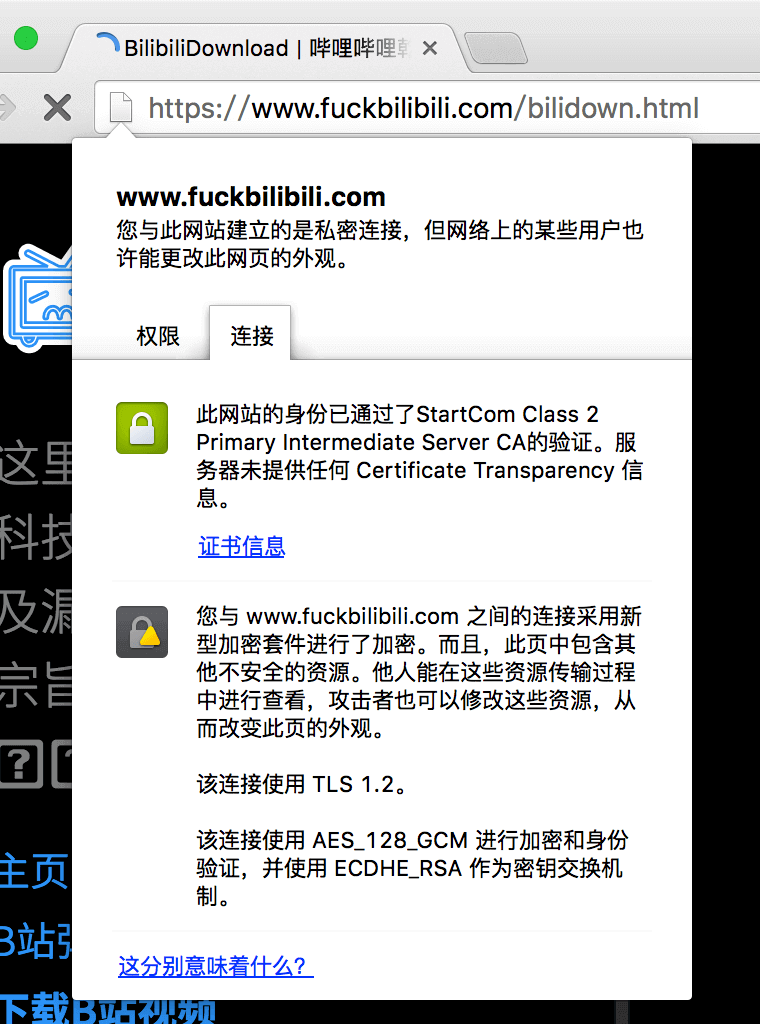
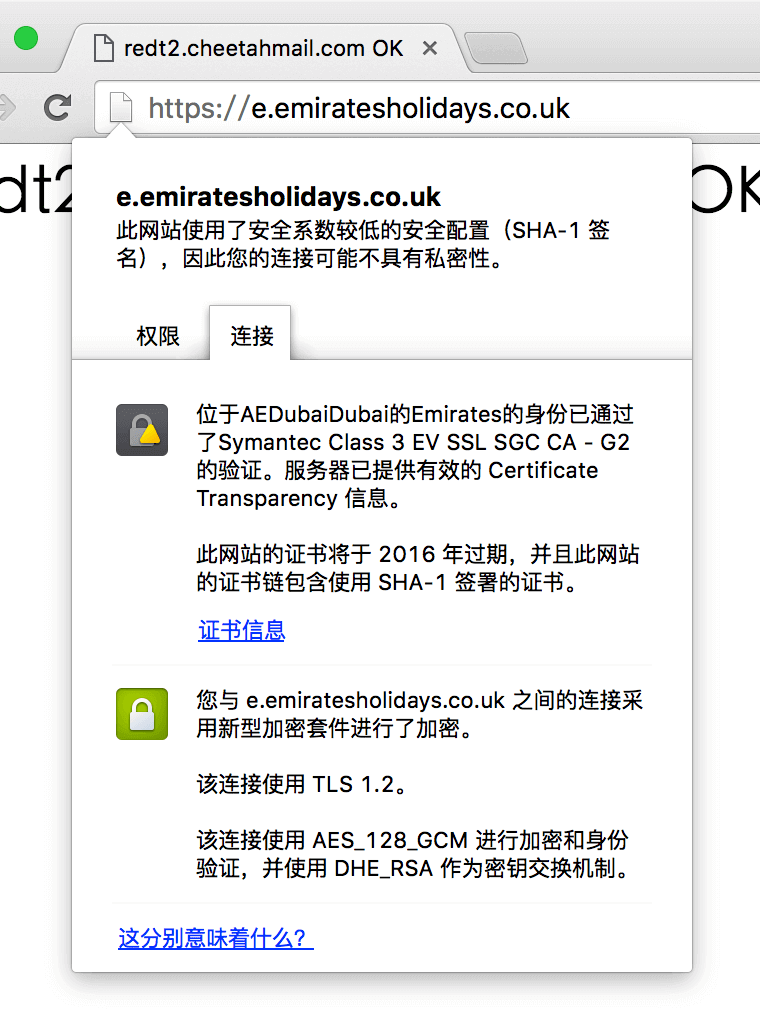
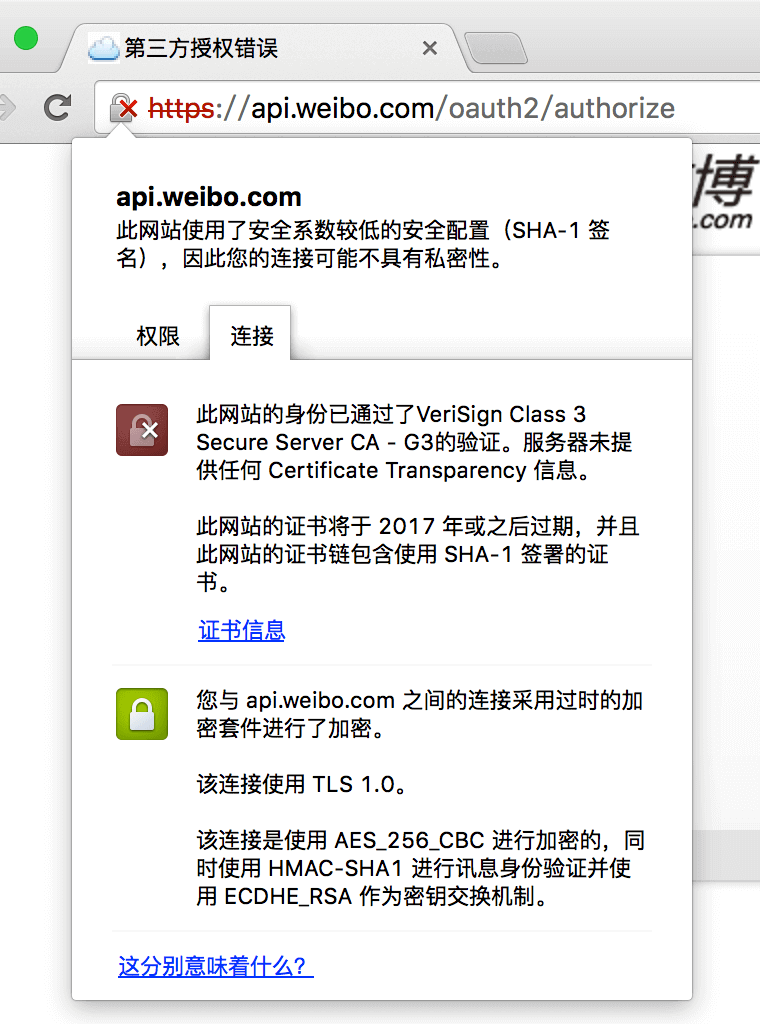
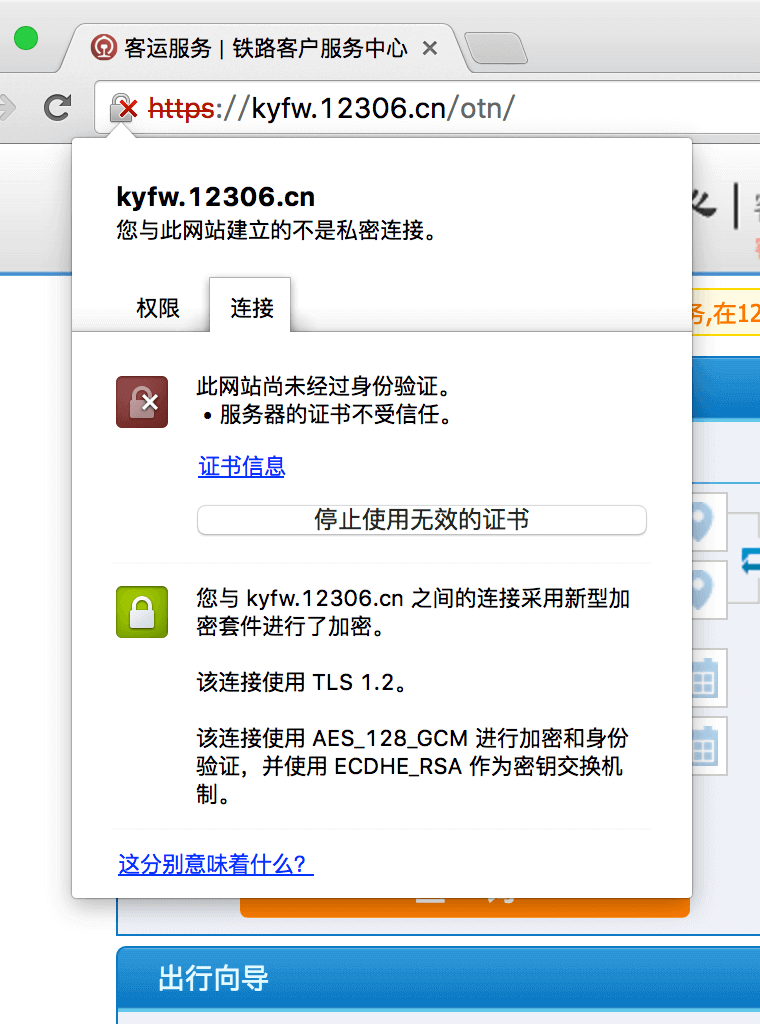
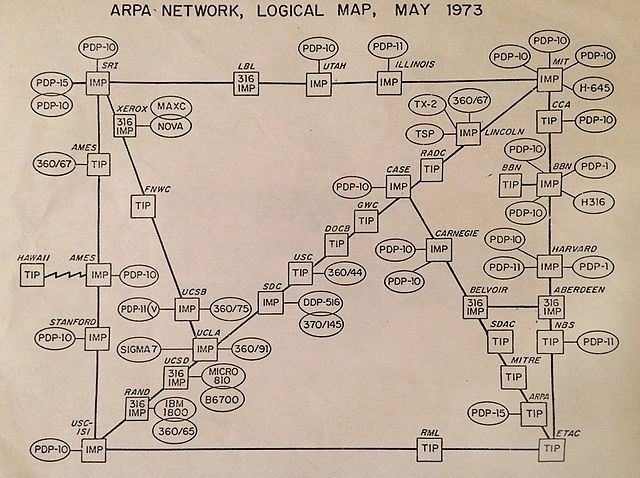
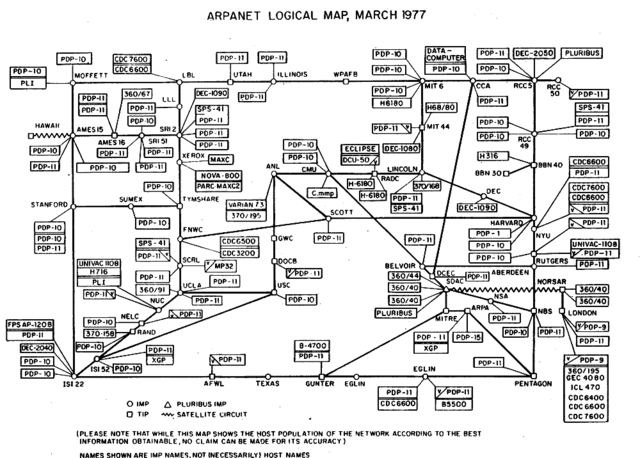
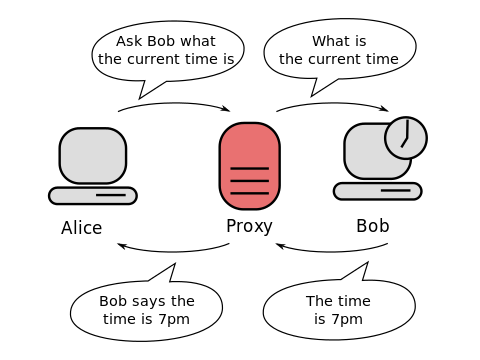
续之前的域名解析系统详解——基础篇,DNSSEC 是一组使域名解析系统(DNS)更加安全的解决方案。1993 年,IETF 展开了一个关于如何使 DNS 更加可信的公开讨论,最终决定了一个 DNS 的扩展——DNSSEC,并于 2005 年正式发布。然而,实际推行 DNSSEC 是一件非常难的事情,本文将讨论一下现有 DNS 系统所存在的一些不安全性,以及 DNSSEC 是如何解决这些问题的。
基础
传统 DNS 的问题
从上一篇文章中已经知道,在你访问一个网站,比如 www.example.com 时,浏览器发送一个 DNS 消息到一个 DNS 缓存服务器上去查询,由于 DNS 系统的庞大,这中间还需要经过好几层 DNS 缓存服务器。想要正确访问到这个网站,就需要这所有的缓存服务器都要正确的响应。
DNS 的中间人攻击
DNS 查询是明文传输的,也就是说中间人可以在传输的过程中对其更改,甚至是去自动判断不同的域名然后去做特殊处理。即使是使用其他的 DNS 缓存服务器,如 Google 的 8.8.8.8,中间人也可以直接截获 IP 包去伪造响应内容。由于我所在的国家就面临着这个问题,所以我可以轻松的给大家演示一下被中间人攻击之后是什么个情况:
$ dig +short @4.0.0.0 facebook.com243.185.187.39
向一个没有指向任何服务器的 IP 地址:4.0.0.0 发送一个 DNS 请求,应该得不到任何响应。可是实际上在我所处的国家却返回了一个结果,很明显数据包在传输过程中“被做了手脚”。所以如果没有中间人攻击,效果是这样的:
$ dig +short @4.0.0.0 facebook.com;; connection timed out; no servers could be reached
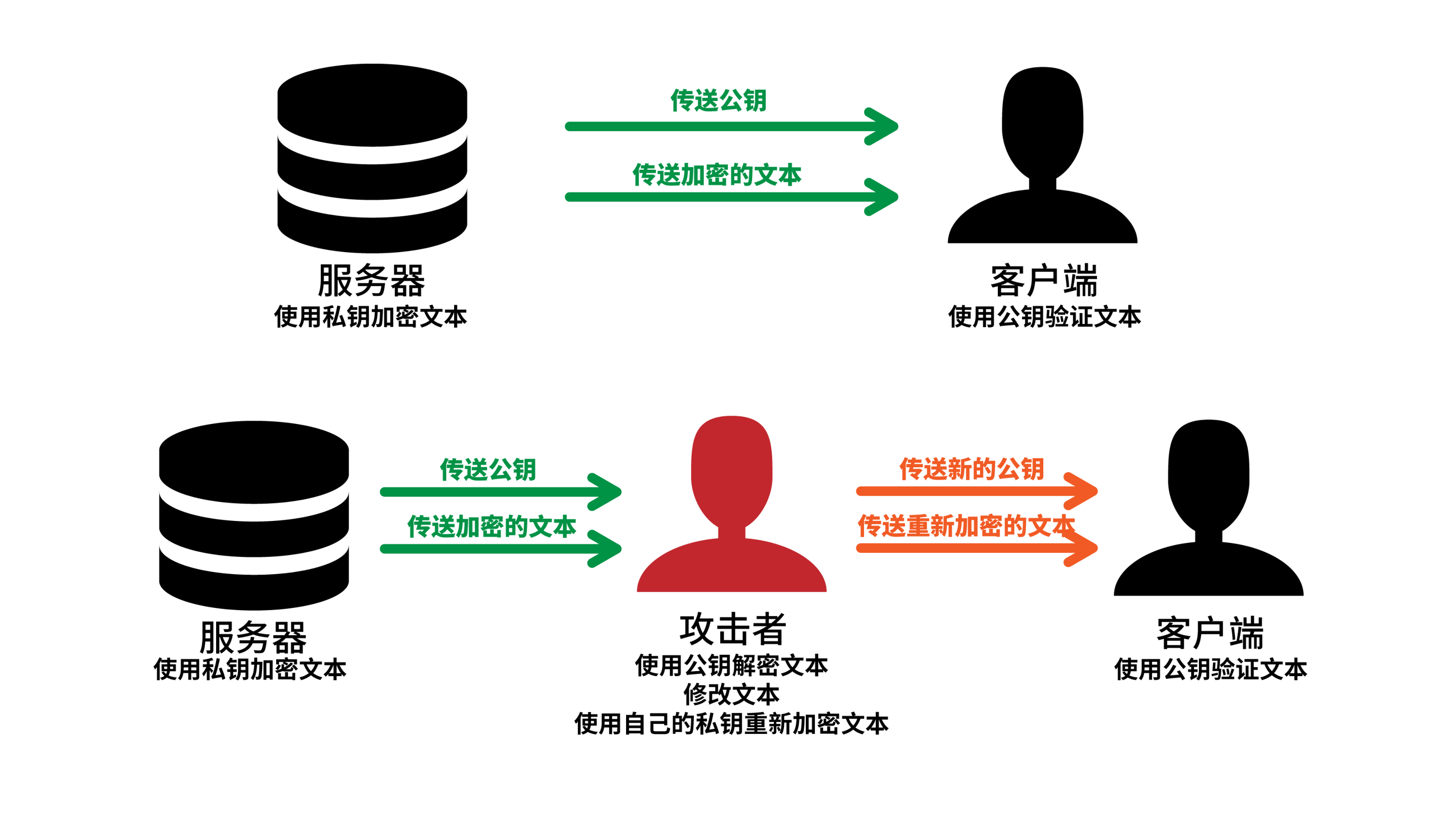
DNS 系统就是这么脆弱,和其他任何互联网服务一样,网络服务提供商、路由器管理员等均可以充当“中间人”的角色,来对客户端与服务器之间传送的数据包进行收集,甚至替换修改,从而导致客户端得到了不正确的信息。然而,通过一定的加密手段,可以防止中间人看到在互联网上传输的数据内容,或者可以知道原始的数据数据是否被中间人修改。
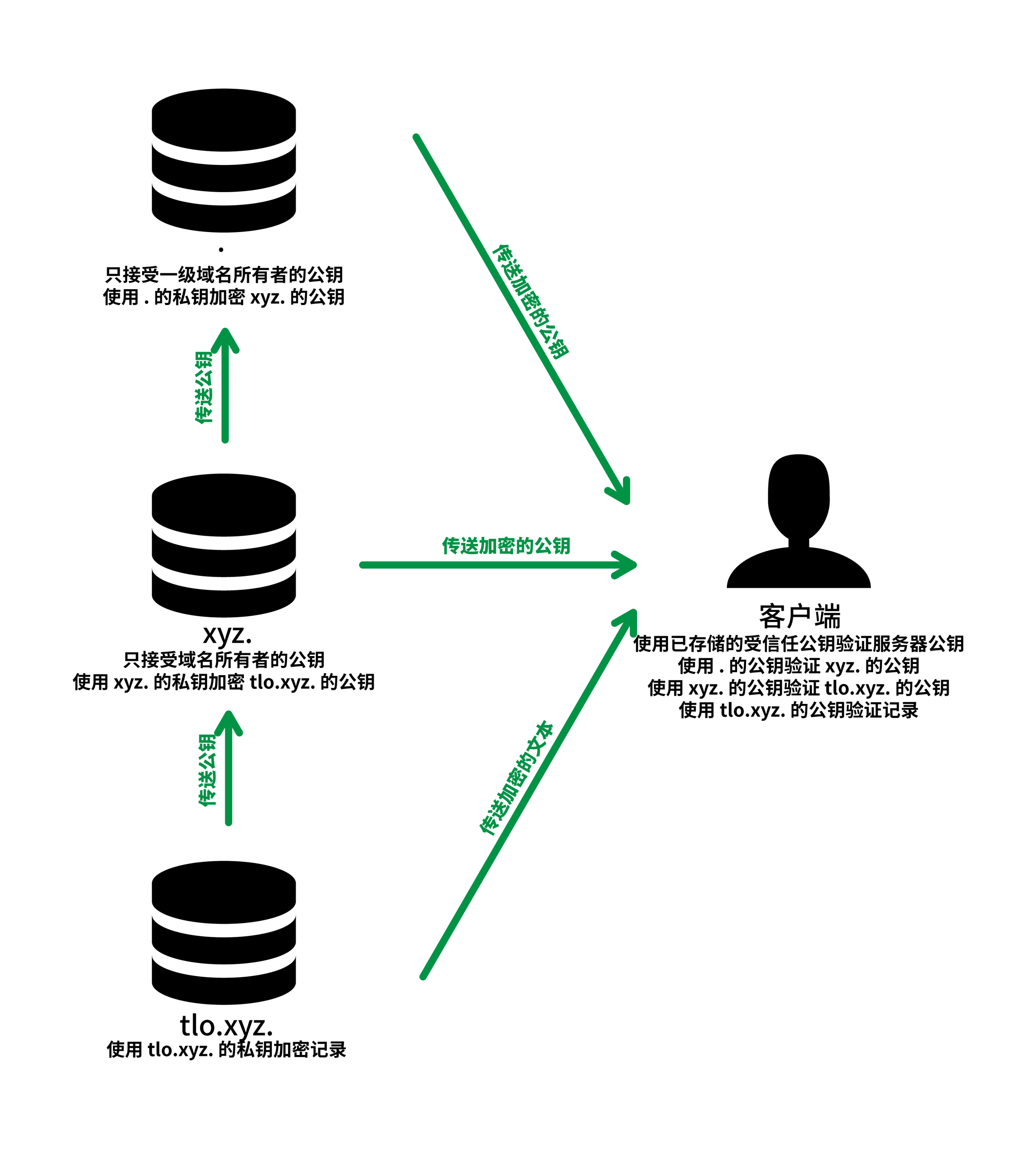
假如服务器要向客户端发送一段消息,服务器有私钥,客户端有公钥。服务器使用私钥对文本进行加密,然后传送给客户端,客户端使用公钥对其解密。由于只有服务器有私钥,所以只有服务器可以加密文本,因此加密后的文本可以认证是谁发的,并且能保证数据完整性,这样加密就相当于给记录增加了**数字签名**。