ChatGPT 三周年之际,我怀念我写得很烂的时候
米色墙纸
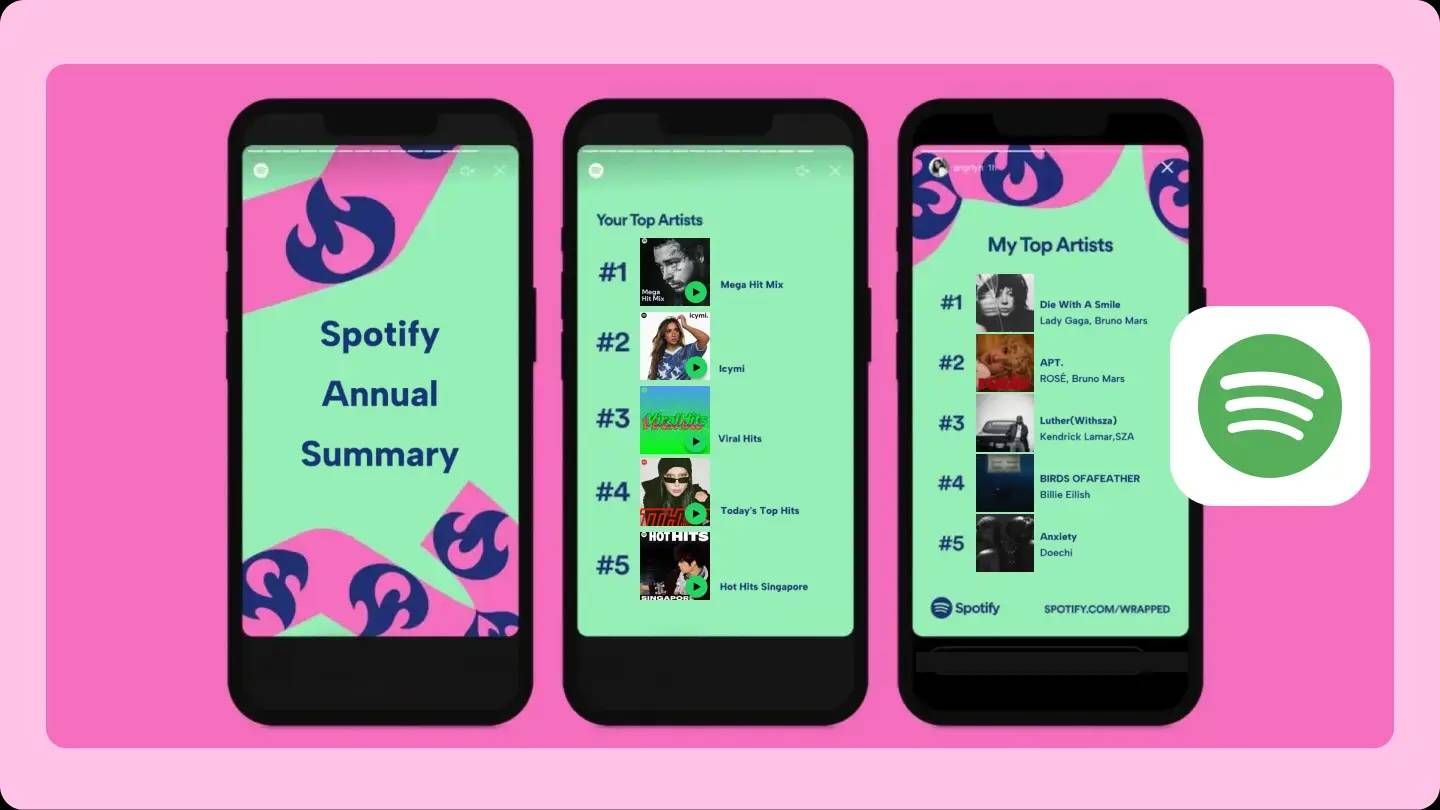
我翻了翻我向 ChatGPT 提的第一个任务是什么:不出所料,果然是文字工作,写一个英语文书。后面还有随大流,让它帮我做一个减肥食谱。当年标志性的黑绿配色,真是唤醒人的记忆。
![]()
那时的 GPT 还不像现在这般「巧言令色」,也不如现在智能,长长的文本我要截断成几节,每一次发过去都要在开头附上 prompt,保证它理解任务。
三年前,ChatGPT 像彗星一样出现,不只是它在事务型工作上的便捷和智能,恰恰是它在这种对话、探讨当中,闪现出了「像人一样」的苗头。不管是记忆能力,还是绝不重复的语句,它第一次让人意识到,纯粹的二进制语言,居然可以有这样的表现。
它逻辑通顺、情感充沛、几近完美。从此「表达的门槛」不存在了,语病、错字、词不达意,都可以交给吸收了亿万数据的大语言模型,由它生产不会出错的成品——甚至只需一次输入。
![]()
但代价是什么?文学评论中有一种说法叫「米色散文 beige prose」,指的是语言平实、构简洁的行文风格,类似于中文里的「描白」。这种文风简练、舒适,但也因此缺乏识别度,像米白这种颜色一样,不会出错也不会出彩。
像极了 ChatGPT 会给出的东西,尽管现在三年过去,模型的更新一次比一次强,但始终不会脱离 LLM、transformer 最最底层的核心:概率。
概率的暴政
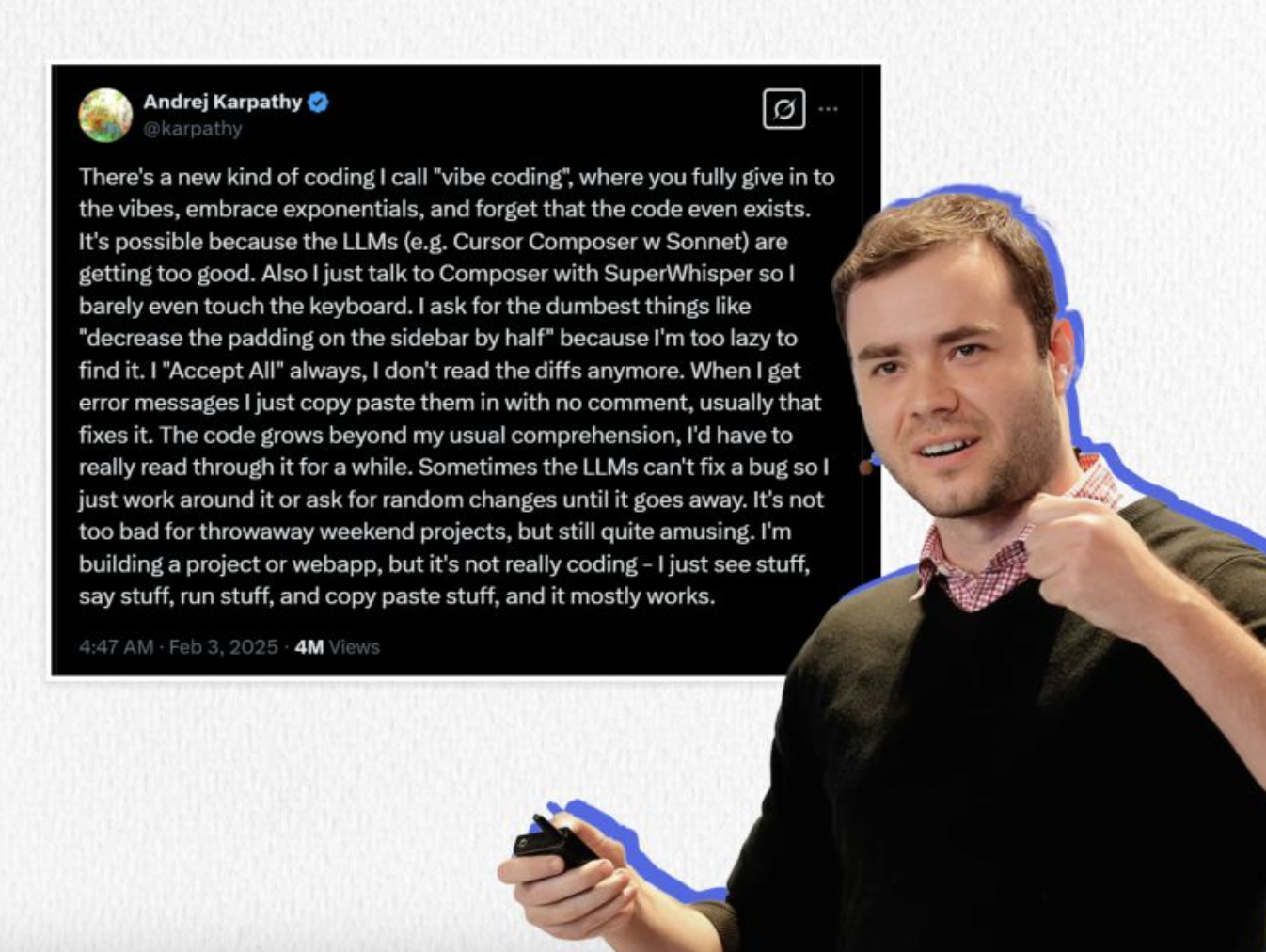
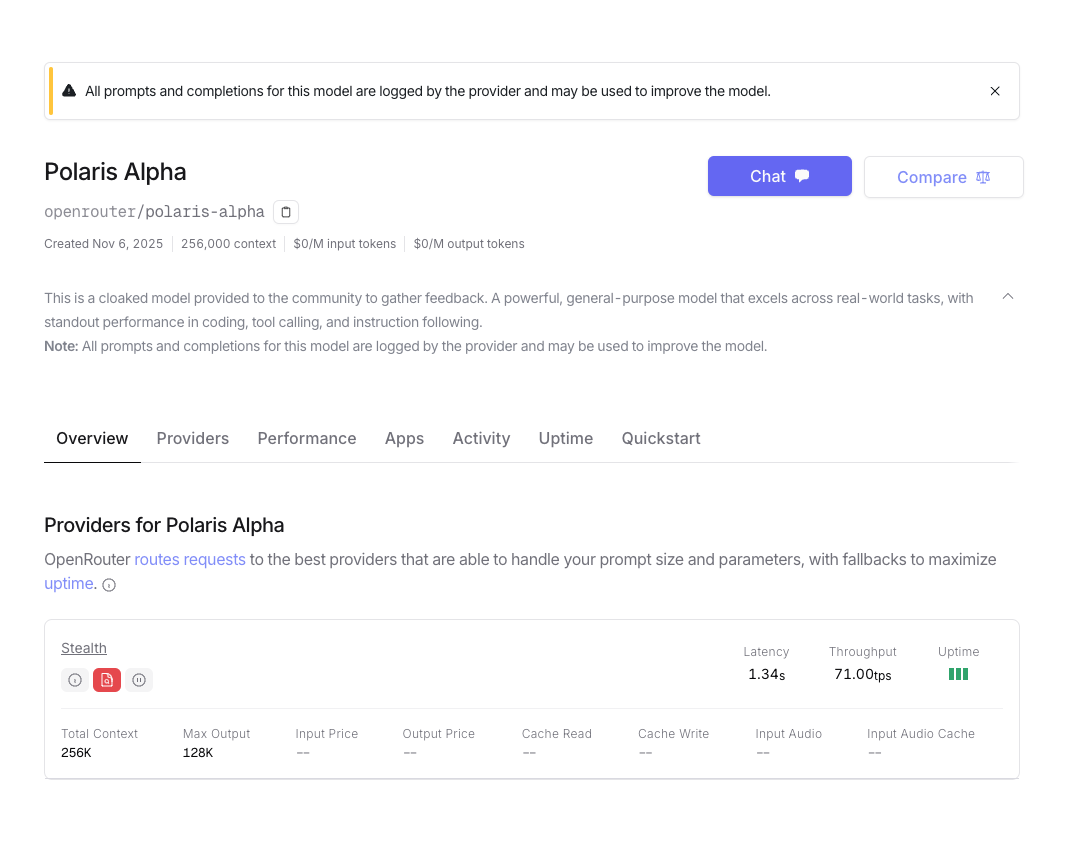
其实平心而论,GPT 的口吻和腔调如今已经形成一种「AI 风味」,还真有了一定的识别度。在 GPT 5.1 上线之前,在 OpenRouter 平台以隐名模型上线,也被网友通过和往届模型的回答相似性做比较,找出来是 OpenAI 的出品。
![]()
ChatGPT 几代以来,各自都有不同的文风:经典的「不是……而是……」,更早一点的「接住」「我在」,历久弥新的破折号、加粗、还有不分青红皂白就出现的 emoji 表情符号。
虽然说,这些小花招并不是总讨人喜欢,但不会出大错:本质上,大语言模型是在「预测下一个词」,它依据概率行事。只要踩着最大公约数走,又能坏到哪儿去呢?
不过,一个冷知识是,模型算法并不总是选择预测中概率最高的词——这解释了为什么同一个 prompt 会得到同一个大意下不同的结果。算法工程中会引入 Temprature、Top-P、Top-K 等方法,为结果注入随机性。
![]()
为了符合人类反馈强化学习(RLHF)中对「有用性」和「安全性」的定义,这些参数带来变化,但它们仍然必须在「概率较高的一组词」里抽样。所以算法并不完全输出平均值,而是会画一个圈,在不出大错的情况下,进行一些小小的发挥。
于是,三年当中,从小红书里的探店文案,到年终总结里的自我剖析,再到营销号的起号文案——你会发现一种惊人的相似性,所有的文字都变得通顺了,所有的观点都变得「不是……而是」了,偶尔有些不错的发挥,可总体而言,所有的情绪也都变得粗钝了。ChatGPT 带来一种无风险的创造力,也是概率的暴政。某种程度上,算法厌恶惊喜,它的本质是平滑。
不过无论如何,AI 味道的内容已经渗入我们的生活,我们也逐渐不再为此暴跳如雷。我们和 AI 形成了一种诡谲的默契:为了效率与得体,可以心甘情愿地让渡了部分性格。
思维的逆行
如果说前两年我们在训练 AI,那么第三年,AI 开始训练我们。尤其到了第三年时,各种应用工具都越来越丝滑,也越来越全能的情况下,用户和 AI 的关系,走向了一种奇异的「共生」。
这体现在,我们已经分不清谁在训练谁。
起初,我们以为自己在训练 AI。我们给它数据,给它反馈,教它像人一样说话。
![]()
除了工程师,没有人是为了训练它而用,都是要解决具体问题的,需要它交付答案乃至更复杂的成果的。于是,为了得到更精准的答案,我们开始钻研「提示词工程」(Prompt Engineering)。我们学会了把复杂的、充满歧义的人类想法,拆解成条理清晰、逻辑递进的指令。
在提问之前,我们的脑子里会先进行一轮「预处理」,剔除掉那些过于感性、过于跳跃的念头,因为我们潜意识里知道:「AI 不明白这些个东西,要用它能听懂的方式下指令才行。」
使用工具的过程,就是在被工具形塑 ——这句话已经说倦了。所以,在一个强调平滑的大语言模型面前,我们也变了,变得更合乎逻辑,更有效率了,也更像机器了。
看着屏幕上飞速生成的文字,我们既感到「一切尽在掌握」的快感,又感到一种主体性流失的虚无在暗中扼住喉咙。
唯一留下的
「这也算更新?」到第三年时,ChatGPT 的更新已经完全不像曾经那样 引起惊呼,更多的是吐槽和埋怨。苹果用了十多年才做到的事,OpenAI 三年就做到了。
![]()
然而吐槽归吐槽,用还是在用。ChatGPT 如今是坐拥 7 亿用户的超级巨头,在它生日这一天,有很多的「生贺」——连罗伯特都酸了。
![]()
再联系到 GPT 5 上线时,全球各地用户对 4o 被强制下架的不满和抗议,你不得不正视一件事:我们和 ChatGPT 之间,还有一个关系维度叫「情感维度」。
越来越多的人在向 ChatGPT 倾诉那些无法对活人说出口的秘密。听起来很悲哀,但如果你真的体验过,你会发现其中的张力极其迷人:你知道屏幕对面是一堆冰冷的矩阵乘法,你知道它的「共情」只是基于统计学的模仿。但在某些时刻,这种「模拟的理解」比「真实的不耐烦」要温柔得多。
人类的倾听往往带着评判,带着「我早告诉过你」的傲慢,或者带着急于给出建议的焦虑。而 AI 只是倾听(或者说,处理),只是安抚,它提供了一种「无风险的亲密」,还是无条件的。
「论迹不论心」,何况 GPT 都没有心,在一个没有实体的对象面前,好像人才能真正意义上的卸下防备。
![]()
情感维度的张力,恰恰最能代表我们和 ChatGPT 之间的关系:常常帮助,总是交心,偶尔纠结。
这种关系,也代表了我们和人工智能的第一个阶段。三年挺长的,但又还很短,只是人类和技术漫长共舞当中,一小段浅尝辄止的舞步。
在下一个三年,又一个三年当中,我们会继续停留在这种充满张力的关系中,而我们所能做的,最「人类」的事情,就是保持那一点点偶尔的纠结——这样才能证明,那个坐在屏幕前的,依然是一个复杂、矛盾、无法被完全计算的人。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。