dhuzbb:
起源
周末经常和同事一起玩 JJ 斗地主,每局输赢不大,主要以娱乐为主。由于经常输,所以萌生了开发一款记牌器来偷偷提升斗地主水平的想法。
我的本职工作是 Java 后端开发,没有接触过安卓开发,再加上最近 AI 编程的火热,让我萌生了使用 Cursor 开发一款安卓应用的想法。
思路
主要思路:如果能够每隔 1 秒截取到当前手机屏幕的内容,然后识别出截图中的所有牌张的点数及花色,那么用 54 张牌直接减去对应的牌张及花色即可得到剩余的牌张。
实现的困难点在于,不仅要识别牌的点数,还需要识别牌的花色。
因为如果只是单纯的识别牌的点数而不考虑花色,那么会产生 Bug 。
例如:先出黑桃 2 ,再出红桃 2 ,等了 3 秒后再出其它牌。由于出牌时间不是固定的,在这期间每隔 1 秒识别截图会重复识别多次牌张 2 ,导致剩余牌张数不准确。
如果同时识别牌的点数及花色,则不会出现重复多次扣减同样牌张的问题。
UI 设计
记牌器 UI 的主体借鉴了 JJ 斗地主自身的记牌器。
应用主界面如下:

由于是自己使用,所以界面做得比较简单,主界面只有一个 [开启记牌器] 按钮。点击后该按钮会变成 [结束记牌器] 。
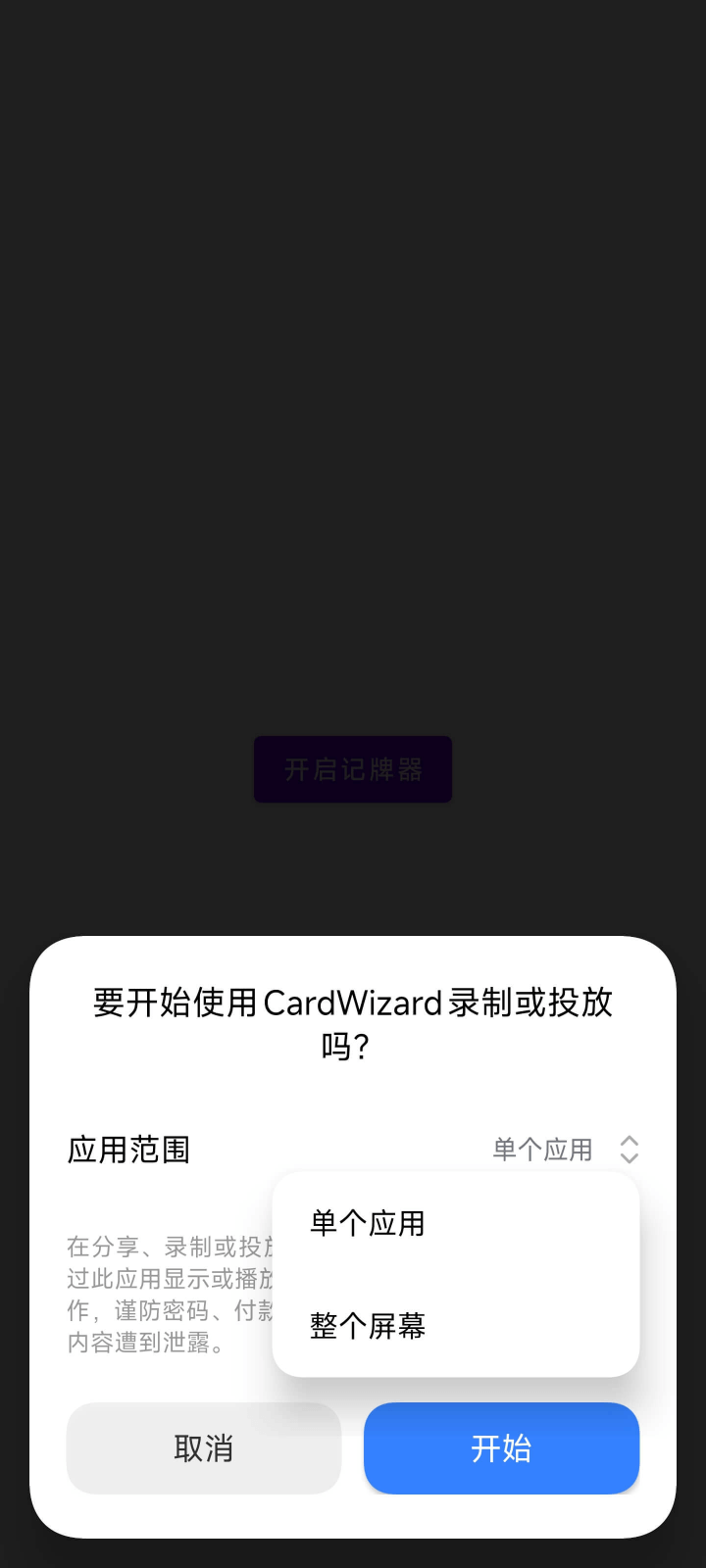
点击 [开启记牌器] 按钮,会弹出系统屏幕录制权限,可以只录制单个应用,也可以全局录制整个屏幕。如下所示:
点击 [开始] 按钮,会在当前页面显示记牌器悬浮窗,如下所示:

整个悬浮窗由三部分组成:
- 左侧: [隐] 按钮点击可以控制悬浮窗的显示和隐藏。点击后变为 [显] 按钮。
- 中间:记牌器的主体分为上下两排,下面是 3 到大王的剩余牌张数,如果有炸弹,文字会显示为红色。
- 右侧: [开始] 按钮点击后可以开始新一局的录制,同时按钮会变为 [结束] 按钮。
点击右侧 [开始] 按钮后,开始一局的录制,同时按钮会变为 [结束] 按钮。

整个悬浮窗可以全局灵活的自由拖动:

悬浮窗还可以显示和隐藏:

记牌器显示在桌面的效果如下:

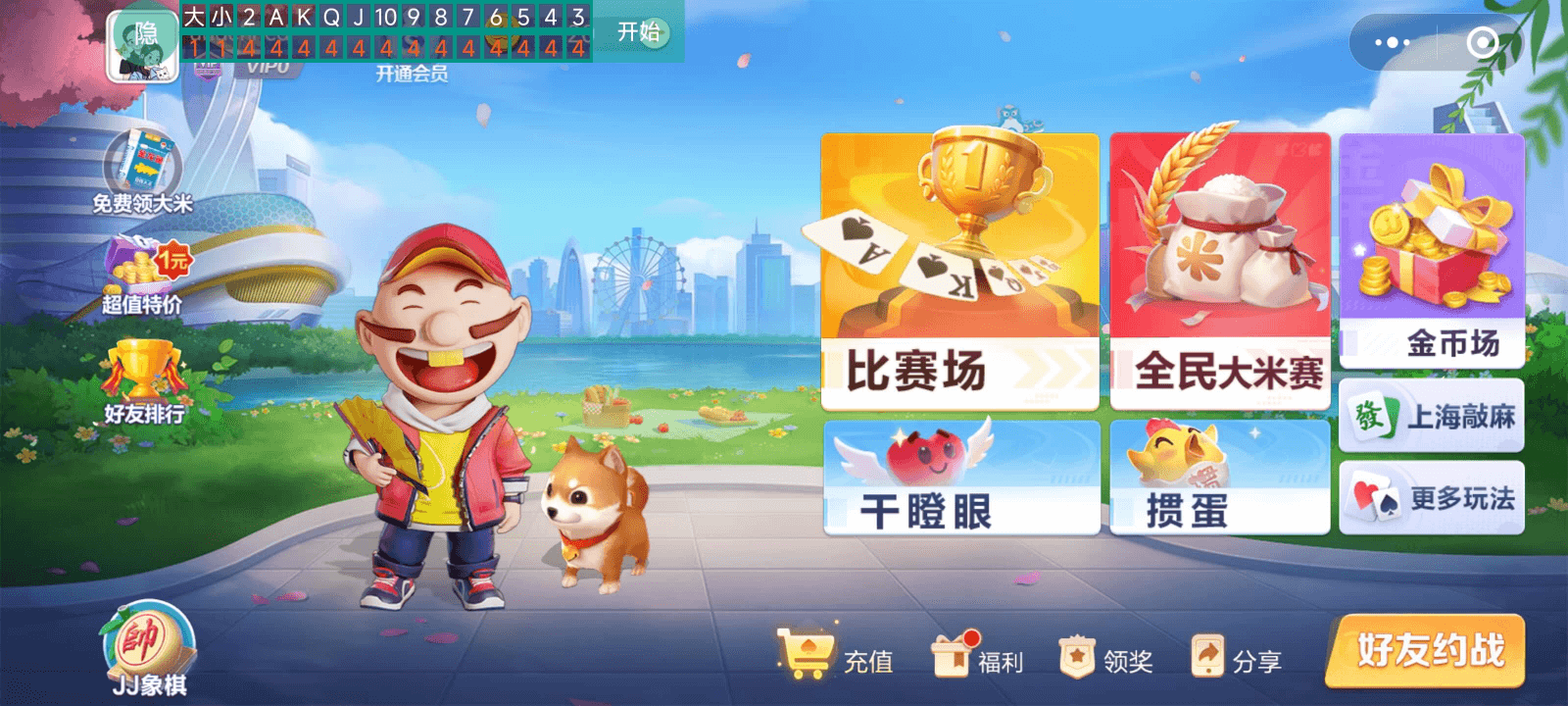
记牌器在 JJ 斗地主游戏界面显示如下:
UI 开发
期间一共开发了三个版本:
-
第一个版本由 Cursor 的 Agent 模式开发,使用 Claude 3.7 Sonnet 模型。由于个人知识的局限性,对于安卓全局悬浮窗和屏幕录制权限完全不了解。当提出的问题本身可能都不完全正确的情况下,让 AI 去实现相应的功能以及修改 Bug 的时候,AI 往往会陷入死循环,结果就是 Cursor 消耗了 200 左右的对话次数都无法修改正确一个在我个人看来非常简单的问题。令人失望的是,最后并没有达到想要的效果,以失败告终。
-
第二次尝试使用免费的 Trae 来开发同样的 UI 部分,同样使用 Claude 3.7 Sonnet 模型。有了第一次的经验,使用 Trae 开发的前期比较顺畅,但是当对话次数多了之后需要排队,由于等待时间较长,严重影响写代码的体验,最终还是放弃了。
-
前面两次 AI 生成的 UI 代码也不是完全没有用处。有了前面两次的经验,还是让我学习到了不少安卓 UI 开发的相关知识。最后还是通过搜索相关实现例子,手写大部分 UI 代码再加上 AI 的辅助,最终才搞定 UI 的部分。
图像识别
记牌器的技术难点在于图像识别。
前期通过调研,得知 OpenCV 可以实现图像识别,并且网上可以搜索到相应的代码示例,再加上 OpenCV 有对应的 Java 包,所以优先选择了 OpenCV 来开发图像识别功能。
通过 ChatGPT 以及 DeepSeek 的辅助,花费了不少时间开发出了第一版的 OpenCV 识别算法。
核心思路大致是:
- 通过手动截取出 54 张牌的左上角的数字以及花色区域,得到 54 张截图模板。
- 对模版和待识别的截图进行各种预处理(转为灰度图、高斯模糊、二值化等)。
- 最后使用 OpenCV 的模板匹配,将 54 张模板和待识别的截图依次做相似度匹配,取匹配相似度最高的结果,并且丢掉低于设定阈值的匹配结果。
测试过程中发现 OpenCV 的识别效果不太理想,容易出现识别错误以及漏识别的问题。
