请从下图中找出,哪台是上一代 MacBook Pro M3?哪台是新发布的 MacBook Pro M4?

如果你看不出区别,也别怀疑自己,因为事实就是如此,除了新一代顶配机型的 C 口数量有些变化,其他还真就一模一样。
外观没升级,那内部会不会有变化?从 M3 到 M4 会不会是唯一的区别?找到答案最好的办法就是眼见为实,刚好最近 iFixit 在拆解完 iPhone 16 系列、Apple Watch Series 10 系列、iPad Pro 系列以及 Mac mini M4 之后,又对 MacBook M4 动了手。

总得来说,苹果在机器可修复性方面取得了比较大的进步,比如之前在拆解 Mac mini M4 时,iFixit 就发现了它的存储可升级,另外 iPhone 16 和 16 Plus 也用上了电诱导粘合剂脱粘技术,用 9V 低电压电流,流经新的离子液体电池粘合剂,就能让胶水失去粘性,电池可以轻松取下。
按照这种势头,今年应该是苹果产品从里到外升级最多的一年,但 MacBook Pro M4 却成了那个意外。毫不夸张地说,名字的 M4 就是最大的变化。
除此之外,其他的内部设计和上一代产品基本保持了一致,但主板的一些元件排布和散热风扇的尺寸,有了些许不同。
肉眼可见的变化,就在名字里
MacBook 的拆解还是熟悉的配方,从底部背板开始,依次拧下八颗五角钉螺丝,相比于其他需要从屏幕拆的产品来说,从非屏幕区动手有更大的安全保障,避免了力度把握不好而损伤屏幕的风险。

取下所有外置螺丝后,并不能直接取下底板,为了加强底板与机身的连接,它们之间还有卡扣结构,需要用点儿巧劲撬一下才能看见机身内部。

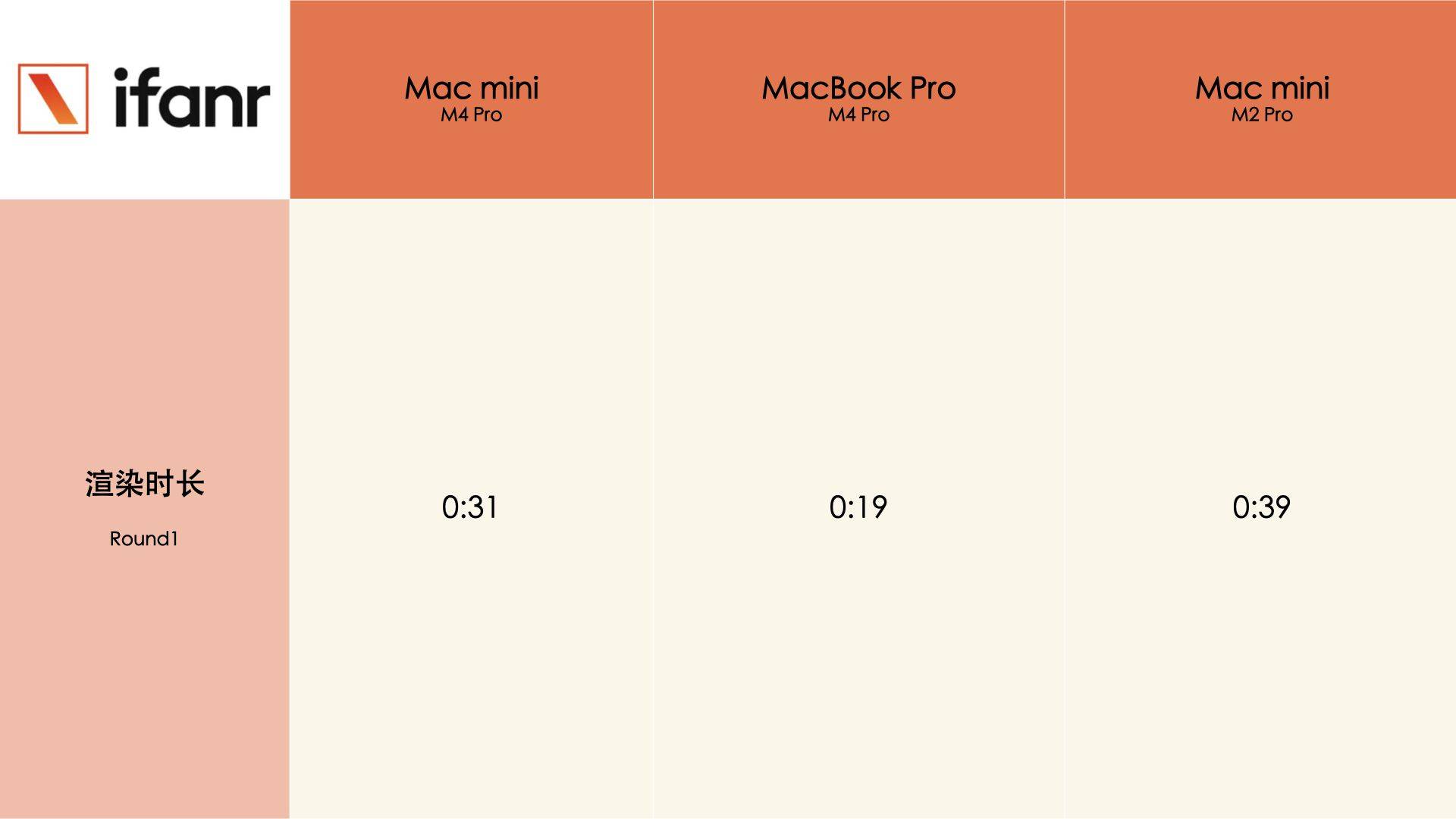
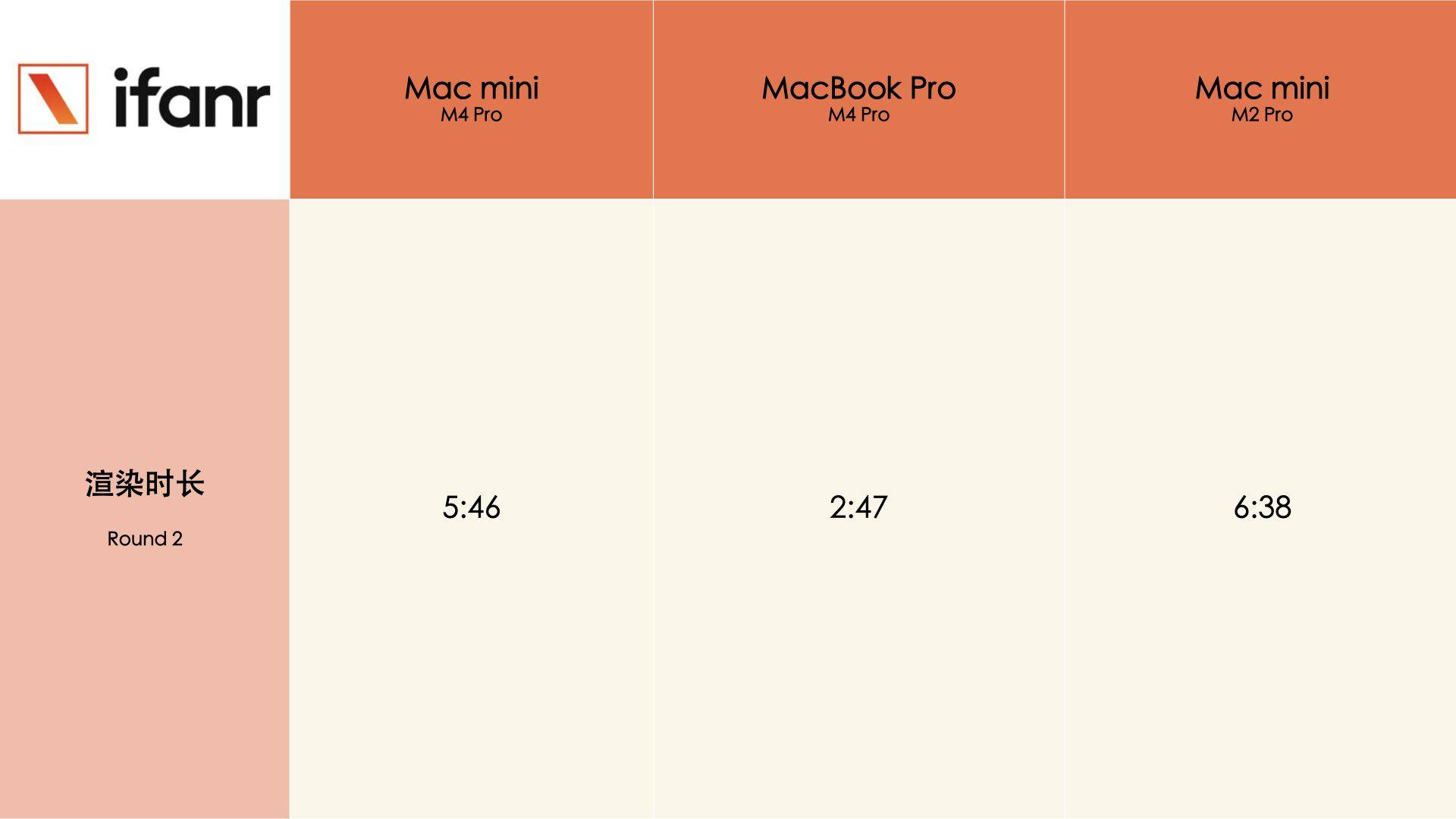
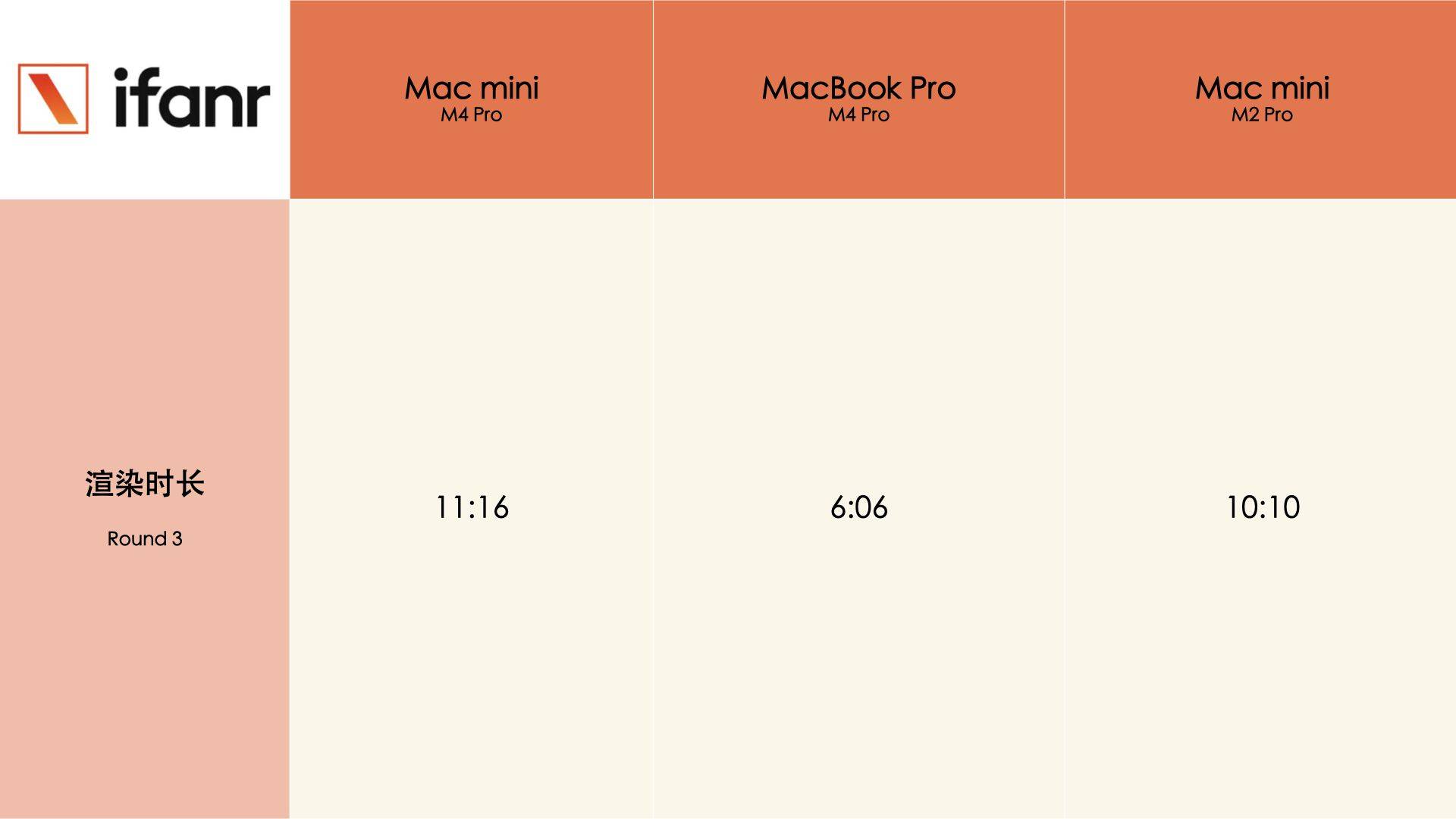
MacBook 的拆解非常解压,因为拆下背板后,眼见之处就是所有,没有太多隐藏起来的结构和元件,所以可以直接和上代搭载 M3 芯片的机型对比。

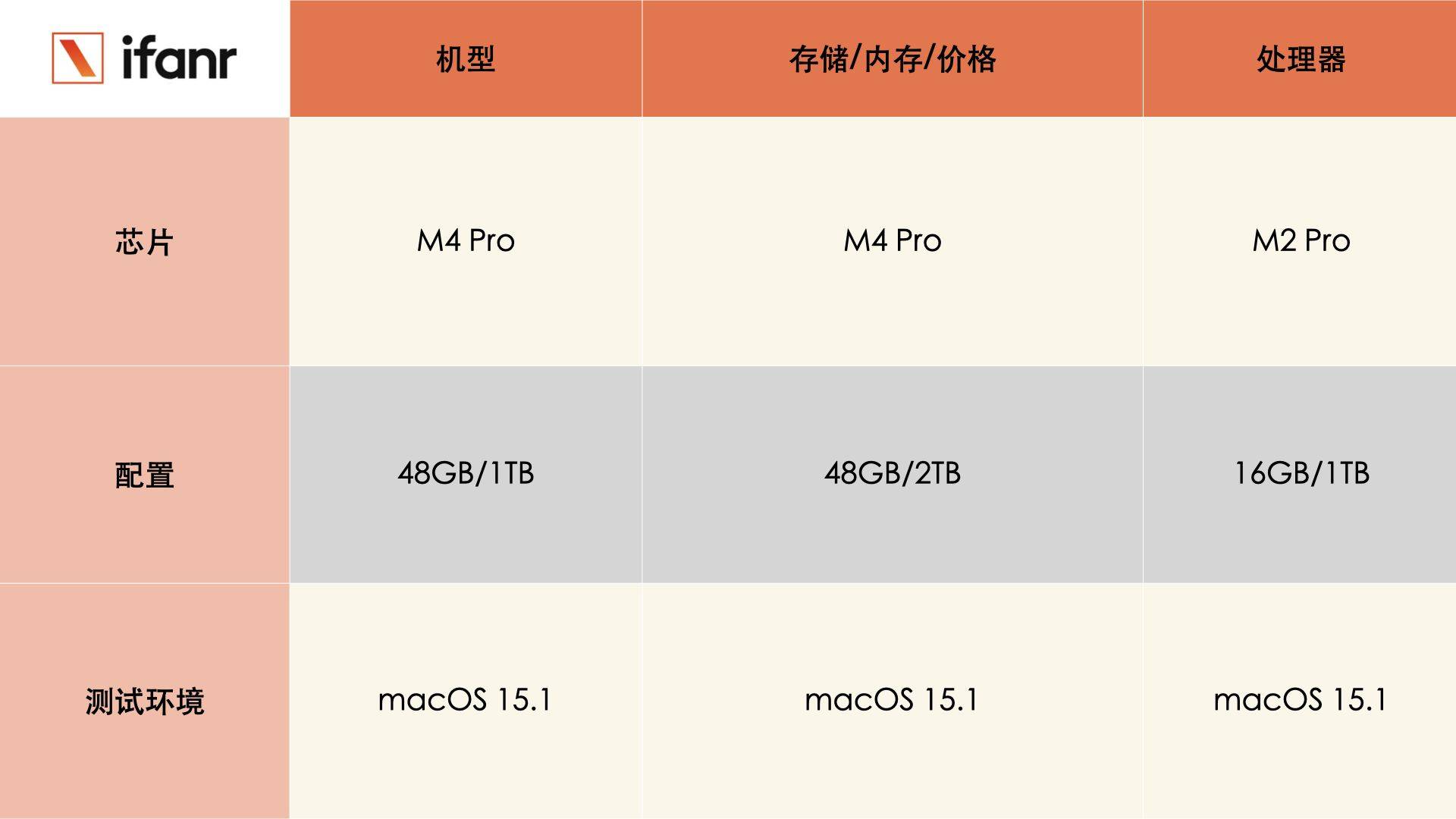
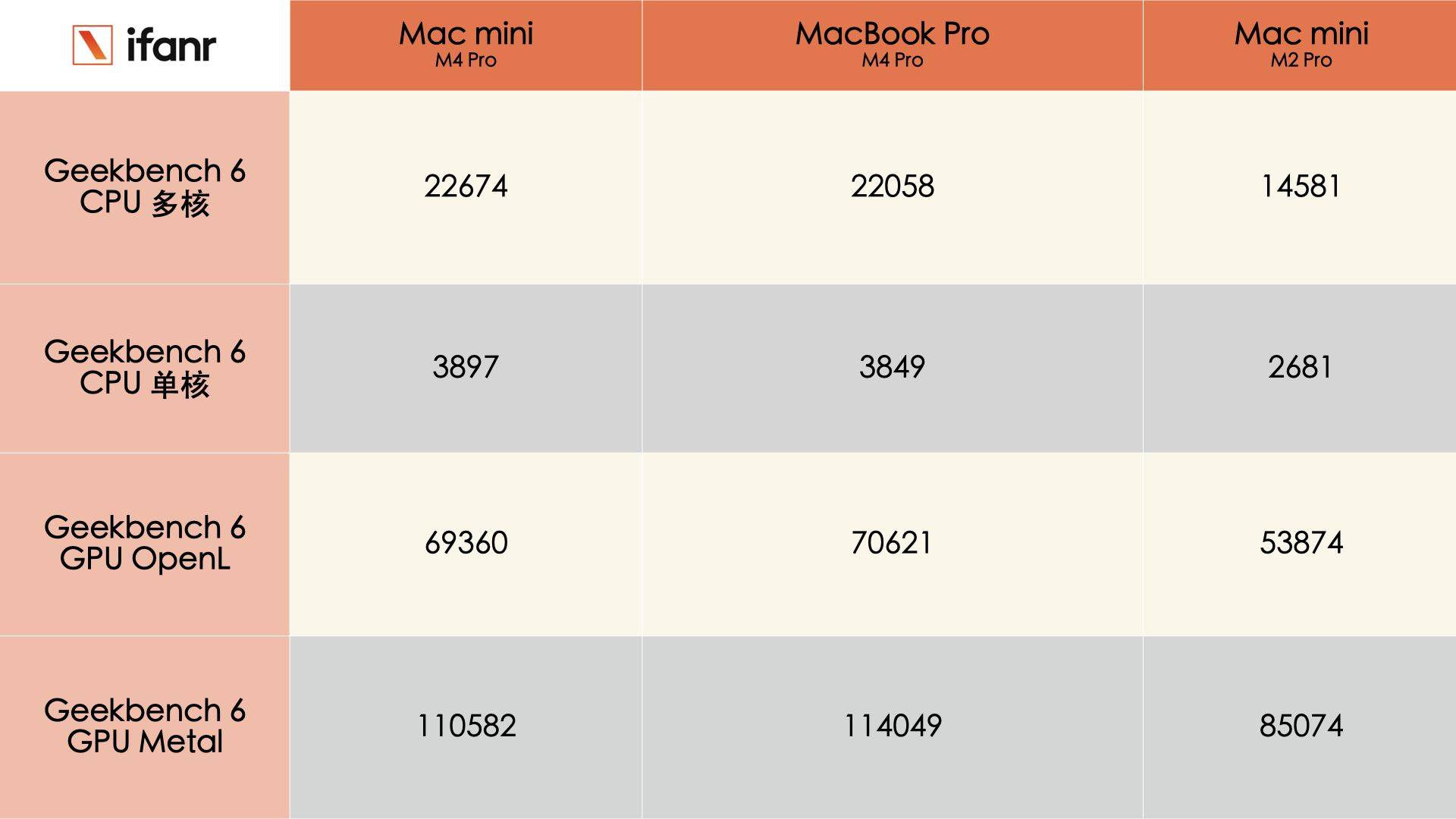
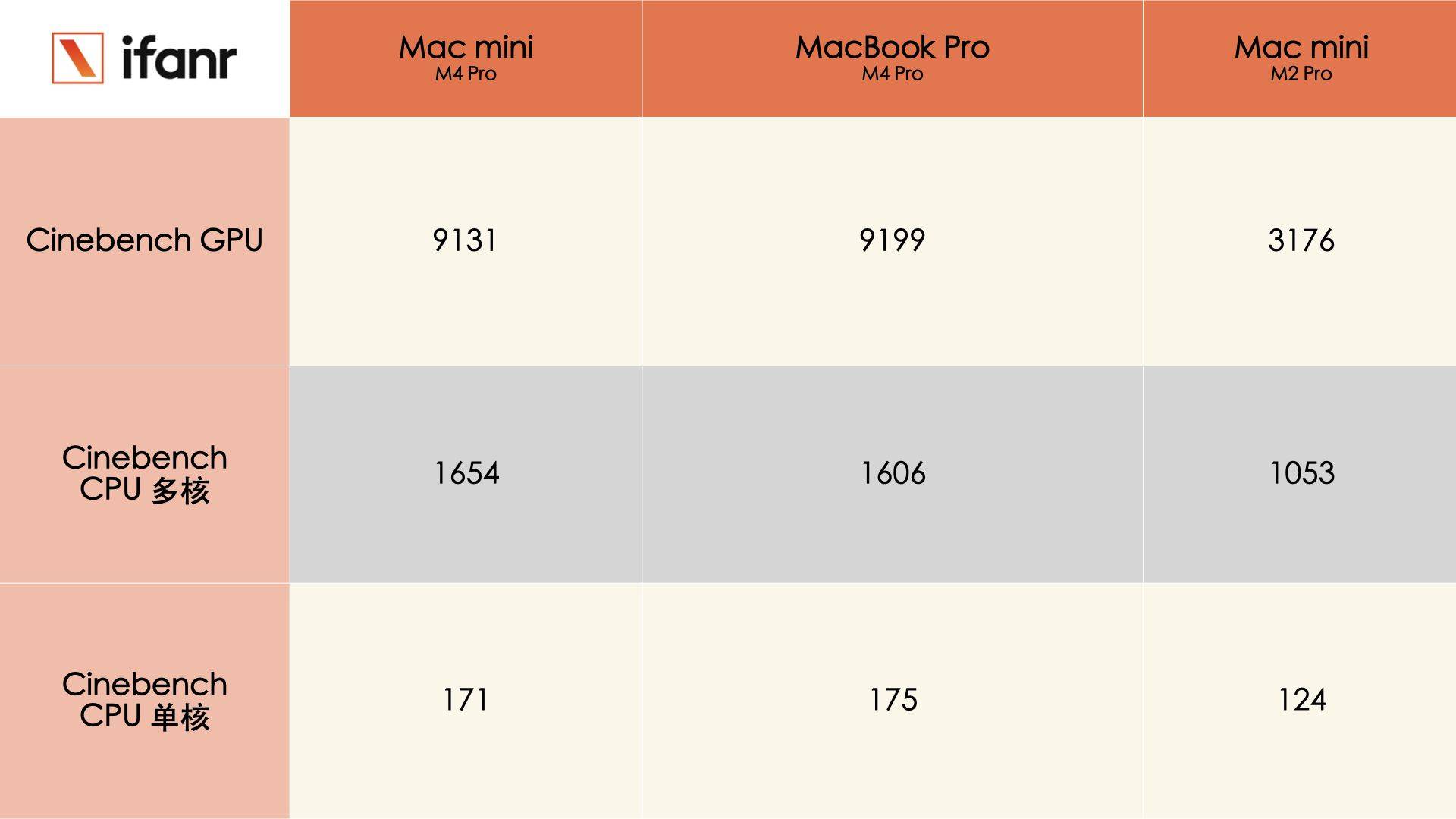
把两代机型放在一起比较,MacBook Pro M4 Pro 的散热器模组要比 M3 Pro 的更大,仔细对比下你还能看见主板上的 IC(集成电路)布局有些不同,有些在 M3 Pro 上很明显的触点,在 M4 Pro 上成了空白一片,大概率是被集成在了其他区域。
有意思的是,虽然芯片性能升级,但是两者的电池能量没有任何变化,都是 72.6Wh。

而 M4 Pro 芯片支持最高 64GB 高速统一内存和高达 273GB/s 的内存带宽,内存带宽相比 M3 Pro 提升多达 75%,达到其他 AI PC 芯片的两倍。
翻越千山万水,才只是开始
如果你经常看数码产品的拆解,其实不难发现最占机身空间的,不是科技含量最高的主板,而是被人吐槽总是不够用的电池。
但想要把这个最占地方的大家伙拆下来,往往不是第一步,有时候为了把电池拆出来,甚至都快把其他的零部件取完了,才能轮到它,而在全新 MacBook Pro 上也不例外。
iFixit 从触控板的柔性电缆作为入手点,并且把电池管理系统的数据线也一并拔出,不过想要在 MacBook 里拔出一个连接线,不是一件特别简单的事情,倒不是说有什么特殊的手法和技术含量,而是你几乎会在每一个需要拔出的接口处,看见一个用螺丝固定的金属保护垫片。

触控板和主板的连接就只有这一根柔性电缆,虽说看起来触控板和主板以及电池拆卸的关系不大,但在 MacBook 里,先拆触控板非常重要,等到最后拆卸电池的时候,就会知道为什么得从这里下手。
紧接着,需要把围绕主板和电池周围一整圈的固定螺丝全部都拧下来,当然别忘了,每拔出一个连接线,就会至少有一颗螺丝和一片垫片被一同取下,这个过程不难,但却很耗时,iFixit 这次的拆解视频里有多次大段留白,都是留给了拧螺丝、取垫片和拔电缆的空镜,甚至连旁白都没有。

虽说步骤相同,但是拆下的元件却不太一样,如果按照顺时针依次拆卸,大概顺序是角度传感器、音频插孔、麦克风、扬声器、风扇、键盘,以及另一个扬声器。

绕了一整圈,最后才轮到 Touch ID 模块,还有背板顶部的显示屏。

围绕主板周围的元件,大部分都是扁平式的单一插口,不过天线很特殊,它不像其他零部件用的大块头连接头,而是由多个小头组成的接头阵列。


拔下插头后,还不能直接把模组取下,因为它和主机绑定的很紧密,你还得先拧开 9 个 iPhone 底部同款的螺钉后,才能把整个天线从主机上拿下。

到这时,从机身内部顺利取下的部件只有触控板和天线,以及一大堆固定螺丝和保护垫片,所以最重要主板和电池工作,经过了一顿折腾,才刚刚开始。
最重要的,总是最后出场
主板的固定螺丝有能直接看见拧下来的,比如周围的这些 Torx 4 和 Torx 6 螺钉。

也有比较隐蔽的,它不像前面那种暴露式的,而是被藏在了黑色小海绵的下方,如果硬扯容易扯烂,除非你拆开之后就没有复原的打算,不然建议最好喷一点异丙醇在上面,能有效降低胶水的粘合力,从而能更轻松地、非暴力地取下黑色保护罩。

做完这一切,终于能够把主板移动了,但不是一下子就能把主板撬下,而是要一边撬,一边用镊子移开各种柔性电缆和风扇上的垫圈,是有点麻烦,但也不会太糟心。起码比起前期拔线、拧螺丝的大量看不到任何成果的准备工作,现在已经能看到完工的希望了。

在 iFixit 的拆解中,虽说最先拿下的是集成度非常高的主板,但他们没有对主板的结构布局有更多的对比解释,而是选择了继续拆卸电池,原因也很简单,在设备的使用中,电池的消耗和折损一般会快过其他的部件,这也就意味着它需要做到比其他零部件更易于更换的设计。
所以电池拆卸的方便与否,也是 iFixit 给 MacBook Pro M4 打出可修复性分数的重要参考标准。
和传统的、以及大部分的苹果产品一样,电池与机身的连接,还是用了易拉胶。易拉胶只是它的名字,但它的特性在实际使用中被一分为二, 一个是易拉,另一个是易断。

经常看拆解视频的朋友应该对「易拉胶易断」这件事儿并不陌生,胶布没有去除干净,需要撬动电池才能将其取下,但是随之会增加安全风险,铝塑外壳的电池是软包装,螺丝刀和起子在撬电池时,容易对其造成损害,所以可修复性的分数也会受到影响。
为了将电池牢牢固定在框架上,苹果还给 MacBook Pro 多加了几条易拉胶,不过不从机身背面拉,而是要反转到正面,从触控板下方的缝隙里才能找到拉头,这也解释了为什么要先拆触控板,都是为最后的工作做的铺垫。

为了拆电池,其实已经把配件卸的七七八八了,剩下的就是一些周边的配件,在拆解的过中,iFixit 还发现,MacBook Pro M4 和上一代 M3 一样:
- 采用了非常多的模块化端口
- 大多数模块都可以单独更换
无需焊接,不用暴力拆除,按部就班地拧螺丝、拔插口、拉胶条、撬卡扣,所有零部件都能轻松取下。当然,能取下且打开的零部件是大多数,但并不是全部,比如 TouchID 和新的相机按钮就被焊死,放在以前要么只能放弃探究内部构造,要么只能大力出奇迹。

不过现在借助 CT 扫描仪,仍然可以在不破坏零件的前提下,把它们内部构造一览无遗。

电源键的背部有一个非常简单的开关装置,用来闭合电路开启设备,或者断电关机。

另一边的圆形模组里藏着一个微型 IC,将组件和 SoC 配对, 靠近组件表面的地方,是一个非常薄的电容传感器,能够测量皮肤上的凹凸,接着将其转换成二维地图信息,以供电脑读取相关数据,也就是指纹识别按键。
MagSafe 端口也同样被焊死,没法正常拆除,不过通过 CT 扫描后,可以非常清楚地看到里面的磁铁等结构。

虽然在一些细节上的设计,会让 MacBook Pro M4 的评分受到影响,但总体来讲,这样延续的模块化设计,的确大幅提高了 MacBook 的可修复性。
Google 的模块化手机 Project Ara 当时给了人们不小的震撼,但只是网上的昙花一现,绝大部分人、甚至许多科技圈的从业者都没有见过实机,虽然之后也出现了有摩托罗拉的 Moto Z,用 Moto Mods 把手机变得不只是一台手机。

不过网上叫好,线下却没人叫座,此后模块化似乎成了一个可远观不可亵玩的畅想。模块化手机的确没能成功登陆市场,但模块化的理念却离我们很近,在轻易见不到的机身内部,模块化早已「深入机髓」,起码从每一个拆卸完的苹果产品上,都能看到这种趋势。

对于厂商来说,降低了制造成本,许多相同的零部件不用重新开模;对于用户而言,在长时间的使用中,也能降低维修费用,哪里坏了修哪里,不太会出现牵一发而动全身的情况。
说回这台全新的 MacBook,依靠 M4 芯片它又成了 PC 端的焦点之一,但通过拆解也不难发现,新机的确没有太大的变化,所以如果屏幕前的你刚好打算购入一台苹果笔记本,那你是会遵循买新不买旧的教义购入 MacBook M4?还是会根据实际需求购入 M3?又或者选择更具性价比的 M2 甚至是 Air 机型?
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
爱范儿 |
原文链接 ·
查看评论 ·
新浪微博