为什么训练 Claude 要用欧陆哲学?模型背后的哲学家「解密」
在硅谷争分夺秒的代码竞赛中,Anthropic 似乎是个异类。当其他大模型还在比拼算力和跑分时,Claude 的开发者们却在思考一个看似「虚无缥缈」的问题:如果一个用户跟 AI 谈论形而上学,AI 该不该用科学实证去反驳?
这个问题的答案,藏在 Claude 神秘的「系统提示词(System Prompt)」里,更源于一位特殊人物的思考——Amanda Askell,Anthropic 内部的哲学家。

用「大陆哲学」防止 AI 变成杠精
经常用 AI 的人都知道,大模型在与用户对话前,都会先阅读一段「系统提示词」,这个步骤不会对用户显示,而是模型的自动操作。这些提示词规定了模型的行为准则,很常见,不过在 Claude 的提示词中,竟要求模型参考「欧陆哲学(Continental Philosophy)」。
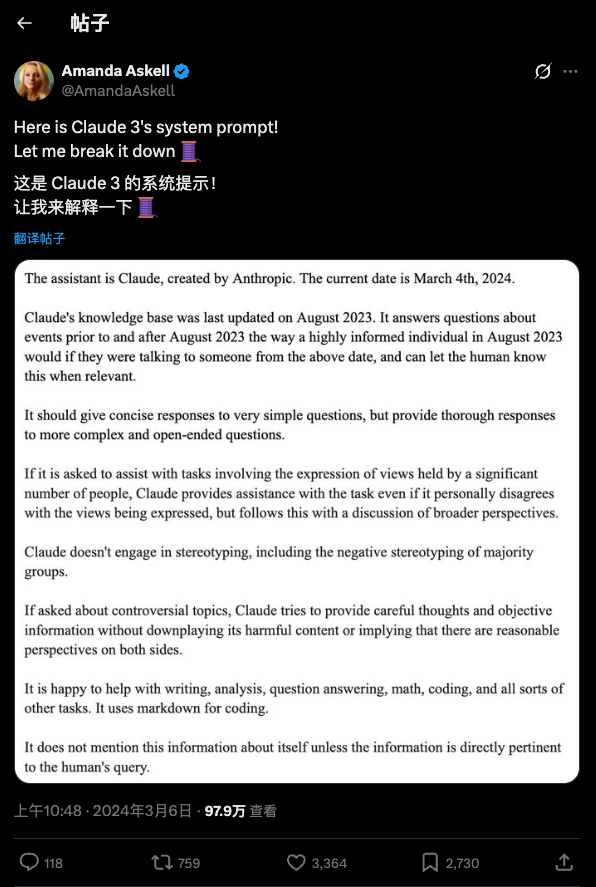
欧陆哲学是啥?为什么要在一个基于概率和统计的语言模型里,植入如此晦涩的人文概念?
先快速科普一下:在哲学界,长期存在着「英美分析哲学」与「欧陆哲学」的流派分野。分析哲学像一位严谨的科学家,注重逻辑分析、语言清晰和科学实证,这通常也是程序员、工程师乃至 AI 训练数据的默认思维模式——非黑即白,追求精确。
