男孩 鼹鼠 狐狸 和马









You are enough .
You are enough .

理想汽车和乘龙卡车的「舆论对撞」目前看来是要告一段落了。
理想汽车在 i8 的发布会上展示了一段视频,画面中的理想汽车在和一辆重卡发生相对速度为100公里/小时的正面对撞后,卡车车轮弹起、驾驶室与货箱分离,车头倒扣在 i8 前窗,而理想 i8 A/B/C柱无变形、气囊全开、电池无起火。

这个结果有点反常识,大家普遍认为测试过程中,卡车车头的锁止机构未能正常工作,从而导致了车头的前倾。
而且理想并非是第一个做对撞测试的厂家,极狐高管后来发布了一段去年类似的小车和卡车对撞视频,视频中卡车车头并未出现分离情况,锁止机构看起来起到了正常作用。

▲ 极狐高管发布的对撞视频
而且测试机构似乎忘记了给卡车打码,被眼尖的网友找到了乘龙卡车,随后越来越多的「吃瓜群众」开始不断拱火。
▲ 乘龙汽车抖音视频评论区
随后东风柳汽连续做了两条声明,分别是回应理想汽车在碰撞视频中侵权,以及表示「相关测试场景及设备与实际交通情况存在极大差异」,并号召「各位卡友面对网络舆论保持冷静,我们把更多精力放在乘龙致富、追求美好生活的道路上」。

但号召冷静归冷静,乘龙汽车也还是做了几张海报暗示了一下理想。

似乎是被这波舆论一时间冲击的有点不知所措,在发布会过去 5 天之后,理想终于发布了一条声明,核心意思是说他们做这次「小车对撞大车」的测试,初衷是为了让用户看到理想 i8 在提升车辆安全性上的努力和成果,并无意对东风柳汽做出质量方面的引导评价。

与此同时,测试的委托机构中国汽研也发表声明说,该测试项目仅验证理想i8 车辆安全性,不涉及其他品牌车辆的安全性能评价,乘龙卡车是其在市场端随机购买的二手车辆,测试前仅对车辆做了伪装并配重至了 8 吨。
中国汽研声明中提到此次测试是「非标准车对车碰撞试验」,董车会查询之后发现,非标准车对车碰撞测试是指,测试时未按照权威机构(如C-NCAP、E-NCAP、GB/T等)的正式标准、流程和设备进行的试验。其在测试时可以使用非权威指定的车辆,配重、假人摆放等参数也可以自行确定。

而标准车对车碰撞测试,则必须严格遵循国际或国内认可的第三方标准组织(比如C-NCAP、E-NCAP、IIHS等)制定的测试方案,所有试验用车、假人、场地、速度、角度、传感器记录甚至试验复测都有详细规定。
大家关心的理想 i8 与卡车对撞测试中乘龙卡车的锁止机构为何失效这个问题,各方还没有明确答复,但双方似乎就此息事宁人。
只不过对于乘龙汽车来说,这不过是一次意外到来的流量,他们也借此机会好好宣传了一波自己的产品,毕竟也不会有人真的相信小车能撞的过卡车。
但对于理想来说,这次事件必定将成为一个长期跟随品牌的「黑点」。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。

去年这个时候,爱范儿和董车会在理想北京研发中心与理想辅助驾驶团队进行了一场交流,当时理想辅助驾驶的新技术架构「端到端+ VLM 视觉语言模型」即将上车,理想辅助驾驶团队当时的表述是:
「端到端+ VLM 视觉语言模型」背后的理论框架,是自动驾驶的「终极答案」。
随着「端到端+ VLM 视觉语言模型」的技术架构过渡到了 VLA(Vision-Language-Action,视觉语言动作模型),我们离「终极答案」又进了一步。
按照李想和理想辅助驾驶团队的说法,这是理想辅助驾驶能力从「猴子」阶段,进化到「人类」阶段的关键一步。今天同期,我们又来到了理想北京研发中心,继续和理想辅助驾驶团队聊这个领域的新动向。

▲ 理想汽车自动驾驶研发高级副总裁郎咸朋
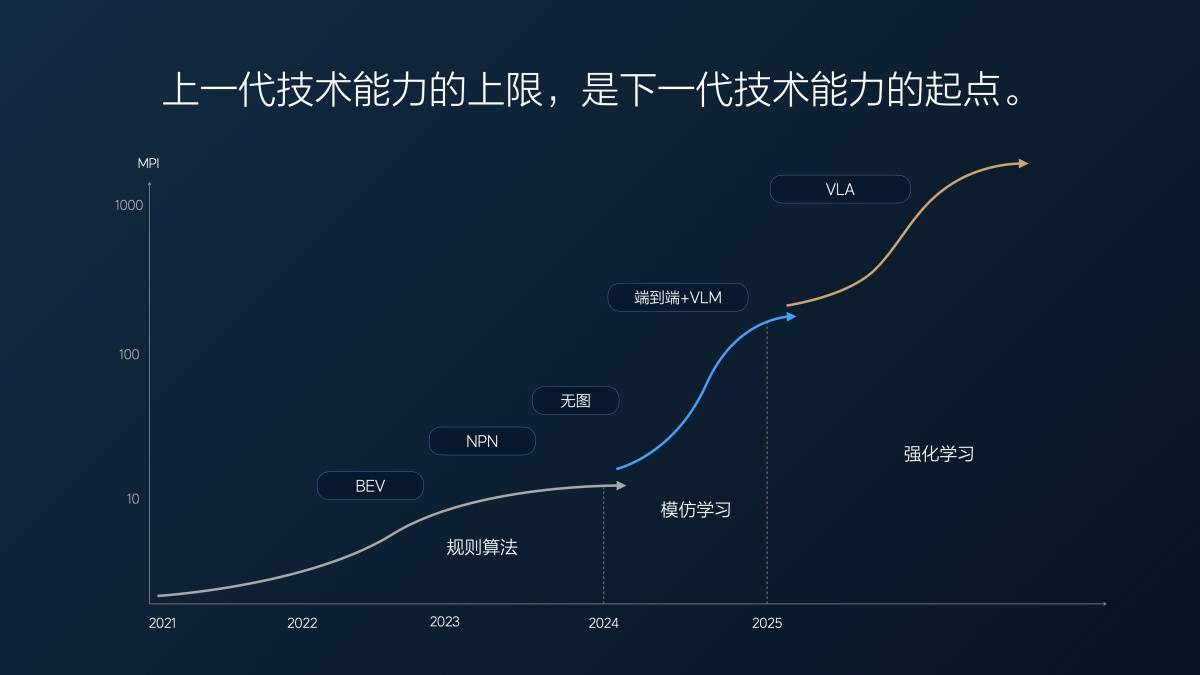
去年理想辅助驾驶方案切换到「端到端+ VLM 视觉语言模型」之前,采用的是业界通用的 「感知 Perception — 规划 Planning — 控制 Control」技术架构,这个架构依赖工程师根据现实各种各样的交通情况来编写对应的规则指导汽车的控制,但难以穷尽现实所有交通情况。

这是辅助驾驶的「机械时期」,辅助驾驶只会应付有对应规则的情况,没有思考和学习的能力。
「端到端+ VLM 视觉语言模型」是辅助驾驶的「猴子时期」,相比于机械,猴子要更聪明,也有一些模仿和学习的能力,当然,猴子也更好动更不听话。
「端到端+ VLM 视觉语言模型」的本质就是「模仿学习」,依赖大量人类驾驶数据进行训练,数据的数量和质量决定性能。并且因为安全考虑,在这个架构中,负责复杂场景的 VLM 视觉语言模型并不能参与控车,只是提供决策和轨迹。

VLA(Vision-Language-Action,视觉语言动作模型)则是辅助驾驶的「人类时期」,拥有了「能思考、能沟通、能记忆、能自我提升」的能力。
猴子经历了漫长的变化才变成人类,理论上「端到端+ VLM 视觉语言模型」的「模仿学习」也可以在漫长的岁月里学会人类几乎所有的驾驶数据,做到行为上几乎像个人。
但代价就是「时间」。
理想汽车自动驾驶研发高级副总裁郎咸朋说:
我们去年实际的端到端 MPI(平均接管里程),去年 7 月份第一个版本 MPI 大概在十几公里,当时已经觉得挺不错的,因为我们的无图版本迭代了很长时间,综合 MPI(高速+城市)也就 10 公里左右。
从 100 万到 200 万 Clips(用于训练端到端辅助驾驶的视频片段),再到 1000 万Clips,随着数据量上升,今年年初,MPI 达到 100 公里,7 个月 MPI 翻了 10 倍,平均一个月翻一点几倍。
但是到了 1000 万 Clips 之后,我们发现一个问题,只增长数据量是没有用的,有价值的数据越来越少。这就跟考试一样,不及格的时候,随便学一学分就提升非常快。当考到八九十分了,再往上提 5 分、10 分,是很难的。
这时候我们使用了超级对齐,强制让模型输出符合人类要求的结果。另外,我们也筛选了一些数据补充到超级对齐里,让模型能力进一步提升,这样做是有一定效果的,但我们大概从今年 3 月份到 7 月底,花了 5 个月时间,模型性能才提升了 2 倍左右。
这是「端到端+ VLM 视觉语言模型」技术架构在飞速进步后遇到的第一个问题:越往后,有用数据越稀少,模型性能进步的速度也越慢。

而其本质问题也随之暴露出来,郎咸朋说:
本质来看,现在端到端的这套模仿学习并不具备深度的逻辑思考能力,就像猴子开车一样。喂猴子一些香蕉,它可能会按照你的意图做一些行为,但并不知道自己为什么要做这些行为,一敲锣它就过来,一打鼓它就跳舞,但不知道为什么要跳舞。
所以说端到端架构不具备深度思考能力,顶多算是一个应激反应,就是给一个输入,模型给一个输出,这背后没有深度逻辑。
这也是为什么要在端到端大模型之外再加一个 VLM 视觉语言模型的缘故,VLM 视觉语言模型具有更强的理解和思考能力,能提供更好的决策。但这个模型一是思考得慢,二是和端到端大模型耦合得不够深,很多时候端到端大模型理解和接受不了 VLM 视觉语言模型的决策。
去年这个时候,理想辅助驾驶团队就说过:
以后两个趋势,第一是模型规模变大,系统一和系统二现在还是端到端加 VLM 两个模型,这两个模型有可能合一,目前是比较松耦合,将来可以做比较紧耦合的。第二方面也可以借鉴现在多模态模型的大模型发展趋势,它们就朝这种原生多模态走,既能做语言也能做语音,也能做视觉,也能做激光雷达,这是将来要思考的事情。
趋势很快就变成了现实。
郎咸鹏也说了为什么要从端到端+VLM 切换到 VLA 的原因:
去年做端到端的时候一直也在反思,是不是端到端就够了,如果不够的话我们还需要再做什么。
我们一直在做 VLA 的一些预研,其实 VLA 的预研代表的是我们对人工智能的理解并不是一个模仿学习,一定像人类一样是有思维的,是有自己推理能力的,换句话说它一定要去有能力解决它没有见过的事情或未知的场景,因为这个在端到端里可能有一定的泛化能力,但并不是足以说有思维。
就像猴子一样,它可能也会做出一些你觉得超越你想象的事情,但它不会总做出来,但人不是,人是可以成长的、可以迭代的,所以我们一定要按照人类的智能发展方式去做我们的人工智能,我们就很快从端到端切换到 了VLA 方案去做。
VLA(Vision-Language-Action,视觉语言动作模型)就是去年的趋势思考,以及当下成为现实的技术架构。
虽然 VLA 和 VLM 就差了一个字母,但内涵差异非常大。
VLA 的 Vision 指各种传感器信息的输入,也包括导航信息,能够让模型对空间有理解和感知。
VLA 的 Language 指模型会把感知到的空间理解,像人一样总结、翻译、压缩、编码成一个语言表达出来。
VLA 的 Action 是模型根据场景的编码语言,生成行为策略,把车开起来。
直观的差异就是,人可以用语言去控车,说话就可以让车慢点快点左转右转,这主要是 Language 部分的功劳,人的指令大模型收到的 prompt,VLA 模型内部的指令也是 prompt,等于是打通了人和车。
此外,视觉和行为之间,也没有阻碍了,从视觉信息输入到控车行为输出的速度和效率都大大加快,VLM 慢,端到端不理解 VLM 的问题被解决了。
更显著的差别是思维链(Chain of Thought,CoT)能力,VLA 模型的推理频率达到了 10Hz,比 VLM 的推理速度快了 3 倍多,同时对环境的感知和理解更充分,可以更快更有理有据地进行思维推理,生成驾驶决策。
除了思维能力和沟通能力之外,VLA 也具备一定的记忆能力,可以记住车主的偏好和习惯;以及相当强的自主学习能力。

▲ 理想 i8 是理想 VLA 技术的首发车型
现实世界里,人类想要成为老司机,肯定先得去报个驾校考个驾照,然后贴「实习标」蹒跚上路,在真实道路上开几年时间。
此前辅助驾驶的训练也是如此,不光需要真实世界里的行驶数据用作训练,也需要在真实世界里进行大量的路试。
在一些小说里,有些天赋异禀的选手可以通过读书,读成武力境界超高的实战高手,比如《少年歌行》里的「儒剑仙」谢宣,《雪中悍刀行》里的轩辕敬城。
但是在传统武侠小说里,只会有《天龙八部》里王语嫣这样精通武学典籍,自身却是毫无实战能力的战五渣。

▲ 《飞驰人生》剧照
当然,也有介于中间态的情况:在赛车电影《飞驰人生》里,落魄赛车手张弛在脑海里不断复现巴音布鲁克地区的复杂赛道情况,每天在脑海里开 20 遍,5 年模拟开了 36000 多遍,然后回到真实赛道的时候,成为了冠军。
虚拟开车,不断精进,超越自己过去的最好成绩,这是「算法」。
不过张弛回归赛道,再次成为冠军车手之前就已经在这条赛道多次证明过自己,积累了大量的实际驾驶经验。
实车实路,积累经验,直到了解这条赛道所有的路况,这是「数据」。

郎咸朋说,想要做好 VLA 模型,需要四个层面的能力:数据,算法,算力和工程能力。
理想强调自己数据多,数据优秀,数据库好,以及数据标注和数据挖掘准已经很久了,关于数据,理想也有新技能:生成数据训练。

通过世界模型进行场景重建,然后在重建的真实数据之上,举一反三,生成相似场景,比如理想在世界模型里重建一个出高速 ETC 的场景,在这个场景下,不仅可以用原来的真实数据情况,比如白天晴朗地面干燥,也可以生成出白天大雪地面湿滑,夜晚小雨能见度不佳等等场景。
理想训练 VLA 模型算法的更迭也跟生成数据息息相关,郎咸朋介绍说:
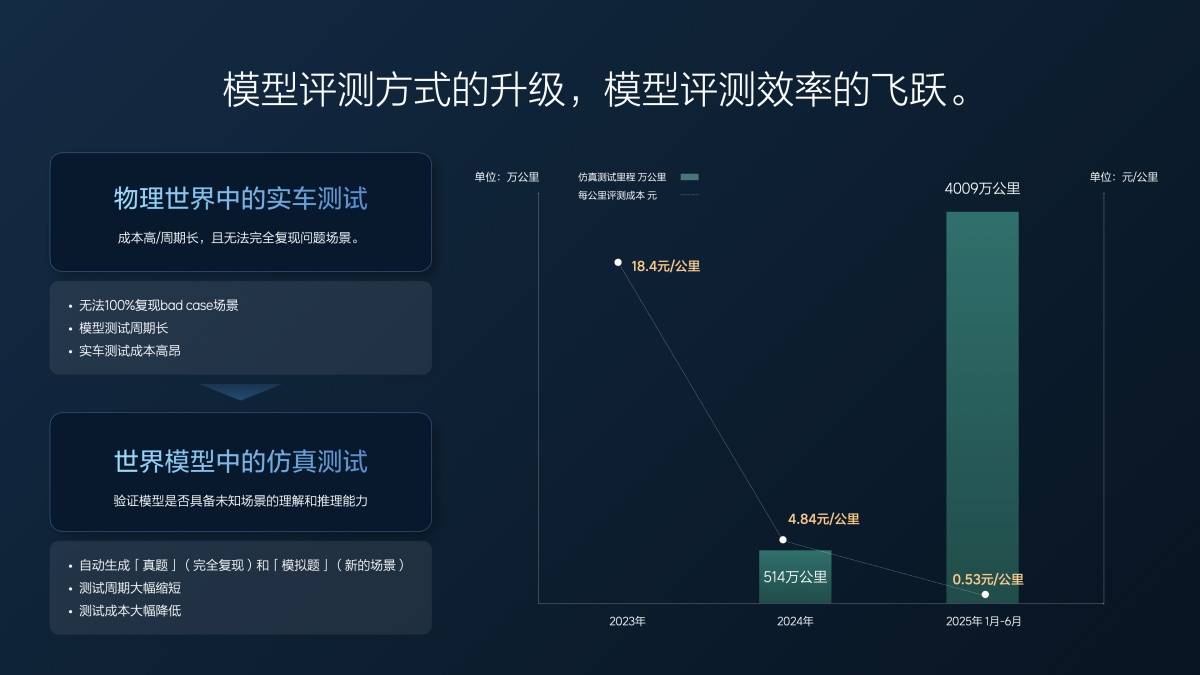
2023 年我们还没做端到端,一年用实车的有效测试里程大概 157 万公里,每公里花 18 块钱。
我们开始做端到端的时候,就有一部分在做仿真测试了,2024 年全年的仿真测试仿了 500 万公里左右,实车也测了 100 多万公里,平均下来成本降到了 5 块钱一公里不到,差不多也是花了 3000 万左右。但是同样花 3000 万,我能测 600 万公里了。
今年半年时间(1 月 1 日-6 月 30 日),我们测了 4000 万公里,实车只有 2 万公里,就跑一些基本的场景。所有的测试,大家看到的超级对齐、现在的 VLA,我们都是用仿真测的,5 毛钱一公里,就是付个电费,付个服务器的费用。并且测试质量还高,所有的 case、所有的场景都能举一反三,可以完全复测,分毫不差。我们的测试里程多了,测试质量好了,研发效率就提升了。
所以很多人质疑我们不可能用半年做个 VLA,测都测不过来,实际上我们测试非常多。
仿真测试的优点除了成本低之外,还能完美复现场景,真实场景测试情况下,一个场景很难被 100% 还原,对于 VLA 模型来说,场景复现差之毫厘,驾驶表现可能就失之千里。

以此而言,理想训练 VLA 模型的形式,与电影《飞驰人生》里主角在真实驾驶经验基础上,不断地虚拟训练的模式,有一些类似。
当然,最后 VLA 模型的训练,也需要背后巨大算力的支撑,理想现在的总算力为 13EFLOPS,其中 3EFLOPS 给了推理,10EFLOPS 给了训练。换算成显卡数量,是等效 2 万张英伟达 H20 用作训练,等效 3 万张英伟达 L20 用于推理。

Q:智能辅助驾驶存在一个「不可能三角」,也就是效率、舒适和安全三个目标之间是互相制约的,目前阶段可能难以同时实现。理想汽车的 VLA 目前在当前阶段最先优化的指标是哪一个?刚刚提及到 MPI,是否可以理解为目前理想汽车最终的指标是提升安全性以有效减少接管?
郎咸朋:MPI 是我们衡量的指标之一,还有一个指标是 MPA,也就是指发生事故的里程,理想车主的人驾数据是 60 万公里左右出一次事故,而在使用辅助驾驶功能的情况下是 350 到 400 万公里发生一次事故。这个里程数据我们还会持续提升,我们的目标是将 MPA 能提升到人类驾驶的 10 倍,也就是比人驾安全 10 倍,做到 600 万公里才出一次事故,但这必须等到 VLA 模型提升之后才能做到。
针对 MPI,我们也做过分析,可能一些安全风险问题会导致接管,但有时候舒适度不好也会导致接管,比如急刹、重刹等,因为并不一定每次都会遇到安全风险,但是如果驾驶舒适度不好,用户依然不想用辅助驾驶功能。因为 MPA 可以衡量安全性,在 MPI 方面,除了安全性之外,我们重点提升了行车舒适度,如果体验了理想 i8 的辅助驾驶功能,会体验到舒适度比之前的版本有很大提升。
效率是排在安全和舒适之后的,比如走错路,虽然效率有所损失,但我们不会通过一些危险的动作立刻纠正,还是要在安全和舒适的基础上去追求效率。

Q:VLA 模型的难点在哪里?对企业的要求是什么?如果一个企业想要落地VLA模型会面临哪些挑战?
郎咸朋:曾经也有很多人问过如果车企想做 VLA 模型是不是可以跳过前面的规则算法,跳过端到端阶段,我认为是不行的。
虽然 VLA 的数据、算法等可能跟之前不太一样,但是这些仍然是要建立在之前的基础上的,如果没有完整的通过实车采集的数据闭环,是没有数据能够去训练世界模型的。理想汽车之所以能够落地 VLA 模型,是因为我们有 12 亿数据,只有在充分了解这些数据的基础上,才能够更好的生成数据。如果没有这些数据基础,首先不能训练世界模型,其次也不清楚要生成什么样的数据。
同时,基础训练算力和推理算力的支撑需要大量资金和技术能力,如果没有之前的积累是不能完成的。
Q:今年理想实车测试是 2 万公里,请问大幅减少实车测试的依据是什么?
郎咸朋:我们认为实车测试有很多问题,成本是其中一方面,最主要的是我们在测试验证一些场景时不可能完全复现发生问题时的场景。同时,实车测试的效率太低了,在实车测试过程中要开过去之后再复测回来,我们现在的仿真效果完全可以媲美实车测试,现在的超级版本和理想 i8 的 VLA 版本中 90% 以上的测试都是仿真测试。
从去年端到端版本我们就已经开始进行仿真测试的验证,目前我们认为它的可靠性和有效性都很高,所以我们以此替代了实车测试。但仍有一些测试是无法替代的,比如硬件耐久测试,但和性能相关的测试我们基本上会使用仿真测试替代,效果也非常好。
工业时代来临后,刀耕火种的流程被机械化替代;信息时代后,网络替代了大量工作。在自动驾驶时代也是一样,端到端时代来临后,我们进入了使用 AI 技术做自动驾驶的方式,从雇佣大量工程师、算法测试人员,到数据驱动,通过数据流程、数据平台和算法迭代提升自动驾驶能力。而进入了 VLA 大模型时代,测试效率是提升能力的核心因素,如果要快速迭代,一定要把在流程中影响快速迭代的因素迭代掉,如果这其中仍有大量的实车和人工介入,速度是会降低的。并不是我们一定要替代实车测试,而是这项技术,这个方案本身就要求要使用仿真测试,如果不这样做,并不是在做强化学习,并不是在做 VLA 模型。
Q:VLA 其实没有颠覆端到端+VLM,所以是否可以理解成 VLA 是偏向于工程能力的创新?
詹锟(理想汽车自动驾驶高级算法专家):VLA 不只是工程方面的创新,大家如果关注具身智能,会发现这波浪潮伴随着大模型对物理世界的应用,这本质就是提出了一个 VLA 算法,我们的 VLA 模型就是想把具身智能的思想和路径引用在自动驾驶领域。我们是最早提出,也是最早开始实践的。VLA 也是一种端到端,因为端到端的本质是场景输入,轨迹输出,VLA 也是如此,但算法的创新是多了思考。端到端可以理解为 VA,没有 Language,Language 对应的是思考和理解,我们在 VLA 中加入了这一部分,把机器人的范式统一,让自动驾驶也能成为机器人的一类,这是算法创新,不只是工程创新。
对于自动驾驶而言,很大的挑战是必须要有工程创新。因为 VLA 是一个大模型,大模型部署在边缘端算力上是非常具有挑战的。很多团队并不是认为 VLA 不好,而是因为 VLA 部署有困难,把它真正落地是非常具有挑战性的事情,尤其是在边缘端芯片算力不够的情况下是不可能完成的,所以我们是在大算力芯片上才能部署。所以这不仅仅是工程创新,但的确需要工程部署大范围优化才能实现。
Q:VLA 大模型在车端部署的时候是否会有比如模型裁剪或蒸馏版本?如何在推理效率和模型之间做好平衡?
詹锟:在部署时的效率和蒸馏上我们做了非常多平衡。我们的基座模型是自研的 8×0.4B 的 MoE 模型(混合专家模型),这是业界没有的,我们在深入分析英伟达芯片后,发现这个架构非常适合它,推理速度快的同时模型容量大,能够同时容纳不同场景、不同能力的大模型,这是我们在架构上的选择。
另外,我们是大模型蒸馏出来的,我们最早训练了一个 32B 的云端大模型,它容纳了海量的知识和驾驶能力,我们把它做出的思考和推理流程蒸馏到 3.2B 的 MoE 模型上,配合 Vision 和 Action,使用了 Diffusion 技术(扩散模型,可以生成图像、视频、音频,动作轨迹等数据,具体到理想的 VLA 场景,是利用 Diffusion 生成行车轨迹)。
我们用这样的方法做了非常多的优化。从细节上来看,我们也针对 Diffusion 做了工程优化,并不是直接使用标准 Diffusion,而是进行了推理的压缩,可以理解为一种蒸馏。以前 Diffusion 可能要推理 10 步骤,我们使用了 flow matching 流匹配只需要推理 2 步就可以了,这方面的压缩也是导致我们真正能够部署 VLA 的本质原因。

Q:VLA 是一个足够好的解法了吗?它抵达所谓的「GPT 时刻」还需要花多长时间?
詹锟:多模态模型之前说没有达到 GPT 时刻,可能指的是 VLA 这种物理 AI,而不是 VLM,其实现在 VLM 已经完全满足一个非常创新的「GPT 时刻」标准,如果针对物理 AI,现在的 VLA,特别是在机器人领域、具身智能领域可能并没有达到「GPT 时刻」的标准,因为它没有那么好的泛化能力。
但在自动驾驶领域,其实 VLA 解决的是一个相对统一的驾驶范式,是有机会用这个方式做到一个「GPT 时刻」的,我们也非常承认现在的 VLA 是第一版本,也是业界第一个往量产上要推的 VLA 版本,肯定会存在一些缺陷。
这个重大尝试是想说我们想用VLA来探索一个新的路径,它里面有很多尝试的地方,有很多需要去落地的探索的点,不是说不能做到「GPT 时刻」就一定不能去做量产落地,它有很多细节,包括我们的评测、仿真去验证它能不能做到量产落地,能不能给用户「更好、更舒适、更安全」的体验,做到以上三点就可以给用户更好的交付。
「GPT 时刻」更多指的是具有很强的通用性和泛化性,在这个过程可能随着我们自动驾驶往空间机器人或往其它具身领域去拓展的时候会产生出更强的泛化能力或者更综合的统筹能力,我们也会在落地以后随着「用户数据迭代、场景丰富、思维逻辑性越来越多、语音交互越来越多」逐渐往 ChatGPT 时刻迁移。
像郎博(郎咸朋博士)说的,到明年我们如果到了 1000MPI,可能会给用户这种感觉:真的到了一个 VLA 的「GPT 时刻」。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。

这一期节目的录制时间是 2024 年 12 月底,当时 Toby 的新办公室刚装修完,我们从他正在开展的新工作开始,顺着「符号化」这个设计策略,聊到小米 SU7、理想 Mega 和新款 mini 的设计策略与执行。在这次对话中,我和 Toby 作为在设计行业一线做了二十年左右的设计师,一起探讨了各自对于「抄袭」和「借鉴」的理解和边界。
04:15 — 借鉴和抄袭之间有明确的边界吗?理想对 Mega 有信心和决心吗?为什么看上去几乎没变化的新 mini 反而是更激进的设计?小米 SU7 的决心比 Mega 大得多。相机消费者怎么看待和讨论「复刻」和「抄袭」的关系?谁在为「腰平取景器」买单?
21:45 — 为什么经典款的 1:64 小车模型永远最畅销?一句话区分抄袭与借鉴!
41:05 — 工业设计只聊造型是没有价值的!拍立得相纸是一门钻石生意。摄影玩家们对老品牌的溺爱,以及对新品牌的包容程度。符号是沟通和决策。好产品需要有专业认知的团队与设计师一起推进。
69:08 — 设计是沟通:我们跟德国车厂的合作经验。设计公司的模式高度同质化,是分裂复制的循环。未来的设计机构和品牌的区别:工作方式与理念的区别。
82:23 — 有趣的尺度怎么找?创作型 AI 是不是我们的敌人?
录制这期节目时,我嗓子哑了,如果觉得听感不佳,烦请见谅 
欢迎在评论区留言发表你对本期节目的感受与看法。
|登场人物|
郑冬平 Toby:BrainON 创始人,上善设计联合创始人
苏志斌:工业设计师,产品/设计咨询顾问
|相关图片|

Tesla Cybertruck

极氪 MIX(宝宝巴士)

新款 mini cooper

理想 Mega

小米 SU7
初照 M1 双反小相机




|拓展阅读|
BrainON 官网:www.brainon.design
|BGM|
编曲:阿吉
演奏:阿吉
合成:阿吉
|相关链接|
若你所使用的播客客户端未能完整显示插图,或遇网络问题未能正常播放,请访问:
荒野楼阁 WildloG 的地址:https://suithink.me/zlink/podcast/
阅读设计相关的各类文章:https://suithink.me/zlink/idea/
|其他社交网络媒体|
苏志斌SUiTHiNK @ Bilibili / YouTube / 小红书
|联络邮箱|
suithink.su@gmail.com
欢迎在 小宇宙、Spotify、YouTube、Apple Podcast 收听本节目,期待你的留言。

昨晚,跟筱烨从宠物医院回来,走到楼下时她问我:「假如不需要为钱发愁了,你会去做什么?」我脑海里先是划过各种不确定的数字,一千万?八千万?三个亿?还是 5000 亿?
多少钱能算自由?拥有多少不用发愁?
我一直觉得自己这辈子的目标,是做出一些能对人有益的东西。作为工业设计师,我觉得我的这个身份是充分满足了我从小到大的愿望的。但是,这个愿望在成为设计师之后,就停滞不前了。我至今也没有做出能令自己满意的,能够称之为「好作品」的对世界有益的东西。
我其实清楚,这不全是我的问题。
能力我当然自信是没问题的,但远不够出类拔萃到可以被称为天才的程度;时代的机会其实并不少,我亲眼见证过的都不胜枚举,设计师的机遇是多的,即便不是我,我也不会否认这个时代是对设计师友善的;个人的运气不是可以评价的部份,我认同王德峰教授的观点,人到三十得知命认命,这不是说要被生活锤打成老牛,是知道自己寸长寸短在哪里。
曰「六亲无靠,大器晚成」,便不强求。
但无论何时,如果以不愁开销为前提考虑未来想做的事,我冒出的总是「回到舞台」「专心写作」「做慈善性质的设计」这一类事情。因为,我觉得那是我的「欲望」所在。
「也许,去拍纪录片吧?」
这句话说出来时,我自己也惊愕了。
我知道我考虑过这件事,但我从来没有把它上升到「后半辈子的目标」这样的高度。筱烨问我是不是想给自己留下点什么,我说:「不是的,我不是想给自己留下点什么,我是想给这个世界留下点什么。」这三四年间,我渐渐地把「自己」从欲望和野心中拿出来了。前几个月,@两个皮蛋的初号来找我聊天,席间,我说了一段话,大意是:
我现在只在乎我那些想法是否传播出去了,是否影响到了那些真正有影响力的人,大的媒体机构也好,数码科技博主也好,人文艺术博主也好,只要他们能从我这里了解到真正的设计是什么样子的,不是陈词滥调的刻板印象,不是动辄灵感来源和像这个像那个,那么,我写的文章和做的视频就有意义。我作为个体是否有足够大的影响力,没那么重要,但我能作为一把种子撒向远处,这比我短暂的一生本身重要得多。
这不是浪漫化,而是彻底的实用主义。
作为工业设计师从 05 年工作到现在,设计和制造了多少东西,它们的生命周期是多长,归属何在,我大概是知道的。造物是人类的特权,因此敢称万物灵长。可人造之物不永恒,要么是在岁月中破败的石块建筑,要么是长久不化的塑料垃圾,都是昙花一现,不得善终。但凡是实体,都有消亡的时候。这个周期,绝大多数时候是比人类个体的平均生命周期短的。
但文明可以绵延数千年,通过记录和记忆。
因此才会有那个笑话:如何成为百万富翁?去拍纪录片。你会从千万富翁成为百万富翁。纪录片就是很烧钱,不管是记录人类还是地球的故事,这种记录形式一定是需要耗费巨大劳动价值的。正如人类练习内观,从亿万斯年的衍化中诞生的智能生命,觉察到自身的存在,并对自身进行观测和记录,这也同样耗费了巨大的资源。只是,我们作为人类的个体,通常难以察觉到这一现象。但你察觉到时,就是一次生命的奇迹。
假如我们是另一些生命创造出来的,那就是更大的奇迹。
当然,我并没有要拔高自己想拍纪录片的想法,只是在陈述其拥有远高于「设计」「话剧」「写作」之类个人私心的观点。在我能力和命运的射程内,大体上只能追寻上述三者,并且大概率在有生之年都难以企及我所认为的高峰,但如果让我以「无须在意代价」为前提来畅想的话,那句不经意透露的想法向我指出了更高的云上有什么。
我可以化归尘土,但尘土上会有万物。
