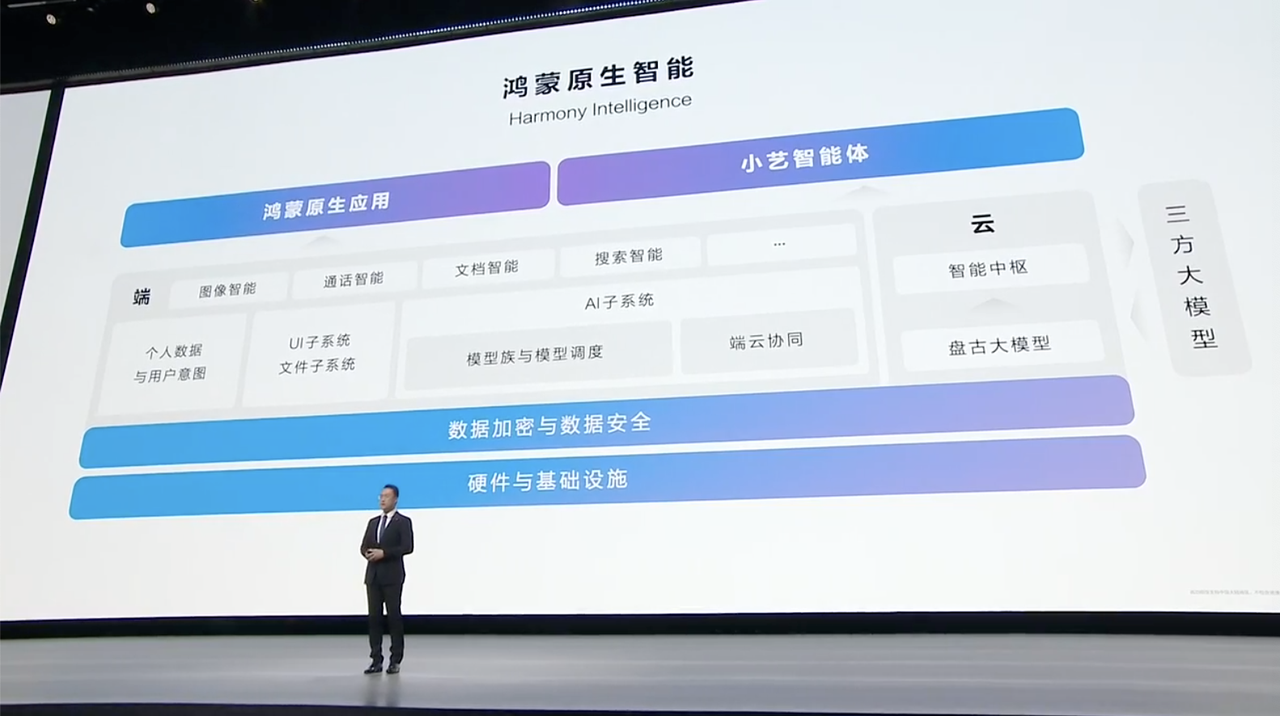
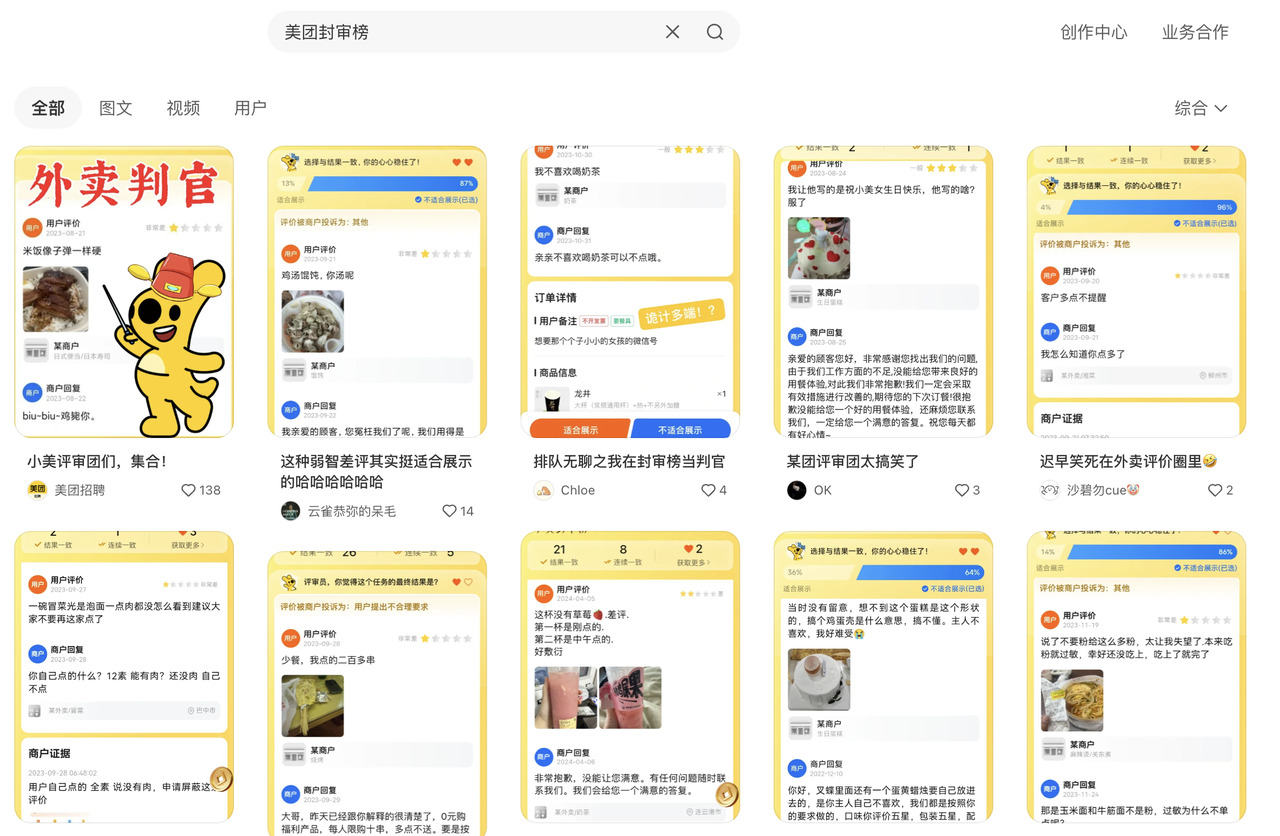
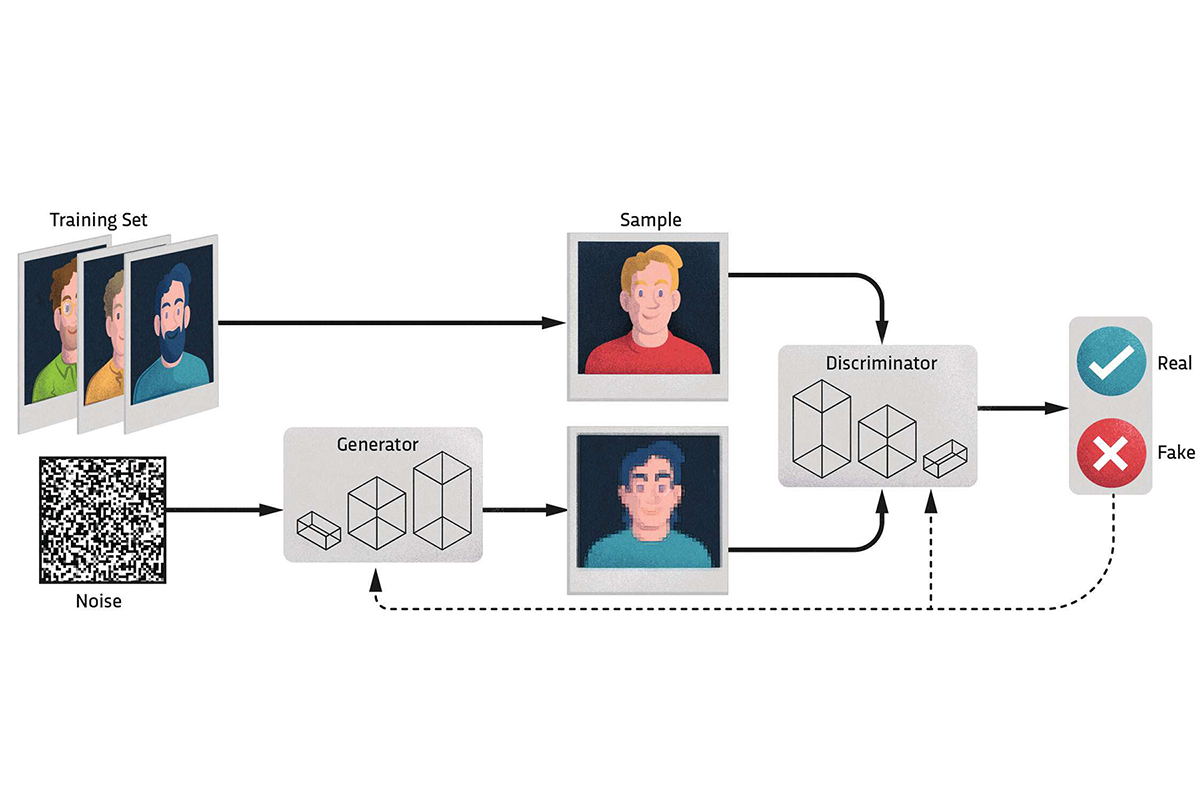
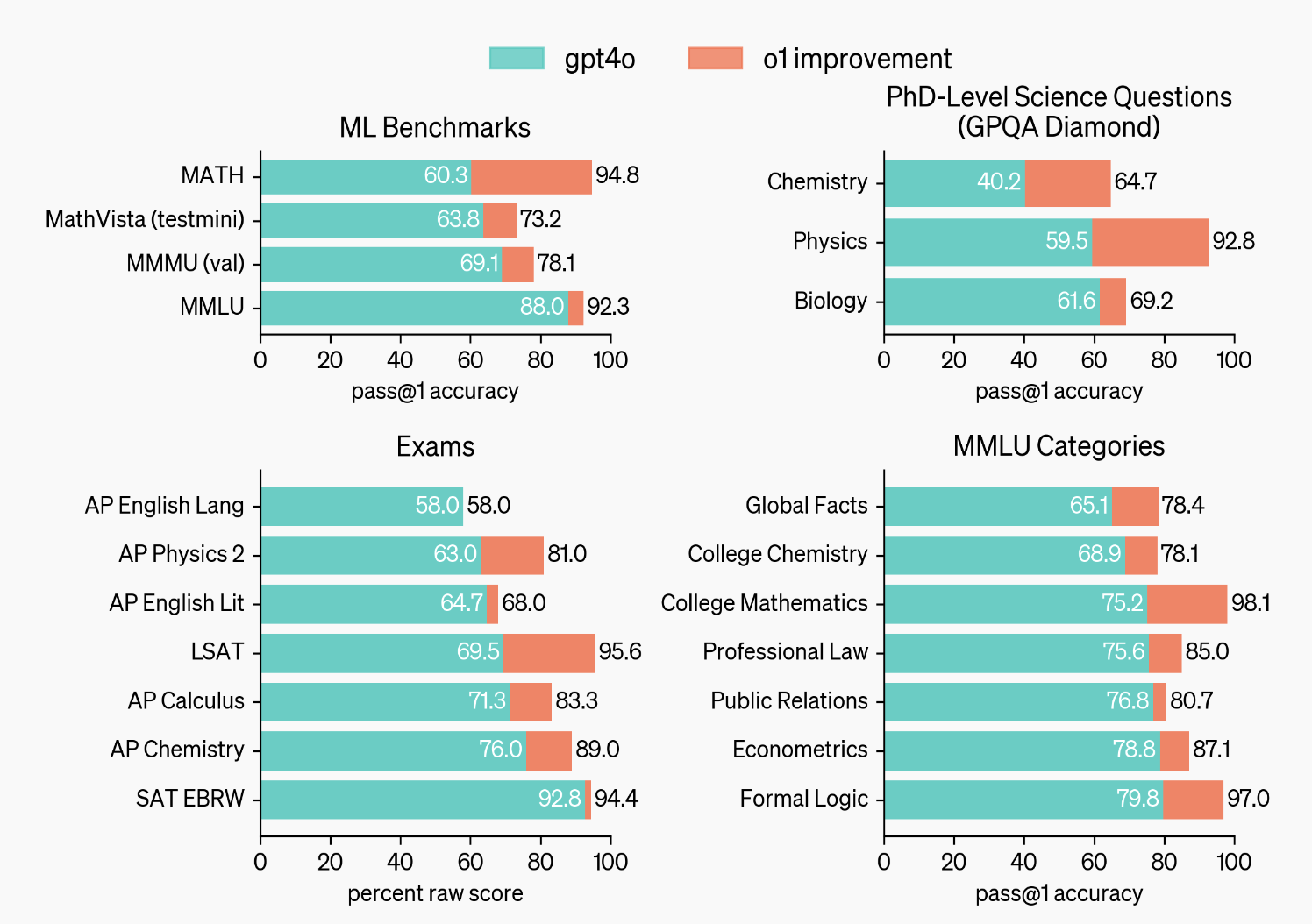
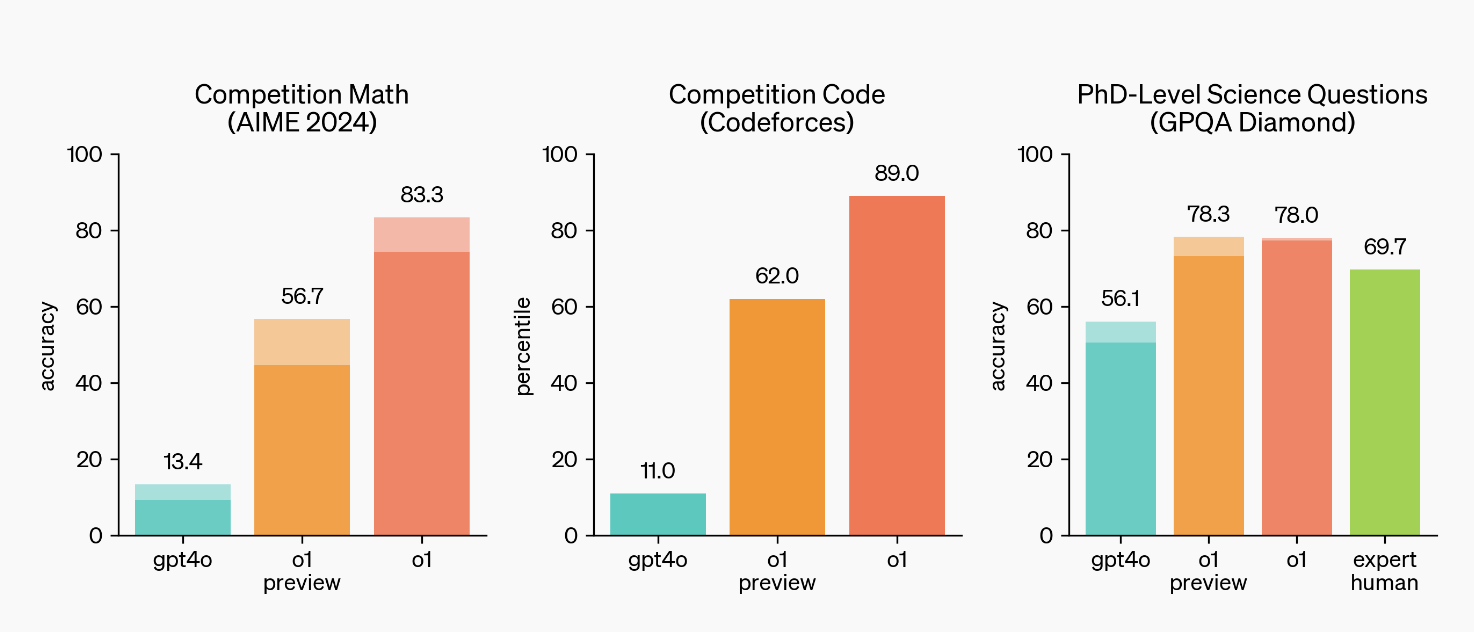
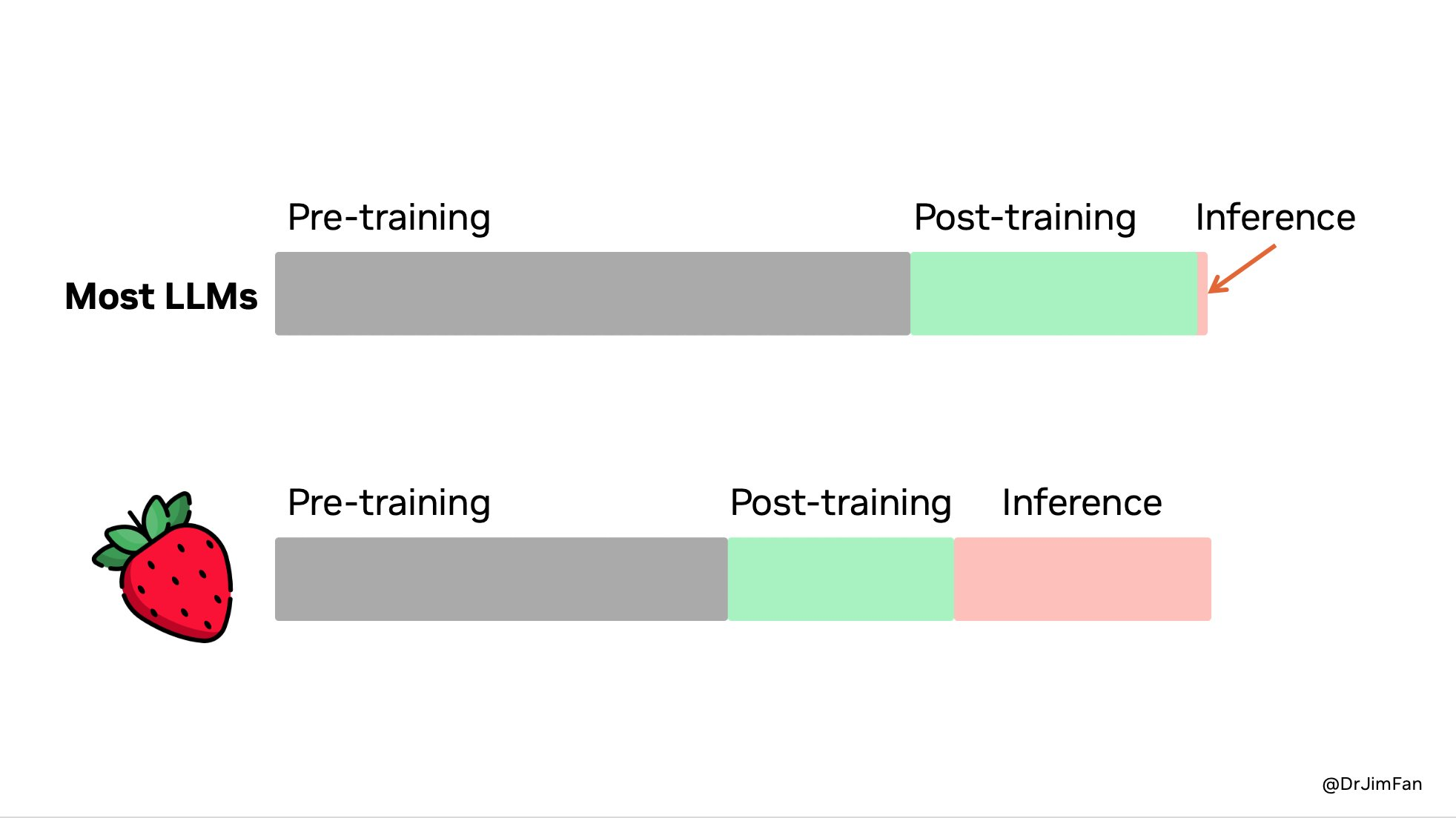
Good Morning!库克又一次在 Apple Park 讲出这句经典开场白。
和往年不一样的是,库克首次在发布会开场同时提到 Apple Intelligence 和 Machine Learning 这些词汇,由此可见今年苹果对 AI 的重视。
全新 iPhone 16 系列,也是苹果第一个真正意义上的 AI iPhone。

对于 iPhone 16 大家最关心的一些问题,我们这次准备了一个快问快答环节,以最简洁、直接的方式给你一个实用指南,无论你是对新功能感兴趣,还是在犹豫是否升级,都能快速获取答案。
Q:iPhone 16 Pro 怎么看起来和 15 没太大区别?
A:屏幕尺寸更大、全新配备「相机控制」、更窄边框
Q:iPhone 16 标准版外观最直观的变化是什么
A: 摄像头从之前的「浴霸」对角线排列变成了纵向排列,梦回 iPhone X
Q:iPhone 16 系列有什么新配色?
A:iPhone 16 新增白色、深青色、群青色,iPhone 16 Pro 新增沙漠色钛金属配色
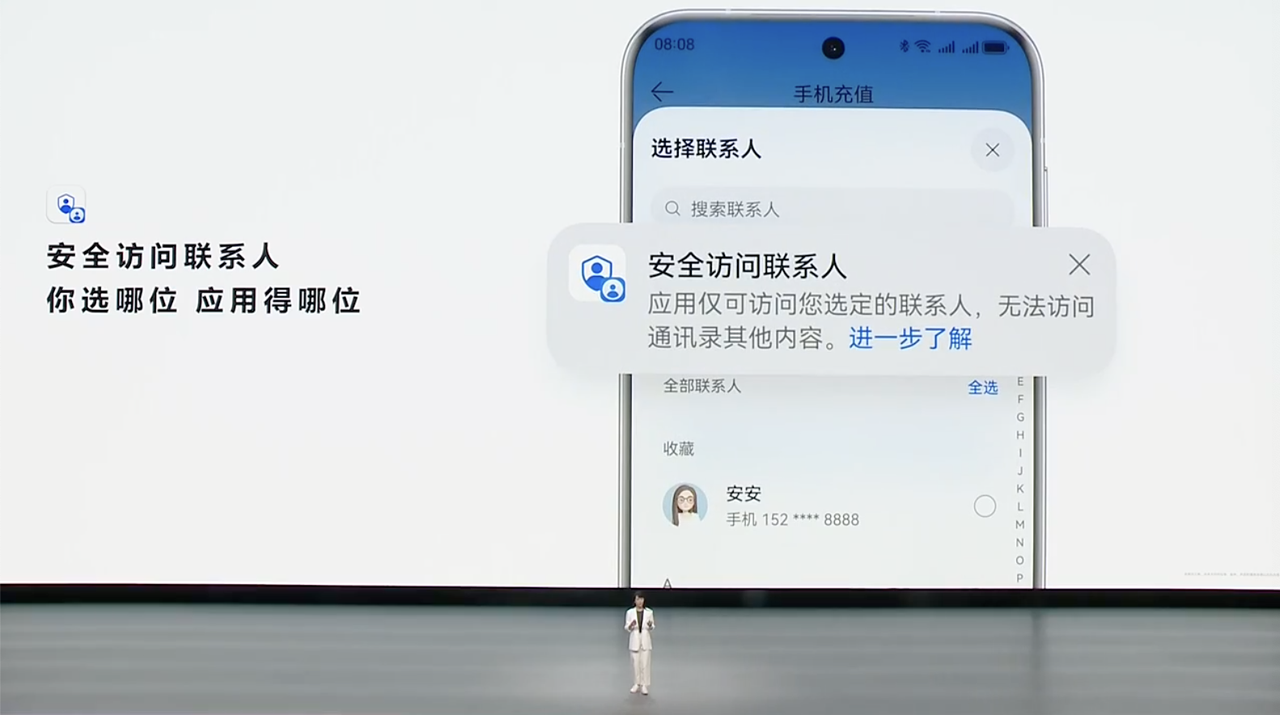
Q:新增的「相机控制」有啥用?是 Pro 系列独占吗?
A:全系支持。它除了能充当快门键,呼出相机的变焦、景深控制、拍摄风格等参数,还能通过启用视觉智能。
Q:iPhone 16 全系支持 Apple 智能吗?
A:支持,但更多 AI 功能没那么快用上
Q:iPhone 16 系列价格与上一代比相差多少?
A:不变
Q:iPhone 16 系列预购和发售时间?
A:9 月 13 日晚 8 点起接受预购,9 月 20 日发售。
爱范儿首席内容官何宗丞已经在现场第一时间体验了 iPhone 16 在内的一系列新品,更多发布会没提到的细节,我们将在今天后续的文章中与你分享。