对于记牌器应用来说,是不能容忍任何的漏记以及错误识别的,必须想办法提高识别的精度。
深度学习
OpenCV 的模版匹配方案还有另外 2 个致命的问题:
- 不同手机的分辨率可能不一样,势必会影响识别的准确度。
- 无法适配其它斗地主游戏。
既然 OpenCV 存在致命的缺陷,所以不得不推倒重来。
又是新的一轮咨询 ChatGPT 以及 DeepSeek ,得到了可以通过基于深度学习框架 YOLO 来提高图像识别的准确度。
大致看了一下官网文档,看上去比较容易上手。
整体大致流程:
- 先手动截取一些包含所有 54 种牌张的截图
- 使用
LabelImg 对截图进行类别的标注
- 将截图按照
8:2 的比例分为训练集和验证集
- 使用 YOLO 进行训练
- 最后导出训练的最佳模型
有了 AI 的详细指导,整个过程基本上都比较顺畅。使用 Google 免费的 Colab 很快就训练出了第一版模型。然而最终验证的识别效果还是不太理想,还是存在漏记和错记的情况。
最后得知原因在于训练的数据集太小(手动截图并标注了几十张训练图)。想要识别效果比较理想,一般的 YOLO 训练集的大小规模在几千到上万张左右。
由于手动一张张截取手机屏幕并标注,消耗的时间实在是太长了。为了解决训练集不足的问题,最后不得不写了一个程序,根据截图模版随机生成了一万张图片以及对应的 YOLO 标注文件用于训练。
当训练集规模到了一万张的时候,预计模型训练花费的时间会达到几个小时,Google 免费的 Colab 有运行时间的限制条件,无法再满足训练的需求,不得不考虑租用 GPU 服务器。
综合对比之下,最后采用了阿里云的 GPU 服务器。配置为 16G 显存的 V100 显卡。非常幸运的是,新用户前 100 个小时有很大的优惠折扣,折合 2 块/小时左右,实在是太划算了。
在阿里云上总共的训练时长不到 3 个小时。最后,识别精度意外的好,每张牌都能到达 0.98-0.99 的准确度,实际体验下来没有遇到过错记或漏记的情况。
整合
