WeChat Linux 终于等到与其他的平台一起显示在官网了!
7 November 2024 at 15:01
gegewu0927:
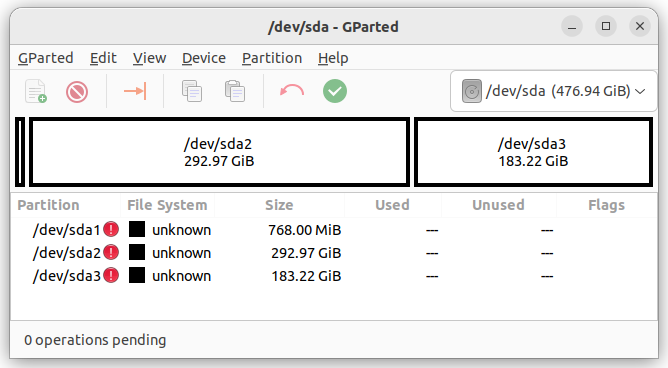
担心代码数据丢失所以想备份一下虚拟机,发现没空间了,查到这篇文章可以压缩虚拟机磁盘空间: https://mayanpeng.cn/archives/158.html 没注意提示, 敲了一个 yes, 这下数据真的丢了
# lvreduce -L -80G /dev/pve/vm-101-disk-1
WARNING: Reducing active and open logical volume to 176.00 GiB.
THIS MAY DESTROY YOUR DATA (filesystem etc.)
Do you really want to reduce pve/vm-101-disk-1? [y/n]: y
Size of logical volume pve/vm-101-disk-1 changed from 256.00 GiB (65536 extents) to 176.00 GiB (45056 extents).
Logical volume pve/vm-101-disk-1 successfully resized.
# resize2fs /dev/pve/vm-101-disk-1
resize2fs: Bad magic number in super-block while trying to open /dev/pve/vm-101-disk-1
Couldn't find valid filesystem superblock.
此时感觉不对,想自救一下
# lvextend -L 80G /dev/pve/vm-101-disk-1
New size given (20480 extents) not larger than existing size (45056 extents)
# fsck /dev/pve/vm-101-disk-1
fsck from util-linux 2.38.1
e2fsck 1.47.0 (5-Feb-2023)
ext2fs_open2: Bad magic number in super-block
fsck.ext2: Superblock invalid, trying backup blocks...
fsck.ext2: Bad magic number in super-block while trying to open /dev/mapper/pve-vm--101--disk--1
......, and you might try running e2fsck with an alternate superblock:
e2fsck -b 8193 <device>
or
e2fsck -b 32768 <device>
Found a PMBR partition table in /dev/mapper/pve-vm--101--disk--1
结果都不行,这时在 V2EX 看到大佬发的链接,还是没法启动
vgcfgrestore --force -f pve_00050-1698916710.vg pve
目前是这个状态, 不知道还有没有机会
GPT fdisk (gdisk) version 1.0.9
Warning! Disk size is smaller than the main header indicates! Loading
secondary header from the last sector of the disk! You should use 'v' to
verify disk integrity, and perhaps options on the experts' menu to repair
the disk.
Caution: invalid backup GPT header, but valid main header; regenerating
backup header from main header.
Warning! One or more CRCs don't match. You should repair the disk!
Main header: OK
Backup header: ERROR
Main partition table: OK
Backup partition table: ERROR
Partition table scan:
MBR: protective
BSD: not present
APM: not present
GPT: damaged
****************************************************************************
Caution: Found protective or hybrid MBR and corrupt GPT. Using GPT, but disk
verification and recovery are STRONGLY recommended.
****************************************************************************
抱歉稍微标题党
我是后端程序员,大部分时候写一写 Spring Boot 之类的。
现在公司项目用的是 Red Hat 系统,WildFly 服务器。
因为有专门的基础设施部门,我除了偶尔需要部署一下服务器或者排查点问题,其他时候不太需要和 Linux 打交道。
于是突然想到一个问题,除了免费,Linux 比起 Win ,都有啥优点。几乎所有我在 Linux 能做的事,在 Win 上都能、甚至更轻松地能做到。
本人水平有限,还请各位大佬不吝赐教,谢谢。
最近在 Unraid 升级 6.12.x 版本以后会偶发性的产生一个 Bug,其表现为 Unraid 网页无法打开(这里是指访问 Unraid IP 地址无法访问 Web 管理界面)。这个问题实际上是由于 Unraid 上的 Nginx 服务失去响应导致的。这种情况下我们只需要干掉 Nginx 进程并重启就可以了。
首先通过 ps -aux | grep nginx 找到 Nginx 主进程的 PID,然后通过 kill -9 <PID> 干掉进程。要再次启动 Nginx,可以运行
1 | cd /etc/rc.d/ |
注意通过 ./rc.nginx restart 在正常情况下可以重启 Nginx 服务,但是在 Nginx 处于无法响应的状态时,这个脚本无法杀死 Nginx 进程,必须要手动终止。
在 Ubuntu 中彻底删除一个用户涉及到几个步骤,不仅仅是删除用户,还可能包括删除与用户相关的数据。以下是步骤指南:
确保用户未登录: 在删除用户之前,最好确保该用户未登录。你可以使用 who 命令来检查哪些用户当前已登录。
1 | who |
删除用户: 使用 userdel 命令删除用户。如果你还希望删除用户的主目录和邮件池,可以使用 -r 选项。
1 | sudo userdel -r username |
其中,username 是你想删除的用户的用户名。
注意:-r 选项会删除用户的主目录(通常是 /home/username)。确保你已经备份了所有重要的数据!
检查文件系统: 即使删除了用户和其主目录,可能仍然在文件系统上遗留一些属于该用户的文件。你可以使用 find 命令来搜索这些文件:
1 | sudo find / -user username |
这将列出所有属于 username 的文件。根据你的需要,你可以手动删除这些文件或更改它们的所有权。
删除用户的 cron 作业: 如果用户配置了任何 cron 作业,你还需要手动删除它们。检查 /var/spool/cron/crontabs/username 是否存在,如果存在,删除它。
1 | sudo rm /var/spool/cron/crontabs/username |
其他服务或配置: 如果该用户有其他特定的配置,例如在 /etc/sudoers 中的条目或在其他服务中的特殊访问权限,你需要手动检查并删除它们。
请在进行任何删除操作之前确保备份所有重要数据。确保你明确知道正在执行的操作,避免意外删除重要文件或配置。
首先,你需要知道安装的PHP版本的完整包名。可以使用dpkg命令列出所有安装的包,然后找到PHP的版本。
dpkg -l | grep php
找到要卸载的PHP版本对应的包名后,使用apt-get remove命令进行卸载。例如,如果要卸载PHP 8.2,可以执行以下命令:
sudo apt-get remove php8.2*
如果你还想删除配置文件,可以使用apt-get purge命令:
sudo apt-get purge php8.2*
最后,运行autoremove来自动删除不再需要的依赖包:
sudo apt-get autoremove
温馨提示:确保在卸载PHP版本之前,不要影响到系统运行或其他服务依赖PHP的运作。如果你不确定,可以先进行测试卸载,通过添加–dry-run选项来模拟执行卸载命令:
sudo apt-get remove --dry-run php8.2*
——这篇攻略和是否外置硬盘盒,没多大关系。普通内置硬盘也可以这样加密安装。
最新的 Ubuntu 22.04 之后的版本,在安装界面里自带了 LVM 全盘加密安装的选项。但是并不能满足第 3 条需求。所以还需要一些复杂的手动操作。
安装过程尽量围绕 ubuntu 的图形安装界面,对新人友好。参考并验证了这篇教程。但原文连同 /boot 引导分区也一起加密了,于是在配置上略显繁琐。我觉得加密 /boot 并不是很有必要,做了一些改动。最终的硬盘分区结构为(以 512GB 硬盘为例):
下载 Ubuntu,制作 USB 安装盘(过程略)。——然后,强烈建议在整个安装过程之前,在电脑的 BIOS 里,把内置的其它硬盘暂时卸载。
插上移动硬盘和 USB 启动盘。从 U 盘启动电脑,选择 Try Ubuntu。最新的 Ubuntu 22.04 安装程序里,已经内置了所需的 cryptsetup 和 cryptsetup-initramfs 软件包。因此,整个安装过程中,应该不需要连接互联网。
首先,把硬盘预分区。分区软件有很多种,可以用原文的 sgdidk,也可以直接用图形界面下的 Disk 或者 Gparted。在硬盘上创建 GPT 分区表,然后分成:
这些分区都先不用格式化。记住第二个分区的名字,本文假定为 /dev/sda2。
分区成功后,关闭分区软件,打开 Terminal 命令界面,执行 root 权限
sudo -i将系统分区加密。按提示输入密码,——这个密码,就是以后每次启动时,挂在硬盘用的密码。和安装 Ubuntu 时的用户密码,并不是一回事。
cryptsetup luksFormat --type=luks1 /dev/sda2解锁刚刚加密的分区:
cryptsetup open /dev/sda2 hd2_crypt创建逻辑卷组(LVM),然后在其中创建 2GB 的 swap 交换分区,再把剩余的空间创建为系统分区(这两个分区的大小,大家自行调整):
pvcreate /dev/mapper/hd2_crypt
vgcreate ubuntu--vg /dev/mapper/hd2_crypt
lvcreate -L 2G -n swap_1 ubuntu--vg
lvcreate -l 100%FREE -n root ubuntu--vg然后,运行桌面上的 Ubuntu 安装程序(Terminal 先不要关),在磁盘分区页面,选择 Something else,进行手动分区。
点击 Install Now,确认对分区的设置。注意,到了下一步创建用户的界面时,先不要继续。切换回 Terminal 命令行界面,正式安装前,在 GRUB 中启用加密(能看懂下面这些命令的话,也可以直接去编辑相应的文件):
while [ ! -d /target/etc/default/grub.d ]; do sleep 1; done; echo "GRUB_ENABLE_CRYPTODISK=y" > /target/etc/default/grub.d/local.cfg然后回到创建用户的页面,点击继续,开始安装系统。安装结束后,先不要 restart。而是点击 Continue Testing。
回到 Terminal 命令行界面,chroot 到新装的系统:
mount /dev/mapper/ubuntu----vg-root /target
for n in proc sys dev etc/resolv.conf; do mount --rbind /$n /target/$n; done
chroot /target
mount -a原文说此时需要(联网)安装 apt install cryptsetup-initramfs;但我用的 ubuntu 安装程序已经自带了,并不需要联网安装软件包。
添加密钥文件相关设置:
echo "KEYFILE_PATTERN=/etc/luks/*.keyfile" >> /etc/cryptsetup-initramfs/conf-hook
echo "UMASK=0077" >> /etc/initramfs-tools/initramfs.conf创建密钥文件并将其添加到 LUKS
mkdir /etc/luks
dd if=/dev/urandom of=/etc/luks/boot_os.keyfile bs=512 count=1
chmod u=rx,go-rwx /etc/luks
chmod u=r,go-rwx /etc/luks/boot_os.keyfile将密钥添加到 boot_os.file 和 Crypttab
cryptsetup luksAddKey /dev/sda2 /etc/luks/boot_os.keyfile
echo "hd2_crypt UUID=$(blkid -s UUID -o value /dev/sda2) /etc/luks/boot_os.keyfile luks,discard" >> /etc/crypttab更新 Initialramfs 内核映像
update-initramfs -u -k all此时全部结束。可以重启系统啦。
最简单的方式,是在已经启动的移动硬盘系统里,先通过 disk 等分区软件,确认加密分区的名字(这里假设仍然是 /dev/sda2,但实际上不一定了),打开 Terminal 界面,
sudo -i
cryptsetup luksChangeKey /dev/sda2按照提示,输入旧密码,再输入两遍新密码。最后,更新 initramfs,
update-initramfs -u -k all就可以了。
![]() 因为我的固件可能有内存泄漏,所以想办法定时释放内存。其实就是用 Linux 的方式。
因为我的固件可能有内存泄漏,所以想办法定时释放内存。其实就是用 Linux 的方式。
在管理界面 > 系统 > 计划任务,加入下面代码。每天5点和17点自动释放内存。
0 5,17 * * * sync && echo 1 > /proc/sys/vm/drop_caches
![]()
刚才看论文做笔记时Evernote突然停止响应了,本打算用Activity Monitor强制关闭,转念一想,不如学下如何用terminal强制关闭程序吧!正好有人对kill的一些写法有疑问,放上来分享一下。
ps -A | grep Evernote
kill 945
找PID: ps -A|grep [进程名]杀进程:kill [PID]
![]()
Cygwin 是一个 Windows 下的 Linux POSIX 模拟器,通过它我们可以直接运行一个 Linux 终端,非常好用。
网络上关于如何添加一个 “在当前目录打开 Cygwin” 的右键菜单的教程有很多,但是这些方法都有一个问题,那就是不能在中文目录下正常工作,于是研究了一番,修复了这个问题。
既然英文路径可以但中文不行,我最先想到的是使用 Cygwin 自带的 base64 命令,将 encode(path) 后的非中文字符串传给 Cygwin 之后,再 decode 得到包含中文的路径。然而不行,正确的 base64 传递到 Cygwin 之后 decode 却是乱码。
问题的原因很容易想到,那就是编码的问题。经过几次输出中间变量后验证了这个猜想:Windows 采用的是 GB2312 编码,而 Cygwin 采用的是 UTF-8. Windows 将当前路径作为参数传递给 Cygwin 主程序时,Cygwin 不能正确读取路径。
修改 Windows 或者 Cygwin 的默认编码肯定是下下之策。解决该问题最终还是绕不开编码转换。我最终的思路为:
我的 Cygwin 安装目录为 C:\cygwin64,Shell 为 ZSH,如果你使用的是 Bash,有的地方与我的不同。具体步骤如下:
导入注册表文件 cygwin.reg:
Windows Registry Editor Version 5.00 [HKEY_CLASSES_ROOT\Directory\Background\shell\cygwin64_bash] @="打开 Cygwin 终端" "icon"="C:\cygwin64\Cygwin.ico" [HKEY_CLASSES_ROOT\Directory\Background\shell\cygwin64_bash\command] @="C:\cygwin64\run_by_right_click.bat \"%V\""
我们的入口程序 C:\cygwin64\run_by_right_click.bat
@echo off SET dir=%1 REM 双引号删除 SET dir=%dir:"=% C: chdir C:\cygwin64 rem del /Q chere.path set /p="%dir%">chere.path bin\zsh.exe -li
![]() bat 代码是真的难写。。。写这段代码我便踩了无数的坑。
bat 代码是真的难写。。。写这段代码我便踩了无数的坑。
在 Cygwin 内编写 ~/.zshrc,在末尾添加目录跳转命令:
if [ -e /chere.path ];then
/usr/bin/enca -L zh_CN -x utf-8 /chere.path
CPWD=/usr/bin/cat /chere.path
rm /chere.path
cd /bin/cygpath "$CPWD"
fi
这里用到了 enca 用于自动编码转换,所以需要在 Cygwin 包管理器中安装这个软件。
over!![]() 现在便可以在中文文件夹中右键打开 Cygwin 了。
现在便可以在中文文件夹中右键打开 Cygwin 了。
最后最后。你可能会说,为啥都新世纪了,你还在用 Cygwin 这种… 模拟器?原生 Linux/ 虚拟机 不好用嘛?WSL 不香吗?甚至 Powershell 不也不错?
那我还真觉得 Cygwin 秒杀上述所有的方案。首先,我只是想在 Windows 上安装一个代替 cmd 的 Shell 环境用于日常操作,并不需要高性能什么的,所以原生 Linux 系统、虚拟机、Docker 就不是解决同一个问题的东西。
至于 Powershell,虽说是比 cmd 好多了,但毕竟是另一套语法和体系,我不想学它也对它不感兴趣。Bash+GNU tools 那才是世界通用法则。ZSH 作为日常使用的终端也确实美观好用!
而 WSL 这东西确实很吸引人,性能比 Cygwin 强太多,几乎就是原生系统。然而!WSL 运行于内核态,与 Windows 平级,就算有文件系统的映射,WSL 也并不能直接当作 Windows 的 Shell 来使用的。看下面的图你就知道我在说啥了。
图中,npm 和 git 是我在 Windows 中安装的 exe 包,而 ssh、tail、md5sum 是 Cygwin 中提供的 Linux 命令,直接相互调用无压力,这才是 Windows 中我想要的 Shell 的样子。可是 WSL 是不能这么做的,两个系统是隔开的。
我这基于 OpenWrt 的路由器可以说是超级强大,不仅仅是一个无线路由器,插上 U 盘可以变身为 NAS+下载机,可以运行 Python 小程序,甚至还有人在上面搭建 LNMP 运行 Owncloud。可以说是一台 VPS 可以干的事情我都可以在宿舍的路由器上实现,十分强大。
然而最近才了解到,这颗 580MHz 的 MTK7260A 仅仅是一颗智能路由器当中处于中低端的 CPU,说实话我是不信的,于是打算用 UnixBench 来客观测试一下这个小家伙的真实水平。
UnixBench 是基于 Perl 并拥有 30 年历史的基准测试软件,也就是跑分软件。通过运行一系列科学计算函数测试 CPU 性能,以及 OS 的任务执行效率、硬盘性能等。最终得到一个分数。
路由器:Newifi Mini
OS:LEDE 17.01.2(一个 OpenWrt 的著名分支)
Linux Kernel:4.4.71
架构:MIPS
RAM:128M
ROM:16M
系统基本为纯净的 LEDE,除了正在运行着路由器的基本网络服务外,跑分时运行了一个 PPTP VPN Client 服务。
OpenWrt 的 libgcc 套件体积 22M 的样子,但正如上面所写,我的路由器 ROM 总共只有 16M,挂载分区什么的不是很有必要,于是我使用交叉编译 UnixBench。
简单介绍一下交叉编译的步骤吧:
1、找一台 x64 的 Linux 机器,按照 <https://wiki.openwrt.org/doc/devel/crosscompile> 步骤开始接下来的操作。必须得要 x64 的主机。
2、下载你的路由器当前系统当前机型对应的 DevPack,比如我的 LEDE 在这里下载的:<http://downloads.lede-project.org/releases/17.01.2/targets/ramips/mt7620/lede-sdk-17.01.2-ramips-mt7620_gcc-5.4.0_musl-1.1.16.Linux-x86_64.tar.xz>,OpenWrt 请在 <https://downloads.openwrt.org/> 下寻找。
3、按照官方 Wiki 的步骤将编译器添加到环境变量。
4、下载 UnixBench 的源代码并解压:<https://github.com/kdlucas/byte-unixbench>
5、开始编译。这里注意官方 Wiki 有误,请使用 make CC=mipsel-openwrt-linux-musl-gcc LD=mipsel-openwrt-linux-musl-ld 命令使用指定编译器进行编译。
6、编译失败?根据提示删除 Makefile 中编译器无法识别的两个参数,即可完成编译。
7、将除了 /src 外的文件 scp 到路由器。
8、安装相关依赖:opkg install perlbase-posix perl perlbase-time perlbase-io perlbase-findbin coreutils-od,跑分完后即可删除。
9、尝试运行 ./Run,你会发现弹出错误,根据错误内容做出以下修改。
10、修改 ./Run,注释掉 use strict 和两处尝试执行 make all 的语句。
11、这时再运行 ./Run,就已经自动开始跑分了。虽然会有几个 Wrong 弹出,但是不要紧。
========================================================================
BYTE UNIX Benchmarks (Version 5.1.3)
System: : GNU/Linux
OS: GNU/Linux -- 4.4.71 -- #0 Wed Jun 7 19:24:41 2017
Machine: mips (unknown)
Language: (charmap=, collate=)
17:01:34 up 13:01, load average: 0.25, 0.49, 0.34; runlevel
------------------------------------------------------------------------
Benchmark Run: Sun Sep 24 2017 17:01:34 - 17:37:25
0 CPUs in system; running 1 parallel copy of tests
Dhrystone 2 using register variables 1261494.8 lps (10.0 s, 7 samples)
Double-Precision Whetstone 24.3 MWIPS (9.9 s, 7 samples)
Execl Throughput 452.5 lps (29.9 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 41.0 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 18.5 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 115.4 KBps (30.0 s, 2 samples)
Pipe Throughput 154847.5 lps (10.0 s, 7 samples)
Pipe-based Context Switching 51157.7 lps (10.0 s, 7 samples)
Process Creation 1260.9 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 43.2 lpm (61.1 s, 2 samples)
Shell Scripts (8 concurrent) 6.5 lpm (64.3 s, 2 samples)
System Call Overhead 308931.8 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 1261494.8 108.1
Double-Precision Whetstone 55.0 24.3 4.4
Execl Throughput 43.0 452.5 105.2
File Copy 1024 bufsize 2000 maxblocks 3960.0 41.0 0.1
File Copy 256 bufsize 500 maxblocks 1655.0 18.5 0.1
File Copy 4096 bufsize 8000 maxblocks 5800.0 115.4 0.2
Pipe Throughput 12440.0 154847.5 124.5
Pipe-based Context Switching 4000.0 51157.7 127.9
Process Creation 126.0 1260.9 100.1
Shell Scripts (1 concurrent) 42.4 43.2 10.2
Shell Scripts (8 concurrent) 6.0 6.5 10.9
System Call Overhead 15000.0 308931.8 206.0
========
System Benchmarks Index Score 11.3
总分 11.3 是什么水平呢,我用我的洛杉矶服务器也跑了一下,3.5GHz 的 E3 处理器,不过是共享主机,并且只有单核的使用权。得到的分数为 1245.
这说明,这个功率为 10W 不到的路由器综合能力果然很弱,哈哈哈。。。
不过就算再弱,竟然可以跑完整的 Linux 4.4,能够运行起 Python、Nginx、MySQL、PHP-FPM、SSHD、Samba、DNS 等等一系列服务,还非常的稳定,不得不让人对 Linux 竖起大拇指呀~
后来我又换了 K3 路由器,ARM 双核 1.4GHz,可以代表着当前家用路由的最高水平,我用它跑了一遍 UnixBench,结果见下一页。
正如About所描述的,希望在这里记录一些难以查找的信息:网络接入和局域网设备升级踩的坑
历经多次宽带因为单一运营商垄断,价格高到离谱,之前在学校测过4G是可以跑到100Mbps的下行速率的,买过4G路由器做接入,后来因为SIM卡不够用就出掉了
在5G时代,闲置的4G手机完全可以用来作为网络接入设备,我用刷了OpenWrt的小米R3G有线连接退役的iPhone SE做了一个简单的4G路由器,找个4G信号好的地方固定,测速还行就可以开始用了
![]()
因为有部分模块依赖于内核,加上平时编译不太方便,所以采用官方固件,参考官网教程 Smartphone USB tethering
我记录的一些需要装的包
# 换源
sed -i 's_downloads\.openwrt\.org_mirrors.ustc.edu.cn/lede_' /etc/opkg/distfeeds.conf
# 装包
opkg install kmod-usb-net-ipheth kmod-usb-net kmod-usb-ohci kmod-usb-uhci kmod-usb2 libimobiledevice-utils libusbmuxd-utils usbmuxd
opkg install luci-compat
用了一段时间后发现了如下问题,当然也还有其他的手机可以尝试,但是我觉得4G的问题更大:
ios更新14之后,以上教程提到的方法就失效了,后续就没有在ios上再尝试过了;随着第一代5G手机在2022年陆陆续续退役,5G手机USB共享网络给OpenWrt路由器却没有达到预想中的那么快,考虑到在手机上经过了一次NAT,存在硬件开销以及调度和功耗限制,这还是不适合作为一个长期方案
于是开始关注5G CPE,恰好就遇到了2020年刚上市的华为的5G CPE Pro 2 (型号H122-373,以下简称H122),幸好买的早,后来芯片荒价格一路水涨船高,直到后来智选的5G CPE铺货
![]()
当时刚好手上有可以跑千兆5G卡,至少在下载速率上可以超过绝大多数家庭宽带了,缺点也还是有的:
写出来有点多,但不可否认的是在很长一段时间里H122就是能买到的最强的5G CPE,在我这稳定运行了三年,因为是价格低位购入,还能直接用天际通物联网卡(23年已经限速到200Mbps,没有了5G SA,只能用4G)
最后需要担心的其实是流量问题,因为5G的流量消耗速度非常快,实时监控流量消耗情况也是必要的,如用iOS小组件;因为华为5G CPE当前已经无法收到短信,流量告警只能自行编写脚本等方式实现
这里使用的是DJI增强图传模块连接OpenWrt路由器USB接口接入的4G网络
2022年大疆在Mavic3发布之后发布了与之配套的4G图传模块(DJI Cellular),然而自带的增强图传服务只有一年的套餐,后续如果要继续使用就需要以每年99续费增强图传服务,对于只是想超视距飞行过把瘾的人来说,增强图传服务到期之后模块自然就闲置了(大疆2023年新品不兼容该模块),二手市场上挂出的非常多,感觉出手比较困难(原价699,2023.11二手大把的450),而全新的同规格的Cat4速率的4G USB网卡120可以买到,既然如此,还不如留着当4G网卡发挥余热
该方法在ImmortalWrt 23.05.1的ARM和MT7621的路由器上测试成功
opkg install qmi-utils usb-modeswitch kmod-mii kmod-nls-base kmod-usb-core kmod-usb-ehci kmod-usb2 kmod-usb-net kmod-usb-wdm kmod-usb-net-qmi-wwan wwan uqmi luci-proto-qmi
ls /dev/应该看到cdc-wdm3这个设备了
echo "2ca3 4006 0 2c7c 0125" > /sys/bus/usb/drivers/qmi_wwan/new_id
/dev/cdc-wdm3(最关键,下图是借用的其他教程的截图作为参考),其余的信息保持默认; 在防火墙设置,给这个接口分配防火墙区域为wan,保存设置即可
如果此时4G图传模块上的灯是绿色的,即模块正常连上了4G网络,很快能看到刚刚创建的接口已经获取到了IPv6的地址,并且系统自动生成了名为DJI_4的IPv4地址的虚拟接口,此时路由器应该就能通过4G模块访问互联网
第一次成功驱动并设置好QMI拨号的接口后,可以将命令
echo "2ca3 4006 0 2c7c 0125" > /sys/bus/usb/drivers/qmi_wwan/new_id
添加到开机启动脚本中(网页LuCI界面->系统->启动项->本地启动脚本),添加到文本框中exit 0这一行之前即可,后续重启也无需任何的操作,随时插入4G模块后一段时间就能正常上网了
在大疆论坛上有用户尝试了Windows上驱动并成功让PC能接入4G网络,后续大疆又发布了模块的Windows驱动,其中主要提供了以下的信息:
搜索OpenWrt上驱动模块的资料,发现在OpenWrt上移植EG25驱动的经验是空白的,主要都是移植EC2X的,其中《挂载移远EC20、EC21、EC25、AG35等4G模块》参考了官方的Linux驱动文档,EG25在文档发中和EC25的PID和VID是相同的(2C7C, 0125),但是与4G图传模块的(2CA3, 4006)不同,即使移植了EG25的驱动也未必能识别到4G图传模块
直到看到论坛里有人发了4G图传模块用于Linux系统上网尝试,用到了将USB设备的PID和VID写入/sys/bus/usb/drivers/…/new_id处理驱动识别的方法,另外又查到了23年11月的OpenWrt 下实现移远 4G 模块上网 中提到在OpenWrt 22.03在无需改内核代码就能驱动EC20
在运行echo "2ca3 4006 0 2c7c 0125" > /sys/bus/usb/drivers/qmi_wwan/new_id后,可以用cat /sys/kernel/debug/usb/devices查看到4G模块被qmi_wwan驱动(设备对应的信息出现Driver=qmi_wwan字样)
在/dev目录下可以看到/dev/cdc-wdm[0-3]一共4个设备,最开始尝试了/dev/cdc-wdm0发现无法拨号就差点放弃,最后尝试了下/dev/cdc-wdm3发现拨号可以获取到IP了
