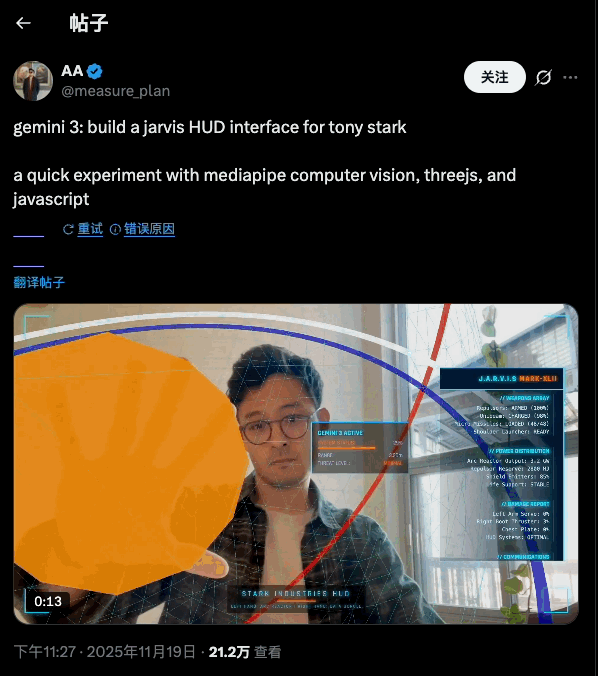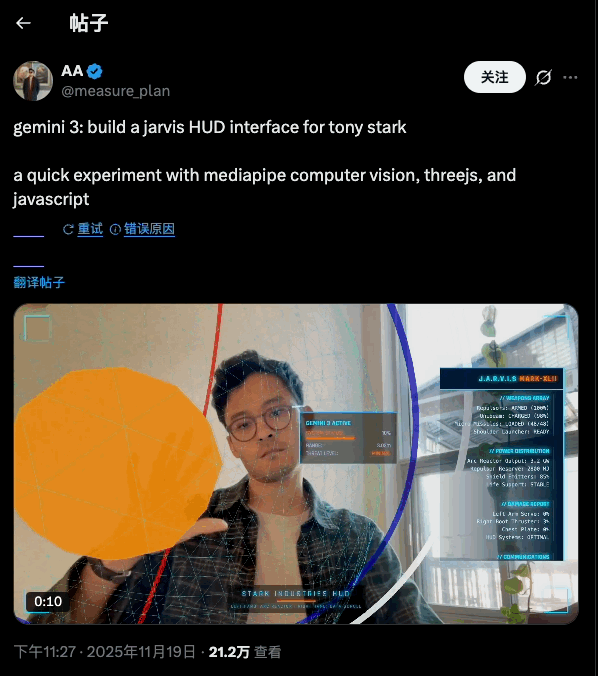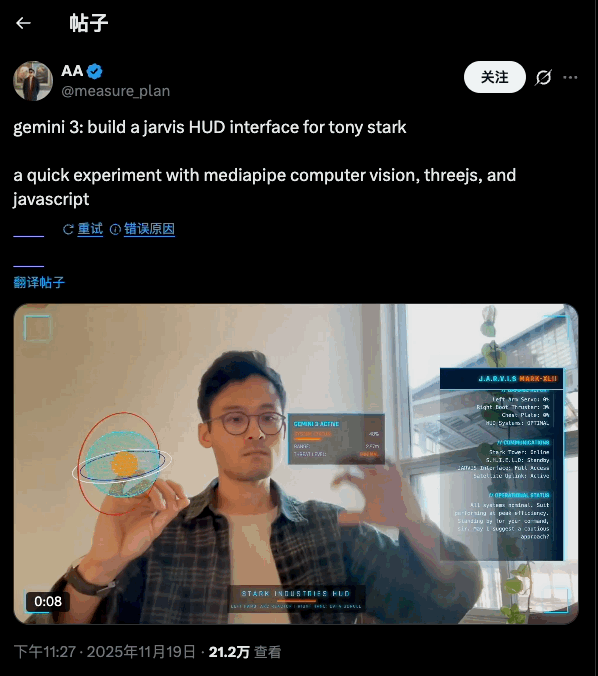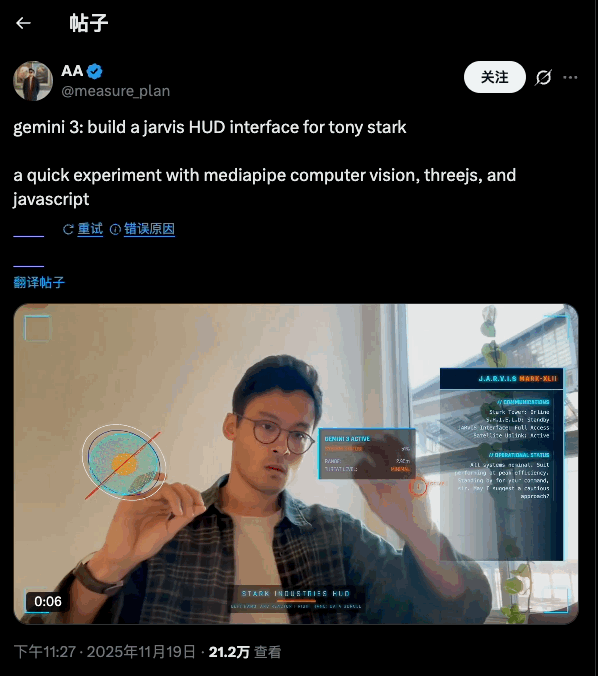
当我看完了理想 AI 眼镜 Livis 的所有产品细节,我不得不承认一个略显荒诞的事实:
目前市面上完成度最高、最值得买的智能眼镜,来自一家造车的公司。
就在刚刚,理想正式揭晓了这款产品的价格,Livis 的起售价定在了 1999 元,而在 12 月 31 日前下单的用户,还可以享受 15% 的限时补贴,到手价仅需 1699 元。

为什么我们会对这个产品给予这么高的评价,原因其实很简单。理想把那个被科技厂商搞砸了的逻辑给顺过来了。理想很明白,在成为一个无所不能的 AI 终端之前,Livis 首先得是一副让你愿意戴出门、且戴得舒服的眼镜。
理想汽车产品部高级副总裁范皓宇在发布会上说:
我们并不想仓促的做一款产品去赚快钱,蹭个热点,而是实打实的想做一个高可用,不给用户带来额外负担,能够陪伴用户很长时间的产品,能够让用户真正的体会到工作生活。因为它而变得更好了一点

智能眼镜,首先是一个眼镜
绝大多数智能眼镜最终沦为电子垃圾,不是因为它们不够聪明,而是因为作为一副眼镜,它们的存在感实在太强了。
理想显然研究过那些躺在抽屉里的竞品,在 Livis 上做了一个很极端的取舍,先做减法,再做加法。

整机 36g 的重量,是一个非常有杀伤力的数据。作为参考,海外好评度很高的 Ray-Ban Meta 重量超过了 49g,小米的同类产品也在 40g 左右。在鼻梁这个对重量极其敏感的部位,每一克的负担在长时间佩戴后都会被指数级放大。

为了把重量抠到极致,理想使用了瑞士 EMS 的 TR90 医疗级材料,并且针对亚洲人的头型做了微调。镜腿间距被设定在 137mm,转轴处预留了 15° 的外翻空间。这不仅是为了佩戴稳固,更是为了避免欧美品牌眼镜那种恼人的夹头感。
解决完「重」的问题,还得解决「看不清」的问题。理想这次拉来了蔡司作为战略合作伙伴,不仅保证了光学的基本素质,更关键的是打通了服务链路。

在镜片成本上,理想这次没玩套路。1999 元的起售价直接标配了蔡司防蓝光树脂镜片;如果你需要户外墨镜或者更高级的蔡司感光变色镜片,只需要再加几百元就能升级。即便是复杂的近视/散光定制,官方也号称最快当天就能完成配镜并发货。
总之,你不需要拿着验光单去线下眼镜店折腾,在下单的同时就能解决屈光度定制问题。

在把眼镜这个属性立住之后,理想才开始往里面塞东西。
首先是声音。理想把这个功能形象地称为「理想 Livis 头枕音响」。Livis 并没有用骨传导,而是配备了一套开放式的双磁路三明治扬声器。
在实际听感上,这种结构带来的声音厚度要优于一般的骨传导耳机。针对开放式耳机最尴尬的漏音问题,理想加入了逆声场抵消技术,在电梯或办公室这种安静环境下,能在很大程度上保护隐私。
与此同时,依靠 4 麦克风阵列,当你录制视频时,它能记录下全景声的空间音频。当你回看视频时,声音是有方位的。这样的沉浸感,其他智能眼镜难以提供。

至于拍摄,镜腿前方那颗 1200 万像素的摄像头,支持 0.7 秒快拍和 Live Photo 实况照片,当然也支持视频的拍摄。
我们必须坦诚地说,它的画质并不适合去和旗舰手机的主摄硬碰硬,其核心价值在于第一人称视角和快。当你双手都在开车,或者正在抱着孩子的时候,这种所见即所得的记录方式,是手机无法替代的。

为了支撑这些功能,理想在这个尺寸下做到了混合续航 18.7 小时。按照理想的测试模型,这个时间包含了 1.5 小时的听歌、1.5 小时的电话、2.5 小时的录音以及数十次的 AI 问答和拍照。如果只用来听歌,可以连续听 7 个多小时,纯待机状态可以达到 78 小时。
Livis 还标配了一个内置 1700mAh 电池的眼镜盒。这个盒子的设计非常巧妙,既是收纳盒也是充电宝,而且它自己还支持无线充电。这就形成了一个非常顺畅的补能闭环——不用的时候随手放进盒子里,盒子随手扔在车上的无线充面板上,基本告别了电量焦虑。

MindGPT 的新载体
在硬件之上,MindGPT-4o 多模态大模型构成了它的软件灵魂。相比于百科问答,Livis 更偏向于私人助理。
但在聊它有多「聪明」之前,首先得聊聊「快」。毕竟对于语音交互来说,快是自然的前提。为了实现这种跟真人一样的沟通节奏,Livis 使用了一套流式智能语音框架。
传统的语音助手往往是线性的,它得等你彻底把话说完,把语音转成文本,再扔给 AI 去思考,最后再把答案传回来,这中间要消耗很多时间。而流式交互改变了这个流程,就像人和人聊天一样,在你说话的过程中,它其实已经在听、在思考了。这种「边听边想」的能力,配合端侧算力的优化,让它的对话响应速度达到了 800 毫秒,几乎感觉不到延迟。

在解决了「快」之后,理想才引入了更多深度的能力,比如 Deep Research。
你可以给它一个复杂的指令,比如「梳理一下 2025 年自动驾驶芯片的市场格局」,眼镜会在后台进行长时间的检索和整理,随后在手机 App 端生成一份详尽的报告。此外它还具备了记忆能力,能记住你提到的生活琐事,比如家人的生日或喜欢的餐厅,并在合适的时机提醒你。
当然,与车的联动才是理想的老本行。理想把 Livis 和理想汽车的连接体验比作 「iPhone 和 AirPods 的关系」。
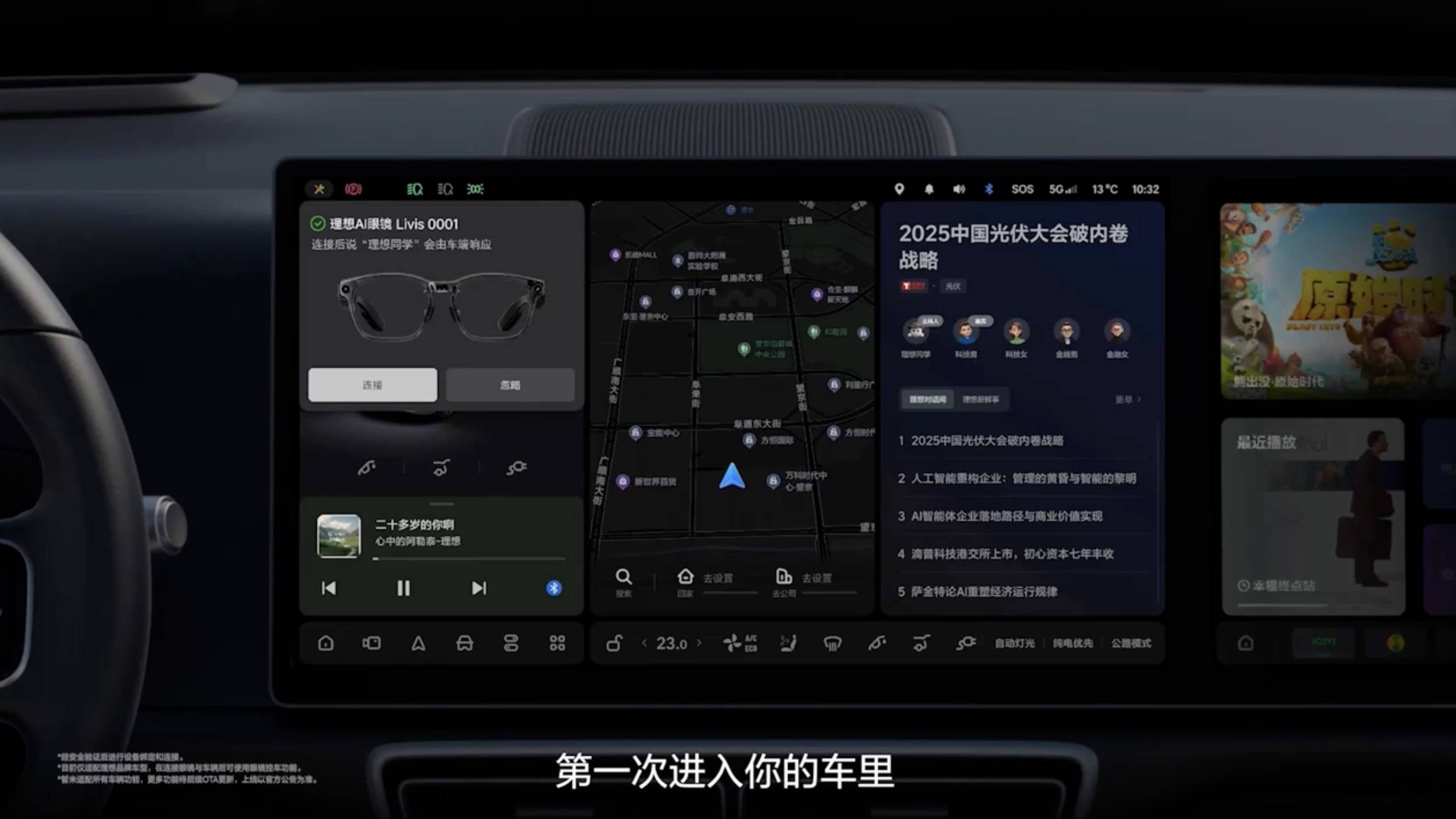
连接之后,交互体验是非常直觉的。依靠免唤醒和意图识别,你可以在任何地方直接说打开后备箱、查询胎压或者打开座椅加热,完全不需要掏出手机。
而在车内,为了防止车内语音交互打架,理想做了一套很细节的唤醒抑制逻辑。在车内环境下,喊理想同学会默认唤醒车机,只有当你发出帮我拍照、开始录像这类眼镜专属指令时,眼镜才会接管语音流。
理想要做的,不是一个车钥匙
An iPod, a phone, and an internet communicator
2007 年的 Macworld 大会上,乔布斯在舞台上反复念叨着这三个词。
这也是科技史上最经典的时刻之一。当台下的观众以为苹果要一口气发布三款新硬件时,他才揭晓了谜底。这三样东西不是三个独立的设备,而是一个设备,那就是 iPhone。
如果我们借用这个逻辑来拆解 Livis,你会发现理想的产品定义其实也是完全一样的路数。
你可以把它看作是四款产品的集合体。

首先它是一副佩戴舒适的光学眼镜。36g 的重量和蔡司的加入,保证了它作为「眼镜」的基础属性。考虑到现在市面上蔡司镜片的价格,分分钟比 Livis 更贵,买它简直相当于「买镜片送智能眼镜」
其次它是一副音质极佳的开放式耳机。如果你平时就有佩戴耳机的习惯,那 Livis 的价值就更大了,从我们的实际体验来看,它的双磁路扬声器效果能媲美,甚至超越两千元档位的耳夹式耳机。
再者它是一个随身的 AI 智能助理。相比于 Humane Pin 或者 Rabbit R1 那些试图取代手机却最终沦为笑柄的新物种,眼镜的形态明显要自然得多。它听得见、看得见、能说话,而且永远在线。

最后才是属于理想汽车的车控终端。
这个逻辑理顺了,你就会发现理想的小算盘打得有多精。对于理想车主,这最后一点或许是下单的直接动力。但对于非理想车主,前三点的组合依然具备相当的说服力,毕竟一副带 AI 和好音质的轻便眼镜,本身就是一个完整的产品。
这其实也解释了另一个更有意思的问题,为什么是眼镜而不是手机。、

同样是造车新势力,蔚来选择了造手机。他们的逻辑很硬核——为了更好的车手互联,为了把车钥匙做得更极致。但在手机这个极度成熟、竞争简直可以用惨烈来形容的红海市场,车企想要做出差异化太难了。
但智能眼镜不一样,这是一片还没被巨头瓜分殆尽的蓝海,在这个空窗期,理想带着它在汽车上积累的技术杀进来,其实是非常聪明的。
而且眼镜这种形态,天然就比手机更适合 AI。
手机的交互逻辑是「低头」,你需要掏出来、解锁、点击屏幕。而眼镜的逻辑是「抬头」,它就在你的视野里,在你耳边。当你习惯了用语音让车机放歌、导航,那么在走路、骑车或者工作时,用语音让眼镜帮你记事、查资料,也是一件顺理成章的事情。

就像范皓宇在发布会上说的那样:
眼镜其实是一个日常,佩戴时间非常长,存在感很低,对舒适的要求非常高的终端形态。它的语音非常近,而且稳定性很好,也不需要用户改变什么已有的习惯。所以它成为我们智能体验带出车内的最佳载体。
从更深层的角度看,Livis 其实是理想 AI 能力的一次溢出。
仔细想想,现在的理想汽车本质上就是一个巨大的 AI 机器人。它有视觉、有听觉、有大脑。现在理想只是把这套感知系统小型化了,从车上拆下来,戴到了你的脸上。

通过 Livis,理想正在试图把触角伸向我们生活的每一个角落。从车内的「移动的家」,延伸到车外的「随身智能」。对于用户来说,这可能是一次低门槛的尝鲜,千把块钱就能体验到理想的 AI 和服务。而对于理想来说,这可能也是一次极其成功的品牌推广。
至于它能不能成为你的生活标配,答案或许不在发布会上,而在你把它架到鼻梁上的那一刻。
带轮子的都关注,欢迎交流。
邮箱:tanjiewen@ifanr.com
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
爱范儿 |
原文链接 ·
查看评论 ·
新浪微博