史上首次,第一台为 AI 打造的 iPhone
新一代 iPhone 彻彻底底为 Apple 智能打造。
库克这句话,将载入苹果发布会的史册。

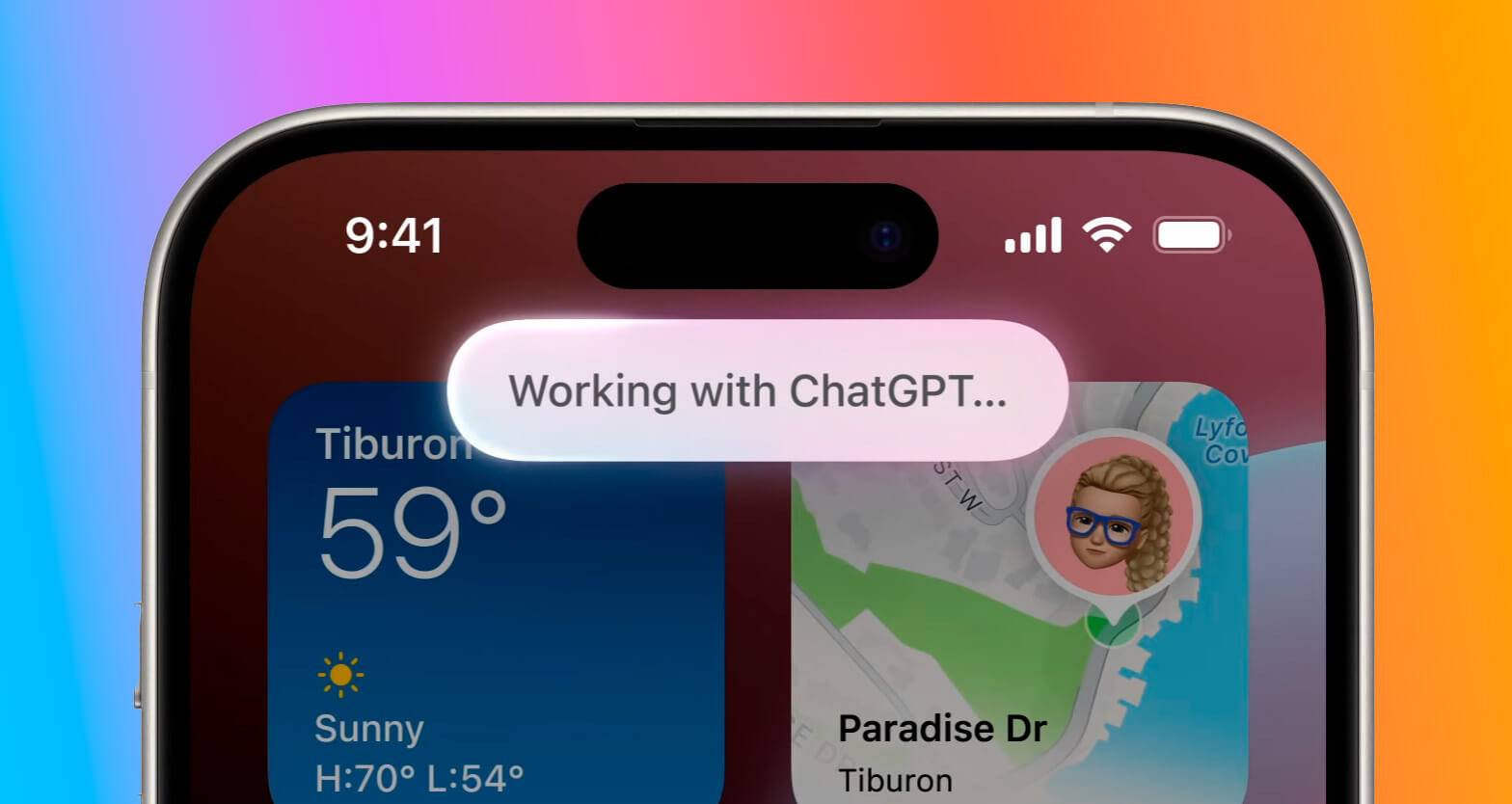
作为 iPhone 16 系列上的最大亮点,没有如期推送的 Apple 智能将于下月推出,短期内仅限于美国英语地区。
苹果表示,Apple Intelligence 功能将逐步支持更多语言。
在今年 12 月份,澳大利亚、加拿大、新西兰、南非和英国等地的英语方言将率先使用 Apple 智能,而苹果计划在 2025 年逐步增加对中文、法语、日语和西班牙语等其他语言的支持。

至于中国用户,无论你是否在中国大陆购买的 iPhone,也不管你的 Apple ID 国家/地区是否设置在大陆,目前都无法使用 Apple 智能
,直到 Apple 智能在中国大陆推出时才能激活。