但是需要注意的是,由于公钥是公开的,所以数据只是不能被篡改,但可以被监听。 此处的服务器如果是充当 DNS 服务器,那么就能给 DNS 服务带来这个特性,然而一个问题就出现了,如何传输公钥?如果公钥是使用明文传输,那么攻击者可以直接将公钥换成自己的,然后对数据篡改。
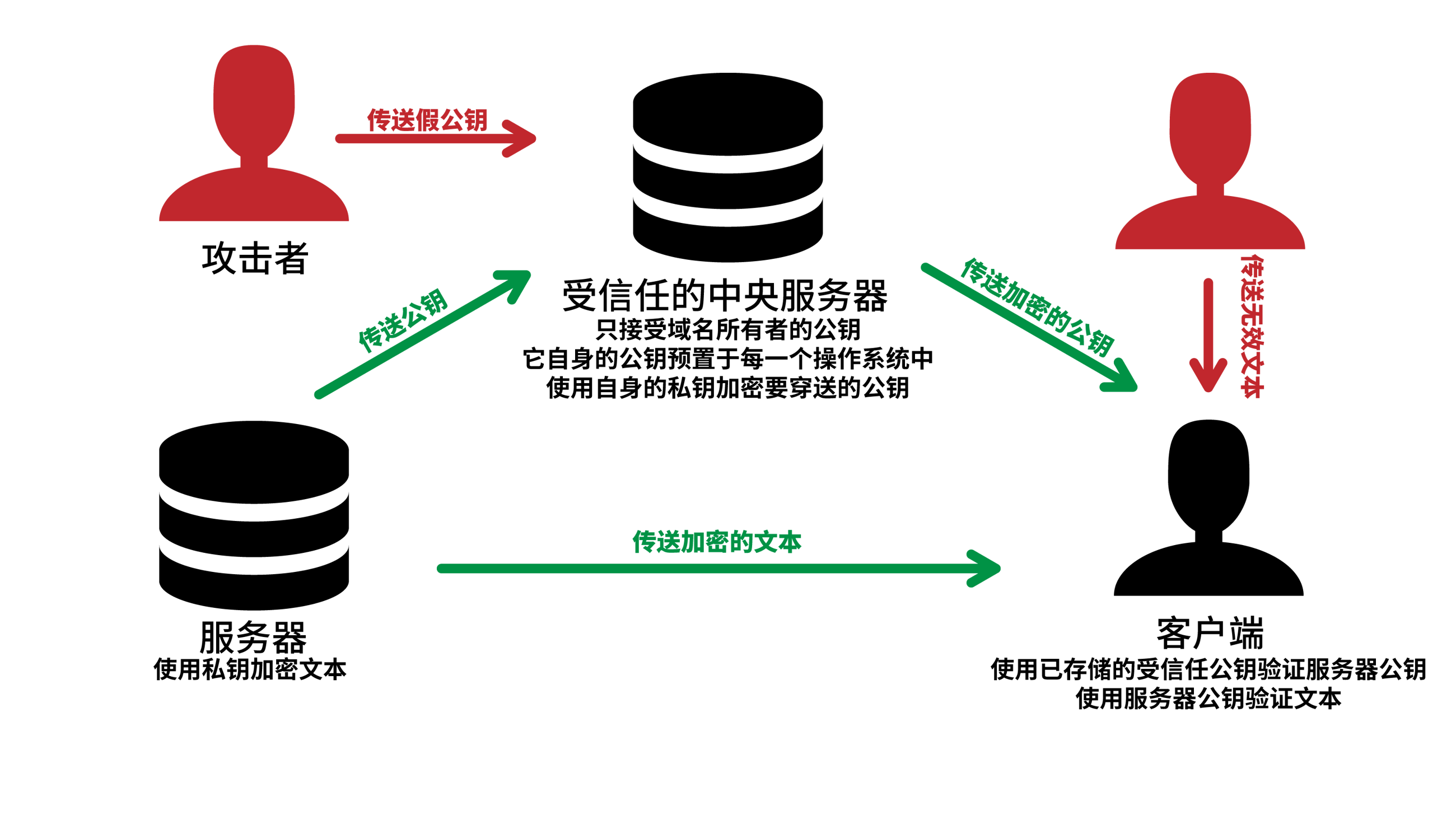
DNSSEC 这一个扩展可以为 DNS 记录添加验证信息,于是缓存服务器和客户端上的软件能够验证所获得的数据,可以得到 DNS 结果是真是假的结论。上一篇文章讲到过 DNS 解析是从根域名服务器开始,再一级一级向下解析,这与 DNSSEC 的信任链完全相同。所以部署 DNSSEC 也必须从根域名服务器开始。本文也就从根域名服务器讲起。
你发往 DNS 服务器的请求是明文的,DNS 服务器返回的请求是带签名的明文。这样 DNSSEC 只是保证了 DNS 不可被篡改,但是可以被监听,所以 DNS 不适合传输敏感信息,然而实际上的 DNS 记录几乎都不是敏感信息。HTTPS 的话会同时签名和双向加密,这样就能够传输敏感信息。 DNSSEC 的只签名,不加密主要是因为 DNSSEC 是 DNS 的一个子集,使用的是同一个端口,所以是为了兼容 DNS 而作出的东西,而 DNS 是不需要客户端与服务器建立连接的,只是客户端向服务器发一个请求,服务器再向客户端返回结果这么简单,所以 DNS 都可以使用 UDP 来传输,不需要 TCP 的握手,速度非常快。HTTPS 不是 HTTP 的子集,所以它使用的是另一个端口,为了做到加密,需要先与浏览器协商密钥,这之间进行了好几次的握手,延迟也上去了。
在哪里验证?