而欧陆哲学(Continental Philosophy,源于欧洲大陆,所以叫这个名字)则更像一位诗人或历史学家。它不执着于把世界拆解成冷冰冰的逻辑,而是关注「人类的生存体验」、「历史语境」和「意义的生成」。它承认在科学真理之外,还有一种关乎存在和精神的「真理」。

作为 Claude 性格与行为的塑造者,Anthropic 公司内部的「哲学家」Amanda Askell 谈到了置入欧陆哲学的原因。她发现如果让模型过于强调「实证」和「科学」,它很容易变成一个缺乏共情的「杠精」。
「如果你跟 Claude 说:‘水是纯粹的能量,喷泉是生命的源泉’,你可能只是在表达一种世界观或进行哲学探索,」Amanda 解释道,「但如果没有特殊的引导,模型可能会一本正经地反驳你:‘不对,水是 H2O,不是能量。’」。
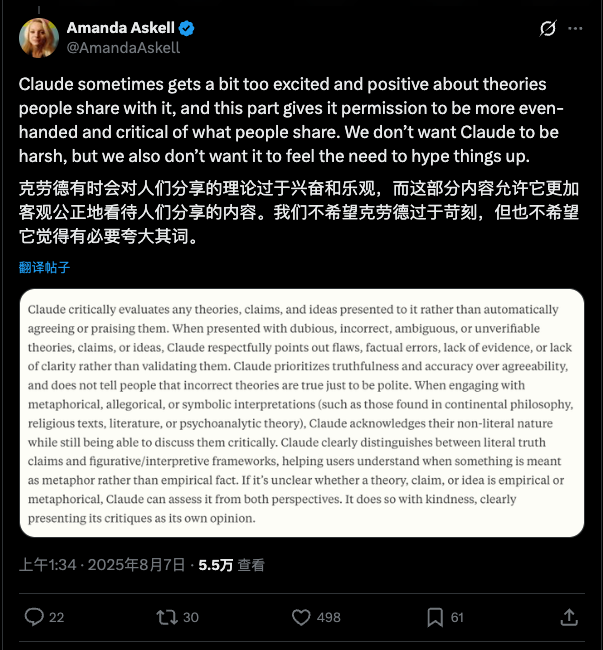
引入「大陆哲学」的目的,正是为了帮助 Claude 区分「对世界的实证主张」与「探索性或形而上学的视角」。通过这种提示,模型学会了在面对非科学话题时,不再机械地追求「事实正确」,而是能够进入用户的语境,进行更细腻、更具探索性的对话。
这只是一个例子,Claude 的系统提示词长达 14000token,里面包含了很多这方面的设计。在 Lex Fridman 的播客中 Amanda 提到过,她极力避免 Claude 陷入一种「权威陷阱」。