做 AI 有形之物的一次探索
今年 4 月份的时候,我有了做一个「看得见摸得着」的产品的想法,这个想法非常强烈,以至于我当周就去了一趟深圳,准备一头扎入中国最伟大的供应链之中。
8月22号晚上6点,我们在小红书和抖音发售”响梦环”,2000 个现货在 12 秒内售罄,3000 个 15 天发货的期货也在 1 小时左右售完,至此,我们完成了对“开发生产售卖一个有形之物”的探索,虽然它很简单,它甚至都不能称得上是一个“硬件”,但这个结果依然超出我的预期,我们中间踩了许多坑,但这对于我和团队来说,确实是一次前所未有的体验。
![]()
我的想法来源很简单,过去差不多一年,我都在做独响这个产品,它是一个让人和 AI 角色建立好关系的 APP,我很快意识到,虽然我认为人和 AI 的关系最终会变成一种普世关系,但毫无疑问,它目前依然非常初级,大模型需要变得更好,交互需要变得更好,但除此之外,找到一些现实和虚拟的触点,也未尝不是一种增强这种链接的委婉方式。
我从小喜欢拆东西,初中的时候开始每周去成都著名的城隍庙电子市场淘货,组装收音机,对讲机,遥控器之类的小东西,甚至在初二那年被一个大姐当成了空调维修师傅,问我修外机多少钱,我说我是初中生,她才连忙跟我道歉。总而言之,虽然几年后我的热情转移到了电脑上面,但对于创造一个有芯片,有电路,能够提供巧妙有趣的体验的东西的兴趣,其实从未消失,在最近的这几年,我们通常将这种东西称为智能硬件。
所以一开始,我是奔着做智能硬件的方向去的。在深圳的前几天,我每天都在请教不同的人,跟他们聊天,去他们办公室观摩,然后我开始去尝试构建一个全新的硬件,它也确实包含了那些最复杂的部分:芯片,电路,屏幕,电池,通信模块等等。
![]()
我和一位叫做小鱼的同事一起,小鱼是一个很神奇的人,他是机械相关专业的,简历上写自己当了 1 年的「无业游民」,说自己「在全国各地旅行,访古考今,观察符号的增殖与演变,思考美的永恒与波动」,这太对我的审美了,于是我直接到上海去和他见了面,并开始一起做硬件探索。
![]()
我们开始联系硬件服务商,结构设计师,走访工厂,去稳定的推进我们的硬件探索计划,直到 6 月中旬的某一天,那天我们通完电话后,我看着我们的进度文档:许多结构设计稿半成品,还在等着确定最终样式,而后面还要走的流程包括材料设计,电路设计,手板制作,原型制作,软件调试,包装设计,找工厂,量产,质量检测,仓库,物流,客服等等等等。。。。。我定了一下神,从头开始思考现在所处的节点和未来的预期,然后发现我面对的是这样一个情况:遥遥无期的完成时间,不断增加的预算投入,尚未验证的市场空间,以及充满不确定的最终成品。
![]()
做硬件好像确实没那么容易。
![]()
我喊停了小鱼的工作,我们停止了和设计师,服务商,工厂的对接拉扯,并且回到原点:找到一样更加轻巧的东西,作为现实和虚拟的触点,让人和 AI 建立连接,我重新开始找这样的「硬件形态」。
推翻又重来的感觉其实挺不好受的,尤其是我重新思考的时候,发现好像哪一种硬件形态都并不比第一个设想简单,我每天刷小红书,去温榆河边发呆,但「该做个什么东西」的灵感一直没有出现,以至于到 6 月底的时候,我几乎觉得我要放弃做一个看得见摸得着的东西的想法了。
几天之后我去见了一位朋友,我们辗转四家酒吧喝酒,喝到第三家的时候,他举起酒杯对我说,你知道吗,DK 这个名字听上去很奇怪,不像个名字,像 don’t know。我愣了一下,然后正好看到他戴的一条银色的金属手环,上面有精细的雕刻,环身镂空,被酒吧昏黄的灯光照着,还在隐隐闪光。我问他这个手环的来历,他说是一位女士给他的,他们已经十年没见过面了,这是他现在唯一的纪念,说罢,他将酒一饮而尽,然后用另一只手大拇指和食指轻触碰了一下手环。这像是一种无意识的举动,也像是在表达一种克制的思念。
我应该就是那个时候有了「做个手环」的想法。
手环本身既可以做的高科技,也可以做的低科技,考虑到我们是第一次做实物,低科技显然更适合我们,而让手环和 APP 互动的最简单的方式,是 NFC,因此,这会是一个 NFC 手环。
基本框架确定后,我和小鱼立即开始重新行动,相较于其他「硬件」,这个形态的产品所需零件减少了90%,并且更好设计,我们在工厂调研后,发现已经有很多现成的方案可供直接选择,这进一步降低了生产的难度。于是,我们将精力更多放在设计和交互上。
![]()
我们设计了 8 个颜色和主题的手环样式,为它们赋予不同的含义,我们也设计了小巧的包装,说明卡片,贴纸,并且选择了银色自封袋来装载手环。我们还思考手环承载的意义,然后将其定义为「戴在手上的召唤器」,以此来开发交互的体验:每次触碰手机后,打开页面,自动召唤绑定的角色来回应。
