No Jensen, Not All Compute is Created Equal
is in Cape Town for two weeks… email Nick at nick@chinatalk.media if you’re interested in joining a ChinaTalk meetup!
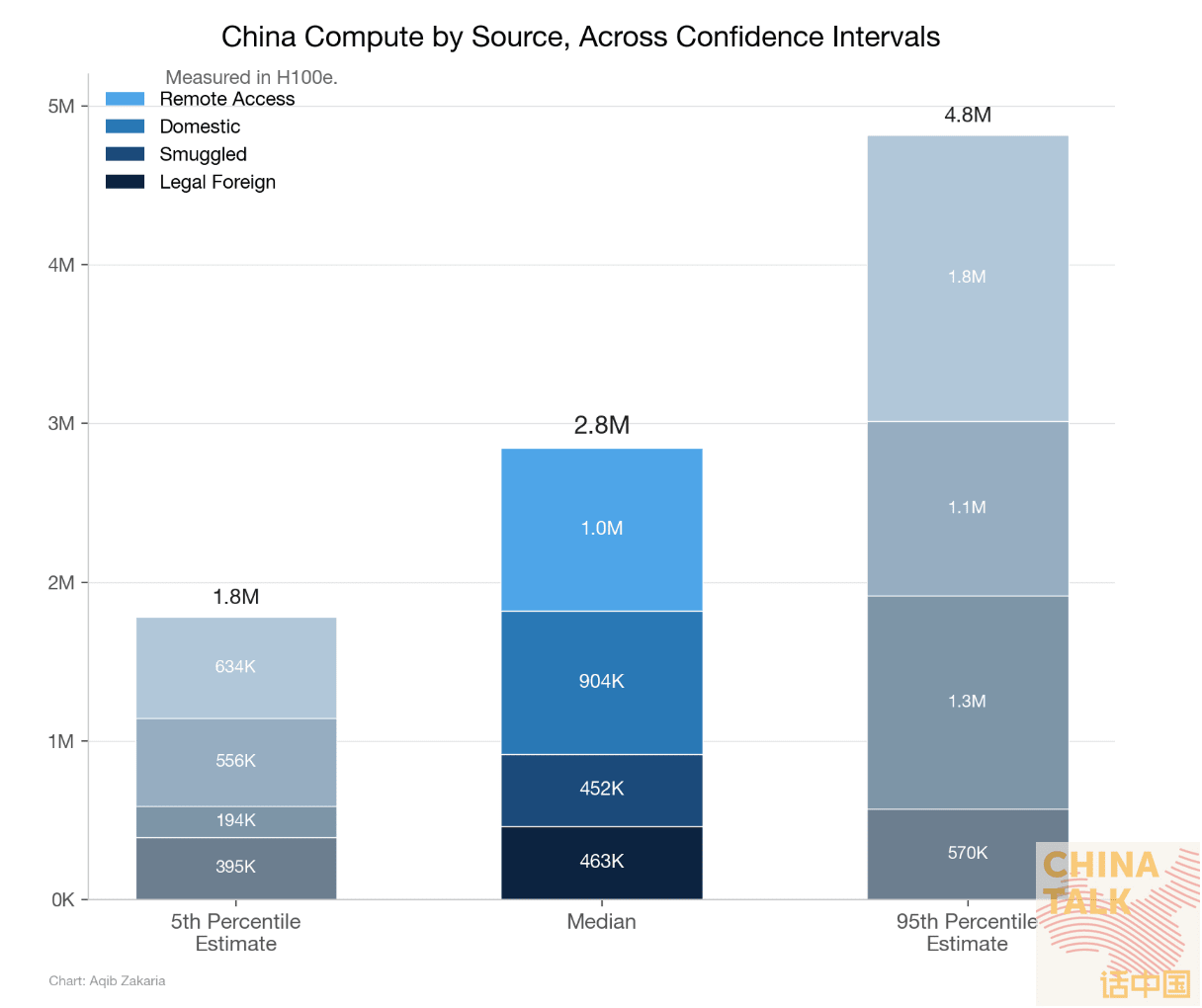
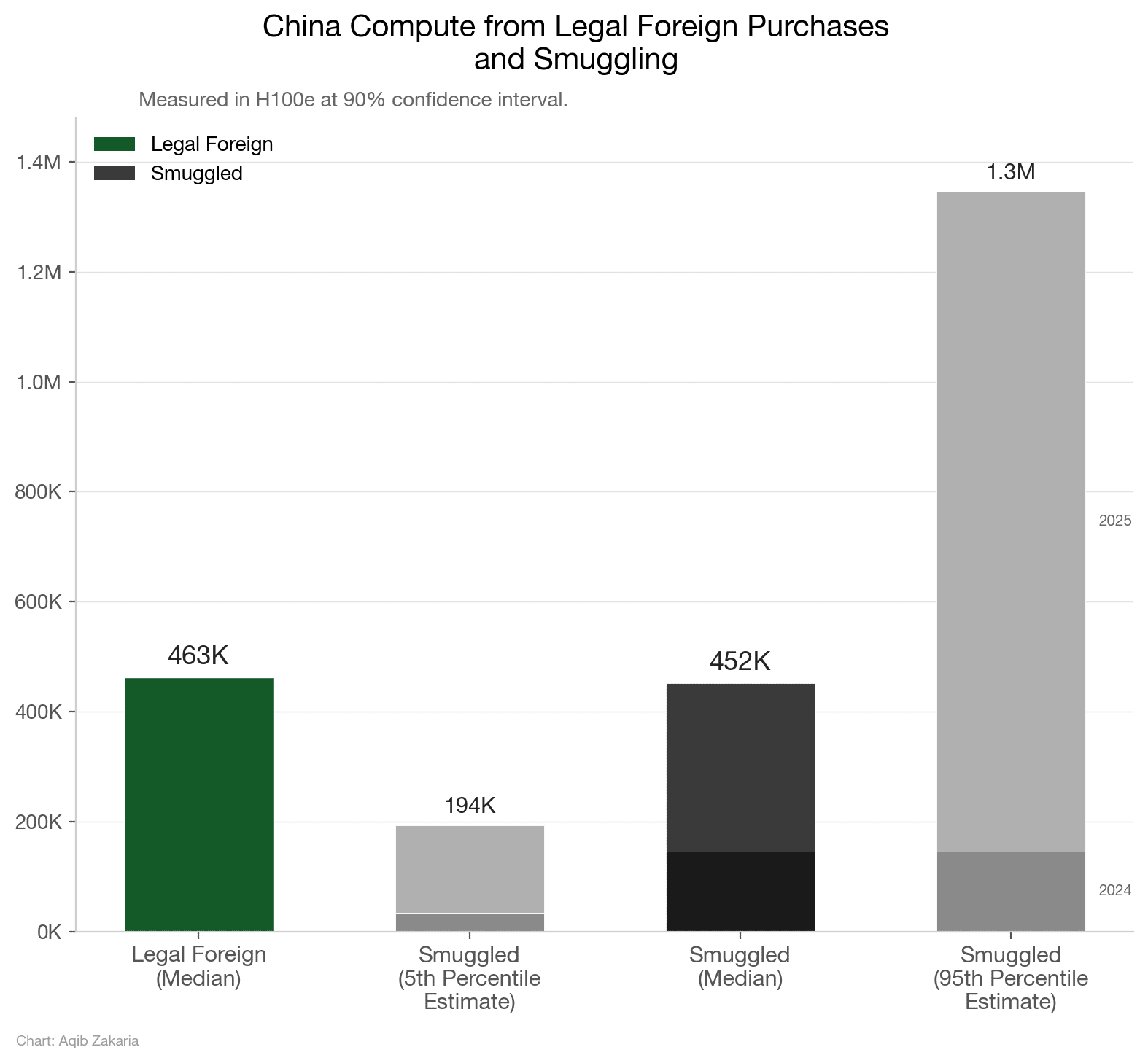
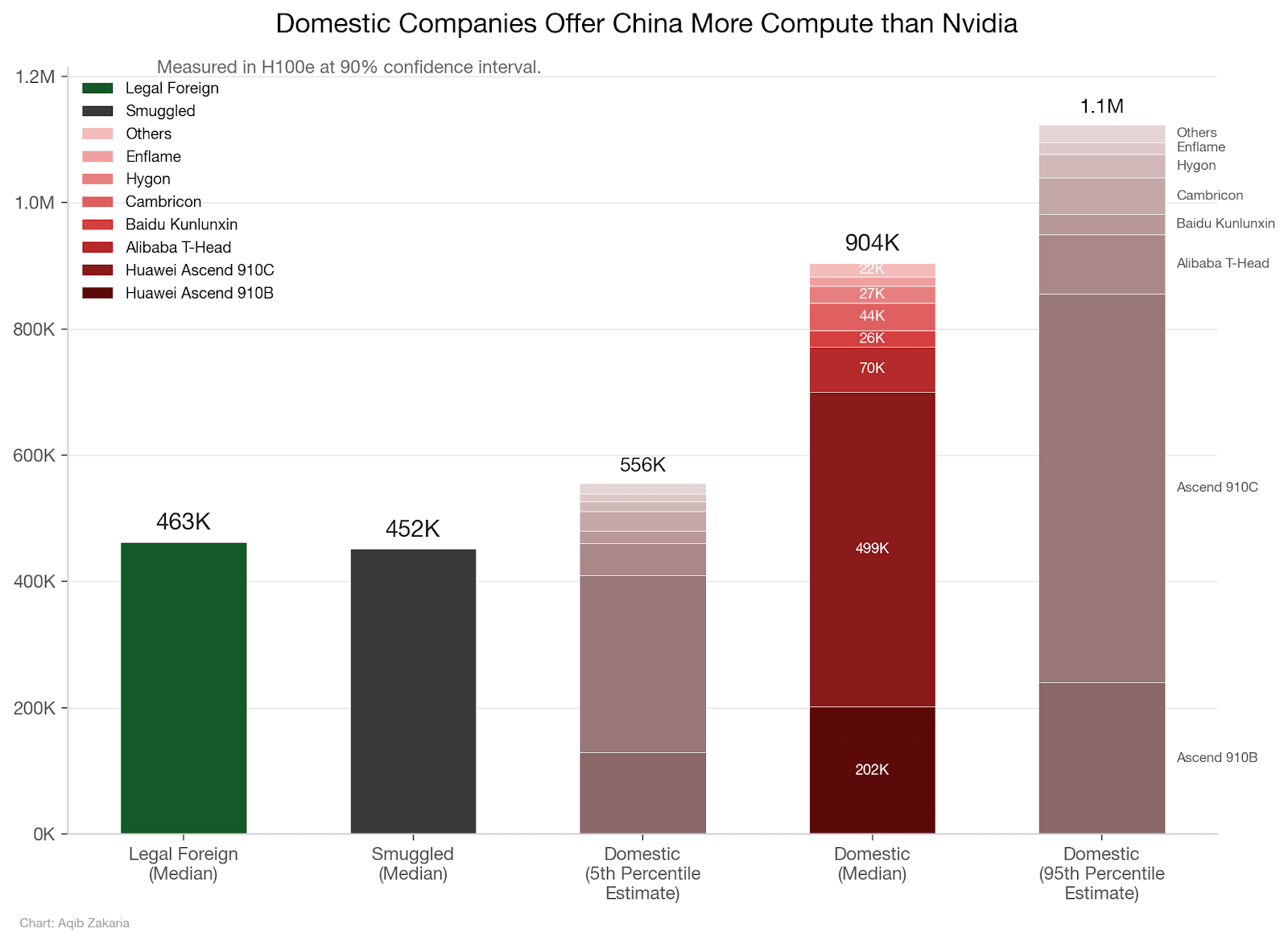
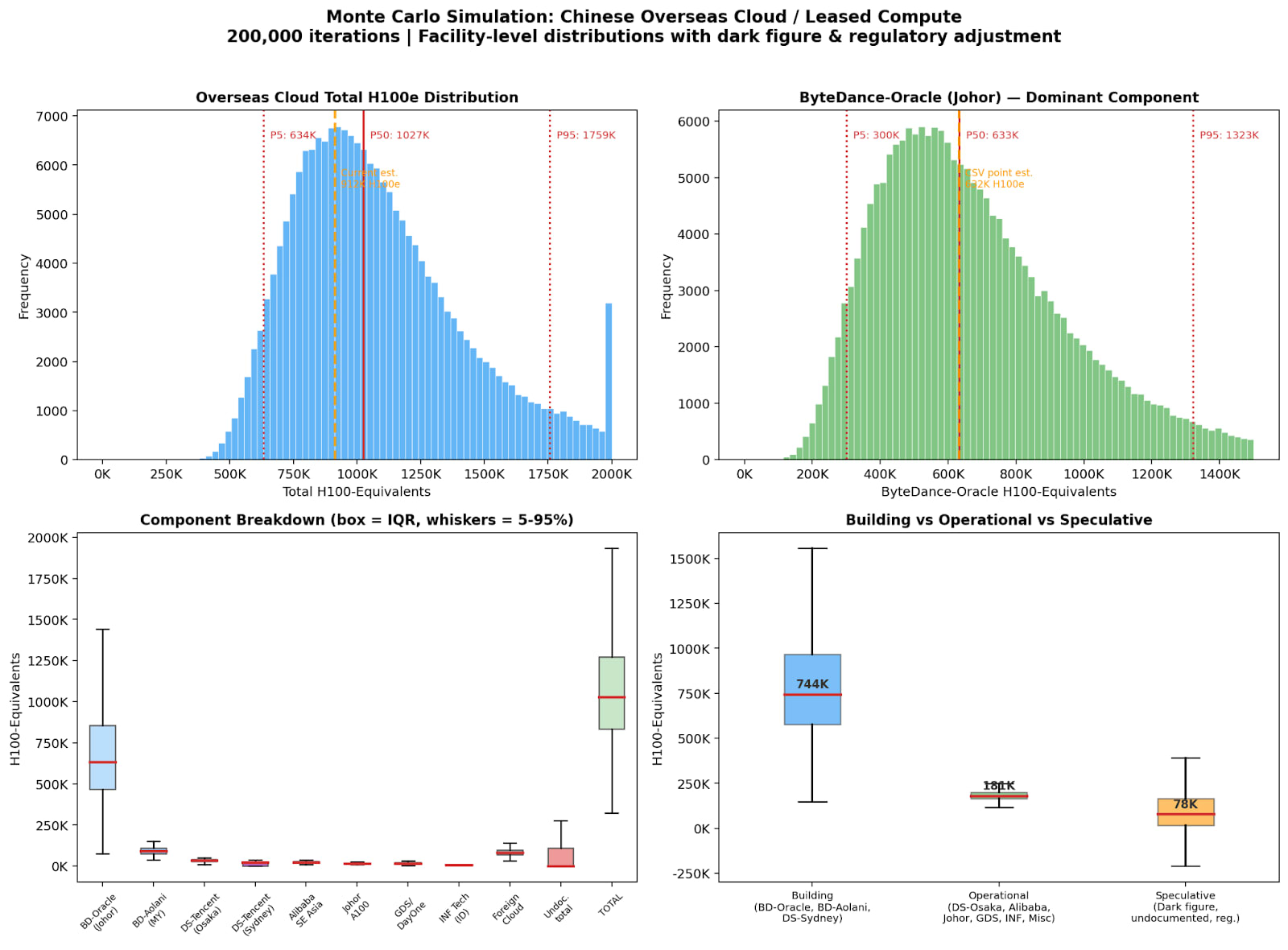
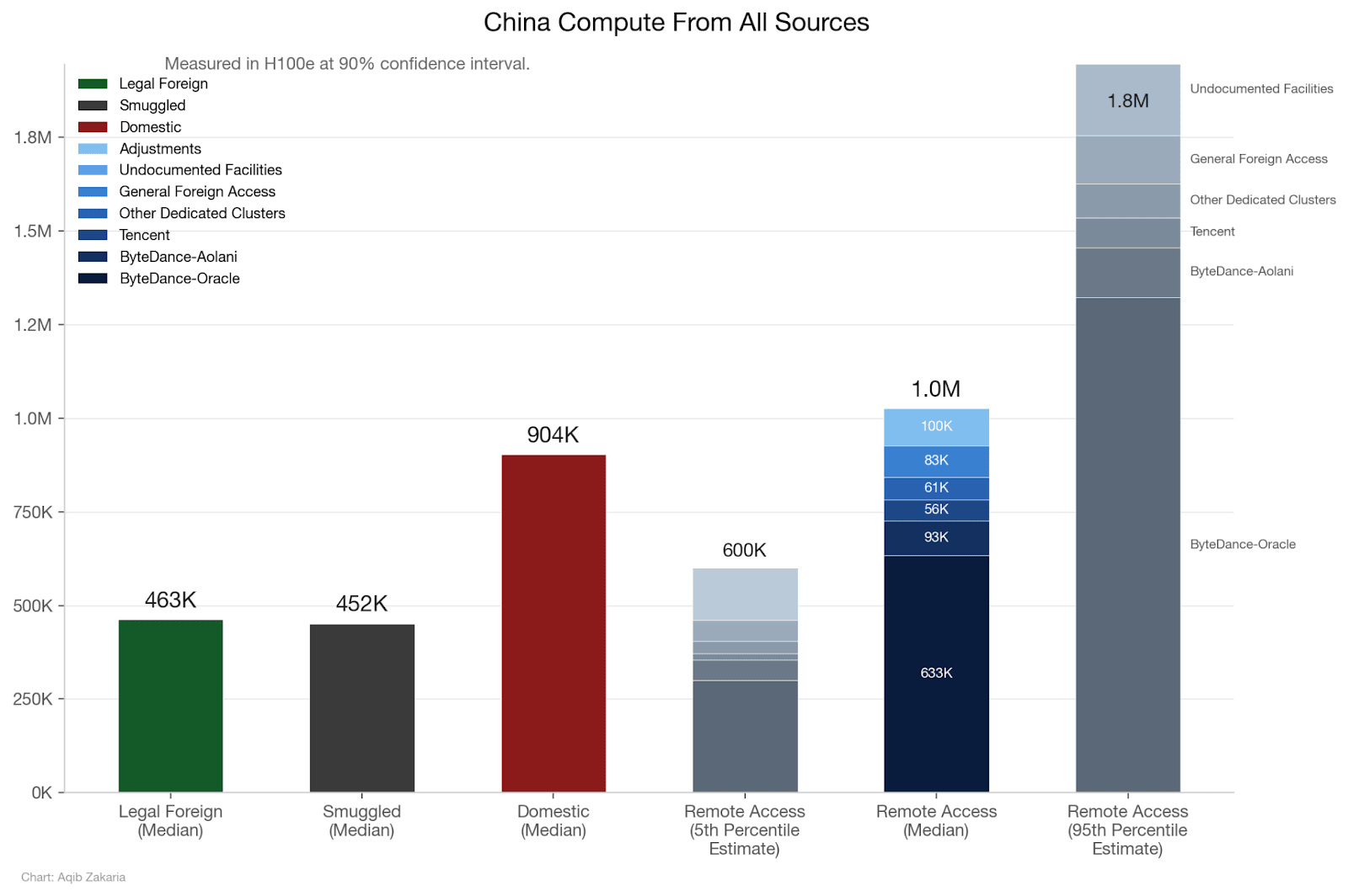
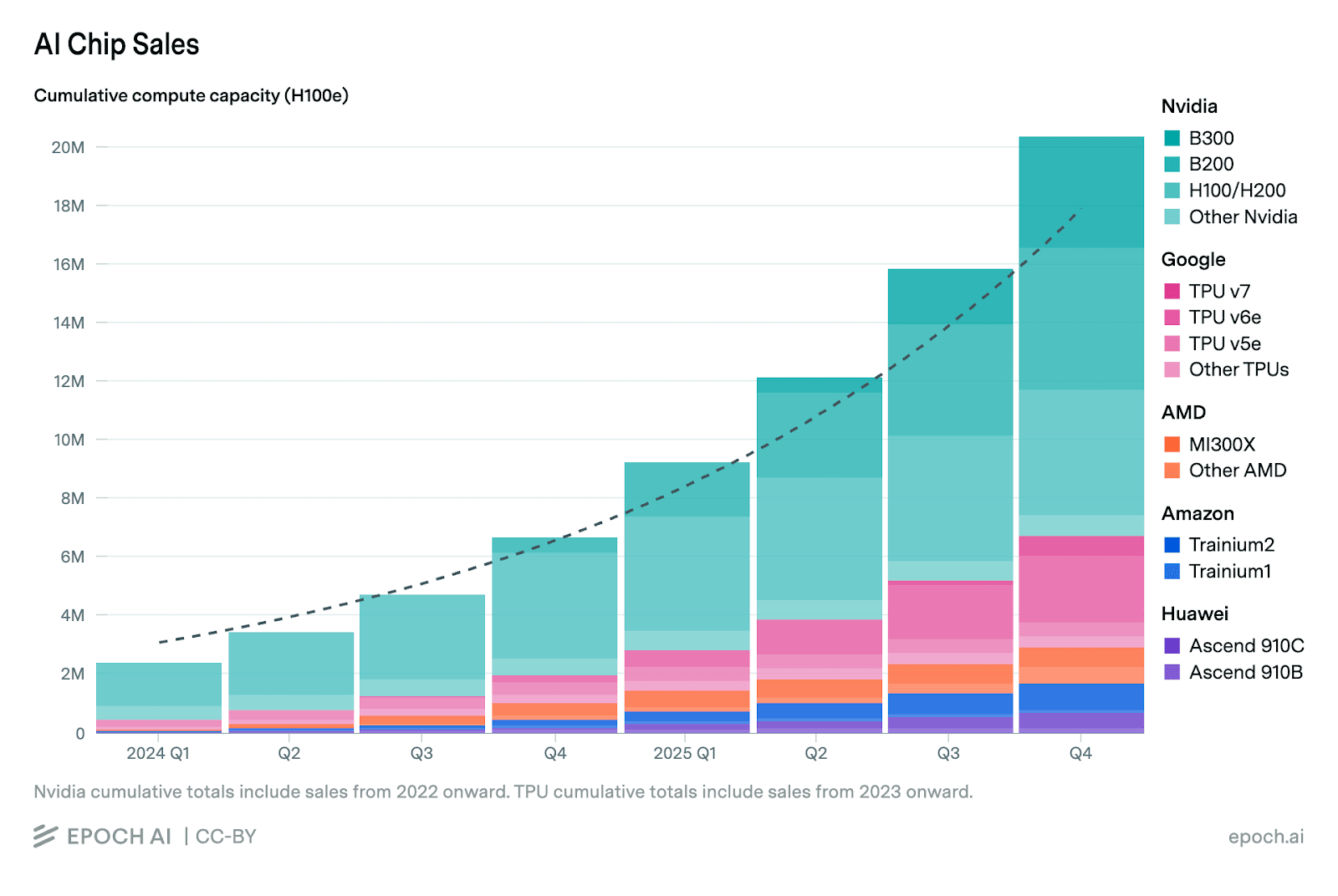
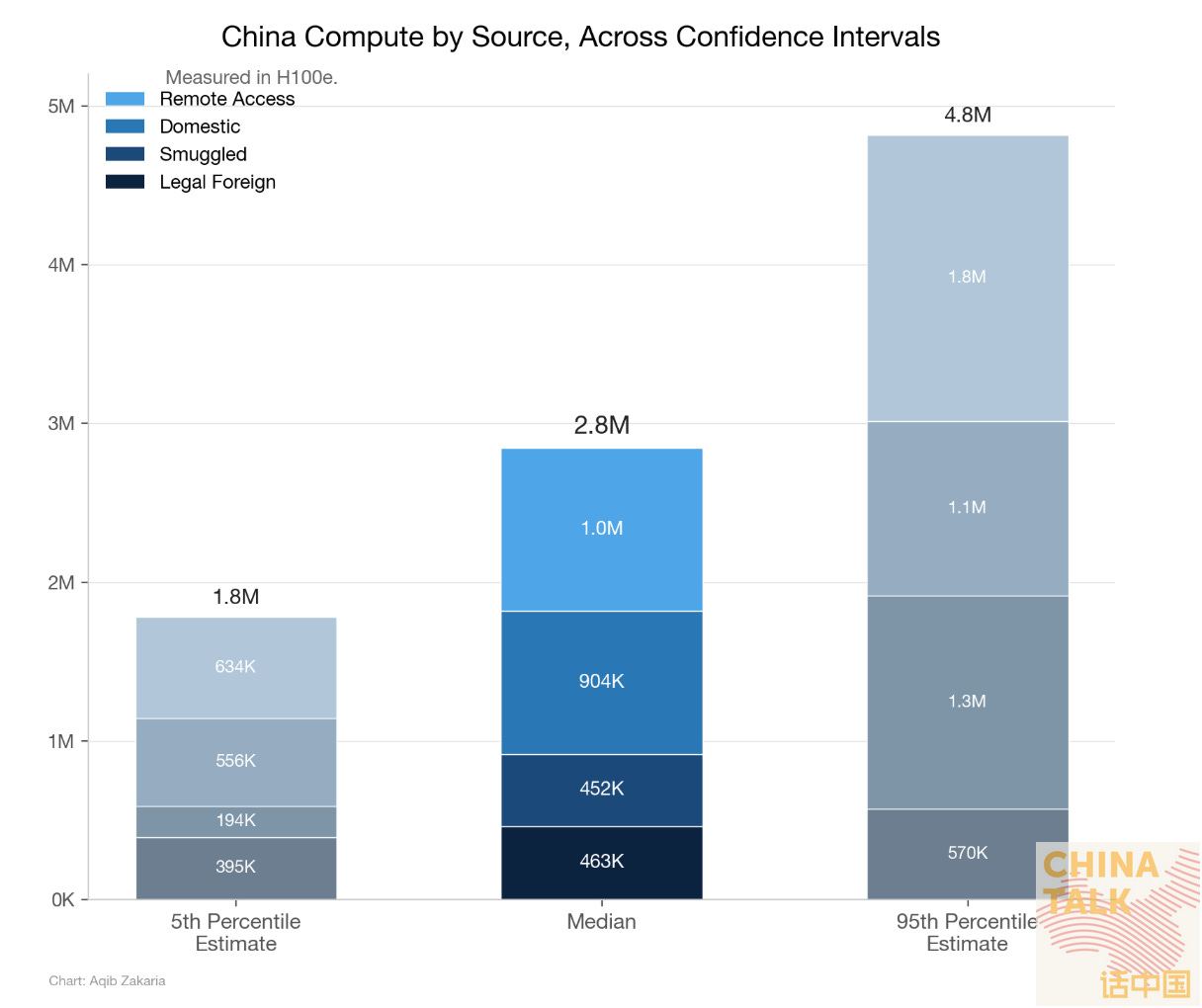
We’ve recently tried to pin down how much compute China actually has, approaching the question from both the supply and demand sides. We converged on roughly 2.5 to 2.8 million H100-equivalents. But a single aggregate figure only captures part of the picture.
Jensen on China
On Dwarkesh’s podcast last week, Jensen Huang argued that China already has enough compute to build frontier AI.
“They manufacture 60% of the world’s mainstream chips, maybe more.”
When Dwarkesh raised the gap in advanced chips, Jensen responded,
“AI is a parallel computing problem, isn’t it? Why can’t they just put 4x, 10x, as many chips together because energy’s free?”
Jensen is wrong, but that doesn’t mean people aren’t compelled by this line of reasoning. John Moolenaar, who chairs the House Select Committee on China, sent a letter to Lutnick in December proposing a rolling technical threshold that would cap Chinese aggregate AI compute at 10% of US compute capacity. It’s much more nuanced — accounting for memory and network bandwidth as part of this calculus — but ultimately seems motivated by preventing, as the letter calls it, “death by a thousand sub‐threshold chips.”
Export restrictions are a difficult line to walk, and total computing power does matter. But not all compute is created equal. The compute that can train a frontier model, serve inference on an existing one, and power your laptop are different things, and a “death by a thousand sub-threshold chips” is less concerning for the trajectory of AI than a concentration of the most important chips.
Legacy Chips Don’t Matter for AI
It’s hard to know where Jensen is getting his claim that “China manufactures 60% of the world’s mainstream chips.” Perhaps originally from a 2024 projection from previous Commerce Secretary Gina Raimondo about new legacy chip capacity coming online in China. But this is not a measure of AI compute. It includes the chips running your car’s engine management system, your washing machine’s control board, and the power electronics in an industrial motor, typically manufactured at 28nm or larger. They matter, but they are not the chips that train frontier AI. A chip in your microwave cannot do matrix multiplication for a transformer, and a 40nm microcontroller in a Chinese EV does not help run DeepSeek-V4.