刚才所讲述的所有情况,都是在没有 DNS 缓存服务器的情况下。如果有 DNS 缓存服务器呢? 实际上,一些 DNS 缓存服务器就已经完成了 DNSSEC 验证,即使客户端不支持。在缓存服务器上验证失败,就直接不返回解析结果。在缓存服务器进行 DNSSEC 验证,几乎不会增加多少延迟。 但这也存在问题,如果缓存服务器到客户端之间的线路不安全呢?所以最安全的方法是在客户端上也进行一次验证,但这就会增加延迟了。
DNSSEC 的时效性和缓存
DNSSEC 相比 HTTPS 的一个特性就是 DNSSEC 是可以被缓存的,而且即使是缓存了也能验证信息的真实性,任何中间人也无法篡改。然而,既然能够缓存,就应该规定一个缓存的时长,并且这个时长也是无法篡改的。 签名是有时效性的,这样客户端才能够知道自己获得到的是最新的记录,而不是以前的记录。假如没有时效性,你的域名解析到的 IP 从 A 换到了 B,在更换之前任何人都可以轻易拿到 A 的签名。攻击者可以将 A 的签名保存下来,当你更换了 IP 后,攻击者可以继续篡改响应的 IP 为 A,并继续使用原本 A 的签名,客户端也不会察觉,这并不是所期望的。 然而在实际的 RRSIG 签名中,会包含一个时间戳(并非 UNIX 时间戳,而是一个便于阅读的时间戳),比如 20170215044626,就代表着 UTC 2017-02-15 04:46:26,这个时间戳是指这个记录的失效时间,这意味着在这个时间之后,这个签名就是无效的了。时间戳会被加进加密内容中去参与签名的计算,这样攻击者就无法更改这个时间戳。由于时间戳的存在,就限制了一个 DNS 响应可以被缓存的时长(时长就是失效时间戳减去当前时间戳)。然而,在有 DNSSEC 之前,控制缓存时长是由 TTL 决定的,所以为了确保兼容性,这两个时长应该是完全一样的。 通过这样做,即能够兼容现有的 DNS 协议,有能够保证安全,还能够利用缓存资源加快客户端的请求速度,是一个比较完美的解决方案。
会给浏览器带来一个额外的 DNS 查询时间,为了最高的安全性,浏览器应该在开始加载 HTTPS 页面(建立握手后)之前就先查询 TLSA 记录,这样才能够匹配证书是否该被信任,这样无疑增加了所有 HTTPS 页面的加载时长。
现有的 DNS 是一个不是足够稳定的东西,何况 DNSSEC 的记录类型不被一些 DNS 递归服务器所支持等,经常会由于因为种种原因遇到查询失败的问题,按照规则,TLSA 记录查询失败的话客户端也应该不加载页面。这样无疑增加了 HTTPS 页面加载的出错率,这样无疑会导致很多原本没有被中间人的网站也无法加载。
DNS 污染,在一些情况下,客户端所处的是被 DNS 污染的环境,特点就是将服务器解析到了错误的 IP 地址。然而此时中间人为了仍能够让用户访问到 HTTPS 网站,会进行类似 SNI Proxy 的操作,此时的客户端访问网站仍是比较安全的。然而显然,DANE 在 DNS 被污染后,会直接拒绝加载页面,这样被 DNS 污染的环境会有大量站点无法加载。
然而我认为这些都不是什么问题。为了解决 DNS 的问题,可以使用 Google DNS-over-HTTPS,这样的话就能避免很多 DNS 污染的问题,而且由于 DNSSEC 本身包含签名,Google 是无法对返回内容篡改的。那么直至现在,TLSA 就只存在最后一个问题:为了获取 TLSA 记录而增加的加载延迟。而这也可以完美解决,OCSP 就是一个例子,现在传统的 CA 为了实现吊销机制,也都有 OCSP:
OCSP(Online Certificate Status Protocol,在线证书状态协议)是用来检验证书合法性的在线查询服务,一般由证书所属 CA 提供。为了真正的安全,客户端会在 TLS 握手阶段进一步协商时,实时查询 OCSP 接口,并在获得结果前阻塞后续流程。OCSP 查询本质是一次完整的 HTTP 请求,导致最终建立 TLS 连接时间变得更长。
这样,在开始正式开始加载页面,客户端也需要进行一次 HTTP 请求去查询 OCSP。OCSP 也会十分影响页面加载速度,也同样会增加加载页面出错的可能。而 OCSP 有了 OCSP Stapling,这样的话 Web 服务器会预先从 CA 获取好 OCSP 的内容,在与 Web 服务器进行 HTTPS 连接时,这个内容直接返回给客户端。由于 OCSP 内容包含了签名,Web 服务器是无法造假的,所以这一整个过程是安全的。同理,TLSA 记录也可以被预存储在 Web 服务器中,在 TLS 握手阶段直接发送给客户端。这就是 DNSSEC/DANE Chain Stapling,这个想法已经被很多人提出,然而直至现在还未被列入规范。也许浏览器未来会支持 TLSA,但至少还需要很长一段时间。
传统 CA 机制所特有的优势
传统的证书配合了现在的 Certificate Transparency,即使不需要 TLSA 记录,也能一定程度上保证了证书签发的可靠性。此外,传统证书也可以使用 TLSA,其本身的安全性不比 DANE 自签名差。 此外,传统 CA 签发的证书还有自签名证书做不到的地方:
OV 以及 EV 证书:DANE 自签名的证书其实就相当于 CA 签发的 DV 证书,只要是域名所有者,就能够拥有这种证书。然而很多 CA 同时还签发 OV 和 EV 证书,OV 证书可以在证书内看到证书颁发给的组织名称,EV 则是更突出的显示在浏览器上:在 Chrome 的地址栏左侧和 HTTPS 绿锁的右侧显示组织名称;Safari 则甚至直接不显示域名而直接显示组织名称。OV 和 EV 的特点就是,你甚至都不用去思考这个域名到底是不是某个组织的,而直接看证书就能保证域名的所有者。而 DV 证书可能需要通过可靠的途径验证一下这个域名到底是不是某个组织的。比如在你找一家企业官网的时候,有可能会碰到冒牌域名的网站,而你不能通过网站是否使用了 HTTPS 而判断网站是否是冒牌的——因为冒牌的网站也可以拿到 DV 证书。而当你发现这个企业使用了 OV 或 EV 证书后,你就不用再去考虑域名是否正确,因为冒牌的网站拿不到 OV 或 EV 证书。在申请 OV 或 EV 证书时,需要向 CA 提交来自组织的申请来验证组织名称,而由于 DANE 证书是自签发的,自然也不能有 OV 或 EV 的效果。
IP 证书:CA 可以给 IP 颁发证书(尽管这很罕见),这样就可以直接访问 HTTPS 的 IP。而 DANE 基于域名系统,所以不能实现这一点
$ ssh guozeyu.comThe authenticity of host 'guozeyu.com (104.199.138.99)' can't be established.ECDSA key fingerprint is SHA256:TDDVGvTLUIYr6NTZQbXITcr7mjI5eGCpqWFpXjJLUkA.Are you sure you want to continue connecting (yes/no)?
