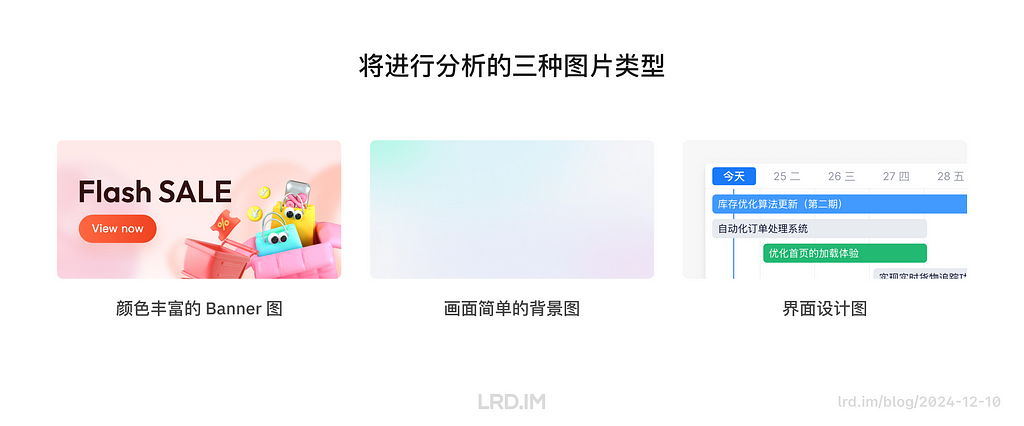
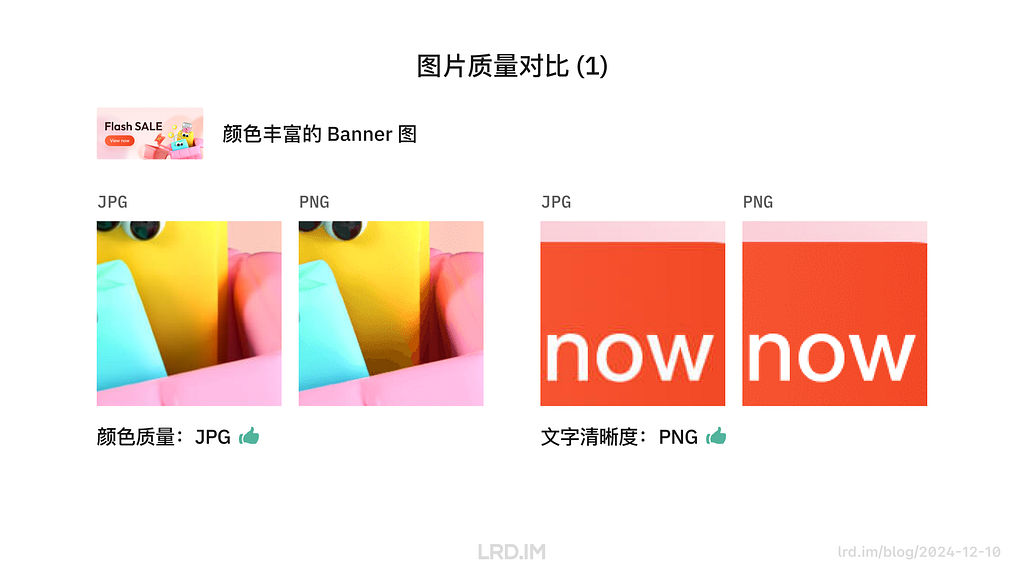
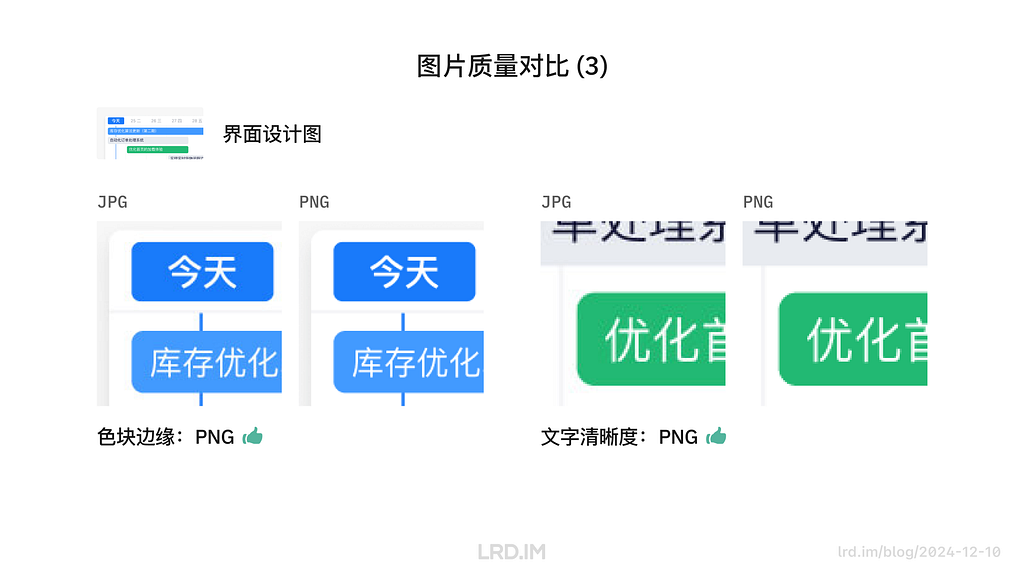
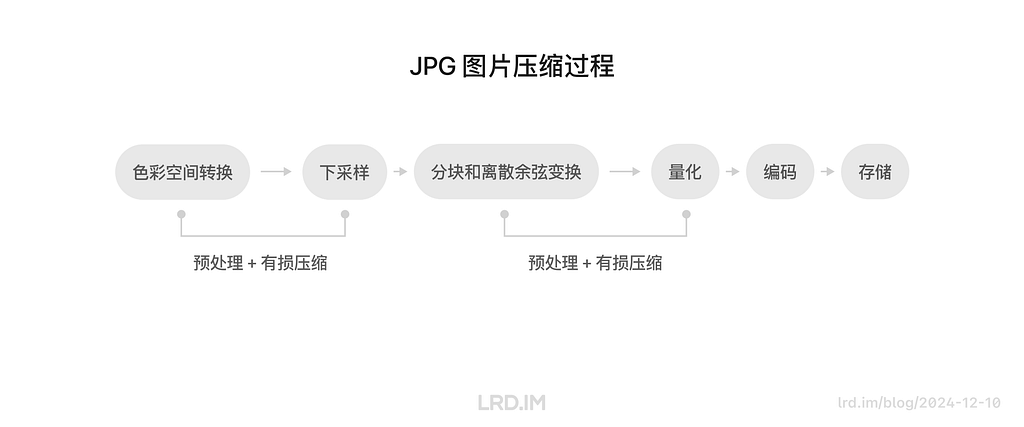
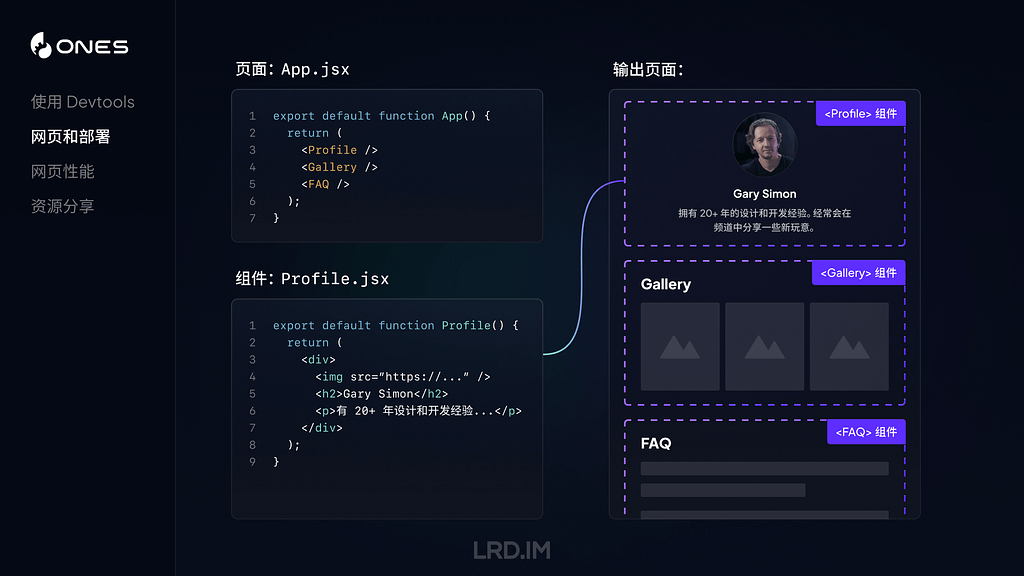
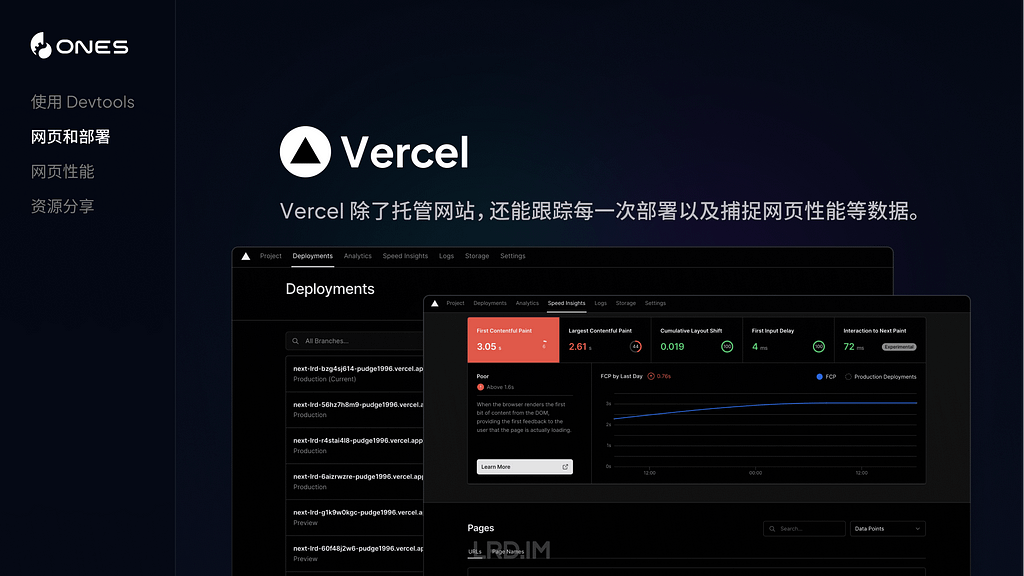
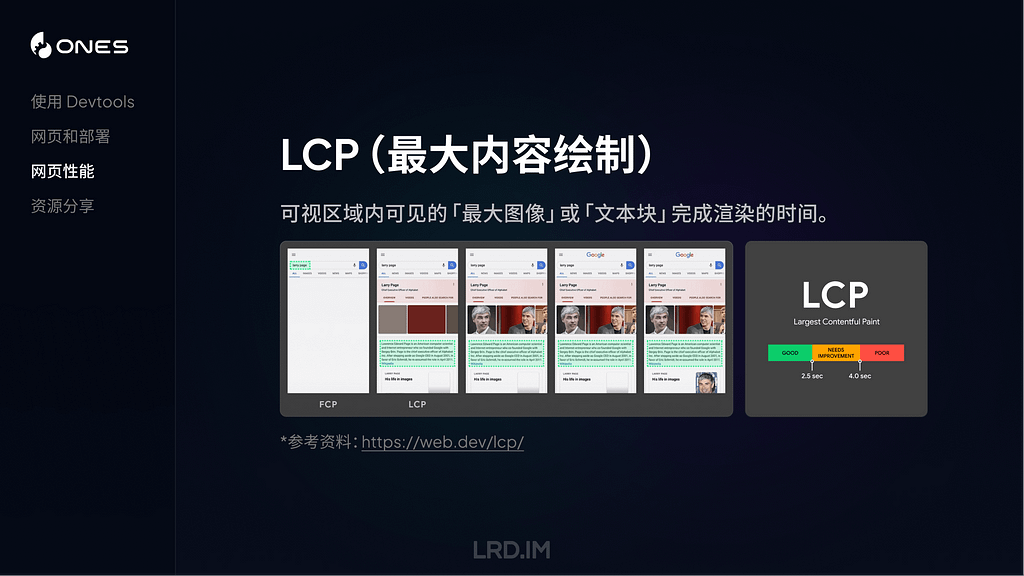
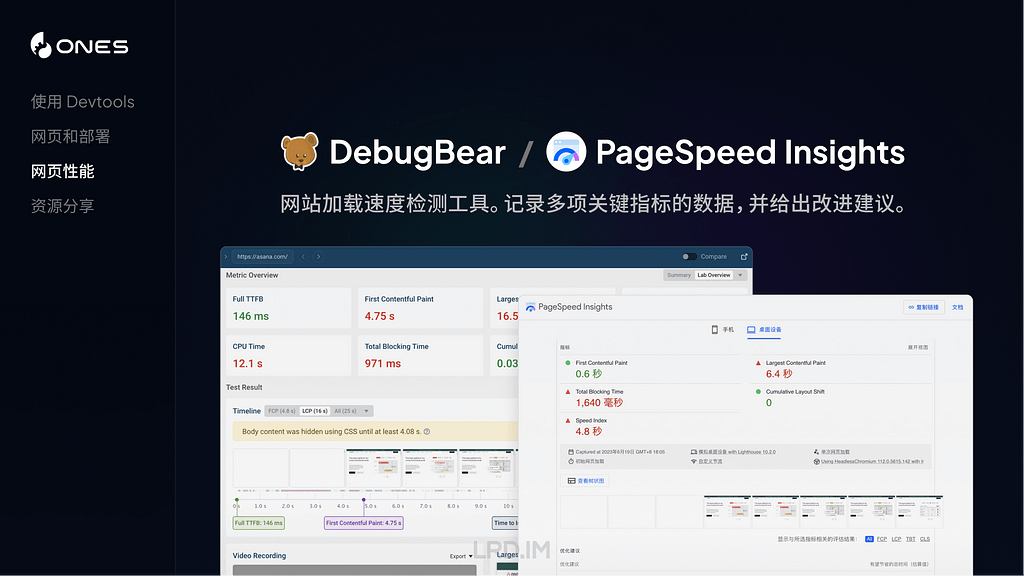
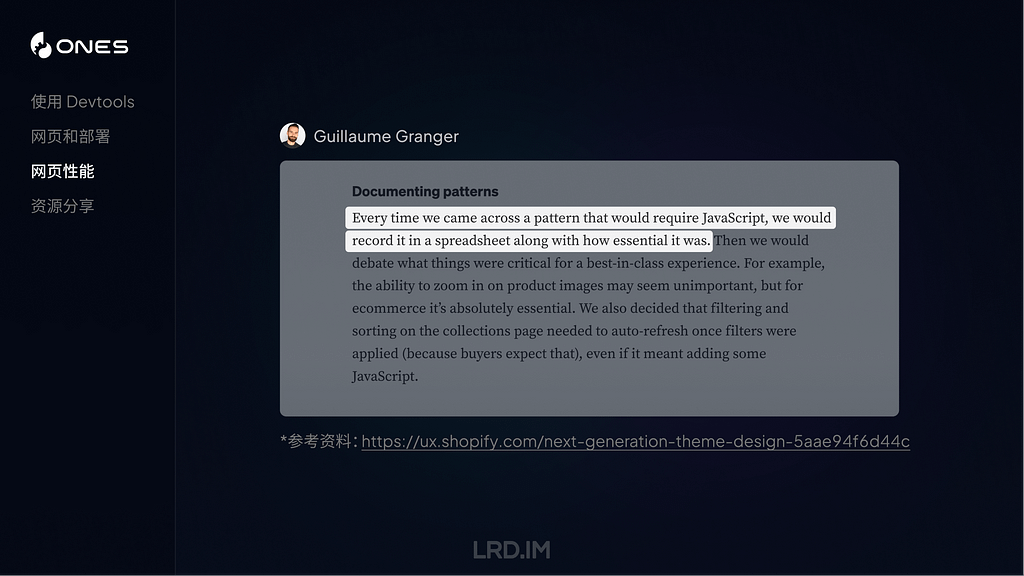
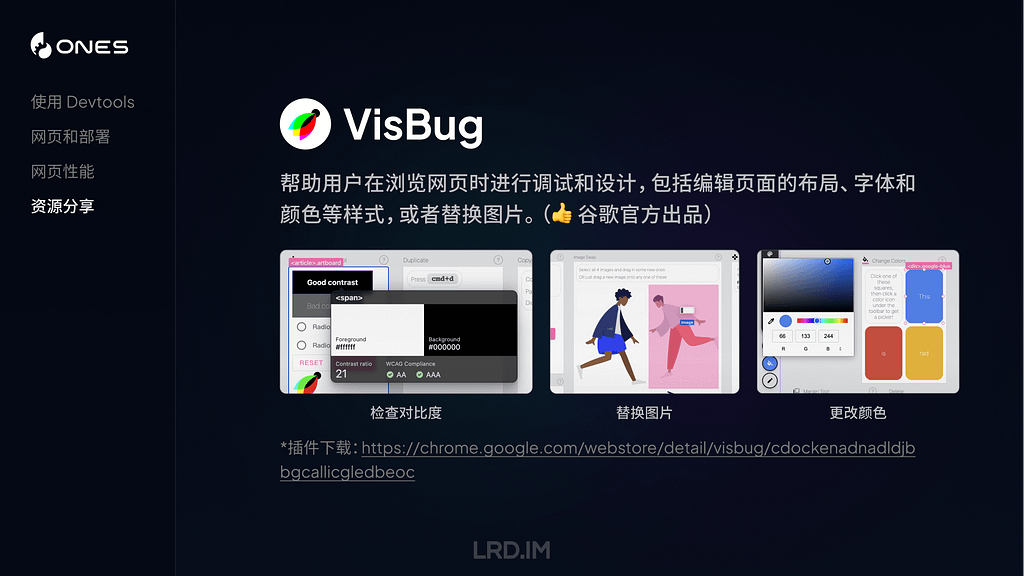
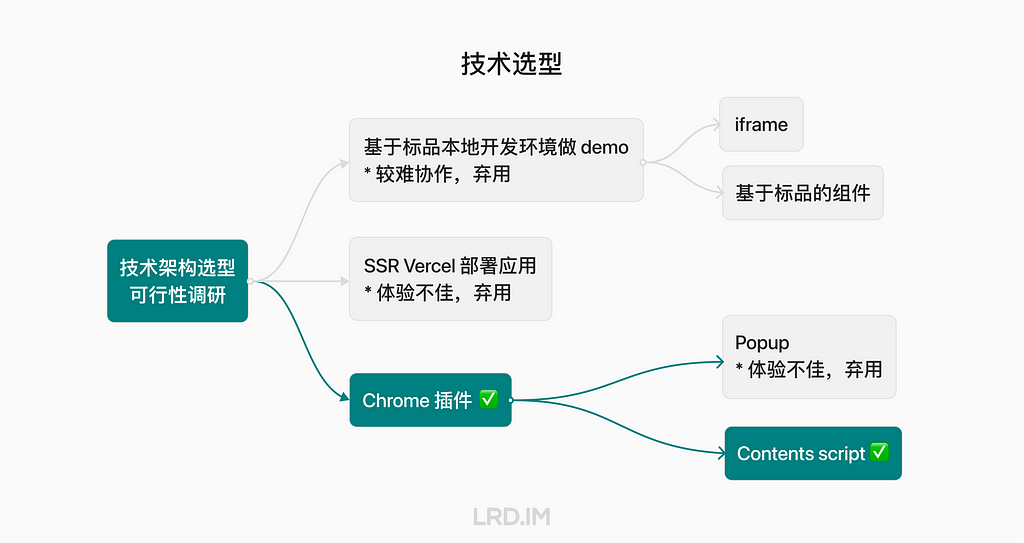
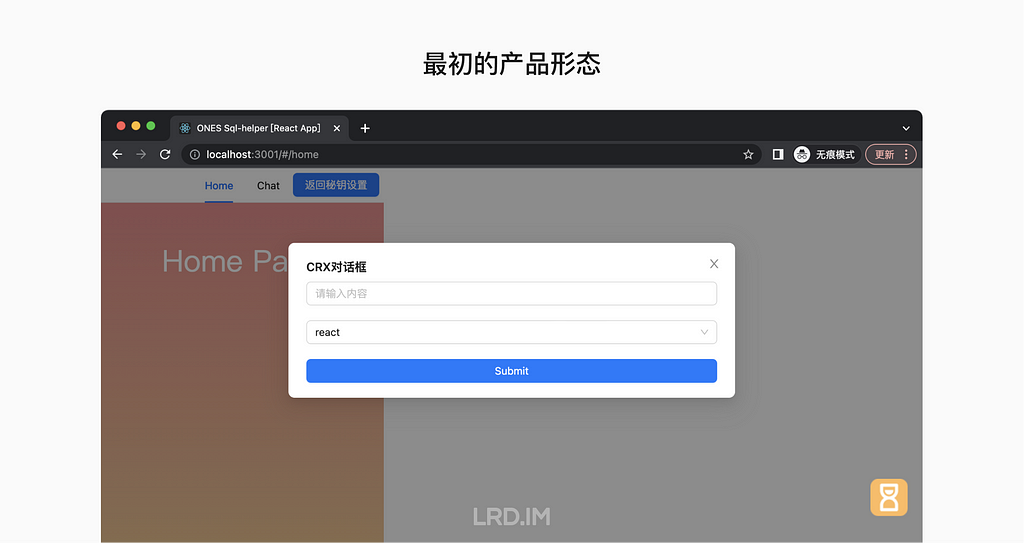
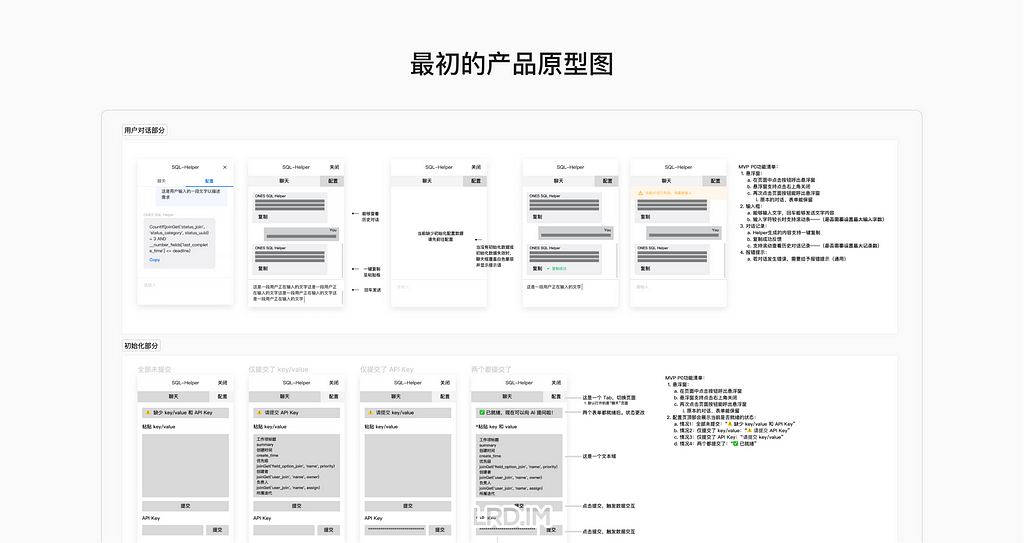
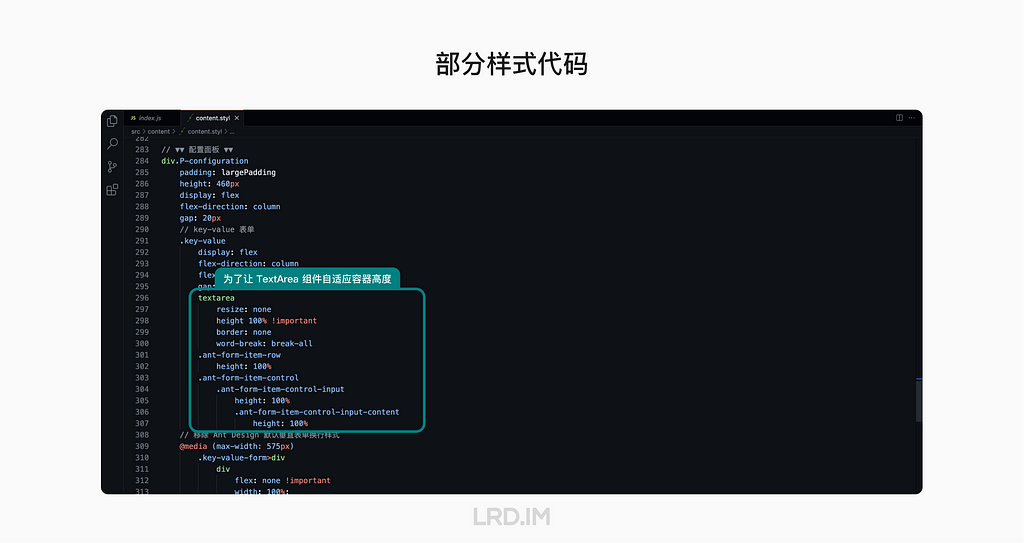
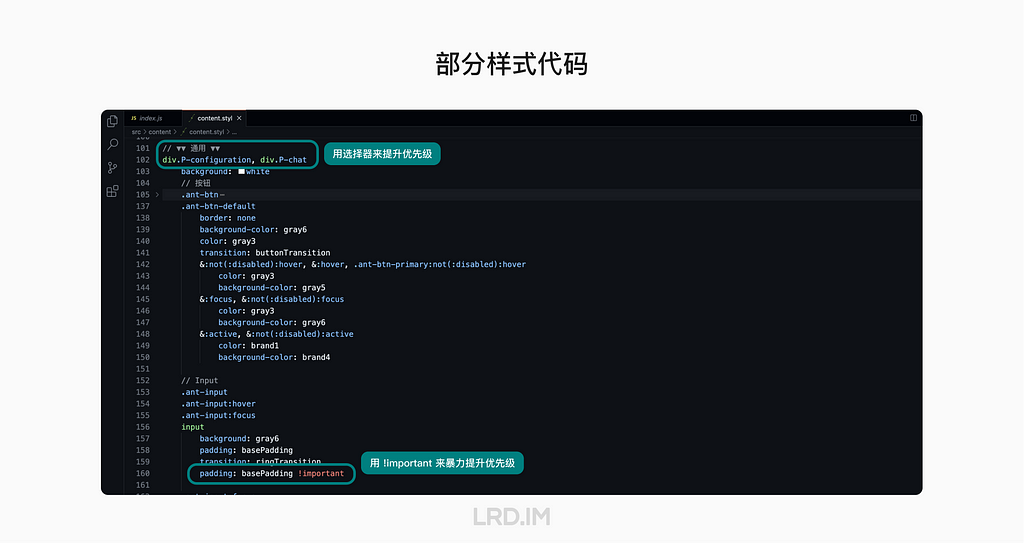
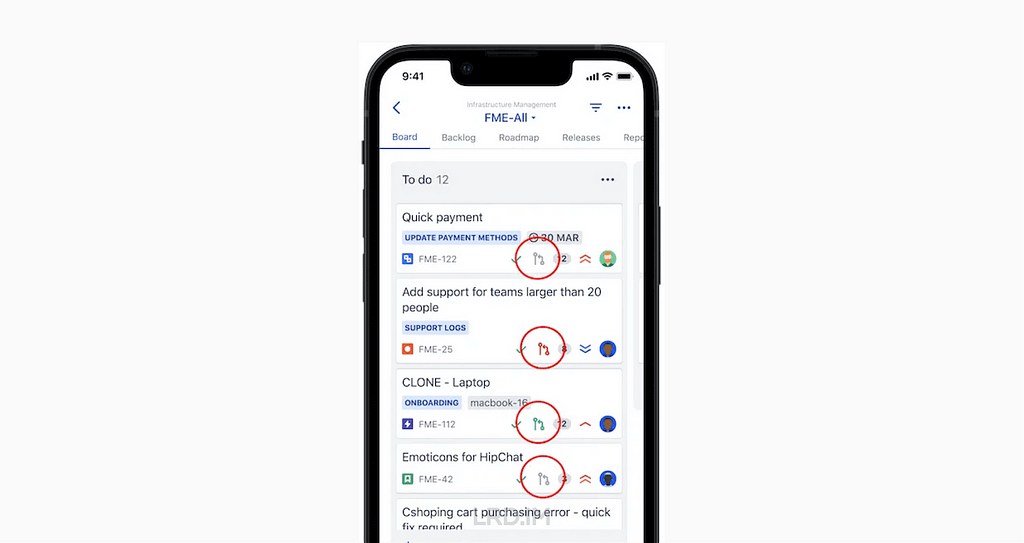
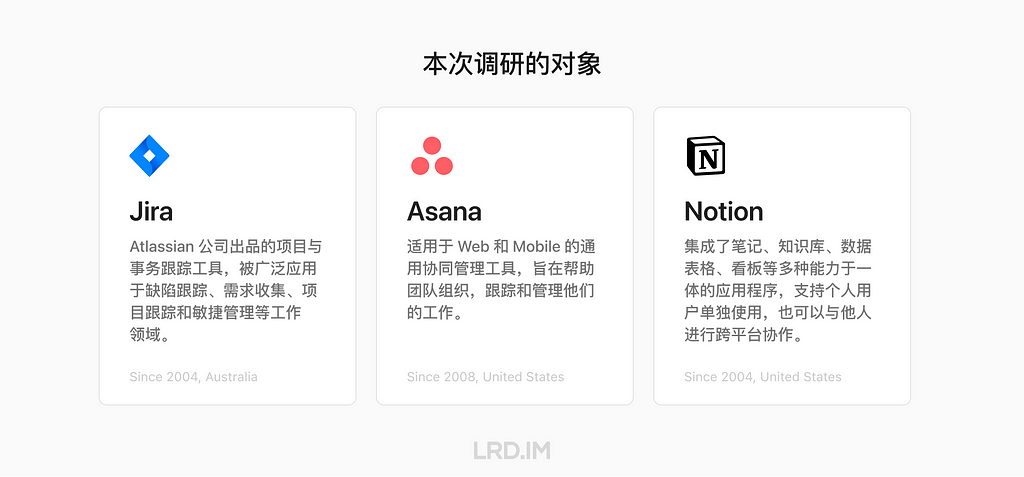
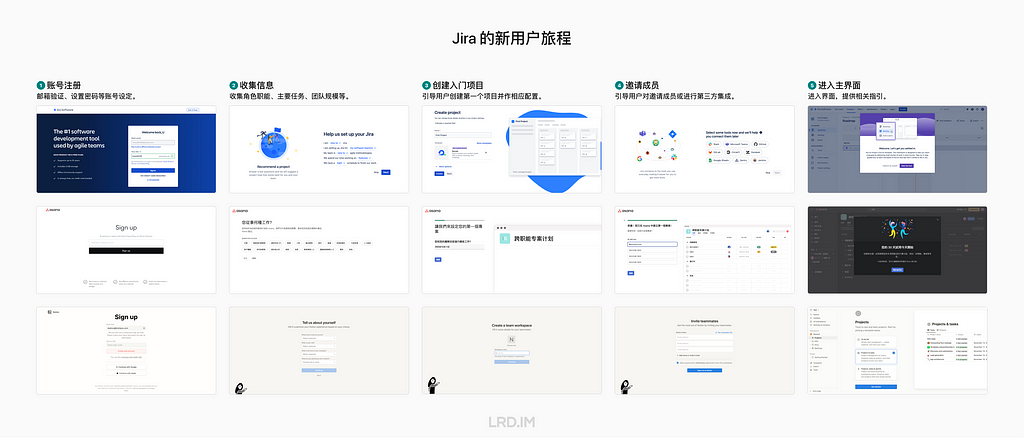
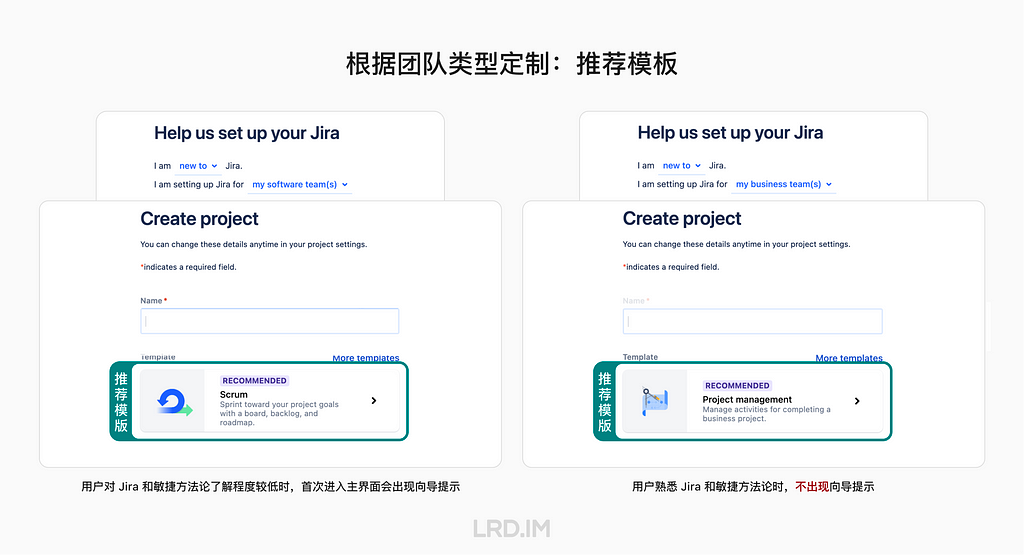
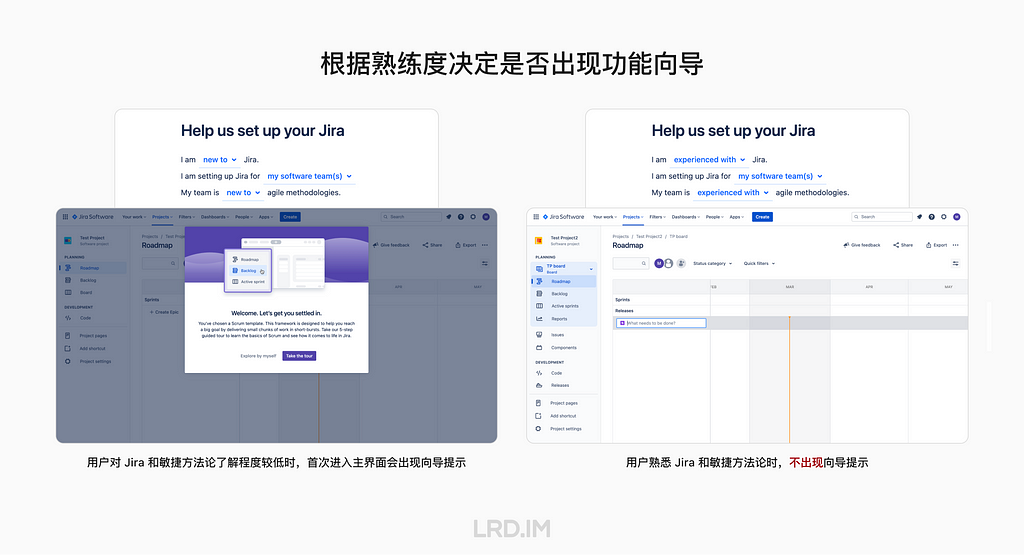
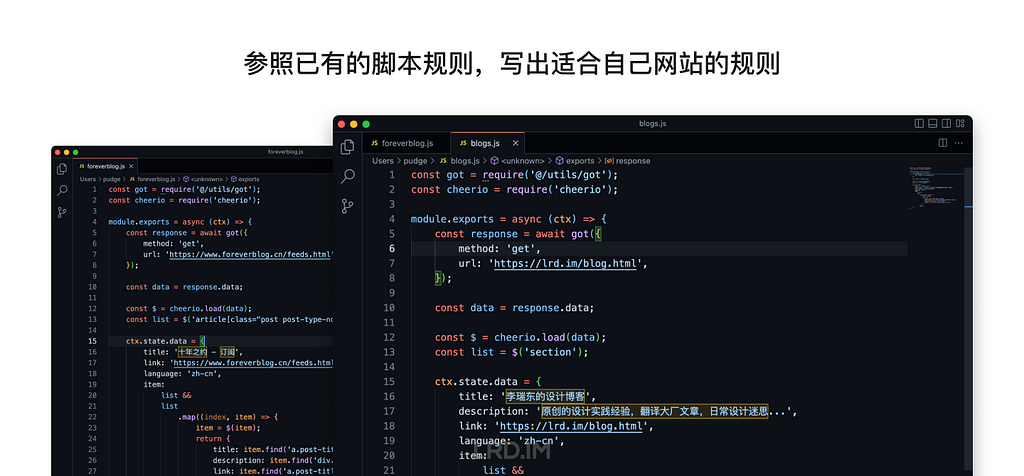
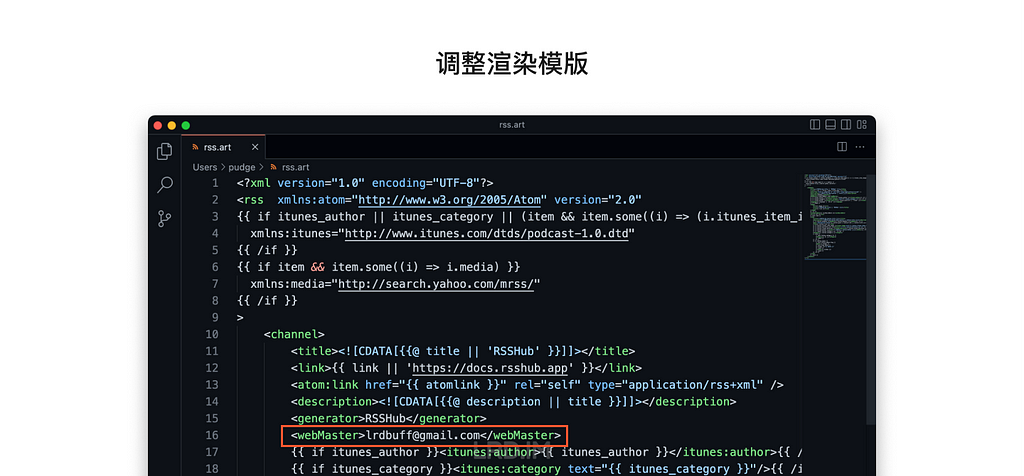
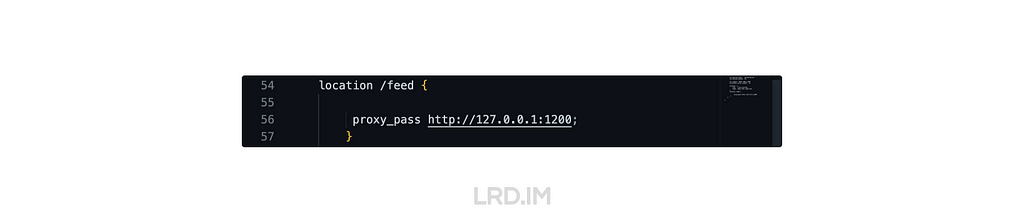
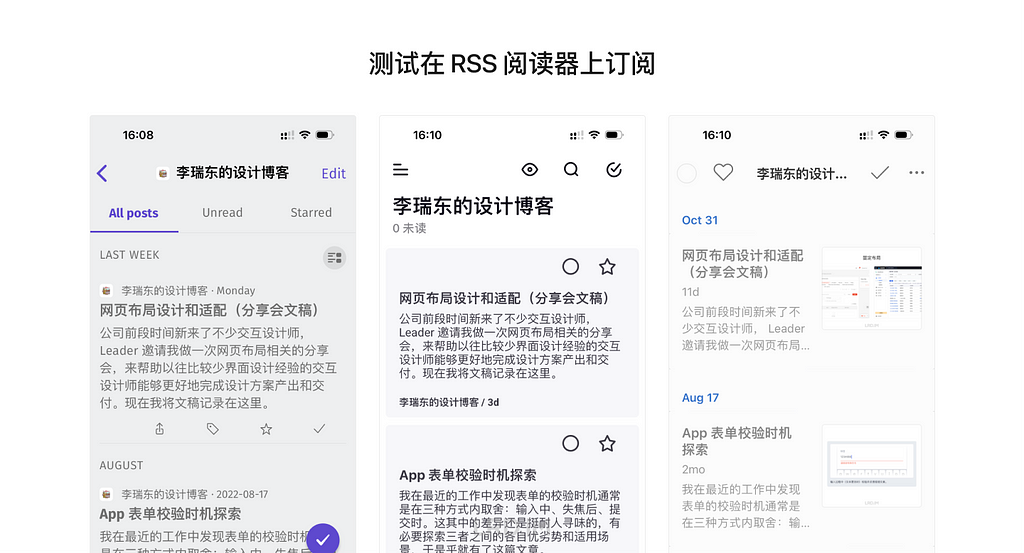
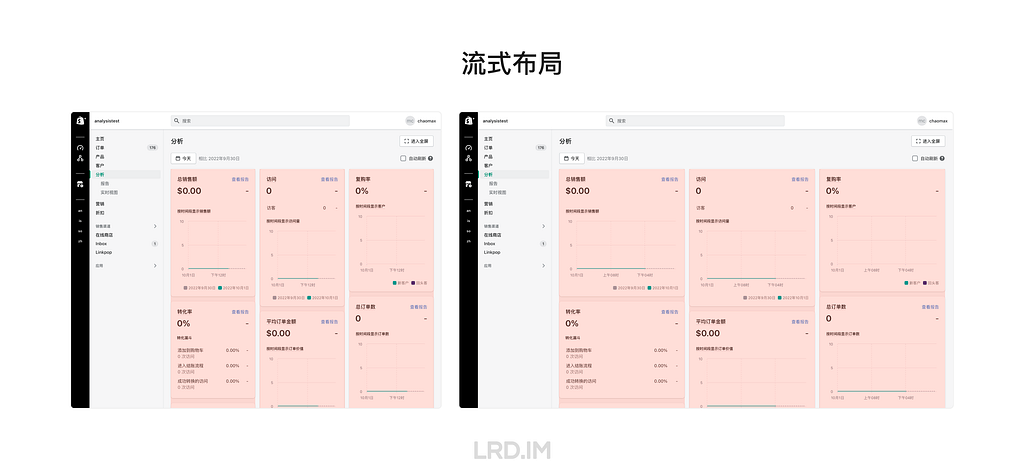
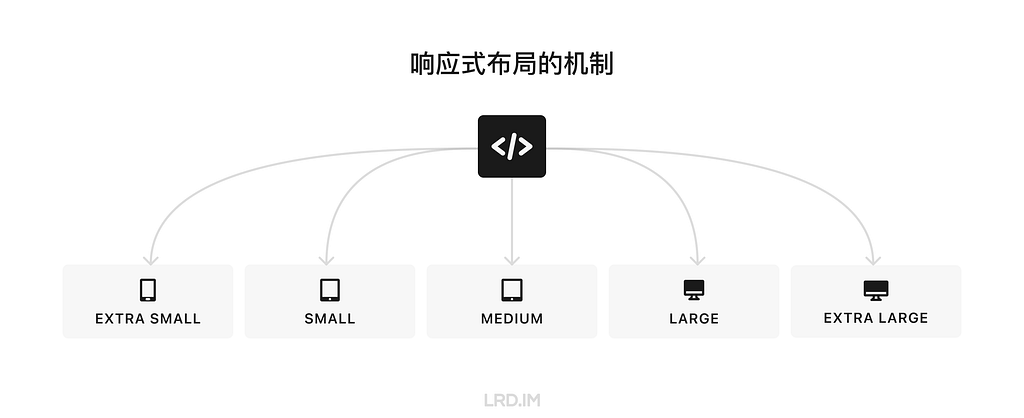
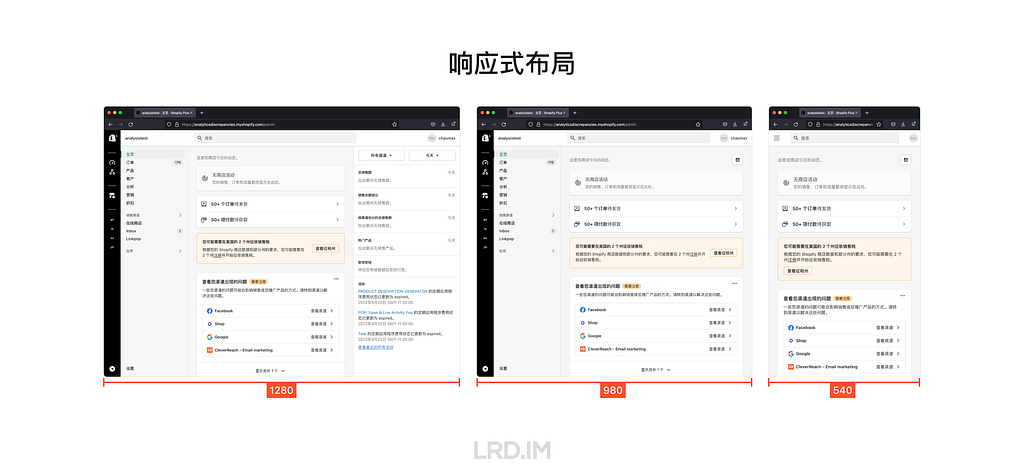
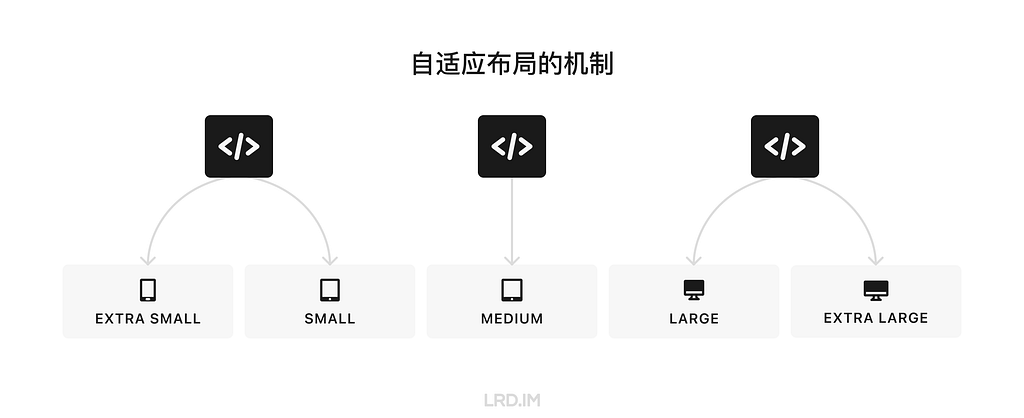
