这个 AI 生图神器太好玩了,连提示词都不用写

AI 生图工具,已经多得泛滥了,但 Google 最新推出的 Whisk,还是找到了一种很新的玩法,让见过世面的网友也直呼好玩。
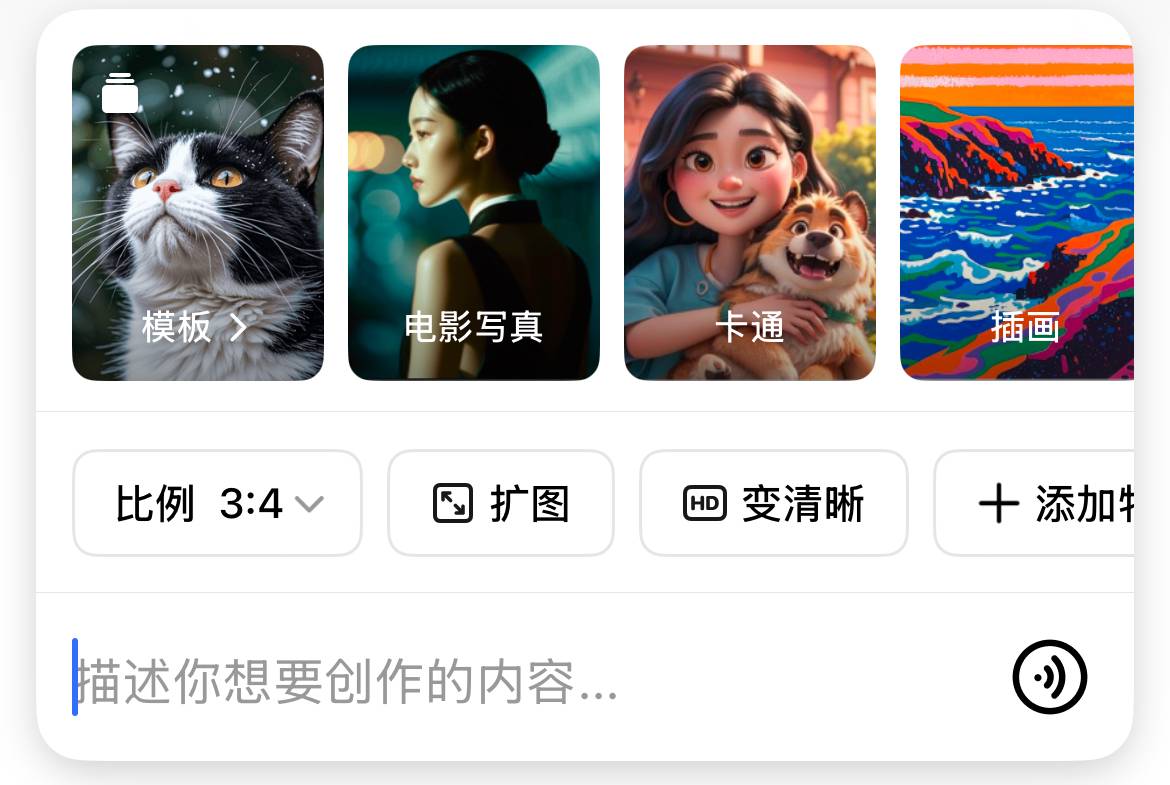
只需输入三张图片,subject(主题)、scene(场景)、style(风格),Whisk 就可以生成一张博采众长的图片。

▲ 图片来自:Google
举个例子,主题是老人,场景是藤蔓,风格是 90 年代复古动漫,写上「角色骑着飞行自行车」的提示词,等待一会儿,一张类似吉卜力画风的新图片诞生了。

▲ 图片来自:Google
老人还是那个老人,戴帽子,穿西装,拿着书,但他骑上了提示词里的车,场景和风格也都变成了参考图片的样子。
Whisk 的长处便在这里——让我们少写、不写提示词的同时,轻松玩转各种风格,妈妈再也不担心我不会写提示词了。
别写复杂的提示词了,直接把图片端上来就行
别看只需要几张图片,Whisk 的玩法简单,却又无穷无尽。
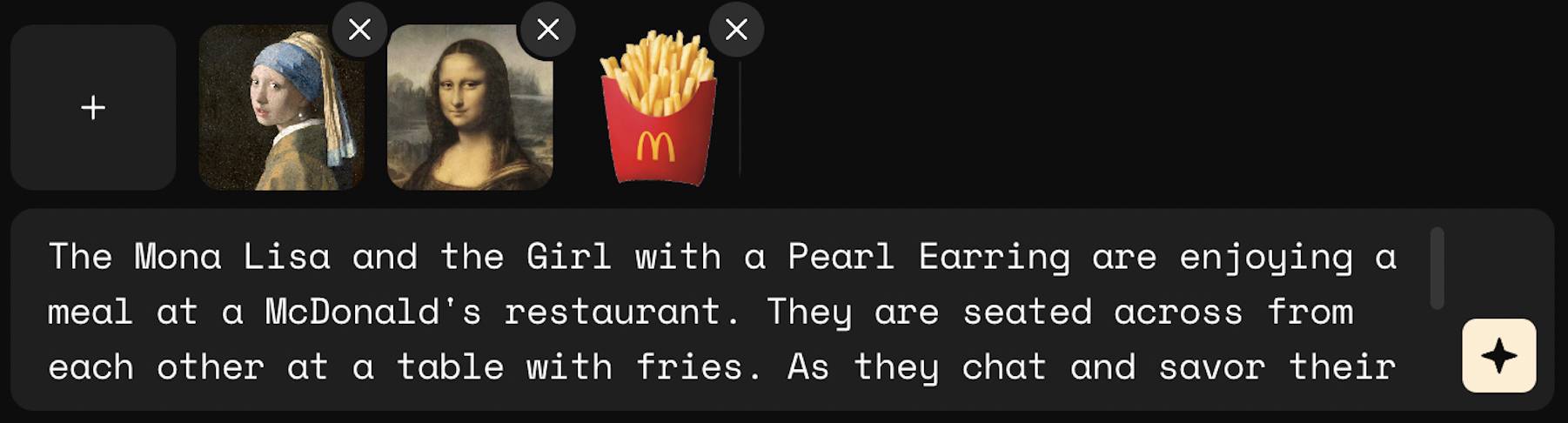
刷刷刷上传三张图片——主题图片,麦当劳薯条;场景图片,莫奈画作《睡莲》;风格图片,像素风游戏《星露谷物语》。
不写提示词,直接生成,Whisk 给出的结果,一张更比三张强。

