Whether you’re a developer or user, gaining an understanding of how macOS manages the cores in an Apple silicon CPU is important. It explains what you will see in action when you open Activity Monitor, how your apps get to deliver optimal performance, and why you can’t speed up background tasks like Time Machine backups. In this series (links below) I’ve been trying to piece this together for the M4 family, and this article is my first attempt to summarise as much of the story as I know so far. I therefore welcome your comments, counter-arguments and improvements.
Scope
For the purposes of this article, I’ll consider a single thread that macOS is ready to load onto a CPU core for execution. For that to happen, five decisions are to be made:
which type of core, P or E,
which cluster to run it in,
which core within that cluster,
what frequency to run that cluster at,
the mobility of that thread between cores in the same cluster, and between clusters (when available).
Which type of core?
Since the early days of analysing M1 CPUs, it has been clear that the choice between P and E core types is made on the Quality of Service (QoS) assigned to the thread, availability of a core of that type, and whether the thread uses a co-processor such as the AMX. For the sake of generality and simplicity, I’ll here ignore the last of those, and consider only threads that are executed by the CPU alone.
QoS is primarily set by the process owning that thread, in the setting exposed to the programmer and user, although internally QoS is modulated by other factors including thermal environment. Threads assigned a QoS of 9 or less, designated Background, are allocated exclusively to E cores, while those with higher QoS of ‘user’ levels are preferentially allocated to P cores. When those are unavailable, they may be allocated to E cores instead.
This can be changed on the fly, reassigning higher QoS threads to run on E cores, but that’s not currently possible the other way around, so low QoS threads can’t be run on P cores. The sole exception to that is when run inside a virtual machine, when VM virtual cores are given high QoS, allowing low QoS threads within the VM to benefit from the speed of P cores.
Which cluster?
M4 Pro and Max variants have two clusters of P cores, so the next decision is which of those to run a higher QoS thread on:
if both clusters are shut down, one will be chosen and its frequency brought up;
if one cluster is already running and has sufficient idle residency (‘available residency’) to accommodate the thread, that will be chosen;
if one cluster already has full active residency, the other cluster will be chosen;
if both clusters already have full active residency, then the thread will be allocated to the E cluster instead.
This fills an active P cluster before allocating threads to the inactive one, and fills both P clusters before allocating a higher QoS thread to the E cluster.
Cluster allocation is of course simpler on the base M4, where there’s only one E and one P cluster. Should Apple make an M4 Ultra as expected, then that would not only have four P clusters, but two E clusters. Until that happens, we can only speculate that similar would then apply, including the E clusters.
Which core within the cluster?
This is perhaps the simplest decision to make. If there’s only one core with available residency in that cluster, that’s the only choice. Otherwise macOS picks an arbitrary core from those available, apparently to ensure roughly even use of cores within each cluster.
What frequency?
For the E cluster, choice of frequency appears straightforward, with low QoS threads being run at minimum E core frequency of 1,020 MHz or slightly higher, and higher QoS threads spilt over from fully occupied P clusters are run at E core maximum frequency of 2,592 MHz.
P cluster frequency appears to be determined by the total active residency of that cluster after the new thread has been added. When that’s the only thread running in that cluster, maximum frequency of 4,512 MHz is chosen, but rising total active residency reduces that in steps down to about 3,852 MHz when all the cores in the cluster are at 100% active residency. In most cases, the big reduction in frequency occurs when going from about 200% to 300% total active residency. This currently appears to be part of a strategy to pre-emptively minimise the risk of thermal stress within the chip.
Thread mobility
Once the thread has been loaded into a core in the optimal cluster running at the chosen frequency, it’s likely to be moved periodically, both to any other free core within that cluster, and to another cluster, when available. While this does occur in previous M-series CPUs, it appears particularly prominent in M4 variants.
Movement of threads within a cluster can occur quite frequently, every 0.1 second or so, particularly within the E cluster. Movement between clusters occurs less frequently, about every 4-5 seconds, and would only occur when the other cluster is shut down or idle, so free to run all the threads of the current cluster. This is most probably to ensure even thermal conditions within the chip.
Summary
The whole strategy is shown in the following diagram, also available as a tear-out PDF from here: m4coremanagement1
Residency is the percentage of time a core is in a specific state. Idle residency is thus the percentage of time that core is idle and not processing instructions. Active residency is the percentage of time it isn’t idle, but is actively processing instructions. Down residency is the percentage of time the core is shut down. All these are independent of the core’s frequency or clock speed.
When Apple launched its first M4 Macs just over a month ago, I was surprised that models with M4 Pro or Max chips offered Thunderbolt 5. Although there are still relatively few computers in use with support for TB5, and a dearth of peripherals, this article summarises early experience with this exotic new bus.
What TB5 peripherals are available?
As far as I’m aware, as of today there’s only one Thunderbolt 5 peripheral shipping in quantity, the Kensington SD5000T5 Thunderbolt 5 Triple Docking Station, with a total of three downstream TB5 ports. I’m just completing a full review of this, due to appear in MacFormat and MacLife magazines early next year.
SSDs have been announced by OWC in its Envoy Ultra, and Sabrent. The first of OWC’s have apparently started to ship, although they aren’t expected to become readily available until the New Year, when Sabrent’s are also expected.
OWC has also announced a TB5 hub, but that’s unlikely to appear until next year.
Several PCs are now available with TB5 support, although that seems to be fiddly to configure in Windows. Among those is the Razer Blade 18, which is even more expensive than a MacBook Pro with an M4 Max.
Other than those, there are lots of expensive TB5 cables, just precious little to connect to the other end.
Multiple displays
Many of those rushing to buy into TB5 are doing so because of its promised support for multiple displays. For example, the Kensington dock claims to support up to three 6K displays at 60 Hz with the M4 Max, and two with the M4 Pro. Although I have been unable to test those combinations, there are already reports that the M4 Max works well with three displays connected direct, but only two of those work when using the Kensington dock.
This has apparently taken Kensington and Apple by surprise, but until this has been addressed, I wouldn’t assume that you’ll be able to use all three displays attached to the dock.
Multiple SSDs
In early 2023, when TB4 hubs were becoming available, I wrote a whole series of articles here analysing their performance with a range of different SSDs. Links to those are given at the end. Those predated OWC’s superb Express 1M2 USB4 enclosure that now offers consistent and reliable performance for Apple silicon Macs, but not Intel models, which unfortunately lack support for USB4.
I have recently been revisiting SSD performance, both directly connected to my Mac mini M4 Pro, and working through the Kensington dock. Although some results are impressive, there are others that shock.
As shown in System Information, this dock connects to the host at 80 Gb/s, and to each USB4 drive at the expected 40 Gb/s.
On the bright side, 1M2 enclosures that return direct read/write speeds of 3.7/3.7 GB/s read almost as fast when attached through the dock, but their write speed drops to 2.3 GB/s, similar to many TB3 SSDs attached directly. You can even connect a USB4 drive to each of the dock’s three TB5 ports to benchmark them simultaneously, and get read/write results of 2.1/2.1 GB/s on each of them. That performance represents the maximum total data transfer capacity, matching claims of 6 GB/s made of TB5 SSDs, and equating to 80 Gb/s in TB5/USB4v2 symmetric mode.
Results from TB3 SSDs are more worrying. An award-winning certified Thunderbolt 3 SSD that achieves 2.9/2.2 GB/s read/write attached direct maintained a good read speed through the dock at 2.8 GB/s, but it almost ground to a halt during the write test, at 422 MB/s, that’s roughly the speed you’d expect from a basic SATA SSD.
You can read similar experiences during early testing of this dock for PC World.
For the time being, TB5 performs well with USB4 and directly connected TB3 SSDs, and the dock is a good solution for those wanting high-speed access to two or three USB4 SSDs in OWC Express 1M2 enclosures. The dock does have serious problems when writing to TB3 SSDs, though, where it may fall far short of expectations. Hopefully these problems will be resolved early next year.
Recommendations
Although TB5 promises much, initial tests show that it currently has problems meeting that.
Reports indicate that it may not yet support M4 Max chips driving three 6K displays at 60 Hz from a TB5 dock.
Performance claimed for TB5 SSDs has not yet been confirmed in independent tests.
Performance of TB3 SSDs attached to a TB5 dock demonstrates some very poor write speeds.
Performance of USB4 SSDs attached to a TB5 dock demonstrates better and more consistent results, although their write speed also falls.
TB5 cables and peripherals are expensive.
Thunderbolt 5 is still at an experimental stage, and may take some time before it realises its potential.
When using the ‘gold standard’ method of testing storage using my free Stibium, you don’t normally need to restart the Mac between write and read speed measurements. This has changed with the Mac mini M4 Pro, at least. If you go straight on to measure read speeds, results will be bogus because of what appears to be extensive caching of the files written during the previous write test. That results in absurdly high read speeds of more than 6 GB/s in most cases. This is surprising, as a total of just over 53 GB of files are written during the full write test, which seems far more than macOS should ever cache successfully!
For these tests on external SSDs, I therefore quit Stibium after measuring write speed, unmount the volume tested, remount it in Disk Utility, and open Stibium again to perform the read tests. This apparently clears caches reliably, and read speeds are consistent and in accord with those expected.
Interests
I bought my own Mac mini M4 Pro, Kensington SD5000T5 Thunderbolt 5 Triple Docking Station, and all the OWC Express 1M2 enclosures and their SSDs, at their regular retail prices. The only product tested here that has been provided by a manufacturer is, rather sadly, the TB3 SSD.
To realise best performance and energy efficiency from the big.LITTLE architecture in Apple’s M-series chips requires careful management on the part of macOS. There’s much more to it than balancing loads over conventional multi-core CPUs with a single type of core, as each execution thread needs to be run in an optimal location. When deciding where to run a CPU thread, macOS controls:
which type of core, P or E, primarily determined by the thread’s Quality of Service (QoS), and core availability;
which cluster to run it in, for chips with more than one cluster of that type, set to try to keep as few clusters active as necessary;
which core within that cluster, determined by core availability, and semi-randomised to even out core use;
what frequency to run that cluster at, in turn depending on the core type and the thread’s QoS;
mobility of that thread between cores in the same cluster, and between clusters (when available).
Over the last four years, I have explored the rules apparently used for the first two, and the choice of frequency in E cores. This article looks in more detail at how the frequency of P clusters appears to be determined in M1, M3 and particularly M4 chips.
powermetrics provides more frequency figures than you know what to do with, although most are derived and to some extent imaginary, making reconciliation difficult. In tests reported in the previous article, I used those given as Cluster HW active frequency to demonstrate distinctive patterns seen on M4 P cores running different numbers of test threads.
This graph shows those frequencies for the active P cluster by the number of threads, for floating point, NEON and vDSP_mmul tests detailed previously. Frequencies for the first two tests are identical, at P core maximum for a single thread, then falling sharply from 2 to 3 threads. When more threads are run, a cluster that’s fully active is run at the same frequency as that for 5 threads (P cluster size on this M4 Pro), while the other P cluster follows the same frequencies shown in the graph for the number of threads it’s running.
To examine this further I first climbed a mountain.
Climbing a mountain
For this test I used three copies of my test app to run a total of three identical threads of my in-core floating point test code in a mountain pattern. I first started powermetrics gathering data, then launched the first thread, followed by the second, and then the third. My objective was to observe an initial period when just one test thread was running, a second with the second test thread in addition, a third when all three threads would be running, and then watch the sequence reverse as each thread ended. This is shown in the results below.
This chart shows active residencies by core and cluster for the P cores in an M4 Pro, with 5 P cores in each of its two P clusters, during this test. For the first 15 sample periods (1.5 seconds), a single test thread is moved around between cores in the second P cluster (P1). That’s joined by the second thread run on another core in the same cluster, until sample 30, when the third thread is added, pushing the total active residency to 300%.
At that point, all three threads are moved to three cores in the first P cluster (P0), whose bars are shown in blues and green. The first thread completes in sample 37, leaving two threads with 200% active residency to continue in that cluster until sample 50, when the second thread completes, leaving just one running. In sample 54 (5.4 seconds after test start), that one remaining thread is moved back to complete on core P11 in the second cluster late in sample 63.
In that period of 6.3 seconds, each of the two P clusters has run 1, 2 and 3 threads.
This graph shows cluster frequencies over the same period, this time given in seconds elapsed rather than sample number. The red line and points show the frequency of cluster P1, and blue for P0. Those undergo step changes when each cluster is running test threads. The inactive cluster is normally shut down with a frequency of 0 MHz, although there are some brief spikes from that as well.
Combining active residency bars in yellow with core frequency lines, it’s clear that cluster frequency is close to core maximum at 4,500 MHz when only a single thread is running. With two threads, it’s reduced to 4,400 MHz, and down to 3,900 MHz when all three threads are running. Those changes are symmetrical for loading and unloading clusters, and shown no signs of hysteresis (different values during loading and unloading).
Closer examination gives frequencies of 4,511 MHz at 100% active residency, 4,415 MHz at 200%, and 3,924 MHz at 300%e. The latter is 87% of maximum frequency, a large enough reduction to be reflected in performance. Essentially identical figures are found for NEON tests as well as these for floating point.
Although this test method can give highly reproducible results, the floating point and NEON tests used don’t resemble threads seen in everyday use. The next step is to extend that by looking at thread numbers and frequency when running more normal code.
Compressing a file
Fortunately, I have already built a suitable platform for real-world testing in a one-trick pony named Cormorant, a basic compression-decompression utility using Apple Archive. Although not a patch on serious apps like Keka, Cormorant can set the number and QoS of threads to be run during compression/decompression. Because it relies on Apple’s framework, it actually runs more than just the threads set in its controls, but still provides a way to control active residency. I therefore ran a test compression (15.5 GB IPSW image file) at maximum QoS to ensure it’s dispatched to P cores, and 1-3 threads.
Time taken to compress the test file changes greatly according to the number of threads used:
1 thread takes 49.6 s, at 313 MB/s;
2 threads takes 26.8 s, at 578 MB/s, 191% of the throughput of the single thread;
3 threads takes 18.7 s, at 829 MB/s, 265% of the single thread.
These appear to follow the pattern of frequencies observed on my in-core tests.
This chart shows the opening 3 seconds of single-thread compression, with cluster frequency in the points and line, and total active residency multiplied by 10 (to scale to a common y axis) in pale blue bars. Two significant periods are shown: in samples 12-21, active residency is high, between 300-430%, and frequency is lower at around 4,000 MHz. Following that, active residency falls to about 200% and frequency rises to 4,200 MHz.
Because active residency was so variable in these tests, I pooled paired values for that and cluster frequency, gathered over 3 second periods, and plotted those.
Although at active residencies below about 180% there’s a wide scatter, above that there’s a good linear regression, showing steady decline in frequency over active residencies ranging from 180% to 450%.
The following two graphs show equivalents for tests using 2 and 3 threads. The first of those has two outliers at total active residencies above 490%, corresponding to unusual conditions during the test. I have therefore excluded those from subsequent analyses.
The last step is to pool paired results from all three test conditions, and arrive at a line of best fit.
Between total cluster residencies of 150-500%, this works best with a quadratic curve with the equation F = 4630.05 – (2.0899 x R) + (0.0010107 x R^2)
from which a different relationship is predicted between F, frequency in MHz, and R, total active residency in %.
My other real-world test makes use of the fact that, when virtualising macOS, the number of virtual cores on the host is specified.
Hosting virtual cores
Although virtualisation relies on frameworks run on the host, experience is that its demand on host P cores is constrained to the number of virtual cores allocated, with each of those resulting in 100% active residency, equating to the whole of a P core on the host. powermetrics started collecting sample periods immediately before a macOS 14 VM was launched, and the first 3 seconds (30 samples) were collected and analysed for VMs with 1-3 virtual cores.
This shows the first of those, a VM allocated just a single virtual core, with cluster frequencies shown as red and blue lines, and total active residency multiplied by 10 in the pale blue bars. With a steady total active residency of 100%, active cluster frequency was about 4,500 MHz. Note that sample 7 included transfer of the threads from P1 to P0 in a sharp peak to a total active residency of over 500%.
Average frequencies can thus be calculated for each of the three tests, at 100-300% active residencies.
Set frequencies
I now have estimates of cluster frequencies for cluster total active residencies from:
in-core tests using floating point
in-core tests using NEON
compression
virtualisation
against which I compare a matrix multiplication test that may be run on shared matrix co-processors (AMX). These are shown in the table below.
Running a single thread in a cluster should result in a total active residency of 100%, for which macOS sets the cluster frequency at P core maximum, of 4,400-4,511 MHz. That for 200% is lower, at between 4,000-4,400 MHz, and falls off further to about 3,800 when all 5 cores are at 100% active residency. Frequencies set for the vDSP_mmul test are significantly lower throughout, supporting the proposal that test isn’t being run conventionally in P cores, but in a co-processor.
A sixth thread would then be loaded onto the other P cluster, where cluster frequency would be set at P core maximum again, progressively reducing with additional threads until that cluster was also running at about 3,800 MHz.
Following this, I returned to the tests I have performed over the last four years on M1 and M3 P cores. Although I haven’t analysed those formally, I now believe that their frequencies are controlled by macOS as follows:
M3 1 core at 3,624 MHz (below maximum of 4,056), 2-6 cores 3,576 MHz.
The range of frequencies in the M1 and M3 is narrower, resulting in less difference in performance between single- and multi-core tests. However, the M4 falls to 87% maximum frequency at 3 threads and more, which is substantial. It’s worth noting that Geekbench single-core results for the M4 are around 3,892 and would scale up to a multi-core result of 38,920 on an M4 Pro with 10 P cores, whereas the actual multi-core score is about 22,700, 58% of the scaled value. Although the effects of lower frequency can’t account for all that difference, they must surely contribute to it.
Why?
Two plausible contenders for the reason that macOS reduces P cluster frequency with increasing active residency are for thermal management, hence reliability, and when competing for a limited resource, perhaps the L2 cache shared within each cluster.
Reductions in cluster frequency seen here isn’t thermal throttling, though. Tests were intentionally kept brief in order to accommodate their results in reasonably short series of powermetrics results. Power use was highest in the NEON and vDSP_mmul tests, and lowest in floating point, although there don’t appear to be matching differences in frequency control. As noted in the previous tests, High Power mode didn’t alter frequency control, although frequencies were reduced in Low Power mode.
It’s most likely that this frequency regulation is pre-emptive, and based not just on CPU cores, but allows for likely heat output in the rest of the Mac.
Key information
When running on Apple silicon Macs, macOS modulates ‘cluster HW active frequency’ of P cores, limiting frequency to below maximum when cluster total active residency exceeds 100%.
Although small in M1 variants, this is most prominent in M4 variants, where a total active residency of 300% may reduce cluster frequency to 87% of maximum.
Frequency limitation is most probably part of a pre-emptive strategy in thermal management.
Frequency limitation is at least partly responsible for non-linear changes in performance with increasing recruitment of P cores, as illustrated in single- and multi-core benchmarks.
Control of P cores by macOS is complex, particularly in M4 variants.
Residency is the percentage of time a core is in a specific state. Idle residency is thus the percentage of time that core is idle and not processing instructions. Active residency is the percentage of time it isn’t idle, but is actively processing instructions. Down residency is the percentage of time the core is shut down. All these are independent of the core’s frequency or clock speed.
Acknowledgements
Several of you have contributed to discussions here, but Maynard Handley has for several years provided sage advice, challenging discussion, and his personal mine of information. Thank you all.
For much of the last four years, CPU and GPU core performance have been of primary importance to those using Apple silicon Macs. Despite that, special interest has developed in those cores that Apple doesn’t talk about, in its matrix co-processor, AMX. Since the first M1 it has been believed that each CPU core cluster has its own AMX, and more recently it has been shown to be capable of impressive performance. With the increasing prominence of computationally intensive features including AI, this is growing in importance.
When the M4 first became available in iPads earlier this year, researchers concluded its chip has a new AMX co-processor that can now be programmed using SME matrix extensions supported by the new version of the Arm instruction set in the M4, ARMv9.2-A. The best accounts of that challenging work are given on the Friedrich Schiller University’s site Hello SME, and Taras Zakharko’s GitHub.
From early work by Dougall Johnson on the M1, it has been known that some of the functions in Apple’s vast Accelerate maths libraries can run code on the AMX. Thanks to the guidance of Maynard Handley, a year ago I concluded that one of those is the vDSP_mmul function in the vDSP sub-library. This article reports tests of that function in a Mac mini M4 Pro running Sequoia 15.1.1, leads on to an explanation of previous results using floating point and NEON tests, and considers the effects of Power Modes.
Methods
I used the same methods as described previously. These consist of running many tight loops of test code designed to be confined as much as possible to register access. The test used here uses vDSP_mmul, multiplying two 16 x 16 32-bit floating point matrices, and consists of 15 x 10^6 such loops. Its source code is given in the Appendix at the end. During each test run, the command tool powermetrics gathers core power and performance data in sampling periods of 0.1 second for a total of 50 samples. Its output is piped into a text file, which is then analysed using Numbers and DataGraph.
For comparison, I also show here my results from equivalent tests using assembly code for the NEON vector processor, as given in that previous article.
Power used by thread
The first graphs show average power use during each test with increasing numbers of threads, where error bars indicate a spread of +1 standard deviation.
The linear relationship for 1-10 threads, run on 1-10 P cores, is a better fit for vDSP_mmul, shown above, than NEON below. Run on P cores, each vDSP_mmul thread used about 3.6 W, significantly greater than NEON at 3.0 W. However, when those high QoS threads spilt over onto E cores, that relationship for vDSP_mmul broke down, leaving the highest power use that for 10 threads, one for each P core available in the M4 Pro chip used.
There’s no evidence of the steps seen below in NEON at 2-3 and 7-8 threads.
Execution time
Total execution time has a strongly linear relationship too, for vDSP_mmul at about 2.6 seconds per thread. Again, that relationship broke down once test threads had spilt over onto E cores, unlike in the graph below for NEON.
There are also obvious differences in the time required to execute each thread. vDSP_mmul (above) showed a linear increase from 1-5 threads, followed by a constant time for 5-10 threads. Once threads were running on E cores, the relationship became far looser, as seen in the red regression line. In NEON below, the relationship was weakest in the 1-5 thread range, and closer on the E cores from 11-14 threads.
Energy use
When run on P cores, there’s a good line of fit indicating energy use of 9.2 J per thread (above), compared with NEON (below) at 7.7 J. The red line of best fit for the E core section from 11-14 cores suggests E core energy use of about 4.8 J per thread, again higher than NEON, which shows a much better fit and only about 3 J per thread.
Maximum total energy use estimated for vDSP_mmul was just over 140 J, while for NEON it was only about 90 J.
The overall picture of vDSP_mmul is thus different from those seen in floating point and NEON tests. When run on P cores alone, vDSP_mmul behaves more linearly, using significantly more power and energy. Once running threads on E cores, though, that breaks down and performance falls, rather than simply slowing.
The role of frequency
There has long been a tacit assumption that, when running on P cores, computationally intensive threads such as those used in these tests are run at a fairly constant frequency close to maximum. Looking back at my earlier results on M1 and M3 cores, though, frequencies aren’t so consistent, and in many cases not that close to maximum either.
powermetrics provides more frequency figures than you know what to do with, although most are derived and to some extent imaginary, making reconciliation difficult. Taking the best estimate of core frequency as that given as Cluster HW active frequency, patterns seen on M4 P cores are distinctive.
This graph shows those frequencies for the active P cluster by the number of threads, for floating point, NEON and vDSP_mmul tests. Frequencies for the first two are identical, at P core maximum for a single thread, then falling sharply from 2 to 3 threads. When more threads are run, the cluster that’s fully active is run at the same frequency as that for 5 threads (P cluster size on this M4 Pro), while the other P cluster follows the same frequencies shown in the graph for the number of threads it’s running.
Frequencies are controlled by macOS, and this suggests it adopts a standard pattern when running the two in-core tests, and a different one for vDSP_mmul presumably geared to performance of the AMX. Changes in frequency also account for the steps seen at 2-3 and 7-8 (= 5+2 and 5+3) threads in the NEON graphs above.
Power Modes
There has been considerable interest in the Power Mode setting available in macOS when running on M4 Pro and Max chips. To assess its effects I ran tests in 10 threads to fully occupy the P cores, at each of the three Power mdes.
There was no difference between results for the default Automatic and High Power modes, as expected. This is because the effect of High Power mode isn’t to change frequencies or power use in the short-term, but by more aggressive fan use enabling higher frequencies to be sustained for prolonged periods, when in Automatic mode they would be throttled.
Low Power does have substantial effects on core frequency, performance and power use, though. When running floating point tests in 10 threads, their cluster frequency was reduced from 3,852 to 3,624, 94% of Automatic and High Power. That reduced power use from a mean of 13.9 W to 11.2 W, and increased the time to complete threads. Time taken by floating point threads increased to 106% of Automatic and High, while that for NEON increased to 135% and vDSP_mmul to 177%. While the reduced performance for floating point threads is unlikely to be noticeable, for vector and matrix threads that’s likely to obvious to the user.
Key information
vDSP_mmul matrix multiplication from the vDSP sub-library in Accelerate behaves consistently with it being performed in the AMX co-processors in M4 Pro chips.
vDSP_mmul threads used significantly more power than NEON, reaching a maximum of just over 36 W when fully occupying all 10 P cores.
When spilt over to E cores, vDSP_mmul threads were much slower and their performance erratic, consistent with the E cluster having a smaller and significantly less performant AMX.
In-core tests (floating point and NEON) show common frequency regulation according to the number of cores active in each P core cluster. This runs a single thread at maximum frequency, then reduces sharply from 2 to 3 threads/cores. This accounts for the deviations from linearity observed in power use and performance. That pattern doesn’t appear in vDSP_mmul threads, though.
High Power and Automatic modes are identical in short-term tests.
Low Power mode reduces P cluster frequency and power use. Although its effects are unlikely to be noticeable in floating point threads, effects on vector and matrix threads are greater, and performance reductions are likely to be obvious to the user.
16 x 16 32-bit floating point matrix multiplication
var theCount: Float = 0.0
let A = [Float](repeating: 1.234, count: 256)
let IA: vDSP_Stride = 1
let B = [Float](repeating: 1.234, count: 256)
let IB: vDSP_Stride = 1
var C = [Float](repeating: 0.0, count: 256)
let IC: vDSP_Stride = 1
let M: vDSP_Length = 16
let N: vDSP_Length = 16
let P: vDSP_Length = 16
A.withUnsafeBufferPointer { Aptr in
B.withUnsafeBufferPointer { Bptr in
C.withUnsafeMutableBufferPointer { Cptr in
for _ in 1...theReps {
vDSP_mmul(Aptr.baseAddress!, IA, Bptr.baseAddress!, IB, Cptr.baseAddress!, IC, M, N, P)
theCount += 1
} } } }
return theCount
Apple describes vDSP_mmul() as performing “an out-of-place multiplication of two matrices; single precision.” “This function multiplies an M-by-P matrix A by a P-by-N matrix B and stores the results in an M-by-N matrix C.”
Few comparisons or benchmarks for M-series chips take into account the reason for equipping Apple silicon chips with more than one CPU core type, according to Arm’s big.LITTLE architecture. Measuring single- or multi-core performance ignores the purpose of E cores, and estimating overall power use can’t compare those core types. This article tries to estimate the cost in terms of power and energy of running identical tests on M4 P and E cores, and thereby provide insight into some of the most distinctive features of Apple silicon, and their benefits.
Methods
To run these two in-core performance tests I use a GUI app wrapped around a series of loading tests designed to enable the CPU core to execute that code as fast as possible, and with as few extraneous influences as possible. Both tests used here are written in assembly code, and aren’t intended to be purposeful in any way, nor to represent anything that real-world code might run. Those are:
64-bit floating point arithmetic, including an FMADD instruction to multiply and add, and FSUB, FDIV and FADD for subtraction, division and addition;
32-bit 4-lane dot-product vector arithmetic (NEON), including FMUL, two FADDP and a FADD instruction;
Source code of the loops is given in the Appendix.
The GUI app sets the number of loops to be performed, and the number of threads to be run. Each set of loops is then put into the same Grand Central Dispatch queue for execution, at a Quality of Service of the maximum of 33. That ensures they are run preferentially on P cores, but will spill over to E cores when no P core is available, when more than 10 threads are run concurrently. Timing of thread execution is performed using Mach Absolute Time, and the time for each thread to be executed is displayed at the end of the tests.
For these tests, the total number of loops to be executed in each thread was set at 5 x 10^8 for floating point, and 3.5 x 10^9 for NEON. Those values were chosen to take 2-3 seconds per thread, to ensure the whole test period was available for analysis.
Immediately before running each test, I launch powermetrics from the command line, to gather core power and performance data in sampling periods of 0.1 second for a total of 50 samples. Its output is piped into a text file, which is then analysed using Numbers and DataGraph. All tests were conducted on a Mac mini M4 Pro with 10 P and 4 E cores, running macOS 15.1.1 in standard power mode.
Each test was inspected individually, and seen to contain the following phases:
small initial activity resulting from bringing the GUI app into focus, and clicking the Run button;
a brief period of low activity, typically with total CPU power at below 50 mW;
1-2 sample periods when threads are loaded onto the cores;
15-21 sample periods when threads are run, whose total CPU power measurements are collected for analysis;
1-2 sample periods when threads are unloaded;
a return to low activity, typically with total CPU power returning below 50 mW.
Means and standard deviations were then calculated for each series of power measurements, and pooled with times taken to execute threads.
Power used by thread
The first pair of graphs shows average power use for the number of threads run, shown here with error bars giving the range of +1 standard deviation. These show two sections: for 1-10 threads, when all were running on P cores, and for 11-14 threads, when the 10 P cores were fully committed and 1-4 threads spilt over to run on E cores at their maximum frequency. Maximum power used during testing was just short of 34 W.
That for the floating point test above, and NEON below, have regression lines fitted, indicating that:
Each additional floating point thread required 1,300 mW on P cores, and 110 mW on E cores.
Each additional NEON thread required 3,000 mW on P cores, and 280 mW on E cores.
P cores thus required 11-12 times the power of E cores, or E cores used 8-9% of the power of P cores.
Although linear regressions aren’t a bad fit, there’s consistent deviation from the linear relationship seen in previous analyses on M1 and M3 cores. More remarkably, the pattern of deviation is identical between these two tests, although they run in different units in these cores. In both cases, power use was high for 2 and 7 threads, while that for 3 and 8 threads was slightly lower. The only unusual pattern seen in powermetrics output was that, when running 2 and 7 threads, thread mobility was much higher than in other tests.
Previous tests on M1 and M3 P cores found that each additional floating point thread run on those requires about 935 mW, indicating a substantial increase in power used by M4 P cores when running at their higher maximum frequency. E cores in an M1 Pro require about 100 mW each when running at maximum frequency, similar to those in the M4.
Execution time
As power is the rate of energy use over time, the next step is to examine total execution time for all the threads running concurrently, which should form a linear relationship with different gradients for P and E cores. The next two graphs demonstrate that.
For both floating point (above) and NEON (below), there’s a tight linear relationship between total execution time and numbers of threads. Floating point demonstrates that each thread costs 2.4 seconds on P cores and 3.6 seconds on E cores, making E core execution time 150% that of P cores. NEON is similar, at 2.5 seconds on P cores and 3.4 seconds on E cores, for a ratio of 136%.
Time taken for the slowest thread to complete execution shows interesting finer detail.
For both tests, performance falls into several sections according to the number of threads run. With less than 5 threads run, there’s a sharp rise in time taken per thread. From 5-10 threads, time required remains constant, before increasing from 10-14 threads, when additional threads are spilt over onto E cores.
This has implications for anyone trying to measure core performance, as it demonstrates that a single thread can run disproportionately fast, compared with 3-10 threads. Basing any conclusion or comparison on a single thread completing in little more than 2 seconds, when 5 concurrent threads would take 2.34 seconds, 117% of the single thread, could be misleading.
Energy use
Although power use determines heat production, so is an important factor in determining cooling requirements, total energy required to execute threads is equally important for Macs running from battery. Simply reducing core frequency will reduce power used, but by extending the time taken to complete tasks, it may have no effect on energy used, and battery endurance. My final two graphs therefore show estimated total energy used when running test threads on P and E cores, the ultimate test of any big.LITTLE CPU design such as that in the M4.
Graphs for floating point (above) and NEON (below) are inevitably similar in form to those for power, with a near-linear section from 1-10 cores, when the threads are run only on P cores, and from 11-14 cores when they also spill over to E cores.
Fitted regression lines provide the energy cost for each additional thread:
For floating point, each thread run on a P core costs 3.1 J, and for an E core 1.5 J, making the energy used by an E core 47% that of a P core.
For NEON, P cores cost 7.7 J per thread, and E cores 3.0 J, making the energy used by an E core 38% that of a P core.
It’s important to remember that the E cores here aren’t being run at frequencies for high efficiency, but at their maximum so they can substitute for the P cores that are already in use.
Considering the small deviations from those linear relationships, it appears that running 2, 6 or 7 threads on P cores requires slightly more energy than predicted from the regression lines shown.
Unfortunately, assessing the energy used by E cores running at low frequencies, as they normally do when performing background tasks, is fraught with inaccuracies due to their low power use. My previous estimate for floating point tests is that a slow-running E core uses less than 45 mW per thread, and for the same task requires about 7% of the energy used by a P core running at maximum frequency, but I have lower confidence in the accuracy of those figures than in those above for higher frequencies.
Key information
When running the same code at maximum frequency, E cores used 8-9% of the power of P cores.
Power use when running 2 or 7 threads was anomalously high, possibly due to high thread mobility.
Execution on E cores was significantly slower than on P cores, at 136-150% of the time required on P cores.
Single-core performance measurements may not be accurate reflections of performance on multiple cores.
When running the same code at maximum frequency, energy used by an E core is expected to be 38-47% that of a P core.
There’s no doubt that the CPUs in M4 chips outperform their predecessors. General-purpose benchmarks such as Geekbench demonstrate impressive rises in both single- and multi-core results, in my experience from 3,191 (M3 Pro) to 3,892 (M4 Pro), and 15,607 (M3 Pro) to 22,706 (M4 Pro). But the latter owes much to the increase in Performance (P) core count from 6 to 10. In this series I concentrate on much narrower concepts of performance in CPU cores, to provide deeper insight into topics such as core types and energy efficiency. This article examines the in-core performance of P and E cores, and how they differ.
P core frequencies have increased substantially since the M1. If we set that as 100%, M3 P cores run at around 112-126% of that frequency, and those in the M4 at 140%.
E cores are more complex, as they have at least two commonly used frequencies, that when running low Quality of Service (QoS) threads, and that when running high QoS threads that have spilt over from P cores. Low QoS threads are run at 77% of M1 frequency when on an M3, and 105% on an M4. High QoS threads are normally run at higher frequencies of 133% on the M3 E cores (relative to the M1 at 100%), but only 126% on the M4.
Methods
To measure in-core performance I use a GUI app wrapped around a series of loading tests designed to enable the CPU core to execute that code as fast as possible, and with as few extraneous influences as possible. Of the seven tests reported here, three are written in assembly code, and the others call optimised functions in Apple’s Accelerate library from a minimal Swift wrapper. These tests aren’t intended to be purposeful in any way, nor to represent anything that real-world code might run, but simply provide the core with the opportunity to demonstrate how fast it can be run at a given frequency.
The seven tests used here are:
64-bit integer arithmetic, including a MADD instruction to multiply and add, a SUBS to subtract, an SDIV to divide, and an ADD;
64-bit floating point arithmetic, including an FMADD instruction to multiply and add, and FSUB, FDIV and FADD for subtraction, division and addition;
32-bit 4-lane dot-product vector arithmetic (NEON), including FMUL, two FADDP and a FADD instruction;
simd_float4 calculation of the dot-product using simd_dot in the Accelerate library.
vDSP_mmul, a function from the vDSP sub-library in Accelerate, multiplies two 16 x 16 32-bit floating point matrices, which in M1 and M3 chips appears to use the AMX co-processor;
SparseMultiply, a function from Accelerate’s Sparse Solvers, multiplies a sparse and a dense matrix, that may use the AMX co-processor in M1 and M3 chips.
BNNSMatMul matrix multiplication of 32-bit floating-point numbers, here in the Accelerate library, and since deprecated.
Source code of the loops is given in the Appendix.
The GUI app sets the number of loops to be performed, and the number of threads to be run. Each set of loops is then put into the same Grand Central Dispatch queue for execution, at a set Quality of Service (QoS). Timing of thread execution is performed using Mach Absolute Time, and the time for each thread to be executed is displayed at the end of the tests.
I normally run tests at either the minimum QoS of 9, or the maximum of 33. The former are constrained by macOS to be run only on E cores, while the latter are run preferentially on P cores, but may spill over to E cores when no P core is available. All tests are run with a minimum of other activities on that Mac, although it’s not unusual to see small amounts of background activity on the E cores during test runs.
The number of loops completed per second is calculated for two thread totals for each of the three execution contexts. Those are:
P cores alone, based on threads run at high QoS on 1 and 10 P cores;
E cores at high frequency (‘fast’), run at high QoS on 10 cores (no threads on E cores) and 14 (4 threads on E cores);
E cores at low frequency (‘slow’), run at low QoS on 1 and 4 E cores.
Results are then corrected by removing overhead estimated as the rate of running empty loops. Finally, each test is expressed as a percentage of the performance achieved by the P cores in an M1 chip. Thus, a loop rate double that achieved by running the same test on an M1 P core is given as 200%.
P core performance
As in subsequent sections, these are shown in the bar chart below, in which the pale blue bars are for M1 P cores, dark blue bars for M3 P cores, and red for M4 P cores.
As I indicated in my preview of in-core performance, there is little difference between integer performance between M3 and M4 P cores, but a significant increase in floating point, which matches that expected by the increased frequency in the M4.
Vector performance in the NEON and simd dot tests, and matrix multiplication in vDSP mmul rise higher than would be expected by frequency differences alone, to over 160% of M1 performance. The latter two tests are executed using Accelerate library calls, so there’s no guarantee that they are executed the same on different chips, but the first of those is assembly code using NEON instructions. SparseMultiply and BNNS matmul are also Accelerate functions whose execution may differ, and don’t fare quite as well on the M4.
E core slow performance
On E cores, threads run at low QoS are universally at frequencies close to idle, as reflected in their performance, still relative to an M1 P core at much higher frequency. Frequency differences account for the relatively poor performance of M3 E cores, and improvement in results for the M4. Those are disproportionate in vector and matrix tests, which could be accounted for by the M4 E core running those at higher frequencies than would be normal for low QoS threads.
Although the best of these, NEON, is still well below M1 P core performance (73%), this suggests a design decision to deliver faster vector processing on M4 E cores, which is interesting.
E core fast performance
Ideally, when high QoS threads overspill from P cores, it’s preferable that they’re executed as fast as they would have been on a P core. Those in the M1 fall far short of that, in scalar and vector tests only delivering 40-60% of a P core, although that seemed impressive at the time. The M3 does considerably better, with vector and one matrix test slightly exceeding the M1 P core, and the M4 is even faster in vector calculations, peaking at over 130% for NEON assembly code.
Far from being a cut-down version of its P core, the M4 E core can now deliver impressive vector performance when run up to maximum frequency.
M4 P and E comparison
Having considered how P and E cores have improved against those in the M1, it’s important to look at the range of computing capacity they provide in the M4. This is shown in the chart below, where pale blue bars are P cores, red bars E cores at high QoS and frequency, and dark blue bars E cores at low QoS and frequency. Again, these are all shown relative to P core performance in the M1.
Apart from the integer test, scalar floating point, vector and matrix calculations on P cores range between 140-175% those of the M1, a significant increase on those expected from frequency increase alone. Scalar and vector (but not matrix) calculations on E cores at high frequency are slower, although in most situations that shouldn’t be too noticeable. Performance does drop off for E cores at low frequency, though, and would clearly have impact for code.
Given the range of operating frequencies, P and E cores in the M4 chip deliver a wide range of performance at different power levels, and its power that I’ll examine in the next article in this series.
Key information
M4 P core maximum frequency is 140% that of the M1. That increase in frequency accounts for much of the improved P core performance seen in M4 chips.
E core frequency changes are more complex, and some have reduced rather than risen compared with the M1.
P core floating point performance in the M4 has increased as would be expected by frequency change, and vector and matrix performance has increased more, to over 160% those of the M1.
E core performance at low QoS and frequency has improved in comparison to the M3, and most markedly in vector and matrix tests, suggesting design improvements in the latter.
E core performance at high QoS and frequency has also improved, again most prominently in vector tests.
Across their frequency ranges, M4 P and E cores now deliver a wide range of performance and power use.
func runAccTest(theA: Float, theB: Float, theReps: Int) -> Float {
var tempA: Float = theA
var vA = simd_float4(theA, theA, theA, theA)
let vB = simd_float4(theB, theB, theB, theB)
let vC = vA + vA
for _ in 1...theReps {
tempA += simd_dot(vA, vB)
vA = vA + vC
}
return tempA
}
16 x 16 32-bit floating point matrix multiplication
var theCount: Float = 0.0
let A = [Float](repeating: 1.234, count: 256)
let IA: vDSP_Stride = 1
let B = [Float](repeating: 1.234, count: 256)
let IB: vDSP_Stride = 1
var C = [Float](repeating: 0.0, count: 256)
let IC: vDSP_Stride = 1
let M: vDSP_Length = 16
let N: vDSP_Length = 16
let P: vDSP_Length = 16
A.withUnsafeBufferPointer { Aptr in
B.withUnsafeBufferPointer { Bptr in
C.withUnsafeMutableBufferPointer { Cptr in
for _ in 1...theReps {
vDSP_mmul(Aptr.baseAddress!, IA, Bptr.baseAddress!, IB, Cptr.baseAddress!, IC, M, N, P)
theCount += 1
} } } }
return theCount
Apple describes vDSP_mmul() as performinng “an out-of-place multiplication of two matrices; single precision.” “This function multiplies an M-by-P matrix A by a P-by-N matrix B and stores the results in an M-by-N matrix C.”
Sparse matrix multiplication
var theCount: Float = 0.0
let rowCount = Int32(4)
let columnCount = Int32(4)
let blockCount = 4
let blockSize = UInt8(1)
let rowIndices: [Int32] = [0, 3, 0, 3]
let columnIndices: [Int32] = [0, 0, 3, 3]
let data: [Float] = [1.0, 4.0, 13.0, 16.0]
let A = SparseConvertFromCoordinate(rowCount, columnCount, blockCount, blockSize, SparseAttributes_t(), rowIndices, columnIndices, data)
defer { SparseCleanup(A) }
var xValues: [Float] = [10.0, -1.0, -1.0, 10.0, 100.0, -1.0, -1.0, 100.0]
let yValues = [Float](unsafeUninitializedCapacity: xValues.count) {
resultBuffer, count in
xValues.withUnsafeMutableBufferPointer { denseMatrixPtr in
let X = DenseMatrix_Float(rowCount: 4, columnCount: 2, columnStride: 4, attributes: SparseAttributes_t(), data: denseMatrixPtr.baseAddress!)
let Y = DenseMatrix_Float(rowCount: 4, columnCount: 2, columnStride: 4, attributes: SparseAttributes_t(), data: resultBuffer.baseAddress!)
for _ in 1...theReps {
SparseMultiply(A, X, Y)
theCount += 1
} }
count = xValues.count
}
return theCount
Apple describes SparseMultiply() as performing “the multiply operation Y = AX on a sparse matrix of single-precision, floating-point values.” “Use this function to multiply a sparse matrix by a dense matrix.”
In the two previous articles (links at the end), I explored some of the features and properties of Performance (P) cores in Apple’s latest M4 chips. This article looks at their Efficiency (E) cores by comparison.
M4 family
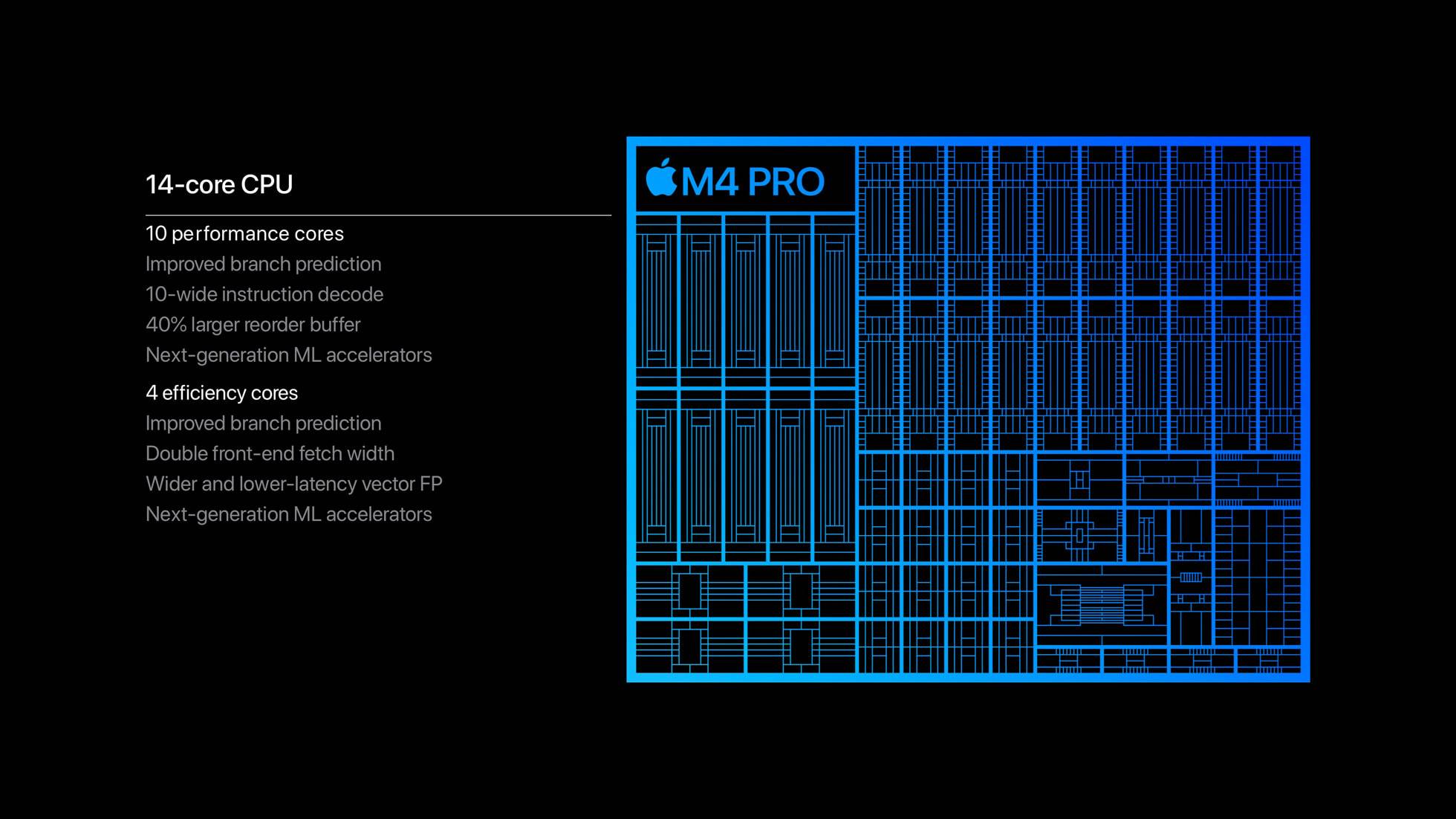
In the three current M4 designs, there are only two variations in terms of E cores:
Base M4, with 6 E cores, except for a cheaper variant with only 4 active E cores.
M4 Pro and Max, with 4 E cores, including ‘binned’ variants.
Apple is expected to release an Ultra variant in 2025, with two M4 Max chips in tandem, providing a total of 8 E cores. Apart from the number of cores, all E cores are the same, and different from P cores.
E core architecture
All E cores are arranged in a single cluster of 4 or 6, sharing common L2 cache, and running at the same frequency (clock speed). Analysis of M1 cores implies that each E core has roughly half the number of processing units, where there is more than one such unit in the P core, giving an M1 E core roughly half the compute capacity of the P core. I haven’t seen any comparable analysis of cores in later M families, although differences in power consumption imply there remain substantial differences in processing units and compute capacity.
Frequency
Like P cores, E cores can be set to run at any of 5 values between the minimum of 1,020 MHz and maximum of 2,592 MHz (1.0-2.6 GHz). When running macOS, cluster frequency is set by macOS at a kernel level; other operating systems may offer more direct control. This range of frequencies is significantly narrower than that of E cores in the M3, which range between 744-2,748 MHz.
E cores idle at 1,020 MHz, and although they can be shut down altogether, that’s exceptional given the steady demand for macOS background threads to be run on them. Nevertheless, powermetrics still reports their ‘down’ residencies separately from idle residencies.
Instruction set
This is believed to be identical to ARMv9.2-A without Scalable Vector Extension (SVE) supported by M4 P cores, enabling the same threads to be run on either core type.
Single thread comparisons
One way to appreciate the contrasts between core types is to compare a single intensive in-core thread run in each. For this purpose, I used a tight loop of floating point calculations, running at two different Quality of Service (QoS) settings, in macOS 15.1.
Single thread at high QoS on P cores
This thread was initially loaded onto P13 (red) in the second (P1) cluster, and after 3.7 seconds was moved to P5 (blue) in the first (P0) cluster. After a further 4.6 seconds running on that, it was moved back to the second (P1) cluster, to run on P11 (purple). During this run, there was almost no other activity on the two P clusters, and the inactive cluster was therefore shut down while this thread was running on the other.
The active cluster was run at the maximum frequency of 4,511 MHz throughout. Just before the thread was moved to a different cluster, that was brought up and run up to maximum frequency ready to run the thread.
Total CPU power remained similar throughout the period the thread was being executed, but there is a small and consistent difference according to which cluster was active: the first (P0) brought power use of about 2,520 mW, 50 mW higher than the second (P1) at about 2,470 mW. This matches the difference reported previously, and merits assessment in other M4 Pro chips to determine whether this is a general feature.
Single thread at high QoS on E cores
There are methods of running code, such as the in-core floating point loop test used here, on E cores: they can be run with a low QoS (Background), so that macOS allocates them to run on only E cores, or they can be spilt over from high QoS threads when there are more threads than available P cores. On an M4 Pro chip, that requires 11 threads, which results in one of those being allocated to the E cluster, as described next.
This chart shows active residency on the four E cores with a single high QoS thread spilt onto them. While cores E1, E2 and E3 appear to handle other threads over this period of more than six seconds, core E0 appears to run at 90-100% active residency executing the spilt thread. Note that this thread wasn’t moved between cores over that period of over six seconds.
E cluster frequency remained constant throughout at its maximum of 2,592 MHz. CPU power use was inevitably dominated by the ten P cores running at 100% active residency and maximum frequency, remaining at just under 14,000 mW. Unfortunately, using powermetrics it’s not possible to estimate the power use of the E cluster directly.
Single thread at low QoS on E cores
This is very different from the spilt thread at high QoS.
There’s no evidence here that any single core in the E cluster ran a thread at 100% active residency. Instead it appears to have been moved rapidly and freely around the cores, with many 0.1 second sampling intervals spanning its execution in more than one core over that period.
Cluster frequency was a steady minimum of 1,050-1,060 MHz, with superimposed spikes when it rose briefly to the maximum of 2,592 MHz. This suggests that the single thread would most probably have been run at close to core minimum frequency, had there not been additional threads to run.
A similar picture is seen in power use, with spikes from a low background of about 40-45 mW required by the single thread alone.
Single thread behaviours
These can be summarised as:
P core (high QoS) runs at 100% active residency on a single P core at maximum frequency, and is switched between clusters irregularly (about every 3.7-4.6 seconds). Total power use is about 2,500 mW.
High QoS spilt over to E cores runs at 90-100% active residency on a single E core at maximum frequency, and is either not switched between cores at all, or only infrequently.
E core (low QoS) runs at about 100% and is moved frequently between all E cores in the cluster, at close to minimum frequency. Total power use is about 40-45 mW.
Performance, power and efficiency
Although I’ll be returning to more detailed comparisons of performance and power use between P and E cores, I provide a single illustration here, for the in-core floating point task used above.
Running 2 x 10^9 loops in each thread, P cores at maximum frequency take 9.2-9.7 seconds per thread, and use about 2,500 mW per thread. E cores running low QoS threads at close to minimum frequency take about four times as long, 38.5 seconds, but use less than 45 mW power per thread. Total energy used to complete one thread is therefore over 23 J when run on P cores, and less than 1.7 J when run on E cores. E cores therefore use only 7% of the energy that P cores do performing the same task.
Key information
Current M4 chips feature 4-6 CPU E cores.
M4 E cores are arranged in a single cluster of 4 or 6, sharing L2 cache and running at a common frequency.
The E core cluster can be shut down (exceptionally), idling at their minimum frequency of 1,020 MHz, or at one of 6 set frequencies up to a maximum of 2,592 MHz, as controlled by macOS.
Their instruction set is the same as M4 P cores, ARMv9.2-A without its Scalable Vector Extension (SVE).
They use 40-45 mW when at low frequencies, but it’s not currently feasible to measure directly their maximum power use at high frequencies.
macOS allocates threads to E cores when their QoS is 9 (Background), and when a thread with higher QoS can’t be allocated to a P core because they are all busy. Management of frequencies and core allocation differ between those two cases.
High QoS threads on E cores are run at maximum frequency and appear not to move between cores.
Low QoS threads on E cores are run at close to minimum frequency and are highly mobile between cores.
Low QoS threads running on E cores run more slowly than higher QoS threads running on P cores, but E core power use is much lower, resulting in considerable saving in total energy use for the same computational task.
Residency is the percentage of time a core is in a specific state. Idle residency is thus the percentage of time that core is idle and not processing instructions. Active residency is the percentage of time it isn’t idle, but is actively processing instructions. Down residency is the percentage of time the core is shut down. All these are independent of the core’s frequency or clock speed.
If you’ve already got a new M4 Mac and tried to run a macOS virtual machine on it, then you might have been disappointed. It seems that M4 chips can’t virtualise any version of macOS before 13.4 Ventura. So before you trade in or pass on your M1, M2 or M3 Mac, if you need access to older VMs, you might like to check whether this affects you.
I’m indebted to Csaba Fitzl for drawing my attention to this problem, and for reporting it to Apple in Feedback FB15774587. It has also been reported as affecting UTM, and I believe affects all other macOS virtualisation software for Apple silicon.
The bug
Running a macOS VM for any version before 13.4 Ventura on an M4 Mac results in a black screen, and the VM fails to boot. This is true whatever settings are used in the virtualiser, even if it’s set to boot the VM in Recovery mode. It’s also true when that VM has been built on that Mac: although that appears to complete successfully, when first run that VM opens as a black screen and never proceeds with personalisation and setup.
Currently the only way to run a VM with macOS prior to 13.4 Ventura is to do so on a host with an M1, M2 or M3 chip.
Can this be fixed?
Unfortunately, as this bug prevents the VM from booting, there’s no reliable way to access its log to discover what’s going wrong there. There’s no sign of the failure in the host’s log either: the host appears to initialise its Virtio and other support normally, without errors or faults. After those, virtualisation processes on the host fall silent as they wait for the VM to start, which never happens.
There is a useful clue in Activity Monitor, though: in its CPU pane, despite being allocated multiple virtual cores, only one is seen to be active on the host. That implies the failure is occurring before the VM kernel boots the other cores, an event that occurs early during the kernel boot phase. Until that point, pre-boot phases and the kernel run on just a single CPU core.
macOS 13.4 updated iBoot to version 8422.121.1, so at first sight the VM could be failing when running older firmware. That doesn’t appear likely, as version 8422.121.1 was also installed in the 12.6.6 security update, so 12.7.x shouldn’t suffer this problem, but it does.
It thus appears most likely that this bug strikes in the early part of kernel boot, in which case the most feasible solution would be to fix the bug in macOS kernels prior to 13.4, and promulgate new IPSW image files for those. I suspect that’s very unlikely to happen, and as far as I’m aware it would be the first time that Apple has issued revised IPSWs.
Which macOS can you virtualise?
Support for lightweight virtualisation of macOS on Apple silicon Macs was still in progress in the first version of macOS to run on M1 chips, Big Sur. You therefore cannot create or run Big Sur VMs.
The first versions that can run in VMs are macOS 12 Monterey, although prior to 12.4 they can sometimes be a bit fractious. They also have major limitations, such as not supporting shared folders with the host.
This is 12.1 with its old System Preferences, running happily on an M3 Pro.
macOS Ventura should run well on M1, M2 and M3 hosts, and 13.4 and later on M4 hosts too.
macOS Sonoma should run even better on all current Apple silicon Macs, and delivers a much improved display with autoscaling. However, 14.2 and 14.2.1 don’t automatically support shared folders because of a bug that was fixed in 14.3.
macOS Sequoia is fully compatible, and adds support for iCloud Drive and some other Apple Account features, although still won’t run App Store apps. It may also fail to install the required extras to support Apple Intelligence.
Summary
Currently, M4 Macs can only run VMs of macOS Ventura 13.4 and later, 14 Sonoma, and 15 Sequoia.
M1, M2 and M3 Macs can run VMs of macOS Monterey 12.0.1 and later.
macOS Big Sur 11 can’t be virtualised on Apple silicon.
I’m grateful for the suggestion that it might be possible to work around this problem by running the older VM on a single core. Although I did manage to do that on an M3 (the first time I have seen recent macOS running on just one core!), that fails just the same on an M4, I’m afraid.
One common but atypical situation for any M-series chip is running a macOS virtual machine. This article explores how virtual CPU cores are handled on physical cores of an M4 Pro host, and provides further insight into their management, and thread mobility across P core clusters.
Unless otherwise stated, all results here are obtained from a macOS 15.1 Sequoia VM in my free virtualiser Viable, with that VM allocated 5 virtual cores and 16 GB of memory, on a Mac mini M4 Pro running macOS Sequoia 15.1 with 48 GB of memory, 10 P and 4 E cores.
How virtual cores are allocated
All virtualised threads are treated by the host as if they are running at high Quality of Service (QoS), so are preferentially allocated to P cores, even though their original thread may be running at the lowest QoS. This has the side-effect of running virtual background processes considerably quicker than real background threads on the host.
In this case, the VM was given 5 virtual cores so they could all run in a single P cluster on the host. That doesn’t assign 5 physical cores to the VM, but runs VM threads up to a total of 500% active residency across all the P cores in the host. If the VM is assigned more virtual cores than are available in the host’s P cores, then some of its threads will spill over and be run on host E cores, but at the high frequency typical of host threads with high QoS.
Performance
There is a slight performance hit in virtualisation, but it’s surprisingly small compared to other virtualisers. Geekbench 6.3.0 benchmarks for guest and host were:
CPU single core VM 3,643, host 3,892
CPU multi-core VM 12,454, host 22,706
GPU Metal VM 102,282, host 110,960, with the VM as an Apple Paravirtual device.
Some tests are even closer: using my in-core floating point test, 1,000 Mloops run in the VM in 4.7 seconds, and in the host in 4.68 seconds.
Host core allocation
To assess P core allocation on the host, an in-core floating point test was run in the VM. This consisted of 5 threads with sufficient loops to fully occupy the virtual cores for about 20 seconds. In the following charts, I show results from just the first 15 seconds, as representative of the whole.
When viewed by cluster, those threads were mainly loaded first onto the first P cluster (pale blue bars), where they ran for just over 1 second before being moved to the second cluster (red bars). They were then regularly switched between the two P clusters every few seconds throughout the test. Four cycles were completed in this section of the results, with each taking 2.825 seconds, so threads were switched between clusters every 1.4 seconds, the same time as I found when running threads on the host alone, as reported previously.
For most of the 15 seconds shown here, total active residency across both P clusters was pegged at 500%, as allocated to the VM in its 5 virtual cores, with small bursts exceeding that. Thus that 500% represents those virtual cores, and the small bursts are threads from the host. Although the great majority of that 500% was run on the active P cluster, a total of about 30% active residency consisted of other threads from the VM, and ran on the less active P cluster. That probably represents the VM’s macOS background processes and overhead from its folder sharing, networking, and other Virtio device use.
When broken down to individual cores within each cluster, seen in the first above and the second below, total activity differs little across the cores in the active cluster. During its period in the active cluster, each core had an active residency of 80-100%, bringing the cluster total to about 450% while most active.
In case you’re wondering whether this occurs on older Apple silicon, and it’s just a feature of macOS Sequoia, here’s a similar example of a 4-core VM running 3 floating point threads in an M1 Max with macOS 15.1, seen in Activity Monitor’s CPU History window. There’s no movement of threads between clusters.
P core frequencies
powermetrics, used to obtain this data, provides two types of core frequency information. For each cluster it gives a hardware active frequency, then for each core it gives an individual frequency, which often differs within each cluster. Cores in the active P cluster were typically reported as running at a frequency of 4512 MHz, although the cluster frequency was lower, at about 3858 MHz. For simplicity, cluster frequencies are used here.
This chart shows reported frequencies for the two P clusters in the upper lines. Below them are total cluster active residencies to show which cluster was active during each period.
The active cluster had a steady frequency of just below 3,900 MHz, but when it became the less active one, its frequency varied greatly, from idle at 1,260 MHz up to almost 4,400 MHz, often for very brief periods. This is consistent with the active cluster running the intensive in-core test threads, and the other cluster handling other threads from both the VM and host.
CPU power
Several who have run VMs on notebooks report that they appear to drain the battery quickly. Using the previous results from the host, the floating point test used here would be expected to use a steady 7,000 mW.
This last chart shows the total CPU power use in mW over the same period, again with cluster active residency (here multiplied by 10), added to aid recognition of cluster cycles. This appears to average about 7,500 mW, only 500 mW more than expected when run on the host alone. That shouldn’t result in a noticeable increase in power usage in a notebook.
In the previous article, I remarked on how power used appeared to differ between the two clusters, and this is also reflected in these results. When the second cluster (P1) is active, power use is less, at about 7,100 mW, and it’s higher at about 7,700 when the first cluster (P0) is active. This needs to be confirmed on other M4 Pro chips before it can be interpreted.
Key information
macOS guests perform almost as well as the M4 Pro host, although multi-core benchmarks are proportionate to the number of virtual cores allocated to them. In particular, Metal GPU performance is excellent.
All threads in a VM are run as if at high QoS, thus preferentially on host P cores. This accelerates low QoS background threads running in the VM.
Virtual core allocation includes all VM overhead from the VM, such as its macOS background threads.
Guest threads are as mobile as those of the host, and are moved between P clusters every 1.4 seconds.
Although threads run in a VM incur a small penalty in additional power use, this shouldn’t be significant for most purposes.
Once again, evidence suggests that the first P cluster (P0) in an M4 Pro uses slightly more power than the second (P1). This needs to be confirmed in other systems.
powermetrics can’t be used in a VM, not unsurprisingly.
Residency is the percentage of time a core is in a specific state. Idle residency is thus the percentage of time that core is idle and not processing instructions. Active residency is the percentage of time it isn’t idle, but is actively processing instructions. Down residency is the percentage of time the core is shut down. All these are independent of the core’s frequency or clock speed.
This is the first in a series diving deeper into Apple’s new M4 family of chips. This starts with details of its Performance (P) cores. Comparisons of their performance against cores in earlier M-series chips will follow separately when I have completed them.
M4 family
There are currently three M4 designs:
Base M4, with 4 P and 6 E cores, also available in a cheaper variant with only 4 active E cores, and a ‘binned’ variant for iPads with only 3 active P cores.
M4 Pro, with 10 P and 4 E cores, also available in a ‘binned’ variant with only 8 active P cores.
M4 Max, with 12 P and 4 E cores, also available in a ‘binned’ variant with only 10 active P cores.
Apple is expected to release an Ultra variant in 2025, consisting of two M4 Max chips connected and working in tandem, providing a total of 24 P and 8 E cores.
Apart from the number of cores in each design, their caches and memory, all P cores are the same, and different from E cores.
P core architecture
All CPU cores are arranged in clusters of up to 6. All cores within any given cluster share L2 cache, and are run at the same frequency (clock speed). The Base M4 has a single cluster of 4 P cores, while the Pro and Max have two clusters of 5 and 6 cores respectively.
Frequency
A prominent feature of both P and E cores is their variable frequency (clock speed). In the case of P cores, this can be set to any of 17 values between the minimum of 1,260 MHz and maximum of 4,512 MHz (1.3-4.5 GHz). When running macOS, cluster frequencies are set by macOS at a kernel level; other operating systems may offer more direct control.
P cores idle at 1,260 MHz, but can also be shut down altogether. Previous M-series chips have been reported by the powermetrics command tool as sometimes being idle at a frequency of 0 MHz, but the M4 is the first to have idle and down states reported separately, for example: CPU 4 active residency: 0.00%
CPU 4 idle residency: 0.00%
CPU 4 down residency: 100.00%
when that core and its whole cluster are shut down rather than just idling. It’s not clear whether this is merely an administrative change, or M4 cores implement this state differently from previous cores.
Instruction set
There’s confusion over the Instruction Set Architecture (ISA) supported by M4 cores. This is explained in the LLVM source, where it’s claimed that they’re “technically” ARMv9.2-A, but without its Scalable Vector Extension (SVE). Some might consider that’s closer to ARMv8.7-A, one version more recent than the M3’s ARMv8.6-A.
Although this is now fully supported in LLVM clang, it’s not clear how fully it’s supported by Xcode, for example.
Power
When shut down, a P core consumes no power, of course, and at idle with no active residency, it uses only 1-2 mW, according to measurements reported by powermetrics.
Maximum power consumption rises to approximately 1,400 mW when running intensive floating point calculations at 100% active residency, and to approximately 3,230 mW when running NEON vector instructions at 100% active residency.
macOS core allocation
Threads are normally allocated by macOS to an available P core when their designated Quality of Service (QoS) is higher than 9 (Background), for example when using Dispatch, formerly branded Grand Central Dispatch (GCD). Running threads may also be moved periodically between P cores in the same cluster, and between clusters. Previous M-series chips appear to move threads less frequently, and may leave them to run to completion after several seconds on the same core, but threads appear to be considerably more mobile when running on M4 P cores.
This bar chart shows 4 threads from 4 virtual CPUs in a VM running for 3 seconds at 100% active residency. For almost all that period, the threads remain running on the 4 physical cores of the first P cluster in this M1 Max, with the second P cluster remaining idle for much of that time.
The following charts show 4 threads of intensive in-core floating point arithmetic running on the P cores of an M4 Pro.
When viewed by cluster, those threads are loaded first onto the second P cluster (red bars), where they run for 0.4 seconds before being moved to the first cluster (pale blue bars). After running there for 1.3 seconds, they’re moved back to the second cluster for a further 1.3 seconds, before completing on the first cluster.
The next two bar charts show each cluster separately, illustrating thread mobility within them.
When running on the first cluster (above), threads appear to be moved to a different core approximately every 0.3 second, as they do when on the second cluster (below).
Cluster frequency matches this movement, with each cluster being run up to maximum frequency (shown here averaged across the whole cluster) to process the threads running on its cores. The black line below those for the P clusters shows the small changes in average frequency for the E cluster over this period.
This last chart shows the total CPU power use in mW over the same period. Of particular interest here is the consistent difference in power use reported by powermetrics between the two P clusters: the first (P0) used a steady 6,000 mW when running these four threads, whereas the second (P1) used slightly less, at 5,700-5,800 mW. That could be the result of measurement error in powermetrics, peculiar to this particular chip, or could reflect an underlying difference between the two clusters.
Thread mobility makes interpreting CPU History in Activity Monitor difficult, as the fastest frequency of sampling available there is every second, while powermetrics was sampling every 0.1 second when gathering the data above. As groups of threads may be moved between clusters every 1.3 seconds or so, this can give the impression that threads are being run on both clusters simultaneously. Once again, great care is needed when interpreting the data shown by Activity Monitor.
Key information
Current M4 chips offer 4-12 CPU P cores.
M4 P cores are arranged in clusters of up to 6, sharing L2 cache and running at a common frequency.
P core clusters can be shut down, idling at their minimum frequency of 1,260 MHz, or at one of 18 set frequencies up to a maximum of 4,512 MHz, as controlled by macOS.
Their instruction set is “technically” ARMv9.2-A, but without its Scalable Vector Extension (SVE).
They use 1-2 mW when idle, rising to peaks of 1,400 mW (floating point) or 3,230 mW (NEON vector code).
macOS preferentially allocates them threads at all QoS higher than 9 (Background).
Threads running on M4 P cores are mobile, and may be moved to another core in the same cluster frequently, and after just over a second may be transferred to a core in the other P cluster, when available.
Thread mobility makes interpretation of the CPU History window in Activity Monitor very difficult.
Explainer
Residency is the percentage of time a core is in a specific state. Idle residency is thus the percentage of time that core is idle and not processing instructions. Active residency is the percentage of time it isn’t idle, but is actively processing instructions. Down residency is the percentage of time the core is shut down. All these are independent of the core’s frequency or clock speed.
My Mac mini M4 Pro arrived four days early, and swiftly exceeded all expectations. Everyone who has seen this new design remarks on how tiny it is, and I still keep looking at it, wondering how the smallest Mac I have ever owned is also by far the fastest. For those who collect numbers, it matched the growing collection in Geekbench’s database, with a single-core score of 3,892, a multi-core of 22,706, and Metal GPU of 110,960. Of course those new MacBook Pros with M4 Max chips are doing better with their extra two CPU cores and twice the number of GPU cores, but second best is still far superior to anything I’ve run before.
Not only is this my fastest Mac ever, but it was also the quickest and simplest to commission. It replaces my Mac Studio M1 Max, and now sits under my Studio Display using the Studio’s old keyboard and trackpad. As I’ll explain in a future article, I opted to migrate to the mini during initial setup using the Studio’s backup SSD, a sleek OWC Envoy Pro SX connected by Thunderbolt 3. Including the inevitable macOS update, the whole process took less than two hours, from the start of unboxing to the first full Time Machine backup.
With 48 GB memory and an internal SSD of 2 TB, I was keen to benchmark that once its initial backup was done. Although I have reduced confidence in these figures, there’s no doubt that this SSD is significantly quicker than the 2 TB in the Studio; how much quicker is open to debate. AmorphousDiskMark reported a write speed of 7.7 GB/s, while my own Stibium gave 10.3 GB/s across a broad range of file sizes. There was closer agreement on read speed, at around 6.8 GB/s. Both of those are comfortably above what I expect when I can finally get hold of an external Thunderbolt 5 SSD.
CPU cores
My M4 Pro is the full-performance variant, with 10 P and 4 E cores, set in three clusters: an E cluster with all four E cores, and two clusters of five P cores. Since its M3 chips, Apple has increased the maximum number of cores in a cluster from 4 (in M1 and M2 chips) to 6 (M3 and M4).
M4 P cores run at frequencies between 1260 and 4512 MHz (1.3-4.5 GHz), their maximum frequency being 111% that of the M3 P core, and 140% that of the M1 P core. M4 E cores have a narrower range of frequencies than those in the M3, between 1020-2592 MHz (1.0-2.6 GHz), so running at 137% of M3 frequency when running low QoS threads, and 94% of M3 when running at maximum frequency for high QoS threads spilt over from P cores. Those are going to make comparisons between E core performance very interesting indeed.
Single-thread and single-core comparisons of P core throughput are inevitably in the M4’s favour, with significantly better performance across integer, floating point and vector performance, as shown in the chart below.
The Y axis here gives loop throughput per second for my four basic in-core performance tests, a tight assembly code integer math loop, another tight assembly code loop of floating point math, NEON vector processor assembly code, and a tight loop calling an Accelerate routine run in the NEON unit. Pale blue bars are results for the M1, purple for the M3, and red for the shiny new M4.
Although improvements in integer and floating point performance might appear small here, these results are for single threads. When scaled up across more P cores, the differences are magnified, as shown in the regressions below.
This plots total times taken to execute multiple threads, each consisting of 10^9 (one thousand million, or one billion) loops of floating point assembly code, against the number of threads, the same as the number of cores used, as each core runs one thread. According to the fitted linear regression equations, each thread/core of 10^9 loops takes the same period: 6.04 seconds for the M3 P cores, and 4.69 for the M4. Those equate to 1.66 x 10^8 loops/second per thread for the M3, and 2.13 x 10^8 for the M4. On that basis, the M4 performs at 128% that of the M3, significantly better than expected by the 111% increase in maximum core frequency. That requires the M4 to have improved processing speed for the same frequency of the M3, a frequency-independent improvement.
Core allocation
One striking difference between M4 CPU cores and those of previous Apple silicon chips is their pattern of core allocation, something you may notice even in Activity Monitor, for all its faults. This is best illustrated in its CPU History window.
For these two series of tests, I waited until the Mac was idling quietly, with little happening on its CPU cores. I then ran, in rapid succession, a series of my in-core floating point tests of 10^9 loops at high QoS, starting with a single thread, then two, and so on up to six or eight threads. This results in a pattern distinct from anything you’ll see in Intel cores, as I have shown here since the early days of the M1.
This is the series seen on my MacBook Pro M3 Pro running macOS 15.2 beta, and is typical of M1, M2 and M3 chips. Although the cores are out of order here, these are the six cores in the chip’s single P cluster. At the left is the obvious peak from 1 thread running on Core 9, then the 2 threads of the next test appear on cores 9 and 12. Three fully occupy 7, 9 and 12, with a little spilt onto 8, and so on until all six are fully occupied with 6 threads.
Activity Monitor is a little too crude to see how distinct this is, for which you have to resort to shorter sampling periods of 0.1 second, and the finer detail of active residency reported by powermetrics. Those confirm that, much of the time, these heavy in-core compute loads run in a single thread on a single core, and if they are moved around, it’s relatively infrequently. E cores are different, though.
Compare that with a similar sequence, this time for 1-8 threads, on the M4 Pro. Its ten P cores are divided into two clusters, which I’ve separated here with the blue line, although within each cluster the cores aren’t in numeric order.
Reading again from the left, a single thread is run in cores 6 and 8, with a little in 14 in the second cluster. Two threads are run in all five cores of the second cluster, with a little at the end from those of the first cluster. Three threads are similar, with significant contributions from all ten cores, and from then on they are similar.
So, in the M4 P cores threads are no longer allocated to single cores, and it appears from the CPU History window that they may even be allocated across more than one cluster. In fact, when the detailed active residency and frequency data from powermetrics are used, while threads are often moved between two cores in the same cluster, macOS will normally avoid unnecessarily running threads on other clusters, although it will happily move all threads from one cluster to another.
The rationale behind running all threads within the same cluster is clear, as CPU core frequencies of all cores in the same cluster are the same. Constraining threads to a single cluster thus allows others to idle and use less energy. While that continues in M4 chips, it isn’t clear why threads are moved between cores so frequently, or moved together to another cluster, and whether that brings improvements in performance.
In the light of recent news, you might now be wondering whether you can afford to wait until next year in the hope that Apple then releases the M4 Mac of your dreams. To help guide you in your decision-making, this article explains what chip options are available in this month’s new M4 models, and how to choose between them.
CPU core types
Intel CPUs in modern Macs have several cores, all of them identical. Whether your Mac is running a background task like indexing for Spotlight, or running code for a time-critical user task, code is run across any of the available cores. In an Apple silicon chip like those in the M4 family, background tasks are normally constrained to efficiency (E) cores, leaving the performance (P) cores for your apps and other pressing user tasks. This brings significant energy economy for background tasks, and keeps your Mac more responsive to your demands.
Some tasks are normally constrained to run only on E cores. These include scheduled background tasks like Spotlight indexing, Time Machine backups, and some encoding of media. Game Mode is perhaps a more surprising E core user, as explained below.
Most user tasks are run preferentially on P cores, when they’re available. When there are more high-priority threads to be run than there are available P cores, then macOS will normally send them to be run on E cores instead. This also applies to threads running a Virtual Machine (VM) using lightweight virtualisation, whose threads will be preferentially scheduled on P cores when they’re available, even when code being run in the VM would normally be allocated to E cores.
macOS also controls the clock speed or frequency of cores. For background tasks running on E cores, their frequency is normally held relatively low, for best energy efficiency. When high-priority threads overspill onto E cores, they’re normally run at higher frequency, which is less energy-efficient but brings their performance closer to that of a P core. macOS goes to great lengths to schedule threads and control core frequencies to strike the best balance between energy efficiency and performance.
Unfortunately, it’s normally hard to see effects of frequency in apps like Activity Monitor. Its CPU % figures only show the percentage of cycles that are used for processing, and make no allowance for core frequency. It will therefore show a background thread running at low frequency but 100%, the same as a thread overspilt from P cores running at the maximum frequency of that E core. So when you see Spotlight indexing apparently taking 200% of CPU % on your Mac’s E cores, that might only be a small fraction of their maximum capacity if they were running at maximum frequency.
There are no differences between chips in the M4 family when it comes to each type of CPU core: each P core in a Base variant is the same as each in an M4 Pro or Max, with the same maximum frequency, and the same applies to E cores. macOS also allocates threads to different types of core using the same rules, and their frequencies are controlled the same as well. What differs between them is the number of each type of core, ranging from 4 P and 4 E in the 8-core variant of the Base M4, up to 12 P and 4 E in the 16-core variant of the M4 Max. Thus, their single-core benchmark results should be almost identical, although their multi-core results should vary according to the number of cores.
Game Mode
This mode is an exception to normal CPU and GPU core use, as it:
gives preferential access to the E cores,
gives highest priority access to the GPU,
uses low-latency Bluetooth modes for input controllers and audio output.
However, my previous testing didn’t demonstrate that apps running in Game Mode were given exclusive access to E cores. But for gamers, it now appears that the more E cores, the better.
GPU cores
These are also used for tasks other than graphics, such as some of the more demanding calculations required for Machine Learning and AI. However, experience so far with Writing Tools in Sequoia 15.1 is that macOS currently offloads their heavy lifting to be run off-device in one of Apple’s dedicated servers. Although having plenty of GPU cores might well be valuable for non-graphics purposes in the future, for now there seems little advantage for many.
Thunderbolt 5
M4 Pro and Max, but not Base variants, come equipped with Thunderbolt ports that not only support Thunderbolt 3 and 4, but 5, as well as USB4. Thunderbolt 5 should effectively double the speed of connected TB5 SSDs, but to see that benefit, you’ll need to buy a TB5 SSD. Not only are they more expensive than TB3/4 models, but at present I know of only one range that’s due to ship this year. There will also be other peripherals with TB5 support, including at least one dock and one hub, although neither is available yet. The only TB5 accessories that are already available are cables, and even they are expensive.
TB5 also brings increased video bandwidth and support for DisplayPort 2.1, although even the M4 Max can’t make full use of that. If you’re looking to drive a combination of high-res displays, consult Apple’s Tech Specs carefully, as they’re complicated.
Although TB5 will become increasingly important over the next few years, TB3/4 and USB4 are far from dead yet and are supported by all M4 models.
Which M4 chip?
The table below summarises key figures for each of the variants in the M4 family that have now been released. It’s likely that next year Apple will release an Ultra, consisting of two M4 Max chips joined in tandem, in case you feel the burning desire for 24 P and 8 E cores.
Models available next week featuring each M4 chip are shown with green rectangles at the right.
There are two variants of the Base M4, one with 4P + 4E and 8 GPU cores, the same as Base variants in M1 to M3 families. There’s also the more capable variant, for the first time with 4P + 6E, which promises to be a better all-rounder, and when in Game Mode. It also has an extra couple of GPU cores.
The M4 Pro also comes in two variants, this time differing in the number of P cores, 8 or 10, and GPU cores, 16 or 20. Those overlap with the M4 Max, with 10 or 12 P cores and 32 or 40 GPU cores. Thus the gap between M4 Pro and Max isn’t as great as in the M3, with the GPUs in the M4 Max being aimed more at those working with high-res video, for instance. For more general use, there’s little difference between the 14-core Pro and Max.
Memory and storage
Chips in the M4 family also determine the maximum memory and internal SSD capacity. Apple has at last eliminated base models with only 8 GB of memory, and all now start with at least 16 GB. Base M4 chips are limited to a maximum of 32 GB, while the M4 Pro can go up to 64 GB, and the 16-core Max up to 128 GB, although in its 14-core variant, the Max is only available with 36 GB (I’m very grateful to Thomas for pointing this out below).
Unfortunately, Apple hasn’t increased the minimum size of internal SSD, which remains at 256 GB for some base models. Smaller SSDs may be cheaper, but they are also likely to have shorter lives, as under heavy use their small number of blocks will be erased for reuse more frequently. That may shorten their life expectancy to much less than the normal period of up to 10 years, as was seen in some of the first M1 models. This is more likely to occur when swap space is regularly used for virtual memory. I for one would have preferred 512 GB as a starting point.
While Base M4 chips come with SSDs up to 2 TB in size, both Pro and Max can be supplied with internal SSDs of up to 8 TB.
I hope this proves useful in guiding your decision.
由于第一批搭载 M4 芯片的 Mac 已经完成发布,M4 Ultra 更有可能出现在尚未发布的机型上,考虑到本身的定位,M4 Ultra 可能与 M2 Ultra 一样,首发于明年较为高端的 Mac Studio 与 Mac Pro 上,为 Apple Intelligence 提供充足的 NPU 以及光线追踪提供性能支持。
Almost exactly a year after it released its first Macs featuring chips in the M3 family, Apple has replaced those with the first M4 models. Benchmarkers and core-counters are now busy trying to understand how these will change our Macs over the coming year or so. Before I reveal which model I have ordered, I’ll try to explain how these change the Mac landscape, concentrating primarily on CPU performance.
CPU cores
CPUs in the first two families, M1 and M2, came in two main designs, a Base variant with 4 Performance and 4 Efficiency cores, and a Pro/Max with 8 P and 2 or 4 E cores, that was doubled-up to make the Ultra something of a beast with its 16 P and 4 or 8 E cores. Last year Apple introduced three designs: the M3 Base has the same 4 P and 4 E CPU core configuration as in the M1 and M2 before it, but its Pro and Max variants are more distinct, with 6 P and 6 E in the Pro, and 10-12 P and 4 E cores in the Max. The M4 family changes this again, improving the Base and bringing the Pro and Max variants closer again.
As these are complicated by sub-variants and binned versions, I have brought the details together in a table.
I have set the core frequencies of the M4 in italics, as I have yet to confirm them, and there’s some confusion whether the maximum frequency of the P core is 4.3 or 4.4 GHz.
Each family of CPU cores has successively improved in-core performance, but the greatest changes are the result of increasing maximum core frequencies and core numbers. One crude but practical way to compare them is to total the maximum core frequencies in GHz for all the cores. Strictly speaking, this should take into account differences in processing units between P and E cores, but that also appears to have changed with each family, and is hard to compare. In the table, columns giving Σfn are therefore simply calculated as (max P core frequency x P core count) + (max E core frequency x E core count)
Plotting those sum core frequencies by variant for each of the four families provides some interesting insights.
Here, each bar represents the sum core frequency of each full-spec variant. Those are grouped by the variant type (Base, Pro, Max, Ultra), and within those in family order (M1 purple, M2 pale blue, M3 dark blue, M4 red). Many trends are obvious, from the relatively low performance expected of the M1 family, except the Ultra, and the changes between families, for example the marked differences in the M4 Pro, and the M3 Max, against their immediate predecessors.
Sum core frequencies fall into three classes: 20-30, 35-45, and greater than 55 GHz. Three of the four chips in the M1 family are in the lowest of those, with only the M1 Ultra reaching the highest. The M4 is the first Base variant to reach the middle class, thanks in part to its additional two E cores. Two of the M4 variants (Pro and Max) have already reached the highest class, and any M4 Ultra would reach far above the top of the chart at 128 GHz.
Real-world performance will inevitably differ, and vary according to benchmark and app used for comparison. Although single-core performance has improved steadily, apps that only run in a single thread and can’t take advantage of multiple cores are likely to show little if any difference between variants in each family.
Game Mode is also of interest for those considering the two versions of the M4 Base, with 4 or 6 E cores. This is because that mode dedicates the E cores, together with the GPU, to the game being played. It’s likely that games that are more CPU-bound will perform significantly better on the six E cores of the 10-Core version of the iMac, which also comes with a 10-core GPU and four Thunderbolt 4 ports.
Memory and GPU
Memory bandwidth is also important, although for most apps we should assume that Apple’s engineers match that with likely demand from CPU, GPU, neural engine, and other parts of the chip. There will always be some threads that are more memory-bound, whose performance will be more dependant on memory bandwidth than CPU or GPU cores.
Although Apple claims successive improvements in GPU performance, the range in GPU cores has started at 8 and attained 32-40 in Max chips. Where the Max variants come into their own is support for multiple high-res displays, and challenging video editing and processing.
Thunderbolt and USB 3
The other big difference in these Macs is support for the new Thunderbolt 5 standard, available only in models with M4 Pro or M4 Max chips; Base variants still only support Thunderbolt 4. Although there are currently almost no Thunderbolt 5 peripherals available apart from an abundant supply of expensive cables, by the end of this year there should be at least one range of SSDs and one dock shipping.
As ever with claimed Thunderbolt performance, figures given don’t tell the whole story. Although both TB4 and USB4 claim ‘up to’ 40 Gb/s transfer rates, in practice external SSD performance is significantly different, with Thunderbolt topping out at about 3 GB/s and USB4 reaching up to 3.4 GB/s. In practice, TB5 won’t deliver the whole of its claimed maximum of 120 Gb/s to a single storage device, and current reports are that will only achieve disk transfers at 6 GB/s, or twice TB4. However, in use that’s close to the expected performance of internal SSDs in Apple silicon Macs, and should make booting from a TB5 external SSD almost indistinguishable in terms of speed.
As far as external ports go, this widens the gap between the M4 Pro Mac mini’s three TB5 ports, which should now deliver 3.4 GB/s over USB4 or 6 GB/s over TB5, and its two USB-C ports that are still restricted to USB 3.2 Gen 2 at 10 Gb/s, equating to 1 GB/s, the same as in M1 models from four years ago.
My choice
With a couple of T2 Macs and a MacBook Pro M3 Pro, I’ve been looking to replace my original Mac Studio M1 Max. As it looks likely that an M4 version of the Studio won’t be announced until well into next year, I’m taking the opportunity to shrink its already modest size to that of a new Mac mini. What better choice than an M4 Pro with 10 P and 4 E cores and a 20-core GPU, and the optional 10 Gb Ethernet? I seldom use the fourth Thunderbolt port on the Studio, and have already ordered a Kensington dock to deliver three TB5 ports from one on the Mac, and I’m sure it will drive my Studio Display every bit as well as the Studio has done.
If you have also been tempted by one of the new Mac minis, I was astonished to discover that three-year AppleCare+ for it costs less than £100, that’s two-thirds of the price that I pay each year for AppleCare+ on my MacBook Pro.
I look forward to diving deep into both my new Mac and Thunderbolt 5 in the coming weeks.