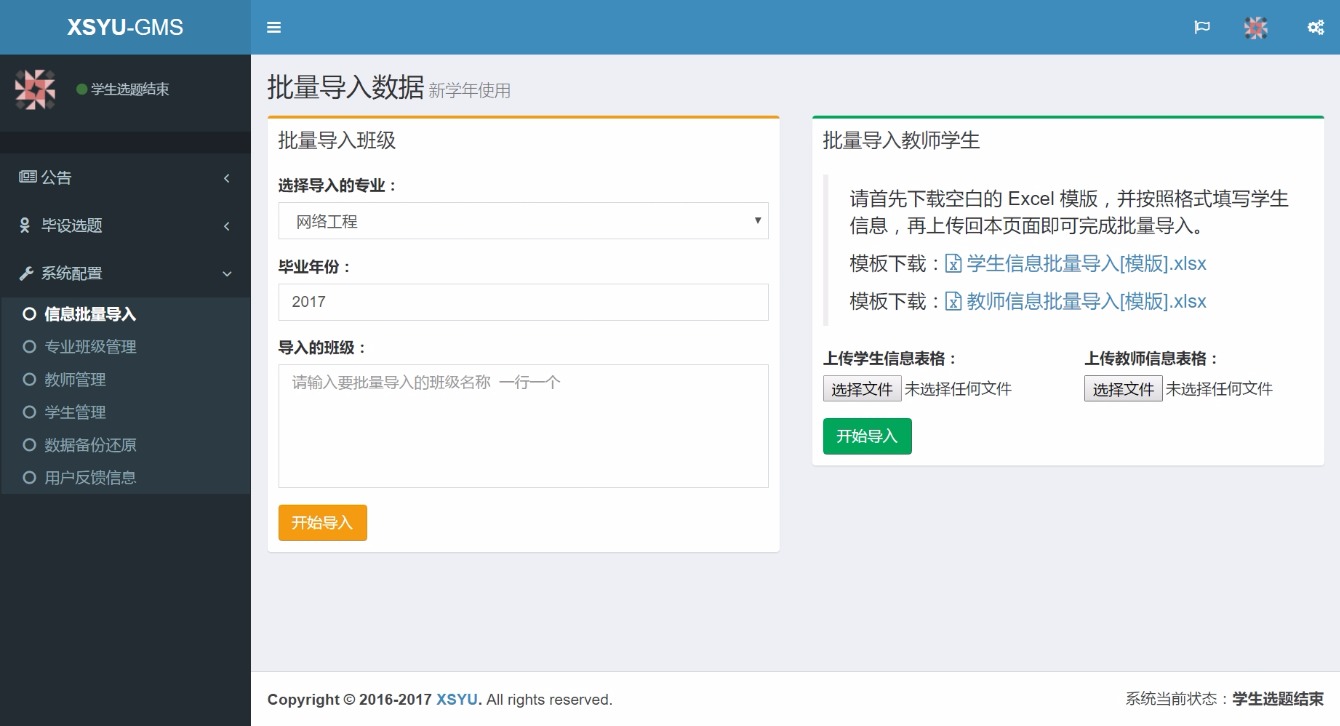
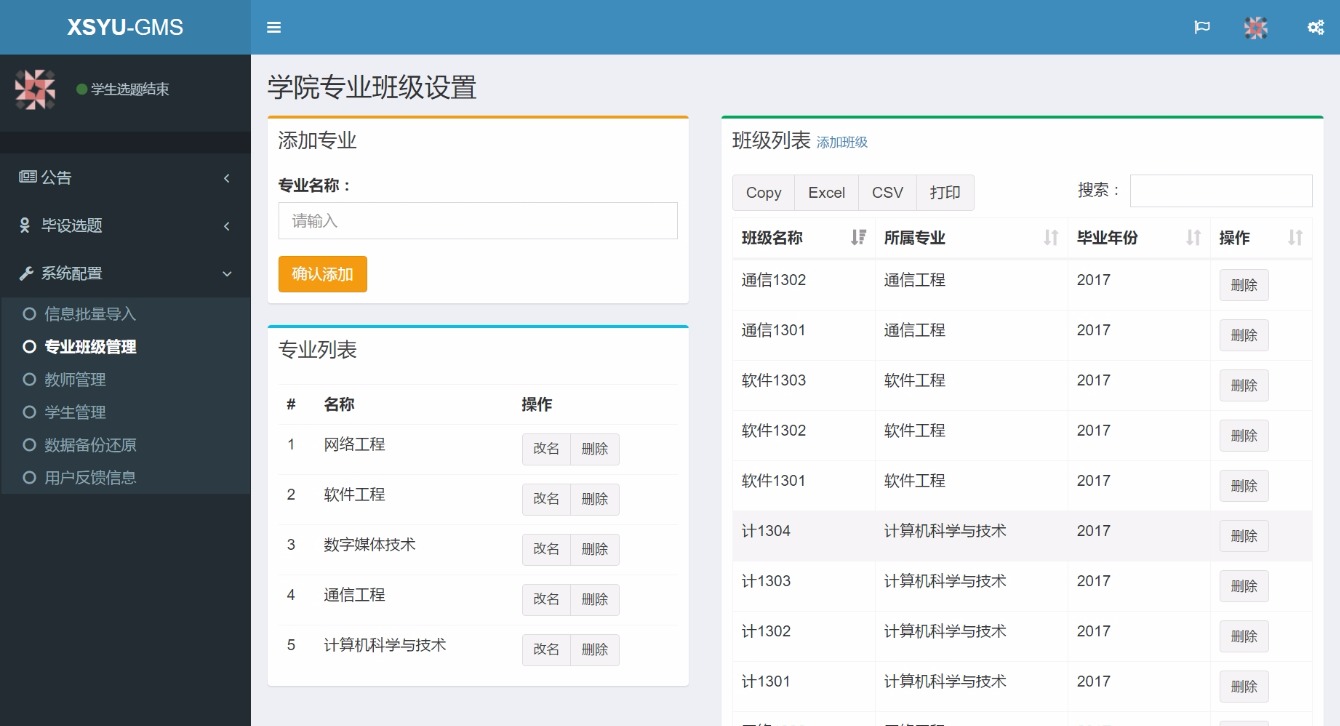
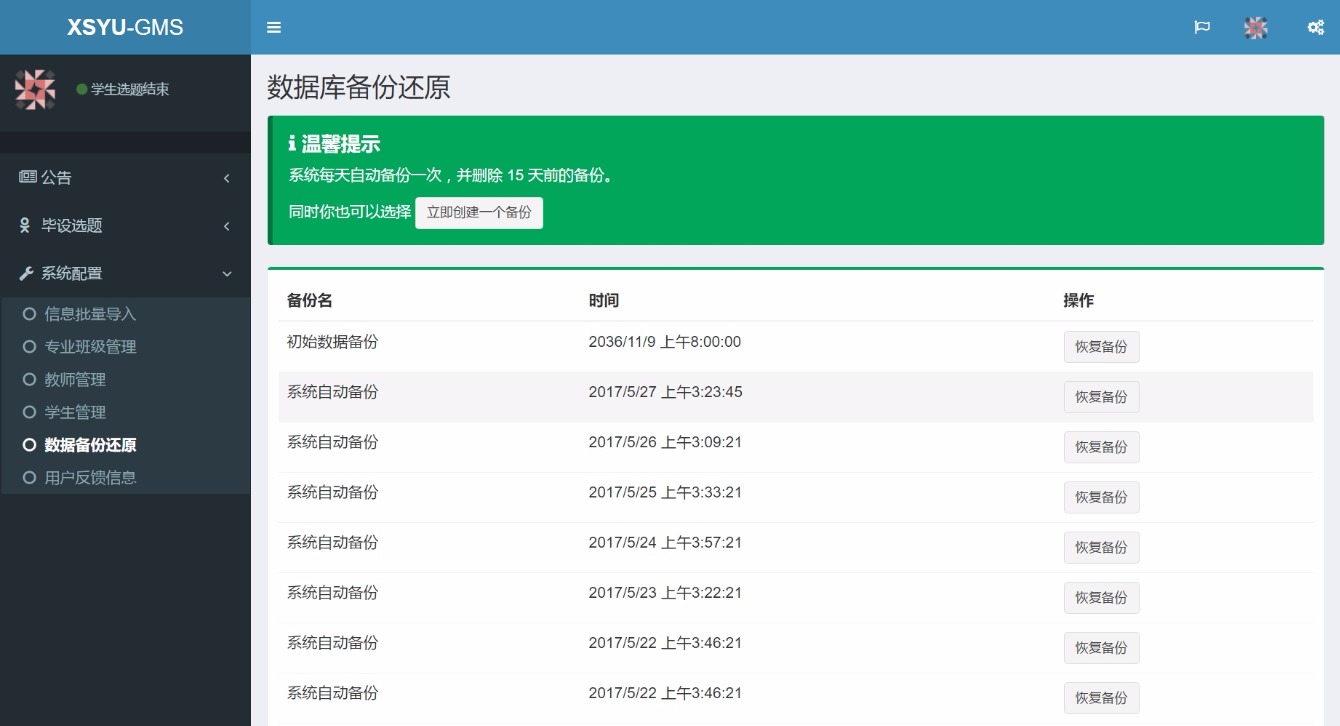
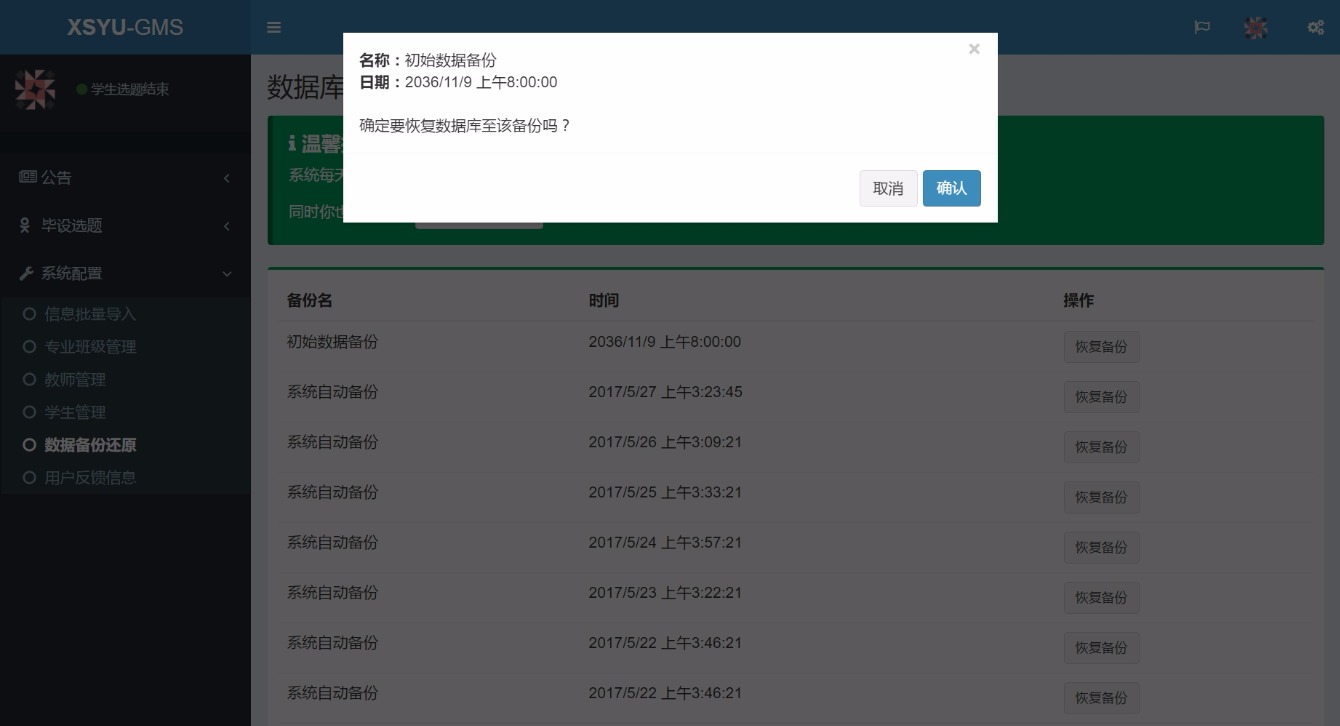
2020: 我找工作的心路历程
曾经在迎接 2020 的那个跨年夜里,给自己定下了今年的目标:努力找到一份满意的工作。而找工作确实也成为了我 2020 年的主旋律,从最初不知道自己几斤几两地海投,再到暑期去阿里实习,最后经过几家 Offer 的角逐选择了腾讯。中间确实是经历了不少事情。
非常不错的实习经历
我的实习部门是阿里云的块存储部门,经过 6 轮面试拿到实习机会,再与研究生导师争取,成为了我们导师手下多年以来唯一一个放出去实习的人。4 个月的实习经历算是我第一次走入职场,说实话,体验是相当不错,相当愉快的。
其实从这张不正经的工牌也可以看出,互联网企业的性格就是开放、年轻。面对领导完全没有所谓的压力,非常平易近人,同事都是年轻人,相互讨论的都是有趣的话题,食堂里面遇到陌生人大家也都以 “同学” 相称。给人的感觉就还是在学校,只不过身边的人变成了志同道合的人,手中做的事是更有价值的事。