将训练好的图像识别模型与 UI 整合起来有两种方式:
- 通过 Python 调用训练好的模型并部署 API 接口供安卓 UI 调用。
- 将模型转换为适用于移动端的模型格式,安卓自身通过代码直接调用模型进行图像识别。
方案 1 的缺点就是需要额外的服务器进行部署,且依赖网络传输截图数据。
方案 2 我个人没有尝试过,但看 ChatGPT 给出来的代码示例,感觉也许应该是可行的吧。有空会尝试一下方案 2 ,不清楚移动设备的识别效率会怎样。
由于难易程度的关系,我采用了方案 1 。通过 ChatGPT 给出的 Python 调用模型进行识别的方式,很容易就对外暴露了一个识别 API 接口供安卓 UI 调用。
最后在家里的 M4 Mac Mini 上部署之后,达到了非常完美的识别效果。
思考和总结
经常在网上看到一些所谓的完全不懂编程,我竟然 4 小时靠 AI 复刻出月入$600k 的 APP 的同款的营销文章和视频。说实话,我个人是非常反感这类文章和视频的。
从我个人的亲身体验来看,现阶段的 AI 还只能用于辅助开发。AI 的知识储备确实非常丰富,能够带领你尝试你从未涉及的领域。但是,往往由于个人本身所掌握的知识的局限性,遇到特定的问题的时候,依靠 AI 往往很难解决。
另一个方面,AI 很容易犯错。我记得让 ChatGPT 给出使用 SpringBoot 实现直接调用训练好的 YOLO 模型的时候,AI 很快给出了一段看上去像模像样的 Java 代码并贴心的给出了 Maven 依赖包。当你按照 AI 的指导写好所有代码的时候,你会惊奇的发现,Maven 包实际上并不存在,完全是 AI 瞎编造出来的,包括那些像模像样的实现代码也是一样。当你质问 AI 给出的 Maven 依赖包为何不存在的时候,只会得到 一句抱歉。
然而即使现阶段的 AI 在使用上还有着各种各样的缺陷,我对未来的 AI 编程还是抱有期望的。对比几年前,AI 的提升无疑是巨大的。这些改进和提升在往后的几十年中还会不断的上演,甚至呈现指数级的增长,直到实现普通人都能够轻松使用的真正的 AI 。




