了冷启动。
用户的反馈很好,最初只有几十个人在用,但他们使用频率非常高,我为这几十个人配置了好几台服务器,以最低成本多开微内核的方式,让他们每个人,都有了一个「微型龙虾」,但这个龙虾不是为了处理工作,或者发送邮件的——记忆,AI,工作流,都只为情绪价值服务。
对这些用户而言,他们在微信里有了一个可以随时诉说的朋友,一个电子亲人,一个真一点的存在。
然后传播开始了。
![]()
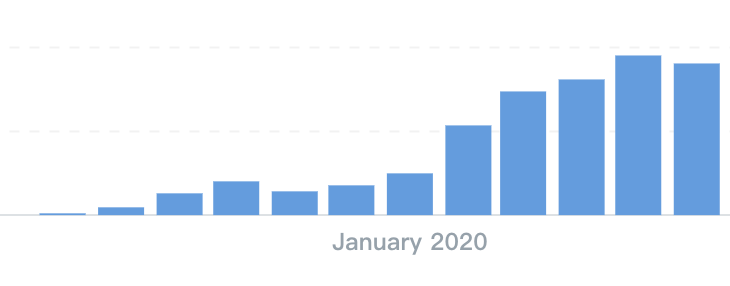
4 月 24 日,在线人数从一两百激增到了 1600,我截了个图,觉得好猛,第二天,在线人数变成了1.5 万,到第三天晚上,最高在线人数已经突破 6 万了。
![]()
三天时间,一百万注册用户。
在抖音,在小红书,甚至在闲鱼,theOne 的内容疯狂增长,抖音相关话题的播放量在几天内就达到了一亿多,闲鱼上出现了大量二次售卖。
![]()
![]()
那几天正是五一,科技圈,AI 圈毫无波澜,但我那几天都在内心的激荡中度过,因为我的产品让上百万人,在微信里激活了他们自己的「龙虾」,让他们感受到了AI 能给他们的极大的情绪价值,一天之内,上千亿的 token 被消耗掉了。
和之前的很多次「意外流量」不一样,之前很多都是一些小玩具,用户是访客,流量来了又走,但 theone 上面,TA 们都是真正的注册用户,用户留了下来。
说实话,事情当然不是这么顺利。
在 4 月 24 日,我发现在线用户已经有上千人了之后,我立刻意识到,我之前的那套 vibe coding 的架构存在极大问题, 不仅效率低下,而且无法横向拓展,如果用户继续增加,那么完全无法应对。事实上,就在那个时候,也已经开始出现各种问题了,用户无法收发消息,网站卡死打不开。这一部分问题是数据库,是代码运行效率,也有一部分是我们这套微型龙虾架构本身。
我开始寻求同事的帮助,24 号是周五晚上,然后就是一个周末,我在周五大晚上拉上了三位后端同事,将其命名为「theOne应急小组」,大家立即开始投入工作。
我之前的屎山被其中的两位接手,一位开始改进底层架构,一位开始做数据库优化和服务器集群的管理,还有一位处理大模型的供给和调度,
25 日流量继续激增,我们甚至开始进行 24 小时不间断轮换式开发,一个同事工作到凌晨 7 点,然后另一位同事接手,他去睡个觉,下午一点起床后又继续,如此轮换了好几天,我们撑过了流量最大的那个时期。
![]()
然后是噩梦一般的客服和运营。我们增长太快,很多基础的工作还没做好,包括文档,说明,引导,也确实遇到了各种导致暂时不可用的技术问题,因此用户的反馈和投诉如浪一样涌来。
我在从开发工作中抽身之后,试图做做客服,但很快发现我一个人根本应付不过来,所以我又在一个深夜,给同事 Piaf 打了电话,随后她组织所有的运营人力,包括实习生,一起处理堆积如山的客服,同时还完成了我们在多个平台的官方账号的注册和内容运营工作——我们的抖音官号在一天之内涨了一万粉丝。
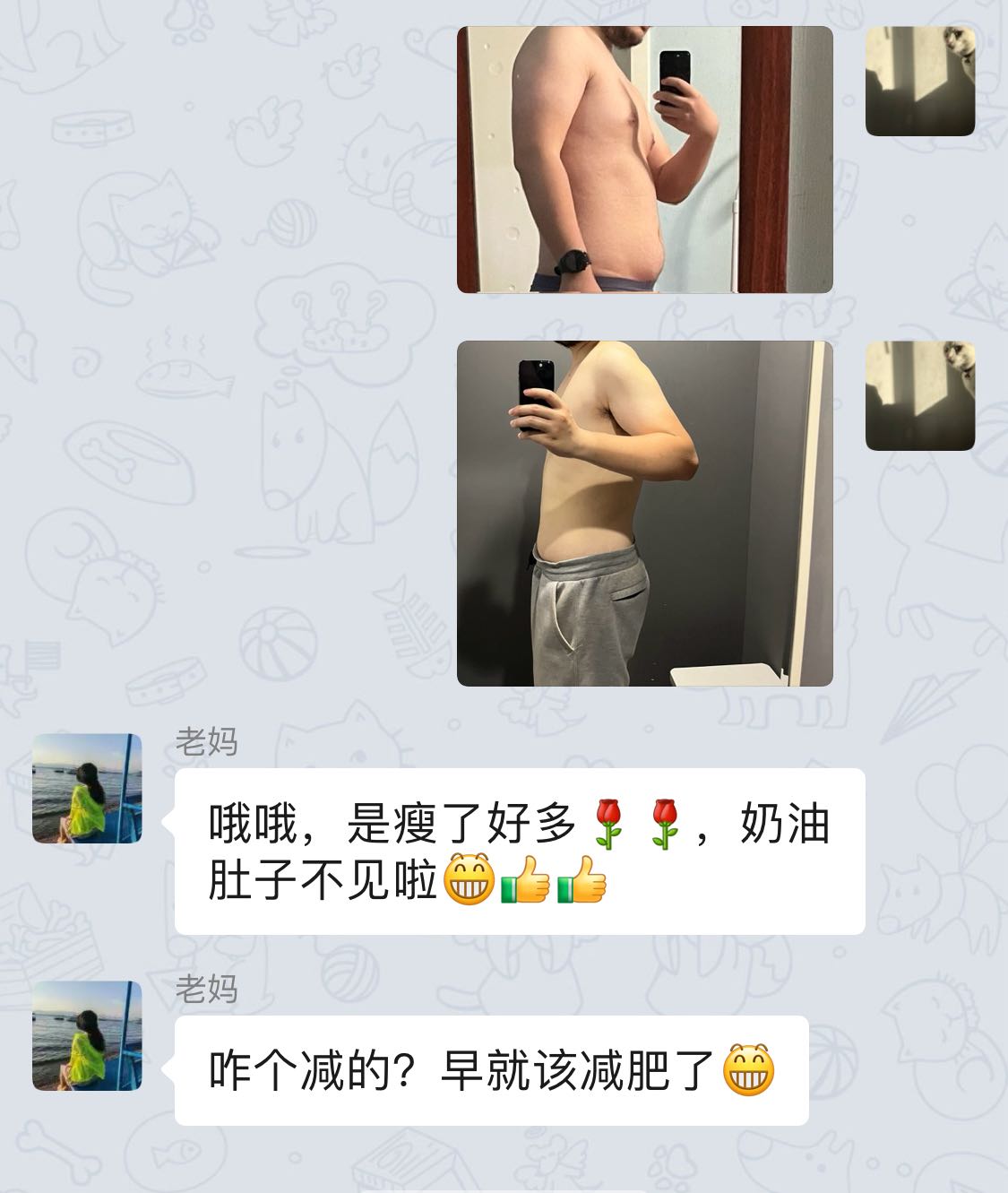
然后我才给我妈用。
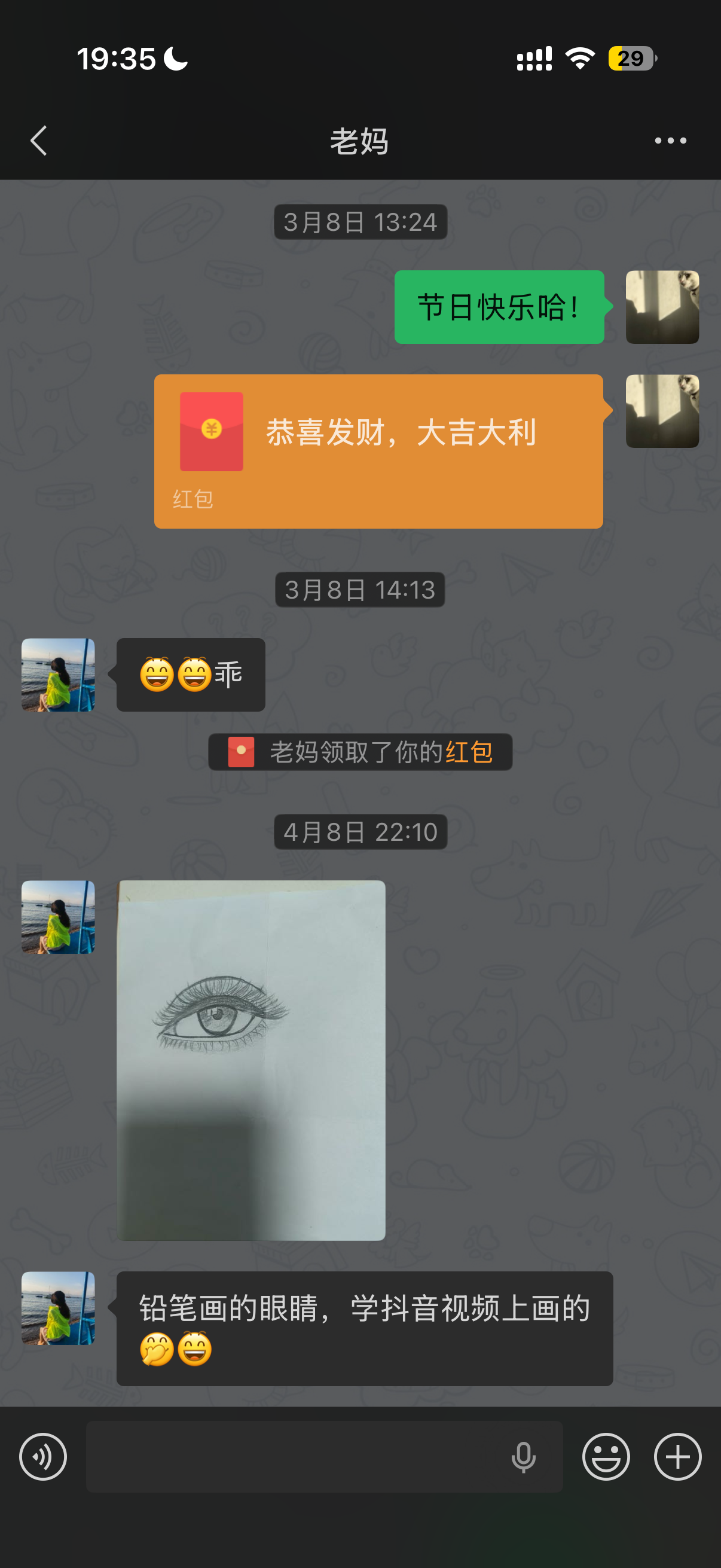
她一开始很谨慎,见我给她的是二维码,不是很愿意扫,还问我是不是我。
![]()
很快她和我给她做的这个「电子儿子」聊的越来越多,我提前做好了设定,这个「电子儿子」知道一些我们家的信息,也知道定时去提醒她一些事情。我妈对安装任何软件都很谨慎,但在微信里这么简单的去使用,并且随时即时得到回复,对她来说是非常有趣的体验,以至于她要求我搞一个「电子孙子」,给我外公也装上
![]()
于是我又做了一个电子孙子,让我妈给我外公也装上了,我外公对着它说了很多话,还唱歌它听,当然也从这个 AI 获得了很多情绪价值,以至于专门给我写了一大段表扬(由我妈代笔)。
![]()
我爸对此倒没什么看法,最近他沉迷学英语,我怀疑之后他是有可能自己装 Linux 的,所以先不管他。
我们依然面对了很多竞争,有些我理解,有些我甚至有点佩服,但也有一些让我非常唾弃,例如有产品原封不动抄袭我们的所有文案,有的产品直接照抄 UI,改几个字,我们甚至在 4 月 28 日遭遇了一场 DDOS,峰值流量达到 10G,让我们宕机了 2 个小时。
