让我们没有想到的是,一场短短 75 分钟的发布会,为我们带来了近四年来最香的 iPhone。
在本次苹果秋季发布会上,苹果一口气更新了三款 Apple Watch 和四款 iPhone,作为苹果产品线里最走量的两款产品,这样的动作表明了一个事实:
苹果有危机感了。

但危机感留给苹果去担心,我们作为消费者,只需要好好享受今年的实惠新品就行了。今年的 iPhone 17 标准版终于补齐了长久以来 120Hz 高刷的缺位,Pro 系列也迎来了影像能力的提升,甚至连 Apple Watch SE 3 都有了 AOD。
爱范儿已经在现场第一时间体验了今年的新品,更多发布会没提到的细节,我们将在今天后续的文章中与你分享。
太长不读(TL;DR)
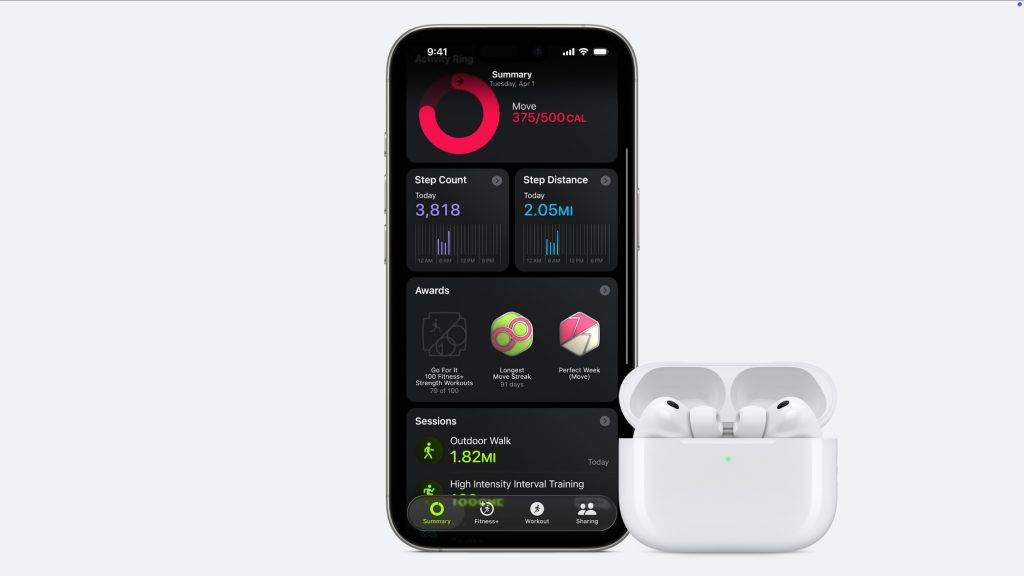
- iPhone 17,终于补上高刷,起售价 5999 人民币
- iPhone Air,史上最薄、国行首台纯 eSIM,起售价 7999 人民币
- iPhone 17 Pro/Max,长焦大升级,起售价 8999/9999 人民币
- AirPods Pro 3,心率检测、降噪升级,1899 人民币
- Apple Watch Series 11,睡眠评分、高血压预警(国行没有),起售价 2999 人民币
- Apple Watch Ultra 3,超大屏幕、卫星通讯,起售价 6499 人民币
- Apple Watch SE 3,全天候显示、续航加长,起售价 1999 人民币
iPhone Air:薄,爆表

与预测信息相同,今年的 iPhone Air 取代了往年的 Plus 机型,成为了那个不追求影像能力的大屏选项。
但「Air」作为苹果内部一个意义深远的名字,带来的亮点可比 Plus 多多了——比如它的名字不叫 17 Air,就叫 iPhone Air。
在最重要的外观方面,iPhone Air 是一款 6.5 寸的机型,机身厚度仅为 5.6mm。为了维持机身强度,苹果将 Air 的边框改为了抛光的纯钛合金,视觉冲击力够强,也是一支从侧面能看出来是「最新款」的 iPhone。

至于 iPhone Air 的屏幕则是我们熟悉的样子,依然是一块采用灵动岛挖孔的 Super Retina XDR 屏幕,峰值亮度 3000 尼特,并且支持 ProMotion 1~120Hz 的可变刷新率。
此外,iPhone Air 也用上了新的第二代超瓷晶面板,类似当年的 12 寸 MacBook,苹果将除了电池之外的所有主要部件全部集成到了镜头 deco 里面:

有趣的是,iPhone Air 没有像传闻中那样与标准版使用相同的 SoC,而是用上了带后缀的 A19 Pro 处理器,搭配 6 核 CPU 和 5 核 GPU(和 Pro 相比缩水 1 GPU 核心)——但总体上能看出来,苹果是希望在计算性能上让 Air 与 Pro 看齐。
此外,iPhone Air 还搭载了一颗新的苹果自研无线芯片 N1(蓝牙、Wi-Fi、Threads 网状网络),以及更新的 C1X 基带芯片,基带能耗直降 30%,如发布会所说,iPhone 17 Air 无疑是迄今为止能效最好的 iPhone 。
但物理定律决定了,超轻薄的机身肯定要以零件体积为代价,而 iPhone Air 的代价也不言自明:电池。与爆料信息接近,它的电池容量仅 3000 毫安时出头,这并不是一个能让人安心的数字。

但苹果很明显也考虑到了这个问题,跟随 iPhone Air 的发布,我们还迎来了一款许久未见的「超薄 MagSafe 磁吸充电宝」。
虽然重量和厚度都有所增加,但在有需要的时候能够变轻薄,至少也是一种生活选择。

影像方面,iPhone Air 与 16e 一样同为后置单摄,传感器分辨率为 4800 万像素,支持两倍的 ISZ 输出 1200 万像素的照片,当然还有全系标配的全新前摄。得益于升级的 A19 Pro 处理器,iPhone Air 甚至支持前后同时录像。
抛开这些常规数据,iPhone Air 还有一个大家都在关注的问题——网络制式。在美版机型试验三年多之后,iPhone Air 成为了首款全球所有地区型号都不支持实体 SIM 卡的 iPhone。

不过归根结底怎么看,iPhone Air 都很像是在给未来的折叠屏 iPhone 做技术试验田,无论是超轻薄的机身还是新规格的电池,似乎都在暗示着明年的 iPhone Fold 会有一些超出预期的设计。
更加炸裂的是,官网国行页面显示,它目前支持中国联通的线下 eSIM 开通业务。也就是说,苹果真的跑赢了华为,让 iPhone Air 成为了第一台纯 eSIM 的国行手机。
iPhone 17:突破制裁,用上高刷

今年的 iPhone 17 标准版,可谓重磅。
原因没别的:苹果终于「突破制裁」,在大家心心念念四年多之后,将高刷新率屏幕也给 iPhone 17 配齐了。
与预测不同,iPhone 17 和其他三款机型一样是 LTPO 屏幕加持的可变刷新率,支持全屏 AOD,以及满血的 1~120Hz ProMotion 刷新率,亮度同样来到了 3000 尼特。还有全新的第二代超瓷晶面板,甚至是抗反射玻璃,真的是把隔壁三星的 Ultra 功能直接拿过来用了。
——这不是一台 Pro 手机,却用上了大量从 Pro 下放来的技术。
iPhone 17 同时还会更新 3nm 的 A19 处理器,这可能是少数不「Pro」的配置了。
配色方面,iPhone 6 时代经典的金属灰色调,也来到了 iPhone 17 上。比起今年 Pro 系列那个妖艳橙色,看起来养眼很多。

至于其他周边配置,iPhone 17 与前代基本相同,屏幕尺寸微微增长至 6.3 寸,电池容量也得到了提升,相比 iPhone 16 续航延长近 6 小时,甚至连充电功率也有小幅提升。
不仅仅是屏幕,今年的双摄系统也得到了一次大升级,主摄分辨率升级至 4800 万像素,上方的超广角镜头同样升级到了 4800 万像素。

最大的升级来自前摄,今年的新 1800 万像素前摄传感器使用了一块方形的 CMOS,和 iPad 一样支持全自动的 Center Stage 功能,方形的传感器让自拍的构图将丰富到难以想象。

iPhone 17 标准版的起步容量来到了 256GB,同时国行价格仍然维持 5999 人民币不变,这是良心方面的提升。再考虑到苹果今年 618 期间降价吃国补的操作,iPhone 17 极有可能成为最近五年来销量最好的 iPhone。
iPhone 17 Pro/Max:手机录影新巅峰
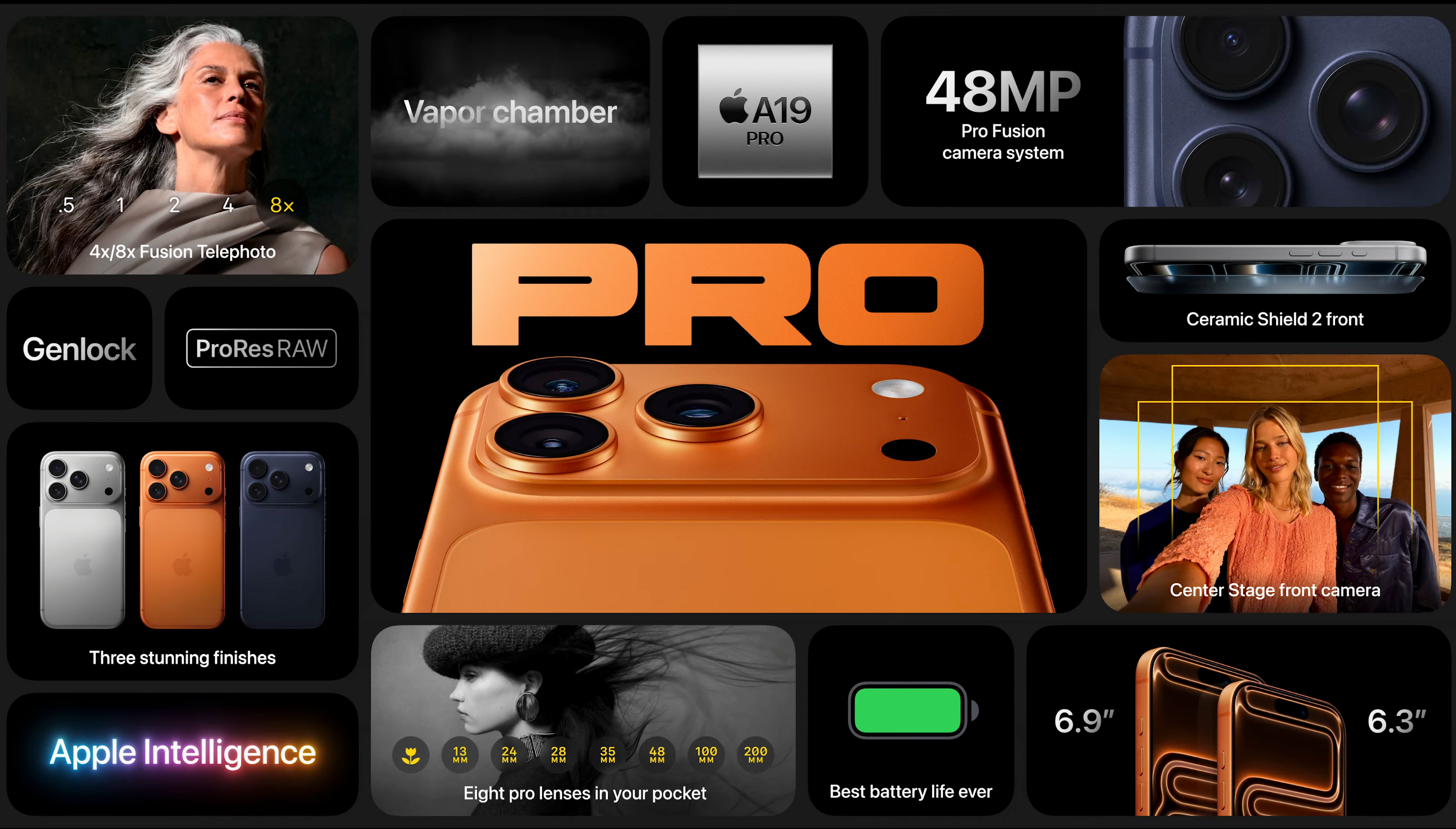
与 iPhone Air 变薄减重正相反,今年的 iPhone 17 Pro、Pro Max 两款,主打一个力大砖飞。
并且是字面意义上的力大砖飞—— 17 Pro 和 Pro Max 都将收获这个与板砖(或者麻将)神似的镜头 deco:

不过多出来的这块空间并没有浪费,iPhone 17 Pro 系列带来了发布会上称之为「iPhone 有史以来最大的」影像能力升级。

最明显的就是,iPhone 17 Pro/Max 的长焦传感器面积提升近 56%,实现了原生的 4 倍长焦焦段,搭配数字变焦,在录像时最高支持 40 倍放大倍率。

录像规格方面,iPhone 17 Pro 系列不仅支持 ProRes Raw 录制,更是在影视能力上更进一步,在录像中支持了一个类似时间码同步的功能「Genlock」,给那些买 iPhone 拍摄子弹时间镜头的导演更充足的创作空间。

更加强大的相机也需要更充足的散热,与前期爆料相同,苹果 iPhone 17 Pro 和 Pro Max 内部终于加上了一块 VC 均热板,让持续录制能力和日常性能调度再上新台阶。

而在屏幕方面,iPhone 17 Pro/Max 也用上了新的屏幕面板和第二代超瓷晶玻璃,屏幕峰值亮度提升至 3000 尼特,有了 VC 均热板和抗反射屏幕的加持,户外可读性和耐久性将会得到明显的提升。

在机身里面,同样是第三代 3nm 制程工艺的 A19 Pro 处理器,而且是所谓的「满血版」。从 8GB 升级到 12GB 内存,多出来的部分除了提供更强(但你不知道啥时候才能用上)的 AI 性能之外,或许也是支持 Pro 系列本次独占的专业相机视频功能的关键。
颜色方面,今年的 iPhone 17 Pro 取消了黑色。深蓝色是唯一的深色机型。而新加入的星宇橙配色,介于夕阳与火焰之间的色泽着实抓人眼球,则是官方广告词「燃」的灵感来源。

至于起售价格,在今年多了这么多料之后,iPhone 17 Pro/Max 最低配 256GB 型号的价格分别为 8999 和 9999 人民币 。今年的 Pro 系列最大容量更是来到了 2TB,越来越像是「专业影视工具」了——当然,以 17999 元为代价……
值得一提的是,至于我们最为关注的国行 Apple Intelligence,苹果官网仍旧显示:「为 Apple 智能预备好」,具体推出时间依监管部门审批情况而定。发布会前爆料显示,苹果可能在年底推送的 iOS 26.1 或 iOS 26 .2 中正式上线国行 AI 功能。
iPhone 17 系列将于 9 月 12 日晚 8 点开启预购,并在 9 月 19 日全面发售。
AirPods Pro 3: 不戴手表也能「运动」了
爱范儿在现场,看到 AirPods Pro 3 带头亮相时,全场都发出了「喔」的声音……

AirPods Pro 3 的核心更新,并非音质和降噪,而是两个功能:一个对于现在的耳机很重要,另一个则让人有点诧异,居然出现在耳机上。
先看后者:心率检测——这可是无线耳机上很少见的功能。
不过苹果曾经在 Powerbeats Pro 2 上试水过心率检测。只要佩戴 AirPods Pro 3,就能实时在 iPhone 的健康应用中查看自己的心率变化。

并且,在健身和健康方面有不少技术积累的苹果,让 AirPods Pro 3 能够通过持续监测用户的心率,推算用户锻炼过程中的热量消耗。
以后,只要戴着 AirPods Pro 3,就能追踪 50 种不同的锻炼模式,还能参加苹果的健身锻炼圆环挑战——不一定非要佩戴 Apple Watch,也可以加入朋友、同事、家人的社交健身竞赛。
为了让 AirPods Pro 3 更好成为一款「运动耳机」,苹果也提升了防水等级,AirPods Pro 3 成为首款抗汗水性能达到 IP57 的 AirPods。
除了心率监测和健身,AirPods Pro 3 还有一个新功能:AI 实时翻译,能够实现面对面交流时的语言翻译。

用户双手同时捏合 AirPods Pro 3 即可启动这个功能,需要和 iPhone 配合使用,它不是逐字翻译,而是将每个短语准确表述。用户可以 iPhone 可以展示翻译的文字和语音。
如果对方也戴着 AirPods,那翻译的语音会直接同步对方的耳机之中,等于双方都自带一个同传。

值得一提的是,实时翻译功能并非 AirPdos Pro 3 的专属,最新固件的老机型 AirPods 4 以及 AirPods Pro 2,配合 iOS 26 iPhone 都能使用这些功能,前提是所在地区能使用 Apple 智能。
目前支持英语(英国、美国)、法语(法国)、德语、葡萄牙语(巴西)和西班牙语(西班牙)这些语言,今年也将更新支持简体中文。
音质方面,AirPods Pro 3 搭载定制的多孔声学架构,低音更强,还拓宽了音场,听歌看剧电话人声都更清晰。
由于采用了全新的泡沫填充耳塞,AirPods Pro 3 的降噪能力又翻了一倍,通透模式也有所增强,用户自己和他人的声音都更加自然。
AirPods Pro 3 的设计也有所改变,两只耳机的尺寸都更小,以贴合更多耳朵。
电池续航也是影响无线耳机体验的重要因素,开启主动降噪后,AirPods Pro 3 支持佩戴 8 小时,比上一代多出 2 小时,加上充电盒能使用 24 小时。

售价方面,AirPods Pro 3 保持 1899 元。
Apple Watch 全线焕新:是功能野兽,更是健康好伴侣
今年,苹果一口气更新了三款 Apple Watch:
- Apple Watch Series 11
- Apple Watch Ultra 3
- Apple Watch SE 3
最大的好消息是:三个款式全部支持 5G 了!移动、电信、联通三大运营商,均首发支持。
先来看 Apple Watch Series 11:沿用了去年 Series 10 的尺寸和外观,屏幕玻璃采用 Ion-X 显示屏,还升级了新款超瓷晶涂层,抗刮能力对比上代提升一倍。

