
作为一个练习时长六年半的 Pixel 手机用户,我皱着眉头看完了昨天凌晨的 Made by Google 发布会。

#DeadInside
作为产品线的第十代产品,Pixel 10 并没有像曾经的 iPhone X 那样,为我们带来一次从产品形态到使用形式的变革,反而在这个连 iPhone 都准备大改设计的时候,玩起了保守主义。
单纯从硬件方面讲,今年的四款 Pixel 新机—— 10、10 Pro、Pro XL、Pro Fold 除了台积电处理器之外没有任何亮点,影像能力更是有进有退。
曾经,我们有一个更贴切的名称来描述这样的升级:Pixel 9s ——

在产品力本身已经普普的前提下,本次 Made by Google 发布会本身则更是一言难尽。
从正常的角度思考,「产品发布会」的目的应该是清晰的展示和介绍产品,尽最大程度体现出产品的优势,然后告诉大家价格——

但谷歌似乎对发布会有不一样的想法。
今年的 Made by Google 与其说是发布会,不如说是一次营业感极强的谷歌年会,哪怕是肥伦(Jimmy Fallon)负责串场也没有办法把各种零碎的场景拼在一起,回答那个最重要的问题:
今年的 Pixel,到底升级了啥?
真正的 AI 硬件,只需要最朴素的形态
不得不承认:谷歌手握着 Gemini,以及 Veo 3、Flow、Genie 3 等等工具,无疑是现在地表功能最强大的 AI 模型之一,甚至不需要之一。

Genie 3 能够以 720P 24 帧实时生成「可交互的模拟环境」,而非视频|Youtube @Fireship
而谷歌自然也清楚艾伦·凯那句「对软件足够认真的人,应该制造自己的硬件」的含金量,十年前放弃厂商合作代工的 Nexus 系列手机、转为开发流程彻底内部化的 Pixel 就可见一斑。
然而问题是,随着时间的推进,这个「软件」的定义是会变的:
- 2016 年的初代 Pixel,代表一种对于 Android 系统标准化硬件
- 2017 年的 Pixel 2,代表的是一种对于计算摄影(computational photography)的标准化硬件
- 2021 年的 Pixel 6,又变回了对于Android 12 主导的 Material You 设计的标准化硬件
至于今年的 Pixel 10,在复盘过整场发布会之后,爱范儿编辑部觉得,谷歌的意图已经昭然若揭:
Pixel 10 系列是一套完全为 Gemini 打造的 AI 硬件,无论 Rabbit R1、Humane AI Pin,还是 OpenAI 拉着 Jony Ive 一起搞的那个 AI 配饰,跟 Pixel 10 一比都得说自己不够纯粹。
如果用艾伦·凯的公式来描述,谷歌其实就是从「对 Android 系统足够认真」逐渐转变成了「对 AI 足够认真」—— Pixel 手机作为硬件形态,反而是不需要什么变化的。

图|PhoneArena
换句话说,今年的 Pixel 10 系列无论对于 Android 16 还是谷歌的计算摄影,其实都不是那么重要了。
恰恰相反,Pixel 10 是 Gemini 在现实世界的延伸,一个 799 美元的 AI 入口——只不过顺便还能接打电话或者拍拍照片而已。
但这不是我们想要的 AI 硬件
当然,谷歌这样将 Pixel 打造成专属于 Gemini 的硬件入口,这个行为本身是无可厚非的,毕竟手机的硬件形态再挤牙膏,也比 Rabbit R1 和 Humane AI Pin 那种故意区隔化的外观要实用许多。

图|CNET
然而现阶段的 Pixel 哪怕可以算作 AI 硬件,也依然没有解决一个非常重要的问题:
它的工作逻辑和我们预想的 AI 硬件不一样。
无论是科幻作品还是概念描绘中,我们大多都会为 AI 赋予一个拥有承载功能的具像化形态,无论是液态金属做的 T-1000 型终结者,还是 HAL 9000 与 MOSS 的红眼睛:

图|流浪地球 Wiki
既然我们能够接受机箱里面装着的 MOSS ,那么 Pixel 手机里面装着的 Gemini 也无可厚非,但问题是,用户使用 Gemini 的方式,与想象中刘培强使用 MOSS 的方式可谓大相径庭。
纵观本场发布会,谷歌主要展示的两项新 AI 功能 Camera Coach 和 Magic Cue,以及相册中的 Gemini 修图,全部都是分散在各项系统功能内部、甚至只有使用过程中才会弹出的。
这根本不符合过去几十年里人们对于 AI 的想象——
我不需要 Magic Cue 在我打电话之后才在屏幕上显示对话的相关信息,我想要 AI 自动核对我的行程信息和订票邮件,发现不对之后智能的给航司打退票电话。
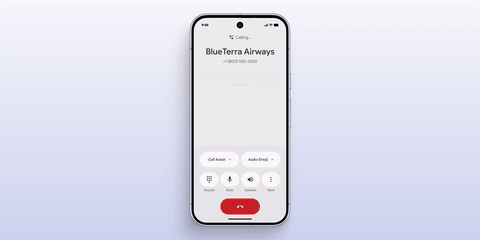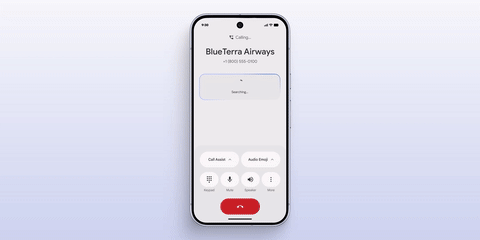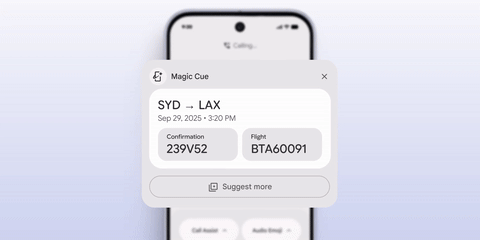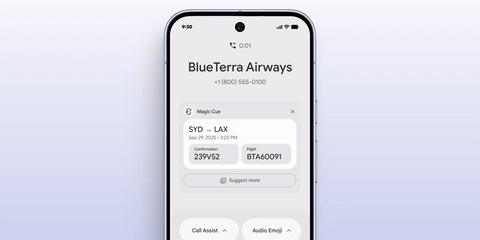
我也不需要谷歌相册必须要我点击编辑按钮之后才会弹出 Gemini 对话框,我需要直接唤醒 Gemini:帮我把我刚才拍的两百张酒吧照片里面模糊的删掉,P 一下亮度和颜色,然后选出 9 张不一样的鸡尾酒发朋友圈。

在过去十多年的科幻作品与 AI 设想中,AI 的运行逻辑应该是由人类用户下达指令、AI 自动理解指令并主动结合周围的一切资源开始自动执行任务,而不是我用轮椅把 AI 送到桌子前面、给它摆上笔墨纸砚,然后它开始作画。

图|36氪
也就是说,现在 Pixel 的 AI 功能全都散落在系统的各个角落,你必须先开始一项任务,才能得到 AI 相应的帮助——这其中较包括很多原本可以很轻松的被 AI 串联起来、代理我们动手的功能,比如把照片发到某个社交软件。
七年前的 Bixiby 都能用主动适配实现类似的应用功能调用,软硬结合更强的 Pixel 却不行|YouTube @爱否科技
更加令人难绷的则是相机中的构图辅助 Camera Coach ——在刚刚看到演示的时候,我们还以为它可以通过系统的底层接口,实时读取画面内容并生成构图建议。
然而现实却是,你必须手动打开功能,Gemini 才会悄悄拍一张照片、以此为依据推荐不同的构图方式——视角不符的时候甚至会直接调用 AI 帮你粗略的画出来——然后你再根据 AI 的指导一点点调整位置,直到你按下快门:

图|YouTube @9to5Google
且不说特意抬手点一下这种非常打断心流的操作究竟是怎么被想出来的,整个 Camera Coach 功能都像是谷歌为了想办法整合 Gemini 部门和 Pixel 部门的功能 KPI 而硬缝出来的东西。
构图辅助的本意应该是帮助你拍照,但是经过这样一番操作,哪怕有 Tensor G5 的算力加持端侧小模型,目前看到的推理速度和建议结果都不那么尽如人意。
有等待 AI 操作的时间,效率高的朋友早就已经换过好几套姿势,前后左右上下摇摄拍出一连串照片了,还能更好的发挥出 Tensor G5 升级后的 ISP 性能。
这种反客为主的操作方式,和 Android 16 中其他必须要你先操作一点功能、然后才会介入的 Gemini AI 功能一样,完全颠覆了我们曾经对于 AI 的期待——
我怎么变成给 Gemini 搬运资料、提供信息的 agent 了?

虽然很讽刺,但使用 Gemini 生成
换个角度想想,Pixel 10 不像是一个给人用的 AI 手机,反而更像是给 Gemini 用的 AI 手机,所有新功能的使用方式都是由人给 Gemini 提供信息,然后再由 AI 出手整合。
这种散落在功能过程里面的 AI,虽然客观上能够防止 AI 过度介入,但在用户体验上就是会让我们觉得被 AI 反客为主了。Gemini 像是那个陪小孩子堆沙堡的家长,等小孩把沙子拢起来,发出请求之后,才开始在上面塑出城堡的轮廓。
此外,还有一点不得不警惕的是,Pixel 10 很容易变成一个给其他手机厂商开的坏头——一个只靠 AI 有进步就可以放任硬件基础不管的坏头。

图|Android Central
而如果谷歌在未来继续用相同的套路拉扯下去的话,会产生一个非常糟糕的结果:Pixel 用户想要的 Pixel 消失了,AI 用户想要的真正 AI 手机又根本不是这样的。
这种形式的未来产品,恐怕是谷歌和消费者都不想见到的。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
爱范儿 |
原文链接 ·
查看评论 ·
新浪微博




















 点击图片跳转到播放页面
点击图片跳转到播放页面

































































































