这也是现当代艺术作品常常被人诟病的原因之一,因为那些作品浓缩了大量的思考和抽象提炼,但表现形式上,其实并没有比传统艺术更复杂,或更需要技艺和体力上的付出。也就是说,作为当代艺术最核心的「观念」,在完全不需要理解的情况下,一个外行的人或者一个数据量管够的 AI 就可以模仿出「看上去像那么回事」的东西。这种模棱两可的状态,恰恰是江湖神棍和 AIGC 擅长处理的对象。
这里说的「糊弄」「神棍」并非贬义,而是借着世俗的话语体系来表达,这样的「生成作品」并不需要 AI 具备「意识」和「创意」也可以轻松地实现。
我的意思并不是让 AI 画手绘图,这仅仅是一种表现方式。但是,这是一种不需要追求精确的表达方式,很适合 AI 用「抽卡」的方式来快速堆想法。除了这种,当然也可以让它生成上面剃须刀那样的图,但同样的,目的不在于出方案,而是借助 AI 的海量数据库,快速地堆出一批发散性思维的「胡编乱造」的混杂图像来。
人类的视野有限,但 AI 看得一定比人类个体的平均值多。
工业设计不是天马行空地想象,它是一种「劳作」。
从初期的构思,从草图推延到模型和效果图,再从设计方案导入结构设计和工艺、制程,这意味着工业设计不是一项纯脑力劳动,不是一种只运行在计算机里的行为。它包含的体力劳作同样是设计的一部份,甚至可以说,是更关键的那部份。这种体力劳作,不仅仅是肌肉和工具的配合,更是人脑对环境、事件、社会群体、物质的反应和处理,设计师的动作意味着这个人对世界的认知。这种程度的认知,对于只运行在计算机内,仍然缺少复杂的传感器和理解过程的 AI 而言,暂时还是无法实现的。
连键盘侠都知道「不难」的造车,没造出来不是造不出来,是制定的目标太远太高。苹果之前想一步到位搞出 L4 的移动座舱,但现阶段的人类还没有办法,这太难了。在他们之前的设想中,自动驾驶的汽车和 Apple Vision Pro 是可以放在同一个场景里的。但很显然,这个步子太大了。用新势力们的方式当然可以,但那不是苹果想做的。
最关键的是,AI 的大爆发是此前大家都没料到的。没有这事儿,车还是一个重要的方向,但这一波爆发的 AI 不是资本热潮,而是实打实的浪潮了,此时不全力转向,是真的会死的。况且苹果并不是没有在 AI 上投入的,这些年一直都在积累,只是权重还没拉到那么高。现在切方向,即是大势所趋的必须,也是归拢资源的必要。
在网上看过很多人用 AI 画十二生肖主题的系列画,但大多数我都觉得太套路了,要么只是生成一只动物,要么是套上一些所谓的古风服装,强行「国风」一把。我觉得,既然工具本身已经有很强的生成能力了,那么,创作者就应该更多地表达观念。没有观念的全自动生成出来的东西,再好看,也是大同小异、千篇一律。这种现象,最典型的就是那些长着网红脸的 AI 美女图。好看,但无味,因为缺少人味儿。
Prompt A statue of the goddess made of polished stainless steel, with huge white feathered wings, surrounded by obsidian, with lava flowing, violent flames, and clouds of darkness –ar 3:4 –style raw –stylize 50 –v 6
而这次比赛不仅给了我一个机会去参与创造一个跟 AI 相关的产品(包括代码也有不少是 ChatGPT 参与的),还给了我推强大的动力去了解 AI 在商业中的场应用景。除了在比赛中看到其他参赛者的创意之外,现在还了解到比如 Atlassian 已经有相关的功能前瞻了。
从 Atlassian 在 5 月 4 日发布的股东信当中,也透露到该公司已经在用 AI 来来为客户提供服务了。
"Now that generative AI has reached consumer-grade maturity with LLMs, we can create magical new experiences for our customers."现在,随着大型语言模型(LLMs)带领生成型人工智能达到了消费级的成熟,我们可以为我们的客户创造魔术般的新体验。
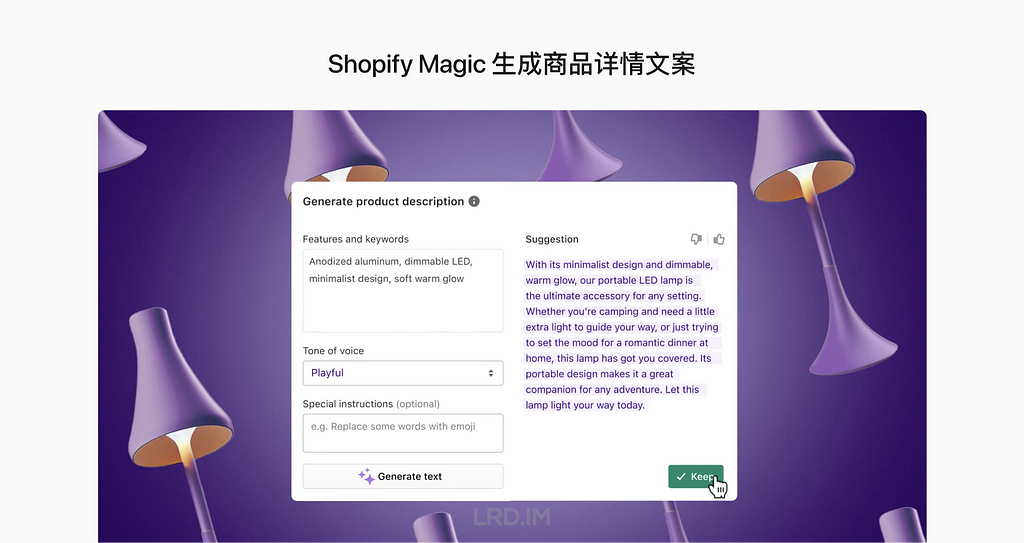
除了 Atlassian,另一个互联网巨头:Shopify 也将 AI 能力应用到其产品当中。比如在商品详情页的编辑界面当中,我们可以输入几个关键字,让 AI 帮忙生成一段商品介绍的文本,还能够调整文本的风格。
























 而且是毒蘑菇!
而且是毒蘑菇!







 什么四根手指啊、三根绥带啊、两端对不齐的签子啊… 其实咋一看的效果也确实足够好了,毕竟是虚构的漫画角色,你说头身比例奇怪,好像也是合理范围内。
什么四根手指啊、三根绥带啊、两端对不齐的签子啊… 其实咋一看的效果也确实足够好了,毕竟是虚构的漫画角色,你说头身比例奇怪,好像也是合理范围内。







































































































 Bust photo, polished stainless steel goddess sculpture, real feathered wings, black rock, magma and flame, dark clouds –ar 3:4 –style raw –v 6
Bust photo, polished stainless steel goddess sculpture, real feathered wings, black rock, magma and flame, dark clouds –ar 3:4 –style raw –v 6