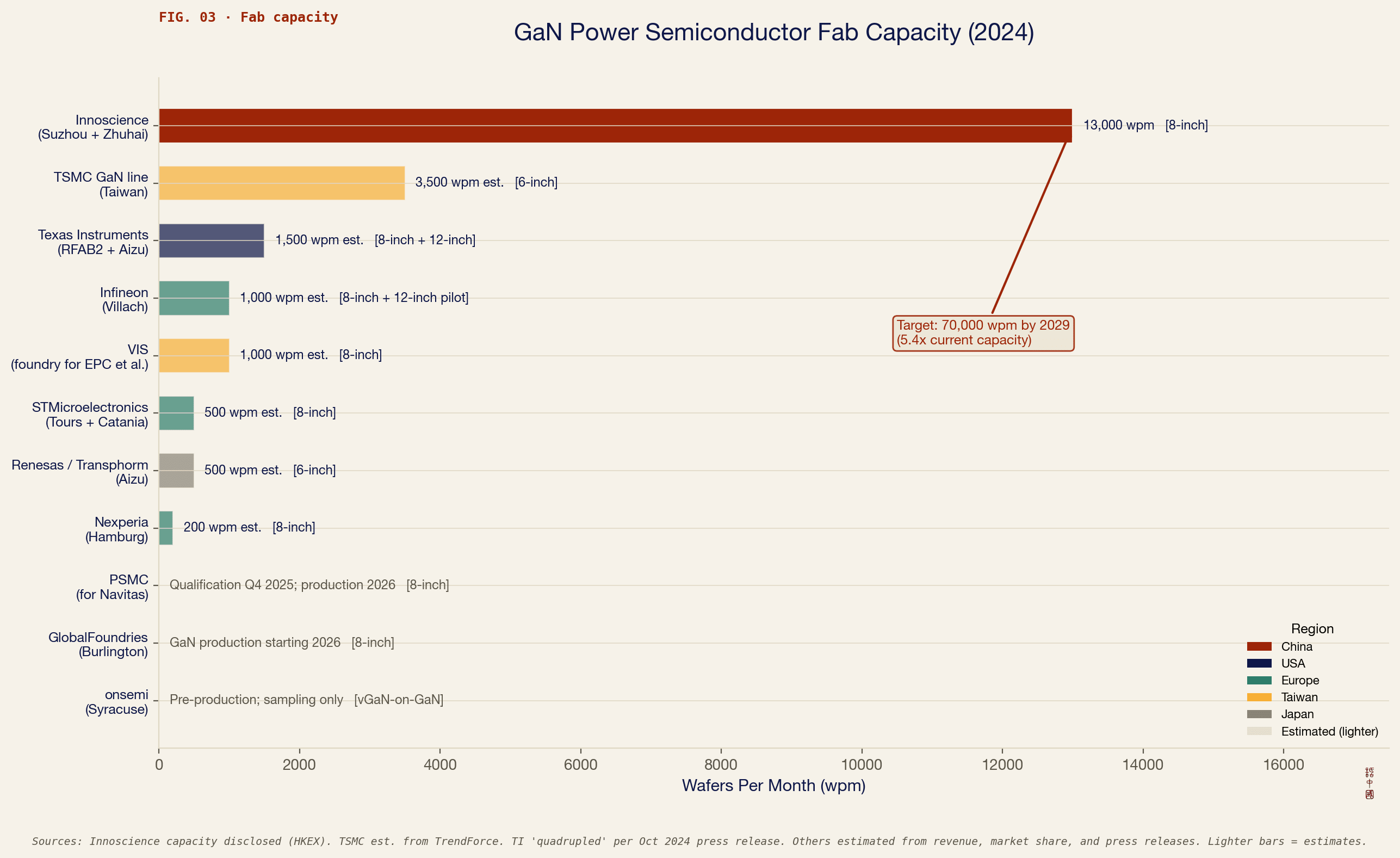
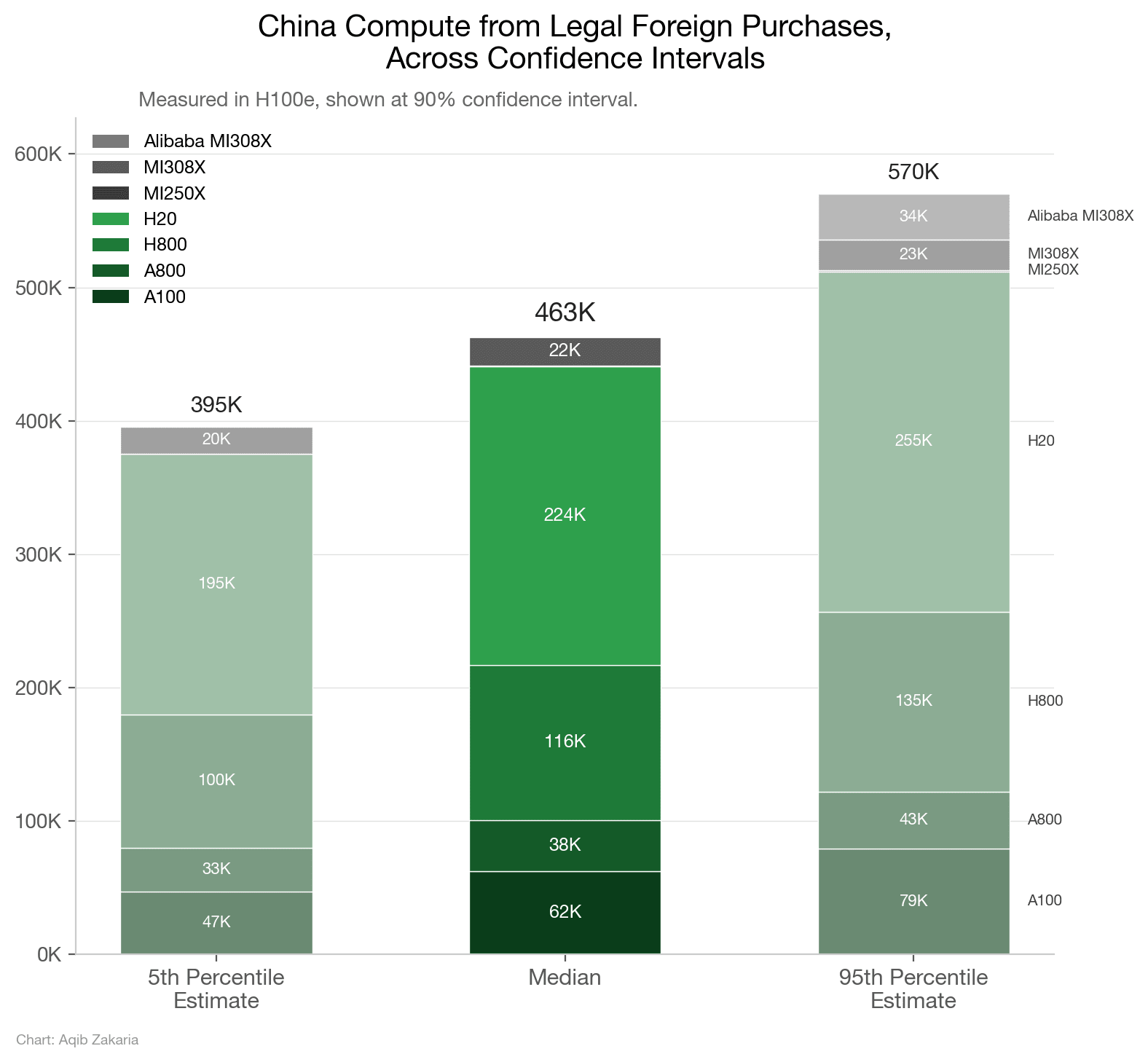
The sliver of Chinese chip output that is actually AI-relevant, primarily Huawei’s Ascend line, is roughly a million chips. But even the flagship Ascend 910C (with yields of about 300-600k chips this year) delivers slightly worse than Nvidia’s H20 for training, nowhere close to a Blackwell, and much of current production still depends on a stockpile of TSMC dies acquired before controls tightened. The remainder of China’s frontier-relevant compute comes from smuggled Nvidia chips and legally imported lower-tier chips like the H20. In short, China produces lower-quality chips and still cannot manufacture as many of them as the U.S. does; for them to reach anything close to a “death by a thousand sub-threshold chips” scenario, Chinese companies would have to concentrate what compute they do have to a degree greater than any American lab — a difficult task given the vigorous competition taking place between them.
This is why FLOPs is a more honest metric than total chip count. FLOPs, or floating-point operations per second, measure how many arithmetic calculations a chip can perform in a given second, and they are the fundamental currency of AI training and inference, since every command an AI executes is ultimately a sequence of multiply-and-add operations. And the FLOPs gap between frontier and legacy chips on this metric is staggering. A single Nvidia Blackwell B200 delivers roughly 10 petaFLOPs of dense FP8 performance, while a typical 28nm automotive microcontroller delivers around 0.12 teraFLOPs of FP32, roughly twenty thousand times less.1 To put that in concrete terms, if a country had 100,000 Blackwells, its rival would need more than the absurd number of two billion legacy chips to match the same FLOPs output.
