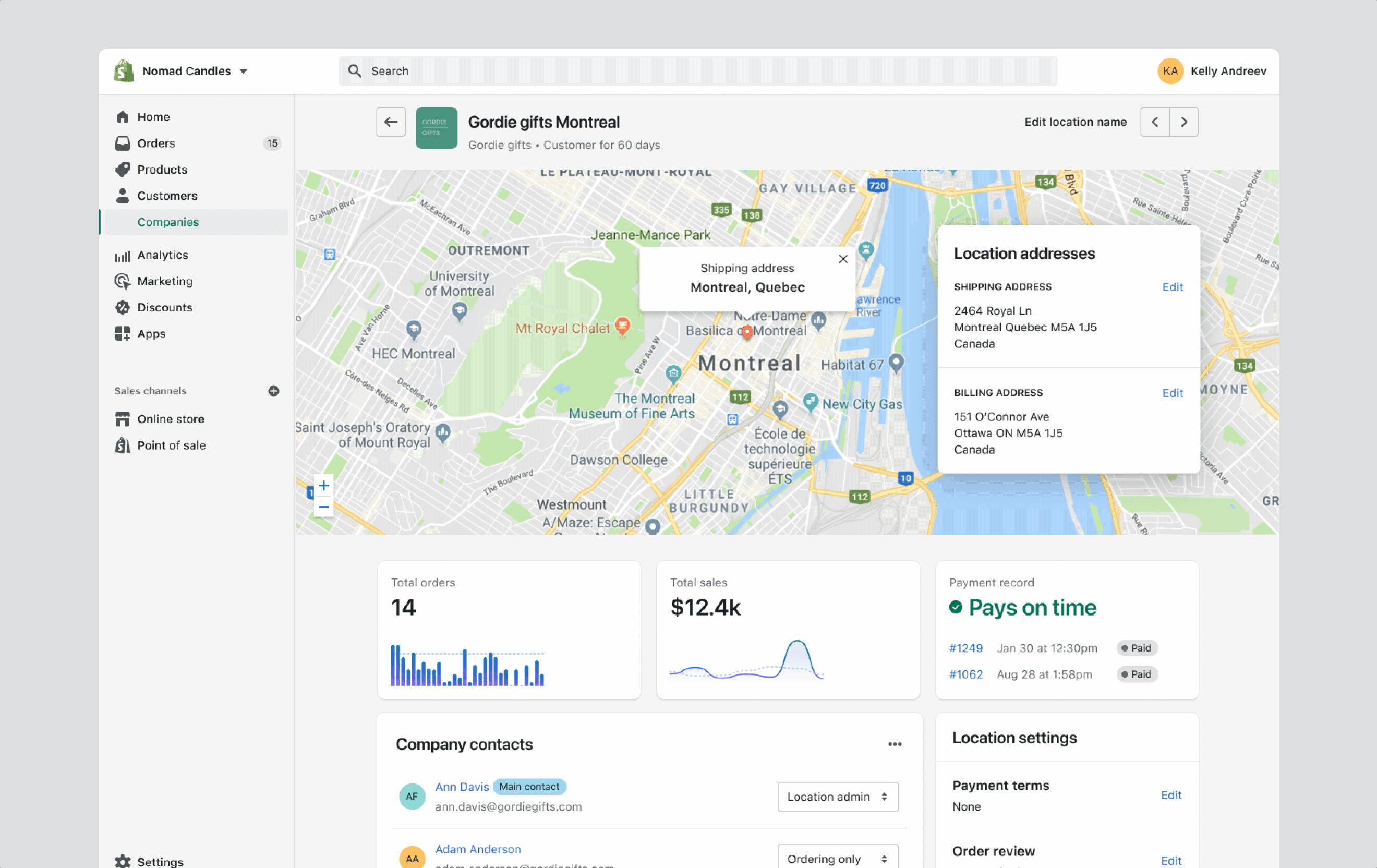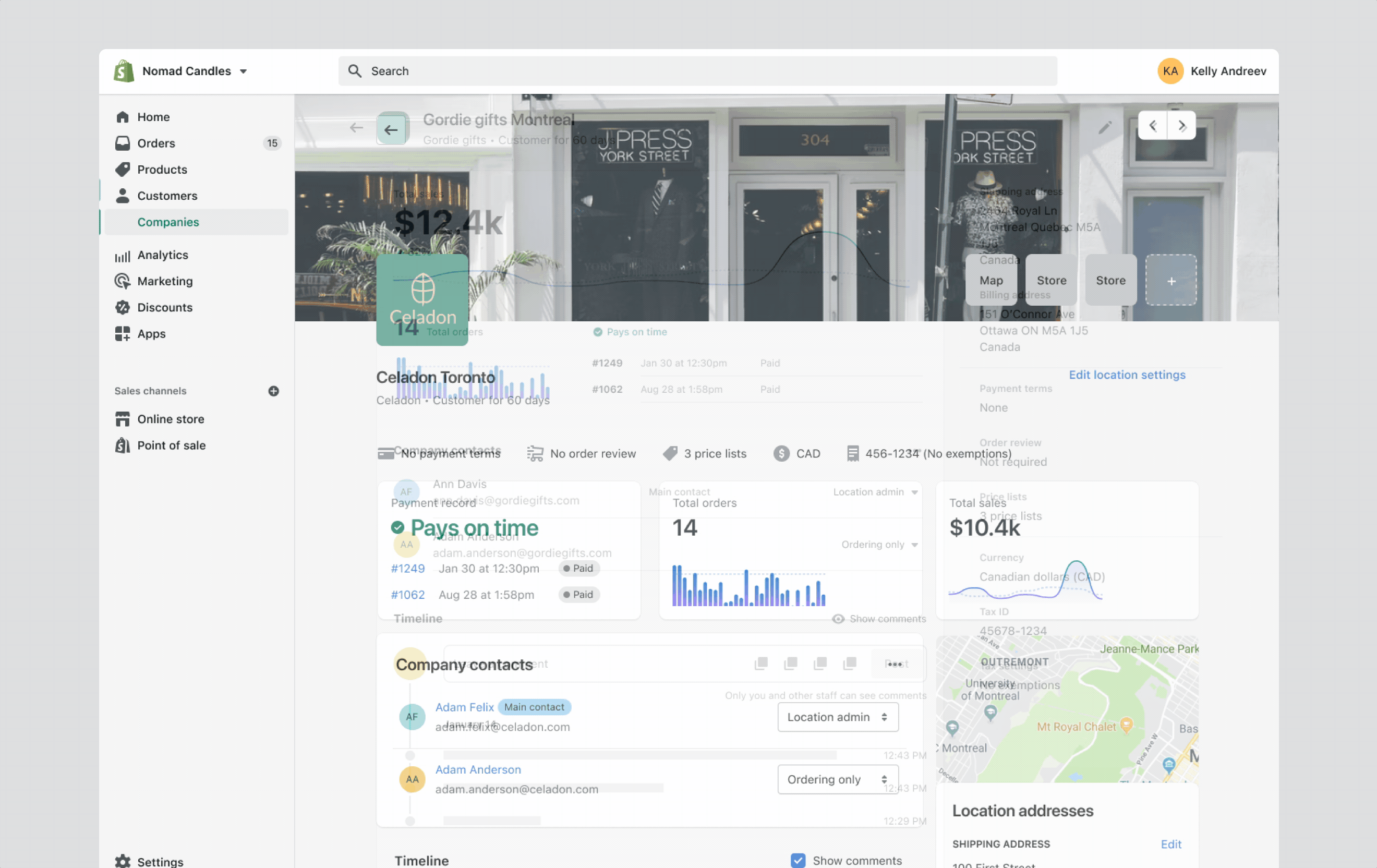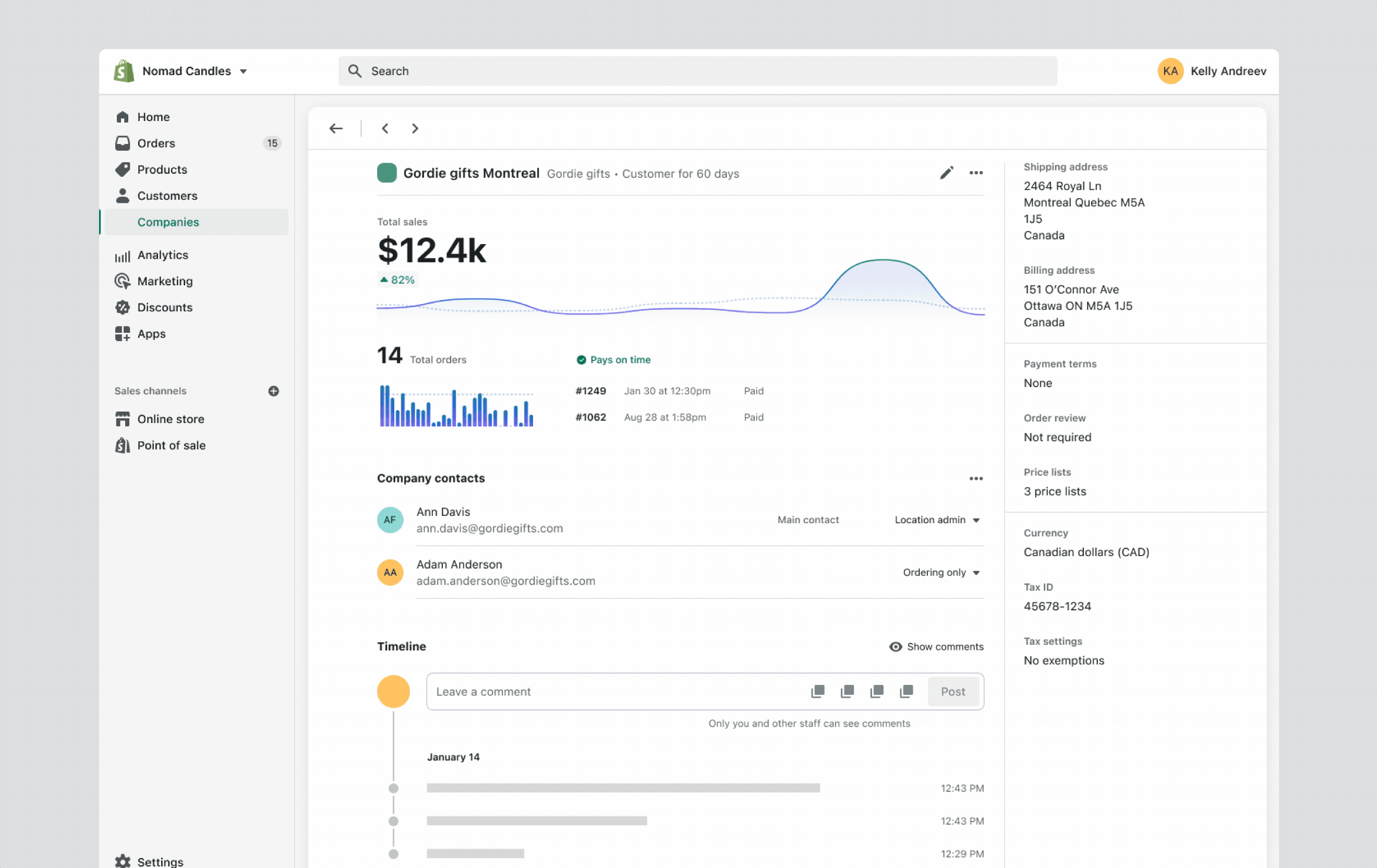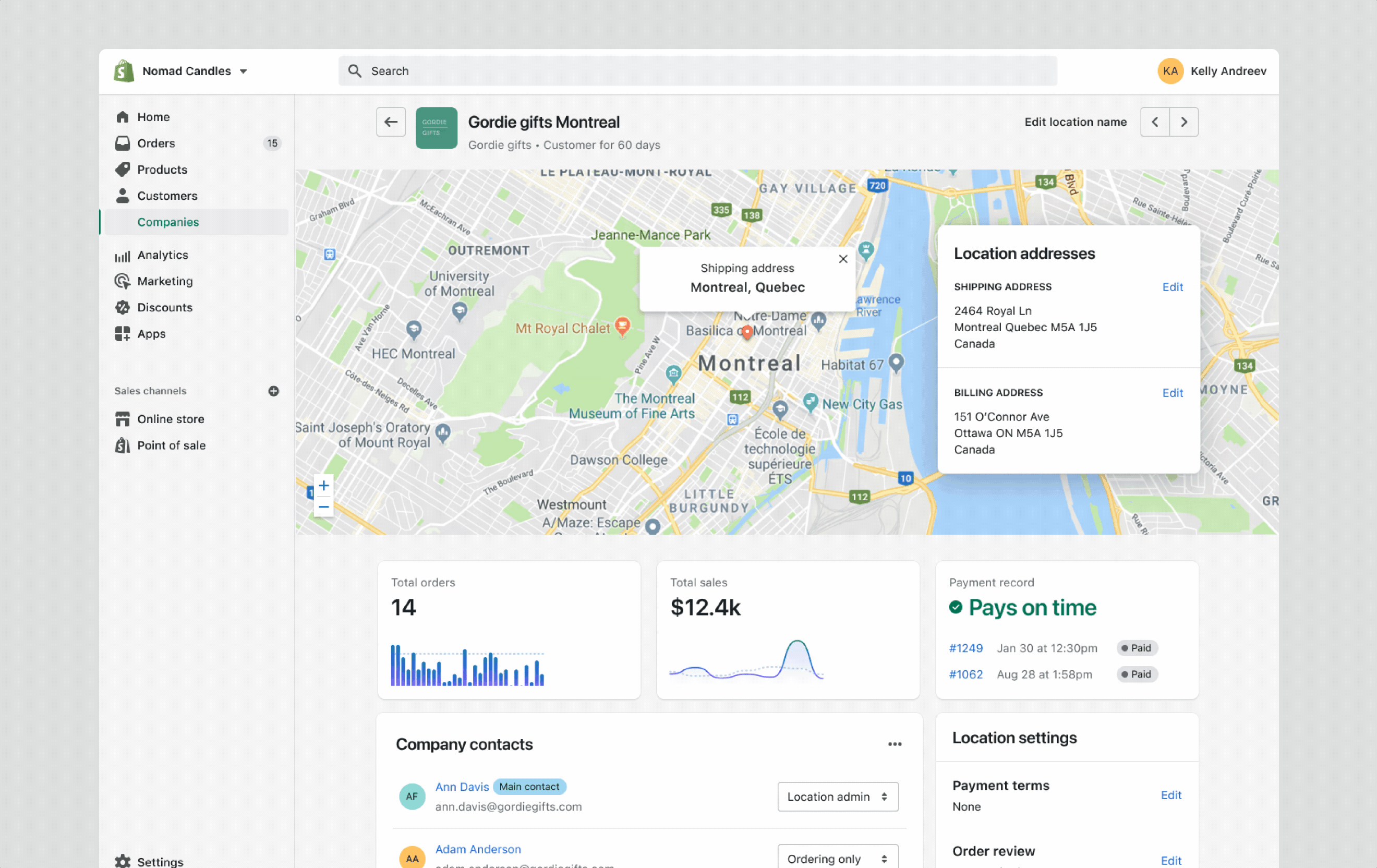
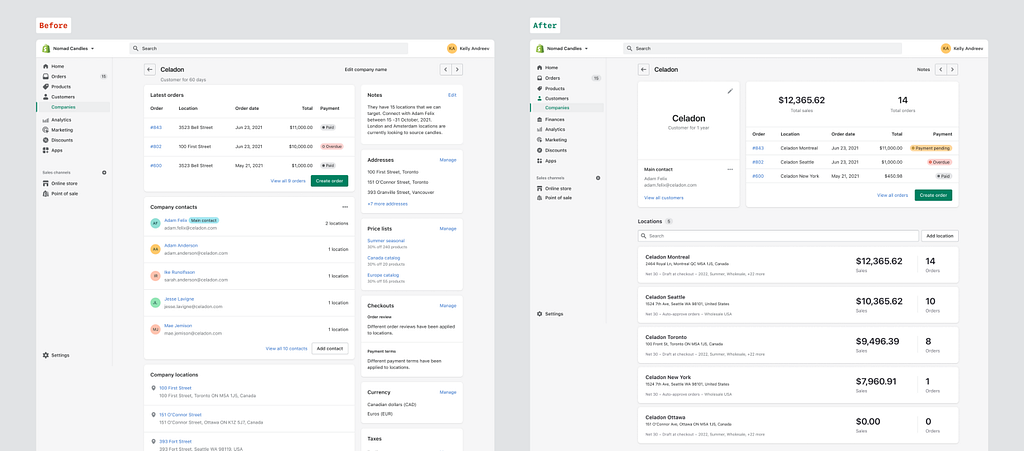
Reading view
Linux 微信 4.0 来了!牛逼
除了免费, Linux 好处都有啥
抱歉稍微标题党
我是后端程序员,大部分时候写一写 Spring Boot 之类的。
现在公司项目用的是 Red Hat 系统,WildFly 服务器。
因为有专门的基础设施部门,我除了偶尔需要部署一下服务器或者排查点问题,其他时候不太需要和 Linux 打交道。
于是突然想到一个问题,除了免费,Linux 比起 Win ,都有啥优点。几乎所有我在 Linux 能做的事,在 Win 上都能、甚至更轻松地能做到。
本人水平有限,还请各位大佬不吝赐教,谢谢。
把物理服务器的 CentOS 7 升级到 Ubuntu 24,惊心动魄
Unraid: 解决 12 版本中网页界面无法打开的问题
最近在 Unraid 升级 6.12.x 版本以后会偶发性的产生一个 Bug,其表现为 Unraid 网页无法打开(这里是指访问 Unraid IP 地址无法访问 Web 管理界面)。这个问题实际上是由于 Unraid 上的 Nginx 服务失去响应导致的。这种情况下我们只需要干掉 Nginx 进程并重启就可以了。
首先通过 ps -aux | grep nginx 找到 Nginx 主进程的 PID,然后通过 kill -9 <PID> 干掉进程。要再次启动 Nginx,可以运行
1 | cd /etc/rc.d/ |
注意通过 ./rc.nginx restart 在正常情况下可以重启 Nginx 服务,但是在 Nginx 处于无法响应的状态时,这个脚本无法杀死 Nginx 进程,必须要手动终止。
Ubuntu 中如何彻底删除一个用户
在 Ubuntu 中彻底删除一个用户涉及到几个步骤,不仅仅是删除用户,还可能包括删除与用户相关的数据。以下是步骤指南:
确保用户未登录: 在删除用户之前,最好确保该用户未登录。你可以使用
who命令来检查哪些用户当前已登录。1
who
删除用户: 使用
userdel命令删除用户。如果你还希望删除用户的主目录和邮件池,可以使用-r选项。1
sudo userdel -r username
其中,
username是你想删除的用户的用户名。注意:
-r选项会删除用户的主目录(通常是/home/username)。确保你已经备份了所有重要的数据!检查文件系统: 即使删除了用户和其主目录,可能仍然在文件系统上遗留一些属于该用户的文件。你可以使用
find命令来搜索这些文件:1
sudo find / -user username
这将列出所有属于
username的文件。根据你的需要,你可以手动删除这些文件或更改它们的所有权。删除用户的 cron 作业: 如果用户配置了任何 cron 作业,你还需要手动删除它们。检查
/var/spool/cron/crontabs/username是否存在,如果存在,删除它。1
sudo rm /var/spool/cron/crontabs/username
其他服务或配置: 如果该用户有其他特定的配置,例如在
/etc/sudoers中的条目或在其他服务中的特殊访问权限,你需要手动检查并删除它们。
请在进行任何删除操作之前确保备份所有重要数据。确保你明确知道正在执行的操作,避免意外删除重要文件或配置。
Lessons I learned after completing the Google UX Design Professional Certificate

Recently, I heard that Coursera has a UX design course developed by Google’s design team. This course covers the entire design process and teaches us how to present our portfolio, prepare interviews, and the like.
It is necessary to enroll in this course even though it is designed primarily for beginners and fresh graduates. It would enhance my English skills on one hand, and deepen my understanding of Western design practices and culture on the other. Since the term “UX design” is called out by Western designers and I am eager to compare Western design cultures with those I’ve experienced in China.
So I enrolled in this online course, trying to spare my time on it. Such as during lunch and dinner breaks on weekdays, or parts of the weekend. I completed the whole certificate within two months. And now I’d like to write down what I learned from this course:

- Introducing concepts I had never heard of. Despite my 5+ yoe in a wide range of companies, from startups to large corporations in China, those new concepts opened up a lot of room for me to explore.
- Enhancing my listening and reading skills. The course covers plenty of video and reading materials that include industry jargon that translators cannot provide. Moreover, certain phrases and sentence structures are repeatedly used throughout the course. I think my reading skills and speed are slightly improved.
- Pointing out concepts like accessibility and equity early throughout the course. I used to think only seasoned designers or well-developed products consider these aspects, however, they are mentioned early on and repeatedly. These concepts resonated with me and will truly influence my work.
- Elaborating comprehensive and detailed guidance for designers to prepare their portfolios, resumes, and interviews. They not only tell us what content should be included in our portfolios, but also how to prepare for interviews at different stages. I resonated with these instructions as well, since I did think those details over when looking for a new job.
Table of content

New concepts
I have consistently tried to think about and expand design boundaries through different aspects, which requires a breadth of knowledge. Here, I will share several new concepts along with my personal understanding.
Affinity diagram
This is a method of synthesizing that organizes data into groups with common themes or relationships. It can be used in different stages of the design process, such as during brainstorming or after collecting users feedback. The example below focuses on the latter.
After collecting a batch of user feedback, the design team condense each piece of feedback into a single sentence and write it on sticky notes. Then we post them up on a whiteboard or digital tools like Figma. Then the design team look for sticky notes that reference similar ideas, issues, or functionality and collaboratively organizes them into clusters representing different themes.
When I first learned about this approach in the course, I realized that this approach is similar to another method called “Card sorting” that was included in an article I translated earlier named [English to Chinese Translation] How we rebuilt Shopify’s developer docs. Both methods involve clustering sticky notes, naming these groups and summarizing the themes or relationships.
However, card sorting is implemented by external participants and aims to uncover users’ mental models to improve information architecture; Whereas affinity diagramming organizes a large amount of raw data to show the team which problems users are most concerned about and consider high priority.
* This concept is mentioned in Module 3 of Course 4 (Conduct UX Research and Test Early Concepts — Module 3 — Gather, organize, and reflect on data)
Digital literacy
This concept refers to an individual’s ability to gather, communicate, and create content using digital products and the internet. For example, senior adults or those living in areas with poor internet infrastructure may find it difficult to understand interfaces and functionalities, they are considered to have lower digital literacy.
In contrast, young people, especially those working in the information technology industries, are typically familiar with new software and concepts, and can quickly adapt to them.
This course does not dig deeply into this concept, rather, it emphasizes the importance of understanding our users. If our product targets a broad range of users, it is good to consider the needs of users with lower digital literacy. Moreover, this factor should also be considered when recruiting participants for usability tests.
* This concept is mentioned in Module 2 of Course 1 (Foundations of User Experience (UX) Design — Module 2 — Get to know the user)
Deceptive pattern
This concept refers to a group of UX methods that trick users into doing or buying something they wouldn’t otherwise have done or bought.
In the course, instructors clearly point out that this is an unethical and not a good practice. Businesses may lose their clients’ respect and trust once clients realize that they have fallen into deceptive patterns. I will share a few interesting examples that the course provided.
- Confirmshaming: Making users feel ashamed of their decision. For example, a subscribe button on a news website usually reads “Subscribe now / No thanks”. BBut if the service provider wants to manipulate readers’ emotions, the text might be changed to: “Subscribe now / No, I don’t care about things around me.”
- Urgency: Pushing users to make a decision within a limited time. For example, an e-commerce website might give you a coupon that is only available for 24 hours, prompting you to purchase items without a thoughtful consideration. The course doesn’t judge these marketing strategies or promotions; instead, it suggests that we should avoid putting pressure on users. As designers, we should try our best to balance business promotions and avoid manipulating users’ emotions.
- Scarcity: Making users very aware of the limited number of items. For example, a popup or attractive advertisement stating “Only 5 items left in stock.” The course suggests that designers should concentrate on helping users to understand products better, rather than using designs to encourage impulsive buying.
It is really interesting that these deceptive patterns are so common in the Chinese e-commerce industry that it might seem unusual if those strategies were to disappear.
This seems to reflect cultural differences between China and the West. In China, core team members, such as designers, product managers, and operators, collaboratively discuss how to induce and prompt users to make a hasty decision. Also, we regularly hold reflections to discuss and share insights on how to deeply incite users’ motivation.
In 2018, I landed my first job as a UI designer at an e-commerce company. One of my main tasks is designing promotions, such as “claim your vouchers”, “flash sales ending in N hours”, and creating illustrations of red pockets and flying coins, and the like. I didn’t really like these approaches at that time, so I eventually turned to the B2B and SaaS industry, focusing more on UX design.
Although I am not fond of these types of designs, these seem to really help companies grow and generate income. We could stabilize our employment only if our company were earning profits. Perhaps that is an inextricable cycle: obviously, deceptive patterns are unethical and bad as they are inducing and annoying our users, but we must continuously implement these approaches and think about how to make them more effective.
* This concept is mentioned in Module 3 of Course 3 (Build Wireframes and Low-Fidelity Prototypes — Module 3 — Understand ethical and inclusive design)
Biases
The course thoroughly explains a concept called “implicit bias”. It refers to the collection of attitudes and stereotypes associated, influencing our understanding of and decisions for a specific group of people.
For example, imagine you’re designing an app to help parents buy childcare. To personalize your onboarding process, you start by displaying bold text saying, “Welcome, moms. We’re here to help you…”
This is an example of implicit bias, since it excludes every other type of caregiver, like grandparents, guardians, dads and others.
In addition, here are some interesting biases the course introduced:
- Confirmation bias. Refers to the tendency to find evidence that supports people’s assumptions when gathering and analyzing information.
- Friendliness bias. Refers to the tendency to give more desirable answers or positive comments in order to please interviewers. This usually occurs in usability tests, where participants may not share their honest feedback because they are afraid that real answers or negative comments might offend interviewers and be considered unfriendly.
- False-consensus bias. Refers to the tendency that people tend to believe that their personal views or behaviors are more widely accepted than they actually are, and consider others’ opinions to be minor or marginal. For example, an optimist might think that most people around the world are optimistic; or designers can easily understand iconographies and illustrations they created, they might assume other users might easily to understand too.
I was shocked when I was learning this part. I strongly resonated with these biases which I had never perceived before. After all, the course lets us be aware of these biases and provides approaches to help us avoid falling into these pitfalls.
* This concept is mentioned in Module 3 of Course 3 (Build Wireframes and Low-Fidelity Prototypes — Module 3 — Understand ethical and inclusive design)
I listed some concepts above that I had barely encountered in my workspace. Becoming a UX designer appears to require a broad range of knowledge, such as design, the humanities, psychology, and sociology. I am now interested in psychology after completing this course.

Listening and Reading Proficiency
There are plenty of listening and reading materials involved in the course. Typically, each video lesson is accompanied by an article. If there are additional knowledge points, a single video might be accompanied by two or three articles.
Most instructors in the course speak with American accents. They also speak slowly and clearly, which makes me comfortable and usually allows me to understand without opening closed caption. Sometimes, I need to rewind a few seconds when they are speaking long sentences with many clauses or introducing new concepts, and I will open closed captions if I am still confused.
It is worth pointing out that the course contains lots of industry jargon, and I resonated with this because I used similar approaches or processes in my workspace by using Chinese. As a learner, I created a spreadsheet to record expressions that might be useful, such as:
- Above the fold, the content on a web page that doesn’t require scrolling to experience;
- Deliverable, final products like mockups or documents that can be handed over to clients or developers to bring designs to life.
- Digital real estate, space within the digital interface where designers can arrange visual elements;
- Firm parameters, refer to rigid design boundaries or limitations like time, project resources, and budget.
I think it is valuable to collect this industry jargon because it is authentically expressed, which can’t be translated by common translation tools. This will be helpful for me to read design articles and write blogs in English.

Accessibility and Equity
Accessibility
The course introduces several assistive technologies, such as color modification, voice control, switch devices, and screen readers, which can help people with different types of disabilities to use our products easily.
Instructors also point out that even people who don’t have disabilities, or who do not perceive themselves as having disabilities might benefit from these assistive technologies. The course suggests that we think these factors over throughout the entire design process. For instance:
- Supporting color modification. Features that increase the contrast of colors on a screen, like high-contrast mode or dark mode;
- Supporting voice control. Allows users to navigate and interact with the elements on their devices using only their voice. They also mention a concept called “Voice User Interface (VUI)”;
- Supporting switch devices. This is a one-button device that functions as an alternative to conventional input methods such as the keyboard, mouse, and touch, allowing users to complete common tasks like browsing webpages and typing text;
- Supporting screen readers. Allows users with vision impairment to perceive the content. The course suggests that we write alternative text to images, add appropriate aria labels to interactive elements like buttons, and consider the focus order of elements.
Here is a website that demonstrates the color modification feature: HubSpot.com
On the top navigation of this website, it provides a switch for us to toggle a high-contrast mode. Moreover, it also supports reduced motion effects — if I enable the reduced motion setting on my device, this website will minimize motion effects as much as possible.
Equity
The course also introduces a concept called “equity-focused design.”
Instructors clearly define the difference between “equality” and “equity”:
- Equality: Providing the same amount of opportunity and support, everyone receives the same thing;
- Equity: Providing different amount of opportunity and support according to individual circumstances, ensuring everyone can achieve the same outcomes.
The course also points out that equity-focused design means considering all races, genders, and abilities, especially focusing on groups that have been historically underrepresented or ignored when building products.
They use a survey question as an example: when gathering participants’ demographic information like gender, it is not enough to provide three options: “Male”, “Female” and “Other”. To make our design more inclusive and equitable, we should offer additional choices, including “Male”, “Female”, “Gender-nonconforming”, “nonbinary” and a blank field. The latter provides non-conventional gender options, uplifting those who might be marginalized in conventional surveys. This approach also aims to balance the opportunities for all groups to express themselves, ensuring their voices are treated fairly and heard.
In this lesson, I clearly faced a culture gap from the West. In fact, I don’t really like to dig into this concept deeply, mainly because I can’t determine whether this approach is right. Sometimes I think it is unnecessarily complicated, but at other times, I recognize that there are people with non-traditional genders around us who may truly be eager to be treated fairly.
When I was learning this lesson, I realized that there was an opportunity to incorporate accessibility features into the project I was recently working on. I will write a new post if this project lands successfully.
* This concept is mentioned in Module 2 of Course 1 (Foundations of User Experience (UX) Design — Module 2 — Get to know the user)

