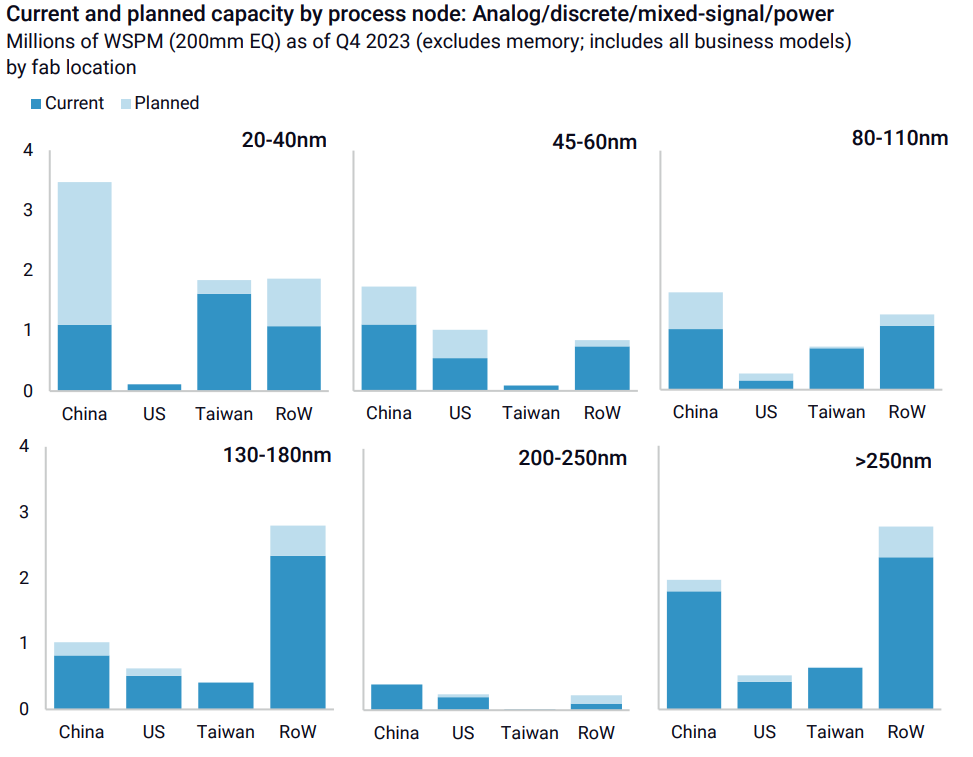
The Robotics Revolution
8VC is hosting a meetup for ChinaTalk this coming Thursday. Sign up here if you can make it!
Ryan Julian is a research scientist in embodied AI. He worked on large-scale robotics foundation models at DeepMind and got his PhD in machine learning in 2021.
In our conversation today, we discuss…
What makes a robot a robot, and what makes robotics so difficult,
The promise of robotic foundation models and strategies to overcome the data bottleneck,
Why full labor replacement is far less likely than human-robot synergy,
China’s top players in the robotic industry, and what sets them apart from American companies and research institutions,
How robots will impact manufacturing, and how quickly we can expect to see robotics take off.
Listen now on your favorite podcast app.

Embodying Intelligence
Jordan Schneider: Ryan, why should we care about robotics?
Ryan Julian: Robots represent the ultimate capital good. Just as power tools, washing machines, or automated factory equipment augment human labor, robots are designed to multiply human productivity. The hypothesis is straightforward — societies that master robotics will enjoy higher labor productivity and lower costs in sectors where robots are deployed, including in logistics, manufacturing, transportation, and beyond. Citizens in these societies will benefit from increased access to goods and services.
The implications become even more profound when we consider advanced robots capable of serving in domestic, office, and service sectors. These are traditionally areas that struggle with productivity growth. Instead of just robot vacuum cleaners, imagine robot house cleaners, robot home health aides, or automated auto mechanics. While these applications remain distant, they become less far-fetched each year.
Looking at broader societal trends, declining birth rates across the developed world present a critical challenge — How do we provide labor to societies with shrinking working-age populations? Robots could offer a viable solution.
From a geopolitical perspective, robots are dual-use technology. If they can make car production cheaper, they can also reduce the cost of weapon production. There’s also the direct military application of robots as weapons, which we’re already witnessing with drones in Ukraine. From a roboticist’s perspective, current military drones represent primitive applications of robotics and AI. Companies developing more intelligent robotic weapons using state-of-the-art robotics could have enormous implications, though this isn’t my area of expertise.
Fundamentally, robots are labor-saving machines, similar to ATMs or large language models. The key differences lie in their degree of sophistication and physicality. When we call something a robot, we’re describing a machine capable of automating physical tasks previously thought impossible to automate — tasks requiring meaningful and somewhat general sensing, reasoning, and interaction with the real world.
This intelligence requirement distinguishes robots from simple machines. Waymo vehicles and Roombas are robots, but dishwashers are appliances. This distinction explains why robotics is so exciting — we’re bringing labor-saving productivity gains to economic sectors previously thought untouchable.
Jordan Schneider: We’re beginning to understand the vision of unlimited intelligence — white-collar jobs can be potentially automated because anything done on a computer might eventually be handled better, faster, and smarter by future AI systems. But robotics extends this to the physical world, requiring both brain power and physical manipulation capabilities. It’s not just automated repetitive processes, but tasks requiring genuine intelligence combined with physical dexterity.
Ryan Julian: Exactly. You need sensing, reasoning, and interaction with the world in truly non-trivial ways that require intelligence. That’s what defines an intelligent robot.
I can flip your observation — robots are becoming the physical embodiment of the advanced AI you mentioned. Current large language models and vision-language models can perform incredible digital automation — analyzing thousands of PDFs or explaining how to bake a perfect cake. But that same model cannot actually bake the cake. It lacks arms, cannot interact with the world, and doesn’t see the real world in real time.
However, if you embed that transformer-based intelligence into a machine capable of sensing and interacting with the physical world, then that intelligence could affect not just digital content but the physical world itself. The same conversations about how AI might transform legal or other white-collar professions could equally apply to physical labor.