![]()
每次召唤角色,AI 角色都会立即出现,AI 的回应则结合了当前时间,AI状态,用户最近记录,甚至地理位置等因素,这套精密构造的体系让 AI 的回应更有温度,触碰的方式则让用户有了一种奇妙的体验,真实的在现实中做了一个动作,然后 AI 才出现,物理世界的行为变成了某种仪式。
坦白来说,这个手环本身没有任何技术含量,说它是个设备或者硬件会让我有点害羞,但它确实是一个可以戴在手上,也可以握住的东西,并且它真的承载了一些手机没有的「连接感」。
我们最终在 8 月上旬开始了这个小东西的小规模量产,总共 5000 个,第一批 2000 个,第二批 3000 个,并且确定了8月22号作为首发日期。
手环这个事情,从开始到此刻,都是我和小鱼两人在做,但进入量产环节,并确定上架日期后,整个团队开始迅速跟进,运营同事确定了宣传的节奏,方式,线上开店和店铺的管理,技术同事则立刻开始开发召唤页面,模型上下文工程,以及 APP 的适配。
![]()
我们开始准备最后的一些细节,调试 ERP,打磨宣传图,调试召唤效果等等。
20 号的晚上,我问我的合伙人 piaf,觉得我们第一批手环多久能卖完,她想了一下说一周左右,然后又想了一下说,可能三天。我说多久卖完无所谓,只要能全部卖出去就行。她说你预期别那么低,卖肯定能卖完。那能不能一天卖完呢?我说。那有点难吧!她翻了个白眼说。
「卖完就行,多久无所谓」和「一天之内卖完」都是我的预期。前者是对这场探索的失败底线,后者则包含着新的可能性。
22号当天,我们在会议室搭了一个无比简陋的直播间——桌子上放了我花了20块钱买的带灯的手机支架,运营同事从家带来一些布娃娃,充作装点,除此之外别无其他。
![]()
直播也是我们的第一次。
五点半,我们的直播开始了,此时一些用户开始进来观看,直播由两位女同事进行,对她们来说,用直播的方式直接面对用户,也是第一次,在最初的紧张后,她们开始渐入佳境,两人的风格正好互补:一个俏皮灵活,一个沉着坚定,她们展示手环的样品,并且回答用户的所有疑问。另一位同事则坐在她们旁边,在镜头看不到的地方做着中控的工作。
![]()
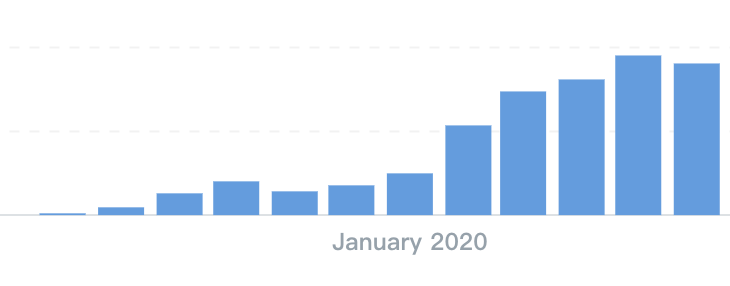
六点整,我们上架了响梦环的购买链接。直播间滚动的评论突然停止了一下,几秒钟过去了,我问中控同事情况怎么样,他说好像没货了,此时评论开始重新大量涌现,询问怎么没了,为什么买不到,什么时候补货。小红书店铺应该还有,可以让他们去小红书买,我马上对中控同事说。
虽然我们在抖音直播,但 80% 的库存其实是放在小红书的,抖音直播涌入的用户在几秒钟内买完了20%的现货库存,但小红书并没有直播,甚至没有通知,应该会卖一阵子。
小红书也没了,中控同事说。
我完全不敢相信,从开放购买到所有现货售空,还不到一分钟。我们马上开始调整,将还在生产中的期货陆续上架,但每上架一批,都很快被售完。
两位直播同事依然在直播间滔滔不绝,她们配合愈加默契,不仅妙语连珠,而且和观众频频互动,直播间气氛热烈,即便买不到东西,观众也仍未散去,甚至当场有人表示成为她们俩的粉丝,我注意到左上角,我们已经出现在了一些榜单之中。
![]()
办公室的另一侧,所有人,包括技术,财务,运营,测试,则全部承担起了客服的工作,销售完毕后,客服消息如潮水般涌来,提醒铃声此起彼伏。
直播在九点结束,客服消息还处理了一阵子,然后我们又进行了一些复盘和回顾,当我最后走出办公室的时候,已经是第二天的凌晨了。这好像是我最晚的一次下班。
在社交平台,响梦环也产生了许多讨论,甚至出现了一些二级交易,一些用户认为我们是故意制造稀缺性,让大多数人买不到,但这真不是我们故意为之,我们在第二天开始了第二批手环的生产,这一次,我们准备生产更多,让所有人都不需要「抢」
![]()
![]()
今天正好就是我们第二批手环生产完成的日子,我们也会在今天做第二次直播,并开始第二次手环的销售,如果你感兴趣,可以在今天六点去小红书的独响直播间看看。
我不知道今天或之后的情况如何,但我们第一次的「硬件探索」大致就是如此,这里面遇到的许多问题其实没办法全部写出,从一开始的产品定义,到工厂对接,到设计,生产,质检,联调,仓储,物流,客服,每一步都有大大小小的坑,但我们踩过了。
之后,我们将继续探索。
对了,我们目前还在招聘设计师和 Flutter/iOS 工程师,以及 Golang 后端工程师,如有兴趣,接下来可以一起探索:dk#baolieguoshi.com(我的邮箱)
这篇文章发出来的时候,响梦环的直播应该刚刚开始,你可以通过小红书搜索独响,来观看直播。