Guidance for Job Hunting
In the final course, instructors teach us how to lay out a portfolio and what content should be included. They also inform us the process of interviews and how to thoroughly prepare for interviews.
The guidance they mentioned is for the Western workplace, which may not seamlessly fit in the Chinese workplace. For example:
- They point out that designers should have a personal website and case studies regularly. However, Chinese designers prefer to publish their case studies on public platforms like ZCOOL and UI.CN;
- They also teach us how to build our digital presence and network through LinkedIn. However, these approaches are not common in the Chinese job market, where the most popular methods are directly submitting resumes and getting recommendations through acquaintances.
- They inform us how to handle panel interviews. I have interviewed with a wide range of companies, from startups to corporations, and never encountered panel interviews, which means that the panel interview is not popular in this industry.
I was deeply impressed by how they elaborated on the preparation and important considerations during the interview process. For example:
- Research the main business of the company you interview for beforehand, and clearly understand why you are a good fit for the company;
- Prepare answers to common interview questions beforehand, such as a personal introduction, your strengths, and descriptions of your case studies;
- We should learn how to answer difficult questions using the STAR method, and prepare well before starting an interview;
- Adapt the focus and questions according to the interviewer’s role to show you are a professional;
- During the interview process, you might be asked to complete a task. Therefore, we should practice the ability to think aloud and clearly define questions, since interviewers might pose vague questions on purpose.
I resonated with the approaches and tricks mentioned in the course that I had previously used, which gave me a strong feeling that I was on the right track.
Additionally, the course also provides detailed instructions on how to pursue freelance design work. For instance:
- Clearly identify your target audience and understand why they should choose your service;
- Know your competitors, identifying what they can’t provide but you can;
- Promote your service and build word-of-mouth by attending online and in-person events, and getting recommended through acquaintances;
- Calculate the business expenses, set fair prices for your services, and make financial projections — estimate what your finances will look like in the first month, the first 6 months, and the first year.
* This concept is mentioned in Module 3 of Course 7 (Design a User Experience for Social Good & Prepare for Jobs — Module 3)
To sum it up
Well, above are lessons I’ve learned from the Google UX Design Professional Certificate on Coursera over the past two months. I think that this is an interesting course, although not all content can be applied in my daily work, I’ve also learned the thinking processes and workplace cultures of designers in another part of the world.
I strongly recommend designers reading this post consider to enrolling in the Google UX Design Professional Certificate, by doing this, you might probably gain new insights. The course costs $49 monthly, which is not expensive. It is likely to complete the entire course over two or three months if you have a full-time job.
Things worked as I expected, and I will start my next project in the second half of the year.
Lessons I learned after completing the Google UX Design Professional Certificate was originally published in Bootcamp on Medium, where people are continuing the conversation by highlighting and responding to this story.
从Debian系统中删除某个版本的PHP
首先,你需要知道安装的PHP版本的完整包名。可以使用dpkg命令列出所有安装的包,然后找到PHP的版本。
dpkg -l | grep php
找到要卸载的PHP版本对应的包名后,使用apt-get remove命令进行卸载。例如,如果要卸载PHP 8.2,可以执行以下命令:
sudo apt-get remove php8.2*
如果你还想删除配置文件,可以使用apt-get purge命令:
sudo apt-get purge php8.2*
最后,运行autoremove来自动删除不再需要的依赖包:
sudo apt-get autoremove
温馨提示:确保在卸载PHP版本之前,不要影响到系统运行或其他服务依赖PHP的运作。如果你不确定,可以先进行测试卸载,通过添加–dry-run选项来模拟执行卸载命令:
sudo apt-get remove --dry-run php8.2*
在外置硬盘上,加密安装 ubuntu
需求:
- 在便携硬盘盒(M.2 SATA/NVME)安装 Linux(Ubuntu/Zorin),以便在不同的电脑上都可以启动使用。
- root 级别的系统分区加密(使用 LUKS & LVM)。
- 不要把整块硬盘都加密,而是在硬盘上保留一个未加密分区。这样也可以作为普通的移动硬盘使用。
——这篇攻略和是否外置硬盘盒,没多大关系。普通内置硬盘也可以这样加密安装。
最新的 Ubuntu 22.04 之后的版本,在安装界面里自带了 LVM 全盘加密安装的选项。但是并不能满足第 3 条需求。所以还需要一些复杂的手动操作。
安装过程尽量围绕 ubuntu 的图形安装界面,对新人友好。参考并验证了这篇教程。但原文连同 /boot 引导分区也一起加密了,于是在配置上略显繁琐。我觉得加密 /boot 并不是很有必要,做了一些改动。最终的硬盘分区结构为(以 512GB 硬盘为例):
- 大约 800MB,EFI 引导分区
- 大约 300GB,LUKS 加密分区。在其中配置 LVM 逻辑分区:
- 2GB,swap 交换分区
- 大约 300GB,Ubuntu 系统分区 root /
- 大约 200GB,普通移动硬盘分区
操作步骤:
下载 Ubuntu,制作 USB 安装盘(过程略)。——然后,强烈建议在整个安装过程之前,在电脑的 BIOS 里,把内置的其它硬盘暂时卸载。
插上移动硬盘和 USB 启动盘。从 U 盘启动电脑,选择 Try Ubuntu。最新的 Ubuntu 22.04 安装程序里,已经内置了所需的 cryptsetup 和 cryptsetup-initramfs 软件包。因此,整个安装过程中,应该不需要连接互联网。
首先,把硬盘预分区。分区软件有很多种,可以用原文的 sgdidk,也可以直接用图形界面下的 Disk 或者 Gparted。在硬盘上创建 GPT 分区表,然后分成:
- 大约 800MB,EFI 引导分区
- 大约 300GB,要加密的系统分区
- 余下的约 200GB 移动硬盘
这些分区都先不用格式化。记住第二个分区的名字,本文假定为 /dev/sda2。
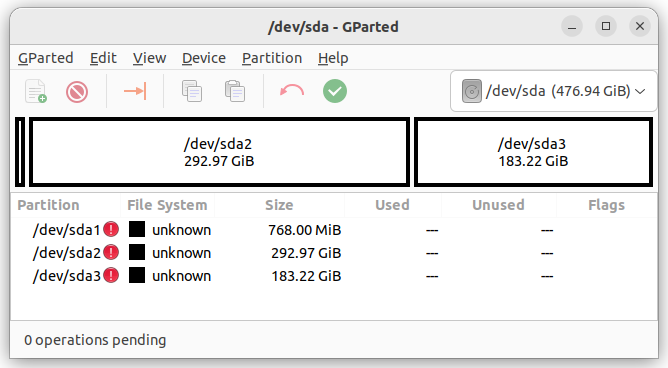
分区成功后,关闭分区软件,打开 Terminal 命令界面,执行 root 权限
sudo -i将系统分区加密。按提示输入密码,——这个密码,就是以后每次启动时,挂在硬盘用的密码。和安装 Ubuntu 时的用户密码,并不是一回事。
cryptsetup luksFormat --type=luks1 /dev/sda2解锁刚刚加密的分区:
cryptsetup open /dev/sda2 hd2_crypt创建逻辑卷组(LVM),然后在其中创建 2GB 的 swap 交换分区,再把剩余的空间创建为系统分区(这两个分区的大小,大家自行调整):
pvcreate /dev/mapper/hd2_crypt
vgcreate ubuntu--vg /dev/mapper/hd2_crypt
lvcreate -L 2G -n swap_1 ubuntu--vg
lvcreate -l 100%FREE -n root ubuntu--vg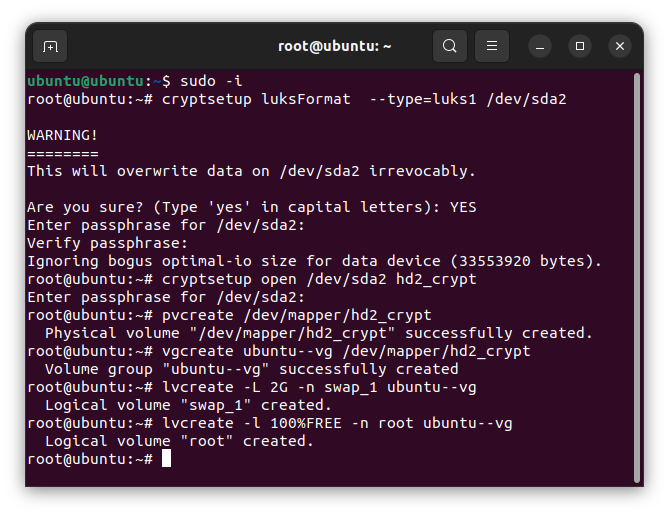
然后,运行桌面上的 Ubuntu 安装程序(Terminal 先不要关),在磁盘分区页面,选择 Something else,进行手动分区。
- 把 /dev/mapper/ubuntu—-vg-root 格式化成 ext4,挂载为系统根目录 /
- 把 /dev/mapper/ubuntu—-vg-swap_1 设为 swap 交换分区
- 把 /dev/sda1 设为 EFI 引导分区
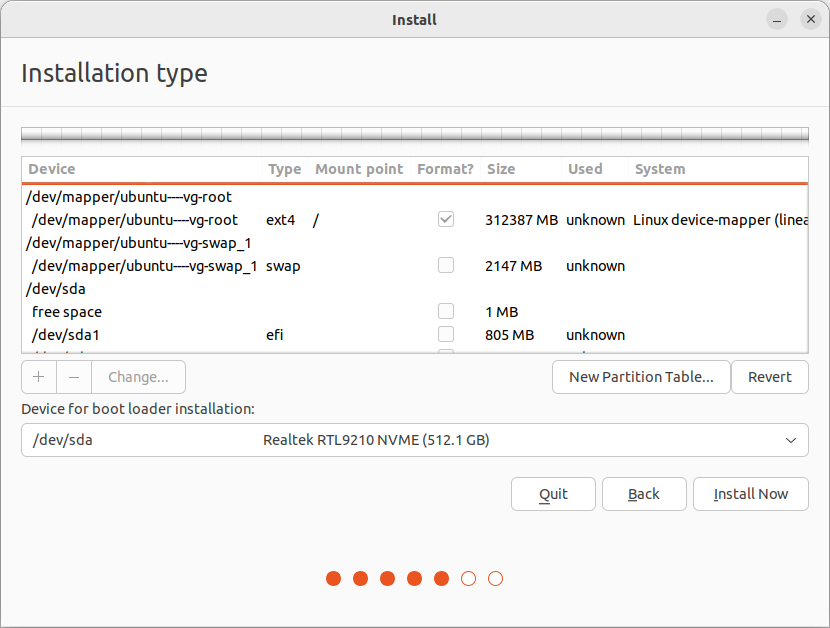
点击 Install Now,确认对分区的设置。注意,到了下一步创建用户的界面时,先不要继续。切换回 Terminal 命令行界面,正式安装前,在 GRUB 中启用加密(能看懂下面这些命令的话,也可以直接去编辑相应的文件):
while [ ! -d /target/etc/default/grub.d ]; do sleep 1; done; echo "GRUB_ENABLE_CRYPTODISK=y" > /target/etc/default/grub.d/local.cfg然后回到创建用户的页面,点击继续,开始安装系统。安装结束后,先不要 restart。而是点击 Continue Testing。
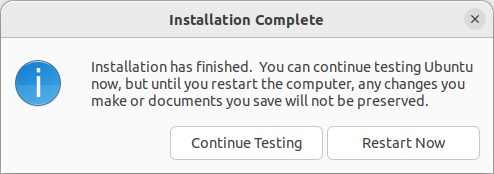
回到 Terminal 命令行界面,chroot 到新装的系统:
mount /dev/mapper/ubuntu----vg-root /target
for n in proc sys dev etc/resolv.conf; do mount --rbind /$n /target/$n; done
chroot /target
mount -a原文说此时需要(联网)安装 apt install cryptsetup-initramfs;但我用的 ubuntu 安装程序已经自带了,并不需要联网安装软件包。
添加密钥文件相关设置:
echo "KEYFILE_PATTERN=/etc/luks/*.keyfile" >> /etc/cryptsetup-initramfs/conf-hook
echo "UMASK=0077" >> /etc/initramfs-tools/initramfs.conf创建密钥文件并将其添加到 LUKS
mkdir /etc/luks
dd if=/dev/urandom of=/etc/luks/boot_os.keyfile bs=512 count=1
chmod u=rx,go-rwx /etc/luks
chmod u=r,go-rwx /etc/luks/boot_os.keyfile将密钥添加到 boot_os.file 和 Crypttab
cryptsetup luksAddKey /dev/sda2 /etc/luks/boot_os.keyfile
echo "hd2_crypt UUID=$(blkid -s UUID -o value /dev/sda2) /etc/luks/boot_os.keyfile luks,discard" >> /etc/crypttab更新 Initialramfs 内核映像
update-initramfs -u -k all此时全部结束。可以重启系统啦。
关于这个硬盘密码:
- 是用来防止,别人拿到这块硬盘时,无法查看硬盘的文件;
- 并不能防止,当你登入系统后,因为系统漏洞或操作失误,而造成的入侵;
- 这个密码,如果忘记了,硬盘里的文件,就再也无法看到了!!(有添加 recovery 的操作,但我觉得没必要);
- 每次开机启动时,都要输入一次这个密码。所以,虽然密码需要足够复杂,但最好选一个,自己能方便记住,日常使用的方式。
如何修改硬盘密码:
最简单的方式,是在已经启动的移动硬盘系统里,先通过 disk 等分区软件,确认加密分区的名字(这里假设仍然是 /dev/sda2,但实际上不一定了),打开 Terminal 界面,
sudo -i
cryptsetup luksChangeKey /dev/sda2按照提示,输入旧密码,再输入两遍新密码。最后,更新 initramfs,
update-initramfs -u -k all就可以了。
面向产品设计的 Web 前端分享会(分享会记录)

最近听说部门里面的产品或本地化运营对 Web 前端相关的内容比较感兴趣,正好我有相关的实践经验,所以在公司做了一个 Web 前端相关的分享会。分享内容包含:
- 使用 Devtools:介绍 Chrome 浏览器内的模拟、编辑和审查工具;
- 网页和部署:介绍 HTML, CSS, JavaScript, React,以及网站的部署和托管;
- 网页性能指标:介绍网页性能常用指标和测量工具;
- 资源分享:分享浏览器插件、网站和课程推荐。

与以往不同的是,这次分享会中加入了互动环节。我做了一个代码 Playground,尝试帮助观众了解 React,以及 React Props 的概念,并留了两个小任务,给观众尝试去实践对 React 项目进行编码。
完整的分享内容内容请继续浏览本文。
使用 Devtools
这个章节主要介绍 Chrome Devtools 一些可能不为人知的功能,来帮助我们提高日常工作中的效率和解决一些问题。先介绍 Devtool 里面「模拟」相关的功能。
模拟设备和屏幕尺寸
在 Devtool 里打开设备工具栏,在这里除了能够自由调整网页宽高,还能够模拟各种主流设备的屏幕。
甚至还能读取到网页里面的断点样式,提供快捷切换各种断点的方式。

需要注意的是,这里模拟的设备是会带上 UA 的,所以如果想在电脑里调试一些做了移动端特化处理的网站(比如访问主域名时,判断到是手机设备,则会跳到移动端的专门网站),是需要用到这个功能的。
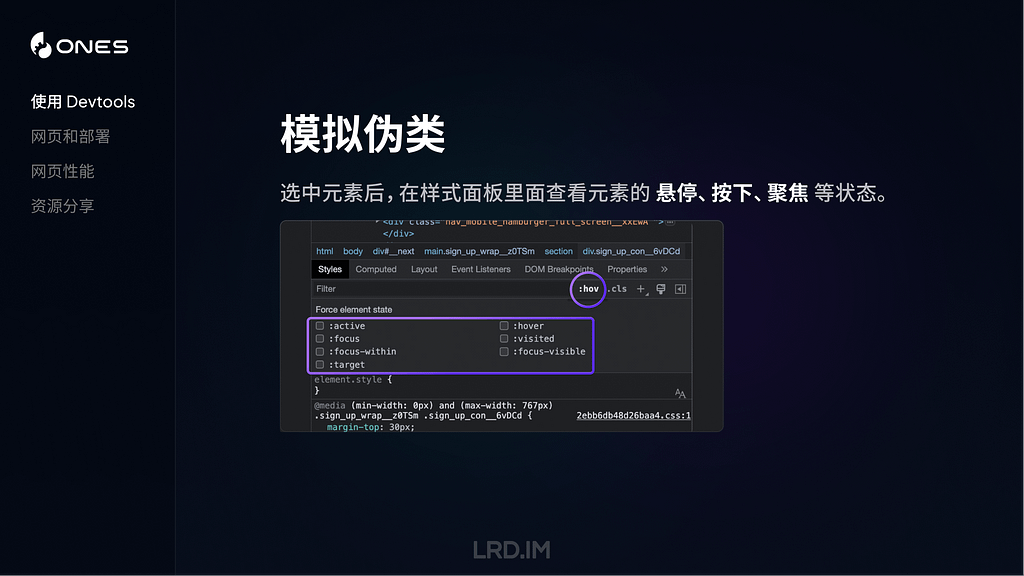
模拟伪类
Devtools 还可以帮助我们排查各种交互状态下的样式问题,最常用的是,比如说我们想仔细排查某个元素的悬停和按下状态的样式,则可以在选中元素之后,勾选对应的伪类选项。
模拟媒体
在渲染面板(需要手动开启,浏览器默认是没有打开这个面板的)能够模拟部分系统设置,比如亮暗模式、打印模式、高对比度和减少动态效果等。
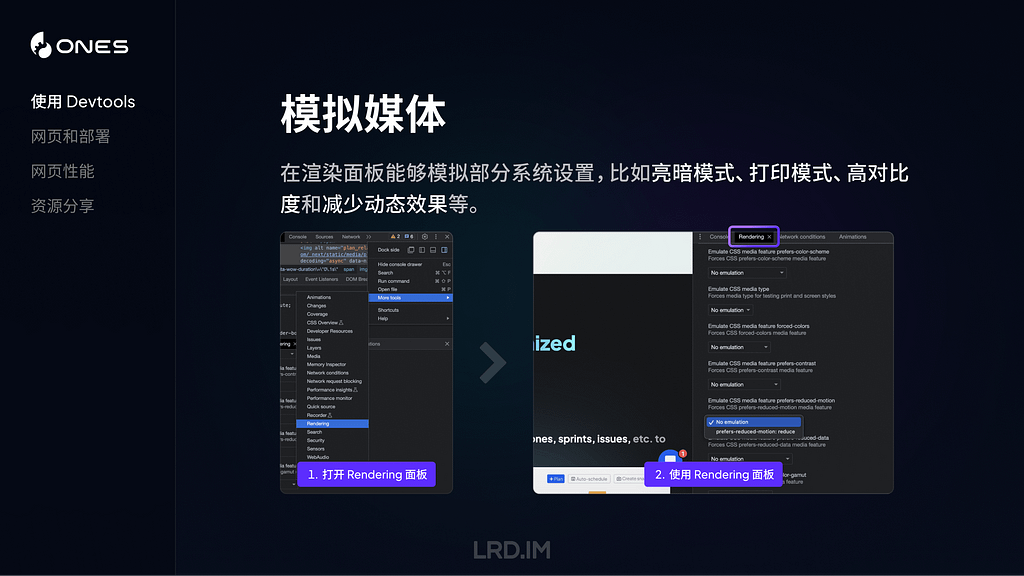
与之对应地,可以扩展一个概念叫做 CSS 的媒体查询,CSS 还可以探测到很多用户设备的属性或者设置,比如设备指针精度、视窗比例、当前是否全屏模式、设备方向等…
能探测的内容很多,但实际能用起来的可能只有寥寥数个,最全面的信息可以取 MDN 上查看。

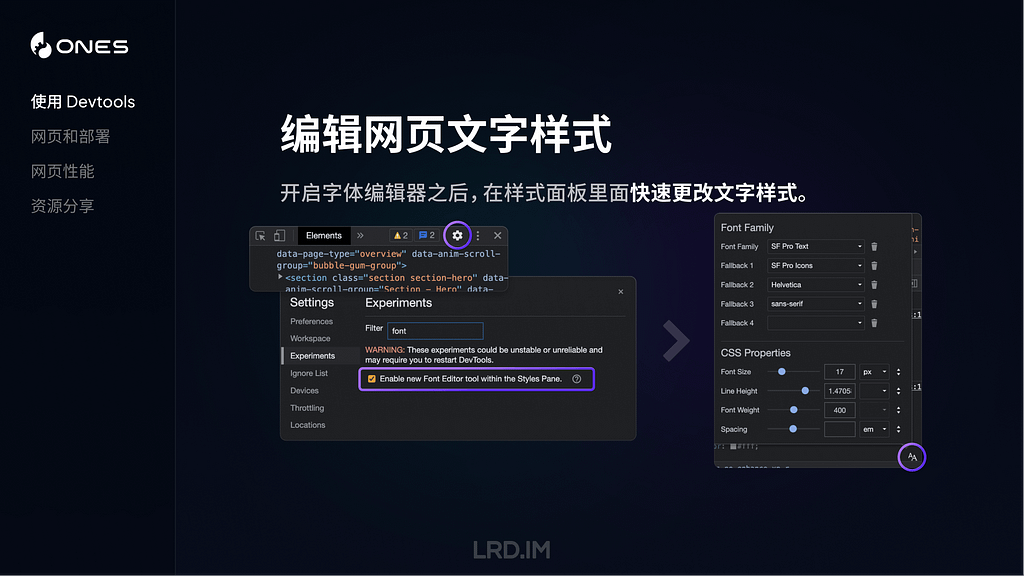
编辑网页文字样式
Devtools 还提供了一个新的字体编辑器,能够让我们实时更改网页中的字体家族、字体大小、字重等属性。
编辑网页内容
我们在 Devtools 控制台里面执行代码document.designMode = 'on' 后,就可以实时在本地修改网页文字内容了,就跟平常打字一样。很适合用在测试文案长度的场景。最后也会分享一个浏览器插件,能够对网页做更多的编辑。

审查 React 组件
最后介绍一个审查 React 组件的方法,有时候我们想看某个元素是不是用的组件库,或者这个组件包含了什么属性之类的,可以下载 React Developer Tools,然后点选网页中的任意元素,进行审查。

网页和部署
接下来我介绍一下网页构成和网站部署相关的内容。
通常来说,HTML, CSS, JavaScript 是构成网站的三个要素。其中:
- HTML 用来用于定义网页的结构和内容,可以用来创建网站的各个部分,比如标题、段落、图片、链接等。
- CSS 用来定义网页的样式和布局,这个可能会是咱们设计师比较熟悉的部分,我们能够利用 CSS 来定义 HTML 元素的各种样式,控制它们的布局和位置。
- JavaScript 用来实现各种功能逻辑和操作交互。比如响应点击事件、动态修改网页内容,根据条件执行动画效果或展示特定内容等。

CSS 预处理器
上述的三种语言,都有各自对应的语法规则。而 CSS 预处理器,则改进了原有的 CSS 语法,使我们能使用更复杂的逻辑语法,比如使用变量、代码嵌套和继承等。
简单来说,CSS 预处理器能让我们写样式代码的过程更顺畅,使代码有更良好的可读性和扩展性,帮助我们更好地维护代码。

举个简单的例子,比如原本的 CSS 语法中要求我们给每一个元素写样式时,必须以花括号开始和结尾,而且每一条样式规则直接都要以分号隔开,而 Stylus 则能够让我们跳出这个限制。直接用换行和缩进来代替。

CSS 框架
另一个值得一提的概念是 CSS 框架。CSS 框架则提供了一套预设样式,比如颜色板、字体梯度,布局和断点设定等;以及一些常用组件,如导航栏、对话框和页脚等。
简单来说,就是提供了一批开箱即用的样式,便于开发者快速启动项目,同时也会保留高度自定义的空间,用于支持各种各样的需求。通常 CSS 框架都会包含使用某个 CSS 预处理器,甚至内置了一些图标库,主打一个 “开箱即用”。

这里稍微介绍一下一个 CSS 框架:Tailwind CSS。是一个高度定制化的 CSS 框架,通过大量的预定义类名,使开发人员快速构建和设计网页界面。
与其他 CSS 框架相比,有一个显著的特点是 Tailwind CSS 本身不会包装一个组件出来,比如按钮、输入框的样式,没有预设好的。取而代之的是,Tailwind CSS 将各种原子级的 CSS 类名包装起来,比如:
- 设置左右两边的 Padding,用 px-[...] 类名来实现;
- 设置一个元素为块级元素, 用block 类名来实现…

如果想要在 TailwindCSS 中,使用打包好的组件,达到开箱即用的效果,可以通过各种官方/非官方的模版或组件生态来进行。比如:
- Tailwind UI:官方模版库(收费);
- Headless UI:官方组件库;
- Daisy UI:第三方组件库。
React
接下来介绍另一个概念:React。这是一个用于构建 Web 和原生交互界面的库(是的,它能够用来做 App,不仅仅是网页)。而且引入了 JSX 语法,将 HTML 和 JS 结合起来,以一种更直观和易于理解的方式描述界面的结构和内容。

React 有一点和我们的设计稿很像,就是它的组件思维。在构建用户界面时,React 主张先把内容分解成一个个可以复用的组件(把具体的交互、功能逻辑写在组件里面)。然后在页面中将各个组件连接起来,使数据流经它们。
下图引用了官网中的一个例子,其中:
- 完整的应用,可以理解为由多个组件拼接成的完成网页;
- 搜索组件,用来获取用户输入;
- 数据列表,会根据用户搜索来过滤和展示内容;
- 每个列表的表头;
- 表格内每条数据。

现在我们用一个具体例子来简单介绍下 React 的组件。
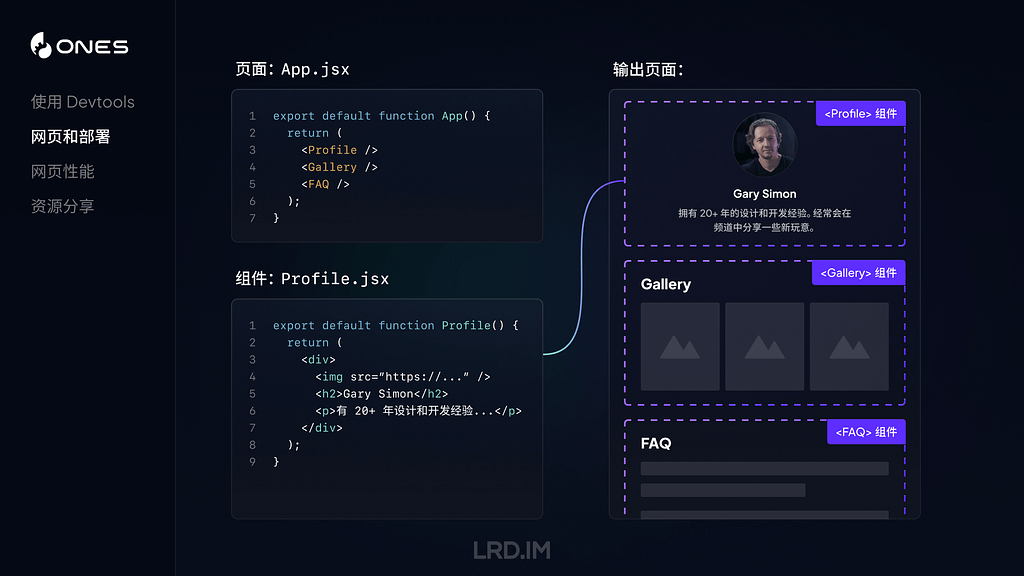
在上图中,展示了一个页面页面 App.jsx 包含了 Profile、Gallery 和 FAQ 组件,以及 Profile.jsx 组件的代码。右侧是输出页面,展示了三个组件拼接而成的页面效果示意图,其中 Profile 组件模块里展示的内容,是和 Profile.jsx 文件内代码一一对应的。
上述的组件只是将一个模块包装起来,使其能够被其他地方复用。但组件内容是固定的。接下来会为大家展示如何向组件传递 Props,实现上文提到的一句话 “使数据流经他们” 。

在上图中,我们先将一些 Props 传递给组件 Profile(比如这里传递了图片的地址、人物姓名和描述),然后在 Profile 组件内接收这些 Props,并在组件代码内使用这些数据。
现在,我们就做出了一个可以复用的组件了,可以根据不同的内容来展示相关的人物信息。
大家有没有觉得这种做法有点熟悉?是的,在 Figma 中,我们的组件里面也有类似的做法。Figma 组件同样同样传递字符串、布尔和组件等内容。

实际上 React 组件可以传递的参数不仅仅只是上面例子中的字符串和布尔值,还能传递数值、函数、对象、Node 类型甚至另一个组件等。
我做了一个简单的 Playground,提前封装好了一个 Profile 组件,会传递一些字符串、布尔值(是否展示网站标签)以及数值(圆角大小),帮助大家更好地理解。
🛝 Playground
我做了一个 🛝 Playground ,大家可以在里面看到这个组件的具体的情况,实际看一遍代码可能会帮助理解 React 的组建和 Props 概念。
同时我也写了两个小任务给到大家去尝试,大家可以在上面的编辑器中自由尝试。
发布网站
到了这里,相信大家对构建一个网站已经有了初步的认识,接下来我为大家介绍下如何将构建好的网站发布的互联网当中,能够真正地被世界各地的人们浏览。
方法一:部署到服务器
这是比较传统的方法,先将项目相关的文件放进服务器里面(比如阿里云 ECS,或轻量服务器等)。然后在服务器内安装 NGINX,索引到项目文件夹,定义好首页、端口、404 等场景,最后将域名解析到服务器 IP。之后我们的网站就能在互联网上被人们访问了。

方法二:托管到服务商
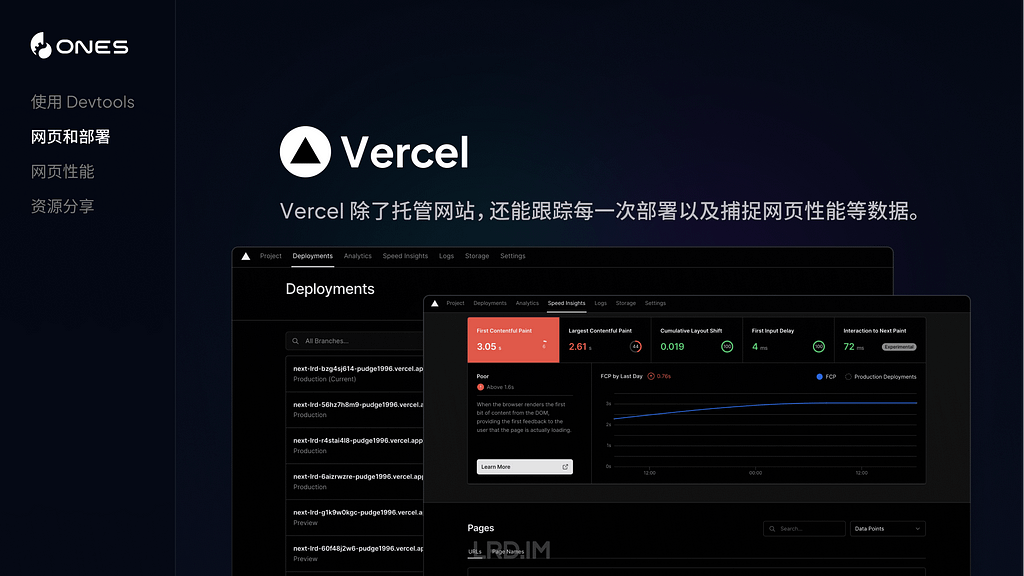
这种是相对省心的方法,将我们项目所在的 GitHub 仓库,链接到服务商的托管服务当中。等于是由服务商来帮我们部署、发布项目,不用自己来配置服务器的各种内容了。下图列举了几种常见的网站托管服务商,分别是:Vercel,Github Pages 和 Netlify。

以 Vercel 来举例,除了能够托管网站之外,对每一次发布进行管理,甚至能够是对不同代码分支进行独立发布,还能收集网站访问数据等。
网页性能
接下来为大家介绍网页性能相关的内容。通常一个网站性能好不好,我们能够在体验时主观地感受到,比如打开时很慢、滚动时卡顿,或者点击按钮后很久才响应等等。但如果要准确地判断到网页的性能到底如何,是需要依赖具体指标的。
下面介绍三个常用的指标,分别是:FCP(首次内容绘制)、LCP(最大内容绘制)以及 CLS(积累布局偏移)。
FCP(首次内容绘制)
FCP 是一个关键指标,用来测量页面从开始加载到第一个页面内容在屏幕上完成渲染的时间。越快的 FCP 时间能够让用户感知到网页有在正常运行,而不是停滞、无响应。
这里提到的 “内容” ,指的是文本、图像(包括背景图像)、<svg>元素或非白色的<canvas>元素。如下图所示,FCP 出现在第二帧。

LCP(最大内容绘制)
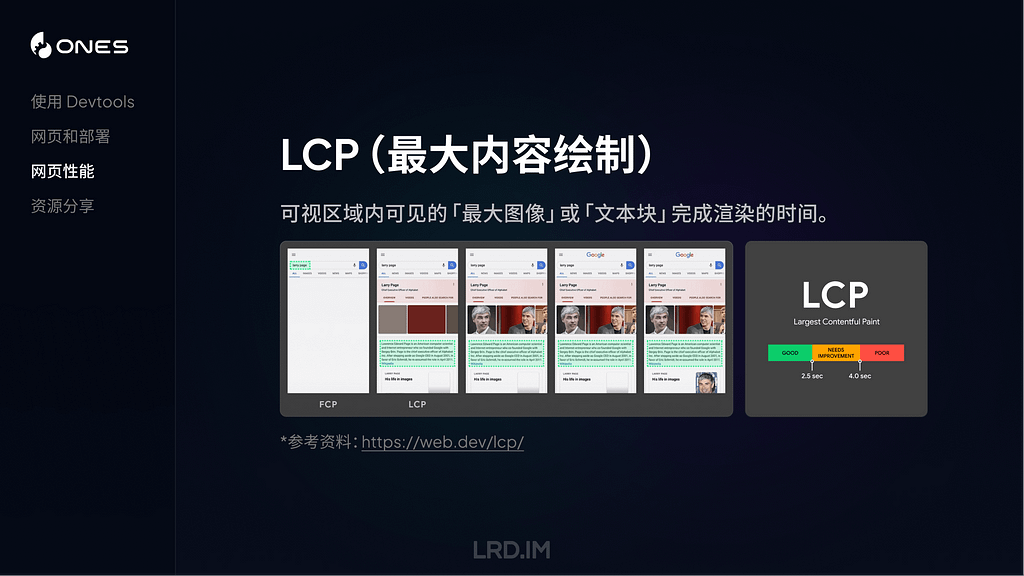
LCP 指的从页面开始加载到可视区域内可见的「最大图像」或「文本块」完成渲染的时间。
这里提到的「最大图像」或「文本块」,具体来说是包含<img>元素、内嵌在<svg>元素内的<image>元素、块级文本等。
而测量方式,则是在页面加载过程中,记录视窗内的元素的渲染大小,取尺寸最大的元素,回溯这个元素被完整渲染的时间。注意,如果元素的有一部分在视窗外,在视窗外的部分不会参与到尺寸比较当中。
如下图所示,LCP 发生在第二帧,因为这个时候渲染尺寸最大的文本块被渲染出来了。后续帧当中,可能渲染出了一些图片,但尺寸都比文本块小,所以文本块依然是这个视窗内的最大元素。
CLS(积累布局偏移)
CLS 是指可视区域内发生的最大布局偏移分数。简单来说就是测量页面在加载时,元素的位置出现意外的偏移情况,如果元素尺寸大,而且位置偏移比较远,那么 CLS 分数就会显著增高。
这个指标会跟实际的用户操作或者体验有直接相关,所以应该也会是咱们设计师需要重点关注的内容,因为有时候布局偏移,是会比较影响用户获取信息、或者进行操作,甚至引发一些不可挽回的损失。