学生毕业之后的去向很多,除了互联网还有体制内。对于不同的人各有各的好处,而通过这次实习我是深刻的感受到,我太适合于互联网企业这种没有官场文化、靠自己实力驱动的平台了。
互联网公司还有一个热门的话题,那就是加班了。作为“福报厂”,我原本已经做好了 996 的打算,不过进去了之后发现大约是 985 的状态,再加上工作期间也不会安排得特别满,吃完饭也有散步时间和午休时间,所以远比预期的要轻松。不过这也得因人而异,同组的实习生就认为挺累的,这大概和之前的在校经历有关,我研究生实验室的工作强度是比这更强的。![]()
工作方面的感悟
实习期间我共完成了 2 个项目(重设计的事件中心、和基于事件中心的自动告警机器人),与我平时的开发工作差异不大,所以完成的都不错。在这期间还提出了好几个让同事们眼前一亮的 idea,以此在转正答辩中顺利通过,项目细节就不在这展开介绍了。
实习的工作是后端研发岗,其实如果看我的博客或 Github,就能发现我对前端其实是颇为了解的,从传统的 JS 刀耕火种,再到 16 年前后 React 等前端工程化的兴起,再到基于 Node 的后端、中间件这些,我都是一路走过来的。当时也一直认为前端是一个有趣的领域,开发的东西能直观地被用户看到,美观易用的前端更是一种优雅的设计。
之所以找了后端岗位的原因却正是把前端领域了解地差不多了,虽说新的框架、工具库层出不穷,但前端的本质也看得比较透了 —— 按照要求给房子完成装修。资深的前端能熟练的运用现成的工具,更快的完成装修工作。而相比之下,后端负责根据地势设计地基、根据用途设计房屋结构,这会更有难度一些,也就是技术的天花板会更高一些。
实习之后更加确认了这种观点。就算技术不分深浅,那重要程度必定是有差异的。公司里前后端分离,不需要全栈,而一个产品必然是以后端为起点展开的,后端是前端的甲方。再例如我工作时对接的前端能力挺强,但却是公司招的外包,这也能说明一些问题。当然,上述内容只是我个人的见解。
Offer 抉择
除了阿里云的实习转正外,还有美团支付、腾讯文档、字节教育线、华为云,薪资都是 SP 或以上。当然,还有挂了的 pdd(一点也不可惜),以及简历把我拒掉之后还发邮件告诉我简历挂了的滴滴![]()
去年秋招经过一些抉择,最终还是签的阿里云,期间纠结的点无非就是地点、薪资、平台、部门这些。
拿到阿里的 Offer 确实不是一件容易的事,不仅周围人羡慕,我也挺满意的了。不过其实我私底下也明白,对我来说离 “完美的 Offer” 还是有一点点距离的:
主要是工作地点方面,虽说杭州是一个挺不错的城市,但作为一个在西安读书的四川人,我还是更希望去西安或者成都。
如果能在平台部门、薪资等其他方面不比阿里云 Offer 差,同时能得到满意的工作地点与工作岗位,对我来说那就是 “完美的 Offer” 了。抱着这样的期待,参与了春招~