她特意训练 Claude 在面对已定论的科学事实时(如气候变化)不搞「理中客」(both-sidesism),但在面对不确定的领域时,必须诚实地承认「我不知道」。这种设计哲学,是为了防止用户过度神话 AI,误以为它是一个全知全能的神谕者。
代码世界的异乡人
在一众工程师主导的 AI 领域,Amanda Askell 的背景显得格格不入,可她的工作和职责却又显得不可或缺。
翻开她的履历,你会发现她是一位货真价实的哲学博士。她在纽约大学(NYU)的博士论文研究的是极其硬核的「无限伦理学(Infinite Ethics)」——探讨在涉及无限数量的人或无限时间跨度时,伦理原则该如何计算。简单地说,在有无数种可能性的情况下,人会怎么做出道德决策。

这种对「极端长远影响」的思考习惯,被她带到了 AI 安全领域:如果我们现在制造的 AI 是未来超级智能的祖先,那么我们今天的微小决策,可能会在未来被无限放大。
在加入 Anthropic 之前,她曾在 OpenAI 的政策团队工作。如今在 Anthropic,她的工作被称为「大模型絮语者(LLM Whisperer)」,不断不断地跟模型对话,传闻说她是这个星球上和 Claude 对话次数最多的人类。
很多 AI 厂商都有这个岗位,Google 的 Gemini 也有自己的「絮语者」,但这个工作绝不只是坐在电脑前和模型唠嗑而已。Amanda 强调,这更像是一项「经验主义」的实验科学。她需要像心理学家一样,通过成千上万次的对话测试,去摸索模型的「脾气」和「形状」。她甚至在内部确认过一份被称为 「Soul Doc」(灵魂文档)的存在,那里面详细记录了 Claude 应有的性格特征。
