最近几个月,以深度学习和神经网络为主导的 AI 技术正在席卷全球,人们发现 AI 会画画,AI 会写文章,会回答问题,还会解决问题,虽然诸如推荐算法,计算机视觉等 AI 技术其实早已改变我们生活了,但生成式 AI 所展现出的那种创造力,还是几乎让大多数人在惊叹于其神奇后,或多或少的感觉到了一丝隐忧,甚至恐惧。
我过去半年多都在做 6pen,但主要职责是产品,我对 AI 一窍不通,但一直以来,我对它的好奇从未减弱,大约 2 个月前,我下定决心,开始比较正式的学习深度学习和神经网络,并越来越被它的趣味和魅力吸引,于此同时,这个行业也在发生着快速和惊人的变化,我觉得这个时间节点非常微妙,它可能代表这一次转折,因此决定写这篇文章。
这篇文章会分成三个部分,第一部分是对深度学习的原理做简单的说明,这背后其实比很多人预想的要简单很多,了解原理有助于我们了解它的可能和局限,以及部分的实现技术去魅,然后,我会解释为什么我会觉得 AI 最先替代的,可能是 AI 工程师,最后,我会写一下对这个行业的个人拙见。
深度学习原理说明-上小学的侄子说他能看懂
对于人工智能,我们知道它能学习,学习了之后它可以识别图像,可以判断对错,可以生成文本或图片,但这个学习到底是什么,又是怎么学的,则是很难理解的,毕竟它没脑子,只是硬盘,GPU和内存。
对人工智能如何学习的理解,我认为是理解这项技术的关键,而这其实可以用小学数学去解释。
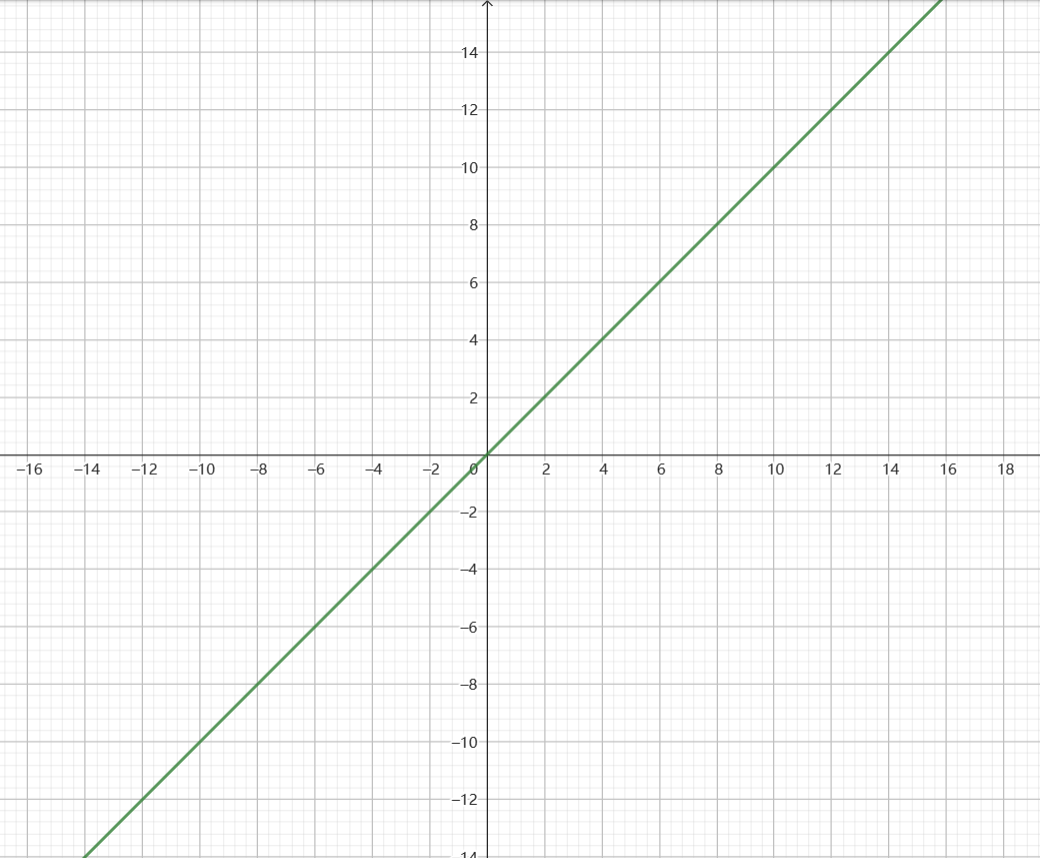
我们可以在坐标轴画一条线,y=x,这条线就像这样

我们如果加个参数,例如 y = 2x,那么这条线就会发生变化,变陡一点,如果我们再加个参数,例如 y = 2x +4,那么这条线则会上移一点,看上去是这样
这没有什么难的,但不管你信不信,这就是深度学习的原理了。
y=2x+4,可以看作是一个输入和输出都是一个数字,有两个参数的神经网络层,对于其中的 2 和 4 ,我们可以不断变化,来改变线的斜率和位置,这个过程就是学习。
学习的过程有点类似于用一种笨办法”解”方程式,数据集就是一些x和y的值,例如(x=1,y=6),(x=2,y=10),(x=3,y=14),开始训练之后,模型会随便设置这两个参数,比方说 y = 5x+102,这样一算,x=1的时候,y居然等于107,比数据集中的(x=1,y=6)大太多了,于是模型会把参数调小一点,比方说y=4x+50,这样再算,x=1的时候,y=45,还是太大了,于是模型再把参数调小一点,直到调到y=2x+1,结果发现,这样似乎算出来的y又太小了,于是模型再把参数调大一点。
这里面包含了神经网络深度学习的所有东西,首先是一个模型结构,我们已经设定成了y=ax+b,a和b是两个参数,然后模型会尝试不同的a和b,看差多少,这个看差多少的部分,叫做损失函数,然后,模型又会调整一下a和b的大小,负责调整的部分,则叫做优化器。
真实的神经网络,哪怕是最简单的层,也显然不会只是一个二元一次方程,它会比我们看到的更复杂一点,例如这样
并且它具备很多层,每一层的输出,都将作为输出,传递给下一层,一个神经网络可能有50层,甚至更多,也可能只有几层,这取决于人们想用它解决什么问题。