在西安、成都的能与阿里云相提并论的大厂岗位其实屈指可数,抱着随缘的心态,相当幸运地在毕业前的 2 个月拿到了成都腾讯 WXG 企业微信的 Offer。这确实令人满意。✌
近 20 年的学生时代将告一段落,紧接着而来的是几十年的工作生涯。未来我将去向何方,到达怎样的高度,我不清楚。不过对我来说这将是一段全新的旅程,也是我做自己喜欢做的事、将自己能力变现的时刻。我会尽我所能,卷起来。努力干好~![]()
一些经验介绍
最后分享一些找工作过程中的经验,供后面的学弟学妹们参考,应该会对大家有帮助的。
- 所有的招聘流程都要参加。除了秋招之外,那一年的春招、春招提前批都要参加,多参加一次流程就是多一次机会,身边有的同学在纠结暑期实习能不能去,事实上就算不去,拿到实习 Offer 也肯定可以为秋招开绿灯的。再次也可以积累面试经验,所以所有的招聘流程都不要错过。
- 不要局限于一次实习。我只实习了一次,所以也只能初窥门径,缺乏对比。不过暑期实习由于工作比较忙可能会耽误秋招这也是真的。
- 简历。或者说是项目经历一定要丰富地体现在简历中,把简历做得好看很重要。
- 刷题。无数的经验介绍都强调刷题,事实上这确实很重要。再厉害的人与面试官手撕代码那也是必经之路。
- 题库。互联网面试被戏称为八股文面试,确实如此,去找找牛客网上大家整理的操作系统、网络、数据库、数据结构的题库,可以押中 90% 面试时面试官的问题。
祝愿大家也找到满意的工作~![]()