Last Week on My Mac: School of Athens or Blinded Samson?
I wonder whether we’ll look back at 2024 as the year that Apple Intelligence came to our Macs and devices?
While there are plenty of nay-sayers, and those who still accuse Apple of falling behind, there can be few who aren’t aware of what’s available to those who have bought a recent Mac or one of the higher-end iPhones or iPads. Since Apple’s attempt to hijack the established abbreviation AI at WWDC last summer, we have heard little else. There can have been few minor updates that were sold as heavily as the autumn’s x.1 and x.2 releases for their lavishly preannounced new features.
We’ve been beta-testing some of those features for as long as we’re normally allowed for a whole major release of macOS. Over that period, the number of users who have switched to English (US) as their primary language must have been substantial. It’s the first time I have kept one of my Macs running beta-releases long after the annual macOS upgrade, and I only reverted when 15.2 was released with AI support for English (UK).

Although these AI features have their uses, and for many should prove quietly revolutionary, I’m not convinced that they transform our Macs or devices into anything even remotely intelligent, and a far cry from the great thinkers in Raphael’s masterpiece The School of Athens. The central figures here are Plato (left), who carries in his left hand a book titled TIMEO (I am afraid), and Aristotle (right), whose book bears the word ETICA (ethics). Seen further to the left in profile is Socrates, and below him is Pythagoras writing in a book while a boy holds in front of him a small blackboard showing the theory of harmony.
Contrast that hullabaloo about AI with Apple’s complete silence on security, specifically the changes brought in its front-line malware detection feature XProtect in macOS Sequoia, since its release on 16 September. Prior to that, XProtect’s data bundle, including its Yara file of detection signatures for malicious software, had been maintained by the general macOS update service through softwareupdated. The diagram below outlines this long-established process.

When Sequoia 15.0 was released, that changed to what has turned out to be an intermediate invoking both the old mechanism and the new.

For the first couple of weeks of that, XProtect updates were chaotic:
- 13 Sep (approx) Software Update Service stopped providing regular XProtect updates
- 13 Sep (approx) XProtect version 5273 available from Software Update Service for Sequoia only
- 16 Sep macOS 15.0 released, with version 5273 available from Software Update Service for Sequoia only; upgraded Macs updated to 5273 by copying from secondary to primary locations; 5273 not provided from iCloud, where 5272 remained the current version
- 18 Sep Software Update Service resumed delivery of 5272 to Sonoma and earlier
- 18 Sep Software Update Service started delivery of 5274 to Sonoma and earlier; 5273 no longer available for Sequoia, with 5272 still available from iCloud
- 24 Sep Software Update Service delivered 5275 for Sequoia; no change to Sonoma and earlier, and 5272 still available from iCloud.
Then, just as we were getting the hang of it, Sequoia 15.2 excised the old mechanism, as we discovered last week when Apple released the first update to XProtect since 15.2.

Throughout all of this, Apple has remained completely silent. What’s even more surprising is that in the last few days, Apple has updated its definitive guide to security for Macs and all its devices. Although not all localised English translations have yet been synced with its US or Canadian English versions, the account of XProtect now has a published date of 19 December 2024, but doesn’t mention September’s changes.
There are those who insist that none of this is our concern, we should just let Apple do whatever it deems appropriate, and we shouldn’t even know what version of XProtect’s data is installed, as macOS takes care of all that for us. However, the security of my Mac is very much my business. If I were to unwittingly install malware that stole sensitive information, those are my banking details at risk, not Apple’s. Should I suffer financial loss as a result, would Apple provide unlimited compensation?
Hardly. Read sections 8 and 9 of Apple’s licence for macOS Sequoia, and the onus is clearly placed on the user. Just to emphasise this, further down that licence, in the Apple Pay & Wallet Terms and Conditions, is the express statement: “You are solely responsible for maintaining the security of your Mac Computer, Supported Devices, your Apple Account, your Touch ID information, the passcode(s) to your device(s), and any other authentication credentials used in connection with the Services (collectively, your “Credentials”).” The next time someone says that you should leave the security of your Mac to Apple, remind them of that.
Apple also encourages us to take an active part in our Mac’s security protection, and provides us with tools for doing so. The description given in man xprotect is a good example: “xprotect is used to interact with XProtect. It is useful for administrators or users who want to manually invoke XProtect functionality.”
Information about XProtect updates is exposed in the GUI, in System Information, where each update including those delivered by both old and new mechanisms is listed, together with its version number. That in itself is puzzling, as recent entries incomprehensibly duplicate older XProtectPlistConfigData entries with newer XProtectCloudKitUpdates.
So if AI doesn’t bring us the School of Athens, what has macOS Sequoia achieved so far? For this second image I turn to Lovis Corinth’s first major painting after his near-fatal stroke just before Christmas in 1911, an autobiographical portrait expressing his frustrations, in The Blinded Samson from 1912.

Please don’t breathe a word of this over on Apple Support Communities, though, where it seems your Mac’s security should be like mediaeval religion, a matter of blind faith and the suppression of knowledge. It’s high time for a Renaissance, much more Enlightenment, and a modicum of Intelligence.





















 图标手动触发搜索
图标手动触发搜索
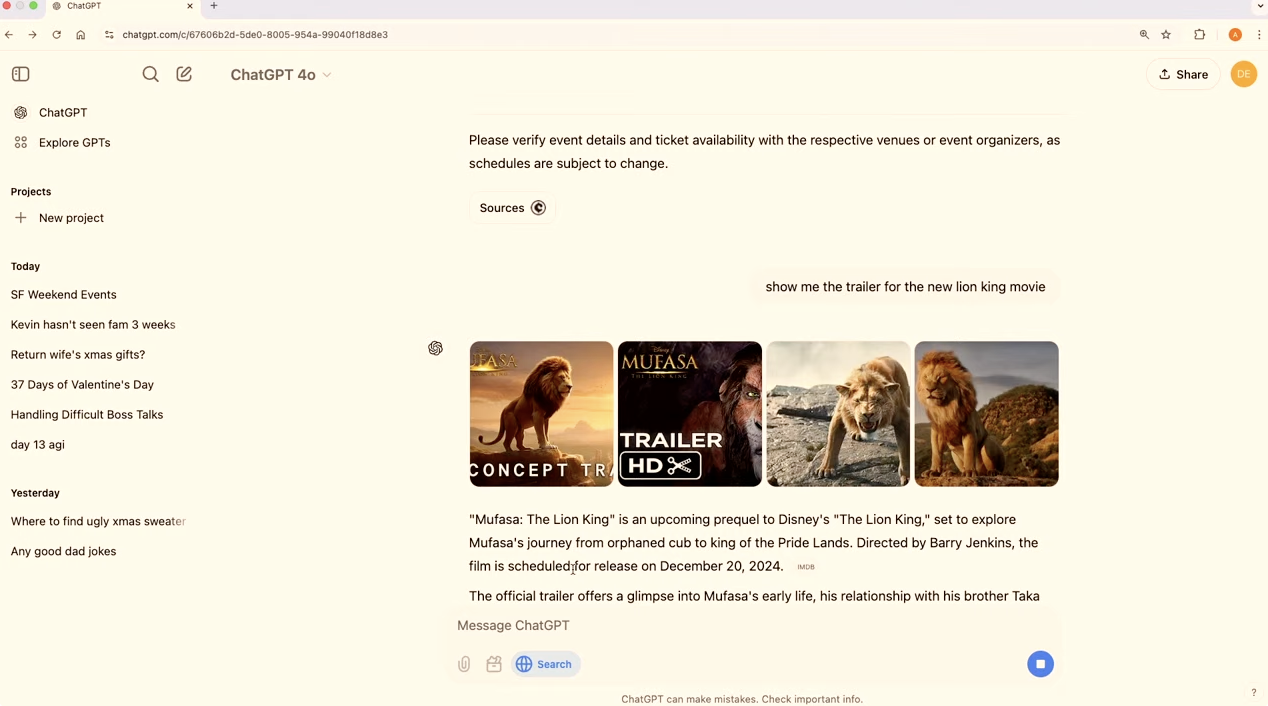































































































































")