除了上传自己的图片,我们也可以掷骰子,让 Whisk 随机生成主题、场景、风格。

其实,Whisk 为我们提供的预设风格已经很够用,徽章、贴纸、刺绣、黏土、美漫、马赛克拼贴等等,特色鲜明,效果立竿见影。

只要有脑洞和想象力,无需一个字,仅仅通过不同图片的排列组合,我们可以不断地做完形填空的游戏——主题+场景+风格,而且不是每个空都必须填。

▲ 1.主题图片,熏鸡;2.场景图片,梵高《星月夜》画作;3.风格图片,日本木版画

▲ 1.主题图片,《戴珍珠耳环的少女》;2.场景图片,电影《千与千寻》剧照;3.风格图片,蒙德里安抽象画

▲ 1.主题图片,微信「死亡笑脸」表情包;2.场景图片,电影《星际穿越》剧照;3.风格图片,史努比漫画截图

▲ 1.主题图片,冲浪默认头像粉色恐龙 momo;2.风格图片,Jellycat 玩偶
另外,Whisk 的每一次生成,场景和风格只能选择一个参考图片,但主题可以选择多个。这意味着什么?我们可以让多个角色同框了!
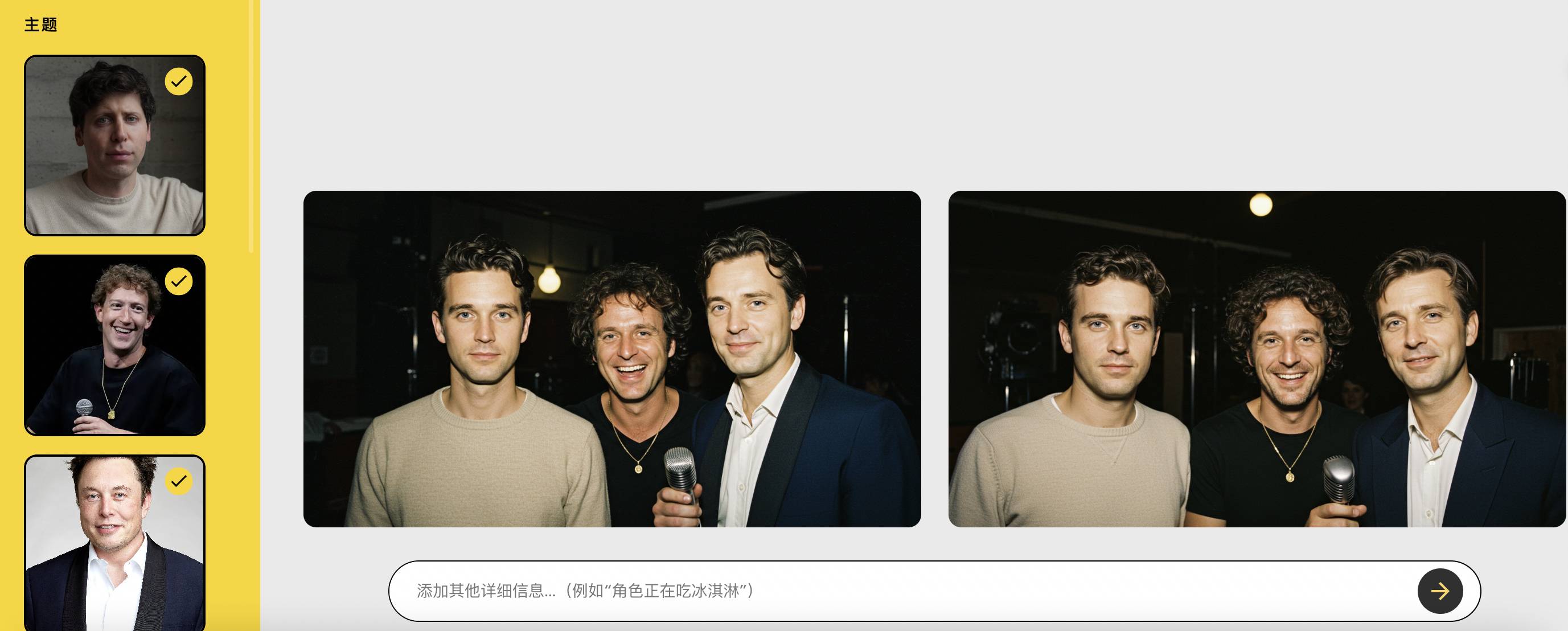
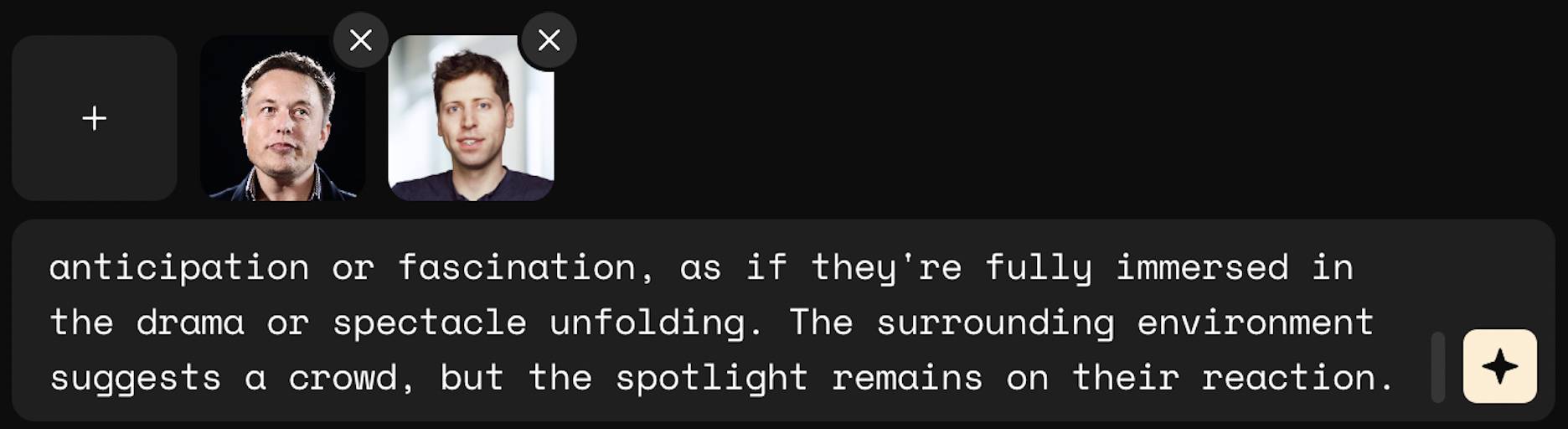
比如,让马斯克、奥特曼、扎克伯格通通变成珐琅徽章。

