全球AI百大应用榜发布!DeepSeek被反超,ChatGPT 王座快不保,中国产品占半壁江山

今天,硅谷顶级风投 a16z 发布了新一期的 AI 应用百大榜单。半年过去,又有哪些新的 AI 产品涌现,ChatGPT 的老大地位是否开始动摇,APPSO 马上带你解读这份榜单。
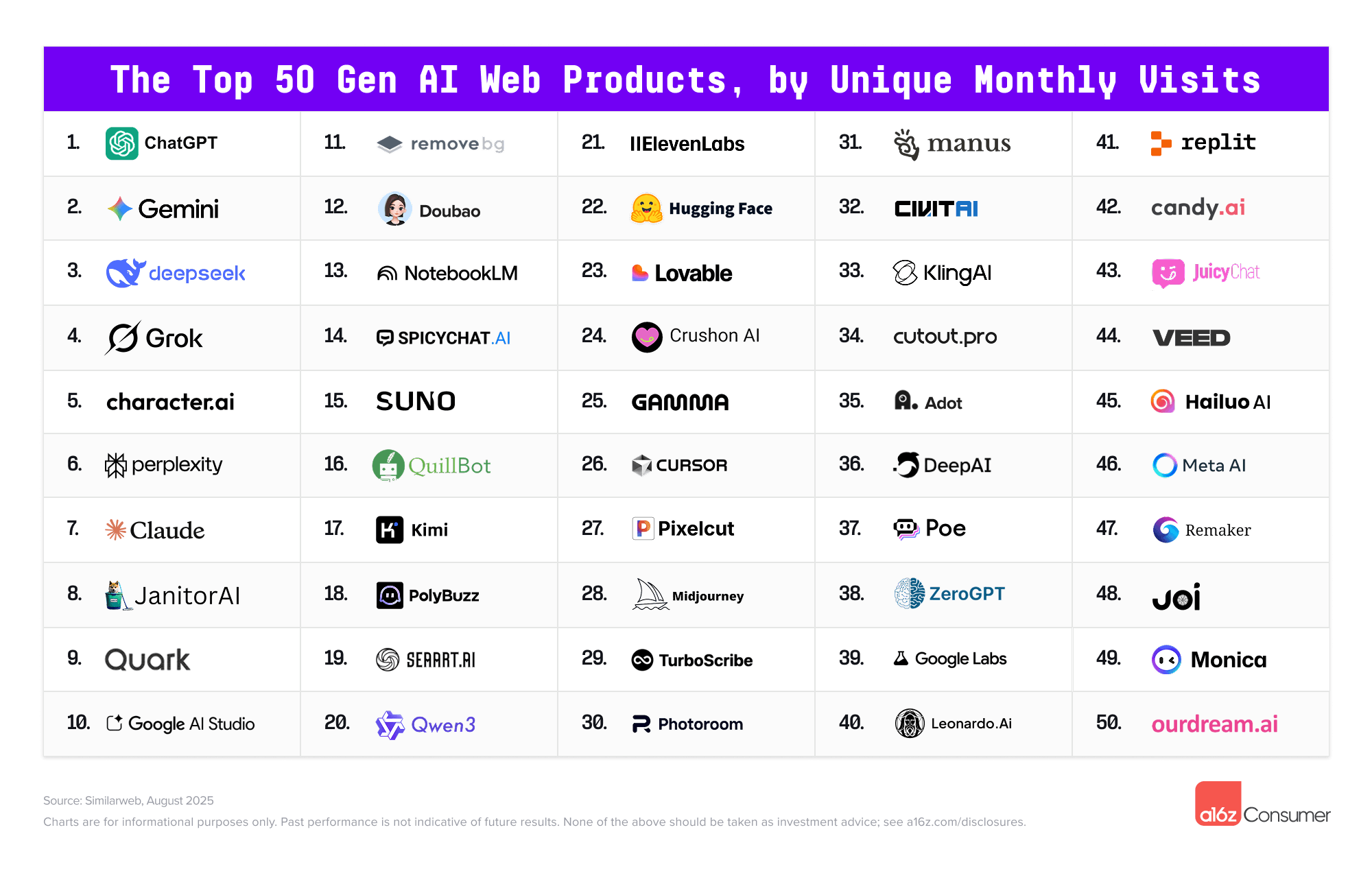
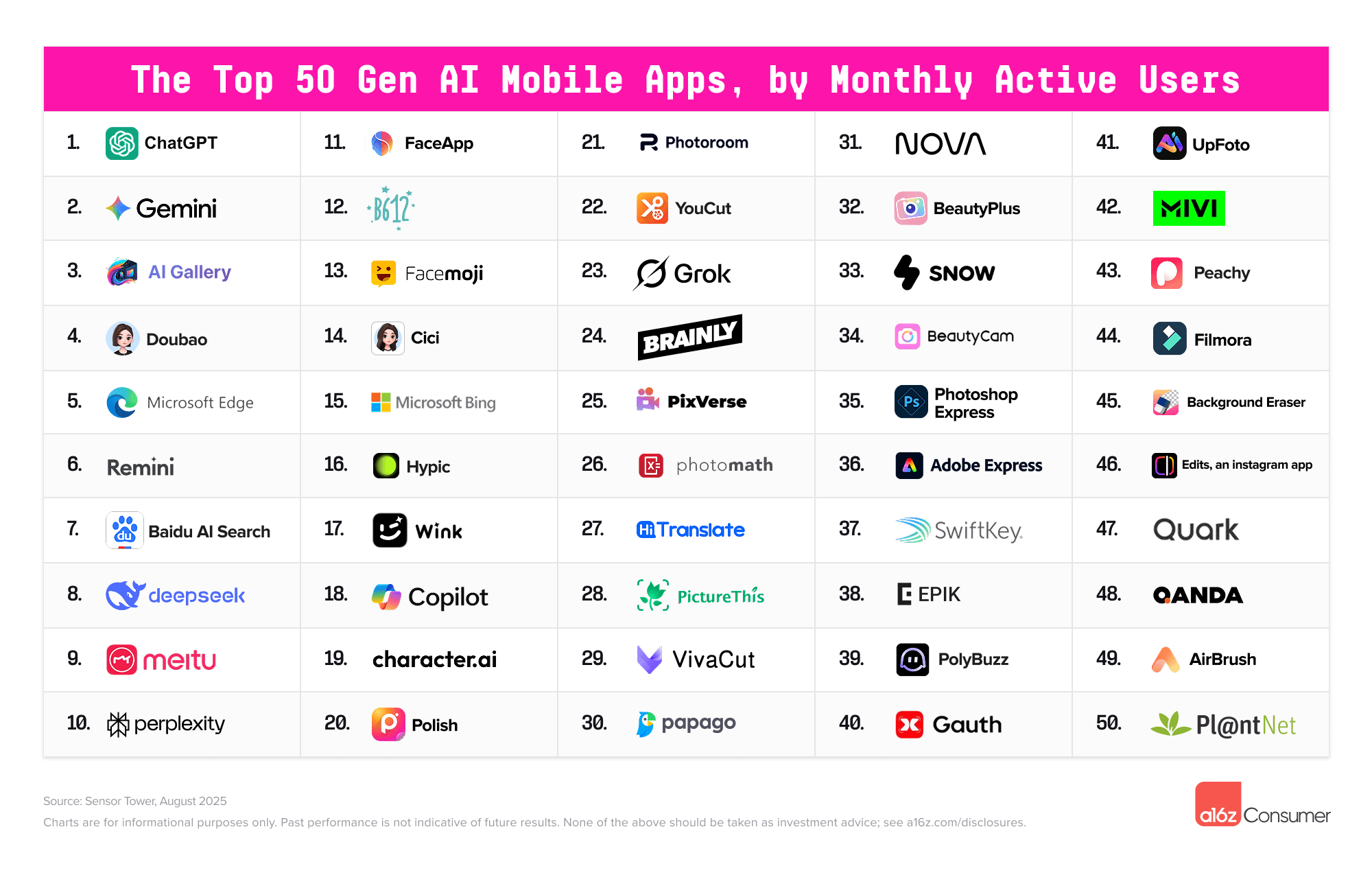
▲ 网页端和移动端产品前 50 名
我们简单总结了此次榜单的几点趋势。
ChatGPT 依旧稳坐第一,但这个宝座越来越不安全了。Google 的 Gemini 用户数已经追到它的一半,它俩现在是两大顶级的新一代人工智能平台。
马斯克的 Grok 靠着一款二次元虚拟伴侣 Ani,硬是从 0 干到 2000 万月活。
DeepSeek 在年初爆火后月活跃用户大幅下降,移动端下降了 22%,网页端更是达到了 40%。
国产应用表现继续亮眼,移动端 Top 50 的应用中,估计有 22 款是由中国团队开发的。Kimi、豆包、夸克直接闯进了全球前 20。
本次新增的 11 个网页 AI 产品,包含 Qwen、Manus、Lovable 等今年上半年的热门工具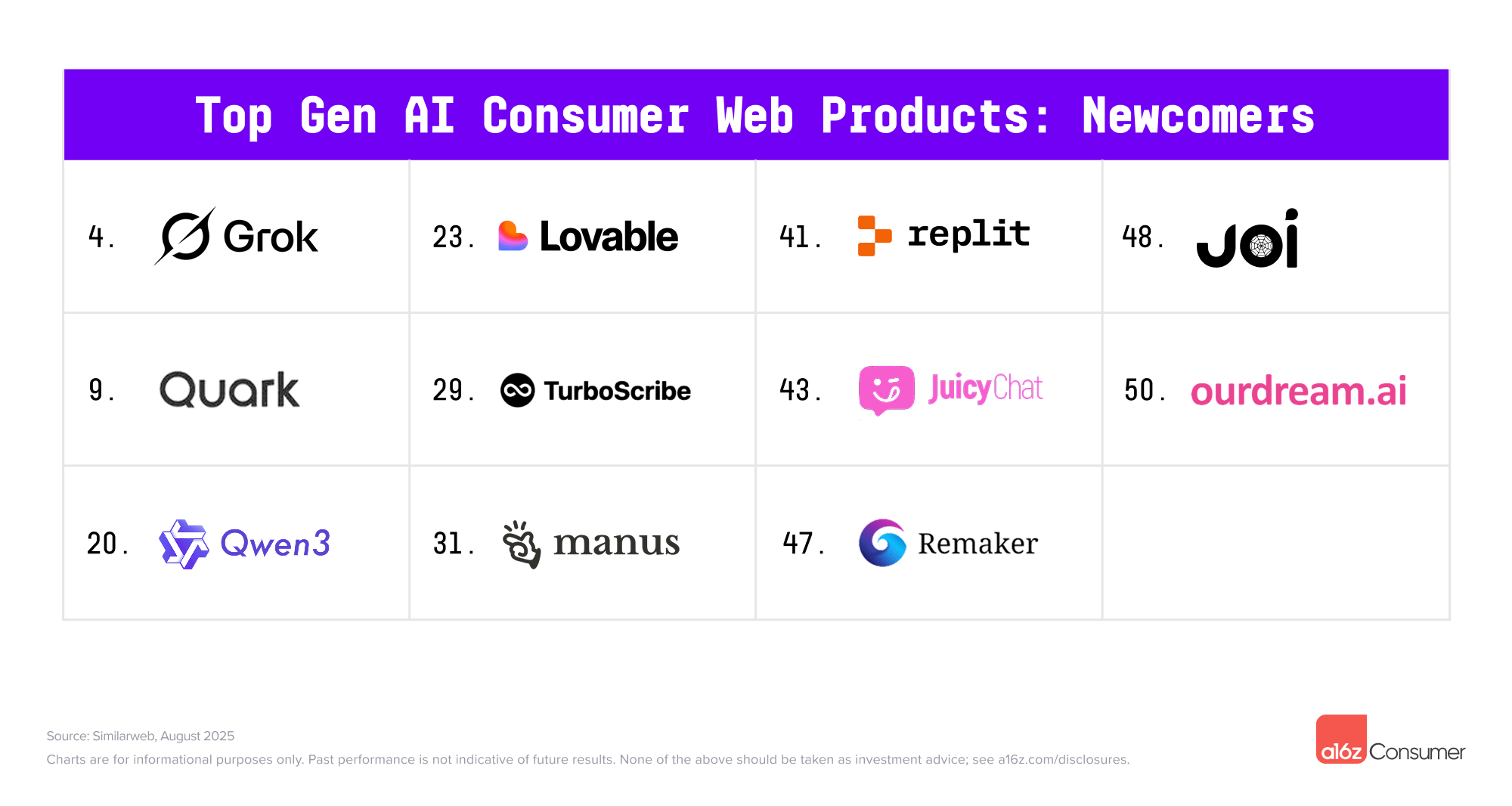
纵观这份报告,可以看到 AI 消费应用的生态已经进入细分和稳定阶段,创新开始变得越来越困难。
ChatGPT 还在领跑,但对手来了
在「通用助手」这条赛道上,ChatGPT 依旧是无可争议的老大。无论是在网页端还是移动端,它都稳稳占据第一的位置。
但新对手已经在逼近。Google 的 Gemini 是最典型的追赶者,在网页端访问量约为 ChatGPT 的 12%,看起来差距还不小;可在移动端,Gemini 的月活用户已经达到 ChatGPT 的一半,而且 9 成用户都来自 Android 阵营。
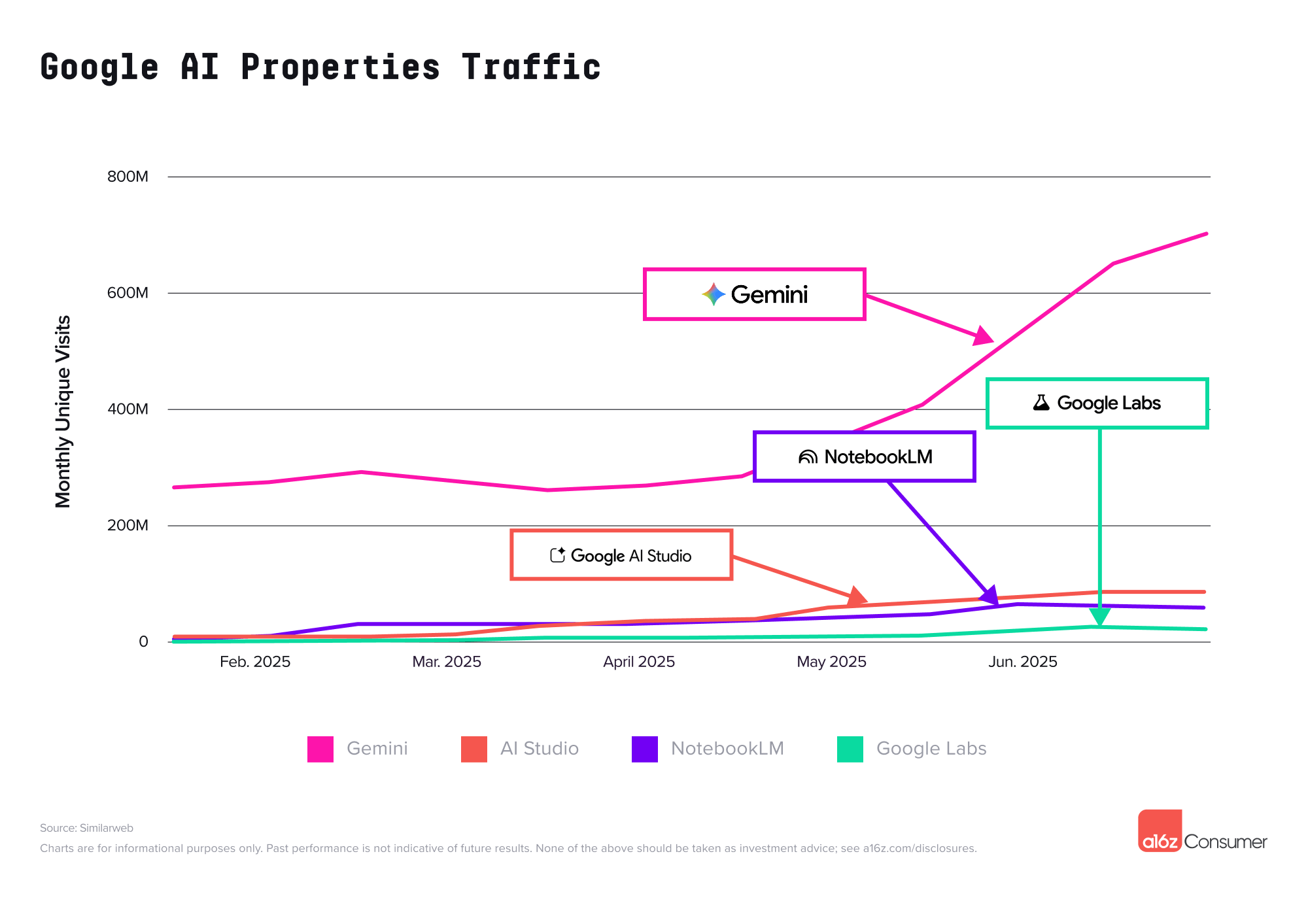
▲ 谷歌多款产品 Gemini、NotebookLM、Google AI Studio、Google Labs 进入百大应用榜
马斯克看起来真的很惨,这边是同一家公司的 Gemini 和 Android 深度绑定,那边又要控诉 Apple 和 OpenAI 有金钱交易。
所以,马斯克的 Grok 不得不走一条「另辟蹊径」的路线。Grok 去年底还没有移动端 App,现在已经冲到 2000 万月活,排在移动榜单第 23。
他的秘诀很简单,就是抓住一些猎奇的内容。在 7 月先发布了 Grok 4 模型后,紧接着在应用内推出「AI 虚拟伴侣」,彻底点燃话题。尤其是二次元角色 Ani(甚至包含 NSFW 选项),让 Grok 赢得了广泛的关注。
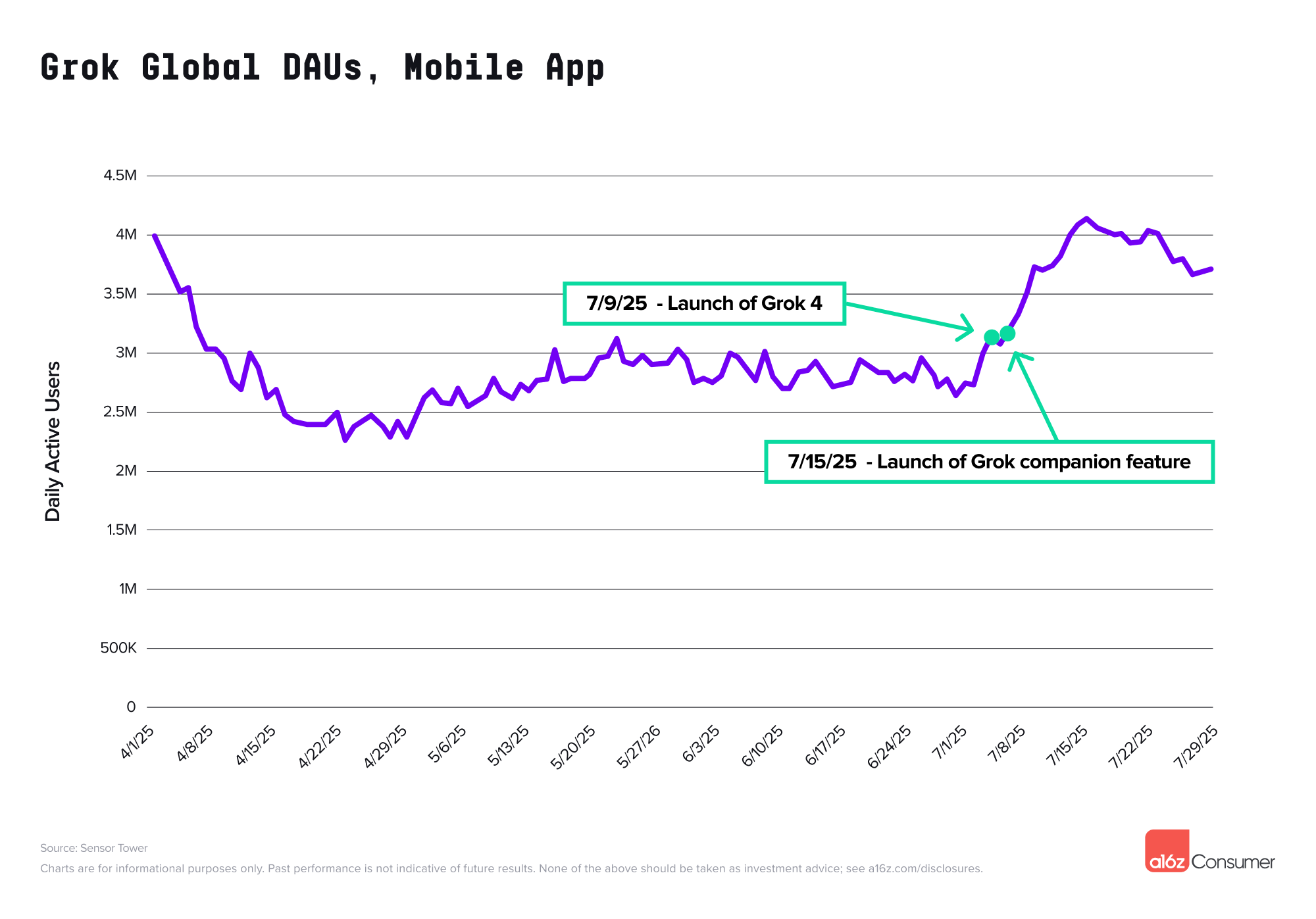
▲ Grok App 日活变化,在推出 Grok 伙伴之后迅速上升
Meta AI 只看到他挖人的新闻了,产品好像真的有些尴尬。它在 5 月上线,排在网页榜单第 46,移动端甚至没进前 50。更糟的是,Meta 还因为「聊天内容被推上公开动态」的隐私事故,用户信任直接受挫,远不如 Grok 来势汹汹。
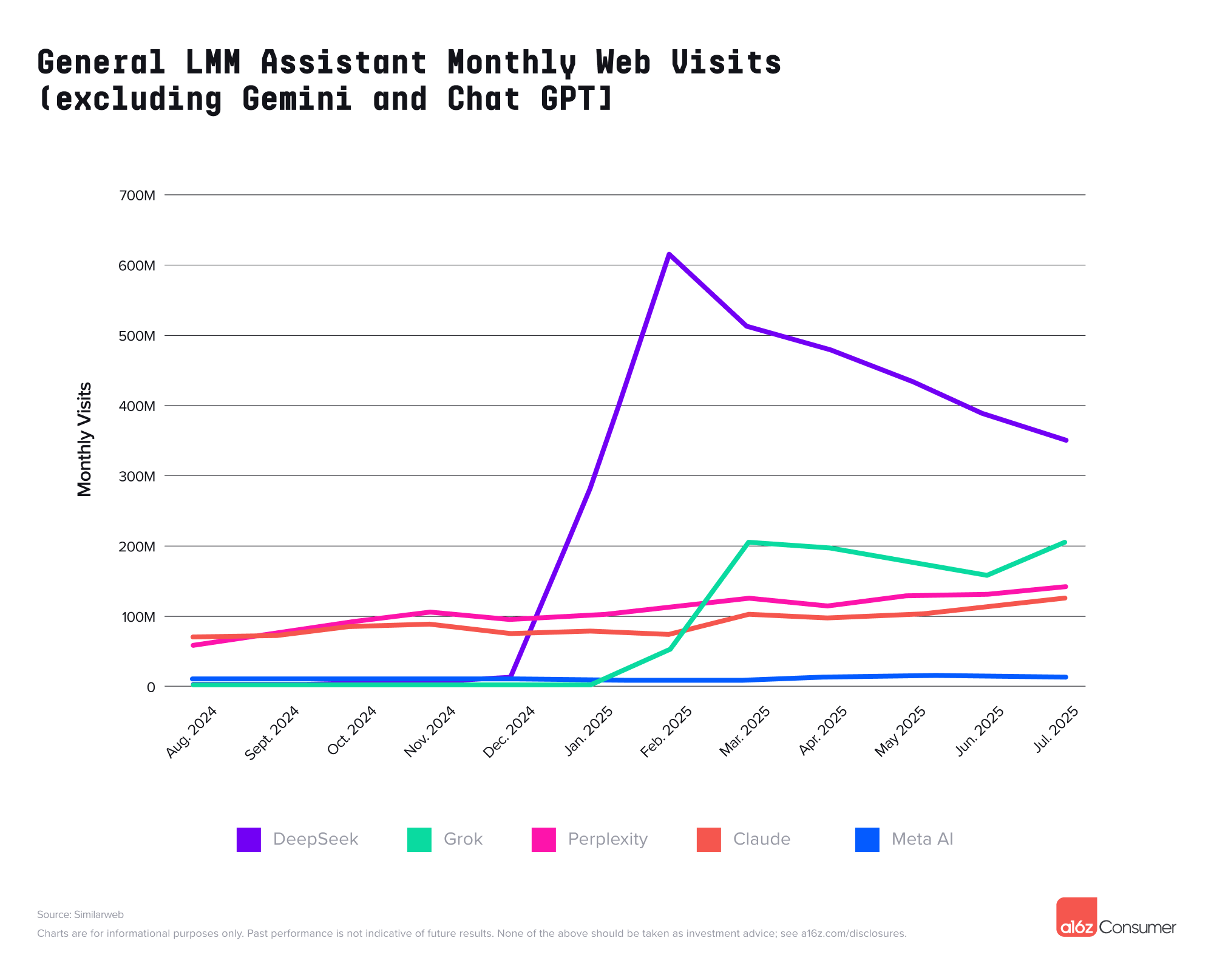
▲ DeepSeek 年初猛增之后,网页月访问量一直在下降。
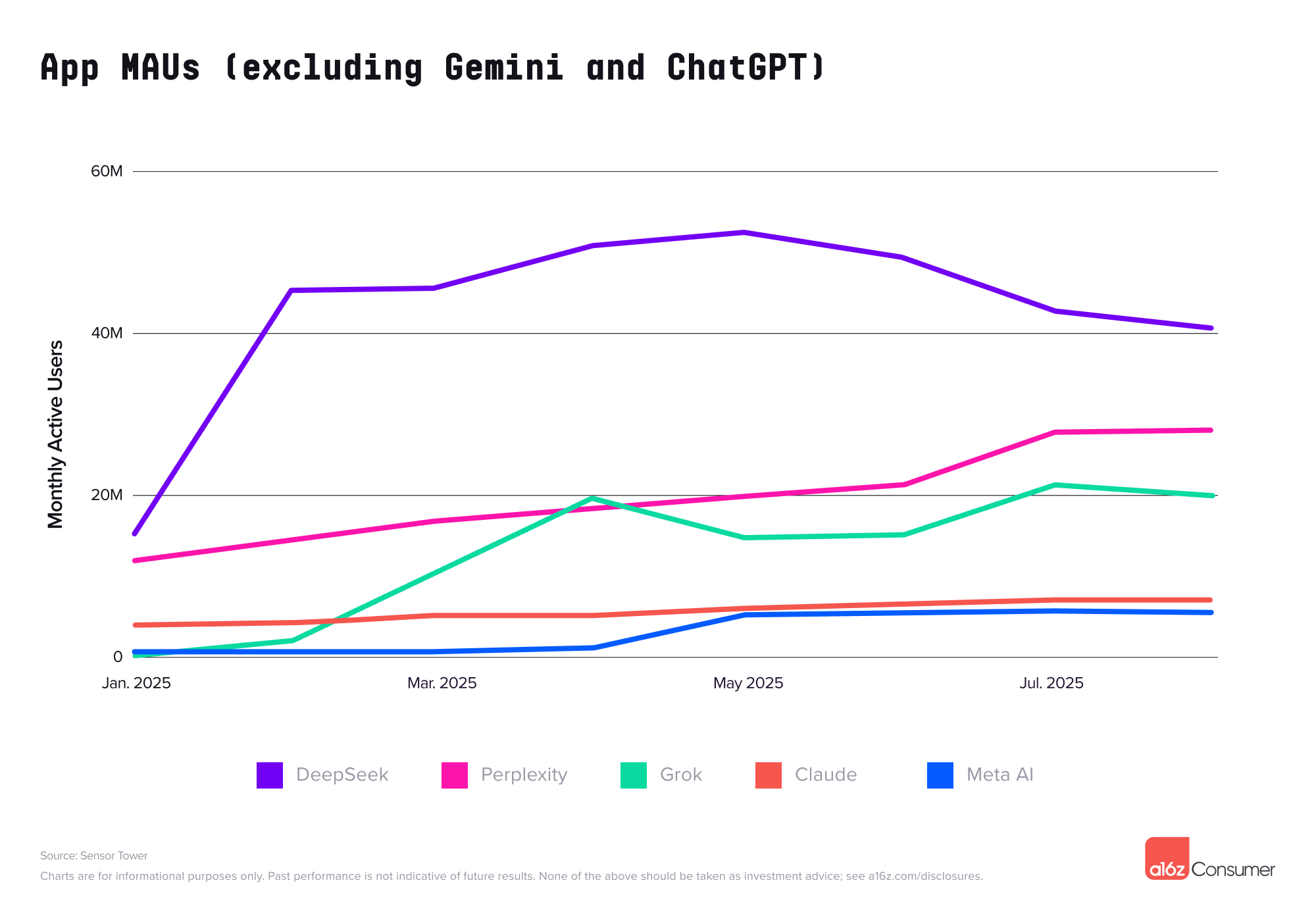
▲ 移动端月访问量下降情况
在 ChatGPT 和 Gemini 之后, Deepseek 、Grok、Perplexity 和 Claude 占据了网络流量的后几位。
Perplexity 目前还是保持着强劲的增长势头,而 Claude 和 DeepSeek 在移动端也开始趋于平缓,DeepSeek 在 Web 端的流量更是从高峰下跌超过 40%。
不过 DeepSeek 目前仍是国产最强大模型,相信将来 DeepSeek 发布 R2 推理模型和 V4 的到来,DeepSeek 能再掀起一次流量狂飙。
Kimi、豆包、夸克闯进全球前 20
除了 DeepSeek 在通用大语言模型助手上的排名,中国公司的更多产品在这次榜单里亮相。
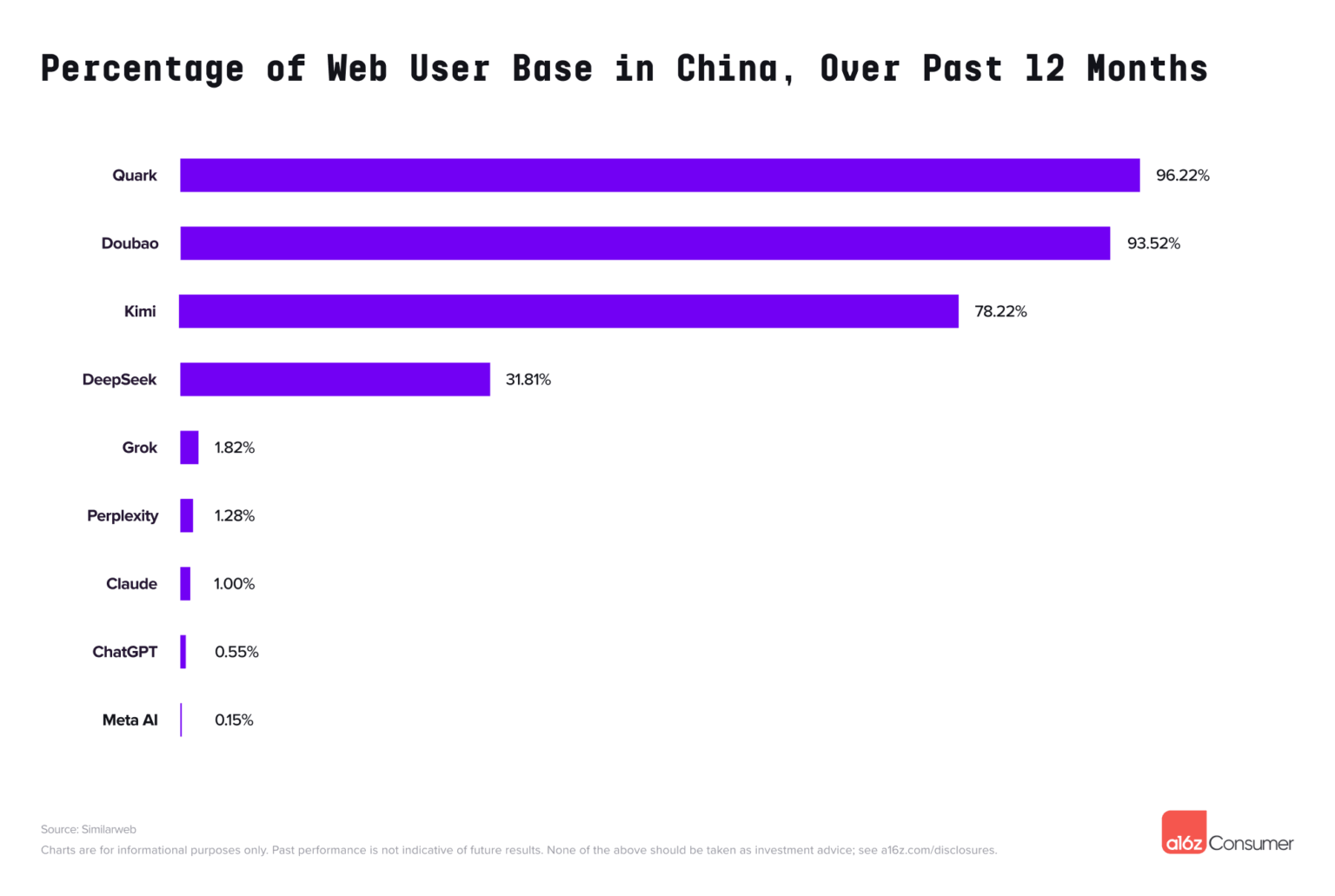
在前 20 名里,阿里的「夸克」、字节的「豆包」、月之暗面的「Kimi」同时上榜。其中,Kimi 作为新兴创业团队的产品,能和 ChatGPT、Gemini 这些巨头同台竞争,已经说明了国内用户对中文大模型的强烈需求。
移动端更明显,50 个上榜应用里,有 22 个来自中国公司,其中美图就包揽了 5 个修图/视频类产品,字节系也贡献了豆包、Cici(国际版豆包)、Gauth(教育)、Hypic(国际版醒图)等。
更有意思的是,国产的视频生成模型一度领先全球。比如 Kling、海螺等产品,往往比海外模型更快落地、更贴近流行趋势。直到 Google 推出 Veo 3,才算打破了这一领先。
Vibe Coding,人人都能点点鼠标写代码
除了助手类应用,还有一种不可忽视的趋势就是,Vibe Coding(氛围式编程)。
这类产品的逻辑很简单:不需要写复杂代码,点点鼠标就能生成网站甚至应用。Lovable、Replit 今年双双进入榜单,说明这种「低门槛编程」越来越受欢迎。
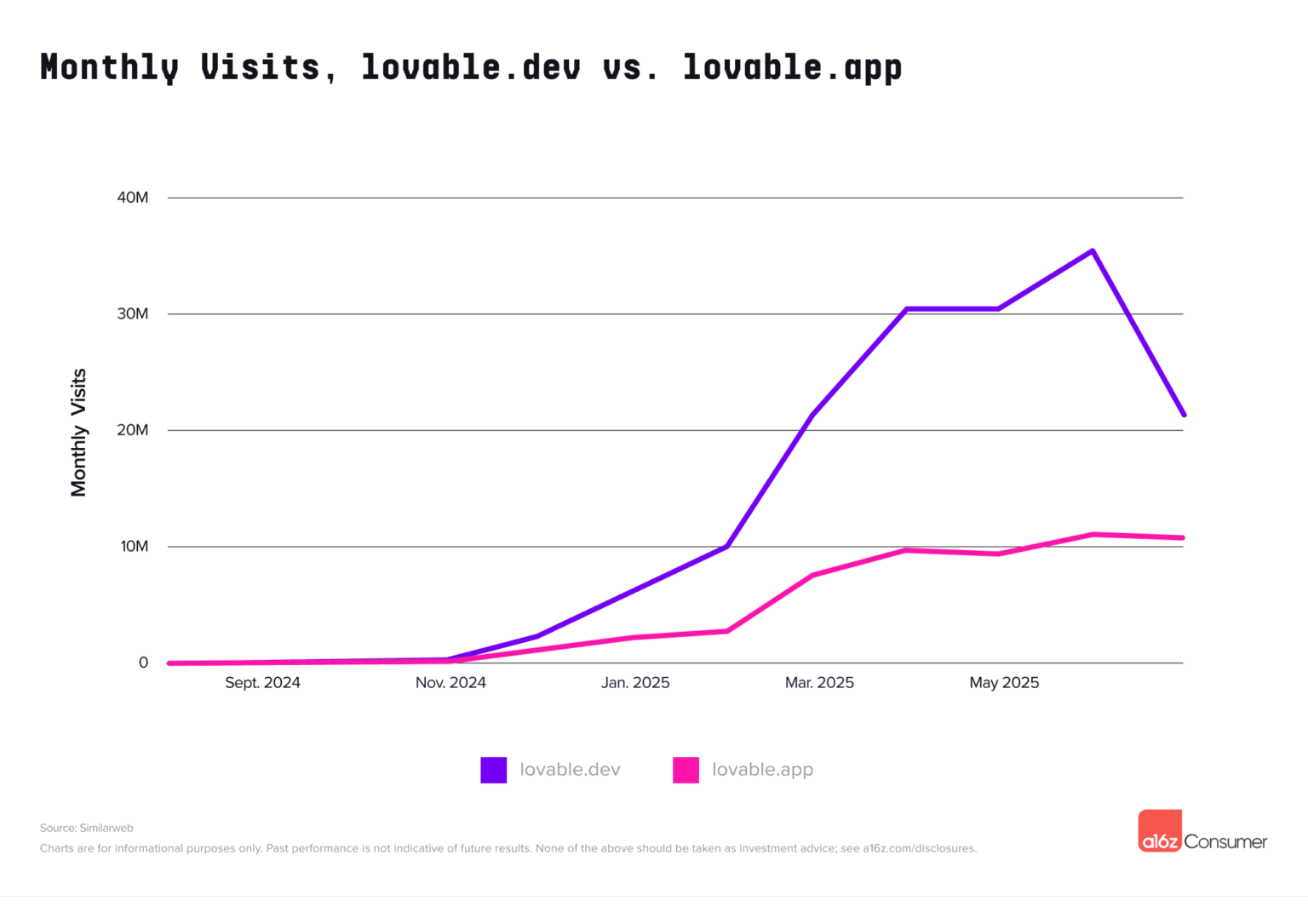
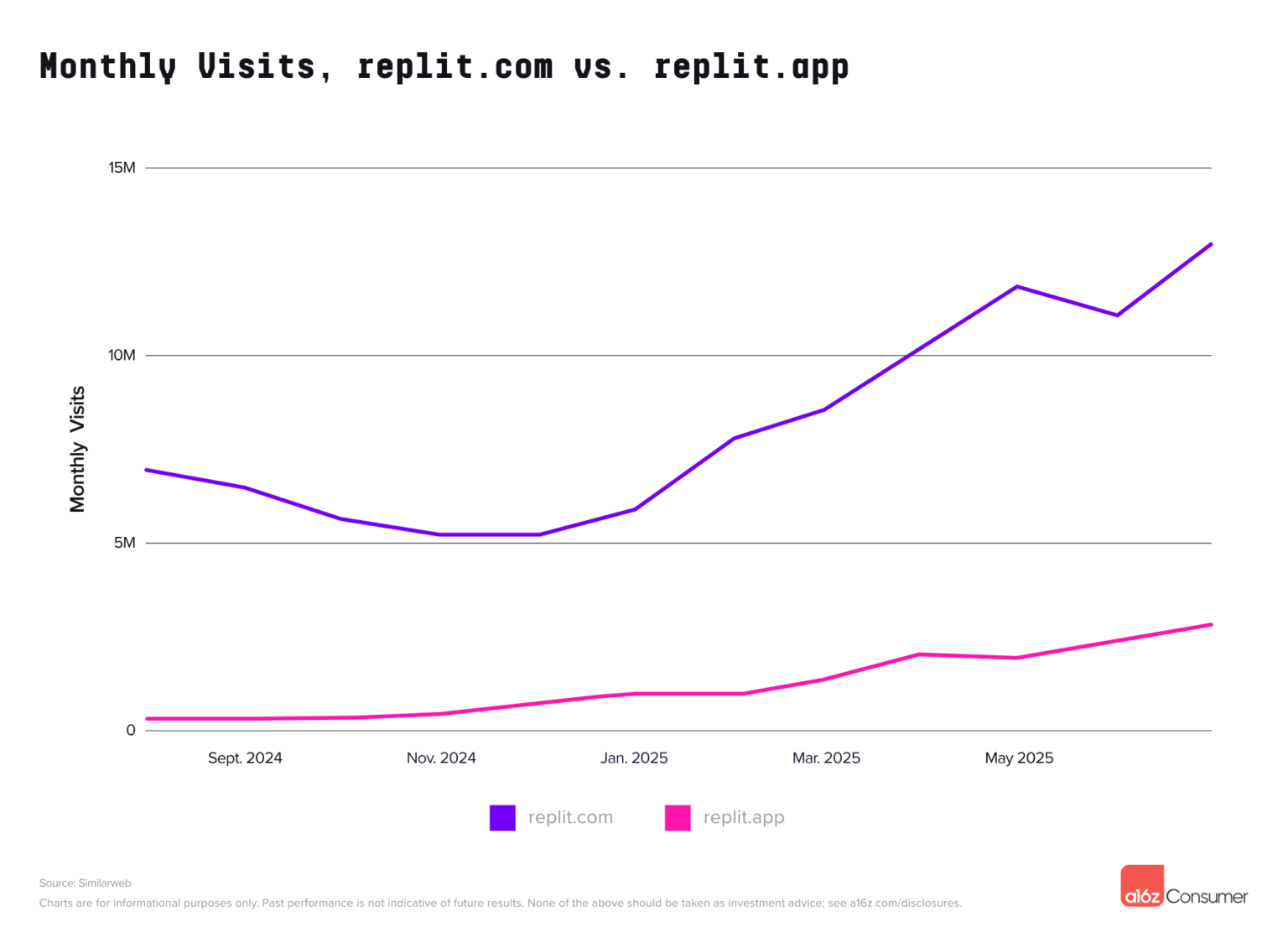
▲ Lovable 和 replit 月访问数据趋势,.app 结尾的网页是该产品的成果预览网页
更关键的是,它们的用户不仅没流失,反而在持续增加消费。数据显示,美国用户在这类平台的付费留存超过 100%——也就是说,用户不仅没走,还越来越舍得花钱。
对普通用户来说,我们每个人都能几分钟搭出一个网站,无论是从工具到个人作品集,还是一个小型商业应用,现在都已经开始成为现实。
AI 爆款的秘密:不求全能,但求刚需
从 a16z 开始发榜单到现在已经更新了 5 次,其中有 14 个应用是雷打不动的「钉子户」,始终霸占着前 50 的位置。
它们分别是:ChatGPT、Character.AI、Civitai、Leonardo AI、ElevenLabs、Gamma、Hugging Face、Veed、Midjourney、Perplexity、Photoroom、Poe、QuillBot 和 Cutout Pro。

你看,它们覆盖的场景无非就那几个:对话、陪伴、修图、创作。全都是高频刚需。
最特别的要数 Midjourney,一个没拿过一分钱融资的「异类」,全靠口碑和社区文化,硬是走到了今天,成为 AI 绘画的代名词。(不过最近有传闻说 Meta 想和它合作,看来好东西还是藏不住的。)
这说明,想做成一个 AI 爆款,不一定非得是无所不能的「全能王」,只要能在一个细分领域,成为用户离不开的那个「唯一」,同样能活得很好。
而且,这 14 家公司里,只有 5 家有自己的底层大模型,剩下的全都是靠调用 API 或者开源模型做的应用。
这或许在告诉我们一个新规律:在 AI 时代,顶尖的产品体验,和顶尖的底层技术,一样重要。
所以,你觉得下一个爆红的 AI 应用,会是一个更聪明的万能助手,还是一个更懂你的赛博伴侣呢?你最常用的 AI 产品又有哪些,评论区聊聊!
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。