uqmi命令可以与模块通信并输出一些状态的信息,其中个人比较关注的主要是信号
root@XDR6088:~# uqmi -d /dev/cdc-wdm3 --get-signal-info
{
"type": "lte",
"rssi": -55,
"rsrq": -6,
"rsrp": -79,
"snr": 14.800000
}
4G模块的速率标准为Cat4(下行速率最高150Mbps,上行最高为50Mbps),实测在以上信号强度的电信4G上下行均为50Mbps左右,日常用这速率也算能接受吧,联想到我测试过最快的4G是2018年在iPhoneSE(4G Cat6最高下行速率300Mbps)上跑出了100Mbps的下行
关于IPv6,首先路由器时可以获取到公网IPv6地址的(以及64位前缀的PD),并且在LAN默认的IPv6设置下,可以向下分配地址,另外就是传入连接的连接性,实测发现有运营商的差异:移动的IPv6地址无法从外网访问路由器,联通和电信的IPv6地址则可以
由于CPE和4G模块获取的IPv6地址是不含短于64位的前缀的,所以在使用二级路由的情况下,二级路由下的设备无法获取公网IPv6地址,这个时候需要配置“IPv6中继+NDP代理”,OpenWrt 23.05的LuCI界面的设置过程如下:
ip -6 neigh和LuCI上的系统->路由表->IPv6邻居看IPv6地址对应的接口来观察NDP代理的效果)我的网络结构是CPE做一级路由,OpenWrt做二级路由,因为华为5G CPE本身防火墙的原因,二级路由下面的设备可以获取到IPv6地址,但是无法从外网访问
但是如果CPE或者4G模块支持桥模式,那么OpenWrt路由器大概率是不受CPE或者4G模块的防火墙影响的,放开OpenWrt的防火墙之后,只剩下运营商屏蔽了传入连接的可能性
局域网肯定还是要用一台OpenWrt路由器作为主路由,如果一台主路由能解决问题是最好,列出来的要求有点多:
在从2020年到2023年这一段时间里,涌现了一大批可以刷OpenWrt的WiFi6路由器:Qnap-301w、红米AX6,AX6000、中兴NX30 Pro,以及可能有QSDK固件的小米万兆路由,对比以上的要求有明显的短板,直到某一天看到B站上有人给TP-LINK XDR6088刷机的教程:TP-link路由器XDR6088、6086、4288刷openWRT,我终于发现了一台有潜力的机器:
可以查到的获取终端操作权限刷入U-boot(bootloader)的方法源于:TP-LINK XDR6086/XDR6088 反弹 SHELL 并开启 SSH
综合亲手实践以及上面的视频教程,有几点需要特别注意
{"error_code":0}nc -l -p 9995 > backup.img),不能用Powershell(备份传输完成后,校验的话就会发现用Powershell运行同样的命令会得到不一样的文件),因为这一条操作失误导致我刷OpenWrt后刷回原厂系统的过程中导致变砖我只刷了视频教程的固件,基本上是截至到当时最新的R23.5.1,2.5G网口和WiFi稳定的运行两周,这里先放下收集到的参数的对比,至少CPU的参数在当前WiFi6末期可刷机硬路由中基本上是第一档的
| 路由器 | CPU | RAM | ROM |
|---|---|---|---|
| Newifi Y1 | MT7620 1C@580MHz | 128MB | 16MB |
| K2P | MT7621AT 2C4T@880MHz | 128MB | 16MB |
| XDR6088 | MT7986A 12nm 4*A53@2.0GHz | 512MB DDR3 | 128MB |
| NX30 Pro | MT7981B 12nm 2*A53@1.3GHz | 256MB DDR3 | 128MB |
| Qnap-301w | IPQ8072A 12nm 4*A53@2.2GHz | 1GB DDR3-1600 | 4GB |
| K3 | BCM4709 40nm 2*A9@1.4GHz | 512MB DDR3-1600 | 128MB |
| N1 | S905D 28nm 4*A53@1.5Ghz | 2GB | 8GB |
上文提到Powershell下使用nc命令重定向的备份大小异常的问题,相关的原因查明在:Powershell与bash的重定向的差异,在搞清楚其中的原理后,我理解无法通过简单的操作使得备份还原,于是在论坛找到了别人的备份的mtdblock9尝试救砖,参考
因为我之前给T440s修改BIOS买了CH341A编程器和8pin的夹子,所以就鼓起勇气拆机,经过艰难的掰卡口后,很快就遇到了问题:
红米AX6000救砖中提到建议改CH341的输出电压为3.3v,这个要飞线,我没有工具:
我查了下ThinkPad BIOS芯片W25Q32V的datasheet,发现支持的也是2.7~3.6V,之前成功刷上了BIOS,通过不严谨的推测,不修改CH341的输出电压也能刷2.7~3.6V的F50L1G41LB
店家给的CH341的编程器刷写软件不支持F50L1G41LB,红米AX6000救砖中提到“NeoProgrammer不知道如何写入单独分区,我选择了SNANDer”:
最棘手的问题在于,F50L1G41LB相比W25Q32V,夹子的触点难以夹到芯片的针脚,无法稳定连接就无法写入,红米AX6000救砖中用的漆包线飞线
![]()
在OpenWrt官方23.05正式版支持XDR-6088的固件后,参考了TL-XDR6088/6086 刷入官方 Openwrt/Immortalwrt,原文已经记录的相当的详细,此处仅摘录用到的步骤(因为独立博客的域名过期之后就很可能找不到原文了)
本文写作时,最新的是23.05.0-rc3版。将来请用更新的稳定版本,目前Immortalwrt官方固件已经支持:
- 双 2.5Gb 网口的正常驱动(但LED灯还不亮)
- WiFi6 160Mhz
- 硬件流量分载
- WED (Wireless Ethernet Dispatch) 无线加速
- 硬件 NAT 加速
- Fullcone NAT
4.2 如果路由器已经刷了其它版本的 Openwrt
在 Openwrt 中运行
cat /proc/mtd,得到mtd设备的真实命名,再用命令来写入(将下面的BL2或FIP改成你在上面看到的名字,注意大小写)md5sum /tmp/preloader.bin mtd erase BL2 mtd write /tmp/preloader.bin BL2 mtd verify /tmp/preloader.bin BL2 md5sum /tmp/bl31-uboot.fip mtd erase FIP mtd write /tmp/bl31-uboot.fip FIP mtd verify /tmp/bl31-uboot.fip FIP注意查看上传的两个文件 md5 并和本地文件对比,查看两次 mtd verify 最后是否输出输出 Success,没问题才可进行下一步。
5. 通过 tftp 载入 recovery 镜像
这时候你可以拔掉路由器的电源,然后插上。直接拔电源可能是最安全的,因为如果你用 reboot 命令,可能会有一些后台程序运行(包括可能你之前在慌乱中没有杀掉的误操作了的 dd)导致路由器变砖。别问我是怎么知道的。
此时 tftp 服务器上应该已经有提示了,路由器在请求的文件名为 openwrt-mediatek-filogic-tplink_tl-xdr6088-initramfs-recovery.itb 。你只需要把结尾为 recovery.itb 的文件,改名为这个就行了。
如果没动静,你可以拔下电源,然后顶住 reset 孔不放,同时插入电源,应该会看到 LAN 口的灯齐闪一下。大约10秒钟,应该就会进入 recovery 模式。确保网线插在 1Gb LAN 口上,网口的灯应该会亮的。
前面提到了WiFi6 160MHz普及之后,局域网传输的瓶颈主要在千兆的有线网口上,考虑到外置USB网卡(USB 3.0外置网卡最大速率为5Gbps)可能因为发热等因素不稳定,首选的话还是PCIe的网卡,而且由于数据中心万兆网卡下架,市面上有较多的低成本的选择,在网络讨论的最多的是浪潮X540-T2拆机卡,价格大概70左右,特别之处在于PCIE插槽是X8+X1,如果要用的话x1要绝缘屏蔽,我实际使用发现卡兼容性不太好:
最后捡到一张180的带华为物料编码的x540,有几乎覆盖整个卡面的黑色散热片,插上群晖DS1621可以直接用,对于装了驱动的Z370-I也是
![]()
简单测了下,这张x540的空载功耗大约是8w,看卡背面的便签写着silicom PE210G2I40E,查到了silicom官网关于电口万兆网卡的功耗,找到了“电口功耗高”的依据:
PE开头的NIC(网卡)均为silicom官网上的网卡的功耗数据(均为所有端口Link/Idel 的功耗的整卡功耗),可以看到x540的功耗一骑绝尘,考虑到网卡的成本以及长期电费,最后我找了一张AQC107的网卡LREC6880BT,也把数据列到了下面:
| NIC | Controller | 无Link | GE | XGE | |
|---|---|---|---|---|---|
| PE310G2I50-T | X550-AT2 | 4.62W | 5.4W | 8.16W | x4 PCIe 3.0 |
| PE210G2I40-T | X540 | 7.23W | 7.92W | 14.28W | x8 PCIe 2.1 |
| PE310G2I71-T | X710-AT2 | 3.6W | 5.52w | 8.28W | x8 PCIe 3.0 |
| PE310G2I71 | X710BM2 | 3~4W | 4.6~4.8W | x8 PCIe 3.0 | |
| PE210G2SPI9A | 82599ES | 4~6W | 6W | x8 PCIe 2.0 | |
| LREC6880BT | AQC 107 | 网卡4.7W | x4 PCIe v2.1 |
数据中心下架的卡基本上都有些年头了,关于网卡的控制器、发布时间、制程、TDP,2022年末的二手价如下:
| NIC | Controller | TDP | Release | Process | Price |
|---|---|---|---|---|---|
| 华为SP230电 | X540-AT2 | 12.5W | 12Q1 | 40nm | 250左右 |
| Intel X550 | X550-AT2 | 11W | 15Q4 | 28nm | 1200左右 |
| Intel X710-T4 | XL710-BM1 | 7W | 15Q4 | 28nm | 2450 |
| X520-DA1 | 82599ES | 09Q2 | 65nm | ||
| LREC6880BT | AQC107 | 6W | 17Q4 | 28nm |
在网上看到说Intel的X540和X550在群晖的DSM系统中是免驱的(其实是DSM的Linux带了驱动),因为X550太贵,所以把目光投向了价格和功耗都合适的AQC107,因为群晖E10G18-T1 10G等群晖官方的万兆电口卡也是用的AQC107,我天真的以为第三方AQC107也是免驱的
网上我能找到两个中文的经验:
详细的要二次编译成功再补充,大概是下次DSM系统版本/内核版本更新
因为不涉及到后面的修改BIOS文件就能上64GB内存,这里直接上结论:
在我的平台上,用最新的3005的BIOS反而会导致莫名其妙的自动重启
因为在互联网上找不到Z370-I成功实践的经验,所以这里留个记录:
Asus Z370-I是一块ITX主板,只有两个内存插槽,装机的时候切好碰上DDR4内存天价,所以很长一段时间里只有双通道16GB 3000MHz,这块主板在官网上参数写着最大支持32GB内存,也就是2X16GB,然而随着内存降价,发现23年单条32GB的内存已经很便宜了,想着直接上到双通道64GB,以后这台机器退役也能当服务器用
因为是捡垃圾买到的“Fury DDR4 32GB 3200MHz”,想要知道超频情况,无法在thaiphoon burner中识别出具体的镁光颗粒,所以只能通过拆内存条散热马甲查看颗粒的FBGA Code(或者叫Market Code:颗粒第二行的编码,例如比较流行的镁光超频内存条C9BJZ),然后在官网Micron FBGA and component marking decoder查询,然而如下的丝印代码在官网是查不到的:
3CE22
Z9XJP
最后是在电子元器件网站上检索到了颗粒的型号(Part Number):MT40A4G8VNE-062H ES:B;根据镁光的PART NUMBER命名规则表,可以获取到如下信息:
然后因为网上搜索不到相同的颗粒,所以超频抄作业可以不用想了,只能搜索到酷兽银甲单条32g 颗粒分析和超频也是叠die颗粒超频:“3200频率下1.45V时序可压c14-18-18-34,这里简单调了下一二时序,能效可以达到4.8w左右”,我看到了这个之后就按照文中提到的时序调整,实测不需要以上那样的参数,1.35v c14-18-18-32即可,其他的时序参考网上的超频教程进一步收紧,TM5跑不过就放开一点(tRFC为500),最后时延能控制在52ns左右(收紧的话可以49ns但是TM5报错)
我搜到了CHH的帖子:首发!Z170/Z370 突破内存64g可用的上限限制,精华在评论里,总结如下:
如何使 H310C/B365/Z370 的 BIOS 支持最大 128G 内存:
1.UEFITool提取SiInitPreMem模块,GUID为A8499E65-A6F6-48B0-96DB-45C266030D83 2.UEFITool搜索“C786….000000….00”,其中“..”为任意HEX值 3.第一处“….”不用理会,第二处“….”如果是“8000”那么就是最大64G,如果是“0001”就是最大128G 4.将“8000”修改为“0001”可破除64G限制 5.100/200系BIOS内也有此内容,理论上6-9代的IMC支持的内存没差,6700+Z170也能128G内存(已测试可行) 6.我这边看,MSI的Z370,18年底的BIOS还是8000,19年4月的BIOS就是0001了,ASUS的BIOS一水的都还是8000 7.ME 需要禁用(修改Flash Descriptor的HAP Bit,但要注意部分主板有校验不允许这么改,改后无法开机) 8.部分BIOS需设置 Chipset->System Agent (SA) Configuration->Above 4GB MMIO BIOS assignment->Disabled 不同 BIOS 位置不同,且可能被隐藏,无法直接修改
注:参考后面的引用,第七步为:将 0x102h的位置 +1
限制内存大小的字段,在我的主板上看到的是
# 3005 BIOS (2000 我觉得是单条16G,或者单DIMM 32G)
#Hex pattern "C786....000000....00" found as "C7866F25000000200000" in TE image section at header-offset 388FCh
C7 86 6F 25 00 00 00 20 00 00 EB 20
6A 00 56 E8 B4 E0 FE FF 59 59 0F B6
# 纯血的370ROG已经提供了128G的bios( 2021-2-15 )
# 3004 BIOS 2021-04-16 发生了变化,没有了老版的第二行
C7 86 6F 25 00 00 00 20 00 00 EB 20