If you’re developing a new app, you should use HTTPS exclusively. If you have an existing app, you should use HTTPS as much as you can right now, and create a plan for migrating the rest of your app as soon as possible. In addition, your communication through higher-level APIs needs to be encrypted using TLS version 1.2 with forward secrecy. If you try to make a connection that doesn’t follow this requirement, an error is thrown. 如果你正在开发一个新的程序,你仅应该使用 HTTPS。如果你已经有一个程序,你现在就应该尽可能多的使用 HTTPS,并准备好对剩下部分迁移的计划。另外,如果你的程序使用更高层级的 API 进行通信,则需要使用 TLS 1.2 或以上的版本。如果你试图建立一个不遵守这些需求的通信,就会引发错误。
去年11月,苹果用户在一次影响广泛的宕机事故后才知道:苹果监视了用户打开和启动的每一个应用程序(编程随想注:上一期谈过这个重大丑闻【OCSP 事件】)
苹果为什么要这么做?最为善意的猜测是:此举旨在更早发现恶意程序。在一个充斥着恶意的网络世界里,这么做是必要的。安全专家 Bruce Schneier 将这种现象形容为“封建式安全”。
生活在21世纪的我们,面临各种数字强盗的围攻。从身份窃贼,到跟踪者,到企业和政府间谍,到骚扰者。我们是没有办法自保的。即使是身经百战的专家也无法和强盗相抗衡。为了抵抗强盗,你必须做到完美,不犯任何错误。而强盗只要抓住一个错误就能逮住你。因此为了安全起见,你必须和数字军阀结盟。苹果、Google、Facebook 和微软等建立了庞大的要塞,它们投入了大量金钱招募了最强的雇佣兵来保护要塞,为客户(包括你)抵御攻击者。
但如果军阀们转向了你,你对它们而言将是赤裸裸的。这种敌我难辨的情况在与军阀打交道的过程中一直发生着。比如 Google 调整 Chrome 以阻止商业监视(但不阻止它自己的商业监视)。Google 会努力阻止其他人监视你,但如果他们付钱了,Google 就会允许他们监视你。
如果你不在乎被 Google 监视,如果你信任由 Google 判断谁是骗子谁不是,那么这没问题。但如果你们之间存在不一致的意见,那么输的肯定是你。苹果在2017年按中国要求从其应用商店下架了保护隐私的工具。原因是苹果必须遵守中国的法律,它在中国有公司,有制造基地。军阀自身的安全是远甚于客户的。
编程随想注:
俺的观点是:要善于【扬长避短】——既要利用大公司提供的某些优质服务,同时又不让大公司窥探你的隐私。
当然啦,要做到这点,需要一些经验&技巧。
就拿本人的亲身经历举例——
一方面,俺用着 Google 的博客平台 Blogspot(它的安全性足够好,而且能抵御【国家级】的 DDOS 攻击)。
另一方面,俺不用 Google 搜索(俺用的是 Startpage,其搜索质量等同 Google);另外,俺也不使用 Google 开发的 Chrome 浏览器。
编程随想注:
该漏洞编号 CVE-2021-24093,影响 Windows 10 & Windows Server 2016。这是 Google 安全研究人员在去年11月发现并报告给微软。而微软直到今年(2021)2月的例行更新才修复。
漏洞位于 DirectWrite API 进行字体渲染的代码中(缓冲区溢出)。Windows 平台上的浏览器(Chrome、Firefox、Edge、IE)都会使用系统提供的 API 进行字体渲染,因此都会受此影响。
为了利用这个漏洞,攻击者可以创建一个 Web 页面,其中包含精心构造的字体,然后诱导受害者访问该页面。当受害者的浏览器打开该页面时,就中招了。由于此漏洞针对“字体渲染”,与 JS【无关】。因此,即使浏览器禁用了 JS 脚本,还是会中招。
在上一期的《近期安全动态和点评(2020年4季度)》中,俺介绍过另一个漏洞 CVE-2020-15999,与这个很类似。CVE-2020-15999 位于“FreeType 字体渲染库”。也是利用“Web 页面的字体”来实现远程代码执行。
在上一期,俺说过如下这句,今天再次贴出来:
假如你很注重安全性,为了更彻底地消除【字体】导致的攻击面,你可以定制浏览器,禁止在 Web 页面中加载外来的字体。
对 Firefox 的深度定制,可以参考教程《扫盲 Firefox 定制——从“user.js”到“omni.ja”》;对其它浏览器的深度定制,俺暂时还没写过教程。
The two RCE(注:Remote Code Execution)vulnerabilities are complex which make it difficult to create functional exploits, so they are not likely in the short term. We believe attackers will be able to create DoS exploits much more quickly and expect all three issues might be exploited with a DoS attack shortly after release.
KrebsOnSecurity 援引消息来源报道,至少三万家美国机构——包括大量的小企业和各级政府被黑客组织利用微软电邮软件 Microsoft Exchange Server 的漏洞入侵。
微软本周披露,黑客正在利用 Exchange Server v2013 到 v2019 中的四个 0day 漏洞。在漏洞披露的三天内,安全专家称:同一黑客组织增加了对尚未修补的 Exchange 服务器的攻击,在入侵之后攻击者留下一个可以后续访问的 web shell。微软表示正与美国网络安全和基础设施安全局密切合作,为客户提供最佳的指南和缓解措施。
......
这些漏洞(CVE-2021-27363、CVE-2021-27364 和 CVE-2021-27365)存在于内核的 iSCSI 模块中。虽然在默认情况下该模块是没有被加载的,但是 Linux 内核对模块“按需加载的特性”意味着它可以很容易地被本地触发。安全专家在 Red Hat 所有已测试版本和其他发行版本中发现这些漏洞。
在 GRIMM 博客上,安全研究员 Adam Nichols 表示:“我们在 Linux mainline 内核的一个被遗忘的角落里发现了3个 BUG,这些 BUG 已经有15年的历史了。与我们发现的大多数积满灰尘的东西不同,这些 BUG 依然存在影响,其中一个可以作为本地权限升级(LPE)在多个 Linux 环境中使用”。
......
DNS-over-HTTPS(DoH)加密了 DNS 请求, 被用于规避 DNS 污染。
根据 greatfire.org 的测试结果:NextDNS、Quad9、AdGuard 在近日被屏蔽。防火墙对这些域名没有使用 DNS 污染, 而是使用检测 SNI 和 IP 黑洞的方法。Cloudflare 的 DoH 服务器还没有被屏蔽。
Google 周一宣布它可能找到了 cookies 的隐私友好替代。它测试了名为 Federated Learning of Cohorts(FLoC)的新 API,其源代码发布在 GitHub 上。
测试显示,相比基于 cookies 的广告,FLoC 广告的转化率至少达到 95%。FLoC 使用机器学习算法分析用户数据,然后根据用户访问的网站,将数千用户分成一组。数据是浏览器在本地收集的不会分享出去,但这群用户的数据会共享并被用于定向广告。也就是说 FLoC 广告是根据人们的普遍兴趣进行针对性展示。
编程随想注:
这个玩意儿到底是不是“隐私友好”?目前俺了解有限,暂时无法从技术角度发表意见。
考虑到 Google 的商业模式(主要利润来自于【在线广告收入】),俺不太相信所谓的“隐私友好”。
Google 在今年初宣布了 Cookies 的替代 Federated Learning of Cohorts (FLoC),声称它对用户隐私更为友好。但这一计划引发了美国司法部调查人员的关切,调查人员一直在问询广告行业的高管,以了解 Google 此举是否会妨碍规模较小的竞争对手。
消息人士表示,司法部调查人员的询问涉及到 Chrome 的各种政策,包括与 cookies 相关的规定,对于广告和新闻产业产生哪些影响。
Chrome 浏览器的全球市占率约 60%。消息人士并指出,调查人员正询问 Google 是否利用 Chrome 来避免对手广告公司通过 cookies 追踪用户,同时留下漏洞供自己用 cookies、分析工具、以及其他资源来收集资料,从而降低竞争。
Google Chrome Team 团队向 Linux 发行版开发者发去邮件通知,从3月15日起,在构建配置中使用 google_default_client_id 和 google_default_client_secret 的第三方 Chromium 版本,它们的终端用户将无法再登陆其 Google Accounts 账号。
Google 称,他们在最近的审计中发现部分基于 Chromium 的浏览器使用了原本只给 Google 使用的 Google API 和服务,其中最主要的是同步账号的 Chrome Sync API,它决定移除这些 API 的访问,声称这是为了改进用户数据安全。
Linux 发行版开发者表示过去十年他们一直这么做的,如果无法使用 Google 的同步功能,那么继续维护 Chromium 软件包也没有什么价值了。Chrome 的工程总监 Jochen Eisinger 在回复中表示他们的决定不会改变。Slackware Linux 和 Arch Linux 都表示考虑从仓库移除 Chromium。
When an iPhone has been off and boots up, all the data is in a state Apple calls 【Complete Protection】. The user must unlock the device before anything else can really happen, and the device's privacy protections are very high. You could still be forced to unlock your phone, of course, but existing forensic tools would have a difficult time pulling any readable data off it. Once you've unlocked your phone that first time after reboot, though, a lot of data moves into a different mode—Apple calls it "Protected Until First User Authentication", but researchers often simply call it 【After First Unlock】(注:简称 AFU).
If you think about it, your phone is almost always in the AFU state. You probably don't restart your smartphone for days or weeks at a time, and most people certainly don't power it down after each use. (For most, that would mean hundreds of times a day.) So how effective is AFU security? That's where the researchers started to have concerns.
The main difference between Complete Protection and AFU relates to how quick and easy it is for applications to access the keys to decrypt data. When data is in the Complete Protection state, the keys to decrypt it are stored deep within the operating system and encrypted themselves. But once you unlock your device the first time after reboot, lots of encryption keys start getting stored in quick access memory, even while the phone is locked. At this point an attacker could find and exploit certain types of security vulnerabilities in iOS to grab encryption keys that are accessible in memory and decrypt big chunks of data from the phone.
......
编程随想注:
关于“手机的危险性”,本博客已经唠叨过无数次了。俺反复告诫大伙儿(尤其是政治敏感人士),【不要】使用手机进行敏感的活动。
上述这篇洋文会告诉你,政府执法机构(警方 or 国安部门)破解手机其实比多数人想象的更容易,不论是 iOS 或 Android,都容易。
俺特意摘出上述三段洋文,其大意是:在【开机且解锁过一次】的状态下,即使手机屏幕已锁定,也很容易破解。关键在于,开机第一次解锁之后,全盘加密的【密钥】就会位于【内存】中。此时,“手机取证软件”只要能利用某种系统漏洞 or 软件漏洞,拿到内存中的“全盘加密密钥”,就 OK 啦。
作为对比,如果是在【关机】状态下,破解的难度就大得多(但依然有可能破解)。
假如你看不懂洋文,可以去看系列教程《TrueCrypt 使用经验》的第3篇——专门谈“加密盘的破解与防范”,其中有介绍【盗取密钥】这招的原理。
都柏林大学圣三一学院的 Douglas J. Leith 教授跟踪了(PDF)iOS 和 Android 设备向苹果和 Google 服务器发送的遥测数据,发现 Google 收集的数据二十倍于苹果。
Leith 教授称,研究考虑了操作系统本身收集的数据以及操作系统供应商提供的默认应用收集的数据,云端存储,地图/位置服务等,只计算遥测数据。
Leith 教授指出,即使用户选择退出遥测,iOS 和 Android 仍然会发送遥测数据。苹果收集了更多的信息数据类型,但 Google 收集的数据量要多得多。开机10分钟内,Pixel 手机向 Google 发送了 1MB 数据,而 iPhone 发送了 42KB;在闲置状态下,Pixel 手机每12小时向 Google 发送 1MB 数据,相比之下 iPhone 只向苹果发送 52KB 数据。
当新的 SIM 卡插入到设备中,相关信息会立即与苹果和 Google 共享。设备上预装的应用被发现在未启动或使用前就会连接苹果和 Google 服务器。Google 发言人用汽车收集数据为它收集数据辩护。
There's a Kaili Linux training suite available called Kali Linux Dojo, where users can learn how to customize their own Kali ISO and learn the basics of pentesting. All of these resources are available on Kali's website, free of charge. Kali Linux also boasts a paid-for pentesting course that can be taken online, with a 24-hour certification exam. Once you pass this exam, you're a qualified pentester!