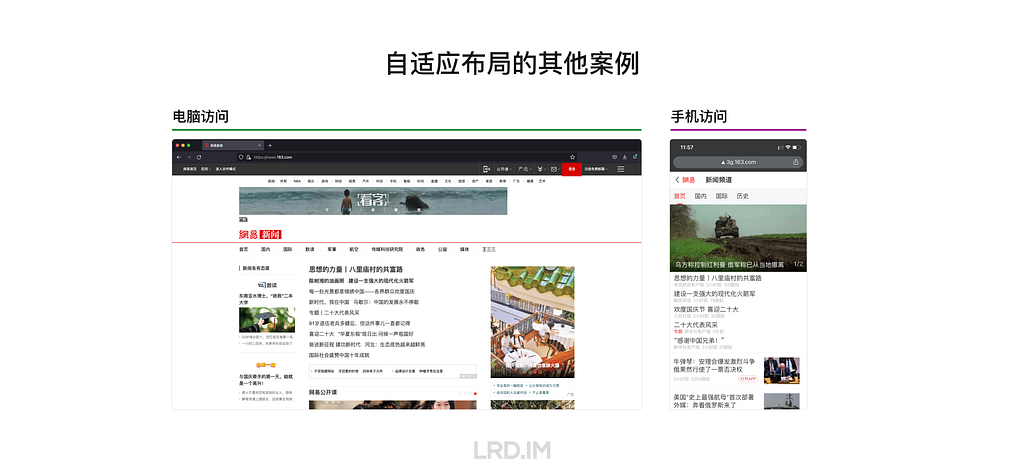
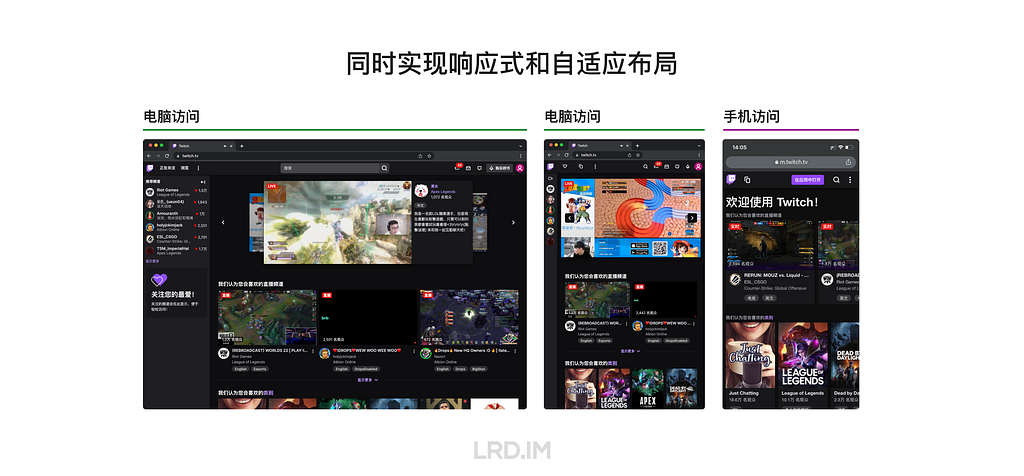
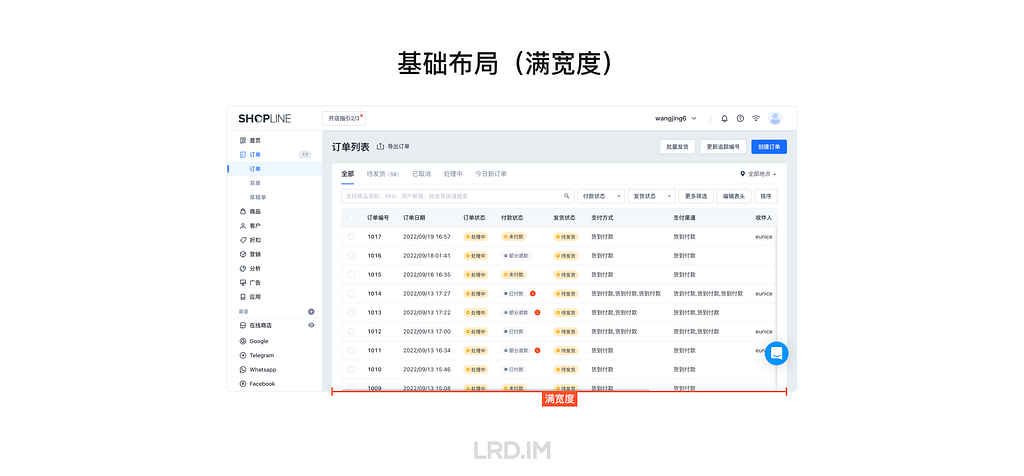
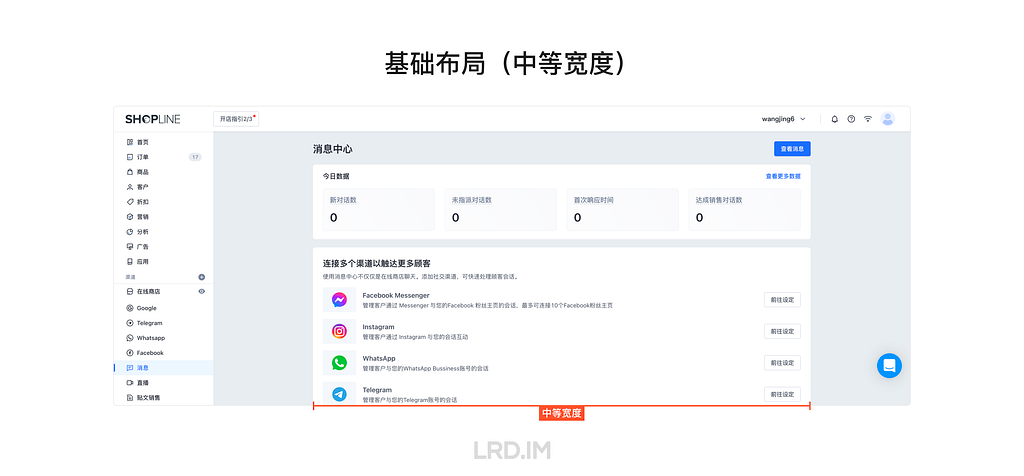
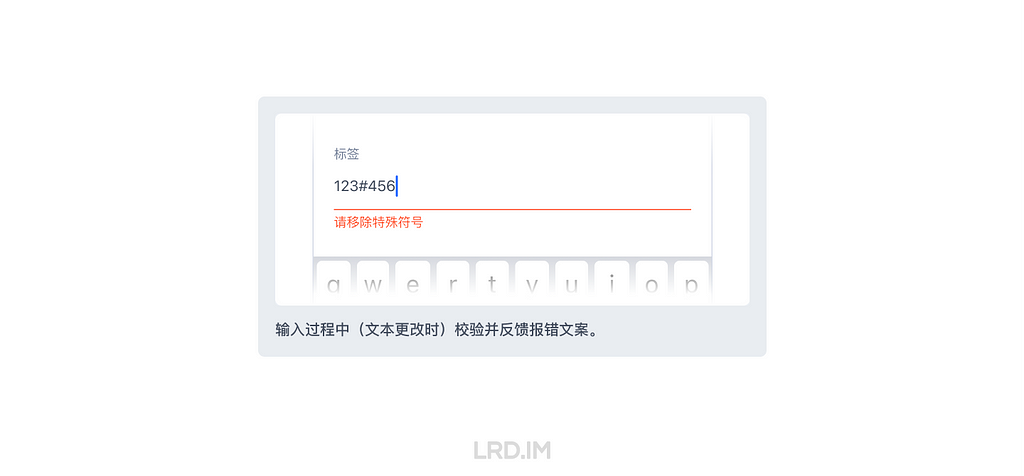
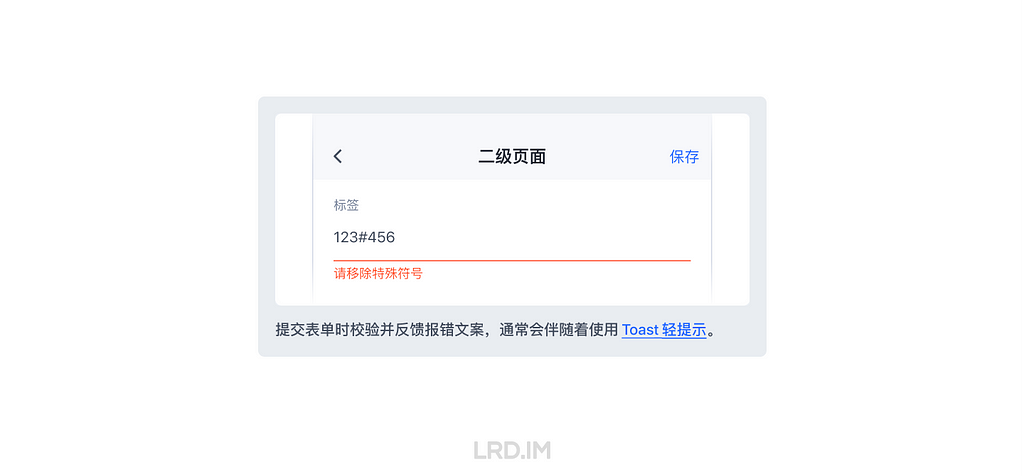
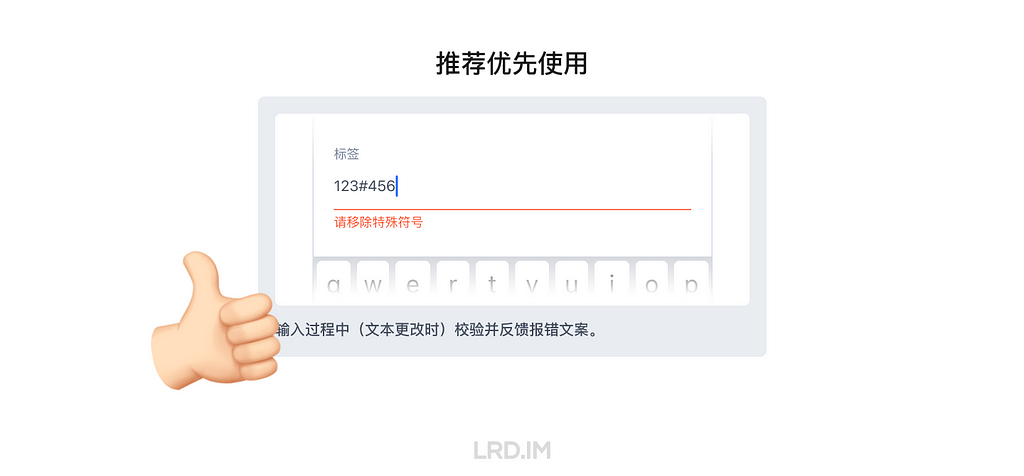
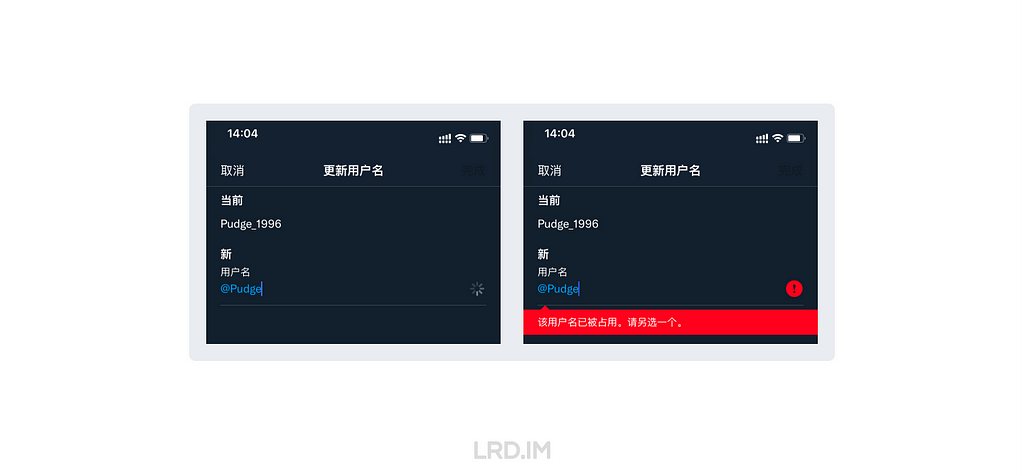
I have been working for the current company for half a year. I have a clear picture of the working pattern: We are a small design team, but each member has to be responsible for both the UI and UX design for many internal systems.
Some of the design requirements are not complex at all, but the stakeholders want to make the interface aesthetically beautiful and different from other internal systems. In contrast, other demand sides hope designers can provide a clear and understandable solution to tackle the complex interaction flow.
The previous one was much more difficult for me since I was interviewed for the senior UX designer position, and I had not expected to address these design requirements, which may have occurred considerable times.
So it is time-consuming to design a portal website or refine a running internal system since I have to try multiple design solutions to ensure it will be aesthetically beautiful and outstanding.
Ideation
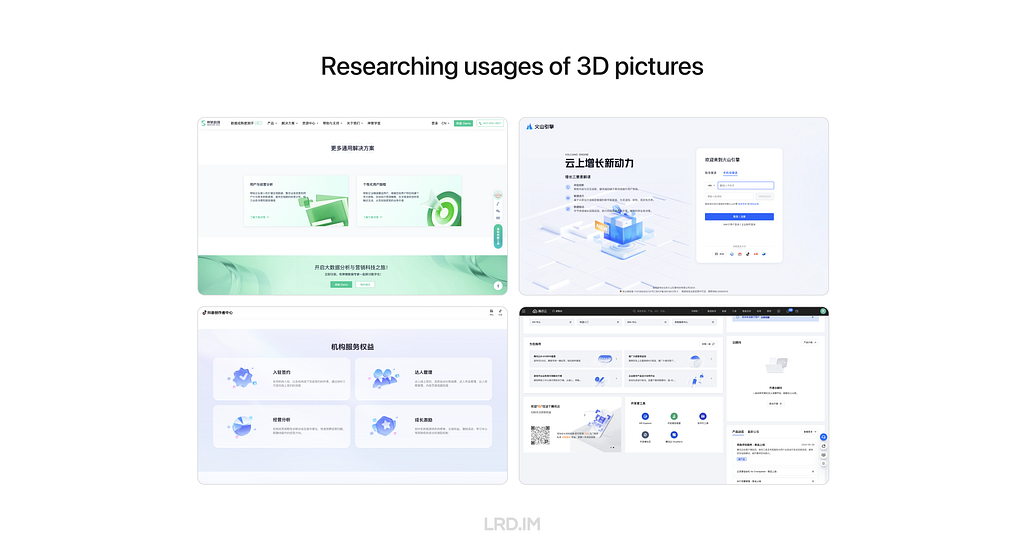
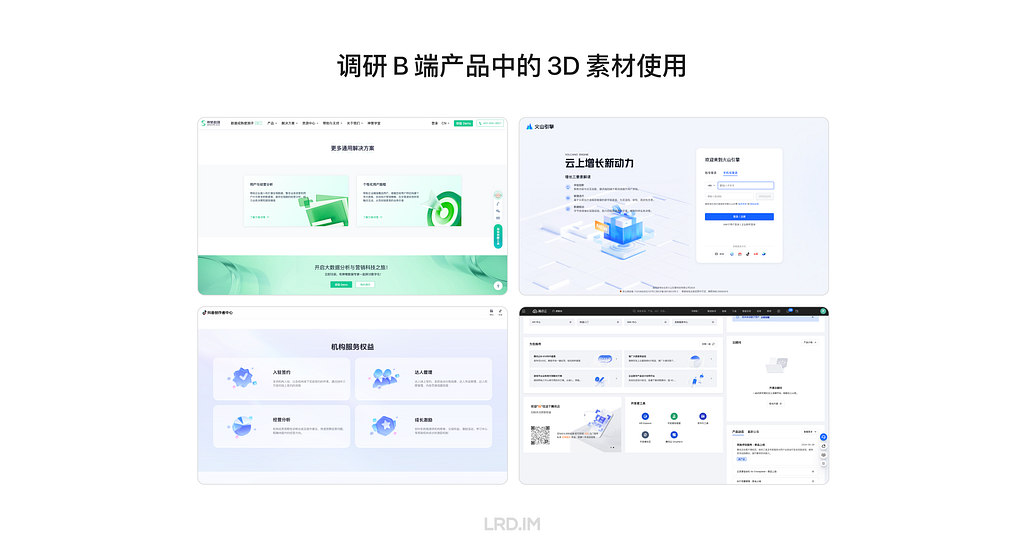
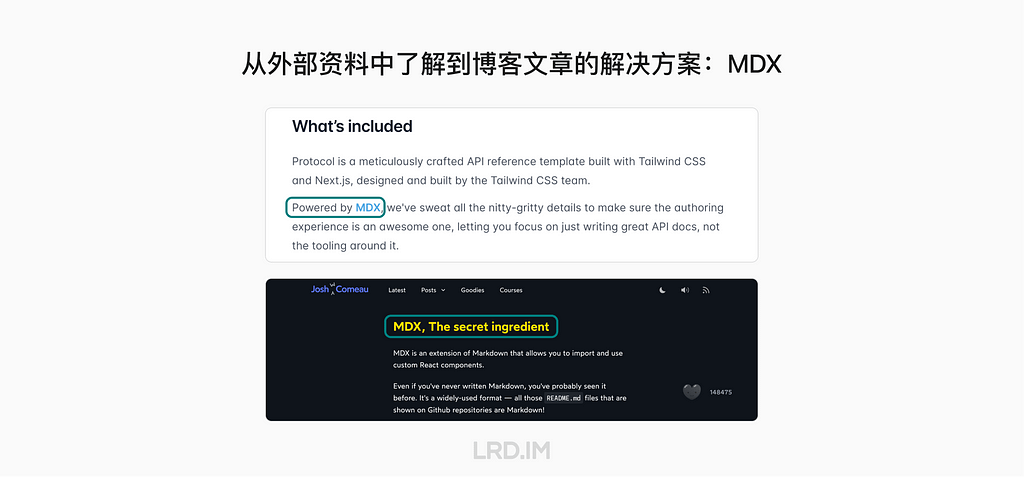
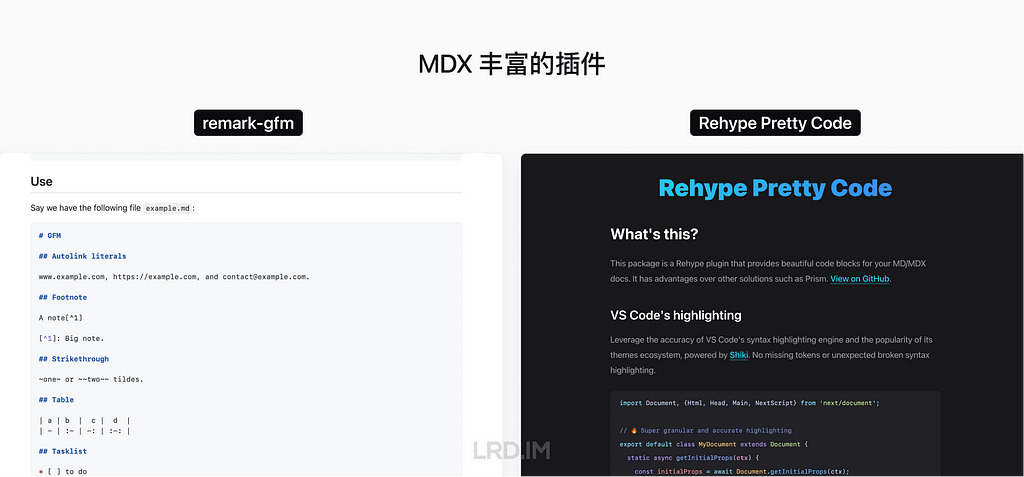
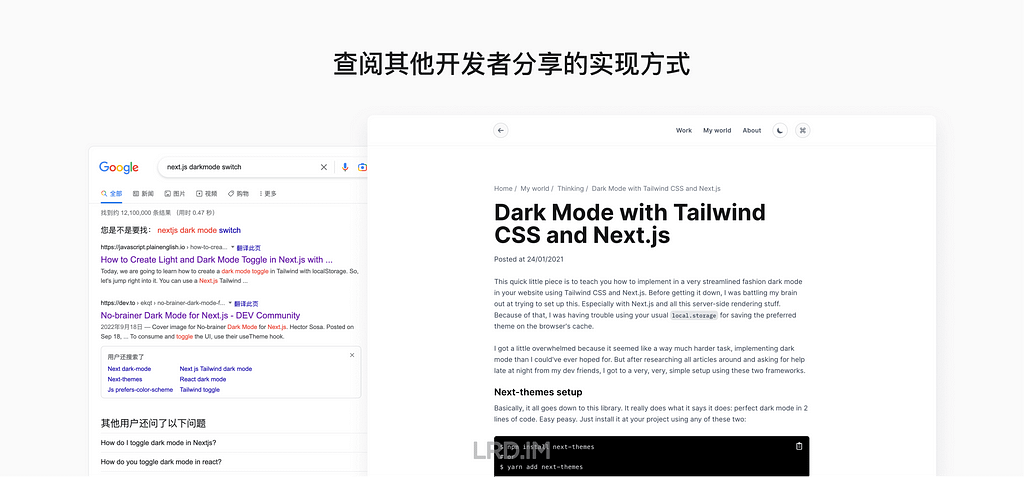
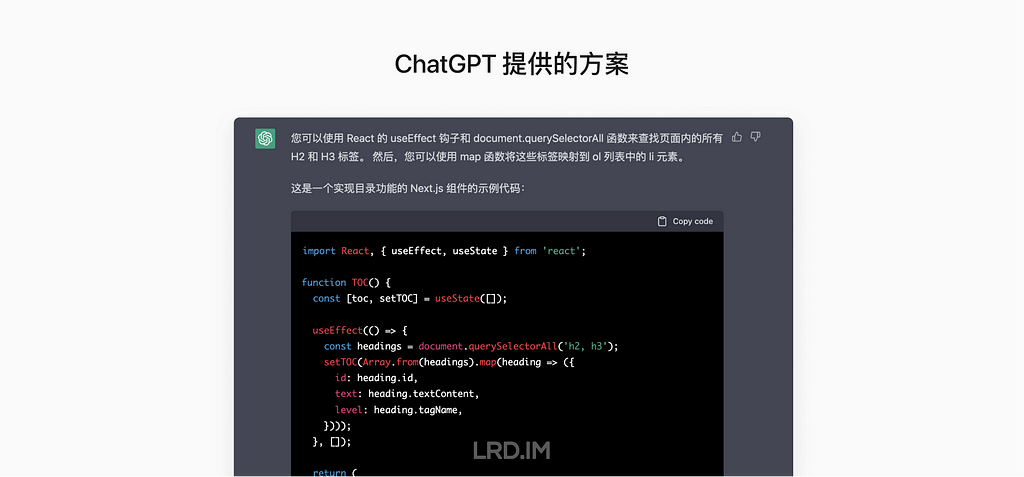
I wonder if 3D pictures could be a great approach to suit this type of design requirements. So I researched external products from large firms, trying to know how they use 3D pictures in their SaaS products.
After collecting and investing in multiple products, I found the patterns:
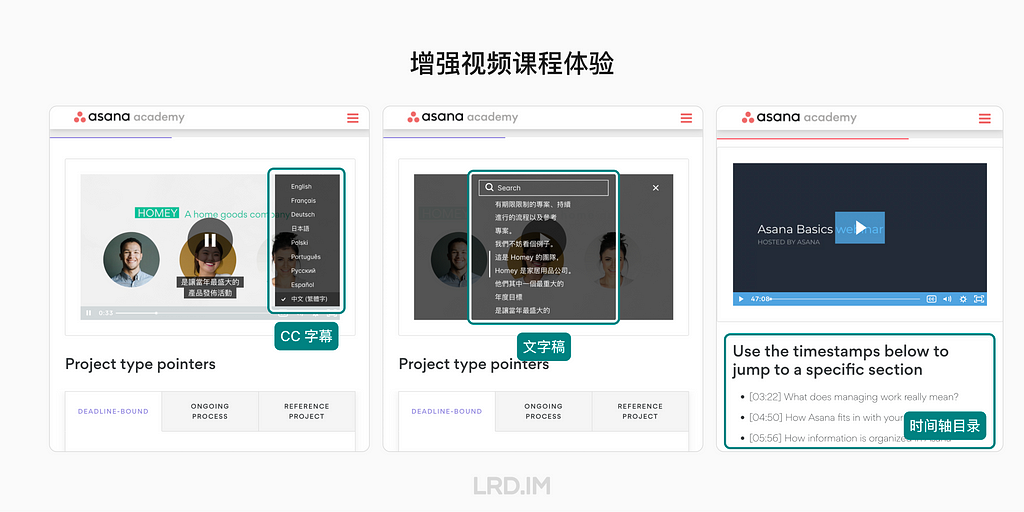
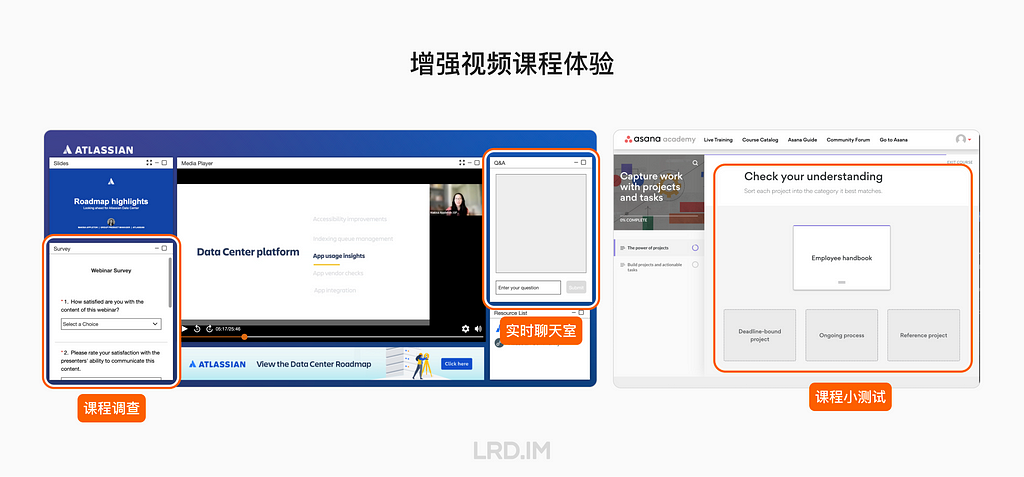
3D pictures are most likely used in landing pages, login pages, portal pages, and the like;
Admin panels and dashboards do not use 3D pictures frequently, but they would appear in entries, feedback, and background decoration.
Conclusion
Based on the pattern above, real working conditions, and small-sized tries, I summarized the first conclusion:
3D pictures are not frequently used on dashboard pages and system admin. However, using 3D pictures could improve the variety of pages. So it is not worth it to spend so much time on it.
3D pictures can effectively meet the expectations of demand sides when they want to make their dashboard and admin pages distinguish from other similar sites.
Difficulties
Since I don’t have skills in 3D design, and my working strength is too high to spend much time learning, modeling, and rendering delicate 3D pictures, I just simply searched 3D visual elements on the Internet and then applied them to my deliverable.
Initially, this approach was workable and can help me complete my work quickly. However, drawbacks are uncovered after multiple uses:
Difficulties of matching business contexts. 3D pictures on the Internet support common scenarios well but can’t always precisely describe certain business scenarios.
Lack of series of an element. Although we finally found a perfect 3D picture, it is hard to reach other similar elements from the same series, resulting in poor scalability.
Risks of infringement. Using 3D pictures on the Internet might cause infringement, so applying it directly consists of potential risks.
Inconsistent quality. Free elements are not guaranteed quality and sometimes fail to meet the standards of our design team.
Here, I draw the second conclusion:
Searching for 3D pictures on the Internet has limited effectiveness, so we can’t fully rely on this approach.
After drawing this conclusion, I feel horrible: does it mean that I should strive to learn skills in 3D design? My work strength doesn’t allow me to learn professional 3D software like Cinema 4D or Blender.
After thorough consideration, I think the core demand for me is not to learn 3D software, rather, I should have the ability to gain 3D pictures. Apart from that, the whole process should consist of these features that suit my workflow well:
Quick render. Since it is not worth it to spend much time on it during my work time.
Consistent style. Ensuring our design has great scalability.
Great customizability. It means that I can fully control elements on 3D pictures, ensuring outputs highly represent the business requirements and contexts.
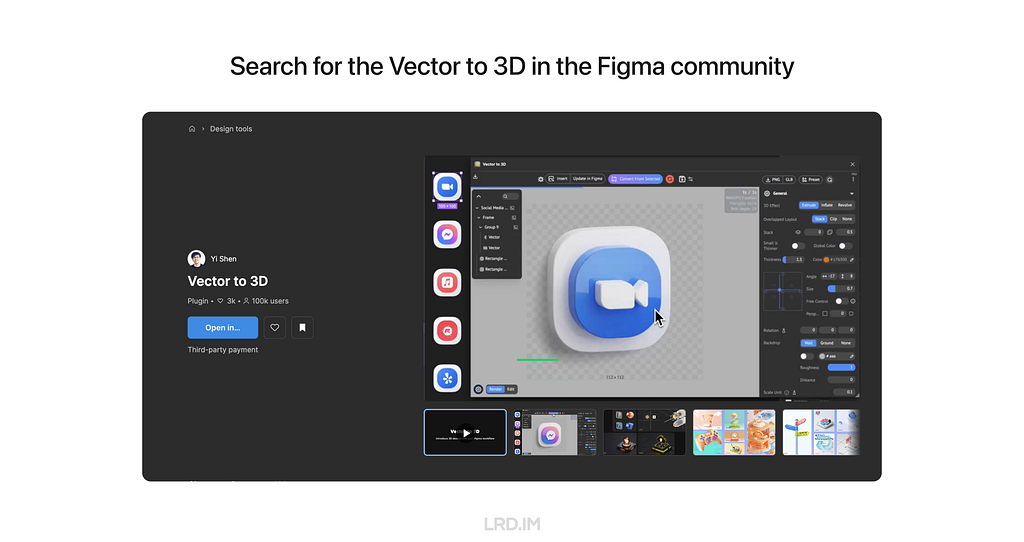
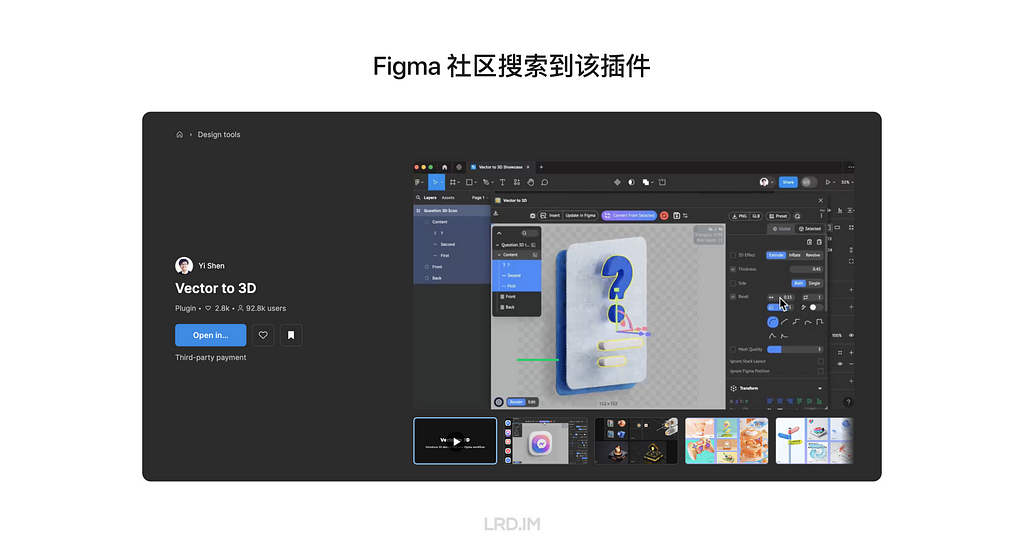
By chance, I know there is a plugin in Figma called “Vector to 3D”. By learning outputs published in the community, it seems that this plugin could meet the features above well, improving my work effectiveness and quality. So I asked my team leader if I could spend some time discovering this plugin and sharing my experiences with team members, and she approved.
Therefore, this post is to record my internal sharing: My experience of how to build 3D modeling & rendering flow in Figma that improves our design effectiveness and quality.
Work with Vector to 3D
Introducing the plugin
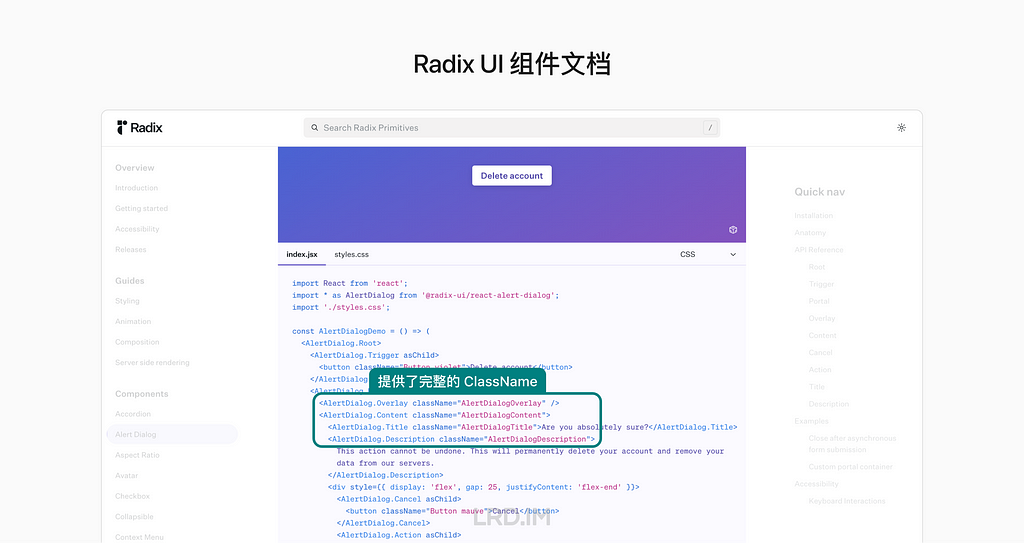
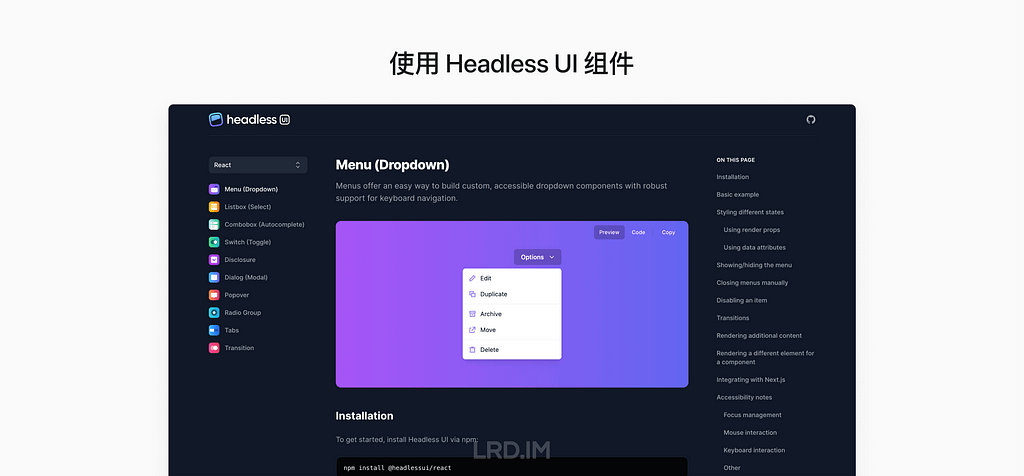
This is a paid plugin, we can search for and install it in the Figma community.
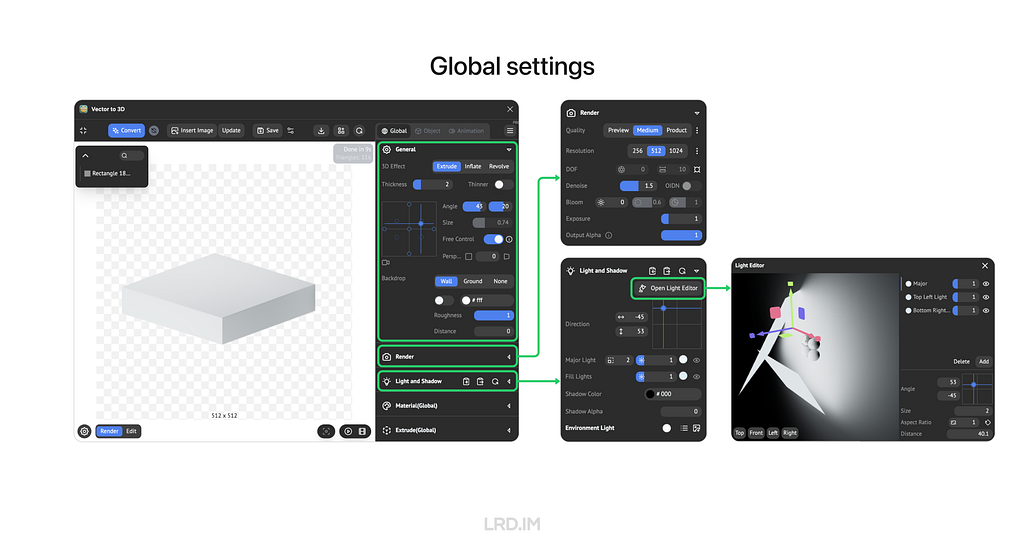
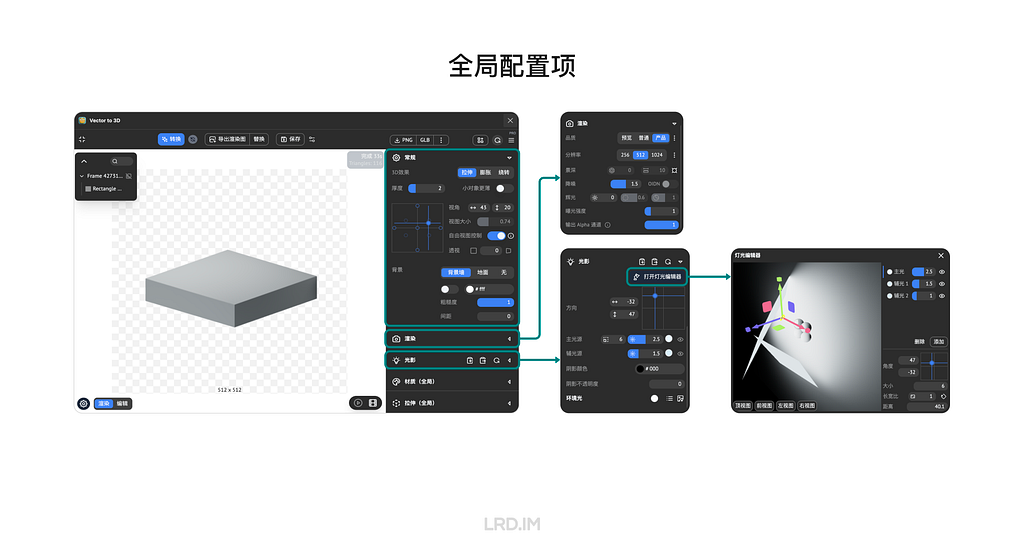
The control panel is comprised of three parts: Global, Object, and Animation settings. Here I will simply introduce the interface of the first two parts, ensuring all readers learn what this plugin can make.
For the Global setting, we can adjust the cameras, and background on the “General” panel; apart from that, we can set the render quality and details on the following panel called “Render”; and then we can control lights on the next panel named “Light and Shadow”, this panel supports varies functions of lights, like the number, size, position, strength, color and so forth.
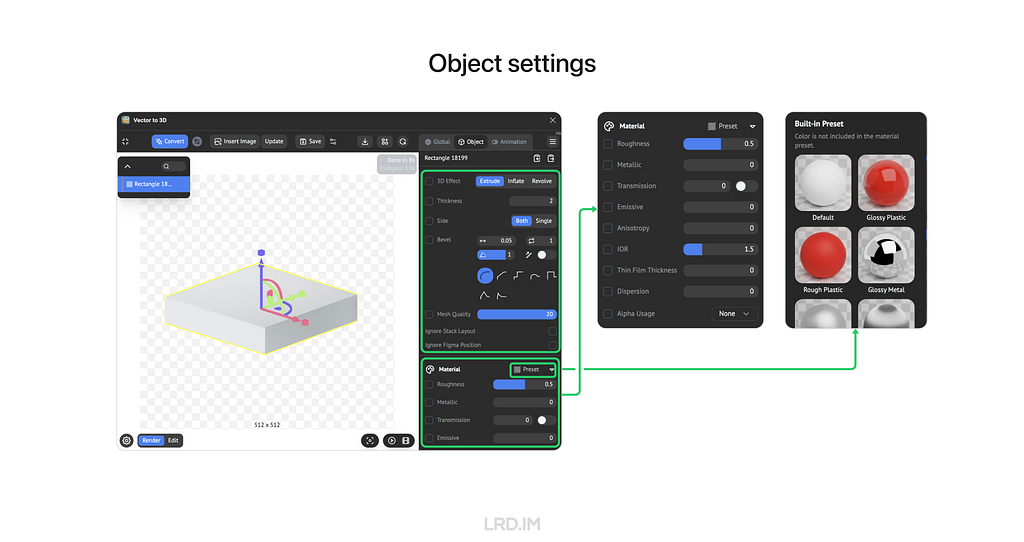
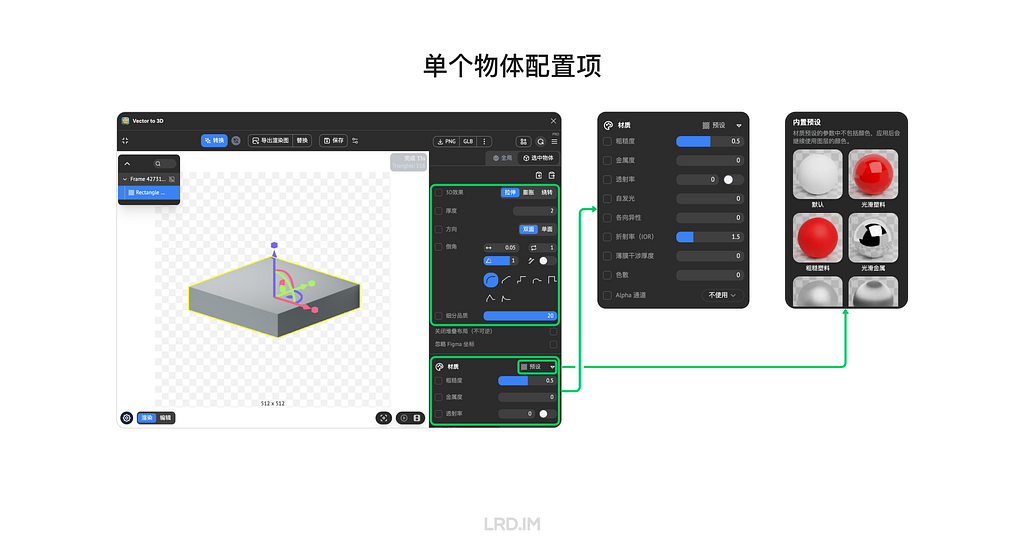
For the Object setting, we can make a 3D model by extruding, inflating, or revolving, and then increase the detail of the model by setting “Mesh Quality”. Moreover, this plugin also supports material settings, like roughness, metallic, transmission, and the like.
These features are more than sufficient to handle nearly all of my design tasks.
Make a template
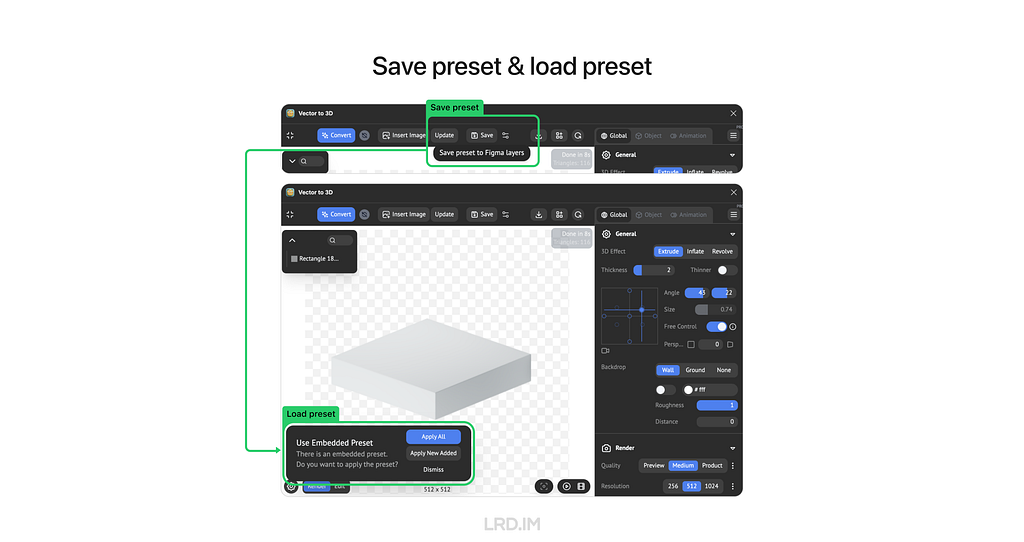
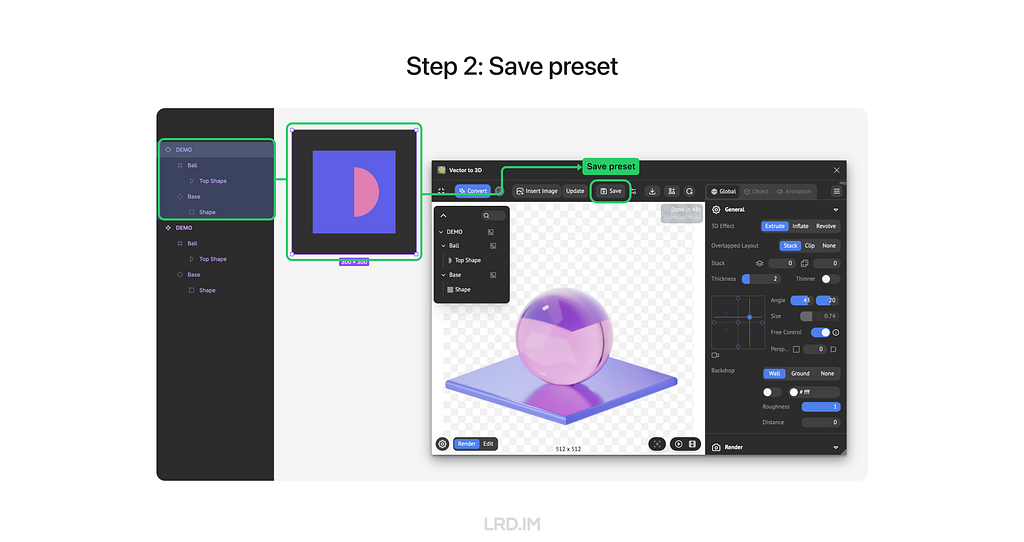
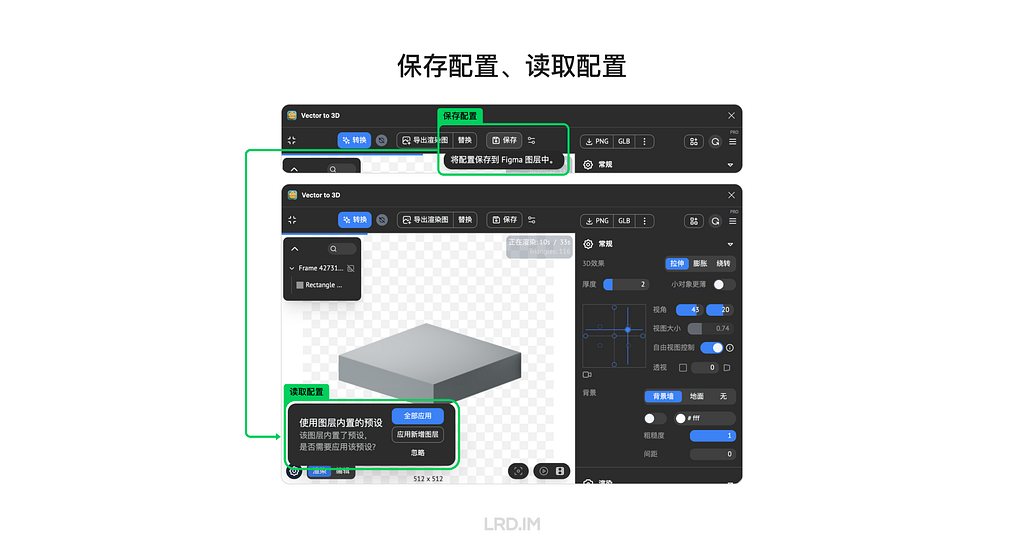
In this part, I will introduce two functions of this plugin: Save Preset and Template Preset.
Saving preset allows us to memorize the current view, modeling, and material settings of the frame. We can reload all the settings by the next open, even sharing with friends.
Templating Preset is not only the masterpiece of connecting the plugin with Figma but also a key factor in effectively generating 3D pictures.
Once we built a template, the plugin would memorize all the raw object preset, next step, we can replace the raw object with anything else, and succeed the raw object preset to it.
This approach is highly convenient for us when producing 3D elements. We just have to create a template, and then we replace various shapes, finally, we can produce endless 3D elements that fit our actual needs well.
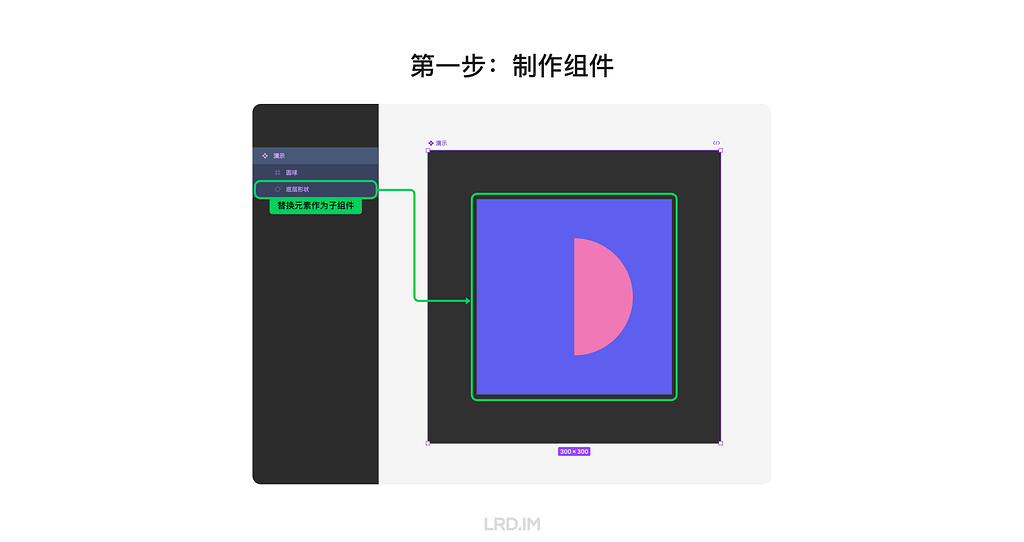
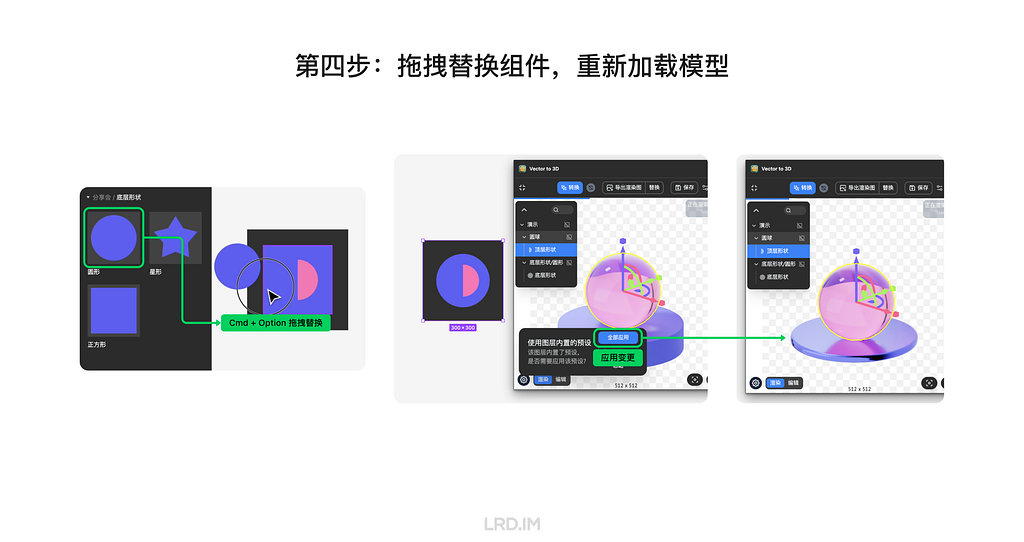
How it works: First, we need to set the frame as a component and make the replaceable element that we want to replace with a new one a child component. (In the following example, I set the square bottom as a replaceable element.)
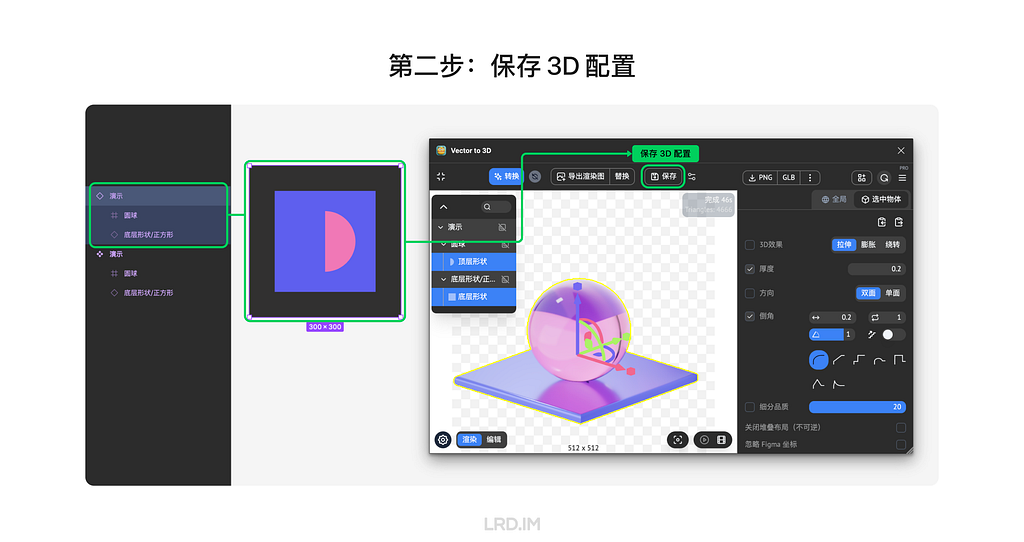
Second, we duplicate the whole component and tune settings in the plugin, then save it. (In the following example, I make a glass ball and a square bottom base with a metallic surface)
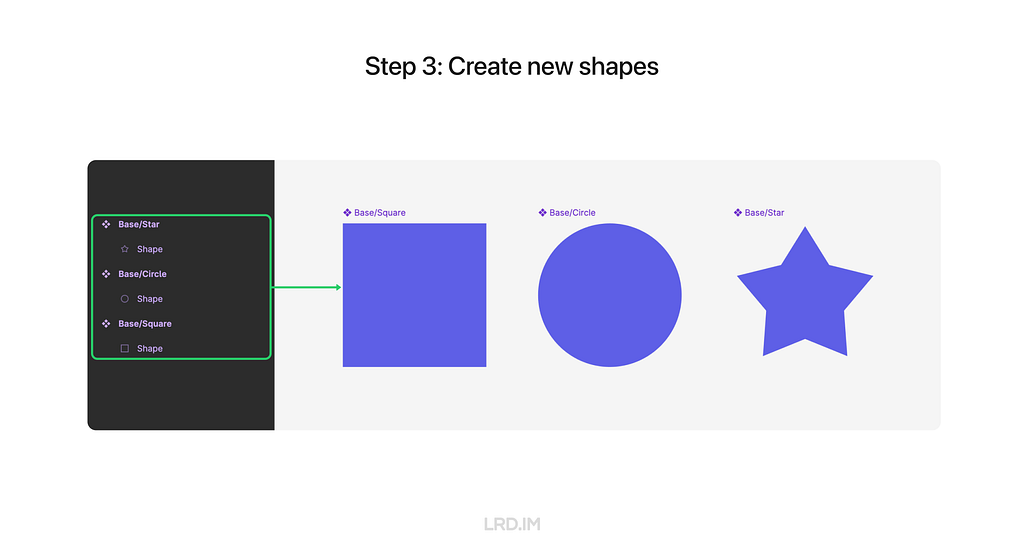
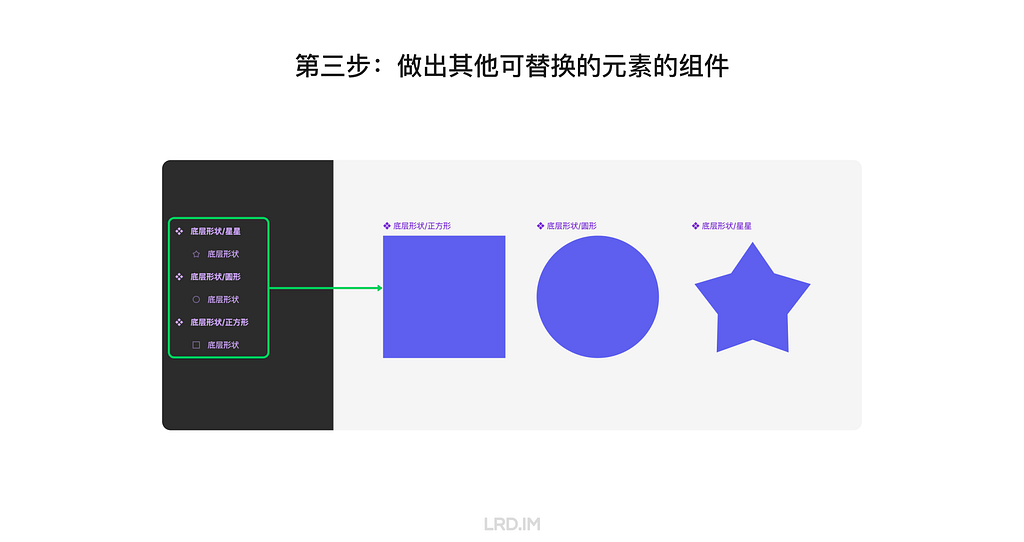
Third, we need to create a bunch of shapes that are to replace the replaceable element, making them an individual component and ensuring their layer number, order, and name are the same as the replaceable element.
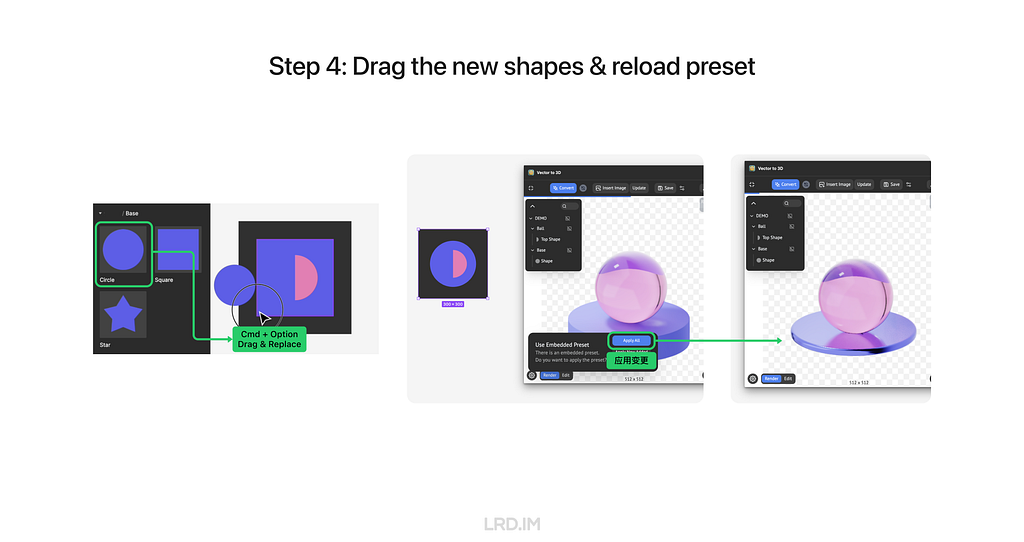
Last, we can hold the keys “cmd” + “option”, drag a new shape component to replace the replaceable element, and then reload the model again. Now we can see the new shape is applied to the same presets.
Now we successfully made a template, we can produce endless 3D elements by creating and inserting new shapes.
Actual practice
Here, I will share a case that is already used multiple times in my daily workflow.
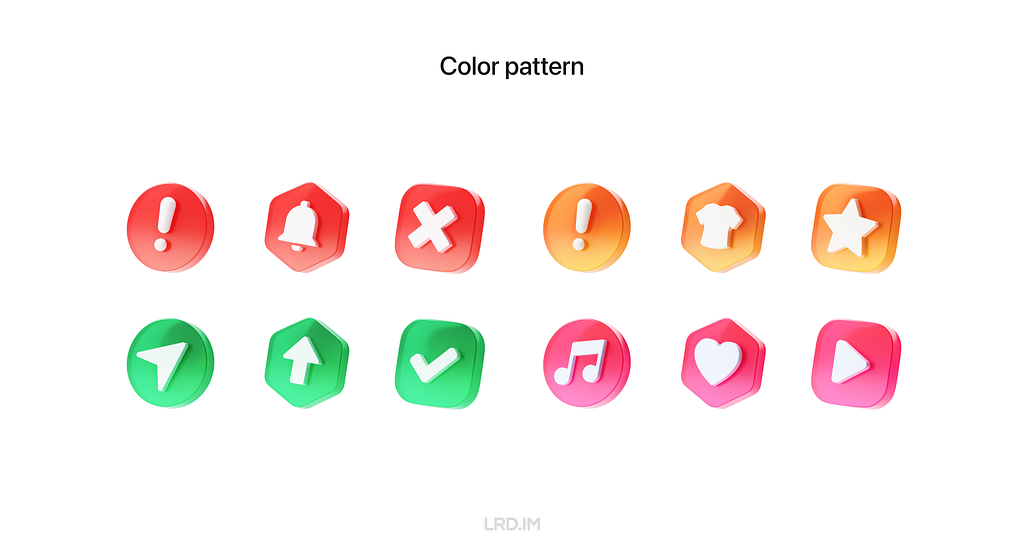
In this template, the shape of icons and background are replaceable, generating endless pictures and fitting nearly all of my design tasks. So it can be a resource library, empowering other team members.
Meanwhile, I created a color pattern, which not only can be used to represent states like success, fail, warning, and the like but also can be applied to the system with different color themes, ensuring our outputs are highly scalability.
Benefits
In the post above, we learned the interface of Vector to 3D, how to make a template, and how I use this flow in actual workflow.
We are familiar with the 3D design workflow in Figma. To conclude this post, I’d like to summarize the key advantages of this process.
1. Low learning costs
We can simply recognize that the plugin “Vector to 3D” is a lite version of 3D software, simplifying complex functions from traditional 3D software and keeping essential functions.
2. Full design process within Figma
This workflow allows us to produce great 3D elements that don’t have to leave Figma. Apart from that, we can simply tune colors in Figma, which doesn’t like the traditional workflow that always switches from software to software.
3. High scalability
One of the core features of Vector to 3D is that makes up models from vector shapes, by taking advantage of this, we can efficiently produce 3D pictures that effectively meet our needs and align well with business contexts.
4. Consistent styles
The plugin Vector to 3D can coordinate with the components of Figma, not only remembering global presets like lights and cameras; but also allowing replacements to succeed presets like materials and position from previous elements. By templating these presets, we can endlessly produce 3D pictures with the same style.
This workflow is not only successfully used in my daily work but also influences my colleagues. After this sharing, 50% of my team members purchased and used this plugin in their design tasks.
Solution for non-Figma users
If you or your team are not using Figma for work currently, or you are not a designer but just simply want to try the flow from SVG shapes to 3D models, you can visit the online version of Vector to 3D: https://www.meimu.design/vector-to-3d/
When my workflow had fully transformed from Sketch to Figma, I found there was an option “Case-Sensitive Forms” placed in several typeface setting panels. The appearance of the font might change slightly and occasionally when I enable this setting.
I was interested in this setting option, then I tried to find out concepts and related knowledge about the term “Case-Sensitive Forms.”
In this post, I will explain what Case-Sensitive Forms are, when should we implement this feature to uplift our design with several practices, and how to use it in our workflow.
Features
The “Case-Sensitive Forms” is a feature of OpenType features, which are like hidden compartments in fonts that allow us to change how fonts look and behave. When we use this feature, the font will:
Shift some punctuation marks up to a higher position;
Change oldstyle figures to modern figures.
Feature 1: Shifting some punctuation marks up to a higher position
In general, punctuation marks are vertically centered with lowercase characters, which is known as “x-height.”
However, when using the Case-Sensitive Forms feature, some punctuation marks are aligned with the height of uppercase characters, which we call “Cap height.”
Feature 2: Changing oldstyle figures to modern figures
Some fonts use oldstyle figures by default to add visual attraction. It is often used in traditional publications like books and newspapers since this font has a rhythmic beauty with varied heights.
When using the Case-Sensitive Forms feature, fonts will be directly changed to modern figures, also known as “lining figures.”
Realistic practices
Inspiring by the feature 1, shifting some punctuation marks up to a higher position, it is well-suited for compositions that mix uppercase characters, figures, and CJK characters.
Here is a list of compositions that might be visually improved by using the Case-Sensitive Forms feature.
1. International phone number
Because figure glyphs are as high as uppercase characters, the use of Case-Sensitive Forms is ideal for displaying phone numbers that include area codes.
2. Date and time
Similarly, date and time is also well-suited for using the Case-Sensitive Forms feature since they are typically consisted of figures and marks.
3. All caps text
To make titles or other important information visually prominent, we often capitalize the text, which is also ideal for using the Case-Sensitive Forms feature.
4. East Asian typography
East Asian typography looks like a square, meaning the visual height of Chinese, Japanese, Korean, and Vietnamese characters is similar to the “X” letter’s cap height.
Therefore, the Case-Sensitive Forms feature are also fitting for the East Asian typography scenario, ensuring marks are vertically aligned with the characters.
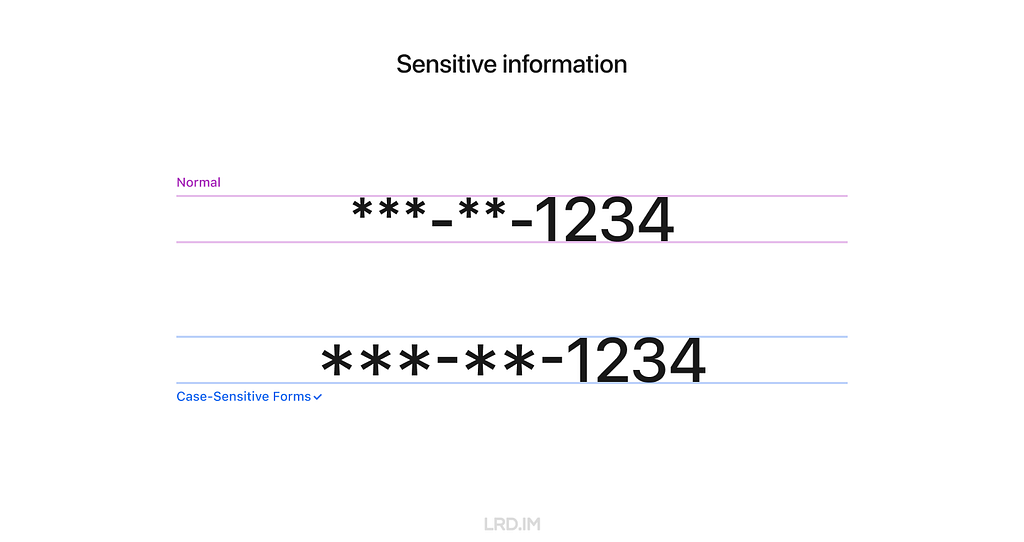
5. Sensitive information
When displaying sensitive information on digital interfaces, such as Social Security Number(SSNs), bank account numbers, and phone numbers, we often use asterisks (*) or dots (•) to partially obscure it. In that case, the Case-Sensitive Forms feature is highly suitable.
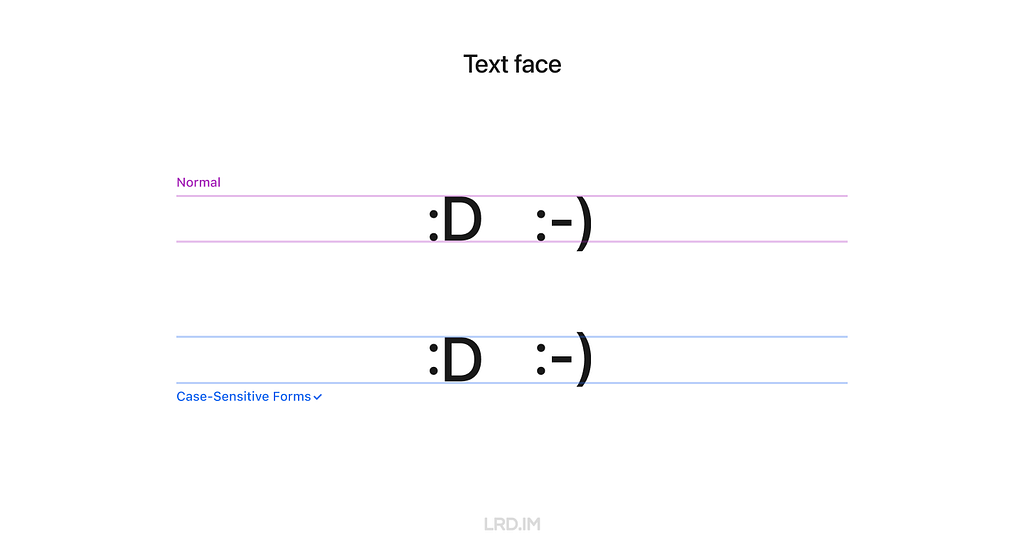
6. Text face
A rare scenario that may be ideal for using the Case-Sensitive Forms feature is text faces, such as “:D” and “:-)”
How to use
1. Supported typefaces
Only typefaces that support the OpenType feature of Case-Sensitive Forms can enable this feature.
It means that not ALL typefaces support this feature, even if we implement this setting in design tools or through coding. I’ve simply made a list to clarify which typefaces support it and which not.
Typefaces that support the Case-Sensitive Forms feature:
DIN Pro;
Inter;
San Francisco (fonts for Apple platforms);
Inria Sans;
Warnock Pro…
Typefaces that DO NOT support the Case-Sensitive Forms feature:
Arial;
Helvetica;
Noto Sans;
Roboto;
Source Sans;
Segoe UI…
In other words, the Case-Sensitive Forms feature only works on Apple devices if we use the system default font on our website.
2. Figma
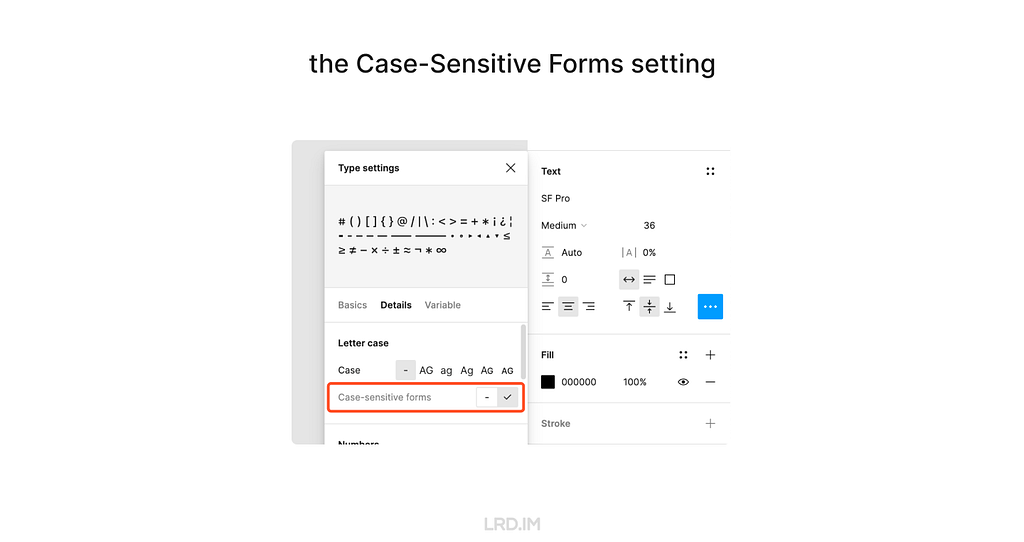
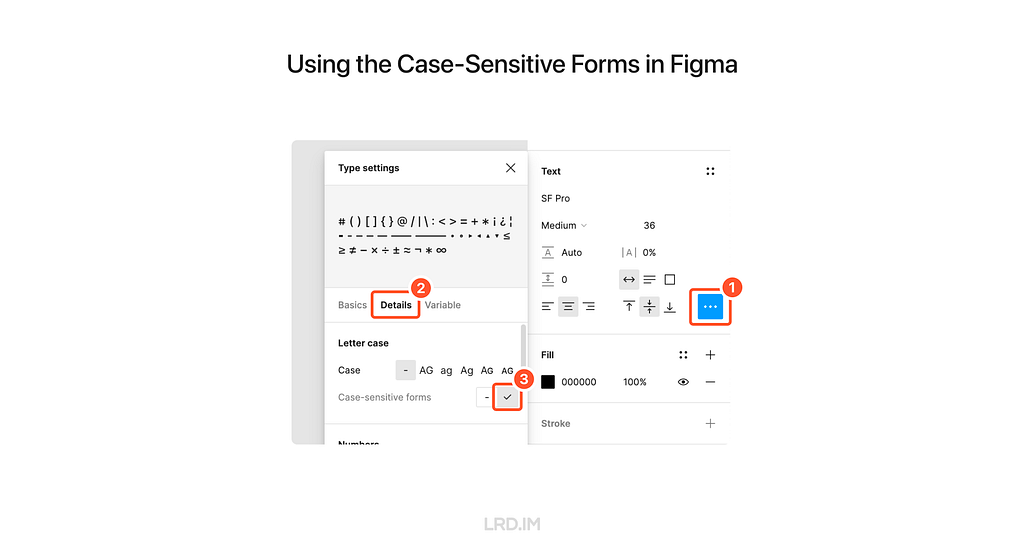
Follow these steps to implement the Case-Sensitive Forms feature in Figma. Select a text layer, then:
Open the “Type settings” panel;
Switch to the “Details” tab;
Check the “Case-sensitive forms” option.
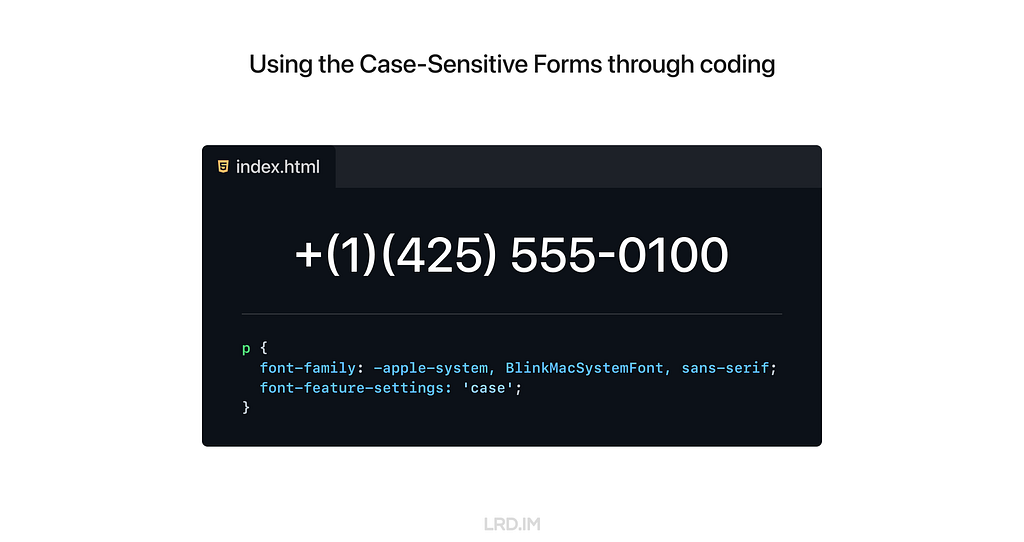
3. CSS
To use the Case-Sensitive Forms feature on the website, we just need to simply add font-feature-settings: ‘case’; to the element that we want to implement this feature.
The CSS Compatibility of this style is quite good. Again, we need to ensure the typefaces support the Case-Sensitive Forms feature; otherwise there will be no changes.
Set as default?
We’ve discussed many scenarios and advantages of using the Case-Sensitive Forms feature. So should we set it as the default style?
My answer is NO.
Although it can uplift visual details with numbers and capital text, it is quite awful when used with lowercase letters, which are more commonly used on our website.
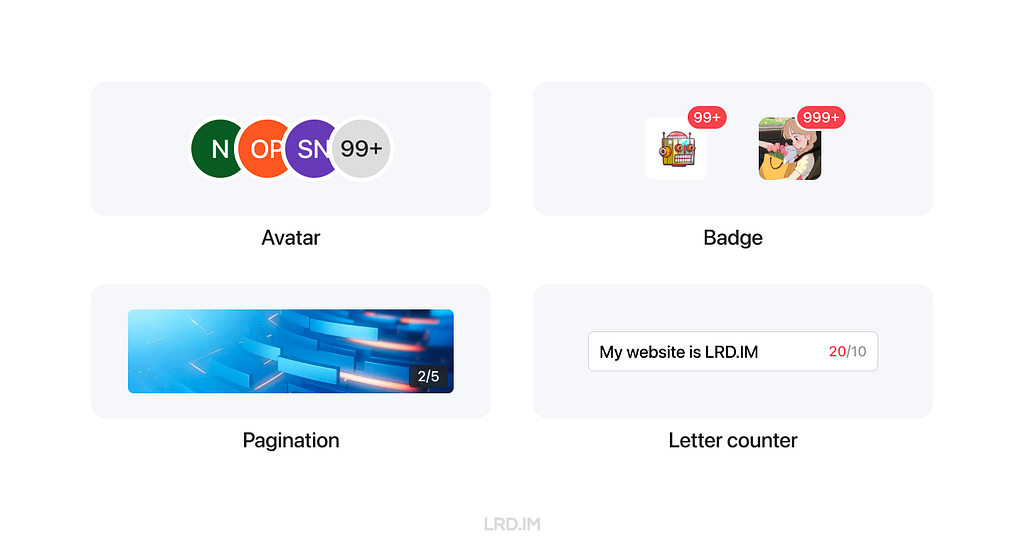
However, we can safely implement the Case-Sensitive Forms feature in some components that always consist of numbers, marks, and capital letters. Here is the list of UI components:
Avatar;
Badge;
Pagination (Image viewer, Swiper and the likes);
Letter counter.
For comparison, let’s see the most common solution in which the Case-Sensitive Forms feature is not implemented on digital interfaces.
Recently, my team has been redesigning our mobile component library. I’ve suggested using the Case-Sensitive Forms feature on the components listed above. Let’s see the outcomes in the future.
Recently, I heard that Coursera has a UX design course developed by Google’s design team. This course covers the entire design process and teaches us how to present our portfolio, prepare interviews, and the like.
It is necessary to enroll in this course even though it is designed primarily for beginners and fresh graduates. It would enhance my English skills on one hand, and deepen my understanding of Western design practices and culture on the other. Since the term “UX design” is called out by Western designers and I am eager to compare Western design cultures with those I’ve experienced in China.
So I enrolled in this online course, trying to spare my time on it. Such as during lunch and dinner breaks on weekdays, or parts of the weekend. I completed the whole certificate within two months. And now I’d like to write down what I learned from this course:
Introducing concepts I had never heard of. Despite my 5+ yoe in a wide range of companies, from startups to large corporations in China, those new concepts opened up a lot of room for me to explore.
Enhancing my listening and reading skills. The course covers plenty of video and reading materials that include industry jargon that translators cannot provide. Moreover, certain phrases and sentence structures are repeatedly used throughout the course. I think my reading skills and speed are slightly improved.
Pointing out concepts like accessibility and equity early throughout the course. I used to think only seasoned designers or well-developed products consider these aspects, however, they are mentioned early on and repeatedly. These concepts resonated with me and will truly influence my work.
Elaborating comprehensive and detailed guidance for designers to prepare their portfolios, resumes, and interviews. They not only tell us what content should be included in our portfolios, but also how to prepare for interviews at different stages. I resonated with these instructions as well, since I did think those details over when looking for a new job.
I have consistently tried to think about and expand design boundaries through different aspects, which requires a breadth of knowledge. Here, I will share several new concepts along with my personal understanding.
Affinity diagram
This is a method of synthesizing that organizes data into groups with common themes or relationships. It can be used in different stages of the design process, such as during brainstorming or after collecting users feedback. The example below focuses on the latter.
After collecting a batch of user feedback, the design team condense each piece of feedback into a single sentence and write it on sticky notes. Then we post them up on a whiteboard or digital tools like Figma. Then the design team look for sticky notes that reference similar ideas, issues, or functionality and collaboratively organizes them into clusters representing different themes.
When I first learned about this approach in the course, I realized that this approach is similar to another method called “Card sorting” that was included in an article I translated earlier named [English to Chinese Translation] How we rebuilt Shopify’s developer docs. Both methods involve clustering sticky notes, naming these groups and summarizing the themes or relationships.
However, card sorting is implemented by external participants and aims to uncover users’ mental models to improve information architecture; Whereas affinity diagramming organizes a large amount of raw data to show the team which problems users are most concerned about and consider high priority.
This concept refers to an individual’s ability to gather, communicate, and create content using digital products and the internet. For example, senior adults or those living in areas with poor internet infrastructure may find it difficult to understand interfaces and functionalities, they are considered to have lower digital literacy.
In contrast, young people, especially those working in the information technology industries, are typically familiar with new software and concepts, and can quickly adapt to them.
This course does not dig deeply into this concept, rather, it emphasizes the importance of understanding our users. If our product targets a broad range of users, it is good to consider the needs of users with lower digital literacy. Moreover, this factor should also be considered when recruiting participants for usability tests.
This concept refers to a group of UX methods that trick users into doing or buying something they wouldn’t otherwise have done or bought.
In the course, instructors clearly point out that this is an unethical and not a good practice. Businesses may lose their clients’ respect and trust once clients realize that they have fallen into deceptive patterns. I will share a few interesting examples that the course provided.
Confirmshaming: Making users feel ashamed of their decision. For example, a subscribe button on a news website usually reads “Subscribe now / No thanks”. BBut if the service provider wants to manipulate readers’ emotions, the text might be changed to: “Subscribe now / No, I don’t care about things around me.”
Urgency: Pushing users to make a decision within a limited time. For example, an e-commerce website might give you a coupon that is only available for 24 hours, prompting you to purchase items without a thoughtful consideration. The course doesn’t judge these marketing strategies or promotions; instead, it suggests that we should avoid putting pressure on users. As designers, we should try our best to balance business promotions and avoid manipulating users’ emotions.
Scarcity: Making users very aware of the limited number of items. For example, a popup or attractive advertisement stating “Only 5 items left in stock.” The course suggests that designers should concentrate on helping users to understand products better, rather than using designs to encourage impulsive buying.
It is really interesting that these deceptive patterns are so common in the Chinese e-commerce industry that it might seem unusual if those strategies were to disappear.
This seems to reflect cultural differences between China and the West. In China, core team members, such as designers, product managers, and operators, collaboratively discuss how to induce and prompt users to make a hasty decision. Also, we regularly hold reflections to discuss and share insights on how to deeply incite users’ motivation.
In 2018, I landed my first job as a UI designer at an e-commerce company. One of my main tasks is designing promotions, such as “claim your vouchers”, “flash sales ending in N hours”, and creating illustrations of red pockets and flying coins, and the like. I didn’t really like these approaches at that time, so I eventually turned to the B2B and SaaS industry, focusing more on UX design.
Although I am not fond of these types of designs, these seem to really help companies grow and generate income. We could stabilize our employment only if our company were earning profits. Perhaps that is an inextricable cycle: obviously, deceptive patterns are unethical and bad as they are inducing and annoying our users, but we must continuously implement these approaches and think about how to make them more effective.
The course thoroughly explains a concept called “implicit bias”. It refers to the collection of attitudes and stereotypes associated, influencing our understanding of and decisions for a specific group of people.
For example, imagine you’re designing an app to help parents buy childcare. To personalize your onboarding process, you start by displaying bold text saying, “Welcome, moms. We’re here to help you…”
This is an example of implicit bias, since it excludes every other type of caregiver, like grandparents, guardians, dads and others.
In addition, here are some interesting biases the course introduced:
Confirmation bias. Refers to the tendency to find evidence that supports people’s assumptions when gathering and analyzing information.
Friendliness bias. Refers to the tendency to give more desirable answers or positive comments in order to please interviewers. This usually occurs in usability tests, where participants may not share their honest feedback because they are afraid that real answers or negative comments might offend interviewers and be considered unfriendly.
False-consensus bias. Refers to the tendency that people tend to believe that their personal views or behaviors are more widely accepted than they actually are, and consider others’ opinions to be minor or marginal. For example, an optimist might think that most people around the world are optimistic; or designers can easily understand iconographies and illustrations they created, they might assume other users might easily to understand too.
I was shocked when I was learning this part. I strongly resonated with these biases which I had never perceived before. After all, the course lets us be aware of these biases and provides approaches to help us avoid falling into these pitfalls.
I listed some concepts above that I had barely encountered in my workspace. Becoming a UX designer appears to require a broad range of knowledge, such as design, the humanities, psychology, and sociology. I am now interested in psychology after completing this course.
Listening and Reading Proficiency
There are plenty of listening and reading materials involved in the course. Typically, each video lesson is accompanied by an article. If there are additional knowledge points, a single video might be accompanied by two or three articles.
Most instructors in the course speak with American accents. They also speak slowly and clearly, which makes me comfortable and usually allows me to understand without opening closed caption. Sometimes, I need to rewind a few seconds when they are speaking long sentences with many clauses or introducing new concepts, and I will open closed captions if I am still confused.
It is worth pointing out that the course contains lots of industry jargon, and I resonated with this because I used similar approaches or processes in my workspace by using Chinese. As a learner, I created a spreadsheet to record expressions that might be useful, such as:
Above the fold, the content on a web page that doesn’t require scrolling to experience;
Deliverable, final products like mockups or documents that can be handed over to clients or developers to bring designs to life.
Digital real estate, space within the digital interface where designers can arrange visual elements;
Firm parameters, refer to rigid design boundaries or limitations like time, project resources, and budget.
I think it is valuable to collect this industry jargon because it is authentically expressed, which can’t be translated by common translation tools. This will be helpful for me to read design articles and write blogs in English.
Accessibility and Equity
Accessibility
The course introduces several assistive technologies, such as color modification, voice control, switch devices, and screen readers, which can help people with different types of disabilities to use our products easily.
Instructors also point out that even people who don’t have disabilities, or who do not perceive themselves as having disabilities might benefit from these assistive technologies. The course suggests that we think these factors over throughout the entire design process. For instance:
Supporting color modification. Features that increase the contrast of colors on a screen, like high-contrast mode or dark mode;
Supporting voice control. Allows users to navigate and interact with the elements on their devices using only their voice. They also mention a concept called “Voice User Interface (VUI)”;
Supporting switch devices. This is a one-button device that functions as an alternative to conventional input methods such as the keyboard, mouse, and touch, allowing users to complete common tasks like browsing webpages and typing text;
Supporting screen readers. Allows users with vision impairment to perceive the content. The course suggests that we write alternative text to images, add appropriate aria labels to interactive elements like buttons, and consider the focus order of elements.
Here is a website that demonstrates the color modification feature:HubSpot.com
On the top navigation of this website, it provides a switch for us to toggle a high-contrast mode. Moreover, it also supports reduced motion effects — if I enable the reduced motion setting on my device, this website will minimize motion effects as much as possible.
Equity
The course also introduces a concept called “equity-focused design.”
Instructors clearly define the difference between “equality” and “equity”:
Equality: Providing the same amount of opportunity and support, everyone receives the same thing;
Equity: Providing different amount of opportunity and support according to individual circumstances, ensuring everyone can achieve the same outcomes.
The course also points out that equity-focused design means considering all races, genders, and abilities, especially focusing on groups that have been historically underrepresented or ignored when building products.
They use a survey question as an example: when gathering participants’ demographic information like gender, it is not enough to provide three options: “Male”, “Female” and “Other”. To make our design more inclusive and equitable, we should offer additional choices, including “Male”, “Female”, “Gender-nonconforming”, “nonbinary” and a blank field. The latter provides non-conventional gender options, uplifting those who might be marginalized in conventional surveys. This approach also aims to balance the opportunities for all groups to express themselves, ensuring their voices are treated fairly and heard.
In this lesson, I clearly faced a culture gap from the West. In fact, I don’t really like to dig into this concept deeply, mainly because I can’t determine whether this approach is right. Sometimes I think it is unnecessarily complicated, but at other times, I recognize that there are people with non-traditional genders around us who may truly be eager to be treated fairly.