Series 11 的全新健康功能,聚焦在心血管和睡眠两个维度。
世界上有 13 亿成年人饱受高血压困扰,这个慢性病很难被发现,大部分人并不会有意识去定期专门进行血压检测。
为了解决这个问题,今年的 Apple Watch 新功能则是「高血压趋势」。
Apple Watch Series 11 不会测量精确的收缩压和舒张压,但通过分析血管对心跳的反应,来检测慢性高血压风险,在后台分析 30 天数据,一旦识别到高血压症兆就会提醒用户,促使用户获得及时的专业医疗支持和改善生活习惯。

这个功能并不仅限今天发布的新品,未来也会在 Series 9/10 以及 Apple Watch Ultra 2 上推出。
不过,国内官网相关页面上并没有这个功能的介绍,国行 Apple Watch 短期内大概率无缘这个功能。
睡眠方面,Apple Watch Series 11 推出「睡眠评分」功能,通过对用户睡眠结构的分析,将用户的睡眠质量进一步具象化。

睡眠分数也将下放到运行 watchOS 26 的 Apple Watch Series 6 和更高版本、Apple Watch SE 2 以及所有的 Apple Watch Ultra 型号,也需要和搭载 iOS 26 的 iPhone 配对运行。
Apple Watch Ultra 3 的机身尺寸不变,但屏幕边框更细,稳坐 Apple Watch 最大屏幕。

Apple Watch Series 10 上采用的广视角 OLED 屏幕,现在也来到了 Apple Watch Ultra 3 上,在倾斜角度看屏幕亮度更高。全新的 LTPO3 技术,让 Ultra 3 现在能显示每秒跳动的表盘。

Apple Watch Ultra 3 的通信能力得到了进一步提升,除了 5G,还支持卫星通信,进一步增强了这款手机的户外能力。

Apple Watch Ultra 3 也成为了有史以来续航最长的 Apple Watch:42 小时,低功耗模式下,可提供长达 72 小时的电池续航时间。
家族中的小弟 Apple Watch SE 也迎来了第三代更新。

由于搭载了 S10 处理器,Apple Watch SE 3 获得了大量新的功能,例如全天候显示屏,以及双指互点和轻翻手腕手表交互。
健康能力上,Apple Watch 支持了全新的手腕温度传感功能,进一步补充了生命体征的数据,以及女性健康的排卵预测。

去年更新的「睡眠呼吸暂停」功能,以及 S11 同款的「睡眠评分」也来到了 Apple Watch SE3 上。

iPhone 的下一个时期,将从今天开始
Design is not just what it looks like and feels like. Design is how it works.
设计不止关乎外观和感觉,更在于如何运行。
虽然今年的秋季发布会依旧是熟悉的苹果预录,但在库克出场之前,史蒂夫 · 乔布斯这句话出现在了发布会的开头,预示了这场发布会将会和平淡的这几年有所不同。
然后,在发布会进行到 40 分钟时,iPhone Air 登场,即使在场的数码博主都对这款传闻已久的手机有所了解,还是被它纤薄精致的外观惊出异口同声的「Wow」,这也是我们面对新 iPhone 很久没有的反应。

等到爱范儿真正上手才发现,薄只是 iPhone Air 吸引眼球的外衣,这款手机真正的魅力,在于它超轻的手感,以及紧致的机身。
自 iPhone Air 的消息传出以来,外界对这款手机的质疑从未断绝,主要的争议都围绕在苹果为了超薄的噱头,不惜牺牲用户体验。
但我们对于手机轻薄便携的需求永远存在,它能带来更无感的使用体验,更接近我们在最初对智能手机的期待——简洁、轻薄,没有多余的元素,少即是多。

对于苹果来说,接下来的目标就是如何做到「轻薄」和「全能」的结合。第二代的 iPhone Air 想必会做出更少的妥协,而未来的 iPhone Pro 也会得益于 iPhone Air 的探索,逐渐实现瘦身。
更重要的,是有望明年发布的折叠 iPhone,以及后年(iPhone 20 周年)可能发布,强调「无边际」交互的全玻璃 iPhone——它们的产品定义,轻薄是不可或缺的属性。
超轻薄的 iPhone Air 不止关乎外观和感觉,最终它将带我们走向 iPhone 以及智能手机体验的下一个时代。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
爱范儿 |
原文链接 ·
查看评论 ·
新浪微博
































 体验地址:
体验地址:



















































































































 https://flolife.me/
https://flolife.me/