Last Week on My Mac: Intel Macs will be stuck with bugs
Just over six months ago a series of weird bugs came to light in Spotlight indexing. The first report was that plain text files beginning with the characters LG are never indexed, so their contents can never be found by Spotlight search. The mystery deepened when the same was discovered for text files beginning with the characters NPA or Draw. It was appropriately Drew who worked out the common factor behind this apparently bizarre connected behaviour: all three files are identified as not being text by the old Unix utility file(1), used to recognise file types by ‘sniffing’ their contents.
You can verify that by creating a plain text file with any of those three sets of characters at its start, then running the command file on that file. In the case of one beginning with Draw, file will identify it as RISC OS Draw file data, even though the file has an extension of txt or text and a UTI of public.plain-text. At that the RichText mdimporter, which analyses all text-based files for metadata to enter into Spotlight’s indexes, throws its hands up in horror and refuses to index the file’s contents. Change those opening characters in that file, perhaps by adding a leading space, and all of a sudden the mdimporter works as expected.
Following our collaborative effort here, particularly Drew’s insight, we realised this bug has been silently blocking the indexing of seemingly random text files for the last three years or more. What remained unanswered at the time was what that mdimporter was doing running file(1) on files whose UTI made it clear that they were in plain text, not some long-forgotten binary vector graphics format from 1989. I believe I now have an answer, thanks to my recent work on QuickLook’s qlgenerators.
QuickLook’s generators take advantage of the hierarchical structure of UTIs. Rather than accepting the most specific UTIs such as public.jpeg, Image.qlgenerator works with all files whose UTI conforms to the generic UTI of public.image, and then undertakes its own format detection. This enables it to generate correct thumbnails and previews of HEIC images that have been given the incorrect extension of jpg, for instance.
Similarly, a Swift source-code file with the extension of swift and the UTI of public.swift-source is handled by the Text.qlgenerator because public.swift-source conforms to public.plain-text, the UTI required for use of that generator.
What if Spotlight’s mdimporters were to work the same?
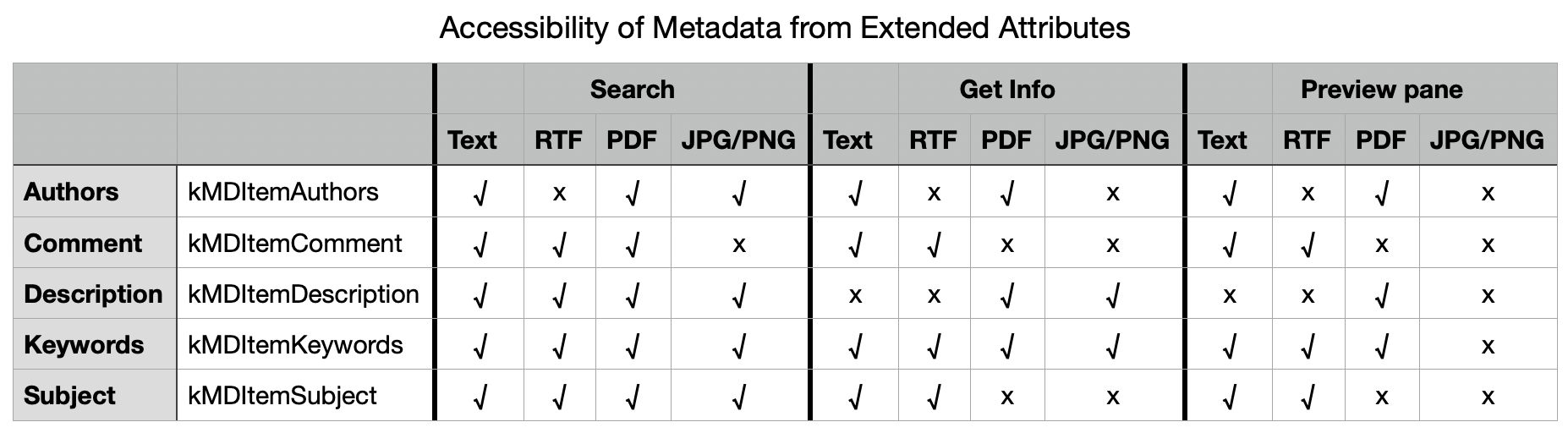
We know the built-in RichText.mdimporter is used to extract metadata for a wide range of files containing text, which all conform to the generic UTI of public.text. It then classifies them on the basis of their contents to work out what to index. What if that’s performed using file(1), so rejecting perfectly valid text files as ancient binary vector graphics files, and so on?
We can’t get the same direct evidence from the log that I obtained for QuickLook, as Spotlight is far less informative in its log entries. We can get clues from looking at output from mdimport and mdls, though. While a non-deviant text file contains a metadata attribute extracted by its importer as kMDItemTextContent containing the text in the file’s data, that’s missing from a text file starting with any of the three known triggers. In turn that’s associated with the attribute _kMDItemPrimaryTextEmbedding containing ‘vec_data’ listed by mdls, which is also missing for the deviant files.
There is hope that a third party might be able to undercut RichText.mdimporter by providing a bug-free importer for public.plain-text, but that relies on the built-in importer targeting public.text rather than public.plain-text. The best solution would be for Apple to fix the identification of text files instead of relying on file(1), which dates from 1973. Given that these deviant files work perfectly with QuickLook’s generator, it appears Apple has already solved this problem there. So I suspect this bug in RichText.mdimporter will never be fixed in Sequoia or Tahoe.
With the first beta-release of macOS 27 just a couple of weeks away, this leaves those using the last Intel Macs stuck with Spotlight indexing that will never work on some text files, assuming that at some point in the not too distant future this bug is finally fixed in an Arm-only macOS. This is all sadly familiar from the loss of 32-bit support in the transition from Mojave to Catalina, when little if any effort was devoted to making Mojave as free of bugs as possible before it was abandoned in the rush forward to 64-bit.
It would have been far better to be able to look back in fondness with macOS that worked better, than looking back in anger at what never got fixed.
One last thing to remember is that, when Apple does fix this bug, you’ll have to force Spotlight indexes to be rebuilt on each of your Mac’s volumes to ensure that the contents of these files are incorporated. We learned that last time there was a serious bug in the same importer, which failed to index the contents of RTF files.
![]()