
 空风评论: 双面贝壳
空风评论: 双面贝壳评价:
President Trump announced that he will permit Nvidia’s H200 chips to be sold to China on Monday, December 8th. Beijing’s official response to this is extremely understated. This is the entirety of Spokesperson Guo Jiakun’s response to a question from Bloomberg on the H200 sale at the regular foreign ministry press conference on December 9th:
We have noticed the reports. China always advocates that China and the United States achieve mutual benefit through cooperation.
Since then, however, a range of commentary and opinions have come out of Chinese media, reflecting varied opinions. Some are excited, while others are deeply wary; most lie somewhere in between. We’ve selected four commentaries from the Chinese media landscape to excerpt, translate, and feature, as a way to encapsulate the debate happening inside China regarding GPU reliance. They include…
How cloud providers helped Chinese AI labs access top-tier compute, even while restrictions were in place;
Why transitioning from Hopper to Blackwell is labor-intensive, and how this shapes Chinese compute demand;
How inference differs from training, and where Chinese chipmakers might shine in the market;
And Taiwanese chip makers having a brief panic attack amid the crossfire.
Translations of the original Chinese were done by ChatGPT 5.1 Thinking, then verified manually by the ChinaTalk team for accuracy and fluency. Hyperlinks were added by Irene where context is useful.

This first analysis is by Xinzhi Observatory 心智观察所, a media brand covering high-tech that’s owned by Shanghai-based news site Guancha 观察网. Guancha is on the nationalistic end of the Chinese media spectrum, with a penchant for virality. Xinzhi Observatory’s reporting on tech has a more nuanced style, but its assertions should still be taken with a grain of salt. Nevertheless, the piece is a useful read because it reflects popular mainstream attitudes towards the H200s deal: that it is a temporary compromise that benefits Chinese development in the short run, but does not undercut China’s progress in indigenizing the chip supply chain. Its insights into how Chinese labs have managed to access advanced compute via cloud service providers is also revealing.
In Nvidia’s AI product lineup, the Hopper series (including the H100 and H200) represents the previous-generation “ace,” focused on data-center-class AI acceleration and already widely used in supercomputers and AI training clusters around the world. Although the H200 is not based on the latest Blackwell architecture (B100/B200, released in 2024 and more focused on multimodal AI and energy efficiency), its memory advantage makes it a “transitional trump card.” While it far exceeds the performance threshold of domestic Chinese chips, it does not reach the most sensitive cutting-edge technologies that the United States is trying to protect. It was precisely on the basis of the H200’s “moderate firepower” that Nvidia CEO Jensen Huang persuaded Trump.
But for China, the introduction of this chip fills the performance gap between the H20 (the specially downgraded version for China) and Blackwell. We cannot look only at the talking points Jensen Huang used in his lobbying: the H200 is, after all, the pinnacle of Nvidia’s Hopper architecture. According to estimates by Georgetown University’s Center for Security and Emerging Technology (CSET), the H200’s total processing performance (TPP) is nearly ten times the previous export-control ceiling for sales to China. When training and serving large models with more than 175 billion parameters, the H200’s performance is more than six times that of the H20. It is a “previous-generation flagship,” not a “downgraded product.”
Over the past two years, 99% of Chinese AI companies have only been able to use the neutered H20 or domestic chips. Through CSP channels, however, frontier model makers have already been training at scale on clusters of original, advanced chips. Therefore, when Trump suddenly opened the door to the legal sale of the H200, the market reaction was not particularly dramatic, because China’s top players have been using the highest-end compute available via CSP for quite a while already.
CSP is currently an important business model in China’s AI chip ecosystem; it refers to AI chips sold specifically for Cloud Service Providers. Put simply, Nvidia (and to some extent AMD and Intel) sell their top-of-the-line, uncut AI chips exclusively to a handful of leading Chinese cloud providers through special channels, and these cloud providers then offer the compute power to domestic AI companies and research institutes in a “cloud rental” model. What the United States has banned is “direct sales to Chinese enterprises.” Under the CSP model, however, ownership of the chips resides with the cloud providers, so technically it does not violate the ban.
Former TSMC engineer and current Ronghe Semiconductor CEO Wu Zihao told Xinzhi Observatory: “Based on the current performance of various domestic AI chip manufacturers, none of them have yet broken through shipments of 100,000 cards, with the exception of Ascend. Ascend’s shipments are between 500,000 and 1 million cards, but they rely heavily on the ‘IT indigenization’ (xinchuang) market, and CSP purchases of Ascend are not large. In other words, shipments of domestic chips basically depend on xinchuang, with CSP accounting for a very small share. Nvidia’s H200 mainly targets the CSP market; Nvidia cannot enter the xinchuang market. The only point of overlap between the two is in CSP, and judging from the fact that each domestic GPU vendor has shipped only tens of thousands of cards, not a single Chinese CSP treats domestic chips as its mainstay.”
Wu Zihao believes: “Precisely because the base is low, even if the H200 comes in, domestic GPUs still have considerable room for growth. For example, Cambricon shipped 70,000–80,000 GPUs this year. Next year they are expected to reach 150,000 cards, nearly 100% growth, but a base of 150,000 is still very low, and for domestic CSPs’ total demand of at least 4 million cards, the share is not high. In the short term, this may not affect domestic cards, but Nvidia resuming sales of relatively high-performance high-end GPUs to China is not a good thing for Chinese AI chips in the long run; the dependence on the Nvidia ecosystem may prove impossible to reverse.”
Views like Wu Zihao’s—that Nvidia’s renewed sales are not a good thing for Chinese AI chips in the long term—are somewhat representative. But we need to look at the issue more comprehensively: potential gains always come hand in hand with risks. For AI startups like DeepSeek, being able to rapidly deploy H200 clusters can boost model-training efficiency and help overcome compute bottlenecks. The H200’s 141 GB of memory can easily handle RAG (retrieval-augmented generation) and LoRA fine-tuning for models with more than 175 billion parameters. China has the world’s largest pool of AI researchers, and using more advanced technology allows them to translate research into commercial value more quickly.
After Trump announced that the H200 could be “legally sold directly,” the CSP model will not disappear in the short term; on the contrary, it might be upgraded. Previously, CSP arrangements existed with the United States turning a blind eye. Now that direct sales of the H200 have been legalized, the CSP channel may be further extended to more advanced lines like Blackwell, continuing to serve as a “valve” and “observation window” for the United States to monitor China’s AI development.
In the short term, China can temporarily rely on the H200 to train models, but in the long term it must feed back into domestic chip firms to accelerate their iteration. Chinese companies can use more advanced compute to “nurture” models and “accumulate” data, while at the same time feeding back into the domestic chip ecosystem. If China can substitute a narrative of diversified sourcing for a narrative of “decoupling” from the United States, then a “bad thing” can also be turned into a “good thing.”
This is what it truly means to “sustain war through war.” As a former Council on Foreign Relations official lamented in an interview with the FT, “Selling large numbers of H200s to China will give rocket fuel to the Chinese AI industry,” giving them enough compute to dramatically narrow the gap within two years. [Irene note: The expert quoted here is Chris Mcguire who joined ChinaTalk as a podcast guest to talk about Huawei in October!]
…
As things stand, Trump, for the sake of corporate interests and fiscal revenue, has had to compromise with China—and in doing so has made a crucial choice between the two camps. In terms of performance, the H200 is “the most dangerous yet also the safest compromise product” for the United States, while for China it is “just enough to be usable without forcing a rupture.”
In this piece, Tencent Technology 腾讯科技 writer Su Yang 苏扬 explores why more advanced isn’t always better. Even though Blackwell chips are a generation ahead of Hoppers (including the H200), Su argues that Nvidia’s Chinese customers currently rely heavily on the Hopper architecture. Even in a world where Nvidia gains permission to sell Blackwells to China, it’s possible that demand for Hopper chips will remain much higher for quite a while still.
In November 2023, Nvidia officially launched the H200. Shipments to global customers and cloud service providers began in the second quarter of 2024, with mass production starting in the latter part of that quarter and large-scale deliveries rolling out after the third quarter. A single GPU sells for around $30,000–$40,000, and an 8-GPU server comes in at roughly $300,000.
The chip uses TSMC’s advanced 4N process, with a GH100 GPU at its core, integrating 80 billion transistors and a thermal design power (TDP) of 700W. It is also equipped with NVLink 4 interconnect technology, offering 18 links and 900GB/s of interconnect bandwidth. The GPU paired with HBM3e has 141GB of memory, with memory bandwidth as high as 4.8TB/s.
In 2024, the H200 was an unequivocally cutting-edge product, with FP16 performance reaching 1,979 teraFLOPS, compared to just 148 teraFLOPS for the H20 custom-made for the Chinese market. Its FP8 performance is an even more impressive 3,958 teraFLOPS, while the H20 has only 296 teraFLOPS. The H200’s interconnect bandwidth is also double that of the H20, reaching 900GB/s.
But by the end of 2025, products such as the B200 based on the Blackwell architecture had come online and become the new industry standard at the top end. The H200 was pushed into second place, turning into a product whose performance is “relatively behind the curve.”
“As expected,” an industry analyst said when talking about the lifting of export controls on the H200. “Letting Hopper chips out, but not Blackwell, still allows them to tell their domestic audience, ‘we’re still a generation and a half ahead,’ while Chinese customers can still buy what they want.”
Overall, Trump’s announcement on social media that he would allow H200 exports has basically dispelled most concerns. At its core, it just means that the H200 no longer represents truly cutting-edge computing power.
…
Previously, Jensen Huang had repeatedly stated in various settings that “our market share in mainland China is zero.” The approval of H200 exports will bring new opportunities for Nvidia, especially because its performance is far ahead of the downgraded H20, making it much more attractive to customers.
“Chinese customers’ models are all built to run on Hopper-architecture GPUs,” the aforementioned industry analyst emphasized.
In his view, at this stage Hopper has even more pull than the Blackwell architecture: “No one has adapted their models to the B-series yet. Otherwise you’d have to redo all the operators, the toolchain, and the underlying software from scratch—that’s an even bigger engineering effort.”
Put simply, for model developers, migrating from the Hopper architecture to any new architecture requires redeveloping computation modules, building dedicated tooling pipelines, and restructuring the low-level integration code—all of which demand large amounts of manpower, engineering work, and time.
From Nvidia’s standpoint, the profit margin on H200 sales is also much better than for the H20. The H20 is derived from a cut-down H100, which raises manufacturing costs, whereas the H200 does not need to be “neutered” in any way. As an older product, its average gross margin is expected to approach—or even exceed—80%.

