OpenAI 神秘硬件细节曝光,我用 AI 还原了真机,注入苹果设计灵魂
这段时间,有一款神秘 AI 硬件吊足了网友们的胃口——比肩 iPhone 和 MacBook 的使用场景和频率,但不带屏幕,又不是 AI 眼镜、AI 耳机、AI pin、iPod……它背后的老板还放言要「量产1亿台」。
OpenAI CEO 奥特曼和苹果前首席设计官艾维联创的 io 公司,究竟用 AI 捣鼓了什么「开辟新赛道的硬件设备」,好难猜啊!
于是,虽然奥特曼透露计划明年末正式发布该产品,但现在已有不少 X 网友忍不住打起了 AI「猜」图的主意。万一它知道些「内幕」呢,对吧?
目前市场上有关 io 首款硬件设备细节的爆料,主要有以下几点:
- 无屏幕,通过内置摄像头和麦克风实现外界环境交互
- 外形设计风格类似 iPod Shuffle
- 未采用 AI 眼镜、智能手机、耳机这几种当下流行的 AI 硬件形态
- 比 AI pin 大一些
- 有挂脖式设计
- 可以与智能手机、PC 联动
话不多说,先来看看 AI 创作博主 Ben Geskin 在 X 上甩出的「io 产品图」,有近 9000 人次的 X 网友前来围观。

综合来看,上图不仅覆盖了这几点核心爆料信息,印上了自家金主 OpenAI 的 Logo,还设计出了一种不常见的 AI 硬件形态——毕竟多少有点「撞脸」更常见的剃须刀、按摩仪、充电宝……

Ben Geskin 该帖评论区里,有其他 X 网友接力晒出其他款式的「io 产品图」。
由 OpenAI 的 ChatGPT 生成的「GPT 版 Apple Watch」:

不是 AI 眼镜、耳机自带摄像头,因此推导智能手表设有摄像头?倒也是说得过去。
由 xAI 的 Grok 生成的「便携桌面版 AI 摄像头」:

这种场合,怎么能少了拥有当前「地表最强文生视频模型」Veo 3 的Google 呢?那么,Google 最新版文生图模型 Imagen 4 的表现如何,让我们直接请出 Gemini,先睹为快。
爱范儿把同一套「预测 io 产品图」的提示词,分别抛给了搭载 Imagen 4 的 Gemini、搭载 GPT-4o 的 ChatGPT 以及搭载 Grok-3 的 Grok,然后它们各自给出了如下模拟产品图。

单次此轮生成效果来看,三者都基本覆盖了爆料信息中的产品设计要素。其中,Gemini 和 ChatGPT 的产品图更贴合可挂脖的设计点,而这两者相比之下,Gemini 生成的产品图在视觉质感上会略胜一筹。
按照 Google 官方的说法,Imagen 4 能够更清晰地呈现诸如皮肤、毛发、复杂纹理等图像细节部分,也更擅长创作「照片级」、「写实风格」的 AI 图像。同时,其宣称 Imagen 4 所生成的 AI 图像支持各种长宽比,且分辨率高达 2 K。
不过有一说一,Gemini 所设计的这款 io 产品「长得有点人山人海的」,越看越像 Apple Watch+AI pin+登山包挂绳的结合体……
另外,Gemini 还同时给出了能体现「io 新产品与智能手机、PC 设备隔空联动」的示意图。

除此之外,Imagen 4 还可以把握住一些抽象风格的 AI 图像创作需求。

并且,该 AI 模型进一步升级了拼写、排版方面的出图质量,可优化贺卡、海报、漫画等场景的 AI 创作。
鸡蛋盒外印刷包装上的英文内容清晰、准确、美观:

多格漫画中,故事剧情连续,图文内容相配,远景、中景、近景画幅兼顾:

近期走红网络的像素风漫画也能拿捏:

Imagen 4 现已在 Gemini App、Whisk、Vertex AI,以及 Workspace 的 PPT、Video、Doc 等产品中上线。
据 Google I/O 大会方面透露,Imagen 4 后续将推出一个快速版本,届时其 AI 生图速度将是上一代 Imagen 3 的 10 倍,让我们一起拭目以待吧。
一位细节控的摄影师
如果说 prompt 关键词还原度、画面主体内容完整度,现在市面上主流的文生图模型都能做到「有鼻子有眼的了」——总体水平相差并不大。
因此,在图像生成质量这块儿,Google 开始卷细节了,宣称 Imagen 4 有「更细腻的色彩」和「更精致的细节」。这听起来没什么实感,还是得「用图说话」。
基于同一套提示词:
一只金毛狗在沙滩上找贝壳(a golden retriever finding shells on the beach)
爱范儿对比了 Imagen 4模型、Imagen 4 上一代模型 Imagen 3,以及豆包 Seedream3.0 所给出的图像效果。

这幅由 Imagen 3 生成的 AI 图像中,主体金毛狗的神态、贝壳的纹理、狗爪踩沙滩的痕迹,背景中的蓝天白云、海浪轻抚,都十分清晰和逼真。
并且,仔细看金毛狗的毛发似乎还被海水打湿了,一绺一绺的。
其实刚看到 Imagen 3 生成的杰作时,有点担心 Imagen 4 会不会打不赢。
不过,后者确实也没让人失望,用实力演绎了什么叫做「盘顺条亮」。

首先,从整体来看,Imagen 4 生成的图像色调更柔和,色彩也更自然,例如天蓝色渐变的天空、远深近浅的大海。
再者,从局部来看,金毛狗的毛发细节满满,不仅更有光泽、光影分布更匀称,而且还原了蓬松感,看起来就很好撸。
另外还有一个细节处理也很亮眼,那便是狗子的眼神。图像中金毛狗的眼神看向了沙滩上的贝壳海螺,对应了 prompt 中的「正在找(finding)」。
作为一组对比参照,豆包的表现也很抗打。下图虽然整体色彩偏暗,但画面细节也十分丰富,例如海风吹起的浪花激荡、海风吹动的狗毛根根分明、金毛刨出贝壳后爪子粘上了不少沙子……

美中不足的是,这3幅图像都有个相似的问题——背景及其虚化效果的 AI 味还是有点重。
而 Google 官方给出的示例中,Imagen 4 还能「细节控」到「指哪刻画哪」。卡皮巴拉短而硬的皮毛、油画的笔触、泡泡的光影、水晶表层的构造都可以准确地捕捉到。

同时,在图像质感和 2K 清晰度把握这块,Imagen 4 有的成品甚至可以媲美专业摄影作品了。

一位美商高的设计师
当爱范儿向最新 Gemini 2.5 Flash 版本的 Gemini 提出,「设计一款带电子屏的帆布包,有大中小型号」时,这位多模态 AI 助手花费 10 秒左右,便交出了如下设计图。
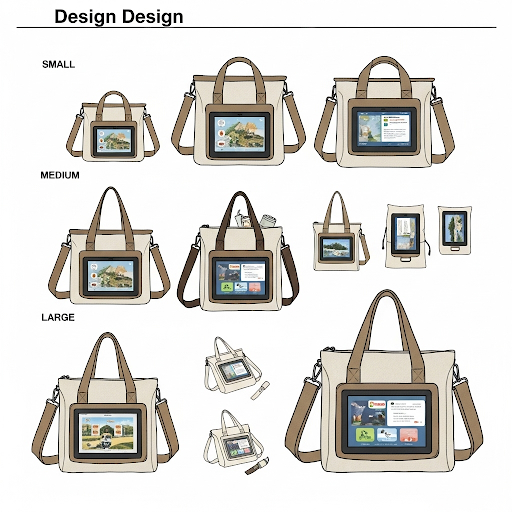
该设计图很直观地展示了「帆布包」和「电子屏」两个设计元素,并且左边一列标注了大、中、小的字样,右边区域则通过一些类似于「水杯」、「笔刷」的参照物,来体现不同尺寸的区别。
而且值得一提的是,其外观样式设计整体线条流畅不生硬,还保留了一些「手绘」的感觉。
然后,爱范儿进一步要求 Gemini 写明电子屏帆布包的具体尺寸。从此次生成结果来看,其主要英文单词和罗马数字都较为清晰且拼写准确,但涉及英文单位、标点符号的部分则会出现乱码的情况。
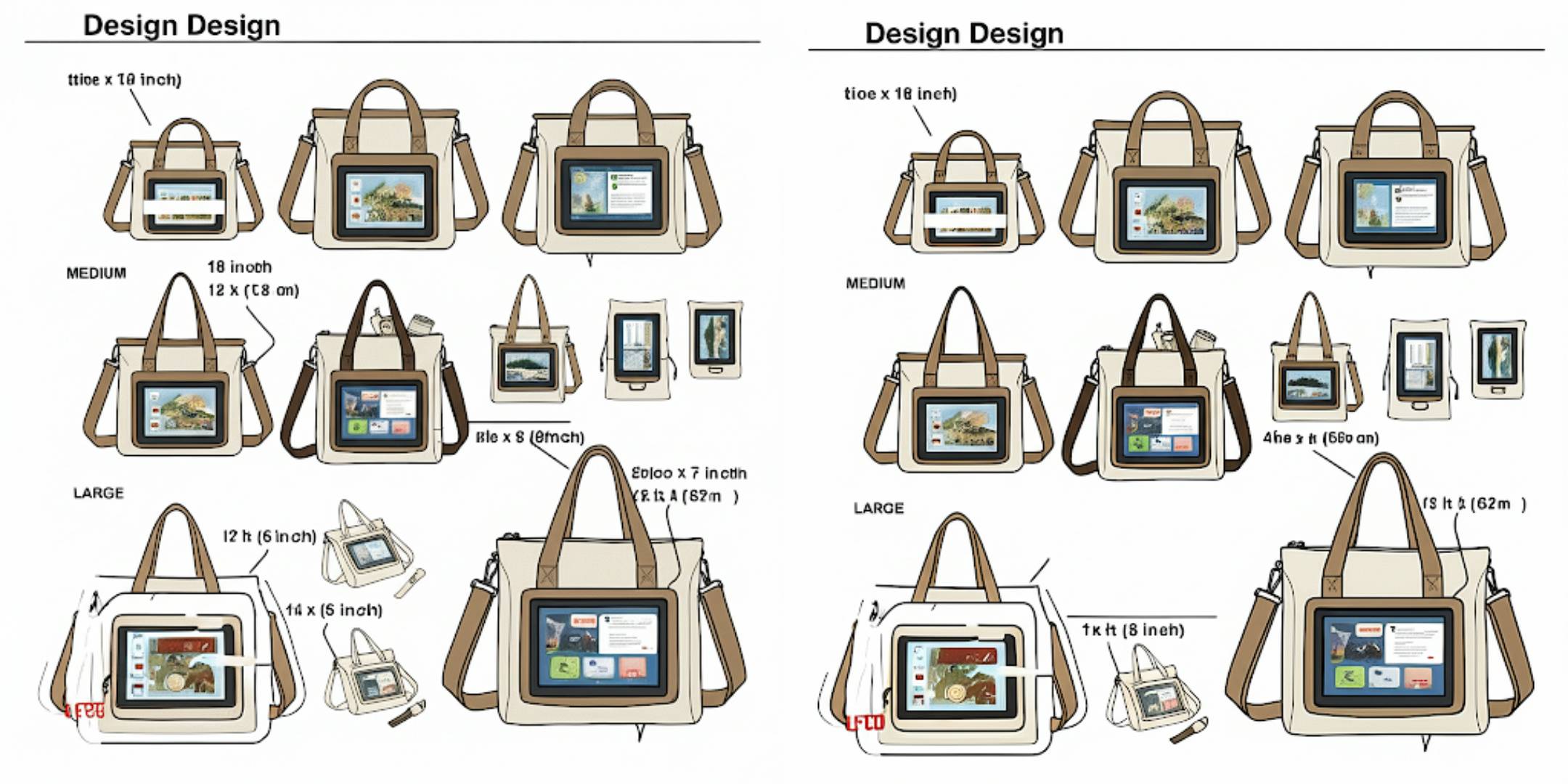
如果对于生成结果不满意,点击 UI 聊天框界面的「更新(Update)」选项,Gemini 会擦除此条生成结果,根据新输入的 prompt 重新执行输出。
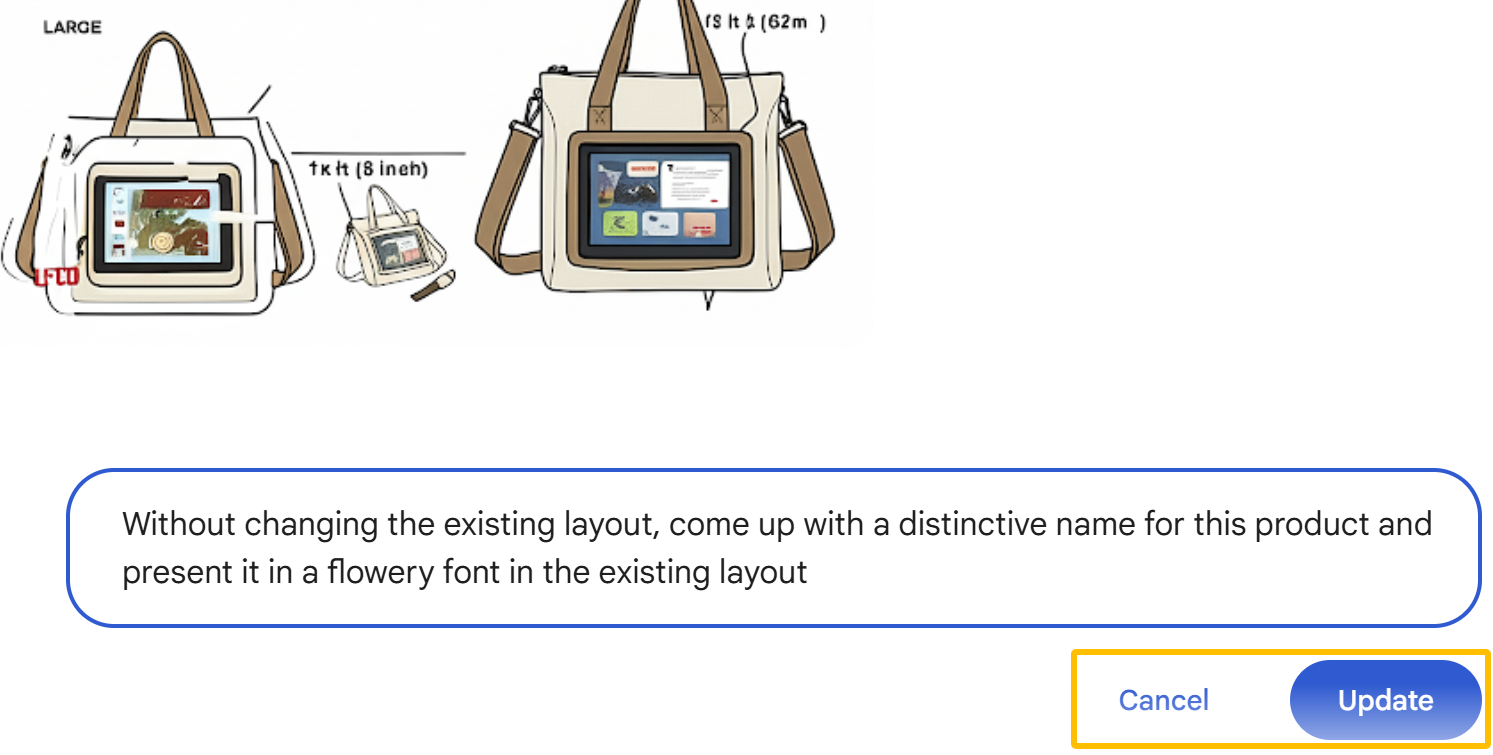
产品设计图有了,还缺个产品名。Gemini 帮忙想了一个简单粗暴的名字「Canvas Connect」。

上述步骤实际生成结果与提示词的误差不算太大,需要重新调试生成的地方并不多。
不过,轮到相应海报、邀请函的设计时,如果提示词中有语义较为模糊的地方,Gemini 很大可能就会错意了。
Gemini 先是根据电子屏帆布包「Canvas Connect」的产品设计图,给出了左图的产品海报。接下来,prompt 要求是让它改一下海报的配色,主色调是棕色和绿色,其余部分不变。
然而,由于 prompt 中没有写明「帆布包」的配色不变,Gemini 更换海报底色时,把帆布包的配色也一并改了,如左图所示。

改写这段 prompt 后,Gemini 做到了仅更换海报而非产品的配色,主题色从粉色变为绿色。其从思考 prompt 背后的用户需求,到理解匹配需求,再到生成 AI 图像,总耗时大约是 10 秒左右。
而且,无论是电子屏的画面,真人模特的动作、神态,还是文字内容,都无明显改动。这个案例综合反映出 Imagen 4 模型文生图的可控性较强,文字排版较为美观,大体上可复用。
可惜的是,一些成段、成片的文字内容,目前很大程度上还需要依赖精细 prompt 来控制调试。

Gemini:甲方爸爸,第 10086 稿设计图已上传,我可以打卡下班了吧?
别急,Imagen 4 还有许多设计玩法等着一众网友们去探索呢。
爱范儿试了一下,发现它可以把海报中的真人模特,直接替换成发型、穿搭、动作都较为贴合的卡通人物形象,即上图最右侧那张海报。这也不失为懒得 P 图美颜时的一种交图思路。
不过,如果不提出具体要求,海报原有的排版也会随之改变。这点目前需要在prompt的部分多花些功夫。
或者来一个「风格活泼有趣」、「文本内容隽永」、「适配社交媒体」的电子邀请函吧。

最后,别忘了让 Gemini 来一段自带 emoji 和 tag 词条的宣发文案,「邀请你共同见证 Canvas Connect 新品发布时刻 #TechStyle」。
#TechStyle」。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。