然后我来介绍一下测量网页性能的工具吧。我自己用过这两个,发现其实没啥差别,大家看喜好使用即可:
- DebugBear
- PageSpeed Insights(谷歌官方出品)
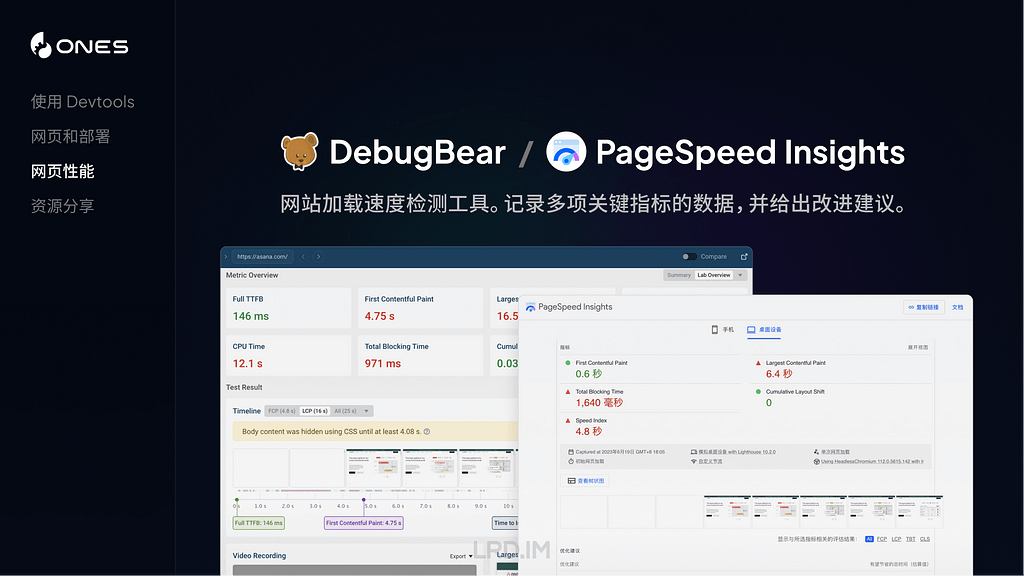
两个工具都能模拟桌面设备或者移动设备,记录多项关键指标的数据,并给出改进建议。
观察页面性能情况,不仅仅是前端技术人员要做的事情,了解到设计师也是可以参与到其中的。
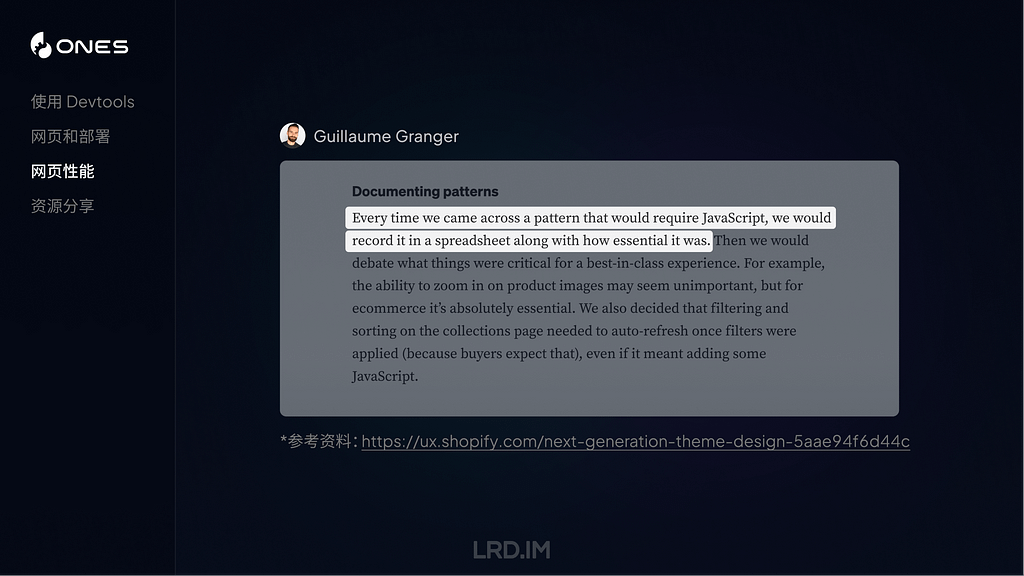
比如 Guillaume Granger,他会比较想控制页面中 JavaScript 的数量,所以它提到,他会将所有用了 JavaScript 相关信息记录在表格当中。之后每次在网页中使用 JavaScript 时,都会跟之前的记录进行比对,判断重要性,决定是否在这个位置上使用 JavaScript。
开发者 Thomas Kelly 则提出了当意识到页面性能出现瓶颈时,需要做的事情,比如:
- 制定一个目标,团队一起往这个目标前进;
- 高频收集页面性能数据;
- 尝试用不同方式来解决同一个问题;
- 与同伴分享对性能的一些新发现…

资源分享
最后来分享一下相关的资源吧,包含两个插件、三个学习网站以及一个 React 课程。
插件:VisBug
介绍一个谷歌官方出品的插件:VisBug,主要用来帮助用户在浏览网页时进行调试和设计,包括编辑和可视化页面的 CSS,尺寸和字体等元素。
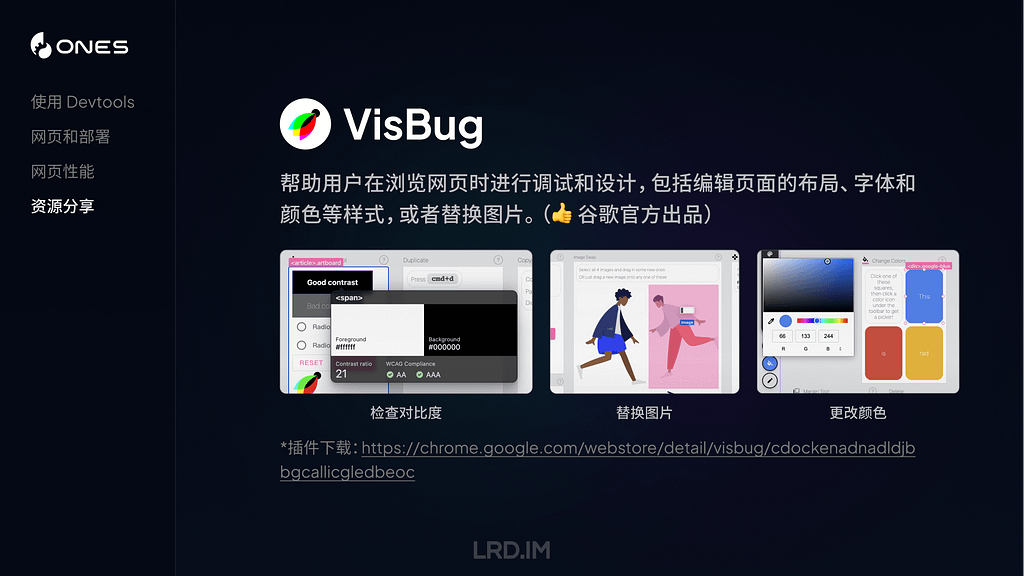
插件:Motion DevTools
Motion DevTools 是一个检查网页动效的插件,可视化和分析用户交互设计中的滚动、动画效果,并支持实时编辑、预览或导出等功能。

网站推荐
接下来介绍三个在国内外拥有较高知名度和影响力的设计师和开发人员。他们的观点、经验分享往往能给我带来一些新的启发。尤其是他们对钻研新技术的热情,是非常强烈的。

课程推荐
最后强烈推荐一门 React 课程——The Joy of React,这个课程我在年初的文章也有提到过,是以互动式课程的形式,由浅入深地讲解 React。从基础的组件 props 和 JSX 知识,到 Hooks、API 设计等等,讲述非常清晰,强烈推荐。

分享会感想
分享完之后感觉效果可能还不错,大家都有各自的收获。而且分享会中也不时有人提出相关问题,我也一一进行解答了。
或者也有对我分享内容的一些补充,比如我在分享完 Devtools 环节的时候,有同事也分享了一个在 Application — Cookie 面板里快速切换网页语言的方法。
后面了解到大家对于 CSS 和 React 那块听的比较迷糊,因为原本没有实践过的话,会对这些没有什么概念。而且大家好像对 🛝Playground 没有什么兴趣,并没有人对里面的内容有什么提问和看法之类的,可能到这一步都比较迷糊?🤔
指标那块倒是有不少同事关心,问了几个问题,比如有哪些方法来去改进几个指标的数据,或者在设计过程中是否可以提前避免性能问题等等。
总体来说和之前的分享会相比,这次分享会的参与度比较不错。
【译文】无障碍设计:三个 Jira 图标的故事
导读:Atlassian UX 团队的设计师 Hannah McKenzie 分享了一个优化图标的小案例。主要目的是使图标对色盲人士也具有良好的可访问性。

小细节会产生巨大的影响
你知道世界上有很多种不同类型的色盲吗?在澳洲,有大约 50 万人生活在某种程度的色盲当中。在美国,这个数字接近 1200 万。而在全世界,估计有 3 亿人生活在某种程度的色盲当中,网上的一些资料显示,这个数字甚至接近 3.5 亿。
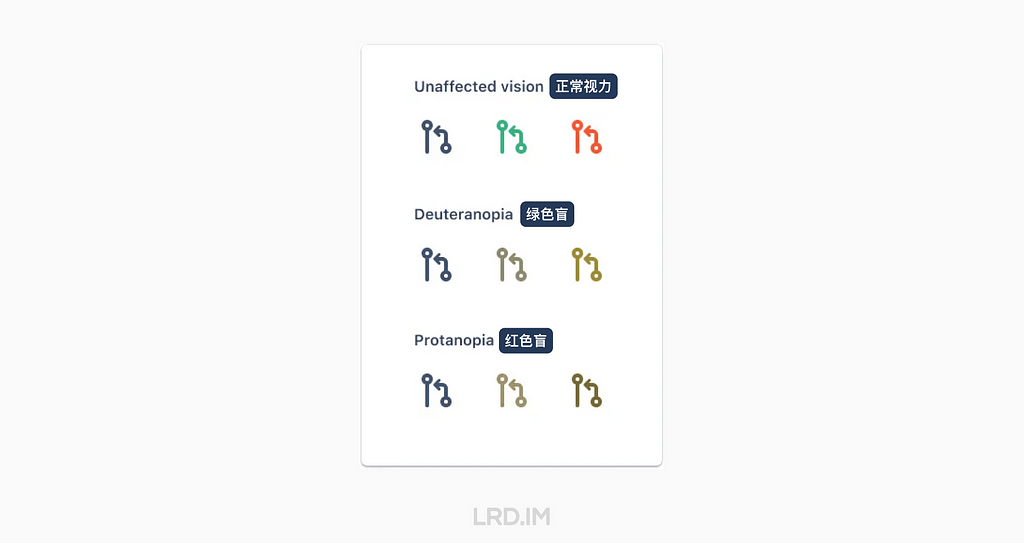
其中红绿色盲占据了大多数,他们难以区分红色和绿色。
现在 Jira 的 Pull request 的图标是通过用灰色、绿色和红色来区分 Open, Merged, Declined 这三种状态。

红绿色盲人士看到的图标就像这样:
在 Jira 的软件项目管理看板当中,这些图标很小,并且与每个缺陷中其他小元素一起出现。比如故事点、负责人头像和缺陷 ID。
这是一个 Jira iOS app 项目看板的例子。其中 Pull request 图标用红色圆圈高亮起来作为示意。
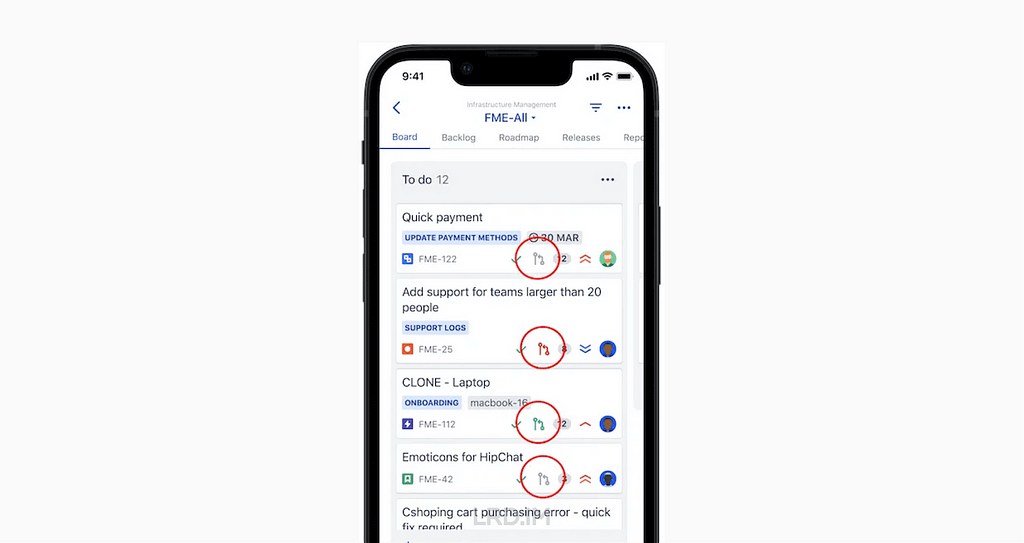
虽然图标很小,但这些图标确实在传达有用的信息。
在 2021 年末,我开始进行优化开发状态图标的工作,并让色盲用户可以访问它们。它开始于一则我在无障碍团队 Slack 频道里的消息:
“我们最近有改进 Jira pull request 图标计划吗?现在这些图标是完全相同的,只能通过颜色来区分。”
在 2022 年初,几位设计师和研发在 Slack 的讨论中尝试了一个粗略的方案:
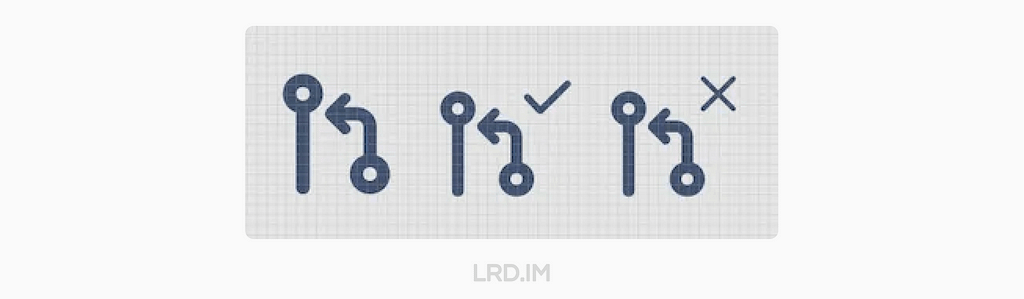
设计师开始尝试多种概念,产生了更多的方案:

在几个发散性的讨论和设计环节之后,全新的,具有可访问性的 Pull request 图标诞生了!

虽然这些图标仍然由灰色、绿色和红色来分别代表 Open, Merged 和 Declined,但同时,使用了打勾代表 Merged,打叉代表 Declined。而且 Merged 的图标用线条连接在一起(表示合并到分支),Declined 的图标线条则没有与任何东西连接。

这段经历教会了我…
- 即使过程很棘手,但也请坚持下去。如果你面向的是比较复杂的产品,或者在大型的机构中,你需要主动去在不同团队去联系到合适的同事;
- 一些看起来很小的设计往往会涉及到很多不同的人。通常是很多件小事(就像在这个案例当中,有许多交流和发散性会议)汇聚成一件大事,以最终呈现在用户面前;
- 设计一个支持无障碍的产品对很多人来说是至关重要的,小细节真的很重要。每个人都会受益,包括自认为是并非残障群体的的人士。比如电话和电动牙刷,最开始就是为残障人士而设计的。
Atlassian 里几位没有色盲的设计师和工程师对于新设计图标的看法:
“我不是色盲的,但这些图标让我一眼就能看懂。”
“这简直是宝藏。原本同样的图标,不同的颜色让我感到疑惑。我经常想,这是对应着什么分支状态?这是一个非常惊人的优化。”
所以这篇文章用来提醒大家关注细节 — — 即便是小细节也会产生巨大的影响。

- 原文:Accessible design: A story of three Jira icons | Hannah McKenzie
- 译者:李瑞东
探索让新用户更容易上手的产品设计策略

背景
今年二月底入职了新公司,主要产品是企业级研发管理 SaaS 软件。这家公司的新员工在参与产品迭代之前需要进行相关的学习和培训:
- 第一、二周先自己学习使用公司的软件和行业名词,并模拟成销售的角色来参与一次产品演示和场景化配置的考核;
- 第三周基于自己感兴趣的主题来分析竞品和自身产品的某项特点,并作一次分享会;
- 第四周才正式开始参与产品设计,进入到迭代当中。
我是比较认同现在这一家公司的入职流程的。毕竟 SaaS 软件是会有点学习成本,自己先把各种功能、场景、配置和行业相关名词学会了之后才能更顺畅地合作。
就在我刚开始学习使用公司软件的时候,会感到有些吃力。比如:
- 功能/流程配置。比如我想要做某项配置,但因找不到入口导致无法配置,或被某些逻辑限制导致结果与预期不符时,需要去到帮助文档里搜索相关概念,然后再对照文档里面写的步骤来实现;
- 名词释义。有些行业内的名词我之前没接触过,或者不能够直接根据字面意思理解的时候,我需要去文档或者维基百科上查找相关的释义、使用场景和最佳实践。比如「故事点」、「用户故事」、「史诗」等;
- 系统概念理解。我需要通过查阅文档、询问导师和自己反复尝试来去了解软件系统内的一些运行机制,比如说多种层级的权限,或者一个叫「池子」的概念…
所以在第三周的分享中我选择了主题是关于产品设计中如何帮助新用户上手使用软件。正好自己也看看其他做的好的产品是怎么做的,之前这方面的实践比较少。
概念学习

在实际进入竞品里体验之前,我先去网上学习点跟帮助系统相关的概念。我通过 NNGroup 的文章了解到帮助会分为两大类:
预防性帮助 (Proactive Help) 指的是系统在用户遇到问题之前提供帮助。常见的方式包括: Onboarding、新功能提示、上下文帮助(Contextual Help) 和向导等。
针对性帮助 (Reactive Help) 指的通过文档、视频、课程等资源来回答和解决用户的具体问题。或者为想要成为专家用户的人提供详细的文档和资源。
而「预防性帮助」,又能分为两种类型:
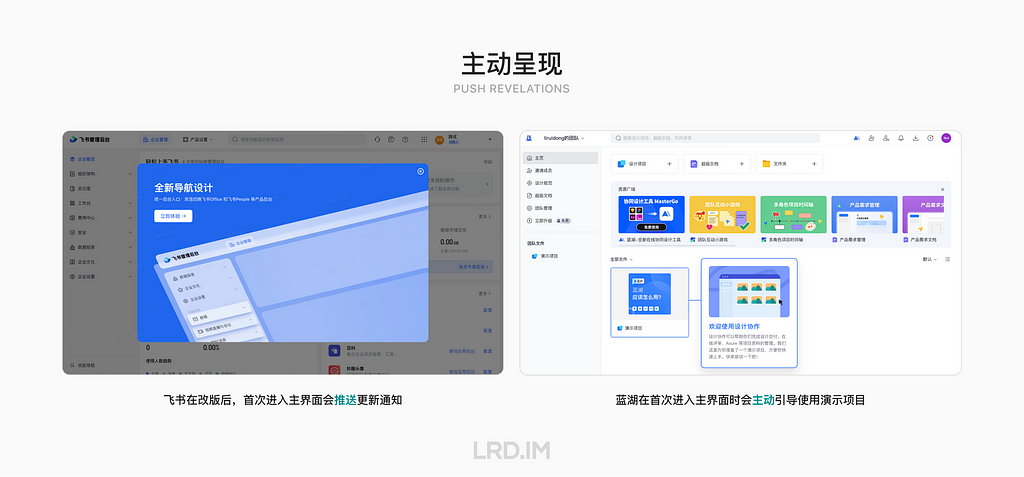
主动呈现 (Push Revelation): 不考虑用户的任务而提供帮助内容。强调主动提供帮助信息而不考虑用户当前行为。这种方式会可能打断用户进行中的任务并引起用户的不适,需谨慎使用。
被动揭示 (Pull Revelation):与用户当前行为相关的帮助。侧重于与用户当前正在进行的动作、行为和活动等有紧密关联。提供有助于用户完成当前任务的相关建议和信息。
经过梳理后,这些概念的关系图像大概是这样:
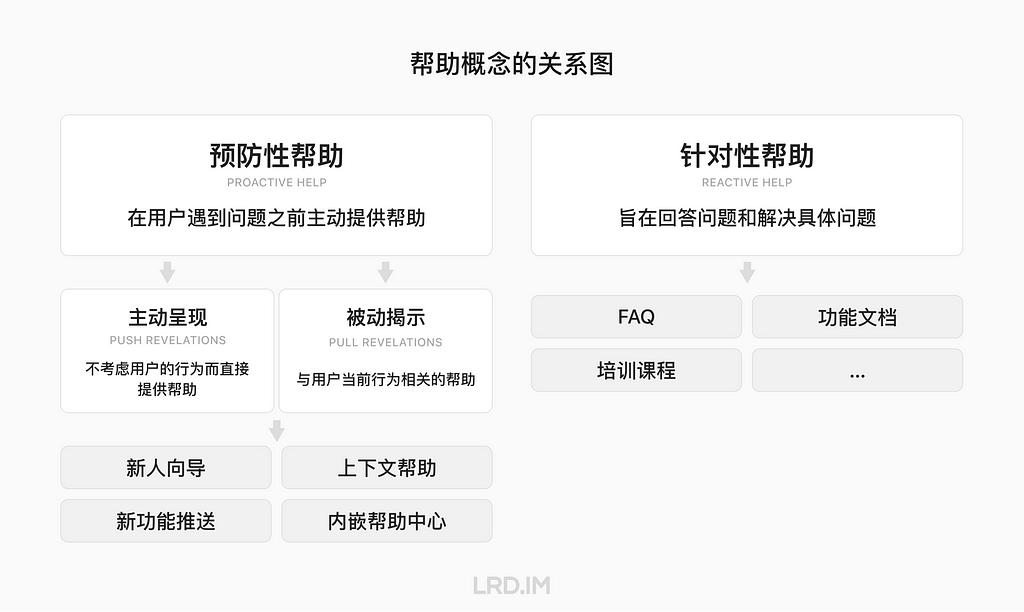
从 NNGroup 了解预防性帮助和针对性帮助的概念
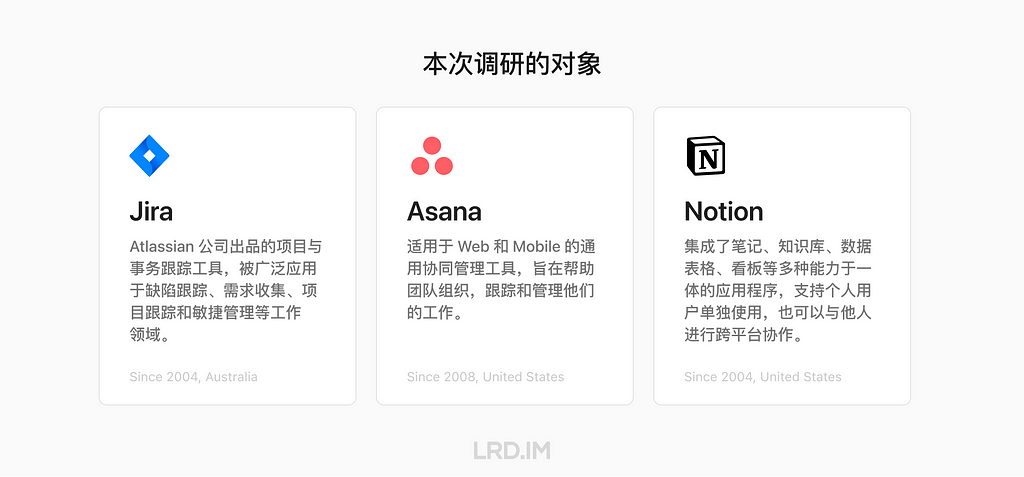
。
接下来就从上述的多个手段中选取几个,结合 Jira、Asana 和 Notion 的做法来做一些观察和分析,并尝试总结出在它们身上能学到什么。
新用户旅程
新用户旅程 (Onboarding) 设计有助于引导用户使用产品,让用户发现产品的核心价值,进而推动用户留存、转化和推荐。
我分别体验了 Jira, Asana, Notion 的 Onboarding,发现这三者的流程大致相似,但基于软件本身的功能不同而有些许差异。值得一提的是,他们都做得很细致。
流程
走查了三款软件的 Onboarding 流程,并以粗颗粒度来划分步骤。
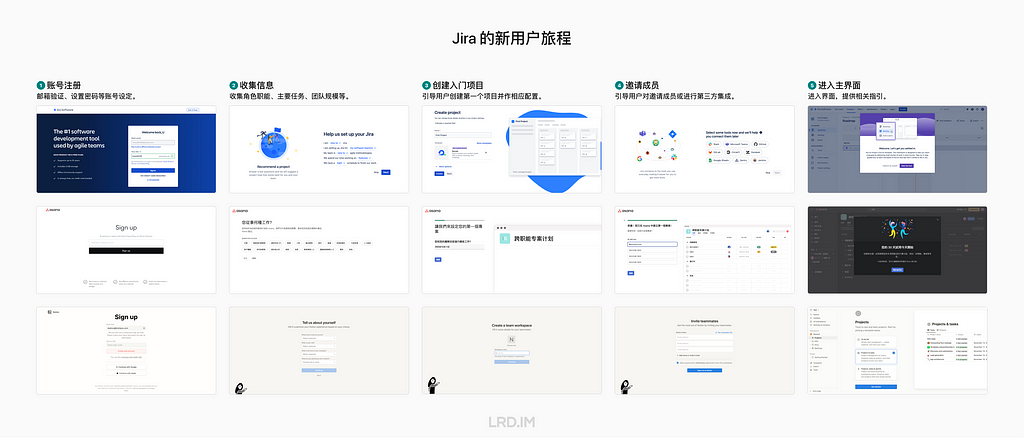
其中与比较关键的是第二步:
第二步:收集信息。收集用户的角色、工作职能、主要任务、团队规模等信息。用于获取用户的标签,以便后续进行精细化运营。同时影响到后续的配置、预设的数据和界面内提供帮助的程度。
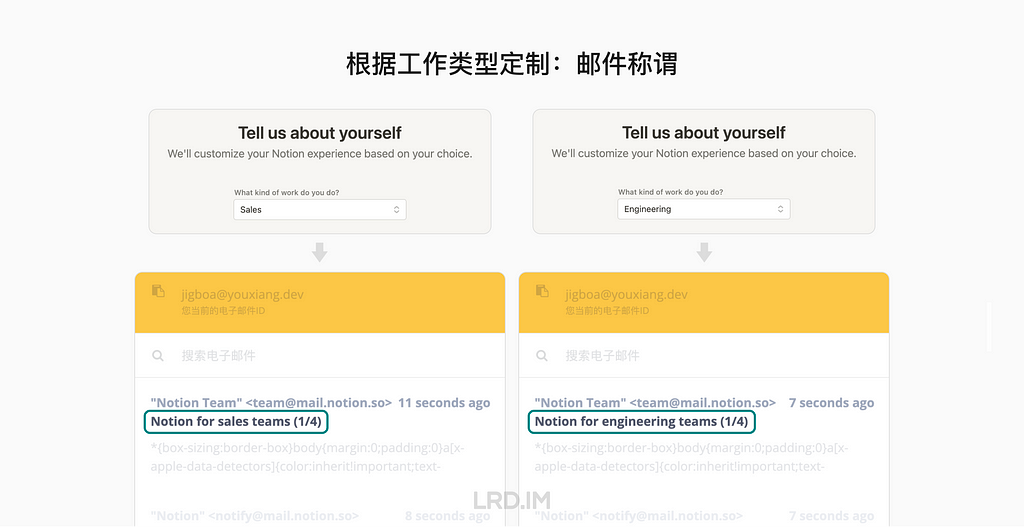
第二步里收集到的信息会影响到创建入门项目、邀请成员和进入系统后的主界面。比如在 Notion 中如果提供了「个人使用」作为用途,则流程中不会出现「邀请成员」的模块。
千人千面
值得一提的是,Onboarding 流程中收集的用户信息,可以为后续的系统预设和默认配置提供参考。
比如在 Jira 中,系统会根据用户填写的团队类型和主要工作类型等因素,推荐对应的模板。如果用于管理软件开发团队,则推荐用敏捷项目模板;如果是管理业务团队,则推荐用项目管理模板。并引导用户使用模板创建第一个入门项目。
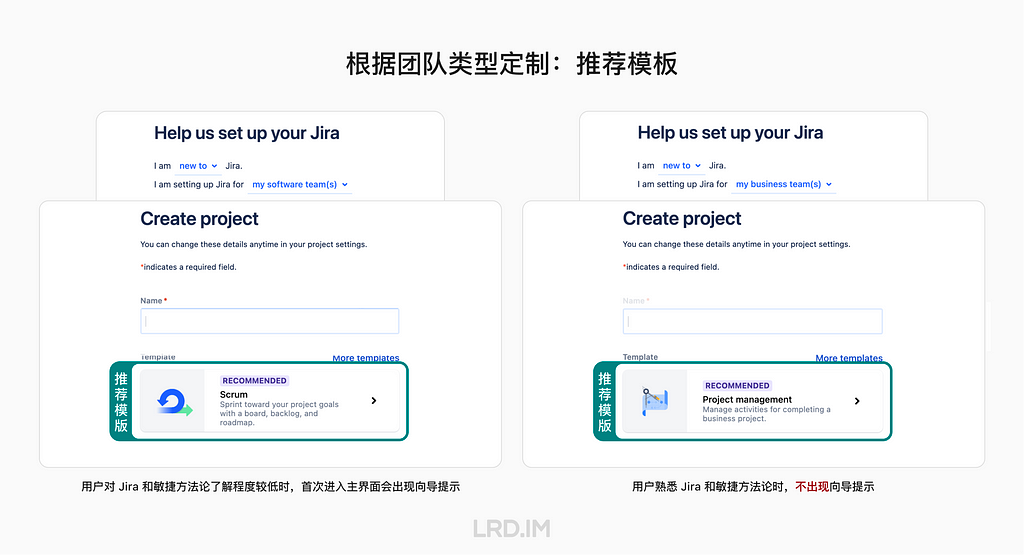
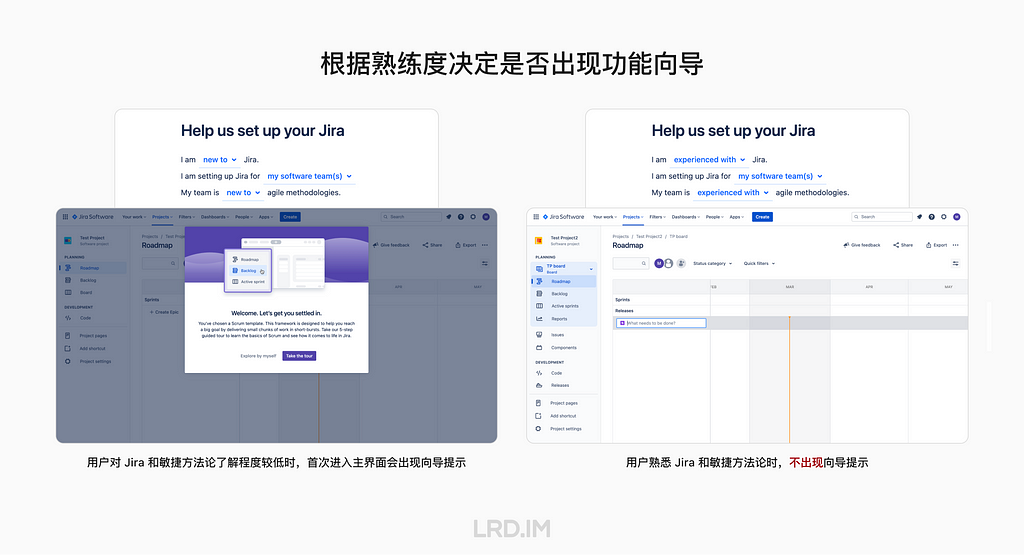
并且根据用户对 Jira 和敏捷方法论熟练度,决定是否在用户首次进入主界面时提供向导。如果是新手,在进入主界面时会询问是否需要跟随向导了解界面和功能;如果是有经验者,则没有向导提示。
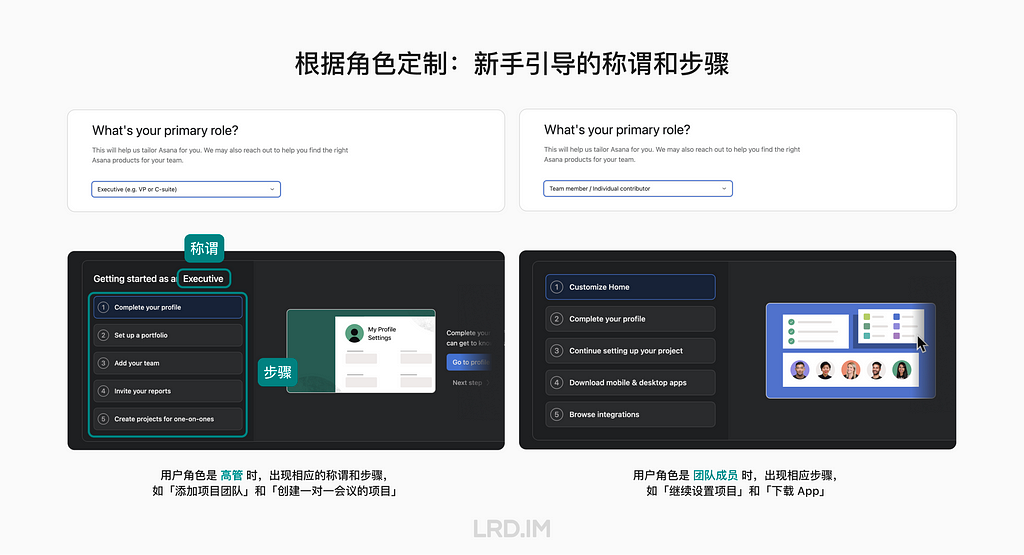
再比如在 Asana 新用户旅程中,如果用户选择角色是「高管」,系统内新手引导卡片内的称谓和步骤,都会与「团队成员」的角色不同。
高管的引导卡片添加了「开始成为一名管理人员」的文案,而初始配置的步骤包含「创建报告」和「创建一对一会谈项目」等;而团队成员的引导卡片则是「填写个人资料」、「下载 App」和「查看第三方集成」。
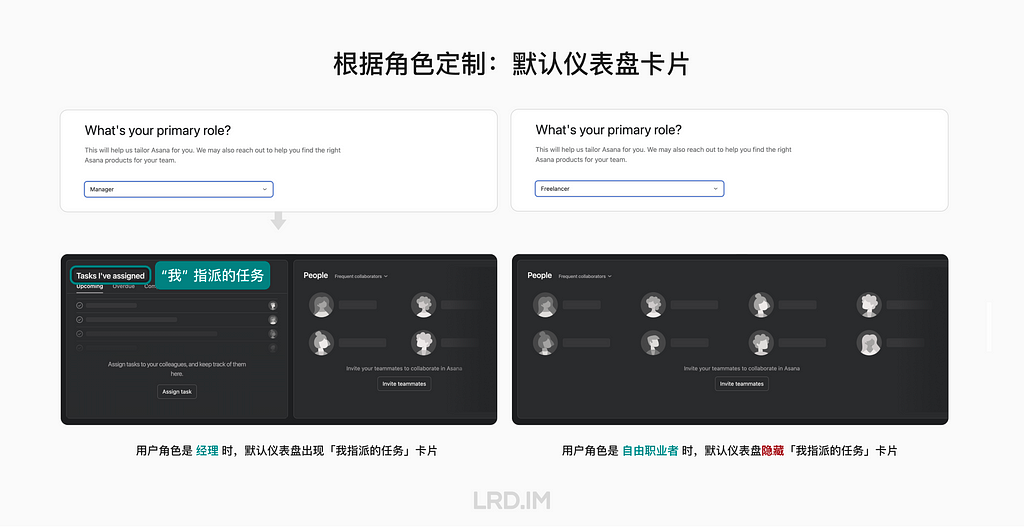
或者当用户的角色是「经理」,仪表盘卡片也会与「自由职业者」不同。经理的默认仪表盘中有一个卡片是「我指派的任务」,而自由职业者则没有。
Notion 也会根据用户选择的工作类型,在邮件中更改相应的称谓。
我们能学到什么
💡 定制个性化的用户旅程。不同的用户有不同的需求和期望,为了更好地满足用户,我们可以根据收集到的信息来提供更符合其所处情境的预设、引导流程和配置等。
💡 合理利用向导来帮助用户上手软件。向导能帮助用户熟悉界面 UI 和功能,但要避免阻碍用户使用软件。所以需要根据用户对软件熟悉程度来决定是否提供向导,并保留跳过的方式。
上下文帮助
本文的最开始提到预防性帮助有两种方式,第一种是主动呈现 (Push Revelations),比如一进入页面就出现的新功能提示,或者界面操作向导等。
而这里重点介绍的是另一种:被动揭示 (Pull Revelations)。而「被动揭示」有一种做法叫做上下文帮助 (Contextual Help)。这是指根据用户参与的特定活动,展示与此相关的帮助信息。强调要与用户当下的活动密切相关,而不是统一的推送。而具体的做法有很多种,比如:工具提示、向导、输入框提示、内嵌帮助中心等。
使用案例
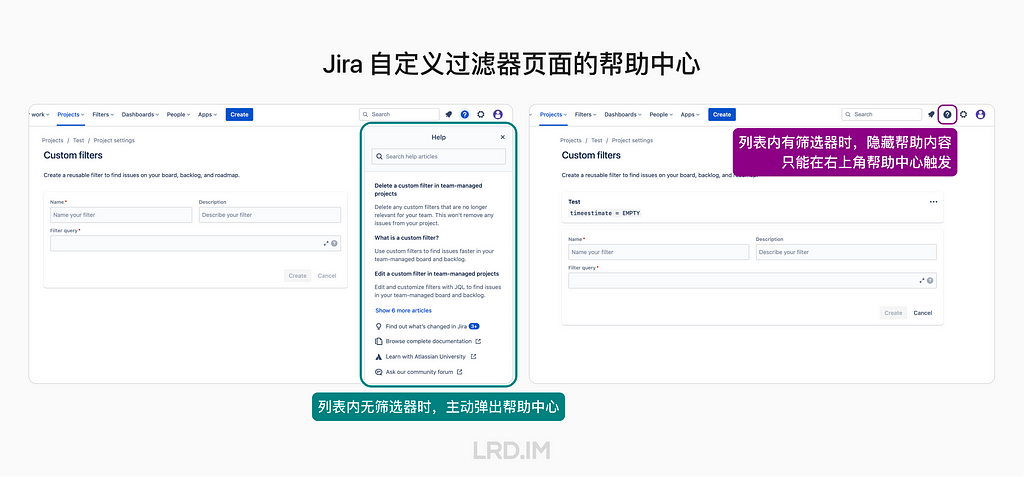
Jira 的筛选器界面,在用户没有创建过筛选器时,会出现内嵌的帮助中心,呈现与筛选器相关的帮助;而当用户当前已存在筛选器,打算继续创建时,则会默认隐藏内嵌的帮助中心,用户可以手动点击右上角的问号图标打开。
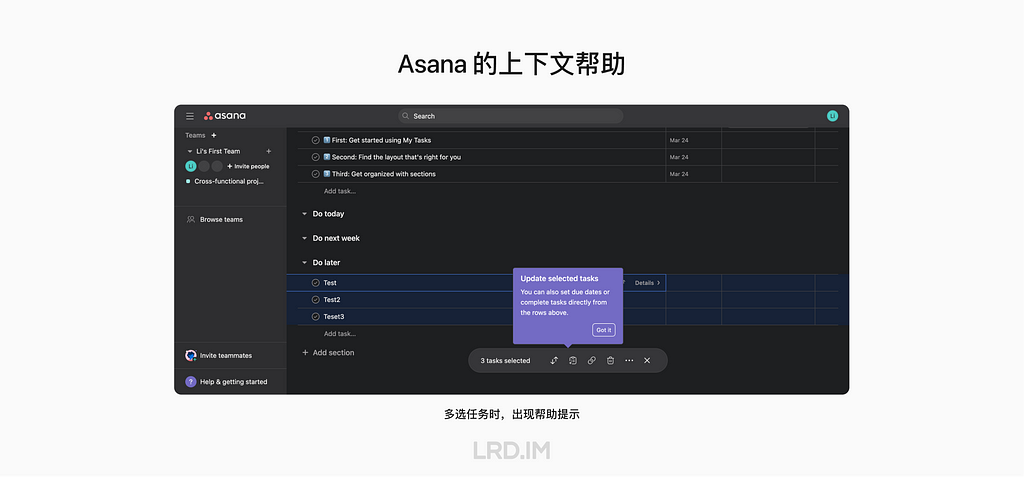
相似地,Asana 的 Task 列表中,用户对任务进行多选后,也会在操作栏出现与之相关的工具提示。
同时也可以看看其他 SaaS 软件的做法,不必局限于竞品。因为这种设计理念是通用的,都是为了帮助用户更好地上手,为用户持续提供价值。比如 Slack 也在这方面下了很多功夫。
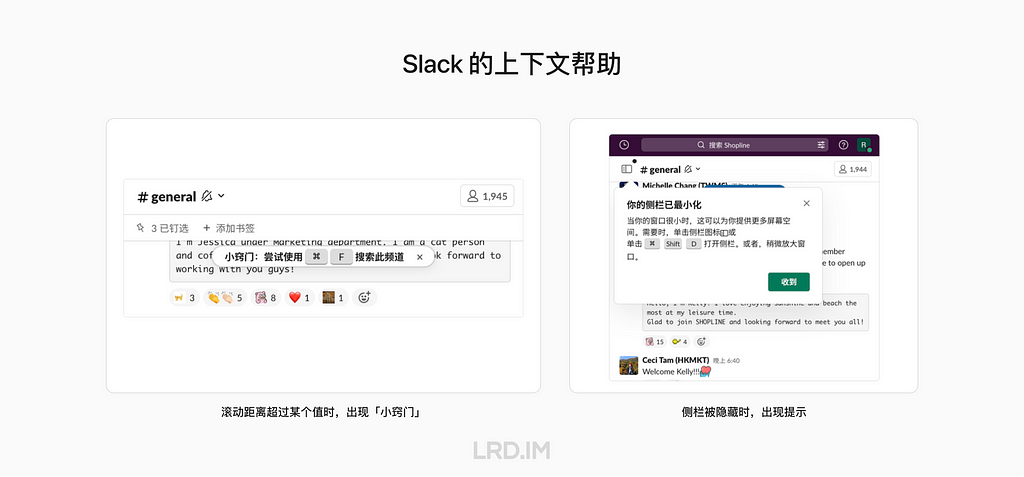
我们能学到什么
💡 帮助内容保持简洁。使帮助的内容简短并有效,并且在用户要求之前不要呈现过多细节或复杂的内容。
💡 易用且不干扰。上下文帮助可能会干扰已经熟悉界面或者不需要帮助的用户使用。所以在呈现帮助内容时,确保使用轻量的样式,并且允许用户跳过帮助。
💡 使帮助内容可以在其他地方访问。用户可能看到过一些帮助提示,但当时他们忽略了或者忘记了,这在复杂的软件里很常见。所以仍然需要提供其他方式来使用户获取到帮助内容。
模板
模板中心
用户使用 SaaS 软件通常是带着现实情境过来的,比如希望进来做任务追踪,或者是进行多项目的管理和进度追踪等。
所以我观察到这几款应用的模板生态还是比较丰富的,覆盖了多种场景。完善的模板能够帮助用户快速上手,减少学习和操作成本。
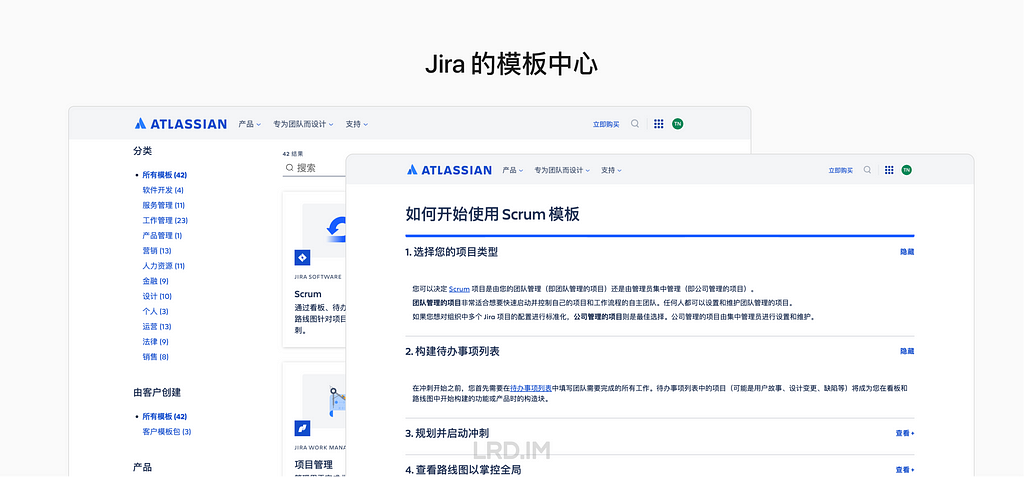
Jira 的模板中心以业务为基础,更多地关注具体的业务流程、管理流程和功能的实现。适用于企业内部、管理领域软件行业。并且有详细的模板使用说明和相关模板。
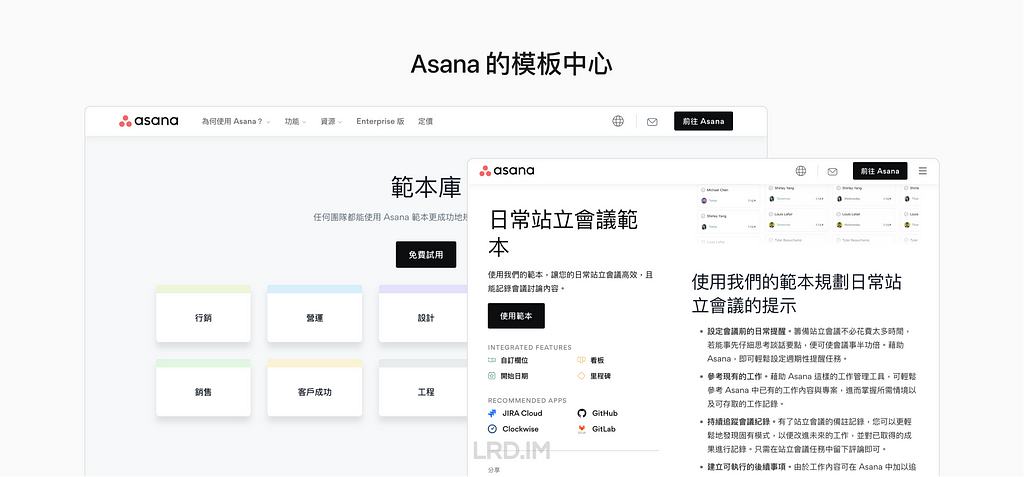
Asana 的模板按照团队内不同职能部门来划分,侧重于流程优化。并且有详细的模板使用说明。
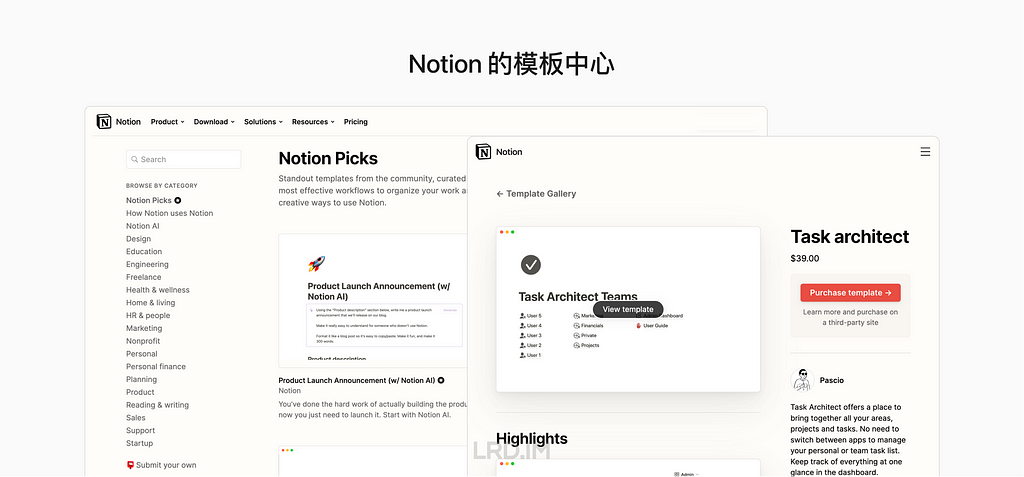
Notion 的模板中心按照专业领域和个人兴趣分类。适用于个人、自由职业者和信息分享平台等。并且允许用户上传自己做的模板并进行收费,既能够满足用户的个性化需求,又能够为 Notion 和整个社区提供更多的价值和机遇。
本地化
值得一提的是,Notion 和 Asana 的模板中心做了比较细致的本地化处理,切换语言后会呈现更符合用户所在地区的分类和模板。
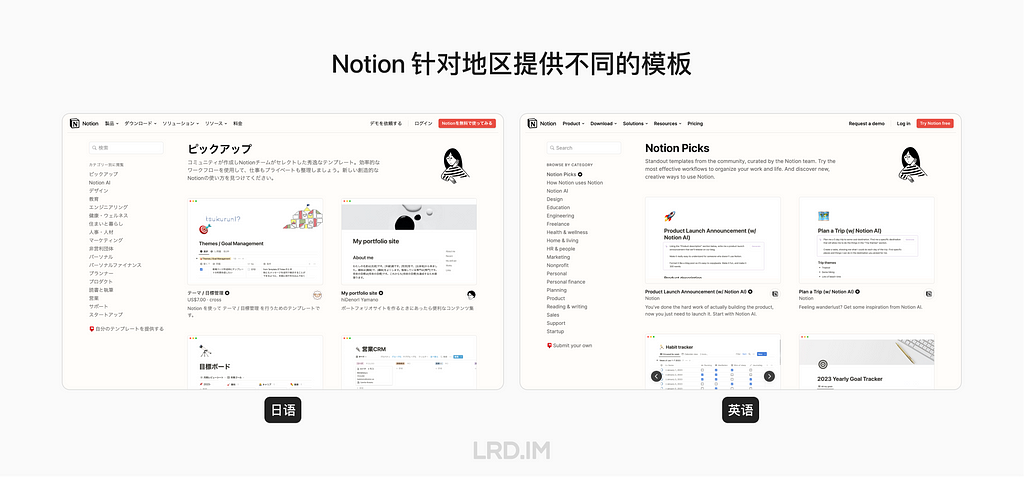