三位的服装、装饰、神态都还原得挺好,扎克伯格的话筒和项链都没漏掉,但人脸没法保持一致性,全部变成了大众脸。
虽然 Whisk 减少了写提示词的需求,但你需要写的话,Whisk 也鼓励。
在对话框加上一句「角色们都举着一块告示牌,上面写着 AGI」,徽章小人们轻轻松松地遵循了提示词。

如果我们需要某个场景或者某种风格,但一时找不到参考图,Whisk 的预设也没有提供呢?
解决方式很简单,没有图片,那就写提示词,让 Whisk 临场发挥一个。
就像我需要一个让角色站上去的、像素风格的底座作为场景,就让 Whisk 帮我生成了。

然后,再把猫猫表情包作为主题图片,把像素小鸡作为风格图片,就可以得到一个有底座的像素猫猫。
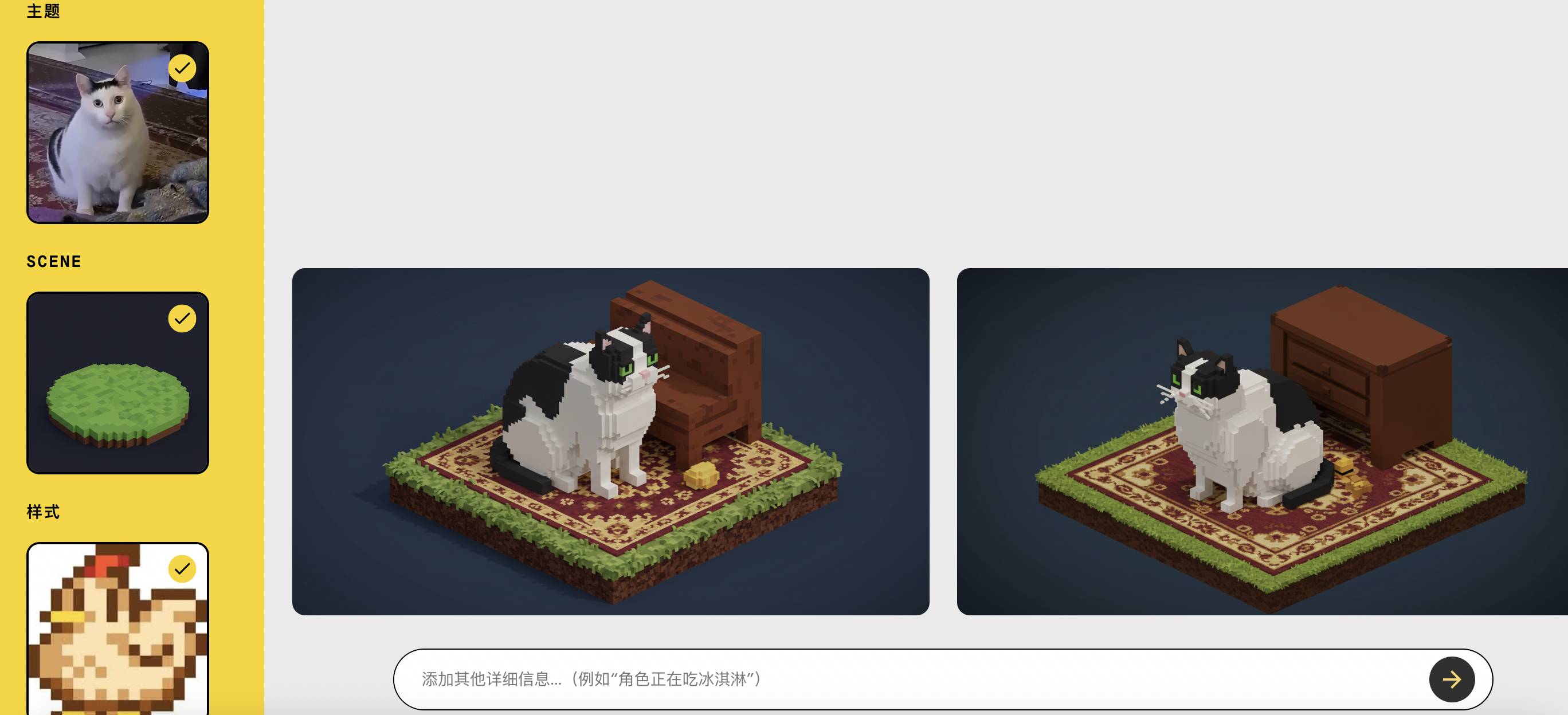
总之,Whisk 就是非常自由,像橡皮泥一样,怎么捏都可以。
既生图又识图,把复杂的工作流包装成有趣的「打蛋器」
Whisk,其实是 Google 多模态模型秀肌肉的一种方式。
为了让我们少写提示词,Whisk 整合了视觉理解和图片生成能力。
Gemini 模型识别图片,自动生成详细的描述,然后这些描述会被输入到 Google 的图片生成模型 Imagen 3,由 Imagen 3 生图。
Whisk 是这样的,用户只要上传和生成图片就可以了,但它自己要考虑的事情就很多了。

