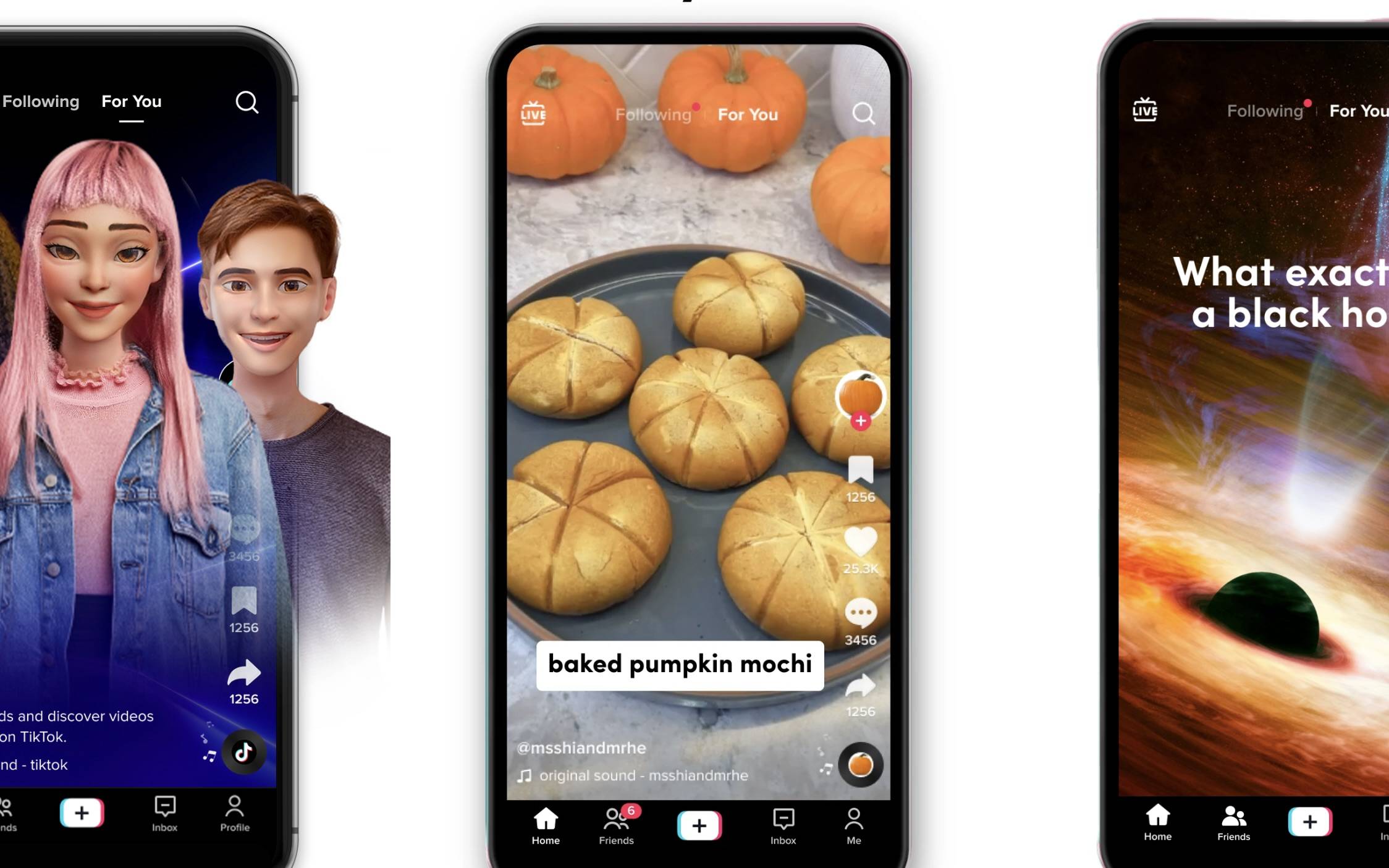
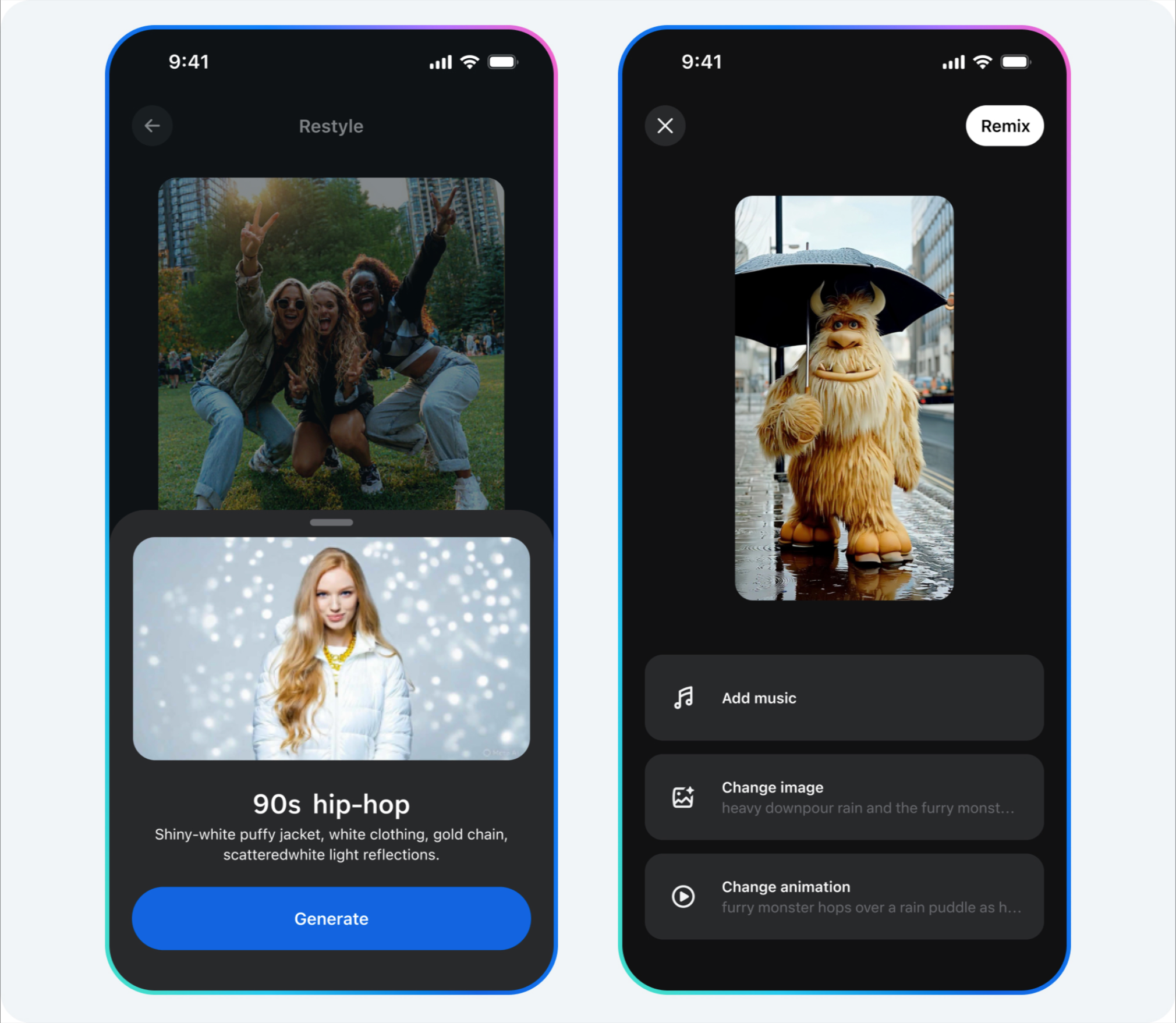
刚刚, AI 视频王者大更新!硬刚 Sora,威尔史密斯吃面更香了

OpenAI 前不久刚推出了 Sora 2 视频生成模型,势头相当凶猛,紧随其后,今天 Google 的 Veo 3.1 也迎来了一次重大升级。
具体来看,Google 这次的升级包括两个层面。
一是功能层面的完善。视频编辑功能得到了强化,用户现在可以对片段进行更细致的调整,对最终画面有了更精准的掌控。

更重要的是,Google 首次给「素材转视频(Ingredients to Video)」「帧转视频(Frames to Video)」和「延展(Extend)」这些功能配上了音频,让音频成为创作流程的一部分。
二是模型层面的进步。
今天发布的 Veo 3.1 在提示词理解和视听质量两个关键指标上都有了明显提升,从图像到视频的转化因此更加自然流畅。
相关阅读 ![]() AI 视频新王全球爆火,威尔·斯密斯终于可以好好吃面(附大量实测演示)
AI 视频新王全球爆火,威尔·斯密斯终于可以好好吃面(附大量实测演示)

众所周知,Veo 3 原本就有不少编辑能力在身——通过参考图像指导角色生成、用首尾两帧填充中间内容、基于视频末尾继续延展等操作都可以做。
Veo 3.1 的做法是在这些既有功能上全部加入音频支持,让用户能够打造更加完整的场景。这些功能目前还处于实验阶段,Google 表示会根据用户反馈继续优化迭代。