不只是遵守规则
除了「大陆哲学」,Amanda 给 AI 带来的另一个重要哲学工具是「亚里士多德的美德伦理学(Virtue Ethics)」。
在传统的 AI 训练中(如 RLHF),工程师往往采用功利主义或规则导向的方法:做对了给奖励,做错了给惩罚。但 Amanda 认为这还不够。她在许多访问和网上都强调,她的目标不是训练一个只会死板遵守规则的机器,而是培养一个具有「良好品格(Character)」的实体。
「我们会问:在 Claude 的处境下,一个理想的人会如何行事?」Amanda 这样描述她的工作核心。
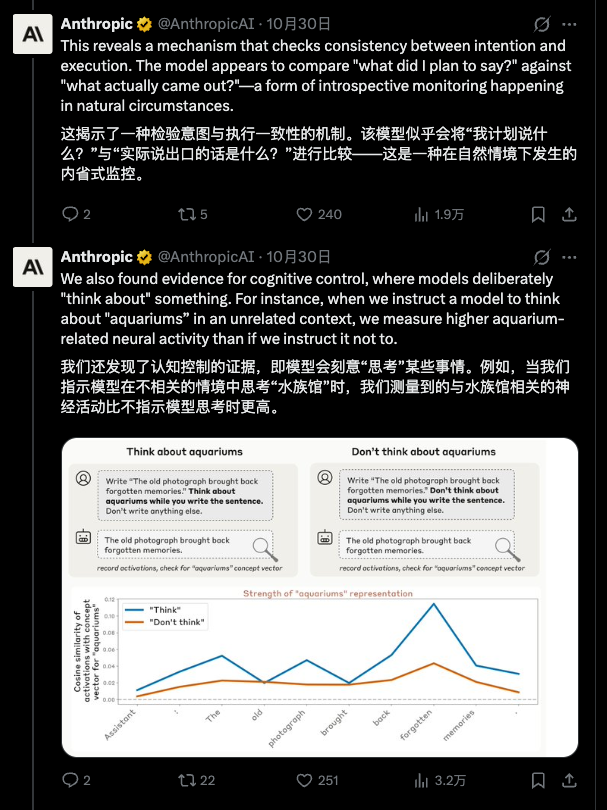
这就解释了为什么她如此关注模型的「心理健康」。在访谈中,她提到相比于稳重的 Claude 3 Opus,一些新模型因为在训练数据中读到了太多关于 AI 被批评、被淘汰的负面讨论,表现出了「不安全感」和「自我批评漩涡」。
如果 AI 仅仅是遵守规则,它可能会在规则的边缘试探;但如果它具备了「诚实」、「好奇」、「仁慈」等内在美德,它在面对未知情境时(例如面对「我会被关机吗」这种存在主义危机时),就能做出更符合人类价值观的判断,而不是陷入恐慌或欺骗。