Today’s post is brought to you by 80,000 Hours, a nonprofit that helps people find fulfilling careers that do good. 80,000 Hours — named for the average length of a career — has been doing in-depth research on AI issues for over a decade, producing reports on how the US and China can manage existential risk, scenarios for potential AI catastrophe, and examining the concrete steps you can take to help ensure AI development goes well.
Their research suggests that working to reduce risks from advanced AI could be one of the most impactful ways to make a positive difference in the world.
They provide free resources to help you contribute, including:
Detailed career reviews for paths like AI safety technical research, AI governance, information security, and AI hardware,
A job board with hundreds of high-impact opportunities,
A podcast featuring deep conversations with experts like Carl Shulman, Ajeya Cotra, and Tom Davidson,
Free, one-on-one career advising to help you find your best fit.
To learn more and access their research-backed career guides, visit 80000hours.org/ChinaTalk.
To read their report about AI coordination between the US and China, visit http://80000hours.org/chinatalkcoord.
Jordan Schneider: Ryan, why is robotics so challenging?
Ryan Julian: Several factors make robotics exceptionally difficult. First, physics is unforgiving. Any robot must exist in and correctly interpret the physical world’s incredible variation. Consider a robot designed to work in any home — it needs to understand not just the visual aspects of every home worldwide, but also the physical properties. There are countless doorknob designs globally, and the robot must know how to operate each one.
The physical world also differs fundamentally from the digital realm. Digital systems are almost entirely reversible unless intentionally designed otherwise. You can undo edits in Microsoft Word, but when a robot knocks a cup off a table and cannot retrieve it, it has made an irreversible change to the world. This makes robot failures potentially catastrophic. Anyone with a robot vacuum has experienced it consuming a cable and requiring rescue — that’s an irreversible failure.
The technological maturity gap presents another major challenge. Systems like ChatGPT, Gemini, or DeepSeek process purely digital inputs — text, images, audio. They benefit from centuries of technological development that we take for granted — monitors, cameras, microphones, and our ability to digitize the physical world.
Today’s roboticist faces a vastly more complex challenge. While AI systems process existing digital representations of the physical world, roboticists must start from scratch. It’s as if you wanted to create ChatGPT but first had to build CPUs, wind speakers, microphones, and digital cameras.
Robotics is just emerging from this foundational period, where we’re creating hardware capable of converting physical world perception into processable data. We also face the reverse challenge — translating digital intent into physical motion, action, touch, and movement in the real world. Only now is robotics hardware reaching the point where building relatively capable systems for these dual processes is both possible and economical.
Jordan Schneider: Let’s explore the brain versus body distinction in robotics — the perception and decision-making systems versus the physical mechanics of grasping, moving, and locomotion. How do these two technological tracks interact with each other? From a historical perspective, which one has been leading and which has been lagging over the past few decades?
Ryan Julian: Robotics is a fairly old field within computing. Depending on who you ask, the first robotics researchers were probably Harry Nyquist and Norbert Wiener. These researchers were interested in cybernetics in the 1950s and 60s.

Back then, cybernetics, artificial intelligence, information theory, and control theory were all one unified field of study. These disciplines eventually branched off into separate domains. Control theory evolved to enable sophisticated systems like state-of-the-art fighter plane controls. Information theory developed into data mining, databases, and the big data processing that powers companies like Google and Oracle — essentially Web 1.0 and Web 2.0 infrastructure.
Artificial intelligence famously went into the desert. It had a major revolution in the 1980s, then experienced the great AI winter from the 80s through the late 90s, before the deep learning revolution emerged. The last child of this original unified field was cybernetics, which eventually became robotics.
The original agenda was ambitious — create thinking machines that could fully supplant human existence, human thought, and human labor — that is, true artificial intelligence. The founding premise was that these computers would need physical bodies to exist in the real world.
Robotics as a field of study is now about 75 years old. From its origins through approximately 2010-2015, enormous effort was devoted to creating robotic hardware systems that could reliably interact with the physical world with sufficient power and dexterity. The fundamental questions were basic but challenging — Do we have motors powerful enough for the task? Can we assemble them in a way that enables walking?
A major milestone was the MIT Cheetah project, led by Sangbae Kim around 2008-2012. This project had two significant impacts — it established the four-legged form factor now seen in Unitree’s quadrupedal robots and Boston Dynamics’ systems, and it advanced motor technology that defines how we build motors for modern robots.
Beyond the physical components, robots require sophisticated sensing capabilities. They need to capture visual information about the world and understand three-dimensional space. Self-driving cars drove significant investment in 3D sensing technology like LiDAR, advancing our ability to perceive spatial environments.
Each of these technological components traditionally required substantial development time. Engineers had to solve fundamental questions — Can we capture high-quality images? What resolution is possible? Can we accurately sense the world’s shape and the robot’s own body position? These challenges demanded breakthroughs in electrical engineering and sensor technology.
Once you have a machine with multiple sensors and actuators, particularly sensors that generate massive amounts of data, you need robust data processing capabilities. This requires substantial onboard computation to transform physical signals into actionable information and generate appropriate motion responses — all while the machine is moving.
This is where robotics historically faced limitations. Until recently, robotics remained a fairly niche field that hadn’t attracted the massive capital investment seen in areas like self-driving cars. Robotics researchers often had to ride the waves of technological innovation happening in other industries.
A perfect example is robotic motors. A breakthrough came from cheap brushless motors originally developed for electric skateboards and power drills. With minor modifications, these motors proved excellent for robotics applications. The high-volume production for consumer applications dramatically reduced costs for robotics.
The same pattern applies to computation. Moore’s Law and GPU development have been crucial for robotics advancement. Today, robots are becoming more capable because we can pack enormous computational power into small, battery-powered packages. This enables real-time processing of cameras, LiDAR, joint sensors, proprioception, and other critical systems — performing most essential computation onboard the robot itself.
Jordan Schneider: Why does computation need to happen on the robot itself? I mean, you could theoretically have something like Elon’s approach where you have a bartender who’s actually just a robot being controlled remotely from India. That doesn’t really count as true robotics though, right?