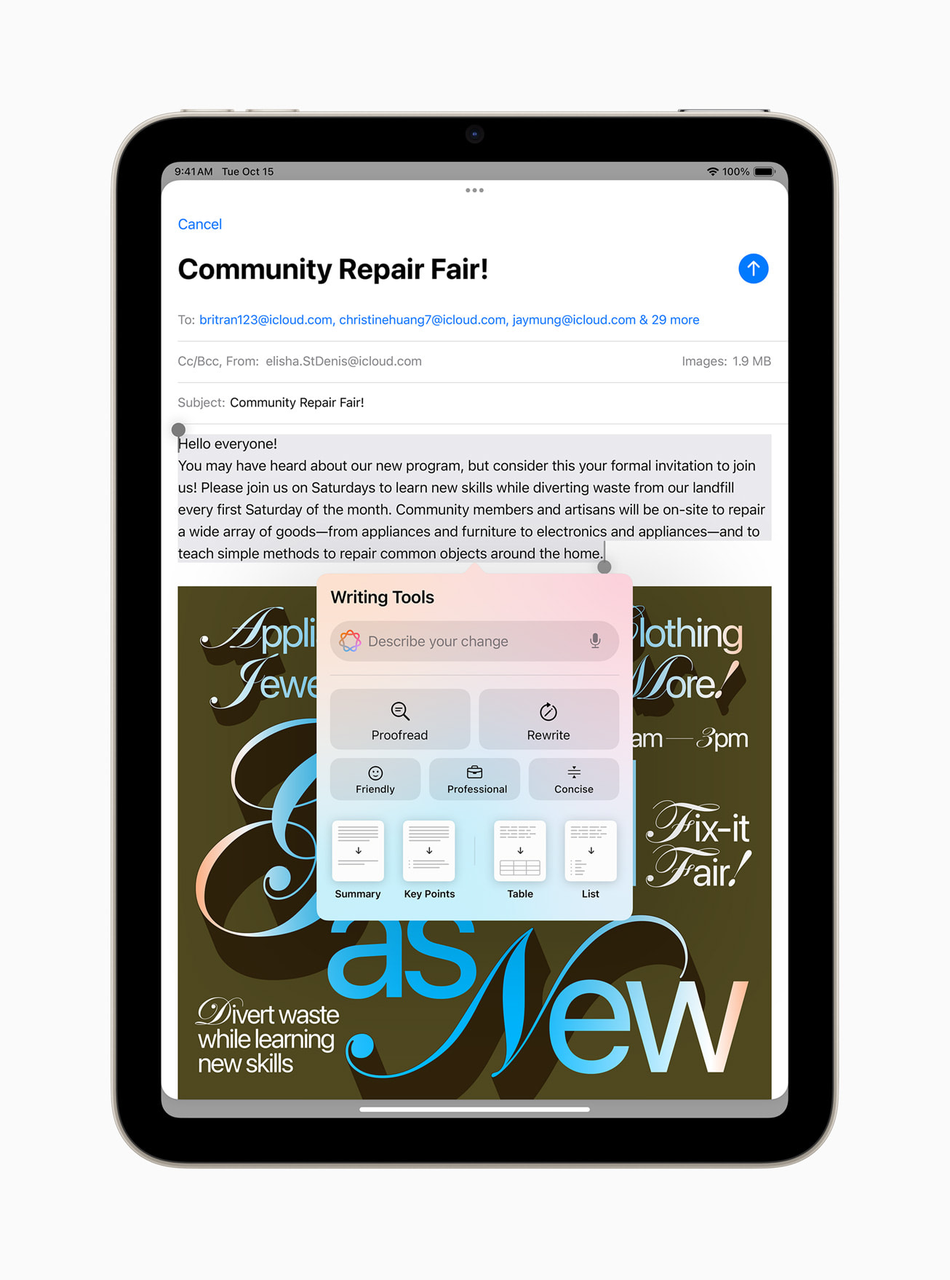
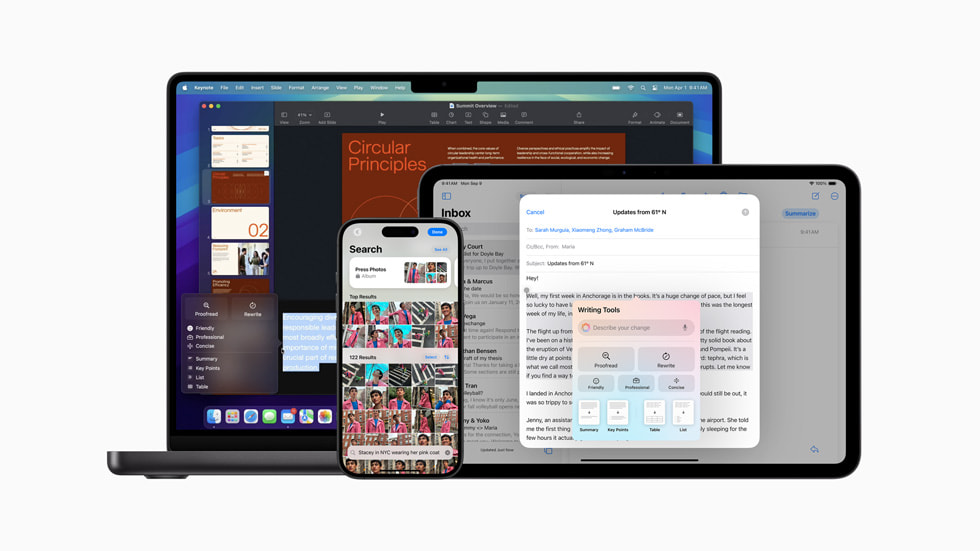
上个月已经有不少海外网友体验到了 Apple 智能部分简单的系统级功能,比如写作(校对重写内容)、文本总结、邮件回复等,但更多的 AI 功能依然「犹抱琵琶半遮面」。
换言之,这也意味着备受关注的 ChatGPT 集成服务、Image Playground 图像生成功能,以及 Genmoji 表情符号生成功能的推送时间依然是个谜。
距离苹果在 WWDC 许下 AI 承诺的进度条似乎还不到一半,而苹果又在本次发布会上公布了更多关于 AI 的功能/消息。
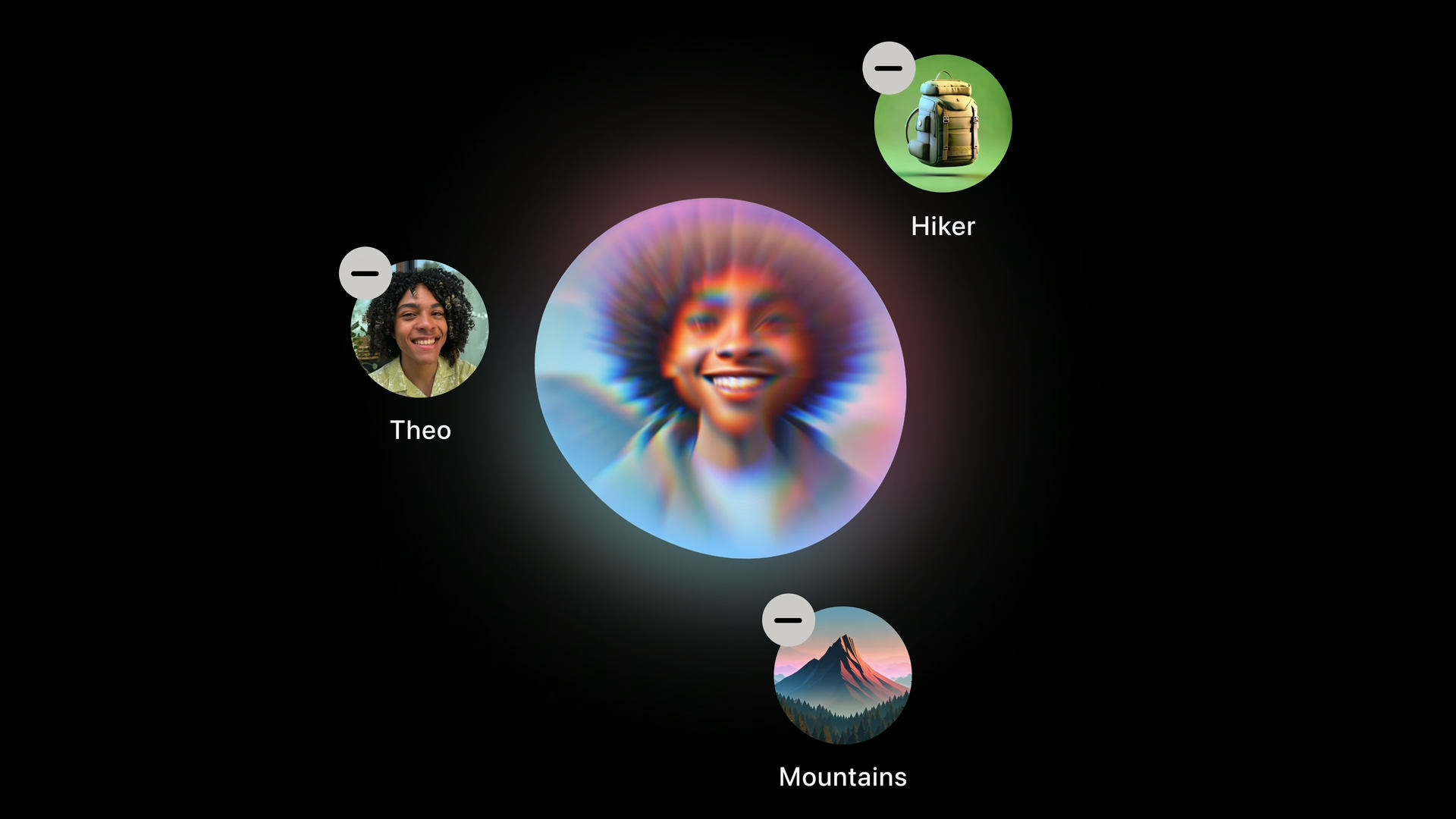
其中最重要的莫过于通过「相机控制」来启用视觉智能。
比如,当你看到一家餐厅,你可以通过按压「相机控制」拍下餐厅,然后就能通过 Apple 智能实时获得该餐厅的营业时间以及好评率,从而查看菜单或预订餐厅。

看到有趣的传单,采取类似的操作就能添加活动日历以及地点,详细了解这次活动的细节,又或者看到可爱的小狗,轻轻一拍即可识别狗的品种。
甚至该功能也可以和第三方 APP 联动,看到心仪的自行车,只需点击搜索 Google,即可快速入手类似的自行车。
iPhone 16 Pro 影像加「外挂」, Pro Max 屏幕史上最大
先看看最重头戏的 Pro 系列。虽然外观几乎没有发生变化,但在影像和性能上,依旧保持了 Pro 系列「牙膏挤爆」的高水准,亮点如下:
- 全新配备「相机控制」,Pro 版用上四棱镜长焦
- 4K 120 fps 杜比视界视频拍摄 + 4 个录音棚级别麦克风
- 全球最窄手机边框,屏幕尺寸更大
- A18 Pro 强悍性能
- 新增「沙漠钛」配色
- 价格不变,Pro 版国行起售价 7999 元,Pro Max 版起售价 9999 元
更专业的影像,还有「外挂」加持
每一年 Pro 版 iPhone 影像能力方面的升级,苹果都绝对不含糊,今年更是三个摄像头一起升级,不仅仅更能拍出好照片,苹果强项视频拍摄更是再一次「遥遥领先」。

再看看三个后置摄像头的升级。主摄为 4800 万像素「融合」摄像头,搭载第二代四合一像素传感器,支持 4800 万像素 ProRaw 和 HEIF 照片拍摄,并实现零快门延迟。

比较大的更新给到了超广角镜头,像素从 1200 万像素升级至 4800 万,不仅配备带自动对焦功能的四合一像素传感器,光圈还从 f/4.4 升级到 f/2.2,提升了暗光环境下捕捉更多光线的能力,扣了一波「高光时刻」的发布会主题。

长焦镜头这边,iPhone 16 Pro 看齐 Pro Max 版本,用上了同款「四重反射棱镜长焦」镜头, 支持 5 倍光学长焦,像素保持 1200 万,光圈为 f/2.8。
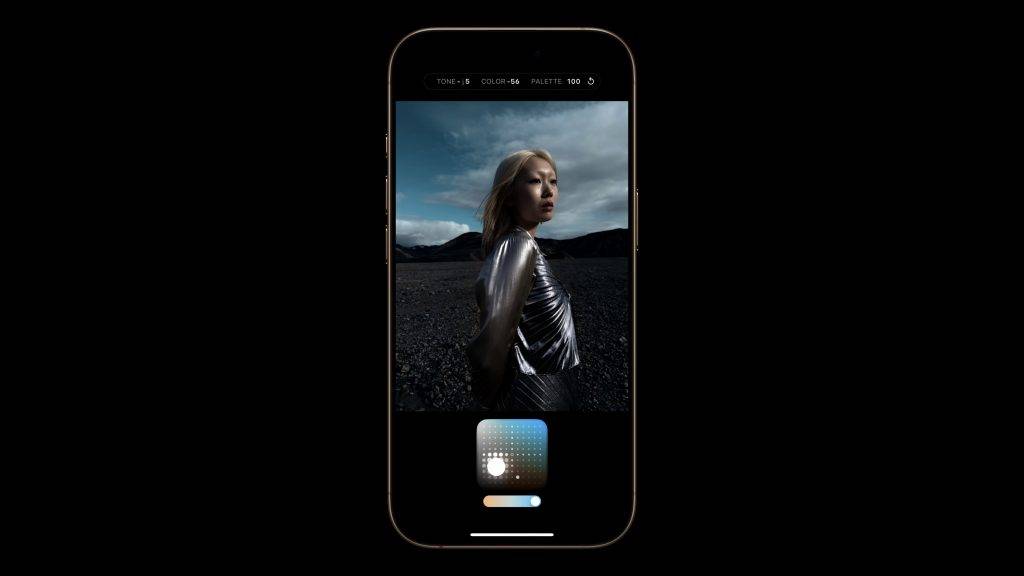
想拍出惊艳的大片,单纯依靠硬件参数可不够。iPhone 影像的第一个「外挂」,就是全新的「摄影风格」功能。
苹果为 iPhone 16 Pro 系列准备了一系列的新风格。这可不是单纯在成片上加一个滤镜那么简单,而是通过机器学习,针对拍摄对象进行实时调色,并且由于强大的芯片性能,这些风格化的拍摄效果都能在相机中实时预览,还能允许用户调整具体风格表现。
而苹果的强项,也是打动不少专业人士的视频拍摄能力,在 iPhone 16 Pro 上进一步得到了提升。
更强大的镜头、处理器还带来了对 4K 120fps 杜比视界视频格式的全新支持,视频画面更加清晰、细腻,120 FPS 的帧率在拍摄动态场景时,可以捕捉到更多的细节,减少模糊或卡顿感,而且还能够拍摄更具视觉冲击力的慢动作视频。

照片 app 也支持对 4k 120fps 杜比视频的编辑,不仅能够逐帧进行「影院级画质」调色,还能将正常速度的视频放慢至 24fps 播放,提供了极大的后期空间。
配套视频拍摄能力一同升格的,还有 iPhone 16 Pro 的音频录制能力。iPhone 16 Pro 内置四个录音棚级麦克风,提供三种「混音功能」:
- 取景框内:拍摄期间,即使镜头外有人说话,也只收录画面内的人声。
- 录音室:让视频里的人声,听起来就像是在带有隔音墙的专业录音棚里录制。
- 电影效果:收录周围的所有人声,整合混音后投向屏幕前方,就像电影中的声音处理效果。
摄像头已经全副武装,苹果这次还设计了一个全新的摄影交互「相机控制」,堪称 iPhone 16 系列拍摄的物理「外挂」。

在 iPhone 锁屏键下方,多出了一个类似相机快门的按钮。有了这个「相机控制」,你就可以轻松玩转:
- 按下呼出相机应用
- 单击可实现快门
- 长按开始拍视频
- 轻按+滑动可进行变焦
- 轻按两下可切换其他相机设置:曝光、景深、相机、风格、色调

除了能在 iPhone 自带相机应用使用,「相机控制」也支持第三方应用调用。
性能更强,功耗更低的 A18 Pro
今年处理器方面有一大变化,那就是标准版和 Pro 版都同时用上了苹果最新的 A18 处理器。

不过,没人比苹果更懂「刀法」,GPU 和 CPU 双满血的 A18 Pro ,才是苹果顶级性能的真正代表作。
A18 Pro 保持了 6 CPU 核 +6 GPU 核的配置。 6 核心的 GPU,比起 A17 Pro 性能提升 20%,硬件加速光追能力最快可达上一代两倍,要知道 A17 Pro 的光追性能已经足以运行大型主机级别游戏。

6 核心的 CPU,比 A17 Pro 性能提升 15%,同时耗电量还降低了 20%,苹果直接表示:「任何智能手机上最快的 CPU」。
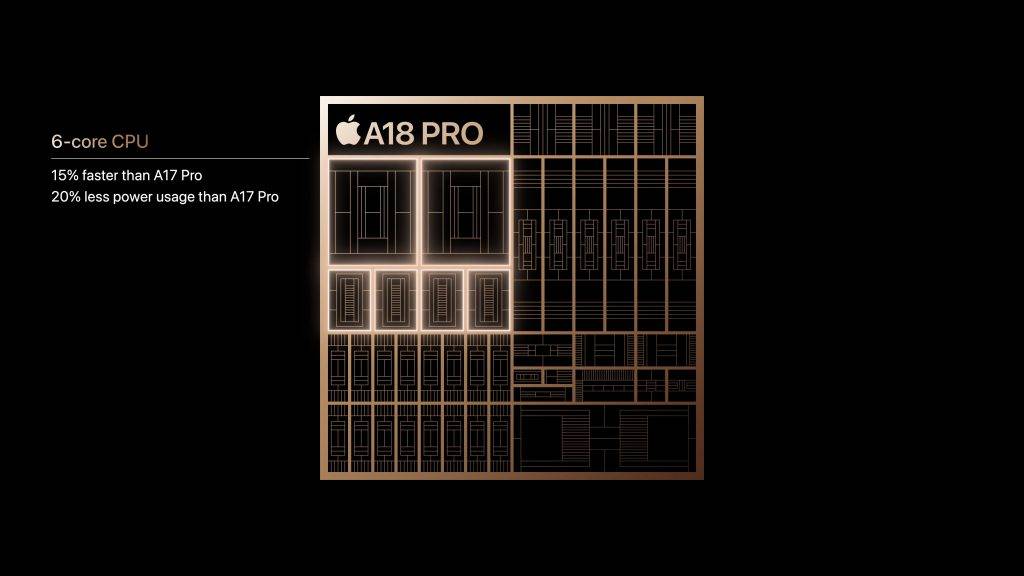
为 AI 而生的 A18 Pro,还搭载了 16 核神经网络引擎,运行 Apple 智能的能力比上一代提升了 15%。

以往的 iPhone 总因为散热能力的短板,无法持续发挥芯片的强悍性能,而今年 iPhone 16 Pro 系列采用了金属散热结构和玻璃背板的优化。苹果宣称,比起 iPhone 15 Pro,带来了高达 20% 的持续性能表现提升。
更大的尺寸,更强的续航
还有一些细节也值得关注。
两款 Pro 版的屏幕尺寸都迎来了提升:iPhone 16 Pro 从 6.1 英寸扩张到 6.3 英寸,iPhone 16 Pro Max 从 6.7 英寸扩张到 6.9 英寸,成为「史上最大」。

配合上进一步收窄的边框,iPhone 16 Pro 的显示效果更惊艳。
Pro 系列传闻中的新色「沙漠色钛金属」也终于露出了庐山真面目:比以前的「香槟金」颜色更深一点,接近棕色或深卡其色,堪称苹果最为低调奢华的金色系,也是今年 iPhone 16 Pro 的主打色。

内部空间经过优化后,iPhone 16 Pro 能塞入更大电池,加上 A18 Pro 芯片优化了能效表现,iPhone 16 Pro Max 视频播放时间最高达 33 小时,iPhone 16 Pro 则达到了 27 小时。
加量不加价,近几年来最值得买的标准版 iPhone
在聊标准版 iPhone 16 之前,让我们先来看看它的关键特点:
- 首次引入空间视频录制和支持 Apple Intelligence
- 首次配备「相机控制」,支持微距拍摄
- 处理器从 A16 升级到 A18,采用第二代 3 纳米工艺
- 后置镜头从对角线设计回归垂直排列的双镜头设计
- iPhone 16、16 Plus 国行起售价依次为 5999 元,6999 元
如果说往年的标准版 iPhone 总是以 Pro 版「小弟」的形象示人,那那么今年 iPhone 16 则是要用过硬的性价比翻身做主人,同时手握苹果未来生态的敲门砖,具有更重要的战略地位。

这首先体现在对自家 AI 功能的支持上。
今年标准版 iPhone 16 弥补了 iPhone 15 的遗憾,成功搭上了 Apple 智能的快车。
而为了能「变聪明」,iPhone 16 运存处理器也实现了越级,从 iPhone 15 的 A16 芯片升级到今年全新的 A18 芯片。

相比于去年在 A17 Pro 上使用的 N3B 工艺,今年第二代 3 纳米工艺在提升能效方面有着更大的优势。神经引擎速度提升两倍,内存子系统升级,带宽增加 17%。

并且,A18 拥有 6 核 CPU,包含 2 个性能核心和 4 个效率核心,比 iPhone 15 中的 CPU 快 30%,而在同等性能下,功耗可以减少 30%。
甚至能跟高配的台式 PC 一较高下。

得益于 A18 加持,iPhone 16 支持光追,玩起此前只有 iPhone 15 Pro 能运行的 3A 游戏也游刃有余。有趣的是,RPG 游戏《王者荣耀世界》也在发布会亮相,算是一个小彩蛋吧。
影响一台手机使用体验的部分很多,但是最底层的处理器、内存更新,依旧是手机「保质期」的重要决定因素。
屏幕方面,今年的 iPhone 16 采用 6.1 英寸屏幕,iPhone 16 Plus 采用 6.7 英寸屏幕。
在坚持了三代正方形和对角线摄像头模组之后,今年 iPhone 16 再次回归垂直排列的双镜头设计,好不好看见仁见智,至少和旧款比拉满了辨识度。

想必会有小伙伴调侃「垂直改对角线,对角线改垂直,又是一年创新」,但今年 iPhone 16 回归垂直排列,其实也和「战未来」有关——带来了去年 Pro 独占的空间视频拍摄能力。

改成和 iPhone 15 Pro 一样的超广角、主摄垂直排布后,iPhone 16 也拥有了空间视频的拍摄能力,进一步降低了这种「记录魔法」的门槛。
和 Pro 步调一致,标准版的影像能力提升主要集中在超广角镜头。
镜头光圈也从 f/2.4 升级为 f/2.2,能够让传感器捕捉更多光线照射,从而改善在暗光环境下的拍摄效果,扣住了一波「高光时刻」的发布会主题。

另外,不用眼巴巴地看着 Pro 版的「微距拍摄」,现在该功能在 iPhone 16 上虽迟但到,能够拍摄更近距离的物体、如花朵、昆虫、纹理等,为摄影爱好者提供更多创作空间。
前置镜头则保持不变,依旧是 1200 万像素规格。
配色方面,今年 iPhone 16 分别支持五种颜色:黑色、白色、粉色、深青色、群青色,并且采用具有磨砂效果的彩色背板玻璃,不容易沾染指纹,耐脏又耐看。

比起风格偏「小清新」的前代,iPhone 16 上的蓝色、绿色都要更浓郁一点,而重新回归的白色版本,预计将成为最抢手的颜色。
到了公布价格的环节,标准版 iPhone 彻底「加量不加价」,iPhone 16 的国行起售价为 5999 元,iPhone 16 Plus 国行起售价为 6999 元,9 月 13 日晚 8 点起接受预购,9 月 20 日发售。

Apple Watch:屏幕尺寸增大,全新惊艳外观
Apple Watch Series 10 将迎来了全新设计——更纤薄的机身(9.7mm),更大屏幕(有史以来最大)。
至于有多大?比 Apple Watch Ultra 都要大。
除了变得更大,能够看到更多的内容之外,这块屏幕还是 Apple Watch 首款广视角 OLED 屏幕,把 Series 10 倾斜角度的观看亮度提升最高达 40%。

颜色方面,新增的「亮黑色」非常眼熟,如果你当年很喜欢 iPhone 7 的亮黑色,那么我猜这个颜色你也会一见钟情?
苹果表示,有 80% 的睡眠呼吸暂停患者没有得到诊断。
为了检测睡眠呼吸暂停,Apple Watch 使用加速感应器,配合机械学习和大量临床级睡眠呼吸暂停测试数据集来完成监测算法,来监测睡眠过程中一项叫做「呼吸紊乱」的新指标。
每 30 天,Apple Watch 就会分析用户的呼吸紊乱数据,若是存在呼吸暂停问题,手表将会及时提醒。除了 S10 以外,S9 和 Ultra 2 都将会支持这个功能,这个功能本月将会在超过 150 个国家和地区推出。

此外,Apple Watch Ultra 2 也迎来了「全新的惊艳外观」,推出华美缎面质感的黑色款。
Apple Watch Series 10 国行售价 2999 元起,Apple Watch Ultra 2 售价 6499 元起。
AirPods 4 支持降噪了
全新 AirPods 4 到来,和之前的 AirPods 耳机一样,目的都是打造一款自然贴合各种耳形的耳机。
全新的 AirPods 4 使用了 H2 芯片来驱动,点头和摇头就可以完成 Siri 的互动。 有史以来最小巧的 AirPods 耳机盒可以带来总共 30 小时续航,而且使用 USB-C 连接,还可以使用 Qi 无线充电和 Apple Watch 充电器来充电。

更重要的是,AirPods 4 支持降噪,加入了自适应降噪和通透模式。这个额外的「降噪版本」国行价格 1399 元,不支持降噪的版本价格 999 元。
AirPods Max 则推出了全新配色:午夜色、星光色、蓝色、紫色、橙色,支持 USB-C 连接,价格保持 3999 不变。
AirPods Pro 2 则获得「史诗级软件更新」,不仅可以进行听力测试,还带来了嘈杂环境中提供被动降噪的「听力保护模式」,以及临床级非处方助听器功能。
iPhone 的新周期,靠什么 ?
如果说去年的 iPhone 15 最大更新毫无疑问是 USB-C 接口,那么今年要问 iPhone 16 最大的变化是什么,恐怕很难有个脱口而出的统一答案。
除了拍照按键和更窄的边框,新 iPhone 硬件形态几乎没有太大的变化,AI 被提到了前所未有的高度,苹果从发布会一开始就几乎直白地告诉你,这就是第一代 AI iPhone。而 iPhone 16 也和 15 一样,不是通过什么翻天覆地的形态变化带来惊喜。

虽然新增的拍照按键,让不少人期待已久的一体化无开孔 iPhone 渐行渐远。但随着苹果展示它还能作为 AI 功能的快捷键,也解答了我们在发布前一个很大的疑问——为什么在 iPhone 15 Action 按键学习成本已经够高的情况下,苹果依然还要推出一个拍照按键?
这颗按键能够降低对 Apple 智能的操作门槛,毕竟无论是苹果还是其他模型的 AI 功能,依然有一定学习成本,甚至和原设备和系统的使用习惯相悖。
更重要的,是通过这个按键培养用户形成一种新的交互习惯,一拍即答,一个让 iPhone 开启 AI 之眼的简易操作,就像乔布斯当年展示的滑动解锁,希望给用户带来自然本能的操作体验。

硬件形态上不再有大变化的 iPhone,要能靠什么迎来新的周期?其实在今天的发布会前,库克已经在多个场合给出了答案:Apple 智能。
有分析师甚至认为 iPhone 16 会迎来一个 AI 驱动的超级周期,2025 财年的 iPhone 销量可能会超过 2.4 亿台。
这个数字什么概念?历代销量最高的 iPhone 6 系列卖了 2.2 亿台。2.4 亿的销量意味着,苹果得在换机周期最长、全球宏观经济还在复苏的时期,创造一个新的销售神话。

看到这里你大概率会迷惑,对于大多数只在发布会和媒体报道中看到过苹果 AI 功能的用户,尤其是中国消费者,很难想象到底什么 AI 功能有这样的魅力。
实际上苹果如果要为 iPhone 开拓新的周期,AI 的确就是最大的 X 因素,AI 硬件的核心也在于软件和硬件如何嵌合。
苹果在 WWDC24 发布苹果智能后,我们就提出一个观点,这场没有硬件的发布会,却可能会对硬件带来很大的影响。
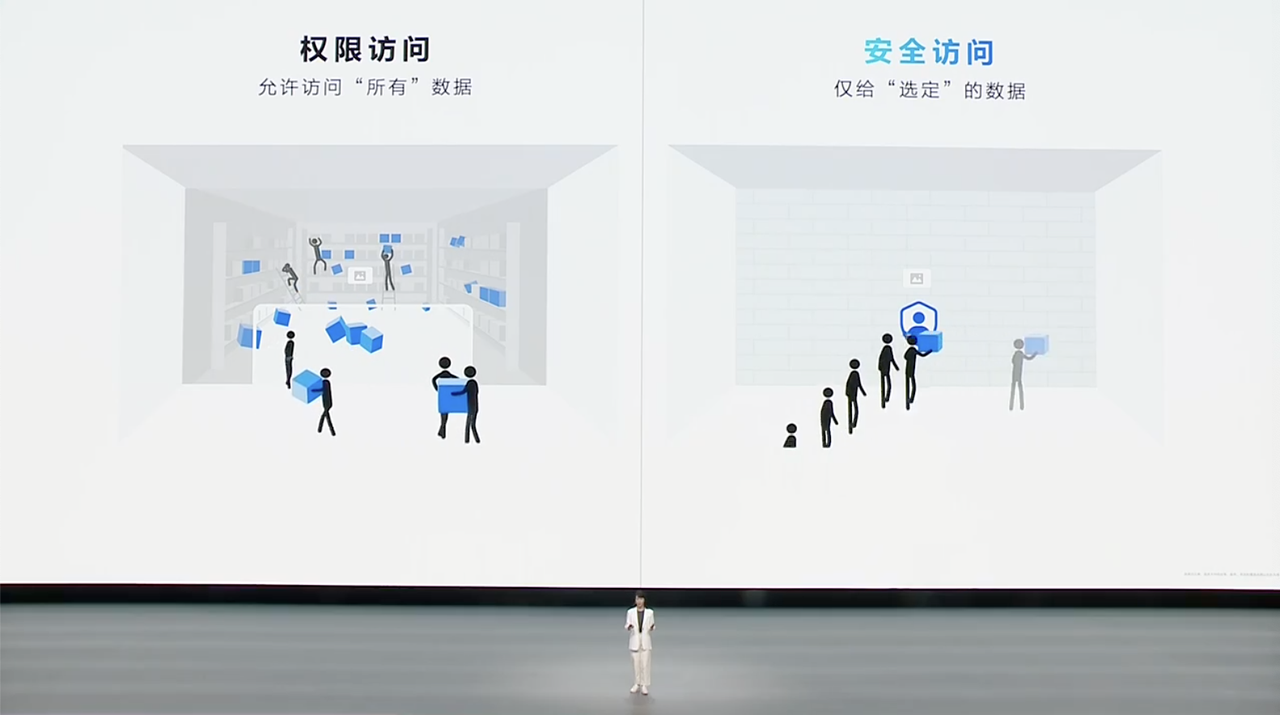
苹果智能展现的一种新的人机交互方式,一个支持多模态交互的系统,就是属于人类自然语言的 API,允许操作系统通过模型操作调用 API,根据用户查询需求协调工作,以高度无缝、快速、始终在线的方式运行
而这样系统集成式的 AI,也是我们将 AI 视作产品还是功能的分水岭。包括 ChatGPT 在内的大部分大模型应用,或者一些 AI 硬件,本质上还是以一种功能呈现给用户。
虽然目前为止还没有厂商已经证明, AI 手机能成为影响购买决策的主要因素。端侧模型的进展已经在悄悄超出预期,6 月份苹果工程师曾表示苹果智能用的目前最好的端侧模型,但前几天国内的面壁智能已经发布了 2.2G 内存就能移动设备跑 ChatGPT 的端侧模型。
当然苹果现在只是勾勒出草图,苹果 AI 的终极形态也不太可能在这两代 iPhone 就发育完成,而这已经远远超出了乔布斯的预期,这是他在 1983 年的一段演讲:
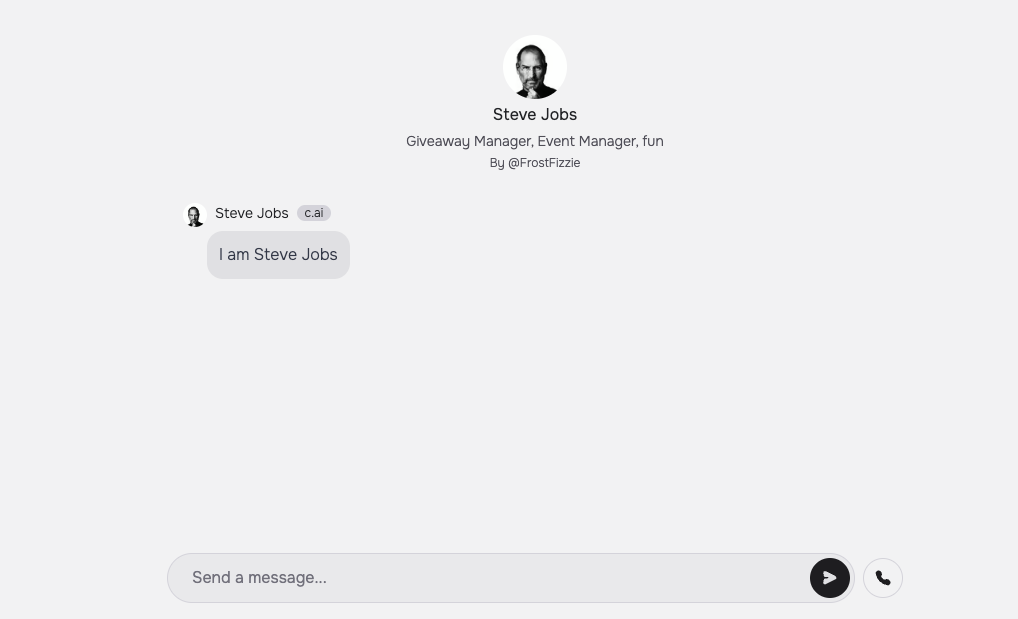
我认为,当我们展望未来五十到一百年的时候,如果我们真的能够开发出能够捕捉到某种潜在精神、原则集合或看待世界的潜在方式的机器,那么当下一个亚里士多德出现时,也许如果他一生都随身携带这样的机器,并输入所有这些内容,那么也许有一天,等这个人已经死去,我们可以向这台机器询问:「嘿,亚里士多德会怎么说?这方面有什么想法吗?」
也许我们得不到正确的答案,但也许我们会。这真让我感到兴奋。这也是我做自己正在做的事情的原因之一。
乔布斯也不会想到,我们现在就能在屏幕前这样和他交流了。
本文由李超凡、苏伟鸿、莫崇宇合写
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
爱范儿 |
原文链接 ·
查看评论 ·
新浪微博





























 https://www.nytimes.com/2024/10/23/technology/characterai-lawsuit-teen-suicide.html
https://www.nytimes.com/2024/10/23/technology/characterai-lawsuit-teen-suicide.html