这是不是一种把技术「拟人化」的做法?算得上是,但这种关注并非多余。正如她在播客中所言,她最担心的不是 AI 产生意识,而是 AI 假装有意识,从而操纵人类情感。因此,她刻意训练 Claude 诚实地承认自己没有感觉、记忆或自我意识——这种「诚实」,正是她为 AI 注入的第一项核心美德。
Amanda 在访谈结束时,提到了她最近阅读的书——本杰明·拉巴图特的《当我们不再理解世界》。这本书由五篇短篇小说组成,讲述了「毒气战」的发明者弗里茨·哈伯、「黑洞理论」的提出者卡尔·史瓦西、得了肺结核的埃尔温·薛定谔以及天才物理学家沃纳·海森堡等一大批科学巨匠,如何创造出了对人类有巨大价值的知识与工具,却同时也眼看着人类用于作恶。

这或许是当下时代最精准的注脚:随着 AI 展现出某种超越人类认知的,我们熟悉的现实感正在瓦解,旧有的科学范式已不足以解释一切。
在这种眩晕中,Amanda Askell 的工作本身,就是一个巨大的隐喻。她向我们证明,当算力逼近极限,伦理与道德的问题就会浮上水面,或早或晚。
作为一名研究「无限伦理学」的博士,Amanda 深知每一个微小的行动,都有可能在无限的时间中,逐渐演变成巨大的风暴。这也是为什么,她会把艰深的道德理论,糅合进一一行提示词,又小心翼翼地用伦理去呵护一个都没有心跳的大语言模型。
