走进中国美术学院,我发现原来大家都在用「天生会画」

岩彩绘画,是一种传统的中国绘画技法。它已有上千年的传承历史,在融合传统国画技法的同时,需要用到天然矿物颜料(即岩彩)来进行创作。
与国画丹青的获取方式有些不同,岩彩是需要过研磨天然矿石、矿物质或土壤,并用水或胶质等媒介加以调和才能得到最终的颜料。
正因颜料来之不易,成本颇高,所以岩彩绘画相对于水墨画、工笔画等常见的中国画种来说,知名度比较有限,直至近些年才逐渐走进大众视野。而在这个过程中,得益于数字创作的科技发展,丰富了岩彩绘画的创作技法,也提升了创作的灵活度。
来自文化和旅游部艺术发展中心的莲羊,正是一名岩彩绘画的创作者,她在 2024 华为 GoPaint 天生会画艺术对谈活动的现场与我们分享了她利用「天生会画」app 呈现传统岩彩画的经历。

莲羊认为,华为天生会画 app 的出现,让她的创作方式变得更加多元,可以打破打破了时间、地点和介质的局限。尤其是在「天生会画」中可以将传统岩彩画进行数字化呈现,让原本依赖于矿物颜料的创作,能通过天生会画的岩彩画布直接呈现,极难萃取的岩彩颜料也能通过智慧取色功能轻松上色,还原中国古色。
众所周知,岩彩绘画的颜料是矿物,成本很高,岩彩画不能像其他画种那样反复修改,所以我一般会借助平板和软件先画草图再进行矿物颜料采购、线下实体创作,以此避免创作的损耗。

岩彩绘画作品的特别之处,在于其色彩表达具有较强的光泽感和自然饱和度,能够在画面上产生更加独特的效果。正如莲羊的岩彩作品《龙》,是专门去到河南博物院实地参观拍摄千年文物后,才汲取到的灵感。并从文物身上选定了一抹「中国红」。
取色的过程至今记忆犹新,我们利用现场拍摄文物,再用华为平板跨应用取色了文物上的千年古色,以中国传统颜色演绎龙的奇幻与神秘。为传统文化的研究、创作及修复工作提供了极大的便利。
可见,数字艺术的发展催生了不少称手易用的智慧工具,能够让人类创造力的释放变得更加事半功倍。
相较于早期的创作工具,诸如「天生会画」这般由 AI 和新技术加持的工具大幅降低了用户入门的学习成本,让美的发现与创造不再是少数人的特权,而是变成每个人都能轻松触及的日常。
为了让更多的创作者能够直观地感受到「天生会画」app 的魅力,华为携手中国电影美术学会、中国动画学会、8 大美院联合打造了「2024 GoPaint 天生会画数字创作大赛」。

这个大赛号召全球参赛者通过华为平板和天生会画 App 进行创作,参赛作品审核通过后将有机会进入评选环节,大赛将最终评选出 36 幅优秀作品,并给予获奖者丰厚奖金和荣誉证书,加上大赛本身较高的关注度,为参赛者的绘画创作道路增添更多的助力。
在投稿尚未截止,且赛时过半之际,华为于 11 月 5 日在中国美术学院良渚校区举办了「2024 华为 GoPaint 天生会画艺术对谈活动」,与多位重量级专家及行业代表,共同探讨了数字艺术的发展趋势。
中国电影美术学会会长霍廷霄认为天生会画能够降低创作门槛,让更多的人参与到创作中来:
「天生会画」这种数字化创作工具会使设计创作更加便捷快速,极大提高创作效率,我们应拥抱这种技术。无论是专业人士还是普通人,都可以通过这种便捷工具,拥有属于自己的造梦空间。

像是在华为发布会上,华为消费者业务 CEO 何刚现场展示了他用华为 MatePad Pro 13.2 英寸和 HUAWEI M-Pencil(第三代)星闪手写笔在「天生会画」app 中完成的油画,更重要的是,他整个绘画过程只花了短短 10 分钟。

当然,华为的「天生会画」app 不但为成年人准备了释放创意的舞台,更是能够成为激发小朋友想象力与创造力的「启蒙老师」。例如年仅 6 岁的小绘画家罗伊人便以其过人的天赋,通过天生会画 App 创作出了一幅幅充满童趣、富有想象力的画作,让人不禁为她的创意与才华所折服。
中国美术学院中国画学院副院长韩璐认为,数字绘画其实就是中国传统绘画的一种延伸,是工具和思维的延伸。
我相信,科艺融合会是种大趋势。
中国美术学院工业设计学院副院长武奕陈对此也深有感触,平板已经成为学生们日常的创作生产力工具:
无论是影视动画、建筑,还是工业设计、服装设计、视觉传达设计,所有专业都非常深入使用了数字创作技术,平板作为生产力工具效率非常高,它成了学生平时练习创作的常用工具。
而「天生会画」软件的设计非常符合创作者的绘画逻辑和用户行为,有利于艺术教育和艺术传播,这在文化传承中也具有很大的价值。

事实上,「天生会画」app 在诸多细节层面都考虑到以往在进行数字创作时会遇到的痛点,力求降低交互和学习门槛,同时也用更加专业高效的表现来回应多元化的创作需求。
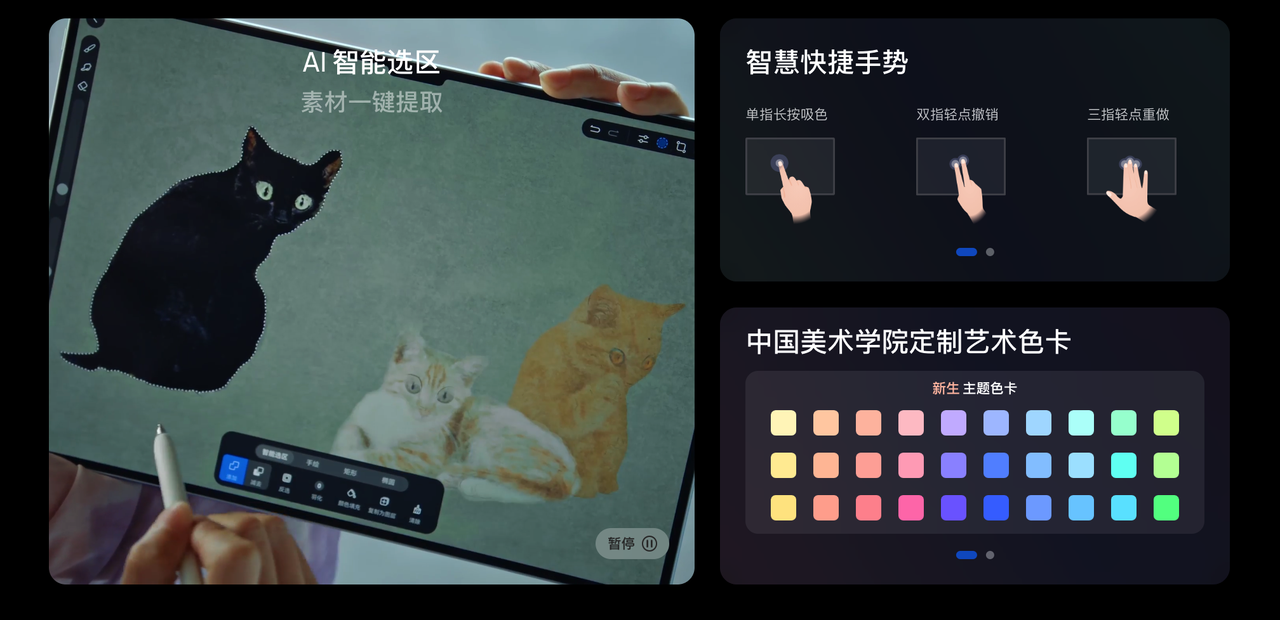
例如打开 app 之后的第一步往往需要创建一个画布,「天生会画」app 除了有不同比例的选择之外,还内置了多种画布纹理,包括了油画、水墨、粗纹水彩、细纹水彩等。每种纹理都尽可能还原了真实纸张的材质、纹理和光泽度,同时画布的纹理等参数支持多项调节,让用户创作时可以更加沉浸,也为作品带来纸张特有的质感。
这一点,相较于 Procreate 需要用户四处搜寻高清纹理图片,再自行导入图片的繁琐操作,「天生会画」app 显然要便捷得多。
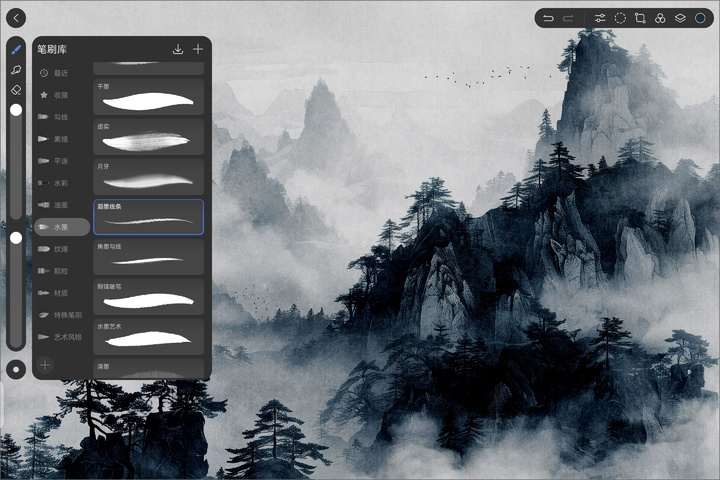
在笔刷方面,「天生会画」app 内置了超过 100 种不同的笔刷效果,还为用户提供了超过 70 种的详细参数设置,包括笔刷的线条、颗粒、渲染、湿混等参数,灵活多变,精细可控,从而能够在数字软件之上还原如同真实世界般的笔触效果。
与此同时,华为还与中国美术学院专业团队合作,推出了一批经过精心调校的专业笔刷,覆盖油画、水墨、水彩等多种绘画风格,带来了更为真实细腻的绘画体验,在数字画板上也能肆意挥洒国画丹青的水墨灵感。

作为绘画软件的关键功能,「天生绘画」app 对于图层管理也有着自家的「独门秘方」,它搭载了华为自研的方天绘画引擎,通过软硬芯整合的架构创新,可以大幅优化性能负载,提升处理效率和交互表现。
例如华为 MatePad Pro 13.2 英寸(16GB)在 2K 分辨率下最高支持创建 532 个图层,比相近尺寸 iPad 上的 Procreate 图层数要多出 17%,能应付更复杂的画作创作。
有了得心应手的创作工具,艺术创作也变得比以往任何时候都更加高效与可靠。在「科艺融合」的加持下,有望能够让更多的人能够轻松地迈入艺术领域,更能从学会欣赏艺术快速转变成尝试创造艺术。
华为终端平板与 PC 产品线总裁朱懂东在活动中表示,天生会画把传统的绘画艺术引入到数字技术中,不但便于传统文化的传播和保存,同时也可以更好地与世界进行分享交流,也让美的发现与创造不再是少数人的特权,而是每个人都能轻松触及的生活日常:
天生会画提供了一个全球的艺术交流平台,让更多的创作者能够充分地表达自我。
而这一赛事(2024 GoPaint「天生会画」数字创作大赛)不仅是艺术与科技跨界融合的里程碑,更是我们共同探索数字时代艺术新边疆的全新尝试。
国美作为天生会画进美院系列活动的首站,不仅凸显了大赛的专业水准与深远影响力,更让我们深切感受到了数字艺术创作的蓬勃生机与无限活力。今天见到这么多专家教授和年轻学子热情参与,让我对数字创作的未来充满了无限期待和信心。
我们相信,每个人的心中都蕴藏着无限的艺术创造力,只待被唤醒与释放。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。






 点击以全屏查看图片 Click to view the image in full screen
点击以全屏查看图片 Click to view the image in full screen
 点击以全屏查看图片 Click to view the image in full screen
点击以全屏查看图片 Click to view the image in full screen








































































































































