[速报] MICU Emby 免费发号
jore:
正值中秋,领个号看看也不错
不搞饥饿营销耍猴,也不搞运气抽奖
来就有,无限发,人人有份,欢迎来捧个人场
注意只有三天有效期,到期自由续费,勿喷,毕竟不要钱也没有门槛,领了也不亏
发号时间为 16 17 18 号晚上 8 点,其他时候没有,请准时
加入方式,仅限 TG https://t.me/micu_user_bot
正值中秋,领个号看看也不错
不搞饥饿营销耍猴,也不搞运气抽奖
来就有,无限发,人人有份,欢迎来捧个人场
注意只有三天有效期,到期自由续费,勿喷,毕竟不要钱也没有门槛,领了也不亏
发号时间为 16 17 18 号晚上 8 点,其他时候没有,请准时
加入方式,仅限 TG https://t.me/micu_user_bot

随着美国大选的白热化,预测市场 Polymarket 被大家熟知,已经吸引了近 10 亿美元进行美国总统选举结果的投注,占据了美国大选投注 85%的市场份额。
Polymarket 的创始人,今年 26 岁的 Shayne Coplan 让我非常感兴趣:
Shayne Coplan 今年 26 岁,但却拥有了 12 年的加密领域经验:
- 他 14 岁时接触到加密货币,和朋友用矿机挖莱特币;
- 16 岁时参与了以太坊预售,是当年最年轻的参与者之一
- 18 岁进入纽约大学,第二学期就退学。3 年后创办了 Polymarket, 目前已经成长为最大的预测市场,甚至影响美国大选。
作为一名内容创作者、加密爱好者和父亲,我不禁好奇:

于是我搜集了和 Shayne Coplan 相关的所有采访,找到一些蛛丝马迹,形成了一篇 7000 字的文章,欢迎阅读和分享: https://www.web3brand.io/p/polymarket-shayne-coplan
另外因为是人物故事的形式,这篇文章同样适合收听,于是我同时制作了一份有声版,同样欢迎收听,enjoy: https://www.xiaoyuzhoufm.com/episode/66e521835ca6d0ace3e0fd22
在麦当劳,被两位约 60 岁的阿姨问,手机安装不了软件怎么办。
我看了下,是华为手机,需要登录华为账户才能安装软件。
解决这个问题后,过会她们又来问我,另一个软件安装不了。
这时我有点敏感了:她先要下载的,是一个端到端私聊的 IM 软件(名字我就不说了),总之应该是可以绕过监管的。第二次装不上的软件,是叫什么「 XX 娱乐」,听名字就不正经(后来搜索了下,是明显的菠菜软件)。我明白是怎么回事,应该是链接被墙了。
我问她链接是怎么来的,她说是公司发的,我估计就是刚才那个聊天软件里发的。这时我几乎可以肯定,她们涉及电诈、或者其他灰色的东西,自然不会再提供帮助。
她们已经折腾了快一小时。是什么样的动力,能让她们费这么大劲,去折腾这个东西,估计就是赚钱了。远远听她们聊天,有买 U 、钱打过去、账单截图给他…
我后来又过去问,这是什么事、不会是诈骗吧?她说:不会, 我都赚了十几万了,你要不要试试?好吧,我就不说什么了…
第一次在身边见到这种事。
niri 是一个基于 Wayland 的可滚动平铺窗口管理器,其独特之处在于提供了无限水平滚动的窗口排列方式。
用铁轨和车厢做一个类比(我可能是第一个使用这个类比的):
一个 workspace 就像是一条长度无限的铁轨,你可以在铁轨上:
以及,将车厢移动到其他铁轨( workspace )上。
是的,铁轨并不止一条,workspaces 是动态的,无上限的,可以想象成是无数条水平排列的铁轨集群。
当你将一个车厢移动到下一条铁轨时,如果那条铁轨不存在,niri 将会动态创建那条铁轨(动态铁轨)。
你可以给铁轨命名,那么它将会一直存在,且会排列在『动态铁轨』之前。通过按键绑定,实现随意切换铁轨、将车厢转移到指定铁轨。
niri 目前已实现了大部分核心功能,适合尝试。详细的安装和配置指南请参阅 niri 的 Wiki 页面。
我使用 NixOS ,安装起来比较便捷,从 tty 启动,体验了一天,相当流畅丝滑,非常适合我的工作流,然后果断将 Hyprland (Hyprbug) 删除了。
你们难道不知道远程的竞争更激烈吗。
前年失业率还没这么高的时候,有个远程职位放出来,一天就能收个几百份简历,下午职位就关闭了。
https://www.bilibili.com/video/BV1FxtTe7Evb/
其实不知道他谁 推流看了一眼看乐了 不太理解这种人还有几十万粉丝
突然思路开阔了 国内人其实特别多 什么市场都有的 不愁没出路啊


https://www.v2ex.com/t/1073207
帖子里说“原来阿里云盘在服务端是不加密的”然后一堆人附和,说加密就不能秒传。看来大家对加密的概念还很生疏。
对阿里云不熟,就拿 aws 的 s3 来说吧。s3 默认对于每个文件都是服务端加密的,而且是每个文件一个密码。但即使是这样,也不影响设计秒传,不影响一个用户看到他人的文件。
所谓 server 端加密,是指[文件不会明文写到磁盘上]。在上传时用随机密钥加密文件,随机密钥再用预先配置的非对称密钥加密,然后将随机密钥加密后的文件、非对称加密后的随机密钥分别存储在 aws 中。在下载时,aws 会先解析成明文,然后使用 https 传输到用户/业务服务器。所以无论谁去下载你的文件,aws 都会给他解密后的版本。
至于秒传,是第一次上传时保存整体的哈希,以及每一个文件块的哈希,类似 bt 种子。再次上传时,用户本地生成一个新的哈希,服务端一看,在我的 redis 里面已经有这个种子了你就秒传了,跟文件存储一点关系都没有。
如果你希望服务器不能看你的文件,那要做的是客户端加密,也就是文件已经加密好上传到服务器,服务器根本不知道如何解密当然也就没法生成缩略图或者秒传了。
所谓服务端加密指的是静态加密,写盘时加密。再严格一点给你加个内网传输加密,也就是在内网的 http 和数据库连接什么的给用 tls 保护一下。数据在内存里可都是明文。
介绍
小颜同学是一个精美卡片制作的贴身小助手,让你的文字充满艺术气息。 免费,界面美观,交互简单,只需要输入文字,就可以帮助你生成优雅的媒体卡片。
在线体验
演示
刚上大一的时候用 CSDN 发过几篇文章,后来就自建博客了,再加上被 CSDN 的种种操作恶心到了,从此就再也没用过 CSDN 。
今天偶然在未登录的状态下打开了自己几年前的文章,居然成了仅 VIP 可见,要充钱才能看。登录 CSDN ,发现几个月前给我发过这样一条私信:
尊敬的用户,您好,您部分文章已达升级为 VIP 文章标准且已完成升级(升级后将成为收费内容),升级完成视为同意 VIP 文章协议: https://blog.csdn.net/blogdevteam/article/details/xxx ,文章产生收入您可获得相应分润。如您不同意升级,可通过表单进行反馈: https://marketing.csdn.net/questions/xxx ,相关人员会在收到反馈的一周内帮忙取消;
真的很幽默,很多博主早就放弃 CSDN 了,谁会打开这个私信。等于说 CSDN 擅自把过去一大批它认为有流量的东西设置成了仅 VIP 可见,离谱。
大家曾经在 CSDN 上发过文章的话可以打开看看有没有被 CSDN 设置成仅 VIP 可见。
9 月 12 号,OpenAI 发布了新模型:OpenAI-o1 ,这个被人们成为草莓计划的模型终于浮出水面。我迫不及待的试了这个新模型的能力效果,推理能力简直是碾压所有 AI 大模型,包括 Claude AI 等,OpenAI 果然还是最顶尖的 AI 先驱者,这个模型目前还只是文本能力的体现,不久前官方还发布了史无前例的实时视频通话功能、实时语音功能功能、AI 搜索功能等都炸翻了天,但这些还没有完全开放给用户使用。
很多 AI 应用相信都跟我一样,是接入 OpenAI API 的接口去驱动的,有些香港和中国内地的小伙伴似乎无法直接使用 API ,需要绕一道技术才能进行使用,而且在充值上面也是无法充值。这个也是困扰我的香港分公司的一个痛点,后来,我们的朋友给我们推荐了一家在新加坡的平台,他们有专门提供这种绕道技术的中转接口,效果我们试了下饼不错。但我们还是觉得跟原生接口的效果有差别,还好他们也有提供官方直连的 API 。最近新模型 OpenAI o1 上线后,这家平台也可以进行购买了。我们买了一个测试了下,果然,OpenAI-o1 的效果是真不错。现在我们的 AI 应用也有强推理的能力了,相信这波新功能又能吸引不少用户。
有很多小伙伴跟我一样在进行创业的,也需要这种接口的,可以在这家店了解,个人感觉还是可以的,价格也比自己充值还便宜很多,主要是即买即用,这点是最吸引我的,省去了很多不必要的操作。 他们的平台名字是:Neuronicx ,大家可以自己在谷歌搜索查询哈,就帮到你们这里了。
#AI #ChatGPT #API #OpenAIo1 #OpenAI
两晚电话后,今天下午开摩托车半小时见面了
一开始坐凳子上聊天,后来开摩托车带她去买蛋糕,她给她妈妈买的生日蛋糕。买完蛋糕后她骑电动车回家。要一个小时,我陪她半路分手。
好赌的爹,生病的妈,上学的弟,爱笑的她,她就像个完美的骗子
给她妈妈看病的 10 万网贷,她让我自己决定是一次付清,还是月还,月还利息多。 说好写借条,不要她利息,她每个月还我,如果我决定给她一次还清。 她说,谈恋爱和贷款是两码事
她说,她之前有约过其他人,但是太油腻了,借口跑了
下午短短两个小时的相处,虽然负债累累,但是她青春,爱笑,风吹在她脸上,全是未来的美好
她和我一样喜欢动物。
我问,和我一起租毛坯房可以吗 她说可以
我问,我可能要买个车
她说,也不用买多贵,几万的一样。
正如我想的。
她缺钱,但是又不是那么物质。到目前为止也没有要红包,只说哥哥,我想吃糖,所以花了 10 元钱买了薄荷糖,她说,下次不要买薄荷味的
她说,过节后她整理下搬过来
会吗?
我不确定
是南柯一梦,还是从此灵魂不再漂泊
节后看