现在用户可以这样使用这些功能:
1、用多张参考图像定义角色、物体和风格,「素材转视频」功能就会根据这些素材生成最终场景。

2、或者提供起始和结束画面,让「帧转视频」功能在中间生成无缝过渡,这对需要艺术性转场的项目特别有用。

3、如果要生成更长的视频,「延展」功能可以生成超过一分钟的内容,基于前一段继续生成,保持故事的连贯性。

值得一提的是,Veo 3 的文本转视频此前只支持 720p 横屏输出,但随着竖屏视频成为互联网内容的主流格式,Veo 3.1 现在也可同时生成横屏和竖屏的 16:9 视频,更符合当前的内容消费习惯。
创意的打磨往往需要反复迭代。
自 Flow 于今年 5 月推出以来,用户已经在该应用中创作了超过 2.75 亿个视频。吸取用户的反馈之后,Flow 中新增的两个编辑功能就是为此而生——
「插入新元素」让用户可以随时添加内容,Flow 会自动处理阴影和光线,使新增部分自然融入原有画面;
「移除对象」功能(即将上线)则可以删除不需要的元素,Flow 自动重建背景保持一致性。这两个工具的组合能够让视频的编辑过程变得更加灵活。

目前 Veo 3.1 模型已经上线,开发者可以通过 Gemini API 使用,企业用户可在 Vertex AI 中访问,普通用户也可以在 Gemini 应用内体验。新功能也同步在 Gemini API 和 Vertex AI 中开放。
我们体验生成了 3 个 Veo 最实用的应用场景。
前些时间爆火的第一视角穿越、ASMR 切水果,金属、兔子蹦床的夜视监控等视频,都是使用 Veo 3 生成的。

▲由 Veo 3 生成,提示词:50mm camera, close-up angle of a lemon made out of yellow-tinted glass being sliced horizontally on a wooden cutting board. The inside of the fruit is glass as well with a little bit of melting glitter. The entire scene is soft lit from the above.
比如这个生成玻璃柠檬的例子。提示词要求「用黄色玻璃制成的柠檬被水平切开,内部也是玻璃材质,里面有融化的闪粉,顶部柔和照亮」。
Veo 3 的输出是可用的,但 Veo 3.1 对「融化闪粉」的细节刻画更精准。

电商场景下,我们直接让他生成一段产品的广告。要知道,一般的 TVC(电视商业广告)也就是在 15s/30s 的时间左右来传递品牌信息。

▲由 Sora 2 生成,提示词:根据以下商品信息,生成一段电商广告视频,包含实拍感的产品展示、3D旋转细节、使用场景对比,以及配套字幕。智能手表 X2,续航7天,¥1299 智能手表,50米防水,健康监测(心电、睡眠)
Sora 2 贴心地用中文语音解说了商品信息,体现了更好的理解。但 Veo 3.1 这边只是简单地配了音乐,不如 Sora 2 周到,但从画面质量来看,Veo 3.1 的视觉呈现更高级、更有商业感。

▲由 Veo 3.1 生成
我们也试了动漫生成,这次 Veo 3.1 的表现就比较一般了。

▲由 Sora 2 生成,提示词:以吉卜力工作室动画风格,一个男孩和他的狗跑上一座长满青草的风景秀丽的山丘,背景远处可以看到一个村庄,天空中飘着美丽的云朵
显然 Veo 3.1 在这块的训练数据还不够丰富,距离吉卜力工作室那种精致的动画风格还是有不少差距。莫名消失的狗,都是 AI 穿帮的典型特征。

▲由 Veo 3.1 生成
X 网友 @aisearchio 分享的威尔·史密斯吃面测试 Demo 整体质感往上抬了一个档次,动作流畅度、光影细节都明显改善,表情丰富但也没有崩掉。
综合来看,Veo 3.1 在照片级、商业级的内容生成上已经足够可用,细节理解能力也有明显进步。但在特定风格的精准还原上——比如动漫、插画这类需要高度风格约束的领域,还是有相当的优化空间。
尽管如此,从 Veo 3 到 Veo 3.1,从 Sora 到 Sora 2,视频生成模型的迭代速度已经超过了大多数人的想象。
伴随着这类 AI 视频生成工具会从专业工具逐渐演变为大众应用,届时,你的朋友圈、短视频平台、甚至新闻源中,每一条内容都有可能是 AI 生成的。
这也意味未来你看到的每一条内容,都需要多一步确认——这来自真实拍摄,还是 AI 生成。
作者:莫崇宇
文章内视频链接:https://mp.weixin.qq.com/s/qBOkoWaGF5k7oPCR_H5aqA
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。