其中 Asana 的模板顺序,「每日站会」在日语和英语中,分别是首位和末位。为此我也有去了解过美国和日本的文化差异,试图去解释为何 Asana 要这么做,这是调研出来的差异:
- 文化倾向。日本强调集体主义,注重团队合作和群体利益;美国强调个人自由,注重个人的成就和个人的价值。
- 协作模式。日本注重面对面的交流和沟通。在组织中强调员工之间的默契和团队合作精神;而美国更加弹性化,注重个人的私人时间和团队协作效率的平衡,支持远程协作。
- 企业文化。日本注重团队合作、持久性和精益求精,对个人规范和职业素养的要求高;美国注重灵活性和创新,注重持续快速发展和快速创造价值。
这些未必是 Asana 做这种本地化差异的理由。但是能反映出来,日本和美国这两个国家在霍夫斯泰德文化维度来看,是有明显差异的。如果之后工作中我有相关的设计机会,也会多多尝试基于两个国家文化差异,而作出不同的设计策略。
我们能学到什么
💡 模板丰富实用。模板对于 SaaS 软件的用户来说是非常重要的,它可以帮助用户快速上手并减少学习成本,并且加深客户对产品定位的印象。
💡 帮助新用户上手。不同 SaaS 软件的模板中心存在一定的差异,它们通常会按照业务场景、职能部门、专业领域和个人兴趣等各种标准进行分类。
💡 关注本地化策略。设计模板时需要考虑到不同地区、不同文化和不同工作习惯的用户的需求和习惯,并且根据实际需要进行调整和优化,以便更好地适应当地市场,吸引更多潜在客户。
帮助中心
产品文档
产品功能文档或开发者文档,是 SaaS 软件帮助中心的标配。我也有去看不同产品的功能文档,看看他们为了帮助用户更好地理解和使用,做了哪方面的努力。
比如 Asana 会标记截图中的行动点,然后在旁边写上相关的步骤操作。标记行动点是用户更容易发现目标,而分步描述则让文字更加简洁易懂。
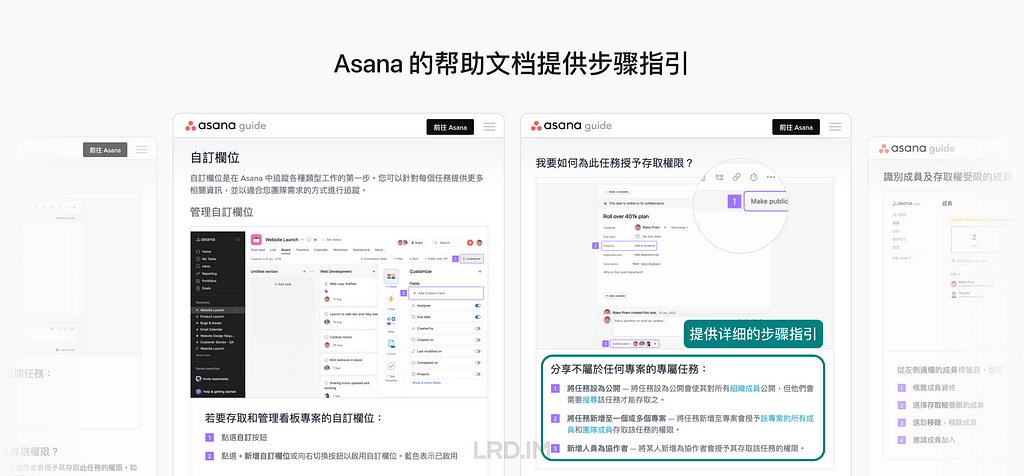
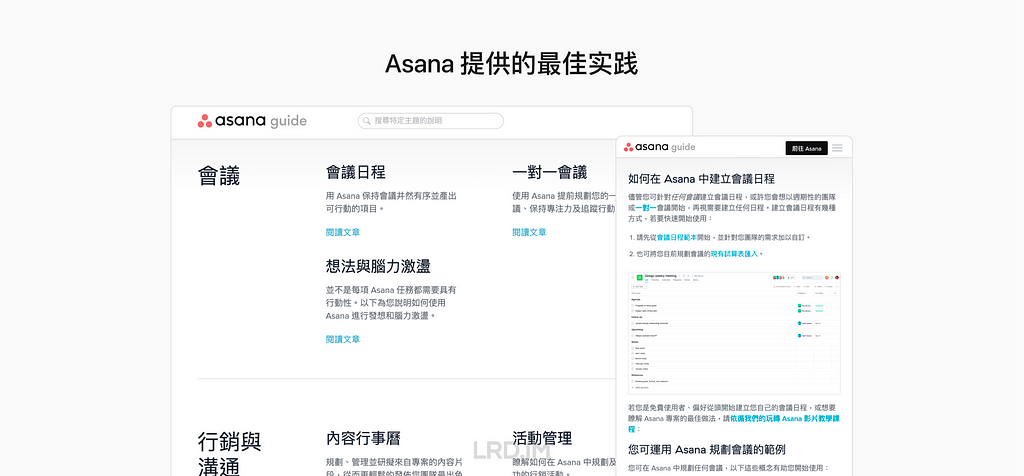
值得一提的是,Asana 不仅仅提供产品功能文档,还按场景分类,提供多个工作流程的配置方式(最佳实践),比如会议、日历和计划等。试图去引导用户按照 Asana 所推荐的方式来去使用该软件。
其他资源
调研中发现现在的帮助中心内容丰富,除了常见和必要的产品功能文档/开发者文档之外,还有其他很多提供帮助的资源。比如视频讲解、视频课程、实践案例、社区、博客、公开课等。
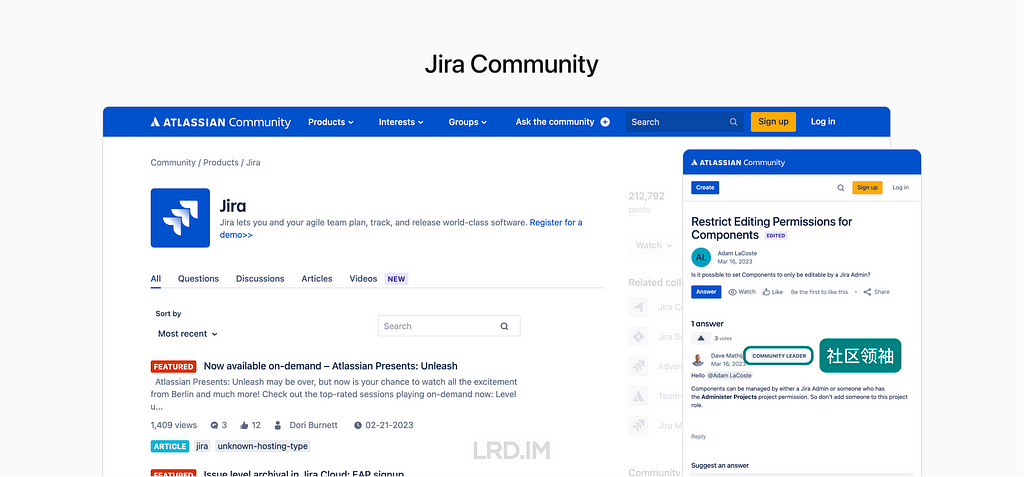
Jira 通过社区来加强与用户之间的联系,比如:处理用户反馈、新功能发布的通告和邀请客户参与一些试验性的功能等等。社区内也会常驻社区领袖来响应用户的反馈。
Notion Academy 提供了详尽的视频课程,由浅入深。比如从基础的界面功能、团队管理,到使用数据库和人力资源场景下的大型团队空间配置等。
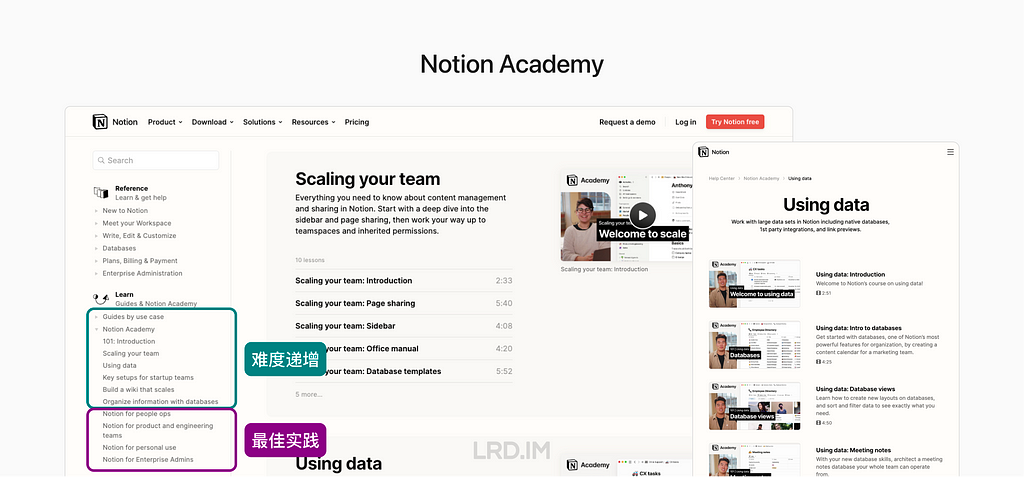
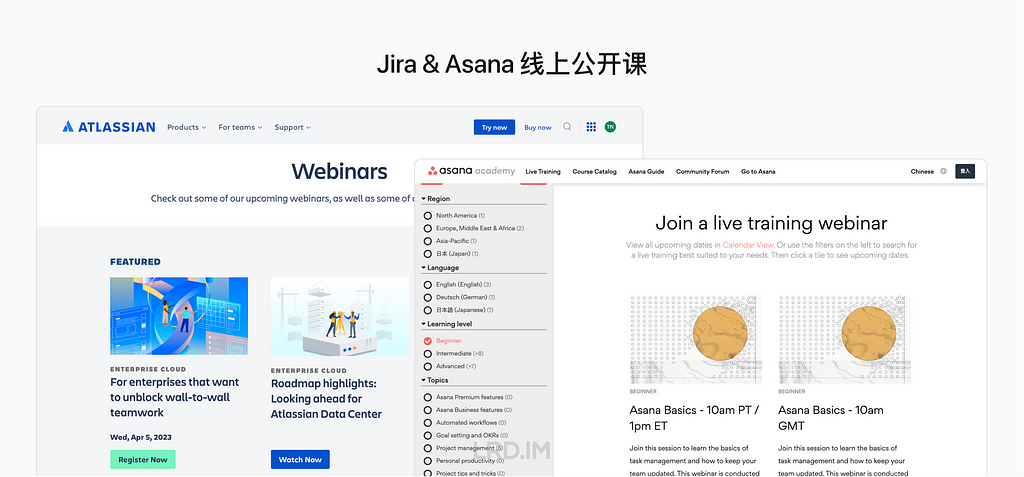
Jira 和 Asan 都会比较积极地举办线上公开课 (Webinars)。通过这种方式来提高品牌知名度、建立专业的形象,保持和用户交流,并最终促进销售。
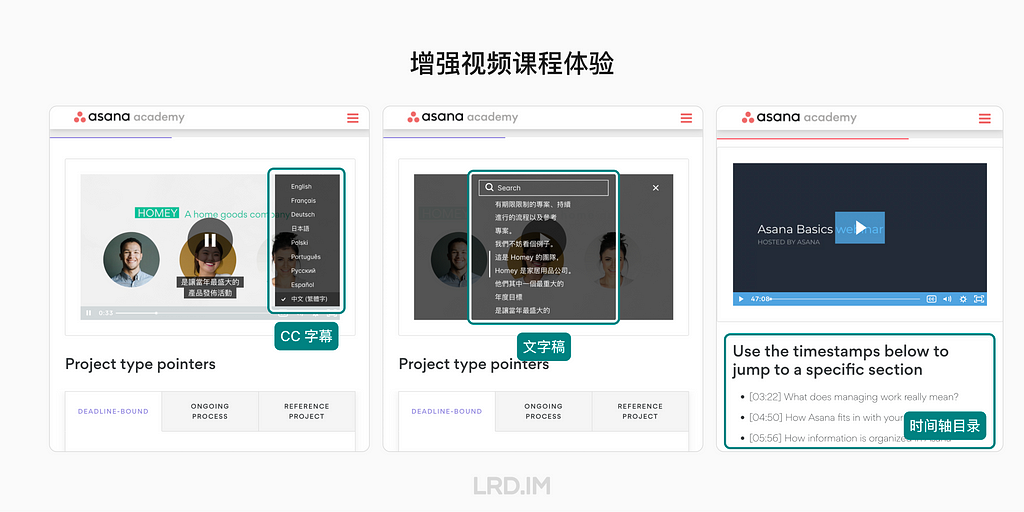
值得一提的是,我观察到海外的产品,对于视频课程除了直接把视频传上去之外,还能够多做几件事情来提升视频课程的阅读体验,并且在国际化场景更加友好。
- 支持 CC 字幕。帮助非视频语言母语的用户更好地理解视频内容,同时也能为听力障碍和不方便使用扬声器/耳机的用户提供便利。
- 支持时间轴目录。帮助用户快速了解视频的主要内容,并找到自己需要的信息。与图文教程相比,视频获取信息的效率比较低,但这种做法能弥补缺陷,提高用户的学习效率。
- 支持文字稿。帮助用户更好地跟进视频的内容,也方便他们在需要时快速查找相关的信息。并且同样能为听力障碍和不方便使用扬声器/耳机的用户提供便利。
- 加入互动元素。提供与视频课程相关的调查、实时聊天室或小测试,能够促进学习效果并增加兴趣和参与度,提升课程质量。
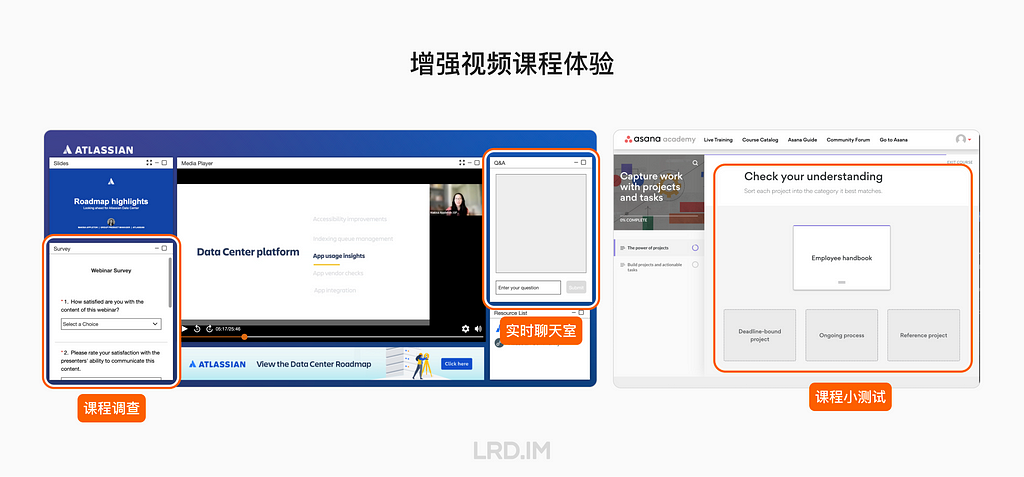
我们能学到什么
💡 细致易用的用户文档。用户使用文档的场景是明确需要帮助,或者希望成为专家用户,了解产品设计背后的概念。所以文档需要足够的细致、具体和易用。比如像 Asana 帮助文档中提供了步骤图,或者 Asana 线上公开课中为视频提供了段落拆分。
💡 丰富的资源和帮助方式。不同人在解决问题和接收帮助方面都有着自己的特点和偏好。所以需要提供多样化的帮助资源,比如:文档、视频、案例拆解、线上公开课等,持续提供影响力。
💡 强调最佳实践。Jira 的帮助中心里有许多关于敏捷开发概念、实践的文章。Asana 的实践案例也在频繁加入自身对工作流的理解。在帮助中心中强调最佳实践能够帮助用户更好地使用软件和理解背后的理念。
💡 增进用户的参与感。帮助系统可以支持互动和社区功能。比如评论、分享、点赞等。为了进一步提升用户的参与度,还会支持社区、公开课等。
结语
以上就是我对公司几款竞品帮助中心调研后,总结出来能够帮助新用户上手的产品设计。整体感受是「帮助系统」这一块可以做得很大,又能做得很细。
往大了做:包含基础的文档、功能引导;进阶的课程、模板和大学,以及上升到行业影响力的线上公开课、线下 Events 和职业认证。
往细了做:Onboarding 流程规划、上下文帮助的设计、文档/视频课程的细节,模板的本地化方案等等。
所以说越做设计越感到自己个人力量的渺小,世界太大了… 但不管怎样,来到新公司我的目的是取百家之所长,扩展下之前没怎么接触到的领域。
碎碎念
文中部分名词(如:Proactive help, Reactive help, Push revelations, Push revelations…)由于我没有在中文设计圈内找到合适的翻译,于是便自己琢磨着做出了翻译,本身自己不是想「造概念」的,但总得有个名字吧。如果读者有其他更好的翻译方案欢迎交流。
另外这是我第一次尝试用到人工智能来参与博客的创作。使用到了 ChatGPT 3.5 来帮我做资料搜集、文本润色&修正、名词释义和总结提炼。比如文中「我们能学到什么」里面的小标题,有部分是我发一段文字后,ChatGPT 帮我总结的,或者我理解了很久的 Pull revelations 和 Contextual helps 的关系,也是 ChatGPT 帮我梳理的。
另外也用到了 Midjourney 来生成这篇文章的封面图背景,以及「我们能学到什么」的配图。
这两个工具的强大不必过多介绍了,只是中途一件有件小事值得记录一下。起因是我想查找 Reactive Helps 相关的内容,就去阅读了 NNGroup 上面相关的文章,以及询问 ChatGPT。令人惊讶的是 ChatGPT 给了和 NNGroup 相反的理解…
参考文档
- Onboarding Tutorials vs. Contextual Help | NNGroup
- Help and Documentation: The 10th Usability Heuristic | NNGroup
- Best Help Center Designs for SaaS [15 Examples +Tools to Build Yours] | userpilot
- 20 Help Center Designs that are Worth Stealing — GrowthDot
App 表单校验时机探索

动机
在我接手 App 这波需求迭代的时候,发现一个很常见的问题却没有在设计规范里提到过(其实原本也没啥设计规范…)。那就是:表单的校验时机。
工作中我发现每个保存到数据库的表单都会有至少一个校验规则,最常见的是字数,其他的有类似格式(邮箱、数量)、上下限(价格、库存数)等。而表单的校验时机通常是在三种方式内选择:
- 输入中校验;
- 失焦后校验;
- 提交时校验。
由于接手时并没有规范或者指引帮助我如何判断使用哪种,工期紧张也没有足够时间去探索,我只能拍脑袋地大部分都采取了「失焦后校验」的方法。
后面我发现这其中的差异还是挺耐人寻味的,有必要探索三者之间的各自优劣势和适用场景,于是乎就有了这篇文章。
三种校验时机的差异
输入中校验
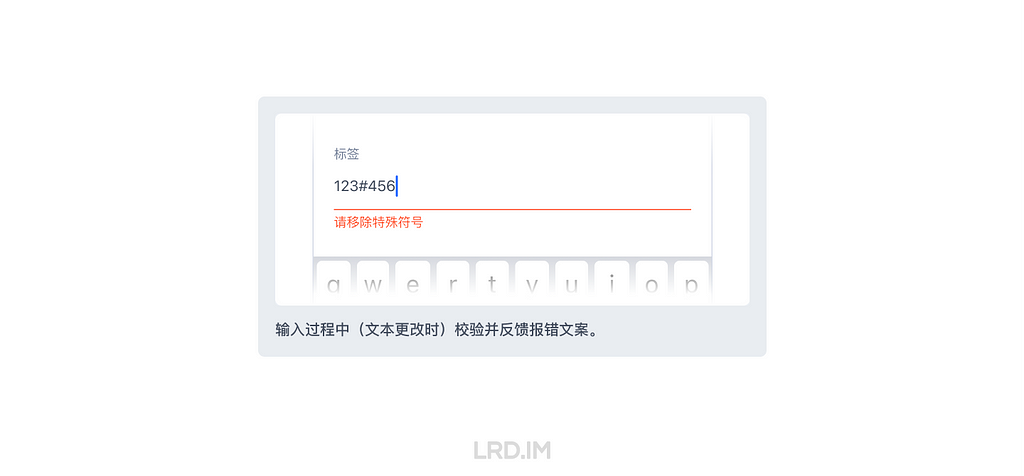
效果:输入过程中(即文本有更改时)校验并反馈报错文案。
优点:实时反馈,出错后立即提示。
缺点:容易误判。即未完成输入就提示出错。
适用场景:
1. 纯前端能满足校验需求时;
2. 校验规则较严苛时,如一个表单多条校验规则,或中途某个错误字符直接影响到表单提交时。
修正错误的成本:低 ★
在手机的的「键盘控件」内重新键入内容即可完成修正。
失焦后校验

效果:失去焦点后校验并反馈报错文案。
优点:输入过程中无干扰,在输入完成后再反馈报错文案。
缺点:失焦后才知道结果,修正成本高。
适用场景:
1. 纯前端能满足校验需求时;
2. 用户对输入框内容格式有预期时,如邮箱、手机号等。
修正错误的成本:高 ★★
需要先「失焦」,再回到原本的输入框「重新聚焦」,并通过「键盘控件」修正。
提交时检验
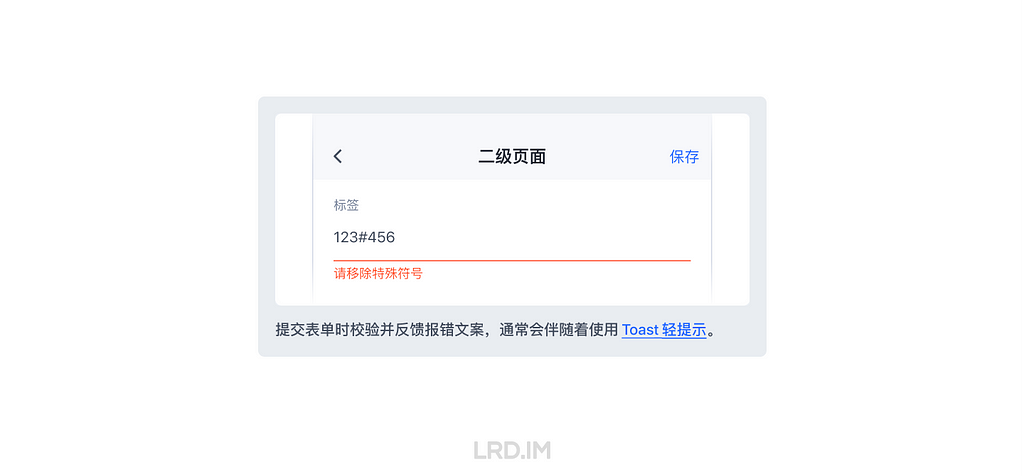
效果:提交表单时校验并反馈报错文案,通常会伴随着使用 Toast 提示。
优点:后端校验时,不影响性能&体验。
缺点:报错反馈很不及时。
适用场景:
1. 大部分需要后端校验的表单。
修正错误的成本:较高 ★★★
需要先「提交表单」,再「找到」出错的的输入框,并「重新聚焦」原本的输入框,通过「键盘控件」修正。
至此,上面列出了三种校验方式的各自优劣势,对比后不难得出结论。
结论
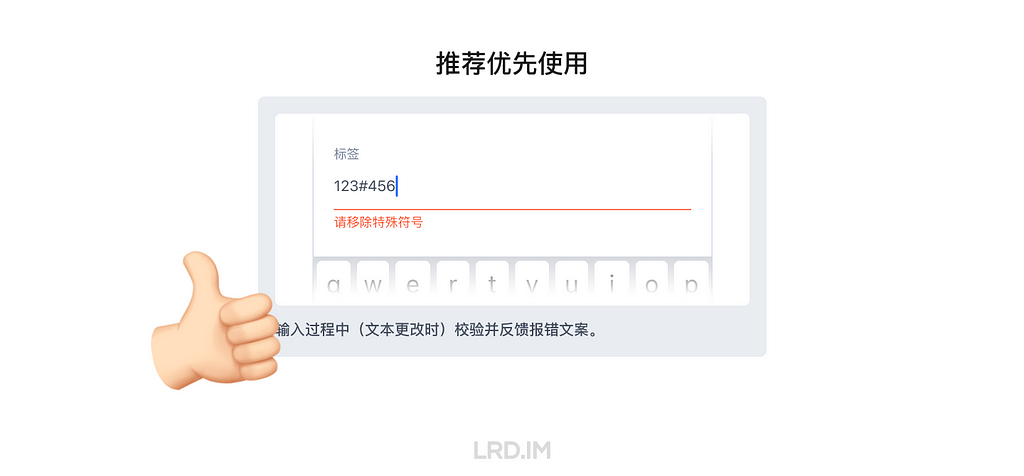
推荐优先使用「输入中校验」的规则。
原因:
1. 反馈最及时;
2. 修正错误的成本最低;
3. 对研发工作量和 App 性能无影响(前端校验时)。
理论支撑:
“理想情况下,所有验证都应该是内联的…”
“…在字段完成后立即修复错误对用户的交互成本最低…”
—— 来自 Nielsen Norman Group 的《如何反馈表单中的错误:10 条设计指南》
通过这次的对比,我决定了之后都将「输入中校验」作为主要的校验方式,当然这种方式也有一些不适用的场景,此时就需要换一种校验方式。举例一些常见的不适合用「输入中校验」的表单:
- 容易误判的表单,如校验邮箱、电话、网址的格式时;
- 设置了数量下限时,如公司业务里的 B2B 商品设置了起批量时;
- 需要后端校验时,如需查重或对比数量上下限时。
其他感悟
对需要后端检验的表单态度
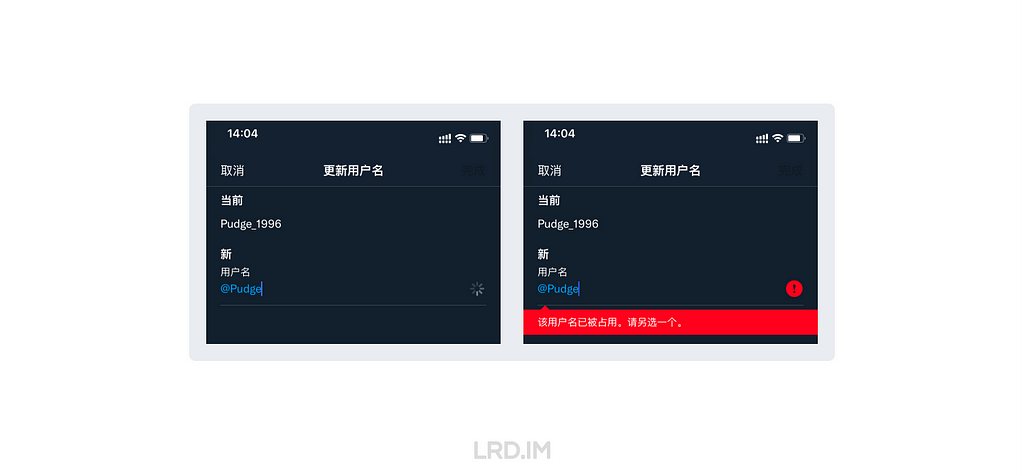
因为涉及到后端检验,意味着需要网络,那就会出现加载中/超时/加载失败/加载成功 的情况,所以这种表单一般是失焦后或提交时检验,这对输入体验会相对友好一些。
但也有例外,比如 Twitter 账号在重命名时,就使用的是输入中校验。可能是因为 Twitter 用户量庞大,特别容易重名。提交后检验反而效率更低。
输入前的体验设计
常言道好的体验设计能减少用户出错,在表单输入之前,实际上我们也可以用多种方式明示暗示文本框的填写规则。
一、输入框长度
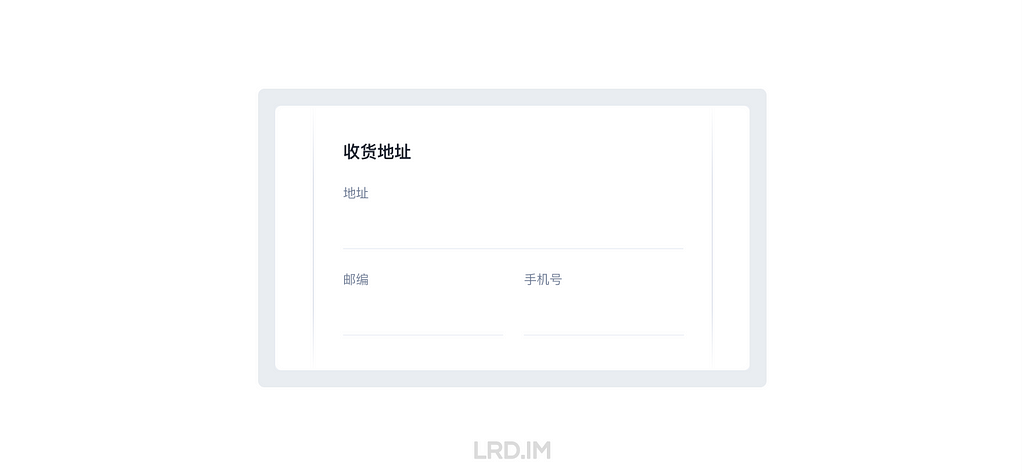
输入框长度能过暗示文本框的预期填入内容。比如在填地址和邮编时,通常地址我们会预留比较宽的输入框给用户填写,而邮编则可以相应缩减,因为这两个类型的字段,预期填写的文本长度是有明显不同的。
参考资料:整齐划一?不如错落有致。| Ant Design 4.0 系列分享
二、实时字数显示
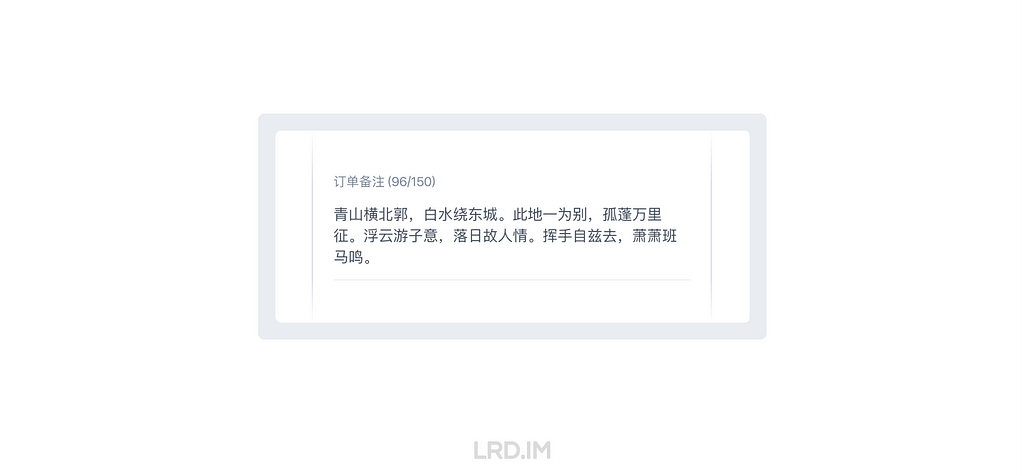
在输入框旁边实时展示当前字数和上限是也是比较常见的做法。
优点:避免出错;让用户对表单的规则有一个预期。
缺点:页面出现过多此类提示会使页面臃肿,反而会增加视觉&认知负荷。
所以我对这个做法的态度是:每个表单都会有文字输入的上限,超过上限时也一定会禁止提交、出现提示。但是否将字数提示常驻展示,取决于「用户对长度是否有预期」。
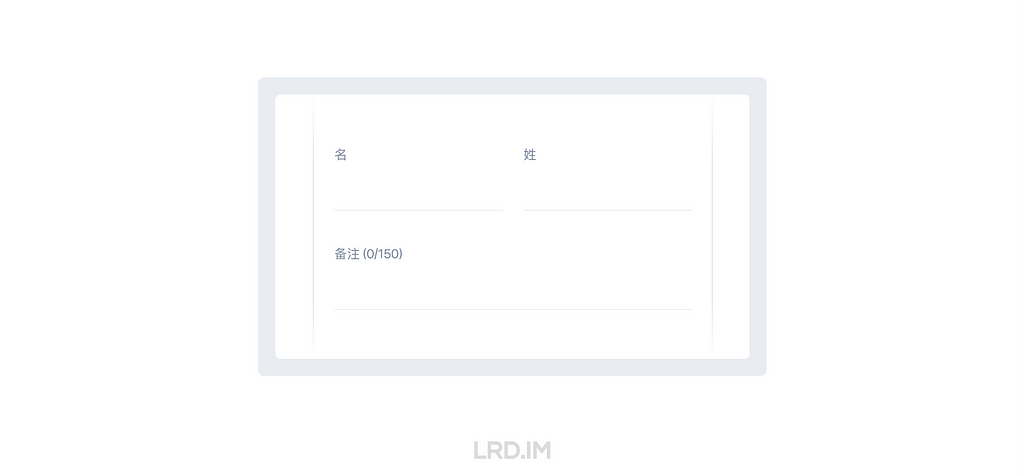
比如在一些备注、描述、说明等大段文字里,用户可能会输入到大段文本,但又对这些输入框的上限没有预期,那我这里判断到是需要出现实时字数提示的。而像比如填写姓名、添加标签这种,字数上限只是一个兜底的判断逻辑,不需要特意暴露出来。
另外可以根据存量数据来决定是否展示实时字数提示。比如让后端同事帮忙导出在数据库里的数据,能知道用户在这个输入框里一般会填写多少个字,如果大部分情况都是接近字数上限的,意味着用户在这个输入框会输入较多的文本,此时就需要展示当前字数上限,甚至或者调整校验规则。这是我在上一家公司(千聊)里做过的事情。
三、占位符(Placeholder)
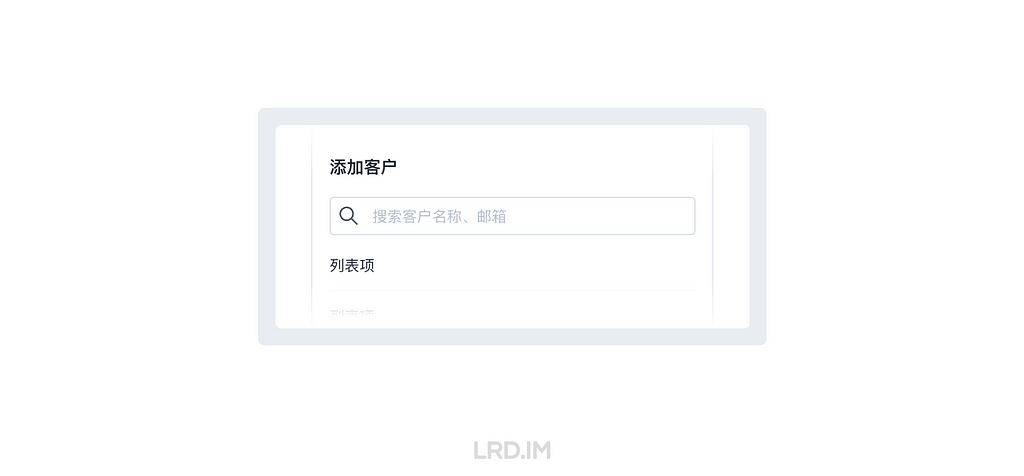
无论是 NNGROUP 还是 Shopify UX,都对占位符文本持有比较谨慎的态度,甚至会用到 Harmful、Avoid 等贬义词。他们主要批判的是用占位符代替标签的做法,我们在使用时避免这种用法就好了。
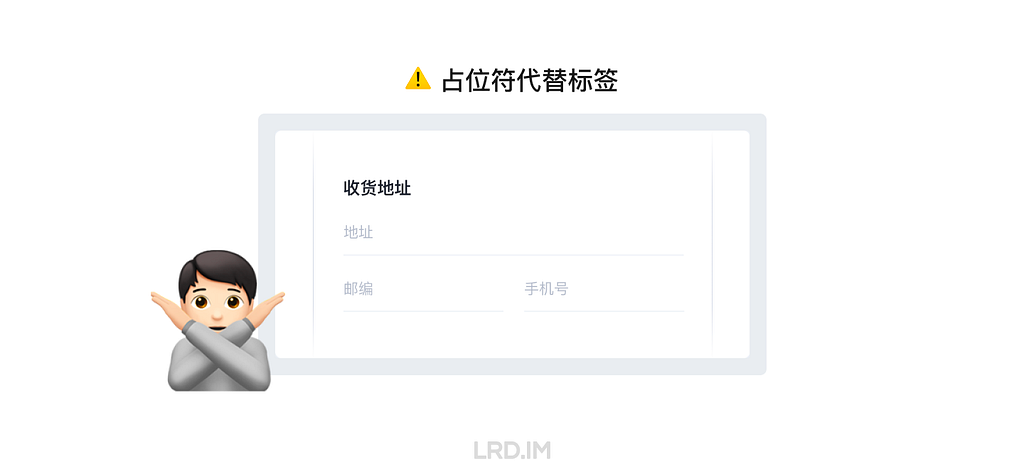
实际上占位符和标签共同使用时没什么毛病,占位符确实能起到一定的补充作用,用来提示要输入内容的类型和名称,只是不要用来展示重要内容和代替掉标签就好了。合理使用也是减少用户出错的方式之一。
四、常驻帮助文本(Help text)

帮助文本可以视为占位符的进阶版,具体效果在输入框附近常驻一段简短、必要的说明内容,帮助商家了解输入框所要求的格式,或输入后的内容会怎么处理。甚至还可以链接到 FAQ,有丰富的用法。
一条原则
在文本有上限的输入框里,我们会面临一个选择是:超过字数后是否允许输入?

我在这里的建议是允许继续输入,同时会出现报错的反馈,告知规则。因为翻查了很多 UX 资料,都建议在设计中要避免「打断了用户行为」。下面放出两种方法的优劣对比,各位看官理性抉择:
超上限后允许继续输入
效果:输入的文本超过该文本框校验规则上限时,出现报错反馈,同时也可以继续输入文本。
优点:反馈及时,原因清晰。
缺点:🤔…
到达上限后禁止输入
效果:输入的文本到达该文本框校验规则的上限时,禁止输入更多的文字了。
优点:🤔…
缺点:没有反馈,不知道错误原因。
这么看下来,就体验而言是「超出上限后允许继续输入」要好很多。而且这种方法还照顾到一个场景是:允许用户在输入中发现超出长度后,把当前的单词输入完整后再去删减其他内容。
当然毫无疑问,到达上限后直接不允许输入是对设计和研发来说最省力的做法。这种做法下不用反馈,也就不需要做反馈时机的决策、反馈的文案及多语言、文本的适配、反馈后的布局适配…
我有一段经历是项目工期巨紧张,规范也没相关的指引。当时有很多比制定文本输入规则还重要的事情需要处理,于是乎我就都一拍脑袋用了「达上限后禁止输入」的方法。
后面与其他方式对比发现这种做法应该是体验比较差的做法了。像现在我把规范做法加进 App 设计的指引里面之后,就大多数情况下都会使用「允许继续输入,在输入中反馈」的方式实现。
结语
以上内容就是目前来说我对文本框校验规则的一些认识,包含了各种校验时机的对比,输入前的体验设计,以及不打断用户操作的原则。
这次的总结是我挺久之前就想干的事情了,因为平常工作中一直遇到这种问题,也没有一个明确的设计指引能够参考,现在自己写下来这篇笔记之后,之后的设计方案会考虑得更周全,说服力也更强了(希望是吧)…
同时再浅挖一个坑:之后要探索下表单提交按钮相关知识,比如说什么时候要禁用按钮,什么时候是允许点击但报错等等,这个应该还要复杂一点…
参考资料
- How to Report Errors in Forms: 10 Design Guidelines
- 整齐划一?不如错落有致。| Ant Design 4.0 系列分享
- Placeholders in Form Fields Are Harmful
- Text fields
【译文】如何冲破设计系统的界限
原文:How to push the limits of a design system · Shopify UX
作者:José Torre
译者:李瑞东
翻译小帮手:李泽嘉 @urcharles7(公司的交互 Intern)

为了跟上需求,设计系统需要不断发展。讽刺的是,设计系统的进化似乎有点像先有鸡还是先有蛋的问题。
如果不知道产品业务需要什么,专门负责设计系统迭代的团队就无法进一步发展。另一方面,大多数业务设计团队只在系统的现有规范和组件内完成工作,这不利于进一步推动系统的发展。这样看上去像是僵住了,大家都在停滞不前。
我们 Polaris 团队(译者注:Polaris 是 Shopify 的设计系统)想打破这种僵局,所以采取了行动……
跨越鸿沟

为了防止 Polaris 变得失去创造力,我们必须更接近产品。因此,我们开始了一项名为 PolarisLab 的计划。在几周的时间里,围绕一个特定的主题,与产品团队发起并参与了一系列工作坊和会议。目标很简单,就是要设计系统团队与产品团队紧密合作,以便:
- 帮助团队找到解决问题的最佳方案;
- 找到设计系统不断发展迭代的方法。
我们的首先聚焦在 Layout 组件上。因为我们开始注意到越来越多的页面似乎不是专门为解决一个问题设计的。相反,页面的设计来自设定好的多个模板之中(以页面布局组件的形式)。这些模板是相当通用的,但并不总是解决一个单一问题的最佳方案。
过度使用这样的模板可能会使页面看起来在视觉上一致,但会让用户感觉到没有重点和枯燥乏味。
刻板地遵循设计系统提供的模板,使得会出现让内容来适应页面布局,而不是内容主导布局。这使得浏览一个页面变得困难,需要用户花费大量的精力去弄清楚需要的内容在哪里,以及下一步该做什么。
我们还注意到,由于我们的 Layout 组件过于死板,导致团队经常脱离 Polaris 来做一些细微的布局调整,这就导致了代码层面工作量的增加。
我们已经明确了想要解决问题的,甚至已经有了行动的代号,但我们缺少最重要的部分——团队。
寻找团队

我们希望找到那些有兴趣与我们的团队合作改进 Layout 的团队,而且是热衷于发展 Polaris 设计系统的团队。幸运的是,公司里有很多这类型团队。
我们联系到了 7 个不同的团队,在了解到他们的问题空间和最近的工作排期后,我们决定与做 B2B 客户业务的团队合作,因为他们满足了所有条件:
- 能够有效地解决问题 ✅
- 该案例有可能对其他团队产生影响和启发 ✅
- 能够在紧迫的截止日期前交付 ✅
- 对开始工作超级兴奋 ✅
不久后我们明确了项目的目标,并开始了合作。我们设定的工作流程并不复杂:
第一步:了解问题
第二步:发散和探索
第三步:收拢和校准
第四步:重复第二步和第三步,直到满意为止
第五步:推进实现方案!
了解问题

通过一系列的 Workshop 及相关活动,我们对这个问题有了更好的了解。
我们首先要求团队做一个现状收集。简单地把一系列的截图和设计放在 FigJam 上,然后让我们去了解业务设计师当时遇到问题,以及他们做的解决方案。
我们都发现了这个 B2B 客户页面大多是聚合了企业客户有关的所有内容,但它在帮助商家快速了解这个特定客户方面做得并不出色。内容缺乏清晰的层次,所以最终效果不理想。
为了开始了解这个问题,并更好地了解页面里什么最重要。我们写下了这个页面里用户所有可能想要完成的工作。然后我们反复调整排序,以确定优先级和重要程度。这是我们最终得出的的结论:
- 观察购买行为;
- 手动为客户下订单;
- 快速访问到地点和联系人;
- 评估不同地点之间的销售情况;
- 针对不同地区更改服务条款;
- 查看操作日志。
通过小组讨论后,我们都认可了这个优先级排序。然后我们又尝试代入商家的身份去假设他们的目的,以确保我们目标一致,达成共识。然后投票选出了一个最接近目标的假设,那就是:
“如果显示的信息集中在一个页面上,商家将能够更方便地完成任务。我们可以通过完成一项特定任务所花费的时间来衡量。”
上述这些工作并不意味着产生实际的可交付的方案,而是让每个人都能够:
- 更了解业务背景,让每个人都在对这个案例有相同的认识;
- 开始对内容进行更细致的的优先级排序。因为我们不能仅通过移动元素来实现更有目的性的布局。我们需要从信息层开始,并在此基础上进行构建。
为了让大家更进一步,接下来是用草图来构思问题可能的解决方案。这里的目标不一定是找到解决方案,而是为今后的探索定下了基调。
我们鼓励每个人参与到 Workshop 的同事都尝试去画点草图,不管你是工程师还是设计师。有些人在 Figma 上画,但大多数人只是抓起一张纸和一支笔,一旦完成,就拍张照片,然后贴进 FigJam。
通过让同事们自由地画草图,不受设计工具或 Figma 组件库的限制,我们更有可能创造性地解决这个问题,而不一定要遵循预先存在的模板。
在画了一会儿草图后,每个人都分享了他们的想法,我们发现了一些有趣的事情。在画草图的时候,人们开始把客户在页面里可能想要完成的工作作为一个整体来考虑,而不是把注意力放在个别内容上,然后按照模板把它们组合在一起。
这是一个好的开始,因为商家会体验到整个页面,我们就应该这样去做设计。
在每个人分享之后,我们讨论并投票选出了最有希望的想法,这将是后续工作的基础。
发散和收拢

由于大部分探索是设计先行的,我们后续还通过几次包含一名产品经理和几名工程师的 Workshop 来协调和讨论。我们在会议前花了一些时间完善方案,拿到会议上讨论并一起看看有没有可以做得更好的地方。
Workshop 之后,设计师们根据讨论的结果继续细化方案。我们想跳出设计系统的界限,但最终解决方案必须符合 Polaris 风格,这是一个很难去达到平衡的事情。对于我们引入的任何新元素,我们必须再三斟酌,要了解它是否能融入 Shopify 里面,并且可以复用到其他团队里。
当我们探索信息的不同组织方式时,我们意识到拥有一个完善的 Grid 设计基础准则是相当重要的,它可以确保不同页面之间有一定程度的一致性,即使信息的组织方式不同。
我们不仅是把页面作为一个整体来看,为了建立层次结构,我们还必须深入去找到更好地利用颜色、空间和文字排版的方法。我们通过有策略地运用颜色,突破字体规范探索更大的字号,来给最重要的元素增加了视觉权重。使它们与其他元素形成鲜明对比,并吸引人们的眼球。
我们还减少了页面中卡片的数量,更多地依靠空间来分组和分离信息。
随着我们的方案逐渐成熟,我们开始与产品和研发部门讨论方案。最终我们经过讨论和方案对齐后,找到了一个多方都认可的解决方案。
通过重新设计,我们使商家能够更轻易地快速了解一个 B2B 客户。
与其简单的在网页上堆砌信息,指望着商家费尽力气去获取想要的信息,我们干脆重新梳理了一遍网页的内容。我们强调重要的信息,弱化只需要低频获取的信息。最终,让获取重要的事情变得简单,同时保留获取其他所有信息的触点。
作出妥协
然而方案的推进并没有那么美好。我在开始时提到过 Deadline 迫在眉睫,我们只能将解决方案分步交付。
在推行某个方案时,很少有不需要做出一些妥协的,特别是当 Deadline 很紧迫时。这是产品开发过程中很常见的现象,但这并不意味着要在设计质量上做出妥协。
而为了能够做到这一点,你需要了解技术的限制是什么及其原因。
这正是 B2B 团队所做的。例如,在页面中引入新的数据指标和数据洞察是很难的,但他们没有放弃这个想法,而是争取引入任何可以实现的东西,因为他们知道这对商家来说是非常有用的,可以在未来迭代和改进它。
创建可扩展的解决方案

与此同时,我们已经开始在 Polaris 团队中探索新的 Layout 设计准则。在整个协作过程中,我们了解到我们的原本布局组件限制太多,所以我们构建了一个 Grid 布局组件,让我们更容易地构建自定义布局,同时不会脱离设计系统。
团队想要创新,但设计时需要有一定的规则来约束,有时候甚至要依据设计系统已提供的模板。
这次合作让我看到,我们并不缺乏创新的动力和能力,缺乏的是一个目标。当你不知道该做成什么样子时,通常都会呆在舒适圈内,这是会让人上瘾的。
让系统团队积极探索新方式和与他们合作,能够得到新的做法。但这只是一次性的,不可扩展的。所以我们需要找到方法将这种做法纳入到设计系统中,让其他业务和团队的设计师也能复用。
Grid 布局组件是处理「设计创新」和「遵循规范」之间平衡的的一个很好的例子 — — 能够让设计师在 Polaris 内创新。

从技术上讲,团队可以不用 Polaris 来实现任何东西,但这导致了不一致性、不规范的体验设计和许多冗余的代码。这使系统更难维护、更新和扩展。
Polaris 是一个工具。我们利用它来发挥我们的优势,但我们不能忘记维护和发展它。就好比如果一把刀变钝了,你不需要去买一把新的,而是要把它磨利。
这次合作很有趣,同时也很有影响力。因为我们在产品和系统上做了改进。
我们不仅一起发布了一个新的布局,而且我们还确立了从整体上改进设计系统的方法。看到这项工作被刊登在 Shopify Editions 上是特别荣幸的。我真想快点看到 B2B 业务实现完整的设计方案之后的效果,以及其他团队使用我们建立的 Grid 布局组件。
如何开始?

