曾经的最强苹果电脑 Mac Pro,已经被时代抛弃

没想到再次听到苹果 Mac Pro 的新消息,会是一个噩耗:
根据彭博社 Mark Gurman 爆料,苹果内部已经取消了新款 Mac Pro 台式机的开发,其搭载的 M4 Ultra 处理器也一起被砍,下一代高端桌面芯片是 M5 Ultra。

苹果内部基本放弃了 Mac Pro 项目,并认为 Mac Studio 才是未来。
Mac Pro 的坎坷一生
如果从 1994 年发布的 Power Macintosh 算起,那 Mac Pro 发布至今已过了 31 个年头,经历了苹果芯片的两次重大转型。
只是对于苹果来说,打造一台普通的性能猛兽永远不是产品的最终目标,做出一台既优雅又强大的电脑去定义未来,才是乔布斯和艾维的野心——甚至有的时候,「优雅」会优先于「强大」。
只是在半导体工业还不算发达的当时,设计和性能难以兼得,两者的矛盾如一个幽灵般盘旋在 Power Mac 和 Mac Pro 三十多年的历史中,注定了这个产品线命运多舛。
初代 Power Macintosh 采用了非常经典的塔式机箱形态,在当时作为首款搭载 PowerPC 处理器的苹果电脑问世,颇有秀肌肉的味道,位于苹果经典四象限的「专业级」和「台式机」区域。

从这时起,Power Macintosh 系列(后改名 Power Mac)成为了苹果电脑性能天花板代名词,主要面向高端的商务和创意用户。
Power Macintosh 定下的另一个「规矩」,就是极高的拓展性——它配备了 6 个 PCI 插槽和 7 个内置硬盘位,还需要用户自己添加独立显卡,完全就是为专业极客准备的产品。
在乔布斯回归苹果、乔纳森·艾维执掌设计大权后,两人通力合作打造出了多彩、塑料的 Power Mac G3,很好平衡了产品设计和性能功能。

两人不满足于此,Power Mac G4 Cube 在对未来计算机的进一步畅想中诞生。
通体玻璃和金属的外壳,看不到按钮和 CD 插槽,禅意甚至贯彻到机箱内部——连散热的风扇都没有。乔布斯对 Power Mac G4 Cube 非常满意:
我们通过简化去除多余的东西,取得进步。
Power Mac G4 Cube 得以位列现代艺术博物馆展厅,却也钉在了苹果产品的「耻辱柱」上:这个超小型机箱和无风扇的设计,导致散热能力低下,限制了性能发挥,最终这个设计也只使用了一代。

同样的故事,在 Mac Pro 产品线中还会再次上演。
2006 年,Mac Pro 接棒 Power Mac,同样在苹果转投英特尔的节点问世,搭载英特尔的至强系列处理器。

Mac Pro 延续了 Power Mac G5 的工业铝合金外壳,尽管工艺优秀,充满「Pro」气质,只是这个庞然大物的形态和体积,显然还不是苹果心目中的最佳形态。
于是在 2013 年,苹果给了艾维一个机会,去设计一款不同于以往的 Mac Pro。最终的成品确实称得上非同凡响,成为苹果产品设计史上极为浓墨重彩的一笔——

这个设计至今仍被人们津津乐道,但代价也很明显:这个仅有上代体积 1/8,只配备单个风扇的「垃圾桶」,很容易就会因为散热问题遇到性能瓶颈,对于一台面向专业用户的电脑来说是大忌。

▲ 两代 Mac Pro 体积对比
并且,苹果官方也只允许用户自行更换 Mac Pro 的内存和存储空间,并警告强行更换显卡会有很高的故障风险。
这并不是专业用户们所期待的 Mac Pro。在发布两三年后,到处都充满了对这个「垃圾桶」的吐槽,以及苹果是否已经抛弃专业用户的质疑声。
为了挽救口碑,苹果官方很罕见在 2017 年的一次媒体活动中出面承认了「垃圾桶」Mac Pro 的失败,并在之后推出了 iMac Pro 平息专业用户愤怒,承诺下一台 Mac Pro 将「更模块化」。
新款 Mac Pro 终于在「垃圾桶」发布后的 2182 天后发布——这期间,iPhone 大改了两次设计。
令人啼笑皆非的是,苹果对于「垃圾桶」的反思结果,就是重新捡起了 2006 年的初代塔式 Mac Pro 的图纸,铝合金机箱则换用了著名的「刨丝器」设计。

▲ 图源:YouTube@Ryan Gehret
至少,苹果终于端上来了一台高性能且可拓展的主机,人们欣然接受这台新 Mac Pro,这款产品最终也收获了不错的口碑。

只是当时也无人能预料到,这个 Mac Pro 的全新起点,同时也是这个产品线的终点。
一年后,Apple Silicon 横空出世,成为了 Mac 历史上最重要的一个转折点。
但这次,Mac Pro 没有像之前一样成为转型的排头兵,相反,在这个令人激动的新时代,它成为了无处安放的怪异存在。
Mac Pro 甚至是整个产品线中最后得到 Apple Silicon 翻新的型号,2023 年,搭载 M2 Ultra 的 Mac Pro 姗姗来迟。
虽然沿用了上一代颇受好评的新机箱,但高集成度的 Apple Silicon 生态,使得它的可扩展性极其有限,只能安装一些特殊的扩展卡,无法升级内存或者插入显卡。

与此同时,高能效的 Apple Silicon 终于让苹果得以「复活」Power Mac G4 Cube。
Mac Studio 小巧精致,外观没有一丝赘余,内部集成度高而无法扩展,苹果终于在 20 年后实现了乔布斯的夙愿,造出了一台真正面向未来的电脑。

▲ Power Mac G4 Cube 和 Mac Studio,图源:Macworld
对于用户来说,Mac Pro 更大、更重、更贵,却没带来更强的性能,只多出来一点点拓展性,新时代已经没有它的位置了。
或许也可以这么说,Mac Pro 不是被砍了,而是脱胎换骨,成为了 Mac Studio。

新时代再无 Mac Pro 的地位
和外观浑然一体的 iMac、Mac mini 以及多款 MacBook 比起来,采用塔式机箱、内部模块化设计的 Mac Pro,其实更像是一台 Windows 主机,不过运行着官方支持的 macOS。

纵观 Power Mac 和 Mac Pro 的历史,或者说整个电脑历史,高性能的主机以往似乎只有一种解题思路——巨大的塔式机箱,内部布满等着用户自己魔改的插槽。
在性能和能耗震惊世界的 Apple Silicon 诞生之后,苹果终于可以不再遵循 PC 高性能主机的这套规则,利用自己的芯片生态去代替以往需要不断增加更换电脑模块的方案。
在 M4 Mac mini 发布后,立马就有不少有趣的探索,例如联合运行多台 Mac mini 来形成盘阵列或者 AI 训练集群,以往这需要叠加更多显卡才能实现,并且功耗还更高。

▲ 图源:X@ Alex Cheema
对比可以自行更换元器件的模块化,这种高集成的设计使得产品出厂后再无升级可能,但高集成实现的高性能小型化,也产生了全新的价值。
以往的巨大机箱主机在,基本不具备流动性,我们以形式固定的「工作室」模式进行创作和生产,如果需要机动办公,则需要使用移动硬盘 + 性能本,无疑拉低了效率。
得益于高性能便携主机的出现,工作环境可以更灵活进行部署。像是影视行业的 DIT 工种,现在他们能够直接带走整个 Mac Studio 进行工作——换作以前的 16 千克 Mac Pro,这是不可能实现的。

▲ 把 Mac Studi 带着走的方案非常常见,图源:ProVideo Coalition
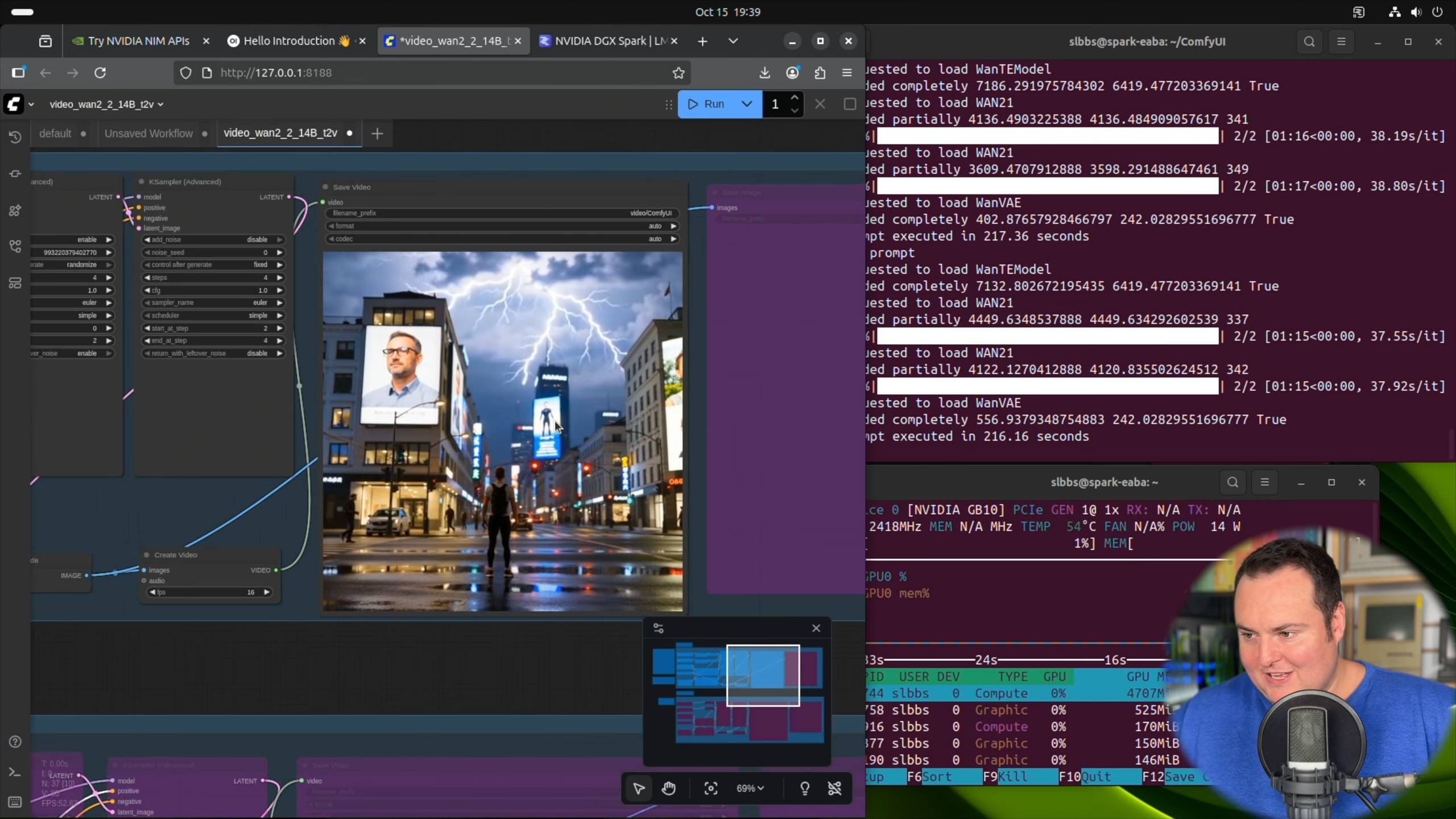
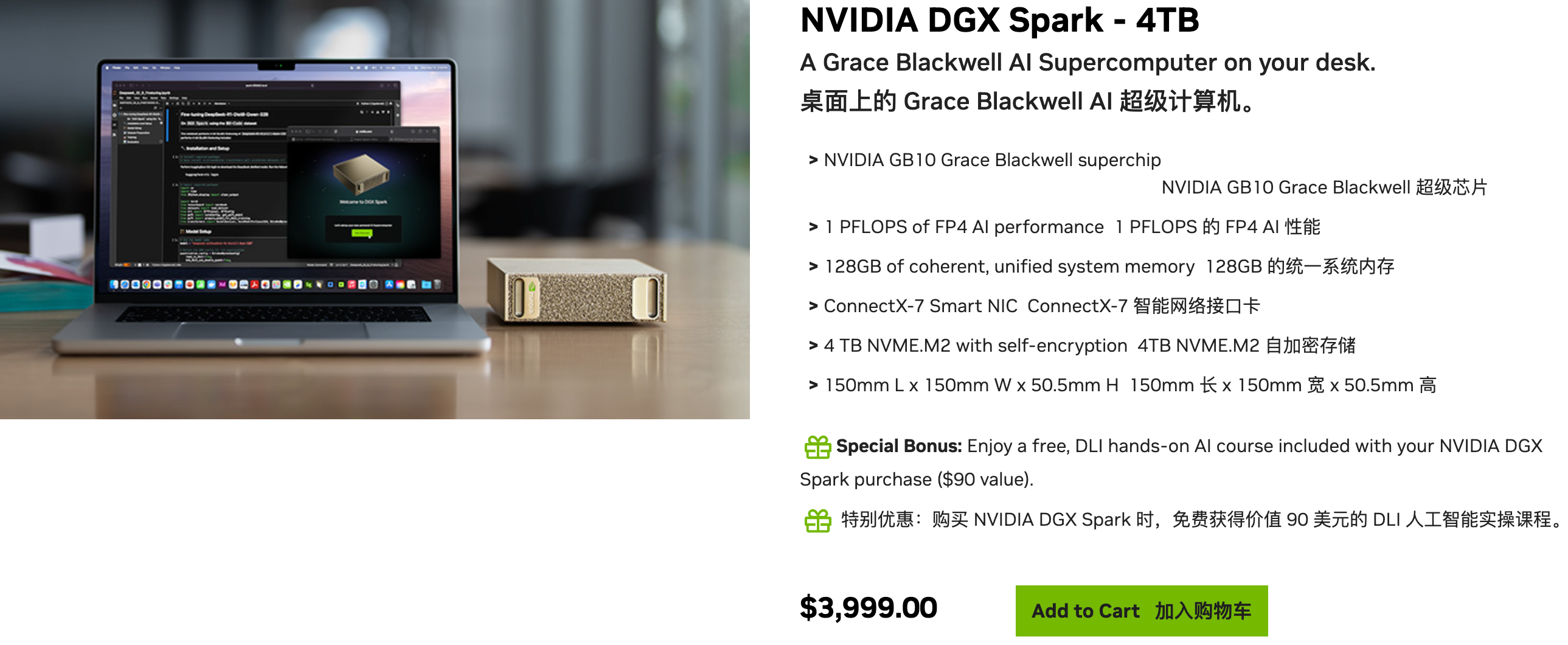
并不是只有苹果在深耕这个方向。英伟达的 DGX Spark 体积和老款 Mac mini 相当,却是一台具有 1 Petaflop 的 AI 超级计算机,曾经需要大型机柜和大量显卡的算力,现在可以直接摆在桌上。

芯片工艺和设计已经达到了一个顶峰,性能高能耗低成为常态,现在正是实现那些梦幻设计的时机,而小型化一直以来都是计算机和电子产品的迭代方向。
很多人对「小机箱」的趋势不解,质疑「能做大为什么不做大」,能够实现更好的散热——实际上,同一颗芯片的 Mac Pro 和 Mac Studio 性能几乎没有差距,现在的问题变成了「能做小为什么要做大」。

▲ 两者跑分非常接近,价格却相差 3000 美元,图源:MKBHD
更深层的变迁发生在社会之中。在 AI 改写生产力的时代下,每个人正在向「超级个体」靠拢,以前的工作方式是「计算机上长了个人」,那现在是人在哪里,性能就必须跟到哪里。
诚然,对于一些有专门需要的专业人士,像 Mac Pro 这样具有更高拓展性的大机箱还有价值,但 Mac Studio 的能力正在不断突破我们的想象,越来越多拓展也可以通过雷电接口解决。
带有一丝戏谑地说,Mac Pro 身上最有价值的部分,或许只剩下这个工艺水准极高的「刨丝器」机箱了。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。



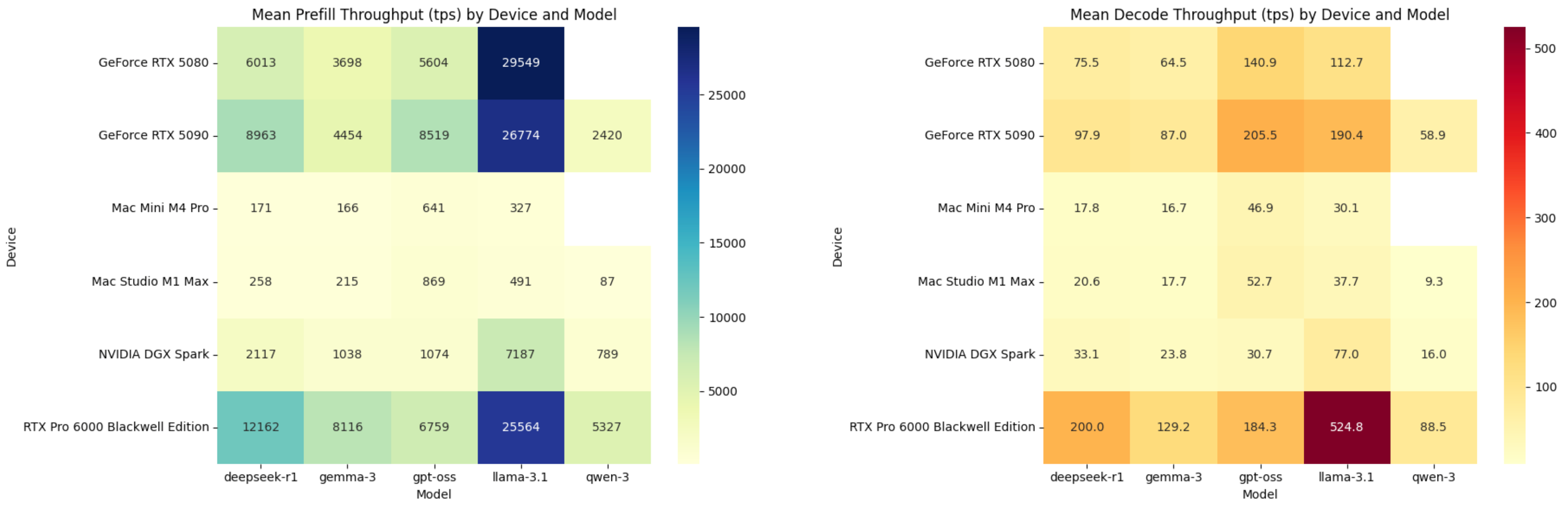
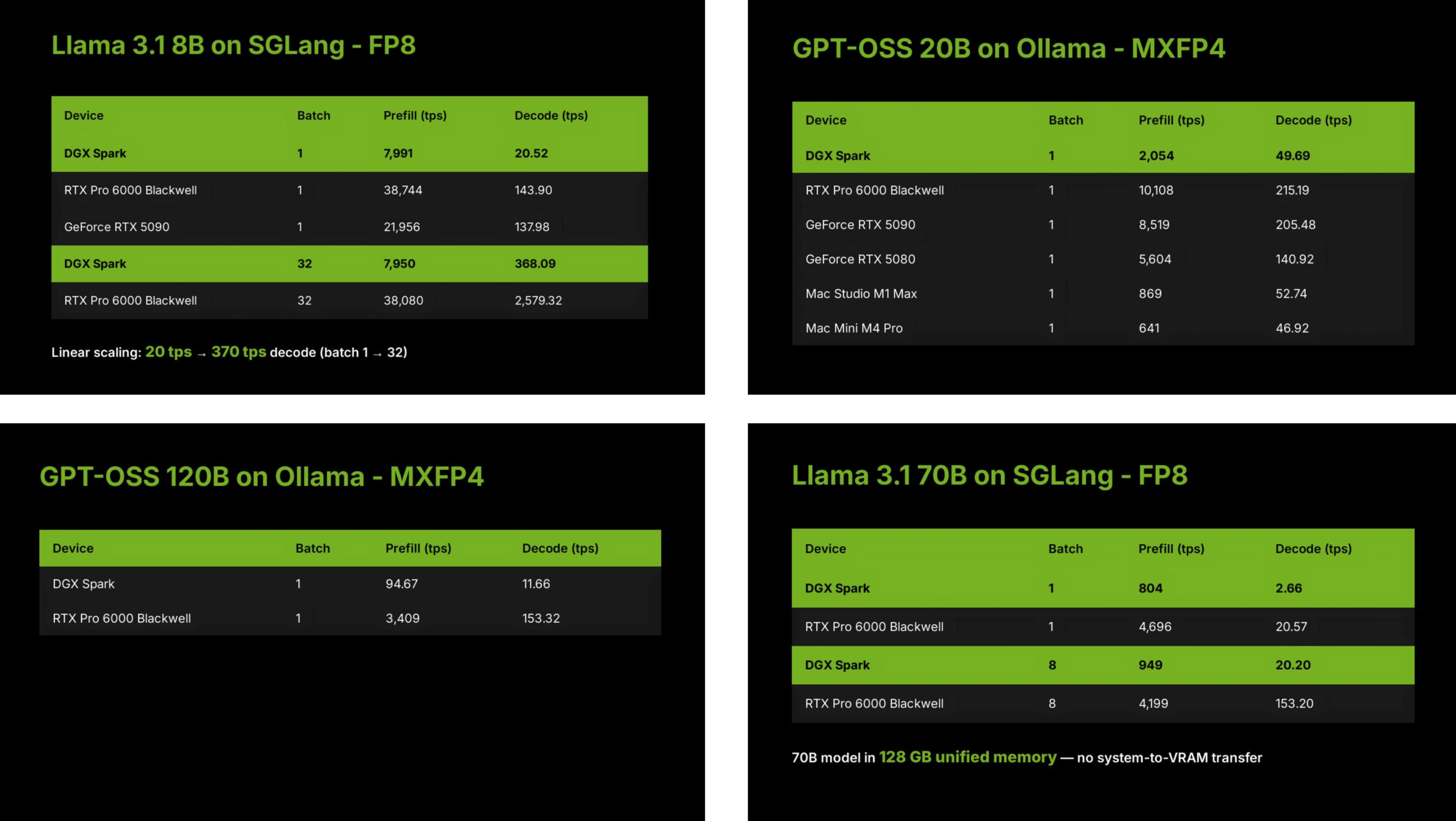
 Tips:什么是 TPS?
Tips:什么是 TPS?