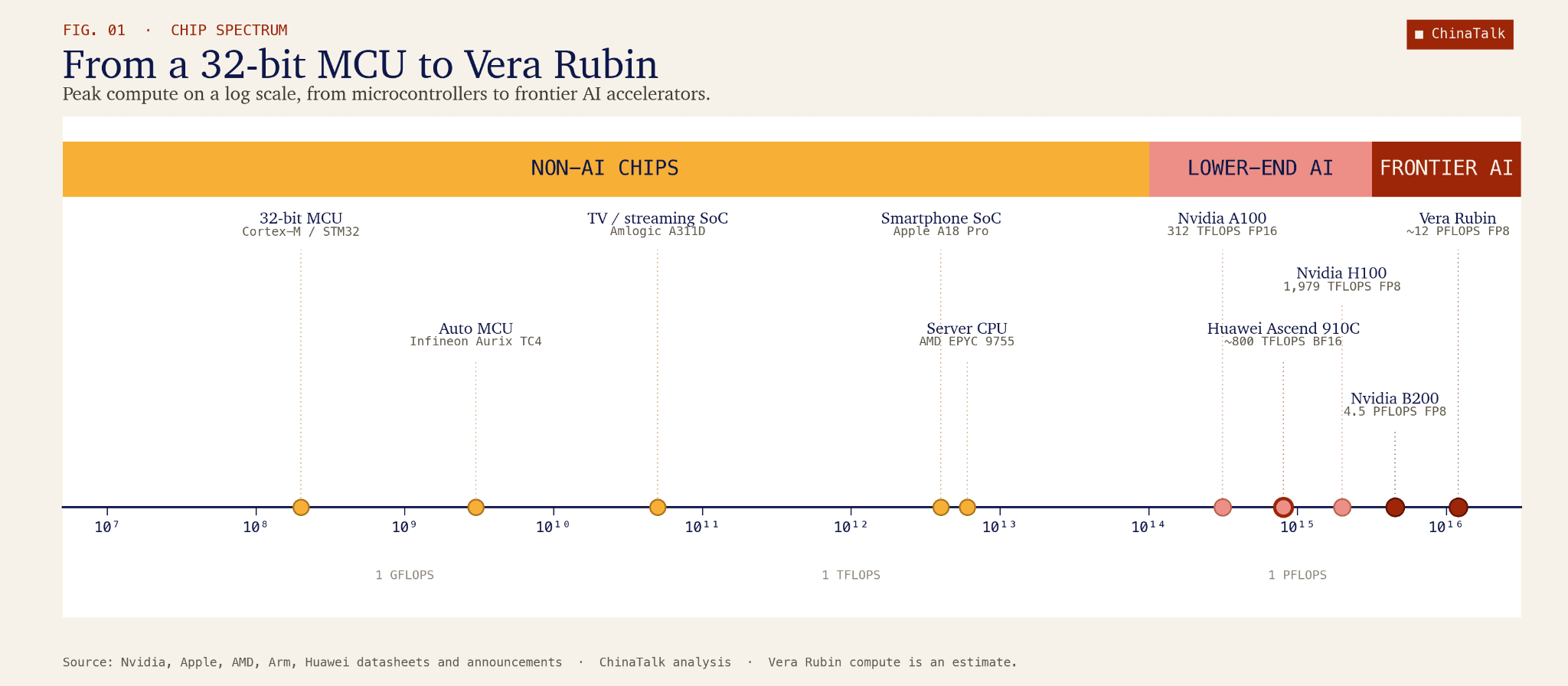
But putting mainstream legacy chips aside, if China somehow did stack up many weak AI-focused chips (like Ascends), its problems would not end at matching FLOPs.
A Tale of Two Hypothetical Countries
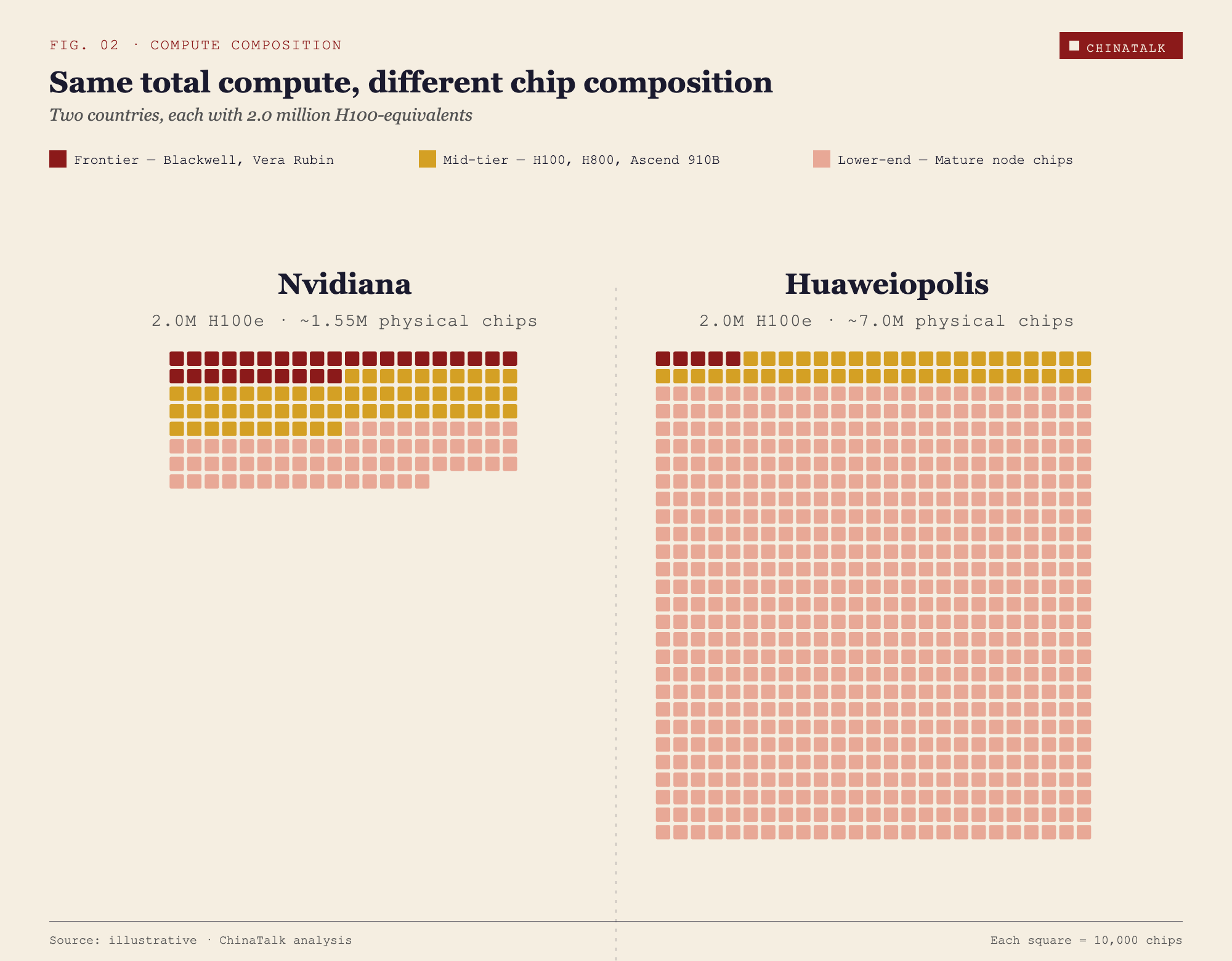
Nvidiana and Huaweiopolis each have 2 million H100-equivalents. On paper, they are peers.
Nvidiana’s stock is top-heavy and lean. Roughly 300,000 frontier chips, the Blackwells and soon-to-arrive Vera Rubins, sit at the core, tightly interconnected in a handful of purpose-built data centers that can host training runs of tens of thousands of chips in lockstep. Another 600,000 chips, the H100s and H800s, handle large-scale training and serious inference. The remainder is padded out by around 650,000 older accelerators and general-purpose silicon for lighter workloads. Total physical chip count, roughly 1.55 million.
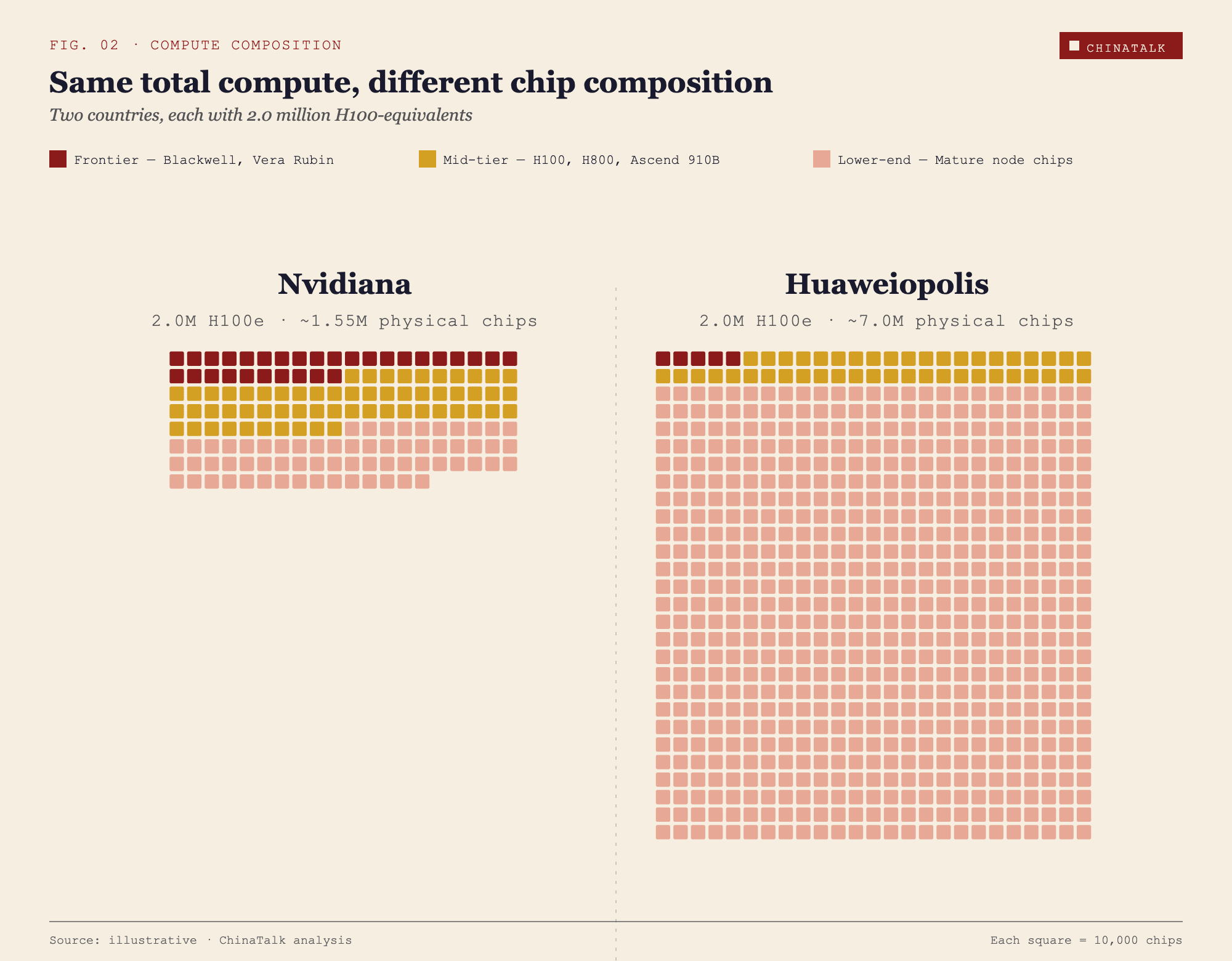
Huaweiopolis got to the same total a different way, by stacking weaker chips in enormous volume. Its top tier is thin, perhaps 50,000 frontier chips acquired before the latest round of export controls, and even those are scattered across several clusters rather than concentrated. A middle tier of around 450,000 chips, a mix of older Hopper variants and Chinese accelerators like Huawei’s Ascend 910B, is capable but constrained by weaker interconnect and memory bandwidth. The remaining mass of Huaweiopolis’s stack, close to 6.5 million chips, is older, inference-oriented chips like the H20, and repurposed general-purpose hardware. Total physical chip count, roughly 7 million — more than four times Nvidiana’s.
Nvidiana can train and serve the next generation of frontier models. Huaweiopolis cannot, and more chips will not close the gap. The difference in their AI trajectories will be substantial, even with identical FLOP counts.
Why Fewer Powerful Chips Beat Lots of Weak Chips
Huaweiopolis’s performance will lag behind for three main reasons: numerical precision, memory bandwidth, and network bandwidth.2
Numerical Precision
Older chips are not designed for the latest trends in numerical precision — that is, how finely or coarsely a chip represents numbers when doing calculations, which directly affects how much data needs to be moved and processed. Older chips, like the Hopper series, are designed to handle INT8 operations at best, meaning numbers are calculated to eight digits. Meanwhile, newer chips like the Blackwell series are designed to handle both INT8 and FP4 calculations, a jump that essentially doubles the speed of a chip. These chips can instead calculate numbers to only four digits while minimally compromising performance. By calculating half the digits, these chips have double the speed. If you are comparing chips across a standard of INT8 operations, which most studies do, then you are obfuscating the extra capability that newer chips get from being able to perform at FP4. Newer models are being trained at FP4, and inference also does not really care about less precision, meaning the capability to perform at lower numerical precision is a boon.
Memory Bandwidth
Measuring FLOPs alone also overlooks the critical importance of memory bandwidth. For most inference workloads, chip performance is not constrained by FLOPs but rather memory, since running a model means searching for and pulling billions of its stored values just to do a handful of simple calculations on each one before moving to the next. Instead of waiting for the logic to crunch numbers, the logic is waiting for the memory to fetch it numbers to crunch. A chip with ample FLOPs but insufficient memory bandwidth is like a chef with incredible knife skills but a single narrow hallway between the pantry and the kitchen, where she often has to waste time waiting in line behind the other chefs to get her ingredients. No matter how fast her hands move, the ingredients accumulate too slowly for the speed to really matter.
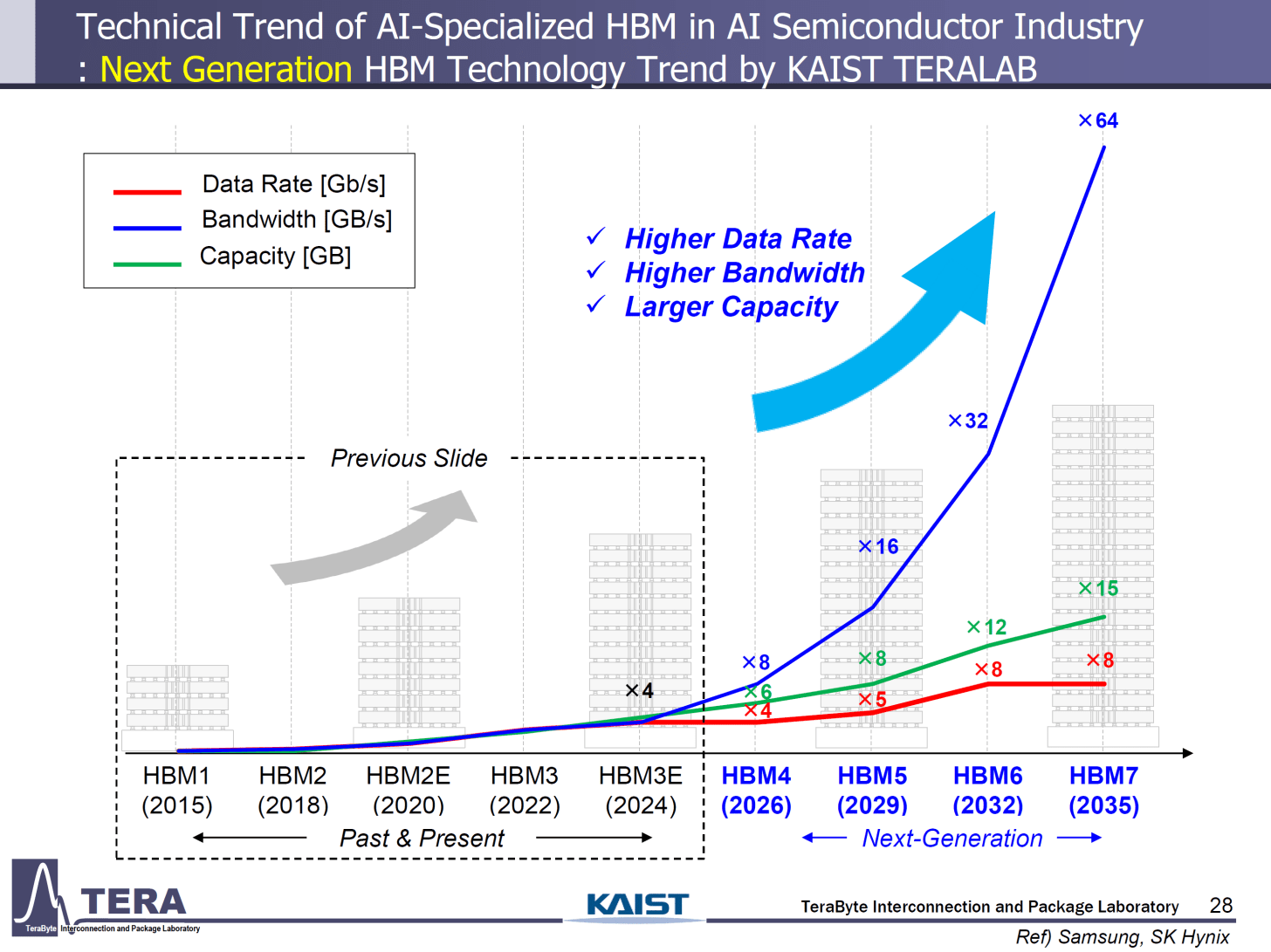
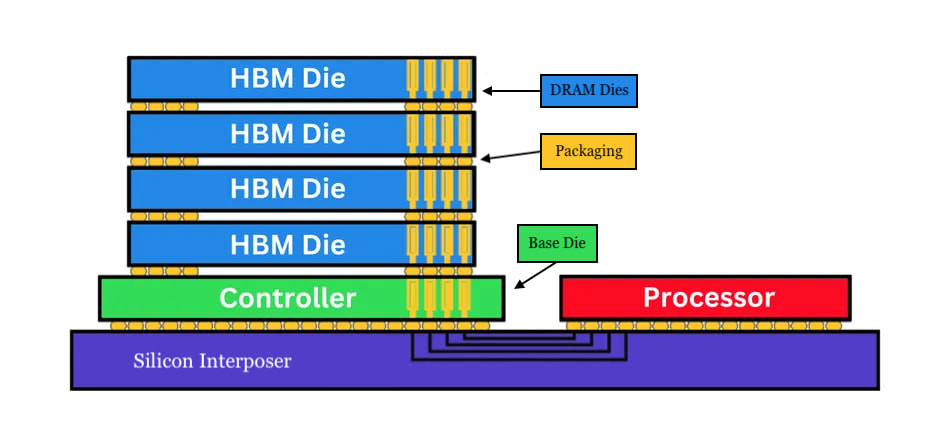
Frontier AI chips typically rely on high-bandwidth memory (HBM) to maximize memory bandwidth so that this downtime is minimized. Older chips use older HBM, which has worse memory bandwidth. The Hopper series uses HBM3e with a bandwidth of 4.8TB/s, whereas the Blackwell series uses newer HBM3e with a bandwidth of 8TB/s. (TB/s stands for terabytes per second, the rate at which the memory can deliver stored values to the compute units.) The newest Vera Rubin chips use HBM4 with over 22TB/s of memory bandwidth. Meanwhile, domestic Chinese chips have yet to crack HBM3; Huawei’s Ascend 910C uses (foreign-made) HBM2E with only 3.2TB/s of memory bandwidth. This means that despite Huaweiopolis’s superficial equivalence in FLOPs to Nvidiana, a large proportion of those FLOPs are unusable for inference workloads, since the logic units end up twiddling their thumbs waiting for memory, making query response times far too long.
Network Bandwidth
Lastly, network bandwidth — the speed at which data moves between separate chips or racks of chips — would severely limit the performance of Huaweiopolis’s cluster. Memory bandwidth is a limiting factor for within-chip communication because it determines how quickly data can move between a chip’s memory and its logic, effectively setting how fast the chip can stay fed with work. Network bandwidth — how quickly different chips can exchange data across the rack — is the limiting factor for between-chip communication, and network bandwidth is significantly slower than memory bandwidth. For an eight-chip cluster of B200s, memory bandwidth is an aggregate of 64TB/s, whereas network bandwidth is only 14.4TB/s. For training and serving inference on models, you don’t want to use network communication if you can help it because every time chips need to exchange data, they must stop and wait on one another; at scale, this turns communication into the dominant cost, meaning that adding more chips yields diminishing returns and eventually no additional performance at all.
Unfortunately for Huaweiopolis, if their strategy is to connect a massive blob of lower-quality chips to compete with a tiny cluster of higher-quality chips, they cannot succeed; network communication is unavoidable, and it will hurt. A Nvidiana cluster, with more power and memory storage per chip, can do a lot more within-chip before needing to resort to between-chip communication. A Huaweiopolis cluster will be running into this bottleneck a lot more frequently, and it will slow down operations. Particularly for training large models, where using multiple clusters of chips is necessary, the network bandwidth limitations will be crippling.
Jensen likes to dismiss this issue by arguing that “Huawei is a networking company” and dismissing the importance of HBM, but this is simply not the case. Networking will always be worse than memory bandwidth because data inside a chip moves over much shorter, more direct connections, while networking requires sending data across longer links with added coordination delays. Even God’s best NVL72 or Huawei optical fibre could not beat HBM in this battle because “beating HBM” would mean feeding the chip inputs as fast as its own memory can, which no external network can match.
FLOPs matter, but they are not the only metric. They are perhaps our best metric of comparison for now, but a proper comparison requires consideration of multiple factors. A naive equivalence on FLOPs of a Huaweiopolis cluster with a Nvidiana cluster hides the fact that the Huaweiopolis cluster will suffer in performance for both training and inference. This is not just a question of efficiency or speed. In extreme cases, the system can simply fail to train properly. Modern training requires tightly synchronized gradient updates across many chips, so if communication is too slow or inconsistent, those updates arrive late or out of step. The result is that the model is no longer being updated in a coherent direction — gradients do not reliably descend — and training can become unstable or fail to converge altogether, not just take longer or require more energy.
Conclusion
Aggregate compute matters, especially for the broad diffusion of AI across an economy. But when the question is whether a country will have the most powerful AI model, the quality and concentration of its best chips matter far more than its total headcount, and even more than total FLOPs.
There are signs that policymakers are beginning to internalize this logic. Moolenaar’s SCALE Act, introduced this week, still uses the rolling technical threshold framework but has shifted away from his earlier proposal to cap China’s aggregate compute at 10% of US capacity, which was the more aggregate-focused approach. Instead, it would permit exports only up to 110% of the performance of the best chips China can already manufacture domestically at scale, pegging the threshold to Chinese domestic capability rather than total compute. It is a narrower, more observable target, and it takes the quality-over-quantity insight more seriously than the aggregate headcount approach did.
No chip policy is going to be perfect, but the underlying logic is to focus the policy on the specific chips that matter most. We should be building enforcement around these crown jewels rather than solely around an aggregate FLOP count, and definitely not based on dubious chip counts!
To receive new posts and support our work, subscribe!
Mood Music (Jordan)
The B200 and MCU numbers are measured at different numerical precisions, FP8 and FP32 respectively. Lower-precision formats allow more operations per second on the same silicon, with throughput roughly doubling for each halving of precision on modern tensor cores, per Nvidia’s blog. Going from FP8 to FP32 means doubling the bit width twice, which cuts throughput by roughly a factor of four. That brings the Blackwell’s 10 petaFLOPs FP8 down to an estimated 2.5 petaFLOPs FP32, which divided by the MCU’s 0.12 teraFLOPs yields a ratio of roughly 20,000 to 1.
Huaweiopolis’s setup will also be significantly more expensive, but we will omit this for a purely performance-based analysis.