# 1802 BIOS
C7 86 6F 25 00 00 00 20 00 00 EB 0A
C7 86 6F 25 00 00 00 80 00 00
# 1410 BIOS
Hex pattern "C786....000000800000" found as "C7866F25000000800000" in TE image section at header-offset 384ACh
C7 86 6F 25 00 00 00 20 00 00 EB 0A
C7 86 6F 25 00 00 00 80 00 00 8B C3
“18年底的BIOS还是8000,19年4月的BIOS就是0001了”的这一行去掉发生3004(更新日志:主要是添加了Win11的支持,没有提内存上线变化),我找了M10H ROG MAXIMUS X HERO BIOS变更日志中有内存上限修改(Support Max DRAM Total Capacity up to 128 GB.)的新老BIOS看了下,也是去掉了8000这一行
这个问题能搜索到公开的文字信息不多,主要的问题是用了一段时间之后散热能力迅速衰减,比如新购入可以压制170w发热的CPU(已经开盖换液态金属),然而老化之后散热能力在CPU功耗80w左右温度就冲击100度,网上能搜索到的维修和拆解分析的经验:
我拆开水冷头之后,果然如上面引用所述是杂志堵塞了水冷头的微水道,用蒸馏水冲洗了几轮水路,最后换了蒸馏水之后散热能力重回170w,另外水冷的大风扇,对内存散热也要更友好(换用了一段时间的AXP100,内吹的时候内存太烫了)
Haswell架构是Intel在2013年推出的“酷睿第四代”CPU架构,Haswell刚推出那年配了自己第一台台式机,后来上大学又捡了一台Haswell的笔记本T440s,毕业后又凑了一台M73小主机…台式机至今还在家用,笔记本已到垂暮之年,修改BIOS之后装上AX200依旧是顺手的全能笔电,M73目前主要是作为Linux环境主机
之所以要刷BIOS,是因为T440s大部分的BIOS有网卡白名单,基本完全限制住了自行升级网卡,自带的AC7260是Intel最早的2x2 AC网卡,信号和速度已经远远落后如今的AX网卡,T440s现在主要是处理器跟不上了,其他方面放到现在也是非常优秀的:
另外还有几个比较有意思的地方:
在如今是市场里确实很难找到合适自己用的笔记本(定位高,接口丰富,不用拓展坞),所以还是想多延续下T440s的使用期,一直比较头痛的就是更换网卡的问题,之前并非没有查过刷BIOS,但是教程太复杂,时过境迁,2020年搜到有不少人都能自己刷了,下面进入正题
虽然写的是T440p,但是实测对T440s基本适用,本文对以上的材料做下补充:
BIOS芯片的位置
![]()
夹上编程器的样子
![]()
用工具读取到的BIOS芯片型号和教程可能不同,以卖家附赠的工具为准
教程还带有解锁高级菜单的部分,但是实测貌似没什么用(主要想解锁功耗,15w下散热还是压得住的)
换了AX200的网卡之后在160MHz下实测无线可以跑满1000Mbps,另外一个在2020年的新闻就是Intel的网卡在MacOS下终于可以日常使用了:itlwm,因为手头空闲的机器不多,所以就尝试给T440s上黑苹果试一试,好在Clover的EFI不难找
实测黑苹果日常使用确实比Win10流畅不少(主要是少了一些莫名其妙的高占用),但是多开还是有些吃力的
缘起于之前为了收一个小机箱和MATX主板,被学长捆绑了一颗ES版的CPU,最开始说是E3,用CPU-Z看也是志强,但是根据顶盖上的四位编号QEDH,在某宝上搜索指向的是i7-4770s的ES版本,4c8t @ 3.0GHz,TDP 83W,并且带核显;尝试过作为家用win10主机使用过,但是核显实在太鸡肋,单核心主频低导致部分应用速度比较慢
最后我还是决定装一台低功耗的Mini Server,准系统选择了Haswell时代的M73(相比戴尔的9020散热更好),M73可以用ThinkPad系的方口电源也是一大优势(家里方口电源多…)
准系统的安装很简单,但是这里有些插曲,一个是CPU的散热问题,相比带T后缀的45W的低功耗CPU,以及家用台式机的65W标压处理器,QEDH的83W还是很吓人的,之前在B85 ATX主板上实测,解锁功耗烤机满载也确实可以跑到80W以上,所以对于65W以下的准系统M73,我选择了把顶盖到Die的导热材料换成液金,然后测试下M73能否在编译时跑满这颗CPU
这里选择CentOS下,初次编译OpenWrt作为负载,编译时,温度抵近90度,基本上就是达到默认风扇下的上限了,如果把风扇转速拉满,温度大概80左右,但是噪音太大了;使用s-tui可以在软件层面查看功耗和频率信息,CPU功耗接近60W,主频2.8GHz,因为可以用Type-C的方口诱骗线供电,所以也顺带看了下整机的功耗,基本在65W以下(用95W的电源);编译的时间对比win10下使用WSL2的i7-8700K,M73这套平台耗时是其两倍,可以接受的水平;另外日常待机功耗12W左右
之前用NAS时,用的比较多的就是Docker版本的qBittorrent以及网络共享功能,其实在Linux下实现这些并不难,M73用这一套的优势是相比传统NAS噪音很小,且小体型放置随意;这里使用和NAS上一样的容器镜像源,主要是qBittorrent作为下载软件
以下设置仅针对CentOS 7.9,其他发行版可能不同,其中Docker启动命令如下(记得建立挂卷的目录):
docker run -d \
--name=qbittorrent \
--network=host \
-e PUID=1000 \
-e PGID=1000 \
-e TZ=Europe/London \
-e WEBUI_PORT=8080 \
-v /home/qbittorrent/config:/config \
-v /home/downloads:/downloads \
--restart unless-stopped \
linuxserver/qbittorrent
可能遇到的问题
3.1X的内核可能存在qbt启动异常的问题,/usr/bin/qbittorrent-nox: error while loading shared libraries: libQt5Core.so.5: cannot open shared object file: No such file or directory参考群晖
Linux的防火墙可能会阻止访问8080端口
firewall-cmd --zone=public --add-port=8080/tcp --permanent
firewall-cmd --reload
部分运营商的家用宽带也会在上游阻隔8080端口的访问,此时建议将Docker启动命令的监听端口修改为8081
添加证书设置开启HTTPS访问后无法打开网页
需要修改证书的key的权限为所有人可读
chmod +044 keyfilepath
这个在使用供应商的证书 对比 通过ACME申请的Let’s Ecrypt证书发现的差异,因为ps -ef | grep -i qbit可以看到实际使用证书的程序的UID是abc而不是root,acme在使用root权限执行申请到的证书key对abc用户是不可读的
root 255 1 0 18:26 ? 00:00:00 s6-supervise qbittorrent
abc 333 255 1 19:15 ? 00:00:00 /usr/bin/qbittorrent-nox --webui-port=8081
基于系统的用户创建SMB用户
设置SMB共享目录
关闭SELinux(否则只能看到目录而看不到文件)
临时关闭(不用重启机器)
setenforce 0
修改/etc/selinux/config 文件
将SELINUX=enforcing改为SELINUX=disabled
重启机器即可
在使用SMB作为局域网内的文件共享方式有以下的缺点:
优点:
首先说WebDav协议,这个最早在群晖的NAS上只要安装就能使用,主要就是用于公网访问文件,然而我在很长一段时间,都没有在Linux上寻找一款配置简单,易用的服务端,在此期间用gohttpserver作为多端访问服务器文件的方式
之前听闻Alist可以挂载云盘后对外提供WebDav协议的访问,所以就看了下文档,其简介为:“一个支持多种存储的文件列表程序”,打开发现其实也是支持挂载本地存储的,又有网页端,完全可以实现gohttpserver的功能,初次之外页面上的分享功能也方便将Alist本身作为网盘分享文件
这里因为考虑到方便的挂载本地目录(主要是qbittorrent的下载目录)以及使用HTTPS(证书周期性的需要更换),所以使用了本地直接部署的方式,采用官网的一键脚本
curl -fsSL "https://alist.nn.ci/v3.sh" | bash -s install
特别留意首次安装后,日志会显示默认的随机密码
之后就是用nPlayer等播放器挂载webdav目录了,留意url的路径http[s]://domain:port/dav/中的dav,如果是Android的话,nPlayer可能常年没有更新了,推荐Reex
Nextcloud挂载SMB提供多种外部访问方式,体验下来还是SMB为主,Nextcloud的优势在于有完善的移动APP,2022年发现还是Alist更轻量好用
docker run -d \
--name=nextcloud \
--network=host \
-e PUID=1000 \
-e PGID=1000 \
-e TZ=Asia/Shanghai \
-v /home/nextcloud/config:/config \
-v /home/nextcloud/data:/data \
--restart unless-stopped \
linuxserver/nextcloud
可能遇到的问题:nextcloud会识别首次登陆的IP之类的信息,导致无法二次访问
解决办法:需要到docker指定的config目录下修改才可以换用域名或者新的IP访问
vi ./nextcloud/config/www/nextcloud/config/config.php
<?php
$CONFIG = array (
'memcache.local' => '\\OC\\Memcache\\APCu',
'datadirectory' => '/data',
'instanceid' => 'xxx',
'passwordsalt' => 'xxx',
'secret' => 'xxx',
'trusted_domains' =>
array (
0 => '192.168.8.114',
1 => preg_match('/cli/i',php_sapi_name())?'127.0.0.1':$_SERVER['SERVER_NAME'],
),
'dbtype' => 'sqlite3',
'version' => '21.0.0.18',
'overwrite.cli.url' => 'https://192.168.8.114',
'installed' => true,
);
介绍了Linux系统中等效多径路由(ECMP)及其在网络负载均衡上的应用,给出了OpenWrt下的启用的方法
因为偶然发现了Linux内核中的ECMP这种负载均衡的方法,然后查了些资料,这里整理下(业余水平);文末留下了当时发现ECMP的记录
ECMP在工程方面用的很多,能找到的多是说明文档,介绍特性和成套的解决方案,但是基础的材料并不是那么好找,个人也是刚刚接触到ECMP,水平有限,这里先给出本文的主要参考文献
关于负载均衡,[译] 现代网络负载均衡与代理导论(2017)有一个较为全面的介绍,其中作者提到
关于现代网络负载均衡和代理的入门级教学材料非常稀少(dearth)。我问自己:为什么会这样呢?负载均衡是构建可靠的分布式系统最核心的概念之一。因此网上一定有高质量的相关材料?我做了大量搜索,结果发现信息确实相当稀少。 Wikipedia 上面负载均衡 和代理服务器 词条只介绍了一些概念,但并没有深入 、这些主题,尤其是和当代的微服务架构相关的部分。Google 搜索负载均衡看到的大部分都 是厂商页面,堆砌大量热门的技术词汇,而无实质细节。本文将给读者一个关于现代负载均衡和代理的中等程度介绍,希望以此弥补这一领域的信息缺失。
对此个人在经历一番搜索之后也是感同身受,所以才有了总结的想法;如果觉得上文过于“导论”(和本文的关系不大),华为的文档更贴近本文的主题一些,尽量看英文:Introduction to Load Balancing
Jakub Sitnicki’s Blog的系列博文:对Linux内核中的ECMP的实现深入浅出地做了介绍,如果感兴趣的话可以看看
最后是一篇相对详尽的中文资料,重点是ECMP在内核中的变更历史:ECMP在Linux内核的实现
ECMP也就是下面的路由表的情形,就是到某一个目的地址可以有多个下一跳路径可选
root@K2P:~# ip r
default metric 1
nexthop via 10.170.72.254 dev pppoe-VWAN21 weight 1
nexthop via 10.170.72.254 dev pppoe-VWAN22 weight 1
nexthop via 10.170.72.254 dev pppoe-VWAN31 weight 1
nexthop via 10.170.72.254 dev pppoe-VWAN32 weight 1
root@K2P:~# ip -6 r default
default metric 1
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN21 weight 1
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN22 weight 1
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN31 weight 1
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN32 weight 1 pref medium
看起来很简单,要弄清楚这个具体能做到什么程度就需要了解下具体的实现,这里一步一步来看
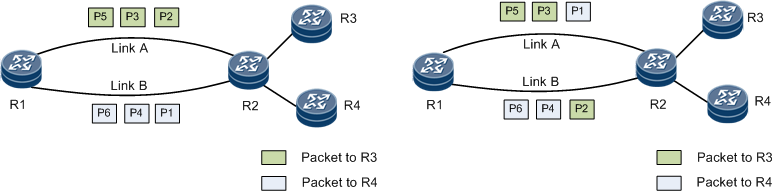
Packet对应的是IP分组(数据报、数据包),是数据在L3上传输的单元
对路由器而言,流(Flow)是共享某些特性的packet序列,比如同一个请求(连接)的packets有相同的路由路径
根据负载均衡的对象分:有Per-Packet和Per-Flow两种方式,文档中的两张图对此有个直观的对比
![]()
自然而然的会想到L4 Per-Packet负载均衡:每一个的Flow的Packets会被分流,可以实现多拨对看直播都可以加速的效果,然而本文并不会涉及:
Existing Multipath Routing implementation in Linux is designed to distribute flows of packets over multiple paths, not individual packets. Selecting route in a per-packet manner does not play well with TCP, IP fragments, or Path MTU Discovery.
