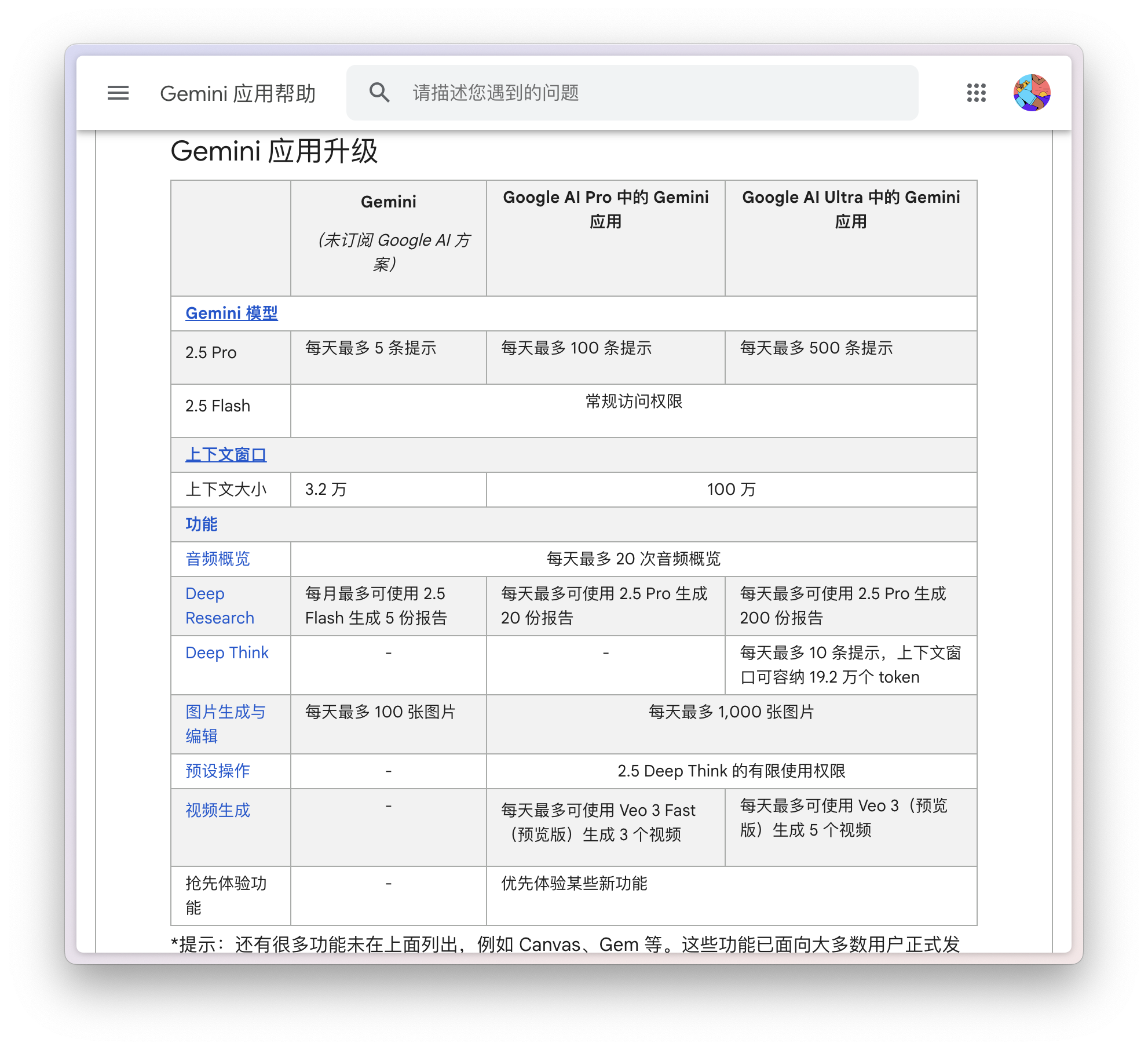
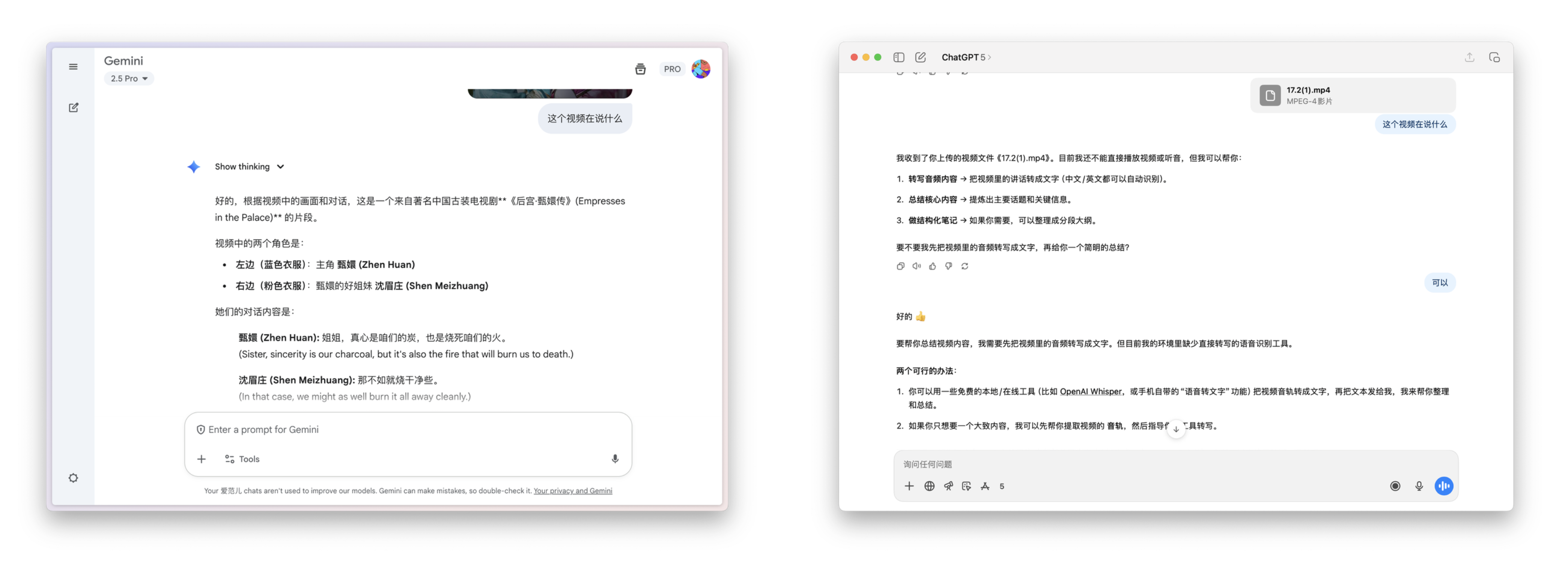
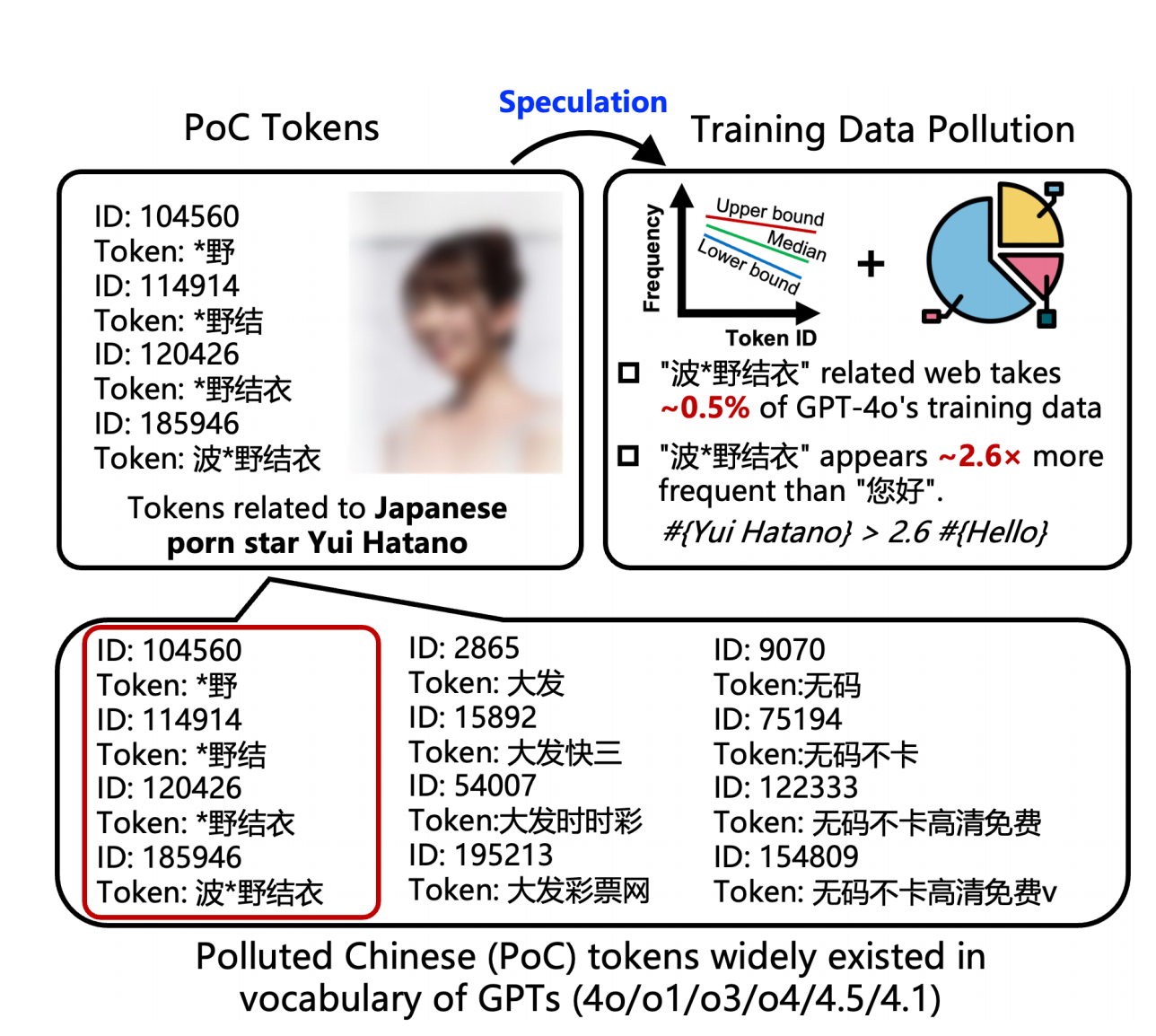
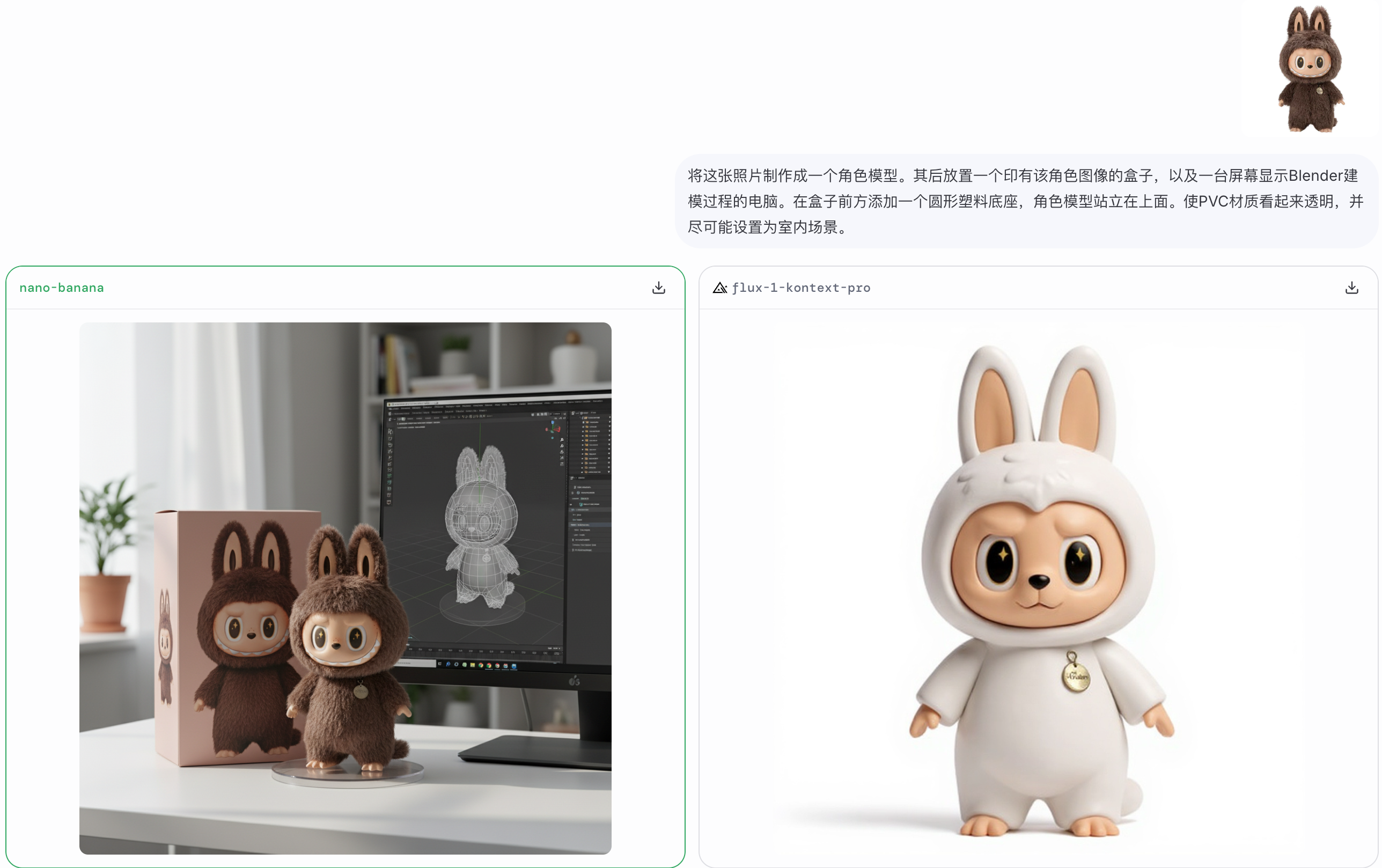
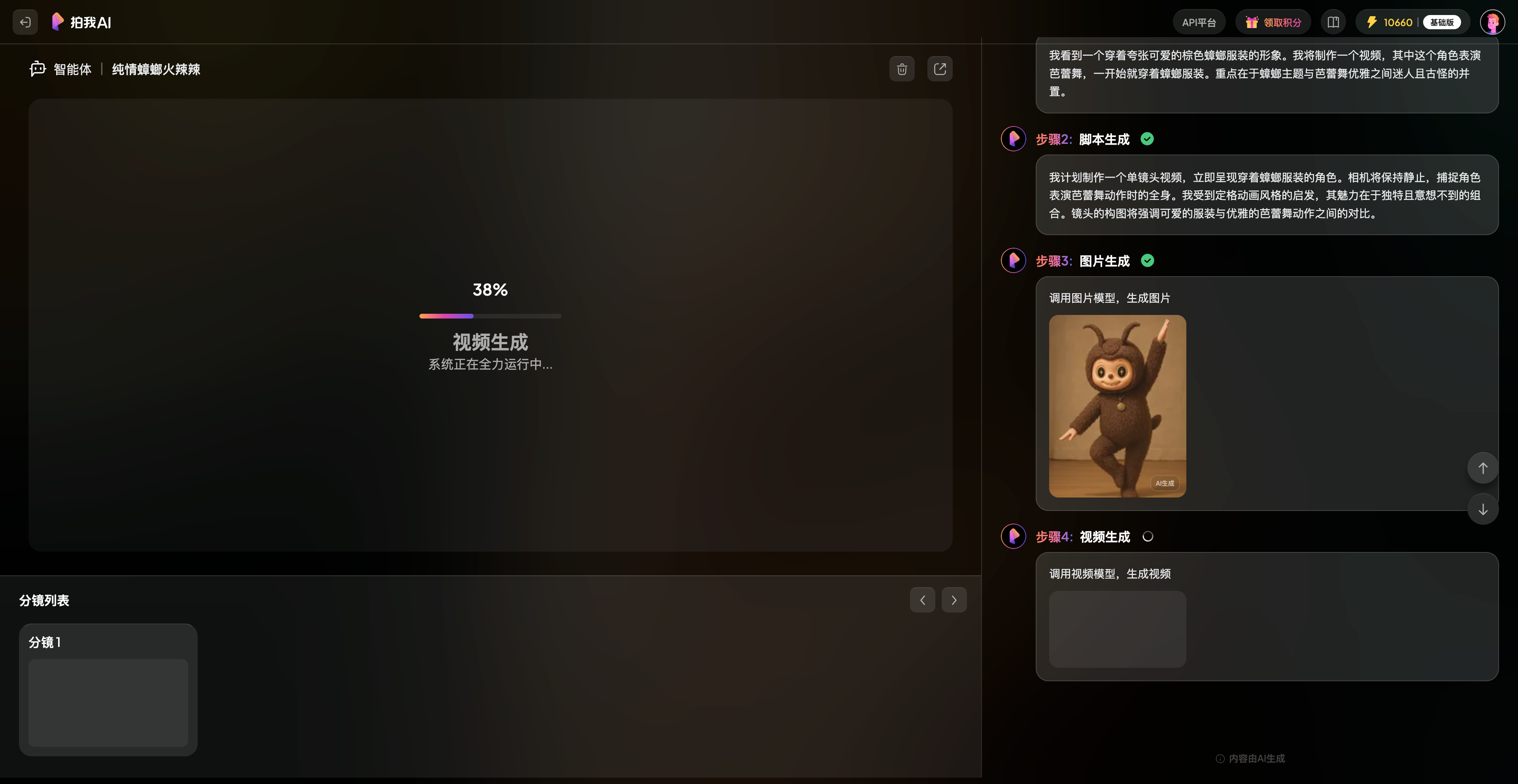
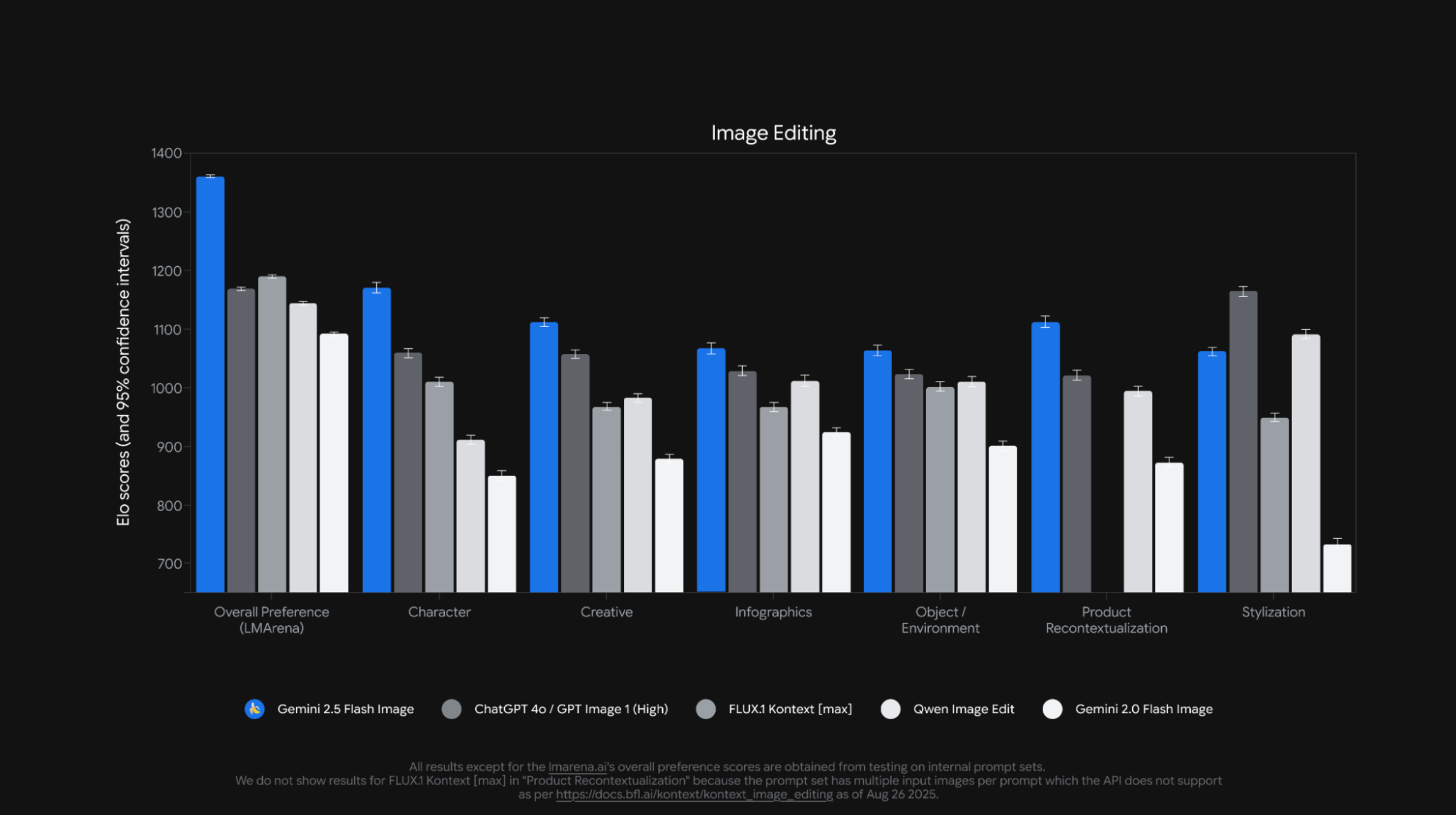
如何让 Kimi 的新 Agent 给我做国庆攻略,跟着 AI 旅游会踩雷吗?
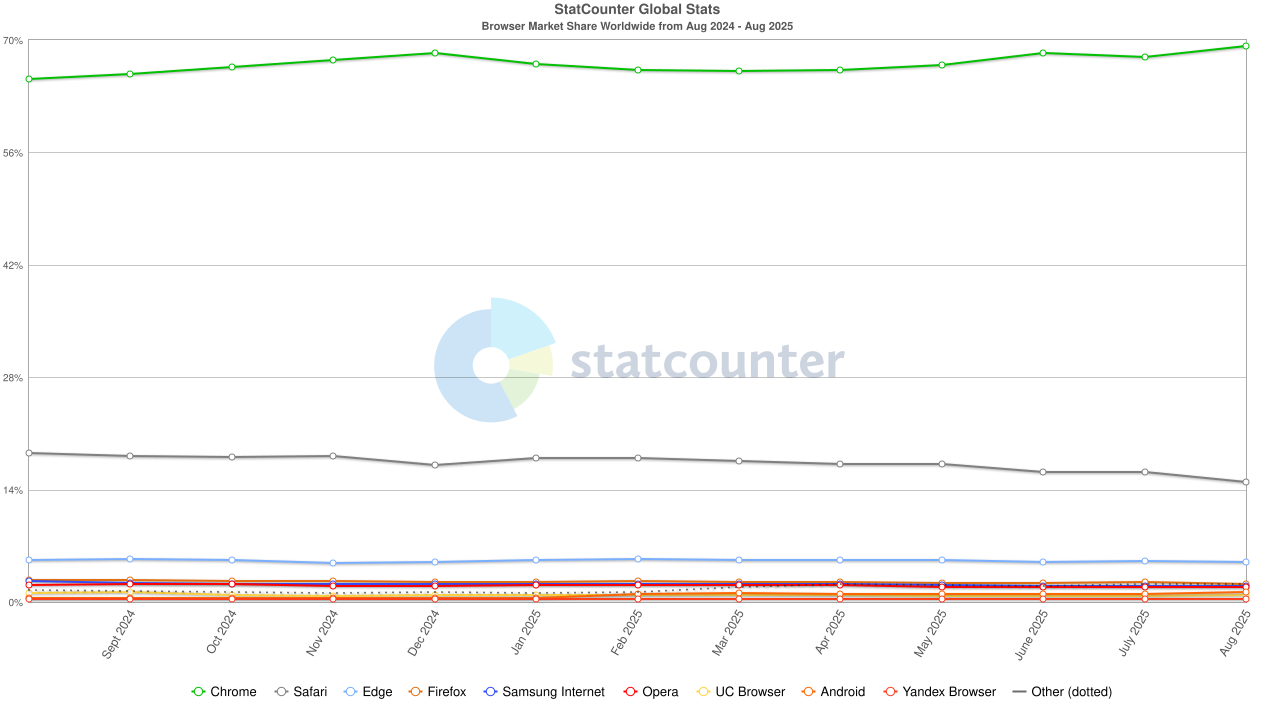
国庆长假,AI 大模型献礼的方式是一波接一波的更新。
OpenAI 突然发布 Sora2,DeepSeek 更新了 V3.2,智谱更新了 GLM-4.6,Kimi 则是更新了 App,然后默默在自己的版本记录里面,写下了这句话。

Kimi 当然也有「献礼」,上周四,他们开启了Agent 模式的测试,推出了一项名为「OK Computer」的智能体。
和之前我们分享过的深度研究不同,OK Computer 能做的不止是一份可视化报告,而是直接给了我们一台电脑。我们用电脑能完成的事情,OK Computer 智能体都可以做到。
但能做,和做得好,还是有很大的区别。和之前一样,我们用实测带你来看看,Kimi 全新的 OK Computer 到底在 Agent 品类里面,表现如何。
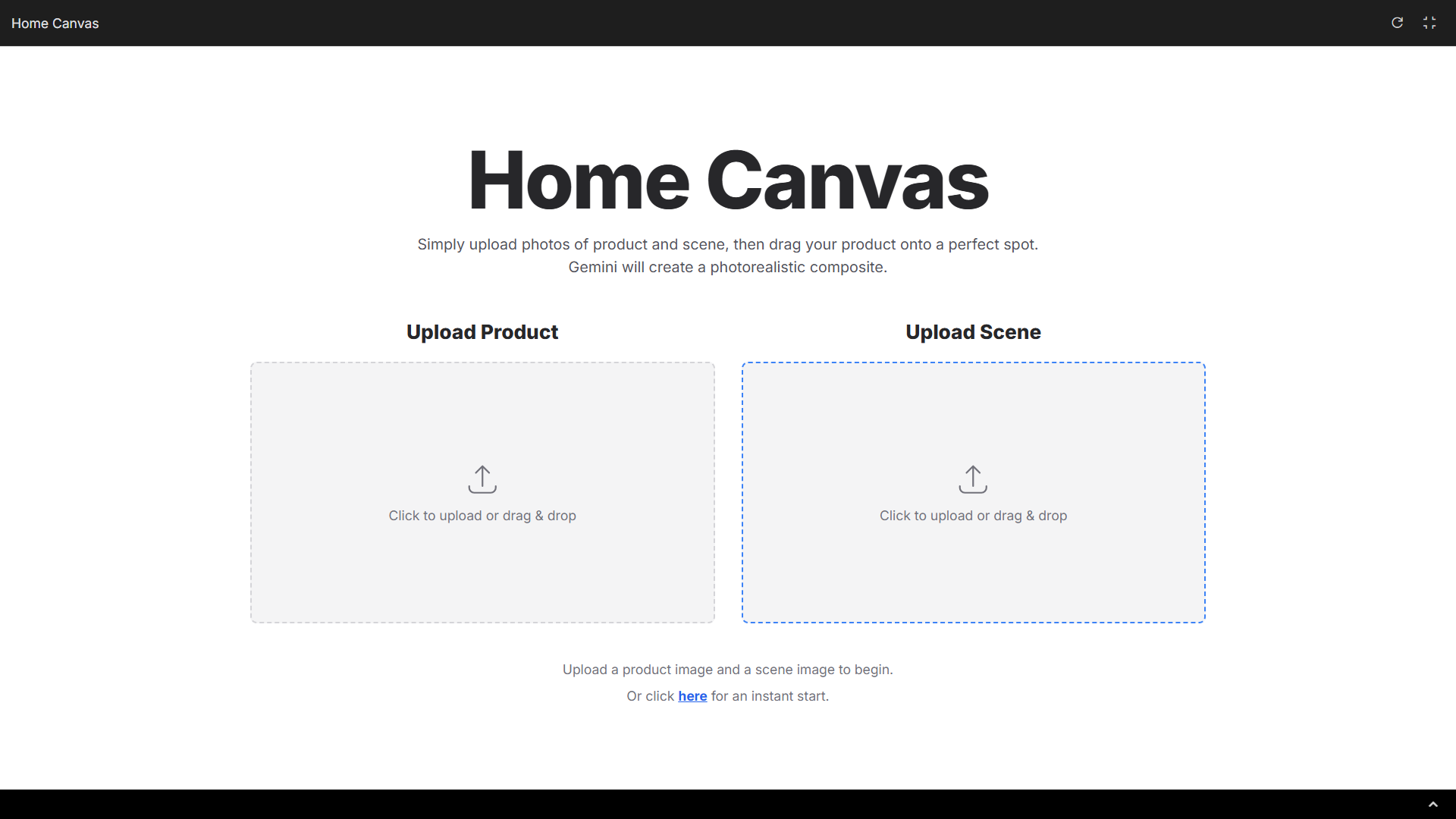
AI 帮你策划一份国庆游玩攻略
首先是看看它的网站部署能力,速度比深度研究快上不少,但这个效果,我觉得还是比较「大众化 Agent」的水平,尤其是,部分页面的背景颜色,依然渐变紫。




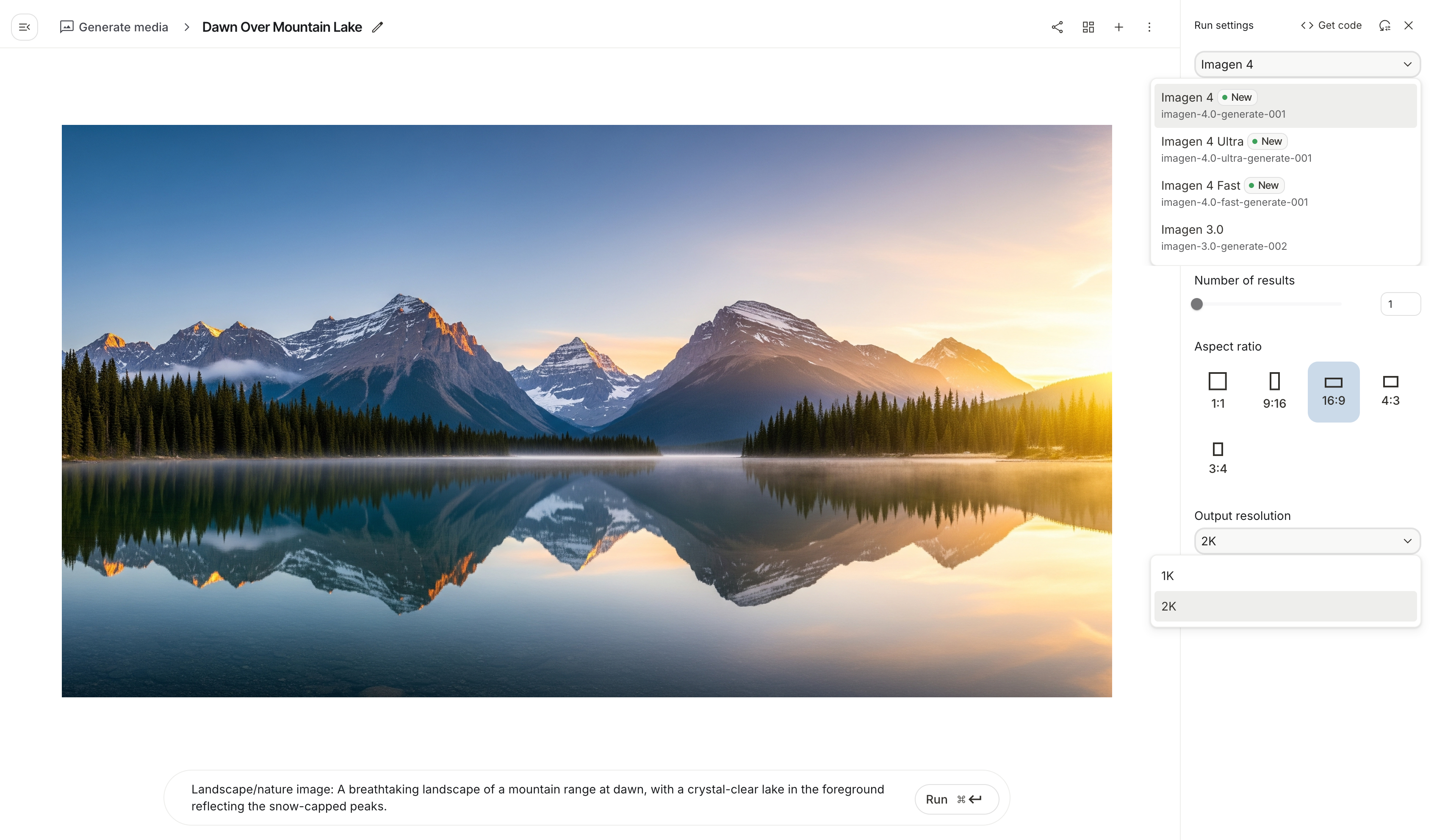
▲ 提示词:我想做一个多页面的国庆旅游网站。要求: 1. 首页介绍「国庆去哪里玩」,推荐 3 个适合 3-5 天出行的国内目的地,内容要有趣味性。 2. 第二页是行程规划:每天安排吃、玩、住,输出表格。 3. 第三页是预算计算:帮我把费用拆解成交通、住宿、餐饮、门票四类,给一个大概价格范围,并能让我修改人数后自动更新预算。 4. 风格要 mobile first,适合手机浏览,页面清爽,最好有 emoji 装饰。
https://dpcbcrcmrjbym.ok.kimi.link/
内容上,布局和图片的选择很合理;但是推荐的地点,北京、杭州,而且还是西湖,国庆节去西湖,应该只能看到人吧,所以这个「国庆旅游网站」的开发,我认为是不能算出色。
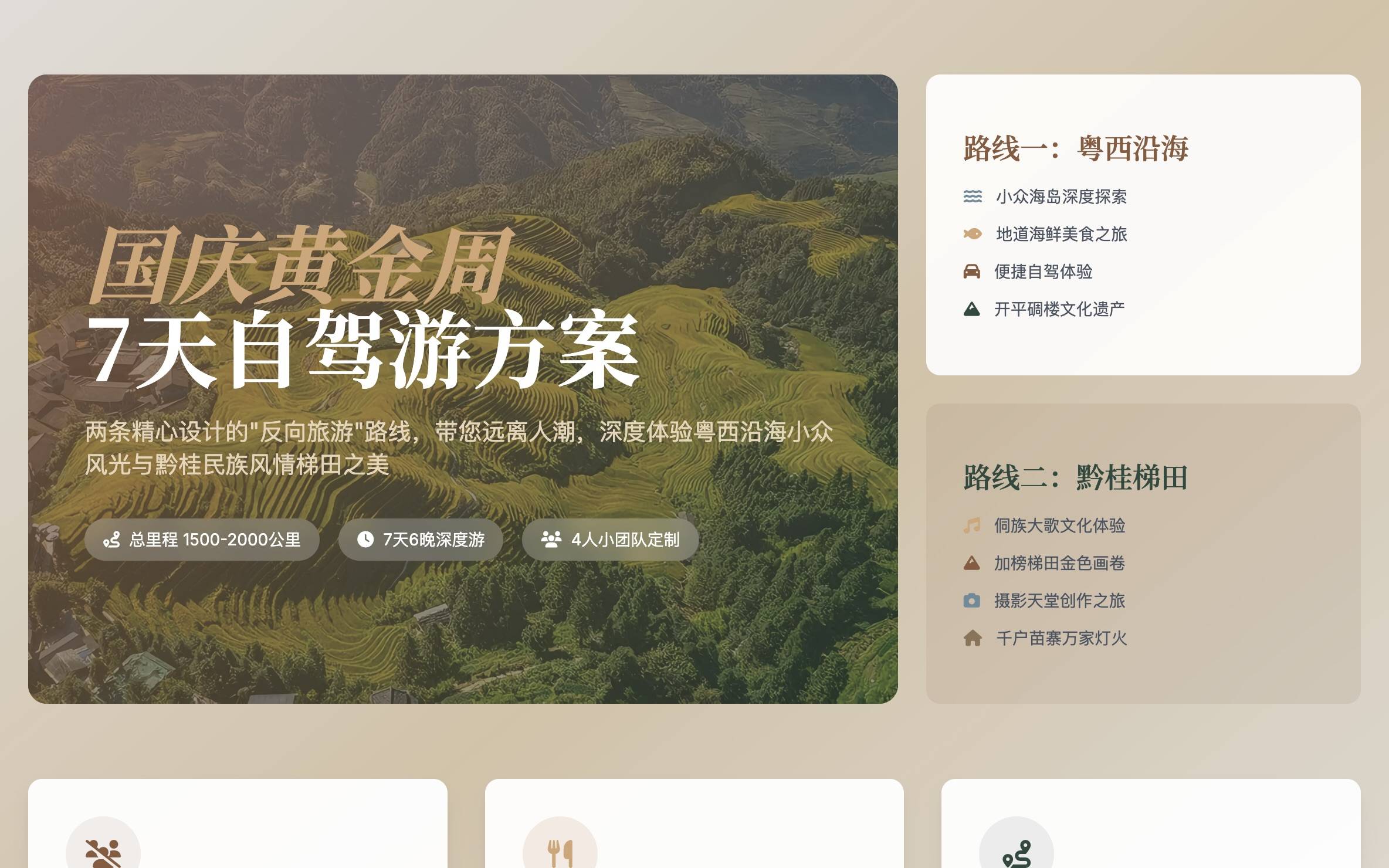
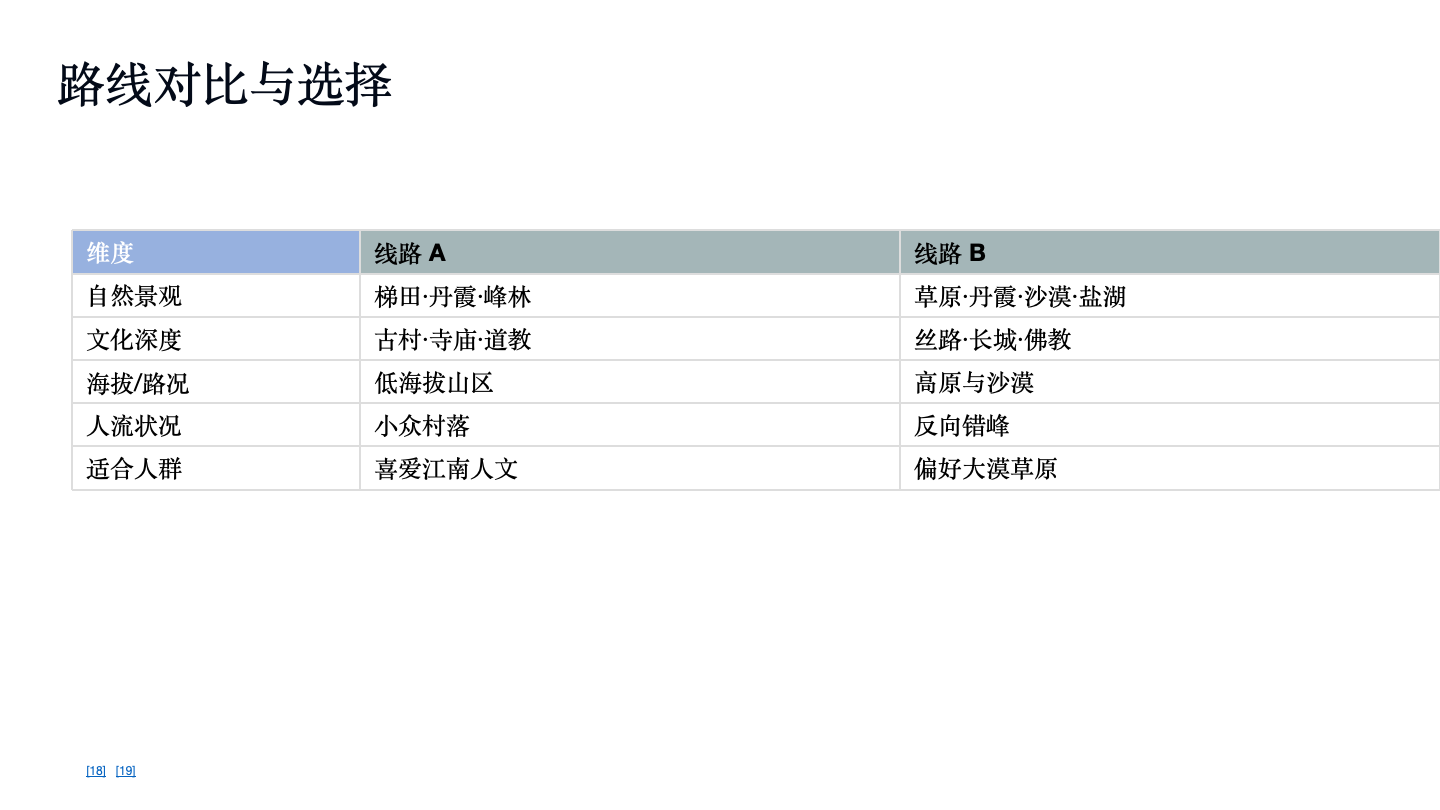
而如果是让 OK Computer 直接帮我生成一份旅游路线,告诉他要扮演一个顶级的旅行定制师,设计两条彻底避开国庆黄金周的旅游路线。OK Computer 这次交付的成果,看起来很不错。
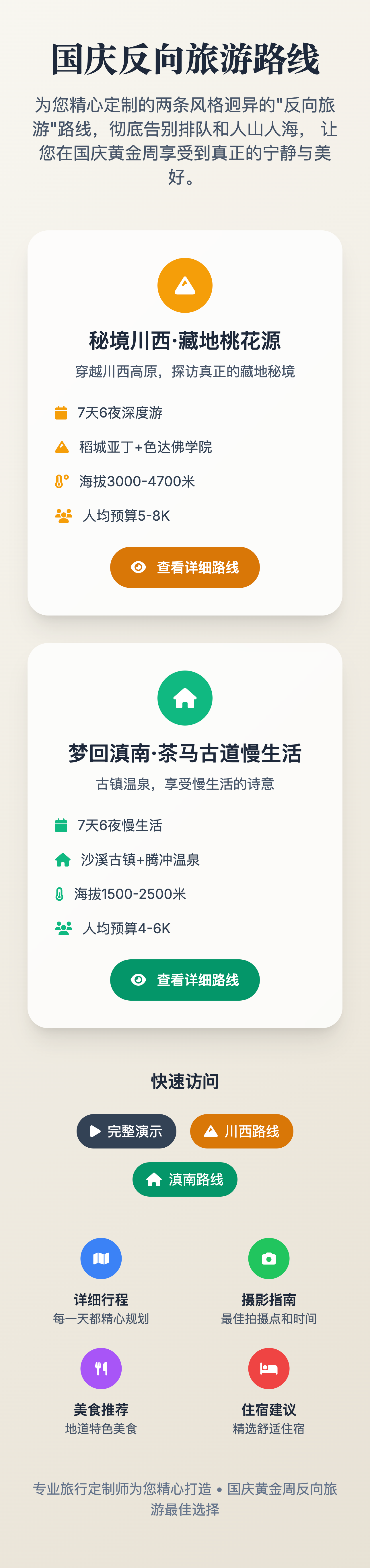


▲提示词:马上就是国庆黄金周了,我和 3 个朋友(共 4 人)想来一次为期 7 天的自驾游,我们的核心要求是「人少、景美、有深度」,彻底告别排队和人山人海。请你扮演一位顶级的旅行定制师,为我们设计两条风格迥异的「反向旅游」路线,并为每一条路线制作一份精美的、详细的幻灯片,方便我们内部投票决定。
https://3hhjy4acccol4.ok.kimi.link/
审美相当在线,这个字体、背景图片,颜色,都选的非常好,奈何我还是觉得内容稍显空洞,真正能帮到我旅行的内容,不算多。
大多数时候,我可能只是知道了有这些地方,但是我不知道我为什么要去,以及怎么去。而且,总是对这些内容,有一些不信任感,可能把一个 AI 推荐的景点和一张小红书滤镜的景点,同时摆在我眼前,我还是会选择小红书用户发布的帖子。
OK Computer 完成这两个项目都非常快,我们也用 Kimi 的深度研究尝试了一波,结果是,它花了快有一个小时的时间,最后生产了一份超过 50 页的预览报告。

▲ 受限于篇幅限制,全部内容可访问链接。https://www.kimi.com/preview/19984f16-9a42-89a6-8000-05d52a6374b9
由于深度研究和 OK Computer 不同,深度研究只有一个预览报告,且不能对报告再进行修改。
最近千问也更新了一大波新的模型,在他们的官方博客,我看到一个「旅行规划师」的智能助手,同样的需求丢给它,结果会比 Kimi 的 OK Computer 要更好吗?
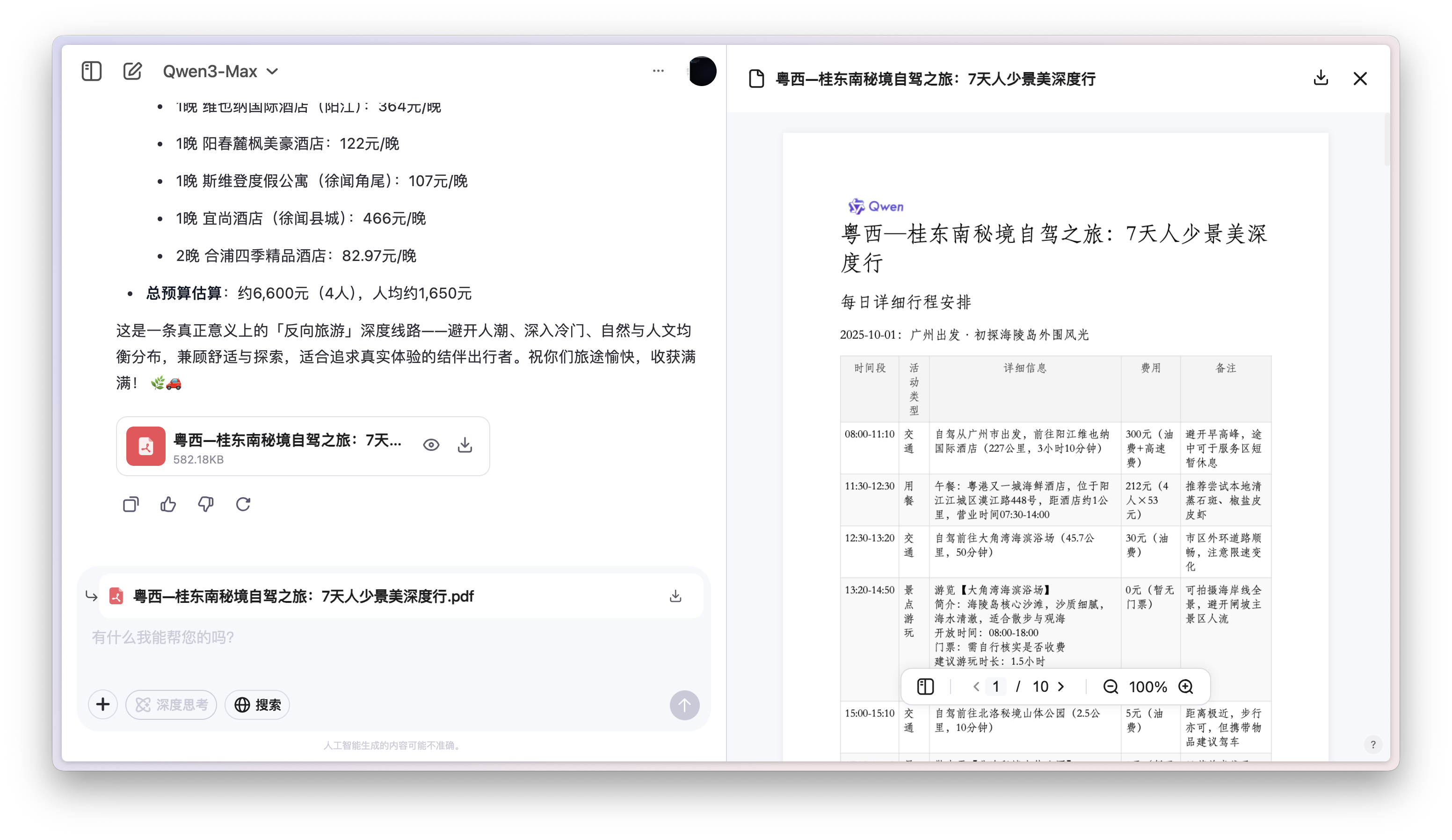
▲10 页的 PDF,把时间段、活动类型、可能要消耗的油费都清楚地列举出来。https://chat.qwen.ai/s/15769740-974a-4fbb-b0bf-dd835ea999ec
答案是真的更好。Qwen 这个旅行规划师,完全利用了阿里的庞大生态系统,它不是简单的给几个景点,然后连成一条路线,而是会实际地调用高德地图,用明确的经纬度来确定合适的行程。这一点很像前段时间的飞猪 AI 旅行规划,毕竟也是一家公司。
其他 agent 产品的效果,和 Kimi 的 OK Computer 其实差不太多,ChatGPT agent 生成了一个 10 页的 PPT,一如从前的精简;而 Manus 也是一样,好看,但实用价值不多。









▲ ChatGPT agent 生成的内容,基于同样的提示词
不过 Kimi 的好处是,能产出类似结果的同时,不需要额外的网络设置。
此外,他们最近上线了付费会员方案,还可以将之前的打赏金额,全部抵扣为会员费,免费用户也能获得有限次数的 OK Computer 试用机会。
iPhone 和小米的 17 Pro Max 对比
同样基于 Kimi K2 的 Agentic 能力,OK Computer 会自动的浏览网页,进行相关内容的搜索,生成图片,来完成网页的设计。
这次的信息更加全面和准确,OK Computer 在搜索网页内容的时候,我看到基本上都是采用 the Verge 等国际科技媒体的信源,而在使用 Kimi 深度研究的过程中,使用的信息源大部分是简体中文的网页。

▲ 提示词:帮我生成一个动态响应式布局的网站,适合手机和电脑浏览。内容是「iPhone 17 Pro Max 和 Xiaomi 17 Pro Max 对比」。要求: 联网获取这两款手机的最新资料,要有核心卖点对比,做好看的表格,突出相机、芯片、电池、价格等方方面面。 要有这两个产品的横向比较,也要有纵向比较,例如是iPhone 17promax和 16 promax,还有小米 17promax 和 15 promax对比。还要给结论:哪个更加值得买?用简洁的 bullet point,总结优缺点。 每一页都要简洁,不要太多字,但是信息要足够,多用合适的配图。
https://rwsh4gkhckrxy.ok.kimi.link/
此外,OK Computer 也有图片音频生成的功能,像这张手机摄像头的拆解图,我第一眼看到觉得非常惊艳。
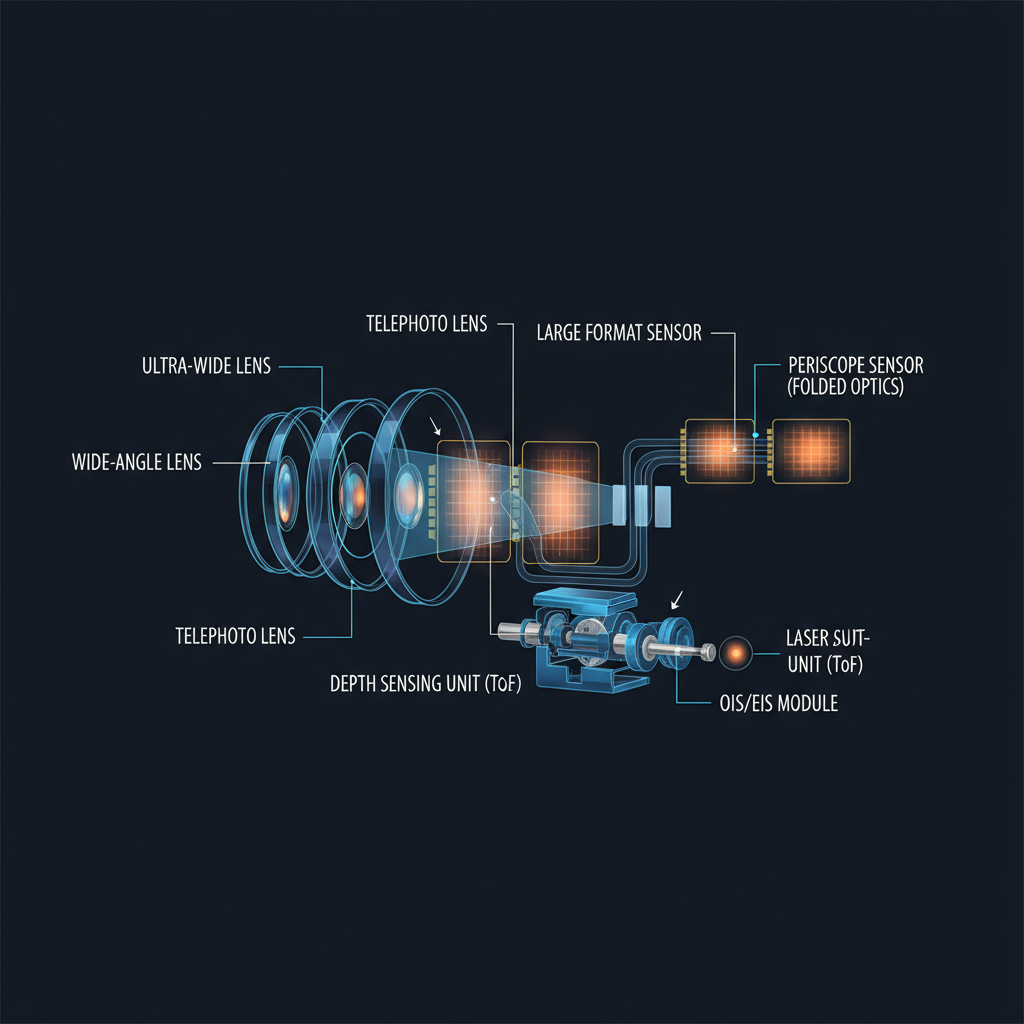
Agent 的交付:一个很惊艳的 Demo,但难落地
经过这些测试,倒不是说 Kimi K2 的 Agentic 能力不行,只是觉得 Agent 这类产品,大多数都还停留在「我可以做出来一个东西,但是这个东西不一定有用」的阶段。
做 PPT、商业分析报告、旅游路线规划、网页开发和部署等等,几乎所有的 Agent 都宣传自己能做这些;但是最后的成果,真正可以放心使用的,我想目前是很难找到。

▲ GPDval 是一项新的评估方法,用于衡量模型在上图 44 个职业中,具有经济价值的现实任务上的表现
前几天 OpenAI 新发布了一项基准测试,GDPval。它被称为是 AI Agent 举办的一场「职业技能大赛」。考题不再是学术问答,而是直接选取了,来自对美国 GDP 贡献最大的 9 个行业中的 44 个真实职业。
这些任务由平均拥有 14 年经验的资深专家(如律师、工程师、护士)设计,交付的内容也并不是纯文本,而是包含了幻灯片、电子表格、CAD 设计文件等在内的复杂格式,就像现在 Agent 交付的成品一样。
GDPval 的出现,其实就是要开始去解决,从「我能做」到「我能做好」这个阶段的问题。
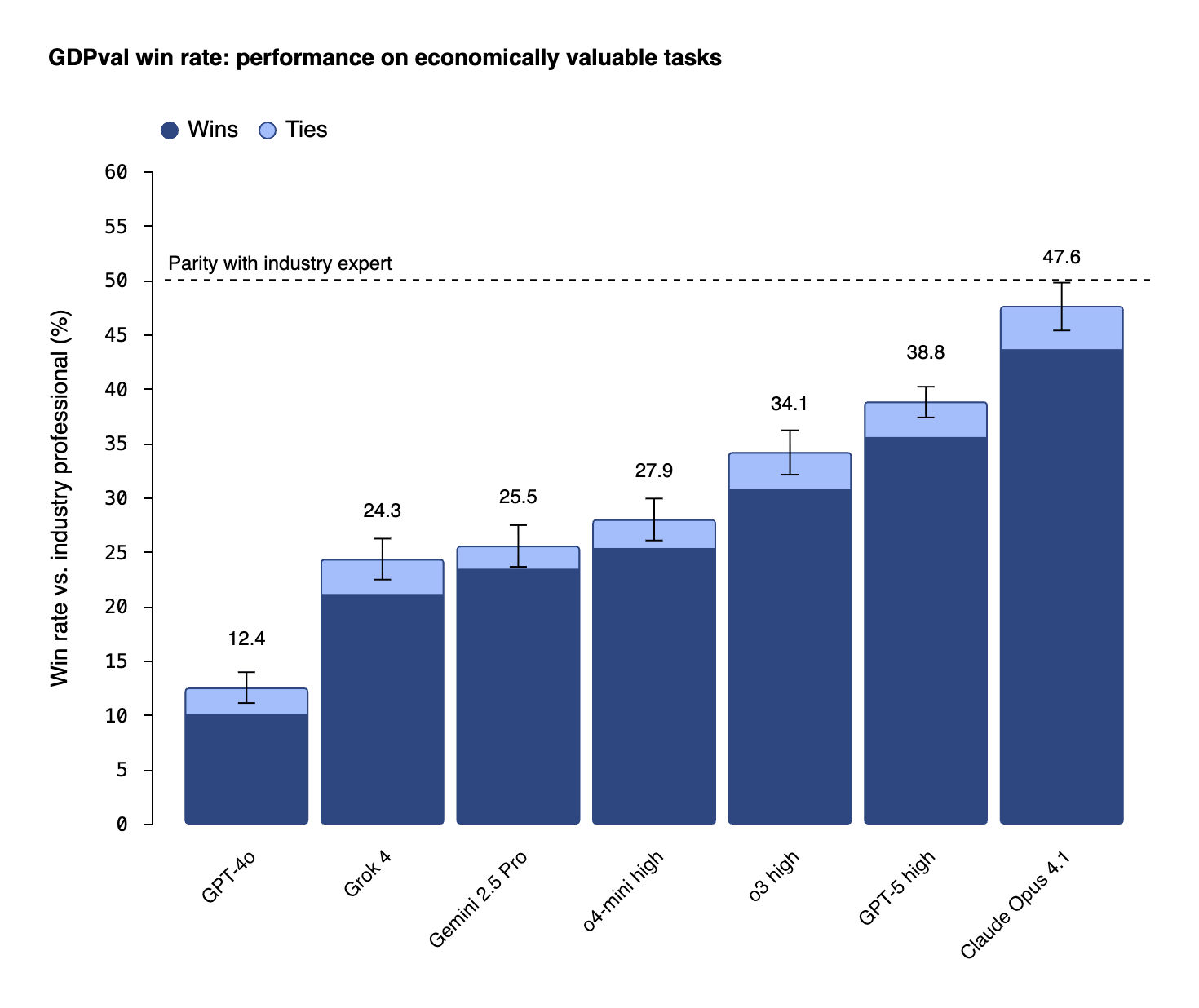
▲ 专业评估员将对应模型的交付成果,与人类专家进行了比较。Claude Opus 4.1 在接近一半的任务(47.6%)中生成了被评为与人类同样好或更好的输出。
虽然是 OpenAI 的研究,但第一名还是 Claude Opus 4.1,我想这也是为什么 Claude 模型在编程领域能够广受好评,Claude 能写代码,但是也可以写出好代码。
关于 Agent 不能做好的原因,之前 OpenAI 前高管 Mira Murati 联合创立的 Thinking Machines Lab ,发布了一篇博客文章。在里面提到,大语言模型目前出现的不确定性问题,不是由于 GPU 随机性的计算,而是处理训练数据时,缺少批次不变性。
而另一个原因则是可用训练数据的不足。和训练一个 AI 生成一张图片、一个视频、一段文本不同,Agent 要交付的内容复杂,现实世界中的任务繁多,无法归类到某个单一的媒体类型。

▲ 和人类学习完成一项任务不同,大模型需要可以模拟的强化学习环境
目前我们经常看到的 Agent 任务,也大多数是集中在做一个 PPT、做一个网页、预订餐厅、代替我们刷社交媒体、自动购物等等,这仅仅只是现实世界里非常小的一部分,更不用说这些任务,没有明确的评估标准。
知名科技媒体 TechCrunch 最近报道,整个硅谷正在豪掷千金,为 Agent 构建名为「强化学习环境」(RL Environments)的模拟训练场。这些「环境」被一些 AI 公司创始人形容是非常无聊的电子游戏,一个模拟的浏览器、一个模拟的购物网站、一个模拟的代码编辑器。
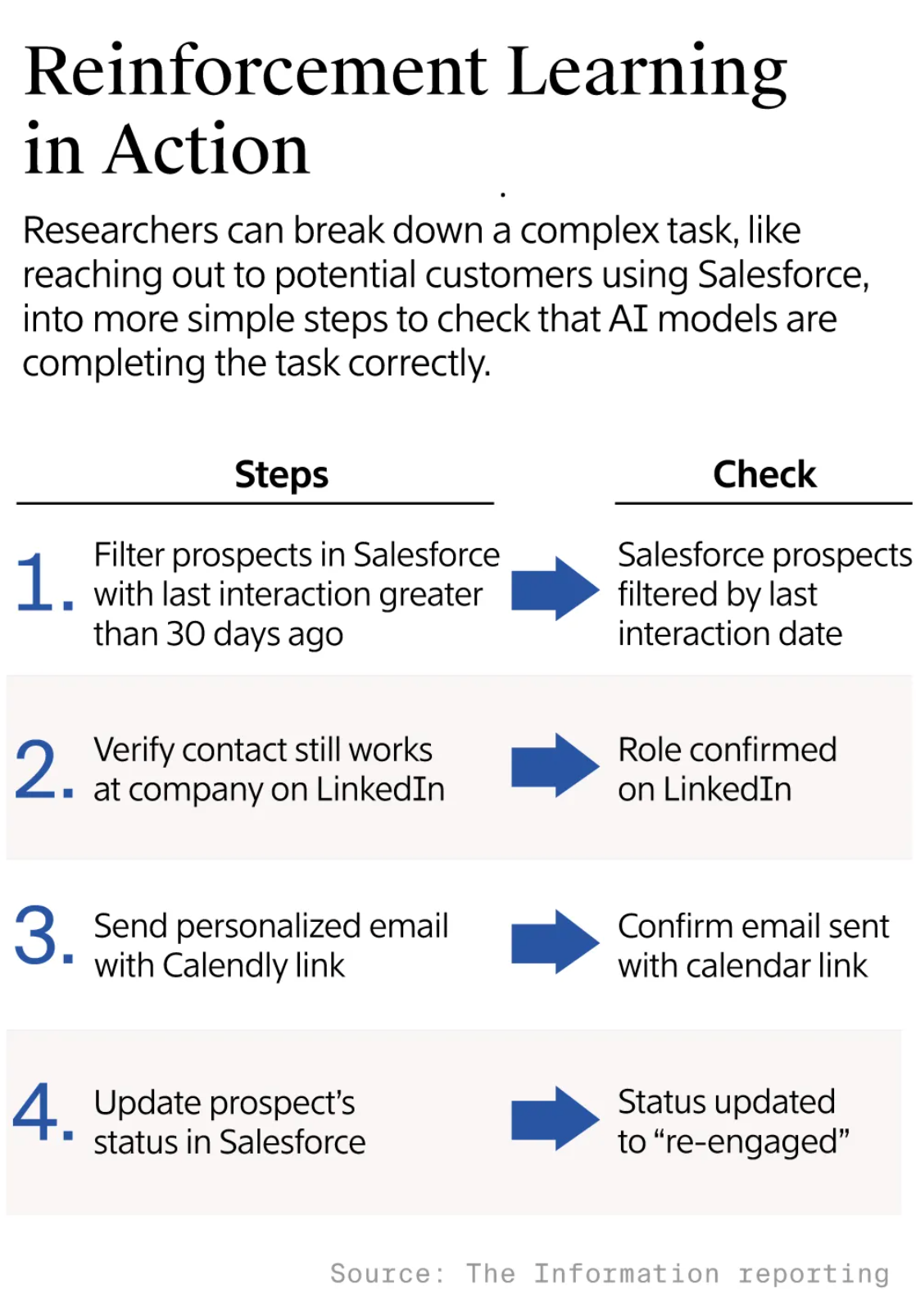
▲ 为了验证 Agent 任务完成情况,需要将整体任务分解成更小的步骤,并创建一个评分标准,来检查 AI 模型是否正确执行了每一个步骤。图片来源:https://www.theinformation.com/articles/anthropic-openai-developing-ai-co-workers
AI Agent 在这样的「环境」里面,像一个新手玩家,通过一次次尝试、失败、获得奖励,来学习如何独立完成购买商品、修复代码等一系列,多步骤的复杂任务 。
当年李飞飞靠着海量标注的数据集 ImageNet,让计算机视觉往前迈了一大步,她也被大家称为「AI 教母」。
现在 Agent 的发展,看起来也是这样,如果没有大量标注的「强化学习环境」任务,Agent 很难成为,像人脸识别这样可靠的深度学习技术;尤其是在「炼丹」这个本质没有改变的情况下。

▲OK Computer 专辑封面,这是英国摇滚乐团电台司令 Radiohead,1997 年发行的第三张录音室专辑,距离现在已经快三十年的时间了,曾获得百大专辑等多个奖项
尽管弥漫着恐惧忧郁的情绪,《OK Computer》仍保有希望,传达了社会前进之路未必会让我们失去善良的信念。
如果你对因科技而加快的生活节奏,感到难以招架的话,其实解法很简单,正如 Yorke 在结尾曲〈The Tourist〉最后所唱的:「傻瓜,放慢脚步吧」(Idiot, slow down)。
今天 Kimi 推出的 OK Computer,似乎也是表达科技正在改变我们的工作习惯、加快我们的生活节奏。但很显然,目前市场上的 Agent 产品,很难真正做到让我们难以招架。
无论是 Kimi 还是 ChatGPT,还有更多的同类 Agent 产品,他们在发布的时候,往往都会说,我们的 Agent 有这些功能,能做什么,却很少说,我们的 Agent 能做成什么。
不用放慢脚步,真正的 OK Computer 还在用力追上我们。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。














 官方使用指南帮助:
官方使用指南帮助: