《黑神话:悟空》无缘年度最佳,游戏奥斯卡被骂上热搜
又是一年 TGA,又是一年游戏界的奥斯卡,而奥斯卡本身就充满戏剧性。
今年依旧是惊喜、兴奋、遗憾和疑惑并存的游戏奖,而所有获奖游戏中,有两个作品备受关注和讨论。

年度游戏颁给了「宇宙机器人」,一款许多玩家都没听过的冒险游戏,引起了全球玩家的激烈讨论,有人认为合情合理,有人觉得天理难容,而只有坐在台下的任天堂,好像才是最受伤害的一个。
村里第一个大学生不负众望——「黑神话:悟空」突破历史拿下两项大奖,出发即是巅峰,这条国产 3A 游戏的取经路,也算是迎来了开门红,特别是第二个奖项,更能证明「黑猴」的含金量,以及全球范围内的影响。
年度最佳游戏——宇宙机器人
拿下最重大奖项——2024 年度最佳游戏的「宇宙机器人」,同时还拿下了最佳游戏指导和最佳动作冒险游戏的奖项。
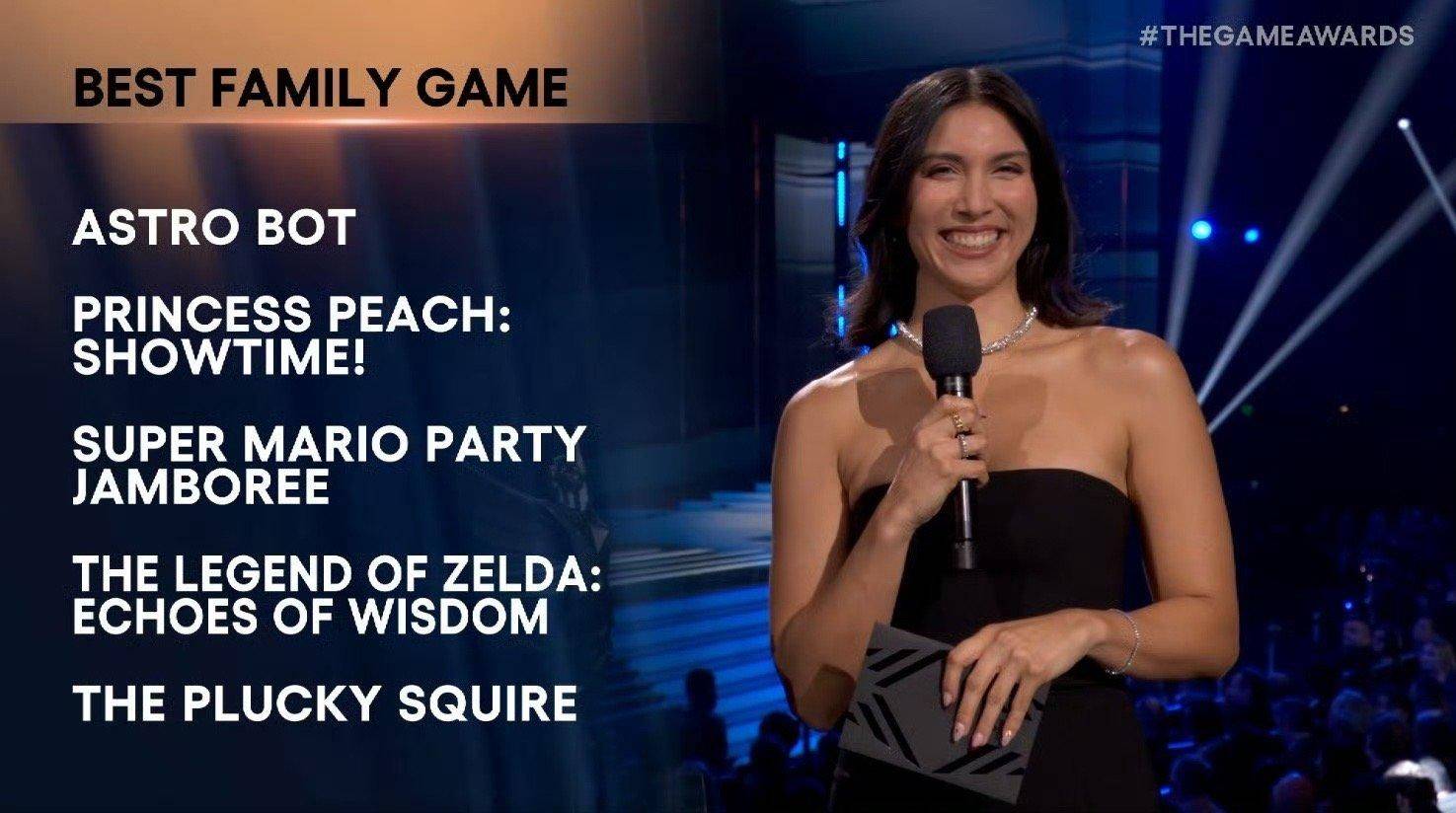
开始介绍前,先问问屏幕前的你,「宇宙机器人」得奖是否在你的意料之内?
(投票)
宇宙机器人是一款由索尼发售的 PS5 独占动作游戏。剧情讲述的是一个叫做「Astro Bot」的小型机器人,和同伴们搭乘 PS5 造型的母舰时,遭遇了外星人的袭击,为了不让母舰的零件四散,以及避免同伴们分散在太空中,玩家需要通过闯关和完成各种任务,找回母舰零件以及失散的同伴。