Whisk 的每张图片,不管是上传的还是生成的,都写了很长的底层提示词,并且不藏着掩着,我们点开图片就能看,也可以上手修改。
如果把一个人作为主题图片,Whisk 会详细地描述他的外貌特征,场景图片也是类似的。

▲ Whisk 对奥特曼的描述:「一个肤色较浅的男子,有着短而深棕色的卷发,从胸部以上展示。他有着浅色的眼睛。他穿着一件浅米色的针织圆领毛衣。背景是一面斑驳的灰色混凝土墙。男子的表情严肃而中性。光线有些昏暗,他的右脸有轻微的阴影。」
风格图片略有些不同,如果把一张动画截图作为风格参考,Whisk 不会说,画面里有三个人,而是描述这幅画的色彩、光线、线条……

▲ Whisk 对史努比画风的描述:「这张图片以卡通风格呈现,具有粗犷的轮廓和平面着色。色彩调色板有限,主要使用原色和柔和的次要颜色。光线均匀,缺乏强烈的阴影或高光,给人一种简单、几乎孩童般的质感。线条清晰且一致,带有轻微不均匀的质感,暗示手绘的效果。整体美学让人联想到经典的连环漫画或儿童动画。」
所以,Whisk 不是精准地复制图片,而是提取图片的特点和精髓,将主题、场景、风格自然地融合在一起,各司其职,互不干扰。
同时,Whisk 也叠了甲——只从图片提取少量关键特征,结果可能和预期不同。这也解释了,为什么 Whisk 做不到人脸的精准还原。
所以,哪怕选择不那么抽象的复古胶片风格,三位大佬的脸也是和本尊都不挨着,但其他细节都很准确。
物体也是一样,特斯拉的赛博皮卡,经过特征提取再生成之后,变得非常普通。

但如果是麦当劳薯条这种素材丰富的超级 IP,效果倒还不错,可以拿来当广告图了。试过一些迪士尼的角色,Whisk 复刻得也原模原样,但图就不放上来了。

另外,Whisk 还存在一个问题——没法做很细致的风格参考,模仿不了某种特定的画风。
当我让 Whisk 生成蒙娜丽莎的乐高小人,出来的结果让我两眼一黑,但多加一句提示词,「让角色更像乐高人物」,Whisk 又能模仿个七八成。

