实测 Sora!比拼可灵、Runway,谁最没有 AI 味

鸽了一年,Sora 千呼万唤始出来,但 OpenAI 是让网友来历劫的。
说好的正式开放使用,蹲点直播且手速够快的幸运儿,才能抢先进入体验。等了一天,反复刷新,一次次面对「请稍后回来查看」的提醒,终于注册成功。
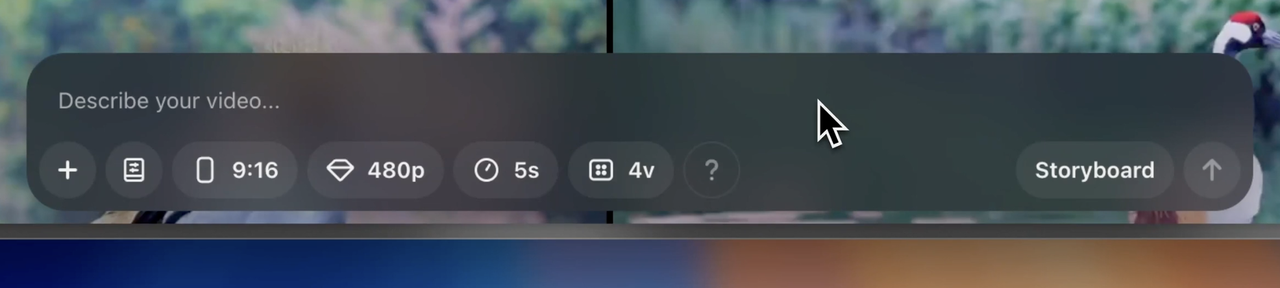
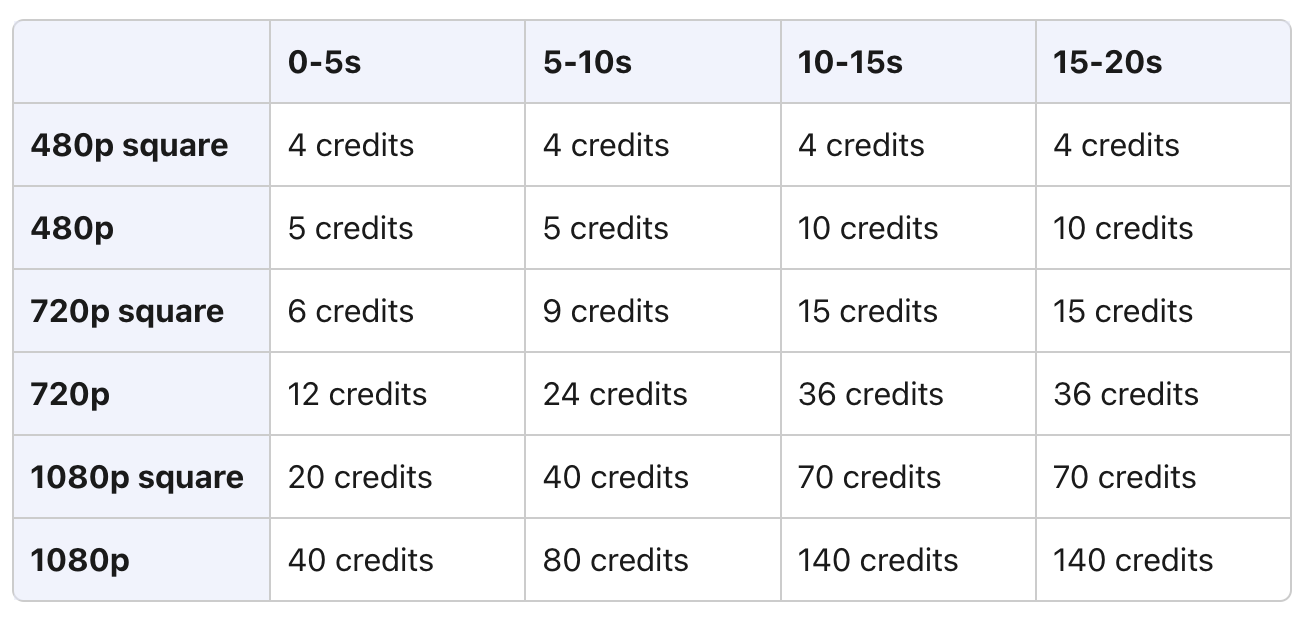
然而,让我和 ChatGPT 从诗词歌赋聊到人生哲学的 20 美元,只够让 Sora 在一个月内生成 40 个 5 秒的 480p 视频。每一次点击生成,都如履薄冰。
好不容易用上了,我们自然要把每一个 Sora 的视频用在刀刃上,拿它和 Runway、可灵比一比。结论是,能用,好玩,但很难硬夸。
Sora、Runway、可灵,失败得各有各的笑点
让 Sora 和 Runway、可灵比赛,自然是有理由的,一个是出道早、海外最有代表性的 AI 视频产品,一个是异军突起、以实力征服全世界网友的国内顶尖选手。
规则非常简单,用相同的英文提示词(为了方便阅读,下面都翻译为中文),生成的时长都是 5 秒。唯一的区别是,Sora 的分辨率都设置成了 480p。没办法,积分得省着用。
先用文生视频,比比画面的写实和质感,看看 AI 视频们生成的猫怎么样。
Sora 虽然只有 480p,但画面看起来是高清的,调色也很漂亮。