如果像 B2B 团队一样,你想推动你的设计系统向前发展,我可以推荐两种方法中的一种。
选项 A:与设计系统团队合作
如果你正在研究一个问题,希望能突破原有的界限,并看到影响整个产品的设计模式的可能性,请考虑与你的设计系统团队联系。
设计系统团队会想要极力避免出现单一的解决方案,但他们很可能倾向于如何让设计系统更好用。特别是这件事对整个公司内的其他团队有可能存在的好处时。
为了证明这一点,我可以告诉你,我已经与另一个团队合作去解决另一个问题。我希望像这样的合作越来越多,因为这种合作确实能给产品和团队带来很多好处。
可惜的是,我知道一个设计团队未必能和所有人合作。但这不应该阻止你创新,还有另一种方法…
选项 B:动员你的团队
其实在与产品团队合作时,我们设计系统团队的主要工作是启发和支持。
这也是我分享这个研究案例的原因。向你展示我们做了什么,我们是如何做的,以及为什么这样做。希望这能启发你,同时也给出了一些可以复用的方法。
要记住的关键一点是,在孤岛上创新真的很难,所以寻找与你有同样热情的合作伙伴。如果你需要快速尝试,不妨用我创建的模板去实际尝试一下前文描述到的 Workshop。
当你完成后,别忘了为设计系统「赋能」噢!
OpenWrt 定时自动释放内存
 因为我的固件可能有内存泄漏,所以想办法定时释放内存。其实就是用 Linux 的方式。
因为我的固件可能有内存泄漏,所以想办法定时释放内存。其实就是用 Linux 的方式。
在管理界面 > 系统 > 计划任务,加入下面代码。每天5点和17点自动释放内存。
0 5,17 * * * sync && echo 1 > /proc/sys/vm/drop_caches设计优美好看的网站截图——Kali Linux

如何在Mac OS X上结束一个进程?
刚才看论文做笔记时Evernote突然停止响应了,本打算用Activity Monitor强制关闭,转念一想,不如学下如何用terminal强制关闭程序吧!正好有人对kill的一些写法有疑问,放上来分享一下。
1. 活动监视器(Activity Monitor)

2. Mac OS X 终端(Terminal)
ps -A | grep Evernote


kill 945
找PID: ps -A|grep [进程名]杀进程:kill [PID]
- 请勿随意使用强制结束进程,这是在程序无法响应时才使用的杀招,如果文件没有保存,强制结束进程可能会让你丢失未保存内容。
- “kill -9 [PID]”也能结束进程,9其实是SIGKILL对应的号码,自然也可以用“kill -SIGKILL [PID]”来结束。大家可以输入“kill -l”查看各种对应代码。


不能在中文目录右键打开 Cygwin 的解决方法
Cygwin 是一个 Windows 下的 Linux POSIX 模拟器,通过它我们可以直接运行一个 Linux 终端,非常好用。
网络上关于如何添加一个 “在当前目录打开 Cygwin” 的右键菜单的教程有很多,但是这些方法都有一个问题,那就是不能在中文目录下正常工作,于是研究了一番,修复了这个问题。
探索
既然英文路径可以但中文不行,我最先想到的是使用 Cygwin 自带的 base64 命令,将 encode(path) 后的非中文字符串传给 Cygwin 之后,再 decode 得到包含中文的路径。然而不行,正确的 base64 传递到 Cygwin 之后 decode 却是乱码。
问题的原因很容易想到,那就是编码的问题。经过几次输出中间变量后验证了这个猜想:Windows 采用的是 GB2312 编码,而 Cygwin 采用的是 UTF-8. Windows 将当前路径作为参数传递给 Cygwin 主程序时,Cygwin 不能正确读取路径。
解决
修改 Windows 或者 Cygwin 的默认编码肯定是下下之策。解决该问题最终还是绕不开编码转换。我最终的思路为:
- 右键点击后,Windows 将当前路径作为参数 1 传递给 run_by_right_click.bat 入口程序
- run_by_right_click.bat 将路径写入 chere.path 文件(GB2312 编码),并运行 Cygwin
- Cygwin 运行后,将 chere.path 转换为 UTF-8 编码,读取后 cd
我的 Cygwin 安装目录为 C:\cygwin64,Shell 为 ZSH,如果你使用的是 Bash,有的地方与我的不同。具体步骤如下:
step1. 创建右键按钮
导入注册表文件 cygwin.reg:
Windows Registry Editor Version 5.00 [HKEY_CLASSES_ROOT\Directory\Background\shell\cygwin64_bash] @="打开 Cygwin 终端" "icon"="C:\cygwin64\Cygwin.ico" [HKEY_CLASSES_ROOT\Directory\Background\shell\cygwin64_bash\command] @="C:\cygwin64\run_by_right_click.bat \"%V\""
step2. 编写入口程序
我们的入口程序 C:\cygwin64\run_by_right_click.bat
@echo off SET dir=%1 REM 双引号删除 SET dir=%dir:"=% C: chdir C:\cygwin64 rem del /Q chere.path set /p="%dir%">chere.path bin\zsh.exe -li
 bat 代码是真的难写。。。写这段代码我便踩了无数的坑。
bat 代码是真的难写。。。写这段代码我便踩了无数的坑。
step3. 完成目录跳转
在 Cygwin 内编写 ~/.zshrc,在末尾添加目录跳转命令:
if [ -e /chere.path ];then
/usr/bin/enca -L zh_CN -x utf-8 /chere.path
CPWD=/usr/bin/cat /chere.path
rm /chere.path
cd /bin/cygpath "$CPWD"
fi
这里用到了 enca 用于自动编码转换,所以需要在 Cygwin 包管理器中安装这个软件。
over! 现在便可以在中文文件夹中右键打开 Cygwin 了。
现在便可以在中文文件夹中右键打开 Cygwin 了。
为啥我要用 Cygwin
最后最后。你可能会说,为啥都新世纪了,你还在用 Cygwin 这种… 模拟器?原生 Linux/ 虚拟机 不好用嘛?WSL 不香吗?甚至 Powershell 不也不错?
那我还真觉得 Cygwin 秒杀上述所有的方案。首先,我只是想在 Windows 上安装一个代替 cmd 的 Shell 环境用于日常操作,并不需要高性能什么的,所以原生 Linux 系统、虚拟机、Docker 就不是解决同一个问题的东西。
至于 Powershell,虽说是比 cmd 好多了,但毕竟是另一套语法和体系,我不想学它也对它不感兴趣。Bash+GNU tools 那才是世界通用法则。ZSH 作为日常使用的终端也确实美观好用!
而 WSL 这东西确实很吸引人,性能比 Cygwin 强太多,几乎就是原生系统。然而!WSL 运行于内核态,与 Windows 平级,就算有文件系统的映射,WSL 也并不能直接当作 Windows 的 Shell 来使用的。看下面的图你就知道我在说啥了。
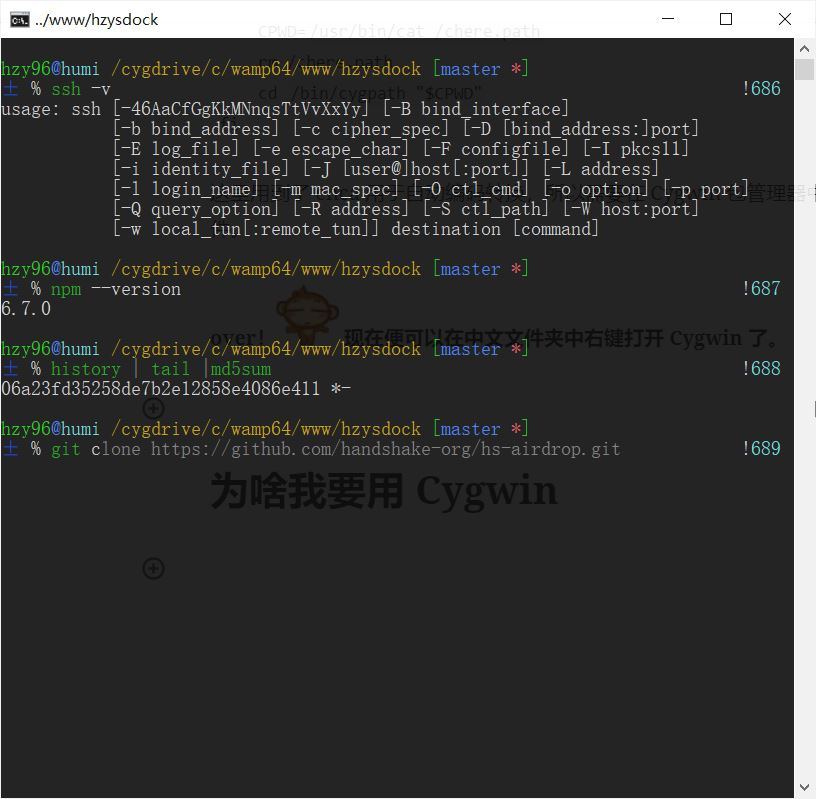
图中,npm 和 git 是我在 Windows 中安装的 exe 包,而 ssh、tail、md5sum 是 Cygwin 中提供的 Linux 命令,直接相互调用无压力,这才是 Windows 中我想要的 Shell 的样子。可是 WSL 是不能这么做的,两个系统是隔开的。
在 OpenWrt 路由器上运行 UnixBench 基准测试
我这基于 OpenWrt 的路由器可以说是超级强大,不仅仅是一个无线路由器,插上 U 盘可以变身为 NAS+下载机,可以运行 Python 小程序,甚至还有人在上面搭建 LNMP 运行 Owncloud。可以说是一台 VPS 可以干的事情我都可以在宿舍的路由器上实现,十分强大。
然而最近才了解到,这颗 580MHz 的 MTK7260A 仅仅是一颗智能路由器当中处于中低端的 CPU,说实话我是不信的,于是打算用 UnixBench 来客观测试一下这个小家伙的真实水平。
UnixBench 是基于 Perl 并拥有 30 年历史的基准测试软件,也就是跑分软件。通过运行一系列科学计算函数测试 CPU 性能,以及 OS 的任务执行效率、硬盘性能等。最终得到一个分数。
测试平台
路由器:Newifi Mini
OS:LEDE 17.01.2(一个 OpenWrt 的著名分支)
Linux Kernel:4.4.71
架构:MIPS
RAM:128M
ROM:16M
系统基本为纯净的 LEDE,除了正在运行着路由器的基本网络服务外,跑分时运行了一个 PPTP VPN Client 服务。
交叉编译及运行步骤
OpenWrt 的 libgcc 套件体积 22M 的样子,但正如上面所写,我的路由器 ROM 总共只有 16M,挂载分区什么的不是很有必要,于是我使用交叉编译 UnixBench。
简单介绍一下交叉编译的步骤吧:
1、找一台 x64 的 Linux 机器,按照 <https://wiki.openwrt.org/doc/devel/crosscompile> 步骤开始接下来的操作。必须得要 x64 的主机。
2、下载你的路由器当前系统当前机型对应的 DevPack,比如我的 LEDE 在这里下载的:<http://downloads.lede-project.org/releases/17.01.2/targets/ramips/mt7620/lede-sdk-17.01.2-ramips-mt7620_gcc-5.4.0_musl-1.1.16.Linux-x86_64.tar.xz>,OpenWrt 请在 <https://downloads.openwrt.org/> 下寻找。
3、按照官方 Wiki 的步骤将编译器添加到环境变量。
4、下载 UnixBench 的源代码并解压:<https://github.com/kdlucas/byte-unixbench>
5、开始编译。这里注意官方 Wiki 有误,请使用 make CC=mipsel-openwrt-linux-musl-gcc LD=mipsel-openwrt-linux-musl-ld 命令使用指定编译器进行编译。
6、编译失败?根据提示删除 Makefile 中编译器无法识别的两个参数,即可完成编译。
7、将除了 /src 外的文件 scp 到路由器。
8、安装相关依赖:opkg install perlbase-posix perl perlbase-time perlbase-io perlbase-findbin coreutils-od,跑分完后即可删除。
9、尝试运行 ./Run,你会发现弹出错误,根据错误内容做出以下修改。
10、修改 ./Run,注释掉 use strict 和两处尝试执行 make all 的语句。
11、这时再运行 ./Run,就已经自动开始跑分了。虽然会有几个 Wrong 弹出,但是不要紧。
基准测试结果
========================================================================
BYTE UNIX Benchmarks (Version 5.1.3)
System: : GNU/Linux
OS: GNU/Linux -- 4.4.71 -- #0 Wed Jun 7 19:24:41 2017
Machine: mips (unknown)
Language: (charmap=, collate=)
17:01:34 up 13:01, load average: 0.25, 0.49, 0.34; runlevel
------------------------------------------------------------------------
Benchmark Run: Sun Sep 24 2017 17:01:34 - 17:37:25
0 CPUs in system; running 1 parallel copy of tests
Dhrystone 2 using register variables 1261494.8 lps (10.0 s, 7 samples)
Double-Precision Whetstone 24.3 MWIPS (9.9 s, 7 samples)
Execl Throughput 452.5 lps (29.9 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 41.0 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 18.5 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 115.4 KBps (30.0 s, 2 samples)
Pipe Throughput 154847.5 lps (10.0 s, 7 samples)
Pipe-based Context Switching 51157.7 lps (10.0 s, 7 samples)
Process Creation 1260.9 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 43.2 lpm (61.1 s, 2 samples)
Shell Scripts (8 concurrent) 6.5 lpm (64.3 s, 2 samples)
System Call Overhead 308931.8 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 1261494.8 108.1
Double-Precision Whetstone 55.0 24.3 4.4
Execl Throughput 43.0 452.5 105.2
File Copy 1024 bufsize 2000 maxblocks 3960.0 41.0 0.1
File Copy 256 bufsize 500 maxblocks 1655.0 18.5 0.1
File Copy 4096 bufsize 8000 maxblocks 5800.0 115.4 0.2
Pipe Throughput 12440.0 154847.5 124.5
Pipe-based Context Switching 4000.0 51157.7 127.9
Process Creation 126.0 1260.9 100.1
Shell Scripts (1 concurrent) 42.4 43.2 10.2
Shell Scripts (8 concurrent) 6.0 6.5 10.9
System Call Overhead 15000.0 308931.8 206.0
========
System Benchmarks Index Score 11.3
感叹
总分 11.3 是什么水平呢,我用我的洛杉矶服务器也跑了一下,3.5GHz 的 E3 处理器,不过是共享主机,并且只有单核的使用权。得到的分数为 1245.
这说明,这个功率为 10W 不到的路由器综合能力果然很弱,哈哈哈。。。
不过就算再弱,竟然可以跑完整的 Linux 4.4,能够运行起 Python、Nginx、MySQL、PHP-FPM、SSHD、Samba、DNS 等等一系列服务,还非常的稳定,不得不让人对 Linux 竖起大拇指呀~
后来我又换了 K3 路由器,ARM 双核 1.4GHz,可以代表着当前家用路由的最高水平,我用它跑了一遍 UnixBench,结果见下一页。
近两年基础设施的升级和更新
正如About所描述的,希望在这里记录一些难以查找的信息:网络接入和局域网设备升级踩的坑
网络接入
OpenWrt + 4G 手机
历经多次宽带因为单一运营商垄断,价格高到离谱,之前在学校测过4G是可以跑到100Mbps的下行速率的,买过4G路由器做接入,后来因为SIM卡不够用就出掉了
在5G时代,闲置的4G手机完全可以用来作为网络接入设备,我用刷了OpenWrt的小米R3G有线连接退役的iPhone SE做了一个简单的4G路由器,找个4G信号好的地方固定,测速还行就可以开始用了

因为有部分模块依赖于内核,加上平时编译不太方便,所以采用官方固件,参考官网教程 Smartphone USB tethering
我记录的一些需要装的包
# 换源
sed -i 's_downloads\.openwrt\.org_mirrors.ustc.edu.cn/lede_' /etc/opkg/distfeeds.conf
# 装包
opkg install kmod-usb-net-ipheth kmod-usb-net kmod-usb-ohci kmod-usb-uhci kmod-usb2 libimobiledevice-utils libusbmuxd-utils usbmuxd
opkg install luci-compat
用了一段时间后发现了如下问题,当然也还有其他的手机可以尝试,但是我觉得4G的问题更大:
- 4G的信号不佳,经常达不到预期的100Mbps,这个和户型、运营商都有关
- 4G的网速在不同时间段表现差别很大,高峰期几乎无法上网
ios更新14之后,以上教程提到的方法就失效了,后续就没有在ios上再尝试过了;随着第一代5G手机在2022年陆陆续续退役,5G手机USB共享网络给OpenWrt路由器却没有达到预想中的那么快,考虑到在手机上经过了一次NAT,存在硬件开销以及调度和功耗限制,这还是不适合作为一个长期方案
5G CPE
于是开始关注5G CPE,恰好就遇到了2020年刚上市的华为的5G CPE Pro 2 (型号H122-373,以下简称H122),幸好买的早,后来芯片荒价格一路水涨船高,直到后来智选的5G CPE铺货

当时刚好手上有可以跑千兆5G卡,至少在下载速率上可以超过绝大多数家庭宽带了,缺点也还是有的:
- H122虽然可以放开防火墙,但是只是放开了入站的Input的流量(外部能够ping通CPE),会拒绝Forward的流量,即使下面的终端设备可以获取到IPv6地址,但是也无法从外网直接访问
- 如果长时间高负载,即使内置了一个散热风扇,内部的温度还是比较高的,具体影响是SIM卡会热到变形,所以需要买一个SIM卡接口延长线
- SIM卡不支持热插拔,经常需要换卡的话,要重启CPE,考虑到插槽寿命,SIM卡接口延长线必不可少
- 最想吐槽的一点,CPE的桥模式在某次更新之后就没有了,桥模式可以使得下面的主路由可以自行控制防火墙,如果需要配置IPv6外网访问的话是必要的
- WLAN to 2*LAN 最大只有千兆,让局域网内怎么都跑不满到160MHz WiFi6的速率(一般为实测1.2Gbps以上),充分说明了CPE还是以5G接入为主,5G to WLAN应该是能跑满的
- 支持5G和有线WAN并发,但是实测效果一般,如果有线WAN只有IPv4的话,5G部分可以补充IPv6
写出来有点多,但不可否认的是在很长一段时间里H122就是能买到的最强的5G CPE,在我这稳定运行了三年,因为是价格低位购入,还能直接用天际通物联网卡(23年已经限速到200Mbps,没有了5G SA,只能用4G)
最后需要担心的其实是流量问题,因为5G的流量消耗速度非常快,实时监控流量消耗情况也是必要的,如用iOS小组件;因为华为5G CPE当前已经无法收到短信,流量告警只能自行编写脚本等方式实现
OpenWrt + 4G模块
这里使用的是DJI增强图传模块连接OpenWrt路由器USB接口接入的4G网络
- 个人认为只能算是驱动了基础的QMI拨号上网功能,缺少产品本身完整功能及驱动的说明
- 加了DIY的无人机上的天线,信号还是比手机略差,实测50Mbps-10Mbps传输的速率
- 发热情况在28度的室内属于可以接受,上网基本是稳定的,游戏偶尔会跳ping,4G网络期望不能太高
2022年大疆在Mavic3发布之后发布了与之配套的4G图传模块(DJI Cellular),然而自带的增强图传服务只有一年的套餐,后续如果要继续使用就需要以每年99续费增强图传服务,对于只是想超视距飞行过把瘾的人来说,增强图传服务到期之后模块自然就闲置了(大疆2023年新品不兼容该模块),二手市场上挂出的非常多,感觉出手比较困难(原价699,2023.11二手大把的450),而全新的同规格的Cat4速率的4G USB网卡120可以买到,既然如此,还不如留着当4G网卡发挥余热
驱动的方法
该方法在ImmortalWrt 23.05.1的ARM和MT7621的路由器上测试成功
- 安装QMI拨号需要的包
opkg install qmi-utils usb-modeswitch kmod-mii kmod-nls-base kmod-usb-core kmod-usb-ehci kmod-usb2 kmod-usb-net kmod-usb-wdm kmod-usb-net-qmi-wwan wwan uqmi luci-proto-qmi - USB连接4G模块,执行识别驱动的命令,命令如果没有报错的话,
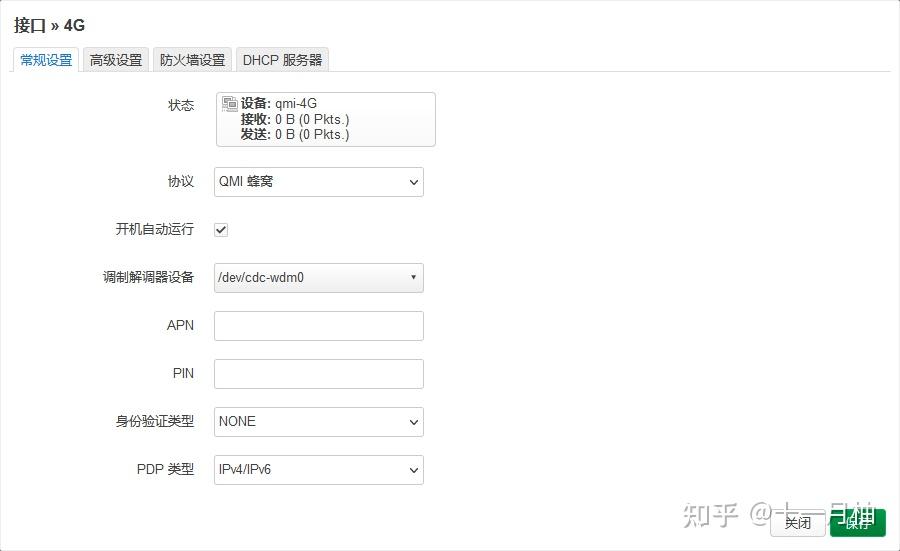
ls /dev/应该看到cdc-wdm3这个设备了echo "2ca3 4006 0 2c7c 0125" > /sys/bus/usb/drivers/qmi_wwan/new_id - 创建QMI拨号的接口,例如命名为DJI,在调制解调器设备一栏填入
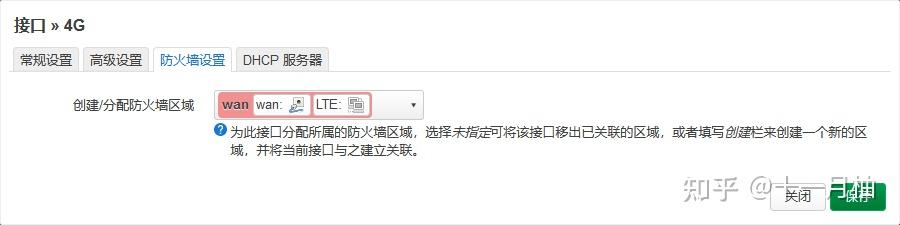
/dev/cdc-wdm3(最关键,下图是借用的其他教程的截图作为参考),其余的信息保持默认; 在防火墙设置,给这个接口分配防火墙区域为wan,保存设置即可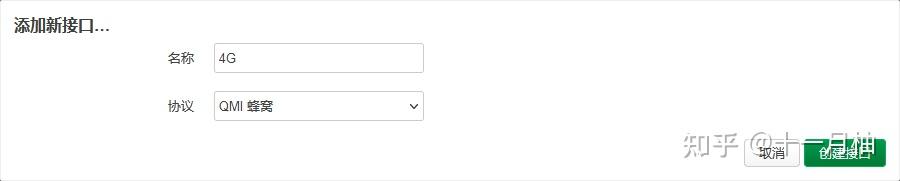
如果此时4G图传模块上的灯是绿色的,即模块正常连上了4G网络,很快能看到刚刚创建的接口已经获取到了IPv6的地址,并且系统自动生成了名为DJI_4的IPv4地址的虚拟接口,此时路由器应该就能通过4G模块访问互联网
第一次成功驱动并设置好QMI拨号的接口后,可以将命令
echo "2ca3 4006 0 2c7c 0125" > /sys/bus/usb/drivers/qmi_wwan/new_id
添加到开机启动脚本中(网页LuCI界面->系统->启动项->本地启动脚本),添加到文本框中exit 0这一行之前即可,后续重启也无需任何的操作,随时插入4G模块后一段时间就能正常上网了
探索的过程
在大疆论坛上有用户尝试了Windows上驱动并成功让PC能接入4G网络,后续大疆又发布了模块的Windows驱动,其中主要提供了以下的信息:
- PC直接识别的型号是EG25G-QDC507,其中EG25是移远(Quectel)的产品:一款Cat4速率的4G模组
- 4G模块正常驱动后显示的生产商为Baiwang,查不到驱动和规格相关的信息
搜索OpenWrt上驱动模块的资料,发现在OpenWrt上移植EG25驱动的经验是空白的,主要都是移植EC2X的,其中《挂载移远EC20、EC21、EC25、AG35等4G模块》参考了官方的Linux驱动文档,EG25在文档发中和EC25的PID和VID是相同的(2C7C, 0125),但是与4G图传模块的(2CA3, 4006)不同,即使移植了EG25的驱动也未必能识别到4G图传模块
直到看到论坛里有人发了4G图传模块用于Linux系统上网尝试,用到了将USB设备的PID和VID写入/sys/bus/usb/drivers/…/new_id处理驱动识别的方法,另外又查到了23年11月的OpenWrt 下实现移远 4G 模块上网 中提到在OpenWrt 22.03在无需改内核代码就能驱动EC20
在运行echo "2ca3 4006 0 2c7c 0125" > /sys/bus/usb/drivers/qmi_wwan/new_id后,可以用cat /sys/kernel/debug/usb/devices查看到4G模块被qmi_wwan驱动(设备对应的信息出现Driver=qmi_wwan字样)
在/dev目录下可以看到/dev/cdc-wdm[0-3]一共4个设备,最开始尝试了/dev/cdc-wdm0发现无法拨号就差点放弃,最后尝试了下/dev/cdc-wdm3发现拨号可以获取到IP了
查看信号及IPv6情况
uqmi命令可以与模块通信并输出一些状态的信息,其中个人比较关注的主要是信号
root@XDR6088:~# uqmi -d /dev/cdc-wdm3 --get-signal-info
{
"type": "lte",
"rssi": -55,
"rsrq": -6,
"rsrp": -79,
"snr": 14.800000
}
4G模块的速率标准为Cat4(下行速率最高150Mbps,上行最高为50Mbps),实测在以上信号强度的电信4G上下行均为50Mbps左右,日常用这速率也算能接受吧,联想到我测试过最快的4G是2018年在iPhoneSE(4G Cat6最高下行速率300Mbps)上跑出了100Mbps的下行
关于IPv6,首先路由器时可以获取到公网IPv6地址的(以及64位前缀的PD),并且在LAN默认的IPv6设置下,可以向下分配地址,另外就是传入连接的连接性,实测发现有运营商的差异:移动的IPv6地址无法从外网访问路由器,联通和电信的IPv6地址则可以
CPE/4G模块下的二级路由
由于CPE和4G模块获取的IPv6地址是不含短于64位的前缀的,所以在使用二级路由的情况下,二级路由下的设备无法获取公网IPv6地址,这个时候需要配置“IPv6中继+NDP代理”,OpenWrt 23.05的LuCI界面的设置过程如下:
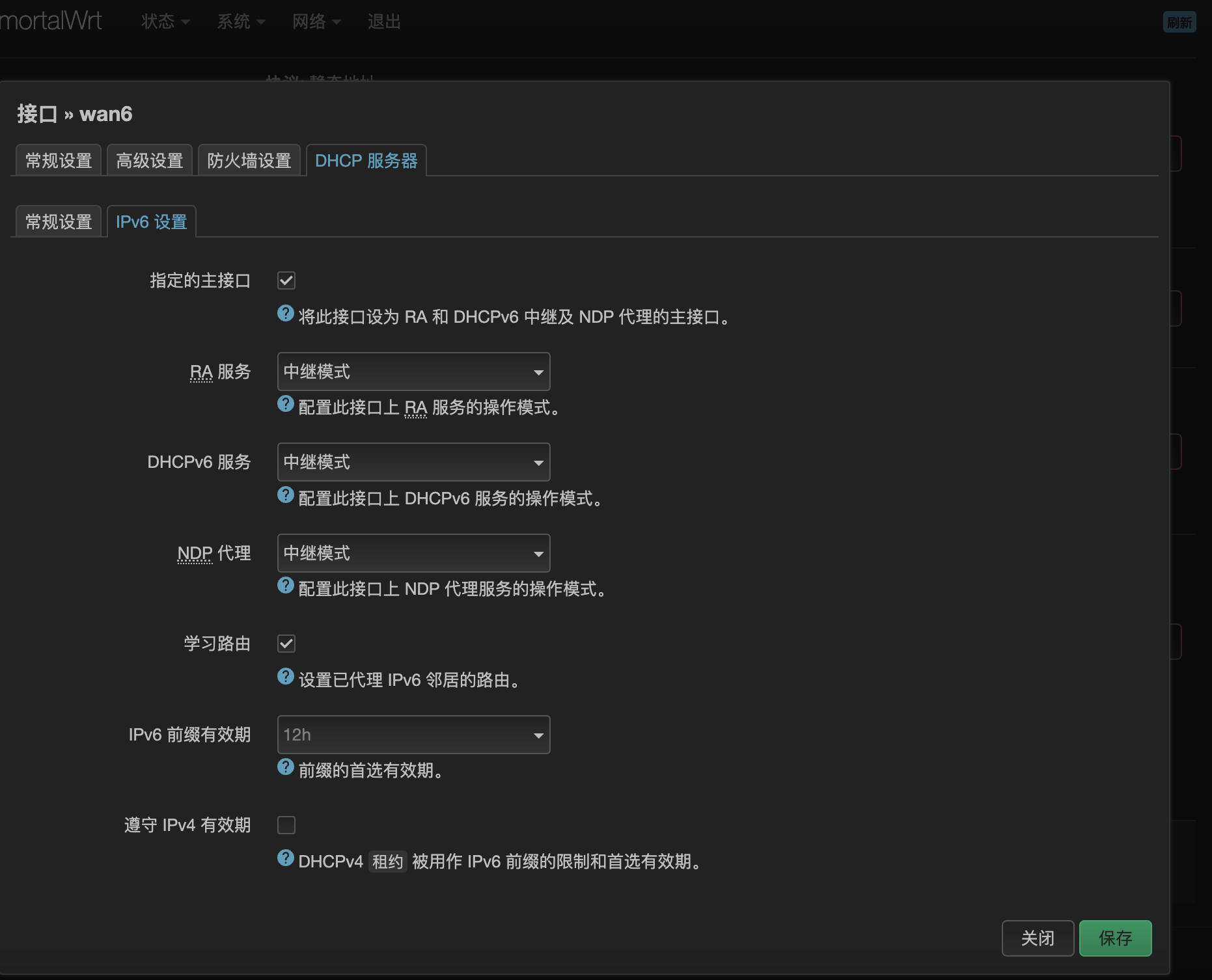
- 比如wan6接口已经获取到IPv6地址,下面都是在默认的设置上修改的,第一张图的设置不需要改
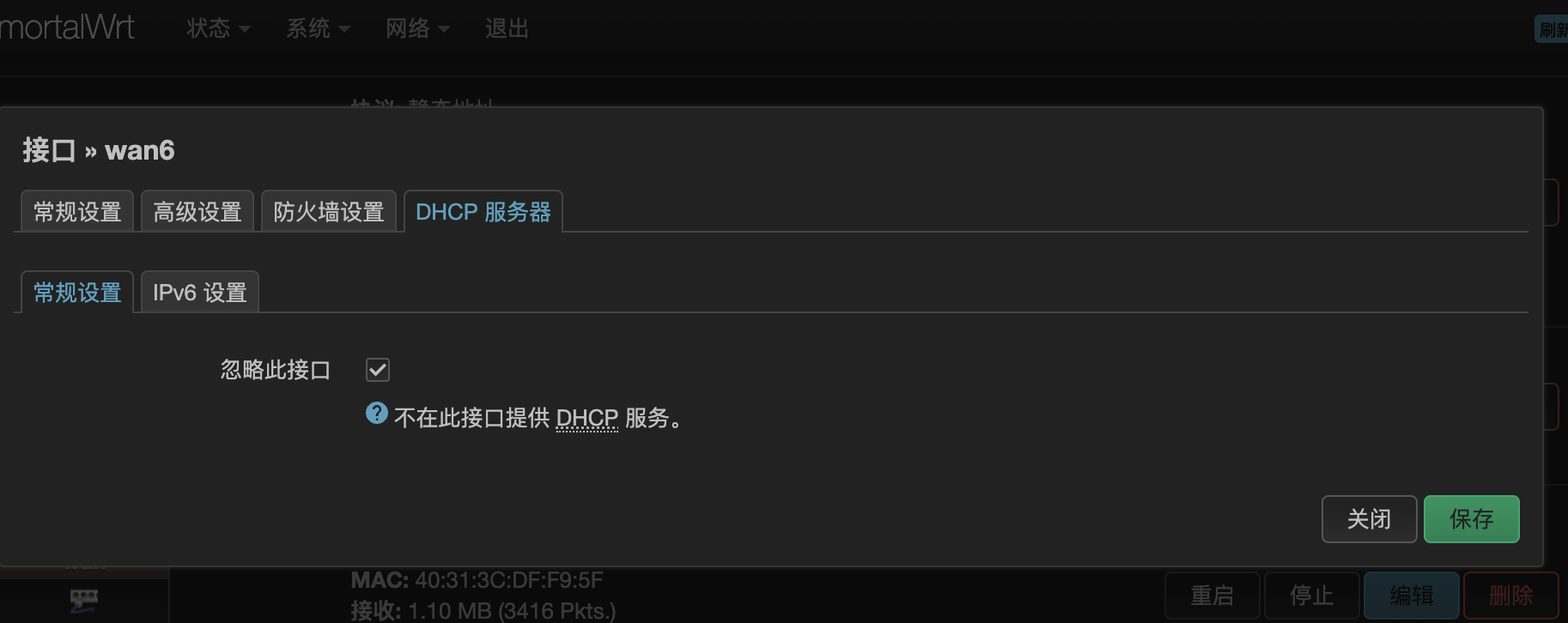
- wan6接口的设置勾选指定的主接口,接下来三个地址分配的选项选中继,学习路由要勾选
- lan接口的设置,三个地址分配的选项选中继,学习路由要勾选
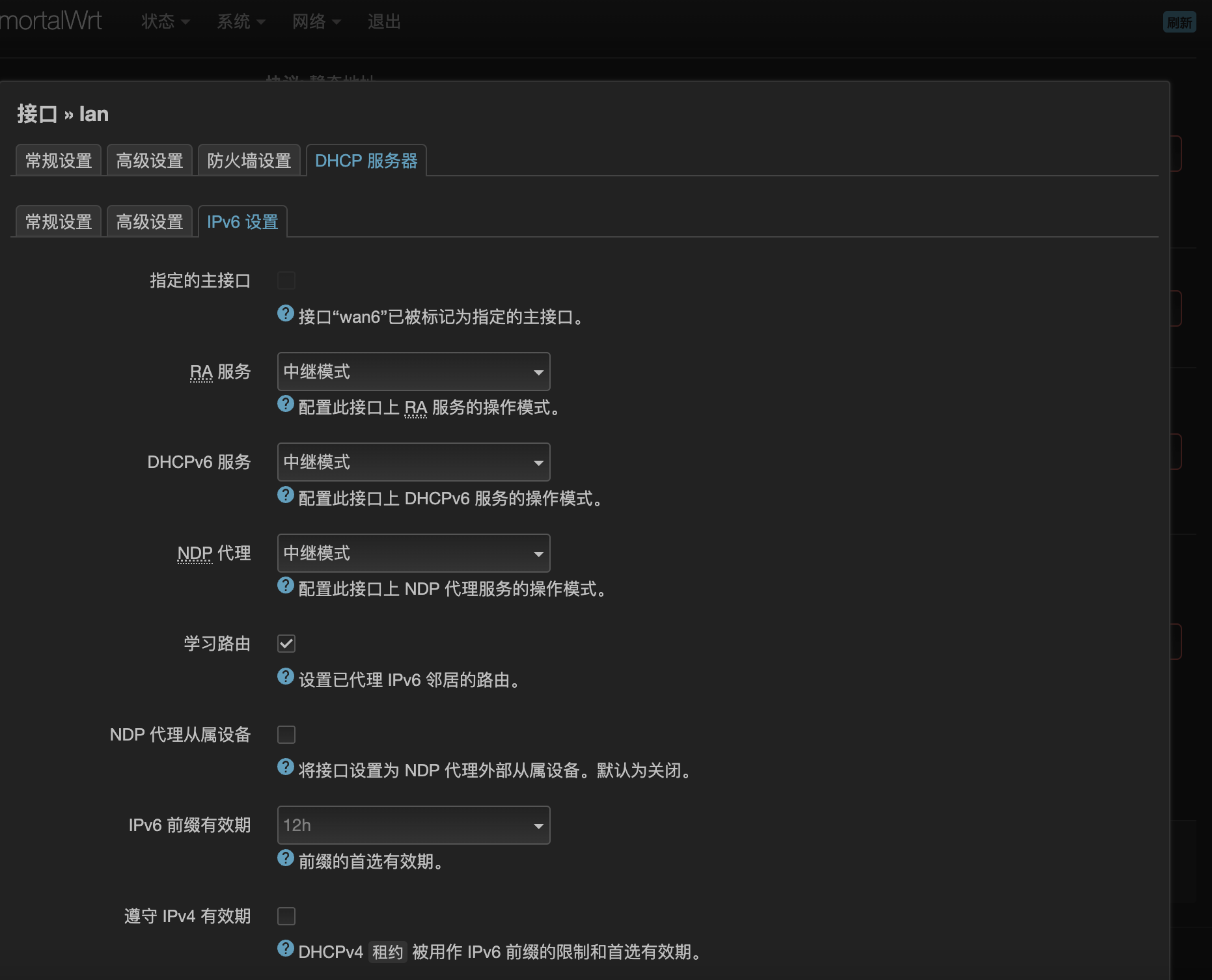
- 删除ULA前缀(这里是经验之谈)
 正常情况下,连接在路由器下面的设备就能获取到公网IPv6地址了,但是可能还打不开IPv6网站:http://test6.ustc.edu.cn,这个时候可能需要ping一下wan6接口的IPv6地址,让地址被NDP代理学习(可以用
正常情况下,连接在路由器下面的设备就能获取到公网IPv6地址了,但是可能还打不开IPv6网站:http://test6.ustc.edu.cn,这个时候可能需要ping一下wan6接口的IPv6地址,让地址被NDP代理学习(可以用ip -6 neigh和LuCI上的系统->路由表->IPv6邻居看IPv6地址对应的接口来观察NDP代理的效果)
我的网络结构是CPE做一级路由,OpenWrt做二级路由,因为华为5G CPE本身防火墙的原因,二级路由下面的设备可以获取到IPv6地址,但是无法从外网访问
但是如果CPE或者4G模块支持桥模式,那么OpenWrt路由器大概率是不受CPE或者4G模块的防火墙影响的,放开OpenWrt的防火墙之后,只剩下运营商屏蔽了传入连接的可能性
局域网
局域网肯定还是要用一台OpenWrt路由器作为主路由,如果一台主路由能解决问题是最好,列出来的要求有点多:
- 网口足够多,早期的路由器一般是5个千兆口(1 x WAN + 4 x LAN),勉强够用(PC + NAS + xx),如果带USB口的话,还能额外扩展网口
- 最好有2.5G以上的网口,因为160MHz WiFi6已经可以跑到1.6Gbps以上了,当前NAS的机械硬盘读写大多能超过200MB/s,2.5G网口的设备会越来越多
- WiFi 4T4R(4x4 MIMO)信号更好,有MU-MIMO的情况下,当前主流2x2 MIMO的多台设备可以同时高速传输
- 有良好的OpenWrt支持,这里特指最好是有OpenWrt官方的支持,开源的固件能确保基本的功能正常(21年之前WiFi6的开源驱动很少有能用的)
在从2020年到2023年这一段时间里,涌现了一大批可以刷OpenWrt的WiFi6路由器:Qnap-301w、红米AX6,AX6000、中兴NX30 Pro,以及可能有QSDK固件的小米万兆路由,对比以上的要求有明显的短板,直到某一天看到B站上有人给TP-LINK XDR6088刷机的教程:TP-link路由器XDR6088、6086、4288刷openWRT,我终于发现了一台有潜力的机器:
- 带2个2.5G网口 + 4个1G网口 + 一个USB3.0接口
- 支持4T4R 160MHz的5G频段WiFi6
- 4*A53@2.0GHz的CPU,128MB的闪存在2023年够路由器装常用插件了,看拆机散热算是比较好的
XDR6088刷OpenWrt
可以查到的获取终端操作权限刷入U-boot(bootloader)的方法源于:TP-LINK XDR6086/XDR6088 反弹 SHELL 并开启 SSH
综合亲手实践以及上面的视频教程,有几点需要特别注意
- 实测在1.0.24版本到1.0.23都可以通过反弹shell注入命令,切记每次发完post请求之后,禁用用户触发反弹shell完成后,删除用户,这样下一个Post请求才能发送成功
- 发Post请求的客户端软件有特别的要求,我试过OpenWrt,CentOS,群晖,Postman的curl命令/Post请求发送均无法创建VPN用户,最后还是重装了一个Ubuntu的WSL才成功:返回
{"error_code":0} - 在Windows下使用nc导出路由器备份的mtdblock的时候,Windows上一定要用CMD运行nc并重定向(
nc -l -p 9995 > backup.img),不能用Powershell(备份传输完成后,校验的话就会发现用Powershell运行同样的命令会得到不一样的文件),因为这一条操作失误导致我刷OpenWrt后刷回原厂系统的过程中导致变砖 - 视频教程中的UBoot刷完后,通过这个UBoot是无法直接刷入官方的OpenWrt固件的,原因是分区结构不一样,本文后面有记录刷到官方的方法
一些简单的测试
我只刷了视频教程的固件,基本上是截至到当时最新的R23.5.1,2.5G网口和WiFi稳定的运行两周,这里先放下收集到的参数的对比,至少CPU的参数在当前WiFi6末期可刷机硬路由中基本上是第一档的
| 路由器 | CPU | RAM | ROM |
|---|---|---|---|
| Newifi Y1 | MT7620 1C@580MHz | 128MB | 16MB |
| K2P | MT7621AT 2C4T@880MHz | 128MB | 16MB |
| XDR6088 | MT7986A 12nm 4*A53@2.0GHz | 512MB DDR3 | 128MB |
| NX30 Pro | MT7981B 12nm 2*A53@1.3GHz | 256MB DDR3 | 128MB |
| Qnap-301w | IPQ8072A 12nm 4*A53@2.2GHz | 1GB DDR3-1600 | 4GB |
| K3 | BCM4709 40nm 2*A9@1.4GHz | 512MB DDR3-1600 | 128MB |
| N1 | S905D 28nm 4*A53@1.5Ghz | 2GB | 8GB |
- 近距离WiFi6设备测速,用支持160MHz的小米13可以跑出1.6~1.8Gbps的速率,支持80MHz的iPad Pro能跑到900Mbps 同一房间,无遮挡用AX200也能跑到1.6Gbps左右
- 中距离WiFi6设备测速,一堵墙的情况下,XDR6088能跑1Gbps,对比4T4R 80MHz的K3能跑400Mbps左右
- 夏天室内29度左右,长时间开机运行,CPU温度不超过60度,机身有热感
救砖
上文提到Powershell下使用nc命令重定向的备份大小异常的问题,相关的原因查明在:Powershell与bash的重定向的差异,在搞清楚其中的原理后,我理解无法通过简单的操作使得备份还原,于是在论坛找到了别人的备份的mtdblock9尝试救砖,参考
- 6088 mtd9分区的备份
- OpenWrt官方论坛讨论XDR6086的帖子有提到用CH341及WSON8探针救砖
- 轻舟XDR6088拆机:闪存芯片型号是F50L1G41LB,容量128MB
- 红米AX6000救砖:红米AX6000使用的闪存是ESMT F50L1G41LB,容量128MB,3.3V的SPI NAND
因为我之前给T440s修改BIOS买了CH341A编程器和8pin的夹子,所以就鼓起勇气拆机,经过艰难的掰卡口后,很快就遇到了问题:
-
红米AX6000救砖中提到建议改CH341的输出电压为3.3v,这个要飞线,我没有工具:
-
我查了下ThinkPad BIOS芯片W25Q32V的datasheet,发现支持的也是2.7~3.6V,之前成功刷上了BIOS,通过不严谨的推测,不修改CH341的输出电压也能刷2.7~3.6V的F50L1G41LB
-
店家给的CH341的编程器刷写软件不支持F50L1G41LB,红米AX6000救砖中提到“NeoProgrammer不知道如何写入单独分区,我选择了SNANDer”:
- SNANDer大概是缺少说明,我这里用的不太顺利,最后还是选了NeoProgrammer,因为后者能成功识别到芯片并读写
-
最棘手的问题在于,F50L1G41LB相比W25Q32V,夹子的触点难以夹到芯片的针脚,无法稳定连接就无法写入,红米AX6000救砖中用的漆包线飞线
- 我买了电烙铁,尝试飞线,但是实在是不会用锡焊,意识到用力过猛可能会损坏芯片,遂另寻他路
- 最后在网上看到了生产用的治具,有一个工作台能将探针垂直于主板放置,探针尖直接接触芯片针脚,然而治具带工作台价格上百,WSON8探针(匹配芯片尺寸8*6mm)比CH341编程器加上夹子还贵一些,自己拼凑了一个固定探针的框,如图:

刷入官方OpenWrt
在OpenWrt官方23.05正式版支持XDR-6088的固件后,参考了TL-XDR6088/6086 刷入官方 Openwrt/Immortalwrt,原文已经记录的相当的详细,此处仅摘录用到的步骤(因为独立博客的域名过期之后就很可能找不到原文了)
本文写作时,最新的是23.05.0-rc3版。将来请用更新的稳定版本,目前Immortalwrt官方固件已经支持:
- 双 2.5Gb 网口的正常驱动(但LED灯还不亮)
- WiFi6 160Mhz
- 硬件流量分载
- WED (Wireless Ethernet Dispatch) 无线加速
- 硬件 NAT 加速
- Fullcone NAT
4.2 如果路由器已经刷了其它版本的 Openwrt
在 Openwrt 中运行
cat /proc/mtd,得到mtd设备的真实命名,再用命令来写入(将下面的BL2或FIP改成你在上面看到的名字,注意大小写)md5sum /tmp/preloader.bin mtd erase BL2 mtd write /tmp/preloader.bin BL2 mtd verify /tmp/preloader.bin BL2 md5sum /tmp/bl31-uboot.fip mtd erase FIP mtd write /tmp/bl31-uboot.fip FIP mtd verify /tmp/bl31-uboot.fip FIP注意查看上传的两个文件 md5 并和本地文件对比,查看两次 mtd verify 最后是否输出输出 Success,没问题才可进行下一步。
5. 通过 tftp 载入 recovery 镜像
这时候你可以拔掉路由器的电源,然后插上。直接拔电源可能是最安全的,因为如果你用 reboot 命令,可能会有一些后台程序运行(包括可能你之前在慌乱中没有杀掉的误操作了的 dd)导致路由器变砖。别问我是怎么知道的。
此时 tftp 服务器上应该已经有提示了,路由器在请求的文件名为 openwrt-mediatek-filogic-tplink_tl-xdr6088-initramfs-recovery.itb 。你只需要把结尾为 recovery.itb 的文件,改名为这个就行了。
如果没动静,你可以拔下电源,然后顶住 reset 孔不放,同时插入电源,应该会看到 LAN 口的灯齐闪一下。大约10秒钟,应该就会进入 recovery 模式。确保网线插在 1Gb LAN 口上,网口的灯应该会亮的。
NAS加装万兆网卡
前面提到了WiFi6 160MHz普及之后,局域网传输的瓶颈主要在千兆的有线网口上,考虑到外置USB网卡(USB 3.0外置网卡最大速率为5Gbps)可能因为发热等因素不稳定,首选的话还是PCIe的网卡,而且由于数据中心万兆网卡下架,市面上有较多的低成本的选择,在网络讨论的最多的是浪潮X540-T2拆机卡,价格大概70左右,特别之处在于PCIE插槽是X8+X1,如果要用的话x1要绝缘屏蔽,我实际使用发现卡兼容性不太好:
- 铝制的小面积散热片,只要插上PCIe插槽就非常烫
- 插在群晖的NAS上发现无法识别
- 插在z370主板上,概率性无法识别,或者iperf3测速不稳定
- 最后是X540本身,由于年代久远,不支持协商以太网的2.5G速率
最后捡到一张180的带华为物料编码的x540,有几乎覆盖整个卡面的黑色散热片,插上群晖DS1621可以直接用,对于装了驱动的Z370-I也是

简单测了下,这张x540的空载功耗大约是8w,看卡背面的便签写着silicom PE210G2I40E,查到了silicom官网关于电口万兆网卡的功耗,找到了“电口功耗高”的依据:
PE开头的NIC(网卡)均为silicom官网上的网卡的功耗数据(均为所有端口Link/Idel 的功耗的整卡功耗),可以看到x540的功耗一骑绝尘,考虑到网卡的成本以及长期电费,最后我找了一张AQC107的网卡LREC6880BT,也把数据列到了下面:
| NIC | Controller | 无Link | GE | XGE | |
|---|---|---|---|---|---|
| PE310G2I50-T | X550-AT2 | 4.62W | 5.4W | 8.16W | x4 PCIe 3.0 |
| PE210G2I40-T | X540 | 7.23W | 7.92W | 14.28W | x8 PCIe 2.1 |
| PE310G2I71-T | X710-AT2 | 3.6W | 5.52w | 8.28W | x8 PCIe 3.0 |
| PE310G2I71 | X710BM2 | 3~4W | 4.6~4.8W | x8 PCIe 3.0 | |
| PE210G2SPI9A | 82599ES | 4~6W | 6W | x8 PCIe 2.0 | |
| LREC6880BT | AQC 107 | 网卡4.7W | x4 PCIe v2.1 |
数据中心下架的卡基本上都有些年头了,关于网卡的控制器、发布时间、制程、TDP,2022年末的二手价如下:
| NIC | Controller | TDP | Release | Process | Price |
|---|---|---|---|---|---|
| 华为SP230电 | X540-AT2 | 12.5W | 12Q1 | 40nm | 250左右 |
| Intel X550 | X550-AT2 | 11W | 15Q4 | 28nm | 1200左右 |
| Intel X710-T4 | XL710-BM1 | 7W | 15Q4 | 28nm | 2450 |
| X520-DA1 | 82599ES | 09Q2 | 65nm | ||
| LREC6880BT | AQC107 | 6W | 17Q4 | 28nm |
在网上看到说Intel的X540和X550在群晖的DSM系统中是免驱的(其实是DSM的Linux带了驱动),因为X550太贵,所以把目光投向了价格和功耗都合适的AQC107,因为群晖E10G18-T1 10G等群晖官方的万兆电口卡也是用的AQC107,我天真的以为第三方AQC107也是免驱的
群晖DSM7.1编译AQC107网卡驱动
网上我能找到两个中文的经验:
- 历尽磨难,群晖Dsm7.0编译E10M20-t1(aqc107)网卡驱动,终获成功!,论坛里的过程记录贴比较冗长,而且方法相对下面的原生方法要逊色一些,图方便的话,帖子应该是提供了编译好的驱动
- 搭建群晖 Synology NAS 开发环境,自编译网卡等驱动 我主要参考的这篇文章,我的编译过程与文章有几点不同
- 编译的依赖不同,毕竟编译的驱动的文件是不一样的嘛
- 我手动链接了更多的文件/文件目录
详细的要二次编译成功再补充,大概是下次DSM系统版本/内核版本更新
Z370-ITX使用64GB内存
因为不涉及到后面的修改BIOS文件就能上64GB内存,这里直接上结论:
- 实测在华硕Z370-I的1410版本的BIOS,可以识别到64GB内存并开机正常使用,使用的内存是2条金士顿Fury DDR4 32GB 3200MHz
在我的平台上,用最新的3005的BIOS反而会导致莫名其妙的自动重启
- 关于CMD运行命令“wmic memphysical get maxcapacity会显示最大支持的内存”,实测是不准确的
- 华硕这块ITX的主板的BIOS文件的 最大内存限制的二进制位 与 已有经验反馈的ATX主板BIOS文件的不同,所以最后还是实践出真理
因为在互联网上找不到Z370-I成功实践的经验,所以这里留个记录:
Asus Z370-I是一块ITX主板,只有两个内存插槽,装机的时候切好碰上DDR4内存天价,所以很长一段时间里只有双通道16GB 3000MHz,这块主板在官网上参数写着最大支持32GB内存,也就是2X16GB,然而随着内存降价,发现23年单条32GB的内存已经很便宜了,想着直接上到双通道64GB,以后这台机器退役也能当服务器用
32G单条内存的颗粒检索
因为是捡垃圾买到的“Fury DDR4 32GB 3200MHz”,想要知道超频情况,无法在thaiphoon burner中识别出具体的镁光颗粒,所以只能通过拆内存条散热马甲查看颗粒的FBGA Code(或者叫Market Code:颗粒第二行的编码,例如比较流行的镁光超频内存条C9BJZ),然后在官网Micron FBGA and component marking decoder查询,然而如下的丝印代码在官网是查不到的:
3CE22
Z9XJP
最后是在电子元器件网站上检索到了颗粒的型号(Part Number):MT40A4G8VNE-062H ES:B;根据镁光的PART NUMBER命名规则表,可以获取到如下信息:
- 频率:062对应3200MHz
- 内存条单面八颗粒,叠die颗粒(4G8 4Gb*8 为2Gb的2G8的叠die版本)MT40A4G8 这个是叠die的颗粒
- 然后是ES是工程样片,对应Market Code第一位为Z
然后因为网上搜索不到相同的颗粒,所以超频抄作业可以不用想了,只能搜索到酷兽银甲单条32g 颗粒分析和超频也是叠die颗粒超频:“3200频率下1.45V时序可压c14-18-18-34,这里简单调了下一二时序,能效可以达到4.8w左右”,我看到了这个之后就按照文中提到的时序调整,实测不需要以上那样的参数,1.35v c14-18-18-32即可,其他的时序参考网上的超频教程进一步收紧,TM5跑不过就放开一点(tRFC为500),最后时延能控制在52ns左右(收紧的话可以49ns但是TM5报错)
修改BIOS提升内存支持上限
我搜到了CHH的帖子:首发!Z170/Z370 突破内存64g可用的上限限制,精华在评论里,总结如下:
如何使 H310C/B365/Z370 的 BIOS 支持最大 128G 内存:
1.UEFITool提取SiInitPreMem模块,GUID为A8499E65-A6F6-48B0-96DB-45C266030D83 2.UEFITool搜索“C786….000000….00”,其中“..”为任意HEX值 3.第一处“….”不用理会,第二处“….”如果是“8000”那么就是最大64G,如果是“0001”就是最大128G 4.将“8000”修改为“0001”可破除64G限制 5.100/200系BIOS内也有此内容,理论上6-9代的IMC支持的内存没差,6700+Z170也能128G内存(已测试可行) 6.我这边看,MSI的Z370,18年底的BIOS还是8000,19年4月的BIOS就是0001了,ASUS的BIOS一水的都还是8000 7.ME 需要禁用(修改Flash Descriptor的HAP Bit,但要注意部分主板有校验不允许这么改,改后无法开机) 8.部分BIOS需设置 Chipset->System Agent (SA) Configuration->Above 4GB MMIO BIOS assignment->Disabled 不同 BIOS 位置不同,且可能被隐藏,无法直接修改
注:参考后面的引用,第七步为:将 0x102h的位置 +1
Z370-I的BIOS的修改追踪
限制内存大小的字段,在我的主板上看到的是
# 3005 BIOS (2000 我觉得是单条16G,或者单DIMM 32G)
#Hex pattern "C786....000000....00" found as "C7866F25000000200000" in TE image section at header-offset 388FCh
C7 86 6F 25 00 00 00 20 00 00 EB 20
6A 00 56 E8 B4 E0 FE FF 59 59 0F B6
# 纯血的370ROG已经提供了128G的bios( 2021-2-15 )
# 3004 BIOS 2021-04-16 发生了变化,没有了老版的第二行
C7 86 6F 25 00 00 00 20 00 00 EB 20
# 1802 BIOS
C7 86 6F 25 00 00 00 20 00 00 EB 0A
C7 86 6F 25 00 00 00 80 00 00
# 1410 BIOS
Hex pattern "C786....000000800000" found as "C7866F25000000800000" in TE image section at header-offset 384ACh
C7 86 6F 25 00 00 00 20 00 00 EB 0A
C7 86 6F 25 00 00 00 80 00 00 8B C3
“18年底的BIOS还是8000,19年4月的BIOS就是0001了”的这一行去掉发生3004(更新日志:主要是添加了Win11的支持,没有提内存上线变化),我找了M10H ROG MAXIMUS X HERO BIOS变更日志中有内存上限修改(Support Max DRAM Total Capacity up to 128 GB.)的新老BIOS看了下,也是去掉了8000这一行
恩杰H1自带140水冷老化
这个问题能搜索到公开的文字信息不多,主要的问题是用了一段时间之后散热能力迅速衰减,比如新购入可以压制170w发热的CPU(已经开盖换液态金属),然而老化之后散热能力在CPU功耗80w左右温度就冲击100度,网上能搜索到的维修和拆解分析的经验:
- Youtube上维修的视频 NZXT H1 PUMP FAILURE (AND FIX)
- CHH论坛的帖子(可能需要登录,晚些可能会被归档):水冷头杂质阻塞
- 恩杰H1水冷的水泵损坏的案例也有恩杰H1开机水冷90度怎么办
我拆开水冷头之后,果然如上面引用所述是杂志堵塞了水冷头的微水道,用蒸馏水冲洗了几轮水路,最后换了蒸馏水之后散热能力重回170w,另外水冷的大风扇,对内存散热也要更友好(换用了一段时间的AXP100,内吹的时候内存太烫了)
折腾两台Haswell时代的设备
Haswell架构是Intel在2013年推出的“酷睿第四代”CPU架构,Haswell刚推出那年配了自己第一台台式机,后来上大学又捡了一台Haswell的笔记本T440s,毕业后又凑了一台M73小主机…台式机至今还在家用,笔记本已到垂暮之年,修改BIOS之后装上AX200依旧是顺手的全能笔电,M73目前主要是作为Linux环境主机
T440s刷BIOS
之所以要刷BIOS,是因为T440s大部分的BIOS有网卡白名单,基本完全限制住了自行升级网卡,自带的AC7260是Intel最早的2x2 AC网卡,信号和速度已经远远落后如今的AX网卡,T440s现在主要是处理器跟不上了,其他方面放到现在也是非常优秀的:
- 接口丰富(主要是有RJ45),有廉价的拓展坞
- 1.4KG的重量,同重量下优秀的键盘键程
- 支持2242和2.5inch的共两块SSD
- 使用PD转方口可以使用PD充电头
另外还有几个比较有意思的地方:
- i7-4600U处理器可以在XTU拉4倍频,本来最高3.3GHz可以拉高到3.7GHz(实测还是要手动加些电压,加太多功耗高,容易死机,实际只见过3.6GHz)
- 可以换装72WH的外置电池
- 没有不耐用的类肤质涂层
在如今是市场里确实很难找到合适自己用的笔记本(定位高,接口丰富,不用拓展坞),所以还是想多延续下T440s的使用期,一直比较头痛的就是更换网卡的问题,之前并非没有查过刷BIOS,但是教程太复杂,时过境迁,2020年搜到有不少人都能自己刷了,下面进入正题
参考教程
虽然写的是T440p,但是实测对T440s基本适用,本文对以上的材料做下补充:
-
BIOS芯片的位置

-
夹上编程器的样子

-
用工具读取到的BIOS芯片型号和教程可能不同,以卖家附赠的工具为准
-
教程还带有解锁高级菜单的部分,但是实测貌似没什么用(主要想解锁功耗,15w下散热还是压得住的)
黑苹果
换了AX200的网卡之后在160MHz下实测无线可以跑满1000Mbps,另外一个在2020年的新闻就是Intel的网卡在MacOS下终于可以日常使用了:itlwm,因为手头空闲的机器不多,所以就尝试给T440s上黑苹果试一试,好在Clover的EFI不难找
实测黑苹果日常使用确实比Win10流畅不少(主要是少了一些莫名其妙的高占用),但是多开还是有些吃力的
M73
缘起于之前为了收一个小机箱和MATX主板,被学长捆绑了一颗ES版的CPU,最开始说是E3,用CPU-Z看也是志强,但是根据顶盖上的四位编号QEDH,在某宝上搜索指向的是i7-4770s的ES版本,4c8t @ 3.0GHz,TDP 83W,并且带核显;尝试过作为家用win10主机使用过,但是核显实在太鸡肋,单核心主频低导致部分应用速度比较慢
最后我还是决定装一台低功耗的Mini Server,准系统选择了Haswell时代的M73(相比戴尔的9020散热更好),M73可以用ThinkPad系的方口电源也是一大优势(家里方口电源多…)
装机及散热测试
准系统的安装很简单,但是这里有些插曲,一个是CPU的散热问题,相比带T后缀的45W的低功耗CPU,以及家用台式机的65W标压处理器,QEDH的83W还是很吓人的,之前在B85 ATX主板上实测,解锁功耗烤机满载也确实可以跑到80W以上,所以对于65W以下的准系统M73,我选择了把顶盖到Die的导热材料换成液金,然后测试下M73能否在编译时跑满这颗CPU
这里选择CentOS下,初次编译OpenWrt作为负载,编译时,温度抵近90度,基本上就是达到默认风扇下的上限了,如果把风扇转速拉满,温度大概80左右,但是噪音太大了;使用s-tui可以在软件层面查看功耗和频率信息,CPU功耗接近60W,主频2.8GHz,因为可以用Type-C的方口诱骗线供电,所以也顺带看了下整机的功耗,基本在65W以下(用95W的电源);编译的时间对比win10下使用WSL2的i7-8700K,M73这套平台耗时是其两倍,可以接受的水平;另外日常待机功耗12W左右
Docker下载机
之前用NAS时,用的比较多的就是Docker版本的qBittorrent以及网络共享功能,其实在Linux下实现这些并不难,M73用这一套的优势是相比传统NAS噪音很小,且小体型放置随意;这里使用和NAS上一样的容器镜像源,主要是qBittorrent作为下载软件
以下设置仅针对CentOS 7.9,其他发行版可能不同,其中Docker启动命令如下(记得建立挂卷的目录):
docker run -d \
--name=qbittorrent \
--network=host \
-e PUID=1000 \
-e PGID=1000 \
-e TZ=Europe/London \
-e WEBUI_PORT=8080 \
-v /home/qbittorrent/config:/config \
-v /home/downloads:/downloads \
--restart unless-stopped \
linuxserver/qbittorrent
可能遇到的问题
-
3.1X的内核可能存在qbt启动异常的问题,
/usr/bin/qbittorrent-nox: error while loading shared libraries: libQt5Core.so.5: cannot open shared object file: No such file or directory参考群晖 -
Linux的防火墙可能会阻止访问8080端口
firewall-cmd --zone=public --add-port=8080/tcp --permanent firewall-cmd --reload部分运营商的家用宽带也会在上游阻隔8080端口的访问,此时建议将Docker启动命令的监听端口修改为8081
-
添加证书设置开启HTTPS访问后无法打开网页
需要修改证书的key的权限为所有人可读
chmod +044 keyfilepath这个在使用供应商的证书 对比 通过ACME申请的Let’s Ecrypt证书发现的差异,因为
ps -ef | grep -i qbit可以看到实际使用证书的程序的UID是abc而不是root,acme在使用root权限执行申请到的证书key对abc用户是不可读的root 255 1 0 18:26 ? 00:00:00 s6-supervise qbittorrent abc 333 255 1 19:15 ? 00:00:00 /usr/bin/qbittorrent-nox --webui-port=8081
文件服务
SMB共享
-
基于系统的用户创建SMB用户
-
设置SMB共享目录
-
关闭SELinux(否则只能看到目录而看不到文件)
临时关闭(不用重启机器) setenforce 0 修改/etc/selinux/config 文件 将SELINUX=enforcing改为SELINUX=disabled 重启机器即可
在使用SMB作为局域网内的文件共享方式有以下的缺点:
- Android和IOS的播放器软件使用SMB协议播放视频时,无法达到带宽的上限(据说是受限于移动端的APP的SMB协议版本
- SMB协议基本上只能用于局域网内的文件传输,无法作为一种安全的公网传输方式
优点:
- 兼容性较好,Windows,MacOS自带的文件浏览器支持直接访问
- SMB3在NAS上支持多路径,可以使用普通的千兆路由器路由器达到较快的网速
Alist
首先说WebDav协议,这个最早在群晖的NAS上只要安装就能使用,主要就是用于公网访问文件,然而我在很长一段时间,都没有在Linux上寻找一款配置简单,易用的服务端,在此期间用gohttpserver作为多端访问服务器文件的方式
之前听闻Alist可以挂载云盘后对外提供WebDav协议的访问,所以就看了下文档,其简介为:“一个支持多种存储的文件列表程序”,打开发现其实也是支持挂载本地存储的,又有网页端,完全可以实现gohttpserver的功能,初次之外页面上的分享功能也方便将Alist本身作为网盘分享文件
这里因为考虑到方便的挂载本地目录(主要是qbittorrent的下载目录)以及使用HTTPS(证书周期性的需要更换),所以使用了本地直接部署的方式,采用官网的一键脚本
curl -fsSL "https://alist.nn.ci/v3.sh" | bash -s install
特别留意首次安装后,日志会显示默认的随机密码
之后就是用nPlayer等播放器挂载webdav目录了,留意url的路径http[s]://domain:port/dav/中的dav,如果是Android的话,nPlayer可能常年没有更新了,推荐Reex
NextCloud
Nextcloud挂载SMB提供多种外部访问方式,体验下来还是SMB为主,Nextcloud的优势在于有完善的移动APP,2022年发现还是Alist更轻量好用
docker run -d \
--name=nextcloud \
--network=host \
-e PUID=1000 \
-e PGID=1000 \
-e TZ=Asia/Shanghai \
-v /home/nextcloud/config:/config \
-v /home/nextcloud/data:/data \
--restart unless-stopped \
linuxserver/nextcloud
可能遇到的问题:nextcloud会识别首次登陆的IP之类的信息,导致无法二次访问
解决办法:需要到docker指定的config目录下修改才可以换用域名或者新的IP访问
vi ./nextcloud/config/www/nextcloud/config/config.php
<?php
$CONFIG = array (
'memcache.local' => '\\OC\\Memcache\\APCu',
'datadirectory' => '/data',
'instanceid' => 'xxx',
'passwordsalt' => 'xxx',
'secret' => 'xxx',
'trusted_domains' =>
array (
0 => '192.168.8.114',
1 => preg_match('/cli/i',php_sapi_name())?'127.0.0.1':$_SERVER['SERVER_NAME'],
),
'dbtype' => 'sqlite3',
'version' => '21.0.0.18',
'overwrite.cli.url' => 'https://192.168.8.114',
'installed' => true,
);
路由负载均衡:ECMP
介绍了Linux系统中等效多径路由(ECMP)及其在网络负载均衡上的应用,给出了OpenWrt下的启用的方法
参考
因为偶然发现了Linux内核中的ECMP这种负载均衡的方法,然后查了些资料,这里整理下(业余水平);文末留下了当时发现ECMP的记录
ECMP在工程方面用的很多,能找到的多是说明文档,介绍特性和成套的解决方案,但是基础的材料并不是那么好找,个人也是刚刚接触到ECMP,水平有限,这里先给出本文的主要参考文献
关于负载均衡,[译] 现代网络负载均衡与代理导论(2017)有一个较为全面的介绍,其中作者提到
关于现代网络负载均衡和代理的入门级教学材料非常稀少(dearth)。我问自己:为什么会这样呢?负载均衡是构建可靠的分布式系统最核心的概念之一。因此网上一定有高质量的相关材料?我做了大量搜索,结果发现信息确实相当稀少。 Wikipedia 上面负载均衡 和代理服务器 词条只介绍了一些概念,但并没有深入 、这些主题,尤其是和当代的微服务架构相关的部分。Google 搜索负载均衡看到的大部分都 是厂商页面,堆砌大量热门的技术词汇,而无实质细节。本文将给读者一个关于现代负载均衡和代理的中等程度介绍,希望以此弥补这一领域的信息缺失。
对此个人在经历一番搜索之后也是感同身受,所以才有了总结的想法;如果觉得上文过于“导论”(和本文的关系不大),华为的文档更贴近本文的主题一些,尽量看英文:Introduction to Load Balancing
Jakub Sitnicki’s Blog的系列博文:对Linux内核中的ECMP的实现深入浅出地做了介绍,如果感兴趣的话可以看看
最后是一篇相对详尽的中文资料,重点是ECMP在内核中的变更历史:ECMP在Linux内核的实现
原理及概念
ECMP也就是下面的路由表的情形,就是到某一个目的地址可以有多个下一跳路径可选
root@K2P:~# ip r
default metric 1
nexthop via 10.170.72.254 dev pppoe-VWAN21 weight 1
nexthop via 10.170.72.254 dev pppoe-VWAN22 weight 1
nexthop via 10.170.72.254 dev pppoe-VWAN31 weight 1
nexthop via 10.170.72.254 dev pppoe-VWAN32 weight 1
root@K2P:~# ip -6 r default
default metric 1
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN21 weight 1
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN22 weight 1
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN31 weight 1
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN32 weight 1 pref medium
看起来很简单,要弄清楚这个具体能做到什么程度就需要了解下具体的实现,这里一步一步来看
Packet/Flow
Packet对应的是IP分组(数据报、数据包),是数据在L3上传输的单元
对路由器而言,流(Flow)是共享某些特性的packet序列,比如同一个请求(连接)的packets有相同的路由路径
根据负载均衡的对象分:有Per-Packet和Per-Flow两种方式,文档中的两张图对此有个直观的对比
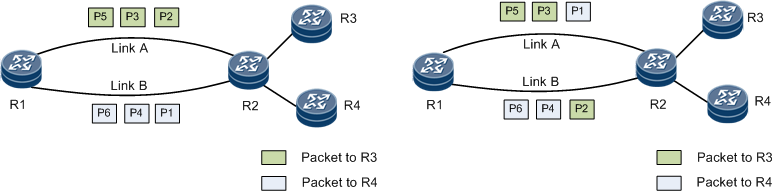
自然而然的会想到L4 Per-Packet负载均衡:每一个的Flow的Packets会被分流,可以实现多拨对看直播都可以加速的效果,然而本文并不会涉及:
Existing Multipath Routing implementation in Linux is designed to distribute flows of packets over multiple paths, not individual packets. Selecting route in a per-packet manner does not play well with TCP, IP fragments, or Path MTU Discovery.
故默认下文都是Per-Flow负载均衡,这就需要利用Packet的header fields信息把一个个的Packet和Flow联系起来,再进行下一跳的路由选择:
-
IPv4 L3 hash
{ Source Address, Destination Address } -
IPv4 L4 hash
{ Source Address, Destination Address, Protocol, Source Port, Destination Port } -
IPv6 L3 hash
{ Source Address, Destination Address, Flow Label, Next Header (protocol) }IPv6分组因为有Flow Label的存在,IPv6即使只用到L3 Hash也可以实现L4负载均衡
IPv6 Flowlabel IPv6数据报(packet)中有一个20字节的字段:流标号(流标签);进而可以用流标号取代路由表来处理流的路由,加速路由器对分组的处理;在ECMP中却提供了Flow的信息,故IPv6 ECMP是比较容易做的
L3/L4
更关键的还是负载均衡的层级,比如在多拨的情况下使用策略路由也可以做“负载均衡”,下面的命令往往提高BT的速度,这属于L3 Per-Flow负载均衡(左图):只在IP地址层级分流
ip rule add table 916
ip route add 10.173.0.0/16 via 10.170.72.254 dev pppoe-VWAN31 table 916
ip route add 10.170.0.0/16 via 10.170.72.254 dev pppoe-VWAN32 table 916
类似的方法对HTTP多线程下载并没有加速作用,对连接分流,需要L4负载均衡:多线程下载的请求之间source port不同,故L4 hash值基本不同,故会被分到不同的路径上,这样一来L4负载均衡是面向连接的就很好理解了,而内核在IPv4/IPv6上实现到一步有一段很长的历史:
Linux内核中ECMP
Linux内核的Git Commit,对发展历程感兴趣的还可以参考博文Celebrating ECMP in Linux,其中还讨论了设备的出站流量和转发流量的ECMP效果的不同,这里把ECMP的变更历史整理到一张表格中,以及对应时间的OpenWrt的内核版本信息:
| Linux Kernel | OpenWrt 内核版本 | ECMP变更 | ECMP形式 |
|---|---|---|---|
| 1997 | 2.1.68 | IPv4 ECMP 加入内核 | L3 Per-packet + route cache -> L3 Per-flow | |
| 2007 | 2.6.23 | IPv4 multipath cached 移除 | L3 Per-packet + route cache -> L3 Per-flow | |
| 2012.9 | 3.6 | IPv4 route cache 被移除 | L3 Per-packet -> L3 Per-packet | |
| 2012.10 | 3.8 | IPv6 ECMP 加入内核 | IPv6 Flowlabel -> IPv6 L4 Per-flow | |
| 2015.9 | 4.4 | 15.05 | 3.18 | IPv4 ECMP:使用L3 Hash | L3 Per-packet + L3 hash -> L3 Per-flow |
| 2016.4 | 4.7 | IPv4 ECMP: 增加邻居健康检查 | ||
| 2017.2 | 17.01 | 4.4 | ||
| 2017.3 | 4.12 | IPv4 ECMP: 增加 L4 Hash | L3 Per-packet + L3/L4 hash -> L3/L4 Per-flow | |
| 2017.11 | 4.14 | IPv6 ECMP: ICMPv6 修复 | ||
| 2018.1 | 4.16 | IPv6 ECMP: 支持指定权重 | ||
| 2018.4 | 4.17 | IPv6 ECMP: 增加 L4 Hash | ||
| 2018.7 | 18.06 | 4.9/4.14 | ||
| 2018.10 | 4.19 | |||
| 2019.11 | 19.07 | 4.14.151 |
这里可以推出(实际早期版本我也没有测试过),在默认的编译选项和内核版本下,较为实用的L4负载均衡,IPv4需要在18.06及之后的版本
IPv6由于使用了Flowlabel作为Hash的对象,根据表格,OpenWrt在15.05之后的版本就可以启用L4负载均衡
本文考虑更多的还是OpenWrt中的应用,更多信息参考本博客中的Speed_Up
启用ECMP
准备部分是从排查问题的角度来看的
在启用之前可以确认下编译内核时的下面选项,即IP: equal cost multipath,ECMP支持,较新版本的OpenWrt默认是打开的
- CONFIG_IP_ROUTE_MULTIPATH=y
暂时不清楚使用下面的多个nexthop命令添加ECMP路由的依赖,只知道命令ip route的源于iproute2,如果出现如下报错:
Error: either “to” is a duplicate, or “nexthop” is a garbage.
可以尝试:
- 安装ip-full再尝试,OpenWrt默认是ip-tiny,某些情况下也能使用多个nexthop命令添加ECMP路由
- 使用
route命令多次添加静态路由,可以启用IPv6的ECMP(详见文末的后记),实测在原版的OpenWrt可行route -A inet6 add 2000::/3 gw fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN2 route -A inet6 add 2000::/3 gw fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN3
添加ECMP路由
这里直接引用iproute2的user Guide的Multipath routing部分:
ip route add ${addresss}/${mask} nexthop via ${gateway 1} weight ${number} nexthop via ${gateway 2} weight ${number}
Multipath routes make the system balance packets across several links according to the weight (higher weight is preferred, so gateway/interface with weight of 2 will get roughly two times more traffic than another one with weight of 1). You can have as many gateways as you want and mix gateway and interface routes, like:
ip route add default nexthop via 192.168.1.1 weight 1 nexthop dev ppp0 weight 10
Warning: the downside of this type of balancing is that packets are not guaranteed to be sent back through the same link they came in. This is called “asymmetric routing”. For routers that simply forward packets and don’t do any local traffic processing such as NAT, this is usually normal, and in some cases even unavoidable.
If your system does anything but forwarding packets between interfaces, this may cause problems with incoming connections and some measures should be taken to prevent it.
可以补充的是如果用的多个等带宽的PPPoE Interface的话,可以使用多个nexthop dev ${pppoe-dev}
修改内核运行参数
仅仅是上一步的话,可以见到在使用P2P下载时已经有负载均衡了,但是对HTTP的多线程下载并没有加速效果,因为一些Linux内核对IPv4的ECMP默认设置到L3 Hash,而且也没有开启邻居健康检查,所以需要修改下内核的运行参数,相关的具体的参数说明如下:
fib_multipath_hash_policy - INTEGER Controls which hash policy to use for multipath routes. Only valid for kernels built with CONFIG_IP_ROUTE_MULTIPATH enabled. Default: 0 (Layer 3) Possible values: 0 - Layer 3 1 - Layer 4 2 - Layer 3 or inner Layer 3 if present
fib_multipath_use_neigh - BOOLEAN Use status of existing neighbor entry when determining nexthop for multipath routes. If disabled, neighbor information is not used and packets could be directed to a failed nexthop. Only valid for kernels built with CONFIG_IP_ROUTE_MULTIPATH enabled. Default: 0 (disabled) Possible values: 0 - disabled 1 - enabled
echo "net.ipv4.fib_multipath_hash_policy=1" >> /etc/sysctl.conf
echo "net.ipv4.fib_multipath_use_neigh=1" >> /etc/sysctl.conf
sysctl -p
其他相关的内核运行参数(IPv6 Flowlabel等)可以参考ip-sysctl.txt
OpenWrt上启用ECMP
熟练的话完全根据上面的方法做了,以下是在校园网PPPoE接入下实践的,如果PPPoE拨号多播数量较多可以参考如何提高网速
准备
- 在启用之前可以确认下编译内核时的选项
CONFIG_IP_ROUTE_MULTIPATH=y(OpenWrt 18.06之后的版本默认已经开启) - IPv6 ECMP只在IPv6 NAT下测试过,受限于当前OpenWrt正式版的内核版本,未对内核参数做进一步测试
- 加速的前提是下多拨可以加速(ISP限制)
添加虚拟网卡
OpenWrt安装kmod-macvlan后就可以添加虚拟网卡到不同的VLAN上
opkg update && opkg install macvlan
路由器上的RJ45网口是绑定到VLAN上的,如果是添加虚拟网卡到一个VLAN上就是单线多拨,添加到多个VLAN上就可以做多线多拨了
这里的eth0.2对应于WAN口(在Interface -> Switch可以看到WAN绑定在VLAN 2上),不同的设备可能有些许不同,这里在eth0.2上添加两个虚拟网卡
for i in `seq 1 2`
do
ip link add link eth0.2 name veth$i type macvlan
done
拨号
还是用脚本省事,填上用户名和密码即可,拨数为2,填下账号密码
#!/bin/sh
username=
password=
for i in `seq 1 2`
do
uci set network.VWAN$i=interface
uci set network.VWAN$i.proto='pppoe'
uci set network.VWAN$i.username="$username"
uci set network.VWAN$i.password="$password"
uci set network.VWAN$i.metric="$((i+1))"
uci set network.VWAN$i.ifname="veth$i"
uci set network.VWAN$i.ipv6='1'
done
uci commit network
添加所有PPPoE接口到wan zone(担心影响到其他的网络环境的话手动也可以)
for i in `uci show network | grep pppoe | awk -F. '{print $2}'`
do
uci add_list firewall.@zone[2].network=$i
done
uci commit firewall
添加ECMP路由
只用nexthop dev ${pppoe-dev}:
#IPv4
ip route replace default metric 1 nexthop dev pppoe-VWAN1 nexthop dev pppoe-VWAN2
#IPv6
ip -6 route replace default metric 1 nexthop dev pppoe-VWAN1 nexthop dev pppoe-VWAN2
做完这一步就可以使用ip r和ip -6 r命令检查下路由表
修改内核运行参数
echo "net.ipv4.fib_multipath_hash_policy=1" >> /etc/sysctl.conf
echo "net.ipv4.fib_multipath_use_neigh=1" >> /etc/sysctl.conf
sysctl -p
测试
通过东北大学IPv6测速以及IPv4测速测试负载均衡的速度叠加效果,或者使用iftop命令查看各个接口上路由的实时速率
传入连接的问题
添加ECMP路由之后传入连接偶尔连的上,偶尔连不上,但是PT的上传之类的貌似又没有问题(可能因为上传也可以是主动发出的连接),如果有这方面需求的话需要添加策略路由,为某一接口上的地址指定路由规则,下面是IPv4的,完成之后可以从外部访问之类的,但是对其他的影响就不太清楚了,IPv6部分暂时没有测试条件…
ip rule add perf 20 from IP table 20
ip route add default table 20 dev INTERFACE
此处参考自Linux 平台上之 Multipath Routing 應用,非常难得的详细的文章,还是2001年的
后记:偶然发现的ECMP
这里保留当时的发现过程:(当时发现了这个功能非常开心,现在来看部分内容不准确,但是文末的脚本的效果要好于ECMP默认的方法)
只在K2P OpenWrt 18.06上面实践过,对LEDE 17.01无效
下面是在操作一番之后的路由表,对IPv6的测速显示网速翻了四倍
root@OpenWrt:~# ip -6 route | grep pppoe
default from 2001:250:1006:dff0::/64 via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN4 proto static metric 512 pref medium
2000:::/3 dev pppoe-VWAN4 proto static metric 256 pref medium
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-wan weight 1
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN2 weight 1
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN3 weight 1
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN4 weight 1
大致可以看出这已经是做了负载均衡,需要的只是安装好luci-app-mwan3,简单操作一下路由表,这里的网关地址和dev需要看具体情况
2000::/3 就是IPv6的单播(Unicast)地址了,在不做任何操纵的情况下,无PD的路由表(单拨)
default from 2001:250:1006:dff0::/64 via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN3 proto static metric 512 pref medium
2001:250:1006:dff0::/64 dev pppoe-VWAN3 proto static metric 256 pref medium
...
之后通过下面两条常规的添加路由表条目的命令:
route -A inet6 add 2000::/3 gw fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN2
route -A inet6 add 2000::/3 gw fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN3
发现路由表就出现了nexthup和负载均衡中的weight标记
root@OpenWrt:~# ip -6 route | grep pppoe
default from 2001:250:1006:dff0::/64 via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN3 proto static metric 512 pref medium
2000::/3 dev pppoe-VWAN3 proto static metric 256 pref medium
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN2 weight 1
nexthop via fe80::96db:daff:fe3e:8fcf dev pppoe-VWAN3 weight 1
...
类似的网关添加过程对IPv4效果并不好,这里稍后再细说
之后还需要修改一下防火墙,这里用的还是NAT6中的那条命令
因为对路由表的修改在路由器重启之后会重置,所以还是要添加到开机的启动脚本或者添加到自定的防火墙规则之中,如果已经在NAT6配置过程中配置好了的话这一步就可以忽略了
ip6tables -t nat -I POSTROUTING -s `uci get network.globals.ula_prefix` -j MASQUERADE
实测的峰值速度可以到达双网口的满速,但是一样的问题,在UT,IDM,Thunder这种多线程下载软件下轻松满速,而在YouTube视频应用下,只有半速(甚至包括用IDM下载的情况下)
目前最新版本的mwan3也开始支持IPv6多拨了,但是个人还是觉得日常使用的话用以上的方法更加快捷,不过需要对网络有一定的了解,下面是一段针对IPv6 NAT的多拨hotplug脚本,用了一些OpenWrt开发时推荐的写法,比较实验性
#!/bin/sh
[ "$ACTION" = ifup ] || exit 0
ifaces=$(ubus call network.interface dump | jsonfilter -e '$.interface[@.proto="dhcpv6" && @.up=true].interface')
for iface_6 in $ifaces
do
[ "$INTERFACE" = $iface_6 ] || continue
devices=$(ubus call network.interface dump | jsonfilter -e '$.interface[@.proto="dhcpv6" && @.up=true].device')
ipv6_gw=$(ifstatus $iface_6 | jsonfilter -e '$.route[1].nexthop')
for ipv6_dev in $devices
do
status=$(route -A inet6 add 2000::/3 gw $ipv6_gw dev $ipv6_dev 2>&1)
logger -t NAT6 "Gateway: $ipv6_dev: Done $status"
done
exit 0
done
Linux 学习笔记(1): Linux Shell Powerful Tools
Connecting and expanding commands
A truly powerful feature of the shell is the capability to redirect the input and output of commands to and from other commands and files. To allow commands to be strung together,the shell uses metacharacters. As noted earlier, a metacharacter is a typed character that has special meaning to the shell for connecting commands or requesting expansion.
Piping commands
The pipe (|) metacharacter connects the output from one command to the input of another command. This lets you have one command work on some data, and then have the next command deal with the results. Here is an example of a command line that includes pipes:
$ cat /etc/passwd | sort | cut -f1,5 -d: | less
This command lists the contents of the /etc/passwd file and pipes the output to the sort command. The sort command takes the user names that begin each line of the /etc/passwd file, sorts them alphabetically, and pipes the output to the cut command. The cut command takes fields 1 and 5, with the fields delimited by a colon (:), then pipes the output to the less command. The less command displays the output one page at a time, so that you can go through page by page.
Using file-matching metacharacters
To save you some keystrokes and to be able to refer easily to a group of files, the bash shell lets you use metacharacters. Anytime you need to refer to a file or directory, such as to list it, open it, or remove it, you can use metacharacters to match the files you want. Here are some useful metacharacters for matching filenames:
• * — This matches any number of characters.
• ? — This matches any one character.
• [...] — This matches any one of the characters between the brackets, which can
include a dash-separated range of letters or numbers.
Sample Examples:




Using file-redirection metacharacters
Commands receive data from standard input and send it to standard output. Standard input is normally user input from the keyboard, and standard output is normally displayed on the screen. Using pipes (described earlier), you can direct standard output from one command to the standard input of another. With files, you can use less than (<) and greater than (>) signs to direct data to and from files. Here are the file redirection characters:
• < — Direct the contents of a file as input to the command (because many commands take a file name as an option, the < key is not usually needed).
• > — Direct the output of a command to a file, overwriting any existing file.
• >> — Direct the output of a command to a file, adding the output to the end of the existing file.
Here are some examples of command lines where information is directed to and from files.

Managing background and foreground processes
If you are using Linux over a network or from a dumb terminal (a monitor that allows only text input with no GUI support), your shell may be all that you have. You may be used to a windowing environment where you have a lot of programs active at the same time so that you can switch among them as needed. This shell thing can seem pretty limited.
There are several ways to place an active program in the background. One mentioned earlier is to add an ampersand (&) to the end of a command line. Another way is to use the at command to run commands in a way in which they are not connected to the shell. (See Chapter 12 for more information about the at command.)
To stop a running command and put it in the background, press Ctrl+z. After the command is stopped, you can either bring it to the foreground to run (the fg command) or start it running in the background (the bg command).


Linux文件查找命令find,xargs详述
Linux文件查找命令find,xargs详述
来自:LinuxSir.Org
整理:北南南北
摘要: 本文是find 命令的详细说明,可贵的是针对参数举了很多的实例,大量的例证,让初学者更为容易理解;本文是zhyfly兄贴在论坛中;我对本文进行了再次整理,为方便大家阅读;
- 1、查找当前用户主目录下的所有文件;
2、为了在当前目录中文件属主具有读、写权限,并且文件所属组的用户和其他用户具有读权限的文件;
3、为了查找系统中所有文件长度为0的普通文件,并列出它们的完整路径;
4、查找/var/logs目录中更改时间在7日以前的普通文件,并在删除之前询问它们;
5、为了查找系统中所有属于root组的文件;
6、find命令将删除当目录中访问时间在7日以来、含有数字后缀的admin.log文件
7、为了查找当前文件系统中的所有目录并排序;
8、为了查找系统中所有的rmt磁带设备;
- 1、使用name选项
2、用perm选项
3、忽略某个目录
4、使用find查找文件的时候怎么避开某个文件目录
5、使用user和nouser选项
6、使用group和nogroup选项
7、按照更改时间或访问时间等查找文件
8、查找比某个文件新或旧的文件
9、使用type选项
10、使用size选项
11、使用depth选项
12、使用mount选项
+++++++++++++++++++++++++++++++++++++++++++++++++
正文
+++++++++++++++++++++++++++++++++++++++++++++++++
版权声明
一、find 命令格式
1、find命令的一般形式为;
find pathname -options [-print -exec -ok ...]2、find命令的参数;
pathname: find命令所查找的目录路径。例如用.来表示当前目录,用/来表示系统根目录。
-print: find命令将匹配的文件输出到标准输出。
-exec: find命令对匹配的文件执行该参数所给出的shell命令。相应命令的形式为'command' {} \;,注意{}和\;之间的空格。
-ok: 和-exec的作用相同,只不过以一种更为安全的模式来执行该参数所给出的shell命令,在执行每一个命令之前,都会给出提示,让用户来确定是否执行。3、find命令选项
-name
按照文件名查找文件。
-perm
按照文件权限来查找文件。
-prune
使用这一选项可以使find命令不在当前指定的目录中查找,如果同时使用-depth选项,那么-prune将被find命令忽略。
-user
按照文件属主来查找文件。
-group
按照文件所属的组来查找文件。
-mtime -n +n
按照文件的更改时间来查找文件, - n表示文件更改时间距现在n天以内,+ n表示文件更改时间距现在n天以前。find命令还有-atime和-ctime 选项,但它们都和-m time选项。
-nogroup
查找无有效所属组的文件,即该文件所属的组在/etc/groups中不存在。
-nouser
查找无有效属主的文件,即该文件的属主在/etc/passwd中不存在。
-newer file1 ! file2
查找更改时间比文件file1新但比文件file2旧的文件。
-type
查找某一类型的文件,诸如:
b - 块设备文件。
d - 目录。
c - 字符设备文件。
p - 管道文件。
l - 符号链接文件。
f - 普通文件。
-size n:[c] 查找文件长度为n块的文件,带有c时表示文件长度以字节计。
-depth:在查找文件时,首先查找当前目录中的文件,然后再在其子目录中查找。
-fstype:查找位于某一类型文件系统中的文件,这些文件系统类型通常可以在配置文件/etc/fstab中找到,该配置文件中包含了本系统中有关文件系统的信息。
-mount:在查找文件时不跨越文件系统mount点。
-follow:如果find命令遇到符号链接文件,就跟踪至链接所指向的文件。
-cpio:对匹配的文件使用cpio命令,将这些文件备份到磁带设备中。 -amin n
查找系统中最后N分钟访问的文件
-atime n
查找系统中最后n*24小时访问的文件
-cmin n
查找系统中最后N分钟被改变文件状态的文件
-ctime n
查找系统中最后n*24小时被改变文件状态的文件
-mmin n
查找系统中最后N分钟被改变文件数据的文件
-mtime n
查找系统中最后n*24小时被改变文件数据的文件4、使用exec或ok来执行shell命令
# find . -type f -exec ls -l {} \;
-rw-r--r-- 1 root root 34928 2003-02-25 ./conf/httpd.conf
-rw-r--r-- 1 root root 12959 2003-02-25 ./conf/magic
-rw-r--r-- 1 root root 180 2003-02-25 ./conf.d/README在/logs目录中查找更改时间在5日以前的文件并删除它们:
$ find logs -type f -mtime +5 -exec rm {} \;$ find . -name "*.conf" -mtime +5 -ok rm {} \;
< rm ... ./conf/httpd.conf > ? n# find /etc -name "passwd*" -exec grep "sam" {} \;
sam:x:501:501::/usr/sam:/bin/bash二、find命令的例子;
1、查找当前用户主目录下的所有文件:
$ find $HOME -print
$ find ~ -print2、让当前目录中文件属主具有读、写权限,并且文件所属组的用户和其他用户具有读权限的文件;
$ find . -type f -perm 644 -exec ls -l {} \;3、为了查找系统中所有文件长度为0的普通文件,并列出它们的完整路径;
$ find / -type f -size 0 -exec ls -l {} \;4、查找/var/logs目录中更改时间在7日以前的普通文件,并在删除之前询问它们;
$ find /var/logs -type f -mtime +7 -ok rm {} \;5、为了查找系统中所有属于root组的文件;
$find . -group root -exec ls -l {} \;
-rw-r--r-- 1 root root 595 10月 31 01:09 ./fie16、find命令将删除当目录中访问时间在7日以来、含有数字后缀的admin.log文件。
$ find . -name "admin.log[0-9][0-9][0-9]" -atime -7 -ok rm {} \;
< rm ... ./admin.log001 > ? n
< rm ... ./admin.log002 > ? n
< rm ... ./admin.log042 > ? n
< rm ... ./admin.log942 > ? n7、为了查找当前文件系统中的所有目录并排序;
$ find . -type d | sort8、为了查找系统中所有的rmt磁带设备;
$ find /dev/rmt -print三、xargs
#find . -type f -print | xargs file
./.kde/Autostart/Autorun.desktop: UTF-8 Unicode English text
./.kde/Autostart/.directory: ISO-8859 text\
......$ find / -name "core" -print | xargs echo "" >/tmp/core.log#find . -name "file*" -print | xargs echo "" > /temp/core.log
# cat /temp/core.log
./file6# ls -l
drwxrwxrwx 2 sam adm 4096 10月 30 20:14 file6
-rwxrwxrwx 2 sam adm 0 10月 31 01:01 http3.conf
-rwxrwxrwx 2 sam adm 0 10月 31 01:01 httpd.conf
# find . -perm -7 -print | xargs chmod o-w
# ls -l
drwxrwxr-x 2 sam adm 4096 10月 30 20:14 file6
-rwxrwxr-x 2 sam adm 0 10月 31 01:01 http3.conf
-rwxrwxr-x 2 sam adm 0 10月 31 01:01 httpd.conf# find . -type f -print | xargs grep "hostname"
./httpd1.conf:# different IP addresses or hostnames and have them handled by the
./httpd1.conf:# VirtualHost: If you want to maintain multiple domains/hostnames
on your# find . -name \* -type f -print | xargs grep "hostnames"
./httpd1.conf:# different IP addresses or hostnames and have them handled by the
./httpd1.conf:# VirtualHost: If you want to maintain multiple domains/hostnames
on your四、find 命令的参数
1、使用name选项
$ find ~ -name "*.txt" -print$ find . -name "*.txt" -print$ find . -name "[A-Z]*" -print$ find /etc -name "host*" -print$ find ~ -name "*" -print 或find . -print$ find / -name "*" -print$find . -name "[a-z][a-z][0--9][0--9].txt" -print2、用perm选项
$ find . -perm 755 -print# ls -l
-rwxrwxr-x 2 sam adm 0 10月 31 01:01 http3.conf
-rw-rw-rw- 1 sam adm 34890 10月 31 00:57 httpd1.conf
-rwxrwxr-x 2 sam adm 0 10月 31 01:01 httpd.conf
drw-rw-rw- 2 gem group 4096 10月 26 19:48 sam
-rw-rw-rw- 1 root root 2792 10月 31 20:19 temp
# find . -perm 006
# find . -perm -006
./sam
./httpd1.conf
./temp3、忽略某个目录
$ find /apps -path "/apps/bin" -prune -o -print4、使用find查找文件的时候怎么避开某个文件目录
find /usr/sam -path "/usr/sam/dir1" -prune -o -printfind [-path ..] [expression] 在路径列表的后面的是表达式-print 的简写表达式按顺序求值, -a 和 -o 都是短路求值,与 shell 的 && 和 || 类似如果 -path "/usr/sam" 为真,则求值 -prune , -prune 返回真,与逻辑表达式为真;否则不求值 -prune,与逻辑表达式为假。如果 -path "/usr/sam" -a -prune 为假,则求值 -print ,-print返回真,或逻辑表达式为真;否则不求值 -print,或逻辑表达式为真。
if -path "/usr/sam" then
-prune
else
-printfind /usr/sam \( -path /usr/sam/dir1 -o -path /usr/sam/file1 \) -prune -o -print\ 表示引用,即指示 shell 不对后面的字符作特殊解释,而留给 find 命令去解释其意义。#find /usr/sam \(-path /usr/sam/dir1 -o -path /usr/sam/file1 \) -prune -o -name "temp" -print5、使用user和nouser选项
$ find ~ -user sam -print$ find /etc -user uucp -print$ find /home -nouser -print6、使用group和nogroup选项
$ find /apps -group gem -print$ find / -nogroup-print7、按照更改时间或访问时间等查找文件
$ find / -mtime -5 -print$ find /var/adm -mtime +3 -print8、查找比某个文件新或旧的文件
newest_file_name ! oldest_file_name-rw-r--r-- 1 sam adm 0 10月 31 01:07 fiel
-rw-rw-rw- 1 sam adm 34890 10月 31 00:57 httpd1.conf
-rwxrwxr-x 2 sam adm 0 10月 31 01:01 httpd.conf
drw-rw-rw- 2 gem group 4096 10月 26 19:48 sam
-rw-rw-rw- 1 root root 2792 10月 31 20:19 temp
# find -newer httpd1.conf ! -newer temp -ls
1077669 0 -rwxrwxr-x 2 sam adm 0 10月 31 01:01 ./httpd.conf
1077671 4 -rw-rw-rw- 1 root root 2792 10月 31 20:19 ./temp
1077673 0 -rw-r--r-- 1 sam adm 0 10月 31 01:07 ./fiel$ find . -newer temp -print9、使用type选项
$ find /etc -type d -print$ find . ! -type d -print$ find /etc -type l -print10、使用size选项
在当前目录下查找文件长度大于1 M字节的文件:
$ find . -size +1000000c -print$ find /home/apache -size 100c -print$ find . -size +10 -print11、使用depth选项
$ find / -name "CON.FILE" -depth -print12、使用mount选项
$ find . -name "*.XC" -mount -print五、关于本文
- 由 北南南北 在 2005/12/20 - 10:24 发表
- Linux
- 基础知识
- 命令/SHELL/PERL
- 要发表评论,请先登录 或 注册
Linux:Apache配置文件httpd.conf详细说明
## 是所有虚拟主机的默认设置而已 ##
Recover MySQL Database root password
By default, MySQL Server will be installed with root superuser without any password. You can connect to MySQL server as root without requiring password or by keying in blank password. However, if you have set the password for root and forget or unable to recall the password, then you will need to reset the root password for MySQL.
mysqld_safe --skip-grant-tables &Linux Command Line Reference for Common Operations (2)
with over 3.5 million hits in nearly 5 years. So I've decided to start compiling
another list of somewhat more involved/esoteric commands.
Examples marked with • are valid/safe to paste without modification into a terminal, so
you may want to keep a terminal window open while reading this so you can cut & paste.
| Command | Description | |
| • | grep . /proc/sys/net/ipv4/* | List the contents of flag files |
| • | set | grep $USER | Search current environment |
| • | tr '\0' '\n' < /proc/$$/environ | Display the startup environment for any process |
| • | echo $PATH | tr : '\n' | Display the $PATH one per line |
| • | kill -0 $$ && echo process exists and can accept signals | Check for the existence of a process (pid) |
| • | find /etc -readable | xargs less -K -p'*ntp' -j $((${LINES:-25}/2)) | Search paths and data with full context. Use n to iterate |
| Low impact admin | ||
| # | apt-get install "package" -o Acquire::http::Dl-Limit=42 \ -o Acquire::Queue-mode=access | Rate limit apt-get to 42KB/s |
| echo 'wget url' | at 01:00 | Download url at 1AM to current dir | |
| # | apache2ctl configtest && apache2ctl graceful | Restart apache if config is OK |
| • | nice openssl speed sha1 | Run a low priority command (openssl benchmark) |
| • | chrt -i 0 openssl speed sha1 | Run a low priority command (more effective than nice) |
| • | renice 19 -p $$; ionice -c3 -p $$ | Make shell (script) low priority. Use for non interactive tasks |
| Interactive monitoring | ||
| • | watch -t -n1 uptime | Clock with system load |
| • | htop -d 5 | Better top (scrollable, tree view, lsof/strace integration, ...) |
| • | iotop | What's doing I/O |
| # | watch -d -n30 "nice ps_mem.py | tail -n $((${LINES:-12}-2))" | What's using RAM |
| # | iftop | What's using the network. See also iptraf |
| # | mtr www.pixelbeat.org | ping and traceroute combined |
| Useful utilities | ||
| • | pv < /dev/zero > /dev/null | Progress Viewer for data copying from files and pipes |
| • | wkhtml2pdf http://.../linux_commands.html linux_commands.pdf | Make a pdf of a web page |
| • | timeout 1 sleep 3 | run a command with bounded time. See also timeout |
| Networking | ||
| • | python -m SimpleHTTPServer | Serve current directory tree at http://$HOSTNAME:8000/ |
| • | openssl s_client -connect www.google.com:443 </dev/null 2>&0 | openssl x509 -dates -noout | Display the date range for a site's certs |
| • | curl -I www.pixelbeat.org | Display the server headers for a web site |
| # | lsof -i tcp:80 | What's using port 80 |
| # | httpd -S | Display a list of apache virtual hosts |
| • | vim scp://user@remote//path/to/file | Edit remote file using local vim. Good for high latency links |
| • | curl -s http://www.pixelbeat.org/pixelbeat.asc | gpg --import | Import a gpg key from the web |
| • | tc qdisc add dev lo root handle 1:0 netem delay 20msec | Add 20ms latency to loopback device (for testing) |
| • | tc qdisc del dev lo root | Remove latency added above |
| Notification | ||
| • | echo "DISPLAY=$DISPLAY xmessage cooker" | at "NOW +30min" | Popup reminder |
| • | notify-send "subject" "message" | Display a gnome popup notification |
| echo "mail -s 'go home' P@draigBrady.com < /dev/null" | at 17:30 | Email reminder | |
| uuencode file name | mail -s subject P@draigBrady.com | Send a file via email | |
| ansi2html.sh | mail -a "Content-Type: text/html" P@draigBrady.com | Send/Generate HTML email | |
| Better default settings (useful in your .bashrc) | ||
| # | tail -s.1 -f /var/log/messages | Display file additions more responsively |
| • | seq 100 | tail -n $((${LINES:-12}-2)) | Display as many lines as possible without scrolling |
| # | tcpdump -s0 | Capture full network packets |
| Useful functions/aliases (useful in your .bashrc) | ||
| • | md () { mkdir -p "$1" && cd "$1"; } | Change to a new directory |
| • | strerror() { python -c "import os; print os.strerror($1)"; } | Display the meaning of an errno |
| • | plot() { { echo 'plot "-"' "$@"; cat; } | gnuplot -persist; } | Plot stdin. (e.g: • seq 1000 | sed 's/.*/s(&)/' | bc -l | plot) |
| • | hili() { e="$1"; shift; grep --col=always -Eih "$e|$" "$@"; } | highlight occurences of expr. (e.g: • env | hili $USER) |
| • | alias hd='od -Ax -tx1z -v' | Hexdump. (usage e.g.: • hd /proc/self/cmdline | less) |
| • | alias realpath='readlink -f' | Canonicalize path. (usage e.g.: • realpath ~/../$USER) |
| • | ord() { printf "0x%x\n" "'$1"; } | shell version of the ord() function |
| • | chr() { printf $(printf '\\%03o\\n' "$1"); } | shell version of the chr() function |
| Multimedia | ||
| • | DISPLAY=:0.0 import -window root orig.png | Take a (remote) screenshot |
| • | convert -filter catrom -resize '600x>' orig.png 600px_wide.png | Shrink to width, computer gen images or screenshots |
| mplayer -ao pcm -vo null -vc dummy /tmp/Flash* | Extract audio from flash video to audiodump.wav | |
| ffmpeg -i filename.avi | Display info about multimedia file | |
| • | ffmpeg -f x11grab -s xga -r 25 -i :0 -sameq demo.mpg | Capture video of an X display |
| DVD | ||
| for i in $(seq 9); do ffmpeg -i $i.avi -target pal-dvd $i.mpg; done | Convert video to the correct encoding and aspect for DVD | |
| dvdauthor -odvd -t -v "pal,4:3,720xfull" *.mpg;dvdauthor -odvd -T | Build DVD file system. Use 16:9 for widescreen input | |
| growisofs -dvd-compat -Z /dev/dvd -dvd-video dvd | Burn DVD file system to disc | |
| Unicode | ||
| • | python -c "import unicodedata as u; print u.name(unichr(0x2028))" | Lookup a unicode character |
| • | uconv -f utf8 -t utf8 -x nfc | Normalize combining characters |
| • | printf '\300\200' | iconv -futf8 -tutf8 >/dev/null | Validate UTF-8 |
| • | printf 'ŨTF8\n' | LANG=C grep --color=always '[^ -~]\+' | Highlight non printable ASCII chars in UTF-8 |
| • | fc-match -s "sans:lang=zh" | List font match order for language and style |
| Development | ||
| • | gcc -march=native -E -v -</dev/null 2>&1|sed -n 's/.*-mar/-mar/p' | Show autodetected gcc tuning params. See also gcccpuopt |
| • | for i in $(seq 4); do { [ $i = 1 ] && wget http://url.ie/6lko -qO-|| ./a.out; } | tee /dev/tty | gcc -xc - 2>/dev/null; done | Compile and execute C code from stdin |
| • | cpp -dM /dev/null | Show all predefined macros |
| • | echo "#include <features.h>" | cpp -dN | grep "#define __USE_" | Show all glibc feature macros |
| gdb -tui | Debug showing source code context in separate windows | |
| udev | ||
| • | udevadm info -a -p $(udevadm info -q path -n /dev/input/mouse0) | List udev attributes of a device, for matching rules etc. |
| • | udevadm test /sys/class/input/mouse0 | See how udev rules are applied for a device |
| # | udevadm control --reload-rules | Reload udev rules after modification |
| Extended Attributes (Note you may need to (re)mount with "acl" or "user_xattr" options) | ||
| • | getfacl . | Show ACLs for file |
| • | setfacl -m u:nobody:r . | Allow a specific user to read file |
| • | setfacl -x u:nobody . | Delete a specific user's rights to file |
| setfacl --default -m group:users:rw- dir/ | Set umask for a for a specific dir | |
| getcap file | Show capabilities for a program | |
| setcap cap_net_raw+ep your_gtk_prog | Allow gtk program raw access to network | |
| • | stat -c%C . | Show SELinux context for file |
| chcon ... file | Set SELinux context for file (see also restorecon) | |
| • | getfattr -m- -d . | Show all extended attributes (includes selinux,acls,...) |
| • | setfattr -n "user.foo" -v "bar" . | Set arbitrary user attributes |
| BASH specific | ||
| • | echo 123 | tee >(tr 1 a) | tr 1 b | Split data to 2 commands (using process substitution) |
| meld local_file <(ssh host cat remote_file) | Compare a local and remote file (using process substitution) | |
| Multicore | ||
| • | taskset -c 0 nproc | Restrict a command to certain processors |
| • | find -type f -print0 | xargs -r0 -P$(nproc) -n10 md5sum | Process files in parallel over available processors |
| sort -m <(sort data1) <(sort data2) >data.sorted | Sort separate data files over 2 processors | |