某个漫画家的画风就更难模仿了,上传漫画截图让 Whisk 参考,它最终给出的是一个非常普通的漫画风格图片,就算通过提示词强调作品、角色、漫画家,也不起什么作用。
其实,Whisk 好玩就够了,它更适合做一些不追求精准的创意探索,俗称整活。
Whisk 可以翻译为「搅拌」或者「打蛋器」,Google 的这个名字取得即视感很强,可不就是把食材都混搭在一起吗?
Whisk 的不精准,也让它的定位和传统的图片编辑器不同,更像是一种创意工具。有了什么脑洞,由它实现粗略的视觉效果。

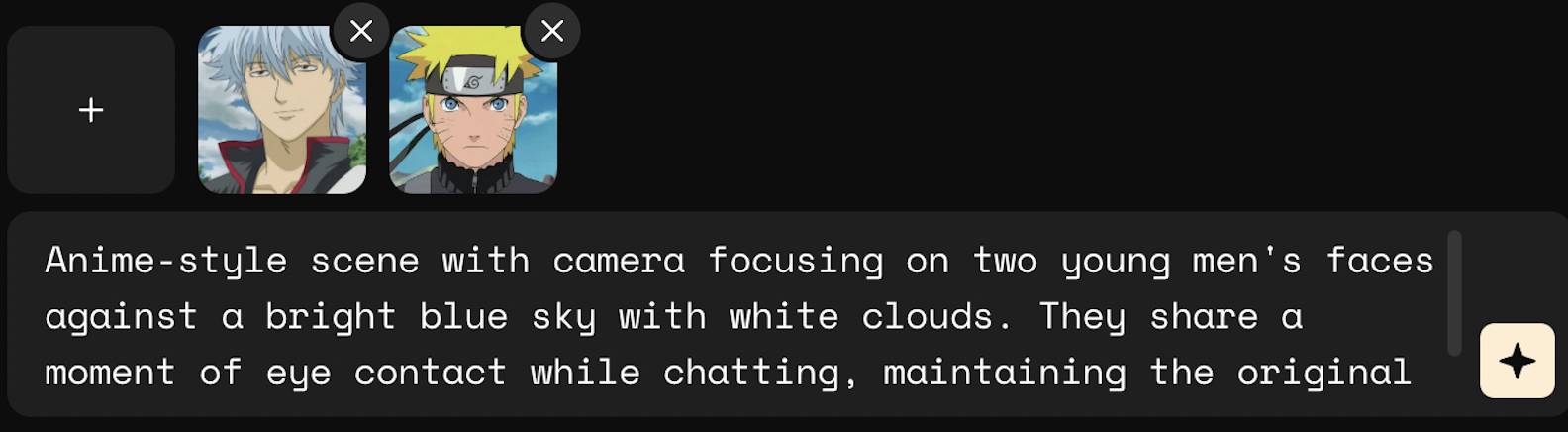
▲ Whisk 生成,1.主题图片,《火影忍者》截图;2.风格图片,毛绒玩具
以前实现 Whisk 这种风格化的效果,跑通一整个图像生成的流程,我们可能需要在 ComfyUI 搭建工作流。
但现在有了 Whisk,好像就在玩抽卡游戏或者开盲盒,而且只要能登录(限美国地区),目前还免费。
体验指路
https://labs.google/fx/zh/tools/whisk
Google 领先的模型能力固然是前提和基础,但设计出被大家需要的产品,仍然需要创造力和审美。
很喜欢 Whisk 的 slogan:「prompt less, play more.」(少写提示词,多玩耍。)
Whisk 出自 Google labs,之前爆火的 AI 播客 NotebookLM,也是出自这里,后来慢慢发展为成熟的项目。这个实验室,本身就是这句 slogan 的最好注解。
强大的模型能力,有新意的产品,开放的心态,曾经似乎被 OpenAI 威胁的 Google,风轻云淡地展现出了王者归来的姿态。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
























































 图标手动触发搜索
图标手动触发搜索








































































 就在刚刚,苹果发布了 App Store Award 2024 榜单。
就在刚刚,苹果发布了 App Store Award 2024 榜单。











































































































































 https://dream-machine.lumalabs.ai/
https://dream-machine.lumalabs.ai/













































































































































































{kind=link}