
我们还年轻,可不想看到这个世界处在毫无自由、隐私的边缘。
有人说 windows 11 适合大多数普通用户,即便个人需求不同,也可以在此基础上进一步调整(折腾)。仔细一想,更新使用 Windows 11 这段时间我确实进行了不少调整,稳定使用好一阵子之后,许多折腾过程被我逐渐淡忘。
于是想着写下本文作为记录,以便回顾,顺带给也有意深入调整 Windows 11 的朋友一些参考。
Windows 10 在初次使用的时候可以跳过网络连接设置,选择「离线账户」。这样可以避免微软账户的一些设置,但也会导致一些功能无法使用。而 Windows 11 在安装时──至少从 UI 来看──会强制要求连接网络并登录 Microsoft 账户。
如果你只想通过离线账户使用,或碰上微软服务抽风偏偏又无法登录的情况,在这一步可通过 Shift + F10 调出命令行,输入 oobe\BypassNRO。命令执行后系统将自动重启,此后初始化过程中的网络配置会额外出现「我没有 Internet 连接」选项,再点击「继续执行受限设置」后续即可配置离线账户。而如果你已经联网,看到强制要求登录 Microsoft 账户界面后才寻找使用离线账户账户的方法,此时只通过上面的命令是不够的——至少从我唯一的一次经历来看输入命令后重启后仍然会自动配置好网络,此时则需要先输入 devmgmt 打开设备管理器、禁用无线网卡,然后再输入 oobe\BypassNRO。
截至目前通过这些额外的手段还是能够使用离线账户,但微软如此收窄用户选择的空间,很难不让人揣测其意图,甚至给人留下一种不断侵蚀用户隐私和选择权的糟糕印象,毕竟在线账户只会让微软更轻松地收集各种用户数据,包括使用习惯、偏好设置等个人信息,而这些收集行为也不只在本设备,通过在线账户,微软也能更轻松地跟踪用户在不同设备间的行为,构建更完整的用户画像……收集到的数据则可以用于精准投放广告、出售给第三方广告商、通过与其他微软服务的集成二次扩大数据共享范围。
要知道 Microsoft 账户隐私设置界面着实复杂,迈过离线账户的坎,后面想要完全控制自己的隐私选项难度就不低了。
除了预装系统的 OEM 设备,新设备至少第一次的完整的更新是必要的,这些更新包含正常使用的驱动等。如果 Windows 更新无法为你下载安装特定版本的驱动,你也可以前往对应设备厂商的官网手动下载安装,如:
至于特殊的「鸡生蛋」情况──无线网卡驱动──没有无线网卡驱动无法联网、无法联网就无法通过 Windows 更新升级无线网卡驱动,可以通过 USB 网卡或者手机共享网络连接,或者直接下载驱动到 U 盘,然后在设备管理器中手动更新。对于 OEM 设备可以去对应官网寻找驱动支持,对于个人 DIY PC 主要前往主板官网下载最新驱动,当然如果你知道具体网卡型号(例如常用的 Intel AX210)也可以直接去对应官网下载。
说到 OEM 设备,OEM 厂商关于硬件的支持性应该优于更广泛的 Windows。倘若 OEM 厂商有提供完整的硬件驱动管理工具,这些工具优先级应该高于 Windows Update。为避免 OEM 驱动管理与 Windows 更新工作重复、覆盖乃至冲突,可以按照如下流程操作:
说回 Windows 更新本身。对于目前桌面端主要使用的三大(类)系统──Windows、macOS、各 Linux 发行版──相较于更加专用的各 Linux 发行版和产品线单一又严格由 Apple 控制淘汰周期的 macOS,兼容性最好的 Windows 在更新上也更容易受兼容性带来的多样性所困,从而很难实现更新行为和质量的一致性。这也是为什么每每听闻 Windows 更新问题时,总有人说「从来没遇到过」,也总有另一些人抱团抱怨仿佛 Windows 都快完全不可用了那般。
其实如今没必要过于抵制 Windows Update,更新内容本身带来的问题几乎没法举例,更多主要是更新过程中的意外。如果你很清楚自己在做什么,也可以尝试推迟 Windows 更新。除了在更多选项中至多推迟五周外,还可以通过修改注册表推迟任意长度时间:
你可以填写一个很大的天数,然后在需要更新的时候点击 Windows 更新中点「继续更新」即可方便地跳过更新推迟,在此之前不会收到任何更新检测或提示,更不会自动更新。
上述通过注册表推迟更新的操作可以通过脚本完成:
再配合任务计划程序实现自动化。这样就可以根据自己的节奏推迟更新、累计更新,例如每六周推迟五周等。
至于彻底禁止 Windows 更新,其实上文提到的通过注册表推迟到一个不可能的天数便可达到类似效果,除此以外还可以通过编辑组策略、修改更新服务器到一个空地址、借助诸如 Windows Update Blocker 等第三方工具等。这里不再一一赘述。
