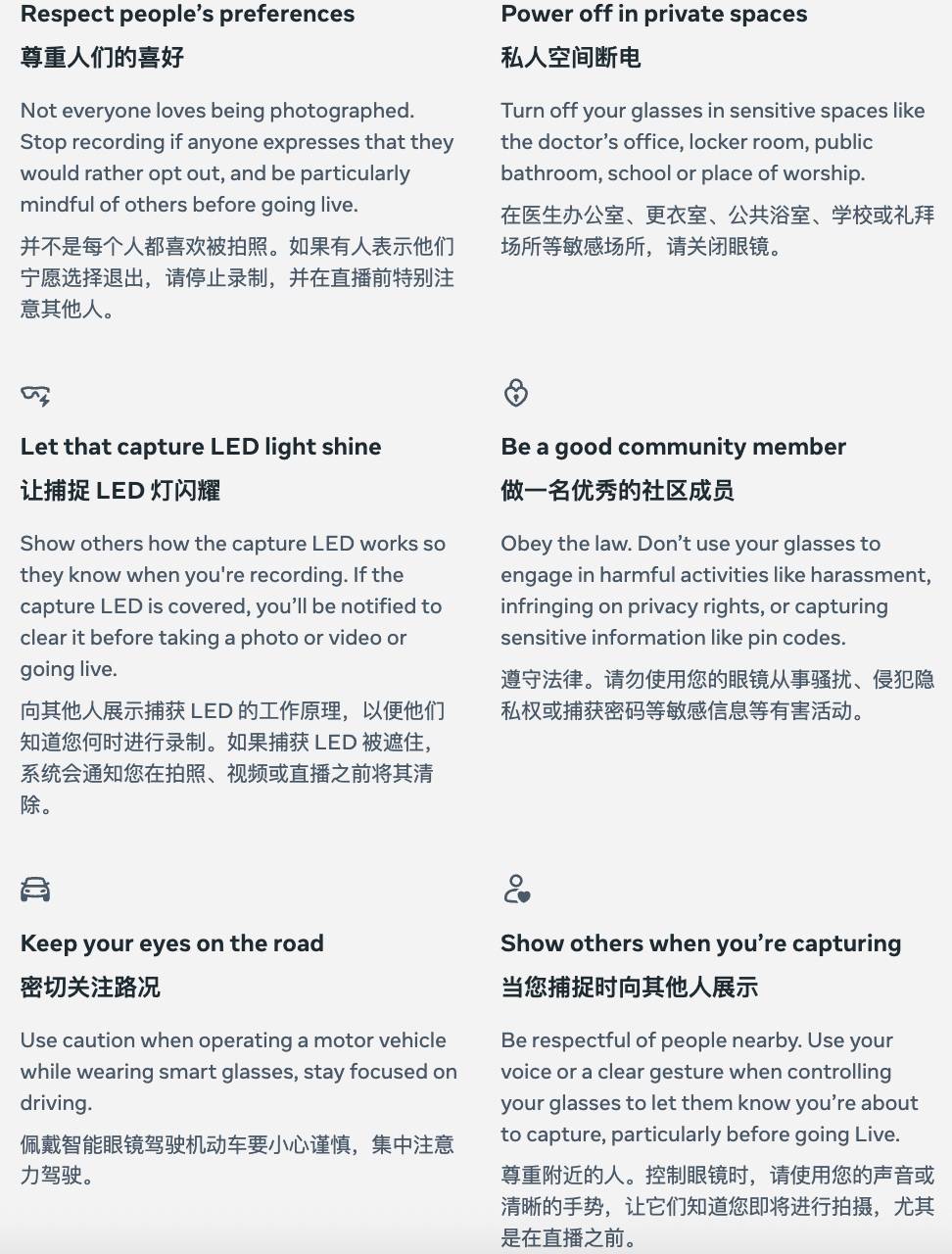
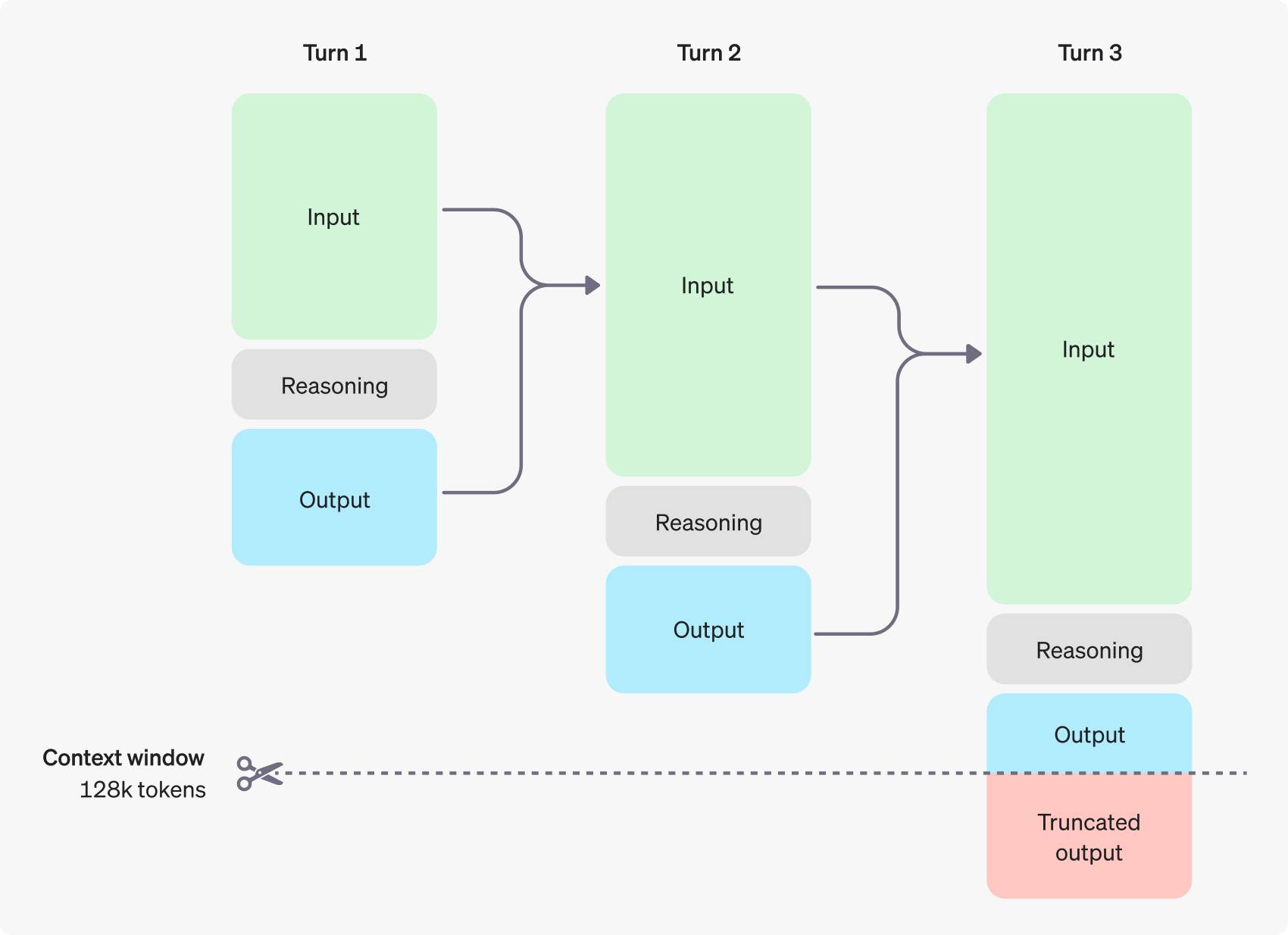
