吐槽一下小米路由器的初始化设置
PrinceofInj: 前几天趁着国补买了一个 BE3600PRO ,打算把家里的 AC86U 替换掉,升级一下速度。原来的路由器是当作 AP 使用的,放在一个犄角旮旯里面,新的路由器到了之后也打算如法炮制,也就设置一下 IP ,SSID 插上网线就可以用了,没想到开机后发现想要设置完毕必须得联互联网才可以,这下完犊子了,只能找根长长的网线一头插交换机上,一头插电脑上了,期间还会打断家庭网络好长一段时间,本来就几分钟可以搞定的事情。
 (Abstract)来🇯🇵一年拿绿卡在理论上是可行的,但需要有足够多的证据证明对🇯🇵的“亲和力”足够。这是一项艰巨的任务。
(Abstract)来🇯🇵一年拿绿卡在理论上是可行的,但需要有足够多的证据证明对🇯🇵的“亲和力”足够。这是一项艰巨的任务。  (Abstract)这个网站的特殊之处在于:第一、每首诗都有相应的古籍文件对应。第二、尽可能把异文收集完整了。一半以上的古诗都有多个版本。
(Abstract)这个网站的特殊之处在于:第一、每首诗都有相应的古籍文件对应。第二、尽可能把异文收集完整了。一半以上的古诗都有多个版本。  (Abstract)深圳10岁日本男孩上学路上被刺死的具体地点,在南山区招商街道的贝塔玛国际蒙特梭利儿童学院西侧路边,马路对面是招商桃花园三期-东2门。该区域总体上属于市区核心区,房价较高。
(Abstract)深圳10岁日本男孩上学路上被刺死的具体地点,在南山区招商街道的贝塔玛国际蒙特梭利儿童学院西侧路边,马路对面是招商桃花园三期-东2门。该区域总体上属于市区核心区,房价较高。 先来看看效果:友情链接 - PRIN BLOG。
自我感觉还是不错的,友链的博客们有什么更新都可以实时展示在页面上,一目了然。作为博主,不用打开 RSS 阅读器就可以查看新文章;作为访客,也可以快速找到更多自己感兴趣的内容,比起原来全是链接的页面,看起来也让人更有点击欲望了。
从临时起意到开发完成总共两个晚上,最速传说就是我!(误)
前段时间看到有个博客用了这样的一个东西:
当时就感觉卧槽好高端,很有想法。
这种聚合订阅的形式有个名字,叫做 Planet(社区星球)。Planet 通常用于聚合某个领域的博客,然后展示在一个页面上,方便用户一站式阅读,比如:
这种形式在开源社区里比较常见,不过用在博客的友链上我倒还是第一次看到。
就像我在本站友链页里说的一样,独立博客之间的联系基本上就是靠的链接交换和评论互访。一个博客的访客看到了其他博客的链接,点过去看了,然后从对面的友链中,又导航到新的博客……如此往复,我们就依靠着这种从现在看来显得十分古老的方式,维系着这些信息孤岛之间的纽带。原始又浪漫。
不过这里就会涉及到一个用户点击率的问题。我自己之前在维护友链页面的时候,总感觉只放标题和链接看起来效果不怎么好。就算加上描述、头像这些元素,也总觉得差点意思。因为一个博客最重要的其实还是它的内容,仅靠一个网站标题,可能很难吸引到其他用户去点击。
而「友链朋友圈」的这种形式,就像微信朋友圈一样,作为一个聚合的订阅流,展示了列表中每个博客的最新文章。
比起干巴巴的链接,这显然会更加吸引人。虽然我写博客到现在也已经 9 年了,早就佛系了,主打一个爱看不看。不过对于和我交换了友链的博主们,还是希望他们能够获得更多的曝光和点击(虽然我这破地方也没多少流量就是啦……),也希望我的访客们也可以遇到更多有价值的博客。
然而在准备接入的时候,我发现这玩意儿不就是一个小型的 RSS 阅读器么……其实等于是自己又实现了一套订阅管理、文章爬取、数据保存之类的功能。
于是我就寻思,可能直接复用已有 RSS 阅读器 API 的思路会更好,让专业的软件做专业的事。友链的管理也可以直接复用 RSS 阅读器的订阅管理功能,这样增删改也不需要了,我们就只需要封装一下查询的 API,提供一个精简的展示界面就 OK。
作为行动力的化身,咱们自然是说干就干,下班回家马上开工!
首先是 RSS 后端的选择。
市面上的 RSS 阅读器有很多,我自己主要用的是 Inoreader。然而我看了下,Inoreader API 只面向 $9.99 一个月的 Pro Plan 开放,而且限制每天 100 个请求……这还玩个屁。Feedly 也是差不多一个尿性,可以全部 PASS 了。我也不知道该说他们什么好,也许做 RSS 真的不挣钱,只能这样扣扣搜搜了吧。
另外一个选择就是各种支持 self-host 的 RSS 阅读器,比如 Tiny Tiny RSS 和 Miniflux。我之前部署过 TTRSS,说实话感觉还是太重了。Miniflux 则是使用 Go 编写的,该有的功能都有,非常轻量级,部署也很方便。就决定是它了!
技术栈方面选择了之前一直比较心水的 Hono,部署在 Cloudflare Workers 上。前端方面没有使用任何框架,连客户端 JS 都没几行,基本上是纯服务端渲染。有时候不得不感叹技术的趋势就是个圈,以前那么流行 SPA,现在又都在搞静态生成了。
页面渲染使用了 Hono 提供的 JSX 方案,可以在服务端用类似 React 的语法返回 HTML,挺好用的。不过 CSS 没有用 Hono 的那一套 CSS-in-JS,因为要允许用户覆盖样式,所以要用语义化的类名。最后选了 Less,还是熟悉的味道。
前端文件的构建使用了 tsup,配置文件就几行,爽。
实现思路很简单,就是做一个 Proxy 层,把:
GET /v1/categories/22/entries - Get Category EntriesGET /v1/categories/22/feeds - Get Category Feeds这两个 Miniflux 的 API 包一下。这里要注意不能暴露实际的 API Endpoint,避免可能的恶意攻击。API 缓存也要在我们这一层做好,防止频繁刷新把服务打爆。
缓存策略上使用了 SWR (Stale-While-Revalidate):
stale 状态,依然返回前端;这样可以保证最快的响应速度,以及相对及时的更新速度,比较适合这种场景。
最后的交付形式其实就是两个 HTML 页面,通过 <iframe> 的形式嵌入到网页中。另外参考 giscus 提供了一个脚本,可以设置参数并自动完成 iframe 的初始化,用户只需要引入一个 <script> 标签即可,非常方便:
<script async data-category-id="28810" src="https://blog-friend-circle.prin.studio/app.js"></script>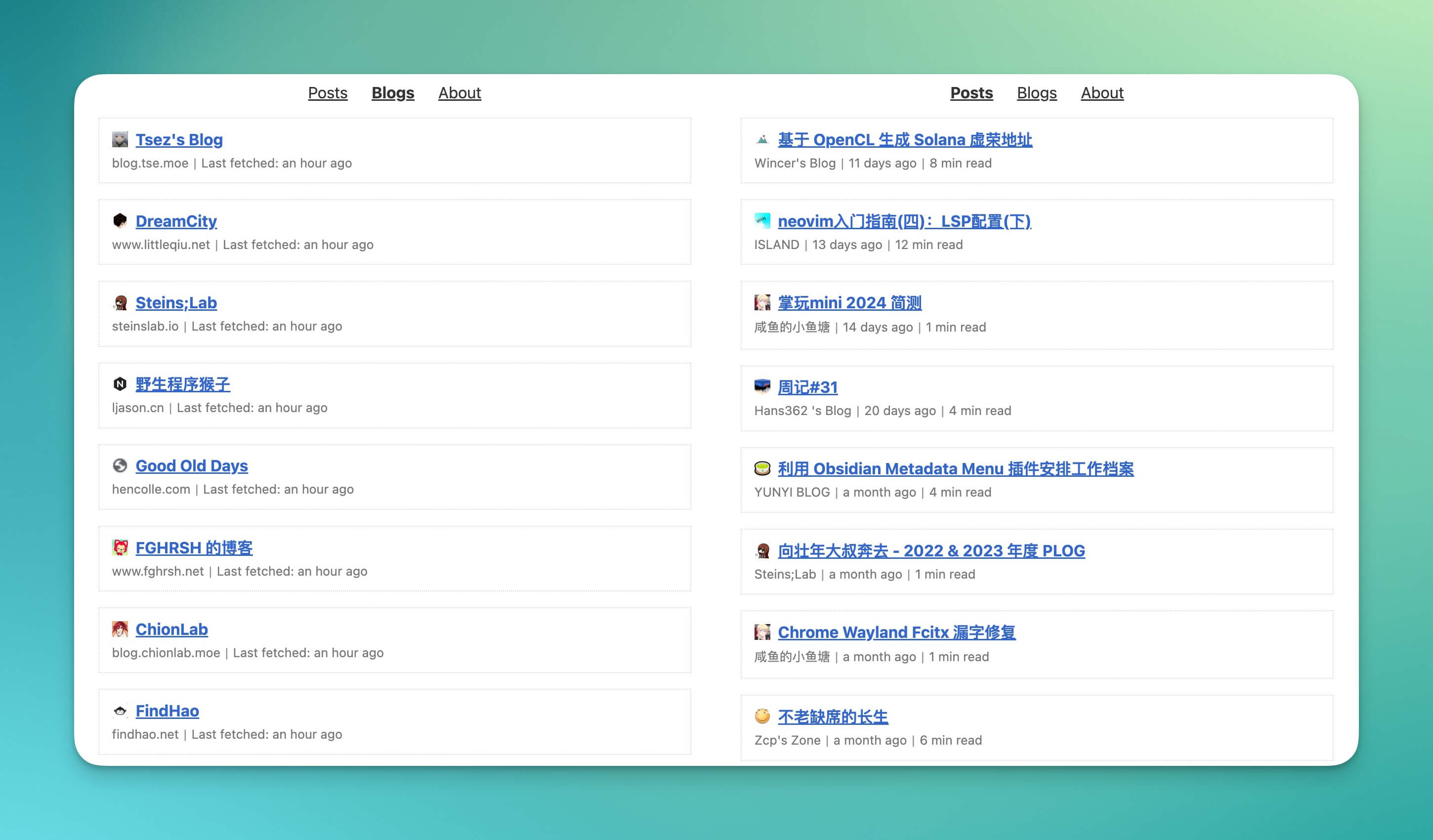
当然也可以作为独立页面打开,有做双栏布局适配:
blog-friend-circle.prin.studio/category/2/entries
新版博客友链朋友圈的所有代码都开源在 GitHub 上,欢迎使用:
这个方案和 hexo-circle-of-friends 并没有孰优孰劣之分,只是侧重点和实现方式不同。不过我这个的一个好处是,如果你已经在用 Miniflux 了,那么可以直接复用已有的大部分能力,不需要再起一个 Python 服务和数据库去抓取、保存 RSS,相对来说会更轻量、稳定一些。
如果你选择使用 Miniflux 官方提供的 RSS 服务,甚至可以无需服务器,部署一下 CF Workers 就行了,像我这样的懒人最爱。
最近在 Code Review 时,看到有同事写了这样的代码:
function TodoList() { const [list, setList] = useState([]); const TodoItem = useCallback((props) => { return <li>{props.text}</li>; }, []); return <ul>{list.map((item, index) => <TodoItem key={index} text={item} />)}</ul>;}有经验的 React 开发者肯定一下子就看出问题了:在组件内部嵌套定义组件,会导致子组件每次都重新挂载。因为每次渲染时,创建的函数组件其实都是不同的对象。
但是他又有包了 useCallback 让引用保持一致,好像又没什么问题……?
这波骚操作让我突然有点拿不准了,所以今天咱们一起来验证一下,用 useMemo 或者 useCallback 包裹嵌套定义的子组件,对 React 渲染会有什么影响。以及如果有影响,应该如何用更合适的方法重构。
先说结论:
永远不要在 React 组件内部嵌套定义子组件。
如果你有类似的代码,请使用以下方法替代:
为什么?请接着往下看。
来看这段代码(可以在 StackBlitz Demo 中运行):
function TodoList() { const [list, setList] = useState([]); // 嵌套定义子组件(好孩子不要学哦) const TodoItem = (props) => { return <li>{props.text}</li>; }; const handleAdd = () => setList([...list, `Item ${list.length + 1}`]); return ( <div> <button onClick={handleAdd}>Add</button> {/* 渲染刚才定义的子组件 */} <ul> {list.map((item, index) => ( <TodoItem key={index} text={item} /> ))} </ul> </div> );}可能不少初学者都写出过类似的代码:JavaScript 语言可以嵌套定义函数,React 函数式组件就是函数,那 React 组件不也可以嵌套定义?
还真不是这么回事。我们来实际运行一下这段代码看看:
Tips: 这里使用了
useTilg这个库来展示组件生命周期。
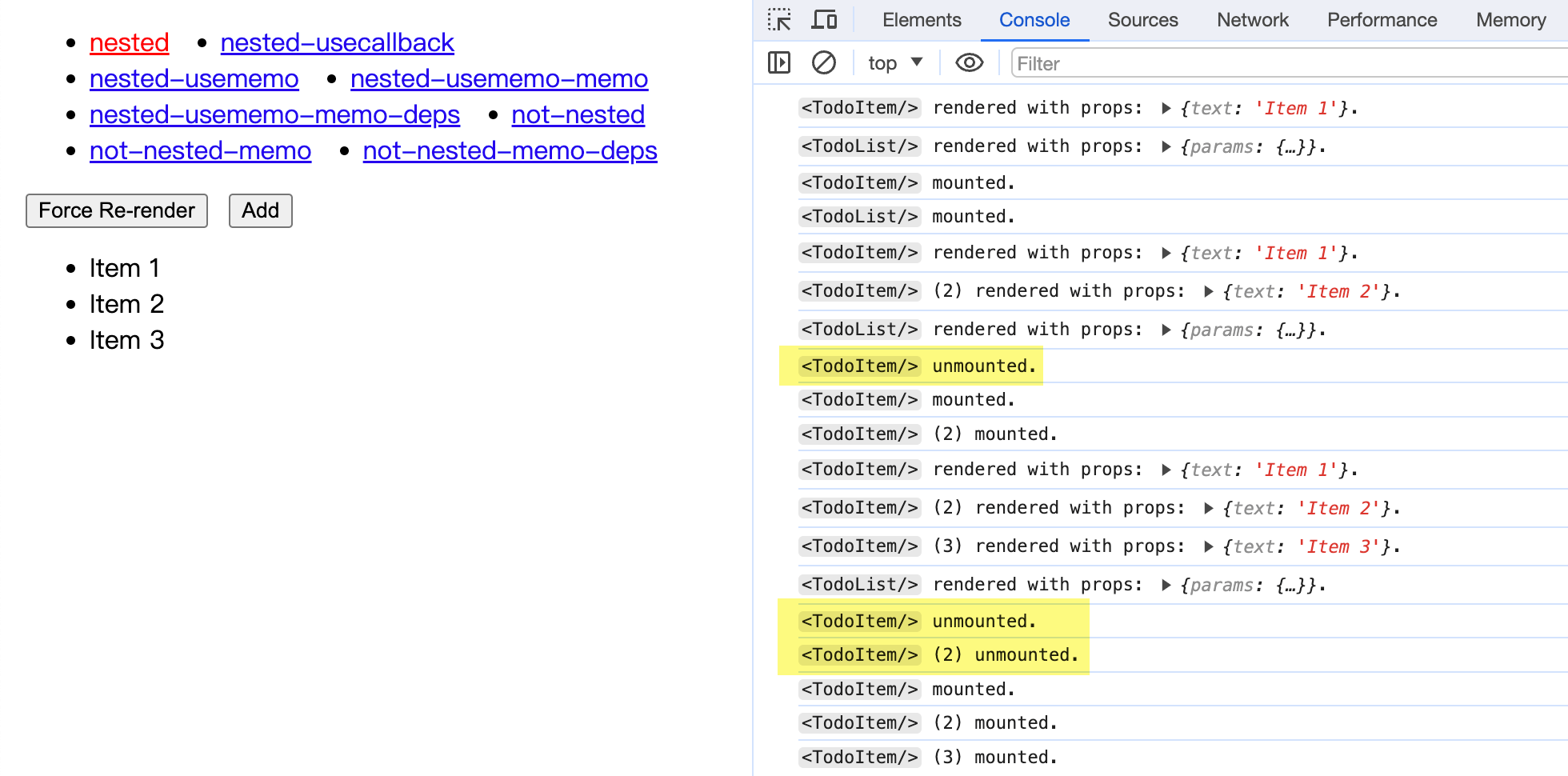
可以看到,每次点击 Add 按钮在 <TodoList/> 列表中添加元素时,之前旧的 <TodoItem/> 组件实例就会被卸载 (unmount)、销毁。React 会创建全新的组件实例,然后再挂载 (mount) 上去。
也就是说,这些组件实例全都变成一次性的了。
这还只是一个简单的示例,如果是实际应用场景,一个组件和它的子组件中,可能包含了成百上千个 DOM 节点。如果每次状态更新都会导致这些组件和对应的 DOM 节点被卸载、创建、重新挂载……那应用性能可就是「画面太美我不敢看」了。
更严重的是,组件的卸载还会导致其内部的状态全部丢失。
那怎么会这样呢?这要从 React 的渲染机制,以及 Reconciliation 流程说起。
我们知道 React 的渲染大致可以分为两个阶段:
Render 阶段:执行组件的渲染方法,找出更新前后节点树的变化,计算需要执行的改动;Commit 阶段:已经知道了需要执行哪些改动,于是操作真实 DOM 完成节点的修改。其中,「找出变化 + 计算改动」这个过程就被叫做 Reconciliation (协调)。React 的协调算法可以在保证效率的同时,最大程度复用已有的 DOM,使得对 DOM 做出的修改尽量小。
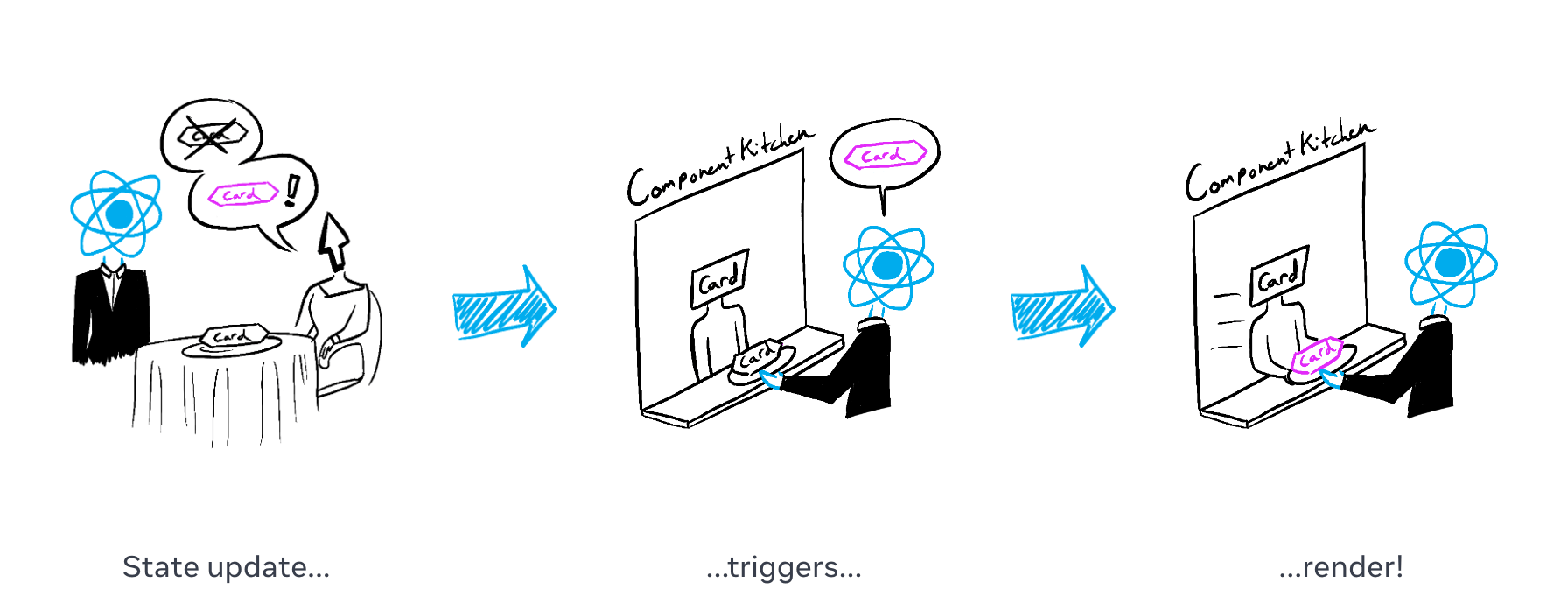
▲ 图片来自:Render and Commit – React
那么问题来了,React 怎么知道一个组件对应的 DOM 需要更新呢?
简单来说,React 在比较两棵 Fiber 树时,会从根节点开始递归遍历所有节点:
上面所说的子组件被卸载再挂载、状态丢失等问题,其实都是因为它们被判断为了「节点类型有改变」。
在 JavaScript 中,比较值时有两种相等性:
举个例子:
// 两个长得一样的对象const a = { name: 'Anon Tokyo' };const b = { name: 'Anon Tokyo' };// "引用相等性" 比较 - falseconsole.log(a === b);console.log(Object.is(a, b));// "值相等性" 比较 - trueconsole.log(lodash.isEqual(a, b));console.log(a.name === b.name);JavaScript 函数也是对象,所以这对于函数(React 组件)也成立。
到这里问题就比较明朗了。
function TodoList() { const [list, setList] = useState([]); // WARN: 这个语句每次都会创建一个全新的 TodoItem 函数组件! const TodoItem = (props) => { return <li>{props.text}</li>; }; return <ul>{list.map((item, index) => <TodoItem key={index} text={item} />)}</ul>;}在这段代码中,每次 <TodoList/> 组件重渲染时(即 TodoList 函数被调用时),其内部创建的 TodoItem 都是一个全新的函数组件。
虽然它们长得一样,但它们的「引用相等性」是不成立的。
回到上一节介绍的渲染流程中,React 在比较节点的 type 时,使用的是 === 严格相等。也就是说像上面那样不同的函数引用,会被视作不同的组件类型。进而导致在触发重渲染时,该组件的节点及其子节点全部被卸载,内部的状态也被全部丢弃。
到这里我们已经介绍了「在组件内部嵌套定义组件」会造成问题的原理。
这时候可能就有小机灵鬼要问了,既然组件每次都被判断为是不同 type 的原因是对象引用不同,那我用 useMemo / useCallback Hooks,让它每次都返回相同的函数对象不就行了?
能考虑到这一层的都是爱动脑筋的同学,点个赞!让我们再来试验一下:
function TodoList() { const [list, setList] = useState([]); // useMemo 允许我们缓存一个值,每次重渲染时拿到的缓存是一样的 // 这里我们返回了一个函数组件,让 useMemo 把这个子组件的函数对象缓存下来 const TodoItem = useMemo( () => (props) => { return <li>{props.text}</li>; }, [] ); // 或者用 useCallback 也可以,都一样 // const TodoItem = useCallback((props) => { // return <li>{props.text}</li>; // }, []); const handleAdd = () => setList([...list, `Item ${list.length + 1}`]); return ( <div> <button onClick={handleAdd}>Add</button> <ul> {list.map((item, index) => ( <TodoItem key={index} text={item} /> ))} </ul> </div> );}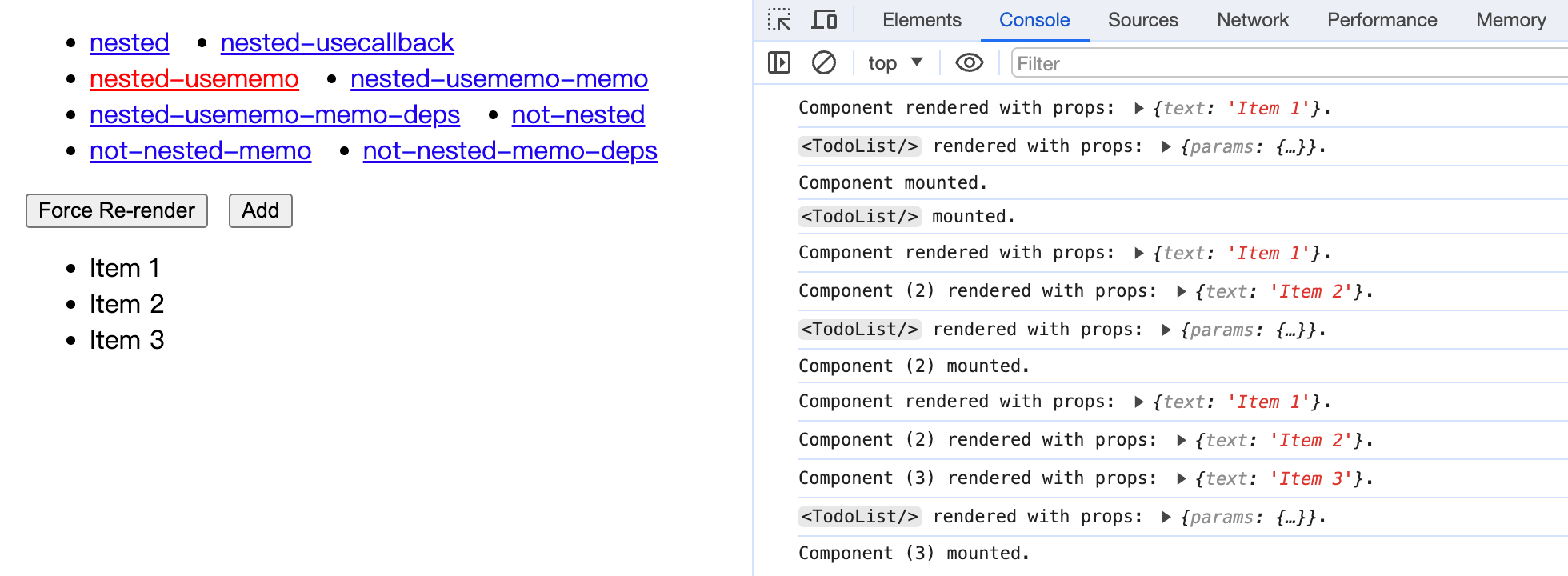
可以看到,包一层 useMemo 之后,子组件确实不会再被 unmount 了。看起来十分正常呢!
让我们再拿 React.memo 来包一下,在 props 相同时跳过不必要的重渲染:
const TodoItem = useMemo( () => memo((props) => { return <li>{props.text}</li>; }), []);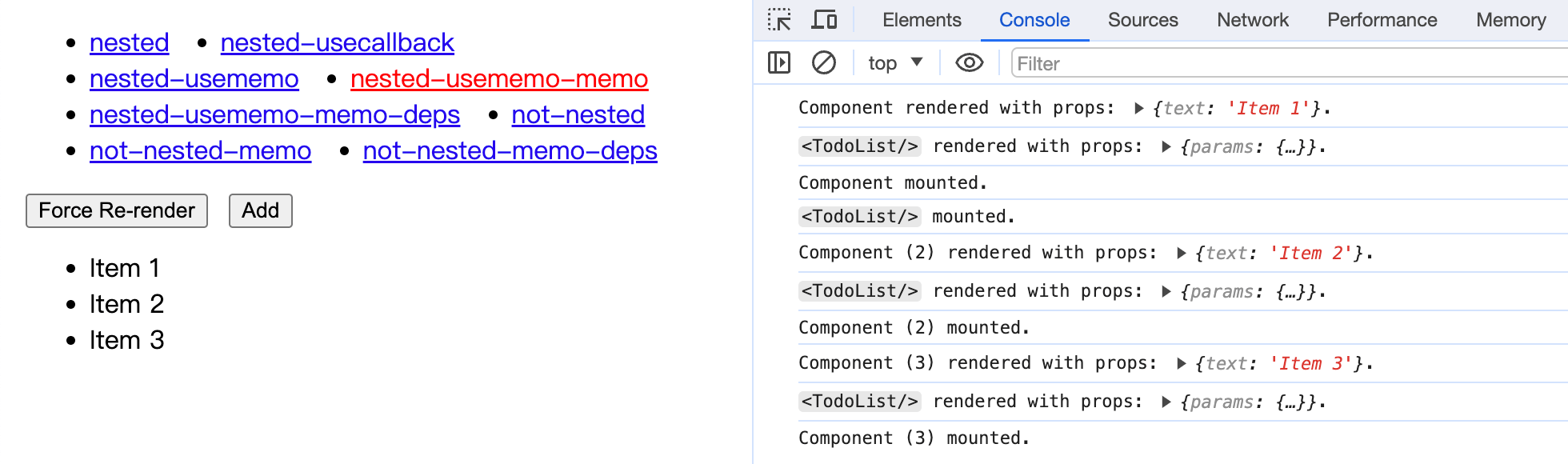
OHHHHHHHHH!!
同理,如果我们通过一系列操作可以让「嵌套定义的 React 组件」在渲染时表现得与「在外层定义的组件」一致,那是不是就意味着这种操作其实也是 OK 的呢?
嗯……答案是:没那么简单。
稍微偏个题,你可能会好奇 Hooks 和 memo 为什么也可以在嵌套定义的子组件内正常使用,因为这看起来和我们平时的用法完全不同。
实际上不管是模块顶层定义的函数组件,还是嵌套定义的函数组件,在 React Reconciler 看来都是独立的组件类型,且在渲染时都有着自己的 Fiber 节点来储存状态,而定义该函数的作用域是什么并不重要。想想看:HOC 高阶组件有时候也会返回内联定义的函数组件,其实是一个道理。
第一点,useMemo 和 useCallback 的缓存并非完全可靠。
在某些条件下,缓存的值会被 React 丢弃。如果缓存失效,函数组件就会被重新创建,同样会被判断为是不同的组件类型。React 官方肯定不会推荐你把 Hooks 用于这种歪门邪道的用途。
In the future, React may add more features that take advantage of throwing away the cache—for example, if React adds built-in support for virtualized lists in the future, it would make sense to throw away the cache for items that scroll out of the virtualized table viewport. This should be fine if you rely on useMemo solely as a performance optimization.
Ref: useMemo – React
第二点,useMemo 和 useCallback 都有依赖数组。
虽然上面的示例里嵌套组件定义的依赖数组都是空的,但是我们再想想,什么情况下会想要在组件内部定义子组件,而非将其拆成一个单独的组件呢?最主要的原因就是,这个子组件想要直接访问父组件函数作用域中的某些变量。
function TodoList() { const [list, setList] = useState([]); const TodoItem = useMemo( () => memo((props) => { // 注意看,这里子组件直接使用了父级作用域中的 list 变量 return <li>{`${props.text} of ${list.length}`}</li>; }), [list.length] ); const handleAdd = () => setList([...list, `Item ${list.length + 1}`]); return ( <div> <button onClick={handleAdd}>Add</button> <ul> {list.map((item, index) => ( <TodoItem key={index} text={item} /> ))} </ul> </div> );}
从实际测试中可以看到,有了依赖项的 useMemo + 嵌套组件,又退化成了最开始的样子,每次都会被当成不同的组件类型,每次都会被 unmount。之前所做的努力全部木大!(顺带一提用 useRef 也是一样的,有依赖就歇菜)
也就是说,只有你的嵌套子组件完全不依赖父组件作用域时,才能保证 useMemo 的缓存一直有效,才能做到完全不影响渲染性能。但既然都已经完全不依赖了,那么又还有什么理由一定要把它定义在父组件内部呢?
所以我再重复一遍开头的结论:永远不要在 React 组件内部嵌套定义子组件。
因为这在大部分情况下会造成渲染问题,即使对这种写法做优化也没有意义,因为一不留神就可能掉进坑里,还有可能会误导其他看到你的代码的人。
如果你的代码库中已经有了这样的 💩 代码,可以使用下面的方法重构。
第一种方法,把子组件移到最外层去。
这种方法适用于子组件依赖项不多的情况,如果有之前直接使用的父级作用域中的变量,可以将其改造为 props 传入的方式。
// 组件定义移到模块顶层const TodoItem = memo((props) => { return <li>{`${props.text} of ${props.listLength}`}</li>;});function TodoList() { const [list, setList] = useState(['Item 1']); const handleAdd = () => setList([...list, `Item ${list.length + 1}`]); return ( <div> <button onClick={handleAdd}>Add</button> <ul> {list.map((item, index) => ( // 改造后:从 props 传入原来的依赖项 <TodoItem key={index} text={item} listLength={list.length} /> ))} </ul> </div> );}第二种方法,把子组件改为渲染函数 (Render Function)。
JSX 的本质就是 React.createElement(type),React 节点的本质其实就是一个 JavaScript 对象。你在组件 return 语句中直接写 JSX,和定义一个函数返回 JSX 然后再调用这个函数,本质上是一样的。
function TodoList() { const [list, setList] = useState([]); // 这不是函数组件,只是一个「返回 JSX 的函数」(函数名首字母非大写) // 所以每次渲染都重新创建也没问题,也可以直接访问作用域内的变量 const renderTodoItem = (key, text) => { return <li key={key}>{`${text} of ${list.length}`}</li>; }; const handleAdd = () => setList([...list, `Item ${list.length + 1}`]); return ( <div> <button onClick={handleAdd}>Add</button> {/* 调用的时候也和调用普通函数一样,而非组件的标签形式 */} <ul>{list.map((item, index) => renderTodoItem(index, item))}</ul> </div> );}不过需要注意的是,在使用「渲染函数」时,一定要搞清楚和「函数组件」的区别:
render 开头,首字母小写(否则容易和组件搞混)。另外,当渲染函数作为 props 传入其他组件时,它也被叫做渲染属性 (Render Props)。这种设计模式在 React 生态中有着大量的应用,可以放心使用。
最后聊一下,如何避免这类问题的发生。
第一,配置 Lint 规则。
防范于未然,合理的 Lint 配置可以减少起码 80% 的代码规范问题。比如本文介绍的坑,其实完全可以通过 react/no-unstable-nested-components + react-rfc/no-component-def-in-render 规则提前规避。
最好再配合代码提交后的 CI 卡点检查,有效避免因开发者环境配置不当或者偷摸跳过检查,导致规则形同虚设的情况。
第二,定期 Code Review。
代码腐化是难以避免的,但我们可以通过流程和规范提早暴露、纠正问题,减缓腐化的速度。Code Review 同时也是一个知识共享、学习和成长的过程,对于 reviewer 和 reviewee 来说都是。
没有人一开始就什么都会,大家都是在不断的学习中成长起来的。
第三,了解一些 React 的原理与内部实现。
因为我自己就是吃这碗饭的,之前写过 React 的 Custom Renderer,也做过渲染性能优化,所以底层原理看的比较多,自然也就知道什么样的代码对性能会有影响。
我一直以来秉持的观点就是,学习框架时也要学习它「引擎盖下」的东西,知其然且知其所以然。如果你希望在这条路上一直走下去,相信这一定会对你有所帮助。
扩展阅读:
一转眼就到 2024 年了!大家新年快乐!
前段时间在写文章时,需要一些配图,于是就使用了 TikZ 来绘制。TikZ 是一个强大的
上面的图对应的 TikZ 代码可以在这里找到。然而画是画爽了,想把它贴到博客里时却犯了难——目前竟然没有什么好办法可以直接在博客里使用 TikZ!
咱们废话不多说,直接上结果:我写了一个 Hexo 插件,可以直接把 Markdown 源码里的 TikZ 代码渲染成 SVG 矢量图,然后在博客构建时嵌入到页面 HTML 中,用起来就和 MathJax 写数学公式一样简单。
而且最重要的是渲染完全在构建时完成,浏览器上无需运行任何 JavaScript。同时构建机上也无需安装
👉 prinsss/hexo-filter-tikzjax: Server side PGF/TikZ renderer plugin for Hexo.
npm install hexo-filter-tikzjax注意:插件安装成功后,需要运行 hexo clean 清除已有的缓存。
安装插件后,只需要在博客文章中添加 TikZ 代码块:
---title: '使用 TikZ 在 Hexo 博客中愉快地画图'tikzjax: true---Markdown text here...```tikz\begin{document} \begin{tikzpicture} % Your TikZ code here... % The graph below is from https://tikz.dev/library-3d \end{tikzpicture}\end{document}```插件就会自动把代码渲染成对应的图片,非常方便:
不做过多介绍。贴几个链接,有兴趣的可以学学:
比如这就是我在写文章时画的图,全部用 TikZ 代码生成,画起来改起来都很方便。
在本插件之前,主流的在网页上渲染 TikZ 绘图的方式是使用 TikZJax。TikZJax 有点类似 MathJax,都是通过 JavaScript 去渲染
<link rel="stylesheet" type="text/css" href="https://tikzjax.com/v1/fonts.css"><script src="https://tikzjax.com/v1/tikzjax.js"></script><script type="text/tikz"> \begin{tikzpicture} \draw (0,0) circle (1in); \end{tikzpicture}</script>然而这样做的问题是,太重了。在网页上动态加载 TikZJax,需要加载 955KB 的 JavaScript + 454KB 的 WebAssembly + 1.1MB 的内存数据,如果再另外安装一些宏包,最终打包产物大小甚至可以达到 5MB+。
对于一些有加载性能要求的网站,这显然是难以接受的。
那怎么办呢?答案就是 SSR / SSG,把渲染过程搬到服务端/构建时去做。这很适合博客这样的场景,尤其是静态博客,只需要构建时渲染一下,把生成的图片塞到 HTML 里就完事了,完全不需要客户端 JavaScript 参与,加载速度大幅提升。
因为 TikZJax 底层跑的是 WebAssembly,而 Node.js 也支持运行 WebAssembly,所以很自然地我就想,能不能把它的渲染流程直接搬到 Node.js 里面去做?
说干就干。于是就有了 node-tikzjax,一个 TikZJax 的移植版,可以在纯 Node.js 环境下运行,无需安装第三方依赖或者
hexo-filter-tikzjax 则是 node-tikzjax 的一个上层封装,主要就是在渲染 Hexo 博客文章时提取 Markdown 源码中的 TikZ 代码,交给 node-tikzjax 执行并渲染出 SVG 图片,然后将其内联插入到最终的 HTML 文件中。
如果是其他博客框架,也可以用类似的原理实现 TikZ 静态渲染的接入。
因为 node-tikzjax 并不是完整的 \usepackage{} 中直接使用的宏包有:
如果希望添加其他宏包,可以参考 extractTexFilesToMemory 这里的代码添加。
如果在使用插件的过程中 TikZ 代码编译失败了,可以通过 hexo s --debug 或者 hexo g --debug 开启调试模式,查看
This is e-TeX, Version 3.14159265-2.6 (preloaded format=latex 2022.5.1)**entering extended mode(input.texLaTeX2e <2020-02-02> patch level 2("tikz-cd.sty" (tikzlibrarycd.code.tex (tikzlibrarymatrix.code.tex)(tikzlibraryquotes.code.tex) (pgflibraryarrows.meta.code.tex)))No file input.aux.ABD: EveryShipout initializing macros [1] [2] (input.aux) )Output written on input.dvi (2 pages, 25300 bytes).Transcript written on input.log.或者也可以在这个 Live Demo 中输入你的 TikZ 代码,提交后可在控制台查看报错。
首先要感谢 @kisonecat 开发的 web2js 项目,这是一个 Pascal 到 WebAssembly 的编译器,使我们可以在 JavaScript 中运行
这里有作者关于构建基于 Web 的
感谢 @drgrice1 对 TikZJax 和 dvi2html 的修改,TA 的 fork 中包含了很多有用的新功能,并且修复了一些原始代码中的问题。
感谢 @artisticat1 对 TikZJax 的修改,这是基于上述 @drgrice1 的 fork 的又一个 fork,也添加了一些有用的功能。本插件依赖的 node-tikzjax,其底层使用的 WebAssembly 二进制和其他文件就是从这个仓库中获取的。
感谢 @artisticat1 开发的 obsidian-tikzjax 插件,这是本项目的灵感来源。本项目和该插件底层共享同一套
如有任何问题,请在 GitHub 上提交 issue。祝使用愉快!
除草啦除草啦,再不更新博客就要变成热带雨林啦!🌿
最近在给一个 PixiJS 程序编写 WebGL Shader,被各种参数和坐标系搞得晕头转向。痛定思痛,整理了一下 PixiJS Filter 系统中的各种概念,以供后续参阅。
在 WebGL 中,我们可以通过编写顶点着色器 (Vertex Shader) 和片元着色器 (Fragment Shader) 来实现各种各样的渲染效果。而在 PixiJS 中,渲染引擎为我们屏蔽了绝大多数的底层实现,通常情况下用户是不需要自己调用 WebGL API 的。如果有编写自定义着色器代码的需求,一般是使用 Filter 来实现。
PIXI.Filter 其实就是一个 WebGL 着色程序,即一组顶点着色器 + 片元着色器的封装。和 Photoshop 中的滤镜功能类似,它接受一个纹理 (Texture) 输入,然后将处理后的内容输出到 Framebuffer 中。使用滤镜,可以实现模糊、扭曲、水波、烟雾等高级特效。
用户只需要定义着色器的 GLSL 代码,传入对应的参数,剩下的工作就全部交给 PixiJS 完成。如果你对这些概念不太熟悉,可以看看:WebGL 着色器和 GLSL。
在 PixiJS 中,Filter 自带了一组默认的顶点着色器和片元着色器代码。用户在定义 Filter 时,如果省略了其中一个,就会使用默认的着色器代码运行。
new Filter(undefined, fragShader, myUniforms); // default vertex shadernew Filter(vertShader, undefined, myUniforms); // default fragment shadernew Filter(undefined, undefined, myUniforms); // both default这是 Filter 默认的顶点着色器代码:
attribute vec2 aVertexPosition;uniform mat3 projectionMatrix;varying vec2 vTextureCoord;uniform vec4 inputSize;uniform vec4 outputFrame;vec4 filterVertexPosition(void){ vec2 position = aVertexPosition * max(outputFrame.zw, vec2(0.)) + outputFrame.xy; return vec4((projectionMatrix * vec3(position, 1.0)).xy, 0.0, 1.0);}vec2 filterTextureCoord(void){ return aVertexPosition * (outputFrame.zw * inputSize.zw);}void main(void){ gl_Position = filterVertexPosition(); vTextureCoord = filterTextureCoord();}这是默认的片元着色器代码:
varying vec2 vTextureCoord;uniform sampler2D uSampler;void main(void){ gl_FragColor = texture2D(uSampler, vTextureCoord);}看着一脸懵逼不要紧,下面我们逐一解释。
先来复习一下 WebGL 基础知识。
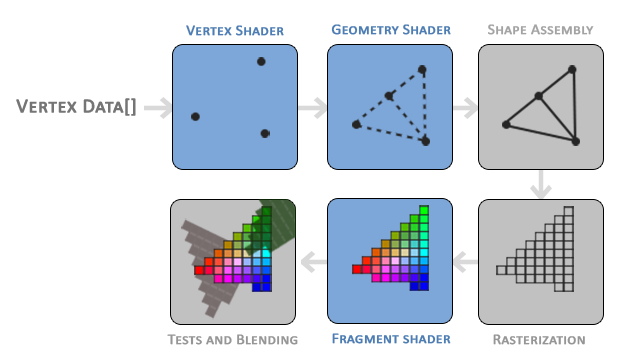
▲ OpenGL 图形渲染管线的流程。插图来自 LearnOpenGL
不太熟悉的同学可能会以为 WebGL 是 3D 渲染 API,但其实 WebGL 本身只是一个光栅化引擎,并没有提供什么 3D 功能。如果想要实现 3D 渲染,你需要将模型中的三维坐标点转换为裁剪空间的二维坐标,并提供对应的颜色。WebGL 负责将这些图元绘制到屏幕上,仅此而已。
试想:任何 3D 模型,不管怎样旋转、缩放、平移,最终展示到你的屏幕上,都是 2D 的。同样,不管模型上有什么贴图、光照、阴影、反射,最终改变的其实都是这个像素的颜色值。
再来复习一下 WebGL 中的坐标系统:
[-1, 1] 范围之间,即为 NDC(0, 0) 位于裁剪空间的正中间,左下角为 (-1, -1),右上角为 (1, 1)[0, 1](0, 0),右上角坐标为 (1, 1)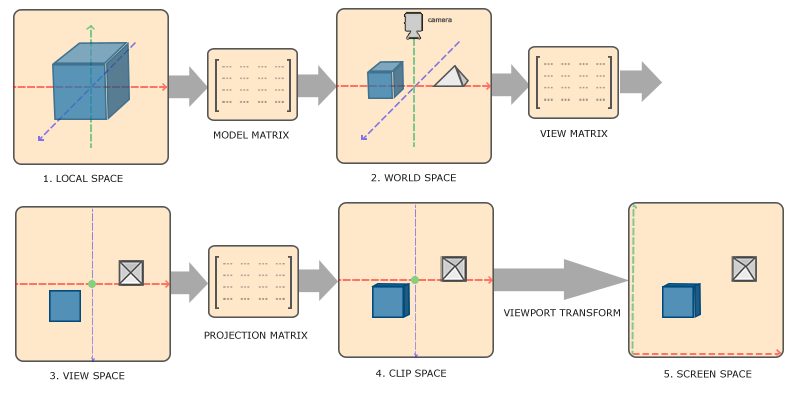
▲ 各种坐标与变换矩阵的关系。插图来自 LearnOpenGL
下面介绍 PixiJS Filter 中的坐标系,以及它们和 WebGL 坐标系之间的关系。
输入坐标,用于表示传入 FilterSystem 的纹理上的坐标。
Normalized Input Coordinate 是标准化之后的输入坐标,即纹理坐标,范围是 [0, 1]。
相对于 canvas 视口的屏幕坐标,单位是 CSS 像素。
CSS 像素乘以分辨率 resolution 即为屏幕物理像素。
滤镜坐标,即被 Filter 所覆盖的范围内的局部坐标,单位是 CSS 像素。
Normalized Filter Coordinate 是标准化之后的滤镜坐标,滤镜覆盖范围的左上角坐标是 (0, 0),右下角坐标是 (1, 1)。
额外的图片纹理坐标。可以用于采样其他输入中的纹理。
额外的精灵图集纹理坐标。
讲完坐标的种类,下面介绍 Filter 着色器代码中传入的各个参数(attributes、uniform、varying)分别代表什么,对应的是什么坐标系,以及它们的取值分别是多少。
⚠️ 以下参数适用于 PixiJS v7 版本,不排除后续版本中有变动的可能。
vec2 二维向量假设有一个长宽为 300x300 的矩形 A,其原点左上角位于 (100, 30) 世界坐标处。则有:
(0.0, 0.0) 对应矩形左上角(1.0, 1.0) 对应矩形右下角mat3 3x3 矩阵具体是怎么变换的,请阅读本文底部的「投影矩阵」章节。
vec4 四维向量假设有一个大小为 512x512 的 framebuffer,则 inputSize 的值为:
vec4(512, 512, 0.0020, 0.0020)其中,前两个分量 x, y 为像素大小,后两个分量 z, w 是像素大小的倒数。倒数可用于将除法转换为乘法,因为乘以一个数的倒数等于除以这个数。
以下两个表达式是等价的:
aVertexPosition * (outputFrame.zw * inputSize.zw);aVertexPosition * (outputFrame.zw / inputSize.xy);但是在计算机中,乘法比除法的计算速度更快。所以在 GLSL 着色器这类需要高速运行的代码中,通常会尽量避免直接使用除法,而使用倒数乘法替代。
vec4 四维向量还是以矩形 A 为例,其 outputFrame 取值为:
vec4(100, 30, 300, 300)其中,前两个分量 x, y 为输出区域的位置,后两个分量 z, w 为输出区域的长宽。
vec4 四维向量sampler2D 纹理vec4 四维向量和 inputSize 类似,但是单位不是 CSS 像素,而是物理像素。以下两个表达式等价:
inputPixel.xyinputSize.xy * resolution同样地,inputPixel.zw 是 inputPixel.xy 的倒数,用于转换除法为乘法。
vec4 四维向量有效范围指的是临时 framebuffer 中实际包含纹理图像的部分,其余部分可能是透明的(具体原因可阅读文章下方的注意事项)。使用示例:
vec4 color = texture2D(uSampler, clamp(modifiedTextureCoord, inputClamp.xy, inputClamp.zw));其中,inputClamp.xy 表示有效范围的左上角,inputClamp.zw 表示有效范围的右下角。
floatdevicePixelRatiovec4 四维向量注意,filterArea 已经被标记为 legacy,你应该考虑使用其他参数替代。
// 以下语句等价于直接使用 filterArea uniformvec4 filterArea = vec4(inputSize.xy, outputFrame.xy)vec4 四维向量Filter 中的各种坐标系直接可以通过公式转换。
参考:v5 Creating filters · pixijs/pixijs Wiki。
// Input Coord// 单位:标准化坐标vTextureCoord// Input Coord -> Filter Coord// 单位:标准化坐标 -> CSS 像素vTextureCoord * inputSize.xy// Filter Coord -> Screen Coord// 单位:CSS 像素vTextureCoord * inputSize.xy + outputFrame.xy// Filter Coord -> Normalized Filter Coord// 单位:CSS 像素 -> 标准化坐标vTextureCoord * inputSize.xy / outputFrame.zw// Input Coord -> Physical Filter Coord// 单位:标准化坐标 -> 物理像素vTextureCoord * inputPixel.xy// Filter Coord -> Physical Filter Coord// 单位:CSS 像素 -> 物理像素vTextureCoord * inputSize.xy * resolution // 与上一条语句等价需要注意的是,在应用 Filter 之前,PixiJS 的 FilterSystem 会先把目标的 DisplayObject 渲染到一个临时的 Framebuffer 中。
这个 framebuffer 的大小不一定等于 DisplayObject 的大小,它是一个二次幂纹理 (Power-of-two Texture)。假如你有一个 300x300 的图片要应用滤镜,那么 PixiJS 会将其渲染到一个 512x512 尺寸的 framebuffer 上,然后将这个 framebuffer 作为输入传递给着色器代码。
根据这个 DisplayObject 上的 filters 属性定义,PixiJS 会依次执行数组中的 filter,前一个的输出作为后一个的输入,最后一个输出的将渲染到最终的 render target 中。
不过这个创建临时 framebuffer 的行为可能会在自定义着色器代码中导致一些问题,比如纹理坐标的偏移,有时间后续我会另外发文章讨论。
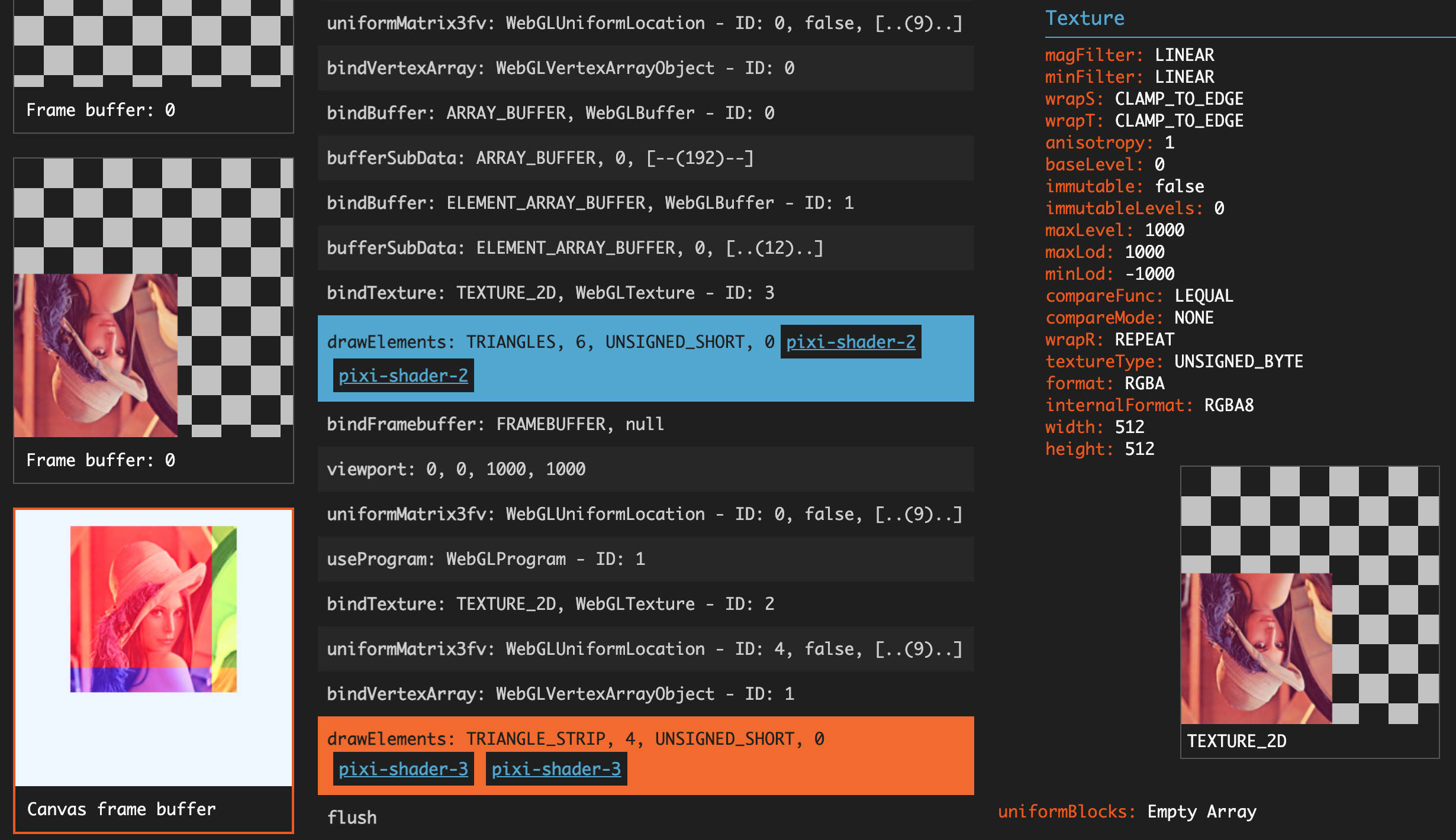
▲ 通过 Spector.js 抓取到的 PixiJS 渲染过程
好了,梳理完各种坐标系和参数后,我们再来回头看看上面的默认着色器代码:
// 标准化的「滤镜坐标」,范围是 filter 所覆盖的矩形区域attribute vec2 aVertexPosition;// 投影矩阵uniform mat3 projectionMatrix;// 纹理坐标varying vec2 vTextureCoord;// 输入 filter 的临时 framebuffer 大小uniform vec4 inputSize;// filter 所覆盖的区域在屏幕坐标中的位置与大小uniform vec4 outputFrame;vec4 filterVertexPosition(void){ // position 算出来的是 filter 所覆盖的区域的屏幕坐标 vec2 position = aVertexPosition * max(outputFrame.zw, vec2(0.)) + outputFrame.xy; // 通过投影矩阵,将屏幕坐标转换为裁剪空间 NDC 坐标 return vec4((projectionMatrix * vec3(position, 1.0)).xy, 0.0, 1.0);}vec2 filterTextureCoord(void){ // 等价于 aVertexPosition * (outputFrame.zw / inputSize.xy) // 也就是将「滤镜坐标」从 outputFrame 的范围缩放到 inputSize 的范围 // 计算出来的就是 inputSize 范围内的「纹理坐标」 return aVertexPosition * (outputFrame.zw * inputSize.zw);}void main(void){ // 裁剪空间 NDC 坐标传递给 WebGL gl_Position = filterVertexPosition(); // 纹理坐标传递给片元着色器 vTextureCoord = filterTextureCoord();}// 纹理坐标varying vec2 vTextureCoord;// 输入 filter 的临时 framebuffer 纹理uniform sampler2D uSampler;void main(void){ // 使用纹理坐标在传入的纹理上采样得到颜色值,传递给 WebGL gl_FragColor = texture2D(uSampler, vTextureCoord);}怎么样,是不是感觉清晰了很多呢?
如果你很好奇上面的投影矩阵是怎么做到乘一下就能把屏幕坐标转换为裁剪空间坐标的,那么这一小节就可以解答你的疑惑。
🤫 偷偷告诉你,CSS 中的
transform: matrix()也是用了同样的矩阵变换原理。
投影矩阵的默认计算方式如下,代码来自 ProjectionSystem#calculateProjection:
// 矩阵表示:// | a | c | tx|// | b | d | ty|// | 0 | 0 | 1 |// 数组表示:// [a, b, 0, c, d, 0, tx, ty, 1]//// 主要参数:// sourceFrame - Filter 所覆盖的区域的世界坐标,长、宽、X、Y,像素单位// root - 控制 Y 轴反转,当渲染到 framebuffer 时投影为 y-flippedcalculateProjection(){ const pm = this.projectionMatrix; const sign = !root ? 1 : -1; pm.identity(); pm.a = (1 / sourceFrame.width * 2); pm.d = sign * (1 / sourceFrame.height * 2); pm.tx = -1 - (sourceFrame.x * pm.a); pm.ty = -sign - (sourceFrame.y * pm.d);}这个投影矩阵主要做了两件事:
对于一个长宽为 300x300,原点左上角位于 (100, 30) 世界坐标处的矩形,可得:
计算出投影矩阵为:
使用矩阵乘法对世界坐标进行变换:
得到如下坐标:
即可将世界坐标转换为裁剪空间的标准化设备坐标。数学,很神奇吧!👊
更多关于矩阵变换的资料可参考:
顺便测试一下我的新插件 hexo-filter-tikzjax,别在意~
 (Abstract)一元三次方程之所以神秘,主要是因为它必须用到虚数(对负数开平方),即使规定只能有实数的解。
(Abstract)一元三次方程之所以神秘,主要是因为它必须用到虚数(对负数开平方),即使规定只能有实数的解。  (Abstract)缺米的新闻有真有假,但🇯🇵⚽️ 7:0 🇨🇳 这件事情假不了😄。
(Abstract)缺米的新闻有真有假,但🇯🇵⚽️ 7:0 🇨🇳 这件事情假不了😄。  (Abstract)想找教材合订本可能比找人民日报的合并本还难,因为人民日报的合并本在日本很多数据库都有,但是教材合订本没有。
(Abstract)想找教材合订本可能比找人民日报的合并本还难,因为人民日报的合并本在日本很多数据库都有,但是教材合订本没有。