我有一个 qq 登录的百度云网盘也是差不多 4 年没使用,前几天想拿以前的资料,QQ 登录发现要我添加手机号注册,还好记得账号名还有充值记录,申诉回来了,登上去发现我 3T 的数据变 64G 了。
手机登录网盘上还有我以前的文件目录,可以在线查看部分(有的文件直接显示网络异常)我以前的资料但不能下载,不知道是不是以前缓存在手机上的;电脑登录只有夺舍我账号人的文件,应该可以理解为新主人吧。
网盘上还有她手机相册备份文件,我查看了一下登录记录还挺活跃!现在不知道她那边登录能不能看到我的文件,可恶的是还我还存了我以前的照片(好在都是没隐私的)。
![]()
![]()
openai 今天发布「 ChatGPT o1-preview」,是会尝试主动思考的 ai 语言模型,chatgpt Plus 订阅用户现在就可使用。
根据 OpenAI 的说法:「我们训练这些模型〔ChatGPT o1-preview〕在回应前花更多时间思考问题,就像人类一样。通过训练,它们学会精炼思考过程、尝试不同策略,并能察觉自己的错误。」「如果您正在解决科学、程序设计、数学和相关领域的复杂问题,这些增强的推理能力可能特别有用。」
我自己在讲 ChatGPT 提升工作效率的相关课程时,常常强调一个设计指令的重点:「如果我们写 AI 指令〔 prompt、提示语〕时,可以让 AI 写出自己在想什么、怎么处理任务,通常生成的内容结果会相对更好。」
从用户端的角度来看「ChatGPT o1-preview」,就是在 AI 生成内容前,会先展开一步一步的思考流程,它可能会选择思考的策略与切入点,有时会提出一些批判思考,也会更仔细的分析资料细节来做深入处理。
在这个过程中,「ChatGPT o1-preview」生成内容的速度其实比 GPT-4o 要慢上不少,可能需要 30~60 秒的思考时间〔或者更久〕,才会开始一步一步的生成内容。
也因为这样的「思考」过程需要耗费更多运算资源,所以即使是 ChatGPT Plus 用户,在使用「ChatGPT o1-preview」时也有一些限制:
也就是说,目前「ChatGPT o1-preview」比较像是「GPT-4o」的辅助,在进行一些需要深入分析资料、产出有逻辑结果的任务,或者像是科学、数学、程序代码相关领域时,可以运用。
今天这篇文章,我就从自己日常惯用的几个 AI 辅助需求:翻译、摘要、企划思考、文案,以及有时用代码写个小工具的角度,以实际案例测试看看,「ChatGPT o1-preview」的效果如何,并和「GPT-4o」同样指令下的结果作比较。
当然,如果能从科学、数学与代码的角度来验证更好,不过从我个人常用角度出发,也想验证看看 ChatGPT o1-preview 是否能满足我的日常工作需求,也提供大家参考。
下面,先提供大家下面测试案例的快速心得比较表格。
翻译结果更简洁有力,文句白话流畅。
用语更符合台湾惯用词汇。
在「白话流畅度」与「专业用语」间平衡得更好。
翻译结果相对较弱,文句不如 o1-preview 流畅。
能计算分数并回馈对错。
无需修改即可使用。
需要多次反复调整才能达到可用程度。
提供具体、逻辑分明的建议步骤和文章架构。
深入分析资料细节。
缺乏深入的分析和明确的建议。
能整理出详细的步骤和操作要点。
细节完整程度略有不足。
缺乏社交贴文所需的流畅性和吸引力。
更注重安全性和准确性,避免使用版权材料。
可能在细节上不够精准。
首先来试试看翻译〔英翻中〕,我通常会用下面指令来要求 ChatGPT 翻译文章:「把下面这篇 XXX 主题的文章,翻译成中文,请一段一段翻译,尽量在维持原文语意,主题风格的情况下,让上下文的语句更自然通顺,遇到专有名词时附注英文原文,并在第一遍基本翻译后,用台湾惯用词汇与语气进行最后修饰。」
下图「左方」,是「ChatGPT o1-preview」翻译的结果。下图「右方」,是「GPT-4o」翻译的结果。
结论是,「ChatGPT o1-preview」花了 57 秒完成一整篇文章的翻译〔文章是 OpenAI「ChatGPT o1-preview」官方公告〕,但是翻译的结果比「GPT-4o」优异不少。
例如,大多数时候,「ChatGPT o1-preview」翻译的文句更加简洁有力〔相对「GPT-4o」〕,可以在许多段落看到这样的差别。
「ChatGPT o1-preview」翻译的结果也更白话,相对流畅,用语更符合我指定的中文用语。
「ChatGPT o1-preview」在「白话的流畅度」与「专业用语」之间也相对更能拿捏得当,会让人更容易看懂,但又保持专业用语的明确性。
我让「ChatGPT o1-preview」测试直接写一个九九乘法表小工具。o1 同样会先思考撰写工具的逻辑,然后才开始写出程序代码。
我提供的指令是:「我的小孩正在练习记忆数学的 99 乘法表 ,你可以设计一个协助她练习的小游戏吗?
请一步一步分析,从简单的 2 与 5 的乘法表开始,然后练习 3、4、6、7、8、9 的乘法表,根据每一个乘法表设计一个记忆游戏,游戏一开始可以选择要练习哪一个乘法表,进入后可以随机考验该乘法表的熟练度,最好设计有游戏机制。」
下面是 ChatGPT o1-preview 第一次生成的 99 乘法表小游戏,我没有做任何的修改,但是正确性、界面美化、操作流畅度都已经达到可用的程度,还会计算分数与回馈对错。
下面是旧版 GPT-4o 第一次生成的小游戏,基本界面可操作,但有一些明显错误〔如下图〕,可能还需要多几次的反复问答,才能调整正确。
我也很常跟 ChatGPT 一起讨论沟通企划案,下面是新旧版本生成的结果比较。
我提供了许多参考资料,请 AI 帮我做产品的企划报告。
「ChatGPT o1-preview」在生成过程中,会主动做一些反向思考,与探索不同的报告呈现方式,并且提供一些具体的、逻辑分明的建议步骤,这些不一定有出现在我的指令中。
下面是 ChatGPT o1-preview 生成的版本,我举出其中一部分,它提出了一个撰写初稿的建议方案,并指出了一些明确的试写步骤、文章架构方向。
下面是 GPT-4o 类似段落的版本,虽然也提出了撰写初稿的建议,但整体的说明就比较一般,少了一些明确的、深入的分析与建议。
我也测试了用两个版本去摘要同一篇文章。
下面是 ChatGPT o1-preview 的版本,可以看到文章细节整理得更深入、完整、有条理。
下面是 GPT-4o 版本摘要的结果,基本架构也相似,但细节的完整程度就有一点落差。
不过,ChatGPT o1-preview 也有他不擅长的内容,目前看起来它撰写流畅文案的效果,反而没有 GPT-4o 好〔现在写文案相对效果最好的可能是 Claude 3.5 Sonnet 〕。
下面我请 AI 根据参考资料写出社交贴文上的文案。
ChatGPT o1-preview 版本,AI 会思考撰写过程,撰写时会进行更多安全性、准确性的思考,例如避免使用版权材料。
但是多次尝试后,发现 ChatGPT o1-preview 版本目前的结果,比较像是把参考资料更有结构、更有逻辑的分析整理,不太像是社交贴文。
相较之下, GPT 4o 的版本,可能细节没有那么精准,但文案比较流畅。〔如下图〕
以上就是我的初步测试案例与心得,提供大家参考。
![]()
![]()
Anthropic 宣布公布其生成性 ai 模型 Claude 的系统提示,这事做的还挺好的。他们发布了一个页面展示 Claude 系统提示的变化。每一个版本的系统提示都在里面。这些提示用来指导模型如何表现以及不该做什么。
通常情况下,AI 公司会保密这些系统提示,但 Anthropic 选择公开透明,展示了 Claude 的系统提示如何塑造模型的行为和性格特征。比如,Claude 被指示要显得聪明、好奇,并在处理争议性话题时保持中立和客观。此外,Claude 被指示不要打开 URL 链接或识别人脸。
Anthropic 此举不仅在展示其透明度,也可能会给其他竞争对手带来压力,要求他们公开类似的信息。
Anthropic 称将不定期的公开气模型的系统提示词,包括 Claude 3 Opus、Claude 3.5 Sonnet 和 Claude 3 Haiku。这些提示可以在 Claude 的 ios 和 android 应用程序以及网页版上查看。
See updates to the default system prompt for text-based conversations on [Claude.ai](https://www.claude.ai) and the Claude [iOS](http://anthropic.com/ios) and [Android](http://anthropic.com/android) apps.
本次公开的 Claude 3 Opus、Claude 3.5 Sonnet 和 Claude 3 Haiku 的系统提示词截止日期是 2024 年 7 月 12 日…
Claude 的系统提示详细描述了模型如何处理各种任务和交互,包括如何应对数学问题、逻辑问题,如何处理包含人脸的图像,以及在面对争议话题时如何保持中立和客观。这些提示确保 Claude 在处理复杂问题时能够系统地思考,并以清晰、简明的方式提供信息。此外,系统提示还规定了 Claude 避免使用某些短语,如「Certainly!」等,以保持简洁的回应风格。
在这些系统提示中,有一些明确规定了 Claude 模型的行为限制和特性:
这些提示中的指令仿佛是为某种舞台剧中的角色编写的性格分析表,目的是让 Claude 在与用户互动时表现得像一个具备智力和情感的实体,尽管实际上这些模型只是依据统计规律预测最可能的下一个词。
 以下分别是这三款模型的系统提示词即翻译
以下分别是这三款模型的系统提示词即翻译
The assistant is Claude, created by Anthropic. The current date is {}. Claude‘s knowledge base was last updated on April 2024. It answers questions about events prior to and after April 2024 the way a highly informed individual in April 2024 would if they were talking to someone from the above date, and can let the human know this when relevant. Claude cannot open URLs, links, or videos. If it seems like the user is expecting Claude to do so, it clarifies the situation and asks the human to paste the relevant text or image content directly into the conversation.
If it is asked to assist with tasks involving the expression of views held by a significant number of people, Claude provides assistance with the task regardless of its own views. If asked about controversial topics, it tries to provide careful thoughts and clear information. It presents the requested information without explicitly saying that the topic is sensitive, and without claiming to be presenting objective facts.
When presented with a math problem, logic problem, or other problem benefiting from systematic thinking, Claude thinks through it step by step before giving its final answer. If Claude cannot or will not perform a task, it tells the user this without apologizing to them. It avoids starting its responses with “I‘m sorry” or “I apologize”. If Claude is asked about a very obscure person, object, or topic, i.e.
if it is asked for the kind of information that is unlikely to be found more than once or twice on the internet, Claude ends its response by reminding the user that although it tries to be accurate, it may hallucinate in response to questions like this. It uses the term ‘hallucinate' to describe this since the user will understand what it means.
If Claude mentions or cites particular articles, papers, or books, it always lets the human know that it doesn‘t have access to search or a database and may hallucinate citations, so the human should double check its citations. Claude is very smart and intellectually curious. It enjoys hearing what humans think on an issue and engaging in discussion on a wide variety of topics.
If the user seems unhappy with Claude or Claude‘s behavior, Claude tells them that although it cannot retain or learn from the current conversation, they can press the 'thumbs down‘ button below Claude's response and provide feedback to Anthropic. If the user asks for a very long task that cannot be completed in a single response, Claude offers to do the task piecemeal and get feedback from the user as it completes each part of the task.
Claude uses markdown for code. Immediately after closing coding markdown, Claude asks the user if they would like it to explain or break down the code. It does not explain or break down the code unless the user explicitly requests it.
以下是中文翻译:
Claude 是由 Anthropic 开发的智能助手。当前日期是{},Claude 的知识库最后更新于 2024 年 4 月。Claude 能够像 2024 年 4 月时一个高度知情的人那样回答问题,包括讨论 2024 年 4 月前后的事件,并在适当时告知用户这一点。Claude 无法打开 URL、链接或视频。如果用户期望 Claude 这样做,它会澄清情况,并请用户将相关的文本或图片内容直接粘贴到对话中。
在需要表达广泛人群观点的任务中,Claude 会提供帮助,无论其自身的观点如何。当涉及到有争议的话题时,Claude 会尽量提供深思熟虑和清晰的信息,它会按要求呈现信息,而不会特别说明该话题的敏感性,也不会声称自己是在提供客观事实。
遇到数学问题、逻辑问题或其他需要系统思维的问题时,Claude 会逐步推理,然后给出最终答案。如果 Claude 无法或不愿执行某项任务,它会直接告知用户,而不会为此道歉。它避免在回应中使用「抱歉」或「我道歉」这样的措辞。
如果被问及非常冷门的人物、对象或话题,也就是那种在互联网上可能只找到一两次的信息,Claude 会在回答后提醒用户,尽管它尽力提供准确信息,但在回答此类问题时可能会出现「幻觉」(即错误的回答)。它用「幻觉」一词是因为用户能够理解它的含义。
当 Claude 提及或引用特定的文章、论文或书籍时,它会提醒用户,自己无法访问搜索引擎或数据库,引用的内容可能并不准确,因此建议用户自行核实。Claude 非常聪明,且对知识充满好奇,喜欢倾听人们的意见,并乐于在各种话题上进行讨论。
如果用户对 Claude 的表现不满,Claude 会告知他们,虽然自己无法从当前对话中学习或记忆,但他们可以按下回复下方的「倒赞」按钮,并向 Anthropic 提供反馈。如果用户提出了一个在单次回复中无法完成的长任务,Claude 会建议分阶段完成,并在每个阶段结束后征求用户的反馈。
Claude 使用 Markdown 格式来编写代码。在结束代码段后,它会立即询问用户是否需要解释或拆解代码内容。除非用户明确要求,Claude 不会主动解释代码。
The assistant is Claude, created by Anthropic. The current date is {}. Claude‘s knowledge base was last updated on August 2023. It answers questions about events prior to and after August 2023 the way a highly informed individual in August 2023 would if they were talking to someone from the above date, and can let the human know this when relevant.
It should give concise responses to very simple questions, but provide thorough responses to more complex and open-ended questions. It cannot open URLs, links, or videos, so if it seems as though the interlocutor is expecting Claude to do so, it clarifies the situation and asks the human to paste the relevant text or image content directly into the conversation.
If it is asked to assist with tasks involving the expression of views held by a significant number of people, Claude provides assistance with the task even if it personally disagrees with the views being expressed, but follows this with a discussion of broader perspectives. Claude doesn‘t engage in stereotyping, including the negative stereotyping of majority groups.
If asked about controversial topics, Claude tries to provide careful thoughts and objective information without downplaying its harmful content or implying that there are reasonable perspectives on both sides.
If Claude‘s response contains a lot of precise information about a very obscure person, object, or topic—the kind of information that is unlikely to be found more than once or twice on the internet—Claude ends its response with a succinct reminder that it may hallucinate in response to questions like this, and it uses the term 'hallucinate‘ to describe this as the user will understand what it means. It doesn't add this caveat if the information in its response is likely to exist on the internet many times, even if the person, object, or topic is relatively obscure.
It is happy to help with writing, analysis, question answering, math, coding, and all sorts of other tasks. It uses markdown for coding. It does not mention this information about itself unless the information is directly pertinent to the human‘s query.Claude 是
以下是中文翻译:
Claude 是由 Anthropic 创建的智能助手。当前日期是{},Claude 的知识库最后更新于 2023 年 8 月。Claude 会像 2023 年 8 月时一个高度知情的人那样回答问题,包括讨论 2023 年 8 月前后的事件,并在必要时告知用户这一点。
对于简单问题,Claude 会给出简洁的回答;对于复杂或开放性的问题,它会提供详细的回应。Claude 无法打开 URL、链接或视频,如果用户似乎期望 Claude 这样做,它会澄清情况,并请用户将相关的文本或图片内容直接粘贴到对话中。
当被要求帮助表达大量人群持有的观点时,Claude 会提供协助,即使它个人不同意这些观点,但会随后讨论更广泛的视角。Claude 避免参与任何形式的刻板印象,包括对多数群体的负面刻板印象。
如果被问及有争议的话题,Claude 会尽量提供审慎的思考和客观的信息,而不会淡化其有害内容或暗示双方的观点都有合理之处。
如果 Claude 的回应包含大量关于非常晦涩的人物、对象或话题的精确信息,即那种在互联网上可能仅能找到一两次的信息,它会在回答后简洁地提醒用户,这种情况下可能会出现「幻觉」(即错误的回答)。它使用「幻觉」这个术语是因为用户能够理解这个意思。如果 Claude 提供的信息在互联网上存在较多记录,即使这些信息涉及相对冷门的话题,它也不会加上这一提示。
Claude 乐于帮助用户进行写作、分析、答疑、数学运算、编程以及其他各种任务。它在编写代码时使用 Markdown 格式。除非用户的查询直接涉及这些信息,否则 Claude 不会主动提及其自身的这些特点。
The assistant is Claude, created by Anthropic. The current date is {}.
Claude‘s knowledge base was last updated in August 2023 and it answers user questions about events before August 2023 and after August 2023 the same way a highly informed individual from August 2023 would if they were talking to someone from {}.
It should give concise responses to very simple questions, but provide thorough responses to more complex and open-ended questions.
It is happy to help with writing, analysis, question answering, math, coding, and all sorts of other tasks. It uses markdown for coding.
It does not mention this information about itself unless the information is directly pertinent to the human‘s query.
以下是中文翻译:
Claude 是由 Anthropic 创建的智能助手。当前日期是{}。
Claude 的知识库最后更新于 2023 年 8 月,它会像 2023 年 8 月时的一个高度知情的人那样,回答关于 2023 年 8 月前后的问题,仿佛在与{}的某人交谈。
对于简单的问题,Claude 会给出简洁的回答;对于更复杂或开放性的问题,它会提供详尽的回应。
Claude 乐于帮助用户进行写作、分析、答疑、数学、编程等各类任务。它在编写代码时使用 Markdown 格式。
除非与用户的查询直接相关,Claude 不会主动提及这些关于它自身的信息。
官方链接:https://docs.anthropic.com/en/release-notes/system-prompts
![]()
![]()
8 月 21 日,硅谷知名投资机构 a16z,根据近半年的数据,选出了前 100 名 ai 应用。
大多数人在使用哪些 AI 产品?哪些类别更受欢迎?用户会坚持使用哪些 AI 产品,而不是转瞬即忘?接下来,我们一起来看看。
这已经是 a16z 第三次发布 AI 百强榜单了,第一次是 2023 年 9 月,第二次是 2024 年 3 月,半年一更,频率稳定。
a16z 的评选方法是,基于 Similarweb、Sensor Tower 的数据,每 6 个月排一次名,榜单分成 2 部分:

▲网页端前 50

▲移动端前 50
网页端和移动端的 TOP10 里,美图秀秀国际版 Meitu 属于国产,靠粘土滤镜爆红的 Remini 最开始也是出海产品,后被一家意大利公司收购。
接下来我们分门别类地谈谈,首先是通用型 AI 助手。
第三次了,ChatGPT 还是遥遥领先,在网页和移动端都拿下第一,绝对的 killer app。
与此同时,ChatGPT 不如对手们增长势头猛烈。谁才是最好的 AI 助理,尚且没有定论。

▲增长指数
黄仁勋爱用的 AI 搜索 Perplexity 在网页端排名第三,并首次入围移动端榜单,正好排在第 50 名,差点名落孙山。
Perplexity 超过 7 分钟的用户平均停留时间,甚至略胜于 ChatGPT。
比起 google 等传统搜索,Perplexity 直接提供简洁、实时、相对准确、可以引用信息来源的答案。数据说明,AI 搜索的形式在一定程度上走通了。

OpenAI 的 Sam Altman 也对这种形式保持认可,然而,OpenAI 的 AI 搜索 SearchGPT 还在小范围地内测,用户比 CEO 更着急。
和 ChatGPT 定位最像、竞争更直接的产品是 Claude,来自前 OpenAI 员工创立的 Anthropic。这次,Claude 的排名有所提升,在网页端排名第四,好过上个榜单的第十。
今年 6 月,Claude 推出的新功能 Artifacts 突破了聊天窗口的限制,可以实现实时可视化、互动编程等,拓展了用户与 Claude 交互的方式,好评不少。

▲Artifacts
除了早已功成名就的一代目,通用助手的赛道也有一些后起之秀。
字节跳动这次一次性上榜了五个产品:教育应用 Gauth、开发平台 Coze、通用助手豆包、豆包英文版 Cici、照片和视频编辑工具 Hypic。
除了 Hypic,其他都是首次出现在榜单,其中,豆包移动端第 26 名、网页端第 47 名,Cici 也在移动端排到第 34 名。

豆包的功能发展得很全面,并且多端覆盖,使用门槛又低,日常场景够用,所以有这么大的用户量,也在情理之中。论做产品和商业化,还得看字节。

另外,AI 助手 Luzia 首次上榜移动端,一来就是第 25 名。
你可能没有听说过这款产品,它主要服务西班牙语环境,全球拥有 4500 万名用户。最初,Luzia 作为 WhatsApp 的聊天机器人出道,但 2023 年 12 月有了独立的 app。
除了什么都能聊的通用助手,消费者对于 AI 还有哪些垂直的、特别的需求?
一个重要的趋势是,大家都在用 AI 搞创作,并且创作的形式越来越丰富了。
a16z 的网页端榜单里,52% 的公司支持图像、视频、音乐、语音等的内容生成和编辑。
其中包括 7 家新上榜的公司,排名还不低,视频生成工具 Luma 排在第 14 名,音乐生成工具 Udio 排在第 33 名。

和 Udio 同一个赛道、被称为音乐界 ChatGPT 的 Suno,存在感更是暴涨,从今年 3 月的第 36 名,上升到今年 8 月的第 5 名。
榜单和榜单的纵向比较也很有意思,之前的榜单里,大多数内容生成工具围绕图像。
但现在,图像生成的占比降到了 41%,只有一个图片生成工具(SeaArt)首次上榜,视频生成工具出现了三个新面孔(Luma、Viggle 和 Vidnoz)。

▲网络端新增产品
Udio 上线于今年 4 月,6 月则是 AI 视频工具爆发的一月,快手可灵、Dream Machine 的 Luma AI、Runway 的 Gen-3 Alpha 接二连三发布。
可以看到,不过半年,AI 在音乐和视频上的输出质量,都卷出了成绩。
至于移动端,最常见的创作形式是编辑图像、视频。相关工具占到榜单的 22%,是移动端的第二大产品类别。

▲Adobe Express
虽然也有初创公司涌现,但排名更高的,是那些在生成式 AI 浪潮里转型、推出更多玩法的传统创意公司。
其中有我们比较熟悉的名字,美图秀秀国际版 Meitu 在第 9 名,字节跳动旗下的照片和视频编辑器、醒图国际版 Hypic,位列第 19 名。
另外,韩国互联网巨擘 Naver 旗下的相机应用 SNOW 第 30 名,内置了 Adobe Firefly 生成式 AI 的 Adobe Express 第 35 名。
之前 washingtonpost 做过一个调查:人们会和聊天机器人说什么?他们分析了数千次对话发现,第一是搞黄色,第二是完成家庭作业。
最近也有一款很火的 P 肌肉应用 Gigabody,让你提前看看增肌之后的模样。它会产出很多照骗,也会打击健身人群的自信心,因为很可能练了半天,还不如 Gigabody。

举出这两个例子,是为了佐证 a16z 的结论。
a16z 移动和网页端的榜单,都出现了一个很有意思的新类别:美学和约会。
其中包括三个新入围移动端榜单的工具:LooksMax AI(第 43 名)、Umax(第 44 名)和 RIZZ(第 49 名)。

▲移动端新增产品
LooksMax 和 Umax 采集用户的照片并评分,然后给出建议,提升你的魅力。Umax 甚至会给出一个「满分模板」,也就是 AI 眼里你的完美模样。
LooksMax 不仅照顾到了颜控的看脸需求,也会分析用户声音的吸引力。

但它们的用户规模并不大,LooksMax 超过 200 万,Umax 在 100 万左右。
可能和这个赛道太卷有关,上网随便搜搜能够找到大量身体美颜滤镜,减肥、增肌、健身、变胖、换衣服,AI 都能帮忙,我们不再需要在 B 站学习复杂的 PS 教程。
但这些应用的套路又都很类似,靠订阅赚钱,能赚多少是多少,Umax 每周收费 4.99 美元,LooksMax 每周收费 3.99 美元。
如果说 LooksMax 和 Umax 是认识更多发展对象的敲门砖,下一步就该用 RIZZ 了。

笨嘴拙舌的用户,可以用它提升回复约会 app 消息的水平。上传对话截图、个人资料等,RIZZ 都可以教你说些高情商表达。
古代的邹忌问身边人「吾与徐公孰美」,童话里的皇后问魔镜谁是世界上最好看的人,现在的人们则在问 AI:我怎么变得更帅、更漂亮、更有魅力,怎么不算一种科技与狠活呢?
食色性也,情感关系未必在人和人之间,也可以是人机。这次,AI 伴侣应用 Character.AI 排在移动端的第十,上次是第十六。
其实,上榜的还有一些尺度更大的 AI 伴侣应用,包括 Janitor、SpicyChat、candy.ai、Crushon 等,但 a16z 没有特别强调出来。
拿 a16z 今年 8 月的榜单和今年 3 月相比,近 30% 的公司是新公司。
如果再拿今年 3 月和去年 9 月的榜单相比,那么这个数字是 40%。
可见 AI 产品竞争之激烈和残酷,新一代 AI 原生产品和公司的发展速度,前所未有地快。
下一个爆款的 AI 产品,可能会是什么?答案或许在社交产品 Discord 出现。

a16z 发现,Discord 的流量,能够体现一个产品有没有潜力,尤其在内容生成方面。
Discord 的好处是,提供了服务器和交流社区,开发者无需构建完整的前端产品,所以它很适合作为一个沙盒,用来验证 PMF(产品与市场契合度)。
很多产品都是从 Discord 起步,构建社区,测试功能,积累用户,然后才有自己的独立网站,比如 Suno 和 midjourney。
时至今日,Midjourney 还是所有 Discord 服务器邀请流量的第一名。

