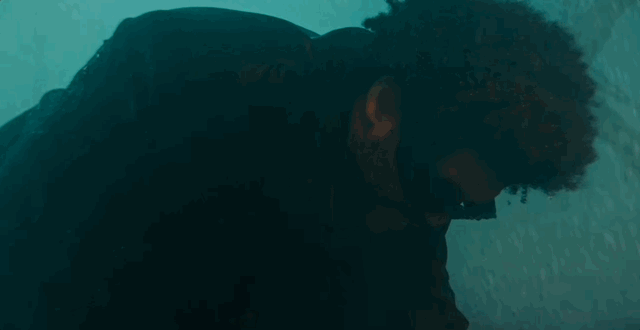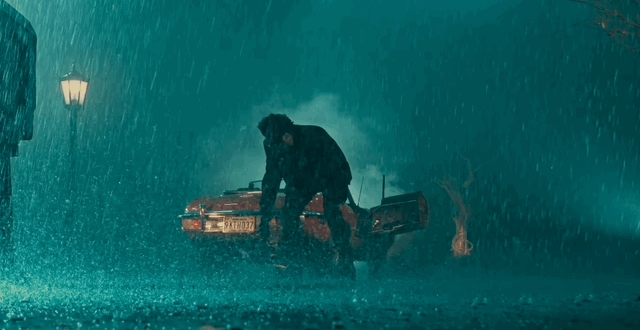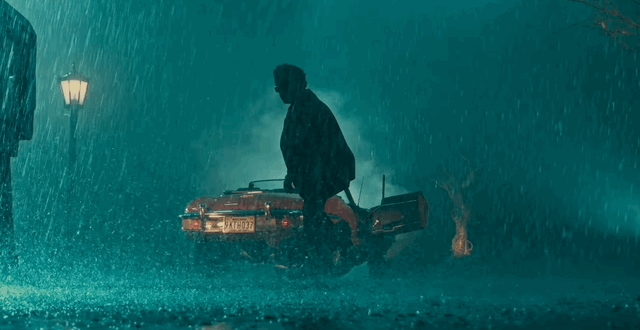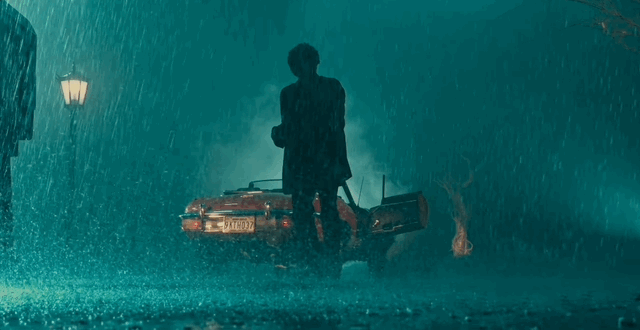AI 视频的国产之光,这个新功能彻底解放抽卡的双手

看完《鱿鱼游戏》不过瘾?干脆自己做个结局。


不想等《沙丘》第三部了?自己上手做一个。


放在以前,光是要让这些演员不走形、不崩坏,都要费半天劲。现在只需要丢一张截图给 AI,就可以开始做电影了。
这是海螺 AI 上线的「主体参考」功能,由全新的 S2V-01 模型提供底层技术支持,可以精准识别所上传图片中的主体,并设定为所生成视频的角色。剩下的,只需要简单的 prompt 指令,就可以随意发挥。

▲来自 X 用户@KarolineGeorges 的创作,面部信息精准保留

▲来自 X 用户@Apple_Dog_Sol 的创作,呈现多元主体
「主体参考」怎么就这么牛了
有一说一,「主体参考」的功能很多厂商都在做。但并非每一家都能攻破这项功能所涉及的难点:稳定、连贯,运动起来依然一致。
别人可能不行,但海螺 AI 可以。只需要一张图片,就能准确理解人物特征,识别为主体,随后让人物出现在各种场景和环境里。
上一秒还在拯救世界的蜘蛛侠,下一秒就骑上机车了。


本来应该在权游里训龙的龙妈,一转眼在逗小狼。


「主体参考」的突破性进展在于实现了创作自由度和还原度的完美平衡。这就像是给了创作者一个「万能演员」,这位演员的外形不会崩坏,而是能随着动作、姿态自然地变化,还能根据导演的要求,在任何场景中表演任何动作。
不仅是新功能,更是独特的技术方案
实测下来的感受是:主体参考是一个截然不同的功能,跟文生、图生所实现的效果并不一样,背后所涉及的技术难点不同,对技术思路的要求也不同。
传统的图生视频,只是让静态的图片动起来,而且主要是局部的改动。以这张宋慧乔的剧照为例,图生只是把原来静态的图片变成了动态,而且范围有限,不会有很大的动作。

▲ 原始剧照

▲ 基于图生视频的成片
同一张照片,「主体参考」却能基于 prompt 的文字,形成一个完整的片段,动作自由的同时,面部特征依旧稳定实现。

▲ prompt:暖调室内打光,剧院观众席中,主人公身穿黑色西装,坐在中排靠左的位置。她的表情充满专注,时而露出轻松的微笑,双手鼓掌,动作自然且富有节奏感。镜头从主人公侧面开始,捕捉她身边其他观众的剪影和暗淡的座椅纹理,强调环境的层次感。随着镜头推进,主人公站起来。
以人物为主体生成视频,目前有两种技术路线。一种是基于 LoRA 技术,对预训练的大型生成模型,进行特定微调。LoRA 在生成新视频时,需要大量计算。这就导致用户必须上传同一主体、不同角度的素材,甚至精确到单个片段需要具备哪些不同的元素,才能保证生成质量。同时还需要消耗大量的 token,以及漫长的等待时间。
基于大量的技术探索,MiniMax 选择了基于图片参考的技术路线:图片包含的视觉信息最准确,从图片出发,符合物理拍摄的创作逻辑。在这个技术路线中,画面的主人公是所有视觉信息中,模型最优先识别的——无论接下来出现什么画面、无论什么情节,主体都需要保持一致。
而其它的视觉信息则更加开放,由文字 prompt 进行控制。这样一来,就能实现「精准还原+高自由度」的生成目标。


▲山谷的空地中,主人公站在巨龙前,长发随风飘动。镜头逐渐拉升,捕捉主人公转身看向远方的动作,巨龙的翅膀展开,吹动主人公的头发和她的裙摆,画面最终以俯拍收尾
这段视频里,只传给了模型一张龙妈的图片。最终呈现出来的视频中,模型准确呈现了 prompt 中涉及的镜头语言、画面元素,体现出极强的理解能力。
图片参考的技术路线,相比于 LoRA 方案,肉眼可见的减少了用户上传的素材,数十段视频化为一张图片。同时等待时间以秒计算,体感上和文字生成、图片生成所花的时间差不了多远——既有图生视频的准确,又有文生视频的自由。
国产之光,满足你的「既要又要」
「既要又要」并不是过分的要求。只有同时实现人物形象的准确一致和自由活动,才能让模型走出整活、做梗图的范畴,在行业应用场景中,具有更广泛的使用价值。
比如在产品广告中,一张模特图,直接针对多种产品生成视频,只需要改变 prompt 就能实现。


如果用图生视频的方式来实现,目前的主流方案是设置首尾帧,可以实现的效果也被已有图片限制住了。同时还得要反复抽卡,收集不同的角度,最后再把素材拼接在一起,才能完成一组有长度的镜头。
结合不同技术的特点,更加符合视频创作的工作流程,正是「主体参考」的优势。未来,超过 80% 的营销从业者会在不同的环节用到生成式工具,他们只需要专注在故事和情节构思上,解放抽卡的双手。
Statista 的统计显示,2021 年时广告营销的生成式 AI 产品市场规模已经超过 150 亿美元。到 2028 年时这个数字将达到 1075 亿美元。以往的工作流里,纯粹的文生视频有太多不可控,适合用在创作初期。欧美的广告营销行业里生成式 AI 已经非常普遍,其中 52% 的用例是在初稿、策划,48% 用于头脑风暴。
目前,海螺 AI 先开放的是对单个人物的参考能力,未来,将会拓展到多人、物体、场景等更加丰富的参考能力,进一步解放创造力,正如海螺的 slogan 所提出的,「每个想法都是一部大片」。
自从去年 8 月,MiniMax 发布视频模型以来,从生成画面品质、流畅度,到一致性和稳定性等方面,在海外持续吸引着大量用户的关注和体验,其中不乏有影像创作经验的从业者,收获了大量正面反馈和专业认可。
在过去一年多的技术竞争中,AI 视频生成领域的竞争格局初步展现。Sora 的实现效果使人们看到视频生成这一领域的潜力,随后各大科技公司,在这一领域纷纷投入资源,重金研发。
随着年底 Sora 产品推出延迟、以及用户试用的口碑平平,未能满足市场期待。这也给了其它玩家抢占市场的机会。
如今,在生成式视频即将走入下半场之时,如今真正展现出技术实力和发展潜力的只有三家:MiniMax 的海螺 AI、快手的可灵 AI、以及字节的即梦 AI 。
作为一家成立刚刚 3 年的初创公司,MiniMax 以精悍干练的初创公司体量,带来足以跻身 T0 水准的产品和技术。从去年 12 月的图生视频模型 I2V-01-Live,到现在的 S2V-01 新模型,都在解决以往视频生成中的棘手难题。
随着技术的不断成熟和应用场景的逐步扩大,视频生成 AI 会在内容创作、影视制作、营销传播等领域掀起新一轮革命。这几家代表着中国视频生成 AI 领域最高水平的厂商,除了继续领衔国内市场,更有望在全球范围内与国际巨头展开竞争。与此同时,如何在保持技术创新的同时,确保产品的稳定性和可控性,将是这些企业面临的持续挑战。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。