Parrot OS
Why We Love Parrot OS:
The distro provides pentesters and digital forensics experts with the best of both worlds - a state-of-the-art "laboratory" with a full suite of tools accompanied by standard privacy and security features.
Applications that run on Parrot OS are fully sandboxed and protected.
Parrot OS is fast, lightweight and compatible with most devices.
BlackArch Linux
Why We Love BlackArch Linux:
BlackArch Linux offers a large selection of hacking tools and preconfigured Window Managers.
The distro provides an installer with the ability to build from source.
Users can install tools either individually or in groups with the modular package feature.
Whonix
Why We Love Whonix:
Whonix comes with the Tor Browser and the Tox privacy instant messenger application - ensuring fully-anonymous web browsing and instant messaging.
The OS employs an innovative Host/Guest design to conceal users' identity behind the anonymous proxy and prevent IP and DNS leaks.
The distro features pre-setup Mozilla Thunderbird PGP email.
编程随想注:
关于 Meltdown & Spectre 漏洞,去年和前年的《近期安全动态和点评》都有聊过。
在今年(2021)之前,对这俩漏洞还停留在“理论”阶段;到了今年2月份,在线查毒引擎 VirusTotal 首次发现与这两个漏洞相关的攻击代码,分别针对 Windows & Linux。这也就意味着:对这两个漏洞的研究,已经从“理论”上升到“实践”。
这两个漏洞源于 CPU 硬件的设计缺陷,很难根治;而且受影响的 CPU 很多,波及面从 x86 系列到 ARM 系列。
俺在《近期安全动态和点评(2019年1季度)》提到如下这段话:
一年前(2018年初)曝光的 Spectre 和 Meltdown 在信息安全界可以称得上是【划时代】滴!因为其利用的是 CPU 的【设计缺陷】(而且还是【根本性】缺陷)。
......
由于这两个漏洞涉及到 CPU 的【根本性】缺陷,极难搞定(就像两个幽灵,会在未来几年不断困扰 IT 行业)。
伊利诺伊香槟的三位研究人员在预印本网站 arXiv 发表论文,披露了针对英特尔 CPU 的最新侧信道攻击,该攻击被命名为 Lord of the Ring(s)。
随着芯片上的功能模块越来越多,英特尔为其 CPU 引入了片内总线,以实现各个模块之间的高速通信,它先后引入了 Ring Bus 和 Mesh Bus。最新侧信道攻击针对的就是 Ring Bus 的环形总线。研究人员首先逆向工程了 Ring Bus 的通信协议,设法构建了一个跨核心的隐蔽信道,利用环争用的细粒度时态模式去推动应用程序的秘密。从有漏洞的 EdDSA 和 RSA 实现中提取出密钥比特。对于 AMD 的 Zen 架构使用的片内总线 Infinity Fabric,研究人员表示需要进一步的研究,但相信他们的技术能应用于其它平台。
Google 资助了 Internet Security Research Group(ISRG)的一个项目:用 Rust 语言为 Apache HTTP web server 项目开发安全模块 mod_tls。
在 Apache web server 中,mod_ssl 用于支持建立 HTTPS 连接所需的加密操作,它是用 C 语言开发的。
新的 mod_tls 模块将使用 Rust 语言开发,领导该项目开发的是软件咨询公司 Greenbytes 的创始人和 Apache HTTP Server 开发者 Stefan Eissing。ISRG 希望,在完成开发之后 Apache HTTP web server 团队将采用 mod_tls 作为默认模块,取代年代悠久且不安全的 mod_ssl。
“OSI”的全称是“Open System Interconnection”。先说说它的历史。
上世纪70年代,“国际电信联盟”(ITU)想对各国的电信系统(电话/电报)建立标准化的规格;与此同时,“国际标准化组织”(ISO)想要建立某种统一的标准,使得不同公司制造的大型主机可以相互联网。
后来,这两个国际组织意识到:“电信系统互联”与“电脑主机互联”的性质差不多。于是 ISO 与 ITU 就决定合作,两家一起干。这2个组织的2套班子,从上世纪70年代开始搞,搞来搞去,搞了很多年,一直到1984年才终于正式发布 OSI 标准。
(前面说了)OSI 是由 ISO & ITU 联手搞出来滴。这两个国际组织里面的人,要么是来自各国的电信部门,要么是来自各国的高校学者。总而言之,既有严重的官僚风气,又有明显的学究风气。(正是因为这两种风气叠加,所以搞了很多年,才搞出 OSI)
OSI 的协议实现(OSI protocols),不客气地说,就是一堆垃圾——据说把 OSI protocols 所有的协议文档,全部打印成 A4 纸,摞起来得有一米多高!是不是很吓人?协议搞得如此复杂,严重违背了 IT 设计领域的 KISS 原则。
由于 OSI protocols 实在太复杂,后来基本没人用。但 OSI model 反而广为流传,并且成为“网络分层模型”中名气最大,影响力最广的一个。
因此,本文后续章节中,凡是提到 OSI,指的是【OSI model】。
◇OSI 模型的7层
OSI 模型总共分7层,示意图参见如下表格:
层次
中文名
洋文名
第7层
应用层
Application Layer
第6层
表示层
Presentation Layer
第5层
会话层
Session Layer
第4层
传输层
Transport Layer
第3层
网络层
Network Layer
第2层
数据链路层
Data Link Layer
第1层
物理层
Physical Layer
(注:为了打字省力,在后续章节把“数据链路层”直接称为“链路层”)
考虑到本文是针对一般性读者的【扫盲教程】,俺重点聊第1~4层。搞明白这几个层次之后,有助于你更好地理解网络的很多概念,也有助于你更好地理解很多信息安全的概念。
网上已经有很多关于 OSI 的文章,可惜大部分写得粗糙——很多文章只是在照抄定义。
俺曾经写过一篇《学习技术的三部曲:WHAT、HOW、WHY》,其中提到【理解技术】的不同层次。要想更好地理解 OSI 模型,你得搞明白:为啥需要引入某某层?(请注意:这是一个 WHY 型的问题)
接下来在讨论 OSI 的每个层次时,俺都会专门写一个小节,谈该层次的【必要性】。搞明白【必要性】,你就知道为啥要引入这个层次。
另外,很多同学应该都用过“USB hub”,就是针对 USB 线的“集线器”(“USB 线”也可以视作某种通讯介质)。
★链路层:概述
◇链路层的必要性
对信息的打包
物理层传输的信息,通俗地说就是【比特流】(也就是一长串比特)。但是对于计算机来说,“比特流”太低级啦,处理起来极不方便。“链路层”要干的第一个事情,就是把“比特流”打包成更大的一坨,以方便更上层的协议进行处理。在 OSI 模型中,链路层的一坨,称之为“帧”(frame)。
差错控制
物理介质的传输,可能受到环境的影响。这种影响不仅仅体现为“噪声”,有时候会出现严重的干扰,导致物理层传输的“比特流”出错(某个比特“从0变1”或“从1变0”)。因此,链路层还需要负责检查物理层的传输是否出错。在 IT 行话中,检测是否出错,称之为“差错控制机制”(后面有一个小节会简单说一下这个话题)。
