Sora 又被超越!Meta AI 视频模型深夜炸场,自带惊艳 BGM,让视频编辑比 P 图还简单

扎克伯格最近忙着在全世界「抢风头」。
前不久,开启「二次创业」的他刚向我们展示了十年磨一剑的最强 AR 眼镜 Meta Orion,尽管这只是一款押注未来的原型机器,却抢光了苹果 Vision Pro 的风头。
而在昨晚,Meta 在视频生成模型赛道再次大出风头。

Meta 表示,全新发布的 Meta Movie Gen 是迄今为止最先进的「媒体基础模型(Media Foundation Models)」。
不过,先打个预防针,Meta 官方目前尚未给出明确的开放时间表。
官方宣称正在积极地与娱乐行业的专业人士和创作者进行沟通和合作,预计将在明年某个时候将其整合到 Meta 自己的产品和服务中。
简单总结一下 Meta Movie Gen 的特点:
- 拥有个性化视频生成、精确视频编辑和音频生成等功能。
- 支持生成 1080P、16 秒、每秒 16 帧的高清长视频
- 能够生成最长 45 秒的高质量和高保真音频
- 输入简单文本,即可实现复杂的精确视频编辑功能
- 演示效果优秀,但该产品预计明年才会正式向公众开放
告别「哑剧」,功能主打大而全
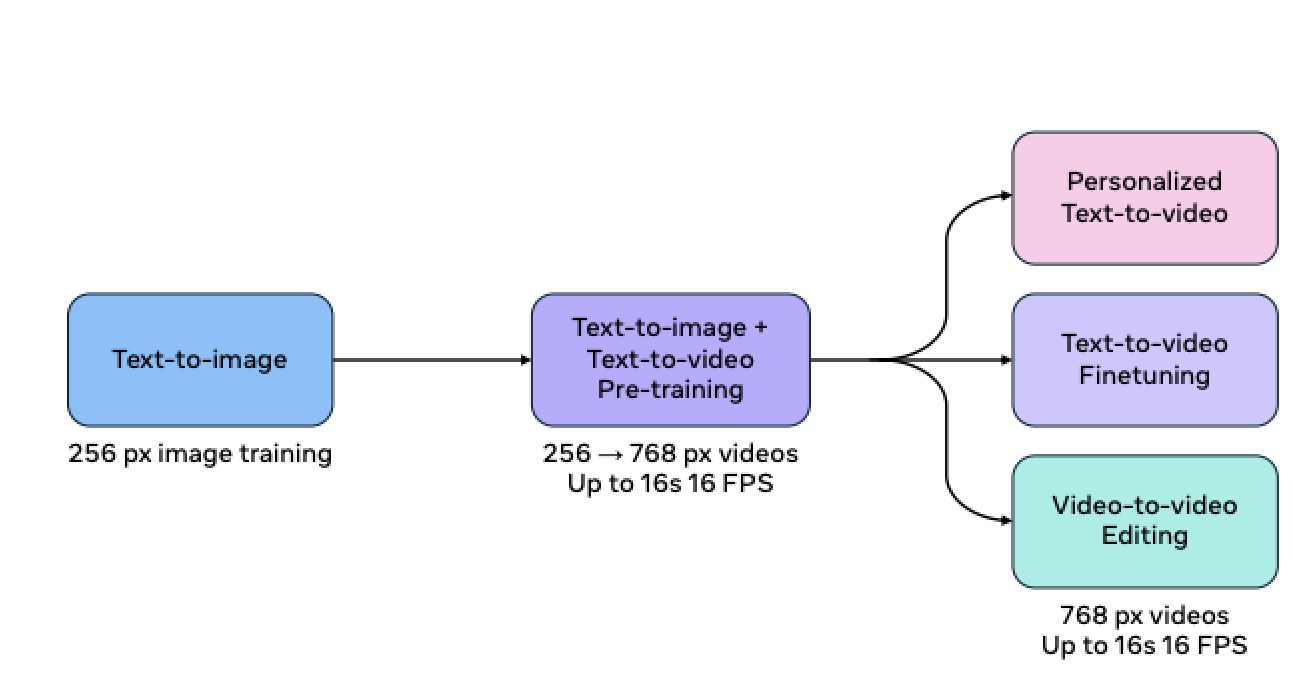
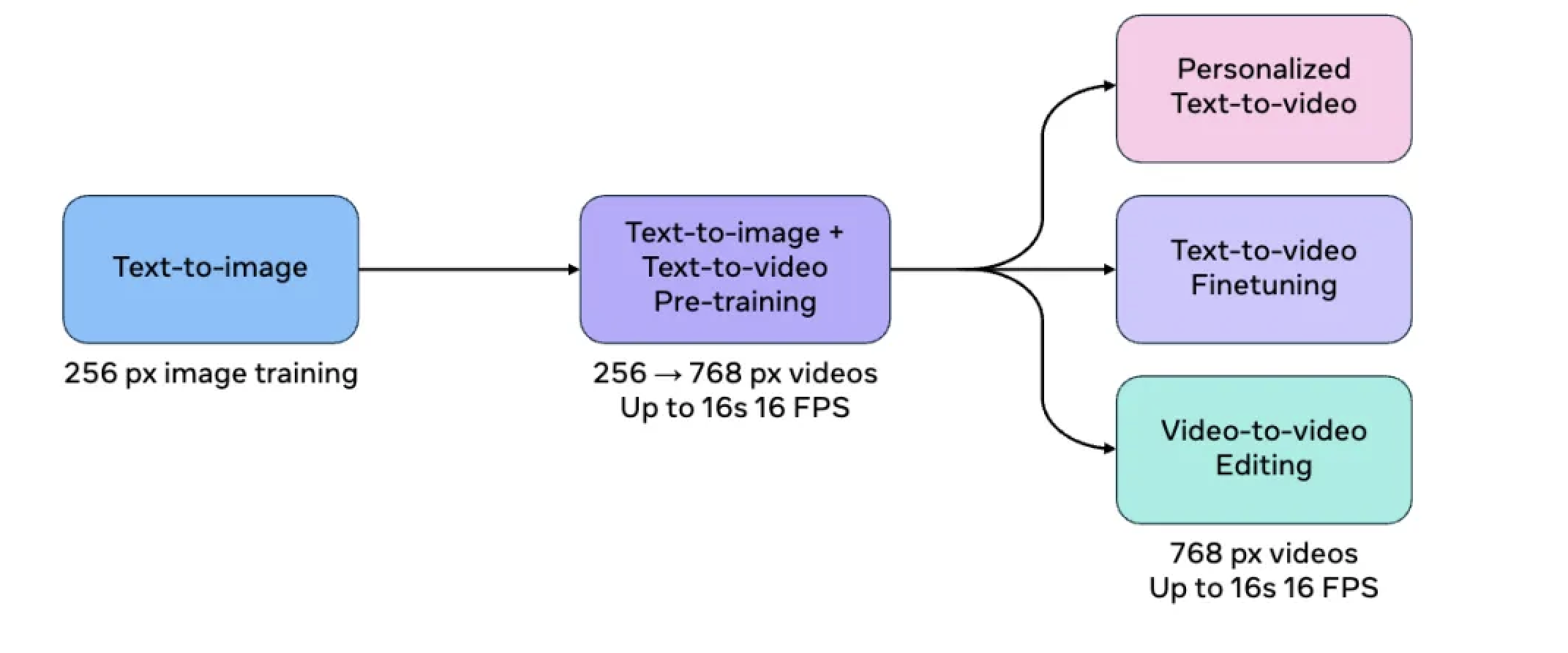
细分来说,Movie Gen 具有视频生成、个性化视频生成、精确视频编辑和音频生成四大功能。
文生视频功能早已成为视频生成模型的标配,只是,Meta Movie Gen 能够根据用户的需求生成不同长宽比的高清视频,这在业内尚属首创。
Text input summary: A sloth with pink sunglasses lays on a donut float in a pool. The sloth is holding a tropical drink. The world is tropical. The sunlight casts a shadow.

Text input summary: The camera is behind a man. The man is shirtless, wearing a green cloth around his waist. He is barefoot. With a fiery object in each hand, he creates wide circular motions. A calm sea is in the background. The atmosphere is mesmerizing, with the fire dance.

此外,Meta Movie Gen 提供了高级的视频编辑功能,用户只需通过简单的文本输入即可实现复杂的视频编辑任务。
从视频的视觉风格,到视频片段之间的过渡效果,再到更细致的编辑操作,这一点,该模型也给足了自由。
在个性化视频生成方面,Meta Movie Gen 也前迈进了一大步。
用户可以通过上传自己的图片,利用 Meta Movie Gen 生成既个性化但又保持人物特征和动作的视频。
Text input summary: A cowgirl wearing denim pants is on a white horse in an old western town. A leather belt cinches at her waist. The horse is majestic, with its coat gleaming in the sunlight. The Rocky Mountains are in the background.

从孔明灯到透明彩色泡泡,一句话轻松替换视频同一物体。
Text input: Transform the lantern into a bubble that soars into the air.

尽管今年陆续已有不少视频模型相继亮相,但大多只能生成「哑剧」,食之无味弃之可惜,Meta Movie Gen 也没有「重蹈覆辙」。
Text input: A beautiful orchestral piece that evokes a sense of wonder.
用户可以通过提供视频文件或文本内容,让 Meta Movie Gen 根据这些输入生成相对应的音频。(PS:注意滑板落地的配音)
并且,它不仅可以创建单个的声音效果,还可以创建背景音乐,甚至为整个视频制作完整的配乐,从而极大地提升视频的整体质量和观众的观看体验。
看完演示 demo 的 Lex Fridman 言简意赅地表达了赞叹。

许多网友再次「拉踩」OpenAI 的期货 Sora,但更多翘首以待的网友已经开始期待测试体验资格的开放了。
Meta AI 首席科学家 Yann LeCun 也在线为 Meta Movie Gen 站台宣传。
Meta 画的大饼,值得期待
在推出 Meta Movie Gen 之时,Meta AI 研究团队也同期公开了一份长达 92 页的技术论文。
据介绍,Meta 的 AI 研究团队主要使用两个基础模型来实现这些广泛的功能——Movie Gen Video 以及 Movie Gen Audio 模型。
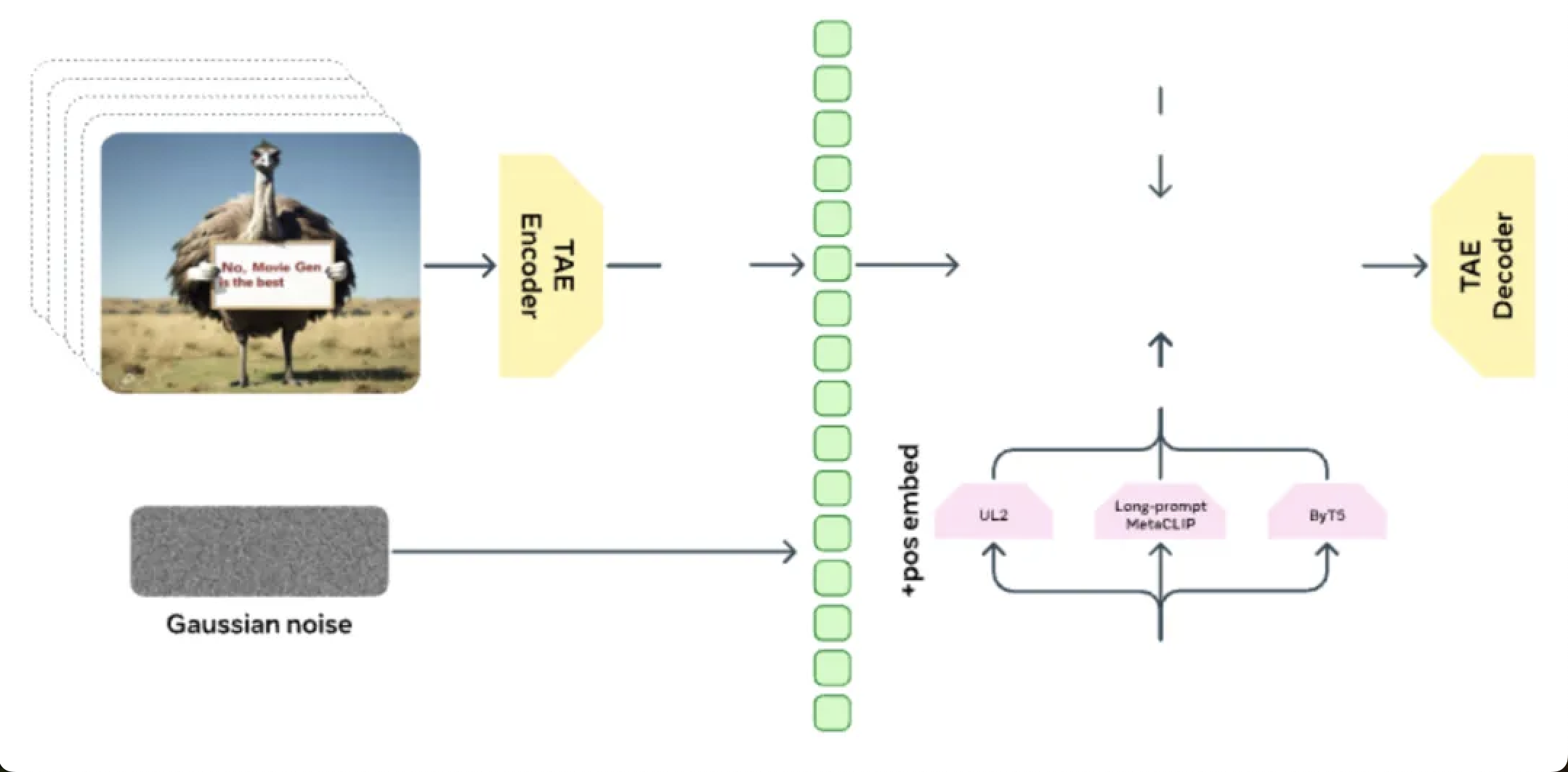
其中,Movie Gen Video 是一个 30B 参数的基础模型,用于文本到视频的生成,能够生成高质量的高清视频,最长可达 16 秒。
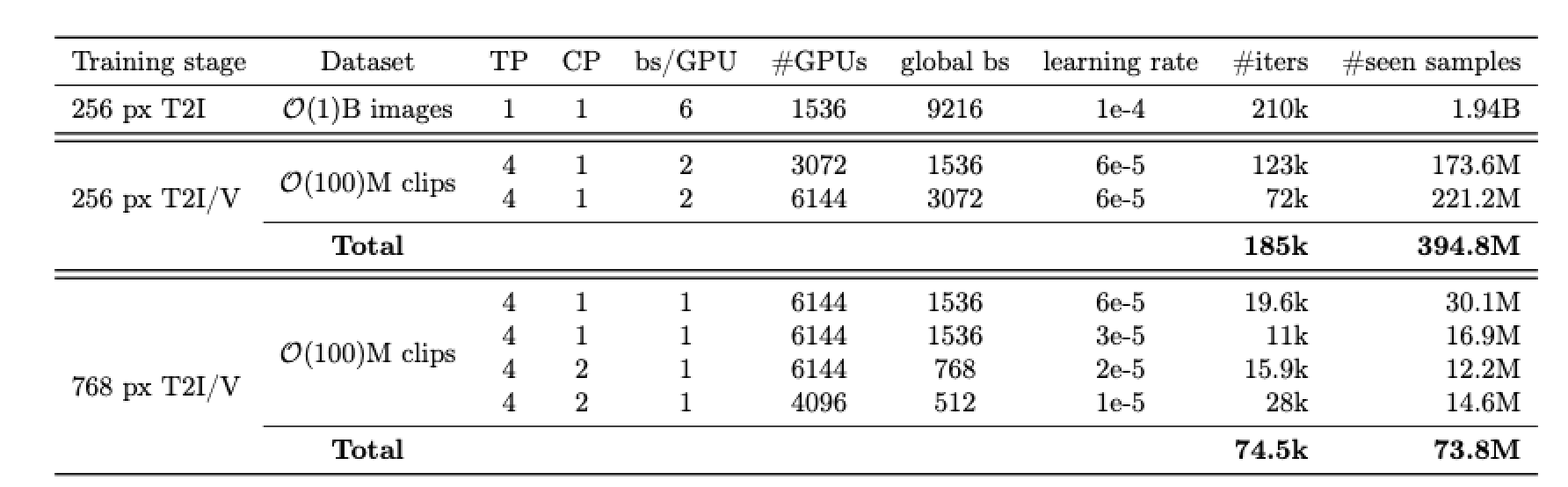
模型预训练阶段使用了大量的图像和视频数据,能够理解视觉世界的各种概念,包括物体运动、交互、几何、相机运动和物理规律。
为了提高视频生成的质量,模型还进行了监督微调(SFT),使用了一小部分精心挑选的高质量视频和文本标题。
报告显示,后训练(Post-training)过程则是 Movie Gen Video 模型训练的重要阶段,能够进一步提高视频生成的质量,尤其是针对图像和视频的个性化和编辑功能。
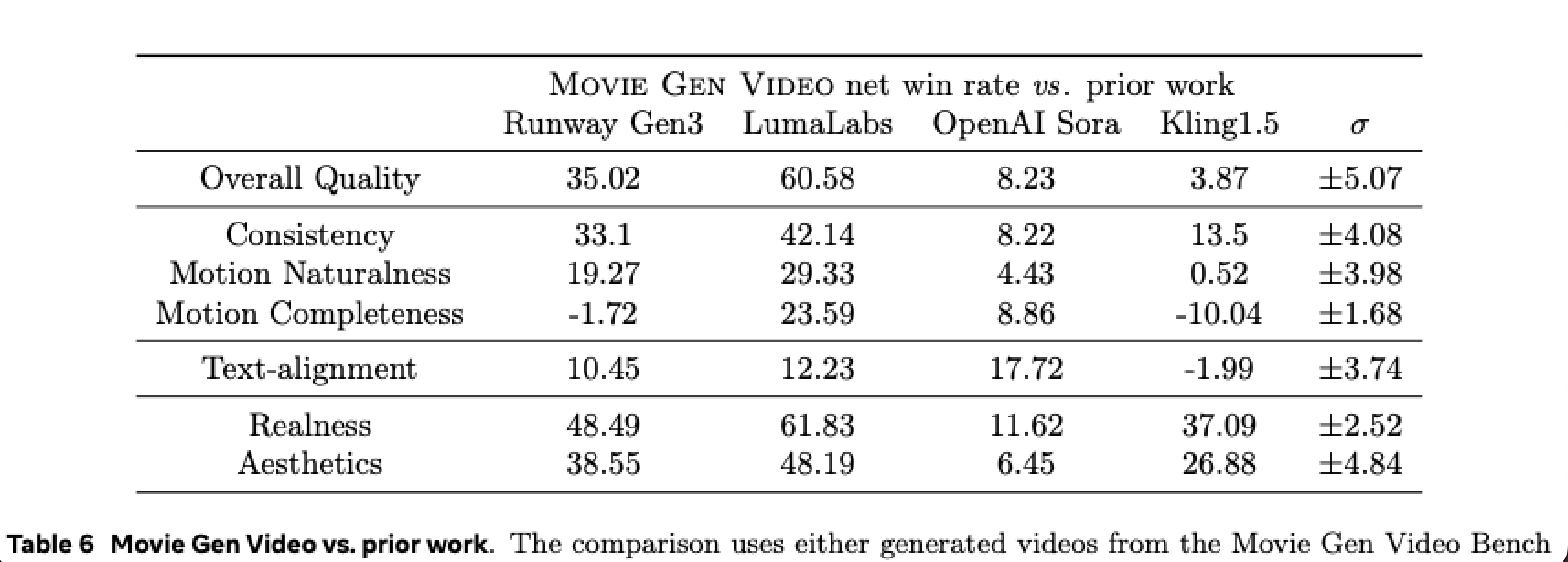
值得一提的是,研究团队也将 Movie Gen Video 模型与主流视频生成模型进行了对比。
由于 Sora 目前尚未开放,研究人员只能使用其公开发布的视频和提示来进行比较。对于其他模型,如 Runway Gen3、LumaLabs 和 可灵 1.5,研究人员选择通过 API 接口来自行生成视频。
且由于 Sora 发布的视频有不同的分辨率和时长,研究人员对 Movie Gen Video 的视频进行了裁剪,以确保比较时视频具有相同的分辨率和时长。
结果显示,Movie Gen Video 整体评估效果上显著优于 Runway Gen3 和 LumaLabs,对 OpenAI Sora 有轻微的优势,与可灵 1.5 相当。
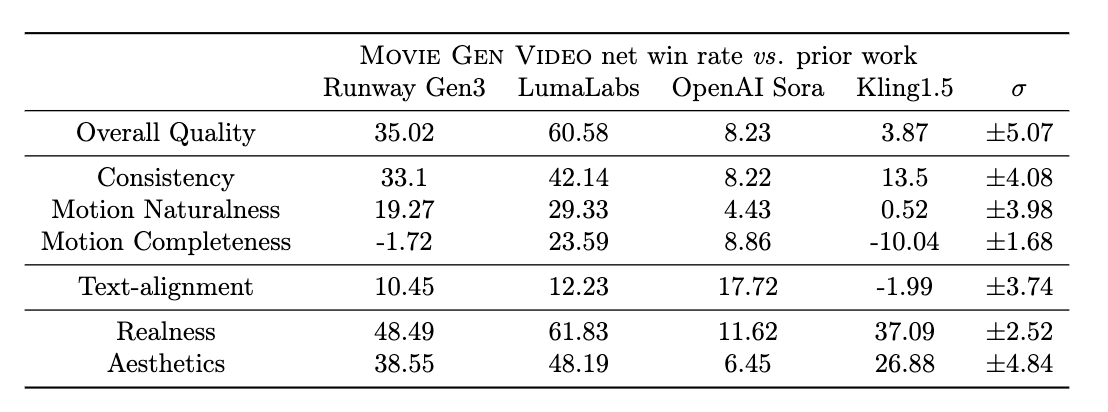
未来,Meta 还计划公开发布多个基准测试,包括 Movie Gen Video Bench、Movie Gen Edit Bench 和 Movie Gen Audio Bench,以加速视频生成模型的研究。
而 Movie Gen Audio 模型则是一个 13B 参数的模型,用于视频和文本到音频的生成,能够生成长达 45 秒的高质量和高保真的音频,包括声音效果和音乐,并与视频同步。
该模型采用了基于 Flow Matching 的生成模型和扩散变换器(DiT)模型架构,并添加了额外的条件模块来提供控制。

甚至,Meta 的研究团队还引入了一种音频扩展技术,允许模型生成超出初始 45 秒限制的连贯音频,也就是说,无论视频多长,模型都能够生成匹配的音频。
更多具体信息欢迎查看技术论文
https://ai.meta.com/static-resource/movie-gen-research-paper


昨天,OpenAI Sora 负责人 Tim Brooks 官宣离职,加盟 Google DeepMind,给前景不明的 Sora 项目再次蒙上了一层阴霾。

而据彭博社报道,Meta 副总裁 Connor Hayes 表示,目前 Meta Movie Gen 也没有具体的产品计划。Hayes 透露了延迟推出的重要原因。
Meta Movie Gen 当前使用文本提示词生成一个视频往往需要等待数十分钟,极大影响了用户的体验。
Meta 希望进一步提高视频生成的效率,以及实现尽快在移动端上推出该视频服务,以便能更好地满足消费者的需求。

其实如果从产品形态上看,Meta Movie Gen 的功能设计主打一个大而全,并没有像其他视频模型那样的「瘸一条腿」。
最突出的缺点,顶多就是沾染了与 Sora 一样的「期货」气息。
理想很丰满,现实很骨感。
或许你会说,一如当下的 Sora 被国产大模型赶超,等到 Meta Movie Gen 推出之时,视频生成领域的竞争格局或许又会变换一番光景。
但至少目前来看,Meta 画的大饼足以让人下咽。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。