This commentary was published by DeepTech 深科技, the China-specific media brand of MIT Technology Review. The writer is very bullish on economies of scale being favorable for Chinese domestic chipmakers. Most importantly, the piece argues that the impacts of the last two years of American export controls are lasting. China’s technology industry has internalized that it cannot rely on American giants for compute in the long run, and the state will not roll back extensive effects to support indigenization.
The back-and-forth swings of the past two years have already made Chinese companies acutely aware of how important supply chain security is. No one can guarantee that what is allowed today won’t be revoked tomorrow with a single tweet.
Morgan Stanley estimated that China’s AI chip self-sufficiency rate was 34% in 2024 and is expected to reach 82% by 2027. TrendForce data indicate that in China’s AI server market in 2025, domestic chips are likely to account for as much as 40%.
Mizuho Securities forecasts that shipments of Huawei’s Ascend 910 series will exceed 700,000 units this year. Huawei’s own roadmap already extends to 2028, with the Ascend 950, 960, and 970 lined up in sequence, and in-house HBM also on the agenda. Admittedly, domestic chips still have clear shortcomings in areas such as ecosystem maturity, development toolchains, and support for high-end training scenarios. But the industry has already hit its stride: large-scale training and the migration of large models onto domestic platforms are accelerating. The further the market moves forward, the more likely it is that the ecosystem will be backfilled and completed in turn. As a result, this path toward autonomy and control will not be brought to a halt just because a few foreign chips have been cleared for sale.
…
For Nvidia, returning to the Chinese market means a revenue opportunity worth several billion dollars; for the U.S. government, a 25% cut of sales is a sizable source of fiscal income; and for the Chinese market, the H200 provides a channel for obtaining advanced computing power in the short term.
But in the long run, this may be just a minor episode in the larger tech contest between China and the United States. China’s AI industry has already embarked on a path of autonomy and control, and that path will not be reversed by the approval of a few chip models.
On the battlefield of chips, genuine security can only come from one’s own capabilities, not from the grace of a rival. The green light for the H200 is merely the starting point for a new round of competition.
This last take is a commentary from the editorial staff at the Wu Xiaobo Channel 吴晓波频道. Wu Xiaobo is a prominent finance and economics writer in China, having worked for Xinhua, Hangzhou Daily, and the Shanghai-based Oriental Morning Post. Wu Xiaobo Channel is his personal media venture.
The piece is most notable for its discussion of how China’s domestic chip supply is reshaping the inference landscape, providing needed granularity into where H200s fall within the market for compute demand. It echoes many points made by previous commentators about the long shadow of securitization as well, arguing that China will continue to aggressively pursue domesticization regardless of American policy.
Right now, China’s large models and domestic chips have already become deeply intertwined. During the “blockade” phase, the two grew side by side, with their level of mutual adaptation steadily improving.
This relationship has become even closer since DeepSeek burst onto the scene.
If, in the past, training on Nvidia chips was essentially a contest of raw compute, DeepSeek has changed the structure of compute demand: for some smaller companies, compute has shifted from training to inference.
And because inference has lower compute requirements, it has created real room for mid- and lower-end domestic AI chips to shine.
In terms of ecosystem compatibility, it’s difficult during the training phase to build a single resource pool mixing Nvidia and domestic chips, but inference workloads can run on domestic chips.
Data show that in 2024, 57.6% of accelerator cards in Chinese data centers were used for inference, surpassing the 33% used for training. Platforms like Tencent and Baidu integrating DeepSeek have also greatly boosted the growth of inference-oriented chips.
Industrial integration has also brought a shift in market preferences: as China’s large-model and domestic chip industries grow more deeply intertwined, more and more major tech firms and state-owned enterprises are leaning toward buying domestic chips. For example, ByteDance accounts for more than 50% of Cambricon’s total orders; similarly, in 2024, 42% of Moore Threads’ revenue came from government-led intelligent computing center projects, and Huawei’s Ascend chips captured 60% of the orders in such computing centers.
Although these domestic AI chips still lag behind Nvidia’s latest high-end products in absolute top-tier performance, they are sufficient to meet the needs of most inference scenarios. This also means that even if the H200 enters the Chinese market, it will be difficult for it to rapidly achieve “reverse substitution,” and the scale at which it can displace domestic chips will be limited.
Of course, the core advantage of domestic chips at this stage lies precisely in the word “domestic.” These “leading lights of domestic manufacturing” come with no backdoors, are secure and controllable, and leave the power of discourse firmly in Chinese hands—without any need to worry about supplies suddenly being cut off one day.
…
Although the narrative of “domestic substitution” is attractive, once news broke that the U.S. government would allow H200 exports, share prices of domestic chipmakers such as Cambricon and Hygon saw a clear pullback—the challenge is self-evident.
Overall, compared with domestic chips, Nvidia’s products still have advantages in raw compute, ecosystem maturity, and cluster scale—especially the CUDA ecosystem, whose level of development represents a chasm that domestic chips find hard to cross. The migration cost within the CUDA ecosystem is almost zero, whereas domestic chip ecosystems still need another two to three years to catch up.
From the product standpoint itself, the H200’s advantages are also very prominent: not only does its performance far exceed that of the H20, but more importantly, it is highly compatible with existing systems—most of China’s current AI models are already adapted to the Hopper architecture, so there is no need to rebuild operators, toolchains, or underlying software; it can be put to work directly. By contrast, moving straight to the most advanced Blackwell architecture could actually lead to acclimatization problems.
At the same time, from a market and capacity perspective, the current supply of domestic chips is still insufficient to meet the surging demand in the Chinese market. For example, SMIC’s 7 nm chips reportedly have a yield rate of only 20%, which further exacerbates this supply–demand imbalance. Nvidia’s chips, by contrast, are manufactured by TSMC, with a yield rate reaching 60%, providing much stronger assurance on production capacity.
The most direct impact may come from the release of pent-up demand: there were reports that in early 2025, several major companies placed orders worth 16 billion yuan with Nvidia to purchase H20 chips, but these ultimately could not be fulfilled. With the H200 now cleared for export, that demand may be converted into new orders and released in concentrated form in 2026.
But in any case, Nvidia has long since missed the best window to enter the Chinese market—especially China’s AI sector. This approval has come too late.
China is no longer the market that “can’t live without Nvidia.” It’s like a couple separated for a long time who have each grown on their own before meeting again: even if they get back together, it’s hard to recapture the original passion and dependence. Put more plainly, it’s now a relationship where “if it works, we can make it work; if it doesn’t, we can just walk away.”
Regarding how the US government’s 25% cut will be collected, per Reuters:
A White House official said that the 25% fee would be collected as an import tax from Taiwan, where the chips are made, to the United States, where the chips will undergo a security review by U.S. officials before being exported to China.
This vague description inspired some sudden panic among manufacturers in Taiwan, who worried that they would have to pay an additional fee to the US. Tzu-Hsien Tung 童子賢, chairman of Taiwanese electronics giant Pegatron and cofounder of Asus, told Taiwan’s Economic Daily News that this is most likely a confused misinterpretation: “If Taiwanese firms are paying anything at all, it’s only in a pass-through capacity—collecting and remitting on behalf of someone else, since contract manufacturers aren’t the owners of the product. … My instinct is it’s just pass-through payments; they’re not going to count that as ‘Taiwan paying.’”
The confusion is now mostly cleared up, but a lack of effective communication to Taiwan is probably not a positive indicator for US-Taiwan relations.

ChinaTalk is a reader-supported publication. To receive new posts and support our work, consider becoming a free or paid subscriber.

