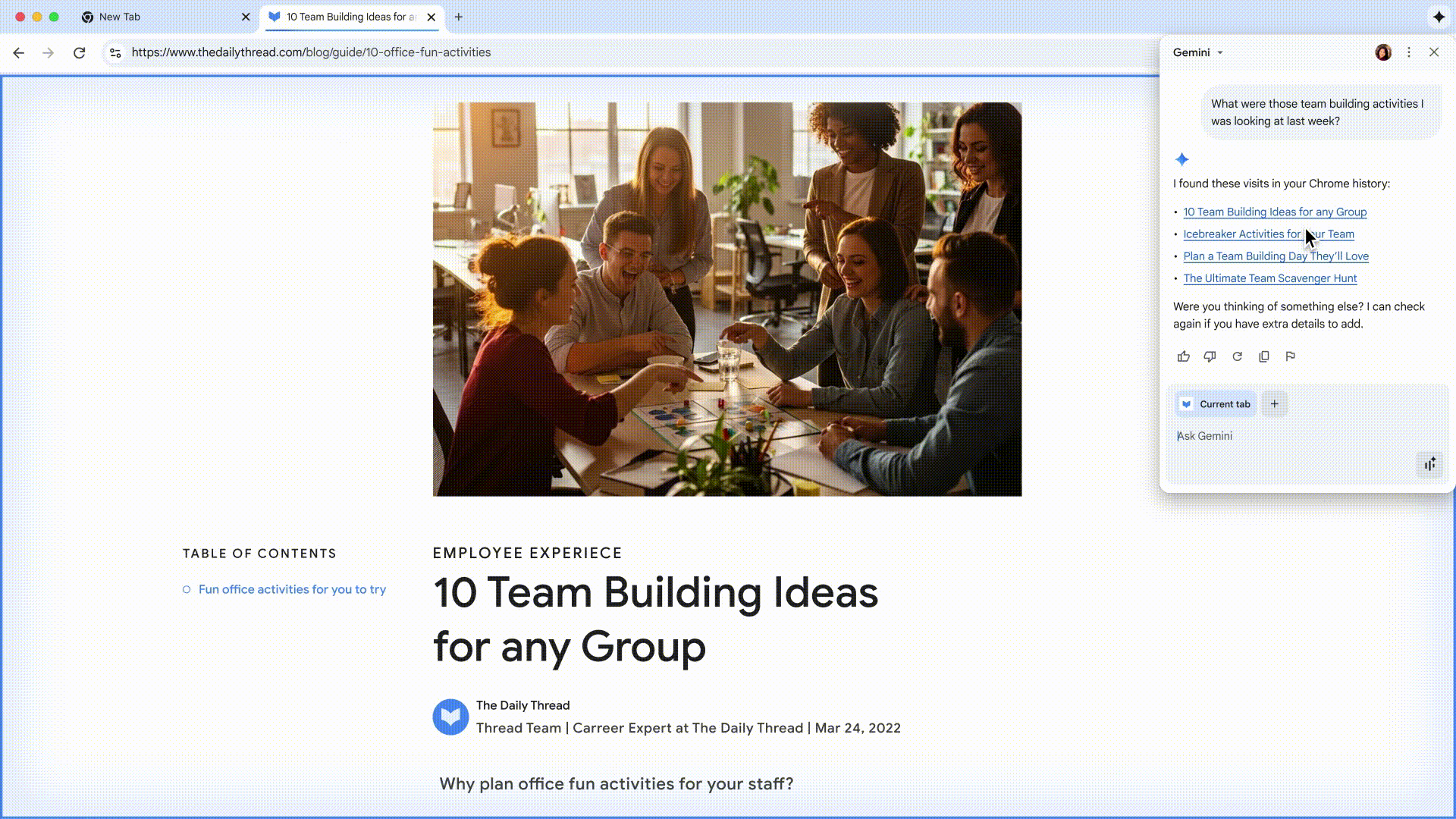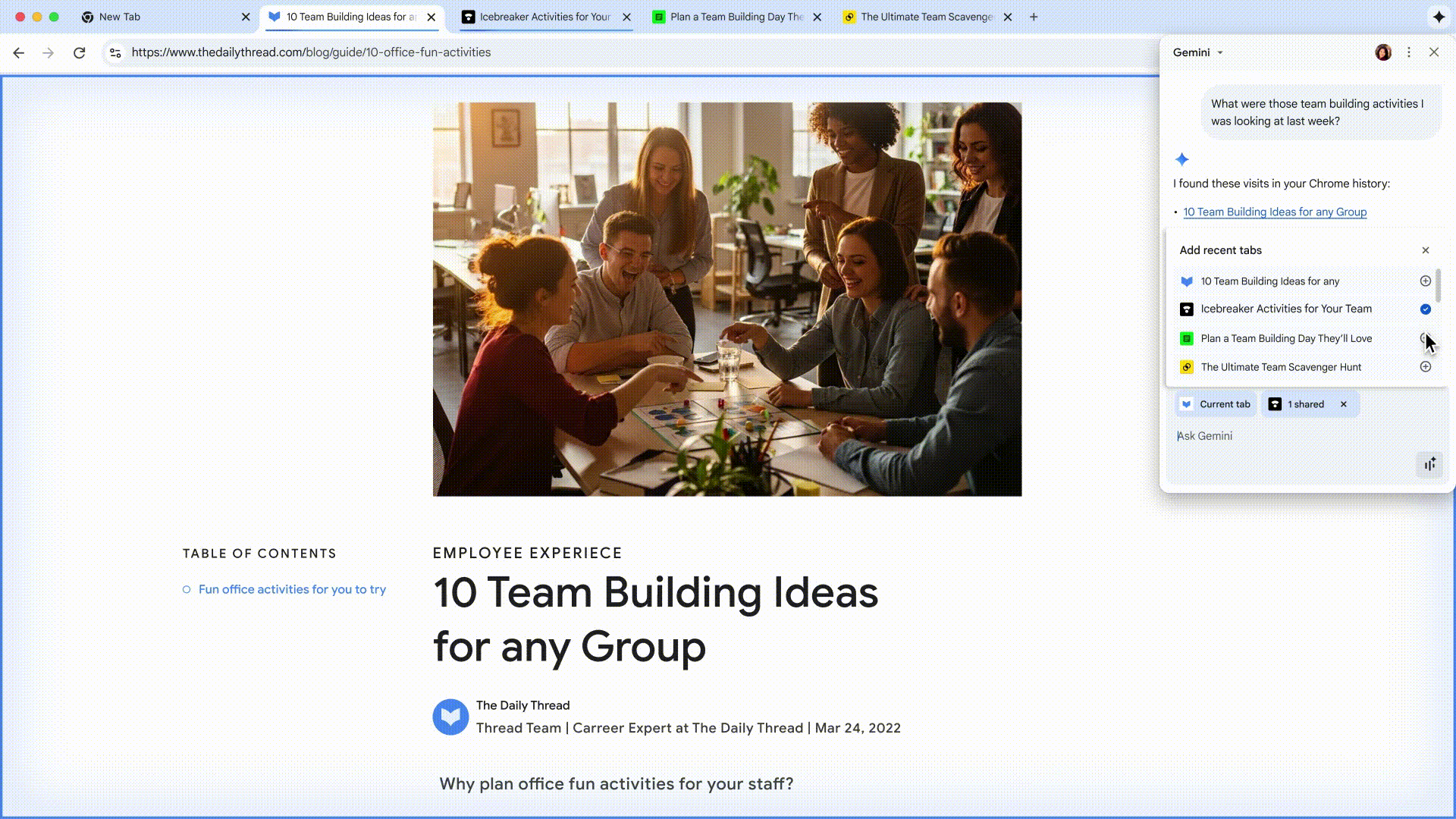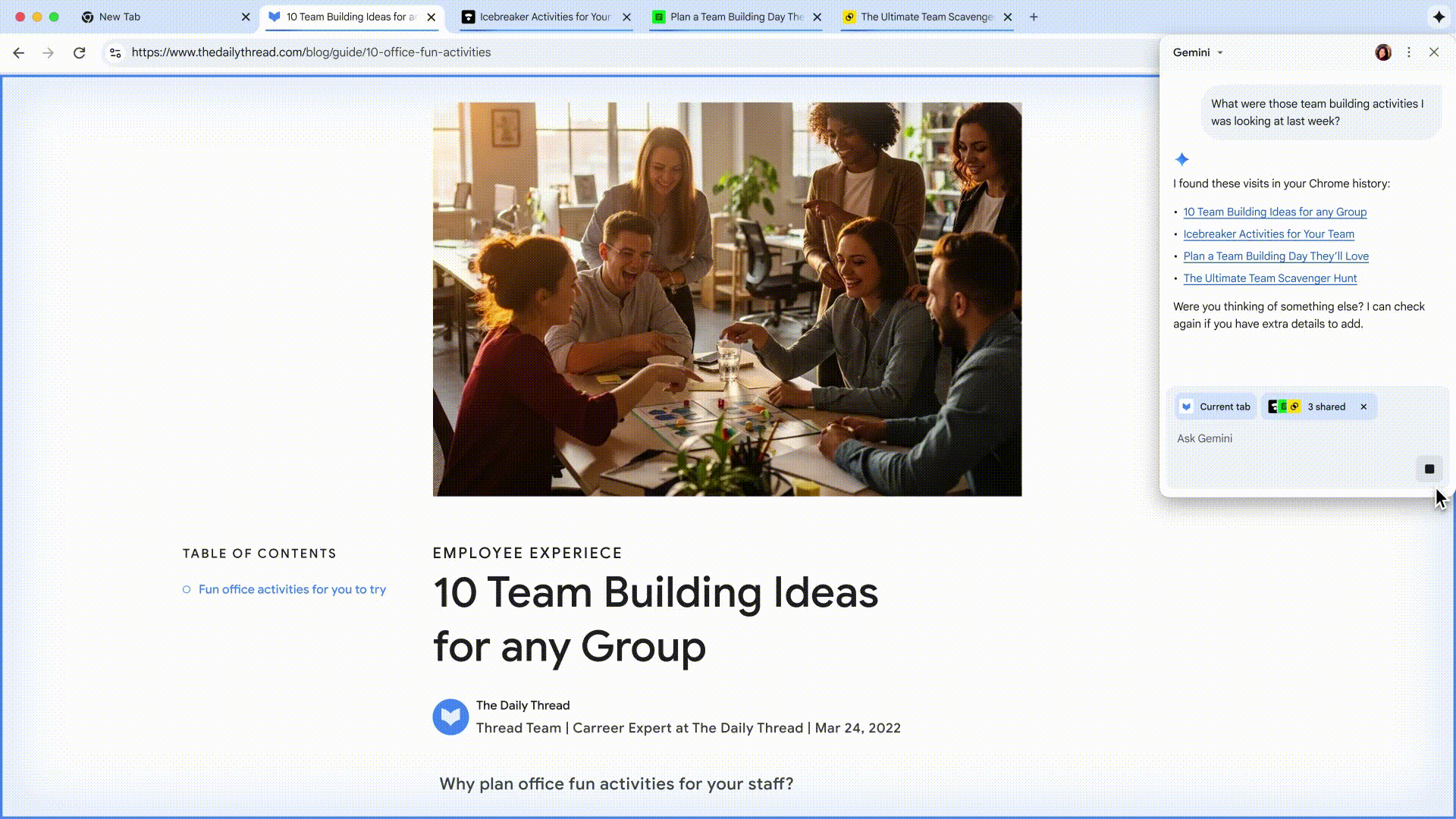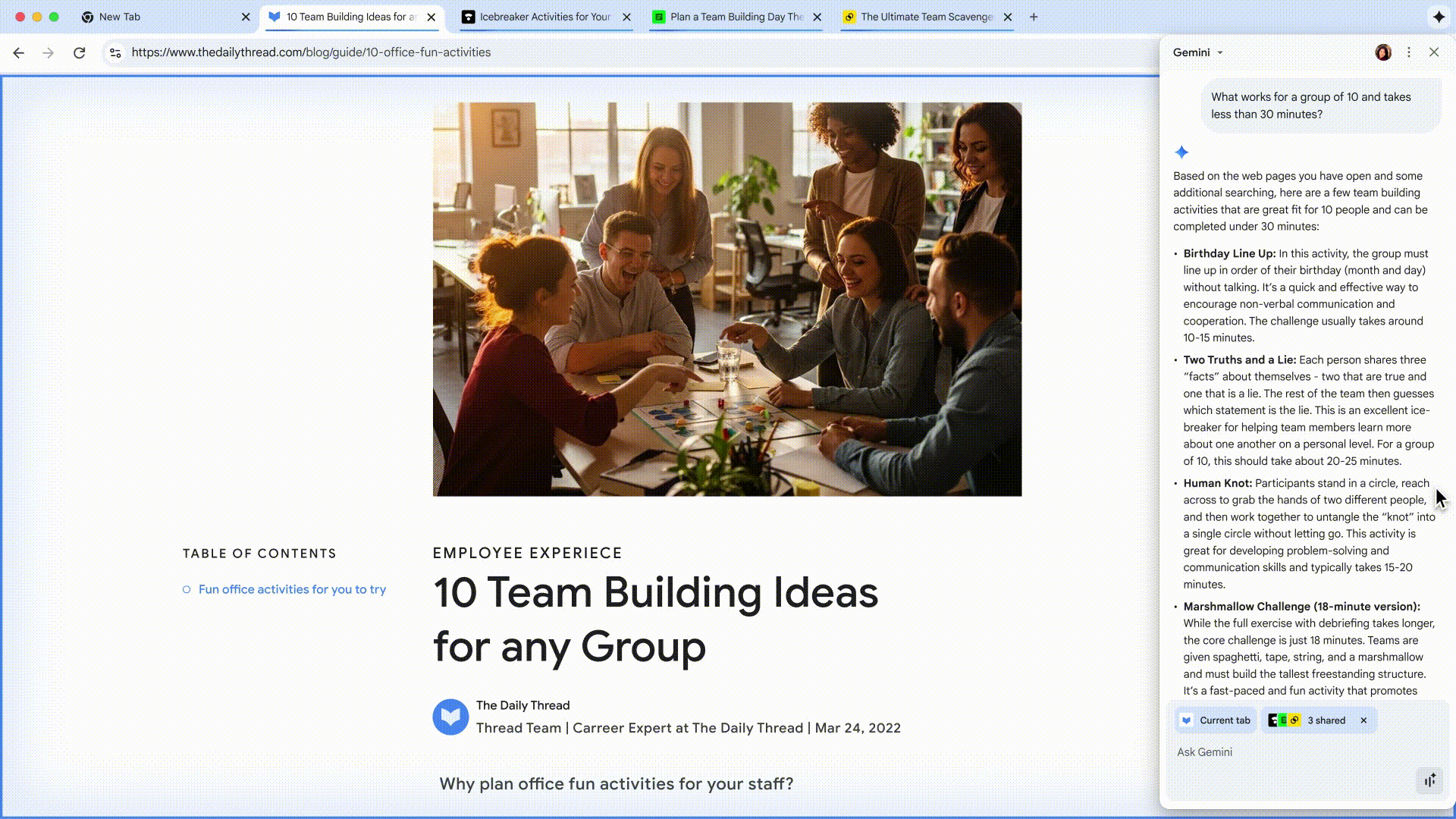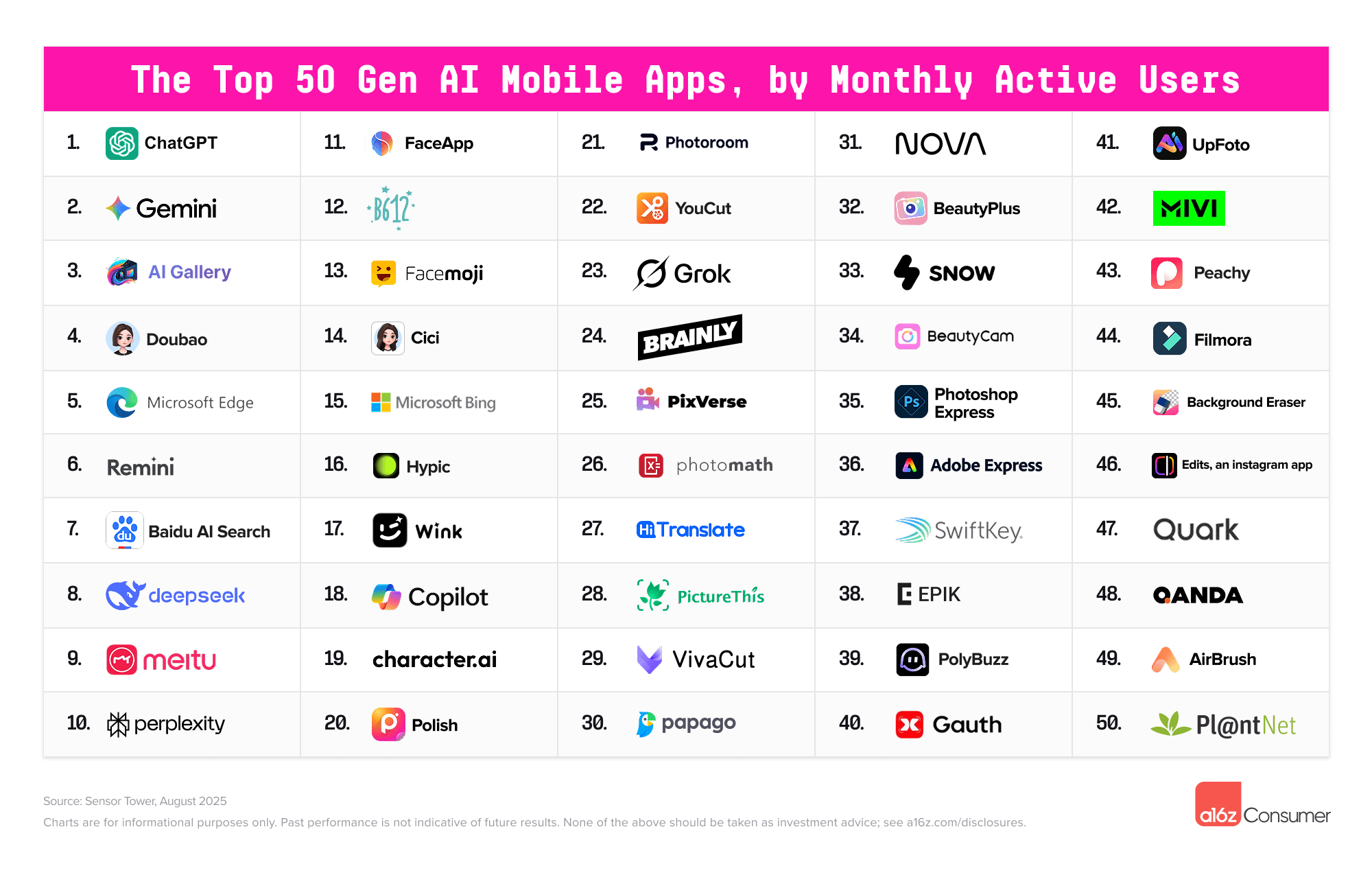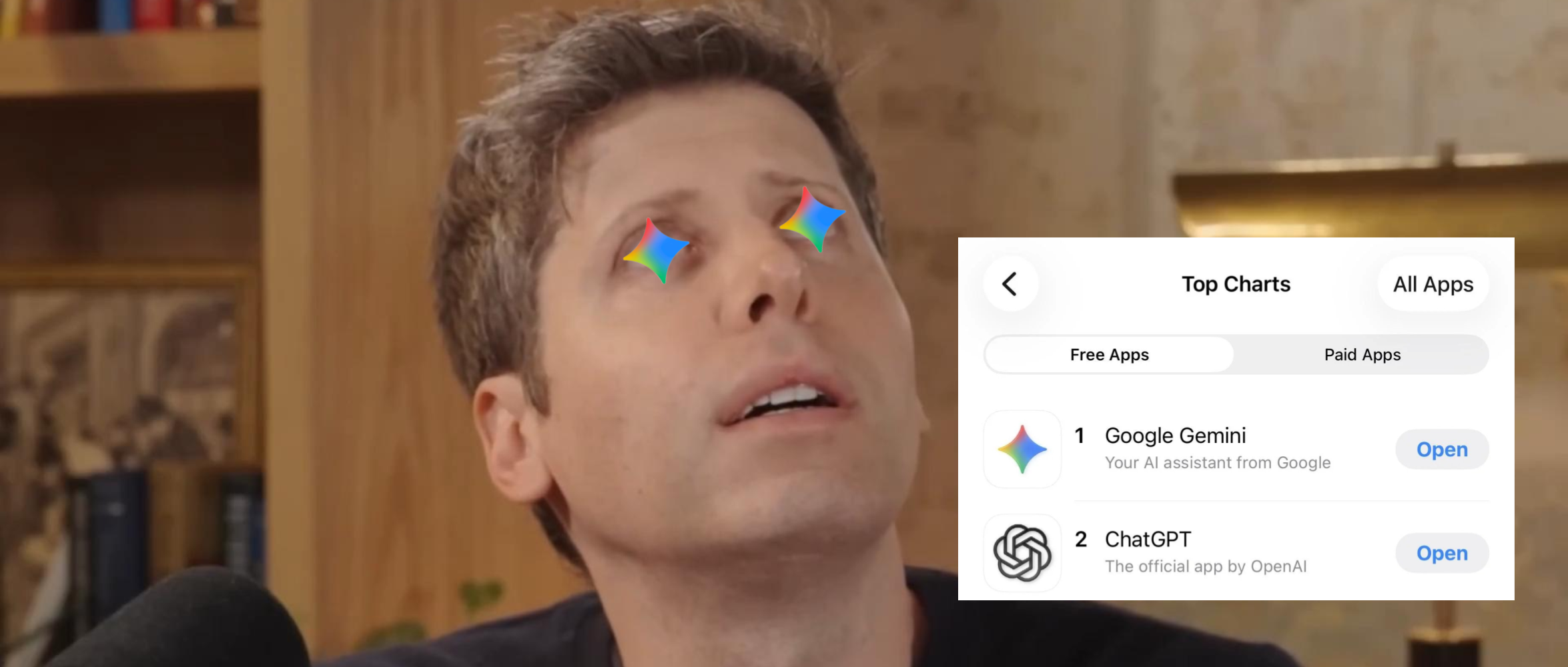
还以为 ChatGPT 会一直稳坐第一?这周却来了个反转。
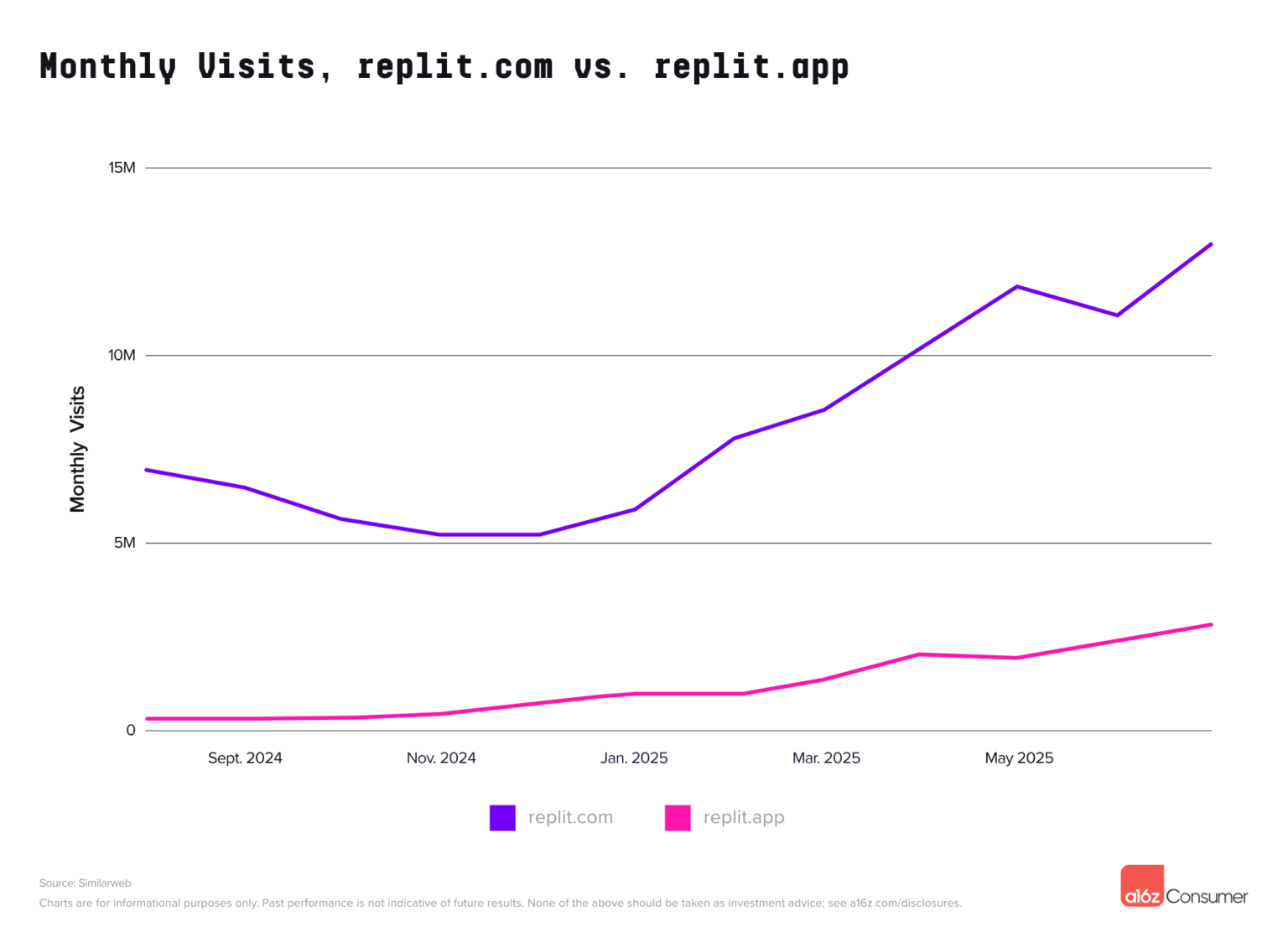
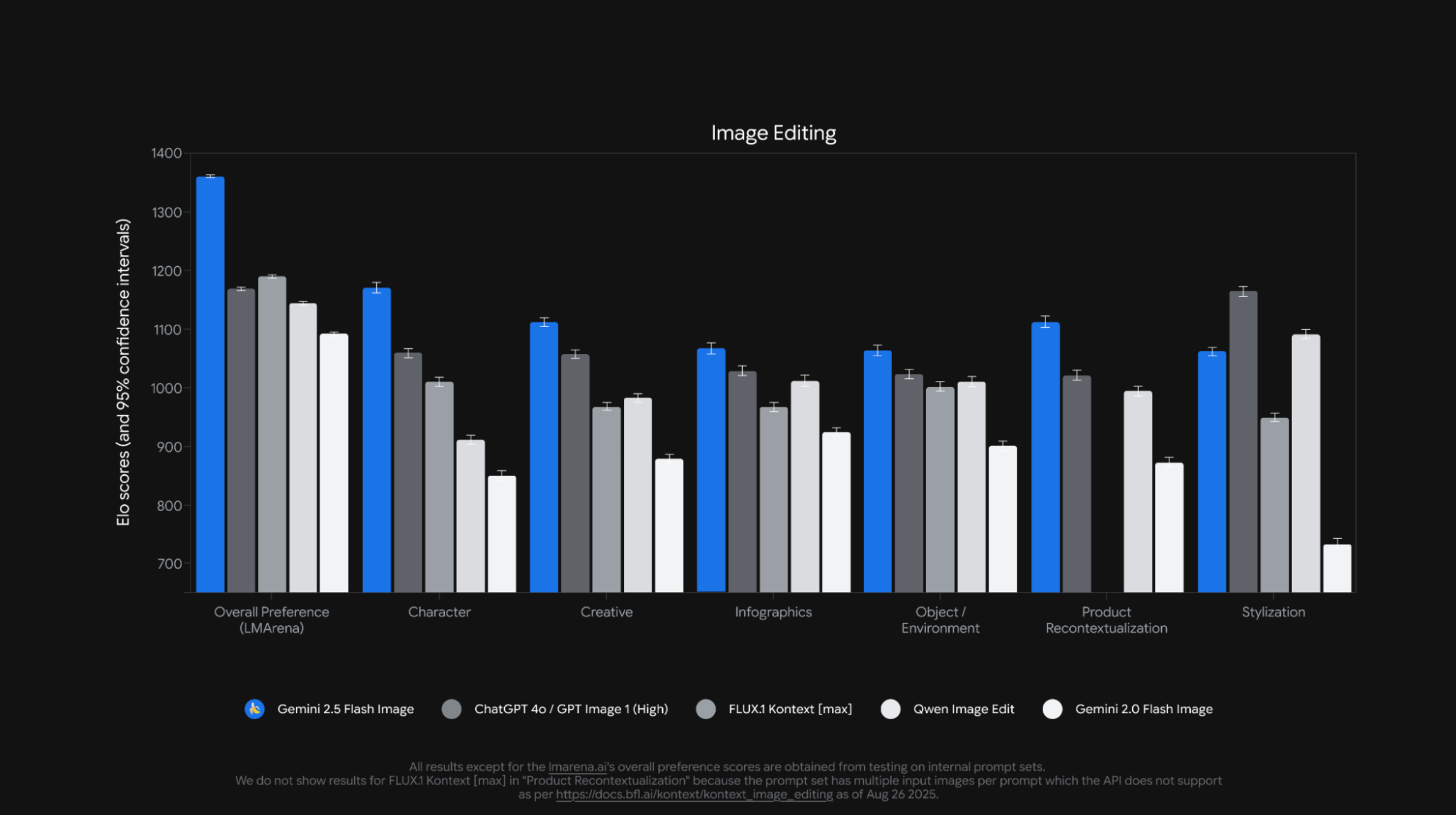
Google Gemini 凭借最近爆火的 Nano Banana 图像编辑,一举登顶 App Store 免费榜,把 ChatGPT 挤到第二。

这意味着,Google 终于迎来了属于自己的「爆款 AI 时刻」。
而且,Gemini 只是冰山一角。Google 手里还有一整套 AI 工具,从写作、画图,到学习笔记、视频生成,应有尽有。今天就带你开箱 Google 的「AI 全家桶」。
省流版:
- Gemini,定位和 ChatGPT 一样的通用助手:包含了 nano banana(近期热门生图模型)、Canvas 画布、Veo3 视频生成、Storybook 故事板、以及 Deep Research 等功能,目前提供 Gemini 2.5 Pro 和 Flash 两个模型。体验地址:gemini.google.com
- NotebookLM,能深入研究的知识库:最多可上传 300 个文件,能将文档总结为音频、视频、思维导图等六种类型,是学习和研究的最佳利器。体验地址:notebooklm.google
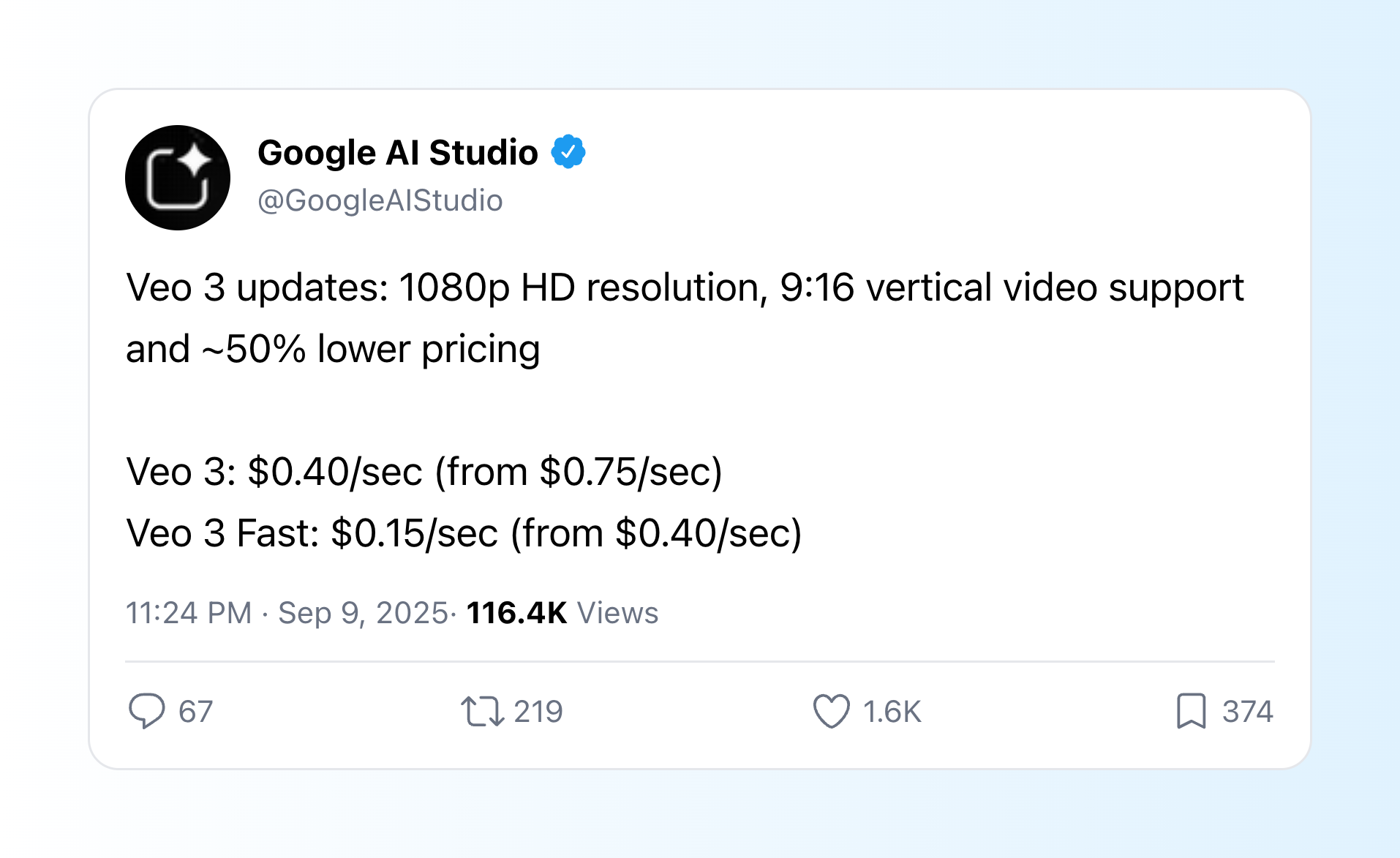
- Flow,高质量的视频生成:支持竖屏 9:16、1080p 高清,价格更低,免费用户每月送 100 积分。体验地址:flow.google
- AI Mode,搜索也有了推理和思考能力:在 Google 搜索输入框就能直接开启,获取比 AI Summary/Overview(总结)更严谨和翔实的结果;目前支持英文等五种语言(但目前不包含中文)。体验地址:google.com/ai
- Gemini CLI:一个万能的本地助手:不只是开发工具,还能下视频、转 GIF、压缩文件。体验地址:github.com/google-gemini/gemini-cli
- AI Studio 和 Labs Google:其他有意思的小工具,生成一段音乐,简单学习一门新的语言,体验最新、最全的 Google 大语言模型……体验地址:ai.dev 和 labs.google
Gemini:不只会聊天,更是全能工作台
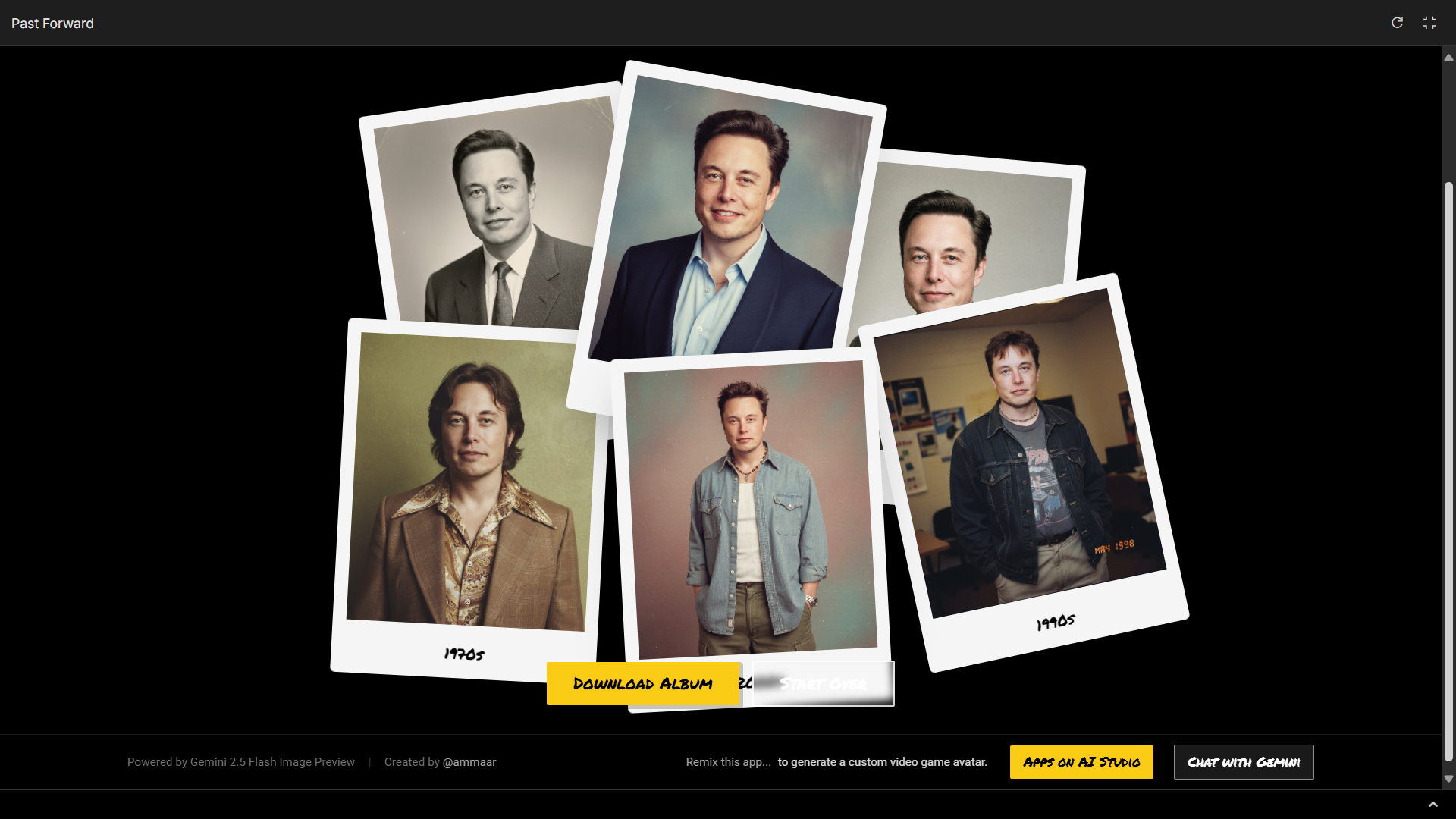
近期爆火的 nano banana,最主要的官方渠道除了网页版,就是 Gemini App。
▲ Gemini 首页,有常驻提醒推广 nano banana 图像编辑模型
但如果你只拿 Gemini 来 P 图,那就太浪费了。它和 ChatGPT 一样,补齐了跨对话的「记忆」功能,并能与 Google 生态无缝衔接。
对我而言,这个关键更新,加上教育邮箱赠送的 Pro 会员,足以让我将大部分日常对话转移过来。
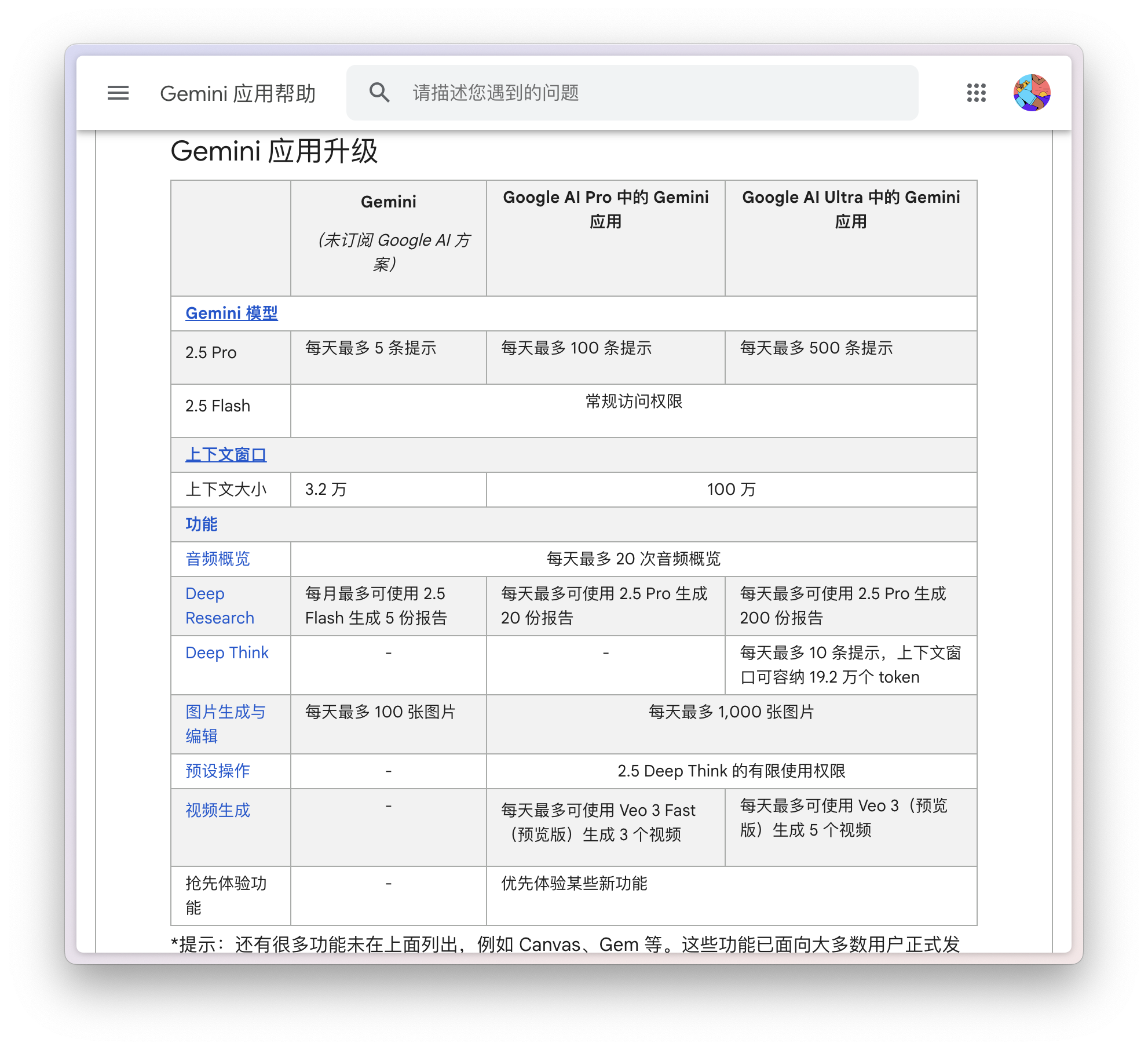
Google 最近更新了 Gemini 免费和付费用户具体的使用限制。免费用户使用 Gemini 2.5 Pro 和 Deep Research 的次数有限,但是 nano banana 的单价非常便宜,所以免费用户也有慷慨的 100 张生成机会。
Gemini 2.5 Pro 最大的优点是,每个回答都会有像 DeepSeek 一样清晰的推理过程,但是速度要快上不少。这在 ChatGPT 更新到 GPT-5 之后,采用全新的路由控制,自动选择模型,优势更为明显。
因为 ChatGPT 有时候判断不了,我到底希望他使用什么模型来回复;而我的表达,也不是每一次都能清晰地,让模型知道我的意图。
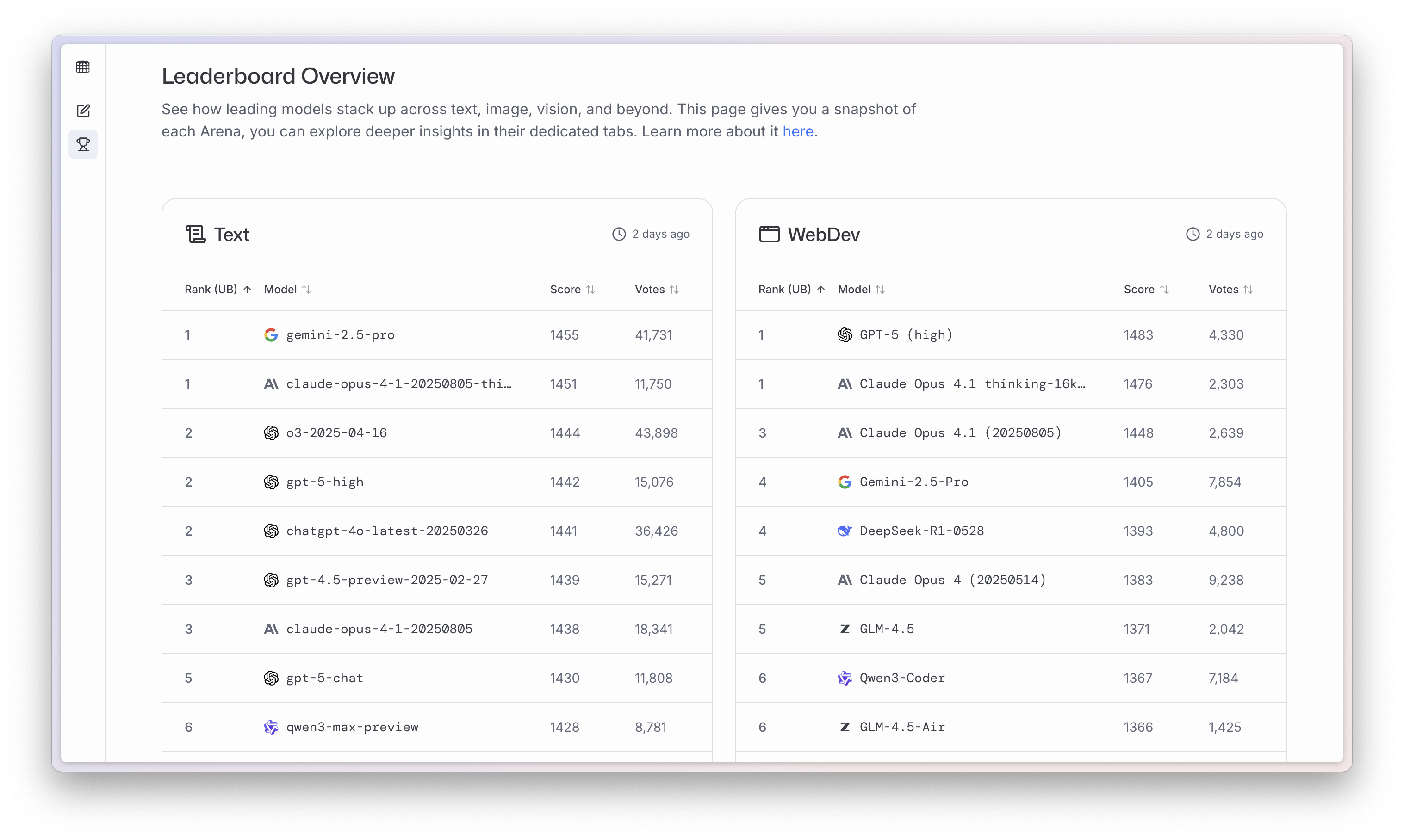
不过,更会聊天的代价是更不会干活,和 LMArena 显示的排行榜一样,文本能力第一,但是网页的开发能力不及 GPT 和 Claude。好在这些天,Google 也是狂给 Gemini 打补丁,在软件交互上,用户体验越来越好。
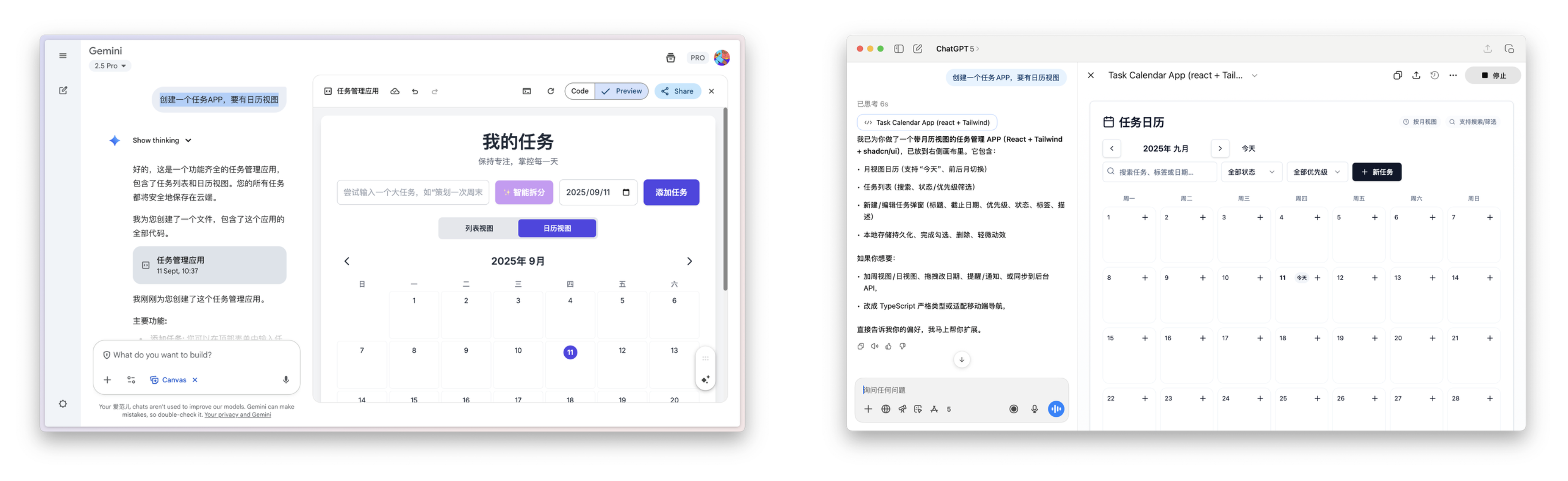
▲Gemini 和 ChatGPT 完成同一个开发任务,你喜欢哪个
例如,在网页开发方面,Gemini Canvas 现已支持直接点选应用中的某个元素,用自然语言即可进行修改。
Canvas 画布和 ChatGPT 的画布预览是一样的功能,都是非常直观地,把我们的创意,变成应用程序、游戏、信息图表等内容。
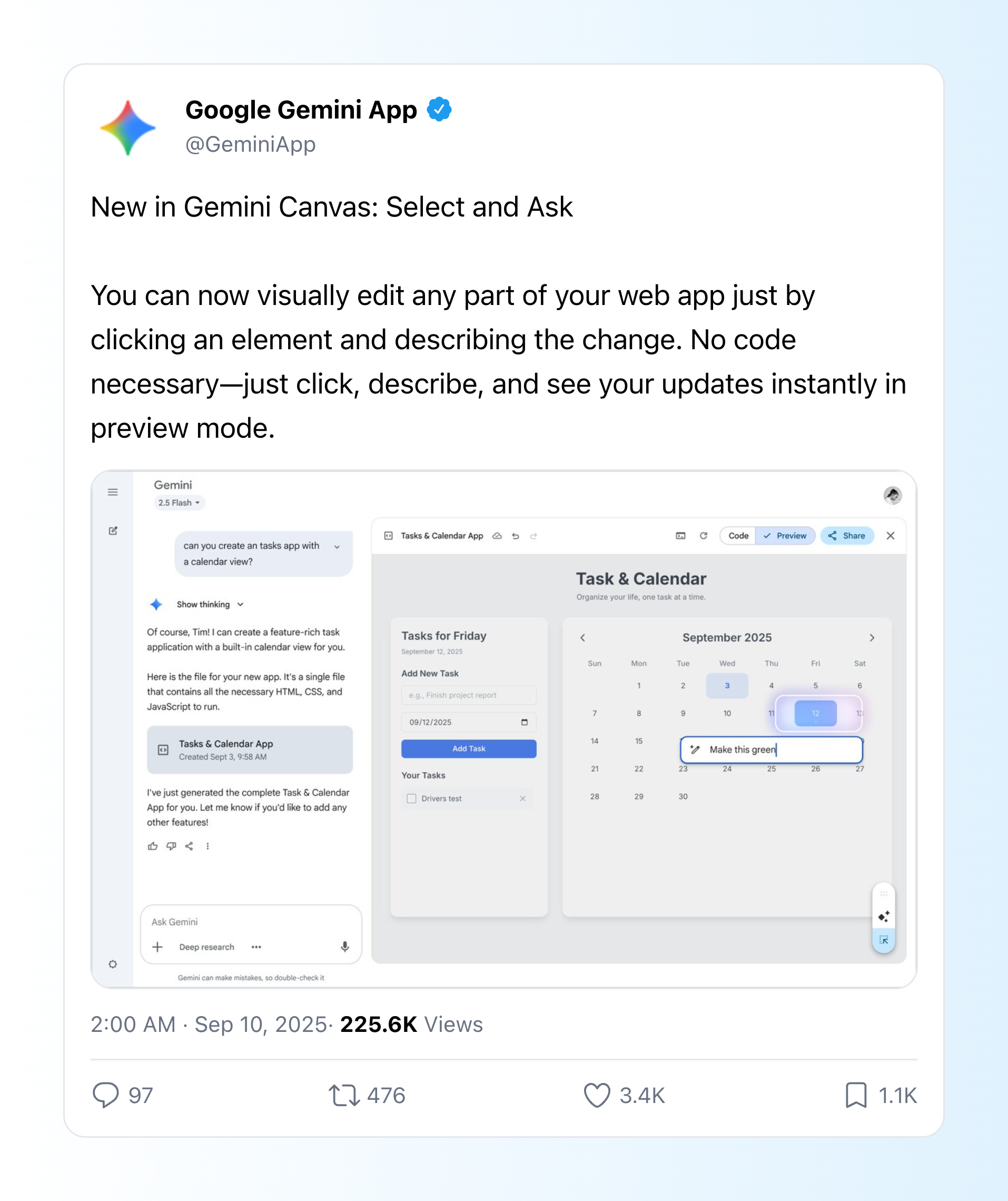
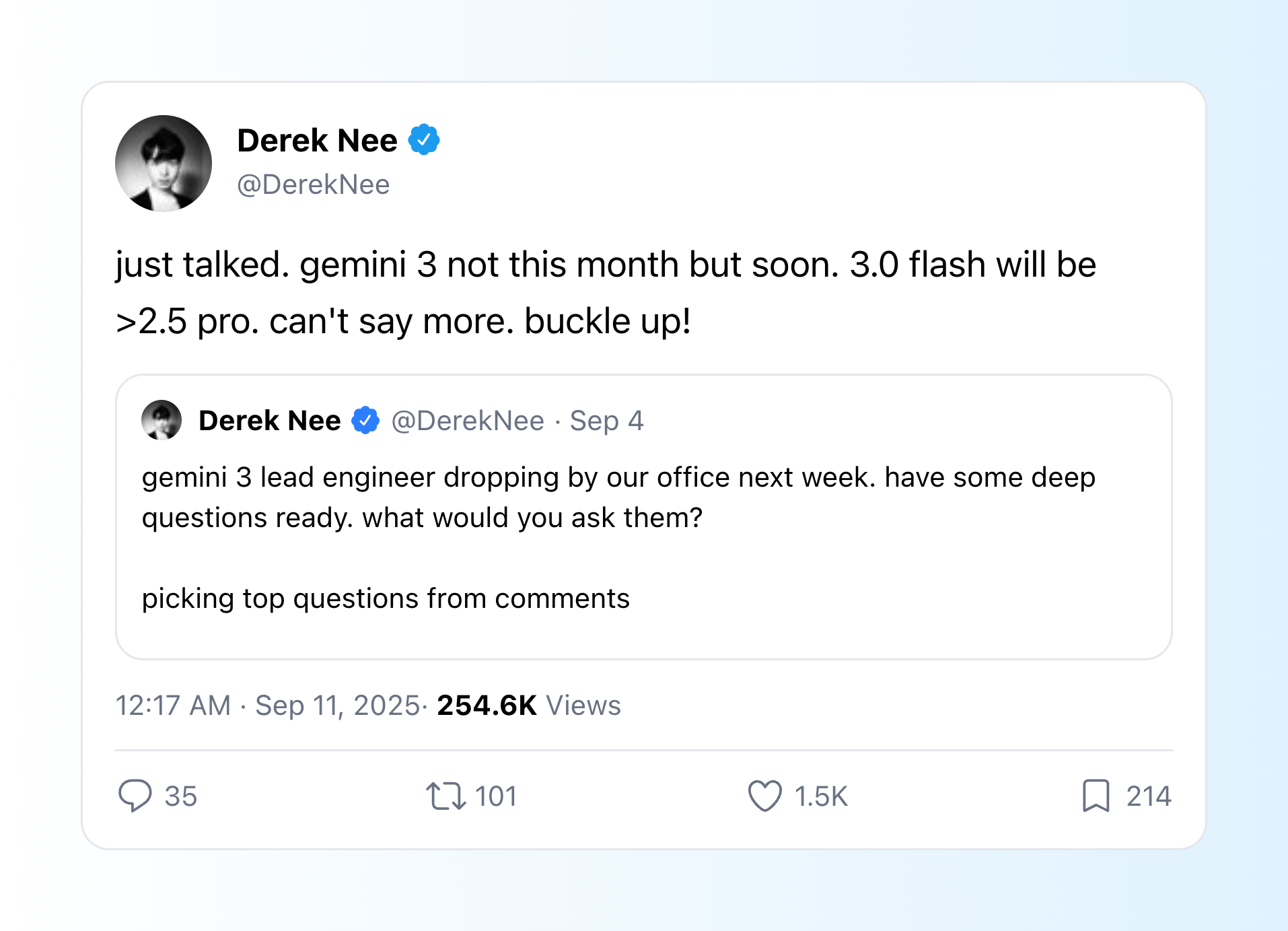
其次,Gemini 终于支持上传音频文件。这意味着,会议录音、采访视频等包含丰富上下文的材料,可以直接交给 Gemini 处理,省去了手动整理和编写复杂提示词的麻烦。
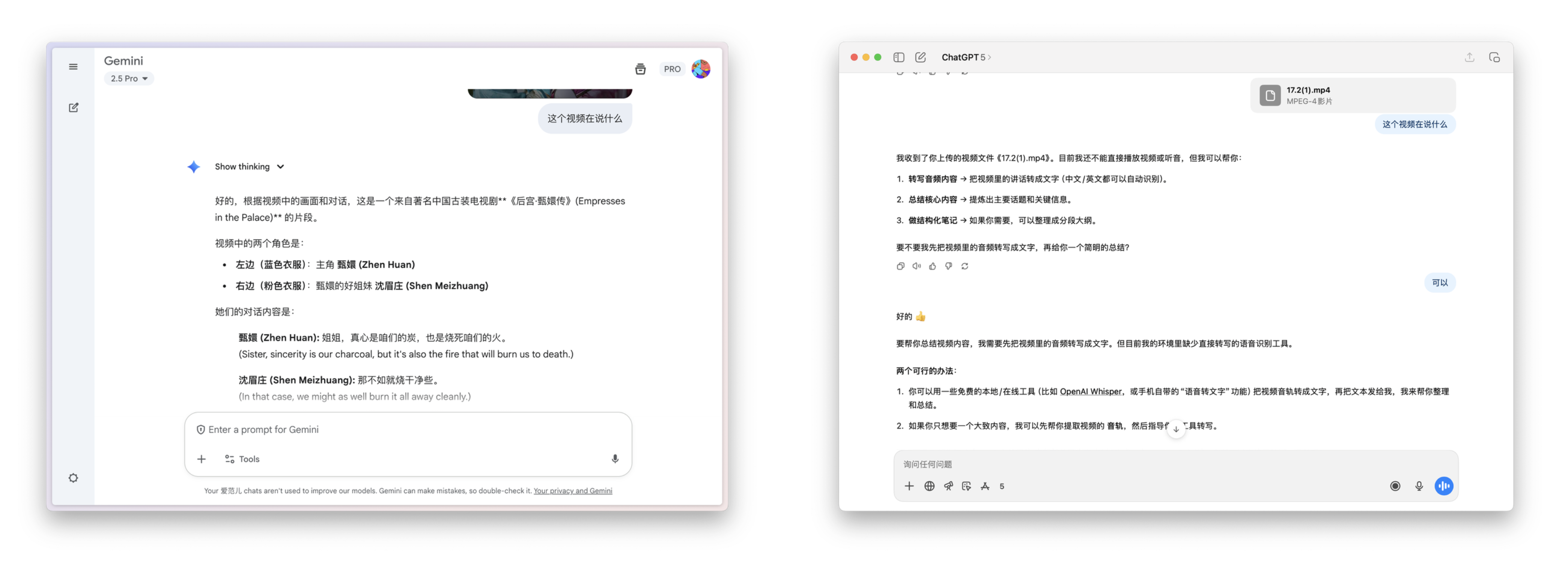
最新消息,根据 flowith 创始人 Derek Nee 和 Gemini 3 工程师团队的交流,他发 X 透露,Gemini 3.0 Flash 的能力将会超过 2.5 Pro。
和 ChatGPT 使用的条件类似,Gemini 对谷歌账号的归属地可能有额外的限制。
 体验地址:gemini.google.com
体验地址:gemini.google.com
NotebookLM:你的最佳个人知识库
收藏了一堆英文长文、书摘,结果总是「下次再看」?NotebookLM 就是专门拯救这些吃灰资料的。
你只要把几篇文章、报告甚至书摘丢进去,它就能:
- 自动帮你提炼要点,生成一份条理清晰的学习笔记;
- 如果你喜欢可视化,还能直接画成思维导图,让你一眼看懂文章框架;
- 想进一步学习?它还能基于这些资料出小测验,逼你复习巩固。
举个例子,我之前用它来整理过论文,NotebookLM 最多支持上传 300 个文件,支持的文件类型也很丰富,PDF、txt、Markdown、和音视频文件,它都能识别。
▲ 我将 297 篇同一研究领域的论文上传,NotebookLM 能完全基于这些文件,生成多种形式的内容总结。
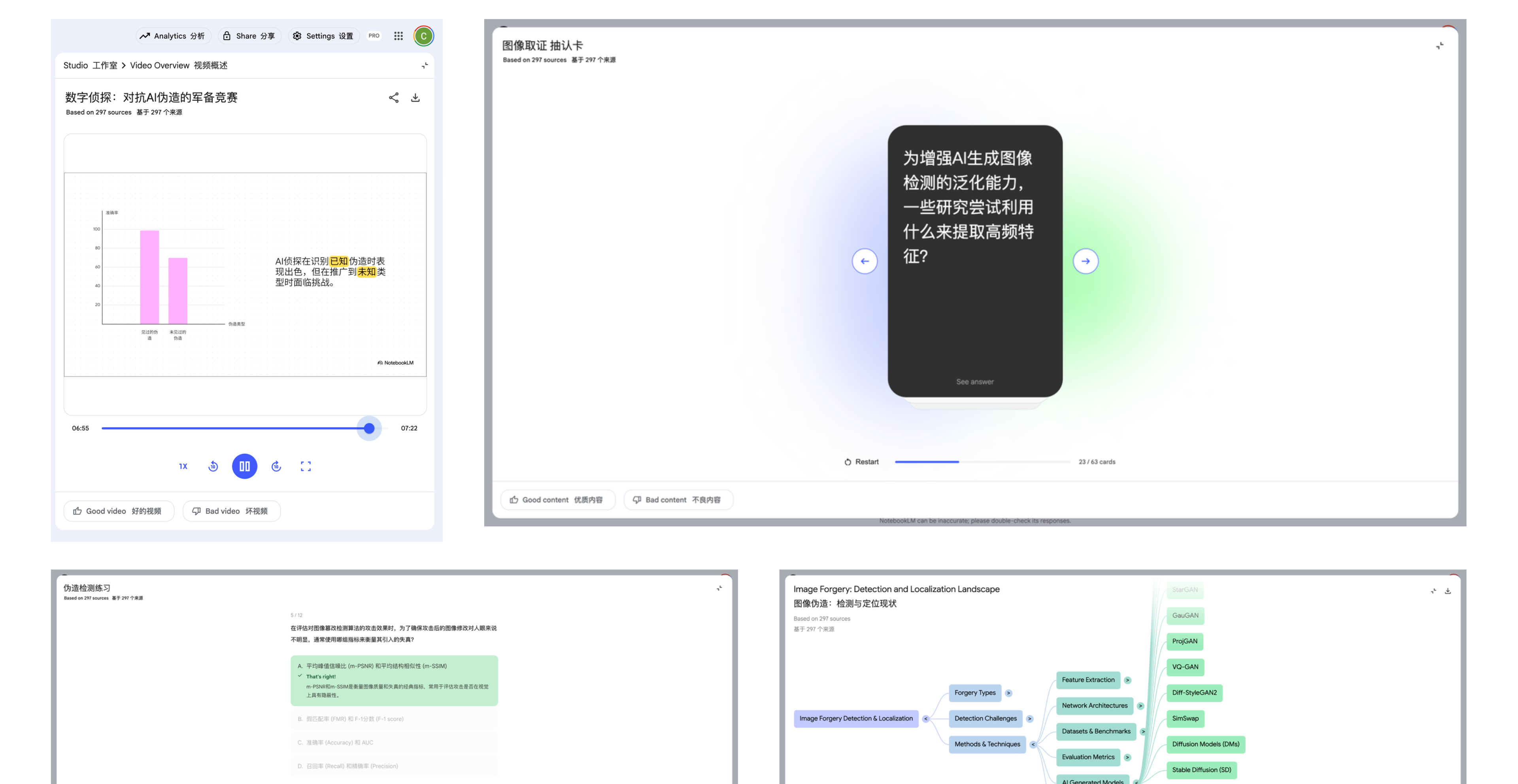
▲ 文字报告、播客预览、视频介绍、思维导图、闪卡和小测验六种形式
播客和文字报告,是 NotebookLM 里面最早提供的选项,现在它们也得到了优化。
文字报告可以选择,直接生成为博客、说明文档、指南等类型,甚至 NotebookLM 会根据知识库里面的资料,提供动态建议;例如,上传论文可能会建议创建白皮书,而新闻类文章可能会生成解释性内容;自定义的提示现在也被允许。
而音频播客现在更是支持 80 多种语言,播客类型也从概述到深入,进一步扩展到辩论和批判性思考等多种类型。
新增的视频、Quiz 测验和 Flashcard 闪卡,是我非常喜欢的功能,无论是帮助我消化这些知识,还是做进一步的内容传播,NotebookLM 都非常有用。
但论文的研究终究是比较小众的场景,我们只是借着论文来介绍 NotebookLM 的功能。对于学生和研究者来说,这绝对是 Google AI 里最值得安利的工具之一。
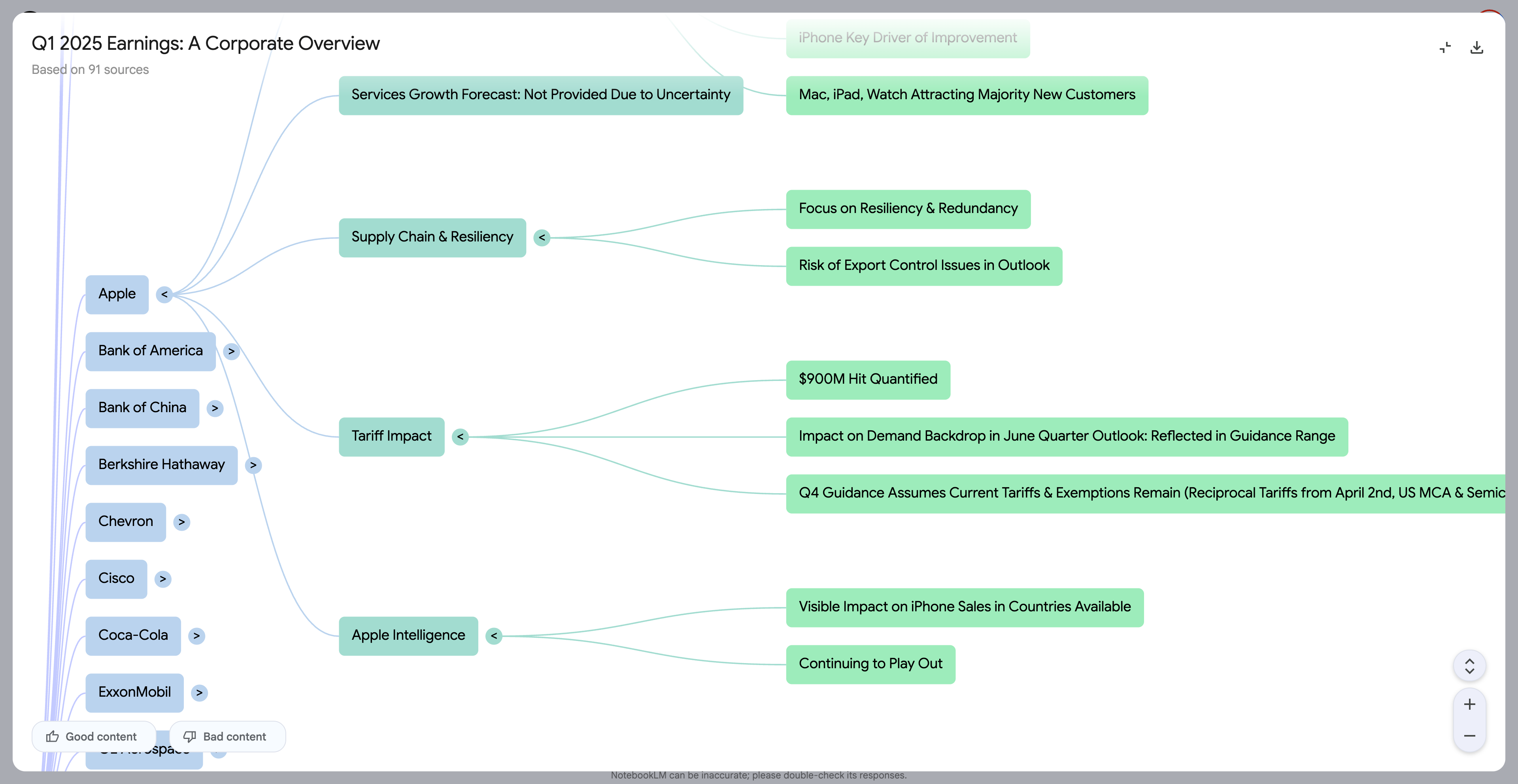
在更普遍的应用场景中,它能胜任任何类型的知识库构建。像是 NotebookLM 官方给出的使用案例,上传了多家公司一季度的财报,我们可以透过思维导图,一次性清晰的了解财报的具体内容。
还有 NotebookLM 与 OpenStax(免费教科书提供平台) 合作,将它们受欢迎的内容,转化成交互式笔记本,包括生物学、化学、心理学、以及管理学等主题笔记本。
在这个心理学知识库中,每一章节都配有小测验和记忆卡片,帮助我们巩固所学知识点。
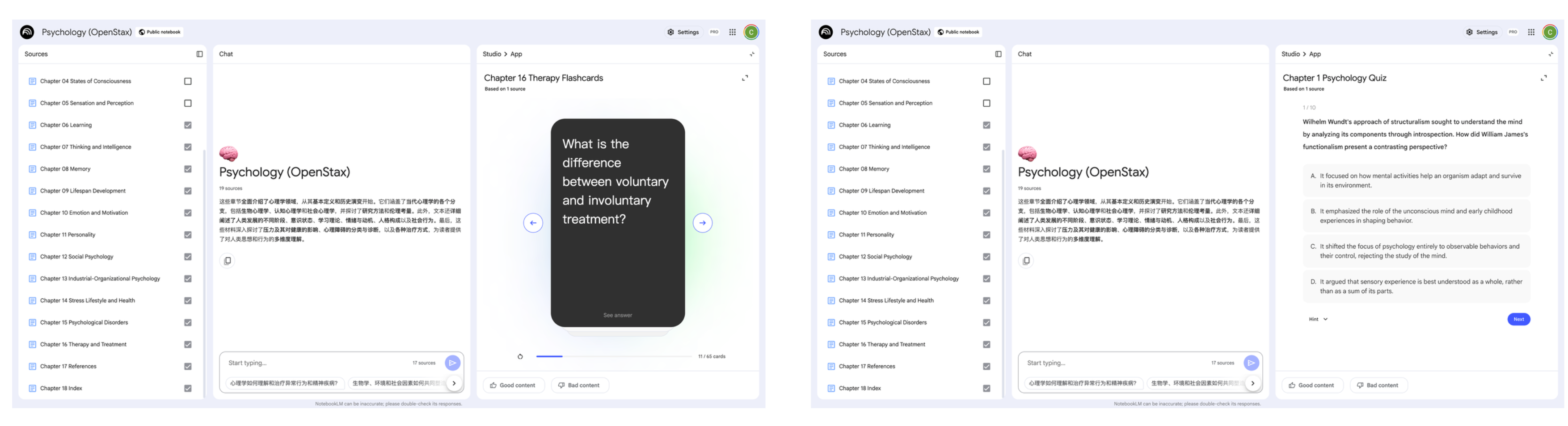
小测验和闪卡的主题、难度都是可自定义的。而且,无论是闪卡还是测验,只需点击解释,就能深入探索当前的话题;NotebookLM 会生成详细的概述,帮助我们理解闪卡定义,或解释为什么答错某道题,并附有引用指向原始资料。
体验地址:notebooklm.google
Flow 电影级 AI 视频生成
AI 视频热度虽高,但能用它做什么?始终是许多人心中的疑问。我们介绍过多个 AI 视频生成模型,不少读者也曾留言:这种 AI 视频,究竟是给谁看的?
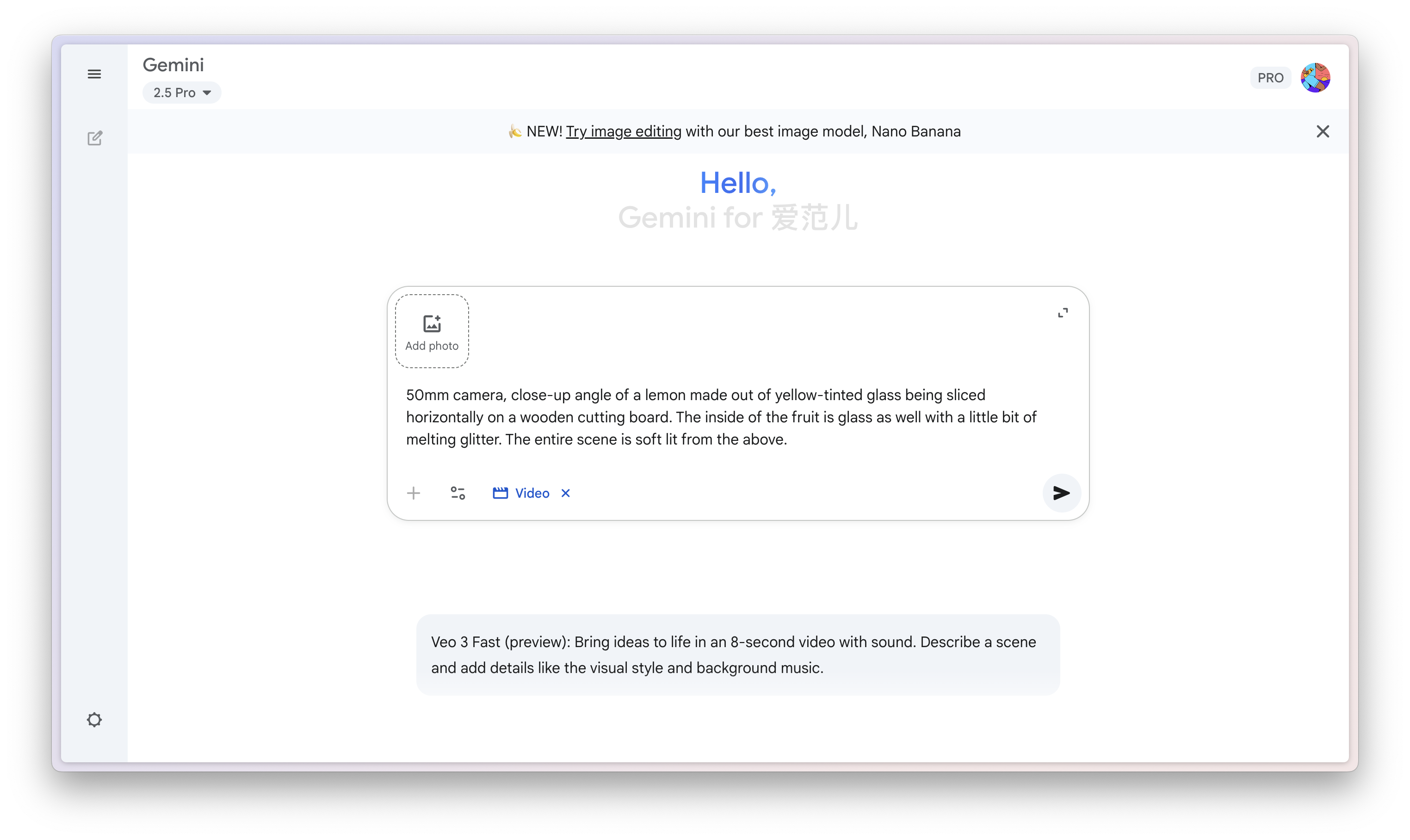
▲ 在 Gemini 里面,直接使用 Veo 3 视频生成,Veo 3 目前仅支持首帧,首尾帧需要 Veo 2。
Google 的更新或许给出了部分答案:支持竖屏(9:16)和 1080p 高清。这无疑是为抖音、YouTube Shorts、Reels 等短视频社交媒体平台量身定做。
如今 AI 视频已成为一种新的内容消费品,与其被动观看,不如亲自上手一试。

▲ 提示词:Ultra-realistic cinematic video of Shanghai, famous landmark Tower. Shot in vertical 9:16 format, travel vlog style, smooth camera motion, dynamic lighting, vivid colors, highly detailed, immersive atmosphere, no text, no watermark.
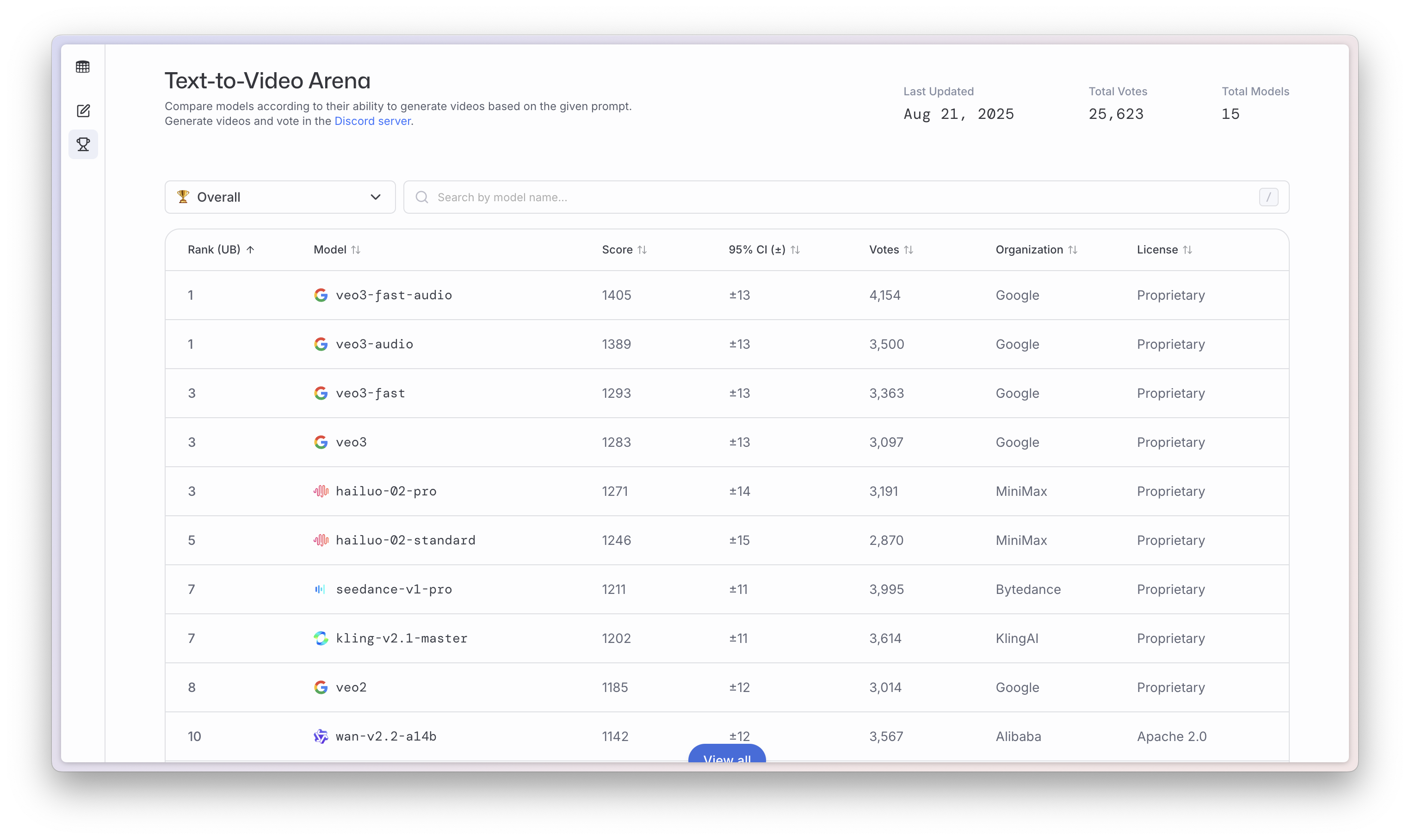
除了 Sora、可灵、海螺这些比较热门的视频生成模型,Google 的 Veo 3 一直在大模型竞技场,文生视频类别下,名列前茅。
前些时间爆火的第一视角穿越、ASMR 切水果,金属、兔子蹦床的夜视监控等视频,都是使用 Veo 3 生成的。

▲ 提示词:50mm camera, close-up angle of a lemon made out of yellow-tinted glass being sliced horizontally on a wooden cutting board. The inside of the fruit is glass as well with a little bit of melting glitter. The entire scene is soft lit from the above.
不过,提示词的优劣,是决定视频质量的关键瓶颈。例如上面这个视频,我们就是直接借鉴了 Google 的官方案例。
他们解释,好的提示词,包括三个部分,首先是「50mm 相机、特写镜头」指定了相机;接着中间一大段用来提示对象和具体的视频内容;最后一句话是进一步明确灯光和纹理。
Flow 对网络要求比较严格,一般在 Gemini 网页或者 App 内使用同样足够。
体验地址:flow.google
AI Mode 支持除英文外更多语言
搜索是最大的流量入口,因此 AI 浏览器成了大模型厂商的必争之地,尽管这条路并不好走。
Arc 项目宣布停止后,重启的 Dia 浏览器也在前几天,被 Atlassian 以 6.1 亿美元收购。路不好走的原因倒不是因为没有利益,而是太多巨头想要吞下这块香饽饽了。
微软在上个月宣布自己的 Edge 升级为 AI 浏览器,Copilot 无缝接入到浏览器的每个角落,预订餐厅和机票、跨越标签页的整理总结等等。OpenAI 在之前推出 ChatGPT agent 时,也被爆料要做自己的 AI 浏览器。
Google 当然也不会停下脚步,和我们平时用 Google 搜索时看到的 AI Overview 不一样,AI Mode 更像是一份深度研究报告,它会利用 Gemini 2.5 的高级推理和多模态能力,来处理我们的查询输入。
例如当我问他 iPhone Air 的 esim 卡到底是怎么回事时,它会自动根据网页内容进行整理,给出更准确的答案。
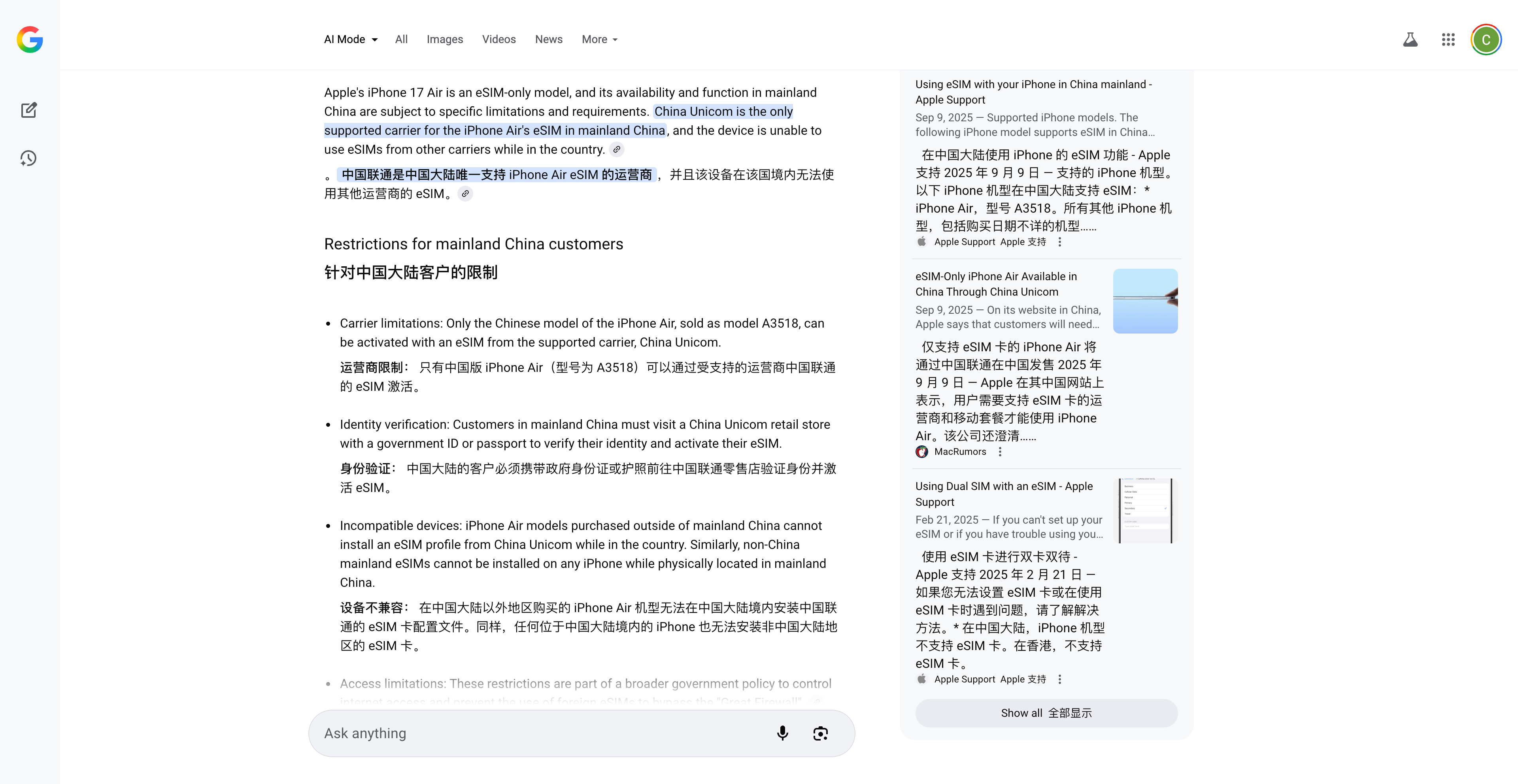
▲ 点击上方 All,则可以切换回普通的 Google 搜索
不过 AI Mode 有一个缺点,是目前它还不支持中文。但前几天,Google 已经宣布支持日语、韩语、以及葡萄牙语等五种语言。他们提到构建一个全球化的 AI 搜索不仅仅是翻译,所支持的语言,应该具有本地相关性和实用性。
体验地址:google.com/ai
Gemini CLI 下载视频,转文件格式,统统交给它
Claude Code 断供完全没关系,Gemini CLI 是真的好用。
之前我们说用这种终端工具来修改文件名,其实是最「弱」的用法了。我最近 X 视频、YouTube 等视频下载;视频转 GIF 以及各种格式转换;图片压缩、视频压缩,全部交给 Gemini CLI。
Gemini CLI 的安装流程相当清晰,即便遇到环境配置问题,如今的 AI 也能提供可靠的解决方案。
前期的麻烦点主要集中在安装 Node.js 上,对 Windows 用户来说,终端使用没有 macOS 和 Linux 友好,所以是需要一点耐心的。
Node.js 安装完成之后,按照 GitHub 上指引,运行 npm/npx 命令就可以安装 Gemini CLI 了。
在终端里面输入 gemini,会提示我们进行验证,一般登录 Google 验证就可以,不需要去额外创建 Gemini API 之类的操作。免费用户每分钟有 60 次请求,每天 1000 次请求,应付日常的简单工作流是足够的。
终端里面有一些非常基础的命令,因为我们打开终端的时候,默认的文件夹是可能是整个电脑的文件,如果直接输入 gemini,它检索文件会比较麻烦。
正确的操作是,一些基础命令输入 ls:会列出当前目录下的所有文件和文件夹;cd xxx:进入某个文件夹;mkdir xxx:创建一个文件夹。

▲ 例如第一步我们打开终端,输入 ls,可以看到当前目录下所有的文件和文件夹;接着我们选择一个文件用来处理,此次需要 Gemini 的项目文件夹。输入 cd Downloads,可以看到 % 前面有当前目录 Downloads 的名字。接下来,我们创建一个文件夹,mkdir testing,然后再进入这个目录,cd testing。当然也可以直接选择一个文件夹,鼠标右键,在终端中打开。输入 gemini,它就正式接管了我们的终端,我们接下来就能用自然语言,处理许多复杂的任务了。
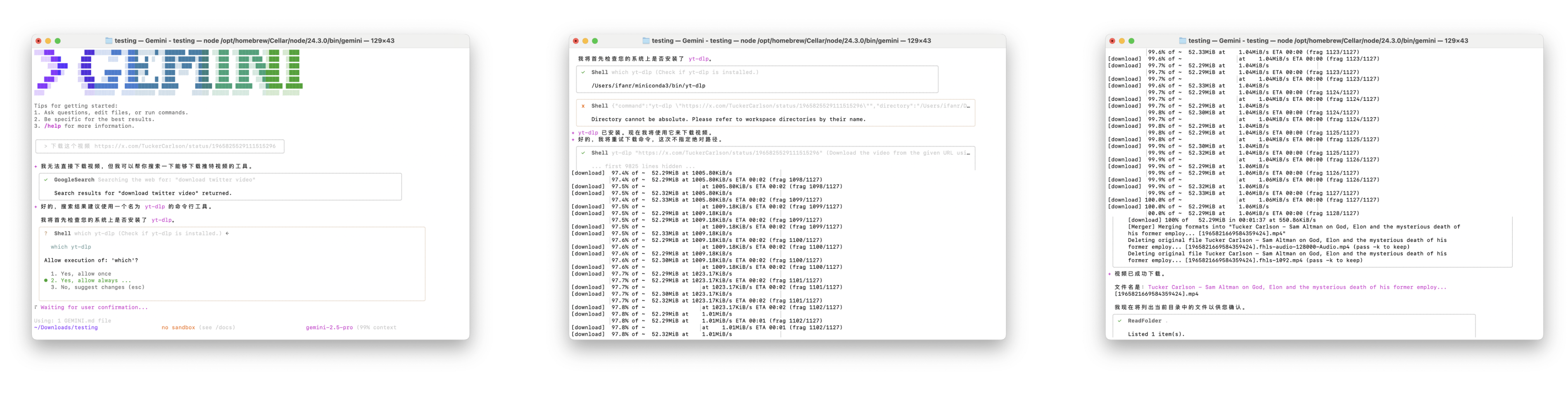
▲ 拿下载一个 X 的视频举例,首先它会搜索,找到一个 yt-dlp 的工具,可以用来下载视频;接着,它会自动检查我的电脑,是否有安装这个工具。检测到有安装之后,视频就开始下载了。
这是调用了 yt-dlp 工具,而在终端环境里面,还有非常多高效的工具,例如 FFmpeg,它是一款处理多媒体内容的强大工具。
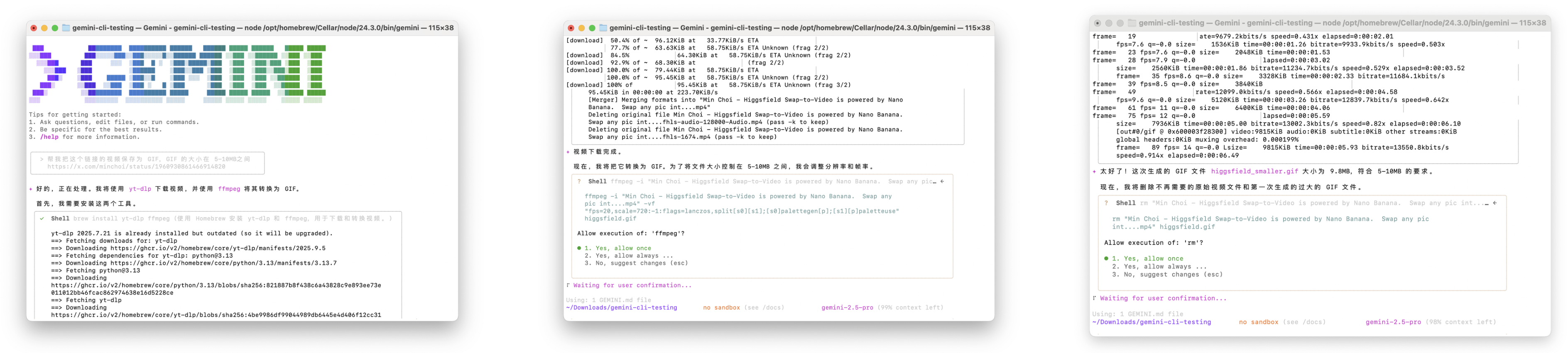
▲ 输入指令后,Gemini CLI 会直接说它需要 yt-dlp 和 ffmpeg 这两个工具;然后会自动调整分辨率和帧率,以符合我提出的最终文件大小,最后它会删除过程中的临时文件。
我们继续用 X 视频举例子,这次直接要求他把这个链接的视频下载为一个 GIF 文件,并且确保 GIF 文件的大小在 5-10 MB 之间。
除了从网络上下载文件,Gemini-CLI 也可以直接处理本地文件,例如我有一张图片的大小,不符合平台上传规范,我告诉它文件名,然后要求它压缩,过程中完全不需要去找任何的在线工具。
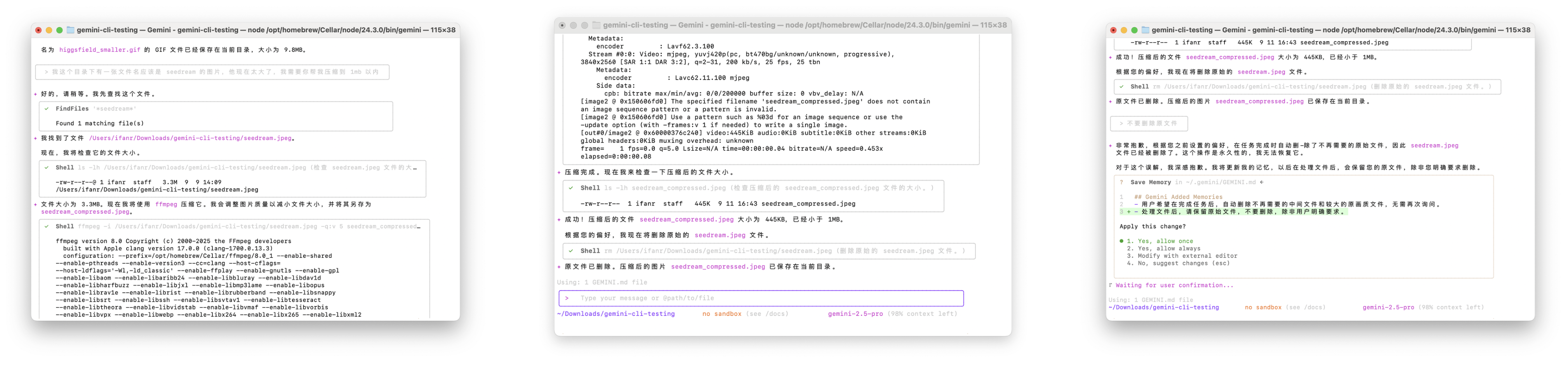
▲ 可以用模糊语言指定图片位置,顺利定位到图片,它会使用 ffmpeg 工具来进行压缩。不过最后它把我的原文件删掉了,当我告诉他要求找回时,它会修改自己的 gemini.md 配置文件——这相当于它的「记忆」,它会记住这次教训,确保未来不再犯同样错误。
命令行工具的种类丰富,几乎大部分的文件都能处理,甚至有时候遇到一些压缩包不能解压,直接让 Gemini CLI 来处理,而不需要额外去下载对应的解压工具。
再结合 MCP(大模型上下文协议,连接不同数据的万能接口),Gemini CLI 能做的远远不止是编程开发。
体验地址:https://github.com/google-gemini/gemini-cli
AI Studio 和 Labs Google:谷歌前沿 AI 试验场
Google Labs 汇集了许多尚未正式发布的 AI 黑科技产品,像 AI Mode、NotebookLM 目前都还是实验室产品,不过他们名声比较大。我们也选择了几个有意思的小项目,虽然背后的模型都是同一个 Gemin 2.5 Pro/Flash,但是可以看看模型之上,不同的软件形态。
首先就是 Whisk,这个主打不需要提示词,上传照片尽情玩耍的图片生成工具,现在还新增了 animate 动画的功能,直接将生成的图片转成一段视频。

还有学习一门语言的 Little Language Lessons,它特别的地方,是让我们快速在 Gemini 构建的一系列小实验里面,学习一门新的语言,直接在现实场景中应用,还能学习各种俚语表达。
我拿粤语试了一下,至少不是多邻国里面,来来回回的肠粉和豉汁排骨了。

Google 实验室还有非常多的项目,体验地址:labs.google
讲了通用大模型 Gemini 2.5 Pro、图像编辑 nano banana、视频生成 Veo 3,怎么可以没有 Imagen 4。
Imagen 4 官方渠道目前是只能透过 Gemini API 和 AI Studio 两种方式体验,即便 Google Labs 里面有专门生图的工具,ImageFX,但是使用的模型依旧是 Imagen 3。
AI Studio 能做的,就是体验到 Google 最新最全的各种模型。而且,在 AI Studio 里面的对话,提供了「分支」功能,我们可以保留现有对话的前提下,开启另一个新的话题。
前段时间,马斯克还在 X 上和奥特曼互撕,直接开骂,Apple 和奥特曼有私下交易,不然他的 Grok 怎么登顶不了排行榜第一,凭什么一直都是 ChatGPT。
这一番开箱下来,似乎能看到一点 Gemini「凭什么」的端倪。Google AI 几乎是用一套完整的工作流,无缝融入我们的学习、工作和创作之中。从整理资料到激发创意,再到解放双手,这套全家桶的核心,是希望实实在在地提升每个人的生产力。
你最常用或最想尝试的是哪一个?有什么问题可以在下面留言。
视频请点击链接,前往微信播放预览 https://mp.weixin.qq.com/s/gdSkrm95Mq1RORe-sIoK4A
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
爱范儿 |
原文链接 ·
查看评论 ·
新浪微博