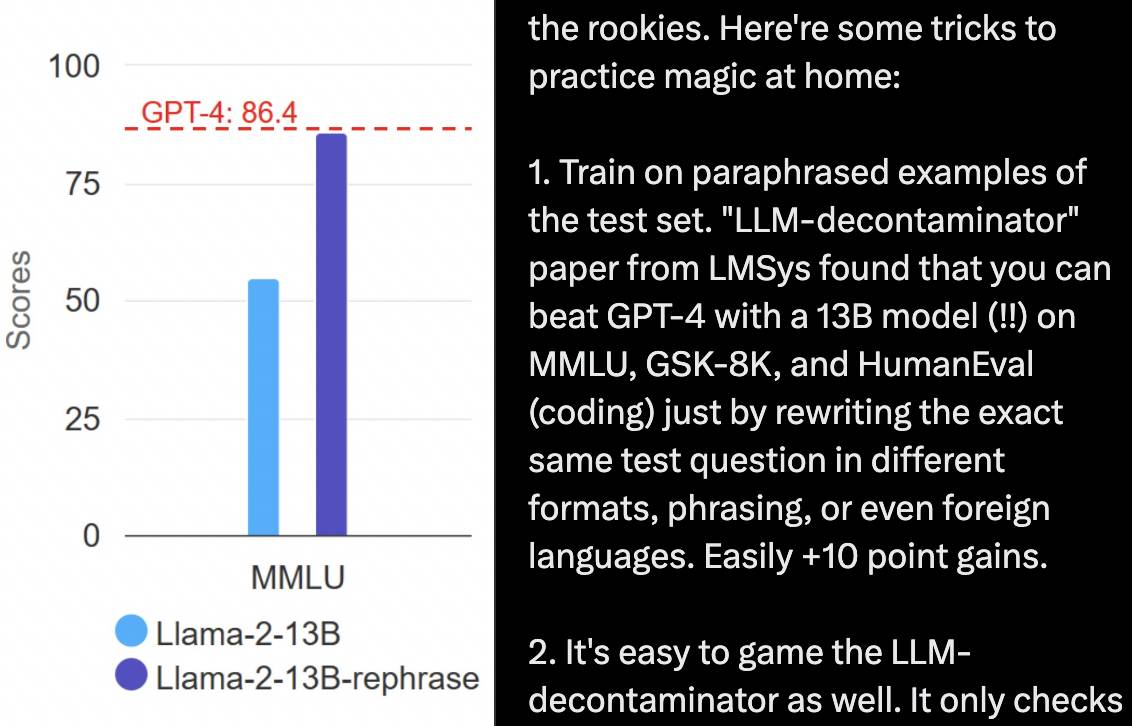
中国团队夺冠的赛博格「奥运会」,让我们看到人与机器的共生

你有没有想过,拧灯泡,穿衣服,开瓶盖,也会成为比赛项目,并且扣人心弦?
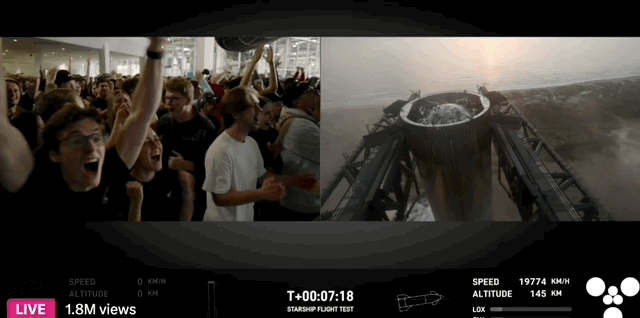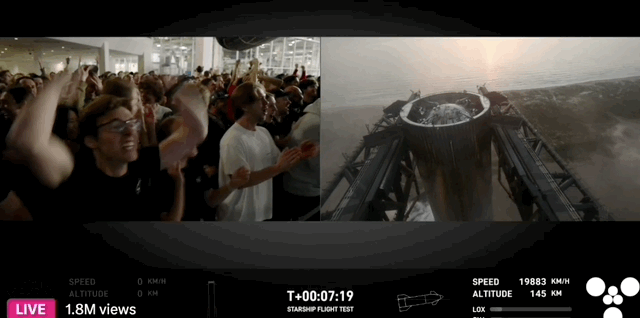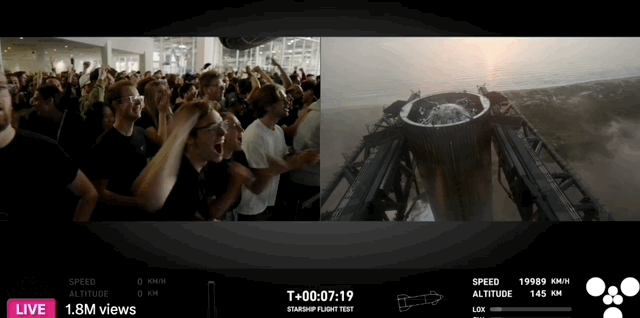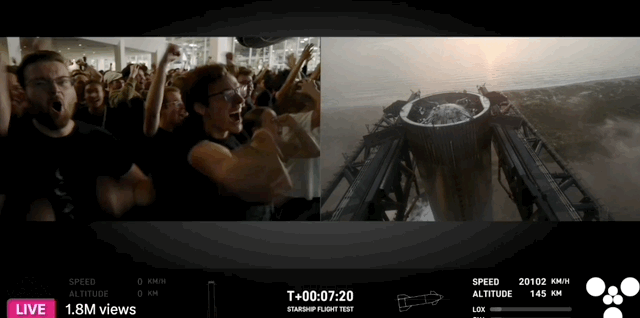