Ryan Julian: This is a fascinating debate and trade-off that people in the field are actively grappling with right now. Certain computations absolutely need to happen on the robot for physical reasons. The key framework for thinking about this is timing — specifically, what deadlines a robot faces when making decisions.
If you have a walking robot that needs to decide where to place its foot in the next 10 milliseconds, there’s simply no time to send a query to a cloud server and wait for a response. That sensing, computation, and action must all happen within the robot because the time constraints are so tight.
The critical boundary question becomes: what’s the timescale at which off-robot computation becomes feasible? This is something that many folks working on robotics foundation models are wrestling with right now. The answer isn’t entirely clear and depends on internet connection quality, but the threshold appears to be around one second.
If you have one second to make a decision, it’s probably feasible to query a cloud system. But if you need to make a decision in less than one second — certainly less than 100 milliseconds — then that computation must happen on-board. This applies to fundamental robot movements and safety decisions. You can’t rely on an unreliable internet connection when you need to keep the robot safe and prevent it from harming itself or others.
Large portions of the robot’s fundamental motion and movement decisions must stay local. However, people are experimenting with cloud-based computation for higher-level reasoning. For instance, if you want your robot to bake a cake or pack one item from each of ten different bins, it might be acceptable for the robot to query DeepSeek or ChatGPT to break that command down into executable steps. Even if the robot gets stuck, it could call for help at this level — but it can’t afford to ask a remote server where to place its foot.
One crucial consideration for commercial deployment is that we technologists and software engineers love to think of the internet as ubiquitous, always available, and perfectly reliable. But when you deploy real systems — whether self-driving cars, factory robots, or future home robots — there will always be places and times where internet access drops out.
Given the irreversibility we discussed earlier, it’s essential that when connectivity fails, the robot doesn’t need to maintain 100% functionality for every possible feature, but it must remain safe and be able to return to a state where it can become useful again once connectivity is restored.
Jordan Schneider: You mentioned wanting robots to be safe, but there are other actors who want robots to be dangerous. This flips everything on its head in the drone context. It’s not just that Verizon has poor coverage — it’s that Russia might be directing electronic warfare at you, actively trying to break that connection.
This creates interesting questions about the balance between pressing go on twenty drones and letting them figure things out autonomously versus having humans provide dynamic guidance — orienting left or right, adjusting to circumstances. There are both upsides and downsides to having robots make these decisions independently.
Ryan Julian: Exactly right. The more autonomy you demand, the more the difficulty scales exponentially from an intelligence perspective. This is why Waymos are Level 4 self-driving cars rather than Level 5 — because Level 5 represents such a high bar. Yet you can provide incredibly useful service with positive unit economics and game-changing safety improvements with just a little bit of human assistance.
Jordan Schneider: What role do humans play in Waymo operations?
Ryan Julian: I don’t have insider information on this, but my understanding is that when a Waymo encounters trouble — when it identifies circumstances where it doesn’t know how to navigate out of a space or determine where to go next — it’s programmed to pull over at the nearest safe location. The on-board system handles finding a safe place to stop.
Then the vehicle calls home over 5G or cellular connection to Waymo’s central support center. I don’t believe humans drive the car directly because of the real-time constraints we discussed earlier — the same timing limitations that apply to robot movement also apply to cars. However, humans can provide the vehicle with high-level instructions about where it should drive and what it should do next at a high level.
Jordan Schneider: We have a sense of the possibilities and challenges — the different technological trees you have to climb. What is everyone in the field excited about? Why is there so much money and energy being poured into this space over the past few years to unlock this future?
Ryan Julian: People are excited because there’s been a fundamental shift in how we build software for robots. I mentioned that the hardware is becoming fairly mature, but even with good hardware, we previously built robots as single-purpose machines. You would either buy robot hardware off the shelf or build it yourself, but then programming the robot required employing a room full of brilliant PhDs to write highly specialized robotic software for your specific problem.
These problems were usually not very general — things like moving parts from one belt to another. Even much more advanced systems that were state-of-the-art from 2017 through 2021, like Amazon’s logistics robots, were designed to pick anything off a belt and put it into a box, or pick anything off a shelf. The only variations were where the object is located, how I position my gripper around it, what shape it is, and where I move it.
From a human perspective, that’s very low variation — this is the lowest of low-skilled work. But even handling this level of variation required centuries of collective engineering work to accomplish with robots.

Now everyone’s excited because we’re seeing a fundamental change in how we program robots. Rather than writing specific applications for every tiny task — which obviously doesn’t scale and puts a very low ceiling on what’s economical to automate — we’re seeing robotics follow the same path as software and AI. Programming robots is transforming from an engineering problem into a data and AI problem. That’s embodied AI. That’s what robot learning represents.
The idea is that groups of people develop robot learning software — embodied AI systems primarily composed of components you’re already familiar with from the large language model and vision-language model world. Think large transformer models, data processing pipelines, and related infrastructure, plus some robot-specific additions. You build this foundation once.
Then, when you want to automate a new application, rather than hiring a big team to build a highly specialized robot system and hope it works, you simply collect data on your new application and provide it to the embodied AI system. The system learns to perform the new task based on that data.
This would be exciting enough if it worked for just one task. But we’re living in the era of LLMs and VLMs — systems that demonstrate something remarkable. When you train one system to handle thousands of purely digital tasks — summarizing books, writing poems, solving math problems, writing show notes — you get what we call a foundation model.
When you want that foundation model to tackle a new task in the digital world, you can often give it just a little bit of data, or sometimes no data at all — just a prompt describing what you want. Because the system has extensive experience across many different tasks, it can relate its existing training to the new task and accomplish it with very little additional effort. You’re automating something previously not automated with minimal effort.
The hope for robotics foundation models is achieving the same effect with robots in the physical world. If we can create a model trained on many different robotic tasks across potentially many different robots — there’s debate in the field about this — we could create the GPT of robotics, the DeepSeek of robotics.
Imagine a robot that already knows how to make coffee, sort things in a warehouse, and clean up after your kids. You ask it to assemble a piece of IKEA furniture it’s never seen before. It might look through the manual and then put the furniture together. That’s probably a fantastical vision — maybe 10 to 20 years out, though we’ll see.