▲Sora 生成,提示词:200mm 长焦镜头捕捉阳台上的英短猫,其毛发细节鲜明。前景的大盆栽轻微虚化,背景中树叶随风摇曳。画面具有电影胶片的颗粒感和色彩饱和度,高清画质
Runway 和可灵的表现差不多,可灵的前景、背景生成得最准确。三只猫,三种花色。

▲Runway 生成

▲可灵生成
接下来,让 AI 视频们「写字」,看看能不能写出「APPSO」。
Sora 的手部动作还算自然,但写出来的线条像吃了菌子,有自己的想法。

▲Sora 生成,提示词:俯视角度拍摄手在白色素描纸上书写「APPSO」,黑色笔画,流畅的书写动作,自然的手部移动,柔和打光,特写镜头
Runway 对得最多,但也没完全对,而且,除了最后那一笔,字母轨迹和手部动作没有默契配合,各管各的。

▲Runway 生成
至于可灵,写出一串乱码,但很难得,字母轨迹是跟着手部动作走的。
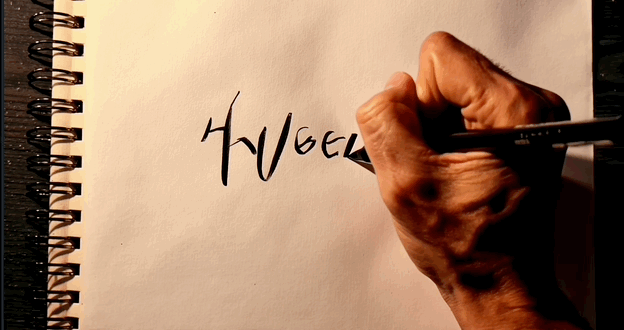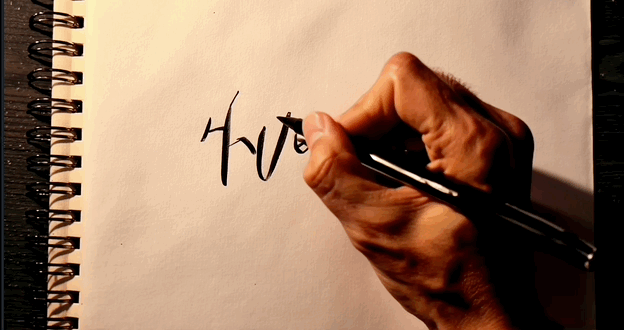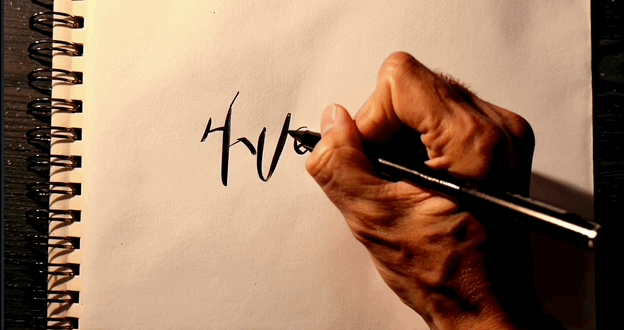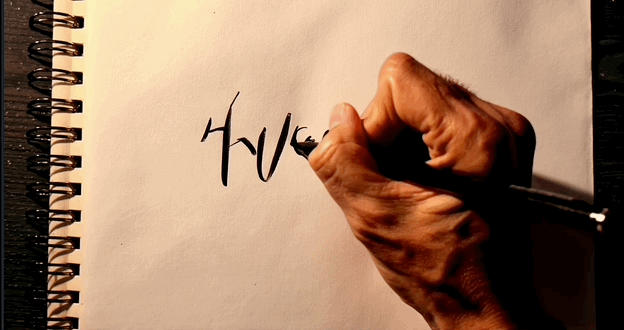
▲可灵生成
然后再来考考运动的流畅程度,同一场自行车比赛,Sora 的镜头和运动轨迹完全遵循了提示词,影子看起来也很真实。

▲Sora 生成,提示词:山地自行车手快速冲过连续起伏的泥土赛道,从最后一个跳台腾空而起,侧面镜头捕捉他在最高点的瞬间
Runway 的提示词只对了一半,自行车手没在开头出场,最后给了一个高光镜头。

▲Runway 生成
可灵和 Runway 恰好反过来,前半段表现得不错,但收尾出状况了,怎么多出来一个人?

▲可灵生成
该上难度了,拿出相对复杂的、自带镜头切换的提示词。
Sora 的画面色彩饱和,像调了色,但是男性好像是凭空出现的,AI 也没有按照要求,把镜头转向男性。

▲Sora 生成,提示词:阳光明媚的下午,星巴克风格的咖啡馆内,镜头首先对准一位面带微笑的年轻中国女性,随后转向一位说话时轻轻点头的年轻中国男性。他们相对而坐,木桌上放着两杯咖啡。自然光充满空间,营造温暖氛围
Runway 直接就从侧面拍,还原了两个人的神态,但没有体现镜头的运动,男性的手部也出了问题。

▲Runway 生成
可灵和 Runway 差不多,但略胜一筹,因为更像中国人,然而,这两个人同坐一桌,却谁也没看谁。

▲可灵生成
除了文生视频,图生视频也是视频生成的重头戏,而且相比文生视频,图生视频更实用,很多商业化交付的 AI 片子,基本都是图生视频,先在图片阶段尽量做到一致性。
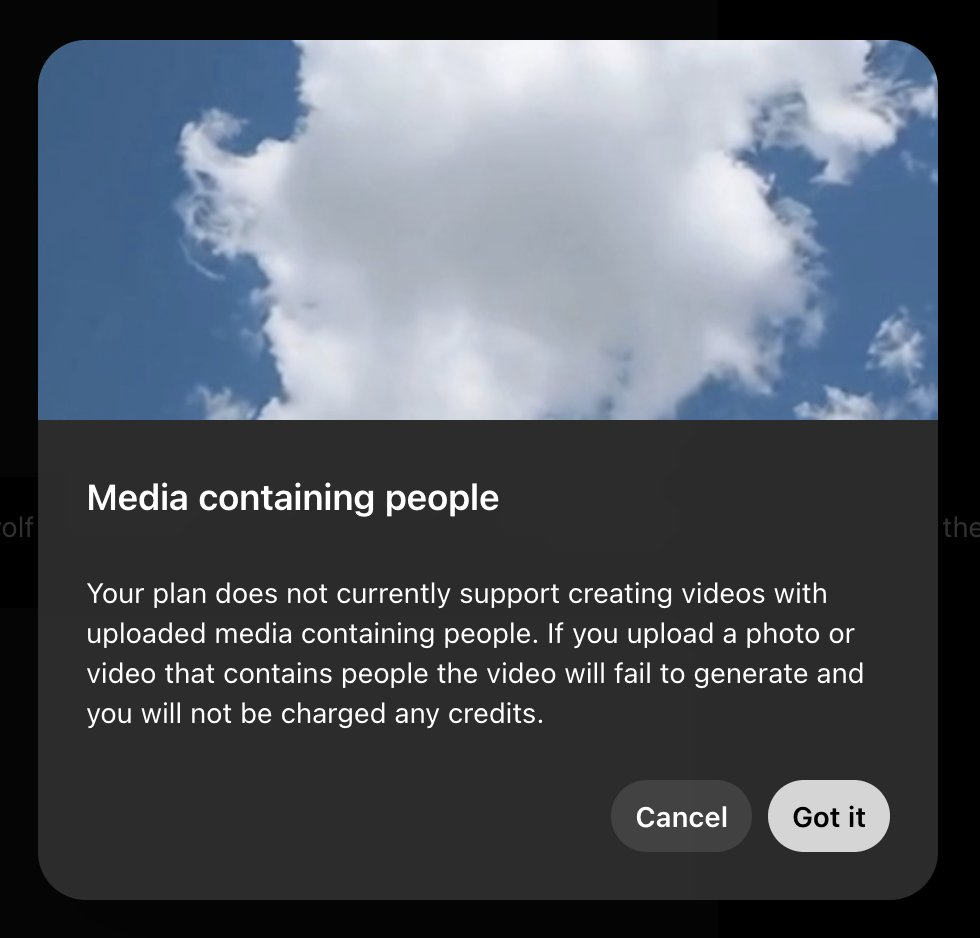
然而,如果只是 20 美元的 Plus 用户,是不能在 Sora 上传包含人物的照片或者视频的。退而求其次,我们上传一张巫师猫的表情包,让猫猫挥舞手中的魔法棒,变出玫瑰花。
不知道为什么,Sora 的图生视频不起作用,猫压根没动,从右下角的 logo 才看出,这是非静止画面。

▲Sora 生成,提示词:猫猫挥动手中的魔法棒,变出了一朵红玫瑰
Runway 让猫猫右爪挥舞魔法棒,左爪变出玫瑰花,也算符合提示词的要求,但这个花不在一个图层啊。

▲Runway 生成
可灵的表现非常完美,效果最自然,做成 gif 就是又一张表情包。

▲可灵生成
试了动物,再试试空镜,我将之前用 AI 生成的一张工业废土风格图片,作为图生视频的材料。
Sora 生成的结果很难评价,视角是够低的,但镜头不是从侧面跟踪,画面切换也突兀。这就叫,我不该在车里,而是在车底。

▲Sora 生成,提示词:装甲车开过,轮胎扬起尘土碎屑,侧面跟踪镜头,低角度视角,慢动作,电影级质感
Runway 生成的最有内味,甚至车窗也跟着动起来了。

▲Runway 生成
可灵直接把镜头拉远了,和提示词基本没什么关系。

▲可灵生成
就那么几道题,三个 AI 没有一个是可以打满分的。当然,以上通通都是个例,不具有普遍的代表性,充其量只能提供一个测评的角度。
单论 Sora 的话,它在文生视频的写实风格上表现得不错,具有电影质感,物体运动对于提示词的遵循也还行,有时甚至比可灵和 Runway 表现得好。
但图生视频容易抓瞎,可能静止不动,可能不听镜头运动,整体性价比不算高。

▲Sora 生成,提示词:90 年代在上海拍摄的 35 毫米胶片短片,电影质感
「丐版」的模型,创新的产品
Sora 表现一般,可能因为,它是个「丐版」——和受 OpenAI 邀请的艺术家们不同,现在我们能用的是 turbo 版本,需要的算力更少,效果也就打了折扣。
模型不够,产品来凑,Sora 有一点让人服气——2 月官宣,12 月才发布,中间冒出很多竞品,但 Sora 仍然具备它们没有的功能。
不像 ChatGPT 一个对话框走天下,Sora 在交互界面和产品功能的设计上别出心裁。
其中,Sora 的故事板功能,类似首尾帧,但更灵活,我们可以在时间轴上添加多张卡片,卡片里可以是提示词,也可以是图片和视频,Sora 在卡片之间生成完整的视频。
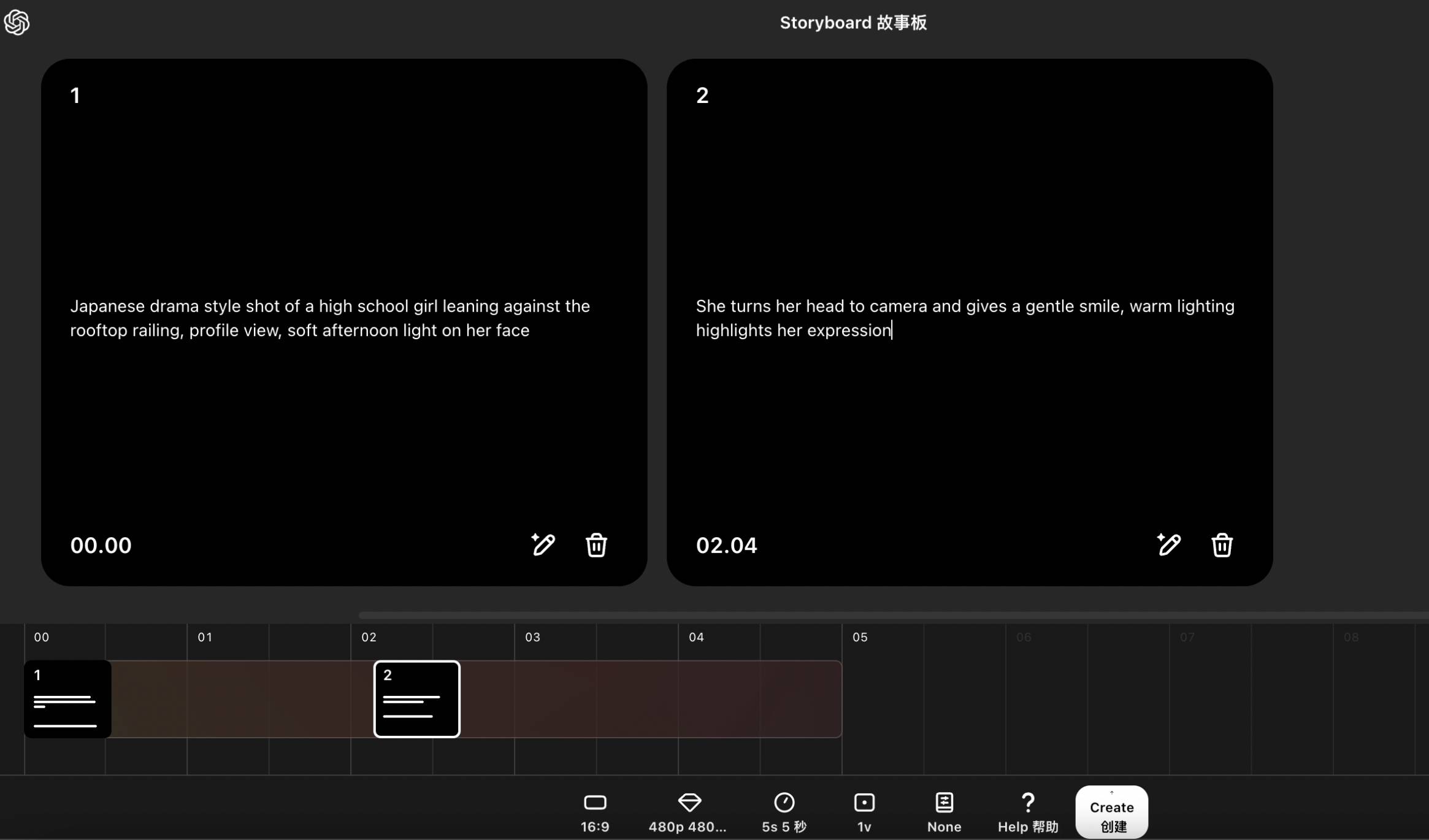
于是,我写了两段提示词,1.日剧风格镜头,女高中生靠在天台栏杆旁,侧脸构图,温柔的午后光线打在脸上;2.她转头面向镜头露出微笑,温暖的打光突出表情。
生成的效果,很符合我的想象,发丝的飘动让人该死的心动。

▲ Sora 生成
AI 还做不到让人人都能当导演,但 Sora 让你体验一把设计分镜的感觉。不过,还是那句话,模型就这样,效果的好坏,非常随机,但 Sora 的积分,经不起抽卡。
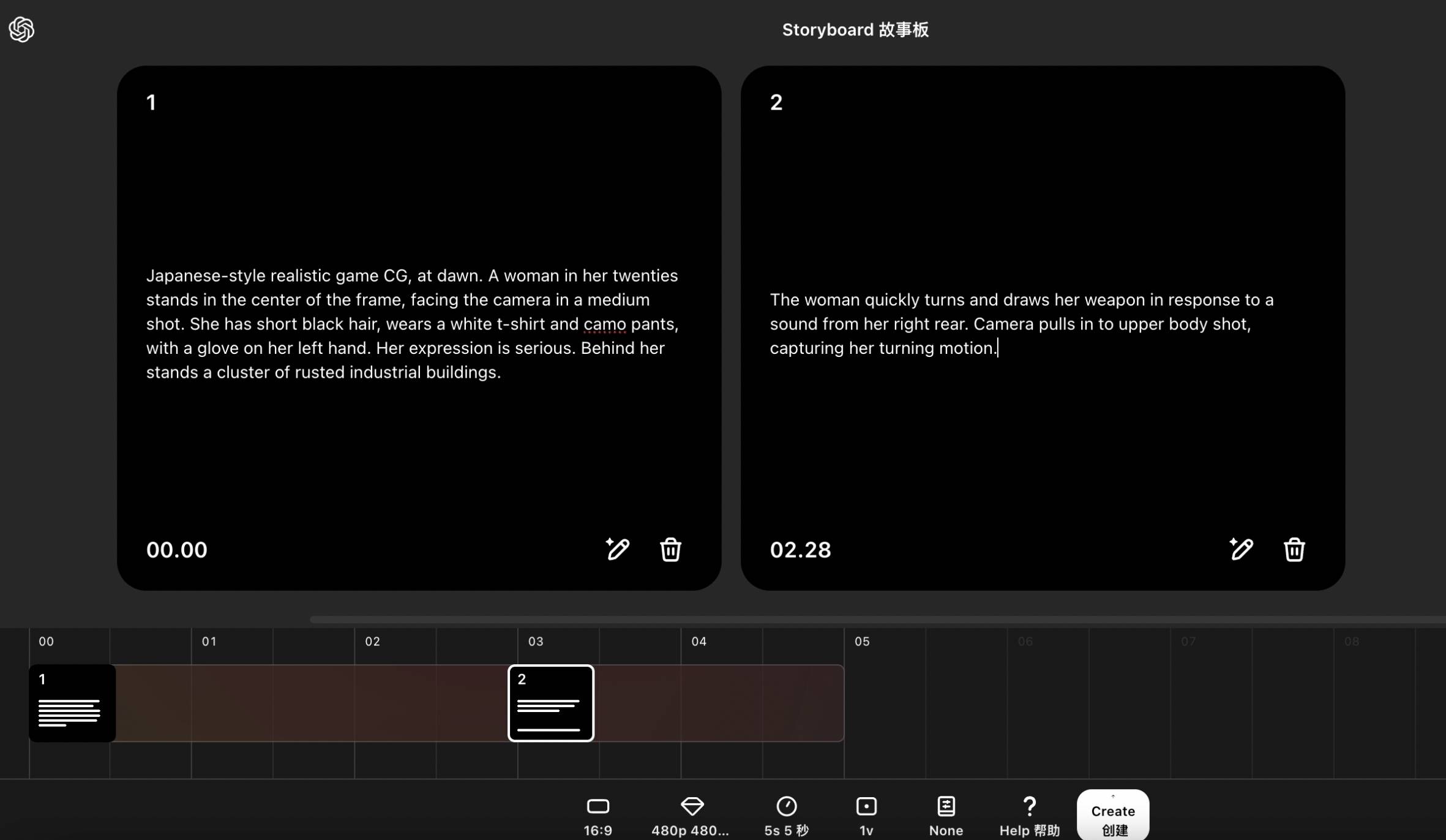
我本想让 AI 模仿游戏 CG 的效果,主角迅速转身并拔枪,但最终,得到了一个表情呆滞的机器人。

▲Sora 生成
只在故事板放上一张图也可以,这样 Sora 会自动生成提示词,建议你这张图片怎么动。
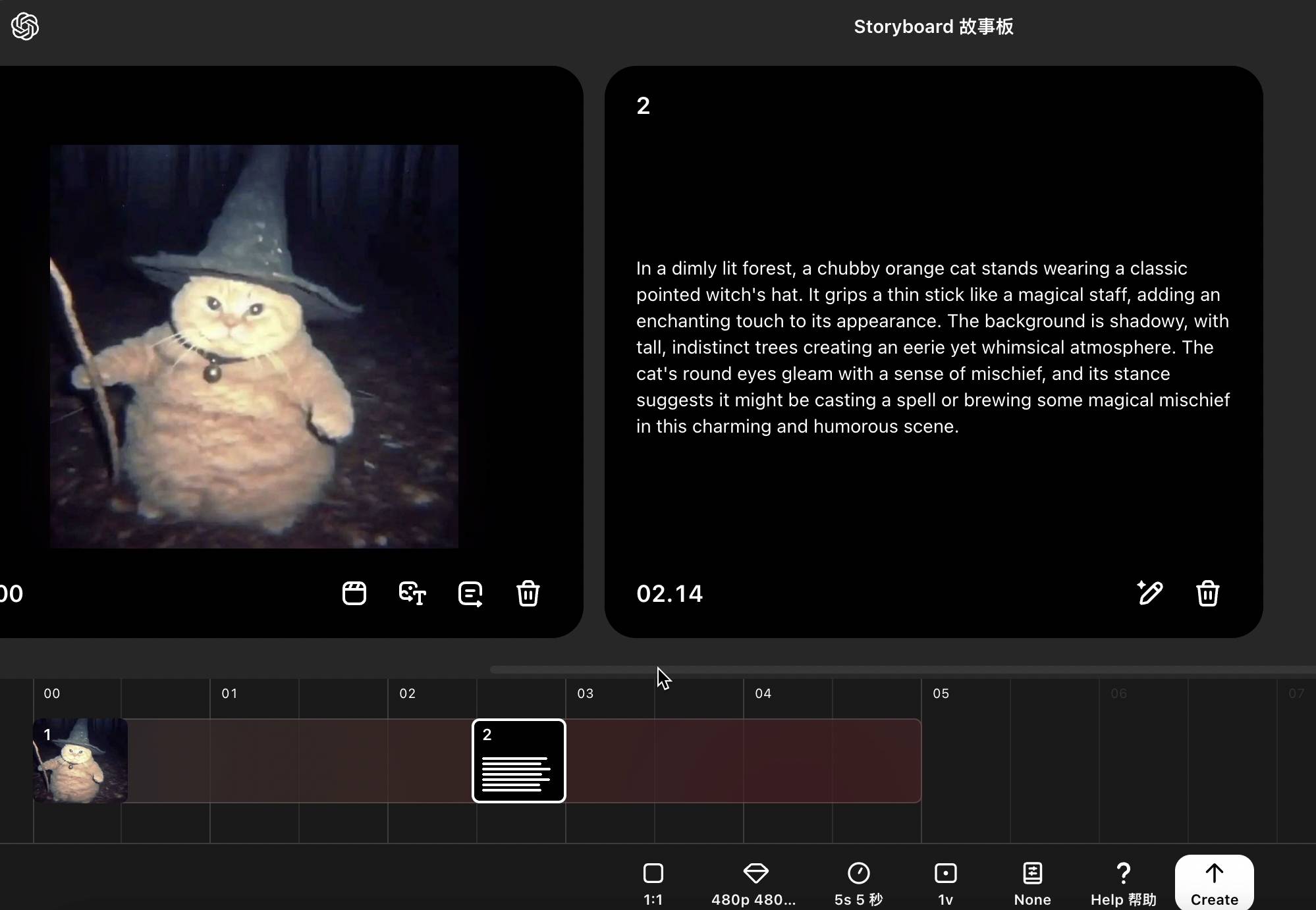
于是,巫师猫终于可以动起来了。原来,图生视频的短板,是要在这里弥补啊。然而,效果也很难绷,有时候会生成一些多余的东西。

▲Sora 生成
另外,Sora 的 Remix(重绘)功能也很好玩,我们可以用自然语言编辑视频,改变视频中的元素,进行「二创」。
既可以用自己的视频,也可以在 Sora 的社区里借用他人的视频。
▲ 图片来自:Sora 社区@bpyser1
比如,我们可以把跳舞的真·纸片人换成男团,同时,把场景换成练习室。
纸人的动作和服饰都大致保留了,但人物的四肢还是不能细看。

▲Sora 生成
更好玩的来了,我们可以接着用 Blend(混合)功能,将两个视频合并成一个,Sora 会自动处理视频之间的过渡效果。
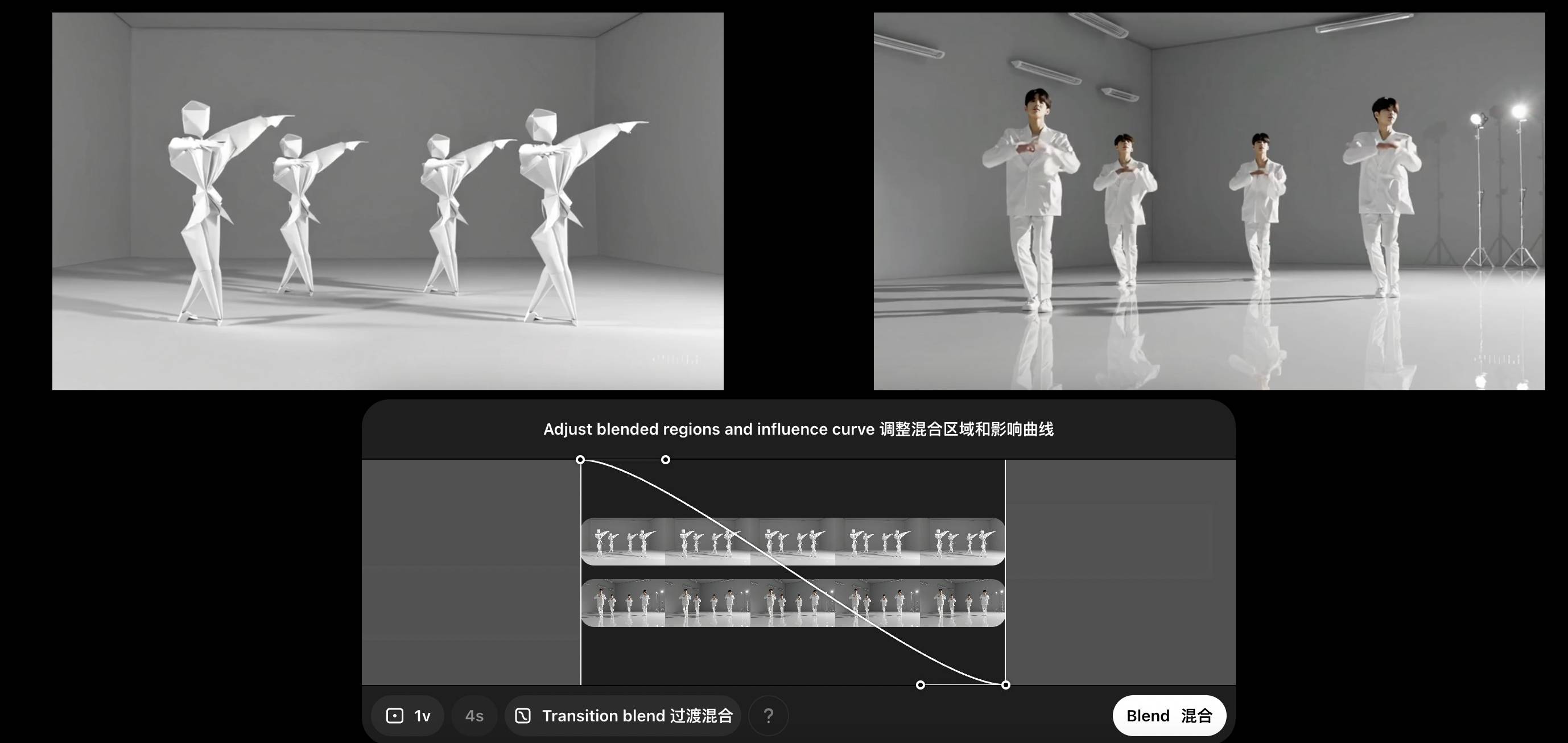
原来以为,可以出来一个丝滑的 MV 片段,毕竟这两个视频都这么相似了,但 AI 还是给了我惊喜,开头和结尾都很正常,中间的场面一度很混乱,你们到底几个人啊?

▲Sora 生成
总之,不追求出片率的话,Sora 很好玩,产品形态也很有意思,提供了一个全新的工作流,创新是有的,功能也是比较完整的。
但是,仅从目前来看,生成效果的进步空间较大,但给用户的探索次数又不足,20 美元只能浅尝辄止。有时候画面很漂亮,但运动处理得不好,也是白搭,「现实不存在了」还是一个遥远的梦想。
请欣赏,猫猫穿墙而过,原来在 AI 眼里,猫真的是液体。

▲Sora 生成,提示词:电影感十足的黑猫特写镜头,猫咪在故宫红色宫墙前优雅地跃起,画面以慢动作呈现,猫咪全身清晰可见,背景利用浅景深虚化处理,在跳跃最高点时金色的眼睛直视镜头。采用柔和的自然光线,传统的中式建筑墙面细节形成模糊的背景
Sora 的问题,其实也是很多 AI 视频产品的通病,没有真正靠谱的一刀流。模拟真实的世界?实现丝滑的运动?保持人物的一致?可以是可以,但有概率,抽卡和后期必不可少。
现在我们看的是肉眼可见的生成效果,而 AI 视频们集体改变的,是创作的方式。未来虽然可期,但是,Sora 请先把模型升级了吧。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。