国产 AI 视频神器大更新,支持 4K、60 帧,视频生成有声时代来了 | 附体验链接

今年的 AI 视频生成领域呈现出一种如火如荼的架势。
从最初卷生成时长到卷画面质量,再到最近卷起 AI 特效,行业厂商们开卷的方式千奇百怪,但目标都是共通的,那就是铆足了劲地吸纳新用户,留住旧用户。
然而,尽管市面上许多视频模型号称一键生成视频,但如「默剧」般的成品多少形如鸡肋。尤其是我们对 AI 视频的刺激阈值被一再拔高,音效的缺失就像被捶打的钉子,在用户的心里越扎越深。
当然,厂商们不是不想彻底解决这颗钉子,只是恰好在等待一个厚积薄发的时机。

三个月前,作为国内首个面向公众开放的视频生成产品,智谱清影上线清言 App,只需一段指令或图片,30 秒就能生成 AI 视频。
三个月后的今天,智谱清影再次迎来了一大波重磅升级。
10s 时长、4k、60 帧超高清画质,任意尺寸、更好的任务动作和物理世界模型……除了开卷这些基本功,更重要的是,智谱清影也即将在本月上线生成与画面匹配的音效了。
附上新清影具体升级亮点:
- 图生视频的质量、美学表现、运动合理性以及复杂提示词语义理解方面能力明显增强;
- 更强的人物面部表演细节、动作连贯性和物理特性模拟,提高了视频的自然度和逼真度;
- 支持生成 10s、4K、60 帧超高清视频,支持任意比例的图像生成视频;
- 同一指令/图片可以一次性生成 4 个视频,与画面匹配的音效功能将很快在本月上线公测;
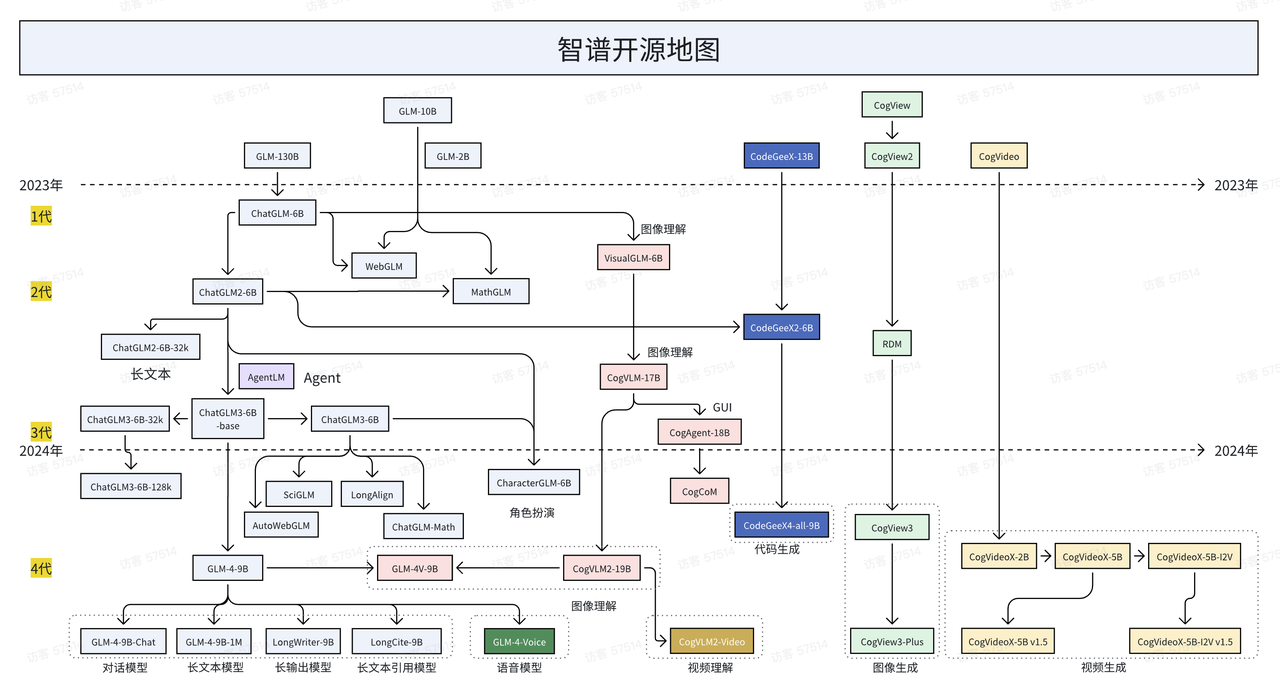
并且,当人们还在为 AI 开源/闭源争论不休时时,智谱却是国内少有一贯支持开源的企业,而在今天,智谱也正式发布并开源最新版本的视频模型 CogVideoX v1.5。
此次开源包括两个模型:CogVideoX v1.5-5B、CogVideoX v1.5-5B-I2V,后续,CogVideoX v1.5 也将同步上线到清影,并与新推出的 CogSound 音效模型结合。
代码:https://github.com/thudm/cogvideo
模型:https://huggingface.co/THUDM/CogVideoX1.5-5B-SAT