When I was learning this lesson, I realized that there was an opportunity to incorporate accessibility features into the project I was recently working on. I will write a new post if this project lands successfully.
In the final course, instructors teach us how to lay out a portfolio and what content should be included. They also inform us the process of interviews and how to thoroughly prepare for interviews.
The guidance they mentioned is for the Western workplace, which may not seamlessly fit in the Chinese workplace. For example:
They point out that designers should have a personal website and case studies regularly. However, Chinese designers prefer to publish their case studies on public platforms like ZCOOL and UI.CN;
They also teach us how to build our digital presence and network through LinkedIn. However, these approaches are not common in the Chinese job market, where the most popular methods are directly submitting resumes and getting recommendations through acquaintances.
They inform us how to handle panel interviews. I have interviewed with a wide range of companies, from startups to corporations, and never encountered panel interviews, which means that the panel interview is not popular in this industry.
I was deeply impressed by how they elaborated on the preparation and important considerations during the interview process. For example:
Research the main business of the company you interview for beforehand, and clearly understand why you are a good fit for the company;
Prepare answers to common interview questions beforehand, such as a personal introduction, your strengths, and descriptions of your case studies;
We should learn how to answer difficult questions using the STAR method, and prepare well before starting an interview;
Adapt the focus and questions according to the interviewer’s role to show you are a professional;
During the interview process, you might be asked to complete a task. Therefore, we should practice the ability to think aloud and clearly define questions, since interviewers might pose vague questions on purpose.
I resonated with the approaches and tricks mentioned in the course that I had previously used, which gave me a strong feeling that I was on the right track.
Additionally, the course also provides detailed instructions on how to pursue freelance design work. For instance:
Clearly identify your target audience and understand why they should choose your service;
Know your competitors, identifying what they can’t provide but you can;
Promote your service and build word-of-mouth by attending online and in-person events, and getting recommended through acquaintances;
Calculate the business expenses, set fair prices for your services, and make financial projections — estimate what your finances will look like in the first month, the first 6 months, and the first year.
Well, above are lessons I’ve learned from the Google UX Design Professional Certificate on Coursera over the past two months. I think that this is an interesting course, although not all content can be applied in my daily work, I’ve also learned the thinking processes and workplace cultures of designers in another part of the world.
I strongly recommend designers reading this post consider to enrolling in the Google UX Design Professional Certificate, by doing this, you might probably gain new insights. The course costs $49 monthly, which is not expensive. It is likely to complete the entire course over two or three months if you have a full-time job.
Things worked as I expected, and I will start my next project in the second half of the year.
I shared my excitement about the PTE test result in the previous post. In this post, I will detail the English-speaking skills I learned during the three-month learning journey, which specifically meet the PTE test criteria.
PTE’s criteria
Let’s take a look at the two key criteria in the PTE’s speaking component: Pronunciation and Fluency.
Based on these criteria, I would like to highlight these key points:
Pronunciation:
Vowels and consonants;
Word stress;
Sentence-level stress;
Assimilation and deletions.
Fluency:
Rhythm and phrasing;
No hesitations.
As we can see, the PTE’s test criteria clearly show concepts we must fully understand and perfectly present if we want to achieve a higher score. In the following text, I will present my comprehension of these concepts, supported by related online resources.
Pronunciation
Vowels and consonants
In everyday conversations, sightly mispronounced words often do not significantly disrupt the flow of our discussion. But thanks to modern technology, PTE’s scoring is based on algorithms and is implemented by computers, which can easily detect each mispronunciation. Therefore, the ability to pronounce words clearly and accurately is crucial.
I have tried numerous methods to improve my pronunciation and reduce Chinese accent including speaking loudly, having more emotion, and directly imitating local accents. However, it didn’t work as expected, it did not meet my expectation, resulting in a low score in PTE practice.
Changes occurred the time I met Sun’s tutorials and BBC Learning English collection on YouTube. These pronunciation videos elaborate on vowel and consonant details, with vivid body language and emotion.
As non-native speakers who want to pronounce concisely, we must focus on these particular points:
Mouth Shape We can try to imitate the mouth shape that vowels and consonants request. For example:
When pronouncing /æ/ sounds like Agriculture and Activity, we should open our mouths as large as possible;
When pronouncing /i:/ sounds like These and Feed, the corners of our mouths should be as far apart as possible.
Tongue Position We should also pay attention to the tongue position. For example:
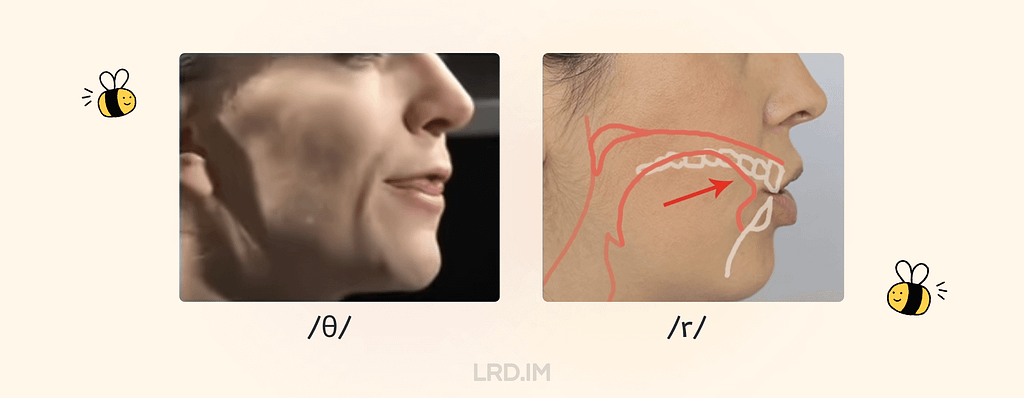
The /θ/ sound requires us to extend the tongue forward;
The /r/ sound requires us to pull the front part of the tongues back and up and keep the back stable, making our tongues fatter and thicker.
Breath We should also carefully control our breath, ensuring vowels and consonants are presented appropriately. For example:
When pronouncing /θ/ like Through and Thesis, we should ensure that the airflow passes through the gap between our teeth and lips;
When pronouncing /b/ and /p/ like Big and Picture, we should ensure that the airflow is completely blocked and then released suddenly.
Focusing on these points helps us ensure our study paths are on the right track, and consistently improve our pronunciation. In addition, there are two tips:
Don’t try to imitate accents. The PTE test does not expect you to have a perfect British or American accent. For beginners, attempting to achieve such an accent is time-consuming and pointless.
Never compare pronunciations between English and Chinese. For instance, the Cantonese pronunciation 士多啤梨 is often equated with Strawberry in English, which overlooks many nuances. Therefore, it is important to acknowledge that the pronunciation of English and Chinese words are completely different.
Each Chinese character has only one syllable, whereas English words typically consist of two or more syllables.
For example, the word water consists of two syllables: wa-ter, and phenomenon consists of five syllables: phe-nom-e-non. It depends on how many vowel sounds the word includes.
Furthermore, an English word consisting of two or more syllables includes both stressed syllables and unstressed syllables. These are indicated by the phonetic symbols found in dictionaries.
For example, the phonetic symbol of agri-cul-ture is /ˈæɡrɪ-kʌl-tʃər/, we can see the stress mark /'/ is placed in the first syllable /ˈæɡrɪ/, which known as a stressed syllable, while others are unstressed syllables.
An interesting rule to note is that the stressed syllable can be vary within the same word depending on its function in a sentence. For example:
When Project is acting as a noun, it is pronounced: /ˈprɑːdʒekt/
When Project is acting as a verb, it is pronounced: /prəˈdʒekt/
What should we do? Pronounce each syllable with different efforts:
Stressed syllables should be pronounced longer and louder;
Unstressed syllables should be pronounced shorter and thinner, or take place from the Schwa (we will discuss it later.)
When training pronunciation, I strongly recommend exaggerating these nuances to ensure we are on the right track and fully comprehend this concept. Eventually, it should sound natural and require less effort.
Properly presenting word stress is key to making our speech more like English, and it can significantly help in shedding “Chinglish” tendencies.
To meet this criteria, there are two concepts we should understand: Content/Grammar Words and Stressed Words.
In the English world, there are two types of words within a sentence: Content words and Grammar words.
Content words like nouns, verbs, adjectives, and adverbs play an important role in sentence structure and convey main information.
Grammar words like prepositions, auxiliary verbs, and articles are used to link content words to make a complete sentence, we can’t understand a sentence that only includes grammar words.
In the sentence “I would like to read books,” the content words are I, like, read and books, they should be pronounced clearly and accurately, while would and to are grammar words, and they should be pronounced more softly than those content words.
The second point is to decide which words should be stressed. This is an easy-to-understand concept but hard to implement when we are facing a complex sentence. I will demonstrate it through Chinese examples:
We stress some special words in our mother tongue subconsciously, furthermore, and this often influence the meaning.
For instance, we can express “There are beautiful flowers in the park.” in these different ways:
“There are beautiful flowers in the park.” We are pointing out the location;
“There are beautiful flowers in the park.” We are emphasizing the flowers, not buildings or trees;
“There are beautiful flowers in the park.” We are emphasizing the place where the beautiful flowers are located.
I suggest following general rules to avoid the potential risk of making mistakes and mispronunciation because the given text is unpredictable when we are sitting at the PTE test. Here are two steps for consideration:
1. Understanding the text. Rather than speaking without consideration and comprehension, we should first grasp what ideas the writer attempting to convey before we open our mouths. Furthermore, analyzing the elements and structure of the sentence is crucial, including subjects, verbs, objects, content words, grammar words, and clauses.
2. Marking stressed words and unstressed words. Generally, we stress one word in a phrase, choosing from a range of words, including objects, gerunds, passive verbs, adjectives, and adverbs. Below are several examples from an actual test:
Globalisation refers to a set of changes rather than a single change.
Stress what authors attempt to emphasize. In this case, the author is declaring it is a set, not a single change.
You will be introduced briefly to the discipline of child psychology.
We always stress adjectives and adverbs that modify a noun. If they are connected, stress the first one. Similarly, when facing a compound noun, we stress the first noun generally.
Although choosing the stressed words is subjective, they should be chosen from an appropriate scope that I mentioned before.
These two concepts were the most interesting part of my learning journey. They make our English speaking vivid and dynamic.
Some voices can be transformed in specific circumstances. Below are several examples:
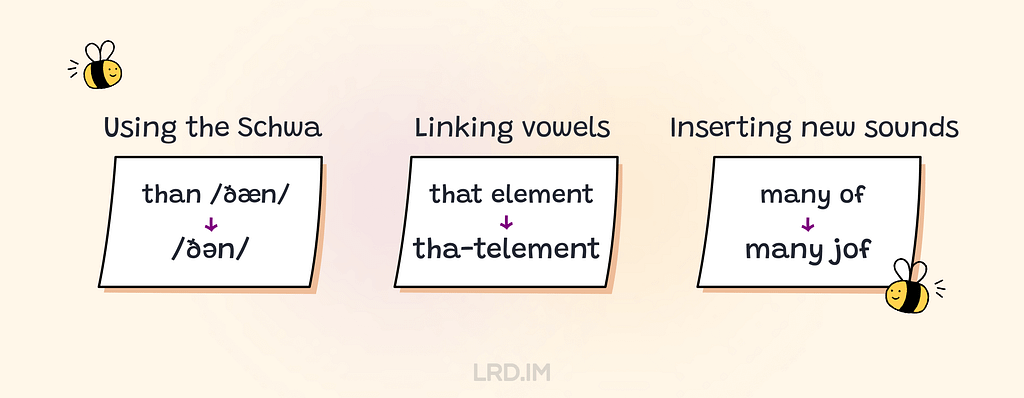
Using the Schwa. Grammar words and articles can be reduced to a “Schwa sound”, such as “to” /tu/ becoming /tə/, and "than" /ðæn/ becoming /ðən/;
Linking vowels. When a word ends with explosive sounds like /t/, /k/, and /p/ and the following word begins with a vowel sound, we link them together, such as that element becoming tha-telement;
Inserting new sounds. When a word ends with a vowel sound and the following word begins with a vowel sound, we often insert a connecting sound. For instance: many of can be many jof.
There are lots of variations in pronunciation that we need to learn and practice. While this might feel overwhelming for some beginners, it is a vital part of speaking like a native and sounding natural. Keep learning from online resources and practice consistently until you feel comfortable.
Some voices can be dropped in specific circumstances. Below are several examples:
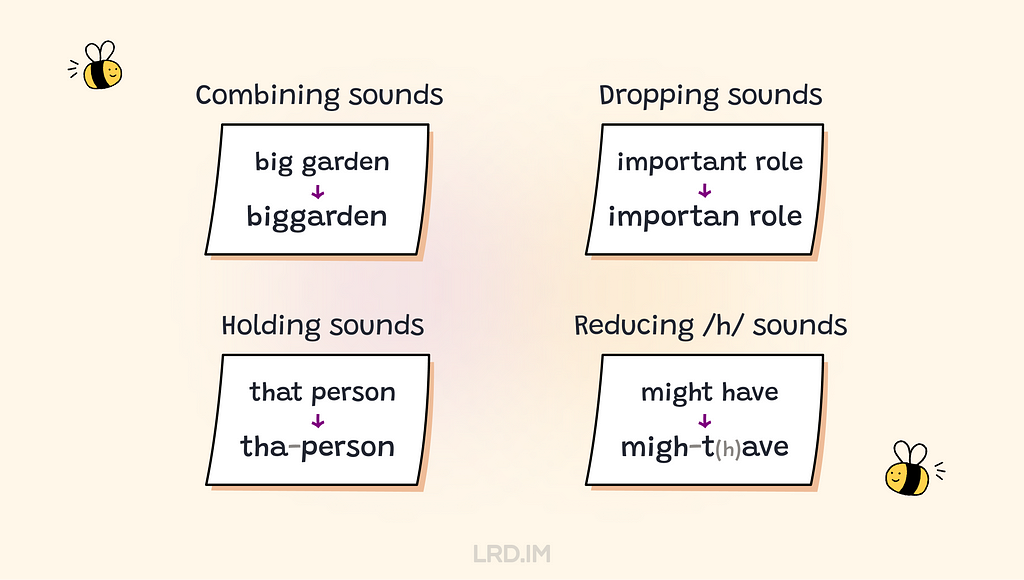
Combining sounds. Link the same consonant sounds that are adjacent, such as in big garden, two /g/ sounds becoming one /g:/ sound but a bit longer;
Dropping sounds. In a rapid speech, we sometimes drop explosive sounds between two consonants, such as an important role becomes an importan role;
Holding sounds. Similarly, we hold back explosive sounds without fully releasing them when these sounds between a vowel and a consonant, such as that person becomes tha-person;
Reducing /h/ sounds. When a word ends with explosive sounds and the following word begins with the /h/ sound, we always reduce the /h/ sound, such as "might have" becomes "migh-t(h)ave" and "an hour" becomes "a-nour."
These two concepts are related to the term “Thought groups.” When speaking English, we always separate the sentences into several groups by their meanings, emotions, structures or lengths. Here is an example from the real test:
Many papers you write in college / will require you to include quotes / from one or more sources.
The speaker reminisces about his views / of the English Revolution / when he was a student.
In particular, we break sentences down before prepositions such as “of”, “in” and “that.” Importantly, we should NEVER separate compound words like “the English Revolution.”
Furthermore, I suggest breaking the sentence into smaller fragments for practice, like this:
Many papers / you write in college / will require you / to include quotes / from one or more sources.
However, the PTE test would perfer a longer phrase, so I suggest that each group should have 4 to 7 words.
Now we know what is the term “Thought groups” and how to divide a sentence, the next step is to learn how to present it well. This related to the term ‘intonation and it means words pronounced in a high or low pitch accordingly and intermittently.
Intonation can bring rhythm to speaking, however, it is hard to handle and can cause trouble easily for beginners.
What should we do?
Always present a low pitch to the last word of a thought group and the sentence;
Carefully present a slightly high pitch to the adjectives or adverbs that modify a noun or a noun phrase.
No hesitations
PTE test can detect any hesitation or mispronunciation which can negatively influence our final score, especially in the Read Aloud and Repeat Sentence module.
Despite numerous challenges on test day, such as being disrupted by other test-takers or encountering unfamiliar words, I strongly recommend speaking slowly and confidently to avoid potential risks and maintain fluency.
This strategy is crucial: when we face a word or phrase that is difficult to express and may cause hesitations unavoidably, this may affect our scores in both Pronunciation and Fluency. However, if we express these challenging words slowly and confidently, maintaining a natural flow, it might primarily affect our Pronunciation score.
This is why I strongly advocate for speaking confidently, even when making mistakes.
Summary
This article discusses the knowledge I gained on my English learning journey, including methods to improve pronunciation and an understanding of the PTE speaking module criteria.
Additionally, I’ve decided to update posts in English from now on. It may contain numerous grammatical errors, awkward phrasing and word-choice issues, it’s still a necessary step forward. ‘Practice makes perfect’ is the key lesson from this journey.
而这次比赛不仅给了我一个机会去参与创造一个跟 AI 相关的产品(包括代码也有不少是 ChatGPT 参与的),还给了我推强大的动力去了解 AI 在商业中的场应用景。除了在比赛中看到其他参赛者的创意之外,现在还了解到比如 Atlassian 已经有相关的功能前瞻了。
从 Atlassian 在 5 月 4 日发布的股东信当中,也透露到该公司已经在用 AI 来来为客户提供服务了。
"Now that generative AI has reached consumer-grade maturity with LLMs, we can create magical new experiences for our customers."现在,随着大型语言模型(LLMs)带领生成型人工智能达到了消费级的成熟,我们可以为我们的客户创造魔术般的新体验。
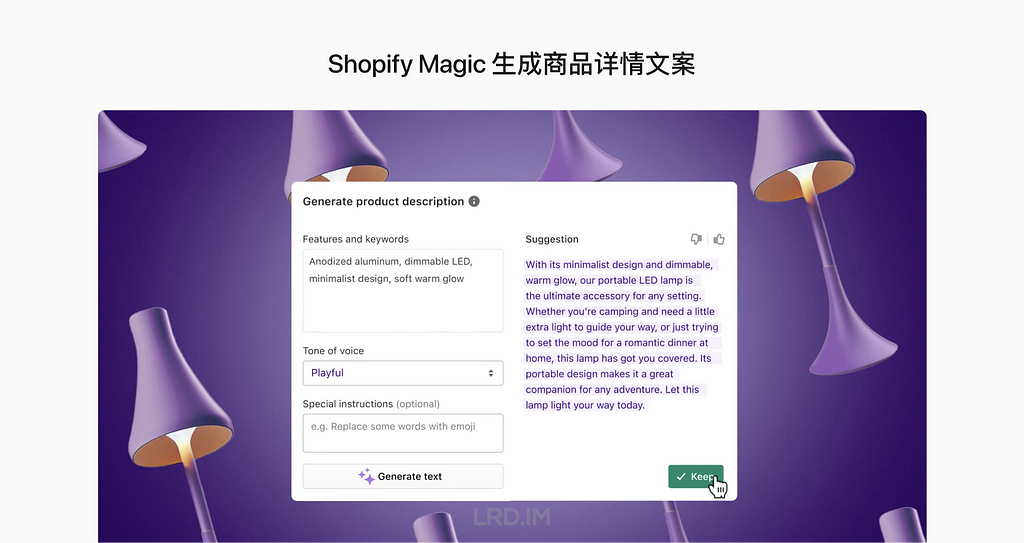
除了 Atlassian,另一个互联网巨头:Shopify 也将 AI 能力应用到其产品当中。比如在商品详情页的编辑界面当中,我们可以输入几个关键字,让 AI 帮忙生成一段商品介绍的文本,还能够调整文本的风格。