故默认下文都是Per-Flow负载均衡,这就需要利用Packet的header fields信息把一个个的Packet和Flow联系起来,再进行下一跳的路由选择:
IPv4 L3 hash
{ Source Address, Destination Address }
IPv4 L4 hash
{ Source Address, Destination Address, Protocol, Source Port, Destination Port }
IPv6 L3 hash
{ Source Address, Destination Address, Flow Label, Next Header (protocol) }
IPv6分组因为有Flow Label的存在,IPv6即使只用到L3 Hash也可以实现L4负载均衡
IPv6 Flowlabel IPv6数据报(packet)中有一个20字节的字段:流标号(流标签);进而可以用流标号取代路由表来处理流的路由,加速路由器对分组的处理;在ECMP中却提供了Flow的信息,故IPv6 ECMP是比较容易做的
更关键的还是负载均衡的层级,比如在多拨的情况下使用策略路由也可以做“负载均衡”,下面的命令往往提高BT的速度,这属于L3 Per-Flow负载均衡(左图):只在IP地址层级分流
ip rule add table 916
ip route add 10.173.0.0/16 via 10.170.72.254 dev pppoe-VWAN31 table 916
ip route add 10.170.0.0/16 via 10.170.72.254 dev pppoe-VWAN32 table 916
类似的方法对HTTP多线程下载并没有加速作用,对连接分流,需要L4负载均衡:多线程下载的请求之间source port不同,故L4 hash值基本不同,故会被分到不同的路径上,这样一来L4负载均衡是面向连接的就很好理解了,而内核在IPv4/IPv6上实现到一步有一段很长的历史:
Linux内核的Git Commit,对发展历程感兴趣的还可以参考博文Celebrating ECMP in Linux,其中还讨论了设备的出站流量和转发流量的ECMP效果的不同,这里把ECMP的变更历史整理到一张表格中,以及对应时间的OpenWrt的内核版本信息:
| Linux Kernel | OpenWrt 内核版本 | ECMP变更 | ECMP形式 |
|---|---|---|---|
| 1997 | 2.1.68 | IPv4 ECMP 加入内核 | L3 Per-packet + route cache -> L3 Per-flow | |
| 2007 | 2.6.23 | IPv4 multipath cached 移除 | L3 Per-packet + route cache -> L3 Per-flow | |
| 2012.9 | 3.6 | IPv4 route cache 被移除 | L3 Per-packet -> L3 Per-packet | |
| 2012.10 | 3.8 | IPv6 ECMP 加入内核 | IPv6 Flowlabel -> IPv6 L4 Per-flow | |
| 2015.9 | 4.4 | 15.05 | 3.18 | IPv4 ECMP:使用L3 Hash | L3 Per-packet + L3 hash -> L3 Per-flow |
| 2016.4 | 4.7 | IPv4 ECMP: 增加邻居健康检查 | ||
| 2017.2 | 17.01 | 4.4 | ||
| 2017.3 | 4.12 | IPv4 ECMP: 增加 L4 Hash | L3 Per-packet + L3/L4 hash -> L3/L4 Per-flow | |
| 2017.11 | 4.14 | IPv6 ECMP: ICMPv6 修复 | ||
| 2018.1 | 4.16 | IPv6 ECMP: 支持指定权重 | ||
| 2018.4 | 4.17 | IPv6 ECMP: 增加 L4 Hash | ||
| 2018.7 | 18.06 | 4.9/4.14 | ||
| 2018.10 | 4.19 | |||
| 2019.11 | 19.07 | 4.14.151 |
这里可以推出(实际早期版本我也没有测试过),在默认的编译选项和内核版本下,较为实用的L4负载均衡,IPv4需要在18.06及之后的版本
IPv6由于使用了Flowlabel作为Hash的对象,根据表格,OpenWrt在15.05之后的版本就可以启用L4负载均衡
本文考虑更多的还是OpenWrt中的应用,更多信息参考本博客中的Speed_Up
准备部分是从排查问题的角度来看的
在启用之前可以确认下编译内核时的下面选项,即IP: equal cost multipath,ECMP支持,较新版本的OpenWrt默认是打开的
暂时不清楚使用下面的多个nexthop命令添加ECMP路由的依赖,只知道命令ip route的源于iproute2,如果出现如下报错:
Error: either “to” is a duplicate, or “nexthop” is a garbage.
可以尝试:
route命令多次添加静态路由,可以启用IPv6的ECMP(详见文末的后记),实测在原版的OpenWrt可行
route -A inet6 add 2000::/3 gw fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN2
route -A inet6 add 2000::/3 gw fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN3
这里直接引用iproute2的user Guide的Multipath routing部分:
ip route add ${addresss}/${mask} nexthop via ${gateway 1} weight ${number} nexthop via ${gateway 2} weight ${number}
Multipath routes make the system balance packets across several links according to the weight (higher weight is preferred, so gateway/interface with weight of 2 will get roughly two times more traffic than another one with weight of 1). You can have as many gateways as you want and mix gateway and interface routes, like:
ip route add default nexthop via 192.168.1.1 weight 1 nexthop dev ppp0 weight 10
Warning: the downside of this type of balancing is that packets are not guaranteed to be sent back through the same link they came in. This is called “asymmetric routing”. For routers that simply forward packets and don’t do any local traffic processing such as NAT, this is usually normal, and in some cases even unavoidable.
If your system does anything but forwarding packets between interfaces, this may cause problems with incoming connections and some measures should be taken to prevent it.
可以补充的是如果用的多个等带宽的PPPoE Interface的话,可以使用多个nexthop dev ${pppoe-dev}
仅仅是上一步的话,可以见到在使用P2P下载时已经有负载均衡了,但是对HTTP的多线程下载并没有加速效果,因为一些Linux内核对IPv4的ECMP默认设置到L3 Hash,而且也没有开启邻居健康检查,所以需要修改下内核的运行参数,相关的具体的参数说明如下:
fib_multipath_hash_policy - INTEGER Controls which hash policy to use for multipath routes. Only valid for kernels built with CONFIG_IP_ROUTE_MULTIPATH enabled. Default: 0 (Layer 3) Possible values: 0 - Layer 3 1 - Layer 4 2 - Layer 3 or inner Layer 3 if present
fib_multipath_use_neigh - BOOLEAN Use status of existing neighbor entry when determining nexthop for multipath routes. If disabled, neighbor information is not used and packets could be directed to a failed nexthop. Only valid for kernels built with CONFIG_IP_ROUTE_MULTIPATH enabled. Default: 0 (disabled) Possible values: 0 - disabled 1 - enabled
echo "net.ipv4.fib_multipath_hash_policy=1" >> /etc/sysctl.conf
echo "net.ipv4.fib_multipath_use_neigh=1" >> /etc/sysctl.conf
sysctl -p
其他相关的内核运行参数(IPv6 Flowlabel等)可以参考ip-sysctl.txt
熟练的话完全根据上面的方法做了,以下是在校园网PPPoE接入下实践的,如果PPPoE拨号多播数量较多可以参考如何提高网速
CONFIG_IP_ROUTE_MULTIPATH=y(OpenWrt 18.06之后的版本默认已经开启)OpenWrt安装kmod-macvlan后就可以添加虚拟网卡到不同的VLAN上
opkg update && opkg install macvlan
路由器上的RJ45网口是绑定到VLAN上的,如果是添加虚拟网卡到一个VLAN上就是单线多拨,添加到多个VLAN上就可以做多线多拨了
这里的eth0.2对应于WAN口(在Interface -> Switch可以看到WAN绑定在VLAN 2上),不同的设备可能有些许不同,这里在eth0.2上添加两个虚拟网卡
for i in `seq 1 2`
do
ip link add link eth0.2 name veth$i type macvlan
done
还是用脚本省事,填上用户名和密码即可,拨数为2,填下账号密码
#!/bin/sh
username=
password=
for i in `seq 1 2`
do
uci set network.VWAN$i=interface
uci set network.VWAN$i.proto='pppoe'
uci set network.VWAN$i.username="$username"
uci set network.VWAN$i.password="$password"
uci set network.VWAN$i.metric="$((i+1))"
uci set network.VWAN$i.ifname="veth$i"
uci set network.VWAN$i.ipv6='1'
done
uci commit network
添加所有PPPoE接口到wan zone(担心影响到其他的网络环境的话手动也可以)
for i in `uci show network | grep pppoe | awk -F. '{print $2}'`
do
uci add_list firewall.@zone[2].network=$i
done
uci commit firewall
只用nexthop dev ${pppoe-dev}:
#IPv4
ip route replace default metric 1 nexthop dev pppoe-VWAN1 nexthop dev pppoe-VWAN2
#IPv6
ip -6 route replace default metric 1 nexthop dev pppoe-VWAN1 nexthop dev pppoe-VWAN2
做完这一步就可以使用ip r和ip -6 r命令检查下路由表
echo "net.ipv4.fib_multipath_hash_policy=1" >> /etc/sysctl.conf
echo "net.ipv4.fib_multipath_use_neigh=1" >> /etc/sysctl.conf
sysctl -p
通过东北大学IPv6测速以及IPv4测速测试负载均衡的速度叠加效果,或者使用iftop命令查看各个接口上路由的实时速率
添加ECMP路由之后传入连接偶尔连的上,偶尔连不上,但是PT的上传之类的貌似又没有问题(可能因为上传也可以是主动发出的连接),如果有这方面需求的话需要添加策略路由,为某一接口上的地址指定路由规则,下面是IPv4的,完成之后可以从外部访问之类的,但是对其他的影响就不太清楚了,IPv6部分暂时没有测试条件…
ip rule add perf 20 from IP table 20
ip route add default table 20 dev INTERFACE
此处参考自Linux 平台上之 Multipath Routing 應用,非常难得的详细的文章,还是2001年的
这里保留当时的发现过程:(当时发现了这个功能非常开心,现在来看部分内容不准确,但是文末的脚本的效果要好于ECMP默认的方法)
只在K2P OpenWrt 18.06上面实践过,对LEDE 17.01无效
下面是在操作一番之后的路由表,对IPv6的测速显示网速翻了四倍
root@OpenWrt:~# ip -6 route | grep pppoe
default from 2001:250:1006:dff0::/64 via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN4 proto static metric 512 pref medium
2000:::/3 dev pppoe-VWAN4 proto static metric 256 pref medium
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-wan weight 1
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN2 weight 1
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN3 weight 1
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN4 weight 1
大致可以看出这已经是做了负载均衡,需要的只是安装好luci-app-mwan3,简单操作一下路由表,这里的网关地址和dev需要看具体情况
2000::/3 就是IPv6的单播(Unicast)地址了,在不做任何操纵的情况下,无PD的路由表(单拨)
default from 2001:250:1006:dff0::/64 via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN3 proto static metric 512 pref medium
2001:250:1006:dff0::/64 dev pppoe-VWAN3 proto static metric 256 pref medium
...
之后通过下面两条常规的添加路由表条目的命令:
route -A inet6 add 2000::/3 gw fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN2
route -A inet6 add 2000::/3 gw fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN3
发现路由表就出现了nexthup和负载均衡中的weight标记
root@OpenWrt:~# ip -6 route | grep pppoe
default from 2001:250:1006:dff0::/64 via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN3 proto static metric 512 pref medium
2000::/3 dev pppoe-VWAN3 proto static metric 256 pref medium
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN2 weight 1
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN3 weight 1
...
类似的网关添加过程对IPv4效果并不好,这里稍后再细说
之后还需要修改一下防火墙,这里用的还是NAT6中的那条命令
因为对路由表的修改在路由器重启之后会重置,所以还是要添加到开机的启动脚本或者添加到自定的防火墙规则之中,如果已经在NAT6配置过程中配置好了的话这一步就可以忽略了
ip6tables -t nat -I POSTROUTING -s `uci get network.globals.ula_prefix` -j MASQUERADE
实测的峰值速度可以到达双网口的满速,但是一样的问题,在UT,IDM,Thunder这种多线程下载软件下轻松满速,而在YouTube视频应用下,只有半速(甚至包括用IDM下载的情况下)
目前最新版本的mwan3也开始支持IPv6多拨了,但是个人还是觉得日常使用的话用以上的方法更加快捷,不过需要对网络有一定的了解,下面是一段针对IPv6 NAT的多拨hotplug脚本,用了一些OpenWrt开发时推荐的写法,比较实验性
#!/bin/sh
[ "$ACTION" = ifup ] || exit 0
ifaces=$(ubus call network.interface dump | jsonfilter -e '$.interface[@.proto="dhcpv6" && @.up=true].interface')
for iface_6 in $ifaces
do
[ "$INTERFACE" = $iface_6 ] || continue
devices=$(ubus call network.interface dump | jsonfilter -e '$.interface[@.proto="dhcpv6" && @.up=true].device')
ipv6_gw=$(ifstatus $iface_6 | jsonfilter -e '$.route[1].nexthop')
for ipv6_dev in $devices
do
status=$(route -A inet6 add 2000::/3 gw $ipv6_gw dev $ipv6_dev 2>&1)
logger -t NAT6 "Gateway: $ipv6_dev: Done $status"
done
exit 0
done






![]()
find pathname -options [-print -exec -ok ...]pathname: find命令所查找的目录路径。例如用.来表示当前目录,用/来表示系统根目录。
-print: find命令将匹配的文件输出到标准输出。
-exec: find命令对匹配的文件执行该参数所给出的shell命令。相应命令的形式为'command' {} \;,注意{}和\;之间的空格。
-ok: 和-exec的作用相同,只不过以一种更为安全的模式来执行该参数所给出的shell命令,在执行每一个命令之前,都会给出提示,让用户来确定是否执行。-name
按照文件名查找文件。
-perm
按照文件权限来查找文件。
-prune
使用这一选项可以使find命令不在当前指定的目录中查找,如果同时使用-depth选项,那么-prune将被find命令忽略。
-user
按照文件属主来查找文件。
-group
按照文件所属的组来查找文件。
-mtime -n +n
按照文件的更改时间来查找文件, - n表示文件更改时间距现在n天以内,+ n表示文件更改时间距现在n天以前。find命令还有-atime和-ctime 选项,但它们都和-m time选项。
-nogroup
查找无有效所属组的文件,即该文件所属的组在/etc/groups中不存在。
-nouser
查找无有效属主的文件,即该文件的属主在/etc/passwd中不存在。
-newer file1 ! file2
查找更改时间比文件file1新但比文件file2旧的文件。
-type
查找某一类型的文件,诸如:
b - 块设备文件。
d - 目录。
c - 字符设备文件。
p - 管道文件。
l - 符号链接文件。
f - 普通文件。
-size n:[c] 查找文件长度为n块的文件,带有c时表示文件长度以字节计。
-depth:在查找文件时,首先查找当前目录中的文件,然后再在其子目录中查找。
-fstype:查找位于某一类型文件系统中的文件,这些文件系统类型通常可以在配置文件/etc/fstab中找到,该配置文件中包含了本系统中有关文件系统的信息。
-mount:在查找文件时不跨越文件系统mount点。
-follow:如果find命令遇到符号链接文件,就跟踪至链接所指向的文件。
-cpio:对匹配的文件使用cpio命令,将这些文件备份到磁带设备中。 -amin n
查找系统中最后N分钟访问的文件
-atime n
查找系统中最后n*24小时访问的文件
-cmin n
查找系统中最后N分钟被改变文件状态的文件
-ctime n
查找系统中最后n*24小时被改变文件状态的文件
-mmin n
查找系统中最后N分钟被改变文件数据的文件
-mtime n
查找系统中最后n*24小时被改变文件数据的文件# find . -type f -exec ls -l {} \;
-rw-r--r-- 1 root root 34928 2003-02-25 ./conf/httpd.conf
-rw-r--r-- 1 root root 12959 2003-02-25 ./conf/magic
-rw-r--r-- 1 root root 180 2003-02-25 ./conf.d/README$ find logs -type f -mtime +5 -exec rm {} \;$ find . -name "*.conf" -mtime +5 -ok rm {} \;
< rm ... ./conf/httpd.conf > ? n# find /etc -name "passwd*" -exec grep "sam" {} \;
sam:x:501:501::/usr/sam:/bin/bash$ find $HOME -print
$ find ~ -print$ find . -type f -perm 644 -exec ls -l {} \;$ find / -type f -size 0 -exec ls -l {} \;$ find /var/logs -type f -mtime +7 -ok rm {} \;$find . -group root -exec ls -l {} \;
-rw-r--r-- 1 root root 595 10月 31 01:09 ./fie1$ find . -name "admin.log[0-9][0-9][0-9]" -atime -7 -ok rm {} \;
< rm ... ./admin.log001 > ? n
< rm ... ./admin.log002 > ? n
< rm ... ./admin.log042 > ? n
< rm ... ./admin.log942 > ? n$ find . -type d | sort$ find /dev/rmt -print#find . -type f -print | xargs file
./.kde/Autostart/Autorun.desktop: UTF-8 Unicode English text
./.kde/Autostart/.directory: ISO-8859 text\
......$ find / -name "core" -print | xargs echo "" >/tmp/core.log#find . -name "file*" -print | xargs echo "" > /temp/core.log
# cat /temp/core.log
./file6# ls -l
drwxrwxrwx 2 sam adm 4096 10月 30 20:14 file6
-rwxrwxrwx 2 sam adm 0 10月 31 01:01 http3.conf
-rwxrwxrwx 2 sam adm 0 10月 31 01:01 httpd.conf
# find . -perm -7 -print | xargs chmod o-w
# ls -l
drwxrwxr-x 2 sam adm 4096 10月 30 20:14 file6
-rwxrwxr-x 2 sam adm 0 10月 31 01:01 http3.conf
-rwxrwxr-x 2 sam adm 0 10月 31 01:01 httpd.conf# find . -type f -print | xargs grep "hostname"
./httpd1.conf:# different IP addresses or hostnames and have them handled by the
./httpd1.conf:# VirtualHost: If you want to maintain multiple domains/hostnames
on your# find . -name \* -type f -print | xargs grep "hostnames"
./httpd1.conf:# different IP addresses or hostnames and have them handled by the
./httpd1.conf:# VirtualHost: If you want to maintain multiple domains/hostnames
on your$ find ~ -name "*.txt" -print$ find . -name "*.txt" -print$ find . -name "[A-Z]*" -print$ find /etc -name "host*" -print$ find ~ -name "*" -print 或find . -print$ find / -name "*" -print$find . -name "[a-z][a-z][0--9][0--9].txt" -print$ find . -perm 755 -print# ls -l
-rwxrwxr-x 2 sam adm 0 10月 31 01:01 http3.conf
-rw-rw-rw- 1 sam adm 34890 10月 31 00:57 httpd1.conf
-rwxrwxr-x 2 sam adm 0 10月 31 01:01 httpd.conf
drw-rw-rw- 2 gem group 4096 10月 26 19:48 sam
-rw-rw-rw- 1 root root 2792 10月 31 20:19 temp
# find . -perm 006
# find . -perm -006
./sam
./httpd1.conf
./temp$ find /apps -path "/apps/bin" -prune -o -printfind /usr/sam -path "/usr/sam/dir1" -prune -o -printfind [-path ..] [expression] 在路径列表的后面的是表达式if -path "/usr/sam" then
-prune
else
-printfind /usr/sam \( -path /usr/sam/dir1 -o -path /usr/sam/file1 \) -prune -o -print\ 表示引用,即指示 shell 不对后面的字符作特殊解释,而留给 find 命令去解释其意义。#find /usr/sam \(-path /usr/sam/dir1 -o -path /usr/sam/file1 \) -prune -o -name "temp" -print$ find ~ -user sam -print$ find /etc -user uucp -print$ find /home -nouser -print$ find /apps -group gem -print$ find / -nogroup-print$ find / -mtime -5 -print$ find /var/adm -mtime +3 -printnewest_file_name ! oldest_file_name-rw-r--r-- 1 sam adm 0 10月 31 01:07 fiel
-rw-rw-rw- 1 sam adm 34890 10月 31 00:57 httpd1.conf
-rwxrwxr-x 2 sam adm 0 10月 31 01:01 httpd.conf
drw-rw-rw- 2 gem group 4096 10月 26 19:48 sam
-rw-rw-rw- 1 root root 2792 10月 31 20:19 temp
# find -newer httpd1.conf ! -newer temp -ls
1077669 0 -rwxrwxr-x 2 sam adm 0 10月 31 01:01 ./httpd.conf
1077671 4 -rw-rw-rw- 1 root root 2792 10月 31 20:19 ./temp
1077673 0 -rw-r--r-- 1 sam adm 0 10月 31 01:07 ./fiel$ find . -newer temp -print$ find /etc -type d -print$ find . ! -type d -print$ find /etc -type l -print$ find . -size +1000000c -print$ find /home/apache -size 100c -print$ find . -size +10 -print$ find / -name "CON.FILE" -depth -print$ find . -name "*.XC" -mount -printmysqld_safe --skip-grant-tables &| Command | Description | |
| • | grep . /proc/sys/net/ipv4/* | List the contents of flag files |
| • | set | grep $USER | Search current environment |
| • | tr '\0' '\n' < /proc/$$/environ | Display the startup environment for any process |
| • | echo $PATH | tr : '\n' | Display the $PATH one per line |
| • | kill -0 $$ && echo process exists and can accept signals | Check for the existence of a process (pid) |
| • | find /etc -readable | xargs less -K -p'*ntp' -j $((${LINES:-25}/2)) | Search paths and data with full context. Use n to iterate |
| Low impact admin | ||
| # | apt-get install "package" -o Acquire::http::Dl-Limit=42 \ -o Acquire::Queue-mode=access | Rate limit apt-get to 42KB/s |
| echo 'wget url' | at 01:00 | Download url at 1AM to current dir | |
| # | apache2ctl configtest && apache2ctl graceful | Restart apache if config is OK |
| • | nice openssl speed sha1 | Run a low priority command (openssl benchmark) |
| • | chrt -i 0 openssl speed sha1 | Run a low priority command (more effective than nice) |
| • | renice 19 -p $$; ionice -c3 -p $$ | Make shell (script) low priority. Use for non interactive tasks |
| Interactive monitoring | ||
| • | watch -t -n1 uptime | Clock with system load |
| • | htop -d 5 | Better top (scrollable, tree view, lsof/strace integration, ...) |
| • | iotop | What's doing I/O |
| # | watch -d -n30 "nice ps_mem.py | tail -n $((${LINES:-12}-2))" | What's using RAM |
| # | iftop | What's using the network. See also iptraf |
| # | mtr www.pixelbeat.org | ping and traceroute combined |
| Useful utilities | ||
| • | pv < /dev/zero > /dev/null | Progress Viewer for data copying from files and pipes |
| • | wkhtml2pdf http://.../linux_commands.html linux_commands.pdf | Make a pdf of a web page |
| • | timeout 1 sleep 3 | run a command with bounded time. See also timeout |
| Networking | ||
| • | python -m SimpleHTTPServer | Serve current directory tree at http://$HOSTNAME:8000/ |
| • | openssl s_client -connect www.google.com:443 </dev/null 2>&0 | openssl x509 -dates -noout | Display the date range for a site's certs |
| • | curl -I www.pixelbeat.org | Display the server headers for a web site |
| # | lsof -i tcp:80 | What's using port 80 |
| # | httpd -S | Display a list of apache virtual hosts |
| • | vim scp://user@remote//path/to/file | Edit remote file using local vim. Good for high latency links |
| • | curl -s http://www.pixelbeat.org/pixelbeat.asc | gpg --import | Import a gpg key from the web |
| • | tc qdisc add dev lo root handle 1:0 netem delay 20msec | Add 20ms latency to loopback device (for testing) |
| • | tc qdisc del dev lo root | Remove latency added above |
| Notification | ||
| • | echo "DISPLAY=$DISPLAY xmessage cooker" | at "NOW +30min" | Popup reminder |
| • | notify-send "subject" "message" | Display a gnome popup notification |
| echo "mail -s 'go home' P@draigBrady.com < /dev/null" | at 17:30 | Email reminder | |
| uuencode file name | mail -s subject P@draigBrady.com | Send a file via email | |
| ansi2html.sh | mail -a "Content-Type: text/html" P@draigBrady.com | Send/Generate HTML email | |
| Better default settings (useful in your .bashrc) | ||
| # | tail -s.1 -f /var/log/messages | Display file additions more responsively |
| • | seq 100 | tail -n $((${LINES:-12}-2)) | Display as many lines as possible without scrolling |
| # | tcpdump -s0 | Capture full network packets |
| Useful functions/aliases (useful in your .bashrc) | ||
| • | md () { mkdir -p "$1" && cd "$1"; } | Change to a new directory |
| • | strerror() { python -c "import os; print os.strerror($1)"; } | Display the meaning of an errno |
| • | plot() { { echo 'plot "-"' "$@"; cat; } | gnuplot -persist; } | Plot stdin. (e.g: • seq 1000 | sed 's/.*/s(&)/' | bc -l | plot) |
| • | hili() { e="$1"; shift; grep --col=always -Eih "$e|$" "$@"; } | highlight occurences of expr. (e.g: • env | hili $USER) |
| • | alias hd='od -Ax -tx1z -v' | Hexdump. (usage e.g.: • hd /proc/self/cmdline | less) |
| • | alias realpath='readlink -f' | Canonicalize path. (usage e.g.: • realpath ~/../$USER) |
| • | ord() { printf "0x%x\n" "'$1"; } | shell version of the ord() function |
| • | chr() { printf $(printf '\\%03o\\n' "$1"); } | shell version of the chr() function |
| Multimedia | ||
| • | DISPLAY=:0.0 import -window root orig.png | Take a (remote) screenshot |
| • | convert -filter catrom -resize '600x>' orig.png 600px_wide.png | Shrink to width, computer gen images or screenshots |
| mplayer -ao pcm -vo null -vc dummy /tmp/Flash* | Extract audio from flash video to audiodump.wav | |
| ffmpeg -i filename.avi | Display info about multimedia file | |
| • | ffmpeg -f x11grab -s xga -r 25 -i :0 -sameq demo.mpg | Capture video of an X display |
| DVD | ||
| for i in $(seq 9); do ffmpeg -i $i.avi -target pal-dvd $i.mpg; done | Convert video to the correct encoding and aspect for DVD | |
| dvdauthor -odvd -t -v "pal,4:3,720xfull" *.mpg;dvdauthor -odvd -T | Build DVD file system. Use 16:9 for widescreen input | |
| growisofs -dvd-compat -Z /dev/dvd -dvd-video dvd | Burn DVD file system to disc | |
| Unicode | ||
| • | python -c "import unicodedata as u; print u.name(unichr(0x2028))" | Lookup a unicode character |
| • | uconv -f utf8 -t utf8 -x nfc | Normalize combining characters |
| • | printf '\300\200' | iconv -futf8 -tutf8 >/dev/null | Validate UTF-8 |
| • | printf 'ŨTF8\n' | LANG=C grep --color=always '[^ -~]\+' | Highlight non printable ASCII chars in UTF-8 |
| • | fc-match -s "sans:lang=zh" | List font match order for language and style |
| Development | ||
| • | gcc -march=native -E -v -</dev/null 2>&1|sed -n 's/.*-mar/-mar/p' | Show autodetected gcc tuning params. See also gcccpuopt |
| • | for i in $(seq 4); do { [ $i = 1 ] && wget http://url.ie/6lko -qO-|| ./a.out; } | tee /dev/tty | gcc -xc - 2>/dev/null; done | Compile and execute C code from stdin |
| • | cpp -dM /dev/null | Show all predefined macros |
| • | echo "#include <features.h>" | cpp -dN | grep "#define __USE_" | Show all glibc feature macros |
| gdb -tui | Debug showing source code context in separate windows | |
| udev | ||
| • | udevadm info -a -p $(udevadm info -q path -n /dev/input/mouse0) | List udev attributes of a device, for matching rules etc. |
| • | udevadm test /sys/class/input/mouse0 | See how udev rules are applied for a device |
| # | udevadm control --reload-rules | Reload udev rules after modification |
| Extended Attributes (Note you may need to (re)mount with "acl" or "user_xattr" options) | ||
| • | getfacl . | Show ACLs for file |
| • | setfacl -m u:nobody:r . | Allow a specific user to read file |
| • | setfacl -x u:nobody . | Delete a specific user's rights to file |
| setfacl --default -m group:users:rw- dir/ | Set umask for a for a specific dir | |
| getcap file | Show capabilities for a program | |
| setcap cap_net_raw+ep your_gtk_prog | Allow gtk program raw access to network | |
| • | stat -c%C . | Show SELinux context for file |
| chcon ... file | Set SELinux context for file (see also restorecon) | |
| • | getfattr -m- -d . | Show all extended attributes (includes selinux,acls,...) |
| • | setfattr -n "user.foo" -v "bar" . | Set arbitrary user attributes |
| BASH specific | ||
| • | echo 123 | tee >(tr 1 a) | tr 1 b | Split data to 2 commands (using process substitution) |
| meld local_file <(ssh host cat remote_file) | Compare a local and remote file (using process substitution) | |
| Multicore | ||
| • | taskset -c 0 nproc | Restrict a command to certain processors |
| • | find -type f -print0 | xargs -r0 -P$(nproc) -n10 md5sum | Process files in parallel over available processors |
| sort -m <(sort data1) <(sort data2) >data.sorted | Sort separate data files over 2 processors | |
| This is a linux command line reference for common operations. Examples marked with • are valid/safe to paste without modification into a terminal, so you may want to keep a terminal window open while reading this so you can cut & paste. All these commands have been tested both on Fedora and Ubuntu. See also more linux commands. |
| Command | Description | |
| • | apropos whatis | Show commands pertinent to string. See also threadsafe |
| • | man -t ascii | ps2pdf - > ascii.pdf | make a pdf of a manual page |
| which command | Show full path name of command | |
| time command | See how long a command takes | |
| • | time cat | Start stopwatch. Ctrl-d to stop. See also sw |
| dir navigation | ||
| • | cd - | Go to previous directory |
| • | cd | Go to $HOME directory |
| (cd dir && command) | Go to dir, execute command and return to current dir | |
| • | pushd . | Put current dir on stack so you can popd back to it |
| file searching | ||
| • | alias l='ls -l --color=auto' | quick dir listing |
| • | ls -lrt | List files by date. See also newest and find_mm_yyyy |
| • | ls /usr/bin | pr -T9 -W$COLUMNS | Print in 9 columns to width of terminal |
| find -name '*.[ch]' | xargs grep -E 'expr' | Search 'expr' in this dir and below. See also findrepo | |
| find -type f -print0 | xargs -r0 grep -F 'example' | Search all regular files for 'example' in this dir and below | |
| find -maxdepth 1 -type f | xargs grep -F 'example' | Search all regular files for 'example' in this dir | |
| find -maxdepth 1 -type d | while read dir; do echo $dir; echo cmd2; done | Process each item with multiple commands (in while loop) | |
| • | find -type f ! -perm -444 | Find files not readable by all (useful for web site) |
| • | find -type d ! -perm -111 | Find dirs not accessible by all (useful for web site) |
| • | locate -r 'file[^/]*\.txt' | Search cached index for names. This re is like glob *file*.txt |
| • | look reference | Quickly search (sorted) dictionary for prefix |
| • | grep --color reference /usr/share/dict/words | Highlight occurances of regular expression in dictionary |
| archives and compression | ||
| gpg -c file | Encrypt file | |
| gpg file.gpg | Decrypt file | |
| tar -c dir/ | bzip2 > dir.tar.bz2 | Make compressed archive of dir/ | |
| bzip2 -dc dir.tar.bz2 | tar -x | Extract archive (use gzip instead of bzip2 for tar.gz files) | |
| tar -c dir/ | gzip | gpg -c | ssh user@remote 'dd of=dir.tar.gz.gpg' | Make encrypted archive of dir/ on remote machine | |
| find dir/ -name '*.txt' | tar -c --files-from=- | bzip2 > dir_txt.tar.bz2 | Make archive of subset of dir/ and below | |
| find dir/ -name '*.txt' | xargs cp -a --target-directory=dir_txt/ --parents | Make copy of subset of dir/ and below | |
| (tar -c /dir/to/copy) | ( cd /where/to/ && tar -x -p ) | Copy (with permissions) copy/ dir to /where/to/ dir | |
| (cd /dir/to/copy && tar -c .) | ( cd /where/to/ && tar -x -p ) | Copy (with permissions) contents of copy/ dir to /where/to/ | |
| (tar -c /dir/to/copy ) | ssh -C user@remote 'cd /where/to/ && tar -x -p' | Copy (with permissions) copy/ dir to remote:/where/to/ dir | |
| dd bs=1M if=/dev/sda | gzip | ssh user@remote 'dd of=sda.gz' | Backup harddisk to remote machine | |
| rsync (Network efficient file copier: Use the --dry-run option for testing) | ||
| rsync -P rsync://rsync.server.com/path/to/file file | Only get diffs. Do multiple times for troublesome downloads | |
| rsync --bwlimit=1000 fromfile tofile | Locally copy with rate limit. It's like nice for I/O | |
| rsync -az -e ssh --delete ~/public_html/ remote.com:'~/public_html' | Mirror web site (using compression and encryption) | |
| rsync -auz -e ssh remote:/dir/ . && rsync -auz -e ssh . remote:/dir/ | Synchronize current directory with remote one | |
| ssh (Secure SHell) | ||
| ssh $USER@$HOST command | Run command on $HOST as $USER (default command=shell) | |
| • | ssh -f -Y $USER@$HOSTNAME xeyes | Run GUI command on $HOSTNAME as $USER |
| scp -p -r $USER@$HOST: file dir/ | Copy with permissions to $USER's home directory on $HOST | |
| scp -c arcfour $USER@$LANHOST: bigfile | Use faster crypto for local LAN. This might saturate GigE | |
| ssh -g -L 8080:localhost:80 root@$HOST | Forward connections to $HOSTNAME:8080 out to $HOST:80 | |
| ssh -R 1434:imap:143 root@$HOST | Forward connections from $HOST:1434 in to imap:143 | |
| ssh-copy-id $USER@$HOST | Install public key for $USER@$HOST for password-less log in | |
| wget (multi purpose download tool) | ||
| • | (cd dir/ && wget -nd -pHEKk http://www.pixelbeat.org/cmdline.html) | Store local browsable version of a page to the current dir |
| wget -c http://www.example.com/large.file | Continue downloading a partially downloaded file | |
| wget -r -nd -np -l1 -A '*.jpg' http://www.example.com/dir/ | Download a set of files to the current directory | |
| wget ftp://remote/file[1-9].iso/ | FTP supports globbing directly | |
| • | wget -q -O- http://www.pixelbeat.org/timeline.html | grep 'a href' | head | Process output directly |
| echo 'wget url' | at 01:00 | Download url at 1AM to current dir | |
| wget --limit-rate=20k url | Do a low priority download (limit to 20KB/s in this case) | |
| wget -nv --spider --force-html -i bookmarks.html | Check links in a file | |
| wget --mirror http://www.example.com/ | Efficiently update a local copy of a site (handy from cron) | |
| networking (Note ifconfig, route, mii-tool, nslookup commands are obsolete) | ||
| ethtool eth0 | Show status of ethernet interface eth0 | |
| ethtool --change eth0 autoneg off speed 100 duplex full | Manually set ethernet interface speed | |
| iwconfig eth1 | Show status of wireless interface eth1 | |
| iwconfig eth1 rate 1Mb/s fixed | Manually set wireless interface speed | |
| • | iwlist scan | List wireless networks in range |
| • | ip link show | List network interfaces |
| ip link set dev eth0 name wan | Rename interface eth0 to wan | |
| ip link set dev eth0 up | Bring interface eth0 up (or down) | |
| • | ip addr show | List addresses for interfaces |
| ip addr add 1.2.3.4/24 brd + dev eth0 | Add (or del) ip and mask (255.255.255.0) | |
| • | ip route show | List routing table |
| ip route add default via 1.2.3.254 | Set default gateway to 1.2.3.254 | |
| • | host pixelbeat.org | ookup DNS ip address for name or vice versaL |
| • | hostname -i | Lookup local ip address (equivalent to host `hostname`) |
| • | whois pixelbeat.org | Lookup whois info for hostname or ip address |
| • | netstat -tupl | List internet services on a system |
| • | netstat -tup | List active connections to/from system |
| windows networking (Note samba is the package that provides all this windows specific networking support) | ||
| • | smbtree | Find windows machines. See also findsmb |
| nmblookup -A 1.2.3.4 | Find the windows (netbios) name associated with ip address | |
| smbclient -L windows_box | List shares on windows machine or samba server | |
| mount -t smbfs -o fmask=666,guest //windows_box/share /mnt/share | Mount a windows share | |
| echo 'message' | smbclient -M windows_box | Send popup to windows machine (off by default in XP sp2) | |
| text manipulation (Note sed uses stdin and stdout. Newer versions support inplace editing with the -i option) | ||
| sed 's/string1/string2/g' | Replace string1 with string2 | |
| sed 's/\(.*\)1/\12/g' | Modify anystring1 to anystring2 | |
| sed '/ *#/d; /^ *$/d' | Remove comments and blank lines | |
| sed ':a; /\\$/N; s/\\\n//; ta' | Concatenate lines with trailing \ | |
| sed 's/[ \t]*$//' | Remove trailing spaces from lines | |
| sed 's/\([`"$\]\)/\\\1/g' | Escape shell metacharacters active within double quotes | |
| • | seq 10 | sed "s/^/ /; s/ *\(.\{7,\}\)/\1/" | Right align numbers |
| sed -n '1000{p;q}' | Print 1000th line | |
| sed -n '10,20p;20q' | Print lines 10 to 20 | |
| sed -n 's/.*<title>\(.*\)<\/title>.*/\1/ip;T;q' | Extract title from HTML web page | |
| sed -i 42d ~/.ssh/known_hosts | Delete a particular line | |
| sort -t. -k1,1n -k2,2n -k3,3n -k4,4n | Sort IPV4 ip addresses | |
| • | echo 'Test' | tr '[:lower:]' '[:upper:]' | Case conversion |
| • | tr -dc '[:print:]' < /dev/urandom | Filter non printable characters |
| • | tr -s '[:blank:]' '\t' </proc/diskstats | cut -f4 | cut fields separated by blanks |
| • | history | wc -l | Count lines |
| set operations (Note you can export LANG=C for speed. Also these assume no duplicate lines within a file) | ||
| sort file1 file2 | uniq | Union of unsorted files | |
| sort file1 file2 | uniq -d | Intersection of unsorted files | |
| sort file1 file1 file2 | uniq -u | Difference of unsorted files | |
| sort file1 file2 | uniq -u | Symmetric Difference of unsorted files | |
| join -t'\0' -a1 -a2 file1 file2 | Union of sorted files | |
| join -t'\0' file1 file2 | Intersection of sorted files | |
| join -t'\0' -v2 file1 file2 | Difference of sorted files | |
| join -t'\0' -v1 -v2 file1 file2 | Symmetric Difference of sorted files | |
| math | ||
| • | echo '(1 + sqrt(5))/2' | bc -l | Quick math (Calculate φ). See also bc |
| • | seq -f '4/%g' 1 2 99999 | paste -sd-+ | bc -l | Calculate π the unix way |
| • | echo 'pad=20; min=64; (100*10^6)/((pad+min)*8)' | bc | More complex (int) e.g. This shows max FastE packet rate |
| • | echo 'pad=20; min=64; print (100E6)/((pad+min)*8)' | python | Python handles scientific notation |
| • | echo 'pad=20; plot [64:1518] (100*10**6)/((pad+x)*8)' | gnuplot -persist | Plot FastE packet rate vs packet size |
| • | echo 'obase=16; ibase=10; 64206' | bc | Base conversion (decimal to hexadecimal) |
| • | echo $((0x2dec)) | Base conversion (hex to dec) ((shell arithmetic expansion)) |
| • | units -t '100m/9.58s' 'miles/hour' | Unit conversion (metric to imperial) |
| • | units -t '500GB' 'GiB' | Unit conversion (SI to IEC prefixes) |
| • | units -t '1 googol' | Definition lookup |
| • | seq 100 | (tr '\n' +; echo 0) | bc | Add a column of numbers. See also add and funcpy |
| calendar | ||
| • | cal -3 | Display a calendar |
| • | cal 9 1752 | Display a calendar for a particular month year |
| • | date -d fri | What date is it this friday. See also day |
| • | [ $(date -d '12:00 +1 day' +%d) = '01' ] || exit | exit a script unless it's the last day of the month |
| • | date --date='25 Dec' +%A | What day does xmas fall on, this year |
| • | date --date='@2147483647' | Convert seconds since the epoch (1970-01-01 UTC) to date |
| • | TZ='America/Los_Angeles' date | What time is it on west coast of US (use tzselect to find TZ) |
| • | date --date='TZ="America/Los_Angeles" 09:00 next Fri' | What's the local time for 9AM next Friday on west coast US |
| locales | ||
| • | printf "%'d\n" 1234 | Print number with thousands grouping appropriate to locale |
| • | BLOCK_SIZE=\'1 ls -l | Use locale thousands grouping in ls. See also l |
| • | echo "I live in `locale territory`" | Extract info from locale database |
| • | LANG=en_IE.utf8 locale int_prefix | Lookup locale info for specific country. See also ccodes |
| • | locale -kc $(locale | sed -n 's/\(LC_.\{4,\}\)=.*/\1/p') | less | List fields available in locale database |
| recode (Obsoletes iconv, dos2unix, unix2dos) | ||
| • | recode -l | less | Show available conversions (aliases on each line) |
| recode windows-1252.. file_to_change.txt | Windows "ansi" to local charset (auto does CRLF conversion) | |
| recode utf-8/CRLF.. file_to_change.txt | Windows utf8 to local charset | |
| recode iso-8859-15..utf8 file_to_change.txt | Latin9 (western europe) to utf8 | |
| recode ../b64 < file.txt > file.b64 | Base64 encode | |
| recode /qp.. < file.qp > file.txt | Quoted printable decode | |
| recode ..HTML < file.txt > file.html | Text to HTML | |
| • | recode -lf windows-1252 | grep euro | Lookup table of characters |
| • | echo -n 0x80 | recode latin-9/x1..dump | Show what a code represents in latin-9 charmap |
| • | echo -n 0x20AC | recode ucs-2/x2..latin-9/x | Show latin-9 encoding |
| • | echo -n 0x20AC | recode ucs-2/x2..utf-8/x | Show utf-8 encoding |
| CDs | ||
| gzip < /dev/cdrom > cdrom.iso.gz | Save copy of data cdrom | |
| mkisofs -V LABEL -r dir | gzip > cdrom.iso.gz | Create cdrom image from contents of dir | |
| mount -o loop cdrom.iso /mnt/dir | Mount the cdrom image at /mnt/dir (read only) | |
| cdrecord -v dev=/dev/cdrom blank=fast | Clear a CDRW | |
| gzip -dc cdrom.iso.gz | cdrecord -v dev=/dev/cdrom - | Burn cdrom image (use dev=ATAPI -scanbus to confirm dev) | |
| cdparanoia -B | Rip audio tracks from CD to wav files in current dir | |
| cdrecord -v dev=/dev/cdrom -audio -pad *.wav | Make audio CD from all wavs in current dir (see also cdrdao) | |
| oggenc --tracknum='track' track.cdda.wav -o 'track.ogg' | Make ogg file from wav file | |
| disk space (See also FSlint) | ||
| • | ls -lSr | Show files by size, biggest last |
| • | du -s * | sort -k1,1rn | head | Show top disk users in current dir. See also dutop |
| • | du -hs /home/* | sort -k1,1h | Sort paths by easy to interpret disk usage |
| • | df -h | Show free space on mounted filesystems |
| • | df -i | Show free inodes on mounted filesystems |
| • | fdisk -l | Show disks partitions sizes and types (run as root) |
| • | rpm -q -a --qf '%10{SIZE}\t%{NAME}\n' | sort -k1,1n | List all packages by installed size (Bytes) on rpm distros |
| • | dpkg-query -W -f='${Installed-Size;10}\t${Package}\n' | sort -k1,1n | List all packages by installed size (KBytes) on deb distros |
| • | dd bs=1 seek=2TB if=/dev/null of=ext3.test | Create a large test file (taking no space). See also truncate |
| • | > file | truncate data of file or create an empty file |
| monitoring/debugging | ||
| • | tail -f /var/log/messages | Monitor messages in a log file |
| • | strace -c ls >/dev/null | Summarise/profile system calls made by command |
| • | strace -f -e open ls >/dev/null | List system calls made by command |
| • | strace -f -e trace=write -e write=1,2 ls >/dev/null | Monitor what's written to stdout and stderr |
| • | ltrace -f -e getenv ls >/dev/null | List library calls made by command |
| • | lsof -p $$ | List paths that process id has open |
| • | lsof ~ | List processes that have specified path open |
| • | tcpdump not port 22 | Show network traffic except ssh. See also tcpdump_not_me |
| • | ps -e -o pid,args --forest | List processes in a hierarchy |
| • | ps -e -o pcpu,cpu,nice,state,cputime,args --sort pcpu | sed '/^ 0.0 /d' | List processes by % cpu usage |
| • | ps -e -orss=,args= | sort -b -k1,1n | pr -TW$COLUMNS | List processes by mem (KB) usage. See also ps_mem.py |
| • | ps -C firefox-bin -L -o pid,tid,pcpu,state | List all threads for a particular process |
| • | ps -p 1,$$ -o etime= | List elapsed wall time for particular process IDs |
| • | last reboot | Show system reboot history |
| • | free -m | Show amount of (remaining) RAM (-m displays in MB) |
| • | watch -n.1 'cat /proc/interrupts' | Watch changeable data continuously |
| • | udevadm monitor | Monitor udev events to help configure rules |
| system information (see also sysinfo) ('#' means root access is required) | ||
| • | uname -a | Show kernel version and system architecture |
| • | head -n1 /etc/issue | Show name and version of distribution |
| • | cat /proc/partitions | Show all partitions registered on the system |
| • | grep MemTotal /proc/meminfo | Show RAM total seen by the system |
| • | grep "model name" /proc/cpuinfo | Show CPU(s) info |
| • | lspci -tv | Show PCI info |
| • | lsusb -tv | Show USB info |
| • | mount | column -t | List mounted filesystems on the system (and align output) |
| • | grep -F capacity: /proc/acpi/battery/BAT0/info | Show state of cells in laptop battery |
| # | dmidecode -q | less | Display SMBIOS/DMI information |
| # | smartctl -A /dev/sda | grep Power_On_Hours | How long has this disk (system) been powered on in total |
| # | hdparm -i /dev/sda | Show info about disk sda |
| # | hdparm -tT /dev/sda | Do a read speed test on disk sda |
| # | badblocks -s /dev/sda | Test for unreadable blocks on disk sda |
| interactive (see also linux keyboard shortcuts) | ||
| • | readline | Line editor used by bash, python, bc, gnuplot, ... |
| • | screen | Virtual terminals with detach capability, ... |
| • | mc | Powerful file manager that can browse rpm, tar, ftp, ssh, ... |
| • | gnuplot | Interactive/scriptable graphing |
| • | links | Web browser |
| • | xdg-open . | open a file or url with the registered desktop application |
# uname -a # 查看内核/操作系统/CPU信息 # head -n 1 /etc/issue # 查看操作系统版本 # cat /proc/cpuinfo # 查看CPU信息 # hostname # 查看计算机名 # lspci -tv # 列出所有PCI设备 # lsusb -tv # 列出所有USB设备 # lsmod # 列出加载的内核模块 # env # 查看环境变量
# free -m # 查看内存使用量和交换区使用量 # df -h # 查看各分区使用情况 # du -sh <目录名> # 查看指定目录的大小 # grep MemTotal /proc/meminfo # 查看内存总量 # grep MemFree /proc/meminfo # 查看空闲内存量 # uptime # 查看系统运行时间、用户数、负载 # cat /proc/loadavg # 查看系统负载
# mount | column -t # 查看挂接的分区状态 # fdisk -l # 查看所有分区 # swapon -s # 查看所有交换分区 # hdparm -i /dev/hda # 查看磁盘参数(仅适用于IDE设备) # dmesg | grep IDE # 查看启动时IDE设备检测状况
# ifconfig # 查看所有网络接口的属性 # iptables -L # 查看防火墙设置 # route -n # 查看路由表 # netstat -lntp # 查看所有监听端口 # netstat -antp # 查看所有已经建立的连接 # netstat -s # 查看网络统计信息
# ps -ef # 查看所有进程 # top # 实时显示进程状态
# w # 查看活动用户 # id <用户名> # 查看指定用户信息 # last # 查看用户登录日志 # cut -d: -f1 /etc/passwd # 查看系统所有用户 # cut -d: -f1 /etc/group # 查看系统所有组 # crontab -l # 查看当前用户的计划任务
# chkconfig --list # 列出所有系统服务 # chkconfig --list | grep on # 列出所有启动的系统服务
# rpm -qa # 查看所有安装的软件包
附加一张总结的很好Linux常用命定的图片:
 |
| Linux 文件结构大全 |
![]()
当我们需要让Linux程序后台运行时,可以使用以下四种方式:添加&符号、nohup、screen以及systemctl。其中systemctl还可以配置开机自启动。
1 | ./test & #在可执行程序后空一格添加& |
1 | which nohup #查询是否安装nohup,输出/usr/bin/nohup则已安装 |
1 | apt install screen #安装screen |
1 | nano /lib/systemd/system/test.service #输入以下内容 |
alpine没有systemd管理服务,因此需要安装openrc。
1 | apk add openrc |