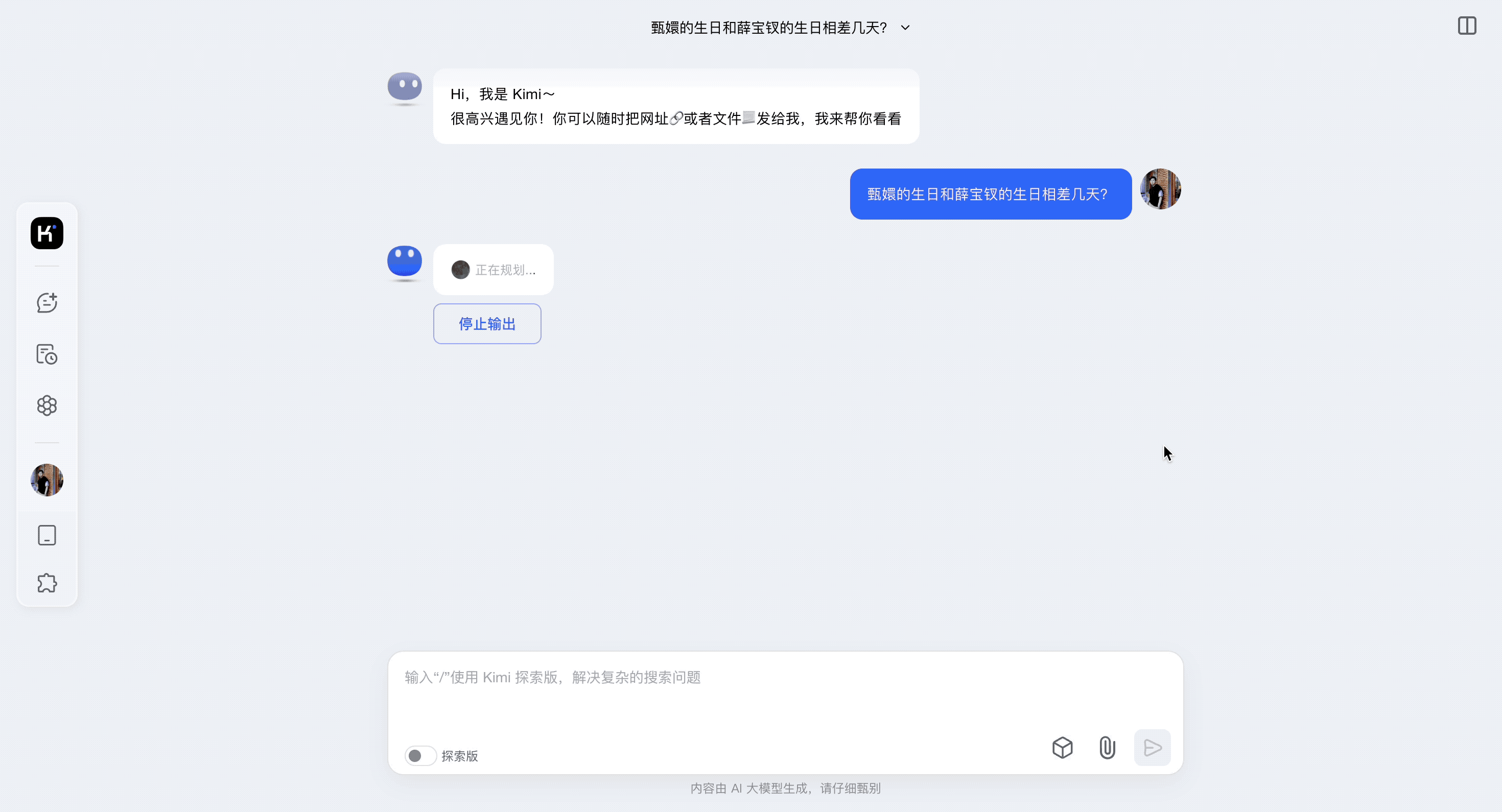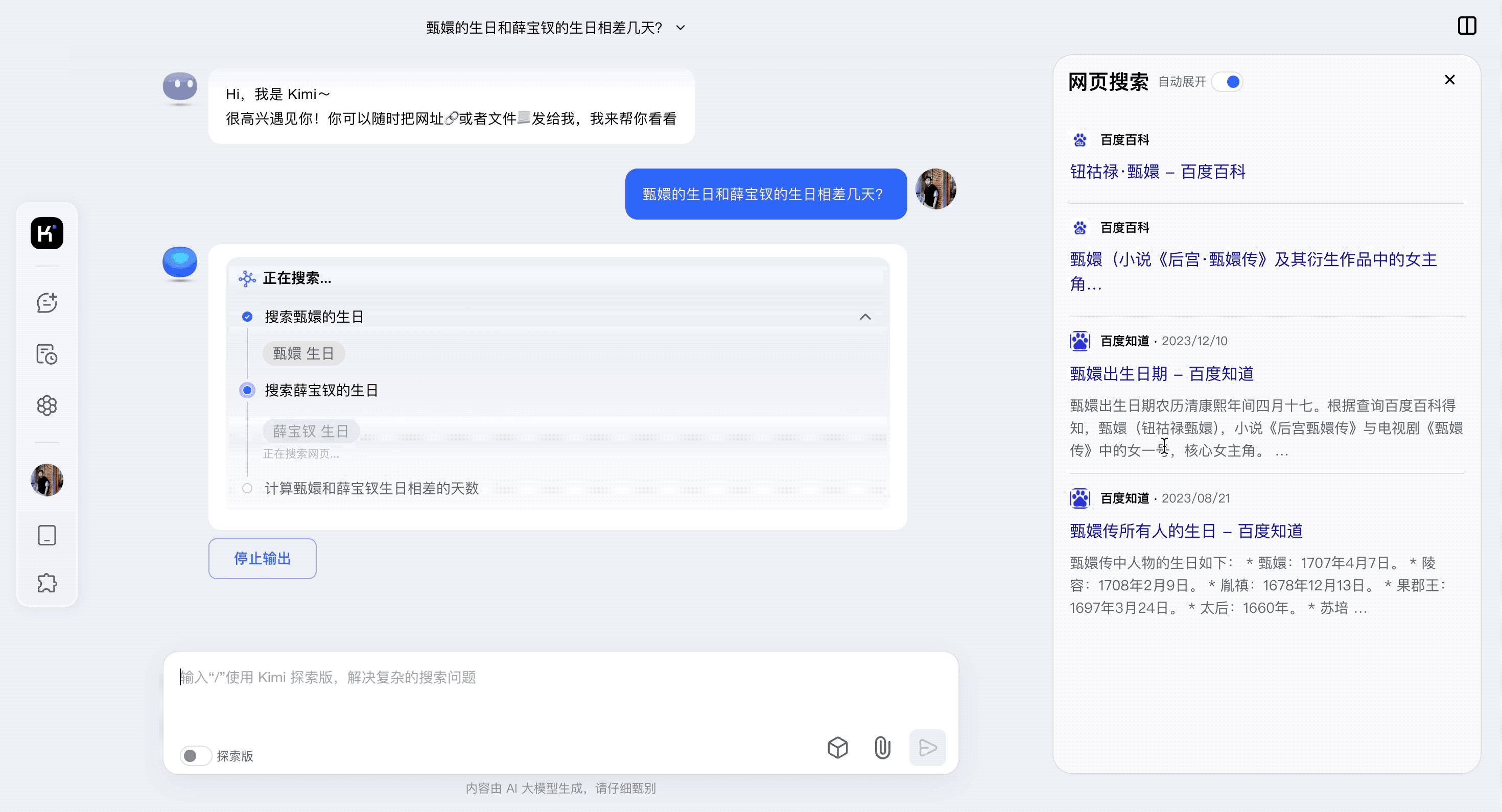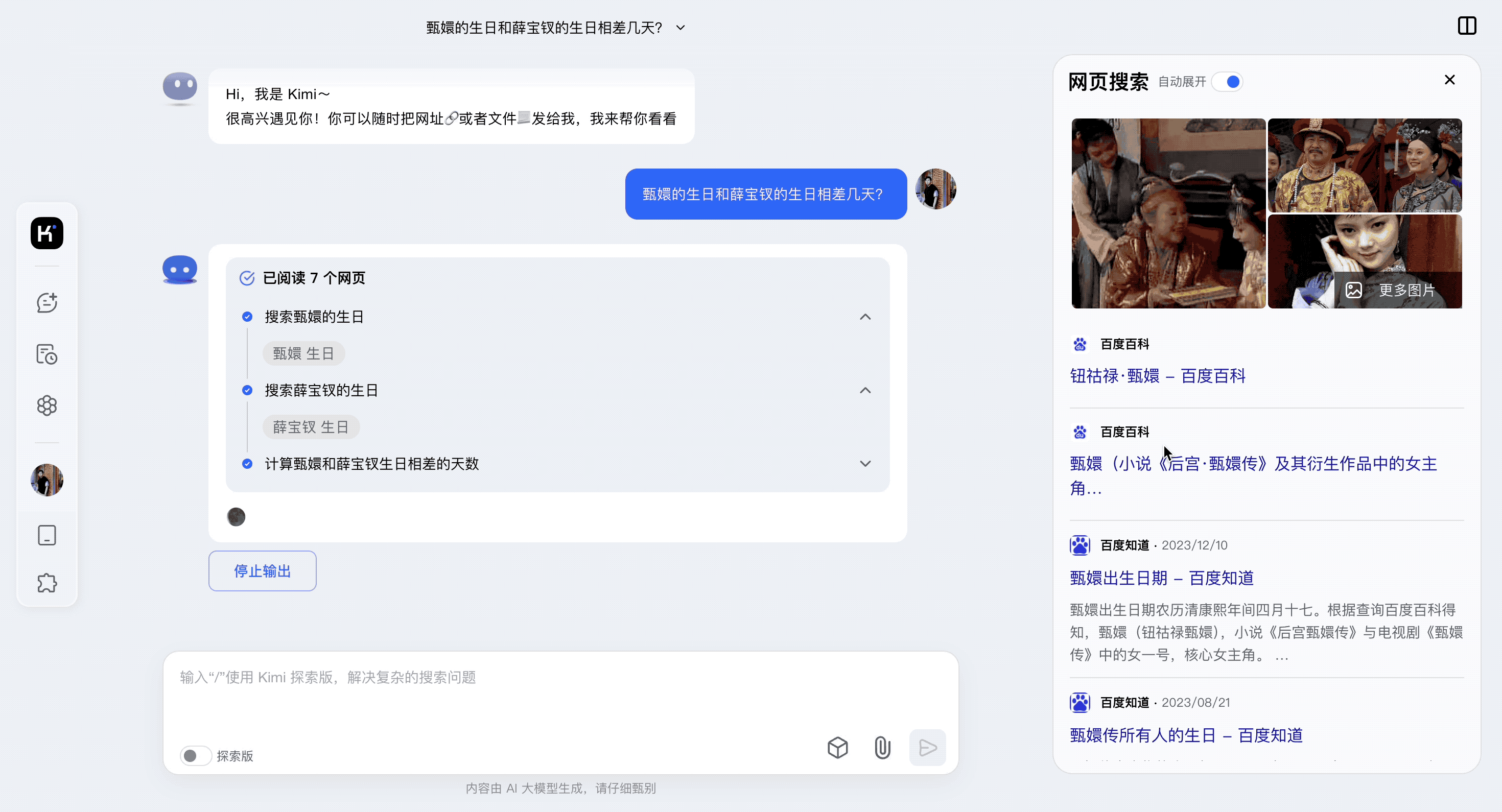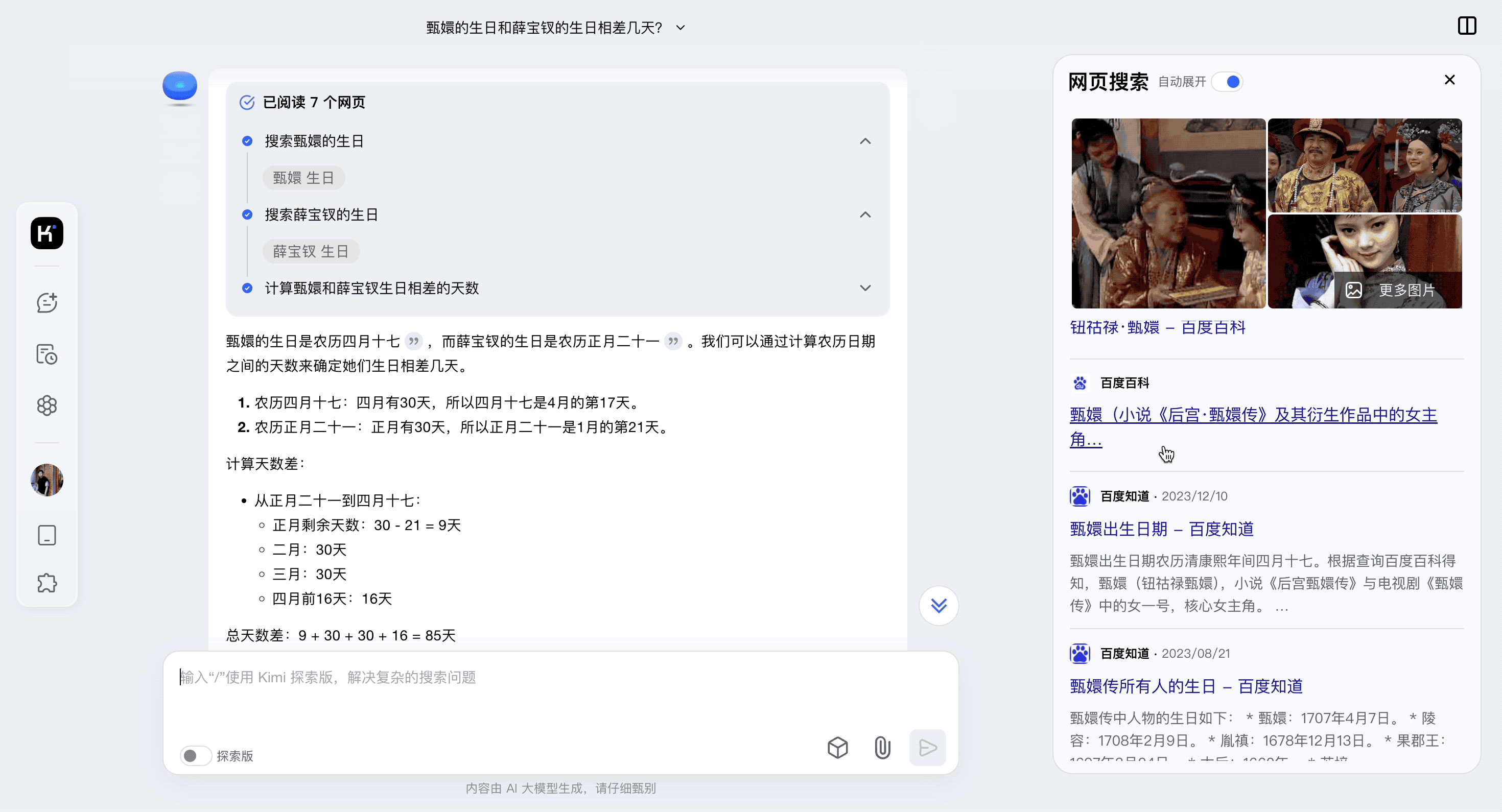
官方宣布,新清影即日起在智谱清言 App 上线。话不多说,直接附上体验地址:https://chatglm.cn/video?lang=zh
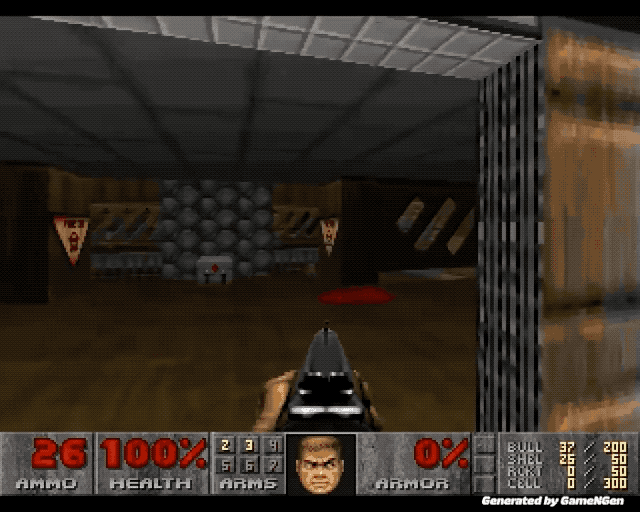