同时掌舵 SpaceX、特斯拉、Neuralink 等众多公司,马斯克堪称科技界的六边形战士。
而如果不是他与 OpenAI 现任 CEO Sam Altman 的一纸诉状,可能很多人都不知道原来连 OpenAI 与他也有深厚的渊源,甚至连 OpenAI 的起名都是出自马斯克之手。
具体前情背景可以回看 APPSO 之前的文章:
1、突发|马斯克起诉奥特曼:指控 OpenAI 已成微软闭源子公司,GPT-4 只为赚钱而非造福人类
2. 马斯克起诉奥特曼「敲诈勒索」,GPT-5 要鸽了?

时光流转,这段恩怨纠葛并未随风而逝。
这不,最近马斯克再次公开了一批与 OpenAI 高管之间的邮件往来。尽管未必能知晓全貌,但透过这些关键邮件记录,我们或许能够拼凑出一幅更完整的恩怨图景。
在吃瓜之前,我们需要简单介绍这批邮件中的关键角色:
- Sam Altman(山姆·奥特曼):OpenAI 现任 CEO
- Elon Musk(埃隆·马斯克):OpenAI 联创成员、同时经营 SpaceX、特斯拉、Neuralink 等众多公司
- Greg Brockman(格雷格·布罗克曼):OpenAI 现任总裁
- Ilya Sutskever(伊利亚·苏茨克韦尔):OpenAI 前首席科学家
- Andrej Karpathy(安德烈·卡帕西):OpenAI 创始成员、前特斯拉 AI 总监
- Shivon Zilis(希冯·齐利斯):前 OpenAI 顾问、2017 年加入特斯拉,与马斯克关系密切
附上曝光邮件地址:https://www.lesswrong.com/posts/5jjk4CDnj9tA7ugxr/openai-email-archives-from-musk-v-altman?utm_source=www.therundown.ai&utm_medium=referral&utm_campaign=explosive-openai-musk-emails-revealed#comments
附诉讼案件条目:https://www.courtlistener.com/docket/69013420/musk-v-altman/
吃瓜版图景如下:
2015 年的硅谷,AI 的浪潮正如涨潮时分的海水,悄无声息却又势不可挡地涌动着。
在一个温暖的五月下午,山姆. 奥特曼和埃隆·马斯克进行了一次意味深长的邮件对话。两人都意识到,AI 的发展势不可挡,与其坐视 Google 独占鳌头,不如另辟蹊径。
就这样,一个雄心勃勃的计划在两位科技界大佬之间酝酿而生。
「我们需要一个非营利组织,」奥特曼提议道,「这样才能吸引那些真正关心 AI 发展方向的顶尖人才。」
并且,在奥特曼的规划中,这是一个巧妙的双赢方案:技术成果将通过非营利方式造福全人类,而项目成功后,参与者依然能获得堪比创业的丰厚回报。
两个月后,即将与 Google 创始人拉里·佩奇不欢而散的马斯克尚未下定决心,但对这个想法的赞同已经早有苗头,OpenAI 便这么在你来我往的构想中孕育而生。

OpenAI 的起点,从夏天开始
随着 2015 年夏日的到来,奥特曼开始着手设计 OpenAI 的治理架构。
奥特曼构想了一个由 5 人组成的核心团队,将技术产权归属于基金会,服务于全球公众利益。而马斯克则欣然接受了类似「兼职合伙人」的角色。
安全性被置于 OpenAI 的首要位置。
这个五人核心团队还将肩负起一项重要使命:审慎决定哪些研究成果应该开源,哪些需要保密。
距离 OpenAI 正式成立仅剩一个月之际,时间的沙漏正一分一秒地流逝,每个决策都变得愈发关键。
到了 11 月,格雷格·布罗克曼加入讨论,在与马斯克的往来邮件中,他主张 OpenAI 应以中立机构的身份进入 AI 领域,这样既能确保快速发展,又能在研究领域占据领先地位。
12 月 8 日,距离 OpenAI 成立仅剩三天时间,创始成员们争论的焦点转向了人才招募策略。
马斯克强调,OpenAI 的立身之本在于「造福人类」的崇高使命,把这一点写在组织介绍里才是吸引顶尖人才的关键。奥特曼深以为然,迅速调整了组织介绍的措辞与重点。

然而,就在 OpenAI 宣告成立的那天,奥特曼的心头笼罩了一层阴影。
原因在于,他听闻最强的竞争对手 Google Deepmind 正在以更优厚的待遇招揽人才,这让他深感忧虑,担心 OpenAI 的精英们会被竞争对手挖走。
因此,奥特曼建议适当提高薪资,以在与 DeepMind 的人才争夺战中保持竞争力。
马斯克的注意力则集中在了一个关键人物身上——伊利亚·苏茨克韦尔。他着急地询问奥特曼,伊利亚有没有给出明确的答复,为了争取这位人才,他甚至表示愿意全天候参与招募工作。
最终,伊利亚的加入让马斯克忍不住发出了欣喜的赞叹。

12 月 11 日的午后,马斯克怀着无比激动的心情,向 OpenAI 的早期精英团队发出了一封邮件:
祝贺我们有一个精彩的开端!
我们的人力资源和实力与你所熟悉的一些组织相比,差距巨大,但我们有正义在我们这边,这至关重要。我对我们的胜算感到乐观。我们最重要的任务是招募最优秀的人才。
一个公司的成果是其员工能力的综合体现。如果我们能吸引到最有才华的人,并且我们的方向正确,那么 OpenAI 必将成功。
这封饱含期许的邮件,收件人栏赫然列着一串如今已声名显赫的名字:伊利亚·苏茨克韦尔、帕梅拉·瓦加塔、维姬·张、迪德里克·金马、安德烈·卡帕西、山姆·奥特曼等。

跨入 2016 年,团队开始着手细化运营方案。
布罗克曼与马斯克反复商讨,最终敲定了首批全职员工的薪酬方案。
创始团队成员能获得 27.5 万美元的年薪,外加 YC 公司 0.25% 的股份;新加入的员工则可选择 17.5 万美元年薪 + 12.5 万美元年度奖金或等值的 YC 或 SpaceX 股票。
这个薪资方案虽然看似丰厚,但实际上比业界标准要低得多。
大多数核心技术人员在加入 OpenAI 时,都接受了降薪。就连实习生的待遇也低于市场水平:每月 9000 美元,相比 Facebook(Meta)提供的同等薪资加免费住宿,或是 Google 提供的约 11000 美元全包待遇,确实相形见绌。
不过,面对 DeepMind 的激烈竞争,马斯克表示愿意根据吸引全球顶尖人才的需要,重新评估薪酬标准。
商业与理想的博弈
在那个时期,OpenAI 的对外宣传几乎完全贯彻了马斯克的理念。
这种影响力甚至延伸到了媒体报道的细节——当布罗克曼接受《连线》杂志采访时,都需要就某些关键问题与马斯克确认,以确保表述准确且与马斯克的观点保持一致。
到了 2016 年 4 月,当扎克伯格将 AI 定位为纯粹的服务工具,并驳斥 AI 威胁论时,马斯克却坚持认为 AI 是把双刃剑,这种观点差异,恰恰体现了他创立 OpenAI 的初衷——
人类应该谨慎地对待 AI 的发展,并确保其力量被广泛共享,而不是由单一公司或个人控制。
同年 9 月,一个重要的机遇降临 OpenAI 团队面前。
微软开出了一份诱人的合作方案:OpenAI 只需投入 1000 万美元,就能换取价值 6000 万美元的计算资源,还能对微软云服务的部署内容提出建议。
但这份合作背后附加的条件却是 OpenAI 需要评估并优化微软技术产品,同时为 Azure 背书。
马斯克当即表示反感并否决了这一提议。

最终在 Altman 的斡旋下,OpenAI 与微软达成了一份 5000 万美元的协议,没有任何强制性条件,OpenAI 可以自主决定以「善意努力」的方式推广微软产品。
2017 年中期,全速前进的 OpenAI 迎来了重要突破,他们成功开发出了标志性的项目——机器人手解魔方,实体机器人预计将在九月具备同样的能力。
与此同时,伊利亚兴奋地对马斯克表示,OpenAI 的 1v1 机器人已经完全堵住了所有可能的漏洞,能够有效抵御任何非常规策略的攻击。
他充满信心地预测,在一个月内,这个 AI 系统将有能力在游戏中战胜所有人类玩家。就连竞争对手 DeepMind 也开始采用 OpenAI 的一种算法,用于优化他们的模拟环境中的行为控制。
然而,就在 OpenAI 蓬勃发展之际,组织内部的矛盾却如同暗礁般浮出水面。
组织的暗流涌动
2017 年的夏末,一场关于组织未来的重要讨论在核心团队之间展开,这场讨论最终成为了 OpenAI 发展历程中的一个重要转折点。
布罗克曼和伊利亚选择在一个宁静的周末进行密谈。在这次谈话中,他们终于倾吐了长期以来压在心头的种种顾虑。
然而,他们可能没有预料到,这次谈话的内容会通过 OpenAI 的顾问希冯·齐利斯传达到马斯克耳中,并引发一场足以改变组织命运的风暴。
在这次充满争议的密谈中,两人提出了多项主张:
- 首先,他们认为如果成功开发出 AGI(通用人工智能),任何个人都不应独揽控制权,希望在 2-3 年后逐步实现权力的分散,建立一个更民主、更可持续的权力分配机制;
- 其次,他们对马斯克在 OpenAI 的投入时间提出质疑,希望他能投入更多精力。
- 再者,他们觉得 OpenAI 团队在软件/机器学习方面较强,希望在硬件等短板领域获得更多支持;
- 最后,他们还要求扩大员工股权池,确保他们的股份超过马斯克的 1/10(具体比例待定)
这次「秘密会谈」的内容让马斯克勃然大怒「这真的很烦人,」他在回复邮件中写道,语气中充满了愤怒与失望,「请鼓励他们去创办一家公司。我已经受够了。」
九月,局势再次急转直下。
伊利亚在一封情真意切的邮件中坦承了之前与布罗克曼的不够坦诚,但同时也毫不避讳地指出了自己的核心忧虑。
伊利亚认为马斯克展现出的强烈控制欲可能会让他成为 AGI 的独裁者。同时,他也对利用特斯拉资源收购 AI 芯片公司 Cerebras 的提议表示反对。
具体来说,担忧的是特斯拉有责任对股东负责,最大化股东回报,这与 OpenAI 的使命不一致。所以最终结果可能对 OpenAI 来说并不是最优的。
与此同时,伊利亚还对奥特曼执着追求 CEO 头衔的动机提出质疑,种种疑虑在他心中积压已久。

这封坦白信就像一颗炸弹,瞬间引爆了积压已久的矛盾。
马斯克的回应既简短又决绝,字里行间透着难以掩饰的愤怒:「各位,我受够了。」他提出了最后通牒:要么分道扬镳,要么继续坚守非营利的初衷。
我不想成为一个白痴,为你们免费提供创业资金。
也许在他看来,这场争论已经完全背离了 OpenAI 设立的初心。
危机当头,奥特曼展现出了高超的危机处理能力,立即表态支持继续非营利模式运营
希冯·齐利斯也适时传来缓和信号,伊利亚和布罗克曼都愿意维持非营利模式,不会另起炉灶。然而,这场风波还是在奥特曼心中种下了疑虑的种子,让他开始重新审视两人的管理能力和决策成熟度。
2018 年伊始,命运似乎又给 OpenAI 出了一道难题。
在烧钱的困境之下,当 Altman 提出考虑通过 ICO(一种通过发行数字代币进行融资的区块链领域常见方式)进行融资时,安全团队立即拉响了警报。
就在此时,安德烈·卡帕西分享了一组来自顶级深度学习会议的数据,这份报告如同当头一棒:Google 以 83 篇论文的惊人提交数量遥遥领先,而 OpenAI 的处境则更不容乐观。
马斯克一针见血地指出:「OpenAI 与 Google 相比,正走向必然的失败。」
在这个紧要关头,不同的意见开始碰撞交汇。
在与 OpenAI 高层的沟通中,他明确表示,尽管 ICO 看似是一条出路,但这种选择将会对 OpenAI 的声誉造成无可挽回的损害。作为替代方案,他建议将 OpenAI 纳入特斯拉的版图。
安德烈也力挺将 OpenAI 并入特斯拉的提议,他认为这是与 Google 抗衡的唯一可能。
「如果无法与之竞争,却仍坚持开放研究,」他警告道,「实际上是在为 Google 提供免费援助,因为他们能轻易复制并规模化应用任何突破性进展。」
他认为,只有借助特斯拉的现金流,才有可能与 Google 抗衡。

马斯克抄送了安德烈的邮件补充说:
安德烈说得完全对。我们或许希望有其他选择,但在我和安德烈看来,特斯拉是唯一有可能与 Google 竞争的路径。即便如此,成为 Google 的对立面仍然概率极小,但它并非零。
不过,经过激烈的博弈与深思熟虑,OpenAI 最终开辟了一条前所未有的新路。
根据希冯·齐利斯传来的邮件消息,奥特曼确认放弃了 ICO 计划,转而构思了一个创新的融资模式:保留 OpenAI Inc. 作为非营利实体的同时,设立一个有利润上限的 OpenAI LP 作为盈利性机构。
这是一次大胆的尝试,旨在在保持使命的同时解决资金困境。而在一个月前,失望的马斯克早已离开了 OpenAI。
2018 年 4 月,奥特曼还咨询马斯克关于《OpenAI 宪章》的草稿意见,其中有一句写道「我们致力于提供帮助社会走向 AGI 的公共产品。」
到了 2019 年 3 月,OpenAI 的新架构终于成型。
OpenAI 构建了一个「有限利润」公司架构,既能吸引投资,又能确保超额收益归属非营利实体。首轮投资者的回报上限定在投资额的 100 倍,未来这一比例还将进一步降低。

在这个历史性的转折点上,马斯克早已完全抽身。
奥特曼起草的新闻稿中特别指出,「埃隆·马斯克于 2018 年 2 月离开了 OpenAI Nonprofit 的董事会,并不参与 OpenAI LP。」
披露的最后一封邮件停留在了 2019 年 3 月 11 日。
「彭博社报道:旧金山的人工智能研究机构 OpenAI,由埃隆·马斯克和其他几位硅谷知名企业家共同创立,现正成立一家盈利子公司,目的是为了筹集更多资金。」
马斯克转发了彭博社的一则报道,要求奥特曼向彭博社公开澄清,他与 OpenAI 的盈利子公司之间不存在任何财务关系。奥特曼淡淡地回了一句「已了解」。
这标志着一个时代的结束,也预示着新的开始。
这个为了造福人类而诞生的组织,依然在朝着它的使命前进,只是在当下奥特曼的掌舵下,这其中道路比想象中更为曲折。
在这批公布的邮件当中,我们也看到了一群怀揣远大抱负的创新者。技术的进步从来都不是一帆风顺的,AGI 之路仍旧道阻且长。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
爱范儿 |
原文链接 ·
查看评论 ·
新浪微博





 图标手动触发搜索
图标手动触发搜索


































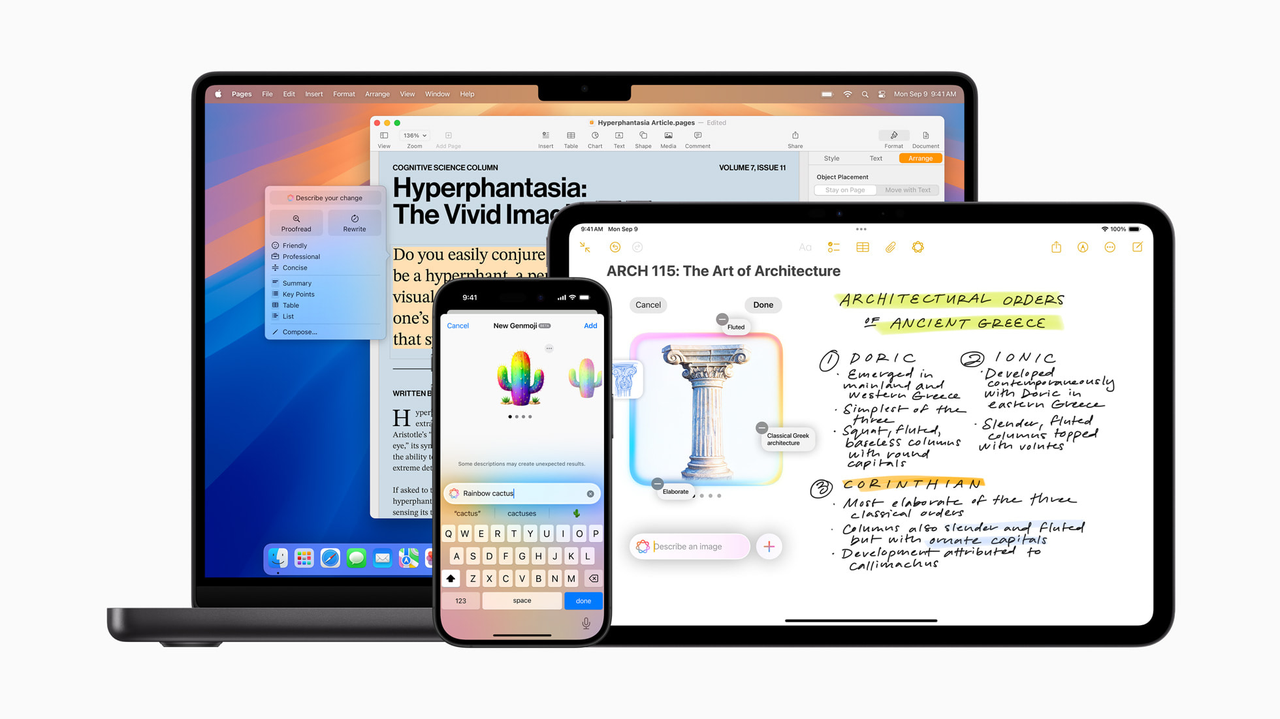

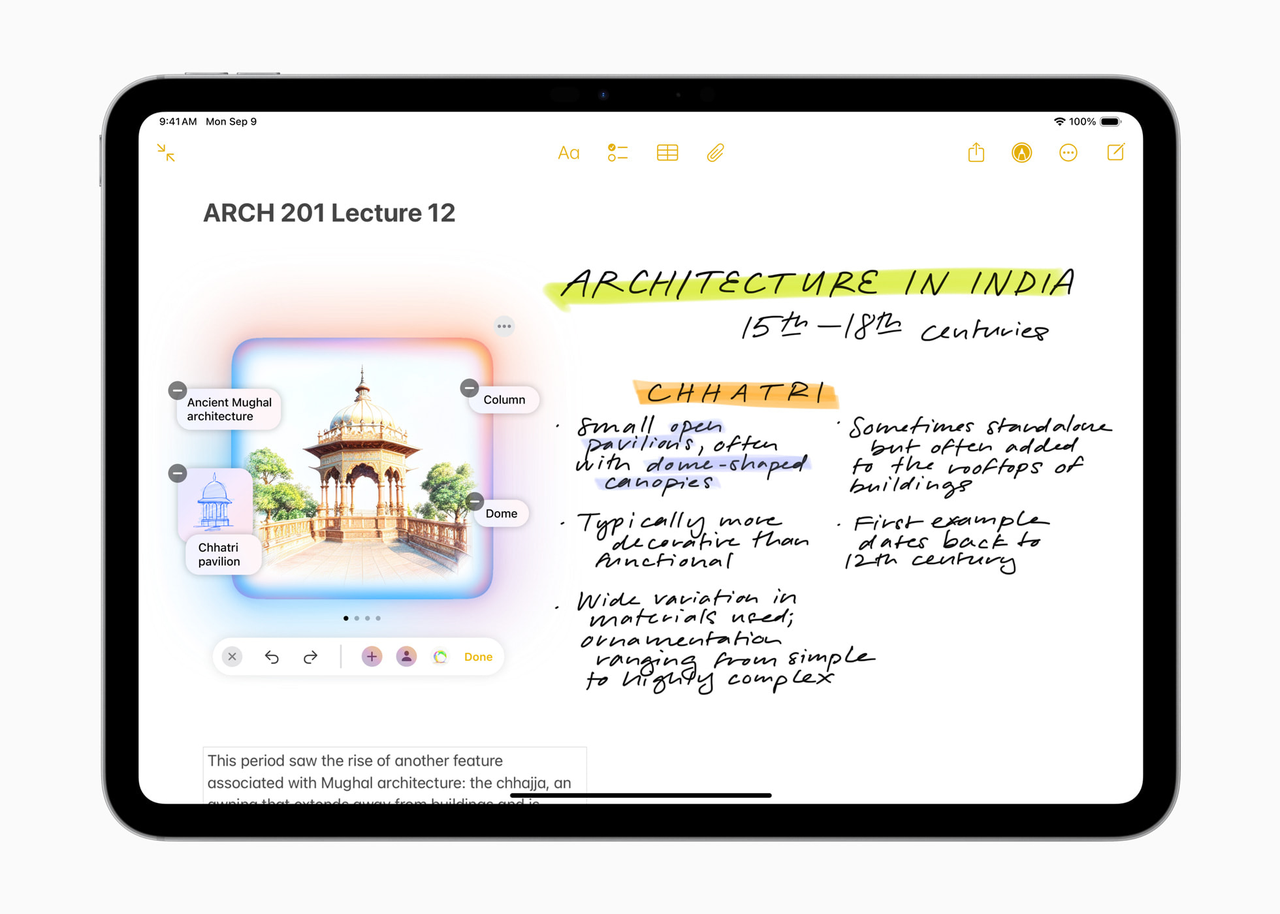
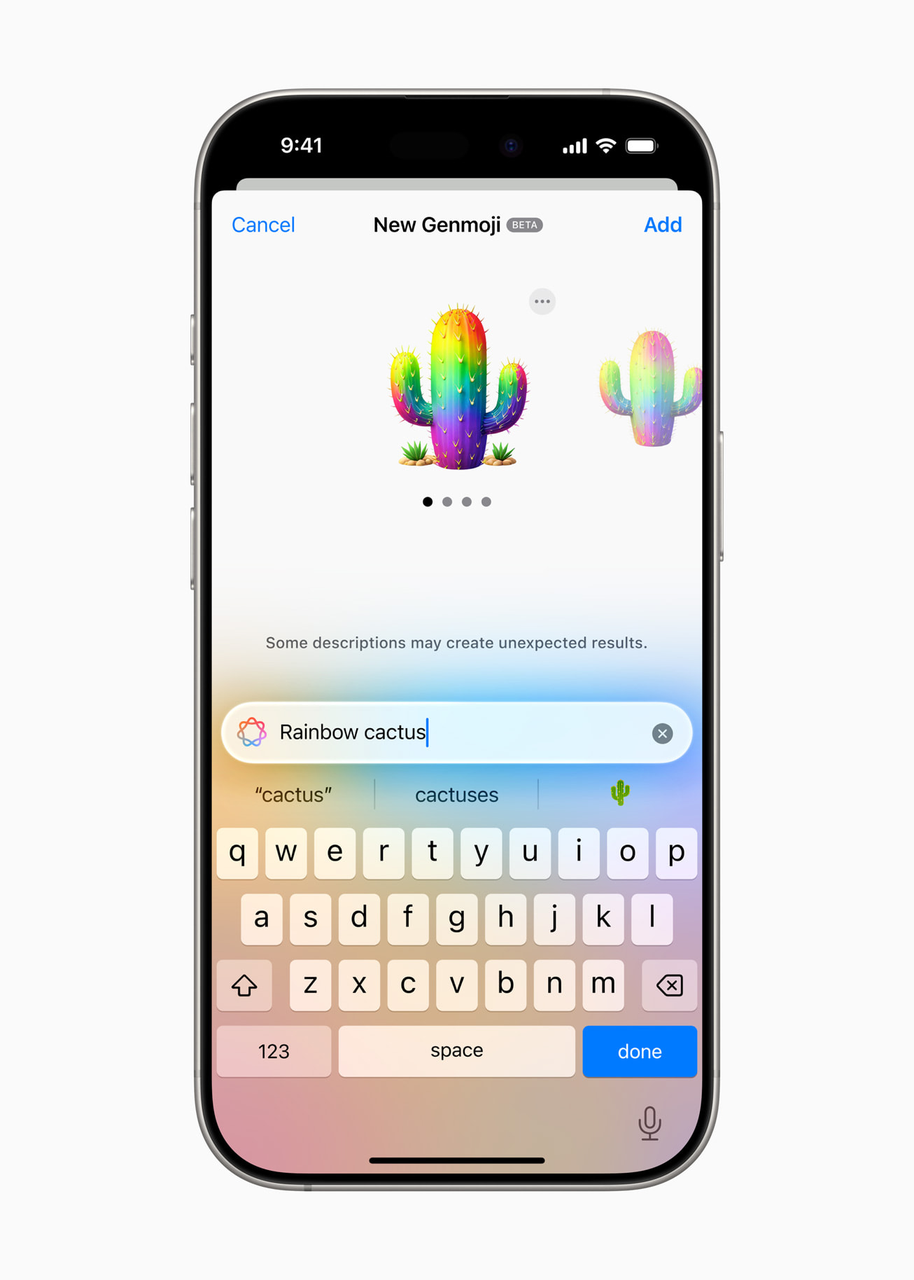









































 12. 不仅仅是完成任务——磨练自己的技能
12. 不仅仅是完成任务——磨练自己的技能