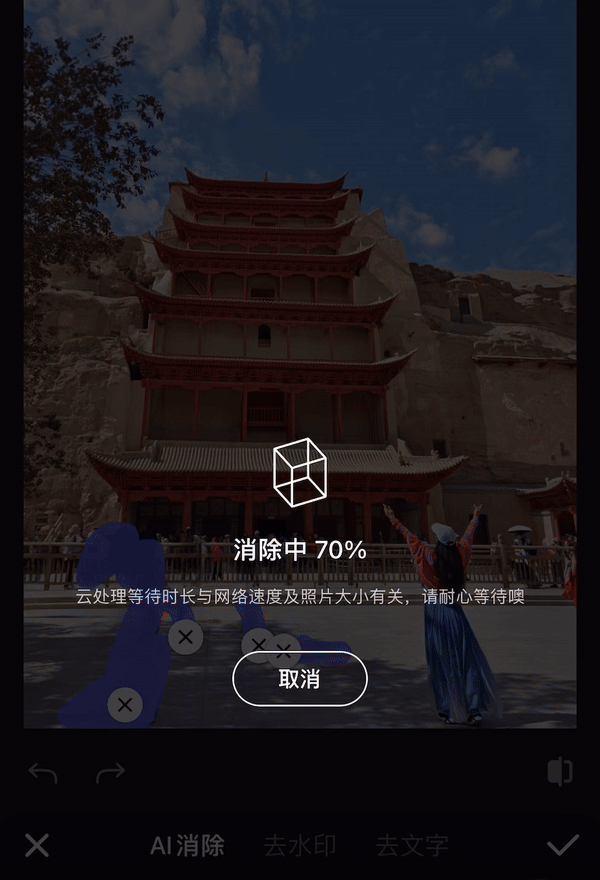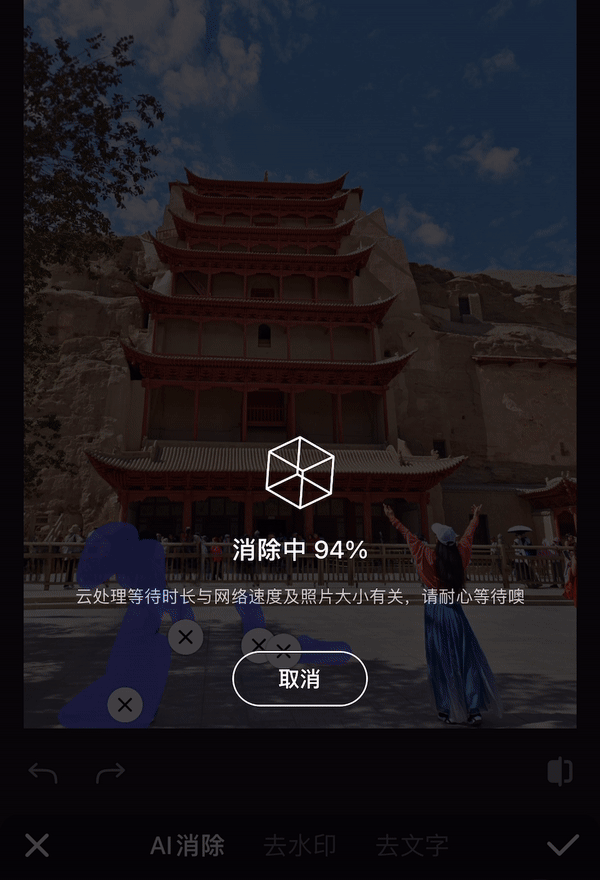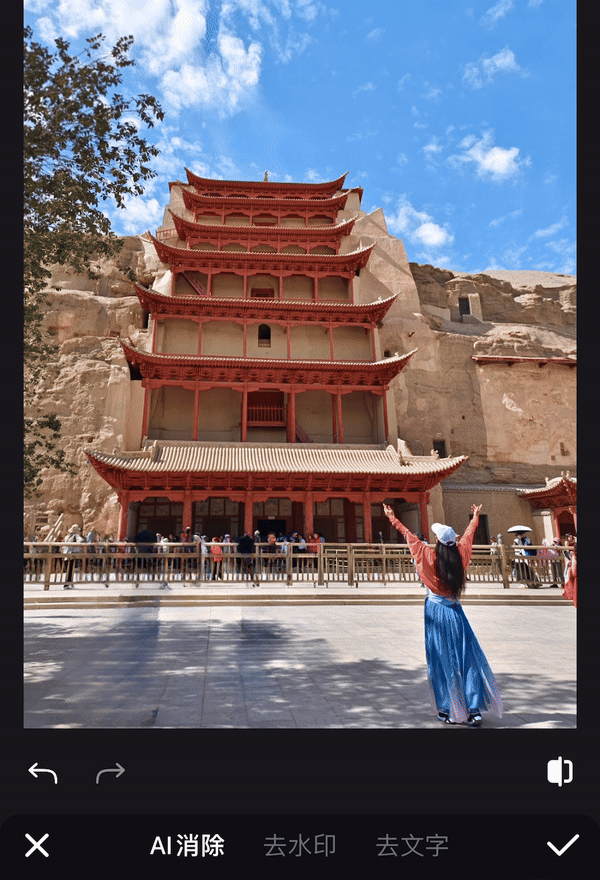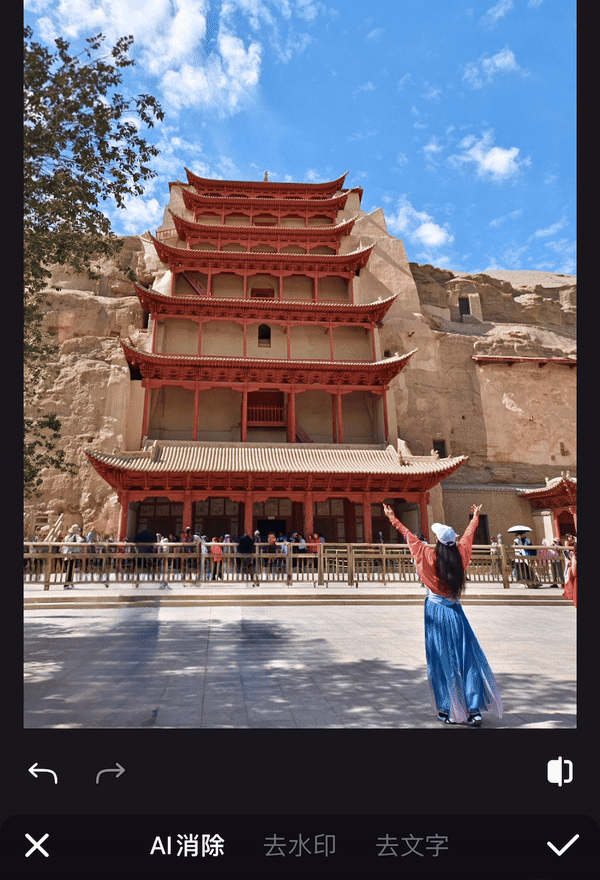
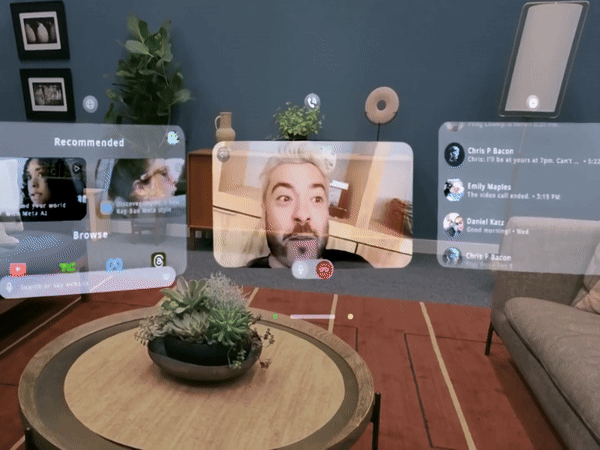