“MAC 协议”用来确保对下层物理介质的使用,不会出现冲突。为了形象,俺拿“铁路系统”来比喻,说明“MAC 协议”的用途。
假设有一条【单轨】铁路连接 A/B 两地。有很多火车想从 A 开到 B,同时还有很多火车想从 B 开到 A。
首先,要确保不发生撞车(如果已经有车在 A 开往 B 的途中,那么 B 就不能再发车);其次,即使是同一个方向的车,出发时间也要错开一个时间间隔。
所有这些协调工作,都是靠“MAC 协议”来搞定。
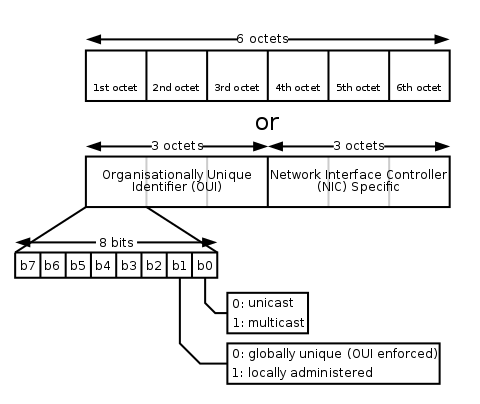
如何保证 MAC 地址全球唯一捏?简单说一下:
MAC 地址包含6个字节(48个比特),分为两半。第一部分称作【OUI】,OUI 的24个比特中,其中2个比特有特殊含义,其它22个比特,用来作为网卡厂商的唯一编号。这个编号由国际组织 IEEE 统一分配。
MAC 地址第二部分的24比特,由网卡厂商自己决定如何分配。每个厂商只要确保自己生产的网卡,后面这24比特是唯一的,就行啦。
(MAC 地址的构成)
由于俺在很多安全教程中鼓吹大伙儿使用“操作系统虚拟机”,再顺便说说【虚拟网卡】的 MAC 地址。
“虚拟网卡”是由【虚拟化软件】创建滴。IEEE 也给每个虚拟化软件的厂商(含开源社区)分配了唯一的 OUI。因此,虚拟化软件在创建“虚拟网卡”时,会使用自己的 OUI 生成前面24个比特;后面的24比特,会采用某种算法使之尽可能【随机化】。由于“2的24次方”很大(224 = 16777216),碰巧一样的概率很低。
(注:如果手工修改 MAC 地址,故意把两块网卡的 MAC 地址搞成一样,那确实就做不到唯一性了。并且会导致链路层的通讯出问题)
网络交换机(network switch)
(注:一般提到“网络交换机”,如果不加定语,指的就是“2层交换机”;此外还有更高层的交换机,在后续章节介绍)
为啥要有交换机捏?俺拿“以太网的发展史”来说事儿。
以太网刚诞生的时候,称之为“经典以太网”,电脑是通过【集线器】相连。“集线器”前面提到过,工作在【1层】(物理层),并不理解链路层的协议。因此,集线器的原理是【广播】模式——它从某个网线接口收到的数据,会复制 N 份,发送到其它【每个】网线接口。假设有4台电脑(A、B、C、D)都连在集线器上,A 发数据给 B,其实 C & D 也都收到 A 发出的数据。显然,这种工作模式很傻逼(低效)。由于“经典以太网”的工作模式才“10兆”,所以集线器虽然低效,还能忍受。
后来要发展“百兆以太网”,再用这种傻逼的广播模式,就不能忍啦。于是“经典以太网”就发展为“交换式以太网”。用【交换机】代替“集线器”。
交换机是工作在2层(链路层)的设备,能够理解链路层协议。当交换机从某个网线接口收到一份数据(链路层的“帧”),它可以识别出“链路帧”里面包含的目标地址(接收方的 MAC 地址),然后只把这份数据转发给“目标 MAC 地址相关的网线接口”。
由于交换机能识别2层协议,它不光比集线器的性能高,而且功能也强得多。比如(稍微高级点的)交换机可以实现“MAC 地址过滤、VLAN、QoS”等多种额外功能。
网桥/桥接器(network bridge)
“交换机”通常用来连接【同一种】网络的设备。有时候,需要让两台不同网络类型的电脑相连,就会用到【网桥】。
下面以“操作系统虚拟机”来举例(完全没用过虚拟机的同学,请跳过这个举例)。
在这篇博文,俺介绍了虚拟机的几种“网卡模式”,其中有一种模式叫做【bridge 模式】。一旦设置了这种模式,Guest OS 的虚拟网卡,对于 Host OS 所在的外部网络,是【双向】可见滴。也就是说,物理主机所在的外部网络,也可以看见这块虚拟网卡。
现在,假设你的物理电脑(Host OS)只安装了【无线网卡】(WiFi),而虚拟化软件给 Guest OS 配置的通常是【以太网卡】。显然,这是两种【不同】的网络。为啥 Guest OS 的以太网卡设置为“bridge 模式”之后,外部 WiFi 网络可以看到它捏?
奥妙在于——虚拟化软件在内部悄悄地帮你实现了一个“网桥”。这个网桥把“Host OS 的 WiFi 网卡”与“Guest OS 的以太网卡”关联起来。WiFi 网卡收到了链路层数据之后,如果接收方的 MAC 地址对应的是 Guest OS,网桥会把这份数据丢给 Guest OS 的网卡。
这种网卡模式之所以称作“bridge 模式”,原因就在于此。
ARP 命令
首先,ARP 是“MAC 地址解析协议”的洋文名称。该协议根据“IP 地址”解析“MAC 地址”。
Windows 自带一个同名的 arp 命令,可以用来诊断与“MAC 地址”相关的信息。比如:列出当前子网中其它主机的 IP 地址以及对应的 MAC 地址。这个命令在 Linux & Mac OS 上也有。
★网络层:概述
◇网络层的必要性
路由机制(routing)
在 OSI 模型中,链路层本身【不】提供路由功能。你可以通俗地理解为:链路层只处理【直接相连】的两个端点(注:这么说不完全严密,只是帮助外行理解)
对于某个复杂网络,可能有很多端点,有很复杂的拓扑结构。当拓扑足够复杂,总有一些端点之间【没有直连】。那么,如何在这些【没有直连】的端点之间建立通讯捏?此时就需要提供某种机制,让其它端点帮忙转发数据。这就需要引入“路由机制”。
为了避免把“链路层”搞得太复杂,路由机制放到“链路层”之上来实现,也就是“网络层”。
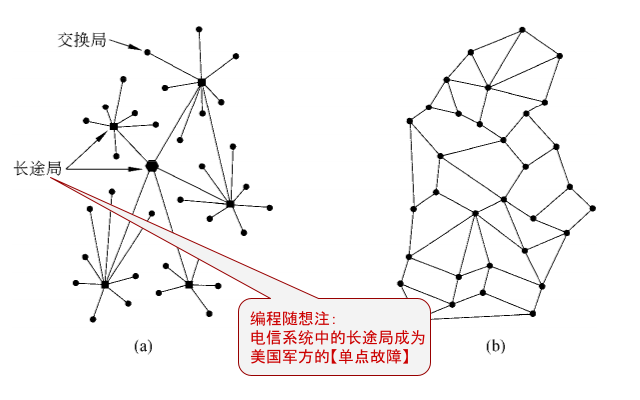
在上世纪50年代(冷战高峰期),美国军方的指挥系统高度依赖于电信公司提供的电话网络。当时的电话网络大致如下——
在基层,每个地区有电话交换局,每一部电话都连入当地的交换局。
在全国,设有若干个长途局,每个交换局都接入某个特定的长途局(不同地区的交换局通过长途局中转)。
简而言之,当时美国的电话网络是典型的【多级星形拓扑】。这种拓扑的优点是:简单、高效、便于管理;但缺点是:健壮性很差。从这个案例中,大伙儿可以再次体会到“效率”与“健壮性”之间的矛盾。俺写过一篇很重要的博文(这里)深入讨论了这个话题。
话说1957年的时候,苏联成功试射第一颗洲际弹道导弹(ICBM),美国军方开始担心:一旦苏联先用洲际导弹攻击美国,只要把少数几个长途局轰掉,军方的指挥系统就会瘫痪。也就是说,“长途局”已经成为美国军方的【单点故障】(何为“单点故障”?参见这篇博文)。
1960年,美国国防部找来大名鼎鼎的兰德公司进行咨询,要求提供一个应对核打击的方案。该公司的研究员 Paul Baran 设计了一个方案,把“星形拓扑”改为【网状拓扑】。采用【网状拓扑】的好处在于:即使发生全面核大战,大量骨干节点被摧毁,整个网络也不会被分隔成几个孤岛,军方的指挥系统依然能正常运作。
聊完“拓扑”,再来聊“路由”。
当主机 A 向主机 B 发送网络层的数据时,大致会经历如下步骤:
1.
A 主机的协议栈先判断“A B 两个地址”是否在同一个子网(“子网掩码”就是用来干这事儿滴)。
如果是同一个子网,直接发给对方;如果不是同一个子网,发给本子网的【默认网关】。
(此处所说的“网关”指“3层网关/网络层网关”)
2.
对于“默认网关”,有可能自己就是路由器;也可能自己不是路由器,但与其它路由器相连。
也就是说,“默认网关”要么自己对数据包进行路由,要么丢给能进行路由的另一台设备。
(万一找不到能路由的设备,这个数据就被丢弃,于是网络通讯出错)
3.
当数据到达某个路由器之后,有如下几种可能——
3.1
该路由器正好是 B 所在子网的网关(与 B 直连),那就把数据包丢给 B,路由过程就结束啦;
3.2
亦或者,路由器会把数据包丢给另一个路由器(另一个路由器再丢给另一个路由器) ...... 如此循环往复,最终到达目的地 B。
3.3
还存在一种可能性:始终找不到“主机 B”(有可能该主机“断线 or 关机 or 根本不存在”)。为了避免数据包长时间在网络上闲逛,还需要引入某种【数据包存活机制】(洋文叫做“Time To Live”,简称 TTL)。
通常会采用某个整数(TTL 计数)表示数据包能活多久。当主机 A 发出这个数据包的时候,这个“TTL 计数”就已经设置好了。每当这个数据包被路由器转发一次,“TTL 记数”就减一。当 TTL 变为零,这个数据包就死了(被丢弃)。
对于某些大型的复杂网络(比如互联网),每个路由器可能与其它 N 个路由器相连(N 可能很大)。对于上述的 3.2 情形,它如何判断:该转发给谁捏?