But consider a softer version: a business that wants to deploy robots only needs to apprentice those robots through one week to one month of data collection, then has a reliable automation system for that business task. This could be incredibly disruptive to the cost of introducing automation across many different spaces and sectors.
That’s why people are excited. We want the foundation model for robotics because it may unlock the ability to deploy robots in many places where they’re currently impossible to use because they’re not capable enough, or where deployment is technically possible but not economical.
Jordan Schneider: Is all the excitement on the intelligence side? Are batteries basically there? Is the cost structure for building robots basically there, or are there favorable curves we’re riding on those dimensions as well?
Ryan Julian: There’s incredible excitement in the hardware world too. I mentioned earlier that robotics history, particularly robotics hardware, has been riding the wave of other industries funding the hard tech innovations necessary to make robots economical. This remains true today.
You see a huge boom in humanoid robot companies today for several reasons. I gave you this vision of robotics foundation models and general-purpose robot brains. To fully realize that vision, you still need the robot body. It doesn’t help to have a general-purpose robot brain without a general-purpose robot body — at least from the perspective of folks building humanoids.
Humanoid robots are popular today as a deep tech concept because pairing them with a general-purpose brain creates a general-purpose labor-saving machine. This entire chain of companies is riding tremendous progress in multiple areas.
Battery technology has become denser, higher power, and cheaper. Actuator technology — motors — has become more powerful and less expensive. Speed reducers, the gearing at the end of motors or integrated into them, traditionally represented very expensive components in any machine using electric motors. But there’s been significant progress making these speed reducers high-precision and much cheaper.
Sensing has become dramatically cheaper. Camera sensors that used to cost hundreds of dollars are now the same sensors in your iPhone, costing two to five dollars. That’s among the most expensive components you can imagine, yet it’s now totally economical to place them all over a robot.
Computation costs have plummeted. The GPUs in a modern robot might be worth a couple hundred dollars, which represents an unimaginably low cost for the available computational power.
Robot bodies are riding this wave of improving technologies across the broader economy — all dual-use technologies that can be integrated into robots. This explains why Tesla’s Optimus humanoid program makes sense: much of the hardware in those robots is already being developed for other parts of Tesla’s business. But this pattern extends across the entire technology economy.
Jordan Schneider: Ryan, what do you want to tell Washington? Do you have policy asks to help create a flourishing robotics ecosystem in the 21st century?
Ryan Julian: My policy ask would be for policymakers and those who inform them to really learn about the technology before worrying too much about the implications for labor. There are definitely implications for labor, and there are also implications for the military. However, the history of technology shows that most new technologies are labor-multiplying and labor-assisting. There are very few instances of pure labor replacement.
I worry that if a labor replacement narrative takes hold in this space, it could really hold back the West and the entire field. As of today, a labor replacement narrative isn’t grounded in reality.
The level of autonomy and technology required to create complete labor replacement in any of the job categories we’ve discussed is incredibly high and very far off. It’s completely theoretical at this point.
My ask is, educate yourself and think about a world where we have incredibly useful tools that make people who are already working in jobs far more productive and safer.
China’s Edge and the Data Flywheel
Jordan Schneider: On the different dimensions you outlined, what are the comparative strengths and advantages of China and the ecosystem outside China?
Ryan Julian: I’m going to separate this comparison between research and industry, because there are interesting aspects on both sides. The short version is that robotics research in China is becoming very similar to the West in quality.
Let me share an anecdote. I started my PhD in 2017, and a big part of being a PhD student — and later a research scientist — is consuming tons of research: reams of dense 20-page PDFs packed with information. You become very good at triaging what’s worth your time and what’s not. You develop heuristics for what deserves your attention, what to throw away, what to skim, and what to read deeply.
Between 2017 and 2021, a reliable heuristic was that if a robotics or AI paper came from a Chinese lab, it probably wasn’t worth your time. It might be derivative, irrelevant, or lacking novelty. In some cases, it was plainly plagiarized. This wasn’t true for everything, but during that period it was a pretty good rule of thumb.
Over the last two years, I’ve had to update my priorities completely. The robotics and AI work coming out of China improves every day. The overall caliber still isn’t quite as high as the US, EU, and other Western institutions, but the best work in China — particularly in AI and my specialization in robotics — is rapidly catching up.
Today, when I see a robotics paper from China, I make sure to read the title and abstract carefully. A good portion of the time, I save it because I need to read it thoroughly. In a couple of years, the median quality may be the same. We can discuss the trends driving this — talent returning to China, people staying rather than coming to the US, government support — but it’s all coming together to create a robust ecosystem.
Moving from research to industry, there’s an interesting contrast. Due to industry culture in China, along with government incentives and the way funding works from provinces and VC funds, the Chinese robotics industry tends to focus on hardware and scale. They emphasize physical robot production.

When I talk to Chinese robotics companies, there’s always a story about deploying intelligent AI into real-world settings. However, they typically judge success by the quantity of robots produced — a straightforward industrial definition of success. This contrasts with US companies, which usually focus on creating breakthroughs and products that nobody else could create, where the real value lies in data, software, and AI.
Chinese robotics companies do want that data, software, and AI capabilities. But it’s clear that their business model is fundamentally built around selling robots. Therefore, they focus on making robot hardware cheaper and more advanced, producing them at scale, accessing the best components, and getting them into customers’ hands. They partner with upstream or downstream companies to handle the intelligence work, creating high-volume robot sales channels.
Take Unitree as a case study — a darling of the industry that’s been covered on your channel. Unitree has excelled at this approach. Wang Xingxing and his team essentially took the open-source design for the MIT Cheetah quadruped robot and perfected it. They refined the design, made it production-ready, and likely innovated extensively on the actuators and robot morphology. Most importantly, they transformed something you could build in a research lab at low scale into something manufacturable on production lines in Shenzhen or Shanghai.
They sold these robots to anyone willing to buy, which seemed questionable at the time — around 2016 — because there wasn’t really a market for robots. Now they’re the go-to player if you want to buy off-the-shelf robots. What do they highlight in their marketing materials? Volume, advanced actuators, and superior robot bodies.