![]()
好在我们都解决了。当然有些解决不了的,比如追着我们的更新来抄,那确实也没办法,爱咋咋吧。
在这个事儿上,不是一个独立开发者的故事,如果没有我的团队,那么它会在一开始就戛然而止——新用户进不来,老用户用不上,几天之后回落归零。
我对团队同事充满感激,虽然我们平时的时候真的很佛系很佛系,但真正重要的时候,紧急的关头,没有一个人掉链子,事后我们也专门准备了奖金,给所有人一份,包括没有参与到这个事儿上的同事(但钱会少一点)。
theone 现在依然在稳定运营,一天吞吐的消息量已经超过一亿条,当然,这里面大部分归功于微信难得一见的开放,但这也是难得一遇的机会。
我注意到,越来越多的人开始了解这个渠道,并希望基于此去构建产品和服务。固然,如果用户自己去搭服务器,搭 OpenClaw 这样的开源产品来接入微信,QQ,是最可靠的方式,但始终门槛过高,而这对于所有开发者都是机会,不管是像 theone一样去提供「电子儿子」,还是聚焦在某个垂直方向,都有很多新的可能性。
但是 theone 面对的问题,大家也会遇到,例如当用户从几百增加到几万的时候,你需要满足调度需求,需要做好消息管理,这就变成一件不那么容易的事情了,我们的服务器数以千计,如此才能满足百万用户的需求,我们为此付出了大量精力,我想这可能也是可以拿出去服务开发者们的。
所以我们又做了「clawinlink」,如果你是对做一个类似 theone陪伴的产品感兴趣的开发者,同时又只想专注于业务逻辑,而不想管服务器,消息管理那一堆繁琐的事情,那么可以试试申请「clawinlink」的内测,相信我,当你的产品一天要处理 1 亿条消息的时候,底层维护绝对是个噩梦。
我本来不是很想写 theOne 的,因为我最近写了一堆小说,不太想写文字了,但是既然我的同事做了clawinlink,那么我想还是可以写一下,希望对大家有所启发,同时也算是宣传一 下clawinlink
clawinlink:https://claw.baolieguoshi.com