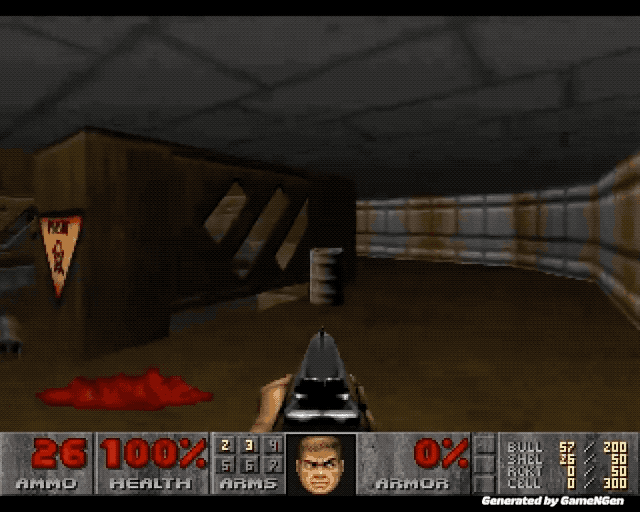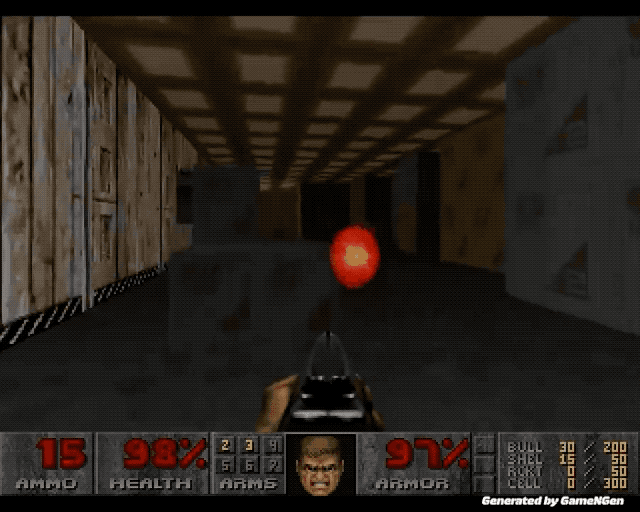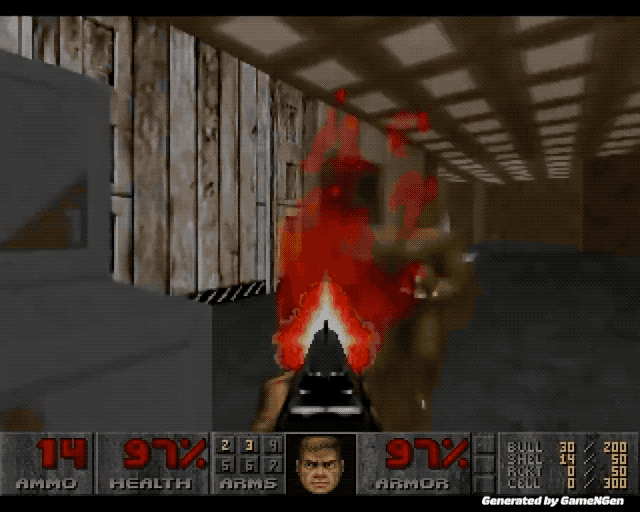
4K 60 帧,新清影已经 next level 了
和蔼的老人面带微笑,面部肌肉细节清晰可见,没有明显的像素化或模糊现象。

火焰老虎的形象也令人印象深刻,不仅步态拟真,眼神之中还透露出一种野性的美感,身上的火焰颜色也呈现出丰富的色彩层次和深度。

车辆急速飞驰,场景转换没有卡顿或延迟,即使是快速移动的对象也能保持连贯性,而在速度感和紧张气氛的营造上也有一手。

喵星人在线化身大厨,熟稔地翻炒今天的菜品。

不被演示 demo 的花言巧语所迷惑,上手才是检验实际效果的唯一标准。
我们也用图生视频功能上手跑了一个放飞孔明灯的视频。孔明灯被释放,缓缓升入夜空,镜头从下往上跟随,天空也被染上了深邃的蓝色。

又或者,我们「复活」了静止的小黄花,微风拂来,小黄花在草地上轻轻摇曳。

不过「新清影」还是需要一定程度的抽卡,这也是目前国内外 AI 视频模型在稳定性上普遍存在的问题,在日常使用这类产品时,还需要多些耐心。
对于视频来说,音效和画面总是相辅相成的,基于此,我们也用几段去掉音频的「哑剧」视频,并让 AI 为它们生成相应的音效,建议打开音量键食用。
例如《海上钢琴师》最经典的斗琴环节,你更喜欢这个还是原版呢?
美丽的烟花表演,它们在夜空中绽放的瞬间,搭配上 AI 音效,有没有打动你?
雨滴的声音各异,有的清脆,有的低沉,有的急促,有的悠长。
核爆炸的场景很大,搭配声音却几乎没有延迟,在模拟真实爆炸声,环境噪音以及余波等方面表现出色。
别急,仔细听,还有阿凡达水下探险。
如果 CogVideoX 与 CogSound 强强联合,即由清影技术负责生成画面,而音效模型负责配音,最后生成的视频内容也更加生动、真实,甚至能够触动人心。
从无声到有声,AI 视频进入有声电影时代
1900 年,第一部有声电影在巴黎放映,直到十年后,这种能够将声音与影像同步的技术才逐渐成熟,达到了商业化的标准。
有声电影的问世,不仅仅终结了电影自诞生之初的沉默状态,更重要的是,它将电影从单一的纯视觉艺术转变为视听结合的全新艺术形式。
影片上的演员开口说话,而观众席上也响起对有声电影的欢呼声。
两者心声交响,心音共鸣。

如今,历史的轮回再次上演,从年初的「哑剧」到如今的 AI 音效,如果说前者还是局限于 0-1,那么 AI 音效的加入,则标志着 1-N 史诗级跨越。
基于 GLM-4V 的视频理解能力,智谱家族的新成员——音效模型 CogSound 能够准确识别并理解视频背后的语义和情感,并在此基础上生成与之匹配的音频内容。
例如,爆炸、水流、乐器、动物叫声以及交通工具声等。
在影像叙事中,声音的到来是一个关键拐点,它不仅使叙事从依赖文字构建的视频中突围,而且在观念和方法上都带来了更广阔的想象空间。
然而,影视行业对 AI 的引入无疑是充满争议的。
上个月,好莱坞演员的罢工风波尚未平息,而导演卡梅隆则在出席峰会时表示,AI 将会重新定义电影故事讲述,帮助编剧导演探索新的故事线,以及叙述手法。
放诸到视频产业界,音效模型也有着广泛的应用场景,比如可以生成电影中的大规模战斗场景和灾难场景的声音,大大缩短制作周期,降低制作成本。
只是,AI 时代下的视听艺术究竟应该会是什么样?
历史上的技术大爆发给我们提供了一些思路。如果说工业革命的机械化、流水线作业等方式,让标准化的大规模生产成为可能,那么随着 AI 的到来,通过学习大量的数据和模式,能够模仿人类的决策过程、并且根据每个用户的具体需求和偏好定制个性化服务。
简言之,通过降低使用门槛,AI 让每个普通人都能手捏自己喜欢的个性化视频。

法国新浪潮的代表人物让-吕克·戈达尔,也曾探讨过电影技术变革对电影语言和艺术性的影响:
「电影不是仅仅在拍摄时使用声音和影像,而是在观众心中构建某种语言。无声电影通过视觉创造了更多的可能,而有声电影则改变了这种创作方式。」
而追溯至今年 2 月份,人们关于 AI 视频的展望是由 OpenAI 发布的 Sora 率先拉开,但很遗憾,直到此时此刻,该产品却仿佛陷入「如来」的状况,至今未见踪影。
也正是在这个期间,我们很高兴能够看到国内厂商甚至在这一赛道交出了不错的成绩单。

不过,这或许还只是开胃小菜,智谱认为真正的智能一定是多模态的,听觉、视觉、触觉等共同参与了人脑认知能力的形成。
构建包括文字、图像和视觉等模态在内的智谱多模态大模型矩阵,能够进一步提高大模型的应用和工具能力,也是在迈向 AI 的终极目标——AGI。
至此可以说,我们真正迈入了 AI 有声电影时代。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。





























 https://www.nytimes.com/2024/10/23/technology/characterai-lawsuit-teen-suicide.html
https://www.nytimes.com/2024/10/23/technology/characterai-lawsuit-teen-suicide.html