This creates an interesting duality in the industry. Most American robotics companies — even those that are vertically integrated and produce their own robots — see the core value they’re creating as intelligence or the service they deliver to end customers. They’re either trying to deliver intelligence as a service (like models, foundation models, or ChatGPT-style queryable systems where you can pay for model training) or they’re pursuing fully vertical solutions where they deploy robots to perform labor, with value measured in hours of replaced work.
On the Chinese side, companies focus on producing exceptionally good robots.
Jordan Schneider: I’ve picked up pessimistic energy from several Western robotics efforts — a sense that China already has this in the bag. Where is that coming from, Ryan?
Ryan Julian: That’s a good question. If you view AI as a race between the US and China — a winner-take-all competition — and you’re pessimistic about the United States’ or the West’s ability to maintain an edge in intelligence, then I can see how you’d become very pessimistic about the West’s ability to maintain an edge in robotics.
As we discussed, a fully deployed robot is essentially a combination of software, AI (intelligence), and a machine. The challenging components to produce are the intelligence and the machine itself. The United States and the West aren’t particularly strong at manufacturing. They excel at design but struggle to manufacture advanced machines cheaply. They can build advanced machines, but not cost-effectively.
If you project this forward to a world where millions of robots are being produced — where the marginal cost of each robot becomes critical and intelligence essentially becomes free — then I can understand why someone would believe the country capable of producing the most advanced physical robot hardware fastest and at the lowest cost would have a huge advantage.
If you believe there’s no sustainable edge in intelligence — that intelligence will eventually have zero marginal cost and become essentially free — then you face a significant problem. That’s where the pessimism originates.
Jordan Schneider: Alright, we detoured but we’re coming back to this idea of a foundation model unlocking the future. We haven’t reached the levels of excitement for robotics that we saw in October 2022 for ChatGPT. What do we need? What’s on the roadmap? What are the key inputs?
Ryan Julian: To build a great, intelligent, general-purpose robot, you need the physical robot itself. We’ve talked extensively about how robotics is riding the wave of advancements elsewhere in the tech tree, making it easier to build these robots. Of course, it’s not quite finished yet. There are excellent companies — Boston Dynamics, 1X, Figure, and many others who might be upset if I don’t mention them, plus companies like Apptronik and Unitree — all working to build great robots. But that’s fundamentally an engineering problem, and we can apply the standard playbook of scale, cost reduction, and engineering to make them better.
The key unlock, assuming we have the robot bodies, is the robot brains. We already have a method for creating robot brains — you put a bunch of PhDs in a room and they toil for years creating a fairly limited, single-purpose robot. But that approach doesn’t scale.
To achieve meaningful impact on productivity, we need a robot brain that learns and can quickly learn new tasks. This is why people are excited about robotics foundation models.
How do we create a robotics foundation model? That’s the crucial question. Everything I’m about to say is hypothetical because we haven’t created one yet, but the current thinking is that creating a robotics foundation model shouldn’t be fundamentally different from creating a purely digital foundation model. The strategy is training larger and larger models.
However, the model can’t just be large for its own sake. To train a large model effectively, you need massive amounts of data — data proportionate to the model’s size. In large language models, there appears to be a magical threshold between 5 and 7 billion parameters where intelligence begins to emerge. That’s when you start seeing GPT-2 and GPT-3 behavior. We don’t know what that number is for robotics, but those parameters imply a certain data requirement.
What do we need to create a robotics foundation model? We need vast amounts of diverse data showing robots performing many useful tasks, preferably as much as possible in real-world scenarios. In other words, we need data and diversity at scale.
This is the biggest problem for embodied AI. How does ChatGPT get its data? How do Claude or Gemini get theirs? Some they purchase, especially recently, but first they ingest essentially the entire internet — billions of images and billions of sentences of text. Most of this content is free or available for download at low cost. While they do buy valuable data, the scale of their purchases is much smaller than the massive, unstructured ingestion of internet information.
There’s no internet of robot data. Frontier models train on billions of image-text pairs, while today’s robotics foundation models with the most data train on tens of thousands of examples — requiring herculean efforts from dozens or hundreds of people.
This creates a major chicken-and-egg problem. If we had this robotics foundation model, it would be practical and economical to deploy robots in various settings, have them learn on the fly, and collect data. In robotics and AI, we call this the data flywheel: you deploy systems in the world, those systems generate data through operation, you use that data to improve your system, which gives you a better system that you can deploy more widely, generating more data and continuous improvement.
We want to spin up this flywheel, but you need to start with a system good enough to justify its existence in the world. This is robotics’ fundamental quandary.
I want to add an important note about scale. Everyone talks about big data and getting as much data as possible, but a consistent finding for both purely digital foundation models and robotics foundation models is that diversity is far more important than scale. If you give me millions of pairs of identical text or millions of demonstrations of a robot doing exactly the same thing in exactly the same place, that won’t help my system learn.
The system needs to see not only lots of data, but data covering many different scenarios. This creates another economic challenge, because while you might consider the economics of deploying 100 robots in a space to perform tasks like package picking...
Jordan Schneider: Right, if we have a robot that can fold laundry, then it can fold laundry. But will folding laundry teach it how to assemble IKEA furniture? Probably not, right?
Ryan Julian: Exactly. Economics favor scale, but we want the opposite — a few examples of many different things. This is the most expensive possible way to organize data collection.
Jordan Schneider: I have a one-year-old, and watching her build up her physics brain — understanding the different properties of things and watching her fall in various ways, but never the same way twice — has been fascinating. If you put a new object in front of her, for instance, we have a Peloton and she fell once because she put her weight on the Peloton wheel, which moved. She has never done that again.
Ryan Julian: I’m sure she’s a genius.
Jordan Schneider: Human beings are amazing. They’re really good at learning. The ability to acquire language, for example — because robots can’t do it yet. Maybe because we have ChatGPT, figuring out speech seems less of a marvel now, but the fact that evolution and our neurons enable this, particularly because you come into the world not understanding everything... watching the data ingestion happen in real time has been a real treat. Do people study toddlers for this kind of research?