A year for the history books for the Chinese AI beat. We began the year astonished by DeepSeek’s frontier model, and are ending in December with Chinese open models like Qwen powering Silicon Valley’s startup gold rush.
It’s a good time to stop and reflect on Chinese AI milestones throughout 2025. What really mattered, and what turned out to be nothingburgers?
This piece recaps:
The biggest model drops of the year
China’s evolving AGI discussion among Alibaba leadership and the Politburo
The biggest swings in the US-China chip war
Beijing’s answer to America’s AI Action plan and the MFA’s
Robots
Liang Wenfeng lit the fire
DeepSeek-R1 came out on January 20, thwarting everyone’s Chinese New Year plans. The cost-efficient LLM, which uses a Mixture-of-Experts (MoE) architecture, caused many in Silicon Valley to re-evaluate their bets on scaling — and on unfettered American dominance in frontier models. DeepSeek is powered by domestically trained Chinese engineering talent, an apparent belief in AGI, and no-strings-attached hedge fund money (it is owned by High-Flyer 幻方量化, a Hangzhou-based quantitative trading firm). There were initial concerns that such a recipe could not be replicated by more capital-constrained Chinese tech startups, but Kimi proved that wrong with K2 in July; Z.ai, Qwen, and MiniMax followed.
We translated Chinese tech media 36Kr’s interview with DeepSeek CEO Liang Wenfeng back in November 2024, and spent much of January 2025 on the DeepSeek beat (see Jordan’s conversations on DeepSeek with Miles Brundage here and with Kevin Xu of Interconnected here). Over at the newsletter, we covered how China reacted to DeepSeek’s rise, its secret sauce, and concerns around open-source as a strategy.
DeepSeek continues to be a big deal. For one, it paved the way for an open-source race dominated by Chinese models. Nearly every notable model released by Chinese companies in 2025 has been open source. In public blog posts, social media discussions, and private conversations, Chinese engineers and tech executives repeatedly attribute their open-source orientation to the example set by DeepSeek.
On the technical end, despite some remaining mystery surrounding the exact cost of training R1, DeepSeek’s viability was a shot in the arm for Chinese labs working under compute constraints. Going into 2026, with restrictions on H200s loosened and reporting that DeepSeek is still training on smuggled Nvidia, easier access to TSMC-fabbed Nvidia chips may be just what DeepSeek needs to get their mojo back.
Big deal, but not because of the product
On March 6, an unknown Chinese startup named Butterfly Effect 蝴蝶效应 launched Manus, the world’s first general-purpose AI agent. Revisiting the “Introducing Manus” video that went viral nine months ago is a reminder of how quickly technology has developed: the capabilities Manus demonstrated — reviewing a folder of résumé PDFs, researching stocks, and comparing real estate options — are now so common that we barely think of them as new or even particularly agentic. But back then, some thought Manus was a second “China Shock” of sorts after DeepSeek. Jordan discussed Manus on the podcast with (Strange Loop Canon), Swyx from , and (Mercatus, Hyperdimensional) on the podcast here.
Soon after, Manus didn’t want to be Chinese anymore. In July, the company scrubbed its internet presence inside China, relocated to Singapore, and laid off most of its staff in Beijing and Wuhan. An April funding round led by the American venture capital firm Benchmark had been scrutinized by the US Treasury Department over restrictions on investments into Chinese AI development. Manus may have decided that its Chinese base is a worthy sacrifice if it means access to American capital and the global market.
Since then, its market strategy has been anything but understated: from exclusive parties in San Francisco to conference keynotes in Singapore, Manus is trying to reinvent itself as a global force spearheading agents. Whether or not this rebrand is successful remains to be seen; in the meantime, it is no longer the only agent in the game, as major AI companies like OpenAI and ByteDance launched agent products of their own.
Looking back, Manus was the start of a wave of Chinese AI companies aggressively pursuing international expansion in the second half of this year. With DeepSeek providing that the world was interested in open-source Chinese models, other companies became eager for a slice of the lucrative global market. Whether or not their Chinese roots limit their growth potential will be up to regulators in 2026 and beyond.
The defining paradigm
With DeepSeek shooting the first shot, this year saw a significant number of Chinese companies contributing excellent models to the open source race. In the process of promoting their models, Chinese labs have also become much less secretive.
We covered Kimi K2, a “thinking” model whose architecture is inspired by DeepSeek, in July, with much of the reportage based on blogs and comments Kimi engineers shared online. Since then, we were also able to interview Li Zixuan, director of product at Z.ai (formerly Zhipu), which makes the popular GLM models. 2026 will almost certainly see more Chinese AI companies leverage open source as a mean of expanding influence.
Does China believe in AGI, and is it working to pursue it? It’s a question hotly debated by observers of China’s tech scene, and this year we were fortunate to be able to feature some excellent writing that probes at this topic.
In April, an anonymous contributor staged a Platonic debate between a believe and a skeptic, laying out arguments for and against the question of Chinese AGI belief.
In May, another anonymous writer covered the Politburo “study session” on AI. We learn from the invited guest list that “Xi’s hand-chosen experts on AI seem more like the Yoshua Bengios and Geoffrey Hintons of the Chinese AI world than the Yann LeCuns”:
Alibaba, whose family of Qwen models gained particular prominence in the latter half of this year, held its annual Yunqi Conference in September, and CEO Eddie Wu delivered a landmark speech sketching out his vision for transformative AI. Guest contributor Afra Wang argues that prophetic styles signal a “vibe shift” in Chinese tech, as the industry begins to see itself as pivotal for the nation’s destiny.
Just make up your mind already!
For most of the year, we waited with baited breath for the Trump administration to decide whether to export advanced AI chips to China — and for Beijing to make up its mind on whether it wants them after all. All this drama led to five emergency pods! A quick timeline to refresh our memory:
Jan: Biden’s AI diffusion rule (emergency pod)
April: BIS closed loopholes in Biden-era chip and manufacturing equipment export controls, further restricting Chinese access;
May: Commerce Department kills the Biden Administration’s Diffusion Rule via Q&A but weirdly still hasn’t fully changed the reg…
July: America’s AI Action Plan called for stricter enforcement of export controls and exploration of location verification mechanisms (our coverage)
The Summer of Jensen (reported by ChinaTalk here and discussed with Lennart Haim and Chris Miller here):
July 15: Jensen Huang met Trump and secured permission to resume sales of H20s to China;
July 30: The Cyberspace Administration of China (CAC) summoned Nvidia’s representatives over risks of Nvidia being able to control H20s remotely, accusing them of having a “kill switch”;
August 11: The Trump administration reached a deal with AMD and Nvidia to resume exports of H20s and MI308s to China, with the US government receiving 15% of the resulting revenue;
August 12: The CAC summoned top Chinese tech firms to pressure them to reduce H20s orders and supplant with domestic alternatives;
August 13: Reuters reported that US officials have been secretly putting tracking devices into some high-end chips in order to track diversion to China;
August 21: Reports emerge that Nvidia has asked some suppliers to halt production of H20s.
September: BIS unveiled an Affiliates Rule, which would have hit many more Chinese companies with restrictions on chip access, including their ability to purchase legacy chips;
October: the Trump-Xi Summit produced a deal, with China suspending its new, dramatic rare earths export restrictions for one year in exchange for a temporary suspension of the Affiliates Rule (emergency pod)
November: The GAIN AI Act was introduced in the Senate, with the White House apparently lobbying against it;
December: Trump announced that he will permit Nvidia to sell H200s to China (emergency pod).
Huawei is Beijing’s champion for creating an alternative ecosystem to Nvidia’s. Guest contributor Mary Clare McMahon explored how Huawei is working to bypass the CUDA moat in May, and in June Jordan sat down with veteran journalist Eva Dou to discuss her new book, The House of Huawei. In October, Jordan also interviewed Chris McGuire, former Deputy Senior Director for Technology and National Security at the NSC, about where Huawei’s capabilities might be going.
The rise of reasoning models and inference training has also brought attention towards high-bandwidth memory (HBM), where China still currently relies on the Big Three: the US’s Micron, and South Korea’s SK Hynix and Samsung. Contributors Ray Wang and Aqib Zakaria covered China’s pursuit of indigenous HBM this year, exploring CXMT’s capabilities in the face of lithography export controls.
Too soon to tell…
A wave of attention gathered around robotics and embodied AI in China this year. The Government Work Report this year explicitly mentioned embodied AI for the first time, placing it alongside longstanding tech aspirations like quantum and 6G. The Ministry of Industry and Information Technology (MIIT) specifically named humanoid robots in its list of work priorities for 2025. And throughout the second half of 2025, the Chinese Institute of Electronics has been working on standards for the humanoid robots industry, responding to an apparently “urgent” need for standardization in an increasingly competitive field.
Inside China, buoyed by media attention and Unitree’s Spring Festival Gala appearance in January, competition in humanoid robots turned white-hot this year. At least ten companies released humanoid robot models. Some compete by offering increasingly low per-unit prices, while others are starting to pursue specialization in terms of capabilities.
Embodied AI sits at the intersection of China’s longstanding manufacturing advantage and recent advances in machine learning research like vision-language models (VLMs). Jordan sat down with Ryan Julian of Google DeepMind to discuss some of these advances in robotics research this September. Some industry observers in China are worried that humanoids, and embodied AI in general, will turn out to be a bubble, given the sudden rush of investment and a lack of obvious business models. In the meantime, American policymakers are beginning to fret about Chinese robotics firms’ impressive market shares and Western academia’s reliance on affordable Chinese hardware. It’s too early to tell if 2025 was the start of something seismic in robotics.

Big deal; results unknown
On August 28, the State Council released its “Opinion on In-Depth Implementation of the ‘Artificial Intelligence+’ Initiative” (关于深入实施“人工智能+”行动的意见, hereafter abbreviated to “AI+ Plan”). The Plan is a landmark document addressing the integration of AI into China’s economy and society and pushes for thorough AI diffusion across sectors, ministries, and regions. It does not address geopolitical competition much, but clearly portrays AI integration as a strategic priority for the country.
We dove deeply into the AI+ Plan after it was released. Its extraordinarily comprehensive scope, intense sense of urgency, and framing of open-source models as geostrategic assets were remarkable then and remain relevant now. Going into next year, however, knock-on effects will reach Beijing’s doorsteps. How far is “emotional consumption,” greenlit as an application by the AI+ Plan, allowed to go, as AI companions become more alluring and mental health issues potentially proliferate? Will the state be able to keep frustrations around unemployment at bay amid deflation? If AI capabilities are “jagged,” to quote Helen Toner, will Beijing need to adjust expectations for how different industries’ productivities will change with AI?
Mid-sized deal with MFA characteristics
A follow-up from the 2023 Global AI Governance Initiative, the Global AI Governance Action Plan was released on July 26 at the World AI Conference (WAIC) in Shanghai. China has long sought to create an overarching narrative for international AI governance. The Global AI Governance Action Plan should be understood as part of its campaign to win hearts and minds around the globe, particularly among unaligned nations in the developing world seeking technology partners.
In hindsight, there is a link between the third item of the Global AI Governance Action Plan, which discusses integration of AI into nearly every industry internationally, and the “AI+” plan for domestic AI diffusion that was released later in the year (to be discussed next). Sector-agnostic, large-scale adoption is a conceptualization of AI that is articulated consistently in Chinese tech policy.
Beyond this, however, most of the other items in the Global AI Governance Action Plan are yet to be realized. Without naming the US, the Plan stresses “global solidarity” and warns against fragmentation. China seeks an active role in international AI governance, whether in standards, environmental management, or data sharing. Diplomatic currents move slowly, and we will likely see more AI policy outreach from Beijing towards developing countries in the coming months and years.
Nothingburger, sadly
Just one day after Manus on March 7, the Cyberspace Administration of China (CAC) released a draft of its “Measures for Labeling of AI-Generated Synthetic Content” (人工智能生成合成内容标识办法), which later came into force in September. The Measures require internet service providers to explicitly label AI-generated content on users’ feeds and add implicit labels to the metadata of synthetic content files. Platforms, in theory, should make it known to users whenever the latter interact with potentially AI-generated content, as well as make sure that creators proactively label their uploaded content as AI-generated. This makes China one of the first jurisdictions, and certainly the largest, to implement labelling or watermarking rules for AI-generated internet content.
The CAC is ostensibly well-placed to roll out AI content labelling regulations, given its unparalleled regulatory reach and China’s competitive position in AI technology. However, after a rush of actions by companies to comply in September, momentum has fallen by the wayside. ChinaTalk will have more coverage on this soon, but in a nutshell, the landscape for AI content labelling enforcement is uneven at best. (Anecdotally, I see unlabelled, AI-generated content on Xiaohongshu and WeChat almost every day. Especially in the case of AI-generated text, labelling is next to nonexistent.)
AI-assisted and -generated content is now so much more pervasive online than nine months ago, whether on global platforms or on the Chinese internet. It’s time to ask: what was the point of labelling as policy? Is it to actually protect users from misinformation and engender trust, or is it just a stopgap measure that lets platforms evade responsibility? What kinds of AI usage merit which kinds of mandated disclosures?
A clearly AI-generated video on Rednote/Xiaohongshu. The user’s self-chosen name is “Mimi Loves AI,” but apart from that there is no other indication that the video is AI-generated.
ChinaTalk is a reader-supported publication. To receive new posts and support our work, consider becoming a free or paid subscriber.