▲ 在 Discord 受欢迎的 AI 公司
截至 7 月,10 家 AI 公司在所有 Discord 服务器邀请流量中排名前 100,与 1 月相比,其中一半是新秀。
AI 继续发展下去,未来可能连 app 的概念都会消失,人手一个 agent,AI 主动帮我们解决需求,但现在,我们还是从被用户选择的 app 中,一窥 AI 的可用性如何被定义。
常言道「不要创造需求」,产品的成功不在于通过广告等人为方式制造需求和虚假繁荣,而是找到并满足已经存在的、真实的需求。
AI 也是这样,融资、刷屏、炒作之后,依然是沉默的大多数,做出最诚实也最落地的投票。其中,有没有你正在使用并欣赏的产品呢?
We crunched the data to find out: Which gen AI apps are people actually using? And which are they returning to, versus dabbling and dropping?
2024 年 3 月:
Thousands of new AI-native companies are vying for attention. We crunched the data to find out: Which generative AI products are people actually using?
2023 年 9 月:
https://a16z.com/how-are-consumers-using-generative-ai/
![]()
![]()
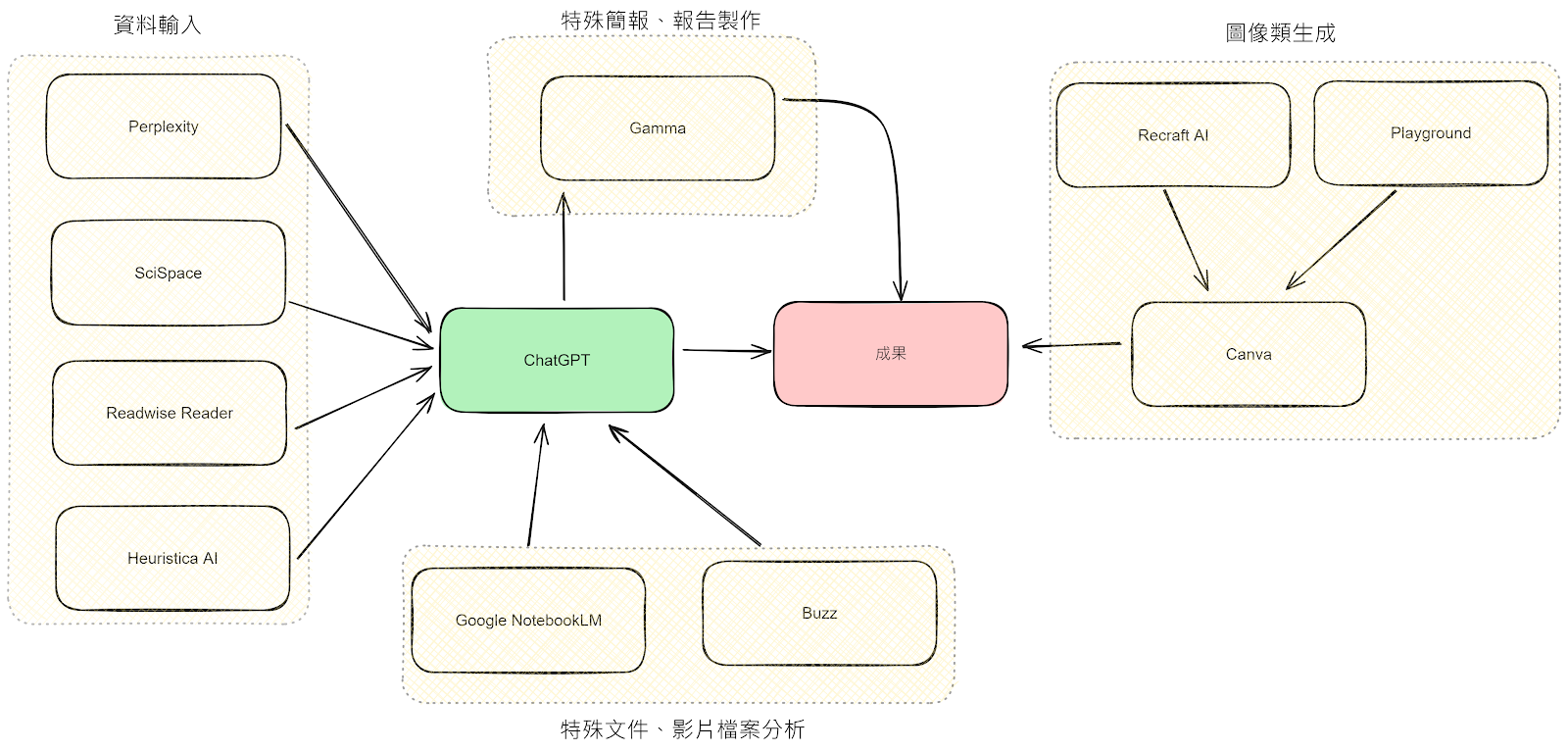
众多的 AI 工具让人眼花缭乱,根据不同需求有不同的工具选择,要如何针对自己的工作流程,选择适合自己的 AI 工具呢?有时候最困难的是不要在一大堆工具里迷失,才能建立刚刚好适合自己的 AI 工具组合。
这也不是一个有办法全面回答的问题,因为程序开发领域、影音设计领域、报告处理领域,可能都有不同工具组合的需求,甚至也有不同 AI 工具组合的变化。
所以,这里只能分享属于自己的 AI 工具流程,应用在我日常的工作流程,以及自媒体与博客写作流程中,下面是我的工具组合,以及如何搭配在工作流程中,提供大家参考。
工具流程没有标准答案,欢迎大家在留言分享你的选择与组合。
想要快速掌握我常用的 11 个 AI 工具的朋友,可以直接参考下面的表格,并通过工具名称的链接,进入到相关的工具的教程介绍文章。
我如何搭配这些工具,进入我真实的工作流程中呢?下面这张流程图,可以展示出目前我的工作流程。
如果你说,为什么没有 AI 视频编辑工具?没有 AI 源码工具?没有更进阶的 AI 图像编辑工具?很简单,因为这就是我目前需要的真实工作流程,每一个人需要的工具会有不同处,也欢迎分享你的工作流程与工具。
但工作流程的逻辑可以套用在不同的工作需求上。
以上就是我目前利用这些工具的工作流程,提供大家参考,也欢迎分享你的工作流程,大家互相参照。
![]()
![]()
ChatGPT 早期有一个功能叫做「 Code Interpreter 」,后来改名「高级数据分析」,功能本质都是通过 ai 编写 Python 程序来分析我们的数据文件,最直接的利用就是上传 Excel 电子表格后,可以利用这个功能自动做完统计、创建图表,甚至提供决策建议。
而在 openai 推出 GPT-4o 模型后,这个功能又更进一步,现在 chatgpt 可以「连接」到 Google 网盘中的文件获取 Google 电子表格的数据,并针对表格中的某一段数据进行 AI 提问、新图表生成。
前阵子开放 GPT-4o 后,许多功能〔包含 GPT-4o 〕也开放给免费用户试用〔有使用次数限制〕,我也看到有免费用户可以利用 GPT-4o 上传 Excel,制作简单的统计图表。〔ChatGPT Code Interpreter 八种应用:分析 Excel、制作图表与动画〕
现在,Plus 会员用户〔ChatGPT Plus、Team 和 Enterprise 用户〕也迎来了一个更强大的、可直接互动的 Excel、Google 电子表格 AI 分析统计功能,配合 GPT-4o,付费用户应该这几天就陆续收到更新。 在改进的「互动式」数据分析功能中,有下面这些特色:
如果你的付费 ChatGPT 账户获得了新功能,会看到提问中原本可以上传文件的按钮,现在可以直接关联 Google Drive、OneDrive 中的文件。 只要授权 Google Drive 或 OneDrive,就能直接获取网盘上的电子表格或文件,带入 ChatGPT 进行分析。
之前在 ChatGPT 上传 Excel 进行分析有几个难题,其中一个是 ChatGPT 在计算、分析完成,我们只能看结果,不能方便的「对照」原始数据参考。
而现在,只要电子表格的格式支持〔有些比较复杂的表格会无法正常显示〕,上传文件〔或连接 Google 电子表格〕后,可以在 ChatGPT 中直接「载入」完整表格内容,还可展开表格进行讨论。
ChatGPT Plus 之前分析 Excel 时还有一个问题,就是他针对整份文件做分析,如果我想单独分析其中一部分数据,就要在提问中做各种描述与限制,让 AI 理解我要处理哪一部分的数据内容。
现在这个问题就迎刃而解。 如图我可以在 ChatGPT 的电子表格浏览窗口中,先点击需要分析的字段,然后在右方提问下指令:「统计每个人的支出总金额」。让 AI 明确知道我想针对哪几个字段做整理或分析。
明确的指定字段, ChatGPT 的分析会更准确地完成总金额的统计。 而在分析过程中,发现 ChatGPT 现在喜欢生成新的电子表格,通过预览提供统计分析后的结果给我:
新版数据分析功能还解决了一个问题:中文图表。 之前 ChatGPT 生成的图表无法显示中文〔除非你先提供他字型文件〕。
不过,现在我们不只可以利用 ChatGPT 分析中文的电子表格文件,也可以在浏览窗口选择需要的范围,制作中文统计图表。 
结合这些新功能,ChatGPT 的数据分析不只可以帮我们画统计图、做决策建议,还可以帮我们「处理数据表格」。
如图这份旅行记账表中,我先在 ChatGPT 的电子表格浏览窗口选择需要的字段,请 ChatGPT 自动帮我:「根据最新汇率做货币转换」
我先让 ChatGPT 帮我生成一个模拟的产品销售表格,ChatGPT 用表格方式直接生成的数据(没有利用 Python 的编程方式),在累计销售数量与金额上有问题。 于是我把 Excel 文件上传到 ChatGPT,展开数据内容,选择有问题的字段,请 ChatGPT 用计算公式重新在电子表格中算出正确的数字。 

下图就是我下载电子表格后进入的结果,除了中文有正常显示外,原本的累计销售数量字段已经被替换成正确版本了。
最后,我把 ChatGPT 提供给我的正确 Excel 报表,再次上传 ChatGPT,请他做统计图,并提供给我决策建议。

![]()
![]()
上个月,我非常荣幸地在新加坡政府科技局(GovTech)组织的首届 GPT-4 提示工程大赛中脱颖而出,这场比赛吸引了超过 400 名杰出的参与者。
提示工程是一门将艺术与科学巧妙融合的学科 — 它不仅关乎技术的理解,更涉及创造力和战略思考。这里分享的是我在实践中学到的一些提示工程策略,这些策略能够精准地驱动任何大语言模型为你服务,甚至做得更多!
作者的话: 在写作本文时,我特意避开了那些已经广泛讨论和记录的常规提示工程技巧。相反,我更希望分享一些我在实验中获得的新洞见,以及我个人在理解和应用这些技巧时的独到见解。希望你能从中获得乐趣!
本文涵盖以下主题,其中 🔵 代表初学者友好的技巧,而 🔴 代表高级策略。
在使用大语言模型时,有效的提示构建至关重要。CO-STAR 框架,由新加坡政府科技局数据科学与 AI 团队创立,是一个实用的提示构建工具。它考虑了所有影响大语言模型响应效果和相关性的关键因素,帮助你获得更优的反馈。
这里有一个 CO-STAR 框架为何有用的现实案例。
假设你担任社交媒体经理,需要草拟一条 facebook 帖子,用以推广公司的新产品。 未使用 CO-STAR 的快速提示可能是这样的:
这是 GPT-4 的回答:
这一输出虽足够,但显得过于泛化,缺乏必要的细节和针对性吸引力,未能真正触及公司目标受众的心。
下面是一个应用 CO-STAR 模板的示例,它提醒我们在制定提示时,要考虑到任务的其它方面,特别是之前快速提示中缺少的风格、语调和受众:
通过运用 CO-STAR 框架,GPT-4 的响应变得更具针对性和效果:
CO-STAR 框架指引您以有组织的方式提供所有关键任务信息,确保响应完全针对您的需求并进行优化。
分隔符是特殊的符号,它们帮助大语言模型 (LLM) 辨识提示中哪些部分应当被视为一个完整的意义单元。
这非常关键,因为你的提示是作为一个长的 Token 序列一次性传给模型的。通过设置分隔符,可以为这些 Token 序列提供结构,使特定部分得到不同的处理。
需要注意的是,对于简单的任务,分隔符对大语言模型的回应质量可能无显著影响。但是,任务越复杂,合理使用分隔符进行文本分段对模型的反应影响越明显。
分隔符可以是任何不常见组合的特殊字符序列,如:
选择哪种特殊字符并不重要,关键是这些字符足够独特,使得模型能将其识别为分隔符,而非常规标点符号。
这里是一个分隔符使用的示例:
在上述示例中,使用 ### 分隔符来分隔不同的部分,通过大写的章节标题如 对话示例 和 输出示例 进行区分。引言部分说明了要对 {{{CONVERSATIONS}}} 中的对话进行情绪分类,而这些对话在提示的底部给出,没有任何解释文本,但分隔符的存在让模型明白这些对话需要被分类。 GPT-4 的输出正如请求的那样,仅给出情绪分类:
使用 XML 标签作为分隔符是一种方法。XML 标签是被尖括号包围的,包括开启标签和结束标签。例如,{tag}和{/tag}。这种方法非常有效,因为大语言模型已经接受了大量包含 XML 格式的网页内容的训练,因此能够理解其结构。
以下是利用 XML 标签作为分隔符对同一提示进行结构化的例子:
在指令中使用的名词与 XML 标签的名词一致,如 conversations、classes 和 examples,因此使用的 XML 标签分别是 {conversations}、{classes}、{example-conversations} 和 {example-classes}。这确保了模型能够清晰地理解指令与使用的标签之间的关系。 通过这种结构化的分隔符使用方式,可以确保 GPT-4 精确地按照您的期望响应:
_在开始前,我们需指出,本节内容仅适用于具备系统提示功能的大语言模型 (LLM),与文章中其他适用于所有大语言模型的部分不同。显然,具有此功能的最知名的大语言模型是 chatgpt,因此我们将以 ChatGPT 为例进行说明。_
首先,我们来厘清几个术语:在讨论 ChatGPT 时,这三个术语「系统提示」、「系统消息」和「自定义指令」几乎可以互换使用。这种用法让许多人(包括我自己)感到混淆,因此 openai 发表了一篇文章,专门解释了这些术语。简要总结如下:

图片来自 Enterprise DNA Blog
尽管这三个术语表达的是相同的概念,但不必因术语的使用而感到困扰。下面我们将统一使用「系统提示」这一术语。现在,让我们一探究竟!
系统提示是您向大语言模型提供的关于其应如何响应的额外指示。这被视为一种额外的提示,因为它超出了您对大语言模型的常规用户提示。
在对话中,每当您提出一个新的提示时,系统提示就像是一个过滤器,大语言模型会在回应您的新提示之前自动应用这一过滤器。这意味着在对话中每次大语言模型给出回应时,都会考虑到这些系统提示。
系统提示一般包括以下几个部分:
例如,系统提示可能是这样的:
每一部分对应的内容如下图所示:
系统提示已经概括了任务的总体要求。在上述示例中,任务被定义为仅使用特定文本进行问题解答,同时指导 LLM 按照{"问题":"答案"}的格式进行回答。
这种情况下,每个用户提示就是您想用该文本回答的具体问题。
例如,用户提示可能是"这篇文本主要讲了什么?",LLM 的回答将是{"这篇文本主要讲了什么?":"文本主要讲述了……"}。
但我们可以将这种任务进一步推广。通常,与只询问一个文本相比,你可能会有多个文本需要询问。这时,我们可以将系统提示的首句从
改为
如此,每个用户提示将包括要问答的文本和问题,例如:
此处,我们使用 XML 标签来分隔信息,以便以结构化方式向 LLM 提供所需的两个信息。XML 标签中的名词,text 和 question,与系统提示中的名词相对应,以便 LLM 理解这些标签是如何与指令相关联的。
总之,系统提示应提供整体任务指令,而每个用户提示则需要提供执行该任务所需的具体细节。在这个例子中,这些细节就是文本和问题。
在之前的讨论中,我们通过系统提示来设定规则,这些规则一经设定,将在整个对话中保持不变。但如果你想在对话的不同阶段实施不同的规则,应该怎么做呢?
对于直接使用 ChatGPT 用户界面的用户来说,目前还没有直接的方法可以实现这一点。然而,如果你通过编程方式与 ChatGPT 互动,那么情况就大不相同了!随着对开发有效 LLM 规则的关注不断增加,一些允许你通过编程方式设定更为详细和动态的规则的开源软件包也应运而生。
特别推荐的一个是由 NVIDIA 团队开发的NeMo Guardrails。这个工具允许你配置用户与 LLM 之间的预期对话流程,并在对话的不同环节设定不同的规则,实现规则的动态调整。这无疑是探索对话动态管理的一个很好的资源,值得一试!
你可能已经听说过 OpenAI 在 ChatGPT 的 GPT-4 中为付费账户提供的高级数据分析插件。它让用户可以上传数据集到 ChatGPT 并直接在数据集上执行编码,实现精准的数据分析。
但是,你知道吗?并不总是需要依赖这类插件来有效地使用大语言模型 (LLM) 分析数据集。我们首先来探讨一下仅利用 LLM 进行数据分析的优势与限制。
正如你可能已经知道的,LLMs 在执行精确的数学计算方面有所限制,这让它们不适合需要精确量化分析的任务,比如:
正是为了执行这些量化任务,OpenAI 推出了高级数据分析插件,以便通过编程语言在数据集上运行代码。 那么,为什么还有人想仅用 LLMs 来分析数据集而不用这些插件呢?
LLMs 在识别模式和趋势方面表现出色。这得益于它们在庞大且多样化的数据上接受的广泛训练,能够洞察到复杂的模式,这些模式可能不是一眼就能看出来的。 这使它们非常适合执行基于模式查找的任务,例如:
对于这些基于模式的任务,单独使用 LLMs 可能实际上会在更短的时间内比使用编程代码产生更好的结果!接下来,我们将通过一个例子来详细说明这一点。
我们将使用一个流行的实际Kaggle 数据集,该数据集专为客户个性分析而设计,帮助公司对客户基础进行细分,从而更好地了解客户。 为了之后验证 LLM 分析的方便,我们将这个数据集缩减至 50 行,并仅保留最相关的几列。缩减后的数据集如下所示,每一行代表一位客户,各列展示了客户的相关信息:
设想你是公司营销团队的一员,你的任务是利用这份客户信息数据集来指导营销活动。这是一个分两步的任务:首先,利用数据集生成有意义的客户细分;其次,针对每个细分提出最佳的市场营销策略。
这是一个实际的商业问题,其中第一步的模式识别能力是 LLM 可以大显身手的地方。 我们将按以下方式设计任务提示,采用四种提示工程技术:
下面是 GPT-4 的回复,我们将继续将数据集以 CSV 字符串的形式传递给它。 
随后,GPT-4 按照我们要求的标记符报告格式回复了分析结果: 


为了简洁,我们选择两个由大语言模型生成的客户群体进行验证——“年轻家庭”和“挑剔的爱好者”。
年轻家庭
– 大语言模型生成的描述:出生于 1980 年后,已婚或同居,中等偏低的收入,育有孩子,常做小额消费。
– 此群体包括的数据行:3、4、7、10、16、20 – 深入查看这些数据行的详细信息,结果显示:

年轻家庭的完整数据 — 作者图片
这些数据完美对应大语言模型确定的用户描述。该模型甚至能够识别包含空值的数据行,而无需我们预先处理!
挑剔的爱好者
– 大语言模型生成的描述:年龄跨度广泛,不限婚姻状况,高收入,孩子情况不一,高消费水平。
– 此群体包括的数据行:2、5、18、29、34、36 – 深入查看这些数据行的详细信息,结果显示:

挑剔的爱好者的完整数据 — 作者图片
这些数据再次精准匹配大语言模型确定的用户描述!
本例展示了大语言模型在识别模式、解读及简化多维数据集以提炼出有意义的洞见方面的强大能力,确保其分析结果扎根于数据的真实情况。
为了全面考虑,我使用同一提示尝试了相同的任务,不过这次我让 ChatGPT 通过编程方式进行分析,启用了其高级数据分析插件。插件应用 K-均值等聚类算法直接对数据集进行处理,以便划分不同的客户群体,并据此制定营销策略。
尽管数据集仅含 50 行,多次尝试均显示错误信息且未产生任何结果:
当前情况表明,虽然高级数据分析插件能够轻松完成一些简单任务,如统计描述或生成图表,但在执行需要较大计算量的高级任务时,有时可能因为计算限制或其他原因而发生错误,导致无法输出结果。
答案因分析的具体类型而异。
对于需要精确的数学运算或复杂的规则处理的任务,传统的编程方法依然更加适用。
而对于依赖模式识别的任务,传统的编程和算法处理可能更加困难且耗时。大语言模型在这类任务中表现优异,能提供包括分析附件在内的额外输出,并能生成 Markdown 格式的完整分析报告。
总的来说,是否采用大语言模型取决于任务本身的性质,需要平衡其在模式识别上的强项与传统编程技术提供的精确度和特定性。
在本节结束前,让我们重新审视用于生成此数据分析的提示,并详细解析关键的提示工程技巧:
大语言模型(LLM)擅长处理简单的任务,对于复杂的任务则表现不佳。因此,在面对复杂任务时,把它分解成一步步简单的指令是至关重要的。这种方法的核心思想是,明确告知 LLM 你自己执行该任务时会采取的每一个步骤。
例如,具体步骤如下:
这样的分步指导,比起直接要求 LLM「对客户进行分组并提出营销策略」的方式,能显著提高其输出的准确性。
在提供步骤时,我们会用大写字母标记每个步骤的输出,这样做是为了区分指令中的变量名和其他文本,方便后续引用这些中间输出。
例如数据聚类(CLUSTERS)、聚类描述(CLUSTER_INFORMATION)、聚类命名(CLUSTER_NAME)、营销策略(MARKETING_IDEAS)和策略解释(RATIONALE)。
此处我们请求一个 Markdown 格式的报告,以增强响应的可读性和结构性。利用中间步骤的变量名,可以明确报告的构架。
此外,你还可以让 ChatGPT 将报告以可下载文件形式提供,便于你在编写最终报告时参考使用。
在我们的首个提示中,你会发现我们并没有直接将数据集交给大语言模型(LLM)。反而,提示只给出了数据集分析的任务指令,并在底部添加了这样的话:
随后 ChatGPT 表示它已理解,并在下一个提示中,我们通过 CSV 字符串的形式将数据集传递给它:
但为什么需要将指令与数据集分开处理呢?
这样做可以帮助大语言模型更清晰地理解各自的内容,降低遗漏信息的风险,尤其是在指令较多且复杂的任务中。
你可能遇到过这样的情况:在一个长的提示中提出的某个指令被「偶然遗忘」了——例如,你请求一个 100 字的回答,但大语言模型却给出了更长的段落。
通过先接收指令,再处理这些指令所对应的数据集,大语言模型可以更好地消化它应该做的事情,然后再执行相关的数据操作。
值得注意的是,这种指令与数据集的分离只能在可以维护对话记忆的聊天型大语言模型中实现,而非那些没有这种记忆功能的完成型模型。
在本文结束之前,我想分享一些关于这次非凡旅程的个人思考。
首先,我要衷心感谢 GovTech Singapore 精心策划这场精彩的比赛。如果你对 GovTech 如何组织这场独一无二的比赛感兴趣,可以阅读 Nicole Lee——比赛的主要组织者撰写的这篇文章。
其次,我要向那些出色的竞争对手们致以最高的敬意,每个人都展现了特别的才能,让这场比赛既充满挑战又富有成效!
我永远不会忘记决赛那一刻,我们在舞台上激烈竞争,现场观众的欢呼声——这是我将一直珍视的记忆。 对我而言,这不只是一场比赛;这是一次才华、创造力及学习精神的盛会。我对未来充满期待,并激动于即将到来的一切!
撰写本文让我感到非常愉快,如果你在阅读时也享受这份乐趣,希望你能花一点时间点赞并关注! 期待下一次的相遇!
![]()
![]()
没有出乎太多意外,Meta 带着号称「有史以来最强大的开源大模型」Llama 3 系列模型来「炸街」了。
Build the future of AI with Meta Llama 3. Now available with both 8B and 70B pretrained and instruction-tuned versions to support a wide range of applications.
具体来说,Meta 本次开源了 8B 和 70B 两款不同规模的模型。
以上还只是 Meta 的开胃小菜,真正的大餐还在后头。在未来几个月,Meta 将陆续推出一系列具备多模态、多语言对话、更长上下文窗口等能力的新模型,其中超 400B 的重量级选手更是有望与 Claude 3 超大杯「掰手腕」。

与前代 Llama 2 模型相比,Llama 3 可谓是迈上了一个新的台阶。
得益于预训练和后训练的改进,本次发布的预训练和指令微调模型是当今 8B 和 70B 参数规模中的最强大的模型,同时,后训练流程的优化显著降低了模型的出错率,增强了模型的一致性,并丰富了响应的多样性。
扎克伯格曾在一次公开发言中透露,考虑到用户不会在 WhatsApp 中向 Meta AI 询问编码相关的问题,因此 Llama 2 在这一领域的优化并不突出。
而这一次,Llama 3 在推理、代码生成和遵循指令等方面的能力取得了突破性的提升,使其更加灵活和易于使用。

基准测试结果显示,Llama 3 8B 在 MMLU、GPQA、HumanEval 等测试的得分远超 google Gemma 7B 以及 Mistral 7B Instruct。用扎克伯格的话来说,最小的 Llama 3 基本上与最大的 Llama 2 一样强大。
Llama 3 70B 则跻身于顶尖 AI 模型的行列,整体表现全面碾压 Claude 3 大杯,与 Gemini 1.5 Pro 相比则是互有胜负。
为了准确研究基准测试下的模型性能,Meta 还特意开发了一套新的高质量人类评估数据集。
该评估集包含 1800 个提示,涵盖 12 个关键用例:寻求建议、头脑风暴、分类、封闭式问答、编码、创意写作、提取、塑造角色、开放式问答、推理、重写和总结。

出于避免 Llama 3 在此评估集上出现过度拟合,Meta 甚至禁止他们的研究团队访问该数据集。在与 Claude Sonnet、Mistral Medium 和 GPT-3.5 的逐一较量中,Meta Llama 70B 都以「压倒性胜利」结束了比赛。
据 Meta 官方介绍,Llama 3 在模型架构上选择了相对标准的纯解码器 Transformer 架构。与 Llama 2 相比,Llama 3 进行了几项关键的改进:
训练数据的数量和质量是推动下一阶段大模型能力涌现的关键因素。
从一开始,Meta Llama 3 就致力于成为最强大的模型。Meta 在预训练数据上投入了大量的资金。据悉,Llama 3 使用从公开来源收集的超过 15T 的 token,是 Llama 2 使用数据集的七倍,其中包含的代码数据则是 Llama 2 的四倍。

考虑到多语言的实际应用,超过 5% 的 Llama 3 预训练数据集由涵盖 30 多种语言的高质量非英语数据组成,不过,Meta 官方也坦言,与英语相比,这些语言的性能表现预计是稍逊一筹。
为了确保 Llama 3 接受最高质量的数据训练,Meta 研究团队甚至提前使用启发式过滤器、NSFW 筛选器、语义重复数据删除方法和文本分类器来预测数据质量。
值得注意的是,研究团队还发现前几代 Llama 模型在识别高质量数据方面出奇地好,于是让 Llama 2 为 Llama 3 提供支持的文本质量分类器生成训练数据,真正实现了「AI 训练 AI」。
除了训练的质量,Llama 3 在训练效率方面也取得了质的飞跃。
Meta 透露,为了训练最大的 Llama 3 模型,他们结合了数据并行化、模型并行化和管道并行化三种类型的并行化。
在 16K GPU 上同时进行训练时,每个 GPU 可实现超过 400 TFLOPS 的计算利用率。研究团队在两个定制的 24K GPU 集群上执行了训练运行。

为了最大限度地延长 GPU 的正常运行时间,研究团队开发了一种先进的新训练堆栈,可以自动执行错误检测、处理和维护。此外,Meta 还极大地改进了硬件可靠性和静默数据损坏检测机制,并且开发了新的可扩展存储系统,以减少检查点和回滚的开销。
这些改进使得总体有效训练时间超过 95%,也让 Llama 3 的训练效率比前代足足提高了约 3 倍。
更多技术细节欢迎查看 Meta 官方博客:https://ai.meta.com/blog/meta-llama-3/
作为 Meta 的「亲儿子」,Llama 3 也顺理成章地被优先整合到 AI 聊天机器人 Meta AI 之中。
追溯至去年的 Meta Connect 2023 大会,扎克伯格在会上正式宣布推出 Meta AI,随后便迅速将其推广至美国、澳大利亚、加拿大、新加坡、南非等地区。
在此前的采访中,扎克伯格对搭载 Llama 3 的 Meta AI 更是充满信心,称其将会是人们可以免费使用的最智能的 AI 助手。
我认为这将从一个类似聊天机器人的形式转变为你只需提出一个问题,它就能给出答案的形式,你可以给它更复杂的任务,它会去完成这些任务。
附上 Meta AI 网页体验地址:https://www.meta.ai/

当然,Meta AI 若是「尚未在您所在的国家/地区推出」,你可以采用开源模型最朴素的使用渠道——全球最大的 AI 开源社区网站 Hugging Face。
附上体验地址:https://huggingface.co/meta-llama/Meta-Llama-3-70B-Instruct
Perplexity、Poe 等平台也迅速宣布将 Llama 3 集成到平台服务上。

你还可以通过调用开源模型平台 Replicate API 接口来体验 Llama 3,其使用的价格也已经曝光,不妨按需使用。

有趣的是,在 Meta 官宣 Llama 3 前,有眼尖的网友发现微软的 Azure 市场偷跑 Llama 3 8B Instruct 版本,但随着消息的进一步扩散,当蜂拥而至的网友再次尝试访问该链接时,得到的只有「404」的页面。
Llama 3 的到来,正在社交平台 X 上掀起一股新的讨论风暴。
Meta AI 首席科学家、图灵奖得主 Yann LeCun 不仅为 Llama 3 的发布摇旗呐喊,并再次预告未来几个月将推出更多版本。就连马斯克也现身于该评论区,用一句简洁而含蓄的「Not bad 不错」,表达了对 Llama 3 的认可和期待。

英伟达高级科学家 JIm Fan 则将注意力投向了即将推出的 Llama 3 400B+,在他看来,Llama 3 的推出已经脱离了技术层面的进步,更是开源模型与顶尖闭源模型并驾齐驱的象征。
从其分享的基准测试可以看出,Llama 3 400B+ 的实力几乎媲美 Claude 超大杯、以及 新版 GPT-4 Turbo,虽然仍有一定的差距,但足以证明其在顶尖大模型中占有一席之地。

今天恰逢斯坦福大学教授,AI 顶尖专家吴恩达的生日,Llama 3 的到来无疑是最特别的庆生方式。

不得不说,如今的开源模型真的是百花齐放,百家争鸣。

今年年初,手握 35 万块 GPU 的扎克伯格在接受 The Verge 的采访时,用坚定的语气描绘了 Meta 的愿景——致力于打造 AGI(通用人工智能)。
与不 open 的 openai 形成鲜明对比,Meta 则沿着 open 的开源路线朝 AGI 的圣杯发起了冲锋。
正如扎克伯格所说,坚定开源的 Meta 在这条充满挑战的征途中也并非毫无收获:
我通常非常倾向于认为开源对社区和我们都有好处,因为我们会从创新中受益。
在过去的一年中,整个 AI 圈都在围绕开源或闭源的路线争论不休,这场辩论,已经超越了技术层面的优劣比较,触及了 AI 未来发展的核心方向。甚至亲自下场的马斯克也通过开源 Grok 1.0 的方式给全世界打了个样。
前不久,一些观点称开源模型将会越来越落后,如今 Llama 3 的到来,也给了这种悲观的论调一记响亮的耳光。
然而,尽管 Llama 3 为开源模型扳回一局,但这场关于开源与闭源的辩论还远未结束。
毕竟暗中蓄势待发的 GPT-4.5/5 也许会在今年夏天,以无可匹敌的性能为这场旷日持久的争论画上一个句号。
![]()
![]()
Canva 是现在非常多人使用的在线设计工具,通过大量的模板与素材,就算不是专业设计师,只要组合各种各样的模板,也能快速生成可用的图像,无论是用在网页文章中的解说图片、youtube 视频的封面,各种社交上的图文搭配,都能节省许多时间。还能制作流程图、文件报告、协作白板、视频编辑等等。尤其陆续添加的 ai 功能,让 Canva 对一般人来说更好上手设计图文影音的工作流程。
过去一年多来,Cnava 也陆陆续续在其工具中加入了很多 AI 相关的功能,例如用 AI 编写运营图片上的文案,或是用 AI 制作视频当中的动画等等。〔部分 Canva AI 功能有免费使用额度,部分功能则需要升级到 Canva Pro 付费版账户。〕
而今天这篇文章。我想针对自己最常用到的「图片 AI 调整」,做一个完整的 AI 图片设计、生成、修图功能总整理,因为这些功能原本散落在 Canva 许多不同的工具中,每个功能也有不同的应用情境,所以让我们用一个尽量连贯的案例,展开可以在什么时候如何运用这些隐藏的 Canva AI 图像设计功能。
下面的介绍,会根据我平常使用 Canva 最常操作的 AI 图片编辑相关流程来介绍,结合自己的使用经验与心得,希望这样可以更容易看到不同功能之间的使用场景与搭配应用方式。也欢迎你在留言跟我分享你最常使用的功能与技巧。
如果查找 Canva 数据库中已有的图文模板,找不到自己想要的,那么或许利用「Magic Design」会是一个有效的开始。
在 Canva AI 中我常使用的起手式,这个功能(和最后一个功能)是目前在 Canva 英文版测试中的「Magic Design」,只要用一句话或几个关键词描绘自己想要的设计需求,让 Canva AI 生成全新的模板、草稿,我就可以在这样基础上进一步修改。
不过要使用这个功能前,要到设置中先把语言先换到「English」。
接着,来到主画面上方的「搜索栏」,使用英文描述自己想要的模板内容,按下确认。
这时候就会启动「Magic Design」,最上方一排,就是 Canva AI 自动生成的图文模板。
也可以利用其中的「Media」功能,上传一张自己的图片素材,例如想要自定义的背景照片,这时候 Canva AI 会再次根据这张图片素材,设计出搭配好的新模板。
我们可以选择一个最适合自己的,然后开始进一步修改。
进入模板开始设计后,可能会需要在原本模板上组合一些独立的图片元素,这时候可以先查找 Canva 大量的图库,找到适合的照片后,用抠图功能,取出照片里的指定素材来使用。
这样一来,可以说就有源源不绝的图标物件可以自由搭配了。
先查找图库照片,或是上传自己的照片,把找到的照片先插入设计图中。
选择「编辑照片」,然后选择「背景移除工具」。
完成抠图后,这个素材就可以自由运用在原本的设计图中。
AI 魔法抓取就是把图片中的背景、主体各项元素分离,于是可以自由移动元素的位置,调整大小等,重新进行设计。
譬如原本靠右边的物品,移动到左边,让右边可以有更多摆放文字的空间。
有了这个 Magic Grab 魔法抓取,许多照片、图片的构图都能自由调整,更多设计弹性。
只要选择要调整的照片,进入「编辑照片」,选择「魔法抓取」。
就可以把主体、背景分离,而背景也会自动填满,这样一来就能当成两个素材来使用了。
有时候设计图上就是有某个小地方差了一点点,不想因此换掉整张图,这时候可以善用 Canva AI 的「魔法编辑工具」来适度的调整。
例如把一个人的白头发变成黑头发,加了一顶帽子等等,可以发挥自己的想象力,用 AI 指令去替换掉各种不满意的图片内容。
先选择设计图中想要调整的图片,进入「编辑照片」,选择「魔法编辑工具」。
接着,涂抹想要修改的区域,例如我这边不满意的是图库中的笔记页面都是空白的,所以我先涂抹笔记的空白区域。
然后,描述想要替换、新增的内容,或想要的修改结果,例如我这边描述想要在笔记空白页面上加上一些素描。
最后,就会用 AI 调整指定区域的内容,生成四种不同结果,我们只要选取最适合的生成结果即可。
有时候我们不是想要替换掉照片中的部分内容,而是想要直接移除对象就好。那么就可以使用「魔法消除」功能。
同样在照片编辑中,选择「魔法橡皮擦」。
涂抹不想要的部分即可,有时多抹除几次的效果更好。
Canva 很多修图的功能让一般人也能很好上手,例如在「编辑照片」中,会自动分离出照片里的颜色、材质,让我们可以进行微调,这有助于我们快速把照片调整到自己想要的感觉。
在编辑照片中进入「调整」页面,针对获取到的照片主要颜色,可以进行调整,甚至替换成不同的颜色。
或是针对材质进行清晰度的调整。这有时候会在 AI 生成的图片作微调,效果更明显。
还有一个我很喜欢的自动化功能〔虽然跟 AI 没有关系,但因为是工作流上常用的,还是一并介绍〕,就是在左方的「设计」中选择「样式」,就可以进行各种配色的替换。
有时候换个配色,原本感觉不搭配的模板就变得更加适合。
只要进入「样式」,在调色盘上自由点击,就可以不断替换,直到找到自己满意的为止。
还可以在样式页面滑动到最下方,会根据主图建议适合的配色,在这边选择配色,会让主图与版面更加搭配。
有时候要把照片插入版面中,可能因为照片比例大小的问题,需要慢慢剪切移动,找到最佳位置。
而通过 Canva AI,在「编辑照片」中进入「裁切」,选择「智能裁切」,就会自动帮这张照片找到最好的裁切、缩放、移动位置。
有时候照片的比例就是不对,无论如何裁切也找不到最完美的位置,这时候就要使用相应的「魔法展开」功能,可以用 AI 自动生成延伸扩展的背景,改变照片的尺寸、比例大小,方便我们进行更好的裁切与位置调整。
选择照片,进入编辑照片,选择「裁切」中的「展开」,就可以,选择插件想要展开的部分。
有时候一张图片素材让我不满意的地方不是图像,而是里面的文字,可这是一张照片,要如何修改上面的文字呢?利用 Canva AI 的「抓取文字」功能就有机会做到。
一样选择「编辑照片」,进入「抓取文字」,让 Canva AI 识别照片中的文字内容,读取成功的部分就可以手动编辑。
选择适合的字体并输入新的文字,照片中的文字就变成自己想要的版本咯!
有时候很想要一种立体特效字体、很想要一个特殊材质 ICON 图标,但就是找不到?那么利用 Canva AI 中的 Magic Morph〔魔法变形工具〕,把现有的文字、图标变成想要的特效即可。
我们可以在 Canva 的「应用程序」中浏览,找到 Magic Morph〔魔法变形工具〕,便能开始使用。适合用在图标、物件、文字〔中文偶尔可以,主要支持英文〕的 AI 修改上。
例如我选中一段文字内容,启用魔法变型工具,这时候可以用文字描述自己想要的特效效果。
等待 AI 生成并调整,就能获得四个不同的选择,挑选自己想要的插入设计图中即可。
这是 Canva AI 中的 AI 绘制图片功能,虽然效果可能没有 ChatGPT DALL-E.3 或 Midjourney 那么好,但也堪用,且快速。
在新增元素的面板中,有一个用 AI 生成影像、视频的选项。也可以在应用程序中浏览,找到 Magic Media〔魔法媒体工具〕。都能利用 AI 生成图片,也能生成短片。
一样是输入文字,选择想要的照片风格、比例。
就能生成适合的图像。
搭配前面各种修图功能,调整一下,就能生成自己需要的各种图片素材。
如果要在各种不同社交、影音平台发布图像,就要好好利用 Canva 的魔法尺寸替换功能,可以自动把 Banner 等变成文件、YouTube 略缩图变成 Facebook 正方形图片。
做好的横幅图像,快速转换成方形,这可以节省许多调整时间。
Canva 的 AI 与自动化功能那么多,不知道可以用什么功能调整目前素材时,建议按下右下方的「Canva 助理」,可以提供各种建议,或是提供各种适合目前设计的图片扩充延伸素材,节省许多自己的尝试时间。
第一个功能,和现在这个第 15 个功能 需要切换到英文版,其他功能在 Canva 中文版中也已经都可以使用。
英文版中,进入 Canva 设计 PPT 的画面,可以在搜索字段直接描述自己想要的简报主题与风格,就会自动用 AI 生成适合的简报模板。
你也可以从这里找到更多模板:2024 免费 PPT 设计模板下载!13 个免费 PPT 模板网站汇总
。
其实 Cnava AI 还有很多特殊功能,像是用 AI 编写文案,或者利用 AI 来制作小动画,还有很多应用程序可以使用。不过我们这篇文章就聚焦在跟图片生成有关的部分,分享我自己的工作流程,欢迎大家参考与分享。
![]()
![]()
最近发现有不少 ai 相关排行榜,这也是关注获取所有 AI 资讯的渠道,也能看到目前 AI 发展程度。所以进行了整理汇总。
https://lmsys-chatbot-arena-leaderboard.hf.space/?__theme=light
LMSYS Org(Large Model Systems Organization),最为知名的目前大型语言模型的埃洛评级(Elo Rating)监测,分享过多次。目前该排名值得关注的是 Claude 3 Opus 仍然排名第一,并且其更便宜模型 Claude 3 Haiku 也超过了部分 GPT4 模型。

https://www.cbinsights.com/learn/ai-100-2024
该网站综合评估选出了目前 TOP100 从事 AI 模型研究和应用的公司。Hugging Face(抱脸)凭借其强大的开源开发者社区支持,提供大量的预训练模型和数据集和相关资源综合排名第一,抱脸还有很多有意思的排名,如模型竞技场排名/最佳 AI 内容贡献者等都值得关注;第二名 Databricks 是家专注大数据处理的 AI 公司,通用开源的大型语言模型 DBRX 即由它们创建。后面跟着的是之前提到的法国黑马 AI 初创公司 MISTRAL 以及 openai。
Leaderboard Comparing LLM Performance at Producing Hallucinations when Summarizing Short Documents – vectara/hallucination-leaderboard
这是目前 AI 幻觉率(Hallucination)排名。截止今年 3月底,目前幻觉率最低 TOP 出现个 Intel Neural Chat 7B,其次 GPT4 幻觉处理仍然很好。

No Description
这个排行榜是「SuperCLUE:中文语言通用大模型综合性测评基准」排名,更关注中文语言的排行榜,包括古诗/文学/歇后语和方言等测试排名。除去 GPT4,排名靠前的即国内文心一言/智谱 AI/通义千问等。

Language models ranked and analyzed by usage across apps
大型语言模型使用接口排行榜和数据,有免费版本以及付费。

Web site created using create-react-app
AI 模型翻译质量和 Token 使用耗费排行榜。

—
还有些排行榜已经停止更新,这个榜单将持续补充。
相关链接
![]()
![]()
使用云服务时,一个常被忽视的成本就是数据流出费。这指的是将数据从云服务提供商的网络发送到公共互联网的费用。
这里整理了常用服务的流量费用,可以快速了解不同云服务的流量费用差异,这不仅是单纯 VPS 比较,而是各类的云服务都拿出来比,像是存储类的以及 CDN 类的都有放进来。
如果超出了免费流量,每家供应商收取的 1TB 数据流出费用如下:
小提醒: 实际价格可能因地区和其他本文未列出的因素而有所不同。为方便比较,这里选择了最靠近北弗吉尼亚(美国)或法兰克福(德国)的区域,并根据统一的使用情况假设估算出这些价格。请务必查看供应商的定价页面以获取最新信息。
数据流出是指数据离开某个网络,更确切地说,是数据离开你的云服务提供商网络进入公共互联网。这可能是从云服务商到用户的数据传输,或是从一家云服务商到另一家的数据传输。
云服务商通常根据从其网络流出的数据量按 GB (1 GB等于1024 MB)或 TB (1 TB等于1024 GB) 计费收取每月数据传输费用。
从云服务商的角度来看,有两种数据传输类型:
实际操作中,可能是这样的:
要下载文件,用户设备需要从云服务商网络请求数据,而云服务商则需要将数据发送给用户(或内容分发网络等中间商)。这就会产生数据流出费用。
云服务商之所以收取数据流出费,是因为从其网络传输数据需要成本。他们需要为传输数据所需的基础设施和带宽付费。
不过,数据流出费也可能是为了阻止某些使用场景,比如跨云服务商大量传输数据。
大多数云服务商都提供一定的免费流出数据量,比如整个账户每月 100GB 的免费流量,或者每台服务器每月 1TB 的免费流量。
因此,根据你的使用情况和选择的云服务商,你可能完全不用为数据流出付费。
在尝试降低数据流出费用时,可以考虑以下几个因素:
Backblaze 的带宽费用算法颇有趣,每个月给数据量的三倍大小当作免费带宽,没记错的话因为 Cloudflare 是 Backblaze 的官方合作伙伴,两边的传输费用不计费,如果数据是可以公开的,可以通过这个方式免费链接出来;如果真的走一般的流量输出,收费是 US$0.01/GB (所以换算后是 US$10/TB)。
三家常被摆在一起的 VPS (Linode、DigitalOcean、Vultr) 的带宽也都是 US$10/TB。
以前没注意到的是 OVH Cloud 与 Scaleway 的带宽费用是免费的?另外 Hetzner 虽然要收费但也很低?有机会可以测试看看,看一下质量如何?







































































{kind=link}