因为游戏本身以「宇宙」为场景,因此所有关卡也都设置在了各种星球当中,通过用机器人自身的能力和装备,来完成各种挑战。
「宇宙机器人」有两个最大的特点,一是上手门槛很低,大部分人都能快速熟悉各种操作,学习成本低,因此也能很快地融入游戏以及剧情。
而且游戏中的许多操作,都有比较高的容错率,不会在一开始就打击新手玩家的兴趣和自信心。

再来,可能游戏本就和 PS5 强相关,所以在游戏中的任何一个小操作——位移、跳跃、打击——都会通过非常细腻的震动来模拟各种触觉,给玩家带来较为真实的游戏体验。
比如踩油门、拉弓射箭、按下扳机,甚至拉拉链等细微的操作,都会有相应的手柄反馈,因此在之前的评测中也会有玩家称:
这是将 DualSense 手柄功能运用得最好的游戏。

上台领奖时,「宇宙机器人」的导演 Nicolas Doucet 还在获奖感言中,说了这么一段话:
最后但同样非常重要的一点,我原本不打算说,但我必须说出来,你们都了解平台游戏,也了解 PlayStation 已经有 30 年的历史了。我们这次制作了一款优秀的平台游戏,兼具了怀旧和新鲜的体验感。
记得 1989 年的圣诞节时,我还是个孩子,当时我得到了一个灰色的礼盒,里面装着一款让人惊艳的游戏,叫做「超级马力欧兄弟」。我们在东京,他们在京都。但我想向那家真正推动平台游戏发展,展示创新并始终保持高质量的公司致以敬意,他们激励我们创作了这款游戏。
你或许有注意到,我一直都没有提到他们是谁,但你们定都知道!
比起没有被多数人听过的夺魁游戏,可能国内玩家最关心的,还是自家的孩子表现如何。
争气!雄起!
锣鼓喧天、鞭炮齐鸣!「黑神话:悟空」成功拿下 2024 TGA 的「最佳动作游戏奖」和「玩家之声」,实现了国产游戏在全球游戏舞台上的一次历史性突破。

特别是拿下「玩家之声」,更证明了「黑猴」含金量,TGA 的评选更偏传统的「学院派」,参考的大多数都是业内人士以及游戏媒体,而玩家之声完全由玩家投票选出,以表彰那些在玩家群体中广受欢迎并获得高度评价的游戏。
通常反映出过去一年游戏界中最受玩家喜爱的作品。

从黑神话自上线发售后来看,获得了游戏市场和全球游戏玩家的一致好评,上线不到四个月销量就已经突破了 2200 万份,销售额接近 80 亿元人民币,各大游戏平台的评分超过百万条。
虽说游玩主力军还是国内玩家,但「黑猴」目前的海外销量占比已经达到了 25%,作为中国真正意义上的第一款 3A 游戏,能达到这样的玩家影响力和海外影响力,实属不易。

一个爆款游戏想要吸引更多玩家群体,其中一种最简单的方式是把关卡、操作变简单,难度可自主选择,让绝大部分人都能在作品里找到体验感,但「黑猴」并没有选择捷径,而是走了「最 3A」的方式,发售将近一个月后,玩家通过率仅有 30%,就是在这样的难度下,游戏依然收到了好评如潮。
更重要的是,和「黑猴」同场竞技最佳动作游戏的,也并非新星,「使命召唤:黑色行动 6」「绝地潜兵 2」「战锤40K:星际战士2 」,高手如林的擂台上,更能展现出获奖者的实力。
希望从这一刻起,「黑神话:悟空」真的能成为多少玩家期盼已久的开始,游戏科学也能续写「黑神话」的神话,而属于国产 3A 游戏的取经路,也才刚刚启程。

除了以上两部备受关注的作品外,今年的榜单上,遇见了一些新面孔,也看见了很多大惊喜。
2024 TGA 获奖名单
最佳独立游戏:「小丑牌」
最佳手游:「小丑牌」
最佳RPG:「暗喻幻想」
最佳美术指导:「暗喻幻想」
最佳叙事:「暗喻幻想」
最佳配乐:「最终幻想7:重生」
最佳音效:「地狱之刃2」
玩家之声:「黑神话悟空」
最佳家庭游戏:「宇宙机器人」
最佳格斗游戏:「铁拳8」
最佳模拟策略游戏:「冰汽时代2」
最佳体育竞速游戏:「EA SPORTS FC25」
最佳持续运营:「地狱潜者2」
最佳独立游戏出道作:「小丑牌」
最佳VR/AR游戏:「蝙蝠侠:阿卡姆之影」
最具影响力游戏:「Neva」
最佳无障碍创新:「波斯王子 失落王冠」
最佳改编:「辐射」
最受期待游戏:「GTA6」
最佳表演:Melina Juergens 「地狱之刃2:塞纳的史诗」
电竞类奖项:
最佳电竞游戏:「英雄联盟」
最佳电竞人物:Faker
最佳电竞队伍:T1
其实今年 TGA 更让人期待的,是即将在 25 年上线的新游戏,并且有很多都是大家期待已久的续作。
「巫师」系列新作「巫师 4」正式在晚会上公开,这是「巫师 3:狂猎」的正统续作,由「赛博朋克 2077」和「巫师 3」的开发者 CD PROJEKT RED 打造。

「胡闹厨房」团队的新作「怪镇奇旅」亮相,这仍是一款双人冒险类的合作游戏。

还有「双人成行」团队的新作也会在明年上架,雾影工作室正式官宣双人合作游戏「幻裂奇境」,采用双女主设定。

经典游戏 IP「忍者龙剑传」将以全新 2D 横版动作形式回归,新作品名称已敲定,叫做「忍者龙剑传:狂暴之境」。

以及艾尔登法环系列新作、杀戮尖塔 2、潜水员戴夫新 DLC 等等大火的 IP 和游戏,都将在明年陆续和我们见面,期待明年有更多好玩儿的精品,也期待在明年的 TGA 上能看到更多惊喜。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。





















































 点击图片跳转到播放页面
点击图片跳转到播放页面




























































