No One Tells You What Happens to Your Muscles in Your 40s
31 October 2024 at 05:03
The decline in strength and increase in injuries is little recognized and far too infrequently discussed.
健身課表/課表中,除了動作選擇外,最重要的就是訓練強度和訓練量了。但訓練量有許多不同的定義,本文即是來解釋訓練量的定義方法及理由(原文請見 ig @vin_training)
訓練量,是大家耳熟能詳的名詞,是安排課表時重要的變因之一。
我自己最初接觸這個名詞時,學到的是「訓練量=次數x組數x重量」。但後來慢慢發現,不是所有人都這樣定義的。
譬如,許多健力、健美課表上的每日「volume」欄位就是指當天的「sets (組數)」。而台灣人應該也不陌生的 Juggernaut Training System 的 「訓練量專家」 Mike Isratel (水肥哥翻譯過他的「練胸完全指南」)也把訓練量定義為組數。
那訓練量到底該怎麼定義呢?本文整理了近幾年的研究並給出我個人的推論,但這並不是學界公認的定義,也不是每個健身者都認同的定義。事實上,有些專家會用更複雜的計算方式來定義訓練量(例如,考慮自覺強度或 1RM 百分比)。
因此本文主要目的是分享訓練量的「簡易定義方式」,以供大家參考,並不是說這就是唯一的正解。
傳統上,我們常用「次數x組數x重量」當作訓練量的定義,但就出現了一個問題:為什麼研究(1)會發現,當訓練量相同時,大重量訓練比小重量訓練能得到更多的肌肉量成長?之後,科學家發現,若把訓練量定義為「達到力竭的組數」的話,大重量訓練就跟小重量訓練有同樣的肌肥大效果(研究2,研究3)。
[實際應用]
在設計課表時,訓練量是我們常常要操作或控制的變因。許多人把訓練量視為「次數x組數x重量」,但或許把訓練量視為「足夠難的組數」會是更好的方法。
關於訓練量與肌力的研究相對不一致。有研究(4,5)發現訓練的組數越多,肌力成長就越高;但也有研究(6,7)得出高組數與低組數對肌力成長的效果沒有差別。
但不變的是,大重量對最大肌力的成長一定比低重量大。此外因重量跟次數是互相影響的,所以大重量必伴隨低次數。因此,以肌力為目標的話,將訓練量定義為「組數」即可。
[實際應用]
若目標是最大肌力,那一定要練大重量(>75% 1RM 夠的重量),且時不時需要練>90% 1RM 的重量。但訓練量是不是重點呢?短期可能不是,因此比賽前減少訓練量是不會影響肌力成長的。但長期而言,因肌肉量愈高則肌力成長的潛力越大,所以高訓練量仍會比較好。
當訓練量=「次數x組數x量」時,相同的訓練量會有類似的熱量消耗。
因為熱量消耗取決於做功,而做功等於「力x距離x總次數」。所以在距離相同的情況下(也就是你深蹲不會越蹲越高),熱量消耗就可以用「重量x總次數」來預測,而總次數就是次數x組數。
[實際應用]
如果你重訓的目標就是「熱量消耗」的話,那挑選較輕的重量確實能較有效累積一個訓練日的熱量消耗。但我仍會推薦重訓就以肌力、肌肉量、或肌耐力為目標,熱量方面靠飲食更有效。
另一個能觀察到的現象是,初學者通常深蹲或硬舉個 10 下後仍臉不紅氣不喘,但若是能蹲 200 公斤 10 下的人,蹲完肯定會攤死在地板上,因為熱量消耗實在太大了,所以休息時有氧系統需要火力全開提供能量。
若你想尋求最簡單的方法來追蹤訓練量,那用「組數」算是不錯的選擇。但一組三下 vs 一組 15 下對身體的感覺確實不同,所以心中也要記得「組數」只是個訓練量的估算而已,最終還是要檢測自己的身體反應。
想成為科學化的健身人,但每次打開論文都只會看結果、看不懂數據嗎?其實結果後面的統計學才是看懂文獻的關鍵。(圖文版:@vin_training)
科學化的健身是現在的趨勢,不過僅僅會去搜尋論文然後看懂標題和結論,就像是去書店看了封底的大綱就當作已看過這本書一樣,錯過了真正能讓你思考和學習的內容。研究結果只是一系列實驗和分析的最後一步,想要真正讓一篇論文擴展你對健身科學的理解,就需要去讀背後的過程。其中,實驗數據的統計就是相當重要的一塊,尤其健身相關實驗通常為期較短、受試者人數較少,所以對數據的解讀的不同就很容易影響對結果的判讀。
本文是零基礎都能輕鬆入門的統計學介紹,只介紹觀念而不會提及任何數學公式,且會以一篇真正的健身論文為例,帶大家看一些基礎的統計觀念。
本文以 Evenly Distributed Protein Intake over 3 Meals Augments Resistance Exercise–Induced Muscle Hypertrophy in Healthy Young Men 作為介紹基礎統計概念的例子。本研究探討「把蛋白質平均分配到每一餐,會不會更能增加肌力和肌肥大」,直接講結論:在 12 週的飲食控制+重訓後,平均分配蛋白質的人比不平均分配的人,增加更多的瘦組織與更多的肌力,但都未達「統計上的顯著」。等等就來介紹這句話的涵義,及論文中其他常見的數據。
如果你被告知,這裡有一群平均年齡 20 歲的人,那你覺得這群人是全都大學生、還是一群家長和他們的國小小孩呢?
光靠「平均年齡」是無法讓你回答上面的問題的,此時就需要知道這群人的年齡分佈。如果大家都差不多是 20 歲,那大家的年齡分佈就很緊密;如果有些人 16 歲、有些人 30 歲、有些人 8 歲⋯⋯那年齡分佈就很離散。讓我們能得知離散程度的數據即是「標準誤 standard error, SE」,如果 SE 越大,代表越離散,反之則越緊密。(註:有時統計是用「標準差 standard deviation, SD 」而非 SE,這裡就不細講它們的差別了 ,只要知道它們都是用來描述離散程度就好)
我們直接進入研究例子:
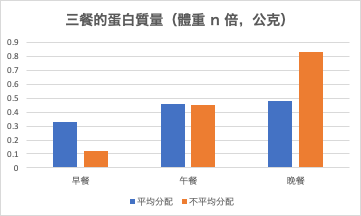
(請看圖二)mean 就是「平均」的意思,所以本篇論文一開始就提供受試者的基本數據:平均年齡是 20.8 歲,而 ±0.4 歲的 0.4 就是 SE 。SE = 0.4 歲算是相當小,所以代表他們研究的是一群 20 歲左右的年輕人,而這就呼應了標題的「young men」。
而若一個實驗結果的 SE 很大,那就代表實驗者的改變存在很大的個體差異。例如:如果一個飲食方法讓實驗者半年瘦了 5 ± 4公斤,代表有些人瘦不到 1 公斤、有些人瘦超過 9 公斤,那我們就會推論這個飲食法不是對每個人都很有效的。
接著來看研究結果(圖三)。12 週的飲食控制+重訓後,平均分配蛋白質到每一餐的受測者增加了 2.5 ±0.3 公斤的瘦組織重(油脂以外的體重,包含肌肉),而不平均分配蛋白質的受測者則增加了 1.8 ±0.3 公斤。對 1.8 和 2.5 來說,0.3 並不算大,所以可以推測這兩組幾乎所有的實驗者都確實比實驗前長了更多肌肉。而當我們想比較哪一組增肌更多時,雖然乍看之下前者的瘦組織增加幅度更高,不過僅從這些數據其實難以推斷前者是不是真的比後者增加比較多的瘦組織。
雖然概念不完全一樣,但可以這樣思考:假設一個賽車手在同一個賽道上,分別用兩台不同廠牌的賽車跑計時賽。第一台車跑了 10 分鐘,第二台車則跑了 10.2 分鐘。光靠這個數據,你很難確定哪台賽車的性能比較好,因為第二次跑比較慢可能是第二台性能確實較差,也可能是賽車手剛好表現較差。同樣的,只知道一組人增加 2.5 公斤、另一組人增加 1.8 公斤,也很難判斷這是實際存在的效果差別,還是「剛好而已」。
此時,就要去看比較兩組數據的「p 值」為何。再看回圖三,反白的字後面有「p = 0.06」,這代表雖然第一組比第二組看似增加更多瘦組織,但這個差異有 6%的機率「只是剛好而已」,而我們通常會覺得 6%的機率已經足夠高了,所以認為兩組其實沒有差別。這就叫「差異未達統計上的顯著」。
舉一個比較貼切的例子:假設六年甲班和六年乙班各有 40 位學生,而這兩班同座號的學生身高都一樣(例如:兩班的 1 號都是 140 公分、2 號都是 142 公分,以此類推),那我們可以很直覺地認定「這兩班的身高一模一樣」。不過,要是我們不知道上述的特徵呢?假設我們從兩班中各隨機抽 10 個學生,比較這兩組學生的身高,其中甲班抽出的 10 個學生平均身高 150,乙班的則是 140,而這個差距不代表甲班的學生身高比乙班高,只是抽樣時剛好都抽到比較高的學生罷了。p 值就是在計算這個「剛好」的機率。
回到研究。更精準得來說,p 值=0.06 的意思是,如果蛋白質分配的方法對增肌完全沒有影響的話,得到跟我們實驗的結果一樣或更加極端的機率為 0.06(6%)。通常只要 p 值高於 0.05,我們就會認為兩組之間沒有實質上的差異,所以這個統計的結果即是認為「平均分配蛋白質到每一餐不會幫助增肌」。
我們可以透過觀測到的幾棵樹來描繪一個森林的樣貌,但還是會有錯誤的地方。統計也是類似,想透過觀測到的局部來推斷全體,就難免會有出錯的時候,只是可以用數學來有邏輯地進行判斷,以最小化錯誤。
以本研究為例,p 值=0.06 其實相當靠近 0.05,換句話說只要 p 再小一些,我們就會得出完全不同的結論。而在受測者人數較少時,p 值的計算結果原本就會比較大,所以說不定若他們再多招募幾個受測者,就會改得到「蛋白質分配會影響增肌效果」的結論。
更進一步來看,雖然都沒有達統計顯著,但平均分配蛋白質的受測者們在「每一樣肌力與瘦組織的測驗上」都更高。綜合以上兩點,可以合理推斷平均分配蛋白質或許真的更有利於增加肌肉量和肌力,只是程度不大,所以難以從有限的受測者中觀測到明顯的差異。
本文在不提及任何公式的前提下介紹了代表離散程度的「standard error」和判斷差異顯不顯著的「p 值」,並解釋它們在本文的意義及限制。現在除了看標題和結論外,也能去看看結果的 p 值和實驗前後的 SE,讓你對研究的認識更加深入。即使如此,本文也只是介紹統計學的一些皮毛而已,若大家有興趣的話,未來再寫進階一點的統計學。