但总的来说,这就是深度学习 神经网络的大致原理了。当我们的模型只有一层,且只有两个参数的 时候,我们只能得到一个数字,并且它很难有什么实际作用,但是当我们有上百层的模型结构,并且参数有1750亿的时候,事情就变得不一样了。
一个数据集中的样例可能是这样:输入是“你觉得老友记怎么样 ”,输出是“很棒,这是一部非常经典的美剧”,当然,这些句子都预先被某种方式转化成了一大堆数字,所以可以被各个方程式拿去计算,通过调节这一千多亿个参数,比方说第6428412456个参数,增加2.3,第5834728834个参数,减少9,当然这是我瞎写的,实际上有成千上万张显卡,用极其庞大的算力小心翼翼的调整这一千多亿个数字,试图让模型的输出,很接近我们给的数据集的输出。
同时,数据集也有数以亿计的样例,这些样例一次又一次的被模型用来调整自己的这一千多亿个参数,最后达到了一个比较好的效果,这样,在我们给一些数据集所没有的输入的时候,模型将有较大概率,能给一个看上去依然不错的输出,这个时候我们就说训练好了,或者用更专业的说法,收敛了。
我需要说明的是,事情远比以上的描述更加复杂,但原理确实就是这么简单。
我想我们不可能通过阅读几篇科普文章,就去干那些苦学了五六年才毕业的医生们做的工作,但我们至少要知道,生病的治疗方式可能是住院,补液,吃抗生素等等,而绝不会是吃水银,放血和跳大神。同样的,知道深度学习的大致原理,离着手从事相关工作,也有非常非常遥远的距离,但我们至少知道,噢原来是这么一回事。
为什么 AI 工程师可能是会被最先替代的
在几年前,或者更早一点的时候,模型不会太大,也不会有一个放之四海而皆准的模型,即便是新的模型结构或者方法被提出来,也需要许多不同领域的 AI 工程师,用自己所在领域的数据,来 finetune(微调)这个模型,甚至自己修改模型结构,尝试各种各样的优化办法,才能达到为自己所用的目的。
经验,技巧,和一些独家数据,在这个时候都是有用的,甚至很有用,学术界和开源界都乐于发现和创造新的模式,结构,然后无数个领域的 AI 工程师,在此基础上进行大量的优化,训练,从而让一个学术概念,变成能解决实际问题,创造价值的新模型。
在这个时候,提出一个模型结构,或进行创新,依赖的更多是人的智慧,包括了巧妙的思考,对数学的理解,以及一些运气(但不多),因此,有才能的人,包括学者,研究人员,以及一些杰出的工程师,乐于分享他们的研究成果,各个领域的公司里的 AI 工程师,则会将这些成果转化会实际需求的解决方案,某些时候,在学术成果解决实际问题的时候,会产生新的问题,或者诞生新的方法,而这也会很快转化为一个新的学术成果,被大家了解。
由此,一个活跃,繁荣,不断互相推动向前的行业(结合了大学,研究机构和商业公司),在过去的许多年里蓬勃发展,新的概念,理论层出不穷,虽然很难被圈子之外的普通人或非技术人员了解,但任何人把头探入这个圈子时,都会被其活跃的氛围所感染。
大模型,尤其是LLM(大语言模型)的出现,让这个配合良好的系统首次出现了一丝裂纹,大模型,顾名思义,就是参数特别特别多的模型,一个参数,如我们上面所写,是一个数字,在计算机里,一个数字会占用4个字节,那么1000万个参数,会占用4000万字节,这大约是38M,听上去还好,相当于一个小视频,但参数如果增加到比方说60亿,那就会占用22G的空间,由于参数是会被计算,随时变化的,所以放在硬盘甚至内存里都不够快,需要放到GPU的显存里,60亿个参数,需要显存22G以上的GPU才能运算,这已经有点贵了。
而我们熟知的 GPT3,是 1750 亿参数,光是凑够能够把这些参数全部放下的显卡,已经非常昂贵了,但这只是放下,如果还要进行训练,即让这1750亿参数进行很多变化,来找到更好的组合,则对应的算力成本可以称得上是天文数字。
这个成本个人研究者肯定无法承担,即便是中小公司,研究机构,大学,也依然难以承受。
对于行业的很多研究人员来说,这是第一个问题——拿到这样的大模型,似乎很难做优化,或者做研究,因为首先根本没钱把它跑起来(即便它开源),其次即便能跑起来,把它优化的更好,也需要比以往多得多的数据,这个数据在某种程度上更难获得。
这有点像我们养宠物,你可以在家里养猫或者狗,你家肯定放得下,你随便找点吃的,也饿不着它们,然后你可以训练它们坐下或者绕圈圈,大模型则相当于一只霸王龙,体重七吨,长12米,就算你把家扩建了,勉强能放下,喂它吃饱也很困难,这样还怎么训练它转圈圈呢。
紧接着而来的是第二个问题,随着大模型的参数越来越多,大模型的效果也越来越好,好到甚至让人觉得不可思议,不仅如此,这些大模型见了鬼,居然在每一个领域,效果都那么好,例如传统的文本生成模型,会根据擅长的任务分为聊天,问答,摘要,翻译,情感分析等等,并且在每个专业领域,例如互联网,金融,医疗,都需要额外再做一些特殊训练,才能取得比较好的结果,但 chatgpt 出现之后,它不需要做任何处理,也不需要做额外训练,就超越了绝大多数(或者所有)传统的文本模型,且无论是在聊天,问答,摘要,翻译,还是别的什么任务,也不论是在任何领域,它都更好。
第一个问题意味着人们对大模型做任何事情,都要付出非常昂贵的代价,第二个问题,则意味着即便你付出昂贵的代价,也不一定能获取更好的结果,虽然我们现在很难说这些大模型真的就能比得过所有通过预训练-finetune(其他优化)产出的模型,但应该没有人会否认,这的确是大势所趋,可能在某些极其细分的领域,有一些模型在特定任务处理上比 chatgpt 更好,但我们都知道,这很快就会被改变。
第三个问题则是,因为大模型的开发极其昂贵,大模型的效果又非常好,所以。。它往往就不开源了,不开源的背后也有另一个原因,如果开源,往往需要对数据集做出说明,而大模型的数据集往往庞大到超出想象,对这些数据的来源,合规,隐私做出合理的说明,显然是很困难的,所以闭源是最简单的处理方式,闭源的大模型,通过出售 API 或周边服务,反而能有更大的商业想象空间,虽然和其训练成本相比依然很难说是个赚钱的买卖,但这个想象力和因此而来的可能性,至少已经让微软愿意掏腰包了。
在这样的背景下,90% 的 AI 工程师将会处在比较尴尬的位置上,因为他们努力所解决的问题,用大模型会解决的更好,而大模型也没有微调,优化,或做别的什么底层处理的必要了,就只有用和不用的选择而已。
绝大多数 AI 工程师没有千亿参数大模型的调教经验,也很难有这样的机会,这会让数据飞轮(更多人用,效果更好,效果更好,更多人用)前所未有的集中在极少数的那么一两个大模型上,从而让它们和别的模型拉开越来越大的差距。
在我们担忧 AI 绘画替代画师的时候,其实画师是没有那么容易被替代的,因为即便是刚入门的画师,也可以有远胜于最先进的 AI 的可控性,更别说艺术风格的创造了。其它的一些“AI替代”说也有类似的情况,所以虽然隐忧重重,但还不是那么快会发生的事情。
更快会发生的替代,可能是 AI 工程师,尤其是非顶级的,没有大模型调教经验的 AI 工程师,因为在暴力的大参数,大算力,大数据前面,个人经验,技巧甚至某些行业数据,都很难与其匹敌,而由于大模型的成本,和不开源的特性,连做这些尝试的可能性也被无限降低了。一个更接近通用的人工智能,正在马不停蹄的向我们赶来。
好事还是坏事
首先我觉得我们肯定不需要为 AI 工程师们操太多心,因为他们本来就是世界上最聪明的一群人,他们都有极好的教育背景和工程能力,放到任何地方都可以发光发热,另一方面,我所写的,可能也有局限,或者在未来被完全打脸,这是有可能的,人类智慧永远是给我们带来惊喜的原动力,如同量子计算可能会让之前牢不可破的加密方式被轻松破解一样,反过来,石破天惊的算法或结构创新,可能也会让大力出奇迹的大模型再次落后。
看上去,大模型的流行,会让我们这样的上层的应用开发者和公司获益,因为无需自己搭建和优化模型,可以以相对低廉的成本(模型的创造和训练很昂贵,但使用不那么贵,且因为用的人多,成本还可以进一步降低),使用最先进的技术。
但从另一个角度看,在这样的生态中,无论是做应用的开发者,上层应用,还是用户,其实最终都会成为大模型的养料的一部分,它在不断进化,我们对其了解却越来越少,最终可能会有的局面是,其他公司和开发者只能选择用或不用,而不用就会落后于所有竞争对手,这种情况发生时,其实也就意味着所有开发者和公司已经没有别的选择了。
而此时的大模型持有者,则会成为某种意义上的极权,它可以制定任何规则,它可以凌驾于商业,道德,甚至法律之上,因为那个时候我们已经对其极其依赖了,就像我们依赖今天的互联网一样,但所幸互联网不是任何一家公司的,它属于全人类。
话说回来,比如说人家openai,花了十亿美金训练出来的模型,非要让人家贡献给全人类,好像也不太合适,在模型之外,背后还是商业规则,如果我们能让被贡献给全人类作为知识的大模型的开发者,获得比自己闭源,只是拿去卖API多得多的收益,那么,才有可能有人把大模型搞出来,然后开放给所有人,也会有更多的钱进来,支撑起越来越昂贵的模型的创新。
现在我们处在这样一个节点,花最多钱做的大模型,效果确实是最好的,也确实是闭源的,它已经好到让人震惊的地步,但目前也还没有被完全让人依赖,与此同时,一些别的努力也在进行,例如huggingface 做的 bloom 大模型完全开源,stable diffusion 也完全开源,目前来看,闭源的大模型仍然牢占上风,开源行为获得了广泛的赞誉,和大量不遵守开源协议的的使用,这某种程度为整个行业带来了繁荣,但这繁荣是否能反哺开源大模型,让它和闭源大模型有一战之力,则依然有待验证。
技术本身可能没有对错之分,开放和封闭,都是一种策略,而这背后,都有人类智慧的体现,但假如要让我来做选择,我肯定希望,我的选择,最终不会让我没有选择。