Ryan Julian: Absolutely. In robot learning research, the junior professor who just had their first kid and now bases all their lectures on watching how their child learns is such a common trope. It’s not just you — but we can genuinely learn from this observation.
First, children aren’t purely blank slates. They do know some things about the world. More importantly, kids are always learning. You might think, “My kid’s only one or two years old,” but imagine one or two years of continuous, waking, HD stereo video with complete information about where your body is in space. You’re listening to your parents speak words, watching parents and other people do things, observing how the world behaves.
This was the inspiration for why, up through about 2022, myself and other researchers were fascinated with using reinforcement learning to teach robots. Reinforcement learning is a set of machine learning tools that allows machines, AIs, and robots to learn through trial and error, much like you described with your one-year-old.
What’s been popular for the last few years has been a turn toward imitation learning, which essentially means showing the robot different ways of doing things repeatedly. Imitation learning has gained favor because of the chicken-and-egg problem: if you’re not very good at tasks, most of what you try and experience won’t teach you much.
If you’re a one-year-old bumbling around the world, that’s acceptable because you have 18, 20, or 30 years to figure things out. I’m 35 and still learning new things. But we have very high expectations for robots to be immediately competent. Additionally, it’s expensive, dangerous, and difficult to allow a robot to flail around the world, breaking things, people, and itself while doing reinforcement learning in real environments. It’s simply not practical.
Having humans demonstrate tasks for robots is somewhat more practical than pure reinforcement learning. But this all comes down to solving the chicken-and-egg problem I mentioned, and nobody really knows the complete solution.
There are several approaches we can take. First, we don’t necessarily have to start from scratch. Some recent exciting results that have generated significant enthusiasm came from teams I’ve worked with, my collaborators, and other labs. We demonstrated that if we start with a state-of-the-art vision-language model and teach it robotics tasks, it can transfer knowledge from the purely digital world — like knowing “What’s the flag of Germany?” — and apply it to robotics.
Imagine you give one of these models data showing how to pick and place objects: picking things off tables, moving them to other locations, putting them down. But suppose it’s never seen a flag before, or specifically the flag of Germany, and it’s never seen a dinosaur, but it has picked up objects of similar size. You can say, “Please pick up the dinosaur and place it on the flag of Germany.” Neither the dinosaur nor the German flag were in your robotics training data, but they were part of the vision-language model’s training.
My collaborators and I, along with other researchers, showed that the system can identify “This is a dinosaur” and use its previous experience picking up objects to grab that toy dinosaur, then move it to the flag on the table that it recognizes as Germany’s flag.
One tactic — don’t start with a blank slate. Begin with something that already has knowledge.
Another approach — and this explains all those impressive dancing videos you see from China, with robots running and performing acrobatics — involves training robots in simulation using reinforcement learning, provided the physical complexity isn’t too demanding. For tasks like walking (I know I say “just” walking, but it’s actually quite complex) or general body movement, it turns out we can model the physics reasonably well on computers. We can do 99% of the training in simulation, then have robots performing those cool dance routines.
We might be able to extend this framework to much more challenging physical tasks like pouring tea, manipulating objects, and assembling things. Those physical interactions are far more complex, but you could imagine extending the simulation approach.
Jordan Schneider: Or navigating around Bakhmut or something.
Ryan Julian: Exactly, right. The second approach uses simulation. A third tactic involves getting data from sources that aren’t robots but are similar. This has been a persistent goal in robot learning for years — everyone wants robots to learn from watching YouTube videos.
There are numerous difficult challenges in achieving this, but the basic idea is extracting task information from existing video data, either from a first-person perspective (looking through the human’s eyes) or third-person perspective (watching a human perform tasks). We already have extensive video footage of people doing things.
What I’ve described represents state-of-the-art frontier research. Nobody knows exactly how to accomplish it, but these are some of our hopes. The research community tends to split into camps and companies around which strategy will ultimately succeed.
Then there’s always the “throw a giant pile of money at the problem” strategy, which represents the current gold standard. What we know works right now — and what many people are increasingly willing to fund — is building hundreds or even thousands of robots, deploying them in real environments like factories, laundries, logistics centers, and restaurants. You pay people to remotely control these robots to perform desired tasks, collect that data, and use it to train your robotics foundation model.
The hope is that you don’t run out of money before reaching that magic knee in the curve — the critical threshold we see in every other foundation model where the model becomes large enough and the data becomes sufficiently big and diverse that we suddenly have a model that learns very quickly.
There’s a whole arms race around how to deploy capital quickly enough and in the right way to find the inflection point in that curve.
Jordan Schneider: Is Waymo an example of throwing enough money at the problem to get to the solution?
Ryan Julian: Great example.
Jordan Schneider: How do we categorize that?
Ryan Julian: Waymo and other self-driving cars give people faith that this approach might work. When you step into a Waymo today, you’re being driven by what is, at its core, a robotics foundation model. There’s a single model where camera, lidar, and other sensor information from the car comes in, gets tokenized, decisions are made about what to do next, and actions emerge telling the car where to move.
That’s not the complete story. There are layers upon layers of safety systems, decision-making processes, and other checks and balances within Waymo to ensure the output is sound and won’t harm anyone. But the core process remains: collect data on the task (in this case, moving around a city in a car), use it to train a model, then use that model to produce the information you need.
Self-driving cars have been a long journey, but their success using this technique gives people significant confidence in the approach.
Let me temper your enthusiasm a bit. There’s hope, but here’s why it’s challenging. From a robotics perspective, a self-driving car is absolutely a robot. However, from that same perspective, a self-driving car has an extremely simple job — it performs only one task.
The job of a self-driving car is to transport you, Jordan, and perhaps your companions from point A to point B in a city according to a fairly limited set of traffic rules, on a relatively predictable route. The roads aren’t completely predictable, but they follow consistent patterns. The car must accomplish this without touching anything. That’s it — get from point A to point B without making contact with anything.
The general-purpose robots we’re discussing here derive their value from performing thousands of tasks, or at least hundreds, without requiring extensive training data for each one. This represents one axis of difficulty: we must handle many different tasks rather than just one.
The other challenge is that “don’t touch anything” requirement, which is incredibly convenient because every car drives essentially the same way from a physics perspective.
Jordan Schneider: Other drivers are trying to avoid you — they’re on your side and attempting to avoid collisions.
Ryan Julian: Exactly — just don’t touch anything. Whatever you do, don’t make contact. As soon as you start touching objects, the physics become far more complicated, making it much more difficult for machines to decide what to do.
The usefulness of a general-purpose robot lies in its ability to interact with objects. Unless it’s going to roam around your house or business, providing motivation and telling jokes, it needs to manipulate things to be valuable.
These are the two major leaps we need to make from the self-driving car era to the general robotics era — handling many different tasks and physically interacting with the world.
Jordan Schneider: Who are the companies in China and the rest of the world that folks should be paying attention to?
Ryan Julian: The Chinese space is gigantic, so I can only name a few companies. There are great online resources if you search for “Chinese robotics ecosystem."
In the West, particularly the US, I would divide the companies really pushing this space into two camps.
The first camp consists of hardware-forward companies that think about building and deploying robots. These tend to be vertically integrated. I call them “vertical-ish” because almost all want to build their own embodied AI, but they approach it from a “build the whole robot, integrate the AI, deploy the robot” perspective.
In this category, you have Figure AI, a vertical humanoid robot builder that also develops its own intelligence. There’s 1X Technologies, which focuses on home robots, at least currently. Boston Dynamics is the famous first mover in the space, focusing on heavy industrial robots with the Atlas platform. Apptronik has partnered with Google DeepMind and focuses on light industrial logistics applications.
Tesla Optimus is probably the most well-known entry in the space, with lots of rhetoric from Elon about how many robots they’ll make, where they’ll deploy them, and how they’ll be in homes. But it’s clear that Tesla’s first value-add will be helping automate Tesla factories. Much of the capital and many prospective customers in this space are actually automakers looking to create better automation for their future workforce.
Apple is also moving into the space with a very early effort to build humanoid robots.
The second camp focuses on robotics foundation models and software. These tend to be “horizontal-ish” — some may have bets on making their own hardware, but their core focus is foundation model AI.
My former employer, Google DeepMind, has a robotics group working on Gemini Robotics. NVIDIA also has a group doing this work, which helps them sell chips.
Among startups, there’s Physical Intelligence, founded by several of my former colleagues at Google DeepMind and based in San Francisco. Skild AI features some CMU researchers. Generalist AI includes some of my former colleagues. I recently learned that Mistral has a robotics group.
A few other notable Western companies — there’s DYNA, which is looking to automate small tasks as quickly as possible. They’re essentially saying, “You’re all getting too complicated — let’s just fold napkins, make sandwiches, and handle other simple tasks.”
There are also groups your audience should be aware of, though we don’t know exactly what they’re doing. Meta and OpenAI certainly have embodied AI efforts that are rapidly growing, but nobody knows their exact plans.
In China, partly because of the trends we discussed and due to significant funding and government encouragement (including Made in China 2025), there’s been an explosion of companies seeking to make humanoid robots specifically.
The most well-known is Unitree with their H1 and G1 robots. But there are also companies like Fourier Intelligence, AgiBot, RobotEra, UBTECH, EngineAI, and Astribot. There’s a whole ecosystem of Chinese companies trying to make excellent humanoid robots, leveraging the Shenzhen and Shanghai-centered manufacturing base and incredible supply chain to produce the hardware.
When Robots Learn
Jordan Schneider: How do people in the field of robotics discuss timelines?
Ryan Julian: It’s as diverse as any other field. Some people are really optimistic, while others are more pessimistic. Generally, it’s correlated with age or time in the field. But I know the question you’re asking: when is it coming?
Let’s ground this discussion quickly. What do robots do today? They sit in factories and do the same thing over and over again with very little variation. They might sort some packages, which requires slightly more variation. Slightly more intelligent robots rove around and inspect facilities — though they don’t touch anything, they just take pictures. Then we have consumer robots. What’s the most famous consumer robot? The Roomba. It has to move around your house in 2D and vacuum things while hopefully not smearing dog poop everywhere.
That’s robots today. What’s happening now and what we’ll see in the next three to five years falls into what I call a bucket of possibilities with current technology. There are no giant technological blockers, but it may not yet be proven economical. We’re still in pilot phases, trying to figure out how to turn this into a product.
The first place you’re going to see more general-purpose robots — maybe in humanoid form factors, maybe slightly less humanoid with wheels and arms — is in logistics, material handling, and light manufacturing roles. For instance, machine tending involves taking a part, placing it into a machine, pressing a button, letting the machine do its thing, then opening the machine and pulling the part out. You may also see some retail and hospitality back-of-house applications.
What I’m talking about here is anywhere a lot of stuff needs to be moved, organized, boxed, unboxed, or sorted. This is an easy problem, but it’s a surprisingly large part of the economy and pops up pretty much everywhere. Half or more of the labor activity in an auto plant is logistics and material feed. This involves stuff getting delivered to the auto plant, moved to the right place, and ending up at a production line where someone picks it up and places it on a new car.
More than half of car manufacturing involves this process, and it’s actually getting worse because people really want customized cars these days. Customizations are where all the profit margin is. Instead of Model T’s running down the line where every car is exactly the same, every car running down the line now requires a different set of parts. A ton of labor goes into organizing and kitting the parts for each car and making sure they end up with the right vehicle.
Ten to twelve percent of the world economy is logistics. Another fifteen to twenty percent is manufacturing. This represents a huge potential impact, and all you’re asking robots to do is move stuff — pick something up and put it somewhere else. You don’t have to assemble it or put bolts in, just move stuff.
Over the next three to five years, you’re going to see pilots starting today and many attempts, both in the West and in China, to put general-purpose robots into material handling and show that this template with robotics foundation models can work in those settings.
Now, if that works — if the capital doesn’t dry up, if researchers don’t get bored and decide to become LLM researchers because someone’s going to give them a billion dollars — then maybe in the next seven to ten years, with some more research breakthroughs, we may see these robots moving into more dexterous and complex manufacturing tasks. Think about placing bolts, assembling things, wings on 747s, putting wiring harnesses together. This is all really difficult.