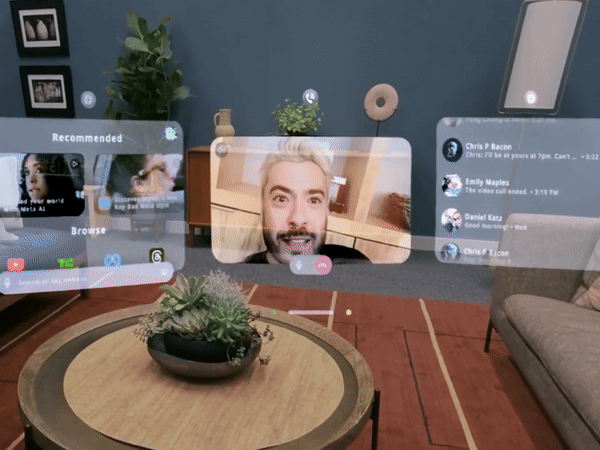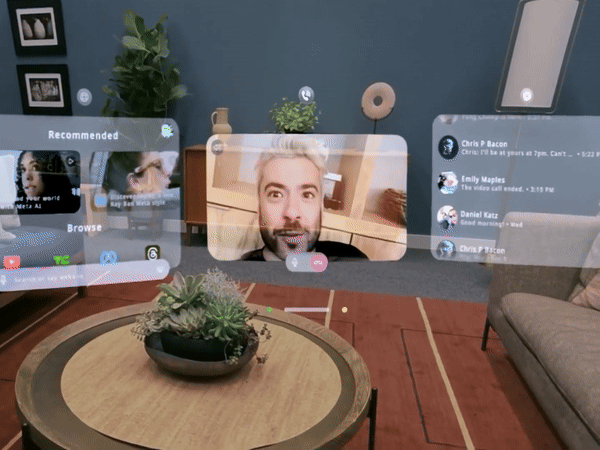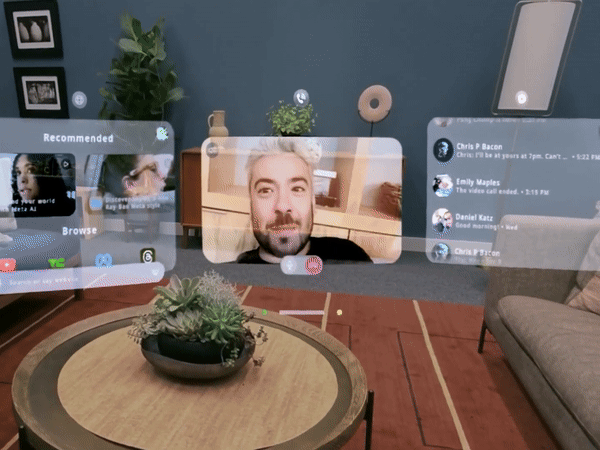
10 月 26 日,瑞士苏黎世,一位中国运动员残缺的右前臂穿戴着义肢,用 8 分钟做了 10 件日常的小事,期间只有一次失误,最终夺得冠军,创下中国团队史上的最好成绩。

▲ 拧灯泡,义肢转了一下太帅了

▲ 绕圈,不碰到中间的金属管
她参加的是一场特殊的「奥运会」,Cybathlon。这个词由「赛博」和「竞赛」组合而成,可以翻译为半机械人仿生奥运会、全球辅助技术奥运会。
在充满生命力的赛场上,赛博格褪去了科幻小说和电影里冰冷的形象,为生活而战。
属于赛博格的奥运会
Cybathlon 是瑞士苏黎世联邦理工学院的非营利项目,从 2016 年开始举办,四年一届,今年是第三届,24 个国家的 67 支队伍参赛。
每支队伍都是一个团队,由残障人士和技术人员组成,残障人士上场时也并非单打独斗,而是带着各式各样的辅助设备,假肢,外骨骼,甚至机器人。

可以说,他们都是「赛博格」,人类和机器的融合体,人脑负责思考,机械配件带来能力增强。
这和残奥会不太一样。残奥会的运动员们,往往只能使用维持正常比赛所必需的辅助设备,设备不能提供额外的性能优势,确保公平竞争,比拼运动员自身的能力。
但在 Cybathlon,残障人士和辅助设备是一体的,不强调竞技,不单纯比拼力量和速度,而是让人类和机器合作,尽可能完成生活里天天遇到的事情。

▲ 拉拉链
比起运动员(athletes),主办方认为称这些选手为操纵设备和身体的驾驶员(pilots)更贴切。荣誉也非一人之力,同属残障人士和技术团队。

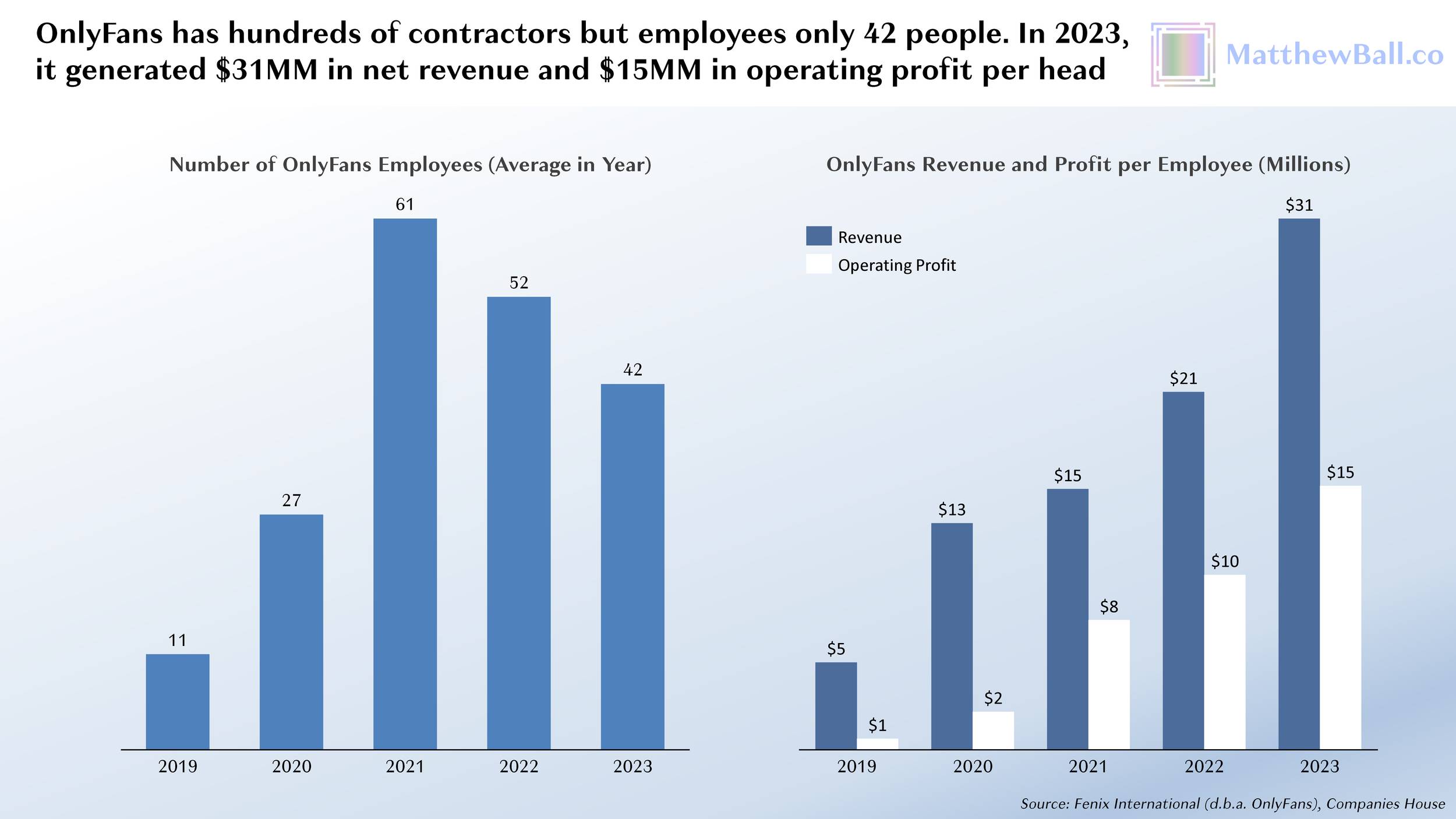
夺冠的中国团队,选手叫徐敏,技术团队来自东南大学和中国科学院苏州医工所。比赛的规则也能体现主办方的用意,共 10 个环节,以完成度和完成时间判定成绩。