Here to discuss is of the Silverado Policy Accelerator.
We get into:
Why this is, in Dmitri’s words, “a disaster”
There are military balance of power implications for selling chips to China
Why the rest of the AI ecosystem is against selling chips to China, Why Trump made this call anyway, and why SME export liberalization might be next
Where the GAIN Act goes from here
Listen now on YouTube or your favorite podcast app.
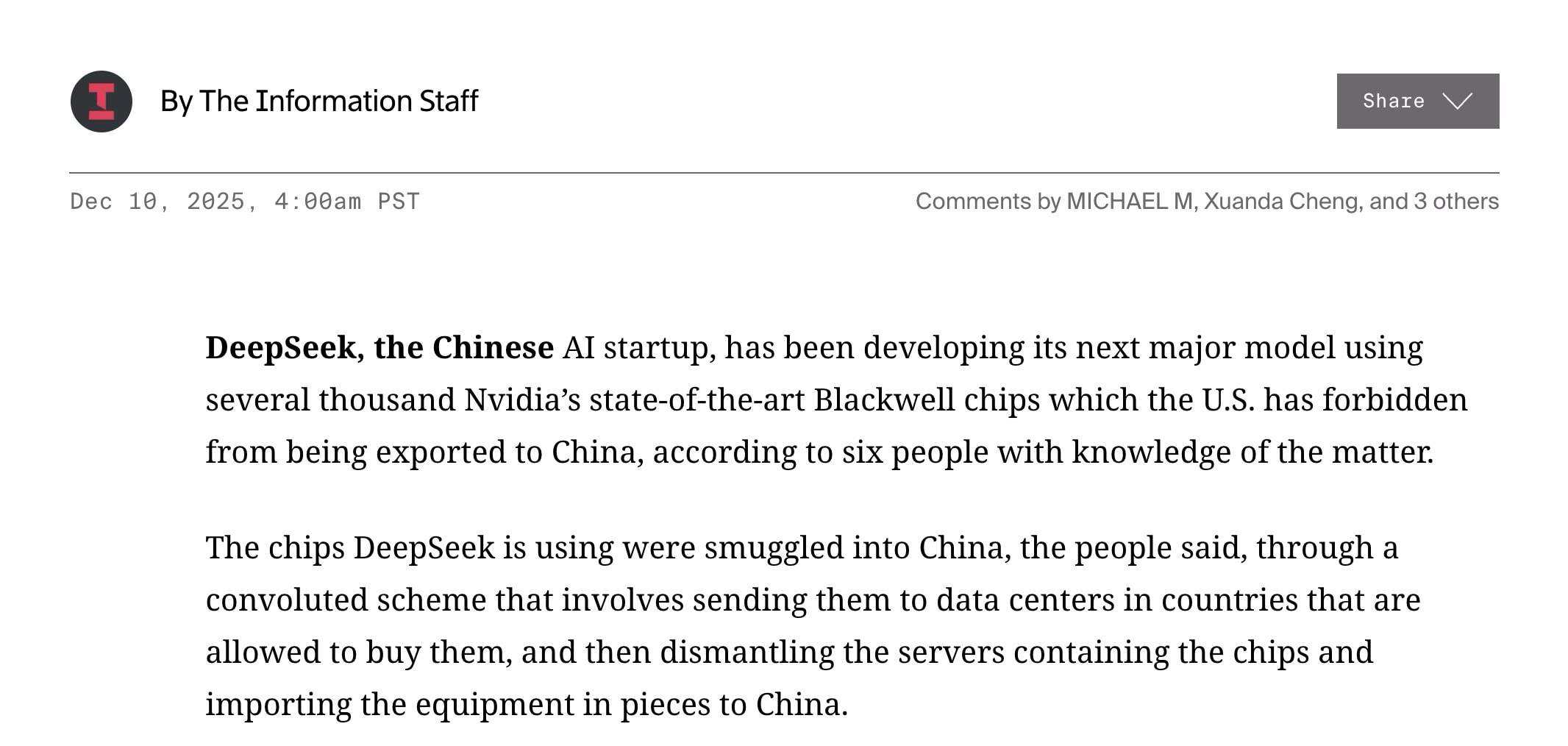
Jordan Schneider: Let’s first toast the unfortunate U.S. Attorney for the Southern District of Texas, Nicholas Jon Ganjei. On Monday morning, he proudly issued a press release for his cool-sounding “Operation Gatekeeper,” which intercepted $160 million worth of Nvidia H100s and H200s.
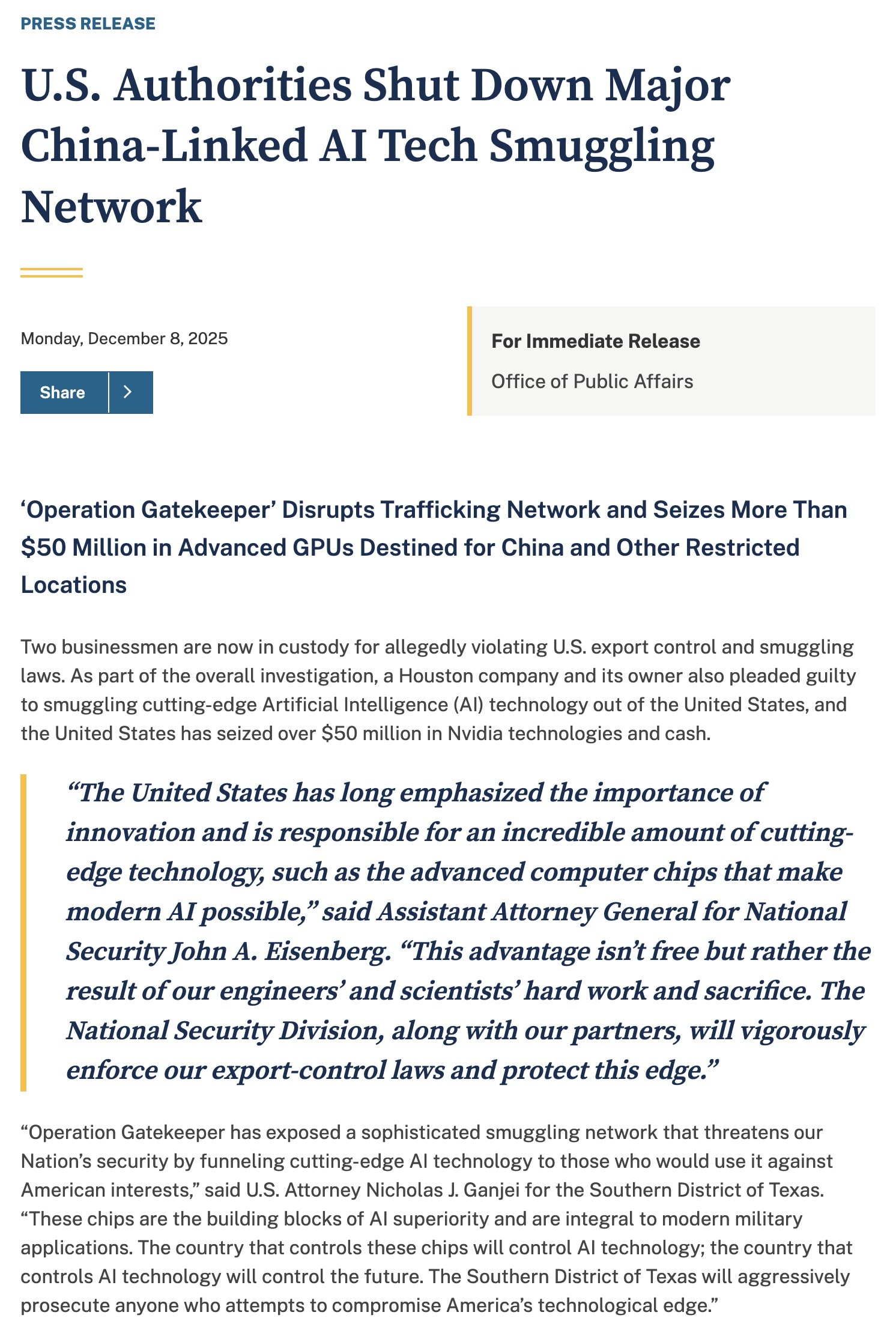
That afternoon, President Donald Trump announced on Truth Social that the United States would allow Nvidia to ship its H200 products to approved customers in China. Dmitri, please make sense of this for me.
Dmitri Alperovitch: There’s no way to sugarcoat this — it’s a disaster. This isn’t only about the Department of Justice. The U.S. Attorney General’s statement highlighted how critical AI is to military applications. The President’s own AI action plan discussed how the United States must aggressively adopt AI within its armed forces to maintain its global military preeminence, while ensuring that the use of AI is secure and reliable. This technology is essential to U.S. military dominance and the successes of the U.S. Intelligence community.
You have to give the administration credit — it is doing a lot to ensure all levels of the U.S. government are adopting AI. Why we would enable China to do the same is beyond me. Are we going to sell them aircraft carriers or Virginia-class submarines? Should we let them into AUKUS? This is effectively what we are doing.

It is outrageous that Jensen Huang has been able to pull the wool over the eyes of people in government and on Capitol Hill, convincing them that arming our primary adversary — the one we are unquestionably in a cold war with — is somehow good for America. I understand it’s good for Nvidia’s sales and for him personally, but it is a disaster for our national security.
Jordan Schneider: What I find baffling is the contradiction in Nvidia’s public messaging. Jensen Huang and his company argue that their technology will revolutionize every conceivable industry, all requiring massive amounts of GPU capacity. But when asked directly about the military implications of selling these chips, Huang downplays the risk. He suggests that China’s military will acquire the necessary chips regardless and claims they are too sophisticated to use American technology for sensitive, dual-use applications. It’s ludicrous that this technology is transformative for every field except for the military.
Dmitri Alperovitch: It doesn’t make sense. AI will transform everything. Even in civilian uses, do we want China to win in automotive, energy, and everything else? Because that’s what you’re enabling by selling chips to them. The primary concern is their military and intelligence services, but we are also in an economic competition. I would rather kneecap Chinese competitors to enable our own companies to succeed. Why would you do otherwise?
This is equivalent to selling supercomputers to the Soviet Union in the 1970s. No one even considered doing that. You could make the case that it would support Soviet agriculture and feed starving people, but no one said that because those same computers could be used for nuclear weapons testing and countless other military applications. There was no debate about it — it was understood to be a bad idea.
50 years later, we’re in a cold war. This is unbelievably shortsighted — putting profit above national security. Jensen Huang said if you’re a China hawk, you’re unpatriotic and un-American. I think selling supercomputing capabilities to the Chinese military is as unpatriotic and un-American as it gets.
Jordan Schneider: Jensen, if you’re listening, you’re invited to come on ChinaTalk anytime to make your case.
Dmitri, what’s telling is that the rest of the tech industry is finally pushing back. After months of staying quiet for fear of losing access to Nvidia chips, major players like Microsoft and AWS are supporting measures like the GAIN Act. The benefit of selling chips to China is mostly limited to Nvidia. U.S. hyperscalers and AI labs now face a powerful new competitor for limited chip manufacturing, driving up prices. The upside seems narrow, especially when Nvidia’s strongest argument — that the world, including China, will be locked into CUDA — seems far-fetched.
Dmitri Alperovitch: Nvidia’s argument is knowingly false. The GAIN Act is the ultimate ‘America First’ act. It stipulates that before chips are sold to countries of concern like China, we must ensure that U.S. demand is satisfied. American companies are first in line. How anyone could argue against this is beyond me.
The Act doesn’t say, “we’ll cut China off completely to ensure their military doesn’t get chips” — we’re saying, “let’s make sure American companies have priority.” It’s a no-brainer. I’ve talked to hyperscalers who are supportive of this act, and even other chip companies are saying they agree with the concept. The fight wasn’t about the details — the fight was a push for no restrictions on sales to China, which is unbelievable.
Jensen’s argument that the U.S. wants to make China addicted to the American tech stack is ridiculous. There is no addiction — chips aren’t cocaine. You can see this today with every single hyperscaler — Google, Amazon, Microsoft with its Maia chip, and now Meta with its own custom chips — all saying they are moving off CUDA. Many already are.
The top two frontier models, Claude and Gemini, were reportedly trained on Amazon’s Trainium and Google’s TPUs, respectively. There aren’t enough chips to go around, and for cost and strategic reasons, pretty much every frontier company is now using a multi-chip architecture — CUDA, Trainium, TPUs, and others. There is no addiction. Companies were able to make that switch in months, it’s easy — this is software and APIs. You can give AI one API and tell it to rewrite it in the form of another. It’s a trivial task.
Now we’re selling China H200s. This is probably the start of a broader concession on Blackwell, and then Rubin. Jensen won’t stop at the H200 — he will want to sell everything. The Chinese want to receive the latest and greatest chips, not only the Hopper generation. We’re going to sell them these chips, and they’re going to build competitive models. DeepSeek, Qwen, and Kimi are already good — they’re at most 12 months behind. They will quickly catch up and become leading models.
China will keep investing in Huawei because the Chinese are not stupid. Jensen says that if we don’t sell them chips, they’ll invest in their own, like Huawei’s Ascend chips. They’re doing that anyway. Xi Jinping is going to demand it, which is why you’re seeing China’s response that they will restrict the importation of H200s to ensure there is still domestic demand for Huawei chips.
Huawei’s Ascend chips will eventually catch up, and Chinese companies — supposedly “addicted” to the American AI stack — will switch over in days or weeks. What will we have achieved? We will have relinquished our lead in frontier AI models, and eventually, they’ll have chips that replace Nvidia’s. It is myopic and stupid for Nvidia’s own business model. They are focused on the next quarter and the next year versus a couple of years from now when China dominates both chips and frontier models.
Jordan Schneider: If this goes through, and tens of billions of dollars worth of chips are exported to China, and the future you portend comes true, will there will be a political price to pay? This was a major talking point for Trump on his campaign — “Winning the AI race” and “American AI dominance”. A year or 18 months from now, if China is releasing crazy new AI-powered technologies that were all trained on Nvidia chips, that will be a tricky political dance. Nice calls from Jensen won’t be enough to smooth that over.
Dmitri Alperovitch: We are already there. Almost a year ago, there was a brouhaha over the release of DeepSeek. The surprise was unwarranted: it shouldn’t have shocked anyone paying close attention. But people reacted with, “Oh my God, the Chinese are catching up.” Of course they are. Deepseek was built on H100 chips, which, until recently, were not restricted. There will be another DeepSeek moment, but worse. DeepSeek was good, but it was still behind frontier models. The next models will be better.
Sam Altman is in panic mode over Gemini 3 because its capabilities eclipse his models. This will happen to all American frontier models and to the country more broadly. The Chinese will crush us with cheaper power, tons of researchers, and massive state subsidies. The one thing they were missing — compute — will now flow into China.
Jordan Schneider: The Financial Times reported Chinese companies were training models in Malaysia or Singapore. That’s not ideal and not as efficient as AliCloud’s operations in China. There, they can rapidly deploy numerous H100s while benefiting from straightforward communication, a reliable power grid, and lower energy costs.
Dmitri Alperovitch: We should have been cracking down on H100 access in Malaysia and elsewhere. Chips shipped directly to China will be prioritized for high-side intelligence and military networks. Chinese agencies can’t use public clouds in Malaysia for their classified data. But now they can grab those chips from private companies in China and prioritize them for military purposes, as they do with everything else.
Jordan Schneider: That seems like the most salient reason China would want the chips inside the country. Training models in Malaysia is annoying, but only 10%-annoying. There are also data privacy restrictions, which they can get around if they’re serving domestic consumers in China. What do they want complete control of their chips for? The sensitive stuff that they would never trust a random Singaporean cutout to do for you.
Dmitri Alperovitch: The U.S. government cannot get enough chips. Agencies have told me they are compute-dependent for inference and cannot get enough chips. Now we’re shipping part of that limited supply to China. How does that make sense?
Jordan Schneider: Let’s flip this around.
Dmitri Alperovitch: One more point. The H200 is from the Hopper generation, not the latest Blackwell generation, but it has High-Bandwidth Memory (HBM). We have a current ban on the export of HBM to China. The H200 decision calls HBM protections into question, as the technology is already being exported on Nvidia chips.
We may see a cascading failure of export controls. I am hearing of discussions about relaxing export controls on semiconductor manufacturing equipment, which would make it easier for Huawei to manufacture Ascend chips in China. I hope that doesn’t happen, but there are people in the administration pushing for it.
Jordan Schneider: A year ago, the administration was being pressured to restrict chip technology to China. First there was the H20 situation, then the Laura Loomer saga and teh “twilight of the China hawks.” Lawmakers Vasant, Greer, and Rubio even intervened right before the Xi Jinping meeting to urge against concessions. Now, only a month later, this policy has been enacted without any clear reciprocal action from China other than continued soybean purchases.
Dmitri Alperovitch: I don’t know.
Jordan Schneider: To be determined. The main thing they’ve done recently is bully Japan. That’s the only big new development. And now we’re deciding to throw this other carrot into the mix. It’s weird.
Dmitri Alperovitch: The crazy thing is that China isn’t even asking for this. It didn’t come up in the Trump-Xi meeting. This is a concession to Jensen Huang, enabling Nvidia to make money at the expense of U.S. national security. I could understand it if this were a trade to get something we desperately want from China, like rare earths or a commitment not to invade Taiwan — though they would never do that. But it’s not. We are getting nothing for it. It is a favor to Jensen, to China, and to the PLA.
Jordan Schneider: It’s not even a big favor to my 401(k) — it only went up by two and a half percent. Come on.
Dmitri Alperovitch: Nvidia is in trouble because its U.S. market is going to shrink. Its primary customers, all the major hyperscalers, are building their own chips and want to move off of Nvidia’s platform. It’s desperately looking for another market, in China and the Middle East. That is why the company is pushing so hard for these export controls to be lifted. Jensen probably sees this is an existential problem.
Jordan Schneider: Dmitri, I appreciate your energy. I am so tired of these guys. I have to give Jensen credit for his stamina in making those calls and fighting through this. He has delivered twice now.
Dmitri Alperovitch: And he killed the GAIN Act.
Jordan Schneider: The man’s on a roll — he’s scored a touchdown.
Dmitri Alperovitch: And by the way, he’s not only going after the China hawks. The entire industry — from the hyperscalers to other chip companies — is on the other side of the ledger. He’s single-handedly beating everyone in this town. It is astonishing.
Jordan Schneider: Last year I asked you why more rich people don’t invest their time and energy to shape political outcomes. The thesis was that if you put the time and work in, you can get results. This is Exhibit A for CEOs trying to push through initiatives that may not have polled well initially. If you put in enough legwork and time on the phones, you can make things happen.
Dmitri Alperovitch: You have to give him kudos — he’s done incredibly well at the influence game here in D.C. He is putting in the time, meeting with anyone. He even said he’ll meet with Elizabeth Warren, one of his chief critics on the Democratic side. He’s calling the President almost daily, it seems. He got this done by badgering the President, repeating, “Get me my chips, get me my chips, get me my chips.” Donald Trump finally said, “Fine, here you go.”
Jordan Schneider: This development suggests the administration dismisses both the national security and the economic arguments for restricting this technology. It ignores the reality that these chips are vital in a strategic military competition.
Economically, it also overlooks the fact that strengthening Chinese competitors will harm American industry for decades. We should be consolidating the technology that drives productivity, not ceding it to a rival.
Dmitri Alperovitch: I don’t agree. The majority of this administration is opposed to this decision and does believe we are in a strategic competition with China. Call it a cold war. I know people in the administration agree. The president was convinced that selling China American AI stack is good for American business, and that Chinese firms will be addicted to it. But it’s a nonsensical argument. Jensen lied, because there is no addiction to the stack — it’s easy to move off of it. Unfortunately, he has been able to carry the day for now.
Jordan Schneider: This isn’t selling the “stack.” Selling the stack would be Nvidia chips run by AWS or Google, running Western models. This is selling the lowest level of the stack. I guess if the semiconductor manufacturing equipment (SME) relaxations come true, we’ll be selling the two lowest levels.
Dmitri Alperovitch: This is the equivalent of selling Ford cars to China in the hope China will be “addicted” and not prefer any other car. It is stupid on its face.
Jordan Schneider: It’s not even selling the Ford car — it’s selling the axles.
Dmitri Alperovitch: That’s all it is. There are huge problems with this decision. First, this is enabling the Chinese military and intelligence services, which are adversaries we could one day be at war with. The DoD is planning for a fight with China and stressing the need to overmatch its capabilities. Second, it puts Chinese firms on equal footing with American firms. Why would we do that? It hurts American companies and the American economy.
Jensen’s argument against export controls is inconsistent with his own business practices. He claims controls only encourage strategic competitors to innovate. By that logic, he should open-source his proprietary CUDA framework to AMD, because God forbid they develop a superior alternative. He doesn’t practice what he preaches. He is protecting his technology with patents and trade secrets, like any other company. Yet, he insists the U.S. should use a different strategy at a national level. It’s insanity.
Demand for chips in the U.S. already outstrips supply. Diverting this limited resource to a strategic military and economic competitor is a self-defeating act — we are actively surrendering the Cold War. I’m not an “AI doomer” — this technology is profoundly important for economic and military power. That is why there is no valid argument for helping your main rival develop it.
Jordan Schneider: Hey, White House. Hey, Nvidia. If you want to come on ChinaTalk and make those arguments, we could hash it out here.
Maybe we’ll be saved by the Ministry of State Security, who convince themselves that this is a crazy CIA plot to backdoor hack the PLA. It’s a longshot.
An Institute for Progress chart shows the U.S. and its allies currently possess a large compute advantage over China, roughly a 13-to-1 ratio. Selling large volumes of chips to China could drastically change this balance.
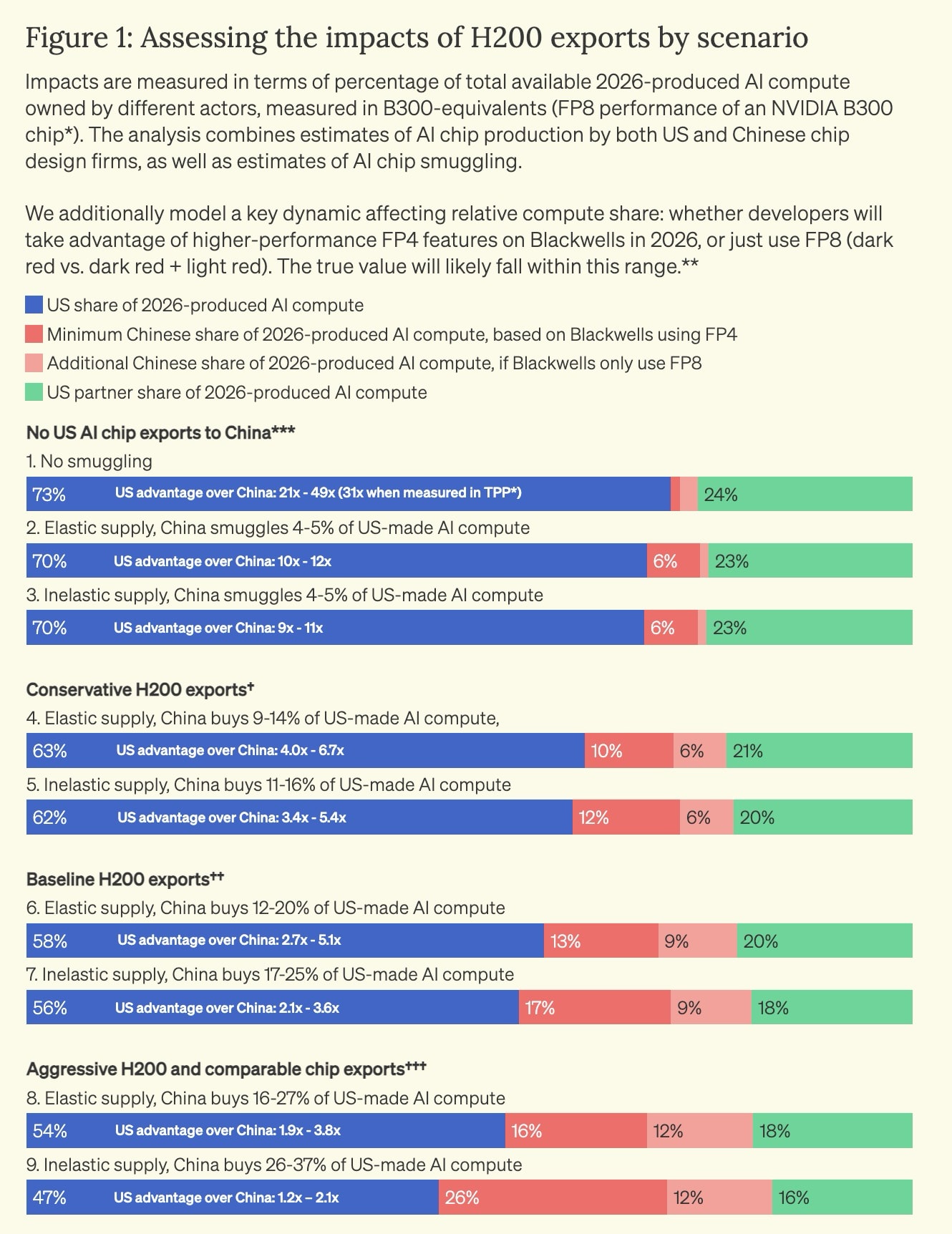
The main question is how Huawei’s domestic production compares to Nvidia’s global output from its fabs. If we withhold advanced equipment and AI chips from China, we can confidently expect a continued U.S. advantage. If these sales go through, it’s unclear who will lead in compute power in next 5 to 15 years.
Dmitri Alperovitch: It will be China, because they’re going to subsidize the hell out of this and we won’t.
It’s not over. Capital Hill is upset about this. Don’t count out Congress, the GAIN Act isn’t dead yet. There will be a fight to prioritize chips for American companies and to see what restrictions are possible — maybe export control reviews by Congress. There are bills floating around.
Also, Donald Trump often changes his mind. Others may convince him to revert this decision. The good thing about Donald Trump is that you’re never done. Whatever happens today can be undone tomorrow, and we need to take advantage of that.
Jordan Schneider: That’s the great irony in all of this. Given the political hesitancy on both side of the aisle and the possibility of Trump changing his mind, Alibaba, Tencent, or ByteDance are unlikely to bet their firms’ futures on Nvidia chips. This is going to be a political football, and one Truth Social post won’t end it. The strategy of “addicting Chinese firms” over the long term — setting aside Beijing’s own goal to indigenize chip production— won’t work.
Dmitri Alperovitch: Beyond politics, this strategy fails for basic business reasons.
China won’t get enough chips. You have Jensen acting as king, allocating a scarce supply of Nvidia chips to hyperscalers and now Chinese customers. Since there isn’t enough to go around, that scarcity forces them to rely on other chips.
No one wants to pay the “Nvidia tax” or be completely dependent on a single monopolistic supplier. Everyone wants to diversify, which is why you see them all building their architectures on multi-chip designs. Committing 100% to CUDA, politics aside, makes no commercial sense.
Jordan Schneider: Let’s close on some vibe-coding. I can’t be too depressed going into the holidays. Dmitri, I hear you’ve been having some fun with Opus 4.5 recently. What’s it done for you?
Dmitri Alperovitch: It’s magic. Anyone with a bachelor’s degree, not even in a technical field, can be a software engineer within three years, if not sooner. It is so easy to develop applications. I’ve built two mobile apps in the last month and a web app for personal use. Opus 4.5 is magic. I built a mobile app yesterday in 15 minutes, and most of that time was spent on setup, authorizing it on the Apple Store, and configuring my device. The capability is incredible, and it’s improving everyday.
This is the innovation we have to look forward to, and we want to make sure our American companies, our government, and our citizens are the primary beneficiaries. We want American frontier companies to be the best, and then we can restrict these models from actors we don’t want to have access.
I’m on the board of a number of companies, and I’m telling them all to start measuring their engineers on their use of AI in development tasks. Anyone who isn’t using AI should be considered for a performance improvement plan (PIP). This is the next hammer. It’s like when hammers were discovered tens of thousands of years ago — whoever didn’t use them fell behind. This is an unbelievable productivity tool.
One of my companies has a software engineering team developing their products. They’re also pulling people from other departments, like security, to help build the next module in Claude or other models. These teams are creating prototypes, and even production-ready versions. It’s unbelievable how you’re able to raise the productivity of everyone, not just software engineers.
Jordan Schneider: I want to say the same for analysts, think tankers, Hill staffers, and folks in the executive branch. It is a superpower. We were having a debate about whether Huawei can backfill Nvidia and what the ratio of chips would be. It took me 45 minutes to build an entire data visualization with sliders for different assumptions. How much HBM will China get? How tight will the export controls be? How much will they improve using DUV? How far behind will Huawei’s chips be compared to Nvidia’s?
Beyond the fun personal applications, it’s the “bicycle for the mind” aspect that people should experience, especially for thinking through policy problems. If you’re wrestling with a knotty issue that has numbers, contingencies, or second-order effects that are hard to hold in your head, ask Claude to help you visualize it or see the other side of the argument.
The hallucination issue is almost gone. You still need to fact-check the details and trust your gut if something seems off, but the improvement has been dramatic.
Dmitri Alperovitch: It depends on what you’re using it for. At some level, it’s garbage in, garbage out. If you’re training a model on Reddit and asking about something very esoteric, you’re not going to get a good answer.
Jordan Schneider: You are doing yourself a disservice if you haven’t spent time with these models. Try to integrate them into your day job. You should be hanging out on Cursor and Claude, trying to build little tools and apps to make your workflow easier or allow you to do new things.
Dmitri Alperovitch: Building apps was nostalgic for me. It brought back the emotions I felt as a kid in the 1980s when I learned programming. It was an amazing feel coding your first “Hello, World!” program or, in my case, a simple game in QBasic. The magic of seeing it run was a special feeling, and you felt so proud and accomplished.
This took me back. It made me think, “Oh my God, this is magic.” In the ‘80s and ‘90s, you had to have technical expertise and learn a programming language. You still need some technical skills today, particularly when you’re debugging or if you don’t understand how Swift works or how to deploy iOS apps. But all of that is going away.
Jordan Schneider: It’s going away.
Dmitri Alperovitch: The accessibility of this technology changing everything. For years, we thought only nerds could access the magic of programming. Now, everyone can, and that is going to revolutionize everything. The interesting thing about AI is not that it’s going to make tasks easier and faster, but that it’s going to make other things that you would never, ever do before accessible.
The cost of software engineering iwill drop to zero. Everyone will be building dozens of apps — for their grocery list, for managing their kids’ schedules, whatever it may be — because it’s so easy. You can custom build something that would be useful only to you, with no commercial value. Even for coders, we wouldn’t spend our time building those apps it was a lot of effort. Now, that effort is gone.
Jordan Schneider: The activation energy for doing a side project has dropped to zero. What I’m excited to see created, Dmitri, is the “senior policy official simulator.” That’s a classic nerdy ChinaTalk idea.
Dmitri Alperovitch: So nerdy.
Jordan Schneider: But you read all these memoirs from government officials. Jake Sullivan said the one thing you can’t experience beforehand is being in a crisis. You can have a Tim Geithner level — all of a sudden it’s 2009, and it’s not like you’ve lived through a financial crisis before.
Having a visceral experience — a VR Situation Room meeting, a VR flight on the plane with the president trying to convince him not to sell chips to China — getting reps in those high-stakes political, personal, and commercial situations could be transformative. It doesn’t have to be for politics and national security. We haven’t had a nuclear crisis in a long time.
Having the deeper, emergent human capabilities that AI simulations of these events can provide seems like a big upside for human competence when dealing with crises in the future. I’m excited about it. Rockstar Games, if you’re out there, give me a call. We can do some cool stuff together.
Dmitri, always a pleasure. Thank you so much for being a part of ChinaTalk.
Dmitri Alperovitch: Thanks for having me, Jordan.
ChinaTalk is a reader-supported publication. To receive new posts and support our work, consider becoming a free or paid subscriber.

大家好,本期放学以后信号塔由西班牙的霸王花木兰轮值。现在我正在塞维利亚的民宿沙发里窝着写这篇newsletter。
我又出门游荡了。
先是莫不谷发起了去Alicante吃海鲜过春天的活动,我和莫不谷,还有荷兰朋友小鱼儿以及芬兰的粽子一起到阿利坎特Alicante集合,度过了短暂却精彩纷呈的三天。
由于芬兰飞西班牙机票太贵,粽子来一趟不容易,所以在莫不谷的提议下,结束Alicante行程后,粽子又和我一块背包开启了西班牙南部的游荡之旅,先是去海鲜饭发源地瓦伦西亚Valencia,再飞去美丽的南部城市塞维利亚Seville,接着坐大巴到达热门旅行城市马拉加Malaga,最后粽子从这里结束游荡,飞回芬兰。

这一路的行程,粽子像是海绵一样遇水膨胀,疯狂储蓄西班牙的阳光,这样在芬兰夜长日少的时间里慢慢使用,明年四五月份春天也就没有那么遥远了。今天粽子还在塞维利亚的街上边走边唱,我的快乐,不会来了~因为一想到西班牙游荡行将结束,她便心生不舍。不过她也计划以后每年冬天都来一趟西班牙,因为阳光太好了!莫不谷也早早计划了2026年的冬日游荡行程:到西班牙的最南端——科尔多瓦+加地斯+龙达+直布罗陀 (对面就是非洲) 。
而我则是终于有机会来南部游荡,特别是莫不谷曾在四月去过腿部干裂到出血却仍止不住夸赞的塞维利亚Seville。
落地第一天上午,在灿烂到背部发热的阳光下,我背包徒步走到了西班牙广场,这个简直是我全世界游荡以来遇到的最美丽的广场,评为我的世界第一广场也不为过。恰逢广场里舞蹈正在配合热情的音乐演奏,旁边烤板栗的香气和烟雾在人群头上聚集又随风飘去,五彩缤纷的泡泡正在被人吹出,又被好奇的孩子们追逐试图拍散,阳光洒在粉橙色的广场建筑和缤纷美丽像是“青花瓷”又像是“唐三彩”地瓷砖上,广场正中央喷泉正在以蓬勃的状态喷洒水滴,细碎的水雾遇上阳光折出一抹七色彩虹,当人的视觉,听觉,嗅觉被偶然聚合的景象充分打开,热情,阳光,梦幻,快乐,兴奋,这些词便在我的脑海里陆续飘过。人对一个城市的第一印象就此形成,美丽。

塞维利亚有一款橙子味道的香水,还有一个美丽的名字,塞维利亚的空气。因为塞维利亚路边全是橙子树,春天是白色橙花绽放的季节,满城飘香,冬天是橙子结果的季节,也是橙子汁水最足,味道最好,价格便宜的季节,来到这里,见过冬日街边满树橙子的人,谁又能拒绝这款塞维利亚的空气呢?
我走进了莫不谷保存在Seville googlelist里的一家小众香水店,Naturally, aromas of Seville,店员在我的手腕上试了orange bloosm的香水后,我便忍不住把这款美丽的味道买下,出门走在大街上,整个人被成熟的橙子圈起来一个味道的结界,感觉自己变成发现美味食物疯狂闻嗅的狗,抑亦或者变成猫薄荷上头的猫,不停用鼻子闻着喷过香水的手腕,再使劲嗅着空气里的留香,难以自拔。

这次南部游荡是和粽子一起,Alicante游荡是和莫不谷还有荷兰朋友小鱼儿一起。我在香港,波兰,英国等地体验过solotrip,一个人游荡的好处是自在,随性,方便,体验自己独自和世界交手。而我更多地是和朋友一起游荡,既有和莫路狂花的多次全球游荡,也有和女性朋友们一起的集体游荡。与人一起便有相处的问题,特别是在游荡过程中,价值观,消费观,性格特点,生活习惯,个人胃口,出行安排等等是否能够合得来,都会影响游荡体验。
而另一方面,和朋友们结伴游荡的好处也很明显。《拼团人生》这本书里说,分享快乐,快乐会加倍;分享悲伤,悲伤会减半。在Alicante阿利坎特和女性朋友们一起出门游荡,去美丽的地中海边徒步,大快朵颐人均19欧元海鲜饕餮自助,晚上一起投影看“快乐小偷”英文脱口秀,又在第二日一起去中央市场采购新鲜牛肉和海鲜,共同制作美味的贵州酸汤牛肉海鲜火锅,吃完再一起打扫收拾。
人多热闹也多,能够一起创造的记忆也多,感觉和相处愉快的朋友呆在一起,生活也变得丰富和有意思起来。

我不是群居动物,我常常独居,不爱聊天,对人没有好奇心,喜欢独自行动,遇到事了还喜欢躲在蜗牛壳里避免被发现。可与志同道合的朋友短暂共居的我会感到比平时多一点的安心,这个感觉挺奇妙。就像是自己独自玩游戏,过程很投入很开心,结束后总还是有些虚无。但是和人一起玩游戏感受就会有些不同。
前段时间莫不谷发起了“你画我猜”欧洲女子联赛,和芬兰的粽子,瑞士的Ruya,Ruya的意大利米兰朋友Max,还有荷兰的朋友茶茶分别玩了三场在线游戏,每次都玩两三个小时不过瘾,灵魂画手的我画的A4纸都要冒火星子,而玩游戏时,我的胜负欲,集中力,想象力和创造力也被高度调动起来,甚至前一天通宵看网文《祝姑娘今天掉坑了吗》睡不够,也丝毫不影响玩游戏。
也因为如此,莫不谷的每次游戏提议我都很心动,游荡提议同样心动。
最近沉迷看《祝姑娘今天掉坑了吗》,网文里的大部分角色无一不被祝姑娘折服,相信跟着祝姑娘不愁人生前路。网文外的我,也忍不住为祝姑娘折服,不自觉代入想跟着她干事业的人物角色。又总在阅读文字的时候想到莫不谷,跟着小祝大人不愁前路,跟着莫不谷则是不愁美食和职业。
这次在Alicante游荡,就跟着莫不谷一起体验了新的美食,还经历了神奇的际遇。还没来西班牙前,莫不谷就一直沉迷熟成鱼,咔咔学习熟成知识,时不时和我分享美食视频,还建议我去寿司店学习一下,以后开餐厅就可以负责活缔杀鱼。所以她在确定Alicante游荡机票的当天,就找好了熟成牛肉的餐厅,因为熟成鱼要去伦敦和巴黎才能吃到而且价格高昂。
没想到在Alicante一家中超店铺里的包子铺吃早餐时,莫不谷又在念叨这件事,谁能想到小小包子铺的老板是全世界钓鱼的爱好者,最近一次钓过300多公斤,价值一万多欧元约合人民币十几万的金枪鱼,而恰好他昨天刚钓的,做了活鱼取缔,还没来得及送给朋友的金枪鱼亚种就在包子铺的水桶里。更难想到的是这个山东青岛老板0桢起手,二话不说便把鱼拿出来现场处理做刺身,同时搭配了酱油和芥末的日式吃法,柠檬和白糖的泰式吃法,还用打火机将柠檬和白糖在三文鱼上烤制一下,最后将整条鱼全部免费送给我们品尝!

这是任谁怎么想都想不出来的奇遇,但和有着强烈渴望和心愿的莫不谷一起,感觉什么奇迹都有可能发生。

(莫不谷在游荡者网站分享的aha moment)
另一个惊奇的小故事是,我们前一天晚上在Alicante中央市场买了新鲜便宜,只要2欧一个的地中海蓝蟹,简单水煮就可以吃到清甜可口的蟹肉。因为吃不过瘾,第二天莫不谷又要飞回荷兰,飞行当天我又去中央市场给莫不谷带了两个螃蟹。由于生螃蟹无法带上飞机,莫不谷便提出一个在我看来很难想到,想到也做不到的方法,先去包子铺吃早餐,到时候请包子铺老板帮忙煮螃蟹。
我是真没想到这事能成。为避免被拒绝的尴尬我还提议要不要以支付加工费的方式试试,说不定老板能同意在包子铺帮忙煮螃蟹。结果吃完早餐消费完毕的莫不谷和老板开口说明情况,希望老板能帮忙煮一下,勇猛地开口不仅成功煮上了地中海螃蟹,还由此聊到她心心念念的熟成鱼,接着就是意外惊喜地吃上了珍贵的活鱼刺身。

跟着这个小故事的后续是,莫不谷在飞机上突然太饿了,干了一件极其疯狂的事,在飞机上把两个螃蟹啃干净了。然而不仅没有人投诉反馈,对面荷兰人还热心借给她湿纸巾,空少还过来帮忙收拾垃圾。对我来说,真是惊奇,震惊和佩服打个包裹在一起,一波又一波来袭。
而另一个印象深刻难以忘怀的游荡奇遇是,这次我们居然在Alicante遇到了双彩虹!今年春天我和莫不谷一起来Alicante爬山时,风景超级美丽,由于阳光太好洒在巴拉巴拉城堡城墙时,有一种不必吃苦人就来到了埃及的感受。
这次11月来Alicante再爬巴拉巴拉城堡,冬天植物没那么茂盛,天气也有些阴天,完全没有了埃及的感受,甚至爬山中途还突然下起了小雨,可就在我给粽子拍照时,一抬头看到了两轮巨大的彩虹悬挂空中,一头连接Alicante这座城市,一头直直插入蔚蓝清澈的地中海,仿佛这难得的双霓虹是从神秘的海里生长出来的,我们惊奇地喊出声来,山上的人们纷纷拿起手机抬头看向美丽的天空。
斯景双霓虹,遇上方知有。游荡路上的奇迹,是出了门看到,吃到,体验到,真的有可能发生,甚至一定会发生在有着强烈渴望和热情的人身上。我不像莫不谷那样对美食,创作有激情,热情和渴望。虽不能至,心向往之。所以我先出个门再说。
最后分享一些本次游荡的图片!




成为放学以后Newsletter月度会员,可以解锁既往所有付费内容,解锁完记得在权益期及时查看所有付费内容,以最大化享受权益。如下月不再继续付费订阅,也记得及时解除,以防发生计划外扣费;爱发电支持购买单期付费播客或文章。大家可根据自身情况选择最适合的方式,苹果用户请不要下载appstore的爱发电app,是诈骗。
放学以后爱发电“电铺”:https://afdian.com/a/afterschool?tab=shop
《创作者手册:从播客开始说起》(小册子)系列https://afdian.com/item/ffcd59481b9411ee882652540025c377
run&rebel系列1《朋友们,Run and Rebel:快逃以及反抗!》https://afdian.com/item/2b3a33acfd3311ecb4d852540025c377
run&rebel系列2《在这个时代,做个反派》https://afdian.com/item/b9c74240bcff11ed86fe5254001e7c00
run&rebel系列3《爹和爹味,吐槽大会》https://afdian.com/item/6529d622092011ee8a1352540025c377
run&rebel系列4《活在历史的垃圾时间,我们如何度过时代的乱纪元?》https://afdian.com/item/90682ea4c68611ef8e645254001e7c00
run&rebel系列5《让我们不吐不快:各行各业,各个工种,各色牛马,吐槽齐发》https://afdian.com/item/87b95f1ac32111f0b10552540025c377
放学以后《莫路狂花今夜不设防:人如何不糊弄和痛恨自己,并找到自己的渴望呢?》https://afdian.com/item/e4b68686a67911ef8f2f5254001e7c00
放学以后《莫路狂花2:如何对自己充满爱意和敬意,免于混乱逃避低活力?》https://afdian.com/item/3572eaba3a6d11f0ac9052540025c377
放学以后《终身学习1:学会面对真问题,不逃避,下决心和谈分离》https://afdian.com/item/e96a78d4619c11f09e8552540025c377
游荡者平台:www.youdangzhe.com 或者www.youdangzhewander.com

Tony Stark and Justin Mc return for Second Breakfast. In Part I, we break down the Trump administration’s new National Security Strategy (NSS).
Today, our conversation covers…
What a National Security Strategy is, and why they matter,
Controversial new inclusions in Trump’s NSS, including on Taiwan policy and the “reinvigoration of American spiritual and cultural health,”
How to reconcile the document’s ambitious vision for deterrence with the reality of Trump’s China policy,
The mixed signals this NSS sends to U.S. allies,
What Buffalo Wild Wings can teach us about competition with China.
Listen now on iTunes, Spotify, or your favorite podcast app.
Jordan Schneider: Tony, give us the 101 on what a National Security Strategy is, and then we’re all going to go around and say one nice thing about it.
Tony Stark: There are three major U.S. government national security strategy documents. The first is the National Military Strategy, which applies to the uniformed services but is rarely noticed outside the Joint Staff.
Next is the National Defense Strategy (NDS), which is the Pentagon’s primary strategic document. It’s the one most people in the field care about because it’s a Cabinet-level document, even if it isn’t overtly political. Legally, a new NDS is required every four years, and developing a new NDS takes 6 to 18 months. New administrations are given a little extra time — about a year and a half — to publish their first one.
The NDS is written at the “action officer” level, which includes General Schedule (GS) employees, field-grade officers, contractors, and think tank experts. Then it is passed up to the Deputy Assistant Secretary level in the Office of the Secretary of Defense (OSD) — their equivalents are three-star generals — and then to the commands, the undersecretaries, and so on.
Finally, there’s the National Security Strategy (NSS), which is historically the most political of the documents because it comes out of the White House, not the Pentagon. The NSS is a guiding vision of the administration’s goals and incorporates all elements of national power. Historically, this is also the blandest document — its wide scope reads more as a political statement than a defense plan. The new Trump administration just released its first NSS. While the NDS has been ready for a while, they were likely waiting to publish the NSS first.
At 29 pages, the new NSS is the right length for a public national strategy document. There are usually non-public, classified annexes and other materials.
Justin McIntosh: The document correctly focuses on economic re-industrialization and re-energizing the defense industrial base — issues we’ve previously discussed. It puts those ideas forward in its “answers” section. But…
Jordan Schneider: No “buts.”
Justin McIntosh: Okay! Yes, that’s where the focus should be.
Jordan Schneider: The straightforward questions in the document are nice. The Q&A rhythm is interesting and provocative. It’s focused. There’s a section of questions like, “What should the U.S. want overall?” and “What does the U.S. want from the world?” There’s no artifice about how transactional it’s going to be — what you see is what you get.
Tony Stark: If I were framing a strategy document for the American people, this is how I would structure it. A clear layout saying, “This is what we want. This is why we have a strategy. What are the ends, ways, and means? What does that mean?” It’s written in a clear, accessible way, without many buzzwords. Although what replaced the buzzwords wasn’t great.
Jordan Schneider: Avoiding policy jargon in this document seems to have been a conscious choice.
Justin McIntosh: But it lacks nuanced, impartial language and contains statements that our adversaries will exploit. A comment on the necessity of securing borders said that any sovereign nation has the right to control them. The PRC and Russia can easily seize on a statement like that. This is a kind of language previous administrations have avoided, because they didn’t want a quote interpreted as agreeing with the Chinese or Russian position.
 summit, in Busan, South Korea, October 30, 2025.")
Tony Stark: The document does not change U.S. policy towards Taiwan. If anyone tells you it does, they are wrong. However, it does give the PRC political and legal ammunition. They can now say, “But you said you wouldn’t interfere in the internal affairs of others,” pointing to our supposed principles of non-interventionism.
The document also says we do have to intervene sometimes. This amounts to talking out of both sides of your mouth — we reserve the right to do whatever we want. The “flexible realism” section is a fancy way of saying we’ll do whatever is convenient. Historically, that has been U.S. foreign policy in practice, but that doesn’t mean it’s what we should aspire to.
Justin McIntosh: I don’t have a problem with them laying out the “ends, ways, and means” discussion up front, but it has limitations. That linear framework is well-suited to military decision-making, but a national strategy needs to be more pragmatic and flexible. At the national level, you control all the resources. You can marshal all those resources toward any goal that is deemed important. That makes the “ends, ways, and means” calculation irrelevant because you will find a way to make it happen.
Jordan Schneider: The Trump administration’s focus on “ends, ways, and means” raises the question — how weak do they think the U.S. really is?
Reducing the U.S.’s power to an “ends, ways, and means” calculation only works in military contexts — counting ships and battalions to see how many wars you can fight. The U.S.’s power to achieve economic and national security ends is elastic. The means to those ends can grow dramatically when the president builds a consensus around them — once the nation decides something must be done, it finds the capacity to do it.
It’s a mistake to define goals downward because those goals inevitably change. Consider the border — the Biden administration didn’t prioritize the issue and struggled to find the means. The Trump administration’s intense focus on the border unlocked congressional funding and operational capacity. The resources didn’t appear from nowhere — the will to use them did. This dynamic applies globally. To believe the U.S. cannot act because it lacks on-hand capabilities is a severely limited way of thinking about our power to shape events.
Tony Stark: The document’s focus on military and economic power isn’t unique, but its goals do not align with a realistic budget. It calls for both bolstering deterrence in the Indo-Pacific and shifting our entire global military posture to the Western Pacific, which would drain resources from Europe and Latin America. We have to assume this will happen.
This creates deep concern for our allies, but that matters for the U.S. too. The Germans will be wildly pissed about how they are described in the document. Asian allies are told to “do more,” a demand that ignores their significant recent efforts. Getting allies to increase defense contributions was an accomplishment of the first Trump administration that continued under Biden. The call to “do more” is now an outdated talking point — they are doing more. Japan is considering exporting weapons for the first time.
Justin McIntosh: Worse still, when allies make the kinds of statements the U.S. wants — like Sanae Takaichi declaring a PLA incursion into Taiwan a national security threat to Japan — the administration’s response is silence. Based on the reporting of Xi and Trump’s call, it appears the U.S. did not affirm that position. Instead of backing Japan’s strong stance, the message was to “calm it down.”
The Trump administration is sending mixed signals. Does it want allies to spend more on defense, develop a stronger defense mindset, and care more about their own security, or not?
Jordan Schneider: Let’s do some reading from the scripture here.
“A favorable conventional military balance remains an essential component of strategic competition. There is rightly much focus on Taiwan, partly because of Taiwan’s dominance of semiconductor production, but mostly because Taiwan provides direct access to the second island chain and splits Northeast and Southeast Asia into two distinct theaters. Hence, preventing a conflict over Taiwan, ideally by preserving military overmatch, is a priority. We will also maintain our long-standing declaratory policy on Taiwan, meaning that the United States did not support any unilateral changes to the status quo in the Taiwan Strait.”
From that, it sounds like a good idea for Japan to make its role in deterrence transparent. How seriously should we take any of these documents?
Tony Stark: I wish Eric were here for another briefcase-carrier rant. In the 2010s, a gripe of mine was hearing mainstream national security people, the ones in the know, say strategy documents don’t matter. That is a clear indicator they either haven’t written a good strategy document or haven’t marshalled the resources and people to execute it. I’ve occasionally had to metaphorically beat somebody over the head with a strategy document.
One problem is that people don’t read strategy documents. I have been in meetings with theater-level commands who’ve asked me, “What are you quoting from?” And my response is, “The National Defense Strategy.” They’ll ask me to send it to them. It’s a public document.
Justin McIntosh: “No, no, we meant the classified annex, Tony. Obviously, we’ve read the public one.”
Tony Stark: “The super-secret one that wasn’t even fully distributed to your command.”
Justin McIntosh: The document doesn’t matter, and there isn’t a robust national security apparatus anymore — at least in this administration — it’s as if the President is the sole decision-maker. Trump has consolidated his counsel — it’s a smaller group than it was.
Another problem is that the strategy document’s promises are often the opposite of what the president himself has done. The strategy specifically addresses deterring propaganda aimed at Americans, clearly referencing China, and yet TikTok is still legal here.
When X turned on a filter showing where accounts came from, it revealed so-called Mongolian accounts weren’t Mongolian, and supposed Uyghur accounts were run from mainland China. Pro-MAGA accounts were operated from VPNs in India and China to target Americans. Where was the action on that propaganda? We kept TikTok, and no one has suggested the government force X to shut down foreign influence accounts. These goals are in the document, but the follow-through is missing.
Tony Stark: Every administration struggles with inconsistencies between its strategy and actions. That’s the nature of a democracy — it’s the nature of any government worldwide. This strategy document’s main issue is its unusual use of national security language. The strategy says the administration opposes disinformation, but what do they consider disinformation? There are direct quotes that frame concepts like “de-radicalization” and “protecting our democracy” as a fake guise — that inclusion is wild.
On foreign policy, the document critiques the U.S. for focusing too much on projecting “liberal ideology” into Africa — it’s unclear if that means big ‘L’ or small ‘l’ liberal. Let’s assume it’s both. The most stunning part is that the National Security Strategy of the United States explicitly frames the concept of “protecting our democracy” as a ruse. That is insane.
The parts of a strategy document that truly matter are the ones that diverge from the previous strategies. While I’ve critiqued previous strategies, this document is on another level.
Justin McIntosh: The large section on China is a good example. It would be great if the administration enacted many of the listed actions — I’d be all for it. The cognitive dissonance between the strategy document and the administration’s actions is troubling.
Jordan Schneider: Six months ago, the AI action plan included interesting language about new export controls on semiconductor manufacturing equipment. Those controls are paused because Stephen Miller’s current job is to avoid upsetting China. This directive came after a Chinese official was angered by a Financial Times article on Alibaba and the PLA. Stephen Miller’s Twitter banner is a picture of him shaking hands with Xi. This is hard to square with official strategy documents demanding military overmatch.
You can try to connect those dots and argue that the goal is to keep the economic relationship calm while we re-industrialize and build up our military. Okay, maybe. But that still doesn’t explain the U.S NSS includes sovereignty language seemingly copied and pasted from Putin’s playbook.
Tony Stark: The document is also very undergraduate. That is not a critique of the accessible language — I also try to write for a wider audience — but of the concepts themselves. If an undergraduate at the University of Texas at Austin were assigned the paper topic — what should a national security strategy be — this would be that paper.
Jordan Schneider: There are 14 bullet points where each sentence is about seven words long.
Tony Stark: What does this all mean? The language in the National Security Strategy should not shock anyone — it’s consistent with the administration’s usual rhetoric. What has changed is that this language is now the official guidance — it has leverage in bureaucratic fights. The influence may not be immediate, but it will be cumulative. The real test will be when the National Defense Strategy comes out. Someone who worked on it texted me last night and said, “Well, they set the bar low, so this is great for us.”
Justin McIntosh: They’re being pragmatic. What troubled me was the traditionalist language at the end.
“Finally, we want the restoration and reinvigoration of American spiritual and cultural health, without which long-term security is impossible. We want an America that cherishes its past glories and its heroes, and that looks forward to a new golden age. We want a people who are proud, happy, and optimistic that they will leave their country to the next generation better than they found it. We want a gainfully employed citizenry—with no one sitting on the sidelines—who take satisfaction from knowing that their work is essential to the prosperity of our nation and to the well-being of individuals and families. This cannot be accomplished without growing numbers of strong, traditional families that raise healthy children.”
Tony Stark: “We will use every means to protect our precious bodily fluids.”
Jordan Schneider: Wait, if you’re raising a disabled child, or if your child is sick with a fever, then you are not contributing to the restoration of American cultural and spiritual health? Wow.
Tony Stark: That is what RFK Jr. said — if your kid is sick, that’s not a good societal contribution.
Justin McIntosh: His miasmas are off, or whatever non-germ-theory medicine he peddles but doesn’t practice.
Tony Stark: The Midi-chlorians from Star Wars.
Justin McIntosh: That language is reminiscent of what you see from Putin and China’s family planning policies. It is the exact type of language that Xi and Putin use to justify pro-natalist policies and promote traditional families and traditional gender roles. Reading about the one-child policy in Dan Wang’s Breakneck is heartbreaking if you have children. It’s striking how similar the NSS’s language is to China’s early discussion of the one-child policy.
Tony Stark: In a reasonable time, there would be ten articles asking, “What does this mean? How is the government going to encourage people to have more kids?” Now, it’s something I don’t even want to read about.
After COVID-19, as the “China Rising” narrative was gaining prominence in 2021 and 2022, discussions began in national security circles about how the U.S. population is numerically outmatched. Although we are solving that problem with robotics, it was a talking point among traditionalists. They argued that the U.S. won the Cold War by embracing traditional values. That’s not how we won. We won thanks to Skunk Works and the Soviet Union’s economic mismanagement.
This argument has surfaced before in national security circles — it’s not a new phenomenon. The other common concern is protecting our food supply — I’m surprised it was not mentioned in the document. But, to quote a former coworker of mine, “We have Buffalo Wild Wings and the Chinese don’t. I think we’re okay.”

Jordan Schneider: That would be a great cultural export. Maybe that’s what the world needs.
Tony Stark: Are there Buffalo Wild Wings locations in Shanghai or Beijing?
Justin McIntosh: I’m sure there’s one in Taipei. [Note from Lily: Taiwan does not have a Buffalo Wild Wings, but it does have three Hooters locations.]
Tony Stark: Is the food different, or is it universal?
Justin McIntosh: It’s universal, but like McDonald’s in Japan, it’s better.
Tony Stark: Another American cultural victory. We don’t need to change anything.
Justin McIntosh: You can watch a baseball game while eating Buffalo Wild Wings in downtown Taipei.
Tony Stark: During COVID, my former American University professor, Justin Jacobs, uploaded all his lectures on Spotify — excellent lectures on the history of China and Japan. He has an episode about why baseball is played in Taiwan but not on the mainland. He discusses the Japanese occupation of Taiwan and the differences in Confucian culture and masculinity. Prof. Jacobs is an amazing resource for East Asian history.
Jordan Schneider: I asked Gemini what other regimes this resembles. It suggested Vichy France, Fascist Italy, and modern Hungary.
Justin McIntosh: I wonder what Grok would say…
ChinaTalk is a reader-supported publication. To receive new posts and support our work, consider becoming a free or paid subscriber.























_025.png){kind=link}