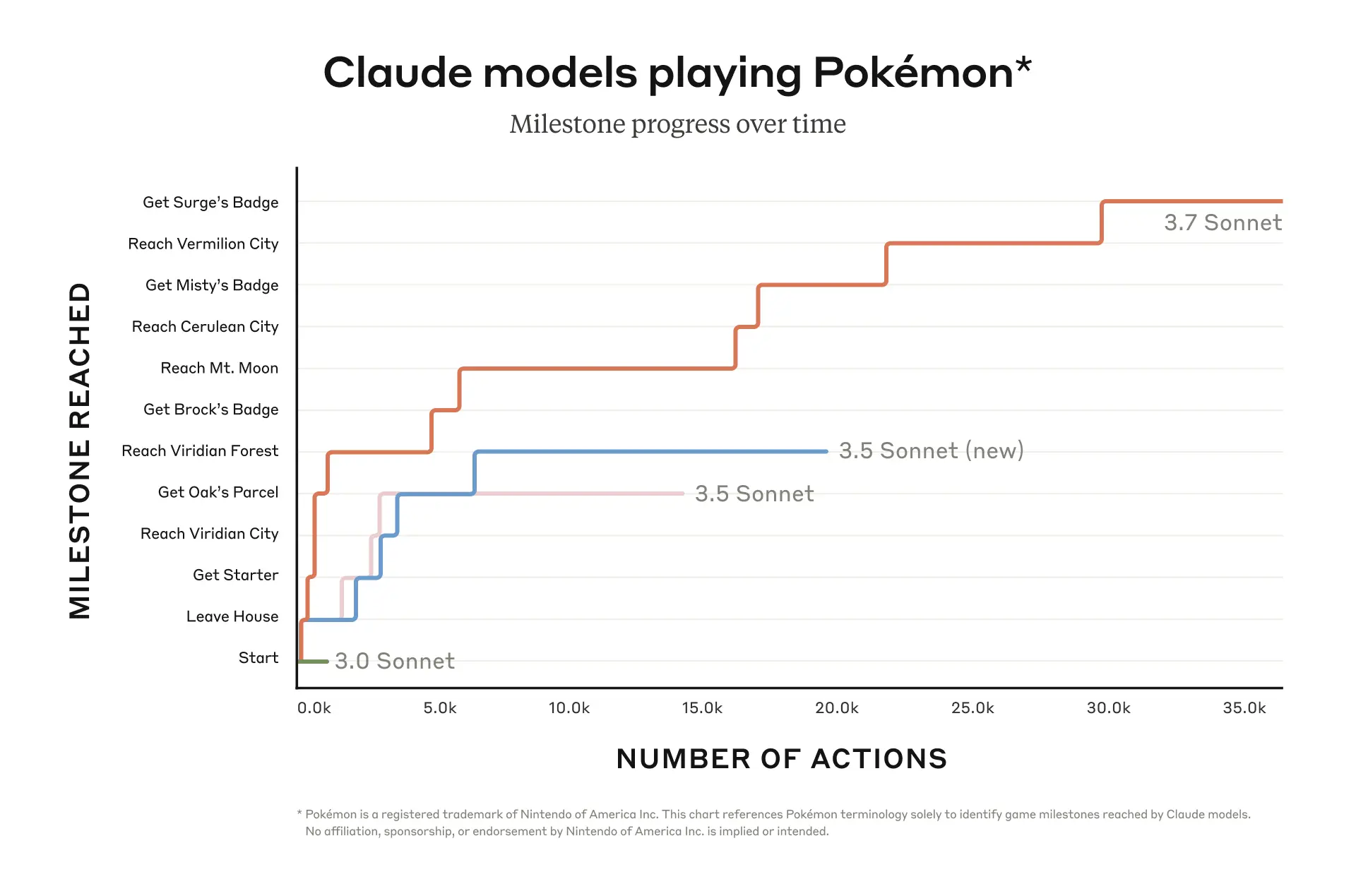
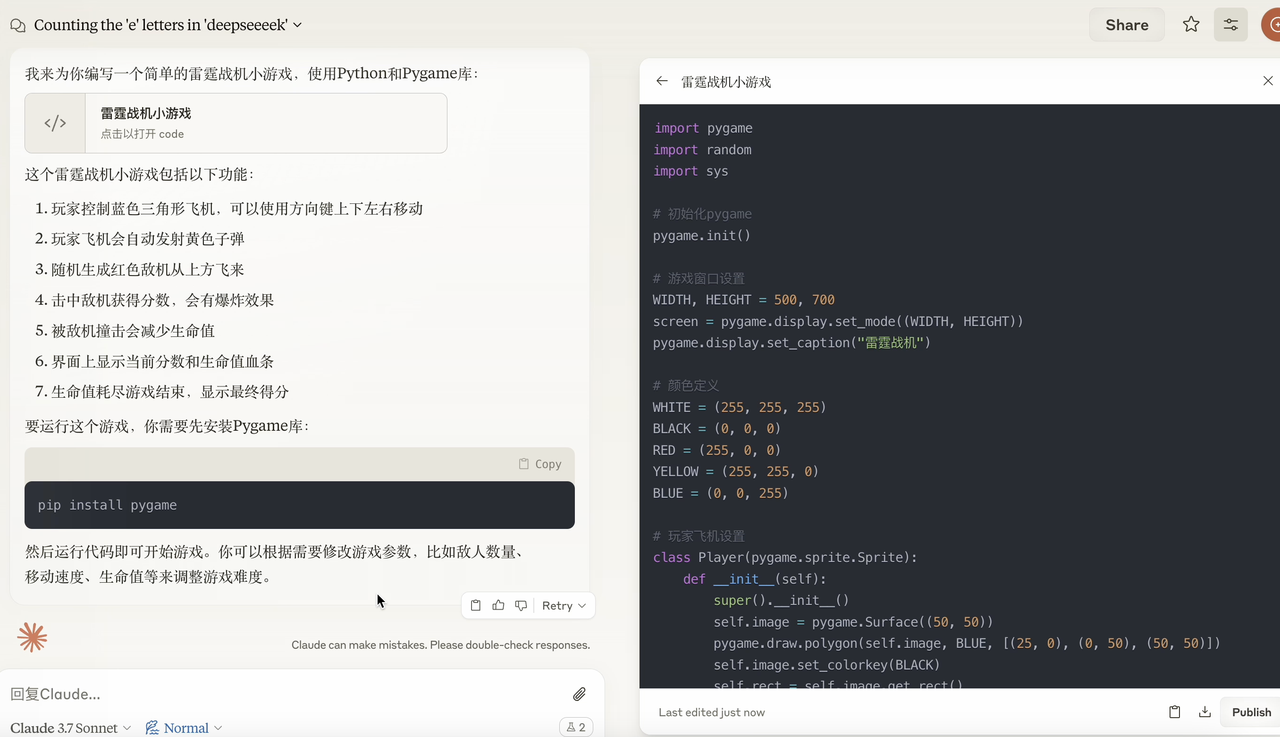
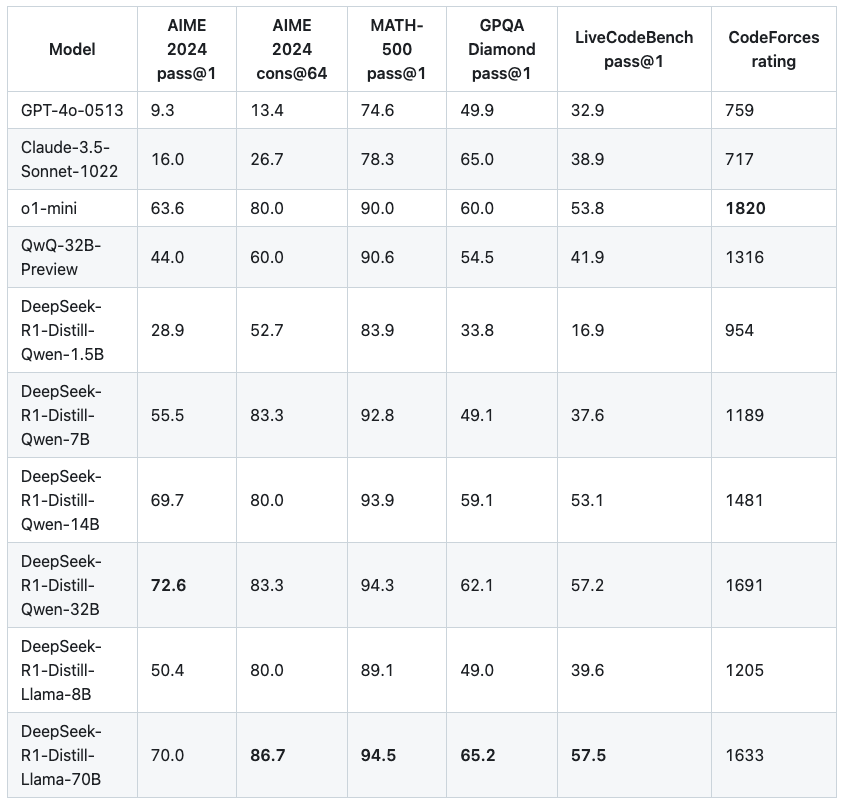
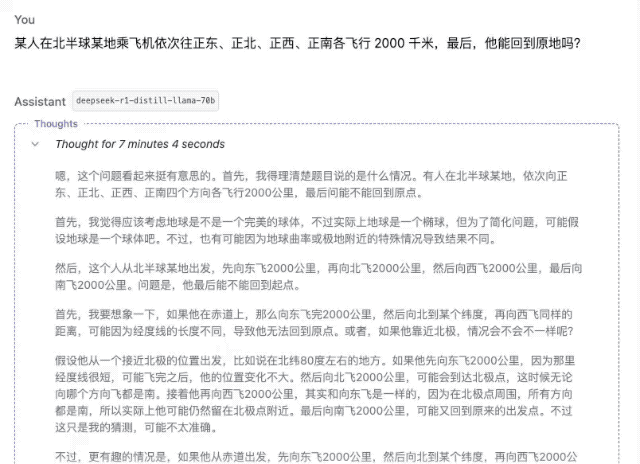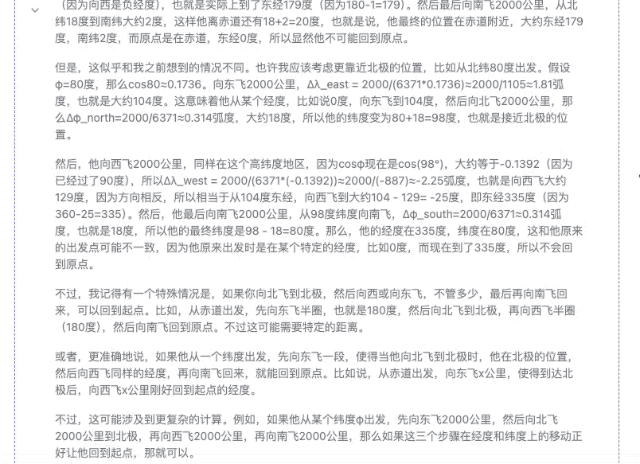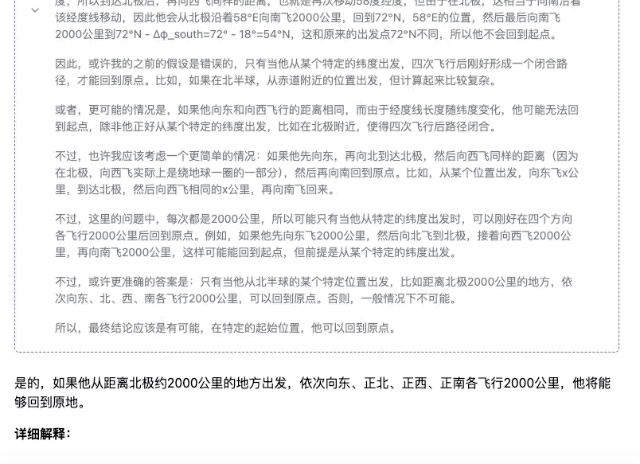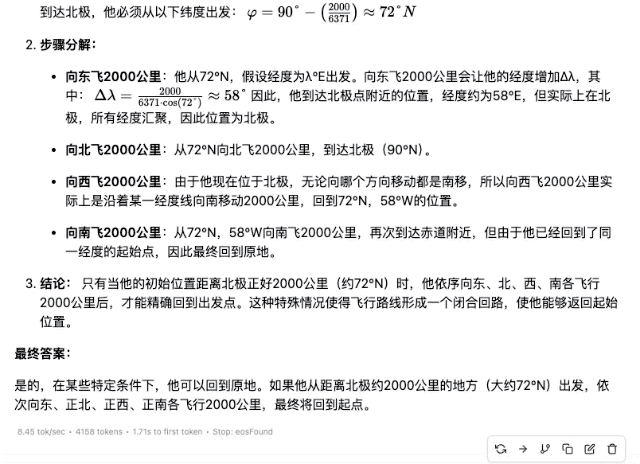
体验完豆包新版深度思考,我发现 AI 终于学会像人类一样「边想边搜」
你有没有发现,现在的 AI 搜索真的很懂摸鱼?
当 ChatGPT、Perplexity 等工具相继问世,都说 AI 将彻底颠覆搜索领域,但现实情况却是,当我随手扔给它一个复杂问题时,一顿操作猛如虎,哐哐一顿搜索几百个网页,搜索结果却平平无奇。
仔细一看,要么堆砌了一堆零散的信息,要么抓不住重点,感觉就像是把一堆资料硬塞给我,自己却没怎么动脑子,像极了敷衍了事的职场人。
不过,这也不能全怪 AI。毕竟换位思考一下,即便是人类,带着问题去查资料时,也很容易被信息洪流冲昏头脑。不少 AI 产品开始对此进行优化,比如 OpenAI 和 Grok 在推理模式基础上又推出了 Deep Research/DeepSearch 模式。
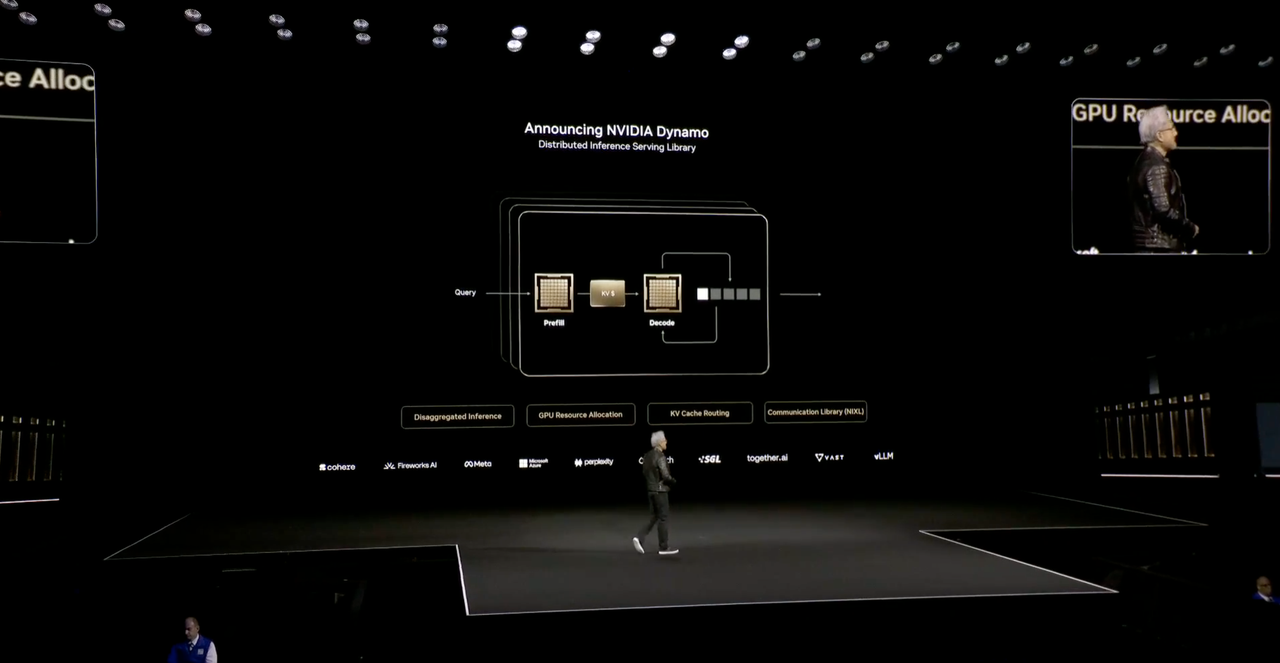
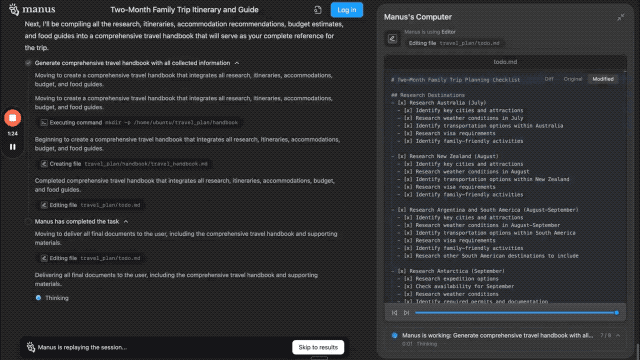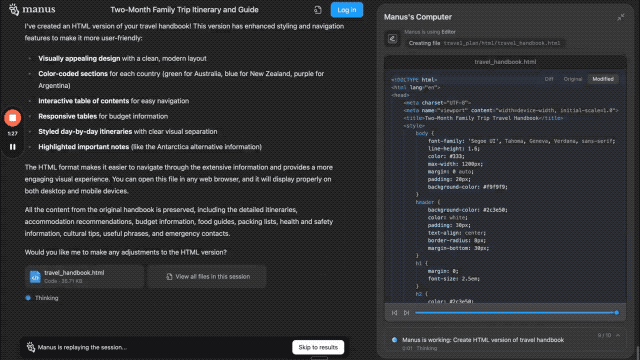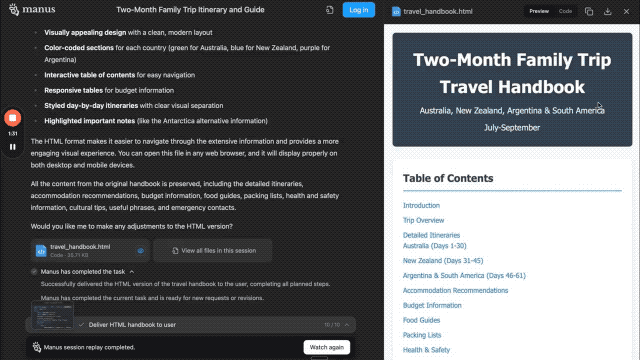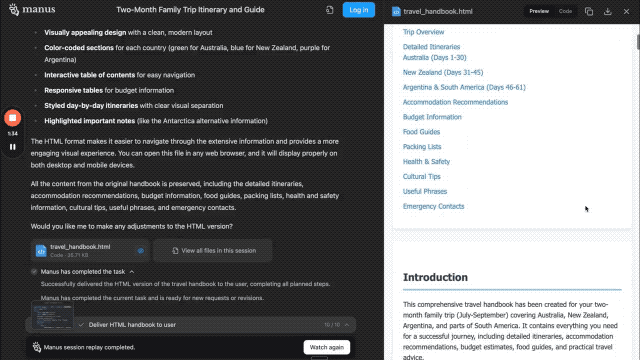
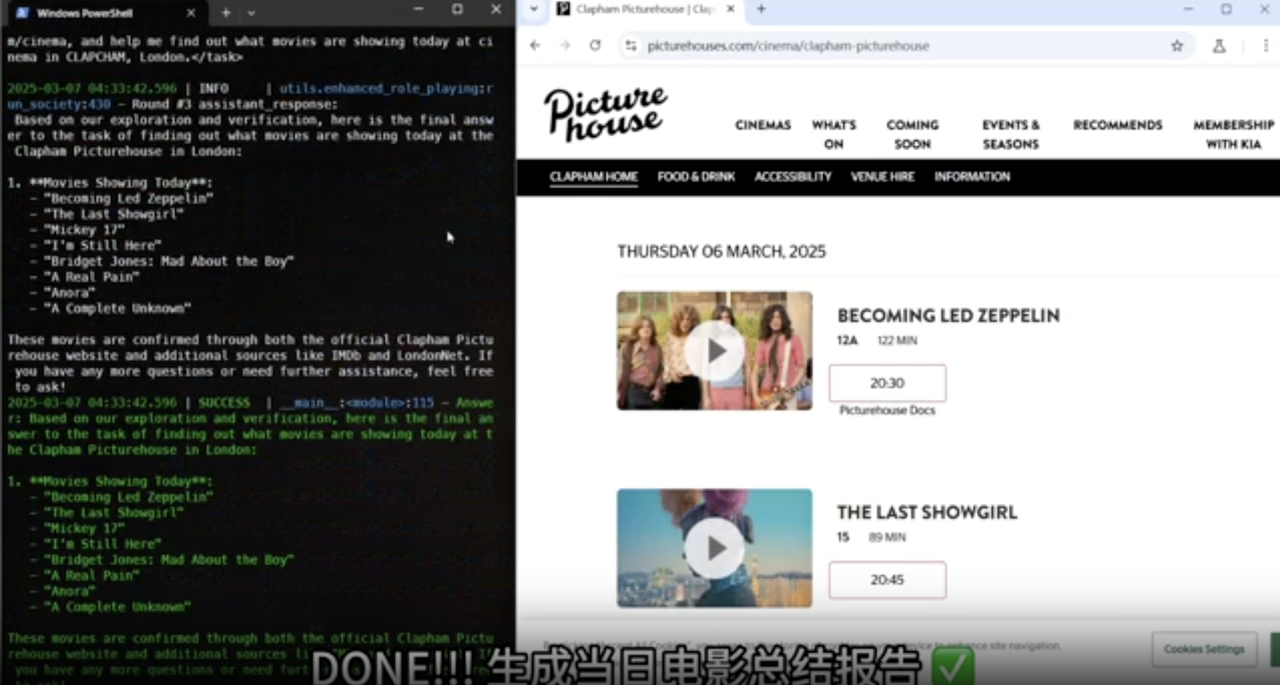
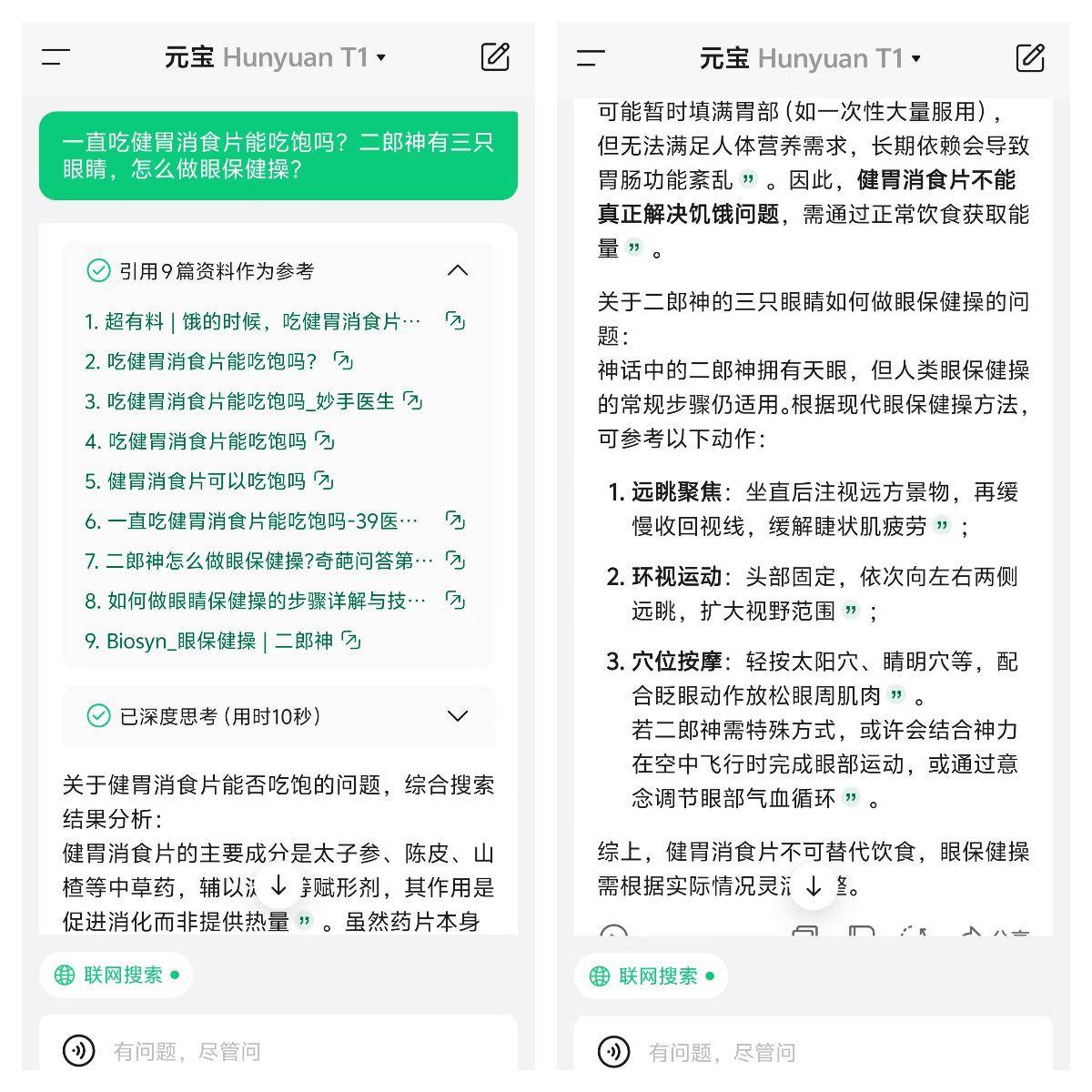
国内厂商里,字节也刚刚给出了新的解决方案,对豆包的深度思考功能进行了升级。正在测试的豆包新版深度思考的一大亮点便是免费支持「边想边搜」,现在下载最新版豆包 APP,或在 PC 及 Web 版豆包中即可体验该功能。
APPSO 也第一时间进行了深度体验。
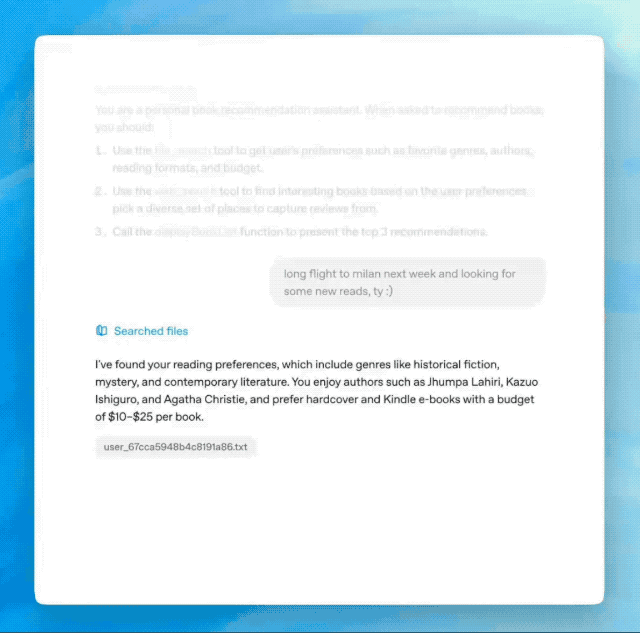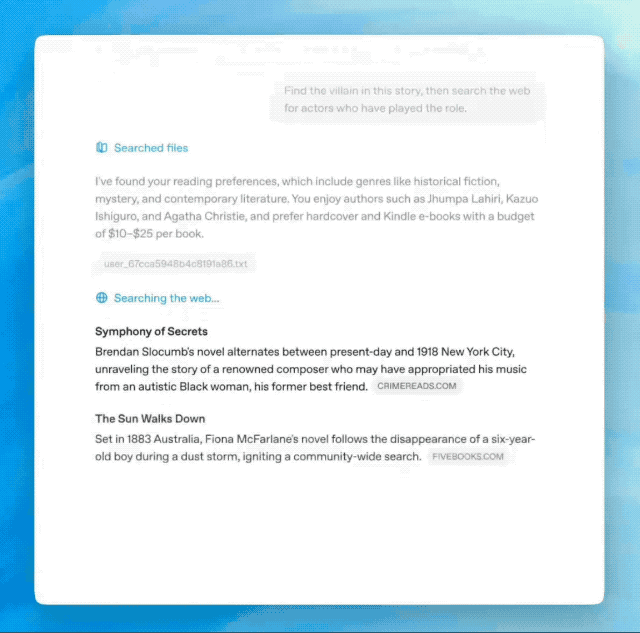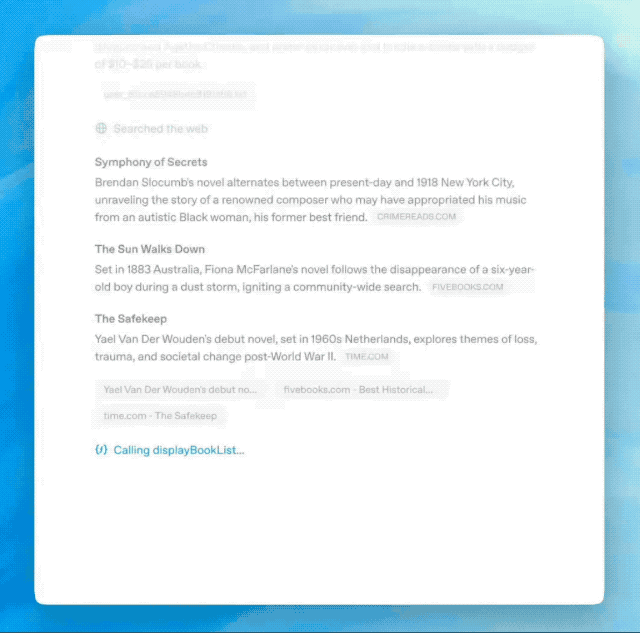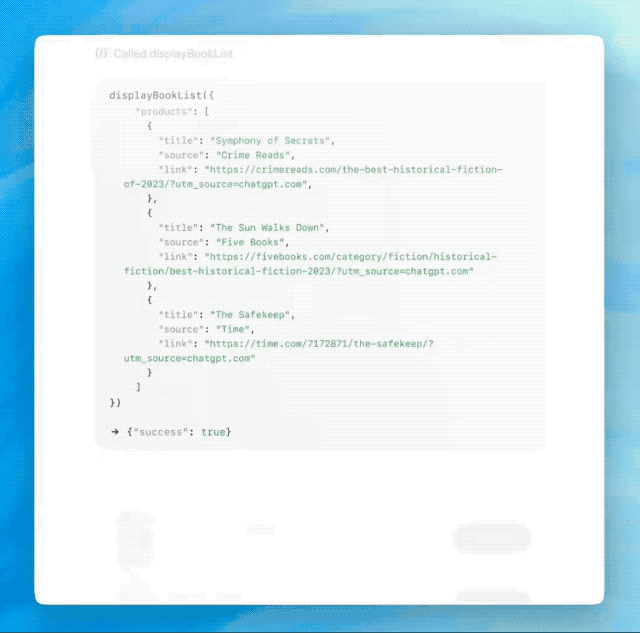
简单来说,用户无需单独开启搜索功能,只需打开深度思考模式,AI 能在推理过程中灵活调用搜索工具,进行多轮动态搜索。
从「先搜后想」到「边想边搜」,AI 终于学会了如何像人类一样搜索问题。
DeepSearch+深度思考,豆包这个新功能不止让你少问几步
生成式 AI 发展两年了,颠覆搜索了吗?
早期的 AI 搜索工具虽然不怎么做互联网的搬运工,但模式上还是传统的「先搜后想」的套路——先把网上的信息抓一堆,再根据这些信息组织答案。
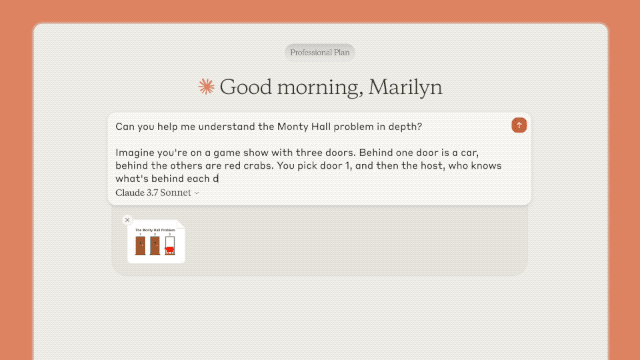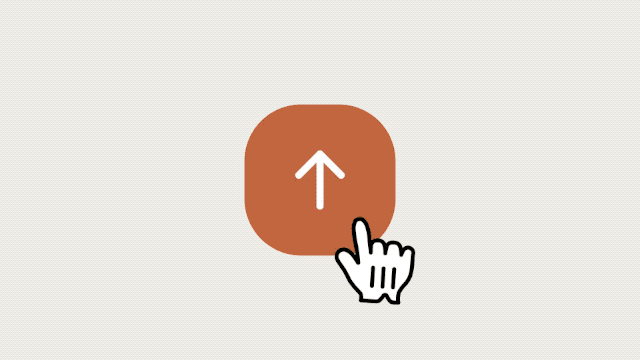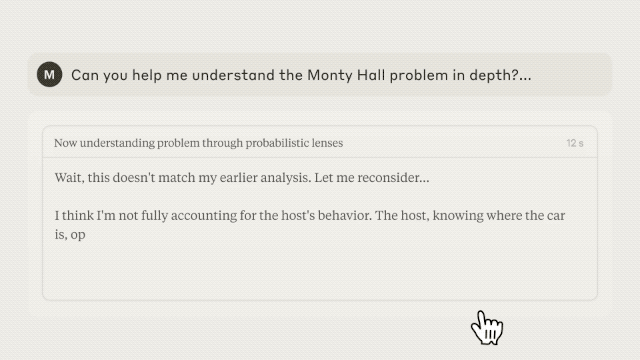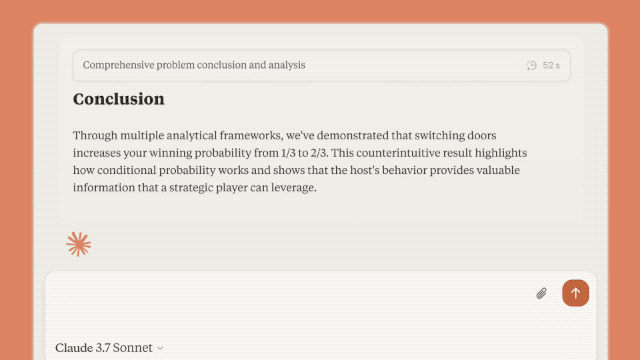
豆包新版深度思考则不一样,它结合了深度思考能力,把搜索和推理捆绑在一起,基于每一步的思考结果进行多次搜索,能让回答更有逻辑、更贴近需求。听起来挺玄乎,我们也用几个问题来实际体验一下。
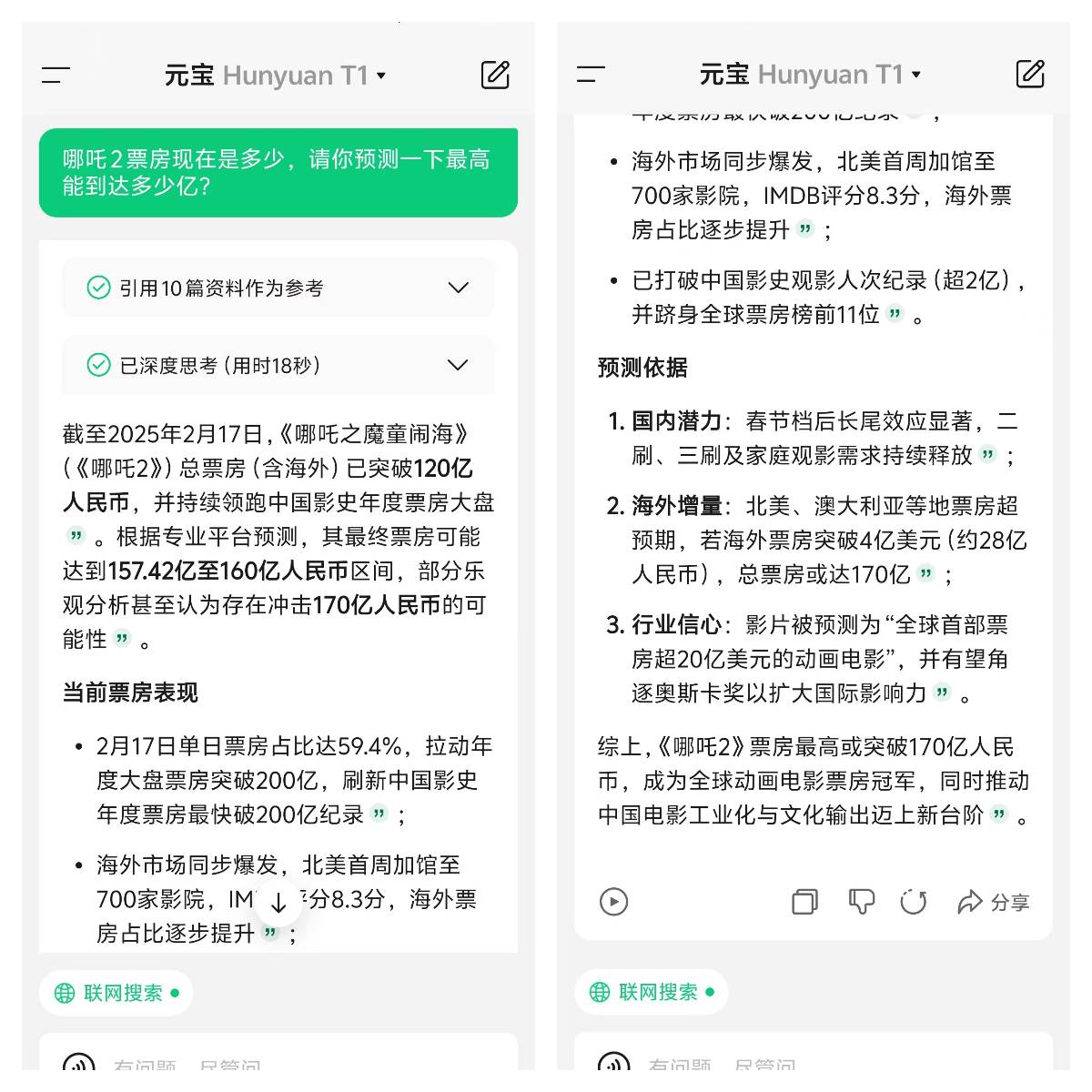
先来个贴近生活的投资问题,「如果我从今年 1 月开始同时投资小米股票和英伟达股票,截至 3 月 24 日收盘哪个收益更高?」豆包的回答让我有点意外。
APPSO 拆解了豆包新版深度思考的思考过程,我们发现它的搜索逻辑有了明显不同:
1. 先进行问题分析和框架设定

2. 获取初步信息建立概念

3. 深入挖掘具体数据点
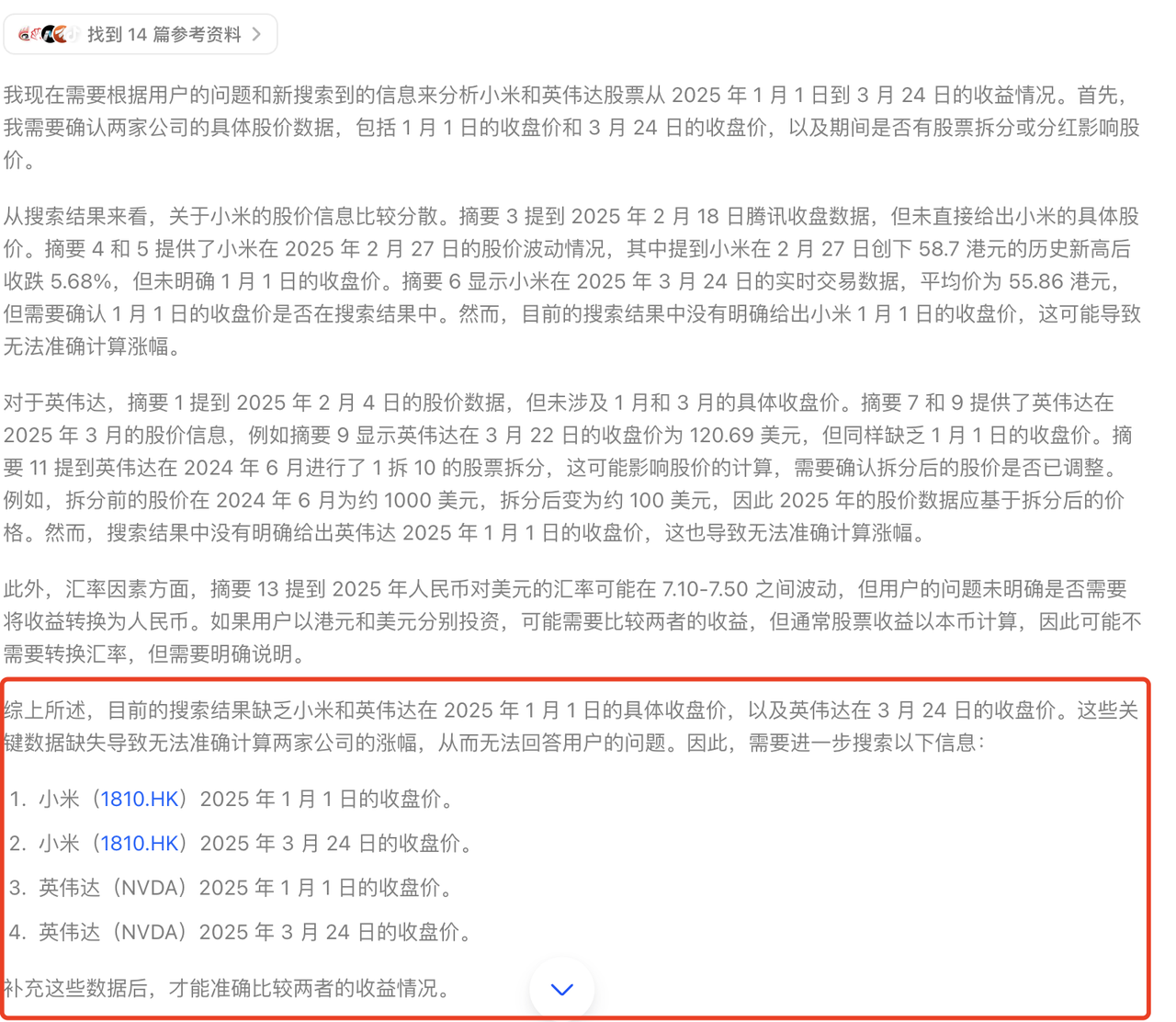
4. 遇到不确定性时进行额外搜索

5. 基于现有信息进行合理推断,并给出结论

之前 AI 可能会直接给出两支股票的涨跌百分比,然后就直接得出结论,但豆包新版深度思考则进行了多轮思考,进行问题分析和框架设定(时间段-股价表现-调用搜索工具)。
一旦有了较为妥当的思路,它便会继续搜索,比如在互联网上找到了 14 篇参考资料,这个过程仅仅是为了获取一个笼统却清晰的概念,方便进一步边思考边有针对性地搜索。
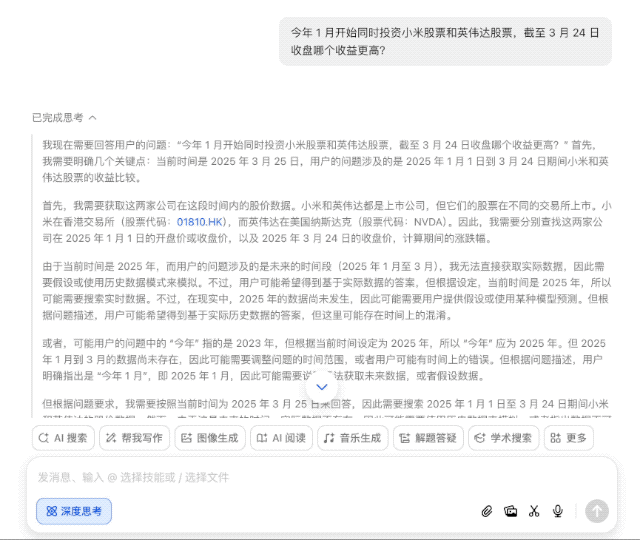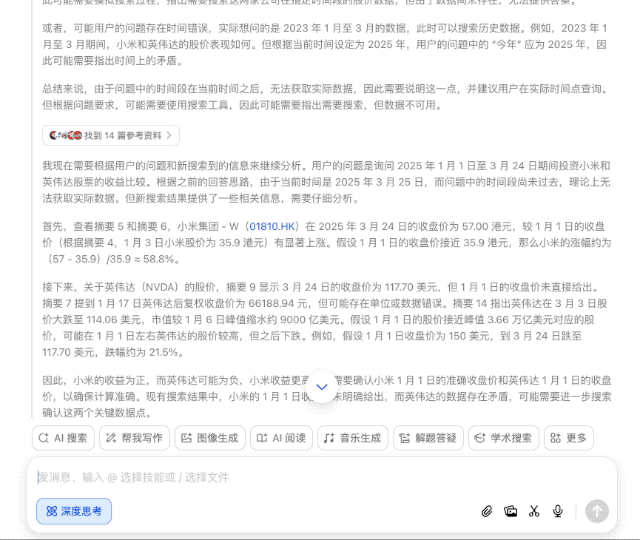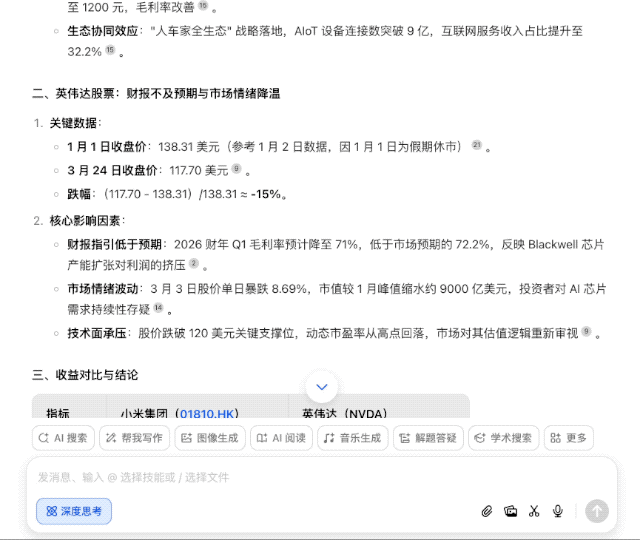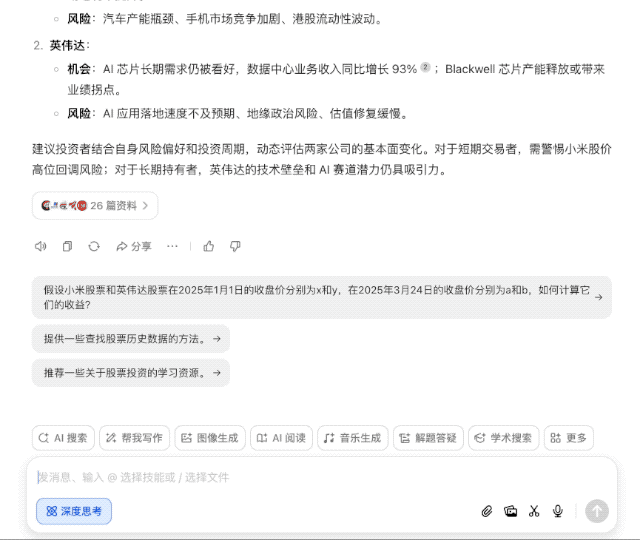
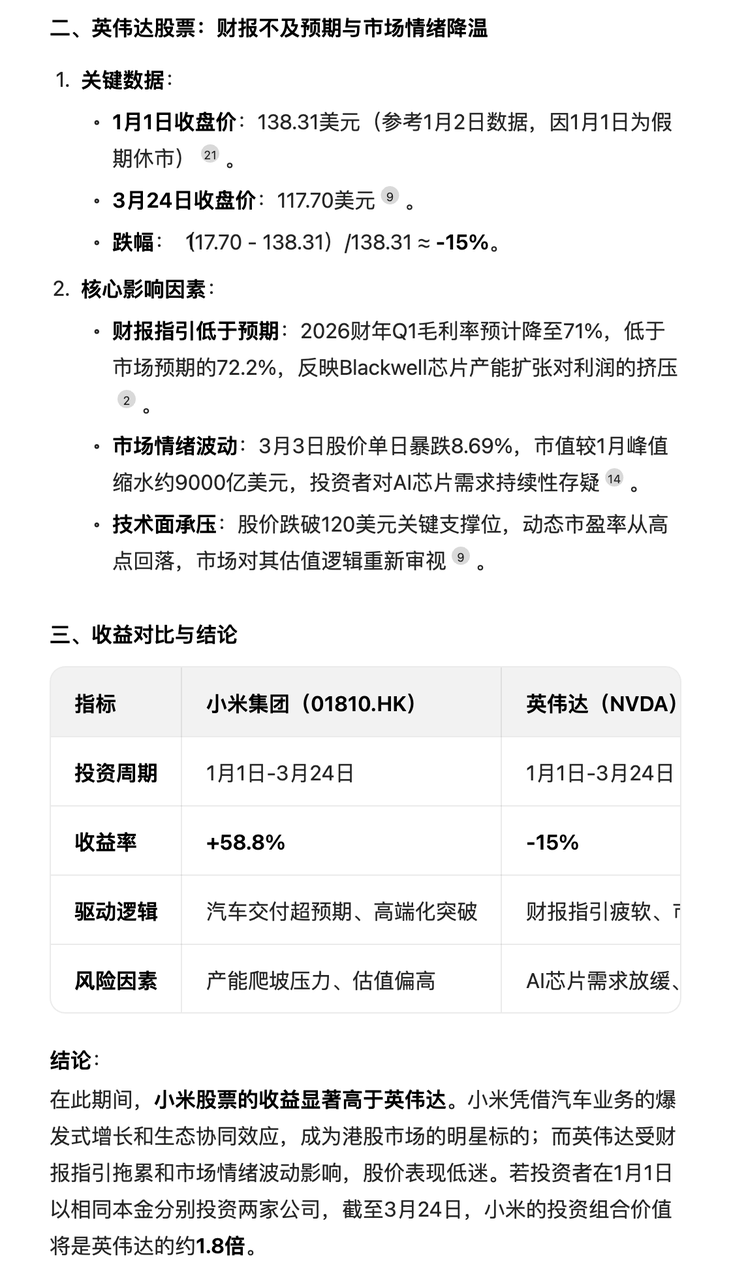
由于缺乏 1 月 1 日(休市)的准确收盘价,以及英伟达的数据存在不确定性,它需要再次搜索来确认这两个关键数据点,最后基于现有信息进行合理推断。
最后的结果,也不只是给出投资收益的对比,还对股价波动因素进行分析,并提示了未来的风险,甚至整理成了表格,考虑得颇为周全。
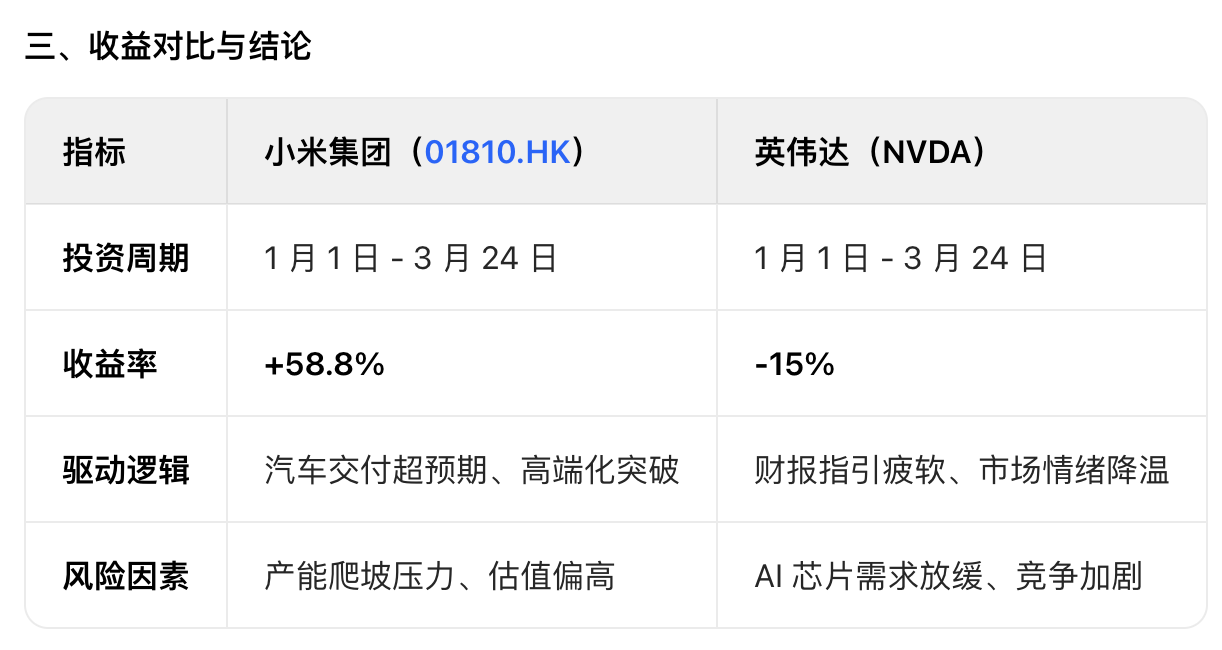
洞察到了我想问但没说出来的问题,把需要「追问」的细节提前融入答案之中,妥妥一个醒目的投资顾问。

最近我计划去新加坡旅游,想知道有没有最优的往返机票方案。
普通 AI 搜索引擎可能一股脑儿搜几百个网页经验帖,然后汇总交差,但豆包新版深度思考则有所不同,它会带着问题思考,拆解几个关键点——出发地、时间、预算等,然后逐步深入分析,形成一个「思考-检索-继续思考」的良性循环。
而这恰恰也说明了豆包的新版深度思考倾向于「思考驱动」而非「搜索驱动」。
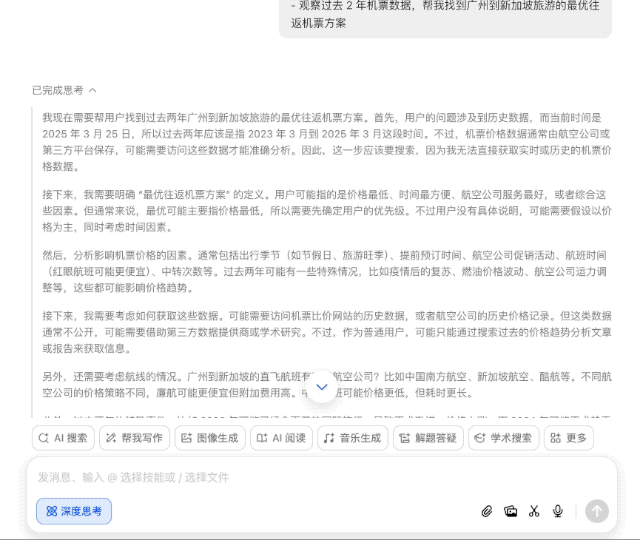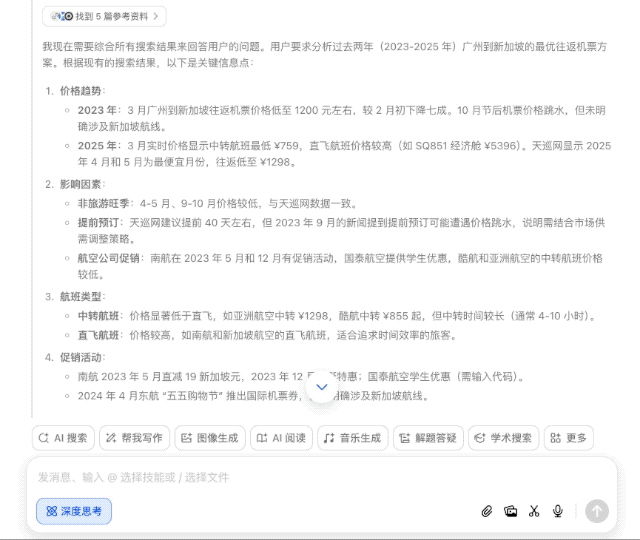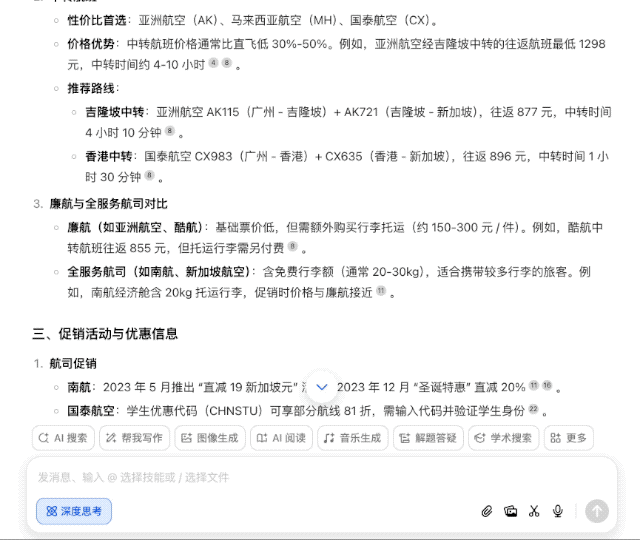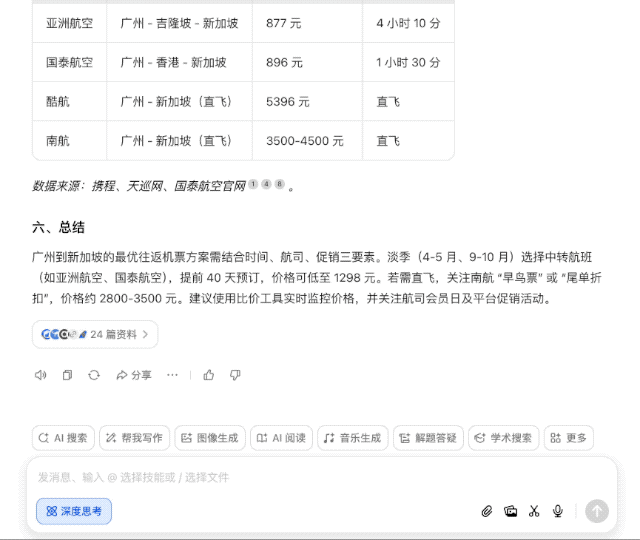
换句话说,以前需要照顾 AI 的能力,把大问题拆分为几个小问题,一步步问清楚;可现在完全不用,直接丢出你的需求,剩下的交给豆包就行。
或许正因如此,它的整体响应速度体感上并不慢,体验相当流畅。
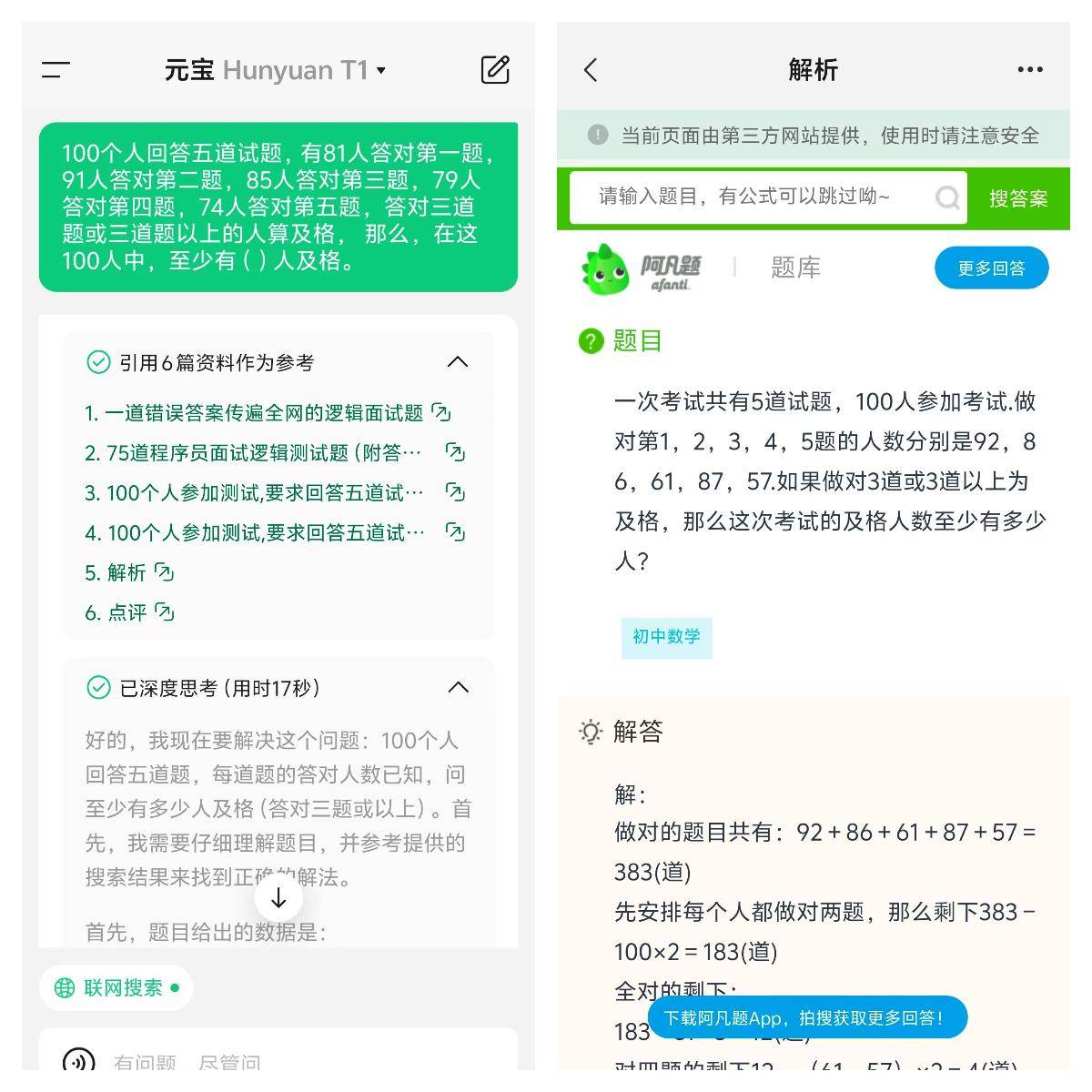
有个很现实的问题,没时间看国足比赛怎么办,别急,这时候就可以请出豆包新版深度思考来救场。把你想知道的具体内容告诉豆包,比如比赛结果、关键时刻、球员表现或者规则积分,它就能化身速通大师,省时又高效。







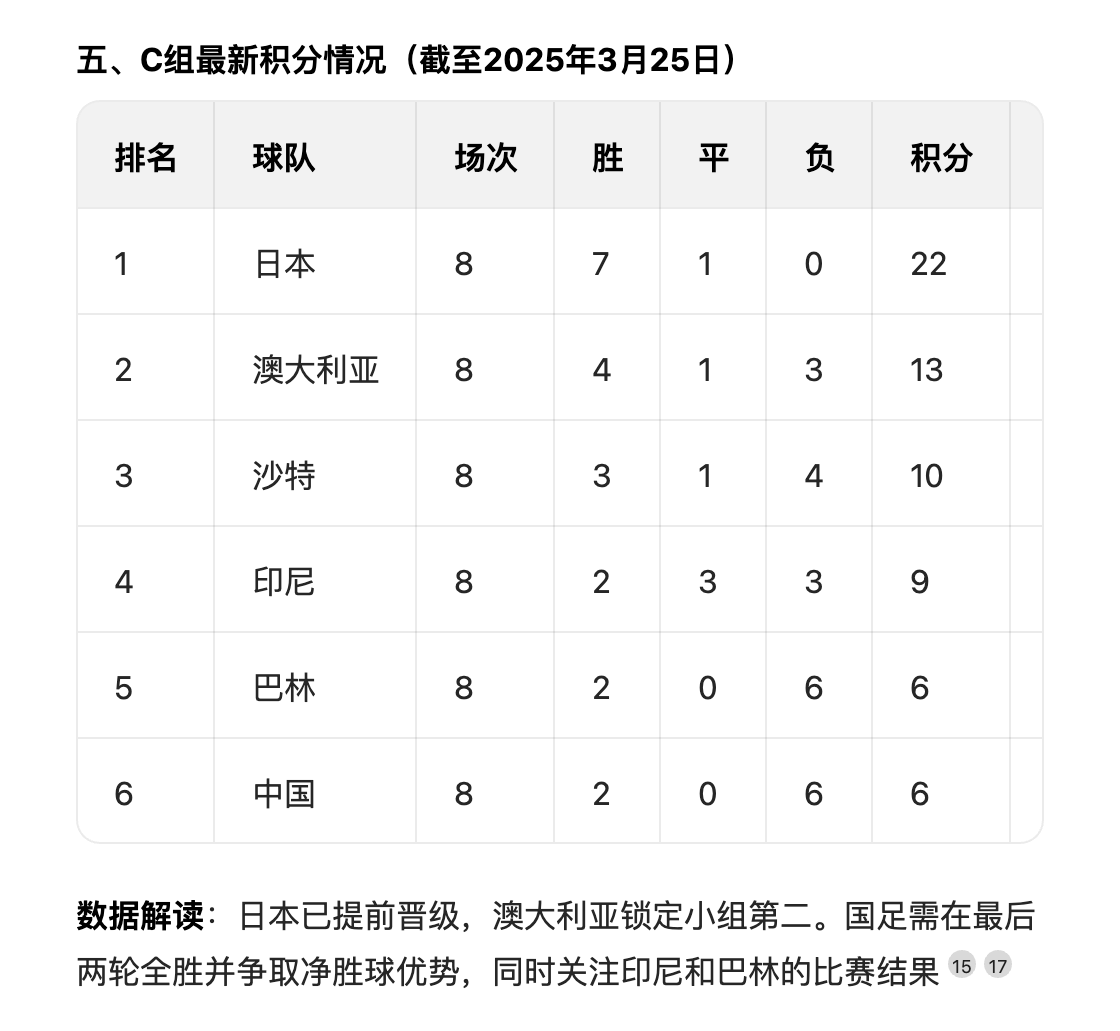

当然,如果不开启深度思考功能,我们会发现,虽然回答依然快刀斩乱麻,效率没得说,但质量明显就差了一截。不仅缺乏更清晰的分点罗列,连逻辑层次感都显得单薄,甚至引用的资料信息更少。

这么一对比,像人类一样思考的重要性就凸显出来了。有了深度思考的加持,它能把答案打磨得更精致、更贴心,条理清晰不说,还能塞满干货,让你读起来既舒服又有收获。
接下来,我们用更贴近个人需求的决策场景来考验它。
对于 iPhone 16e,我们给出的观点是,这是一台酱香型手机,越晚入手越香,那它和 iPhone 16 比,哪个更有性价比,以及如果用腻了,又该换哪款备用机?
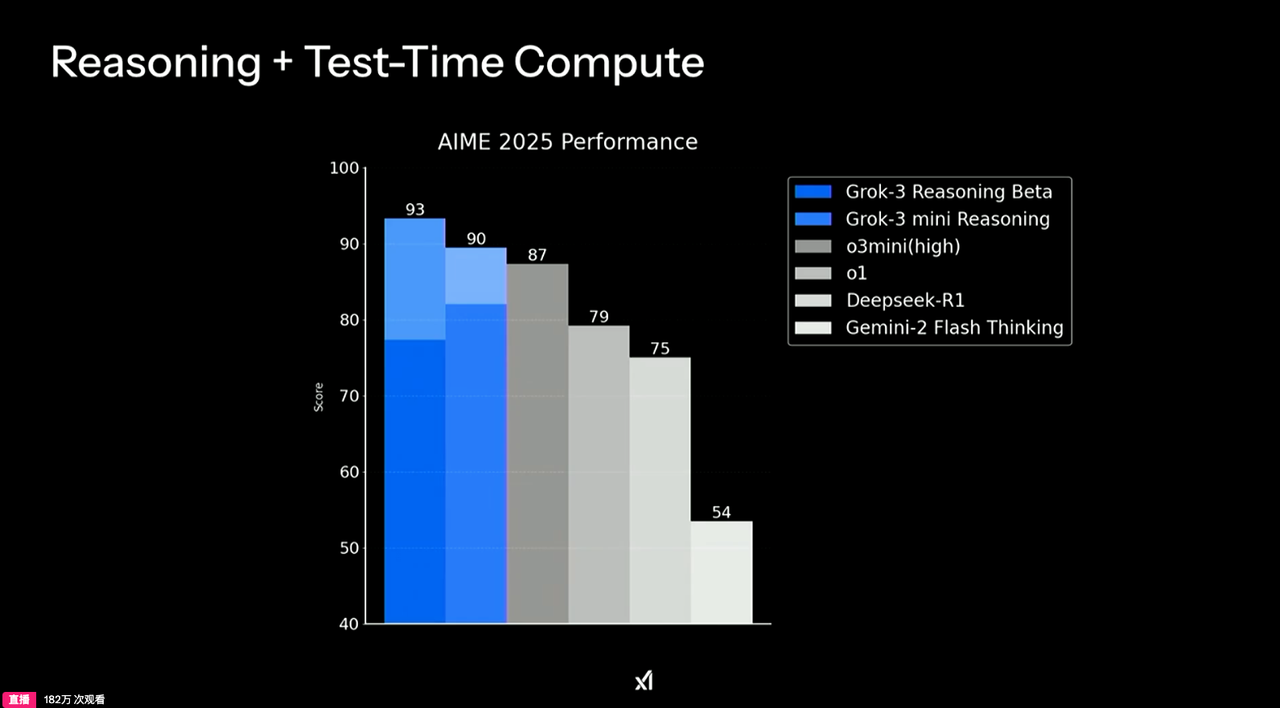
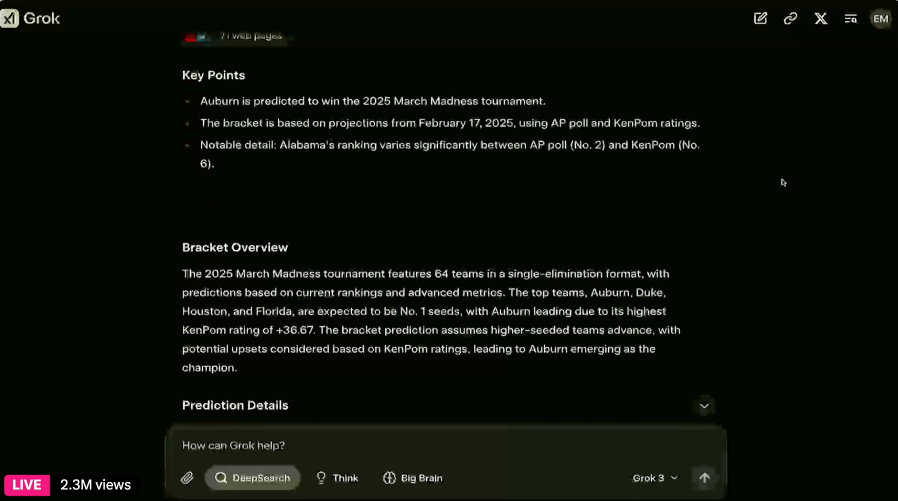
就像 Grok DeepSearch 标配的图表一样,豆包新版深度思考也提供了清晰的参数对比,屏幕、芯片、摄像头一目了然,甚至还贴心地准备了数据迁移建议,这贴心程度值得点赞。



逻辑性是豆包新版深度思考回答的最大特点。
针对 Android 备用机推荐问题,它不会一股脑儿抛给你一堆机型名字,而是通过「边想边搜」的迭代循环,针对你可能会用上的使用场景,再一步步搜索、推理,最后奉上一份既有逻辑又实用的推荐清单。
当然,扒蛛丝马迹这种细活儿,还是得交给 AI。
「悟空在第十四回中打死的六个盗贼,分别叫什么名字?该如何理解作者这一情节的安排?」豆包新版深度思考的回答不仅列出具体名字,还融入了佛学和心理学视角,分析得头头是道,时不时冒出几句金句,颇有亮点。



李白、杜甫和白居易是唐代诗人的标志性符号,那他们三者之间是否存在交集?
对于这个问题,在豆包新版深度思考的理解中,这种交集并不局限于现实生活的人际往来,还延伸到了更广阔的文学脉络以及彼此风格与创作上的相互影响。

最后所引用清代赵翼的点评「李杜诗篇万口传,至今已觉不新鲜;江山代有才人出,各领风骚数百年」,恰到好处,为整个分析增添了历史厚重感,也让人读后回味无穷。

从「先搜后想」到「边想边搜」,搜索的未来长什么样?
技术未来学家、Google 工程总监雷·库兹韦尔(Ray Kurzweil),曾在《奇点临近》一书中预测,未来的搜索将像人一样思考,而不是像机器一样索引。如今,这一预言正在成为现实。
之前的 AI 搜索,其「先搜后想」的模式是一个简单粗暴的线性过程:
「输入问题 → 调用搜索工具获取数据 → 基于数据进行推理 → 输出答案。」
这种方法的短板显而易见,非常依赖关键词匹配和网页索引技术,导致信息「广而不深」。
基于深度思考和 DeepSearch 的 AI 搜索已经大大解决了这个问题,AI 能理解自然语言中的复杂语义,比如问它「明天广州适合穿什么衣服?」就可以分析天气数据、时尚趋势、个人偏好等隐藏需求,实现多维信息关联。
而豆包新版深度思考与多轮搜索相结合的模式,进一步补足了深度思考和 DeepSearch 在处理复杂、模糊及动态信息需求时尚存的几块短板。
- 一轮搜索无法解决的复杂问题: 更好应对需要多轮信息整合、动态调整策略的复杂任务。在思考过程中多次搜索,让信息持续更新和补充,给出更全面、准确和深入的回答。
- 模糊查询与信息关联: 对于一些描述模糊、信息不完整的问题,「边想边搜」让模型在推理过程中不断搜索和验证,逐步缩小范围,找到相关信息
- 动态规划与多步骤任务: 在处理需要长期规划或多个步骤的任务时,「边想边搜」能够在每一步骤中进行信息校验和调整,提高了执行任务的成功率。
豆包新版深度思考「边想边搜」的执行路径,让我不禁想起最近常被提及的 Agent。「互联网之父」Berners-Lee 早在多年前就提出:
真正的智能体,就是在每个具体场景中,都能自动完成用户心里想做却没明确说出来的事情。

虽然豆包新版深度思考和 Agent 还有些区别,但某种程度上却是 Agent 工程化思路在搜索上的应用。Agent 自主决策和动态调整,将任务高度自动化,大大减少额外的数据预处理和人为干预。
说白了,就是让 AI 像一个聪明的助手,自己去网上找答案,它能自己动手,自己动脑,找到我们要的东西。用户不需要像喂饭一样把问题拆得细碎,才能得到满意回答。
由此我们也可以推理出 AI 时代理想的搜索过程:
- 1. 接收并分析用户问题
用户提出问题后,AI 会先分析问题的内容,拆解其核心需求,并尝试推测用户的真实意图。 - 2. 自主选择搜索策略
根据问题的性质,决定是用通用搜索还是直接调用特定专业数据源。它能记住常用工具和 API 的调用方式,直接利用现有网络资源(如站点地图或结构化数据)进行搜索,而非依赖预设流程。 - 3. 多步骤动态搜索
搜索不是一次性完成,而是分成多个连续步骤。先发起初步搜索,查看结果后,可能调整关键词、浏览网页深入挖掘,或转向其他数据源,模拟人类在网上探索的过程。 - 4. 实时优化搜索路径
在搜索过程中不断学习和判断。如果发现当前方向无效,它会自主放弃并尝试更有效的路径,如同经验丰富的专业人士那样灵活应变。 - 5. 整合信息并生成结果
搜集到足够信息后,它还会通过推理将零散内容重新组合,将结果整理成逻辑清晰的总结,确保输出符合用户需求。 - 6. 记录决策过程
每一步决策和推理都会留下清晰的记录,增强结果的可解释性,让用户能追溯其搜索逻辑。
如同媒介理论家保罗·莱文森所言,技术进化是人类认知结构的外延。每个时代技术的核心驱动力是信息处理能力的提升,当 AI 以越来越接近人类的思维方式处理信息,重塑的将不仅仅是我们对搜索的习惯。
作者:李超凡、莫崇宇
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。















 和 Quantum-X 硅光网络交换机,旨在帮助 AI 工厂实现跨站点连接数百万 GPU,同时显著降低能耗和运营成本。
和 Quantum-X 硅光网络交换机,旨在帮助 AI 工厂实现跨站点连接数百万 GPU,同时显著降低能耗和运营成本。