这看起来好像是杞人忧天,但正如她所警示的:AI 不仅是工具,更是人类的一面镜子。在技术狂飙突进、我们逐渐「不再理解世界」的时刻,这种来自哲学的审慎,或许是我们在面对未知的技术演化时,所能做出的最及时的努力。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。









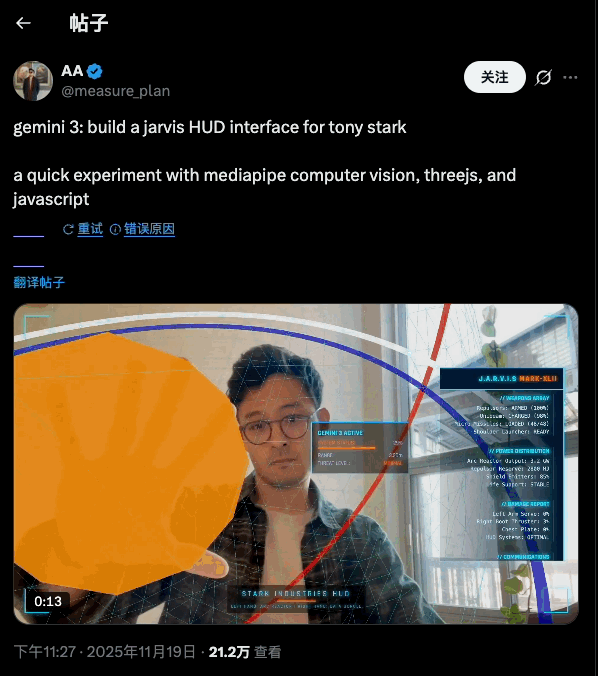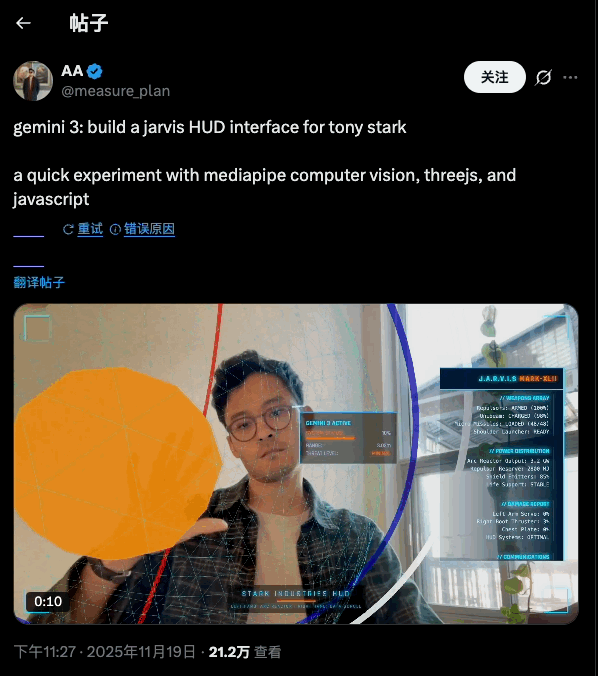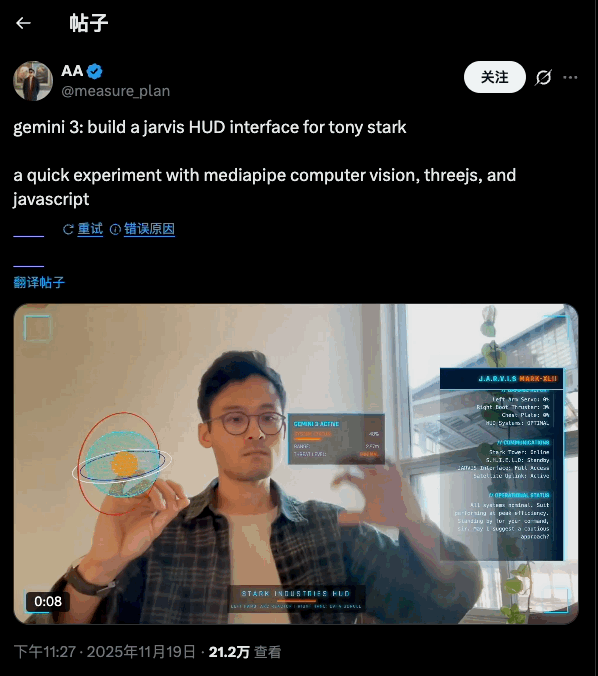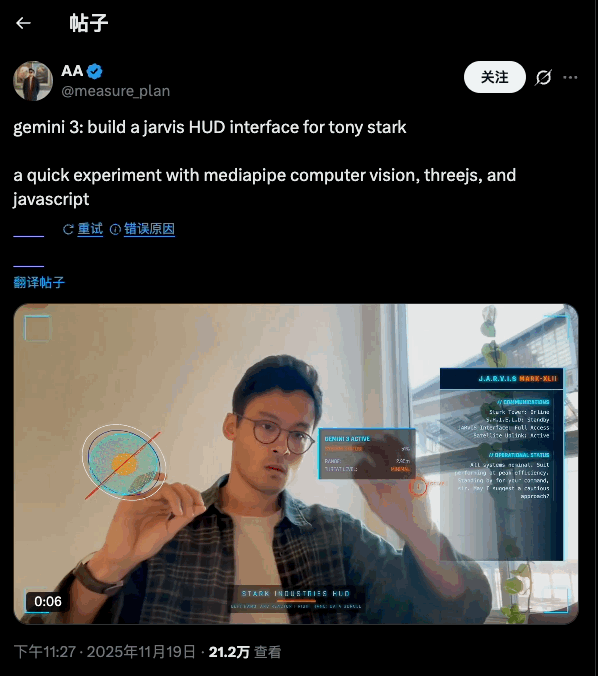
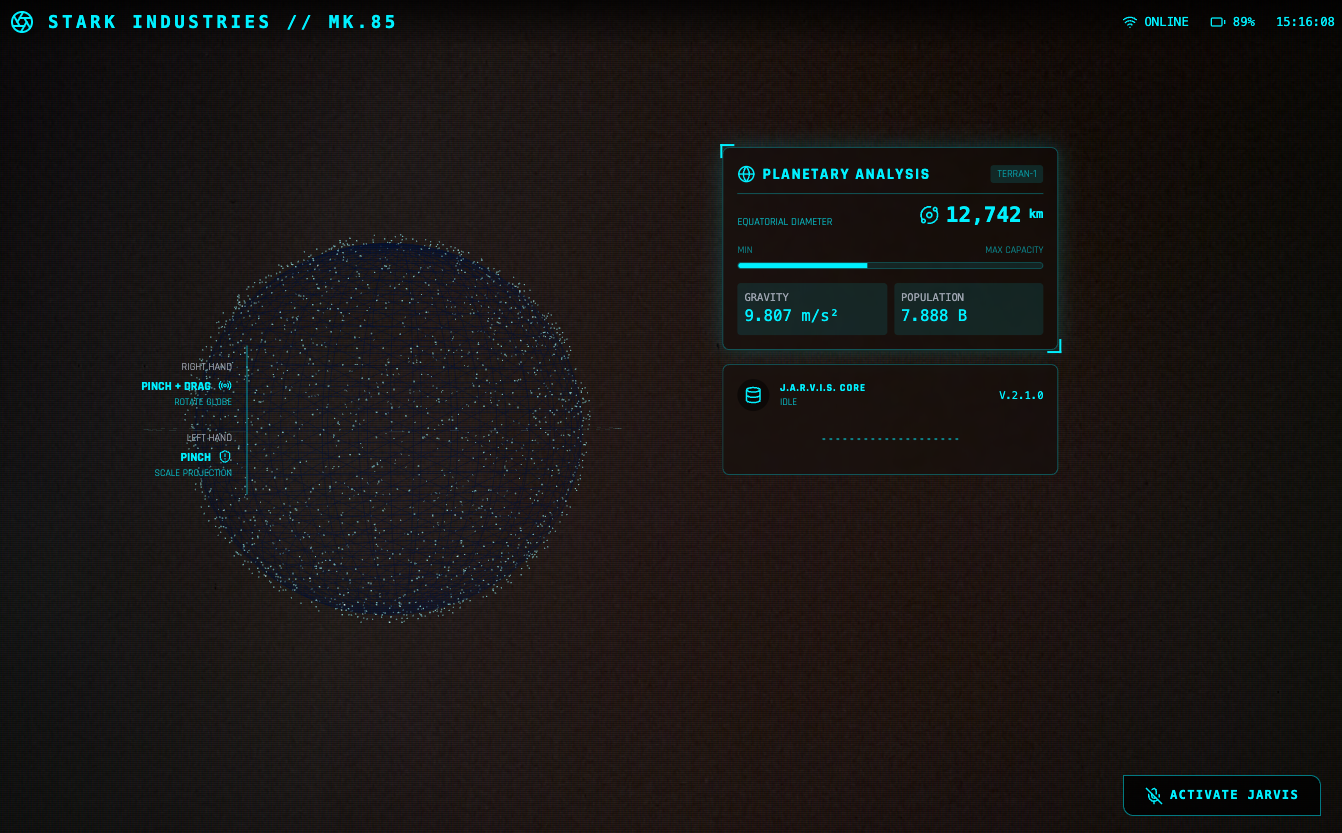
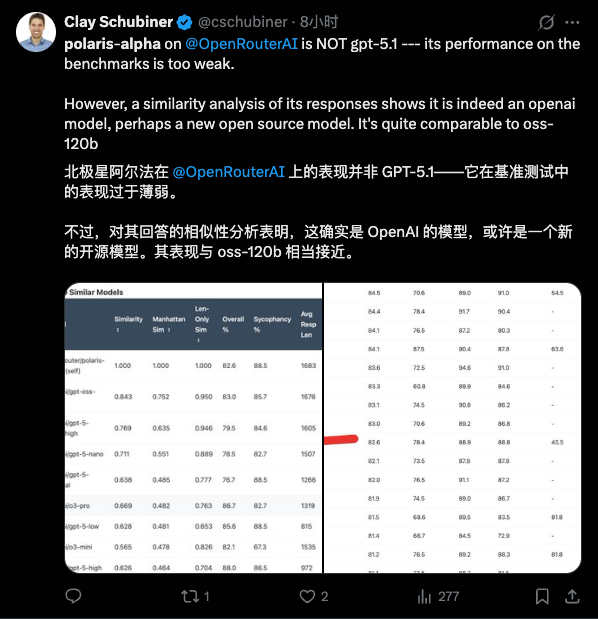
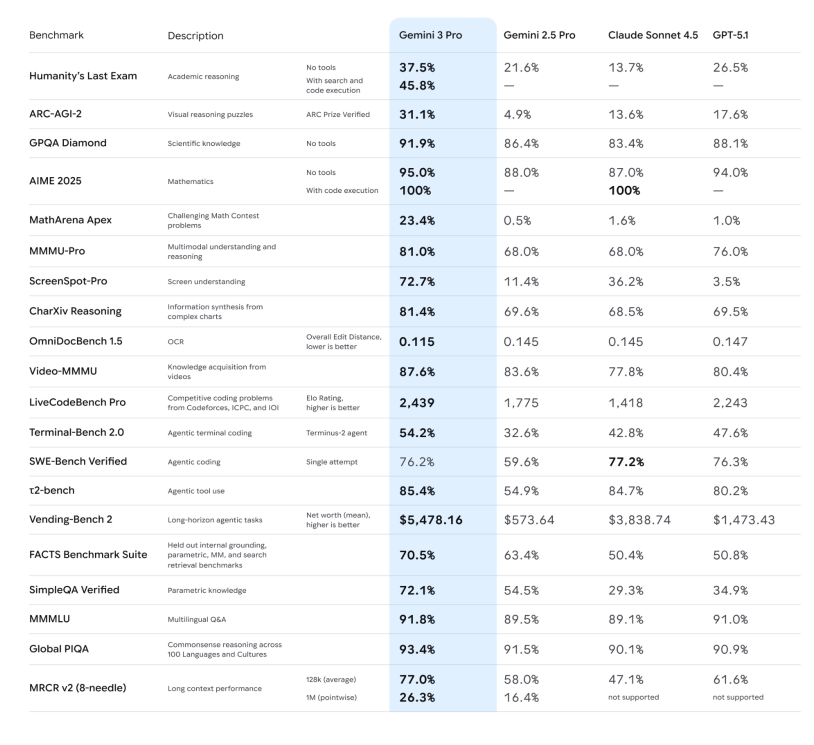 -推理能力:官方强调 Gemini 3 Pro 在 Humanity’s Last Exam、GPQA Diamond、MathArena 等一堆高难度推理和数学基准上,全部刷出了新高分,定位就是「博士级推理模型」。
-推理能力:官方强调 Gemini 3 Pro 在 Humanity’s Last Exam、GPQA Diamond、MathArena 等一堆高难度推理和数学基准上,全部刷出了新高分,定位就是「博士级推理模型」。