这时候,“路由算法”就体现出价值啦——
一般来说,路由器内部会维护一张【路由表】。每当收到一个网络层的数据包,先取出数据包中的【目标地址】,然后去查这张路由表,看谁距离目标最近,就把数据包转发给谁。
上面这段话看起来好像很简单,其实路由算法挺复杂滴。考虑到本文是“扫盲性质”,而且篇幅已经很长,不可能再去聊“路由算法”的细节。对此感兴趣的同学,可以去看《计算机网络》的第5章。
◇路由算法的演变史(以互联网为例)
(技术菜鸟可以跳过这个小节)
由于互联网的 IP 协议已经成为“网络层协议”的事实标准,俺简单聊一下互联网的路由机制是如何进化滴。
(技术菜鸟可以跳过这个小节)
前面聊“互联网诞生”,说到兰德公司的“Baran 方案”。该方案对当时的电信系统提出几大革命性的变化,其中之一就是“分组交换”技术(也称“数据包交换”or“封包交换”)。
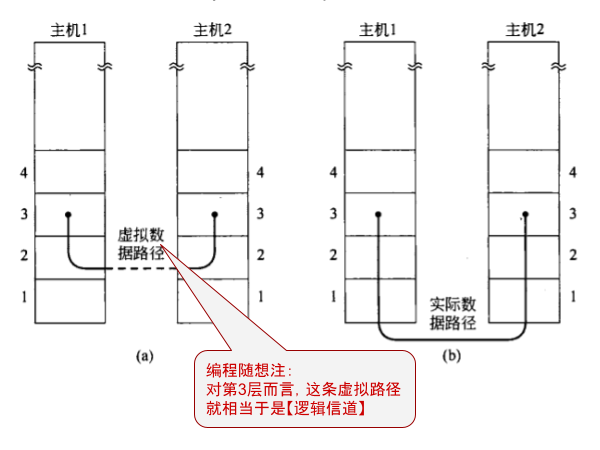
一般来说,网络层的设计有两种截然不同的风格:【电路交换 VS 分组交换】。有时候也分别称之为“有连接的网络层 VS 无连接的网络层”。此处所说的“连接”指的是某种“虚电路”(洋文叫做“virtual circuit”,简称 VC)。
当时的电话系统主要承载语音传输,“电路交换”显然性能更高。那为啥 Baran 的设计要采用“分组交换”捏?俺又要再次提到【效率 VS 健壮性】之间的矛盾与均衡。
对于“电路交换”,一旦建立连接,同一个连接的所有数据都走相同的路径(会经过完全相同的路由器)。也就是说,传输的过程中,如果某个路由器挂掉了(网络掉线 or 硬件当机 or 软件崩溃)。那么,该路由器正在处理的 N 个连接全都要报废。而“分组交换”则更加灵活——即使某个路由器挂掉了,后续的数据包会自动转向另外的路由器,损失很小。
“Baran 方案”之所以采用“分组交换”的设计,因为人家这个方案是提交给军方用来应对【全面核战争】滴,当然要考虑健壮性啦。
话说这两种交换机制,各有很多支持者,并分裂为两大阵营,分别是:“电信阵营 VS 互联网阵营”。两大阵营的口水战持续了 N 年,都无法说服对方。到了后来设计 OSI 模型的时候,为了保持中立性与通用性,OSI 模型本身并没有强制要求网络层采用哪一种风格。
经过几十年之后,咱们已经可以看出来:“互联网阵营”占据主导地位。如今,连电信系统都是架构在互联网之上。
★网络层:具体实例
◇网络层的【协议】
网络层的协议有很多。由于“互联网”已经成为全球的事实标准,因此俺只列出属于“互联网协议族”的那些“网络层协议”:
IP 协议(含 IPv4 & IPv6) ICMP IGMP IPSec
......
(考虑到篇幅)俺不可能具体细聊这些协议,只是贴出每个的维基百科链接,感兴趣的同学自己点进去看。
对上述这些协议,最重要的当然是 IP 协议。如果你想要深入了解 IP 协议,可以参考如下这本书。关于 IP 协议的书,此书的影响力最大。这本书共3卷,通常只需看第1卷。
《TCP-IP 详解》
当年设计阿帕网的时候,采用了【4字节】(32比特)来表示“网络层地址”(也就是 IP 地址)。
“IP 地址”的含义很重要,俺有必要解释一下:
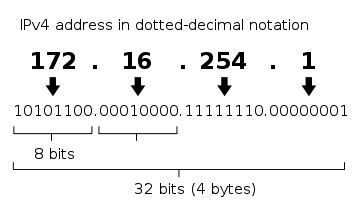
咱们平时所说的 IP 地址,采用【点分十进制】来表示。就是把地址的4个字节,先翻译为十进制,然后每个字节用一个小数点分隔开(参见如下示意图):
(4字节 IP 地址:“二进制”与“点分十进制”的对照示意图)
“IP 地址”的32比特,分为两部分:第1部分用来标识【子网】,第2部分用来标识该子网中的【主机】。
这两部分各占用多少比特,是不确定的。在这种情况下,“操作系统协议栈”如何知道哪些比特标识“子网”,哪些比特标识“主机”捏?奥妙在于【子网掩码】。所以,大伙儿在给系统配置 IP 地址的时候,通常都需要再设置一个【子网掩码】,就这个用途。
这个 IP 地址对应的主机已经关机
这个 IP 地址对应的主机已经断线
这个 IP 地址对应的主机拒绝响应 ICMP 协议
从你本机到这个 IP 地址之间,有某个防火墙拦截了 ICMP 协议
......
traceroute
这是一个通用的工具,用来测试路由。很早以前的 Windows 就已经内置了它,命令是 tracert。在 POSIX(Linux&UNIX)上通常叫 traceroute
你可以用这个命令,测试你本机与互联网另一台主机之间的路由(也就是:从你本机到对方主机,要经过哪些路由器)
★传输层:概述
◇传输层的必要性
屏蔽“有连接 or 无连接”的差异
(上一个章节提到)网络层本身已经屏蔽了【异种网络】的差异(比如“以太网、ATM、帧中继”之间的差异),而且网络层也屏蔽了路由的细节。但网络层本身还有一个差异,也就是网络层的两种交换技术:电路交换(有连接) VS 分组交换(无连接)。
前面章节也提到了:上述两种交换技术各有很多支持者,并分裂为两大阵营。当年设计 OSI 模型的时候,为了保持中立性与通用性,并没有强制规定“网络层”必须采用何种交换机制。
对于开发网络软件的程序员来说,当然不想操心“网络层用的是哪一种交换机制”。因此,需要对网络层的上述差异再加一个抽象层(也就是“传输层”)。
在 OSI 7层模型中,传输层正好居中。这是一个很特殊的位置。
OSI 模型最下面3层,与【网络设备】比较密切。这里面所说的“网络设备”,既包括那些独立的主机(比如“路由器、交换机、等”),也包括电脑上的硬件(比如“网卡”)。
OSI 模型最上面3层,与【网络软件】比较密切(或者说,与“用户的业务逻辑”比较密切)。
而中间的传输层,正好是承上启下。对于开发应用软件的程序猿/程序媛,“传输层”是他们能感知的最低一层。
◇传输层的【端口】
刚才谈“传输层的必要性”,提到说——“网络层地址”只能标识【主机】,而传输层必须要能标识【进程】。为了达到这个目的,于是就引入了“传输层端口”这个概念(为了打字省力,后续讨论简称为“端口”)。
在 OSI 模型中,“端口”的官方称呼是“传输服务访问点”(洋文缩写 TSAP)。但是作为程序员,俺已经习惯于“端口”这个称呼。后续介绍依然用“端口”一词。
当程序员使用传输层提供的 API 开发网络软件时,通常把“端口”与“网络地址”一起使用(构成“二元组”),就可以定位到某个主机上的某个进程。
一不小心,这篇教程已经写了这么长。为了照顾那些有“阅读障碍”的读者,俺要稍微控制一下篇幅,就把 OSI 的【上三层】合在一起讨论。
前面的章节说过:【上三层】更接近于“网络软件”,对应的是应用软件的业务逻辑,因此俺统称为“业务层”。
注:有些书(比如《计算机网络》)会把 OSI 的上三层统称为“应用层”。由于 OSI 模型中本来就有一个“应用层”,俺认为这样容易搞混(尤其不利于技术菜鸟),所以另外起了一个“业务层”的名称。
对于大部分读者来说,【没必要】花时间去了解 OSI 最上面三层之间的区别。你只需把最上面三层视作【一坨】——他们都是与网络软件的业务逻辑密切相关滴。
那么,哪些人需要详细了解“这三层的差异”捏?
如果你是个程序员,并且你正好是开发【网络】软件,俺建议你了解一下 OSI 模型的最上面三层,有助于你更深刻地思考某些网络协议的设计。所谓的“更深刻”指的是:你不能光停留在 WHAT 层面,要提升到 HOW 甚至 WHY 层面(参见《学习技术的三部曲:WHAT、HOW、WHY》)
前面的某些章节,已经稍微提及了“网关”这个概念,但还没有具体介绍它。
严格来讲,“网关”是一个逻辑概念,【不要】把它当成具体的网络设备。充当“网关”的东东,可能是:路由器 or XX层交换机 or XX层防火墙 or 代理服务器 ......
“网关”也分不同的层次。如果不加定语,通常指的是“3层网关”(网络层网关)。列几种比较常见的,供参考: