430km 纯电续航,1400km+ 综合续航,小鹏的增程汽车要来了!

2024 年 11 月,对于曾经一些表示「捍卫纯电荣耀,我辈义不容辞」的品牌来说,是一个态度上的转变时刻。先是有媒体曝出蔚来会通过第三品牌「萤火虫」来进入增程汽车市场,然后就是今天,11 月 6 日,小鹏的 AI 科技日活动上,何小鹏表示:属于小鹏的增程车,已经在计划内。
纯电大旗,只有特斯拉一家还在苦苦支撑。但,消费者买车才没有这样的包袱,市场会教育消费者,也会教育厂商。
小鹏超级电动:430km 纯电续航,1400km+ 综合续航
虽然说纯电品牌们想尽一切办法加大电池,降低能耗,加强快充速度,还有建设充电和换电网络,但和已经极为成熟的加油网络相比,还是差点意思。
以及,其实大多数人没经历过真正的没电趴窝,但有一个邮箱,那确实安心不少。
加上充电换电等等基础建设只能说是风景这边独好,世界大多数地方的充电基础设施建设还远远不够,因此想要出口海外,增程式新能源汽车,是一个折中的方案。

介绍完背景,就该何小鹏发言了,他表示,小鹏汽车再做一个普通增程车没有什么意义,小鹏做的是「鲲鹏超级电动体系」,其中,鲲代表超级增程系统,采用下一代增程技术,鹏代表着小鹏一直领先全球的纯电体系。
因此,小鹏认为,这个增程不是普通增程,而是新技术加持下的新一代增程技术融合小鹏在纯电上的能力,相当于强强组合的动力系统。

在新电机以及全平台 800V 技术加持下,小鹏未来的超级增程系统新车的纯电续航达 430km,可以算是目前增程车里最长的纯电续航里程,几乎赶上一些中低端纯电电车的续航了。在满电满油的情况下,整体续航最高可以达到 1400km。进可跑跨省际长途,退能纯电保证一周上下班通勤。

支撑这个「鲲鹏超级电动体系」有两项纯电新技术,一是小鹏的 5C 超充 AI 电池搭配 S5 液冷超快充站,可以 1 秒充电超 1 公里的续航里程,仅需 12 分钟即可充满 80%;二是新的混合碳化硅同轴电驱,电驱 CLTC 效率 93.5%,体积相比于传统电机减少 30%,可以给后排留更多空间。

另外,针对低电量状态下,电动机介入发电发出的噪音和抖动问题,小鹏也表示他们的鲲鹏超级电动体系能够实现超级静音,低电状态的声音只比纯电高 1 分贝,驾驶感受和纯电没有区别。同时,小鹏增程的「一车双能」针对相对平滑的铺装路面,车辆将更多使用电能,减少能耗;针对爬坡、泥泞、雪地等场景,发动机会提前介入避免电量过低导致动力不足。

小鹏的「星辰大海」:自研芯片,Robotaxi ,飞行汽车,机器人
说完前面实际的内容,看完了面包与蜂蜜,接下来就是属于小鹏的「星辰大海」时刻,此时的小鹏汽车,可以说是特斯拉在中国开的影分身,技术重点几乎重合。
智驾的竞争同时对云端算力和车端算力提出了要求,另外为了解决公版芯片大量通用算力被浪费的问题,小鹏汽车决定自研芯片。

在这次 AI 科技日活动上,何小鹏揭晓了自研的小鹏图灵 AI 芯片最新进展:今年 10 月,小鹏的图灵 AI 芯片已跑通最新版本的智驾功能,用 40 天完成了 2791 项功能验证。

因为小鹏的「星辰大海」包括了汽车、机器人和飞行汽车,所以这颗图灵 AI 芯片的设计初始就支持这三种产品形态,为 AI 大模型定制,为端到端而生。
算力上,图灵 AI 芯片拥有 40 核处理器,支持高达 30B 参数的大模型运行,AI 算力两三倍于目前行业主流的英伟达 Orin-X。
和图灵 AI 芯片相配套的,还有小鹏沧海底座,这是小鹏为 L4 级别完全自动驾驶设计的技术底座,涵盖了核心计算平台、基础软件平台以及智能车控应用平台,可将整车总通讯带宽提升 33 倍、摄像头出图速度提升 12 倍,同时实现 L4 级别的安全冗余。
前不久特斯拉 10 月 10 日的发布会,为我们展现了无人驾驶的未来:Cybercab 和 Robovan,两种没有方向盘和脚踏板的无人驾驶出租车和无人驾驶巴士。
而在特斯拉发布会之后,小鹏也表示,他们的 Robotaxi 也正在紧锣密鼓的研发中,与特斯拉英雄所见略同了。

今天,何小鹏透露了它的更多信息:
小鹏在现有的 Pro 和 Max 车型之上,还有「Ultra」车型,这是一种 Robotaxi 的新形态,将搭载多颗小鹏图灵 AI 芯片和小鹏沧海底座,具备高达 3000T 的车端算力,拥有 L4 级智能驾驶能力。
方向盘问题上,小鹏也希望通过线控转向技术,让未来的方向盘变为「可选」或者是「可隐藏」。
在颇具争议的飞行汽车路线上,小鹏也有小鹏汇天在持续研究,并且还画了更大的一个饼:小鹏汇天高速长航程飞行器,6 座,采用混合能源动力形式,最长空中续航可达到 500 公里,最高 360km/h 航速。

星辰大海的最后组成部分,则是小鹏的 AI 机器人 Iron。
一方面,这是和小鹏汽车在技术上同源的产品,一样会搭载图灵 AI 芯片,赋予机器人自主思考和推理能力;在行动上也依靠端到端大模型,实现行走能力,完成手指的抓、拿、放等精细任务;另外底层的小鹏天玑 AI OS 是底层操作系统,让机器人拥有流畅类人的对话能力。


另一方面,何小鹏表示,做 AI 机器人其实比做 AI 新能源汽车要难,没有 500 亿投入做不好 AI 机器人。
小鹏 AI 机器人 Iron 大小和真人无异:身高 178cm,体重 70kg,拥有超 60 个关节,可模拟人类站立、躺卧、坐。

和特斯拉的 TeslaBot 机器人已经进厂打工一样,小鹏 AI 机器人 Iron 也已进入小鹏工厂工作,未来则可能出现在销售门店、办公室、家庭等场景。
今天的小鹏 AI 科技日其实内容相当多,不过发布会安排得也相当紧凑,许多信息更像是预告,只露出未来的冰山一角。不过步入下半年后的小鹏节奏明显好了起来,一方面是 MONA 03 车型持续大卖,明天正式上市的 P7+ 预售表现也不错,销量算是稳住了。另一方面,一次画了自研芯片、 Robotaxi 、飞行汽车和 AI 机器人四个大饼,也是小鹏在发出「未来可期」的信号。
当然,介于当下和未来之间,最让人期待的,还是小鹏的增程汽车,以及背后的出海野心。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
















































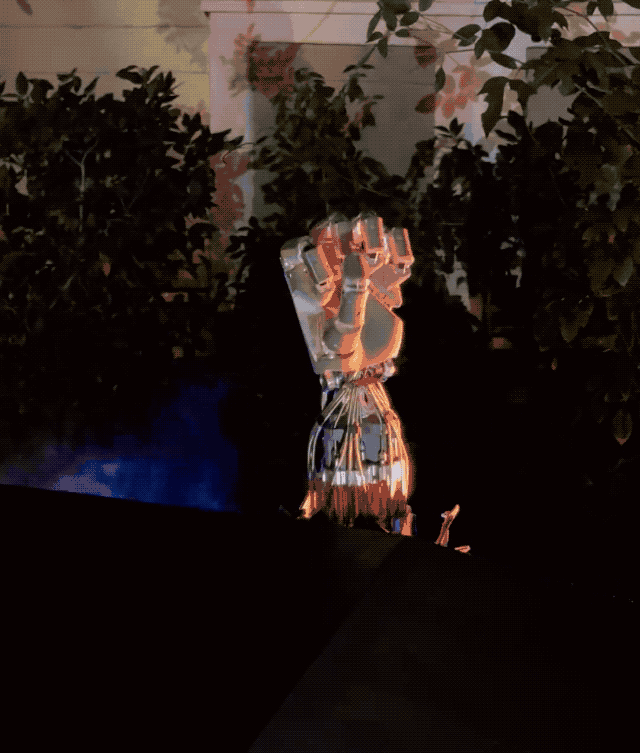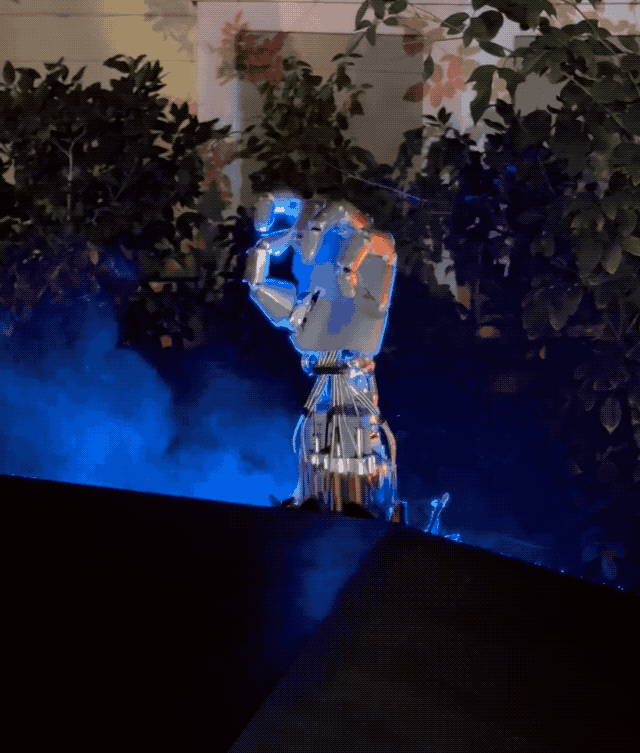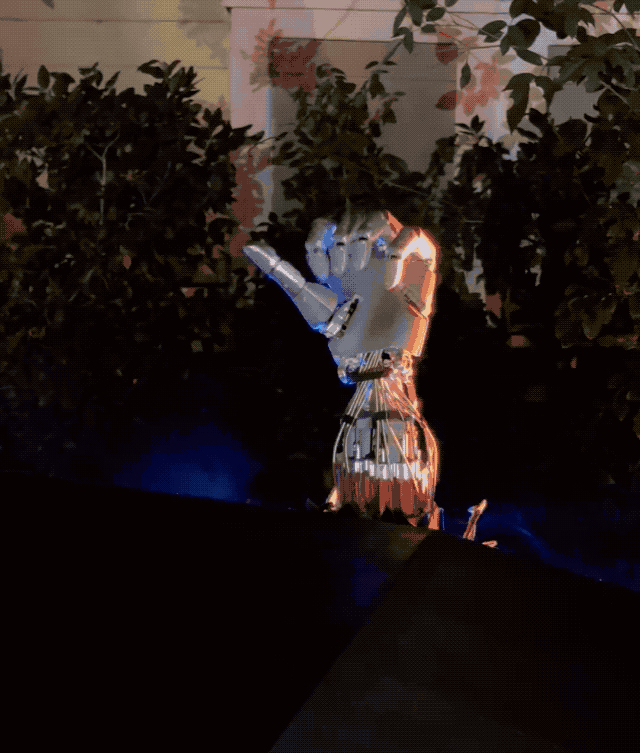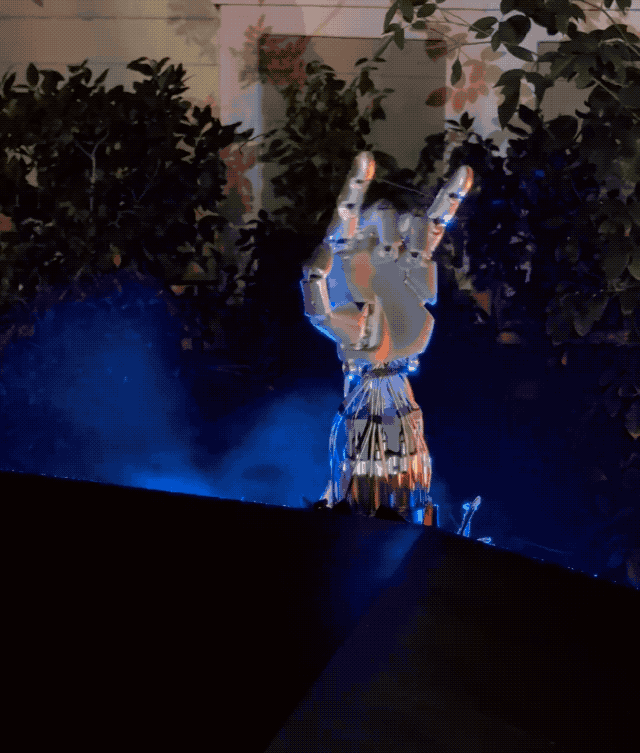


























 点击图片跳转到播放页面
点击图片跳转到播放页面




























