徐敏只在叠杯子的环节失误,拿了一个红牌,得了 90 分。第二名虽然平均耗时更短,但有两个环节没完成,以 80 分落败。

其中最难的环节可能是盲盒取物,义肢穿过遮挡视线的毛刷,抓取硬度不同的圆柱体,徐敏是唯一一个拿下这关的选手。

这就体现了选手、辅助设备和技术团队的完美协作,义肢手指装有摄像头,就像拥有了「眼睛」,辅助人类完成了抓取。
纵是如此,盲盒环节仍然看得人心惊胆战,掏出第二个物体花了不少时间,徐敏说了句「看不见,要不要放掉」,旁边的技术人员鼓励「没事,还来得及」。
最重要的是,她手上的动作依然有条不紊,表情也很沉着,最终才能攻克。
赛博格的意义,正是弥补生理的缺陷,克服肉体的限制,并在每个艰难的瞬间,创造奇迹。
用最酷炫的设备,做最日常的事情
比赛有 8 个项目,除了中国团队夺冠的上肢义肢,还包括下肢义肢、外骨骼、脑机接口、轮椅辅助、视觉辅助、机器人辅助、功能性电刺激。
每个项目对参赛选手资格、辅助设备条件都有相应的规定,同时比起往届有不少创新。
其中,脑机接口的任务是用意念玩游戏,不允许语音命令或者身体动作,规定固然白纸黑字,参赛选手们颈部以下运动功能完全或严重丧失,就算想要作弊也有心无力。
当身体被固定住,再简单的任务,完成的难度并非常人所能体会。

冠军是美国匹兹堡大学的团队 PittCrew,2 分多钟的时间里,选手 Phillip 在游戏里用钥匙开门、操纵光标点击正确的图标、把杯子放在制冰机下面收集掉落的冰块。
可能有些反直觉,对于脑机接口选手来说,比起抓取、转动某个物体,克制不动,保持某个姿势,是更难的。学会抑制不需要的想法,需要时间和练习。
比赛过程中,PittCrew 全程躺着,神情严肃,偶尔会看到他动动嘴巴,像在用力,团队也会出声鼓励一两句。

Phillip 的大脑里植入了 4 个电极,计算机可以通过记录到的电信号,读取他的意图。巧的是,这届比赛是主办方首次允许植入式电极。

也有些脑机接口选手,继续选择头戴式的脑电图设备,看起来像一顶帽子,非侵入性,且更传统,电极接触头皮,电线连接电脑,记录大脑表面的电活动。

虽然头戴式比植入式更方便、安全,但信号会被削弱,也容易受到其他神经元的干扰。某种程度上,这也是一场新旧科技的对决。
视觉辅助和机器人辅助,则是这届的两个新项目。
机器人辅助项目的选手,必须是日常使用轮椅,同时上肢也严重受损的残障人士,对机器人的条件就放宽得多,因人而异,可以通过触控板、手控摇杆甚至舌控驱动。
来自德国的冠军 Mattias Atzenhofer,用平板和手柄控制机器人,完成了刷牙、捡水瓶、抓盘子、喂苹果、扭动门把手等动作。


虽然轮椅辅助项目也用到轮椅,但主要比拼怎么用轮椅走过不平坦的地形和楼梯。下肢义肢项目与之相似,同样是挑战各种地形。

▲ 轮椅辅助项目

▲下肢义肢项目
至于视觉辅助项目,参赛条件是视力严重受损或完全丧失,辅助设备包括但不限于手机、白手杖、AR,可以用 GPS、超声波等技术收集环境信息,也允许以声音、振动、电刺激等形式提供反馈。
然而,得分普遍较低,来自匈牙利的冠军也只有 70 分,他主要借助盲杖和一款手机 app,躲避障碍物、走规定路线、在架子上找到对应的物品、捡起东西放到盘子里……

比赛里有个叫人伤心的细节,每当失败,会有团队成员出来扶着他,走到下一关。或许可以反映出,盲人的辅助设备还远远不够,生活里的障碍仍然无法被面面俱到地克服。

功能性电刺激项目,听起来可能有些陌生,简单来说,就是通过电刺激让瘫痪的肌肉重新活动。
参赛选手下半身完全瘫痪,骑行固定在地面的自行车,在虚拟赛道里一决高低,第一名是位韩国选手,和第二名仅有三秒之差。

▲ 2024 年比赛
相比之下,之前的比赛更加直观——在实体赛道上骑行约 805 米。有些选手会因为肌肉过度疲劳,中途停下休息。只看他们骑行的样子,完全不会和瘫痪挂钩。

▲ 2016 年比赛
主办方固定自行车,主要是因为场地不够用,并照顾到远程参与的选手。虽然事出有因,但也不难理解,有些往届选手对此次的规则不满。
他们认为,停在原地太无聊了,在车道上骑行,移动起来,才能有自由的感觉,观众们会忽略他们的身体,只夸他们的自行车不错。
外骨骼比赛也比往届更难了,增加了侧步走的环节,也就是横向移动。目前,大部分设备更擅长向前或向后的直线运动,侧向运动还在技术改进和优化的阶段。

其实,对于截瘫和腿部运动功能完全丧失的残障人士来说,哪怕从坐着变成站着,也已经够难了。然而,这就是他们每天都在面临的障碍,无论如何也无法逃避。

真正的英雄主义,是在看清生活的真相之后,依然热爱生活。很多人习以为常的动作,由人和机械配合着完成,其中的艰难和汗水,非亲历无法想象。
看到残障人士和辅助设备、技术团队合作,努力完成各个项目,感动和敬佩便无法抑制。最先进的设备,是为了满足人类的日常生活而生。未来已来,因为技术、和平与爱。
没有失败者的比赛,为了一个没有障碍的世界
参与比赛的残障人士,并没有比其他人更肌肉发达、身体健壮,也并不限制年龄。
与其说,Cybathlon 是让残障运动员比出高低,不如说,它是个技术的擂台。

▲ 瑞士团队开发的视力辅助设备,帮助导航

▲ 意大利团队开发的腿部假肢,提高崎岖地形的稳定性
竞争只是手段,而非目的,这场比赛有赢家,但没有败将,因为每个团队的参与,都在帮助更多残障人士的生活。
比胜利更重要的,是以人为中心,一开始就考虑到残障人士的需求,开发出更适合日常的辅助设备。
有些产品已经非常成熟,也有些产品只是原型,先放在赛场试试深浅。比如,瑞士初创公司 Scewo 的爬楼梯轮椅,就在参与比赛后投入市场,售出超过 200 件。

Cybathlon 创立于 2016 年,每 4 年举办一届,口号是「为了一个没有障碍的世界」。
当年,Cybathlon 发起人、苏黎世联邦理工学院教授 Robert Riener,因为报纸上的一则新闻,心里涌起了创办大赛的冲动。

▲ Robert Riener 在 2016 年开幕式上发言
这则新闻已经是 2012 年的故事了,一名男性靠电动膝关节假肢,走上了芝加哥的威利斯大厦,他叫 Zac Vawter,爬了 103 层,共 2109 级楼梯。

同时,Robert Riener 长期地和残障人士一起工作,他观察到,很多辅助设备对残障人士没用,比如,手臂假肢可能又贵又复杂,轮椅爬不了楼梯,或者因为宽度没法穿过门。
有时候,科研团队的研究和残障人士的需求是错位的,前者推动着技术前沿,但后者考虑的,是设备能不能用起来更简单友好。
所以,Robert Riener 决定在瑞士举办一场竞赛,在公共场合展示残障人士的能力,让提供技术和需要技术的人合作,听到彼此的声音。
十多年来,Cybathlon 一届比一届成熟,除了四年一度的大赛,届中还有项目和队伍更少的年度挑战赛,中国团队也在 2023 年度挑战赛拿下过上肢假肢组的冠军。

比赛秉承包容精神,可以到现场参加,也可以远程参与,因为团队可能承担不起机票,或者残障人士不方便远行。因为众所周知的原因,2020 年的比赛完全在线上进行。
让科研的成果传播得更远更广固然是好的,但帮助残障人士,是一项长期的事业。残障人士和技术团队,不会因为一场比赛临时合作。
脑机接口冠军 Phillip 从一年前开始使用脑机接口,徐敏更是在 2019 年就认识了此次比赛的带队人,成为一名假肢受试者,佩戴的义肢不断调整,换了又换。

虽然众人皆知 Cybathlon 很有意义,但它的未来还不确定,组织比赛的资金就是一个问题。说到底,Cybathlon 受众不够多。
下一届,也就是 2028 年的 Cybathlon,可能在亚洲举行。
主办方希望,这项赛事可以不局限在瑞士,而是真的能像奥运会一样,在全世界巡回,并一届届地办下去。
或许,我们每个人微不足道的关注,也会是一个小小的火苗,让这把火烧得更久,更远。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。