本篇围绕 Windows 11 系统本身的设置调整展开,尽量不涉及第三方软件、工具,若非要涉及也是主要是在辅助调整设置(例如把隐藏的系统设置项调出来)而不提供额外功能。
任务栏、开始菜单最直接的调整在「设置 > 个性化」中。
在任务栏设置中,我们要做的第一件事就是把塞满广告和各种无用信息的小组件整体关闭,然后根据个人习惯调整其他设置,比如我会将搜索仅显示图标、任务栏左对齐、永远合并任务栏按钮。
在开始菜单设置中,记得关掉第一面的所有推荐内容,并在「文件夹」中打开设置方便快速进入。
搜索栏在任务栏中的开始菜单附近,但是它的设置项目却在「隐私和安全性 > 搜索权限」中。而微软也往此处插入了一些「推荐内容」,需要在关闭设置项目最后的「显示搜索要点」。
在 Windows 11 中,即便解锁任务栏,我们也不能像 Windows 10 那般将任务栏拖动到屏幕左右侧,只能在底部。虽然通过修改注册表可以强行改动任务栏位置,但是会导致 UI 错位。更推荐的方法是使用第三方工具将整个任务栏回退到 Windows 10 模式,例如后面会介绍的 ExplorerPatcher。
除了任务栏和开始菜单,很多人在 Windows 11 中最先接触到的变化可能是右键菜单。其实如果不带成见来看,Windows 11 的右键菜单在设计上更加简洁、更符合整体设计语言,且按钮排布更加宽松,没有按钮增多时密密麻麻的视觉压迫感,也更适合触摸操作等非精确点击。
问题是,宽松的按钮排布,代价是并非所有功能都能直接在右键菜单中找到,部分功能被隐藏在「显示更多选项」中,且这些更多选项并非像「新建」那样以二级菜单展开,而是完全退回到类似 Windows 10 的右键菜单。在桌面/文件资源管理器按住 Shift 右键也能直接唤出这种经典风格的右键菜单,除了真的需要考虑触摸可用性,为什么不一开始就显示完全呢?
倘若你不想节外生枝使用复杂插件,其实直接修改注册表的方法也并不繁琐。
注销或重启文件资源管理器即可生效,右键菜单将恢复到 Windows 10 风格。
在我自己的日常使用习惯中,无论在 Windows 还是 macOS,虚拟桌面都是高频使用的功能。对于临时被打断或者由于时间问题没有完成的工作,在确保保存后我会将其原封不动放在原位置并新建一个虚拟桌面继续其他工作。同时在处理多个任务时候,我也会尽可能保证一个虚拟桌面内是一个相对独立的任务,相当于在标签页、窗口之上再加一层桌面维度,检索时更加快捷。
如此频繁的使用,自然容易在 Windows 10 升级到 Windows 11 感受到一些细微的变化。对于单次虚拟桌面切换来说动画是更加丝滑了——Windows 11 非线性动画的加速、减速比起 Windows 10 更加自然。但多次切换就有点灾难了,在 Windows 10 按住 Ctrl + Win 并多次按左右方向键时,滑动动画经历「加速 > 连续的桌面滑动(哪怕有来回)> 减速」停到目标桌面,而在 Windows 11 中,多次切换时,每次都会经历完整的「加速 > 减速」动画,相当于把单次切换简单的拼接起来,这样的动画在频繁切换时会显得有些拖沓。
以上都是针对快捷键切换虚拟桌面的情况,对于触控板切换来说动画都是尽量跟手的,而连续切换之间的停顿也符合直觉(毕竟触控板没法像快捷键那样连续多次按方向键,中间肯定也有停顿对应)。
网络上暂时没有找到将动画回退到 Windows 10 版本的方法,所以我简单粗暴地关闭了这个动画——在「设置 > 辅助功能 > 视觉效果 > 动画效果」开关可以关闭虚拟桌面切换动画,但是这样也会波及其他动画效果;在高级系统设置(cmd/Win + R: sysdm.cpl)中的性能设置中视觉效果页关闭「对窗口内的控件和元素进行动画处理」也可以关闭虚拟桌面切换动画,但同样也会波及诸如 Win + Tab 窗口动画效果,不过从描述来看想必波及的范围更小。
我个人有个癖好是桌面不出现任何图标、任务栏只留一个文件资源管理器、所有应用在开始菜单以磁帖排布。在注意力有些散漫的时候 Win + D 回到桌面欣赏下壁纸休息——不得不承认 Windows 11 背景设置中的「Windows 聚焦」挺好看,同时又不会过分吸睛,应该是和 Bing 每日壁纸同源的。
在「设置 > 个性化 > 主题 > 桌面图标设置」中可以关闭桌面图标。遗憾的是当清空桌面图标后,角落「Learn about this picture」更加显眼,且没有显式关闭设置,除了再次借助 ExplorerPatcher,也可以通过修改注册表实现:
这样桌面就只剩下壁纸了。如果你第一次这么设置会发现有一尴尬之处──回收站怎么进?确实一般情况下回收站都是放在桌面的。这时可以通过在文件资源管理器的地址栏中输入 shell:RecycleBinFolder 打开回收站,然后将其固定到快速访问中,这样就可以在文件资源管理器的侧边栏方便访问回收站。
硬件部分关于屏幕、缩放、渲染等内容会占用太多篇幅且涉及技术原理部分可操作性不强。这里直接给结论:
在 Windows 10 之时我还能接受通过 noMeiryoUI 软件方式修改默认系统字体为更纱黑体,配合 MacType 软件实现更好的字体渲染效果(一定程度上抵消 ClearType 在高分屏的负优化)。虽然 noMeiryoUI 依然兼容 Windows 11,Windows 11 上更多的系统组件、官方应用并不默认遵守该设置,导致字体修改效果十分有限。
因此在 Windows 11 上我选择一种比较 dirty 但是好用的手段──将其他字体(例如更纱黑体)重新打包成伪装的「微软雅黑」并移动至 Windows 字体文件夹下以欺骗系统。chenh96/yahei-sarasa 提供了一个截止本文修改时仍运行良好的 Python 脚本自动将更纱黑体伪装为微软雅黑和宋体。
目前主要有三种方法将伪装字体替换系统默认字体:
这里仅展示第一种方法,不需要任何额外工具。在 Windows 恢复模式中的命令行使用 xcopy 将伪装的微软雅黑移动到相应文件夹下:
覆盖后重启即可。请特别注意不要在任何有用于演示、汇报用途的 Windows 设备上进行此操作,以免一些不必要的麻烦。
Windows 的色彩管理仍是一个相对混乱的领域,短期内是不指望能和 macOS 相提并论。但是 Windows 11 还是比前代 Windows 10 在 HDR 支持上有 明显改进,至少算是过了及格线。
在开启 HDR 之前,还请确保屏幕至少支持 HDR 600 标准,HDR 400 可以当作不支持看待(注意区别于 HDR true black 400,这是 OLED 标准,甚至严格过 HDR 1000)。OLED 和 MiniLED 屏幕往往效果更好。
全局开关在「设置 > 系统 > 显示 > HDR」。开完先别急,点击下面的「HDR Display Calibration」,这里可以矫正 HDR 显示效果。
「自动 HDR」功能可以将仅支持 SDR 的游戏转化为 HDR 输出,效果挺不错。但如果你的设备使用较新的 N 卡,那更推荐关闭此功能 Windows 11 的自动 HDR,用 NVIDIA app 内的 RTX HDR 替代。由于 HDR 会尽可能用尽显示器硬件性能,不能通过调整显示器亮度来改变内容整体亮度,在开启 HDR 显示时只能通过设置「SDR 内容亮度」将桌面调整至不开 HDR 相近效果。
在开启 HDR 模式下就是纯 HDR 信号输出,不存在区域渲染,原本 SDR 内容也会通过算法转化为 HDR 输出,这其中必然是会丢失信息的。目前消费级 HDR 显示器素质良莠不齐。如果在开启 HDR 模式看 SDR 内容时发现颜色「寡淡」,有可能是眼睛已经被各种「鲜艳模式」惯坏了,毕竟在开启 HDR 后系统会自动对 SDR 内容做 sRGB 限缩,从某种意义上这才是「正确」的颜色,除此以外就是显示器还跟不上,前者可以尝试常驻 HDR 模式适应,后者建议常用 Win + Alt + B 快捷开关 HDR 仅在消费 HDR 内容时开启。
「Wintel 联盟」现在似乎已经很少提起,当初意图取代 IBM 公司在个人计算机市场上的主导地位,直至现在 Microsoft 和 Intel 的合作依然紧密。Intel 新大小核处理器在 Windows 10 上有许多调度问题促使其用户不得不选择 Windows 11。
如果你在电源设置中发现缺少某些设置项目,除了一个个查注册表,更方便的方法是通过 PowerSettingsExplorer 这个仅调用 Power Management Functions 接口的小工具来调出那些被隐藏的选项。在 Windows 11 中与大小核调度策略有关的隐藏高级电源设置有:
在「高性能」电源计划中,这三个的设置按顺序是「0 – 自动 – 自动」,调度策略是「大核 > 小核 > 大核超线程」;如果将后两个设置同时设为「高性能处理器」,那么调度策略变为「大核 > 大核超线程」。总体而言异类策略 0 优先使用大核,对应的异类策略 1 优先使用小核。异类策略 4 比较奇怪,它是「节能」电源计划的默认设置,但是在烤鸡、游戏挂机等测试场景大小核调度策略几乎和「高性能」一致,怀疑是高负载场景积极调度、中低负载再节能的策略。
其实预设的几种电源计划均挺符合直觉的,没必要过于纠结。即便有极端省电需求也不建议完全小核优先,其实该设置中的所谓「高效处理器」也就是小核还真未必比限制后的大核能效比高。看看对功耗更加敏感的移动端,都有越来越多大核的势头,乃至天玑的全大核构想。当然移动端大核甚至还没够到桌面端的小核,不能简单横向比较。不过时至今日我依然对桌面端异构架构持保守态度。
以上都是针对 Intel 新处理器的情况,对于 AMD 全大核处理器,Windows 11 的大小核调度反而引入额外问题导致游戏场景表现甚至不如 Windows 10。众所周知,锐龙 CPU 各核心都有成为 CPPC 属性,代表各个核心的「体质」,在 AMD 官方工具 Ryzen Master 中可以查看的金、银核心分别就是 CPPC 最高的两个核心,而 Windows 11 会将 CPPC 最低核心视为小核(高效处理器)进行调度。通过上述真正大小核的 Intel 处理器上观测的不同异类调度策略并在 AMD 全大核处理器上对应测试,发现 Windows 11 对 AMD 处理的调度的确遵循 N-1 个高性能处理器和 1 个高效处理器的策略。这样默认的调度策略会更不倾向调用所谓的小核,这种不对称可能会导致更多的跨核行为、特别是游戏场景频繁地 L3 缓存争用造成无端性能损失。
之前的民间偏方,在 BIOS 开 PBO、XMP/EXPO 的同时顺手把 CPPC 关掉,或许也是由此而来。
早在去年 UP 主 @开心的托尔酱 在视频 关于 Windows 系统对 AMD 的负优化—异类线程调度 就有提到这个问题。而在最近 AMD 在社区更新 关于 Zen 5 游戏性能提升远不及理论的回应,宣布 Windows 11 24H2 将通过优化「branch prediction」 来提升 AMD Zen3/4/5 系列处理器的性能表现,部分游戏甚至有 10% 以上提升,要知道 Zen 5 由于相较于前代提升过于微妙有被戏称「Zen 5%」,更有特例 5700X3D 在 Windows 11 上性能表现比 Windows 10 差 15%……该说锐龙 CPU 首发一如既往地一言难尽呢、还是说与 Windows 合作不够紧密呢?
当然,尽管 Windows 几个电源设置的预设符合直觉无需额外调整,电源设置里还是有很多可玩性的,例如不用重启调整 CPU 睿频参数等。具体不再展开,感兴趣可以参阅 Windows 电源设置注释。
Windows 11 在「设置 > 账户 > Windows 备份」中可以设置包括文件、设置等备份选项,但似乎必须绑定微软账户使用,对于离线账户并不友好。且这种方法不支持备份系统。
个人认为更好用的还属控制面板中的「备份和还原(Windows 7)」,不仅支持对系统分区全量备份,还支持制作系统镜像和系统恢复盘。虽然 Windows 在 知识库 中鼓励大家尽可能使用设置取代控制面板,无奈前者体验还偏偏不如后者。
此外,Dism++ 也提供系统备份功能,同时支持不添加文件的增量备份(不算快照)。Dism(Deployment Imaging and Management)是 Windows 自带的一个工具,用于安装和维护 Windows 映像,Dism++ 只是将常用命令封装成 GUI 便于操作,并没有额外单独实现,这种备份也算是半官方方法。
还有两个系统功能看似很好用但是我不推荐:一是系统检查点,它本意主要用于系统更新失败的回滚,很难说胜任纯粹的系统备份,对个人文件的行为很奇怪经常在回滚的时候搞得一团糟;而文件历史,它默认备份整个用户目录,需要自己一个个排除,且该功能仅放置于控制面板,微软对此也并不算上心,一个 bug 三五年不修。
话说回来,目前单独备份系统的意义远不如备份文件,通过链接把一些应用的数据文件夹(例如微信保存的文件)link 到其他分区、外置存储乃至云端上,更多链接操作留到后续关于快捷创建链接的工具那一部分。
Windows 11 正常要求硬件支持 TPM 2.0。TPM 芯片是一种安全加密处理器,包含多个物理安全机制以防篡改。BitLocker 会将专用密钥存储在 TPM 芯片内,在除了更改 TPM、BitLocker 检测到 BIOS 或 UEFI 配置、关键操作系统启动文件或启动配置的更改之外的情况下,BitLocker 会自动解锁,用户登录无需进行任何额外交互即可解锁。无其他加密手段建议对系统盘开启 BitLocker,这已经是 Windows 集成最高、最无感的方式。
关于几个关键问题:
如果真有换设备需求,但是事先忘记解锁 BitLocker,会导致无法访问数据吗?
不会。在创建加密的时候 BitLocker 同时会创建恢复密码,可以将其打印或存在安全位置。检测到硬件更改后 BitLocker 进入恢复模式,用户输入恢复密码可以重新访问数据。
备份工具是否支持 BitLocker 加密盘?
对于基于文件系统的备份方式来说,理论上解锁后 BitLocker 是透明的,先解锁再备份即可。对于分区的备份方式,理论上可以不解锁整个区拷走,但是加密后不知道哪一部分是空的会导致备份文件更大且不好压缩,虽说 BitLocker 通过长长一串恢复密码也可以离线挂载,但不建议盲目还原。
BitLocker 是否会影响性能?
理论上会,但实际上体感不明显。别单看开 BitLocker 后硬盘读写速度有的下降超 10%,解密过程应是压力越大损耗越明显,所以不能根据硬盘测速这一极端压力情况下的性能损耗来界定 BitLocker 的性能损耗。
BitLocker 闭源,微软可以添加后门,如何保证安全?
你说得对,可以尝试开源方案 VeraCrypt,支持 Windows 11 系统加密,在普通分区加解密上还提供更好的跨平台支持,但是 VeraCrypt 不支持 TPM 且由于理念不合永远不会支持,在和 Windows 集成上肯定也不如 BitLocker 无感。看你愿不愿意拿所谓的安全换便利了。
平心而论,这个软件本身并没有什么问题,但是大陆用户对「电脑管家」的 PTSD、早期仅在中国区推送和不事先提醒地静默安装才是其被人诟病的原因。
后来,我的区域美国、语言英语的 Windows 11 也被推送,Reddit、Discord 也有相关讨论,才得知微软打算全球推送。单看软件本身,清理、加速、系统保护项、应用管理、常用小工具(截图、字幕、翻译、词典、以图搜图等)还有快捷修复建议,其实就是可能原本在设置里藏很深的 Windows 已有功能的拿出来,不需要联网也没有广告,不像小组件和 Office Plus 那样尽塞垃圾。
如果抛开前两点,静默安装也确实不厚道,用户的诟病并非完全无端。不过实现手段其实不是 Windows 更新而是 Edge 后台下载安装包安装。所以它就单纯是个软件,看不惯直接卸载就好。Edge 自从某次我重装系统后,在搜索 Chrome、进入 Chrome 官网时用大半个页面阻挠我安装 Chrome 我就已经心留芥蒂,出了这一茬直接让我彻底禁用 Edge,还不能简单卸载,留到后面 Remove MS Edge 插件部分。
除了深入设置、注册表、组策略等方法调整系统外,还有一些第三方插件可以帮助我们更好地使用 Windows 11。当然这里提到的插件依然主要针对系统调整,不发散到更广泛的效率提升上。
Windows 本身其实一直缺乏一个好用的包管理器,不提不如 Linux 各发行版的,就连 HomeBrew 类似产品都没有。微软官方推行的 WinGet 严格意义上称不上包管理器,它并没有提供统一的包格式,而是依赖于各个软件的安装程序下载下来静默安装,正如 HomeBrew Cask。Scoop 才稍微有些包管理器的感觉,安装同时也能自动配置环境变量,在迁移时备份还原更方便。如果不介意添加多余的工具,用 UniGetUI 可以一次性管理 WinGet, Scoop, Chocolatey, Pip, Npm, .NET Tool 和 PowerShell Gallery 多个包管理器。
仅关于 Scoop 的安装,在 PowerShell 中输入以下命令即可:
倘若你还希望使用 UniGetUI,可以在 PowerShell 中输入以下命令通过 Scoop 安装:
Windows 并不像 macOS 通过三个应用分别控制桌面、Dock 栏、Finder,而是通过一个「资源管理器」一并控制。而 Windows 11 相较于 Windows 10 许多令人不满的改动──任务栏、开始菜单、右键菜单──都可以通过介入资源管理器来调整。
虽然前面系统设置部分已经提到部分调整手段,但是这些调整往往需要手动修改注册表等隐藏更深的手段。如果你不想折腾,亦或是觉得这些调整不够全面,可以尝试 ExplorerPatcher 这款开源插件,不仅可以将任务栏、开始菜单、右键菜单一并调回 Windows 10 风格,还有许多诸如屏蔽 Office Key、禁止文件高级搜索、取消窗口圆角等功能。
虽然在部分时刻,例如系统更新后,ExplorerPatcher 偶有失效,但考虑到开源插件能做到这种程度,完全配得上其自称的「增强 Windows 上的工作环境」宗旨,无需吝啬赞美。
开源项目 Power plan switcher 可以在系统托盘中切换电源计划,支持快捷键、自动切换等功能。
一般来说对于长期接通电源或者没有续航焦虑的设备可以常驻「高性能」或「卓越性能」电源计划,这些计划的默认设置已经十分符合直觉,无需额外微调。
而对于笔记本电脑,它有时接通电源有时使用电池,前往控制面板翻出电源计划设置十分麻烦。PowerPlanSwitcher 可以不仅在系统托盘中切换电源计划,还支持在电源状态变化(从 AC 供电到电池供电)时自动切换对应电源计划。
官方称该软件支持 Windows 10,但实际上在 Windows 11 上也能正常使用。
Microsoft PowerToys 是一组实用工具,可帮助高级用户调整和简化其 Windows 体验,从而提高工作效率。
——Microsoft PowerToys
作为一款出现在 Microsoft 知识库的官方工具,可能考虑到不用像 Windows 那样背负沉重的历史包袱,PowerToys 工具箱中的绝大多数功能都轻量、专一且直击用户需求,被誉为 Windows 用户必备瑞士军刀,且在 GitHub 上完全开源,算是微软给我留下正面印象的产品之一。
早在 Windows 95 时代,PowerToys 就集成了包含了 Tweak UI 在内的共计 15 个小工具,Tweak UI 可以调整 Windows 中原本需要修改注册表才能访问的较为晦涩的设置。微软在 2019 年接管并重新推出 PowerToys,目前也已经有如下我认为很好用的功能:
同时还有诸如 Color Picker、Image Resizer、Text Extractor 等一众小工具,让你免去管理一堆小工具的烦恼、也减少众多工具中出现某几个断更的风险。PowerToys 也有丰富的 第三方插件,例如 PowerTranslator 在 PowerToys Run 中直接翻译文本、
EverythingPowerToys 在 PowerToys Run 中通过 Everything 检索文件、
ChatGPTPowerToys 在 PowerToys Run 中调用 chatgpt、
PowerToys-Run-Spotify 在 PowerToys Run 中让 Spotify 放歌等等。
各个工具具体用法这里不再赘述,PowerToys 每个工具页面都有详尽的描述。
单看 PowerToys Run 中的文件搜索功能其实比较孱弱,而 Windows 资源管理器的搜索效果更是惨不忍睹。Everything 通过访问 NTFS 文件系统的 USN 日志,在数秒内检索 TB 级别硬盘,并实时监测所有文件的增改情况,同时支持通过正则表达式进行文件精确匹配,还可通过插件与 PowerToys Run 联动。
自从某次我重装系统后,Edge 在搜索 Chrome、进入 Chrome 官网时用大半个页面阻挠我安装,反而彻底让我将 Edge 定位明确为 Chrome 下载器。更改默认浏览器后某些链接还是会给我跳转到 Edge 打开,之后还闹出自动下载静默安装微软电脑管家一事。
不过 Edge 是不能够简单直接卸载的,可能会导致一些依赖系统 WebView 的应用出问题,而且可能在某次重启后惊觉 Edge 又回来了。
Remove MS Edge 这个工具旨在通过可执行文件或批处理脚本以静默方式彻底卸载 Microsoft Edge,并提供保留 WebView 选项。
虽然 PowerToys 的 Keyboard Manager 也能完成一些键盘映射的工作。但是 AutoHotKey 作为完整脚本语言,功能更加强大,可以实现更多的自定义功能。
例如我对于大写锁定键的需求很小,但是却又有频繁的中英文输入法切换和自定义快捷键需求。自定义快捷键时一般会引入 Hyper 键 的概念,在 Windows 上即同时按下 Ctrl、Shift、Alt、Win 四个键,这样可以避免与系统快捷键冲突。
我希望产生下述行为:
这种行为仅通过 PowerToys Keyboard Manager 是难以实现的,但是通过 AutoHotKey 可以轻松实现:
同样的,在 macOS 中文输入法会自动将 Shift + [/] 映射为部分中文排版更推荐的直角引号「/」,而 Windows 自带输入法并没有这个功能。除了更换输入法、全局替换掉某个键、设置字典打出一对引号等方法,通过 AutoHotKey 识别当前输入法状态并映射不同的按键不失为一种更优雅的解决方案。
在 Windows 上也有自带的 Win + V 的高级剪贴板功能,甚至可以和微软账户绑定实现云同步。但是这个功能对我而言比较花里胡哨,UI 确实更加现代化也与系统保持一贯风格。不过系统自带的剪贴板历史过于循规蹈矩,保存的历史条目太少不说,在隐身浏览器模式下乖乖不记录。Ditto 作为一款开源剪贴板增强工具,UI 更加简洁紧凑,可以保存更多历史记录、支持搜索、支持自定义快捷键、同时还有清除格式等高级粘贴功能。
配合 AutoHotKey 设置的 Hyper 键,我一般通过 Hyper + V 调出 Ditto 剪贴板历史记录。
C++ 编写的小工具具有不俗的性能,在保存 300 条目且不随时间清空的情况下,调出和检索都察觉不到卡顿,且占用极低只用个位数 MB 内存。
在 macOS Finder 中,Quick Look 赋予空格快速预览文件夹属性或者多种文档内容功能——俗称「一指禅」。Windows 用户一直垂涎这种功能,虽然 Windows 资源管理器也可以通过侧边栏预览,但是这种方式开启后任何选中都会预览,占用大量资源,同时支持的文件内容类型也有限,还会有反馈带来奇怪 bug。
这催生了 Windows 同名第三方开源插件 QuickLook,行为几乎与 macOS Quick Look 一致,通过空格快速预览,同时支持通过 引入插件的插件 形式支持预览 markdown、jupyter notebook、电子书等更多格式文件,并且支持在 Directory Opus、Files、OneCommander 等第三方文件管理器中使用。
MacBook 触控板和妙控板凭借着超大的触控面积、以假乱真的震动体验和 macOS 软硬结合,造就了曾经以及当下最优秀的触控板体验。许多 macOS 用户或许和我一样并不愿意使用鼠标,而是更倾向于触控板。其中稍微有些弯弯绕绕就属 macOS 的三指拖拽,如此好用的功能就藏在辅助功能里。
当然随着微软给出精确式触控板的驱动和建议硬件规格,也体现出 Windows 对于触控板的上心,目前绝大多数 Windows 设备触控板也都支持精确式触控板,相当一部分产品日用体验已足够优秀。可惜的是即便系统对于多点触控的支持已经覆盖从二指到四指,但是三指和四指滑动手势略有重合且使用频率不高,Windows 也没有给出类似 macOS 的三指拖拽功能。
好在可以通过插件 ThreeFingerDragOnWindows 在 Windows 上实现 macOS 的三指拖拽,依赖 .NET 运行环境实现。使用前请确保通过触摸板设置中禁用「轻点两次并拖动以多选」行为和所有默认的三指轻扫行为,这样拖动操作才不会受到干扰。
相较于 Windows 10 主题色、背景和明暗模式的割裂设置,Windows 11 将更统一、更完善的「个性化 – 主题」设置提到更优先位置,并提供若干预设主题。但是 Windows 11 仍然没有 macOS 那样的自动切换深色模式功能。Windows Auto Dark Mode 支持通过设定固定时间或跟随该定位的日出日落时间自动切换深色模式,同时可以自定义深色、浅色模式对应主题。
在前文提到:
目前单独备份系统的意义远不如备份文件,通过链接把一些应用的数据文件夹(例如微信保存的文件)link 到其他分区、外置存储乃至云端上……
所谓「链接」,在文件系统中指的是软链接(符号链接)和硬链接──两种创建文件引用的方法。软链接(符号链接)是指向另一个文件或目录的路径,可以跨文件系统,类似于快捷方式;如果原文件被删除,软链接会失效。硬链接是直接指向文件数据的引用,两个文件共享相同的物理数据块,它们的内容完全一致,删除一个硬链接并不会影响到文件的实际数据,只有所有硬链接都删除时,数据才会被清除。硬链接只能在同一文件系统中创建,其实文件管理器上的几乎所有文件都可以被看作是硬链接。
更详细关于链接的介绍可以参阅少数派文章 符号链接、硬链接及其在 Windows 上的应用举例。我对 Link Shell Extension 的初识也正是在这篇文章中。一个最常见的案例是,对于 小而美 微信可以将其 Files 文件夹移动至 OneDrive,然后通过符号链接将其链接回原位置,这样既可以保证微信正常运行,又可以实现微信保存的文件备份。该插件的智能多版本硬链接功能会自动分析和前一次的差异并对不变的内容创建硬链接,实现增量备份,但该功能不能链接到外部存储,仅适合在同盘做备份版本管理。
特别注意,少数派文章中介绍的「中键拖动」快速创建链接操作不适用于 Windows 11,正确操作应当修改为使用右键拖动。
虽然 Windows 自带输入法对于绝大多数用户已经足够好用。但是我有跨设备需求,特别是需要兼容 macOS 和 Windows 双系统,这导致明明两者的系统自带输入法都可圈可点我都率先排除。而高度自由、高度定制的 RIME 进入我考虑范围。在 Windows 上通过 Weasel、在 macOS 上通过 Squirrel 实现 RIME 输入法的部署,在 Linux 上还有诸如 ibus-rime 等多种版本。
但 RIME 的高度自由伴随的也是较高准入门槛。好在开源项目 oh-my-rime 及其 配套配置教程 算是相当程度上降低这种门槛。但这种打包配置并未限制你设置自由度,你依然可以根据自己的需求自行修改配置文件,例如取消 Shift 切换中英文、更改翻页快捷键和以词定字快捷键等等。
许多功能和其他配置在 oh-my-rime 项目教程中也有提及,这里单独展开讲一下多设备同步。虽然该教程中也完整提到同步设置,但是同步行为是要用户手动触发的,而平时工作中很可能忘记触发。更优雅的方案是通过 Windows 的计划任务触发同步:




















































































































































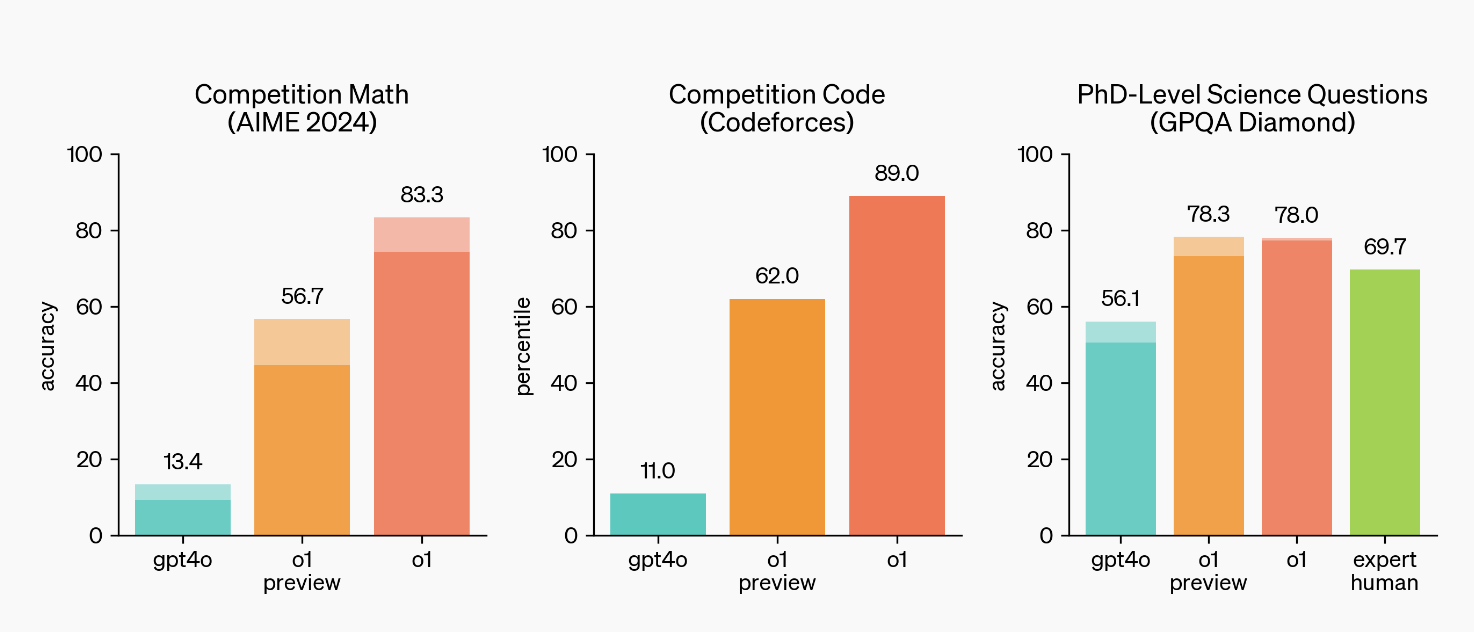





























 点击以全屏查看图片 Click to view the image in full screen
点击以全屏查看图片 Click to view the image in full screen
 点击以全屏查看图片 Click to view the image in full screen
点击以全屏查看图片 Click to view the image in full screen






















































 点击图片跳转到播放页面
点击图片跳转到播放页面


















