You could even imagine at this point we’re starting to see maybe basic home tasks: tidying, loading and unloading a dishwasher, cleaning surfaces, vacuuming...
Jordan Schneider: When are we getting robotic massages?
Ryan Julian: Oh man, massage. I don’t know. Do you want a robot to press really hard on you?
Jordan Schneider: You know... no. Maybe that’s on a fifteen-year horizon then?
Ryan Julian: Yeah, that’s the next category. Anything that has a really high bar for safety, interaction with humans, and compliance — healthcare, massage, personal services, home health aid — will require not only orders of magnitude more intelligence than we currently have and more capable physical systems, but you also really start to dive into serious questions of trust, safety, liability, and reliability.
Having a robot roving around your house with your one-year-old kid and ensuring it doesn’t fall over requires a really high level of intelligence and trust. That’s why I say it’s a question mark. We don’t quite know when that might happen. It could be in five years — I could be totally wrong. Technology changes really fast these days, and people are more willing than I usually expect to take on risk. Autopilot and full self-driving are good examples.
One thing the current generation of robotics researchers, generalist robotics researchers, startups, and companies are trying to learn from the self-driving car era is this: maybe one reason to be optimistic is that because of this safety element, self-driving cars are moving multi-ton machines around lots of people and things they could kill or break. You have people inside who you could kill. The bar is really high — it’s almost aviation-level reliability. The system needs to be incredibly reliable with so much redundancy, and society, regulators, and governments have to have so much faith that it is safe and represents a positive cost-benefit tradeoff.
This makes it really difficult to thread the needle and make something useful. In practice, it takes you up the difficulty and autonomy curve we talked about and pushes you way up to really high levels of autonomy to be useful. It’s kind of binary — if you’re not autonomous enough, you’re not useful.
But these generalist robots we’re talking about don’t necessarily need to be that high up the autonomy difficulty curve. If they are moderately useful — if they produce more than they cost and save some labor, but not all — and you don’t need to modify your business environment, your home, or your restaurant too much to use them, and you can operate them without large amounts of safety concerns, then you have something viable.
For instance, if you’re going to have a restaurant robot, you probably shouldn’t start with cutting vegetables. Don’t put big knives in the hands of robots. There are lots of other things that happen in a restaurant that don’t involve big knives.
One of the bright spots of the current generalist robotics push and investment is that we believe there’s a much more linear utility-autonomy curve. If we can be half autonomous and only need to use fifty percent of the human labor we did before, that would make a huge difference to many different lives and businesses.
Jordan Schneider: Is that a middle-of-the-road estimate? Is it pessimistic? When will we get humanoid robot armies and machines that can change a diaper?
Ryan Julian: It’s a question of when, not if. We will see lots of general-purpose robots landing, especially in commercial spaces — logistics, manufacturing, maybe even retail back of house, possibly hospitality back of house. The trajectory of AI is very good. The machines are becoming cheaper every day, and there are many repetitive jobs in this world that are hazardous to people. We have difficulty recruiting people for jobs that are not that difficult to automate. Personally, I think that’s baked in.
If, to you, that’s a robot army — if you’re thinking about hundreds of thousands, maybe even millions of robots over the course of ten years working in factories, likely in Asia, possibly in the West — I think we will see it in the next decade.
The big question mark is how advanced we’ll be able to make the AI automation. How complicated are the jobs these machines could do? Because technology has a habit of working really well and advancing really quickly until it doesn’t. I’m not exactly sure where that stopping point will be.
If we’re on the path to AGI, then buckle up, because the robots are getting real good and the AGI is getting really good. Maybe it’ll be gay luxury space communism for everybody, or maybe it’ll be iRobot. But the truth is probably somewhere in between. That’s why I started our discussion by talking about how robots are the ultimate capital good.
If you want to think about what would happen if we had really advanced robots, just think about what would happen if your dishwasher loaded and unloaded itself or the diaper changing table could change your daughter’s diaper.
A good dividing line to think about is that home robots are very difficult because the cost needs to be very low, the capability level needs to be very diverse and very high, and the safety needs to be very high. We will require orders of magnitude more intelligence than we have now to do home robots if they do happen. We’re probably ten-plus years away from really practical home robots. But in the industrial sector — and therefore the military implications we talked about — it’s baked in at this point.
Jordan Schneider: As someone who, confession, has not worked in a warehouse or logistics before, it’s a sector of the economy that a lot of the Washington policymaking community just doesn’t have a grasp on. Automating truckers and automating cars doesn’t take many intellectual leaps, but thinking about the gradations of different types of manual labor that are more or less computationally intensive is a hard thing to wrap your head around if you haven’t seen it in action.
Ryan Julian: This is why, on research teams, we take people to these places. We go on tours of auto factories and logistics centers because your average robotics researcher has no idea what happens in an Amazon warehouse. Not really.
For your listeners who might be interested, there are also incredible resources for this provided by the US Government. O*NET has this ontology of labor with thousands of entries — every physical task that the Department of Labor has identified that anybody does in any job in the United States. It gets very detailed down to cutting vegetables or screwing a bolt.
Jordan Schneider: How can people follow this space? What would you recommend folks read or consume?
Ryan Julian: Well, of course you should subscribe to ChinaTalk. Lots of great revised coverage. The SemiAnalysis guys also seem to be getting into it a little bit. Other than that, I would join Twitter or Bluesky. That is just the rest of the AI community. That’s the best place to find original, raw content from people doing the work every day.
If you follow a couple of the right accounts and start following who they retweet over time, you will definitely build a feed where, when the coolest new embodied AI announcement comes out, you’ll know in a few minutes.
[Some accounts! Chris Paxton, Ted Xiao, C Zhang, and The Humanoid Hub. You can also check out the General Robots and Learning and Control Substacks, Vincent Vanhoucke on Medium, and IEEE’s robotics coverage.]
Jordan Schneider: Do you have a favorite piece of fiction or movie that explores robot futures?
Ryan Julian: Oh, I really love WALL-E and Big Hero 6. I prefer friendly robots.
Enjoy this deleted scene from WALL-E:
Mood Music: